TensorFlow-2.x-Quantization-Toolkit
安装
Docker
推荐使用来自 NGC 的最新 TensorFlow 2.x docker 镜像。
克隆 tensorflow-quantization 仓库,拉取 docker 镜像,并启动容器。
$ cd ~/ $ git clone https://github.com/NVIDIA/TensorRT.git $ docker pull nvcr.io/nvidia/tensorflow:22.03-tf2-py3 $ docker run -it --runtime=nvidia --gpus all --net host -v ~/TensorRT/tools/tensorflow-quantization:/home/tensorflow-quantization nvcr.io/nvidia/tensorflow:22.03-tf2-py3 /bin/bash
在最后一个命令之后,您将被放置在正在运行的 docker 容器内的 /workspace 目录中,而 tensorflow-quantization 仓库则挂载在 /home 目录中。
$ cd /home/tensorflow-quantization $ ./install.sh $ cd tests $ python3 -m pytest quantize_test.py -rP
如果所有测试都通过,则安装成功。
本地
$ cd ~/
$ git clone https://github.com/NVIDIA/TensorRT.git
$ cd TensorRT/tools/tensorflow-quantization
$ ./install.sh
$ cd tests
$ python3 -m pytest quantize_test.py -rP
如果所有测试都通过,则安装成功。
注意
此工具包仅支持量化感知训练 (QAT) 作为量化方法。
此工具包的当前版本不支持子类模型。原始 Keras 层使用 TensorFlow 的 clone_model 方法包装到量化层中,该方法不支持子类模型。
基础知识
量化函数
quantize_model 是用户量化任何 Keras 模型唯一需要使用的函数。它具有以下签名
(function) quantize_model:
(
model: tf.keras.Model,
quantization_mode: str = "full",
quantization_spec: QuantizationSpec = None,
custom_qdq_cases : List['CustomQDQInsertionCase'] = None
) -> tf.keras.Model
注意
有关更多详细信息,请参阅 Python API。
示例
import tensorflow as tf
from tensorflow_quantization import quantize_model, utils
assets = utils.CreateAssetsFolders("toolkit_basics")
assets.add_folder("example")
# 1. Create a simple model (baseline)
input_img = tf.keras.layers.Input(shape=(28, 28, 1))
x = tf.keras.layers.Conv2D(filters=2, kernel_size=(3, 3))(input_img)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(10)(x)
model = tf.keras.Model(input_img, x)
# 2. Train model
model.fit(train_images, train_labels, batch_size=32, epochs=2, validation_split=0.1)
# 3. Save model and then convert it to ONNX
tf.keras.models.save_model(model, assets.example.fp32_saved_model)
utils.convert_saved_model_to_onnx(assets.example.fp32_saved_model, assets.example.fp32_onnx_model)
# 4. Quantize the model
q_model = quantize_model(model)
# 5. Train quantized model again for a few epochs to recover accuracy (fine-tuning).
q_model.fit(train_images, train_labels, batch_size=32, epochs=2, validation_split=0.1)
# 6. Save the quantized model with QDQ nodes inserted and then convert it to ONNX
tf.keras.models.save_model(q_model, assets.example.int8_saved_model)
utils.convert_saved_model_to_onnx(assets.example.int8_saved_model, assets.example.int8_onnx_model)
保存的 ONNX 文件可以使用 Netron 可视化。下图 1 显示了原始 FP32 基线模型的快照。
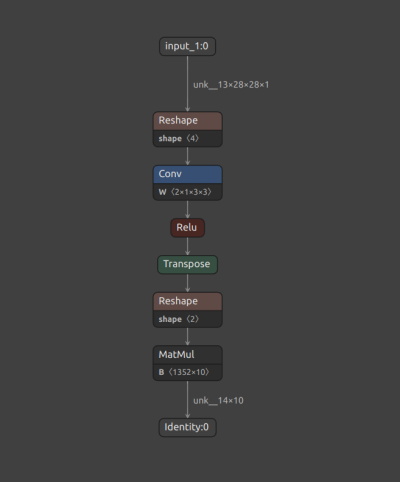
图 1. 原始 FP32 模型。
量化过程根据 TensorRT™ 量化 策略,在所有受支持层的输入和权重(如果层是加权层)处插入 Q/DQ 节点。 对于每个受支持的层,可以在下图 2 的 Netron 可视化中验证是否存在量化节点 (QuantizeLinear ONNX op) ,后跟反量化节点 (DequantizeLinear ONNX op)。
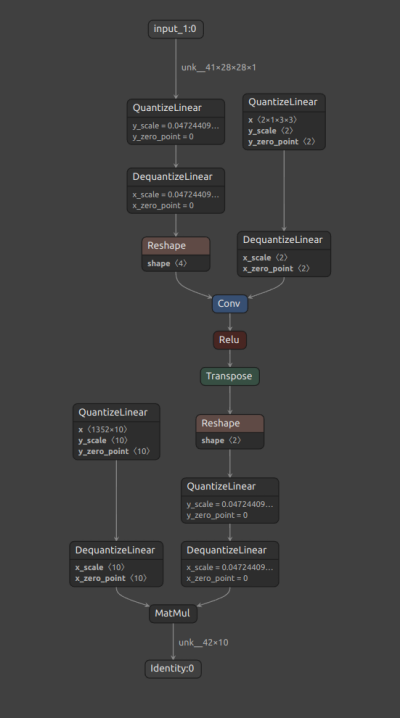
图 2. 量化 INT8 模型。
TensorRT™ 将带有 Q/DQ 节点的 ONNX 模型转换为 INT8 引擎,该引擎可以利用最新 NVIDIA® GPU 中的 Tensor Cores 和其他硬件加速。
量化模式
在某些情况下,可能需要自定义默认量化方案。 我们根据量化的层集合,将量化(即添加 Q/DQ 节点的过程)大致分为 完整 和 部分 模式。 此外,完整量化可以是 默认 或 自定义,而部分量化始终是 自定义。
- 完整默认量化
给定模型的所有受支持层都按照默认工具包行为进行量化。
- 完整自定义量化
可以通过传递
QuantizationSpec类和/或CustomQDQInsertionCase类的对象来编程工具包的行为,以不同方式量化特定层。 剩余的受支持层按照 默认行为 进行量化。
- 部分量化
仅量化使用
QuantizationSpec和/或CustomQDQInsertionCase类对象传递的层。
注意
有关每种模式的示例,请参阅 教程。
术语
层名称
用户或 Keras 分配的 Keras 层名称。 默认情况下,这些名称是唯一的。
import tensorflow as tf
l = tf.keras.layers.Dense(units=100, name='my_dense')
这里 ‘my_dense’ 是用户分配的层名称。
提示
对于给定的层 l,可以使用 l.name 找到层名称。
层类别
Keras 层类别的名称。
import tensorflow as tf
l = tf.keras.layers.Dense(units=100, name='my_dense')
这里 ‘Dense’ 是层类别。
提示
对于给定的层 l,可以使用 l.__class__.__name__ 或 l.__class__.__module__ 找到层类别。
NVIDIA® 与 TensorFlow 工具包
TFMOT 是 TensorFlow 官方量化工具包。 TFMOT 使用的量化方案在 Q/DQ 节点放置方面与 NVIDIA® 的不同,并且针对 TFLite 推理进行了优化。 另一方面,NVIDIA® 量化方案针对 TensorRT™ 进行了优化,这可以在 NVIDIA® GPU 和硬件加速器上实现最佳模型加速。
其他差异
功能 |
TensorFlow 模型优化工具包 (TFMOT) |
NVIDIA® 工具包 |
|---|---|---|
QDQ 节点放置 |
输出和权重 |
输入和权重 |
量化支持 |
整个模型(完整)和某些层(按层类别部分量化) |
扩展了 TF 量化支持:按层名称进行部分量化,并通过扩展 |
量化方案 |
|
|
其他资源
关于此工具包
GTC 2022 技术讲座 (NVIDIA)
博客
视频
生成每个张量的动态范围
使用 C++ 设置每个张量的动态范围 (NVIDIA)
TensorRT 的 8 位推理 (NVIDIA)
文档 (NVIDIA)
入门指南:端到端
NVIDIA® TensorFlow 2.x 量化工具包提供了一个简单的 API 来量化给定的 Keras 模型。 在更高的层面上,量化感知训练 (QAT) 是一个三步工作流程,如下所示
最初,网络在目标数据集上训练直到完全收敛。 量化步骤包括在预训练网络中插入 Q/DQ 节点,以模拟训练期间的量化。 请注意,简单地添加 Q/DQ 节点会导致精度降低,因为量化参数尚未针对给定模型进行更新。 然后,网络将重新训练几个 epoch 以恢复精度,这一步骤称为“微调”。
目标
在 Fashion MNIST 数据集上训练一个简单的网络,并将其保存为基线模型。
量化预训练的基线网络。
微调量化网络以恢复精度,并将其保存为 QAT 模型。
1. 训练
导入所需的库并创建一个带有卷积层和密集层的简单网络。
import tensorflow as tf
from tensorflow_quantization import quantize_model
from tensorflow_quantization import utils
assets = utils.CreateAssetsFolders("GettingStarted")
assets.add_folder("example")
def simple_net():
"""
Return a simple neural network.
"""
input_img = tf.keras.layers.Input(shape=(28, 28), name="nn_input")
x = tf.keras.layers.Reshape(target_shape=(28, 28, 1), name="reshape_0")(input_img)
x = tf.keras.layers.Conv2D(filters=126, kernel_size=(3, 3), name="conv_0")(x)
x = tf.keras.layers.ReLU(name="relu_0")(x)
x = tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), name="conv_1")(x)
x = tf.keras.layers.ReLU(name="relu_1")(x)
x = tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), name="conv_2")(x)
x = tf.keras.layers.ReLU(name="relu_2")(x)
x = tf.keras.layers.Conv2D(filters=16, kernel_size=(3, 3), name="conv_3")(x)
x = tf.keras.layers.ReLU(name="relu_3")(x)
x = tf.keras.layers.Conv2D(filters=8, kernel_size=(3, 3), name="conv_4")(x)
x = tf.keras.layers.ReLU(name="relu_4")(x)
x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), name="max_pool_0")(x)
x = tf.keras.layers.Flatten(name="flatten_0")(x)
x = tf.keras.layers.Dense(100, name="dense_0")(x)
x = tf.keras.layers.ReLU(name="relu_5")(x)
x = tf.keras.layers.Dense(10, name="dense_1")(x)
return tf.keras.Model(input_img, x, name="original")
# create model
model = simple_net()
model.summary()
Model: "original"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
nn_input (InputLayer) [(None, 28, 28)] 0
reshape_0 (Reshape) (None, 28, 28, 1) 0
conv_0 (Conv2D) (None, 26, 26, 126) 1260
relu_0 (ReLU) (None, 26, 26, 126) 0
conv_1 (Conv2D) (None, 24, 24, 64) 72640
relu_1 (ReLU) (None, 24, 24, 64) 0
conv_2 (Conv2D) (None, 22, 22, 32) 18464
relu_2 (ReLU) (None, 22, 22, 32) 0
conv_3 (Conv2D) (None, 20, 20, 16) 4624
relu_3 (ReLU) (None, 20, 20, 16) 0
conv_4 (Conv2D) (None, 18, 18, 8) 1160
relu_4 (ReLU) (None, 18, 18, 8) 0
max_pool_0 (MaxPooling2D) (None, 9, 9, 8) 0
flatten_0 (Flatten) (None, 648) 0
dense_0 (Dense) (None, 100) 64900
relu_5 (ReLU) (None, 100) 0
dense_1 (Dense) (None, 10) 1010
=================================================================
Total params: 164,058
Trainable params: 164,058
Non-trainable params: 0
_________________________________________________________________
加载 Fashion MNIST 数据并拆分训练集和测试集。
# Load Fashion MNIST dataset
mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# Normalize the input image so that each pixel value is between 0 to 1.
train_images = train_images / 255.0
test_images = test_images / 255.0
编译模型并训练五个 epoch。
# Train original classification model
model.compile(
optimizer="adam",
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
model.fit(
train_images, train_labels, batch_size=128, epochs=5, validation_split=0.1
)
# get baseline model accuracy
_, baseline_model_accuracy = model.evaluate(
test_images, test_labels, verbose=0
)
print("Baseline test accuracy:", baseline_model_accuracy)
Epoch 1/5
422/422 [==============================] - 4s 8ms/step - loss: 0.5639 - accuracy: 0.7920 - val_loss: 0.4174 - val_accuracy: 0.8437
Epoch 2/5
422/422 [==============================] - 3s 8ms/step - loss: 0.3619 - accuracy: 0.8696 - val_loss: 0.4134 - val_accuracy: 0.8433
Epoch 3/5
422/422 [==============================] - 3s 8ms/step - loss: 0.3165 - accuracy: 0.8855 - val_loss: 0.3137 - val_accuracy: 0.8812
Epoch 4/5
422/422 [==============================] - 3s 8ms/step - loss: 0.2787 - accuracy: 0.8964 - val_loss: 0.2943 - val_accuracy: 0.8890
Epoch 5/5
422/422 [==============================] - 3s 8ms/step - loss: 0.2552 - accuracy: 0.9067 - val_loss: 0.2857 - val_accuracy: 0.8952
Baseline test accuracy: 0.888700008392334
# save TF FP32 original model
tf.keras.models.save_model(model, assets.example.fp32_saved_model)
# Convert FP32 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.example.fp32_saved_model, onnx_model_path = assets.example.fp32_onnx_model)
INFO:tensorflow:Assets written to: GettingStarted/example/fp32/saved_model/assets
INFO:tensorflow:Assets written to: GettingStarted/example/fp32/saved_model/assets
ONNX conversion Done!
2. 量化
完整模型量化是任何人都可以遵循的最基本的量化模式。 在此模式下,Q/DQ 节点被插入到所有受支持的 keras 层中,只需一个函数调用即可
# Quantize model
quantized_model = quantize_model(model)
Keras 模型摘要显示所有受支持的层都包装在 QDQ wrapper 类中。
quantized_model.summary()
Model: "original"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
nn_input (InputLayer) [(None, 28, 28)] 0
reshape_0 (Reshape) (None, 28, 28, 1) 0
quant_conv_0 (Conv2DQuantiz (None, 26, 26, 126) 1515
eWrapper)
relu_0 (ReLU) (None, 26, 26, 126) 0
quant_conv_1 (Conv2DQuantiz (None, 24, 24, 64) 72771
eWrapper)
relu_1 (ReLU) (None, 24, 24, 64) 0
quant_conv_2 (Conv2DQuantiz (None, 22, 22, 32) 18531
eWrapper)
relu_2 (ReLU) (None, 22, 22, 32) 0
quant_conv_3 (Conv2DQuantiz (None, 20, 20, 16) 4659
eWrapper)
relu_3 (ReLU) (None, 20, 20, 16) 0
quant_conv_4 (Conv2DQuantiz (None, 18, 18, 8) 1179
eWrapper)
relu_4 (ReLU) (None, 18, 18, 8) 0
max_pool_0 (MaxPooling2D) (None, 9, 9, 8) 0
flatten_0 (Flatten) (None, 648) 0
quant_dense_0 (DenseQuantiz (None, 100) 65103
eWrapper)
relu_5 (ReLU) (None, 100) 0
quant_dense_1 (DenseQuantiz (None, 10) 1033
eWrapper)
=================================================================
Total params: 164,791
Trainable params: 164,058
Non-trainable params: 733
_________________________________________________________________
让我们检查一下在插入 Q/DQ 节点后立即量化模型的精度。
# Compile quantized model
quantized_model.compile(
optimizer=tf.keras.optimizers.Adam(0.0001),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Get accuracy immediately after QDQ nodes are inserted.
_, q_aware_model_accuracy = quantized_model.evaluate(test_images, test_labels, verbose=0)
print("Quantization test accuracy immediately after QDQ insertion:", q_aware_model_accuracy)
Quantization test accuracy immediately after QDQ insertion: 0.883899986743927
一旦插入 Q/DQ 节点,模型的精度就会略有下降,需要进行微调才能恢复。
注意
由于这是一个非常小的模型,因此精度下降很小。 对于像 ResNet 这样的标准模型,在 QDQ 插入后立即进行的精度下降可能很显着。
3. 微调
由于量化模型的行为类似于原始 keras 模型,因此相同的训练方案也可以用于微调。
我们对模型进行两个 epoch 的微调,并在测试数据集上评估模型。
# fine tune quantized model for 2 epochs.
quantized_model.fit(
train_images, train_labels, batch_size=32, epochs=2, validation_split=0.1
)
# Get quantized accuracy
_, q_aware_model_accuracy_finetuned = quantized_model.evaluate(test_images, test_labels, verbose=0)
print("Quantization test accuracy after fine-tuning:", q_aware_model_accuracy_finetuned)
print("Baseline test accuracy (for reference):", baseline_model_accuracy)
Epoch 1/2
1688/1688 [==============================] - 26s 15ms/step - loss: 0.1793 - accuracy: 0.9340 - val_loss: 0.2468 - val_accuracy: 0.9112
Epoch 2/2
1688/1688 [==============================] - 25s 15ms/step - loss: 0.1725 - accuracy: 0.9373 - val_loss: 0.2484 - val_accuracy: 0.9070
Quantization test accuracy after fine-tuning: 0.9075999855995178
Baseline test accuracy (for reference): 0.888700008392334
注意
如果网络没有完全收敛,则微调模型的精度可能会超过原始模型的精度。
# save TF INT8 original model
tf.keras.models.save_model(quantized_model, assets.example.int8_saved_model)
# Convert INT8 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.example.int8_saved_model, onnx_model_path = assets.example.int8_onnx_model)
tf.keras.backend.clear_session()
WARNING:absl:Found untraced functions such as conv_0_layer_call_fn, conv_0_layer_call_and_return_conditional_losses, conv_1_layer_call_fn, conv_1_layer_call_and_return_conditional_losses, conv_2_layer_call_fn while saving (showing 5 of 14). These functions will not be directly callable after loading.
INFO:tensorflow:Assets written to: GettingStarted/example/int8/saved_model/assets
INFO:tensorflow:Assets written to: GettingStarted/example/int8/saved_model/assets
ONNX conversion Done!
在此示例中,由于量化造成的精度损失在短短两个 epoch 内就得以恢复。
此 NVIDIA® 量化工具包提供了一个简单的界面来创建量化网络,从而可以利用 TensorRT™ 在 NVIDIA® GPU 上进行 INT8 推理。
完整网络量化
在本教程中,我们将使用一个带有 ResNet 样网络的示例网络,并执行 完整 网络量化。
目标
采用类似 resnet 的模型并在 cifar10 数据集上进行训练。
执行完整模型量化。
微调以恢复模型精度。
在执行 ONNX 转换时保存原始模型和量化模型。
#
# SPDX-FileCopyrightText: Copyright (c) 1993-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
# SPDX-License-Identifier: Apache-2.0
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://apache.ac.cn/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
import tensorflow as tf
from tensorflow_quantization import quantize_model
import tiny_resnet
from tensorflow_quantization import utils
import os
tf.keras.backend.clear_session()
# Create folders to save TF and ONNX models
assets = utils.CreateAssetsFolders(os.path.join(os.getcwd(), "tutorials"))
assets.add_folder("simple_network_quantize_full")
# Load CIFAR10 dataset
cifar10 = tf.keras.datasets.cifar10
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
# Normalize the input image so that each pixel value is between 0 and 1.
train_images = train_images / 255.0
test_images = test_images / 255.0
nn_model_original = tiny_resnet.model()
tf.keras.utils.plot_model(nn_model_original, to_file = assets.simple_network_quantize_full.fp32 + "/model.png")
You must install pydot (`pip install pydot`) and install graphviz (see instructions at https://graphviz.gitlab.io/download/) for plot_model/model_to_dot to work.
# Train original classification model
nn_model_original.compile(
optimizer=tiny_resnet.optimizer(lr=1e-4),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
nn_model_original.fit(
train_images, train_labels, batch_size=32, epochs=10, validation_split=0.1
)
# Get baseline model accuracy
_, baseline_model_accuracy = nn_model_original.evaluate(
test_images, test_labels, verbose=0
)
baseline_model_accuracy = round(100 * baseline_model_accuracy, 2)
print("Baseline FP32 model test accuracy: {}".format(baseline_model_accuracy))
Epoch 1/10
1407/1407 [==============================] - 16s 9ms/step - loss: 1.7653 - accuracy: 0.3622 - val_loss: 1.5516 - val_accuracy: 0.4552
Epoch 2/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.4578 - accuracy: 0.4783 - val_loss: 1.3877 - val_accuracy: 0.5042
Epoch 3/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.3499 - accuracy: 0.5193 - val_loss: 1.3066 - val_accuracy: 0.5342
Epoch 4/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.2736 - accuracy: 0.5486 - val_loss: 1.2636 - val_accuracy: 0.5550
Epoch 5/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.2101 - accuracy: 0.5732 - val_loss: 1.2121 - val_accuracy: 0.5670
Epoch 6/10
1407/1407 [==============================] - 12s 9ms/step - loss: 1.1559 - accuracy: 0.5946 - val_loss: 1.1753 - val_accuracy: 0.5844
Epoch 7/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.1079 - accuracy: 0.6101 - val_loss: 1.1143 - val_accuracy: 0.6076
Epoch 8/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.0660 - accuracy: 0.6272 - val_loss: 1.0965 - val_accuracy: 0.6158
Epoch 9/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.0271 - accuracy: 0.6392 - val_loss: 1.1100 - val_accuracy: 0.6122
Epoch 10/10
1407/1407 [==============================] - 13s 9ms/step - loss: 0.9936 - accuracy: 0.6514 - val_loss: 1.0646 - val_accuracy: 0.6304
Baseline FP32 model test accuracy: 61.65
# Save TF FP32 original model
tf.keras.models.save_model(nn_model_original, assets.simple_network_quantize_full.fp32_saved_model)
# Convert FP32 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.simple_network_quantize_full.fp32_saved_model, onnx_model_path = assets.simple_network_quantize_full.fp32_onnx_model)
# Quantize model
q_nn_model = quantize_model(model=nn_model_original)
q_nn_model.compile(
optimizer=tiny_resnet.optimizer(lr=1e-4),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
INFO:tensorflow:Assets written to: /home/nvidia/PycharmProjects/tensorrt_qat/docs/source/notebooks/tutorials/simple_network_quantize_full/fp32/saved_model/assets
WARNING:tensorflow:From /home/nvidia/PycharmProjects/tensorrt_qat/venv38_tf2.8_newPR/lib/python3.8/site-packages/tf2onnx/tf_loader.py:711: extract_sub_graph (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.extract_sub_graph`
ONNX conversion Done!
_, q_model_accuracy = q_nn_model.evaluate(test_images, test_labels, verbose=0)
q_model_accuracy = round(100 * q_model_accuracy, 2)
print(
"Test accuracy immediately after quantization: {}, diff: {}".format(
q_model_accuracy, (baseline_model_accuracy - q_model_accuracy)
)
)
Test accuracy immediately after quantization:50.45, diff:11.199999999999996
tf.keras.utils.plot_model(q_nn_model, to_file = assets.simple_network_quantize_full.int8 + "/model.png")
You must install pydot (`pip install pydot`) and install graphviz (see instructions at https://graphviz.gitlab.io/download/) for plot_model/model_to_dot to work.
# Fine-tune quantized model
fine_tune_epochs = 2
q_nn_model.fit(
train_images,
train_labels,
batch_size=32,
epochs=fine_tune_epochs,
validation_split=0.1,
)
_, q_model_accuracy = q_nn_model.evaluate(test_images, test_labels, verbose=0)
q_model_accuracy = round(100 * q_model_accuracy, 2)
print(
"Accuracy after fine-tuning for {} epochs: {}".format(
fine_tune_epochs, q_model_accuracy
)
)
print("Baseline accuracy (for reference): {}".format(baseline_model_accuracy))
Epoch 1/2
1407/1407 [==============================] - 27s 19ms/step - loss: 0.9625 - accuracy: 0.6630 - val_loss: 1.0430 - val_accuracy: 0.6420
Epoch 2/2
1407/1407 [==============================] - 25s 18ms/step - loss: 0.9315 - accuracy: 0.6758 - val_loss: 1.0717 - val_accuracy: 0.6336
Accuracy after fine-tuning for 2 epochs: 62.27
Baseline accuracy (for reference): 61.65
# Save TF INT8 original model
tf.keras.models.save_model(q_nn_model, assets.simple_network_quantize_full.int8_saved_model)
# Convert INT8 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.simple_network_quantize_full.int8_saved_model, onnx_model_path = assets.simple_network_quantize_full.int8_onnx_model)
tf.keras.backend.clear_session()
WARNING:absl:Found untraced functions such as conv2d_layer_call_fn, conv2d_layer_call_and_return_conditional_losses, conv2d_1_layer_call_fn, conv2d_1_layer_call_and_return_conditional_losses, conv2d_2_layer_call_fn while saving (showing 5 of 18). These functions will not be directly callable after loading.
INFO:tensorflow:Assets written to: /home/nvidia/PycharmProjects/tensorrt_qat/docs/source/notebooks/tutorials/simple_network_quantize_full/int8/saved_model/assets
INFO:tensorflow:Assets written to: /home/nvidia/PycharmProjects/tensorrt_qat/docs/source/notebooks/tutorials/simple_network_quantize_full/int8/saved_model/assets
ONNX conversion Done!
注意
ONNX 文件可以使用 Netron 可视化。
部分网络量化
此示例说明了如何使用 NVIDIA TensorFlow 2.x 量化工具包仅量化 TensorFlow 2.x 模型中的少量层。
目标
采用类似 resnet 的模型并在 cifar10 数据集上进行训练。
仅量化模型中名为 'conv2d_2' 和 'dense' 的层。
微调以恢复模型精度。
在执行 ONNX 转换时保存原始模型和量化模型。
背景
要量化的少量/特定层作为 QuantizationSpec 类的对象传递给 quantize_model 函数。 量化模式在 quantize_model 函数中设置为 partial。
将具有单个输入的层添加到 QuantizationSpec 相当简单。 但是,对于多输入层,还提供了量化特定输入的灵活性。
例如,用户想要量化名称为 conv2d_2 和 add 的层。
Add 层类别的默认行为是不量化任何输入。 当使用以下代码片段时,Add 类层的输入均未量化。
q_spec = QuantizationSpec()
layer_name = ['conv2d_2']
q_spec.add(name=layer_name, quantization_index=layer_quantization_index)
q_model = quantize_model(model, quantization_spec=q_spec)
但是,当 Add 类别的层通过 QuantizationSpec 对象传递时,所有输入都将被量化。
q_spec = QuantizationSpec()
layer_name = ['conv2d_2', 'add']
q_spec.add(name=layer_name, quantization_index=layer_quantization_index)
q_model = quantize_model(model, quantization_spec=q_spec)
用于量化层 add 的特定索引(在本例中为 1)处的输入的代码可能如下所示。
q_spec = QuantizationSpec()
layer_name = ['conv2d_2', 'add']
layer_quantization_index = [None, [1]]
q_spec.add(name=layer_name, quantization_index=layer_quantization_index)
q_model = quantize_model(model, quantization_spec=q_spec)
可以从 Functional 和 Sequential 模型的 model.summary() 函数的输出中找到层名称。 对于子类模型,请使用 tensorflow_quantization.utils 中的 KerasModelTravller 类。
有关更多详细信息,请参阅 Python API 文档。
#
# SPDX-FileCopyrightText: Copyright (c) 1993-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
# SPDX-License-Identifier: Apache-2.0
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://apache.ac.cn/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
import tensorflow as tf
from tensorflow_quantization import quantize_model, QuantizationSpec
from tensorflow_quantization.custom_qdq_cases import ResNetV1QDQCase
import tiny_resnet
import os
from tensorflow_quantization import utils
tf.keras.backend.clear_session()
# Create folders to save TF and ONNX models
assets = utils.CreateAssetsFolders(os.path.join(os.getcwd(), "tutorials"))
assets.add_folder("simple_network_quantize_partial")
# Load CIFAR10 dataset
cifar10 = tf.keras.datasets.cifar10
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
# Normalize the input image so that each pixel value is between 0 and 1.
train_images = train_images / 255.0
test_images = test_images / 255.0
nn_model_original = tiny_resnet.model()
tf.keras.utils.plot_model(nn_model_original, to_file = assets.simple_network_quantize_partial.fp32 + "/model.png")
# Train original classification model
nn_model_original.compile(
optimizer=tiny_resnet.optimizer(lr=1e-4),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
nn_model_original.fit(
train_images, train_labels, batch_size=32, epochs=10, validation_split=0.1
)
# Get baseline model accuracy
_, baseline_model_accuracy = nn_model_original.evaluate(
test_images, test_labels, verbose=0
)
baseline_model_accuracy = round(100 * baseline_model_accuracy, 2)
print("Baseline FP32 model test accuracy:", baseline_model_accuracy)
Epoch 1/10
1407/1407 [==============================] - 18s 10ms/step - loss: 1.7617 - accuracy: 0.3615 - val_loss: 1.5624 - val_accuracy: 0.4300
Epoch 2/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.4876 - accuracy: 0.4645 - val_loss: 1.4242 - val_accuracy: 0.4762
Epoch 3/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.3737 - accuracy: 0.5092 - val_loss: 1.3406 - val_accuracy: 0.5202
Epoch 4/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.2952 - accuracy: 0.5396 - val_loss: 1.2768 - val_accuracy: 0.5398
Epoch 5/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.2370 - accuracy: 0.5649 - val_loss: 1.2466 - val_accuracy: 0.5560
Epoch 6/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.1857 - accuracy: 0.5812 - val_loss: 1.2052 - val_accuracy: 0.5718
Epoch 7/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.1442 - accuracy: 0.5972 - val_loss: 1.1836 - val_accuracy: 0.5786
Epoch 8/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.1079 - accuracy: 0.6091 - val_loss: 1.1356 - val_accuracy: 0.5978
Epoch 9/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.0702 - accuracy: 0.6220 - val_loss: 1.1244 - val_accuracy: 0.5940
Epoch 10/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.0354 - accuracy: 0.6368 - val_loss: 1.1019 - val_accuracy: 0.6108
Baseline FP32 model test accuracy: 61.46
# save TF FP32 original model
tf.keras.models.save_model(nn_model_original, assets.simple_network_quantize_partial.fp32_saved_model)
# Convert FP32 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.simple_network_quantize_partial.fp32_saved_model, onnx_model_path = assets.simple_network_quantize_partial.fp32_onnx_model)
INFO:tensorflow:Assets written to: /home/sagar/nvidia/2021/Customers/Waymo/QAT/tensorrt_qat/docs/source/notebooks/tutorials/simple_network_quantize_partial/fp32/saved_model/assets
WARNING:tensorflow:From /home/sagar/miniconda3/lib/python3.8/site-packages/tf2onnx/tf_loader.py:711: extract_sub_graph (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.extract_sub_graph`
ONNX conversion Done!
# Quantize model
# 1.1 Create a dictionary to quantize only two layers named 'conv2d_2' and 'dense'
qspec = QuantizationSpec()
layer_name = ['conv2d_2', 'dense']
qspec.add(name=layer_name)
# 1.2 Call quantize model function
q_nn_model = quantize_model(
model=nn_model_original, quantization_mode="partial", quantization_spec=qspec)
q_nn_model.compile(
optimizer=tiny_resnet.optimizer(lr=1e-4),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
[I] Layer `conv2d` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `re_lu` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `conv2d_1` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `re_lu_1` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `re_lu_2` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `conv2d_3` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `re_lu_3` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `conv2d_4` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `re_lu_4` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `conv2d_5` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `conv2d_6` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `re_lu_5` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `flatten` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `re_lu_6` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `dense_1` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
tf.keras.utils.plot_model(q_nn_model, to_file = assets.simple_network_quantize_partial.int8 + "/model.png")
_, q_model_accuracy = q_nn_model.evaluate(test_images, test_labels, verbose=0)
q_model_accuracy = round(100 * q_model_accuracy, 2)
print(
"Test accuracy immediately after quantization:{}, diff:{}".format(
q_model_accuracy, (baseline_model_accuracy - q_model_accuracy)
)
)
Test accuracy immediately after quantization:58.96, diff:2.5
# Fine-tune quantized model
fine_tune_epochs = 2
q_nn_model.fit(
train_images,
train_labels,
batch_size=32,
epochs=fine_tune_epochs,
validation_split=0.1,
)
_, q_model_accuracy = q_nn_model.evaluate(test_images, test_labels, verbose=0)
q_model_accuracy = round(100 * q_model_accuracy, 2)
print(
"Accuracy after fine tuning for {} epochs :{}".format(
fine_tune_epochs, q_model_accuracy
)
)
Epoch 1/2
1407/1407 [==============================] - 20s 14ms/step - loss: 1.0074 - accuracy: 0.6480 - val_loss: 1.0854 - val_accuracy: 0.6194
Epoch 2/2
1407/1407 [==============================] - 19s 14ms/step - loss: 0.9799 - accuracy: 0.6583 - val_loss: 1.0782 - val_accuracy: 0.6242
Accuracy after fine tuning for 2 epochs :62.0
# Save TF INT8 original model
tf.keras.models.save_model(q_nn_model, assets.simple_network_quantize_partial.int8_saved_model)
# Convert INT8 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.simple_network_quantize_partial.int8_saved_model, onnx_model_path = assets.simple_network_quantize_partial.int8_onnx_model)
tf.keras.backend.clear_session()
WARNING:absl:Found untraced functions such as conv2d_2_layer_call_fn, conv2d_2_layer_call_and_return_conditional_losses, dense_layer_call_fn, dense_layer_call_and_return_conditional_losses while saving (showing 4 of 4). These functions will not be directly callable after loading.
INFO:tensorflow:Assets written to: /home/sagar/nvidia/2021/Customers/Waymo/QAT/tensorrt_qat/docs/source/notebooks/tutorials/simple_network_quantize_partial/int8/saved_model/assets
INFO:tensorflow:Assets written to: /home/sagar/nvidia/2021/Customers/Waymo/QAT/tensorrt_qat/docs/source/notebooks/tutorials/simple_network_quantize_partial/int8/saved_model/assets
ONNX conversion Done!
注意
ONNX 文件可以使用 Netron 可视化。
部分网络量化:特定层类别
目标
采用类似 resnet 的模型并在 cifar10 数据集上进行训练。
仅量化 ‘Dense’ 层类别。
微调以恢复模型精度。
在执行 ONNX 转换时保存原始模型和量化模型。
背景
要量化的特定层类别通过 QuantizationSpec 对象传递给 quantize_model()。 对于层 l,可以使用 l.__class__.__name__ 找到类名。 </br>
有关更多详细信息,请参阅 Python API 文档。
#
# SPDX-FileCopyrightText: Copyright (c) 1993-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
# SPDX-License-Identifier: Apache-2.0
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://apache.ac.cn/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
import tensorflow as tf
from tensorflow_quantization import quantize_model, QuantizationSpec
import tiny_resnet
from tensorflow_quantization import utils
import os
tf.keras.backend.clear_session()
# Create folders to save TF and ONNX models
assets = utils.CreateAssetsFolders(os.path.join(os.getcwd(), "tutorials"))
assets.add_folder("simple_network_quantize_specific_class")
# Load CIFAR10 dataset
cifar10 = tf.keras.datasets.cifar10
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
# Normalize the input image so that each pixel value is between 0 and 1.
train_images = train_images / 255.0
test_images = test_images / 255.0
nn_model_original = tiny_resnet.model()
tf.keras.utils.plot_model(nn_model_original, to_file = assets.simple_network_quantize_specific_class.fp32 + "/model.png")
# Train original classification model
nn_model_original.compile(
optimizer=tiny_resnet.optimizer(lr=1e-4),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
_ = nn_model_original.fit(
train_images, train_labels, batch_size=32, epochs=10, validation_split=0.1
)
Epoch 1/10
1407/1407 [==============================] - 17s 10ms/step - loss: 1.7871 - accuracy: 0.3526 - val_loss: 1.5601 - val_accuracy: 0.4448
Epoch 2/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.4970 - accuracy: 0.4641 - val_loss: 1.4441 - val_accuracy: 0.4812
Epoch 3/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.3885 - accuracy: 0.5040 - val_loss: 1.3627 - val_accuracy: 0.5178
Epoch 4/10
1407/1407 [==============================] - 13s 10ms/step - loss: 1.3101 - accuracy: 0.5347 - val_loss: 1.3018 - val_accuracy: 0.5332
Epoch 5/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.2473 - accuracy: 0.5591 - val_loss: 1.2233 - val_accuracy: 0.5650
Epoch 6/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.1926 - accuracy: 0.5796 - val_loss: 1.2065 - val_accuracy: 0.5818
Epoch 7/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.1475 - accuracy: 0.5972 - val_loss: 1.1449 - val_accuracy: 0.5966
Epoch 8/10
1407/1407 [==============================] - 13s 10ms/step - loss: 1.1041 - accuracy: 0.6126 - val_loss: 1.1292 - val_accuracy: 0.6048
Epoch 9/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.0636 - accuracy: 0.6275 - val_loss: 1.1122 - val_accuracy: 0.6112
Epoch 10/10
1407/1407 [==============================] - 13s 10ms/step - loss: 1.0268 - accuracy: 0.6406 - val_loss: 1.0829 - val_accuracy: 0.6244
# Get baseline model accuracy
_, baseline_model_accuracy = nn_model_original.evaluate(
test_images, test_labels, verbose=0
)
baseline_model_accuracy = round(100 * baseline_model_accuracy, 2)
print("Baseline FP32 model test accuracy:", baseline_model_accuracy)
Baseline FP32 model test accuracy: 61.51
# Save TF FP32 original model
tf.keras.models.save_model(nn_model_original, assets.simple_network_quantize_specific_class.fp32_saved_model)
# Convert FP32 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.simple_network_quantize_specific_class.fp32_saved_model, onnx_model_path = assets.simple_network_quantize_specific_class.fp32_onnx_model)
INFO:tensorflow:Assets written to: /home/sagar/nvidia/2021/Customers/Waymo/QAT/tensorrt_qat/docs/source/notebooks/tutorial_onnx_models/simple_network_quantize_specific_class/fp32/saved_model/assets
WARNING:tensorflow:From /home/sagar/miniconda3/lib/python3.8/site-packages/tf2onnx/tf_loader.py:711: extract_sub_graph (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.extract_sub_graph`
ONNX conversion Done!
# Quantize model
# 1.1 Create a list with keras layer classes to quantize
qspec = QuantizationSpec()
qspec.add(name="Dense", is_keras_class=True)
# 1.2 Call quantize model function
q_nn_model = quantize_model(model=nn_model_original, quantization_mode='partial', quantization_spec=qspec)
q_nn_model.compile(
optimizer=tiny_resnet.optimizer(lr=1e-4),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
[I] Layer class `Conv2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `ReLU` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Conv2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `ReLU` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Conv2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `ReLU` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Conv2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Add` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `ReLU` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Conv2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `ReLU` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Conv2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Conv2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Add` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `ReLU` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `MaxPooling2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Flatten` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `ReLU` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
_, q_model_accuracy = q_nn_model.evaluate(test_images, test_labels, verbose=0)
q_model_accuracy = round(100 * q_model_accuracy, 2)
print(
"Test accuracy immediately after quantization:{}, diff:{}".format(
q_model_accuracy, (baseline_model_accuracy - q_model_accuracy)
)
)
Test accuracy immediately after quantization:60.28, diff:1.2299999999999969
tf.keras.utils.plot_model(q_nn_model, to_file = assets.simple_network_quantize_specific_class.int8 + "/model.png")
# Fine-tune quantized model
fine_tune_epochs = 2
q_nn_model.fit(
train_images,
train_labels,
batch_size=32,
epochs=fine_tune_epochs,
validation_split=0.1,
)
_, q_model_accuracy = q_nn_model.evaluate(test_images, test_labels, verbose=0)
q_model_accuracy = round(100 * q_model_accuracy, 2)
print(
"Accuracy after fine tuning for {} epochs :{}".format(
fine_tune_epochs, q_model_accuracy
)
)
Epoch 1/2
1407/1407 [==============================] - 18s 13ms/step - loss: 0.9981 - accuracy: 0.6521 - val_loss: 1.0761 - val_accuracy: 0.6324
Epoch 2/2
1407/1407 [==============================] - 18s 13ms/step - loss: 0.9655 - accuracy: 0.6631 - val_loss: 1.0572 - val_accuracy: 0.6302
Accuracy after fine tuning for 2 epochs :61.82
# Save TF INT8 original model
tf.keras.models.save_model(q_nn_model, assets.simple_network_quantize_specific_class.int8_saved_model)
# Convert INT8 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.simple_network_quantize_specific_class.int8_saved_model, onnx_model_path = assets.simple_network_quantize_specific_class.int8_onnx_model)
tf.keras.backend.clear_session()
WARNING:absl:Found untraced functions such as dense_layer_call_fn, dense_layer_call_and_return_conditional_losses, dense_1_layer_call_fn, dense_1_layer_call_and_return_conditional_losses while saving (showing 4 of 4). These functions will not be directly callable after loading.
INFO:tensorflow:Assets written to: /home/sagar/nvidia/2021/Customers/Waymo/QAT/tensorrt_qat/docs/source/notebooks/tutorial_onnx_models/simple_network_quantize_specific_class/int8/saved_model/assets
INFO:tensorflow:Assets written to: /home/sagar/nvidia/2021/Customers/Waymo/QAT/tensorrt_qat/docs/source/notebooks/tutorial_onnx_models/simple_network_quantize_specific_class/int8/saved_model/assets
ONNX conversion Done!
注意
ONNX 文件可以使用 Netron 可视化。
ResNet50 V1
这假设我们的工具包及其基本要求已满足,包括访问 ImageNet 数据集。 请参阅 examples 文件夹中的 “Requirements”。
1. 初始设置
import os
import tensorflow as tf
from tensorflow_quantization.quantize import quantize_model
from tensorflow_quantization.custom_qdq_cases import ResNetV1QDQCase
from tensorflow_quantization.utils import convert_saved_model_to_onnx
HYPERPARAMS = {
"tfrecord_data_dir": "/media/Data/ImageNet/train-val-tfrecord",
"batch_size": 64,
"epochs": 2,
"steps_per_epoch": 500,
"train_data_size": None,
"val_data_size": None,
"save_root_dir": "./weights/resnet_50v1_jupyter"
}
加载数据
from examples.data.data_loader import load_data
train_batches, val_batches = load_data(HYPERPARAMS, model_name="resnet_v1")
2. 基线模型
实例化
model = tf.keras.applications.ResNet50(
include_top=True,
weights="imagenet",
classes=1000,
classifier_activation="softmax",
)
评估
def compile_model(model, lr=0.001):
model.compile(
optimizer=tf.keras.optimizers.SGD(learning_rate=lr),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=["accuracy"],
)
compile_model(model)
_, baseline_model_accuracy = model.evaluate(val_batches)
print("Baseline val accuracy: {:.3f}%".format(baseline_model_accuracy*100))
781/781 [==============================] - 41s 51ms/step - loss: 1.0481 - accuracy: 0.7504
Baseline val accuracy: 75.044%
保存并转换为 ONNX
model_save_path = os.path.join(HYPERPARAMS["save_root_dir"], "saved_model_baseline")
model.save(model_save_path)
convert_saved_model_to_onnx(saved_model_dir=model_save_path,
onnx_model_path=model_save_path + ".onnx")
INFO:tensorflow:Assets written to: ./weights/resnet_50v1_jupyter/saved_model_baseline/assets
ONNX conversion Done!
3. 量化感知训练模型
量化
q_model = quantize_model(model, custom_qdq_cases=[ResNetV1QDQCase()])
微调
compile_model(q_model)
q_model.fit(
train_batches,
validation_data=val_batches,
batch_size=HYPERPARAMS["batch_size"],
steps_per_epoch=HYPERPARAMS["steps_per_epoch"],
epochs=HYPERPARAMS["epochs"]
)
Epoch 1/2
500/500 [==============================] - 425s 838ms/step - loss: 0.4075 - accuracy: 0.8898 - val_loss: 1.0451 - val_accuracy: 0.7497
Epoch 2/2
500/500 [==============================] - 420s 840ms/step - loss: 0.3960 - accuracy: 0.8918 - val_loss: 1.0392 - val_accuracy: 0.7511
<keras.callbacks.History at 0x7f9cec1e60d0>
评估
_, qat_model_accuracy = q_model.evaluate(val_batches)
print("QAT val accuracy: {:.3f}%".format(qat_model_accuracy*100))
781/781 [==============================] - 179s 229ms/step - loss: 1.0392 - accuracy: 0.7511
QAT val accuracy: 75.114%
保存并转换为 ONNX
q_model_save_path = os.path.join(HYPERPARAMS["save_root_dir"], "saved_model_qat")
q_model.save(q_model_save_path)
convert_saved_model_to_onnx(saved_model_dir=q_model_save_path,
onnx_model_path=q_model_save_path + ".onnx")
WARNING:absl:Found untraced functions such as conv1_conv_layer_call_fn, conv1_conv_layer_call_and_return_conditional_losses, conv2_block1_1_conv_layer_call_fn, conv2_block1_1_conv_layer_call_and_return_conditional_losses, conv2_block1_2_conv_layer_call_fn while saving (showing 5 of 140). These functions will not be directly callable after loading.
INFO:tensorflow:Assets written to: ./weights/resnet_50v1_jupyter/saved_model_qat/assets
INFO:tensorflow:Assets written to: ./weights/resnet_50v1_jupyter/saved_model_qat/assets
ONNX conversion Done!
4. QAT 与基线比较
print("Baseline vs QAT: {:.3f}% vs {:.3f}%".format(baseline_model_accuracy*100, qat_model_accuracy*100))
acc_diff = (qat_model_accuracy - baseline_model_accuracy)*100
acc_diff_sign = "" if acc_diff == 0 else ("-" if acc_diff < 0 else "+")
print("Accuracy difference of {}{:.3f}%".format(acc_diff_sign, abs(acc_diff)))
Baseline vs QAT: 75.044% vs 75.114%
Accuracy difference of +0.070%
注意
对于包括 TensorRT™ 部署在内的完整工作流程,请参阅 examples/resnet。
模型动物园结果
在 NVIDIA 的 A100 GPU 和 TensorRT 8.4 上获得的结果。
ResNet
ResNet50-v1
模型 |
精度 (%) |
延迟 (ms, bs=1) |
|---|---|---|
基线 (TensorFlow) |
75.05 |
7.95 |
PTQ (TensorRT) |
74.96 |
0.46 |
QAT (TensorRT) |
75.12 |
0.45 |
ResNet50-v2
模型 |
精度 (%) |
延迟 (ms, bs=1) |
|---|---|---|
基线 (TensorFlow) |
75.36 |
6.16 |
PTQ (TensorRT) |
75.48 |
0.57 |
QAT (TensorRT) |
75.65 |
0.57 |
ResNet101-v1
模型 |
精度 (%) |
延迟 (ms, bs=1) |
|---|---|---|
基线 (TensorFlow) |
76.47 |
15.92 |
PTQ (TensorRT) |
76.32 |
0.84 |
QAT (TensorRT) |
76.26 |
0.84 |
ResNet101-v2
模型 |
精度 (%) |
延迟 (ms, bs=1) |
|---|---|---|
基线 (TensorFlow) |
76.89 |
14.13 |
PTQ (TensorRT) |
76.94 |
1.05 |
QAT (TensorRT) |
77.15 |
1.05 |
QAT 微调超参数:bs=32 ( bs=64 为 OOM)。
MobileNet
MobileNet-v1
模型 |
精度 (%) |
延迟 (ms, bs=1) |
|---|---|---|
基线 (TensorFlow) |
70.60 |
1.99 |
PTQ (TensorRT) |
69.31 |
0.16 |
QAT (TensorRT) |
70.43 |
0.16 |
MobileNet-v2
模型 |
精度 (%) |
延迟 (ms, bs=1) |
|---|---|---|
基线 (TensorFlow) |
71.77 |
3.71 |
PTQ (TensorRT) |
70.87 |
0.30 |
QAT (TensorRT) |
71.62 |
0.30 |
EfficientNet
EfficientNet-B0
模型 |
精度 (%) |
延迟 (ms, bs=1) |
|---|---|---|
基线 (TensorFlow) |
76.97 |
6.77 |
PTQ (TensorRT) |
71.71 |
0.67 |
QAT (TensorRT) |
75.82 |
0.68 |
QAT 微调超参数:bs=64, ep=10, lr=0.001, steps_per_epoch=None.
EfficientNet-B3
模型 |
精度 (%) |
延迟 (ms, bs=1) |
|---|---|---|
基线 (TensorFlow) |
81.36 |
10.33 |
PTQ (TensorRT) |
78.88 |
1.24 |
QAT (TensorRT) |
79.48 |
1.23 |
QAT 微调超参数:bs=32, ep20, lr=0.0001, steps_per_epoch=None.
添加新的层支持
此工具包使用 TensorFlow Keras wrapper 层在可量化层之前插入 QDQ 节点。
支持的层
下表显示了此工具包支持的层及其默认行为
层 |
量化输入 |
量化权重 |
量化索引 |
|---|---|---|---|
tf.keras.layers.Conv2D |
是 |
是 |
- |
tf.keras.layers.Dense |
是 |
是 |
- |
tf.keras.layers.DepthwiseConv2D |
是 |
是 |
- |
tf.keras.layers.AveragePooling2D |
是 |
- |
- |
tf.keras.layers.GlobalAveragePooling2D |
是 |
- |
- |
tf.keras.layers.MaxPooling2D |
否* |
- |
- |
tf.keras.layers.BatchNormalization |
否* |
- |
- |
tf.keras.layers.Concatenate |
否* |
- |
无* |
tf.keras.layers.Add |
否* |
- |
无* |
tf.keras.layers.Multiply |
否* |
- |
无* |
注意
*默认情况下不量化输入。 但是,可以通过将这些层作为 QuantizationSpec 传递给 quantize_model() 来实现量化。 或者,还可以通过实现 自定义 QDQ 插入案例 来实现对层行为的细粒度控制。
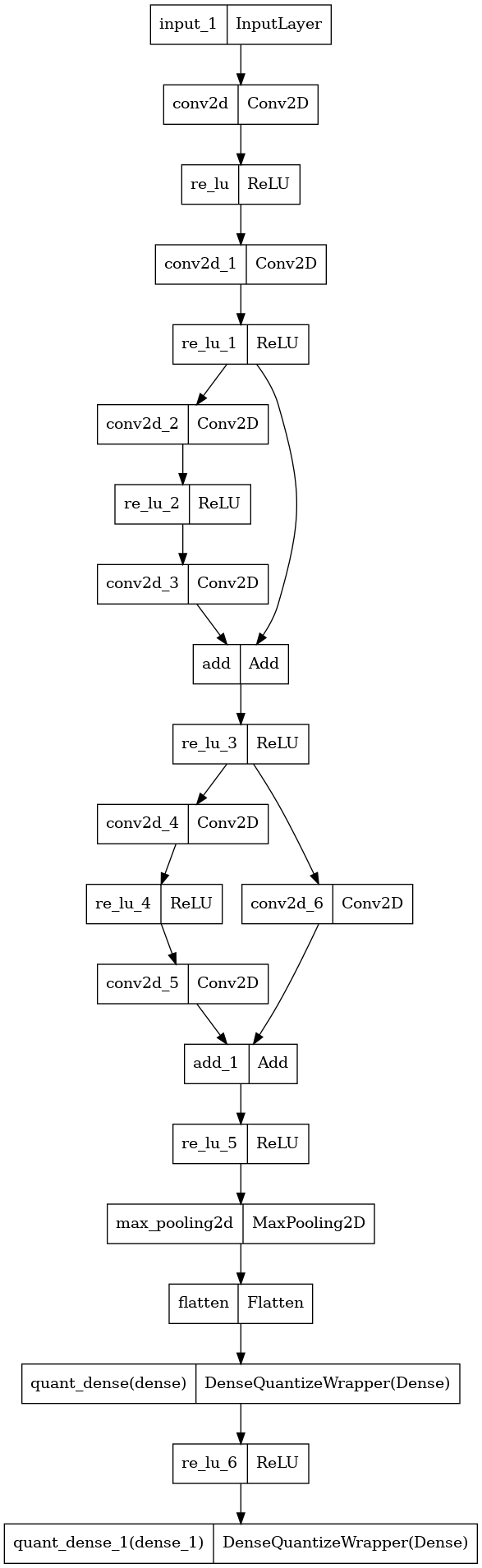
请注意,要量化的层集合可能取决于网络。 例如,在 ResNet-v1 中,MaxPool 层不需要量化,但 ResNet-v2 由于它们在残差连接中的位置而需要量化。 因此,此工具包提供了根据需要量化任何层的灵活性。
wrapper 是如何开发的?
BaseQuantizeWrapper 是一个核心量化类,它继承自 tf.keras.layers.Wrapper keras wrapper 类,如下图 1 所示。
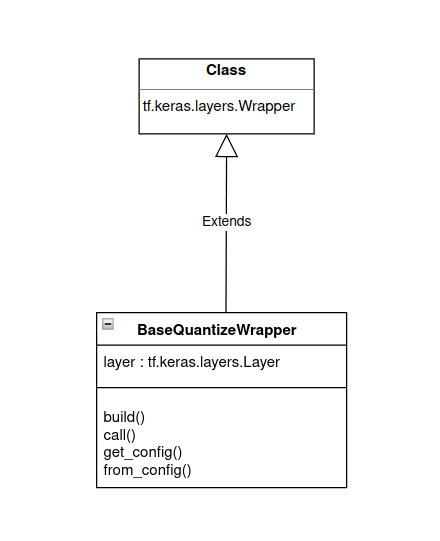
图 1. BaseQuantizeWrapper 继承。
所有量化 wrapper 都派生自 BaseQuantizeWrapper 类。 每个 wrapper 都以 layer(tf.keras.layers.Layer) 作为参数,该参数由工具包在内部处理。 为了简化开发过程,层分为加权层、非加权层或其他类型。
加权层
加权层继承自 WeightedBaseQuantizeWrapper 类,该类本身继承自 BaseQuantizeWrapper,如下图 2 所示。 WeightedBaseQuantizeWrapper 类的 layer 参数由库处理,但是,在开发 wrapper 时必须选择 kernel_type 参数。 加权层的 kernel_type 允许访问层权重。
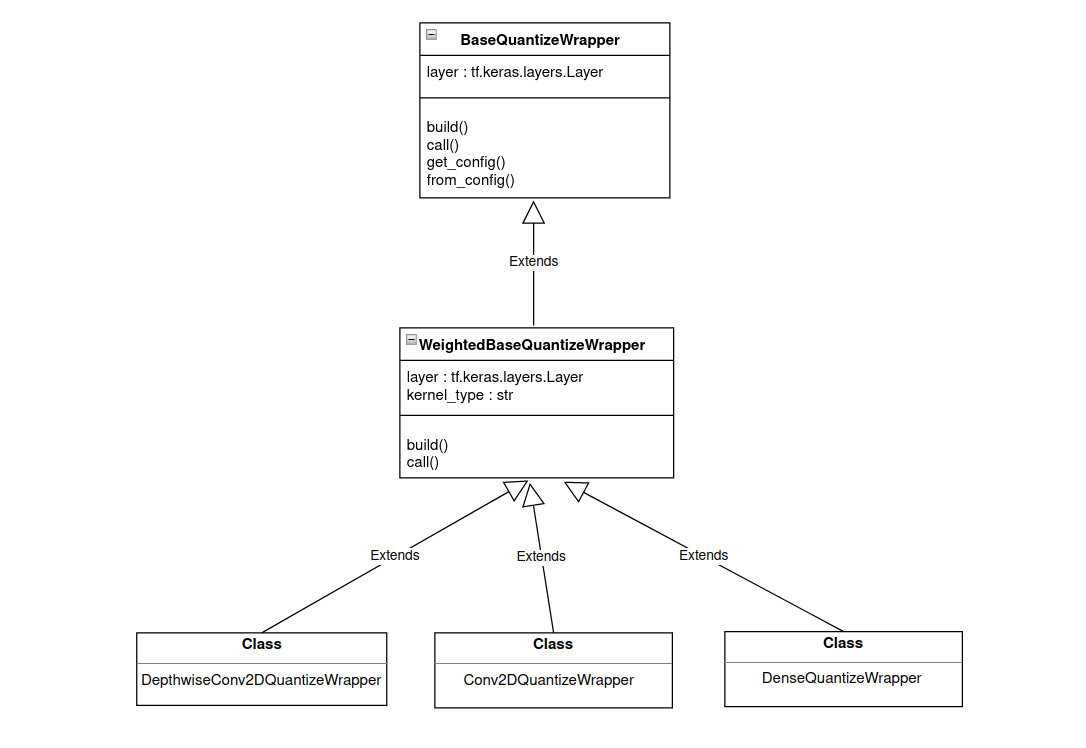
图 2. 加权层的继承流程。
非加权层
加权层继承自 WeightedBaseQuantizeWrapper 类,该类本身继承自 BaseQuantizeWrapper,如下图 3 所示。 WeightedBaseQuantizeWrapper 类的 layer 参数由库处理。
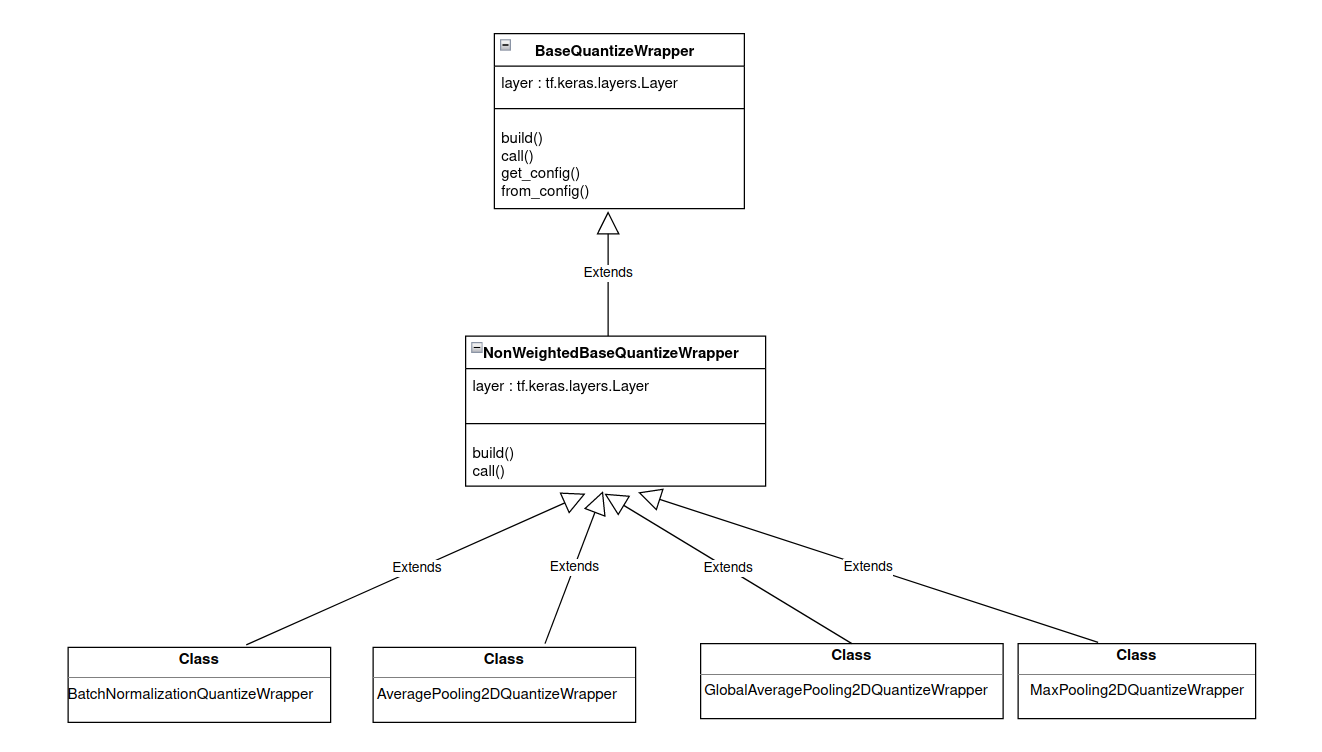
图 3. 非加权层的继承流程。
其他层 其他层直接从 BaseQuantizeWrapper 继承,如下图 4 所示。
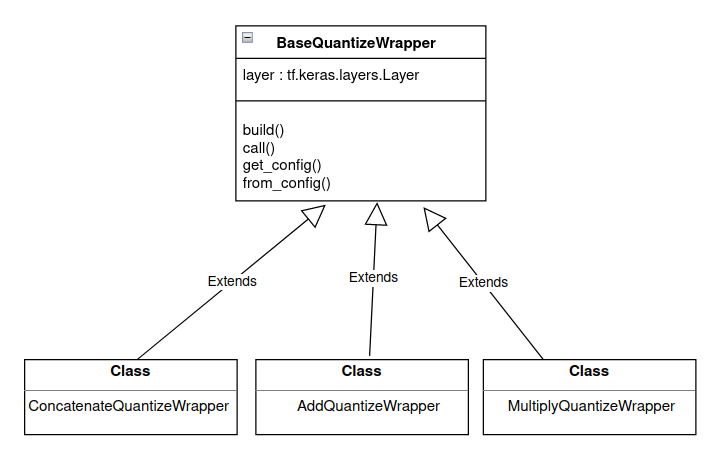
图 4. 其他层的继承流程。
如何添加新的 wrapper?
研究
tensorflow_quantization/quantize_wrappers.py脚本中的当前 wrapper。通过继承
BaseQuantizeWrapper、WeightedBaseQuantizeWrapper或NonWeightedBaseQuantizeWrapper类之一,基于新的层类型创建新类。根据层行为更新
build和call方法。
注意
仅当遵循工具包命名约定,新类才会自动注册。 对于 keras 层 l,类名称必须为 <l.__class__.__name__>QuantizeWrapper。
示例
让我们看看如何添加对新的 Keras 层 GlobalMaxPool2D 的支持。
这是一个非加权层,因此我们将继承 NonWeightedBaseQuantizeWrapper。
按照工具包命名约定,这个新的 wrapper 应命名为 GlobalMaxPool2DQuantizeWrapper。
from tensorflow_quantization import NonWeightedBaseQuantizeWrapper
class GlobalMaxPool2DQuantizeWrapper(NonWeightedBaseQuantizeWrapper):
def __init__(self, layer, **kwargs):
"""
Creates a wrapper to emulate quantization for the GlobalMaxPool2D keras layer.
Args:
layer: The keras layer to be quantized.
**kwargs: Additional keyword arguments to be passed to the keras layer.
"""
super().__init__(layer, **kwargs)
def build(self, input_shape):
super().build(input_shape)
def call(self, inputs, training=None):
return super().call(inputs, training=training)
这个新的 wrapper 类与现有的 GlobalAveragePooling2D、AveragePooling2D 和 MaxPool2D wrapper 类相同,这些类可以在 tensorflow_quantization/quantize_wrappers.py 中找到。
注意
新类注册基于跟踪 BaseQuantizeWrapper 父类的子类。 因此,除非显式调用(这是当前的限制),否则新类不会被注册。
为了确保新 wrapper 类已注册,
如果新的 wrapper 类在单独的模块中定义,请将其导入到调用
quantize_model函数的模块中。如果新的 wrapper 类与
quantize_model函数在同一模块中定义,请创建此新类的对象。 您不必在任何地方传递该对象。
添加自定义 QDQ 插入案例
此工具包中每个受支持层的默认量化行为显示在 添加新的层支持 部分中。
在大多数情况下,它会量化(向其添加 Q/DQ 节点)受支持层的所有输入和权重(如果该层是加权层)。 但是,默认行为可能并不总是导致 TensorRT™ 中的最佳 INT8 融合。 例如,需要在 ResNet 模型中的残差连接中添加 Q/DQ 节点。 我们在本页后面的“自定义 Q/DQ 插入案例量化”部分中提供了有关此案例的更深入的解释。
为了解决这些情况,我们添加了 自定义 Q/DQ 插入 案例 库功能,该功能允许用户以编程方式决定在特定情况下应如何以不同方式量化特定层。 请注意,提供 QuantizationSpec 类的对象是实现相同目标的硬编码方法。
让我们讨论库提供的 ResNetV1QDQCase,以了解传递自定义 Q/DQ 插入案例对象如何影响 Add 层的 Q/DQ 插入。
为什么需要这个?
自定义 Q/DQ 插入 功能的主要目标是调整框架的行为,以满足特定于网络的量化要求。 让我们通过一个示例来检查一下。
目标:对类似 ResNet 的模型执行自定义量化。 更具体地说,我们的目标是量化模型的残差连接。
我们展示了三种量化方案:1) 默认,2) 使用 QuantizationSpec 的自定义(次优),以及 3) 使用 自定义 Q/DQ 插入 案例 的自定义(最优)。
默认量化
注意
请参阅 完整 默认 量化 模式。
模型的默认量化是通过以下代码片段完成的
# Quantize model
q_nn_model = quantize_model(model=nn_model_original)
下图 1 显示了基线 ResNet 残差块及其对应的具有默认量化方案的量化块。
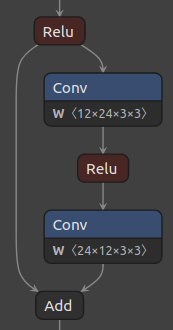
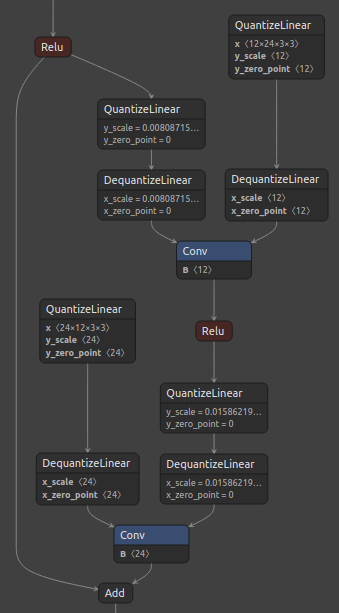
图 1. ResNet 残差块(左)和默认量化块(右)。
请注意,默认量化行为是不在 Add 层之前添加 Q/DQ 节点。 由于 AddQuantizeWrapper 已在工具包中实现,并且默认情况下已禁用,因此量化该层的最简单方法是启用对 Add 类类型的层进行量化。
使用 ‘QuantizationSpec’ 进行自定义量化(次优)
注意
请参阅 完整 自定义 量化 模式。
以下代码片段启用了对所有 Add 类类型的层进行量化
# 1. Enable `Add` layer quantization
qspec = QuantizationSpec()
qspec.add(name='Add', is_keras_class=True)
# 2. Quantize model
q_nn_model = quantize_model(
model=nn_model_original, quantization_spec=qspec
)
下图 2 显示了标准 ResNet 残差块及其对应的具有建议的自定义量化的量化块。
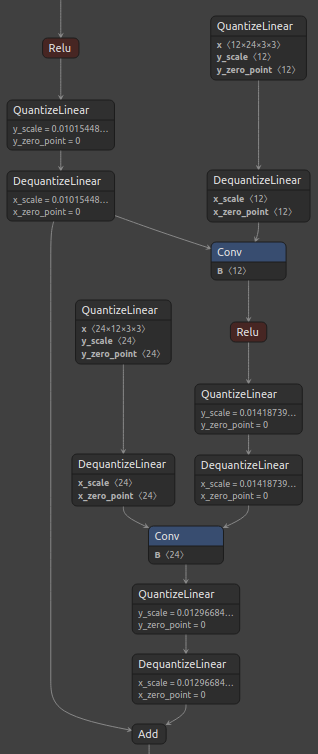
图 2. ResNet 残差块(左)和通过 QuantizationSpec 传递的 Add 层的 Q/DQ 节点插入(右)。
请注意,Add 层的所有输入都已量化。然而,这仍然无法实现 TensorRT™ 中的最佳层融合,在层融合中,卷积层后接一个 ElementWise 层(例如 Add)可以融合到一个单独的卷积核中。在这种情况下,建议仅在残差连接中添加 Q/DQ 节点(而不是在 Add 和 Conv 之间添加)。
使用“自定义 Q/DQ 插入案例”的自定义量化(最佳)
注意
请参阅 完整 自定义 量化 模式。
库提供的 ResNetV1QDQCase 类通过编程 Add 层类来解决此问题,如果某个路径连接到 Conv,则跳过该路径中的 Q/DQ。这次,我们将 ResNetV1QDQCase 类的对象传递给 quantize_model 函数
# 1. Indicate one or more custom QDQ cases
custom_qdq_case = ResNetV1QDQCase()
# 3. Quantize model
q_nn_model = quantize_model(
model=nn_model_original, custom_qdq_cases=[custom_qdq_case]
)
下图 3 显示了标准的 ResNet 残差块及其对应的量化块以及建议的自定义量化。
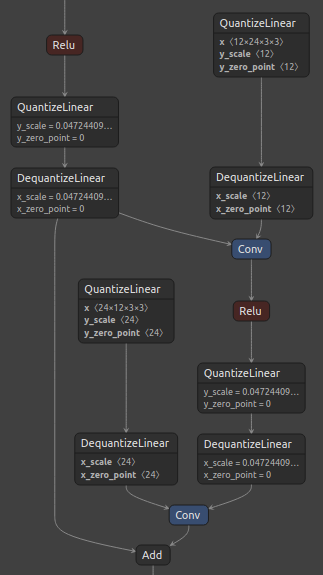
图 3. ResNet 残差块(左)和通过 ResNetV1QDQCase 传递的 Add 层的 Q/DQ 节点插入(右)。
请注意,Q/DQ 节点未添加到来自 Conv 层的路径。此外,由于第一个 Relu 层的两个输出都已量化,因此可以对它们执行水平融合,从而在该位置仅产生一对 Q/DQ 节点。这种量化方法为 TensorRT INT8 融合带来了最佳图。
库提供的自定义 Q/DQ 插入案例
我们为模型库中提供的模型提供了自定义 Q/DQ 插入案例。库提供的自定义 Q/DQ 插入案例类可以从 tensorflow_quantization.custom_qdq_cases 模块导入,并传递给 quantize_model 函数。
注意
有关更多详细信息,请参阅 tensorflow_quantization.custom_qdq_cases 模块。
如何添加新的自定义 Q/DQ 插入案例?
通过继承
tensorflow_quantization.CustomQDQInsertionCase类来创建一个新类。覆盖两个方法
case(强制性)
此方法具有如下所示的固定签名。库自动调用
quantize_model函数内部custom_qdq_cases参数的所有成员的case方法。更改默认图层行为的逻辑应在此函数中编码,并且必须返回QuantizationSpec类的对象。(function)CustomQDQInsertionCase.case( self, keras_model : 'tf.keras.Model', qspec : 'QuantizationSpec' ) -> 'QuantizationSpec'
info(可选)
这只是一个辅助方法,用于解释
case方法内部的逻辑。将此新类的对象添加到列表中,并将其传递给
quantize_model函数的custom_qdq_cases参数。
注意
如果编写了 CustomQDQInsertionCase,则必须返回 QuantizationSpec 对象。
示例,
class MaxPoolQDQCase(CustomQDQInsertionCase):
def __init__(self) -> None:
super().__init__()
def info(self) -> str:
return "Enables quantization of MaxPool layers."
def case(
self, keras_model: tf.keras.Model, qspec: QuantizationSpec
) -> QuantizationSpec:
mp_qspec = QuantizationSpec()
for layer in keras_model.layers:
if isinstance(layer, tf.keras.layers.MaxPooling2D):
if check_is_quantizable_by_layer_name(qspec, layer.name):
mp_qspec.add(
name=layer.name,
quantize_input=True,
quantize_weight=False
)
return mp_qspec
如上面的 MaxPool 自定义 Q/DQ 案例类所示,需要覆盖 case 方法。可选的 info 方法返回一个简短的描述字符串。
在 case 方法中编写的逻辑可能会或可能不会使用用户提供的 QuantizationSpec 对象,但它必须返回一个新的 QuantizationSpec,其中包含有关更新后的图层行为的信息。在上面的 MaxPoolQDQCase 案例中,自定义 Q/DQ 插入逻辑取决于用户提供的 QuantizationSpec 对象(check_is_quantizable_by_layer_name 检查图层名称是否在用户提供的对象中,并优先考虑该规范)。
tensorflow_quantization
- tensorflow_quantization.G_NUM_BITS
默认情况下使用 8 位量化。但是,可以使用
G_NUM_BITS全局变量来更改它。以下代码片段执行 4 位量化。import tensorflow_quantization # get pretrained model ..... # perform 4 bit quantization tensorflow_quantization.G_NUM_BITS = 4 q_model = quantize_model(nn_model_original) # fine-tune model .....
查看
quantize_test.py测试模块中的test_end_to_end_workflow_4bit()测试用例。- tensorflow_quantization.G_NARROW_RANGE
如果为 True,则量化最小值的绝对值与量化最大值相同。例如,对于 8 位量化,使用 -127 的最小值而不是 -128。TensorRT ™ 仅支持 G_NARROW_RANGE=True。
- tensorflow_quantization.G_SYMMETRIC
如果为 True,则 0.0 始终位于实际最小值和最大值之间,即零点始终为 0。TensorRT ™ 仅支持 G_SYMMETRIC=True。
注意
使用时,请在调用 quantize_model 函数之前立即设置全局变量。
tensorflow_quantization.quantize_model
注意
目前仅支持 Functional 和 Sequential 模型。
示例
import tensorflow as tf
from tensorflow_quantization.quantize import quantize_model
# Simple full model quantization.
# 1. Create a simple network
input_img = tf.keras.layers.Input(shape=(28, 28))
r = tf.keras.layers.Reshape(target_shape=(28, 28, 1))(input_img)
x = tf.keras.layers.Conv2D(filters=2, kernel_size=(3, 3))(r)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Conv2D(filters=2, kernel_size=(3, 3))(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Flatten()(x)
model = tf.keras.Model(input_img, x)
print(model.summary())
# 2. Quantize the network
q_model = quantize_model(model)
print(q_model.summary())
tensorflow_quantization.QuantizationSpec
示例
让我们编写一个简单的网络以在所有示例中使用。
import tensorflow as tf
# Import necessary methods from the Quantization Toolkit
from tensorflow_quantization.quantize import quantize_model, QuantizationSpec
# 1. Create a small network
input_img = tf.keras.layers.Input(shape=(28, 28))
x = tf.keras.layers.Reshape(target_shape=(28, 28, 1))(input_img)
x = tf.keras.layers.Conv2D(filters=126, kernel_size=(3, 3))(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3))(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3))(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Conv2D(filters=16, kernel_size=(3, 3))(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Conv2D(filters=8, kernel_size=(3, 3))(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(100)(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Dense(10)(x)
model = tf.keras.Model(input_img, x)
基于图层名称选择图层
目标:量化以下网络中的第 2 个 Conv2D、第 4 个 Conv2D 和第 1 个 Dense 层。
# 1. Find out layer names print(model.summary()) # 2. Create quantization spec and add layer names q_spec = QuantizationSpec() layer_name = ['conv2d_1', 'conv2d_3', 'dense'] """ # Alternatively, each layer configuration can be added one at a time: q_spec.add('conv2d_1') q_spec.add('conv2d_3') q_spec.add('dense') """ q_spec.add(name=layer_name) # 3. Quantize model q_model = quantize_model(model, quantization_mode='partial', quantization_spec=q_spec) print(q_model.summary()) tf.keras.backend.clear_session()
基于图层类选择图层
目标:量化所有 Conv2D 层。
# 1. Create QuantizationSpec object and add layer class q_spec = QuantizationSpec() q_spec.add(name='Conv2D', is_keras_class=True) # 2. Quantize model q_model = quantize_model(model, quantization_mode='partial', quantization_spec=q_spec) q_model.summary() tf.keras.backend.clear_session()
同时基于图层名称和图层类选择图层
目标:量化所有 Dense 层和第 3 个 Conv2D 层。
# 1. Create QuantizationSpec object and add layer information q_spec = QuantizationSpec() layer_name = ['Dense', 'conv2d_2'] layer_is_keras_class = [True, False] """ # Alternatively, each layer configuration can be added one at a time: q_spec.add(name='Dense', is_keras_class=True) q_spec.add(name='conv2d_2') """ q_spec.add(name=layer_name, is_keras_class=layer_is_keras_class) # 2. Quantize model q_model = quantize_model(model, quantization_mode='partial', quantization_spec=q_spec) q_model.summary() tf.keras.backend.clear_session()
为多输入图层选择特定索引处的输入
对于具有多个输入的图层,用户可以选择哪些输入需要量化。假设一个网络具有两个 Add 类的图层。
目标:量化 add 图层的索引 1、add_1 图层的索引 0 和第 3 个 Conv2D 层。
# 1. Create QuantizationSpec object and add layer information q_spec = QuantizationSpec() layer_name = ['add', 'add_1', 'conv2d_2'] layer_q_indices = [[1], [0], None] """ # Alternatively, each layer configuration can be added one at a time: q_spec.add(name='add', quantization_index=[1]) q_spec.add(name='add', quantization_index=[0]) q_spec.add(name='conv2d_2') """ q_spec.add(name=layer_name, quantization_index=layer_q_indices) # 2. Quantize model q_model = quantize_model(model, quantization_mode='partial', quantization_spec=q_spec) q_model.summary() tf.keras.backend.clear_session()
仅量化权重,而不量化输入
目标:量化以下网络中的第 2 个 Conv2D、第 4 个 Conv2D 和第 1 个 Dense 层。此外,仅量化第 2 个 Conv2D 的权重。
# 1. Find out layer names print(model.summary()) # 2. Create quantization spec and add layer names q_spec = QuantizationSpec() layer_name = ['conv2d_1', 'conv2d_3', 'dense'] layer_q_input = [False, True, True] """ # Alternatively, each layer configuration can be added one at a time: q_spec.add('conv2d_1', quantize_input=False) q_spec.add('conv2d_3') q_spec.add('dense') """ q_spec.add(name=layer_name, quantize_input=layer_q_input) # 3. Quantize model q_model = quantize_model(model, quantization_mode='partial', quantization_spec=q_spec) print(q_model.summary()) tf.keras.backend.clear_session()
tensorflow_quantization.CustomQDQInsertionCase
示例
class EfficientNetQDQCase(CustomQDQInsertionCase):
def __init__(self) -> None:
super().__init__()
def info(self):
return "In Multiply operation quantize inputs at index 0 and 1."
def case(self, keras_model: 'tf.keras.Model', qspec: 'QuantizationSpec') -> 'QuantizationSpec':
se_block_qspec_object = QuantizationSpec()
for layer in keras_model.layers:
if isinstance(layer, tf.keras.layers.Multiply):
se_block_qspec_object.add(layer.name, quantize_input=True, quantize_weight=False, quantization_index=[0, 1])
return se_block_qspec_object
tensorflow_quantization.BaseQuantizeWrapper
示例
Conv2DTranspose 层是用于执行与 Convolution 相反方向的变换的加权层。
注意
Conv2DTranspose 是一个 Keras 类,因此新的包装器类是 Conv2DTransposeQuantizeWrapper。这遵循工具包命名约定。
from tensorflow.python.util import tf_inspect
from tensorflow_quantization.quantize_wrapper_base import BaseQuantizeWrapper
class Conv2DTransposeQuantizeWrapper(BaseQuantizeWrapper):
def __init__(self, layer, kernel_type="kernel", **kwargs):
"""
Create a quantize emulate wrapper for a keras layer.
This wrapper provides options to quantize inputs, outputs amd weights of a quantizable layer.
Args:
layer: The keras layer to be quantized.
kernel_type: Options=['kernel' for Conv2D/Dense, 'depthwise_kernel' for DepthwiseConv2D]
**kwargs: Additional keyword arguments to be passed to the keras layer.
"""
self.kernel_type = kernel_type
self.channel_axis = kwargs.get("axis", -1)
super(Conv2DTransposeQuantizeWrapper, self).__init__(layer, **kwargs)
def build(self, input_shape):
super(Conv2DTransposeQuantizeWrapper, self).build(input_shape)
self._weight_vars = []
self.input_vars = {}
self.output_vars = {}
self.channel_axis = -1
if self.kernel_type == "depthwise_kernel":
self.channel_axis = 2
# quantize weights only applicable for weighted ops.
# By default weights is per channel quantization
if self.quantize_weights:
# get kernel weights dims.
kernel_weights = getattr(self.layer, self.kernel_type)
min_weight = self.layer.add_weight(
kernel_weights.name.split(":")[0] + "_min",
shape=(kernel_weights.shape[self.channel_axis]),
initializer=tf.keras.initializers.Constant(-6.0),
trainable=False,
)
max_weight = self.layer.add_weight(
kernel_weights.name.split(":")[0] + "_max",
shape=(kernel_weights.shape[self.channel_axis]),
initializer=tf.keras.initializers.Constant(6.0),
trainable=False,
)
quantizer_vars = {"min_var": min_weight, "max_var": max_weight}
self._weight_vars.append((kernel_weights, quantizer_vars))
# Needed to ensure unquantized weights get trained as part of the wrapper.
self._trainable_weights.append(kernel_weights)
# By default input is per tensor quantization
if self.quantize_inputs:
input_min_weight = self.layer.add_weight(
self.layer.name + "_ip_min",
shape=None,
initializer=tf.keras.initializers.Constant(-6.0),
trainable=False,
)
input_max_weight = self.layer.add_weight(
self.layer.name + "_ip_max",
shape=None,
initializer=tf.keras.initializers.Constant(6.0),
trainable=False,
)
self.input_vars["min_var"] = input_min_weight
self.input_vars["max_var"] = input_max_weight
def call(self, inputs, training=None):
if training is None:
training = tf.keras.backend.learning_phase()
# Quantize all weights, and replace them in the underlying layer.
if self.quantize_weights:
quantized_weights = []
quantized_weight = self._last_value_quantizer(
self._weight_vars[0][0],
training,
self._weight_vars[0][1],
per_channel=True,
channel_axis=self.channel_axis
)
quantized_weights.append(quantized_weight)
# Replace the original weights with QDQ weights
setattr(self.layer, self.kernel_type, quantized_weights[0])
# Quantize inputs to the conv layer
if self.quantize_inputs:
quantized_inputs = self._last_value_quantizer(
inputs,
training,
self.input_vars,
per_channel=False)
else:
quantized_inputs = inputs
args = tf_inspect.getfullargspec(self.layer.call).args
if "training" in args:
outputs = self.layer.call(quantized_inputs, training=training)
else:
outputs = self.layer.call(quantized_inputs)
return outputs
tensorflow_quantization.utils
量化简介
为什么要量化?
在高精度训练期间,对于细粒度的权重更新是必要的。
高精度在推理期间通常不是必要的,并且可能会阻碍 AI 模型在实时和/或资源受限设备中的部署。
INT8 的计算成本较低,并且内存占用空间更小。
INT8 精度可以实现更快的推理,并且具有相似的性能。
量化基础知识
有关更详细的解释,请参阅白皮书。
设 [β, α] 为为量化选择的可表示实值范围,b 为有符号整数表示的位宽。
均匀量化的目标是将范围 [β , α] 中的实值映射到 [-2b-1, 2b-1 - 1] 范围内。超出此范围的实值将被裁剪到最近的边界。
仿射量化
考虑 8 位量化 (b=8),范围 [β, α] 内的实值被量化为位于量化范围 [-128, 127] 内(参见来源)
xq=clamp(round(x/scale)+zeroPt)
其中,scale = (α - β) / (2b-1)
zeroPt = -round(β * scale) - 2b-1
round 是将值四舍五入到最接近整数的函数。然后将量化值钳制在 -128 到 127 之间。
仿射反量化
反量化是量化的逆过程(参见来源)
x=(xq−zeroPt)∗scale
TensorRT 中的量化
TensorRT™ 仅支持对称均匀量化,这意味着 zeroPt=0 (即 0.0 的量化值始终为 0)。
考虑 8 位量化 (b=8),范围 [min_float, max_float] 内的实值被量化为位于量化范围 [-127, 127] 内,选择不使用 -128 以支持对称性。重要的是要注意,我们在对称量化表示中丢失了 1 个值,但是,对于 8 位量化,在 256 个可表示值中丢失 1 个值是微不足道的。
量化
对称量化 (zeroPt=0) 的数学表示为
xq=clamp(round(x/scale))
由于 TensorRT 仅支持对称范围,因此比例是使用最大绝对值计算的:max(abs(min_float), abs(max_float))。
设 α = max(abs(min_float), abs(max_float)),
scale = α/(2b-1-1)
舍入类型是四舍五入到最接近的偶数。然后将量化值钳制在 -127 和 127 之间。
反量化 对称反量化是对称量化的逆过程
x=(xq)∗scale
直觉
量化比例
缩放因子将给定的实值范围划分为若干个分区。
让我们以 3 位量化为例,了解缩放因子公式背后的直觉。
非对称量化
实值范围:[β, α]
量化值范围:[-23-1, 23-1-1]
即 [-4, -3, -2, -1, 0, 1, 2, 3]
正如预期的那样,3 位量化有 8 个量化 (23) 值。
比例将范围划分为分区。3 位量化有 7 个 (23-1) 分区。因此,
scale = (α - β) / (23-1)
对称量化
对称量化带来了两个变化
实值现在不是自由的,而是受到限制的。即 [-α, α]
其中 α =max(abs(min_float), abs(max_float))从量化范围中删除一个值以支持对称性,从而导致新的范围 [-3, -2, -1, 0, 1, 2, 3]。
现在有 6 个 (23-2) 分区(与非对称量化的 7 个分区不同)。
比例将范围划分为分区。
scale = 2*α /(23 - 2) = α/(23-1-1)
类似的直觉适用于 b 位量化。
量化零点
常量 zeroPt 与量化值 xq 的类型相同,实际上是对应于实值 0 的量化值 xq。这使我们能够自动满足实值 r = 0 可以由量化值精确表示的要求。此要求的动机是,神经网络运算符的有效实现通常需要在边界周围对数组进行零填充。
如果我们有负数据的值,则零点可以偏移范围。因此,如果我们的零点为 128,则未缩放的负值 -127 到 -1 将由 1 到 127 表示,正值 0 到 127 将由 128 到 255 表示。
量化感知训练 (QAT)
将连续值转换为离散值(量化)和反之亦然(反量化)的过程,需要设置 scale 和 zeroPt(零点)参数。根据这两个参数的计算方式,有两种量化方法
- 训练后量化 (PTQ)
训练后量化在网络训练完成后计算 scale。使用代表性数据集来捕获每个激活张量的激活分布,然后使用此分布数据来计算每个张量的 scale 值。每个权重的分布用于计算权重 scale。
TensorRT 为 PTQ 提供了一个工作流程,称为 calibration(校准)。
flowchart LR id1(校准数据) --> id2(预训练模型) --> id3(捕获图层分布) --> id4(计算 'scale') --> id5(量化模型)
- 量化感知训练 (QAT)
量化感知训练旨在在训练期间计算比例因子。一旦网络完全训练完成,就会按照一组特定的规则将量化 (Q) 和反量化 (DQ) 节点插入到图中。然后对网络进行进一步的几个 epoch 的训练,这个过程称为 Fine-Tuning(微调)。Q/DQ 节点模拟量化损失,并将其添加到微调期间的训练损失中,从而使网络对量化更具弹性。换句话说,与 PTQ 相比,QAT 能够更好地保持精度。
flowchart LR id1(预训练模型) --> id2(添加 Q/DQ 节点) --> id3(微调模型) --> id4(存储 'scale') --> id5(量化模型)
注意
此工具包仅支持 QAT 作为量化方法。请注意,我们在模型中插入 Q/DQ 节点时,遵循 TensorRT™ 实现的量化算法。这使得量化网络在 TensorRT™ 引擎构建步骤期间具有最佳的层融合。
注意
由于 TensorRT™ 仅支持对称量化,我们假设 zeroPt = 0。