MIG 用户指南
本用户指南描述了 NVIDIA® Ampere 架构首次引入的多实例 GPU 功能。
1. 简介
新的多实例 GPU (MIG) 功能允许将 GPU(从 NVIDIA Ampere 架构开始)安全地划分为最多七个独立的 GPU 实例,用于 CUDA 应用程序,为多个用户提供独立的 GPU 资源,以实现最佳 GPU 利用率。此功能对于无法完全饱和 GPU 计算容量的工作负载尤其有利,因此用户可能希望并行运行不同的工作负载以最大化利用率。
对于拥有多租户用例的云服务提供商 (CSP),MIG 除了为客户提供增强的隔离外,还确保一个客户端不会影响其他客户端的工作或调度。
借助 MIG,每个实例的处理器都具有通过整个内存系统的独立且隔离的路径 - 片上交叉开关端口、L2 缓存库、内存控制器和 DRAM 地址总线都唯一分配给单个实例。这确保了即使其他任务正在争用自己的缓存或饱和其 DRAM 接口,单个用户的工作负载也可以以可预测的吞吐量和延迟运行,并具有相同的 L2 缓存分配和 DRAM 带宽。MIG 可以对可用的 GPU 计算资源(包括流式多处理器或 SM,以及 GPU 引擎,如复制引擎或解码器)进行分区,从而为不同的客户端(如虚拟机、容器或进程)提供具有故障隔离的定义的服务质量 (QoS)。MIG 使多个 GPU 实例能够在单个物理 NVIDIA Ampere 架构 GPU 上并行运行。
借助 MIG,用户将能够像使用物理 GPU 一样在其新的虚拟 GPU 实例上查看和调度作业。MIG 与 Linux 操作系统配合使用,支持使用 Docker Engine 的容器,并支持 Kubernetes 和使用 Red Hat Virtualization 和 VMware vSphere 等虚拟机管理程序的虚拟机。MIG 支持以下部署配置
裸机,包括容器
在支持的虚拟机管理程序之上,将 GPU 直通虚拟化到 Linux 客户机
在支持的虚拟机管理程序之上的 vGPU
MIG 允许在单个 GPU 上并行运行多个 vGPU(以及虚拟机),同时保留 vGPU 提供的隔离保证。有关使用 vGPU 和 MIG 进行 GPU 分区的更多信息,请参阅技术简报。
图 1 MIG 概述
本文档的目的是介绍 MIG 背后的概念、部署注意事项,并提供 MIG 管理示例,以演示用户如何在支持 MIG 的 GPU 上运行 CUDA 应用程序。
2. 支持的 GPU
MIG 在 NVIDIA Ampere 一代 GPU(即计算能力 >= 8.0 的 GPU)上受支持。下表提供了受支持 GPU 的列表
产品 |
架构 |
微架构 |
计算能力 |
内存大小 |
最大实例数 |
|---|---|---|---|---|---|
H100-SXM5 |
Hopper |
GH100 |
9.0 |
80GB |
7 |
H100-PCIE |
Hopper |
GH100 |
9.0 |
80GB |
7 |
H100-SXM5 |
Hopper |
GH100 |
9.0 |
94GB |
7 |
H100-PCIE |
Hopper |
GH100 |
9.0 |
94GB |
7 |
GH200 上的 H100 |
Hopper |
GH100 |
9.0 |
96GB |
7 |
H200-SXM5 |
Hopper |
GH100 |
9.0 |
141GB |
7 |
A100-SXM4 |
NVIDIA Ampere 架构 |
GA100 |
8.0 |
40GB |
7 |
A100-SXM4 |
NVIDIA Ampere 架构 |
GA100 |
8.0 |
80GB |
7 |
A100-PCIE |
NVIDIA Ampere 架构 |
GA100 |
8.0 |
40GB |
7 |
A100-PCIE |
NVIDIA Ampere 架构 |
GA100 |
8.0 |
80GB |
7 |
A30 |
NVIDIA Ampere 架构 |
GA100 |
8.0 |
24GB |
4 |
此外,DGX、DGX Station 和 HGX 等包含上述支持产品的系统也支持 MIG。
3. 支持的配置
MIG 支持的部署配置包括
裸机,包括容器和MIG 与 Kubernetes
在支持的虚拟机管理程序之上,将 GPU 直通虚拟化到 Linux 客户机
在支持的虚拟机管理程序之上的 vGPU
4. 虚拟化
MIG 可以与两种类型的虚拟化一起使用
在支持的虚拟机管理程序上的 Linux 客户机下,当支持 MIG 的 GPU 处于 GPU 直通模式时,裸机上可用的相同工作流程工作流程、工具和支持的 MIG 配置文件可以使用。
MIG 允许在单个支持 MIG 的 GPU 上并行运行多个 vGPU(以及虚拟机),同时保留 vGPU 提供的隔离保证。要配置 GPU 以用于 vGPU 虚拟机,请参阅配置 GPU 以用于 MIG 支持的 vGPU。另请参阅技术简报,了解有关使用 vGPU 进行 GPU 分区的更多信息。
5. 概念
5.1. 术语
本节介绍一些用于描述 MIG 背后概念的术语。
流式多处理器
流式多处理器 (SM) 在 GPU 上执行计算指令。
GPU 上下文
GPU 上下文类似于 CPU 进程。它封装了在 GPU 上执行操作所需的所有资源,包括不同的地址空间、内存分配等。GPU 上下文具有以下属性
故障隔离
单独调度
不同的地址空间
GPU 引擎
GPU 引擎是在 GPU 上执行工作的组件。最常用的引擎是执行计算指令的计算/图形引擎。其他引擎包括负责执行 DMA 的复制引擎 (CE)、用于视频解码的 NVDEC、用于编码的 NVENC 等。每个引擎都可以独立调度并为不同的 GPU 上下文执行工作。
GPU 内存切片
GPU 内存切片是 GPU 内存的最小部分,包括相应的内存控制器和缓存。GPU 内存切片大约是 GPU 总内存资源(包括容量和带宽)的八分之一。
GPU SM 切片
GPU SM 切片是 GPU 上 SM 的最小部分。当配置为 MIG 模式时,GPU SM 切片大约是 GPU 中可用 SM 总数的七分之一。
GPU 切片
GPU 切片是 GPU 的最小部分,它结合了单个 GPU 内存切片和单个 GPU SM 切片。
GPU 实例
GPU 实例 (GI) 是 GPU 切片和 GPU 引擎(DMA、NVDEC 等)的组合。GPU 实例内的任何内容始终共享所有 GPU 内存切片和其他 GPU 引擎,但其 SM 切片可以进一步细分为计算实例 (CI)。GPU 实例提供内存 QoS。每个 GPU 切片都包含专用的 GPU 内存资源,这些资源限制了可用容量和带宽,并提供内存 QoS。每个 GPU 内存切片获得 GPU 总内存资源的 1/8,每个 GPU SM 切片获得 SM 总数的 1/7。
计算实例
一个 GPU 实例可以细分为多个计算实例。计算实例 (CI) 包含父 GPU 实例的 SM 切片子集和其他 GPU 引擎(DMA、NVDEC 等)。CI 共享内存和引擎。
5.2. 分区
使用上面介绍的概念,本节概述用户如何在 GPU 上创建各种分区。为了便于说明,本文档将使用 A100-40GB 作为示例,但对于其他支持 MIG 的 GPU,该过程类似。
GPU 实例
GPU 的分区是使用内存切片进行的,因此 A100-40GB GPU 可以被认为具有 8x5GB 内存切片和 7 个 SM 切片,如下图所示。
图 2 A100 上可用的切片
如上所述,要创建 GPU 实例 (GI),需要将一些内存切片与一些计算切片组合起来。在下图中,一个 5GB 内存切片与一个计算切片组合在一起,以创建 1g.5gb GI 配置文件

图 3 组合 5GB 内存和一个计算切片
类似地,4x5GB 内存切片可以与 4x1 计算切片组合在一起,以创建 4g.5gb GI 配置文件
图 4 组合 4x5GB 内存和 4x1 计算切片
计算实例
GPU 实例的计算切片可以进一步细分为多个计算实例 (CI),CI 共享父 GI 的引擎和内存,但每个 CI 都有专用的 SM 资源。
使用上面的相同 4g.20gb 示例,可以创建一个 CI 以仅消耗第一个计算切片,如下图所示
图 5 组合内存和第一个计算切片
在这种情况下,可以通过选择任何计算切片来创建四个不同的 CI。两个计算切片也可以组合在一起以创建 2c.4g.20gb 配置文件
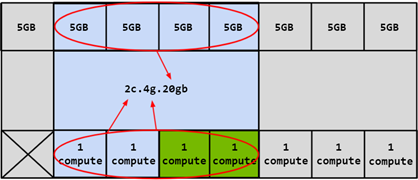
图 6 组合内存和两个计算切片
在此示例中,也可以组合 3 个计算切片以创建 3c.4g.20gb 配置文件,或者可以组合所有 4 个计算切片以创建 4c.4g.20gb 配置文件。当组合所有 4 个计算切片时,该配置文件简称为 4g.20gb 配置文件。
配置文件放置
可以创建 GI 的切片数量不是任意的。NVIDIA 驱动程序 API 提供了许多“GPU 实例配置文件”,用户可以通过指定其中一个配置文件来创建 GI。
在给定的 GPU 上,只要有足够的切片来满足请求,就可以从这些配置文件的混合搭配中创建多个 GI。
注意
下表显示了 A100-SXM4-40GB 产品上的配置文件名称。对于 A100-SXM4-80GB,配置文件名称将根据内存比例而变化 - 例如,分别为 1g.10gb、2g.20gb、3g.40gb、4g.40gb、7g.80gb。
有关支持 MIG 的 GPU 上所有受支持的配置文件组合的列表,请参阅有关支持的配置文件的部分。
配置文件名称 |
内存比例 |
SM 比例 |
硬件单元 |
L2 缓存大小 |
复制引擎 |
可用实例数 |
|---|---|---|---|---|---|---|
MIG 1g.5gb |
1/8 |
1/7 |
0 NVDEC / 0 JPEG / 0 OFA |
1/8 |
1 |
7 |
MIG 1g.5gb+me |
1/8 |
1/7 |
1 NVDEC / 1 JPEG / 1 OFA |
1/8 |
1 |
1(单个 1g 配置文件可以包含媒体扩展) |
MIG 1g.10gb |
1/8 |
1/7 |
1 NVDEC / 0 JPEG / 0 OFA |
1/8 |
1 |
4 |
MIG 2g.10gb |
2/8 |
2/7 |
1 NVDEC / 0 JPEG / 0 OFA |
2/8 |
2 |
3 |
MIG 3g.20gb |
4/8 |
3/7 |
2 NVDEC / 0 JPEG / 0 OFA |
4/8 |
3 |
2 |
MIG 4g.20gb |
4/8 |
4/7 |
2 NVDEC / 0 JPEG / 0 OFA |
4/8 |
4 |
1 |
MIG 7g.40gb |
完整 |
7/7 |
5 NVDEC / 1 JPEG / 1 OFA |
完整 |
7 |
1 |
下图显示了如何构建 GPU 实例的所有有效组合的图形表示。
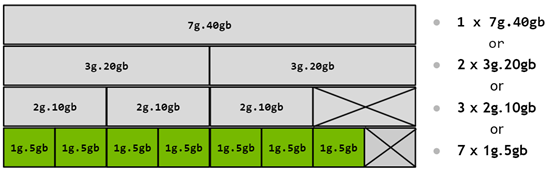
图 7 A100 上的 MIG 配置文件
在此图中,可以通过从左侧的实例配置文件开始,并将其与向右移动的其他实例配置文件组合来构建有效的组合,这样任何两个配置文件都不会垂直重叠。有关 A100 和 A30 上所有受支持的配置文件组合和放置的列表,请参阅有关支持的配置文件的部分。
请注意,在 NVIDIA 驱动程序 R510 版本之前,不支持(4 个内存,4 个计算)和(4 个内存,3 个计算)配置文件的组合。此限制在新驱动程序上不再适用。
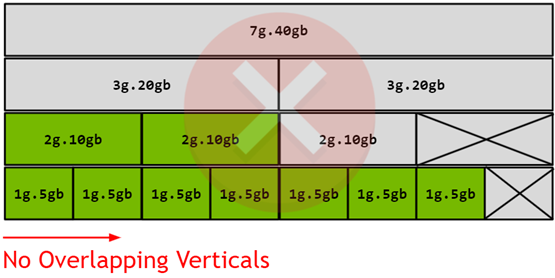
图 8 A100 上的配置文件放置
请注意,该图表示 GPU 实例在 GPU 上实例化后的物理布局。由于 GPU 实例在不同的位置创建和销毁,因此可能会发生碎片,并且一个 GPU 实例的物理位置将对接下来可以实例化在其旁边的其他 GPU 实例产生影响。
5.3. CUDA 并发机制
MIG 的设计在很大程度上对 CUDA 应用程序是透明的 - 因此 CUDA 编程模型保持不变,以最大限度地减少编程工作。CUDA 已经公开了多种在 GPU 上并行运行工作的技术,值得展示这些技术与 MIG 的比较。请注意,流和 MPS 是 CUDA 编程模型的一部分,因此在使用 GPU 实例时可以工作。
CUDA 流是 CUDA 编程模型功能,在 CUDA 应用程序中,不同的工作可以提交到独立的队列,并由 GPU 独立处理。CUDA 流只能在单个进程中使用,并且不能提供太多隔离 - 地址空间是共享的,SM 是共享的,GPU 内存带宽、缓存和容量是共享的。最后,任何错误都会影响所有流和整个进程。
MPS 是 CUDA 多进程服务。它允许协作式多进程应用程序共享 GPU 上的计算资源。它通常由协作的 MPI 作业使用,但也用于在不相关的应用程序之间共享 GPU 资源,同时接受这种解决方案带来的挑战。MPS 目前不提供客户端之间的错误隔离,虽然每个 MPS 客户端使用的流式多处理器可以有选择地限制为所有 SM 的百分比,但调度硬件仍然是共享的。内存带宽、缓存和容量在 MPS 客户端之间都是共享的。
最后,MIG 是 NVIDIA GPU 提供的新型并发形式,同时解决了其他 CUDA 技术在运行并行工作方面的一些限制。
流 |
MPS |
MIG |
|
|---|---|---|---|
分区类型 |
单进程 |
逻辑 |
物理 |
最大分区数 |
无限制 |
48 |
7 |
SM 性能隔离 |
否 |
是(按百分比,非分区) |
是 |
内存保护 |
否 |
是 |
是 |
内存带宽 QoS |
否 |
否 |
是 |
错误隔离 |
否 |
否 |
是 |
跨分区互操作 |
始终 |
IPC |
有限的 IPC |
重新配置 |
动态 |
进程启动 |
空闲时 |
6. 部署注意事项
MIG 功能作为 NVIDIA GPU 驱动程序的一部分提供。
H100 GPU 从 CUDA 12/R525 驱动程序开始受支持。
A100 和 A30 GPU 从 CUDA 11/R450 驱动程序开始受支持。
6.1. 系统注意事项
以下系统注意事项与 GPU 处于 MIG 模式时相关。
MIG 仅在 CUDA 支持的 Linux 操作系统发行版上受支持。还建议使用最新的 NVIDIA Datacenter Linux。请参阅快速入门指南。
注意
另请注意用于公开 MIG 设备的设备节点和
nvidia-capabilities。/proc机制用于系统级接口已从 450.51.06 开始弃用,建议使用基于/dev的系统级接口,通过 cgroup 控制 MIG 设备的访问机制。此功能从 450.80.02+ 驱动程序开始提供。支持的配置包括
裸机,包括容器
在支持的虚拟机管理程序之上,将 GPU 直通虚拟化到 Linux 客户机
在支持的虚拟机管理程序之上的 vGPU
MIG 允许在单个 A100 上并行运行多个 vGPU(以及虚拟机),同时保留 vGPU 提供的隔离保证。有关使用 vGPU 和 MIG 进行 GPU 分区的更多信息,请参阅技术简报。
在 A100/A30 上设置 MIG 模式需要 GPU 重置(因此需要超级用户权限)。一旦 GPU 处于 MIG 模式,实例管理就是动态的。请注意,该设置是按 GPU 进行的。
在 NVIDIA Ampere 架构 GPU 上,与 ECC 模式类似,MIG 模式设置在重启后仍然持久,直到用户显式切换设置
在启用 MIG 之前,需要停止所有持有驱动程序模块句柄的守护程序。
对于 DGX 等可能正在运行系统健康监控服务(如 nvsm)或 GPU 健康监控或遥测服务(如 DCGM)的系统,情况确实如此。
切换 MIG 模式需要
CAP_SYS_ADMIN功能。其他 MIG 管理(如创建和销毁实例)默认需要超级用户,但可以通过调整/proc/中 MIG 功能的权限来委派给非特权用户。
6.2. 应用程序注意事项
当 A100 处于 MIG 模式时,用户应注意以下事项
不支持图形 API(例如,OpenGL、Vulkan 等)。
不支持 GPU 到 GPU 的 P2P(PCIe 或 NVLink)。
CUDA 应用程序将计算实例及其父 GPU 实例视为单个 CUDA 设备。请参阅关于 CUDA 的设备枚举的此部分。
不支持跨 GPU 实例的 CUDA IPC。支持跨计算实例的 CUDA IPC。
支持 CUDA 调试(例如,使用 cuda-gdb)和内存/竞争检查(例如,使用 cuda-memcheck 或 compute-sanitizer)。
MIG 之上支持 CUDA MPS。唯一的限制是将客户端的最大数量 (48) 按比例降低到计算实例大小。
从 GPU 实例使用时,支持 GPUDirect RDMA。
7. MIG 设备名称
默认情况下,MIG 设备由单个“GPU 实例”和单个“计算实例”组成。下表重点介绍了一种命名约定,用于按其 GPU 实例的计算切片计数及其总内存(以 GB 为单位)而不是仅按其内存切片计数来引用 MIG 设备。
当仅创建一个 CI(消耗 GI 的全部计算容量)时,CI 大小调整在设备名称中隐含。

图 9 MIG 设备名称
注意
以下描述显示了 A100-SXM4-40GB 产品上的配置文件名称。对于 A100-SXM4-80GB,配置文件名称将根据内存比例而变化 - 例如,分别为 1g.10gb、2g.20gb、3g.40gb、4g.40gb、7g.80gb。
内存 |
20gb |
10gb |
5gb |
|---|---|---|---|
GPU 实例 |
3g |
2g |
1g |
计算实例 |
3c |
2c |
1c |
MIG 设备 |
3g.20gb |
2g.10gb |
1g.5gb |
GPC GPC GPC |
GPC GPC |
GPC |
每个 GI 可以进一步细分为多个 CI,这取决于用户的工作负载需求。下表重点介绍了在这种情况下 MIG 设备的名称外观。显示的示例是将 3g.20gb 设备细分为一组具有不同计算实例切片计数的子设备。
内存 |
20gb |
20gb |
|||
|---|---|---|---|---|---|
GPU 实例 |
3g |
3g |
|||
计算实例 |
1c |
1c |
1c |
2c |
1c |
MIG 设备 |
1c.3g.20gb |
1c.3g.20gb |
1c.3g.20gb |
2c.3g.20gb |
1c.3g.20gb |
GPC |
GPC |
GPC |
GPC GPC |
GPC |
|
7.1. 设备枚举
GPU 实例 (GI) 和计算实例 (CI) 在 /proc 文件系统布局中为 MIG 枚举。
$ ls -l /proc/driver/nvidia-caps/
-r--r--r-- 1 root root 0 Nov 21 21:22 mig-minors
-r--r--r-- 1 root root 0 Nov 21 21:22 nvlink-minors
-r--r--r-- 1 root root 0 Nov 21 21:22 sys-minors
对应的设备节点(在 mig-minors 中)在 /dev/nvidia-caps 下创建。有关更多信息,请参阅CUDA 设备枚举。
7.2. CUDA 设备枚举
MIG 支持通过指定应用程序应在其上运行的 CUDA 设备来运行 CUDA 应用程序。对于 CUDA 11/R450 和 CUDA 12/R525,仅支持单个 MIG 实例的枚举。换句话说,无论创建了多少 MIG 设备(或提供给容器),单个 CUDA 进程只能枚举单个 MIG 设备。CUDA 应用程序将 CI 及其父 GI 视为单个 CUDA 设备。CUDA 仅限于使用单个 CI,如果多个 CI 可见,它将选择第一个可用的 CI。总而言之,有两个约束
CUDA 只能枚举单个计算实例
如果在任何其他 GPU 上枚举任何计算实例,CUDA 将不会枚举非 MIG GPU
请注意,这些约束在未来的 NVIDIA 驱动程序版本中可能会放宽以支持 MIG。CUDA_VISIBLE_DEVICES 已扩展以添加对 MIG 的支持。根据使用的驱动程序版本,支持两种格式
对于驱动程序 >= R470 (470.42.01+),每个 MIG 设备都分配有一个以
MIG-<UUID>开头的 GPU UUID。对于驱动程序 < R470(例如,R450 和 R460),每个 MIG 设备都通过指定 CI 和相应的父 GI 来枚举。格式遵循以下约定:
MIG-<GPU-UUID>/<GPU 实例 ID>/<计算 实例 ID>。
注意
对于 R470 NVIDIA 数据中心驱动程序 (470.42.01+),以下示例显示了在 8-GPU 系统中如何为 MIG 设备分配 GPU UUID,其中每个 GPU 的配置都不同。
$ nvidia-smi -L
GPU 0: A100-SXM4-40GB (UUID: GPU-5d5ba0d6-d33d-2b2c-524d-9e3d8d2b8a77)
MIG 1g.5gb Device 0: (UUID: MIG-c6d4f1ef-42e4-5de3-91c7-45d71c87eb3f)
MIG 1g.5gb Device 1: (UUID: MIG-cba663e8-9bed-5b25-b243-5985ef7c9beb)
MIG 1g.5gb Device 2: (UUID: MIG-1e099852-3624-56c0-8064-c5db1211e44f)
MIG 1g.5gb Device 3: (UUID: MIG-8243111b-d4c4-587a-a96d-da04583b36e2)
MIG 1g.5gb Device 4: (UUID: MIG-169f1837-b996-59aa-9ed5-b0a3f99e88a6)
MIG 1g.5gb Device 5: (UUID: MIG-d5d0152c-e3f0-552c-abee-ebc0195e9f1d)
MIG 1g.5gb Device 6: (UUID: MIG-7df6b45c-a92d-5e09-8540-a6b389968c31)
GPU 1: A100-SXM4-40GB (UUID: GPU-0aa11ebd-627f-af3f-1a0d-4e1fd92fd7b0)
MIG 2g.10gb Device 0: (UUID: MIG-0c757cd7-e942-5726-a0b8-0e8fb7067135)
MIG 2g.10gb Device 1: (UUID: MIG-703fb6ed-3fa0-5e48-8e65-1c5bdcfe2202)
MIG 2g.10gb Device 2: (UUID: MIG-532453fc-0faa-5c3c-9709-a3fc2e76083d)
GPU 2: A100-SXM4-40GB (UUID: GPU-08279800-1cbe-a71d-f3e6-8f67e15ae54a)
MIG 3g.20gb Device 0: (UUID: MIG-aa232436-d5a6-5e39-b527-16f9b223cc46)
MIG 3g.20gb Device 1: (UUID: MIG-3b12da37-7fa2-596c-8655-62dab88f0b64)
GPU 3: A100-SXM4-40GB (UUID: GPU-71086aca-c858-d1e0-aae1-275bed1008b9)
MIG 7g.40gb Device 0: (UUID: MIG-3e209540-03e2-5edb-8798-51d4967218c9)
GPU 4: A100-SXM4-40GB (UUID: GPU-74fa9fb7-ccf6-8234-e597-7af8ace9a8f5)
MIG 1c.3g.20gb Device 0: (UUID: MIG-79c62632-04cc-574b-af7b-cb2e307120d8)
MIG 1c.3g.20gb Device 1: (UUID: MIG-4b3cc0fd-6876-50d7-a8ba-184a86e2b958)
MIG 1c.3g.20gb Device 2: (UUID: MIG-194837c7-0476-5b56-9c45-16bddc82e1cf)
MIG 1c.3g.20gb Device 3: (UUID: MIG-291820db-96a4-5463-8e7b-444c2d2e3dfa)
MIG 1c.3g.20gb Device 4: (UUID: MIG-5a97e28a-7809-5e93-abae-c3818c5ea801)
MIG 1c.3g.20gb Device 5: (UUID: MIG-3dfd5705-b18a-5a7c-bcee-d03a0ccb7a96)
GPU 5: A100-SXM4-40GB (UUID: GPU-3301e6dd-d38f-0eb5-4665-6c9659f320ff)
MIG 4g.20gb Device 0: (UUID: MIG-6d96b9f9-960e-5057-b5da-b8a35dc63aa8)
GPU 6: A100-SXM4-40GB (UUID: GPU-bb40ed7d-cbbb-d92c-50ac-24803cda52c5)
MIG 1c.7g.40gb Device 0: (UUID: MIG-66dd01d7-8cdb-5a13-a45d-c6eb0ee11810)
MIG 2c.7g.40gb Device 1: (UUID: MIG-03c649cb-e6ae-5284-8e94-4b1cf767e06c)
MIG 3c.7g.40gb Device 2: (UUID: MIG-8abf68e0-2808-525e-9133-ba81701ed6d3)
GPU 7: A100-SXM4-40GB (UUID: GPU-95fac899-e21a-0e44-b0fc-e4e3bf106feb)
MIG 4g.20gb Device 0: (UUID: MIG-219c765c-e07f-5b85-9c04-4afe174d83dd)
MIG 2g.10gb Device 1: (UUID: MIG-25884364-137e-52cc-a7e4-ecf3061c3ae1)
MIG 1g.5gb Device 2: (UUID: MIG-83e71a6c-f0c3-5dfc-8577-6e8b17885e1f)
8. 支持的 MIG 配置文件
本节概述了受支持的配置文件以及支持的 GPU 上 MIG 配置文件的可能放置位置。
8.1. A30 MIG 配置文件
下图显示了 NVIDIA A30 上支持的配置文件

图 10 A30 上的配置文件
下表显示了 A30-24GB 产品上支持的配置文件。
配置文件名称 |
内存比例 |
SM 比例 |
硬件单元 |
L2 缓存大小 |
复制引擎 |
可用实例数 |
|---|---|---|---|---|---|---|
MIG 1g.6gb |
1/4 |
1/4 |
0 NVDEC / 0 JPEG / 0 OFA |
1/4 |
1 |
4 |
MIG 1g.6gb+me |
1/4 |
1/4 |
1 NVDEC / 1 JPEG / 1 OFA |
1/4 |
1 |
1(单个 1g 配置文件可以包含媒体扩展) |
MIG 2g.12gb |
2/4 |
2/4 |
2 NVDEC / 0 JPEG / 0 OFA |
2/4 |
2 |
2 |
MIG 2g.12gb+me |
2/4 |
2/4 |
2 NVDEC / 1 JPEG / 1 OFA |
2/4 |
2 |
1(单个 2g 配置文件可以包含媒体扩展) |
MIG 4g.24gb |
完整 |
4/4 |
4 NVDEC / 1 JPEG / 1 OFA |
完整 |
4 |
1 |
注意
只有从 R470 驱动程序开始,才能使用 1g.6gb+me 配置文件。
只有从 R525 驱动程序开始,才能使用 2g.12gb+me 配置文件。
8.2. A100 MIG 配置文件
下图显示了 NVIDIA A100 上支持的配置文件
图 11 A100 上的配置文件
下表显示了 A100-SXM4-40GB 产品上支持的配置文件。对于 A100-SXM4-80GB,配置文件名称将根据内存比例而变化 – 例如,1g.10gb、1g.10gb+me、1g.20gb、2g.20gb、3g.40gb、4g.40gb、7g.80gb 分别对应。
配置文件名称 |
内存比例 |
SM 比例 |
硬件单元 |
L2 缓存大小 |
复制引擎 |
可用实例数 |
|---|---|---|---|---|---|---|
MIG 1g.5gb |
1/8 |
1/7 |
0 NVDEC / 0 JPEG / 0 OFA |
1/8 |
1 |
7 |
MIG 1g.5gb+me |
1/8 |
1/7 |
1 NVDEC / 1 JPEG / 1 OFA |
1/8 |
1 |
1(单个 1g 配置文件可以包含媒体扩展) |
MIG 1g.10gb |
1/8 |
1/7 |
1 NVDEC /0 JPEG /0 OFA |
1/8 |
1 |
4 |
MIG 2g.10gb |
2/8 |
2/7 |
1 NVDEC /0 JPEG /0 OFA |
2/8 |
2 |
3 |
MIG 3g.20gb |
4/8 |
3/7 |
2 NVDEC / 0 JPEG / 0 OFA |
4/8 |
3 |
2 |
MIG 4g.20gb |
4/8 |
4/7 |
2 NVDEC / 0 JPEG / 0 OFA |
4/8 |
4 |
1 |
MIG 7g.40gb |
完整 |
7/7 |
5 NVDEC / 1 JPEG / 1 OFA |
完整 |
7 |
1 |
注意
只有从 R470 驱动程序开始,才能使用 1g.5gb+me 配置文件。
只有从 R525 驱动程序开始,才能使用 1g.10gb 配置文件。
8.3. H100 MIG 配置文件
下图显示了 NVIDIA H100 上支持的配置文件
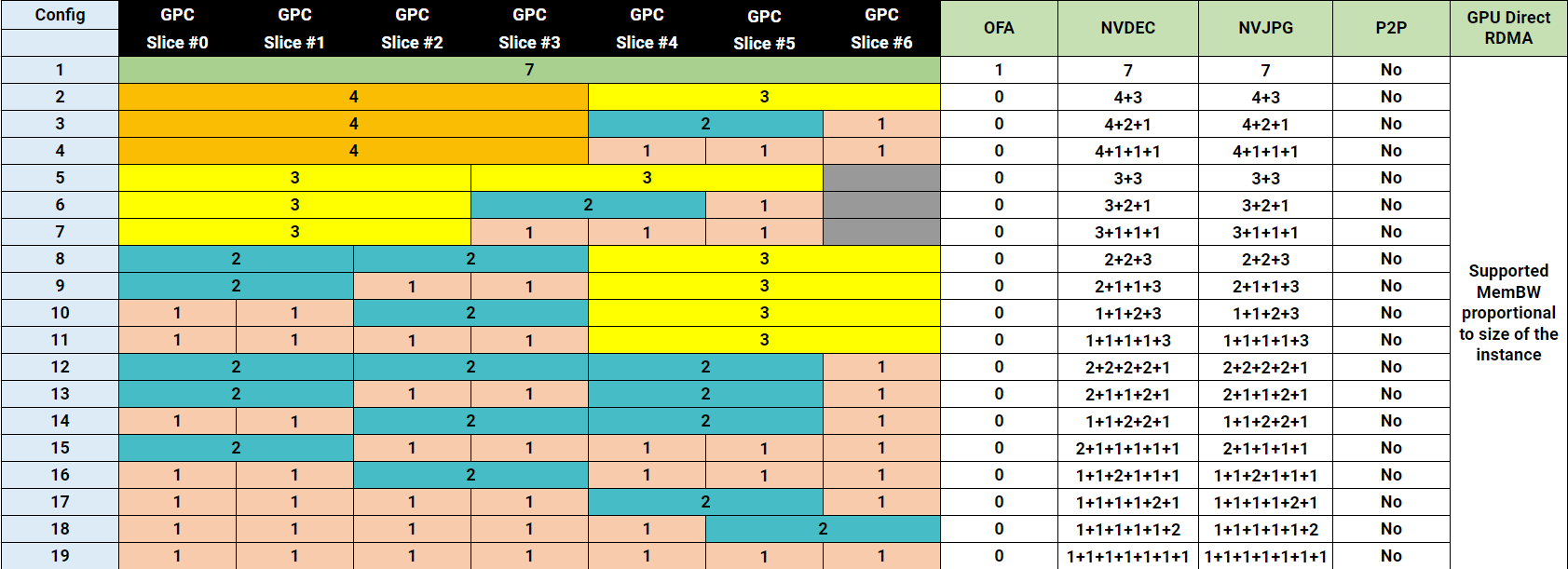
图 12 H100 上的配置文件
下表显示了 H100 80GB 产品(PCIe 和 SXM5)上支持的配置文件。
配置文件名称 |
内存比例 |
SM 比例 |
硬件单元 |
L2 缓存大小 |
复制引擎 |
可用实例数 |
|---|---|---|---|---|---|---|
MIG 1g.10gb |
1/8 |
1/7 |
1 NVDEC /1 JPEG /0 OFA |
1/8 |
1 |
7 |
MIG 1g.10gb+me |
1/8 |
1/7 |
1 NVDEC / 1 JPEG / 1 OFA |
1/8 |
1 |
1(单个 1g 配置文件可以包含媒体扩展) |
MIG 1g.20gb |
1/4 |
1/7 |
1 NVDEC /1 JPEG /0 OFA |
1/8 |
1 |
4 |
MIG 2g.20gb |
2/8 |
2/7 |
2 NVDECs /2 JPEG /0 OFA |
2/8 |
2 |
3 |
MIG 3g.40gb |
4/8 |
3/7 |
3 NVDECs /3 JPEG /0 OFA |
4/8 |
3 |
2 |
MIG 4g.40gb |
4/8 |
4/7 |
4 NVDECs /4 JPEG /0 OFA |
4/8 |
4 |
1 |
MIG 7g.80gb |
完整 |
7/7 |
7 NVDECs /7 JPEG /1 OFA |
完整 |
8 |
1 |
下表显示了 H100 94GB 产品(PCIe 和 SXM5)上支持的配置文件。
配置文件名称 |
内存比例 |
SM 比例 |
硬件单元 |
L2 缓存大小 |
复制引擎 |
可用实例数 |
|---|---|---|---|---|---|---|
MIG 1g.12gb |
1/8 |
1/7 |
1 NVDEC /1 JPEG /0 OFA |
1/8 |
1 |
7 |
MIG 1g.12gb+me |
1/8 |
1/7 |
1 NVDEC / 1 JPEG / 1 OFA |
1/8 |
1 |
1(单个 1g 配置文件可以包含媒体扩展) |
MIG 1g.24gb |
1/4 |
1/7 |
1 NVDEC /1 JPEG /0 OFA |
1/8 |
1 |
4 |
MIG 2g.24gb |
2/8 |
2/7 |
2 NVDECs /2 JPEG /0 OFA |
2/8 |
2 |
3 |
MIG 3g.47gb |
4/8 |
3/7 |
3 NVDECs /3 JPEG /0 OFA |
4/8 |
3 |
2 |
MIG 4g.47gb |
4/8 |
4/7 |
4 NVDECs /4 JPEG /0 OFA |
4/8 |
4 |
1 |
MIG 7g.94gb |
完整 |
7/7 |
7 NVDECs /7 JPEG /1 OFA |
完整 |
8 |
1 |
下表显示了 H100 96GB 产品(GH200 上的 H100)上支持的配置文件。
配置文件名称 |
内存比例 |
SM 比例 |
硬件单元 |
L2 缓存大小 |
复制引擎 |
可用实例数 |
|---|---|---|---|---|---|---|
MIG 1g.12gb |
1/8 |
1/7 |
1 NVDEC /1 JPEG /0 OFA |
1/8 |
1 |
7 |
MIG 1g.12gb+me |
1/8 |
1/7 |
1 NVDEC / 1 JPEG / 1 OFA |
1/8 |
1 |
1(单个 1g 配置文件可以包含媒体扩展) |
MIG 1g.24gb |
1/4 |
1/7 |
1 NVDEC /1 JPEG /0 OFA |
1/8 |
1 |
4 |
MIG 2g.24gb |
2/8 |
2/7 |
2 NVDECs /2 JPEG /0 OFA |
2/8 |
2 |
3 |
MIG 3g.48gb |
4/8 |
3/7 |
3 NVDECs /3 JPEG /0 OFA |
4/8 |
3 |
2 |
MIG 4g.48gb |
4/8 |
4/7 |
4 NVDECs /4 JPEG /0 OFA |
4/8 |
4 |
1 |
MIG 7g.96gb |
完整 |
7/7 |
7 NVDECs /7 JPEG /1 OFA |
完整 |
8 |
1 |
8.4. H200 MIG 配置文件
下图显示了 NVIDIA H200 上支持的配置文件
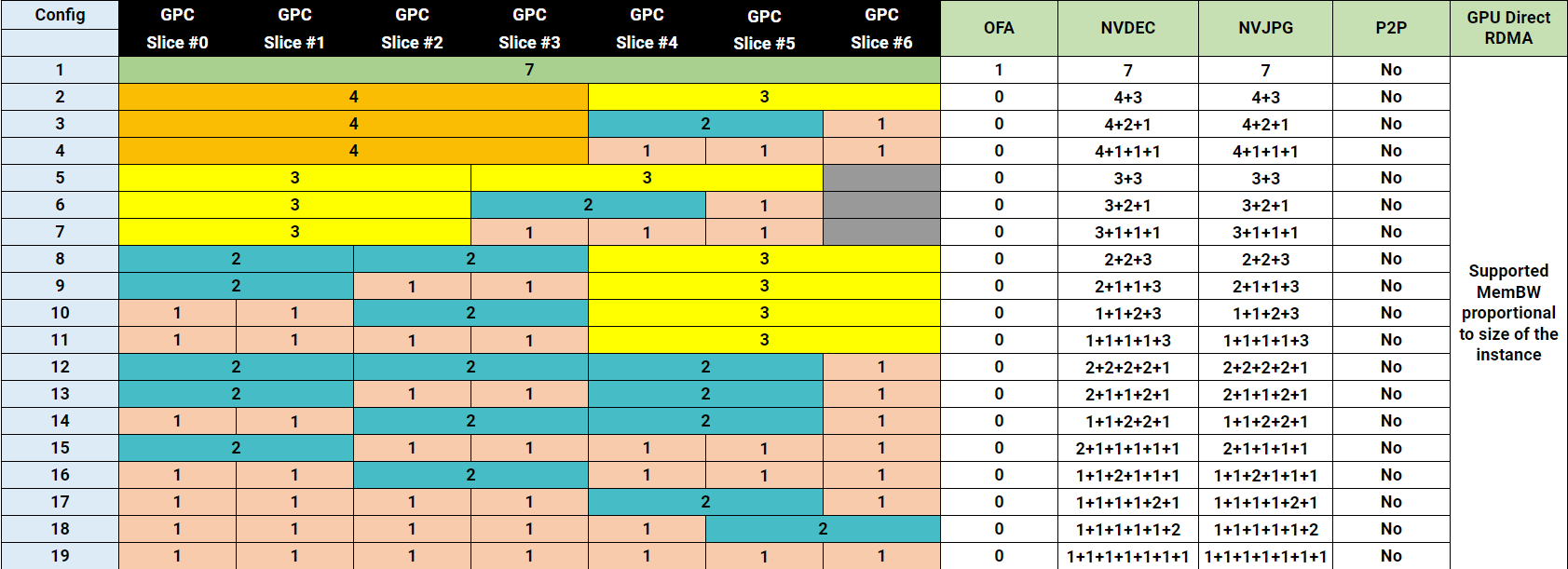
图 13 H200 上的配置文件
下表显示了 H200 141GB 产品上支持的配置文件。
配置文件名称 |
内存比例 |
SM 比例 |
硬件单元 |
L2 缓存大小 |
复制引擎 |
可用实例数 |
|---|---|---|---|---|---|---|
MIG 1g.18gb |
1/8 |
1/7 |
1 NVDECs /1 JPEG /0 OFA |
1/8 |
1 |
7 |
MIG 1g.18gb+me |
1/8 |
1/7 |
1 NVDEC / 1 JPEG / 1 OFA |
1/8 |
1 |
1(单个 1g 配置文件可以包含媒体扩展) |
MIG 1g.35gb |
1/4 |
1/7 |
1 NVDECs /1 JPEG /0 OFA |
1/8 |
1 |
4 |
MIG 2g.35gb |
2/8 |
2/7 |
2 NVDECs /2 JPEG /0 OFA |
2/8 |
2 |
3 |
MIG 3g.71gb |
4/8 |
3/7 |
3 NVDECs /3 JPEG /0 OFA |
4/8 |
3 |
2 |
MIG 4g.71gb |
4/8 |
4/7 |
4 NVDECs /4 JPEG /0 OFA |
4/8 |
4 |
1 |
MIG 7g.141gb |
完整 |
7/7 |
7 NVDECs /7 JPEG /1 OFA |
完整 |
8 |
1 |
9. MIG 入门
9.1. 先决条件
当在 MIG 模式下使用受支持的 GPU 时,建议使用以下先决条件和最低软件版本
MIG 仅在此处列出的 GPU 和系统上受支持。
建议安装最新的 NVIDIA 数据中心驱动程序。最低版本为
如果使用 H100,则需要 CUDA 12 和 NVIDIA 驱动程序 R525(
>= 525.53)或更高版本如果使用 A100/A30,则需要 CUDA 11 和 NVIDIA 驱动程序 R450(
>= 450.80.02)或更高版本
CUDA 支持的 Linux 操作系统发行版。
如果运行容器或使用 Kubernetes,则需要
NVIDIA Container Toolkit (nvidia-docker2): v2.5.0 或更高版本
NVIDIA K8s Device Plugin: v0.7.0 或更高版本
NVIDIA gpu-feature-discovery: v0.2.0 或更高版本
可以使用 NVIDIA Management Library (NVML) API 或其命令行界面 nvidia-smi 以编程方式管理 MIG。请注意,为了简洁起见,以下示例中的某些 nvidia-smi 输出可能被裁剪,以展示相关的感兴趣部分。
有关 MIG 命令的更多信息,请参阅 nvidia-smi 手册页或 nvidia-smi mig --help。有关 MIG 管理 API 的信息,请参阅 CUDA Toolkit 软件包中包含的 NVML 标头 (nvml.h)(cuda-nvml-dev-*;安装在 /usr/local/cuda/include/nvml.h 下)。有关使用配置 MIG 的自动化工具支持,请参阅 NVIDIA MIG Partition Editor(或 mig-parted)工具。
9.2. 启用 MIG 模式
默认情况下,GPU 上未启用 MIG 模式。例如,运行 nvidia-smi 表明 MIG 模式已禁用
$ nvidia-smi -i 0
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.80.02 Driver Version: 450.80.02 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 A100-SXM4-40GB Off | 00000000:36:00.0 Off | 0 |
| N/A 29C P0 62W / 400W | 0MiB / 40537MiB | 6% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
可以使用以下命令在每个 GPU 的基础上启用 MIG 模式
nvidia-smi -i <GPU IDs> -mig 1
可以使用逗号分隔的 GPU 索引、PCI 总线 ID 或 UUID 来选择 GPU。如果未指定 GPU ID,则 MIG 模式将应用于系统上的所有 GPU。
当在 GPU 上启用 MIG 时,根据 GPU 产品,驱动程序将尝试重置 GPU,以便 MIG 模式可以生效。
$ sudo nvidia-smi -i 0 -mig 1
Enabled MIG Mode for GPU 00000000:36:00.0
All done.
$ nvidia-smi -i 0 --query-gpu=pci.bus_id,mig.mode.current --format=csv
pci.bus_id, mig.mode.current
00000000:36:00.0, Enabled
9.2.1. Hopper+ GPU 上的 GPU 重置
从 Hopper 一代 GPU 开始,启用 MIG 模式不再需要 GPU 重置才能生效(因此驱动程序不会尝试在后台重置 GPU)。
请注意,MIG 模式(Disabled 或 Enabled 状态)的持久性仅限于驱动程序驻留在系统中的时间(即,内核模块已加载)。MIG 模式不再跨系统重启持久存在(GPU InfoROM 中不再存储状态位)。
因此,卸载并重新加载驱动程序内核模块将禁用 MIG 模式。
9.2.2. NVIDIA Ampere 架构 GPU 上的 GPU 重置
在 NVIDIA Ampere 架构 GPU 上,当启用 MIG 模式时,驱动程序将尝试重置 GPU,以便 MIG 模式可以生效。
请注意,MIG 模式(Disabled 或 Enabled 状态)在系统重启后是持久存在的(GPU InfoROM 中存储了一个状态位)。因此,必须显式禁用 MIG 模式才能将 GPU 返回到其默认状态。
注意
如果您在虚拟机中使用 NVIDIA Ampere GPU(A100 或 A30)进行直通,则可能需要重启虚拟机以允许 GPU 处于 MIG 模式,因为在某些情况下,出于安全原因,不允许通过虚拟机监控程序进行 GPU 重置。这可以在以下示例中看到
$ sudo nvidia-smi -i 0 -mig 1
Warning: MIG mode is in pending enable state for GPU 00000000:00:03.0:Not Supported
Reboot the system or try nvidia-smi --gpu-reset to make MIG mode effective on GPU 00000000:00:03.0
All done.
$ sudo nvidia-smi --gpu-reset
Resetting GPU 00000000:00:03.0 is not supported.
9.2.3. 驱动程序客户端
在某些情况下,如果系统上有使用 GPU 的代理(例如,监控代理),则可能无法启动 GPU 重置。例如,在 DGX 系统上,您可能会遇到以下消息
$ sudo nvidia-smi -i 0 -mig 1
Warning: MIG mode is in pending enable state for GPU 00000000:07:00.0:In use by another client
00000000:07:00.0 is currently being used by one or more other processes (e.g. CUDA application or a monitoring application such as another instance of nvidia-smi). Please first kill all processes using the device and retry the command or reboot the system to make MIG mode effective.
All done.
在此特定的 DGX 示例中,您必须停止 nvsm 和 dcgm 服务,在所需的 GPU 上启用 MIG 模式,然后恢复监控服务
$ sudo systemctl stop nvsm
$ sudo systemctl stop dcgm
$ sudo nvidia-smi -i 0 -mig 1
Enabled MIG Mode for GPU 00000000:07:00.0
All done.
文档中显示的示例使用超级用户权限。如设备节点部分所述,授予对 mig/config 功能的读取访问权限允许非 root 用户在 GPU 配置为 MIG 模式后管理实例。mig/config 文件上的默认文件权限如下。
$ ls -l /proc/driver/nvidia/capabilities/*
/proc/driver/nvidia/capabilities/mig:
total 0
-r-------- 1 root root 0 May 24 16:10 config
-r--r--r-- 1 root root 0 May 24 16:10 monitor
9.3. 列出 GPU 实例配置文件
NVIDIA 驱动程序提供了许多配置文件,用户可以在 A100 中配置 MIG 功能时选择这些配置文件。这些配置文件是用户可以创建的 GPU 实例的大小和功能。驱动程序还提供有关放置的信息,这些信息指示可以创建的实例的类型和数量。
$ nvidia-smi mig -lgip
+-----------------------------------------------------------------------------+
| GPU instance profiles: |
| GPU Name ID Instances Memory P2P SM DEC ENC |
| Free/Total GiB CE JPEG OFA |
|=============================================================================|
| 0 MIG 1g.5gb 19 7/7 4.75 No 14 0 0 |
| 1 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 1g.5gb+me 20 1/1 4.75 No 14 1 0 |
| 1 1 1 |
+-----------------------------------------------------------------------------+
| 0 MIG 1g.10gb 15 4/4 9.62 No 14 1 0 |
| 1 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 2g.10gb 14 3/3 9.62 No 28 1 0 |
| 2 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 3g.20gb 9 2/2 19.50 No 42 2 0 |
| 3 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 4g.20gb 5 1/1 19.50 No 56 2 0 |
| 4 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 7g.40gb 0 1/1 39.25 No 98 5 0 |
| 7 1 1 |
+-----------------------------------------------------------------------------+
使用以下命令列出可用的放置。放置的语法为 {<index>}:<GPU Slice Count>,并显示实例在 GPU 上的放置。显示的放置索引指示配置文件如何在 GPU 上映射,如支持的配置文件表中所示。
$ nvidia-smi mig -lgipp
GPU 0 Profile ID 19 Placements: {0,1,2,3,4,5,6}:1
GPU 0 Profile ID 20 Placements: {0,1,2,3,4,5,6}:1
GPU 0 Profile ID 15 Placements: {0,2,4,6}:2
GPU 0 Profile ID 14 Placements: {0,2,4}:2
GPU 0 Profile ID 9 Placements: {0,4}:4
GPU 0 Profile ID 5 Placement : {0}:4
GPU 0 Profile ID 0 Placement : {0}:8
该命令显示用户可以创建两个 3g.20gb 类型的实例(配置文件 ID 9)或七个 1g.5gb 类型的实例(配置文件 ID 19)。
9.4. 创建 GPU 实例
在开始使用 MIG 之前,用户需要使用 -cgi 选项创建 GPU 实例。可以使用以下三个选项之一来指定要创建的实例配置文件
配置文件 ID(例如 9、14、5)
配置文件的短名称(例如
3g.20gb)实例的完整配置文件名称(例如
MIG 3g.20gb)
创建 GPU 实例后,您需要创建相应的计算实例 (CI)。通过使用 -C 选项,nvidia-smi 会创建这些实例。
注意
如果不创建 GPU 实例(和相应的计算实例),则 CUDA 工作负载无法在 GPU 上运行。换句话说,仅在 GPU 上启用 MIG 模式是不够的。另请注意,创建的 MIG 设备在系统重启后不是持久存在的。因此,如果 GPU 或系统重置,用户或系统管理员需要重新创建所需的 MIG 配置。有关此目的的自动化工具支持,请参阅 NVIDIA MIG Partition Editor(或 mig-parted)工具,包括创建可以在系统启动时重新创建 MIG 几何结构的 systemd 服务。
以下示例显示了用户如何创建 GPU 实例(和相应的计算实例)。在此示例中,用户可以创建两个 GPU 实例(3g.20gb 类型),每个 GPU 实例都具有可用计算和内存容量的一半。在此示例中,我们特意使用配置文件 ID 和短配置文件名称来展示如何使用任一选项
$ sudo nvidia-smi mig -cgi 9,3g.20gb -C
Successfully created GPU instance ID 2 on GPU 0 using profile MIG 3g.20gb (ID 9)
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 2 using profile MIG 3g.20gb (ID 2)
Successfully created GPU instance ID 1 on GPU 0 using profile MIG 3g.20gb (ID 9)
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 1 using profile MIG 3g.20gb (ID 2)
现在列出可用的 GPU 实例
$ sudo nvidia-smi mig -lgi
+----------------------------------------------------+
| GPU instances: |
| GPU Name Profile Instance Placement |
| ID ID Start:Size |
|====================================================|
| 0 MIG 3g.20gb 9 1 4:4 |
+----------------------------------------------------+
| 0 MIG 3g.20gb 9 2 0:4 |
+----------------------------------------------------+
现在验证 GI 和相应的 CI 是否已创建
$ nvidia-smi
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 1 0 0 | 11MiB / 20224MiB | 42 0 | 3 0 2 0 0 |
+------------------+----------------------+-----------+-----------------------+
| 0 2 0 1 | 11MiB / 20096MiB | 42 0 | 3 0 2 0 0 |
+------------------+----------------------+-----------+-----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
9.4.1. 实例几何结构
如关于分区的部分所述,NVIDIA 驱动程序 API 提供了许多用户可以选择的可用 GPU 实例配置文件。
如果用户指定了配置文件的混合几何结构,则 NVIDIA 驱动程序会选择各种配置文件的放置。这可以在以下示例中看到。
示例 1:创建 4-2-1 几何结构。创建实例后,可以观察到配置文件的放置
$ sudo nvidia-smi mig -cgi 19,14,5
Successfully created GPU instance ID 13 on GPU 0 using profile MIG 1g.5gb (ID 19)
Successfully created GPU instance ID 5 on GPU 0 using profile MIG 2g.10gb (ID 14)
Successfully created GPU instance ID 1 on GPU 0 using profile MIG 4g.20gb (ID 5)
$ sudo nvidia-smi mig -lgi
+----------------------------------------------------+
| GPU instances: |
| GPU Name Profile Instance Placement |
| ID ID Start:Size |
|====================================================|
| 0 MIG 1g.5gb 19 13 6:1 |
+----------------------------------------------------+
| 0 MIG 2g.10gb 14 5 4:2 |
+----------------------------------------------------+
| 0 MIG 4g.20gb 5 1 0:4 |
+----------------------------------------------------+
示例 2:创建 3-2-1-1 几何结构。
注意:由于 API 的已知问题,配置文件 ID 9 或 3g.20gb 必须首先指定。否则,将导致以下错误
$ sudo nvidia-smi mig -cgi 19,19,14,9 Successfully created GPU instance ID 13 on GPU 0 using profile MIG 1g.5gb (ID 19) Successfully created GPU instance ID 11 on GPU 0 using profile MIG 1g.5gb (ID 19) Successfully created GPU instance ID 3 on GPU 0 using profile MIG 2g.10gb (ID 14) Unable to create a GPU instance on GPU 0 using profile 9: Insufficient Resources Failed to create GPU instances: Insufficient Resources
为 3g.20gb 配置文件指定正确的顺序。配置文件的其余组合没有此要求。
$ sudo nvidia-smi mig -cgi 9,19,14,19
Successfully created GPU instance ID 2 on GPU 0 using profile MIG 3g.20gb (ID 9)
Successfully created GPU instance ID 7 on GPU 0 using profile MIG 1g.5gb (ID 19)
Successfully created GPU instance ID 4 on GPU 0 using profile MIG 2g.10gb (ID 14)
Successfully created GPU instance ID 8 on GPU 0 using profile MIG 1g.5gb (ID 19)
$ sudo nvidia-smi mig -lgi
+----------------------------------------------------+
| GPU instances: |
| GPU Name Profile Instance Placement |
| ID ID Start:Size |
|====================================================|
| 0 MIG 1g.5gb 19 7 0:1 |
+----------------------------------------------------+
| 0 MIG 1g.5gb 19 8 1:1 |
+----------------------------------------------------+
| 0 MIG 2g.10gb 14 4 2:2 |
+----------------------------------------------------+
| 0 MIG 3g.20gb 9 2 4:4 |
+----------------------------------------------------+
示例 3:创建 2-1-1-1-1-1 几何结构
$ sudo nvidia-smi mig -cgi 14,19,19,19,19,19
Successfully created GPU instance ID 5 on GPU 0 using profile MIG 2g.10gb (ID 14)
Successfully created GPU instance ID 13 on GPU 0 using profile MIG 1g.5gb (ID 19)
Successfully created GPU instance ID 7 on GPU 0 using profile MIG 1g.5gb (ID 19)
Successfully created GPU instance ID 8 on GPU 0 using profile MIG 1g.5gb (ID 19)
Successfully created GPU instance ID 9 on GPU 0 using profile MIG 1g.5gb (ID 19)
Successfully created GPU instance ID 10 on GPU 0 using profile MIG 1g.5gb (ID 19)
$ sudo nvidia-smi mig -lgi
+----------------------------------------------------+
| GPU instances: |
| GPU Name Profile Instance Placement |
| ID ID Start:Size |
|====================================================|
| 0 MIG 1g.5gb 19 7 0:1 |
+----------------------------------------------------+
| 0 MIG 1g.5gb 19 8 1:1 |
+----------------------------------------------------+
| 0 MIG 1g.5gb 19 9 2:1 |
+----------------------------------------------------+
| 0 MIG 1g.5gb 19 10 3:1 |
+----------------------------------------------------+
| 0 MIG 1g.5gb 19 13 6:1 |
+----------------------------------------------------+
| 0 MIG 2g.10gb 14 5 4:2 |
+----------------------------------------------------+
9.5. 在裸机上运行 CUDA 应用程序
9.5.1. GPU 实例
以下示例显示了如何在两个不同的 GPU 实例上并行运行两个 CUDA 应用程序。在此示例中,BlackScholes CUDA 示例在 A100 上创建的两个 GI 上同时运行。
$ nvidia-smi -L
GPU 0: A100-SXM4-40GB (UUID: GPU-e86cb44c-6756-fd30-cd4a-1e6da3caf9b0)
MIG 3g.20gb Device 0: (UUID: MIG-c7384736-a75d-5afc-978f-d2f1294409fd)
MIG 3g.20gb Device 1: (UUID: MIG-a28ad590-3fda-56dd-84fc-0a0b96edc58d)
$ CUDA_VISIBLE_DEVICES=MIG-c7384736-a75d-5afc-978f-d2f1294409fd ./BlackScholes &
$ CUDA_VISIBLE_DEVICES=MIG-a28ad590-3fda-56dd-84fc-0a0b96edc58d ./BlackScholes &
现在验证两个 CUDA 应用程序是否在两个单独的 GPU 实例上运行
$ nvidia-smi
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 1 0 0 | 268MiB / 20224MiB | 42 0 | 3 0 2 0 0 |
+------------------+----------------------+-----------+-----------------------+
| 0 2 0 1 | 268MiB / 20096MiB | 42 0 | 3 0 2 0 0 |
+------------------+----------------------+-----------+-----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 1 0 58866 C ./BlackScholes 253MiB |
| 0 2 0 58856 C ./BlackScholes 253MiB |
+-----------------------------------------------------------------------------+
9.5.2. GPU 利用率指标
NVML(和 nvidia-smi)不支持将利用率指标归因于 MIG 设备。从前面的示例中,当运行 CUDA 程序时,利用率显示为 N/A
$ nvidia-smi
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 1 0 0 | 268MiB / 20096MiB | 42 0 | 3 0 2 0 0 |
| | 4MiB / 32767MiB | | |
+------------------+----------------------+-----------+-----------------------+
| 0 2 0 1 | 268MiB / 20096MiB | 42 0 | 3 0 2 0 0 |
| | 4MiB / 32767MiB | | |
+------------------+----------------------+-----------+-----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 1 0 6217 C ...inux/release/BlackScholes 253MiB |
| 0 2 0 6223 C ...inux/release/BlackScholes 253MiB |
+-----------------------------------------------------------------------------+
为了监控支持 MIG 的 GPU(如 A100)上的 MIG 设备,包括 GPU 指标(包括利用率和其他性能分析指标)的归因,建议使用 NVIDIA DCGM v2.0.13 或更高版本。有关入门的更多详细信息,请参阅 DCGM 用户指南中的性能分析指标部分。
9.5.3. 计算实例
如本文档前面所述,通过使用计算实例 (CI) 可以实现更高级别的并发。以下示例显示了如何在同一 GI 上运行 3 个 CUDA 进程(BlackScholes CUDA 示例)。
首先,使用我们之前在 A100 上创建 2 个 GI 的配置,列出可用的 CI 配置文件。
$ sudo nvidia-smi mig -lcip -gi 1
+--------------------------------------------------------------------------------------+
| Compute instance profiles: |
| GPU GPU Name Profile Instances Exclusive Shared |
| Instance ID Free/Total SM DEC ENC OFA |
| ID CE JPEG |
|======================================================================================|
| 0 1 MIG 1c.3g.20gb 0 0/3 14 2 0 0 |
| 3 0 |
+--------------------------------------------------------------------------------------+
| 0 1 MIG 2c.3g.20gb 1 0/1 28 2 0 0 |
| 3 0 |
+--------------------------------------------------------------------------------------+
| 0 1 MIG 3g.20gb 2* 0/1 42 2 0 0 |
| 3 0 |
+--------------------------------------------------------------------------------------+
在第一个 GI 上创建 3 个 CI,每个 CI 的类型为 1c 计算容量(配置文件 ID 0)。
$ sudo nvidia-smi mig -cci 0,0,0 -gi 1
Successfully created compute instance on GPU 0 GPU instance ID 1 using profile MIG 1c.3g.20gb (ID 0)
Successfully created compute instance on GPU 0 GPU instance ID 1 using profile MIG 1c.3g.20gb (ID 0)
Successfully created compute instance on GPU 0 GPU instance ID 1 using profile MIG 1c.3g.20gb (ID 0)
使用 nvidia-smi,现在在 GI 1 上创建了以下 CI
$ sudo nvidia-smi mig -lci -gi 1
+-------------------------------------------------------+
| Compute instances: |
| GPU GPU Name Profile Instance |
| Instance ID ID |
| ID |
|=======================================================|
| 0 1 MIG 1c.3g.20gb 0 0 |
+-------------------------------------------------------+
| 0 1 MIG 1c.3g.20gb 0 1 |
+-------------------------------------------------------+
| 0 1 MIG 1c.3g.20gb 0 2 |
+-------------------------------------------------------+
驱动程序现在枚举了在 A100 上创建的 GI 和 CI
$ nvidia-smi
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 1 0 0 | 11MiB / 20224MiB | 14 0 | 3 0 2 0 0 |
+------------------+ +-----------+-----------------------+
| 0 1 1 1 | | 14 0 | 3 0 2 0 0 |
+------------------+ +-----------+-----------------------+
| 0 1 2 2 | | 14 0 | 3 0 2 0 0 |
+------------------+----------------------+-----------+-----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
现在,可以并行创建和运行三个 BlackScholes 应用程序
$ CUDA_VISIBLE_DEVICES=MIG-c7384736-a75d-5afc-978f-d2f1294409fd ./BlackScholes &
$ CUDA_VISIBLE_DEVICES=MIG-c376546e-7559-5610-9721-124e8dbb1bc8 ./BlackScholes &
$ CUDA_VISIBLE_DEVICES=MIG-928edfb0-898f-53bd-bf24-c7e5d08a6852 ./BlackScholes &
并使用 nvidia-smi 将其视为在三个 CI 上运行的进程
$ nvidia-smi
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 1 0 0 | 476MiB / 20224MiB | 14 0 | 3 0 2 0 0 |
+------------------+ +-----------+-----------------------+
| 0 1 1 1 | | 14 0 | 3 0 2 0 0 |
+------------------+ +-----------+-----------------------+
| 0 1 2 2 | | 14 0 | 3 0 2 0 0 |
+------------------+----------------------+-----------+-----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 1 0 59785 C ./BlackScholes 153MiB |
| 0 1 1 59796 C ./BlackScholes 153MiB |
| 0 1 2 59885 C ./BlackScholes 153MiB |
+-----------------------------------------------------------------------------+
9.6. 销毁 GPU 实例
一旦 GPU 处于 MIG 模式,就可以动态配置 GI 和 CI。以下示例显示了如何销毁先前示例中创建的 CI 和 GI。
注意:如果打算销毁所有 CI 和 GI,可以使用以下命令完成
$ sudo nvidia-smi mig -dci && sudo nvidia-smi mig -dgi
Successfully destroyed compute instance ID 0 from GPU 0 GPU instance ID 1
Successfully destroyed compute instance ID 1 from GPU 0 GPU instance ID 1
Successfully destroyed compute instance ID 2 from GPU 0 GPU instance ID 1
Successfully destroyed GPU instance ID 1 from GPU 0
Successfully destroyed GPU instance ID 2 from GPU 0
在此示例中,我们删除在 GI 1 下创建的特定 CI。
$ sudo nvidia-smi mig -dci -ci 0,1,2 -gi 1
Successfully destroyed compute instance ID 0 from GPU 0 GPU instance ID 1
Successfully destroyed compute instance ID 1 from GPU 0 GPU instance ID 1
Successfully destroyed compute instance ID 2 from GPU 0 GPU instance ID 1
可以验证 CI 设备现在已在 GPU 上拆除
$ nvidia-smi
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| No MIG devices found |
+-----------------------------------------------------------------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
现在必须删除 GI
$ sudo nvidia-smi mig -dgi
Successfully destroyed GPU instance ID 1 from GPU 0
Successfully destroyed GPU instance ID 2 from GPU 0
9.7. 监控 MIG 设备
为了监控 MIG 设备,包括 GPU 指标(包括利用率和其他性能分析指标)的归因,建议使用 NVIDIA DCGM v3 或更高版本。有关入门的更多详细信息,请参阅 DCGM 用户指南中的性能分析指标部分。
注意
在 NVIDIA Ampere 架构 GPU(A100 或 A30)上,NVML(和 nvidia-smi)不支持将利用率指标归因于 MIG 设备。从前面的示例中,当运行 CUDA 程序时,利用率显示为 N/A
$ nvidia-smi
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 1 0 0 | 268MiB / 20096MiB | 42 0 | 3 0 2 0 0 |
| | 4MiB / 32767MiB | | |
+------------------+----------------------+-----------+-----------------------+
| 0 2 0 1 | 268MiB / 20096MiB | 42 0 | 3 0 2 0 0 |
| | 4MiB / 32767MiB | | |
+------------------+----------------------+-----------+-----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 1 0 6217 C ...inux/release/BlackScholes 253MiB |
| 0 2 0 6223 C ...inux/release/BlackScholes 253MiB |
+-----------------------------------------------------------------------------+
9.8. MIG 与 CUDA MPS
如CUDA 并发机制中所述,CUDA 多进程服务 (MPS) 使协作式多进程 CUDA 应用程序能够在 GPU 上并发处理。MPS 和 MIG 可以协同工作,从而可能为某些工作负载实现更高的利用率。
请参阅 MPS 文档以了解 MPS 的架构和配置序列。
在以下各节中,我们将逐步介绍在 MIG 设备上运行 MPS 的示例。
9.8.1. 工作流程
总而言之,使用 MPS 运行的工作流程如下
在 GPU 上配置所需的 MIG 几何结构。
设置
CUDA_MPS_PIPE_DIRECTORY变量以指向唯一目录,以便多个 MPS 服务器和客户端可以使用命名管道和 Unix 域套接字相互通信。通过使用
CUDA_VISIBLE_DEVICES指定 MIG 设备来启动应用程序。
注意
MPS 文档建议设置 EXCLUSIVE_PROCESS 模式,以确保单个 MPS 服务器正在使用 GPU。但是,当 GPU 处于 MIG 模式时,不支持此模式,因为我们使用多个 MPS 服务器(每个 MIG GPU 实例一个)。
9.8.2. 配置 GPU 实例
按照前面部分中概述的步骤在 GPU 上配置所需的 MIG 几何结构。在此示例中,我们将 GPU 配置为 3g.20gb,3g.2gb 几何结构
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.73.01 Driver Version: 460.73.01 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 A100-PCIE-40GB On | 00000000:65:00.0 Off | On |
| N/A 37C P0 66W / 250W | 581MiB / 40536MiB | N/A Default |
| | | Enabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 1 0 0 | 290MiB / 20096MiB | 42 0 | 3 0 2 0 0 |
| | 8MiB / 32767MiB | | |
+------------------+----------------------+-----------+-----------------------+
| 0 2 0 1 | 290MiB / 20096MiB | 42 0 | 3 0 2 0 0 |
| | 8MiB / 32767MiB | | |
+------------------+----------------------+-----------+-----------------------+
9.8.3. 设置 MPS 控制守护程序
在此步骤中,我们启动 MPS 控制守护程序(具有管理员权限),并确保为每个守护程序使用不同的套接字
export CUDA_MPS_PIPE_DIRECTORY=/tmp/<MIG_UUID>
mkdir -p $CUDA_MPS_PIPE_DIRECTORY
CUDA_VISIBLE_DEVICES=<MIG_UUID> \
CUDA_MPS_PIPE_DIRECTORY=/tmp/<MIG_UUID> \
nvidia-cuda-mps-control -d
9.8.4. 启动应用程序
现在,我们可以通过使用 CUDA_VISIBLE_DEVICES 指定所需的 MIG 设备来启动应用程序
CUDA_VISIBLE_DEVICES=<MIG_UUID> \
my-cuda-app
9.8.5. 完整示例
我们现在在下面提供一个脚本,我们在其中尝试在 GPU 上创建的两个 MIG 设备上运行之前的 BlackScholes
#!/usr/bin/env bash
set -euo pipefail
#GPU 0: A100-PCIE-40GB (UUID: GPU-63feeb45-94c6-b9cb-78ea-98e9b7a5be6b)
# MIG 3g.20gb Device 0: (UUID: MIG-GPU-63feeb45-94c6-b9cb-78ea-98e9b7a5be6b/1/0)
# MIG 3g.20gb Device 1: (UUID: MIG-GPU-63feeb45-94c6-b9cb-78ea-98e9b7a5be6b/2/0)
GPU_UUID=GPU-63feeb45-94c6-b9cb-78ea-98e9b7a5be6b
for i in MIG-$GPU_UUID/1/0 MIG-$GPU_UUID/2/0; do
# set the environment variable on each MPS
# control daemon and use different socket for each MIG instance
export CUDA_MPS_PIPE_DIRECTORY=/tmp/$i
mkdir -p $CUDA_MPS_PIPE_DIRECTORY
sudo CUDA_VISIBLE_DEVICES=$i \
CUDA_MPS_PIPE_DIRECTORY=/tmp/$i \
nvidia-cuda-mps-control -d
# now launch the job on the specific MIG device
# and select the appropriate MPS server on the device
CUDA_MPS_PIPE_DIRECTORY=/tmp/$i \
CUDA_VISIBLE_DEVICES=$i \
./bin/BlackScholes &
done
运行此脚本时,我们可以观察到每个 MIG 设备上的两个 MPS 服务器,以及在使用 nvidia-smi 时作为 MPS 客户端启动的相应 CUDA 程序
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 1 0 46781 M+C ./bin/BlackScholes 251MiB |
| 0 1 0 46784 C nvidia-cuda-mps-server 29MiB |
| 0 2 0 46797 M+C ./bin/BlackScholes 251MiB |
| 0 2 0 46798 C nvidia-cuda-mps-server 29MiB |
+-----------------------------------------------------------------------------+
9.9. 将 CUDA 应用程序作为容器运行
NVIDIA Container Toolkit 已得到增强,可以为 MIG 设备提供支持,从而允许用户使用 Docker 等运行时运行 GPU 容器。本节概述了在 A100 上使用 MIG 运行 Docker 容器。
9.9.1. 安装 Docker
许多 Linux 发行版可能预装了 Docker-CE。如果未安装,请使用 Docker 安装脚本来安装 Docker。
$ curl https://get.docker.com | sh \
&& sudo systemctl start docker \
&& sudo systemctl enable docker
9.9.2. 安装 NVIDIA Container Toolkit
现在安装 NVIDIA Container Toolkit(以前称为 nvidia-docker2)。
为了访问 /dev nvidia 功能,建议至少使用 v2.5.0 版本的 nvidia-docker2。有关更多信息,请参阅安装指南。
为了简洁起见,此处提供的安装说明适用于 Ubuntu 18.04 LTS。有关其他 Linux 发行版的说明,请参阅 NVIDIA Container Toolkit 页面。
设置存储库和 GPG 密钥
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvda.org.cn/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvda.org.cn/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
安装 NVIDIA Container Toolkit 软件包(及其依赖项)
$ sudo apt-get install -y nvidia-docker2 \
&& sudo systemctl restart docker
9.9.3. 运行容器
要在特定 MIG 设备上运行容器 - 无论是 GI 还是特定的底层 CI,都可以使用 NVIDIA_VISIBLE_DEVICES 变量(或 Docker 19.03+ 的 --gpus 选项)。NVIDIA_VISIBLE_DEVICES 支持以下格式来指定 MIG 设备
MIG-<GPU-UUID>/<GPU instance ID>/<compute instance ID>当使用 R450 和 R460 驱动程序时,或MIG-<UUID>从 R470 驱动程序开始。GPUDeviceIndex>:<MIGDeviceIndex>
如果使用 Docker 19.03,则可以使用 --gpus 选项通过使用以下格式指定 MIG 设备:"device=MIG-device",其中 MIG-device 可以遵循上面为 NVIDIA_VISIBLE_DEVICES 指定的任一格式。
以下示例显示了如何使用两种格式从 CUDA 容器中运行 nvidia-smi。正如示例中所示,当使用任一格式时,只有选择的一个 MIG 设备对容器可见。
$ sudo docker run --runtime=nvidia \
-e NVIDIA_VISIBLE_DEVICES=MIG-c7384736-a75d-5afc-978f-d2f1294409fd \
nvidia/cuda nvidia-smi
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 1 0 0 | 11MiB / 20224MiB | 42 0 | 3 0 2 0 0 |
+------------------+----------------------+-----------+-----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
# For Docker versions < 19.03
$ sudo docker run --runtime=nvidia \
-e NVIDIA_VISIBLE_DEVICES="0:0" \
nvidia/cuda nvidia-smi -L
GPU 0: A100-SXM4-40GB (UUID: GPU-e86cb44c-6756-fd30-cd4a-1e6da3caf9b0)
MIG 3g.20gb Device 0: (UUID: MIG-c7384736-a75d-5afc-978f-d2f1294409fd)
# For Docker versions >= 19.03
$ sudo docker run --gpus '"device=0:0"' \
nvidia/cuda nvidia-smi -L
GPU 0: A100-SXM4-40GB (UUID: GPU-e86cb44c-6756-fd30-cd4a-1e6da3caf9b0)
MIG 3g.20gb Device 0: (UUID: MIG-c7384736-a75d-5afc-978f-d2f1294409fd)
一个更复杂的示例是运行 TensorFlow 容器以使用 MNIST 数据集上的 GPU 进行训练运行。如下所示
$ sudo docker run --gpus '"device=0:1"' \
nvcr.io/nvidia/pytorch:20.11-py3 \
/bin/bash -c 'cd /opt/pytorch/examples/upstream/mnist && python main.py'
=============
== PyTorch ==
=============
NVIDIA Release 20.11 (build 17345815)
PyTorch Version 1.8.0a0+17f8c32
Container image Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
Copyright (c) 2014-2020 Facebook Inc.
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
Copyright (c) 2011-2013 NYU (Clement Farabet)
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
Copyright (c) 2015 Google Inc.
Copyright (c) 2015 Yangqing Jia
Copyright (c) 2013-2016 The Caffe contributors
All rights reserved.
NVIDIA Deep Learning Profiler (dlprof) Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION. All rights reserved.
NVIDIA modifications are covered by the license terms that apply to the underlying project or file.
NOTE: Legacy NVIDIA Driver detected. Compatibility mode ENABLED.
9920512it [00:01, 7880654.53it/s]
32768it [00:00, 129950.31it/s]
1654784it [00:00, 2353765.88it/s]
8192it [00:00, 41020.33it/s]
/opt/conda/lib/python3.6/site-packages/torchvision/datasets/mnist.py:480: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at ../torch/csrc/utils/tensor_numpy.cpp:141.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ../data/MNIST/raw/train-images-idx3-ubyte.gz
Extracting ../data/MNIST/raw/train-images-idx3-ubyte.gz to ../data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ../data/MNIST/raw/train-labels-idx1-ubyte.gz
Extracting ../data/MNIST/raw/train-labels-idx1-ubyte.gz to ../data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ../data/MNIST/raw/t10k-images-idx3-ubyte.gz
Extracting ../data/MNIST/raw/t10k-images-idx3-ubyte.gz to ../data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ../data/MNIST/raw/t10k-labels-idx1-ubyte.gz
Extracting ../data/MNIST/raw/t10k-labels-idx1-ubyte.gz to ../data/MNIST/raw
Processing...
Done!
Train Epoch: 1 [0/60000 (0%)] Loss: 2.320747
Train Epoch: 1 [640/60000 (1%)] Loss: 1.278727
9.10. MIG 与 Kubernetes
Kubernetes 中的 MIG 支持从 Kubernetes 的 NVIDIA Device Plugin 的 v0.7.0 开始提供。访问文档以开始使用 MIG 和 Kubernetes。
9.11. MIG 与 Slurm
Slurm 是一种工作负载管理器,广泛用于高性能计算中心,例如政府实验室、大学。
从 21.08 开始,Slurm 支持 MIG 设备的使用。请参阅官方文档以开始使用。
10. 设备节点和功能
目前,NVIDIA 内核驱动程序通过几个系统范围的设备节点公开其接口。每个物理 GPU 都由其自己的设备节点表示 - 例如,nvidia0、nvidia1 等等。这在下面的 2-GPU 系统中显示。
/dev
├── nvidiactl
├── nvidia-modeset
├── nvidia-uvm
├── nvidia-uvm-tools
├── nvidia-nvswitchctl
├── nvidia0
└── nvidia1
从 CUDA 11/R450 开始,引入了一个名为 nvidia-capabilities 的新抽象概念。其思想是,需要访问特定功能才能通过驱动程序执行某些操作。如果用户有权访问该功能,则将执行该操作。如果用户无权访问该功能,则该操作将失败。唯一的例外是,如果您是 root 用户(或任何具有 CAP_SYS_ADMIN 权限的用户)。使用 CAP_SYS_ADMIN 权限,您隐式地拥有对所有 nvidia-capabilities 的访问权限。
例如,mig-config 功能允许在任何支持 MIG 的 GPU(例如,A100 GPU)上创建和销毁 MIG 实例。如果没有此功能,所有创建或销毁 MIG 实例的尝试都将失败。同样,fabric-mgmt 功能允许以非 root 但特权守护程序身份运行 Fabric Manager。如果没有此功能,所有以非 root 用户身份启动 Fabric Manager 的尝试都将失败。
以下部分将介绍用于管理这些新 nvidia-capabilities 的系统级接口,包括授予和撤销对其访问权限的必要步骤。
10.1. 系统级接口
有两个不同的系统级接口可用于 nvidia-capabilities。第一个是通过 /dev,第二个是通过 /proc。/proc 基于的接口依赖于用户权限和挂载命名空间来限制对特定功能的访问,而 /dev 基于的接口依赖于cgroups。从技术上讲,/dev 基于的接口也依赖于用户权限作为第二级访问控制机制(在实际的设备节点文件本身上),但主要的访问控制机制是 cgroups。当前的 CUDA 11/R450 GA(Linux 驱动程序 450.51.06)同时支持这两种机制,但将来 /dev 基于的接口是首选方法,而 /proc 基于的接口已弃用。目前,用户可以通过使用 nvidia.ko 内核模块上的 nv_cap_enable_devfs 参数来选择所需的接口
当
nv_cap_enable_devfs=0时,启用/proc基于的接口。当
nv_cap_enable_devfs=1时,启用/dev基于的接口。nv_cap_enable_devfs=0的设置是 R450 驱动程序(截至 Linux 450.51.06)的默认设置。所有未来的 NVIDIA 数据中心驱动程序都将默认设置为
nv_cap_enable_devfs=1。
以下是加载 nvidia 内核模块并设置此参数的示例
$ modprobe nvidia nv_cap_enable_devfs=1
10.1.1. 基于 /dev 的 nvidia-capabilities
与基于 /dev 的功能交互的系统级接口实际上是通过 /proc 和 /dev 的组合。
首先,一个新的主设备现在与 nvidia-caps 关联,并且可以从标准 /proc/devices 文件中读取。
$ cat /proc/devices | grep nvidia-caps
508 nvidia-caps
其次,在 /proc/driver/nvidia/capabilities 下存在完全相同的文件集。这些文件不再直接控制对功能的访问,而是这些文件的内容指向 /dev 下的设备节点,通过该设备节点可以使用 cgroups 来控制对功能的访问。
这可以在以下示例中看到
$ cat /proc/driver/nvidia/capabilities/mig/config
DeviceFileMinor: 1
DeviceFileMode: 256
DeviceFileModify: 1
设备主号为 nvidia-caps 的设备以及此文件中 DeviceFileMinor 的值表明,mig-config 功能(允许用户创建和销毁 MIG 设备)由 major:minor 为 238:1 的设备节点控制。因此,需要使用 cgroups 授予进程对此设备节点的读取权限,以便配置 MIG 设备。此文件中 DeviceFileMode 和 DeviceFileModify 字段的用途将在本节稍后解释。
这些设备节点的标准位置在 /dev/nvidia-caps 下
$ ls -l /dev/nvidia-caps
total 0
cr-------- 1 root root 508, 1 Nov 21 17:16 nvidia-cap1
cr--r--r-- 1 root root 508, 2 Nov 21 17:16 nvidia-cap2
...
遗憾的是,NVIDIA 驱动程序无法在创建/删除 /proc/driver/nvidia/capabilities 下的文件时自动创建/删除这些设备节点(由于 GPL 兼容性问题)。因此,提供了一个名为 nvidia-modprobe 的用户级程序,可以从用户空间调用以执行此操作。例如
$ nvidia-modprobe \
-f /proc/driver/nvidia/capabilities/mig/config \
-f /proc/driver/nvidia/capabilities/mig/monitor
$ ls -l /dev/nvidia-caps
total 0
cr-------- 1 root root 508, 1 Nov 21 17:16 nvidia-cap1
cr--r--r-- 1 root root 508, 2 Nov 21 17:16 nvidia-cap2
nvidia-modprobe 查看每个功能文件中的 DeviceFileMode,并使用指示的权限创建设备节点(例如,对于 mig-config,从值 256 (o400) 来看,权限为 +ur)。
诸如 nvidia-smi 等程序将自动调用 nvidia-modprobe(如果可用)以代表您创建这些设备节点。在其他情况下,不一定需要使用 nvidia-modprobe 来创建这些设备节点,但它确实使过程更简单。
如果您实际上想阻止 nvidia-modprobe 代表您创建特定的设备节点,您可以执行以下操作
# Give a user write permissions to the capability file under /proc
$ chmod +uw /proc/driver/nvidia/capabilities/mig/config
# Update the file with a "DeviceFileModify" setting of 0
$ echo "DeviceFileModify: 0" > /proc/driver/nvidia/capabilities/mig/config
然后,您将负责管理对 /proc/driver/nvidia/capabilities/mig/config 引用的设备节点的创建。如果您想在将来更改它,只需使用相同的命令序列将其重置为 DeviceFileModify: 1 的值。
这在容器上下文中非常重要,因为我们可能希望授予容器对某个功能的访问权限,即使该功能在 /proc 层次结构中尚不存在。
例如,授予容器 mig-config 功能意味着我们也应该授予它访问系统上任何 GPU 可能创建的所有 gis 和 cis 的功能。否则,一旦实际创建了这些 gis 和 cis,容器将无法使用它们。
关于基于 /dev 的功能,最后需要注意的是,所有可能功能的次号都是预先确定的,可以在各种格式的文件下查询
/proc/driver/nvidia-caps/*-minors
例如,所有与 MIG 相关的功能都可以通过以下方式查找
$ cat /proc/driver/nvidia-caps/mig-minors
config 1
monitor 2
gpu0/gi0/access 3
gpu0/gi0/ci0/access 4
gpu0/gi0/ci1/access 5
gpu0/gi0/ci2/access 6
...
gpu31/gi14/ci6/access 4321
gpu31/gi14/ci7/access 4322
内容的格式为:GPU<设备次号>/gi<GPU 实例 ID>/ci<计算 实例 ID>
请注意,GPU 设备次号可以通过以下任一机制获得
NVML API
nvmlDeviceGetMinorNumber(),它返回设备次号或使用
/proc/driver/nvidia/gpus/domain:bus:device:function/information下可用的 PCI BDF。此文件包含“Device Minor”字段。
注意
NVML 设备编号(例如通过 nvidia-smi))不是设备次号。
例如,如果 MIG 几何结构如下创建
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 1 0 0 | 19MiB / 40192MiB | 14 0 | 3 0 3 0 3 |
| | 0MiB / 65535MiB | | |
+------------------+ +-----------+-----------------------+
| 0 1 1 1 | | 14 0 | 3 0 3 0 3 |
| | | | |
+------------------+ +-----------+-----------------------+
| 0 1 2 2 | | 14 0 | 3 0 3 0 3 |
| | | | |
+------------------+----------------------+-----------+-----------------------+
那么,将创建相应的设备节点:/dev/nvidia-cap12、/dev/nvidia-cap13、/dev/nvidia-cap14 和 /dev/nvidia-cap15。
10.1.2. 基于 /proc 的 nvidia-capabilities(已弃用)
与基于 /proc 的 nvidia-capabilities 交互的系统级接口根植于 /proc/driver/nvidia/capabilities。此层次结构下的文件用于表示每个功能,对这些文件的读取权限控制用户是否具有给定的功能。这些文件没有内容,仅存在以表示给定的功能。
例如,mig-config 功能(允许用户创建和销毁 MIG 设备)表示如下
/proc/driver/nvidia/capabilities
└── mig
└── config
同样,一旦创建 MIG 设备,在 MIG 设备上运行工作负载所需的功能表示如下(即访问构成 MIG 设备的 GPU 实例和计算实例)
/proc/driver/nvidia/capabilities
└── gpu0
└── mig
├── gi0
│ ├── access
│ └── ci0
│ └── access
├── gi1
│ ├── access
│ └── ci0
│ └── access
└── gi2
├── access
└── ci0
└── access
相应的具有读取权限的文件系统布局如下所示
$ ls -l /proc/driver/nvidia/capabilities/gpu0/mig/gi*
/proc/driver/nvidia/capabilities/gpu0/mig/gi1:
total 0
-r--r--r-- 1 root root 0 May 24 17:38 access
dr-xr-xr-x 2 root root 0 May 24 17:38 ci0
/proc/driver/nvidia/capabilities/gpu0/mig/gi2:
total 0
-r--r--r-- 1 root root 0 May 24 17:38 access
dr-xr-xr-x 2 root root 0 May 24 17:38 ci0
为了使 CUDA 进程能够在 MIG 之上运行,它需要访问计算实例功能及其父 GPU 实例。因此,MIG 设备由以下格式标识
MIG-<GPU-UUID>/<GPU instance ID>/<compute instance ID>
例如,具有对以下路径的读取权限将允许在 <gpu0, gi0, ci0> 表示的 MIG 设备上运行工作负载
/proc/driver/nvidia/capabilities/gpu0/mig/gi0/access
/proc/driver/nvidia/capabilities/gpu0/mig/gi0/ci0/access
请注意,没有表示在 gpu0 上运行工作负载的功能的访问文件(仅在 gpu0 下的 gi0 和 ci0 上)。这是因为仍然需要使用 cgroups 控制对顶级 GPU 设备(以及任何所需的元设备)的访问的传统机制。如文档前面所示,cgroups 机制适用于
/dev/nvidia0
/dev/nvidiactl
/dev/nvidiactl-uvm
...
在容器的上下文中,应在 /proc/driver/nvidia/capabilities 的路径之上覆盖一个新的挂载命名空间,并且应仅将用户希望授予容器的那些功能绑定挂载到其中。由于主机的用户/组信息在绑定挂载中保留,因此必须确保在将这些功能注入容器之前,在主机上为这些功能设置正确的用户权限。
11. 通知
11.1. 通知
本文档仅供参考,不得视为对产品的特定功能、条件或质量的保证。NVIDIA 公司(“NVIDIA”)对本文档中包含信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对使用此类信息造成的后果或用途,或因使用此类信息而可能导致的侵犯专利或第三方的其他权利不承担任何责任。本文档不构成对开发、发布或交付任何材料(如下定义)、代码或功能的承诺。
NVIDIA 保留在任何时候,无需另行通知的情况下,对此文档进行更正、修改、增强、改进和任何其他更改的权利。
客户在下订单前应获取最新的相关信息,并应验证此类信息是否为最新和完整。
NVIDIA 产品的销售受 NVIDIA 标准销售条款和条件的约束,这些条款和条件在订单确认时提供,除非 NVIDIA 和客户的授权代表签署的单独销售协议中另有约定(“销售条款”)。NVIDIA 在此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档不直接或间接地形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命支持设备,也不适用于 NVIDIA 产品的故障或失灵可以合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在上述设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不保证基于本文档的产品适用于任何特定用途。NVIDIA 不一定对每个产品的所有参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合客户计划的应用,并执行必要的应用测试,以避免应用程序或产品出现故障。客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同的条件和/或要求。NVIDIA 对可能基于或归因于以下原因的任何默认设置、损坏、成本或问题不承担任何责任:(i) 以任何与本文档相悖的方式使用 NVIDIA 产品,或 (ii) 客户产品设计。
本文档未授予 NVIDIA 专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。NVIDIA 发布的关于第三方产品或服务的信息不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成对此的保证或认可。使用此类信息可能需要获得第三方在专利或第三方的其他知识产权下的许可,或获得 NVIDIA 在 NVIDIA 的专利或其他知识产权下的许可。
仅当事先获得 NVIDIA 书面批准、未经修改复制并完全遵守所有适用的出口法律法规,并附带所有相关的条件、限制和通知的情况下,才允许复制本文档中的信息。
本文件和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文件(统称为“材料”)均“按原样”提供。NVIDIA 对材料不作任何明示、暗示、法定或其他形式的保证,并明确否认所有关于不侵权、适销性和特定用途适用性的默示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对任何损害负责,包括但不限于任何直接、间接、特殊、偶然、惩罚性或后果性损害,无论何种原因造成,也无论何种责任理论,均不承担因使用本文档而引起的责任,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因遭受任何损害,但 NVIDIA 对本文所述产品的对客户的累计和累积责任应根据产品的销售条款进行限制。
11.2. OpenCL
OpenCL 是 Apple Inc. 的商标,经 Khronos Group Inc. 许可使用。
11.3. 商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。