功能概述
以下章节回顾了 DCGM 的关键功能,以及使用 dcgmi CLI 的输入和输出示例。 还包括常见的使用场景和建议的最佳实践。 从 v1.3 开始,非 Tesla 品牌 GPU 也支持 DCGM。 下表列出了不同 GPU 产品上可用的功能。
功能组 |
Tesla |
Titan |
Quadro |
GeForce |
|---|---|---|---|---|
字段值监视(GPU 指标) |
X |
X |
X |
X |
配置管理 |
X |
X |
X |
X |
主动健康检查(GPU 子系统) |
X |
X |
X |
X |
作业统计信息 |
X |
X |
X |
X |
拓扑 |
X |
X |
X |
X |
内省 |
X |
X |
X |
X |
策略通知 |
X |
|||
GPU 诊断(诊断级别 - 1、2、3) |
所有级别 |
级别 1 |
级别 1 |
级别 1 |
注意
虽然显示了 DCGM 接口,但以下所有功能也可以通过 C、Python 和 Go API 访问。
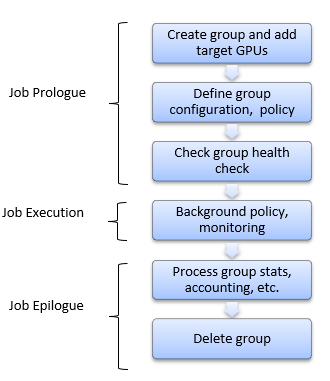
组
几乎所有 DCGM 操作都在组上进行。 用户可以在本地节点上创建、销毁和修改 GPU 集合,使用这些构造来控制所有后续的 DCGM 活动。
组旨在帮助用户将 GPU 集合作为单个抽象资源进行管理,通常与调度程序对节点级作业的概念相关联。 通过这种方式,客户端可以询问有关整个作业的问题,例如作业级健康状况,而无需跟踪各个资源。
注意
目前,DCGM 不强制执行超出自身范围的组行为,例如通过 cgroups 等操作系统隔离机制。 预计客户端会在外部执行此操作。 客户端选择加入 DCGM 以强制执行此状态的功能可能在未来实现。
在只有一台 GPU 的机器中,可以完全忽略组概念,因为所有需要组的 DCGM 操作都可以使用包含该唯一 GPU 的组。 为了方便起见,在初始化时,DCGM 会创建一个默认组,代表系统中所有受支持的 GPU。 DCGM 中的组不必是不相交的。 在许多情况下,为不同的需求维护重叠的组可能是有意义的。 由系统中所有 GPU 组成的全局组对于节点级概念(如全局配置或全局健康状况)非常有用。 仅由 GPU 子集组成的分区组对于作业级概念(如作业统计信息和健康状况)非常有用。
提示
建议客户端为节点级活动维护一个长期存在的全局组。 对于具有多个瞬态并发工作负载的系统,建议在每个作业的基础上维护额外的分区组。
例如,为管理与单个作业关联的 GPU 而创建的组可能具有以下生命周期。 在序言操作期间,创建和配置组,并用于验证 GPU 是否已准备好工作。 在尾声操作期间,组用于提取目标信息。 在作业运行时,DCGM 在后台工作以处理请求的行为。
管理组非常简单。 使用 dcgmi group 子命令,以下示例演示了如何创建、列出和删除组。
$ dcgmi group -c GPU_Group
Successfully created group "GPU_Group" with a group ID of 1
$ dcgmi group -l
1 group found.
+----------------------------------------------------------------------------+
| GROUPS |
+============+===============================================================+
| Group ID | 1 |
| Group Name | GPU_Group |
| GPU ID(s) | None |
+------------+---------------------------------------------------------------+
$ dcgmi group -d 1
Successfully removed group 1
要将 GPU 添加到组,首先需要识别它们。 这可以通过首先向 DCGM 询问系统中所有受支持的 GPU 来完成。
$ dcgmi discovery -l
2 GPUs found.
+--------+-------------------------------------------------------------------+
| GPU ID | Device Information |
+========+===================================================================+
| 0 | Name: Tesla K80 |
| | PCI Bus ID: 0000:07:00.0 |
| | Device UUID: GPU-000000000000000000000000000000000000 |
+--------+-------------------------------------------------------------------+
| 1 | Name: Tesla K80 |
| | PCI Bus ID: 0000:08:00.0 |
| | Device UUID: GPU-111111111111111111111111111111111111 |
+--------+-------------------------------------------------------------------+
$ dcgmi group -g 1 -a 0,1
Add to group operation successful.
$ dcgmi group -g 1 -i
+----------------------------------------------------------------------------+
| GROUPS |
+============+===============================================================+
| Group ID | 1 |
| Group Name | GPU_Group |
| GPU ID(s) | 0, 1 |
+------------+---------------------------------------------------------------+
配置
管理 GPU 的一个重要方面,尤其是在多节点环境中,是确保跨工作负载和跨设备配置的一致性。 在这种情况下,术语“配置”指的是 NVIDIA 公开的用于调整 GPU 行为的一组管理参数。 DCGM 使客户端可以更轻松地定义目标配置并确保这些配置随时间推移得到维护。
重要的是要注意,不同的 GPU 属性具有不同的持久性级别。 有两个大的类别:
设备 InfoROM 生命周期
每个板载的非易失性存储器,保存某些可配置的固件设置。
无限期持久存在,尽管可以刷新固件。
GPU 初始化生命周期
驱动程序级别的数据结构,保存易失性 GPU 运行时信息。
持续存在,直到 GPU 被内核模式驱动程序取消初始化。
DCGM 主要关注维护属于第二类的配置设置。 这些设置通常是易失性的,每次 GPU 变为空闲状态或重置时都可能重置。 通过使用 DCGM,客户端可以确保这些设置在所需的生命周期内保持不变。
在大多数常见情况下,客户端应在系统初始化时为系统中的所有 GPU(全局组)定义配置,或在每个作业的基础上定义单个分区组设置。 一旦定义了配置,DCGM 将强制执行该配置,例如跨驱动程序重启、GPU 重置或作业启动。
DCGM 目前支持以下配置设置:
设置 |
描述 |
默认值 |
|---|---|---|
同步加速 |
协调组中 GPU 之间的自动加速 |
无 |
目标时钟 |
尝试将时钟固定在目标值 |
无 |
ECC 模式 |
在整个 GPU 内存中启用 ECC 保护 |
通常开启 |
功率限制 |
设置允许的最大功耗 |
各异 |
计算模式 |
限制并发进程对 GPU 的访问 |
无限制 |
要为组定义目标配置,请使用 dcgmi config 子命令。 使用上一节中创建的组,以下示例演示了如何设置计算模式目标,然后列出现有配置状态。
$ dcgmi config -g 1 --set -c 2
Configuration successfully set.
$ dcgmi config -g 1 --get
+--------------------------+------------------------+------------------------+
| GPU_Group | | |
| Group of 2 GPUs | TARGET CONFIGURATION | CURRENT CONFIGURATION |
+==========================+========================+========================+
| Sync Boost | Not Specified | Disabled |
| SM Application Clock | Not Specified | **** |
| Memory Application Clock | Not Specified | **** |
| ECC Mode | Not Specified | **** |
| Power Limit | Not Specified | **** |
| Compute Mode | E. Process | E. Process |
+--------------------------+------------------------+------------------------+
**** Non-homogenous settings across group. Use with -v flag to see details.
$ dcgmi config -g 1 --get --verbose
+--------------------------+------------------------+------------------------+
| GPU ID: 0 | | |
| Tesla K20c | TARGET CONFIGURATION | CURRENT CONFIGURATION |
+==========================+========================+========================+
| Sync Boost | Not Specified | Disabled |
| SM Application Clock | Not Specified | 705 |
| Memory Application Clock | Not Specified | 2600 |
| ECC Mode | Not Specified | Disabled |
| Power Limit | Not Specified | 225 |
| Compute Mode | E. Process | E. Process |
+--------------------------+------------------------+------------------------+
+--------------------------+------------------------+------------------------+
| GPU ID: 1 | | |
| GeForce GT 430 | TARGET CONFIGURATION | CURRENT CONFIGURATION |
+==========================+========================+========================+
| Sync Boost | Not Specified | Disabled |
| SM Application Clock | Not Specified | 562 |
| Memory Application Clock | Not Specified | 2505 |
| ECC Mode | Not Specified | Enabled |
| Power Limit | Not Specified | 200 |
| Compute Mode | E. Process | E. Process |
+--------------------------+------------------------+------------------------+
设置配置后,DCGM 会维护目标状态和当前状态的概念。 目标跟踪用户对配置状态的请求,而当前状态跟踪 GPU 和组的实际状态。 这些通常保持一致,以便在状态丢失或更改的情况下,DCGM 将当前状态恢复为目标状态。 这在 DCGM 执行了一些侵入性策略(如健康检查或 GPU 重置)的情况下很常见。
策略
DCGM 提供了一种方式,供客户端配置响应各种条件的自动 GPU 行为。 这对于事件->操作情况非常有用,例如在发生严重错误时进行 GPU 恢复。 它对于事件->通知情况也很有用,例如当客户端希望在发生 RAS 事件时收到警告。 在这两种情况下,客户端都必须定义一个触发进一步行为的条件。 这些条件是从一组预定义的可能指标中指定的。 在某些情况下,客户端还必须提供一个阈值,高于/低于该阈值会触发指标条件。 通常,条件是致命和非致命 RAS 事件,或面向性能的警告。 这些包括以下示例:
条件 |
类型 |
阈值 |
描述 |
|---|---|---|---|
PCIe/NVLINK 错误 |
致命 |
硬编码 |
未更正,或更正后高于 SDC 阈值 |
ECC 错误 |
致命 |
硬编码 |
单个 DBE,多个共址 SBE |
页面停用限制 |
非致命 |
可设置 |
ECC 错误的生命周期限制,或高于 RMA 率 |
功率偏移 |
性能 |
可设置 |
偏移高于指定的板载功率阈值 |
热偏移 |
性能 |
可设置 |
偏移高于指定的 GPU 热阈值 |
XID |
全部 |
硬编码 |
XID 代表 NVIDIA 驱动程序中的几种事件,例如挂起的页面停用或 GPU 从总线上掉线。 有关详细信息,请参阅 https://docs.nvda.net.cn/deploy/xid-errors/index.html。 |
通知
策略的最简单形式是指示 DCGM 在满足目标条件时通知客户端。 除此之外,不执行任何进一步操作。 这主要作为编程接口中的回调机制很有意义,作为一种避免轮询的方式。
在嵌入式模式下运行 DCGM 时,每次命中注册条件时,DCGM 都会自动调用此类回调,此时客户端可以根据需要处理该事件。 客户端必须通过相应的 API 调用进行注册才能接收这些回调。 这样做会透明地指示 DCGM 跟踪触发这些结果的条件。
注意
一旦收到特定条件的回调,该通知注册就会终止。 如果客户端想要重复的条件通知,则应在处理每个回调后重新注册。
dcgmi policy 子命令允许从命令行访问此功能的某些部分,通过设置条件和通过阻塞通知机制。 这在监视特定问题时可能很有用,例如在调试会话期间。
例如,以下内容显示了为 PCIe 致命和非致命事件设置通知策略
$ dcgmi policy -g 2 --set 0,0 -p
Policy successfully set.
$ dcgmi policy -g 2 --get
Policy information
+---------------------------+------------------------------------------------+
| GPU_Group | Policy Information |
+===========================+================================================+
| Violation conditions | PCI errors and replays |
| Isolation mode | Manual |
| Action on violation | None |
| Validation after action | None |
| Validation failure action | None |
+---------------------------+------------------------------------------------+
**** Non-homogenous settings across group. Use with -v flag to see details.
$ dcgmi policy -g 2 --get --verbose
Policy information
+---------------------------+------------------------------------------------+
| GPU ID: 0 | Policy Information |
+===========================+================================================+
| Violation conditions | PCI errors and replays |
| Isolation mode | Manual |
| Action on violation | None |
| Validation after action | None |
| Validation failure action | None |
+---------------------------+------------------------------------------------+
+---------------------------+------------------------------------------------+
| GPU ID: 1 | Policy Information |
+===========================+================================================+
| Violation conditions | PCI errors and replays |
| Isolation mode | Manual |
| Action on violation | None |
| Validation after action | None |
| Validation failure action | None |
+---------------------------+-----------------------------------------------
一旦设置了这样的策略,客户端将相应地收到通知。 虽然这主要对编程用例有意义,但可以调用 dcgmi policy 来等待策略通知
$ dcgmi policy -g 2 --reg
Listening for violations
...
A PCIe error has violated policy manager values.
...
操作
操作策略是上述通知策略的超集。
某些客户端可能会发现将条件与 DCGM 在满足条件后立即自动执行的操作相关联很有用。 当条件是阻止 GPU 正常运行的 RAS 事件时,这尤其相关。
定义为操作的策略包括三个附加组件:
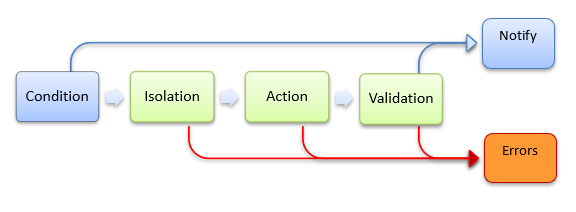
隔离模式 - DCGM 是否在执行后续策略步骤之前获取对 GPU 的独占访问权限。
操作 - 要执行的 DCGM 入侵行为。
验证 - 操作后对 GPU 状态的任何后续验证。
基于操作的常见策略是在发生 ECC DBE 后配置 DCGM 以自动停用内存页。 通过停用页面并重新初始化 GPU,DCGM 可以隔离硬件故障并为下一个作业准备 GPU。 由于此操作涉及重置 GPU,因此快速系统验证是后续步骤,以确保 GPU 运行状况良好。
基于操作的常见策略是在发生 ECC DBE 后配置 DCGM 以自动停用内存页。 通过停用页面并重新初始化 GPU,DCGM 可以隔离硬件故障并为下一个作业准备 GPU。 由于此操作涉及重置 GPU,因此快速系统验证是后续步骤,以确保 GPU 运行状况良好。
设置操作策略的客户端在每次运行策略时都会收到两个通知。
当命中条件并实施策略时,通知回调。
操作完成时,即在验证步骤之后,通知回调。
使用 dcgmi policy 子命令,可以按如下方式配置这种基于操作的策略
$ dcgmi policy -g 1 --set 1,1 -e
Policy successfully set.
$ dcgmi policy -g 1 --get
Policy information for group 1
+----------------------------------------------------------------------------+
| GPU ID: 0 | Policy Information |
+===========================+================================================+
| Violation Conditions | Double-bit ECC errors |
| Isolation mode | Manual |
| Action on violation | Reset GPU |
| Validation after action | NVVS (Short) |
| Validation failure action | None |
+---------------------------+------------------------------------------------+
...
如上一节所示,dcgmi policy 也可用于监视与此策略关联的通知。
作业统计信息
DCGM 提供后台数据收集和分析功能,包括在目标工作负载的生命周期内以及跨所涉及的 GPU 聚合数据的能力。 这使客户端可以轻松地在单个请求中收集作业级别的数据,例如记帐。
要请求此功能,客户端必须首先为目标组启用统计信息记录。 这告诉 DCGM 必须定期监视这些 GPU 的所有相关指标,以及设备上的进程活动。 对于每个作业级别的组,只需在初始化时执行一次此操作。
$ dcgmi stats -g 1 --enable
Successfully started process watches on group 1.
必须在目标工作负载启动之前启用统计信息记录,以便获得可靠的信息。
作业完成后,可以查询 DCGM 以获取有关该作业的信息,包括组的摘要级别,以及(如果需要)在组内的 GPU 之间单独分解。 建议的行为是客户端在尾声脚本中执行此查询,作为作业清理的一部分。
由 dcgmi stats 提供的组级别数据示例
$ dcgmi stats --pid 1234 -v
Successfully retrieved process info for pid: 1234. Process ran on 1 GPUs.
+----------------------------------------------------------------------------+
| GPU ID: 0 |
+==================================+=========================================+
|------- Execution Stats ----------+-----------------------------------------|
| Start Time * | Tue Nov 3 17:36:43 2015 |
| End Time * | Tue Nov 3 17:38:33 2015 |
| Total Execution Time (sec) * | 110.33 |
| No. of Conflicting Processes * | 0 |
+------- Performance Stats --------+-----------------------------------------+
| Energy Consumed (Joules) | 15758 |
| Power Usage (Watts) | Avg: 150, Max: 250, Min: 100 |
| Max GPU Memory Used (bytes) * | 213254144 |
| SM Clock (MHz) | Avg: 837, Max: 875, Min: 679 |
| Memory Clock (MHz) | Avg: 2505, Max: 2505, Min: 2505 |
| SM Utilization (%) | Avg: 99, Max: 100, Min: 99 |
| Memory Utilization (%) | Avg: 2, Max: 3, Min: 0 |
| PCIe Rx Bandwidth (megabytes) | Avg: N/A, Max: N/A, Min: N/A |
| PCIe Tx Bandwidth (megabytes) | Avg: N/A, Max: N/A, Min: N/A |
+------- Event Stats --------------+-----------------------------------------+
| Single Bit ECC Errors | 0 |
| Double Bit ECC Errors | 0 |
| PCIe Replay Warnings | 0 |
| Critical XID Errors | 0 |
+------- Slowdown Stats -----------+-----------------------------------------+
| Due to - Power (%) | 0 |
| - Thermal (%) | 0 |
| - Reliability (%) | 0 |
| - Board Limit (%) | 0 |
| - Low Utilization (%) | 0 |
| - Sync Boost (%) | Not Supported |
+----------------------------------+-----------------------------------------+
(*) Represents a process statistic. Otherwise device statistic during process lifetime listed.
对于某些框架,进程及其 PID 无法直接与作业关联,并且与作业关联的进程可能会派生出许多子进程。 为了获得此类场景的作业级别统计信息,必须在作业开始和停止时通知 DCGM。 客户端需要在作业序言时使用用户定义的作业 ID 和相应的 GPU 组通知 DCGM,并在作业尾声时使用作业 ID 通知 DCGM。 用户可以使用作业 ID 查询作业统计信息,并获得在感兴趣的时间段内所有 PID 的聚合统计信息。
使用 dcgmi 在作业开始和结束时通知 DCGM 的示例
$ dcgmi stats -g 1 -s <user-provided-jobid>
Successfully started recording stats for <user-provided-jobid>
$ dcgmi stats -x <user-provided-jobid>
Successfully stopped recording stats for <user-provided-jobid>
可以使用 dcgmi 检索已监视的作业 ID 对应的统计信息
$ dcgmi stats -j <user-provided-jobid>
Successfully retrieved statistics for <user-provided-jobid>
+----------------------------------------------------------------------------+
| GPU ID: 0 |
+==================================+=========================================+
|------- Execution Stats ----------+-----------------------------------------|
| Start Time | Tue Nov 3 17:36:43 2015 |
| End Time | Tue Nov 3 17:38:33 2015 |
| Total Execution Time (sec) | 110.33 |
| No. of Processes | 0 |
+----- Performance Stats ----------+-----------------------------------------+
| Energy Consumed (Joules) | 15758 |
| Power Usage (Watts) | Avg: 150, Max: 250, Min 100 |
| Max GPU Memory Used (bytes) | 213254144 |
| SM Clock (MHz) | Avg: 837, Max: 875, Min: 679 |
| Memory Clock (MHz) | Avg: 2505, Max: 2505, Min: 2505 |
| SM Utilization (%) | Avg: 99, Max: 100, Min: 99 |
| Memory Utilization (%) | Avg: 2, Max: 3, Min: 0 |
| PCIe Rx Bandwidth (megabytes) | Avg: N/A, Max: N/A, Min: N/A |
| PCIe Tx Bandwidth (megabytes) | Avg: N/A, Max: N/A, Min: N/A |
+----- Event Stats ----------------+-----------------------------------------+
| Single Bit ECC Errors | 0 |
| Double Bit ECC Errors | 0 |
| PCIe Replay Warnings | 0 |
| Critical XID Errors | 0 |
+----- Slowdown Stats -------------+-----------------------------------------+
| Due to - Power (%) | 0 |
| - Thermal (%) | 0 |
| - Reliability (%) | 0 |
| - Board Limit (%) | 0 |
| - Low Utilization (%) | 0 |
| - Sync Boost (%) | Not Supported |
+----------------------------------+-----------------------------------------+
健康状况和诊断
DCGM 提供了几种用于了解 GPU 健康状况的机制,每种机制都针对不同的需求。 通过利用这些接口中的每一个,客户端可以轻松地以非侵入方式(在工作负载运行时)和主动方式(在 GPU 可以运行专用测试时)确定总体 GPU 健康状况。 DCGM 的一项新的主要功能是能够运行在线硬件诊断。
更详细的针对性用例如下:
后台健康检查.
这些是非侵入式监控操作,在作业运行时发生,并且可以随时查询。 对应用程序行为或性能没有影响。
序言健康检查.
快速、侵入式健康检查,只需几秒钟,旨在验证 GPU 在提交作业之前是否已准备好工作。
尾声健康检查.
中等持续时间的侵入式健康检查,需要几分钟时间,可以在作业失败或 GPU 健康状况可疑时运行
完整系统验证.
长时间的侵入式健康检查,需要数十分钟,可以在系统正在积极调查硬件问题或其他严重问题时运行。
警告
所有这些都是在线诊断,这意味着它们在当前环境中运行。 GPU 以外的因素可能会以负面方式影响行为。 虽然这些工具尝试识别这些情况,但完整的硬件验证需要通过不同的 NVIDIA 工具提供的完整离线诊断,并且 RMA 也需要这些诊断。
后台健康检查
这种形式的健康检查基于对各种硬件和软件组件的被动式后台监控。 目标是在不影响应用程序行为或性能的情况下识别关键领域中的问题。 这些类型的检查可以捕获严重问题,例如无响应的 GPU、损坏的固件、热失控等。
当识别出此类问题时,DCGM 会将其报告为警告或错误。 每种情况可能需要不同的客户端响应,但以下准则通常是正确的:
警告 - 检测到某个问题,该问题不会阻止当前工作完成,但应检查该问题并在将来可能解决。
错误 - 检测到严重问题,当前工作可能已受损或中断。 这些情况通常对应于致命 RAS 事件,通常表示需要终止作业并分析 GPU 健康状况。
可以通过简单的 DCGM 接口设置和监视后台健康检查。 使用 dcgmi health 作为接口,以下代码为组设置了多个健康检查,然后验证这些检查当前是否已启用
$ dcgmi health -g 1 -s mpi
Health monitor systems set successfully.
要查看组中所有 GPU 的当前状态,客户端只需查询组的总体健康状况即可。 结果是组的总体健康评分以及每个受影响 GPU 的单独结果,从而识别关键问题。
例如,当检测到过多的 PCIe 重放事件或 InfoROM 问题时,DCGM 将显示以下内容:
$ dcgmi health -g 1 -c
Health Monitor Report
+----------------------------------------------------------------------------+
| Group 1 | Overall Health: Warning |
+==================+=========================================================+
| GPU ID: 0 | Warning |
| | PCIe system: Warning - Detected more than 8 PCIe |
| | replays per minute for GPU 0: 13 |
+------------------+---------------------------------------------------------+
| GPU ID: 1 | Warning |
| | InfoROM system: Warning - A corrupt InfoROM has been |
| | detected in GPU 1. |
+------------------+---------------------------------------------------------+
系统 |
错误代码 |
原因 |
|---|---|---|
PCIe |
DCGM_FR_PCI_REPLAY_RATE |
在过去一分钟内,PCIe 重放次数超过 8 次。 |
内存 |
DCGM_FR_VOLATILE_DBE_DETECTED |
报告了一个或多个易失性 DBE(自上次 GPU 重置以来的不可恢复的内存错误) |
内存 |
DCGM_FR_PENDING_PAGE_RETIREMENTS |
有一个或多个挂起的页面停用。 |
内存 |
DCGM_FR_RETIRED_PAGES_LIMIT |
在一台 GPU 上发生了 63 个或更多停用页面。 |
内存 |
DCGM_FR_RETIRED_PAGES_DBE_LIMIT |
由于 DBE,总共发生了超过 15 个停用页面,并且最近一周至少发生了一个。 |
内存 |
DCGM_FR_ROW_REMAP_FAILURE |
发生了一个或多个行重映射失败。 |
内存 |
DCGM_FR_UNCONTAINED_ERROR |
GPU 遇到了未包含的错误(发生了 XID 95)。 |
Inforom |
DCGM_FR_CORRUPT_INFOROM |
检测到 Inforom 损坏。 |
散热 |
DCGM_FR_CLOCKS_EVENT_THERMAL |
在过去一分钟内,在 GPU 上检测到热违规。 |
散热 |
DCGM_FR_FIELD_THRESHOLD_DBL |
CPU 一分钟前的温度及其当前温度都高于警告温度。 |
散热 |
DCGM_FR_FIELD_THRESHOLD_DBL |
CPU 的当前温度高于临界温度。 |
功率 |
DCGM_FR_CLOCKS_EVENT_POWER |
在过去一分钟内,GPU 检测到功率违规。 |
功率 |
DCGM_FR_FIELD_THRESHOLD_DBL |
CPU 的功耗高于其功率限制。 |
NVLink |
DCGM_FR_NVLINK_ERROR_CRITICAL |
NVLink 报告了 1 个或多个重放或恢复错误。 |
NVLink |
DCGM_FR_NVLINK_CRC_ERROR_THRESHOLD |
NVLink 报告的 CRC 错误超过每秒 100 个。 |
NVSwitch 致命 |
DCGM_FR_NVSWITCH_FATAL_ERROR |
NVSwitch 报告了一个或多个致命错误 |
NVSwitch 致命 |
DCGM_FR_NVLINK_DOWN |
一个或多个 NVLink 被报告为已关闭。 |
NVSwitch 非致命 |
DCGM_FR_NVSWITCH_NON_FATAL_ERROR |
NVSwitch 报告了一个或多个非致命错误 |
注意
上面的 dcgmi 接口仅报告当前的健康状况。 通过其他接口公开的底层数据捕获了有关事件时间范围及其与 GPU 上执行进程的连接的更多信息。
主动健康检查
这种形式的健康检查是侵入式的,需要独占访问目标 GPU。 通过运行实际工作负载并分析结果,DCGM 能够识别各种类型的常见问题。 这些包括:
部署和软件问题
NVIDIA 库访问和版本控制
第三方软件冲突
集成问题
PCIe/NVLINK 总线上的可纠正/不可纠正问题
拓扑限制
操作系统级别设备限制、cgroups 检查
基本功率和热约束检查
压力检查
功率和热应力
PCIe/NVLINK 吞吐量压力
恒定相对系统性能
最大相对系统性能
硬件问题和诊断
GPU 硬件和 SRAM
计算稳健性
内存
PCIe/NVLINK 总线
DCGM 通过其诊断和策略接口公开这些健康检查。DCGM 提供三个级别的诊断能力(请参阅命令行上的 dcgmi diag help)。DCGM 在每个级别运行更深入的测试,以验证 GPU 的健康状况。下表提供了每个级别的测试名称和运行的测试
测试套件名称 |
运行级别 |
测试时长 |
测试类别 |
||||
|---|---|---|---|---|---|---|---|
软件 |
硬件 |
集成 |
压力 |
||||
快速 |
-r 1 |
~ 秒 |
部署 |
– |
– |
||
中等 |
-r 2 |
~ 2 分钟 |
部署 |
内存测试 |
PCIe/NVLink |
– |
|
长 |
-r 3 |
~ 15 分钟 |
部署 |
|
PCIe/NVLink |
|
|
虽然在非 Tesla GPU 上可以进行运行时库和配置的简单测试(运行级别 1),但 DCGM 还能够在 Tesla GPU 上执行硬件诊断、连接诊断和一套压力测试,以帮助验证健康状况并隔离问题。每个测试类型中的操作在 GPU 参数 部分中进一步描述。
例如,运行完整的系统验证(长测试)
$ dcgmi diag -r 3
Successfully ran diagnostic for group.
+---------------------------+------------------------------------------------+
| Diagnostic | Result |
+===========================+================================================+
|----- Metadata ----------+------------------------------------------------|
| DCGM Version | 4.0.0 |
| Driver Version Detected | 550.90.07 |
| GPU Device IDs Detected | 25b6, 25b6, 25b6, 25b6 |
|----- Deployment --------+------------------------------------------------|
| software | Pass |
| | GPU0: Pass |
| | GPU1: Pass |
| | GPU2: Pass |
| | GPU3: Pass |
+----- Hardware ----------+------------------------------------------------+
| memory | Pass |
| | GPU0: Pass |
| | GPU1: Pass |
| | GPU2: Pass |
| | GPU3: Pass |
| diagnostic | Pass |
| | GPU0: Pass |
| | GPU1: Pass |
| | GPU2: Pass |
| | GPU3: Pass |
+----- Integration -------+------------------------------------------------+
| pcie | Pass |
| | GPU0: Pass |
| | GPU1: Pass |
| | GPU2: Pass |
| | GPU3: Pass |
+----- Stress ------------+------------------------------------------------+
| memory_bandwidth | Pass |
| | GPU0: Pass |
| | GPU1: Pass |
| | GPU2: Pass |
| | GPU3: Pass |
| targeted_stress | Pass |
| | GPU0: Pass |
| | GPU1: Pass |
| | GPU2: Pass |
| | GPU3: Pass |
| targeted_power | Pass |
| | GPU0: Pass |
| | GPU1: Pass |
| | GPU2: Pass |
| | GPU3: Pass |
+---------------------------+------------------------------------------------+
诊断测试也可以作为基于操作的策略的验证阶段的一部分运行。例如,一个常见的场景是运行测试的短版本作为 DBE 页面退役操作的验证。
DCGM 会将这些测试的日志存储在主机文件系统上。存在两种类型的日志
硬件诊断包括一个加密的二进制日志,只能由 NVIDIA 查看。
系统验证和压力检查通过 JSON 文本文件提供额外的时间序列数据。这些文件可以在许多程序中查看,以了解每次测试期间 GPU 行为的更详细信息。
拓扑
DCGM 提供了几种机制来理解 GPU 拓扑,包括详细的设备级视图和非详细的组级视图。这些视图旨在向用户提供有关系统中与其他 GPU 的连接以及 NUMA/亲和性信息。
对于设备级视图
$ dcgmi topo --gpuid 0
+-------------------+--------------------------------------------------------+
| GPU ID: 0 | Topology Information |
+===================+========================================================+
| CPU Core Affinity | 0 - 11 |
+-------------------+--------------------------------------------------------+
| To GPU 1 | Connected via an on-board PCIe switch |
| To GPU 2 | Connected via a PCIe host bridge |
+-------------------+--------------------------------------------------------+
对于组级视图
$ dcgmi topo -g 1
+-------------------+--------------------------------------------------------+
| MyGroup | Topology Information |
+===================+========================================================+
| CPU Core Affinity | 0 - 11 |
+-------------------+--------------------------------------------------------+
| NUMA Optimal | True |
+-------------------+--------------------------------------------------------+
| Worst Path | Connected via a PCIe host bridge |
+-------------------+--------------------------------------------------------+
.........
NVLink 计数器
DCGM 提供了一种检查系统中各种链路的 nvlink 错误计数器的方法。这使得客户端可以轻松捕获异常并监视 nvlink 通信的健康状况。DCGM 考虑了多种类型的 nvlink 错误,如下所示
CRC FLIT 错误:数据链路接收流控制数字 CRC 错误
CRC 数据错误:数据链路接收数据 CRC 错误。
重放错误:传输重放错误。
恢复错误:传输恢复错误。
要检查 gpuId 为 0 的 GPU 中所有存在的 nvlink 计数器
$ dcgmi nvlink --errors -g 0
+-------------------------------------------------------------+
| GPU ID: 0 | NVLINK Error Counts |
+-------------------------------------------------------------+
|Link 0 | CRC FLIT Error | 0 |
|Link 0 | CRC Data Error | 0 |
|Link 0 | Replay Error | 0 |
|Link 0 | Recovery Error | 0 |
|Link 1 | CRC FLIT Error | 0 |
|Link 1 | CRC Data Error | 0 |
|Link 1 | Replay Error | 0 |
|Link 1 | Recovery Error | 0 |
|Link 2 | CRC FLIT Error | 0 |
|Link 2 | CRC Data Error | 0 |
|Link 2 | Replay Error | 0 |
|Link 2 | Recovery Error | 0 |
|Link 3 | CRC FLIT Error | 0 |
|Link 3 | CRC Data Error | 0 |
|Link 3 | Replay Error | 0 |
|Link 3 | Recovery Error | 0 |
+-------------------------------------------------------------+
字段组
DCGM 提供了预定义的字段组,如作业统计信息、进程统计信息和健康状况,以便于使用。此外,DCGM 允许用户创建自己的自定义字段组,称为字段组。用户可以监视 GPU 组上的字段组,然后检索组中每个 GPU 的字段组中每个字段的最新值或值范围。
字段组不直接在 DCGMI 中使用,但您仍然可以从 DCGMI 中查看和管理它们。
要查看系统上所有活动的字段组,请运行
$ dcgmi fieldgroup -l
4 field groups found.
+----------------------------------------------------------------------------+
| FIELD GROUPS |
+============+===============================================================+
| ID | 1 |
| Name | DCGM_INTERNAL_1SEC |
| Field IDs | 38, 73, 86, 112, 113, 119, 73, 51, 47, 46, 66, 72, 61, 118,...|
+------------+---------------------------------------------------------------+
| ID | 2 |
| Name | DCGM_INTERNAL_30SEC |
| Field IDs | 124, 125, 126, 130, 131, 132, 133, 134, 135, 136, 137, 138,...|
+------------+---------------------------------------------------------------+
| ID | 3 |
| Name | DCGM_INTERNAL_HOURLY |
| Field IDs | 117, 55, 56, 64, 62, 63, 6, 5, 26, 8, 17, 107, 22, 108, 30, 31|
+------------+---------------------------------------------------------------+
| ID | 4 |
| Name | DCGM_INTERNAL_JOB |
| Field IDs | 111, 65, 36, 37, 38, 101, 102, 77, 78, 40, 41, 121, 115, 11...|
+------------+---------------------------------------------------------------+
如果您想创建自己的字段组,请为其选择一个唯一的名称,确定您想要包含在其中的字段 ID,然后运行
$ dcgmi fieldgroup -c mygroupname -f 50,51,52
Successfully created field group "mygroupname" with a field group ID of 5
请注意,字段 ID 来自 dcgm_fields.h,并且是以 DCGM_FI_ 开头的宏。
创建字段组后,您可以查询其信息
$ dcgmi fieldgroup -i --fieldgroup 5
+----------------------------------------------------------------------------+
| FIELD GROUPS |
+============+===============================================================+
| ID | 5 |
| Name | mygroupname |
| Field IDs | 50, 51, 52 |
+------------+---------------------------------------------------------------+
如果您想删除字段组,请运行以下命令
$ dcgmi fieldgroup -d -g 5
Successfully removed field group 5
请注意,DCGM 在内部创建了一些字段组。内部创建的字段组(如上面的那些)无法删除。以下是尝试删除 DCGM 内部字段组的示例
$ dcgmi fieldgroup -d -g 1
Error: Cannot destroy field group 1. Return: No permission.
链路状态
从 DCGM 1.5 开始,您可以使用以下命令查询连接到系统的 GPU 和 NVSwitch 的 NVLink 状态
$ dcgmi nvlink --link-status
+----------------------+
| NvLink Link Status |
+----------------------+
GPUs:
gpuId 0:
U U U U U U
gpuId 1:
U U U U U U
gpuId 2:
U U U U U U
gpuId 3:
U U U U U U
gpuId 4:
U U U U U U
gpuId 5:
U U U U U U
gpuId 6:
U U U U U U
gpuId 7:
U U U U U U
gpuId 8:
U U U U U U
gpuId 9:
U U U U U U
gpuId 10:
U U U U U U
gpuId 11:
U U U U U U
gpuId 12:
U U U U U U
gpuId 13:
U U U U U U
gpuId 14:
U U U U U U
gpuId 15:
U U U U U U
NvSwitches:
physicalId 8:
U U U U U U X X U U U U U U U U U U
physicalId 9:
U U U U U U U U U U U U U U X X U U
physicalId 10:
U U U U U U U U U U U U X U U U X U
physicalId 11:
U U U U U U X X U U U U U U U U U U
physicalId 12:
U U U U X U U U U U U U U U U U X U
physicalId 13:
U U U U X U U U U U U U U U U U X U
physicalId 24:
U U U U U U X X U U U U U U U U U U
physicalId 25:
U U U U U U U U U U U U U U X X U U
physicalId 26:
U U U U U U U U U U U U X U U U X U
physicalId 27:
U U U U U U X X U U U U U U U U U U
physicalId 28:
U U U U X U U U U U U U U U U U X U
physicalId 29:
U U U U X U U U U U U U U U U U X U
Key: Up=U, Down=D, Disabled=X, Not Supported=_
CPU 监控
概述
DCGM 支持 NVIDIA 数据中心 CPU 的 CPU 监控。一般来说,CPU 字段的处理方式与其他 NVIDIA 硬件实体相同。本节包含其他信息,以帮助您入门。
要求
此处描述的功能仅支持 NVIDIA Grace CPU,并且对这些功能的支持从 DCGM 3.3 开始。
简介
DCGM 中 CPU 的两个实体组是 DCGM_FE_CPU 和 DCGM_FE_CPU_CORE,分别对应于 Grace 中的 CPU 和内核。某些字段仅在 CPU 级别测量,而其他字段具有每个内核的测量值。
CPU 和内核字段
字段名称 |
描述 |
字段 ID |
测量位置 |
|---|---|---|---|
DCGM_FI_DEV_CPU_UTIL_TOTAL |
总使用时间百分比 |
1100 |
内核 |
DCGM_FI_DEV_CPU_UTIL_USER |
用户使用时间百分比 |
1101 |
内核 |
DCGM_FI_DEV_CPU_UTIL_NICE |
低优先级(高 nice 值)程序的使用时间百分比 |
1102 |
内核 |
DCGM_FI_DEV_CPU_UTIL_SYS |
系统使用时间百分比 |
1103 |
内核 |
DCGM_FI_DEV_CPU_UTIL_IRQ |
中断使用时间百分比 |
1104 |
内核 |
DCGM_FI_DEV_CPU_TEMP_CURRENT |
瞬时温度(摄氏度) |
1110 |
CPU |
DCGM_FI_DEV_CPU_CLOCK_CURRENT |
瞬时时钟速度 (KHz) |
1120 |
内核 |
DCGM_FI_DEV_CPU_POWER_UTIL_CURRENT |
瞬时功耗(瓦特) |
1130 |
CPU |
DCGM_FI_DEV_CPU_POWER_LIMIT |
瞬时功率限制(瓦特) |
1131 |
CPU |
DCGM_FI_DEV_CPU_VENDOR |
供应商名称 |
1140 |
CPU |
DCGM_FI_DEV_CPU_MODEL |
型号名称 |
1141 |
CPU |
示例
创建一个组并将一些 CPU 和内核添加到其中
$ dcgmi group -c cpu_group1 -a cpu:{0-3},core:{0-287}
使用 dcgmi dmon 监视字段温度
$ dcgmi dmon --entity-id cpu:{0-3} -e 1130
性能分析指标
随着支持 GPU 的服务器在数据中心变得越来越普遍,更好地了解应用程序的性能和集群中 GPU 资源的利用率变得非常重要。DCGM 中的性能分析指标可以使用 GPU 上的硬件计数器收集一组指标。DCGM 以低性能开销持续访问设备级指标。此功能从 DCGM 1.7 开始在生产环境中受支持。
DCGM 包括一个新的性能分析模块,以提供对这些指标的访问。新指标通过常规 DCGM API(例如 C、Python、Go 绑定或 dcgmi 命令行实用程序)作为新字段(即新 ID)提供。安装程序包还包括一个基于 CUDA 的示例测试负载生成器(称为 dcgmproftester),以演示新功能。
指标
支持以下新的设备级性能分析指标。列出了定义和相应的 DCGM 字段 ID。默认情况下,DCGM 以 1Hz 的采样率(每 1000 毫秒)提供指标。用户可以从 DCGM 以任何可配置的频率(最小为 100 毫秒)查询指标(例如,请参阅 dcgmi dmon -d)。
指标 |
定义 |
DCGM 字段名称 (DCGM_FI_*) 和 ID |
|---|---|---|
图形引擎活动 |
图形或计算引擎的任何部分处于活动状态的时间比例。如果绑定了图形/计算上下文并且图形/计算管道繁忙,则图形引擎处于活动状态。该值表示一段时间间隔内的平均值,而不是瞬时值。 |
PROF_GR_ENGINE_ACTIVE(ID:1001) |
SM 活动 |
至少一个 warp 在多处理器上处于活动状态的时间比例,在所有多处理器上取平均值。请注意,“活动”不一定意味着 warp 正在积极计算。例如,等待内存请求的 warp 被认为是活动的。该值表示一段时间间隔内的平均值,而不是瞬时值。有效使用 GPU 需要但不充分的值为 0.8 或更大。小于 0.5 的值可能表示 GPU 使用效率低下。 给定简化的 GPU 架构视图,如果 GPU 有 N 个 SM,则在整个时间间隔内运行的、使用 N 个块的内核将对应于 1 (100%) 的活动。在整个时间间隔内运行的、使用 N/5 个块的内核将对应于 0.2 (20%) 的活动。在五分之一的时间间隔内运行的、使用 N 个块的内核,SM 在其他时间空闲,也将具有 0.2 (20%) 的活动。该值对每个块的线程数不敏感(请参阅 |
PROF_SM_ACTIVE(ID:1002) |
SM 占用率 |
多处理器上常驻 warp 的比例,相对于多处理器上支持的最大并发 warp 数。该值表示一段时间间隔内的平均值,而不是瞬时值。更高的占用率不一定表示更好的 GPU 使用率。对于 GPU 内存带宽受限的工作负载(请参阅 计算占用率并不简单,并且取决于 GPU 属性、每个块的线程数、每个线程的寄存器数以及每个块的共享内存等因素。使用 CUDA 占用率计算器 探索各种占用率场景。 |
PROF_SM_OCCUPANCY(ID:1003) |
张量活动 |
张量 (HMMA / IMMA) 管道处于活动状态的周期比例。该值表示一段时间间隔内的平均值,而不是瞬时值。更高的值表示张量核心的利用率更高。1 (100%) 的活动等效于在整个时间间隔内每隔一个周期发出一个张量指令。0.2 (20%) 的活动可能表示 20% 的 SM 在整个时间段内以 100% 的利用率运行,100% 的 SM 在整个时间段内以 20% 的利用率运行,100% 的 SM 在 20% 的时间段内以 100% 的利用率运行,或者介于两者之间的任何组合(请参阅 |
PROF_PIPE_TENSOR_ACTIVE(ID:1004) |
FP64 引擎活动 |
FP64(双精度)管道处于活动状态的周期比例。该值表示一段时间间隔内的平均值,而不是瞬时值。更高的值表示 FP64 核心的利用率更高。1 (100%) 的活动等效于在整个时间间隔内,在 Volta 上 每个 SM 每四个周期 执行一个 FP64 指令。0.2 (20%) 的活动可能表示 20% 的 SM 在整个时间段内以 100% 的利用率运行,100% 的 SM 在整个时间段内以 20% 的利用率运行,100% 的 SM 在 20% 的时间段内以 100% 的利用率运行,或者介于两者之间的任何组合(请参阅 DCGM_FI_PROF_SM_ACTIVE 以帮助消除这些可能性)。 |
PROF_PIPE_FP64_ACTIVE(ID:1006) |
FP32 引擎活动 |
FMA(FP32(单精度)和整数)管道处于活动状态的周期比例。该值表示一段时间间隔内的平均值,而不是瞬时值。更高的值表示 FP32 核心的利用率更高。1 (100%) 的活动等效于在整个时间间隔内每隔一个周期执行一个 FP32 指令。0.2 (20%) 的活动可能表示 20% 的 SM 在整个时间段内以 100% 的利用率运行,100% 的 SM 在整个时间段内以 20% 的利用率运行,100% 的 SM 在 20% 的时间段内以 100% 的利用率运行,或者介于两者之间的任何组合(请参阅 |
PROF_PIPE_FP32_ACTIVE(ID:1007) |
FP16 引擎活动 |
FP16(半精度)管道处于活动状态的周期比例。该值表示一段时间间隔内的平均值,而不是瞬时值。更高的值表示 FP16 核心的利用率更高。1 (100%) 的活动等效于在整个时间间隔内每隔一个周期执行一个 FP16 指令。0.2 (20%) 的活动可能表示 20% 的 SM 在整个时间段内以 100% 的利用率运行,100% 的 SM 在整个时间段内以 20% 的利用率运行,100% 的 SM 在 20% 的时间段内以 100% 的利用率运行,或者介于两者之间的任何组合(请参阅 |
PROF_PIPE_FP16_ACTIVE(ID:1008) |
内存带宽利用率 |
数据发送到设备内存或从设备内存接收数据的周期比例。该值表示一段时间间隔内的平均值,而不是瞬时值。更高的值表示设备内存的利用率更高。1 (100%) 的活动等效于在整个时间间隔内每周期执行一个 DRAM 指令(实际上,峰值约为 0.8 (80%) 是最大可实现的)。0.2 (20%) 的活动表示在时间间隔内 20% 的周期正在从设备内存读取或写入设备内存。 |
PROF_DRAM_ACTIVE(ID:1005) |
NVLink 带宽 |
通过 NVLink 传输/接收的数据速率,不包括协议标头,单位为字节/秒。该值表示一段时间间隔内的平均值,而不是瞬时值。速率在时间间隔内取平均值。例如,如果在 1 秒内传输了 1 GB 的数据,则速率为 1 GB/s,无论数据是以恒定速率还是以突发方式传输。理论最大 NVLink Gen2 带宽为每个链路每个方向 25 GB/s。 |
PROF_NVLINK_TX_BYTES (1011) 和 PROF_NVLINK_RX_BYTES (1012) |
PCIe 带宽 |
通过 PCIe 总线传输/接收的数据速率,包括协议标头和数据有效负载,单位为字节/秒。该值表示一段时间间隔内的平均值,而不是瞬时值。速率在时间间隔内取平均值。例如,如果在 1 秒内传输了 1 GB 的数据,则速率为 1 GB/s,无论数据是以恒定速率还是以突发方式传输。理论最大 PCIe Gen3 带宽为每通道 985 MB/s。 |
PROF_PCIE_[T|R]X_BYTES(ID:1009 (TX);1010 (RX)) |
从 Linux 驱动程序 418.43 或更高版本开始,GPU 计数器的性能分析需要管理员权限。这在 此处 有文档记录。当使用 DCGM 的性能分析指标时,请确保以超级用户权限启动 nv-hostengine。
性能分析计数器的多路复用
某些指标需要多次传递才能收集,因此并非所有指标都可以一起收集。由于 GPU 上的硬件限制,只有某些指标组可以一起读取。例如,SM 活动 | SM 占用率不能与 V100 上的张量利用率一起收集,但可以在 T4 上完成。为了克服这些硬件限制,DCGM 支持指标的自动多路复用,通过统计采样请求的指标并在内部执行分组。对于请求了可能无法一起收集的指标的用户来说,这可能是透明的。
多路复用的副作用是,以更高的频率收集将导致返回零,因为 DCGM 尝试将指标分组在一起进行收集。
可以一起收集的特定 GPU 的指标可以通过运行以下命令来确定
$ dcgmi profile -l -i 0
+----------------+----------+------------------------------------------------------+
| Group.Subgroup | Field ID | Field Tag |
+----------------+----------+------------------------------------------------------+
| A.1 | 1002 | sm_active |
| A.1 | 1003 | sm_occupancy |
| A.1 | 1004 | tensor_active |
| A.1 | 1007 | fp32_active |
| A.2 | 1006 | fp64_active |
| A.3 | 1008 | fp16_active |
| B.0 | 1005 | dram_active |
| C.0 | 1009 | pcie_tx_bytes |
| C.0 | 1010 | pcie_rx_bytes |
| D.0 | 1001 | gr_engine_active |
| E.0 | 1011 | nvlink_tx_bytes |
| E.0 | 1012 | nvlink_rx_bytes |
+----------------+----------+------------------------------------------------------+
从上面的输出中,我们可以确定,对于此 GPU(在本例中为 NVIDIA T4),可以收集来自每个字母组的指标而无需多路复用。从此示例中,可以收集来自 A.1 的指标和来自 A.1 的另一个指标,而无需多路复用。来自 A.1 的指标将与来自 A.2 或 A.3 的另一个指标多路复用。来自不同字母组的指标可以组合用于并发收集(无需 DCGM 进行多路复用)。
在此示例的基础上进一步扩展,在 T4 上,这些指标可以一起收集而无需多路复用
sm_active + sm_occupancy + tensor_active + fp32_active
上面的 DCGM 命令将显示硬件支持哪些分组用于并发收集。
并发使用 NVIDIA 性能分析工具
由于当前的硬件限制,使用 DCGM 收集性能分析指标会与 NVIDIA 的其他开发人员工具(如 Nsight Systems 或 Nsight Compute)的使用冲突。用户可能会遇到来自 DCGM 的错误(无论是使用 dcgmi 还是使用 API),例如
Error setting watches. Result: The requested operation could not be completed because the affected resource is in use.
为了使 DCGM 能够与其他性能分析工具的使用共存,建议在使用这些工具时暂停 DCGM 的指标收集,并在工具使用完成后恢复。
使用 dcgmi profile,可以使用 --pause 和 --resume 选项
$ dcgmi profile --pause
$ dcgmi profile --resume
当使用 DCGM API 时,可以从监控进程调用以下 API:dcgmProfPause() 和 dcgmProfResume()
暂停时,DCGM 将为性能分析指标发布 BLANK 值。这些 BLANK 值可以使用 C 或 Python 绑定中的 DCGM_FP64_IS_BLANK(value) 进行测试。
CUDA 测试生成器 (dcgmproftester)
dcgmproftester 是一个 CUDA 负载生成器。它可用于生成确定性的 CUDA 工作负载,以读取和验证 GPU 指标。该工具作为简单的 x86_64 Linux 二进制文件以及编译为 PTX 的 CUDA 内核一起提供。客户可以将该工具与 dcgmi 结合使用,以快速在 GPU 上生成负载,并通过 stdout 上的 dcgmi dmon 查看 DCGM 报告的指标。
dcgmproftester 接受两个重要的参数作为输入:-t 用于为特定指标生成负载(例如,使用 1004 为张量核心生成半精度矩阵乘法累加),-d 用于指定测试时长。添加 --no-dcgm-validation 以仅让 dcgmproftester 生成测试负载。
有关可用于生成特定测试负载的所有字段 ID 的列表,请参阅性能分析指标部分中的表格。本节的其余部分包含一些使用 dcgmi 命令行实用程序的示例。
例如,在控制台中,在 A100 上为 TensorCore 生成 30 秒的负载。可以看出,A100 能够使用 TensorCore 实现接近 253TFLops 的 FP16 性能。
$ /usr/bin/dcgmproftester11 --no-dcgm-validation -t 1004 -d 10
Skipping CreateDcgmGroups() since DCGM validation is disabled
Skipping CreateDcgmGroups() since DCGM validation is disabled
Skipping WatchFields() since DCGM validation is disabled
Skipping CreateDcgmGroups() since DCGM validation is disabled
Worker 0:0[1004]: TensorEngineActive: generated ???, dcgm 0.000 (250362.2 gflops)
Worker 0:0[1004]: TensorEngineActive: generated ???, dcgm 0.000 (252917.0 gflops)
Worker 0:0[1004]: TensorEngineActive: generated ???, dcgm 0.000 (253971.7 gflops)
Worker 0:0[1004]: TensorEngineActive: generated ???, dcgm 0.000 (253700.2 gflops)
Worker 0:0[1004]: TensorEngineActive: generated ???, dcgm 0.000 (252599.0 gflops)
Worker 0:0[1004]: TensorEngineActive: generated ???, dcgm 0.000 (253134.6 gflops)
Worker 0:0[1004]: TensorEngineActive: generated ???, dcgm 0.000 (252676.7 gflops)
Worker 0:0[1004]: TensorEngineActive: generated ???, dcgm 0.000 (252861.4 gflops)
Worker 0:0[1004]: TensorEngineActive: generated ???, dcgm 0.000 (252764.1 gflops)
Worker 0:0[1004]: TensorEngineActive: generated ???, dcgm 0.000 (253109.4 gflops)
Worker 0:0[1004]: Message: Bus ID 00000000:00:04.0 mapped to cuda device ID 0
DCGM CudaContext Init completed successfully.
CU_DEVICE_ATTRIBUTE_MAX_THREADS_PER_MULTIPROCESSOR: 2048
CUDA_VISIBLE_DEVICES:
CU_DEVICE_ATTRIBUTE_MULTIPROCESSOR_COUNT: 108
CU_DEVICE_ATTRIBUTE_MAX_SHARED_MEMORY_PER_MULTIPROCESSOR: 167936
CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MAJOR: 8
CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MINOR: 0
CU_DEVICE_ATTRIBUTE_GLOBAL_MEMORY_BUS_WIDTH: 5120
CU_DEVICE_ATTRIBUTE_MEMORY_CLOCK_RATE: 1215
Max Memory bandwidth: 1555200000000 bytes (1555.2 GiB)
CU_DEVICE_ATTRIBUTE_ECC_SUPPORT: true
在另一个控制台中,使用 dcgmi dmon -e 命令查看 DCGM 报告的各种性能指标(流式传输到 stdout),因为 CUDA 工作负载在 GPU 上运行。在此示例中,DCGM 以 1Hz(或 1000 毫秒)的频率报告 GPU 活动、TensorCore 活动和内存利用率。可以看出,GPU 正忙于工作(~99% 的图形活动表明 SM 很忙),TensorCore 活动固定在 ~93%。请注意,dcgmi 当前正在返回 GPU ID: 0 的指标。在多 GPU 系统上,您可以指定 DCGM 应返回指标的 GPU ID。默认情况下,指标是为系统中的所有 GPU 返回的。
$ dcgmi dmon -e 1001,1004,1005
# Entity GRACT TENSO DRAMA
Id
GPU 0 0.000 0.000 0.000
GPU 0 0.000 0.000 0.000
GPU 0 0.000 0.000 0.000
GPU 0 0.552 0.527 0.000
GPU 0 0.969 0.928 0.000
GPU 0 0.973 0.931 0.000
GPU 0 0.971 0.929 0.000
GPU 0 0.969 0.927 0.000
GPU 0 0.971 0.929 0.000
GPU 0 0.971 0.930 0.000
GPU 0 0.973 0.931 0.000
GPU 0 0.974 0.931 0.000
GPU 0 0.971 0.930 0.000
GPU 0 0.974 0.932 0.000
GPU 0 0.972 0.930 0.000
多实例 GPU 上的指标
多实例 GPU (MIG) 功能允许受支持的 NVIDIA GPU 安全地划分为最多七个独立的 GPU 实例,用于 CUDA 应用程序,为多个用户提供独立的 GPU 资源,以实现最佳 GPU 利用率。此功能对于未完全饱和 GPU 计算能力的工作负载尤其有利,因此用户可能希望并行运行不同的工作负载以最大化利用率。有关 MIG 的更多信息,请参阅 MIG 用户指南。
DCGM 可以为在 MIG 设备上运行的工作负载提供指标。DCGM 为 MIG 提供两种指标视图
GPU 设备级指标
MIG 设备(GPU 实例或计算实例)粒度的指标
示例 1
在此示例中,让我们使用 dcgmproftester 生成 CUDA 工作负载,并使用 dcgmi dmon 观察指标。
在此示例中,我们按照以下步骤演示 MIG 设备的指标收集
创建 MIG 设备(假设 GPU 已启用 MIG 模式)
验证 DCGM 可以列出设备
创建一个设备组供 DCGM 监控
在所需的 MIG 设备上运行 CUDA 工作负载
使用 dcgmi dmon 流式传输指标
$ sudo nvidia-smi mig -cgi 9,9 -C
...
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 1 0 0 | 11MiB / 20096MiB | 42 0 | 3 0 2 0 0 |
| | 0MiB / 32767MiB | | |
+------------------+----------------------+-----------+-----------------------+
| 0 2 0 1 | 11MiB / 20096MiB | 42 0 | 3 0 2 0 0 |
| | 0MiB / 32767MiB | | |
+------------------+----------------------+-----------+-----------------------+
$ dcgmi discovery -c
+-------------------+--------------------------------------------------------------------+
| Instance Hierarchy |
+===================+====================================================================+
| GPU 0 | GPU GPU-5fd15f35-e148-2992-4ecb-9825e534f253 (EntityID: 0) |
| -> I 0/1 | GPU Instance (EntityID: 0) |
| -> CI 0/1/0 | Compute Instance (EntityID: 0) |
| -> I 0/2 | GPU Instance (EntityID: 1) |
| -> CI 0/2/0 | Compute Instance (EntityID: 1) |
+-------------------+--------------------------------------------------------------------+
$ dcgmi group -c mig-ex1 -a 0,i:0,i:1
Successfully created group "mig-ex1" with a group ID of 8
Specified entity ID is valid but unknown: i:0. ParsedResult: ParsedGpu(i:0)
Specified entity ID is valid but unknown: i:1. ParsedResult: ParsedGpu(i:1)
Add to group operation successful.
现在,我们可以列出添加到组中的设备,并查看该组包含 GPU (GPU:0)、GPU 实例(0 和 1)
$ dcgmi group -l
+-------------------+----------------------------------------------------------+
| GROUPS |
| 1 group found. |
+===================+==========================================================+
| Groups | |
| -> 8 | |
| -> Group ID | 8 |
| -> Group Name | mig-ex1 |
| -> Entities | GPU 0, GPU_I 0, GPU_I 1 |
+-------------------+----------------------------------------------------------+
dcgmproftester。请注意,dcgmproftester 将在 GPU 上所有可用的 GPU 实例上运行。目前无法从 dcgmproftester 限制 GPU 实例(尽管可以通过运行 dcgmproftester 容器来做到这一点,我们将在下一个示例中看到)。$ sudo dcgmproftester11 --no-dcgm-validation -t 1004 -d 120
Skipping CreateDcgmGroups() since DCGM validation is disabled
Skipping CreateDcgmGroups() since DCGM validation is disabled
Skipping CreateDcgmGroups() since DCGM validation is disabled
Skipping WatchFields() since DCGM validation is disabled
Skipping CreateDcgmGroups() since DCGM validation is disabled
Worker 0:0[1004]: TensorEngineActive: generated ???, dcgm { GPU: 0.000, GI: 0.000, CI: 0.000 } (102659.5 gflops)
Worker 0:1[1004]: TensorEngineActive: generated ???, dcgm { GPU: 0.000, GI: 0.000, CI: 0.000 } (102659.8 gflops)
Worker 0:0[1004]: TensorEngineActive: generated ???, dcgm { GPU: 0.000, GI: 0.000, CI: 0.000 } (107747.3 gflops)
Worker 0:1[1004]: TensorEngineActive: generated ???, dcgm { GPU: 0.000, GI: 0.000, CI: 0.000 } (107787.3 gflops)
Worker 0:0[1004]: TensorEngineActive: generated ???, dcgm { GPU: 0.000, GI: 0.000, CI: 0.000 } (108107.6 gflops)
Worker 0:1[1004]: TensorEngineActive: generated ???, dcgm { GPU: 0.000, GI: 0.000, CI: 0.000 } (108102.3 gflops)
Worker 0:0[1004]: TensorEngineActive: generated ???, dcgm { GPU: 0.000, GI: 0.000, CI: 0.000 } (108001.2 gflops)
snip...snip
Worker 0:0[1004]: Message: DCGM CudaContext Init completed successfully.
CU_DEVICE_ATTRIBUTE_MAX_THREADS_PER_MULTIPROCESSOR: 2048
CUDA_VISIBLE_DEVICES: MIG-GPU-5fd15f35-e148-2992-4ecb-9825e534f253/1/0
CU_DEVICE_ATTRIBUTE_MULTIPROCESSOR_COUNT: 42
CU_DEVICE_ATTRIBUTE_MAX_SHARED_MEMORY_PER_MULTIPROCESSOR: 167936
CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MAJOR: 8
CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MINOR: 0
CU_DEVICE_ATTRIBUTE_GLOBAL_MEMORY_BUS_WIDTH: 5120
CU_DEVICE_ATTRIBUTE_MEMORY_CLOCK_RATE: 1215
Max Memory bandwidth: 1555200000000 bytes (1555.2 GiB)
CU_DEVICE_ATTRIBUTE_ECC_SUPPORT: true
Worker 0:1[1004]: Message: DCGM CudaContext Init completed successfully.
CU_DEVICE_ATTRIBUTE_MAX_THREADS_PER_MULTIPROCESSOR: 2048
CUDA_VISIBLE_DEVICES: MIG-GPU-5fd15f35-e148-2992-4ecb-9825e534f253/2/0
CU_DEVICE_ATTRIBUTE_MULTIPROCESSOR_COUNT: 42
CU_DEVICE_ATTRIBUTE_MAX_SHARED_MEMORY_PER_MULTIPROCESSOR: 167936
CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MAJOR: 8
CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MINOR: 0
CU_DEVICE_ATTRIBUTE_GLOBAL_MEMORY_BUS_WIDTH: 5120
CU_DEVICE_ATTRIBUTE_MEMORY_CLOCK_RATE: 1215
Max Memory bandwidth: 1555200000000 bytes (1555.2 GiB)
CU_DEVICE_ATTRIBUTE_ECC_SUPPORT: true
Skipping UnwatchFields() since DCGM validation is disabled
dcgmi dmon 流式传输指标dcgmi dmon 观察归因于每个 MIG 设备的指标。请注意,在此示例中,我们显示了我们在步骤 3 中创建的组 8 的 GPU 活动 (1001) 和张量核心利用率 (1004)。$ dcgmi dmon -e 1001,1004 -g 8
# Entity GRACT TENSO
Id
GPU 0 0.000 0.000
GPU-I 0 0.000 0.000
GPU-I 1 0.000 0.000
GPU 0 0.000 0.000
GPU-I 0 0.000 0.000
GPU-I 1 0.000 0.000
GPU 0 0.457 0.442
GPU-I 0 0.534 0.516
GPU-I 1 0.533 0.515
GPU 0 0.845 0.816
GPU-I 0 0.986 0.953
GPU-I 1 0.985 0.952
GPU 0 0.846 0.817
GPU-I 0 0.987 0.953
GPU-I 1 0.986 0.953
GPU 0 0.846 0.817
GPU-I 0 0.987 0.954
GPU-I 1 0.986 0.953
GPU 0 0.843 0.815
GPU-I 0 0.985 0.951
GPU-I 1 0.983 0.950
GPU 0 0.845 0.817
GPU-I 0 0.987 0.953
GPU-I 1 0.985 0.952
GPU 0 0.844 0.816
GPU-I 0 0.985 0.952
GPU-I 1 0.984 0.951
GPU 0 0.845 0.816
GPU-I 0 0.986 0.952
GPU-I 1 0.985 0.952
理解指标
为了理解指标归因,GRACT 是根据分配给计算资源的数量与 GPU 上可用的计算资源总数计算得出的。我们可以使用 nvidia-smi 命令查看计算资源(SM)的总数
$ sudo nvidia-smi mig -lgip
+--------------------------------------------------------------------------+
| GPU instance profiles: |
| GPU Name ID Instances Memory P2P SM DEC ENC |
| Free/Total GiB CE JPEG OFA |
|==========================================================================|
| 0 MIG 1g.5gb 19 0/7 4.75 No 14 0 0 |
| 1 0 0 |
+--------------------------------------------------------------------------+
| 0 MIG 2g.10gb 14 0/3 9.75 No 28 1 0 |
| 2 0 0 |
+--------------------------------------------------------------------------+
| 0 MIG 3g.20gb 9 0/2 19.62 No 42 2 0 |
| 3 0 0 |
+--------------------------------------------------------------------------+
| 0 MIG 4g.20gb 5 0/1 19.62 No 56 2 0 |
| 4 0 0 |
+--------------------------------------------------------------------------+
| 0 MIG 7g.40gb 0 0/1 39.50 No 98 5 0 |
| 7 1 1 |
+--------------------------------------------------------------------------+
由于此示例中的 MIG 几何形状为 3g.20gb,因此计算资源 = 2*42/98 或 85.71%。我们现在可以解释 dcgmi dmon 输出中的 GRACT
GPU 0 0.845 0.816
GPU-I 0 0.986 0.952
GPU-I 1 0.985 0.952
由于每个 GPU 实例的活动率为 98.6%,因此整个 GPU = 0.8571*0.986 或 84.5% 的利用率。相同的解释可以扩展到张量核心利用率。
平台支持
性能分析指标目前在数据中心产品上受支持,从 Linux x86_64、Arm64 (aarch64) 和 POWER (ppc64le) 平台上的 Volta 架构开始。