概述#
nvmath-python 的主要目标是将 NVIDIA 数学库的强大功能引入 Python 生态系统。该软件包旨在提供直观的 Pythonic API,使用户能够在各种执行空间中完全访问我们库提供的所有功能。
我们希望通过提供对高性能核心数学运算(如 FFT、稠密和稀疏线性代数等)的轻松访问,来增强广泛的 Python 用户群体。这包括以下用户群体:
从业者:需要强大、高性能数学工具的研究人员和应用程序员。
库软件包开发者:开发依赖于高级数学运算的库的开发者。
CUDA 内核作者:编写 CUDA 内核并需要定制数学功能的程序员。
nvmath-python 提供的 API 可以分为:
主机 API:从主机调用并在选定的空间(目前仅限于单个 GPU)中执行。
设备 API:直接从 CUDA 内核内部调用。
nvmath-python 致力于提供以下关键特性和承诺:
逻辑功能对等:虽然 Pythonic API 表面(API 的数量和每个 API 的复杂性)比 C 库更简洁,但它提供了对其完整功能的访问。
一致的设计模式:所有模块采用统一的设计,以简化用户体验。
透明性和显式性:避免隐式、代价高昂的操作,例如在同一内存空间中复制数据、自动类型提升以及更改用户环境或状态(当前设备、当前流等)。这允许用户执行一次所需的转换,以便在所有后续操作中使用,而不是在每次调用时产生隐藏成本。
清晰、可操作的错误消息:确保错误信息丰富,有助于解决问题。
DRY 原则合规性:自动利用可用信息(如当前流和内存池)来避免冗余规范(“不要重复自己”)。
使用 nvmath-python,只需几行代码即可解锁 NVIDIA 数学库的广泛性能功能。在 GitHub 上的 examples 目录 中探索我们的示例 Python 代码和更详细的示例。
架构#
nvmath-python 旨在支持用户所需的任何级别的集成。这种灵活性允许:
Alice,一位 Python 软件包开发者,利用核心数学运算来组合成更高级别的算法,或将这些运算适配到她偏好的接口中。
Bob,一位 应用程序开发者,直接从 nvmath-python 使用核心运算,或通过其他利用 math-python 的库间接使用。
Carol,一位 研究人员,完全用 Python 编写内核,调用核心数学运算(如 FFT)。
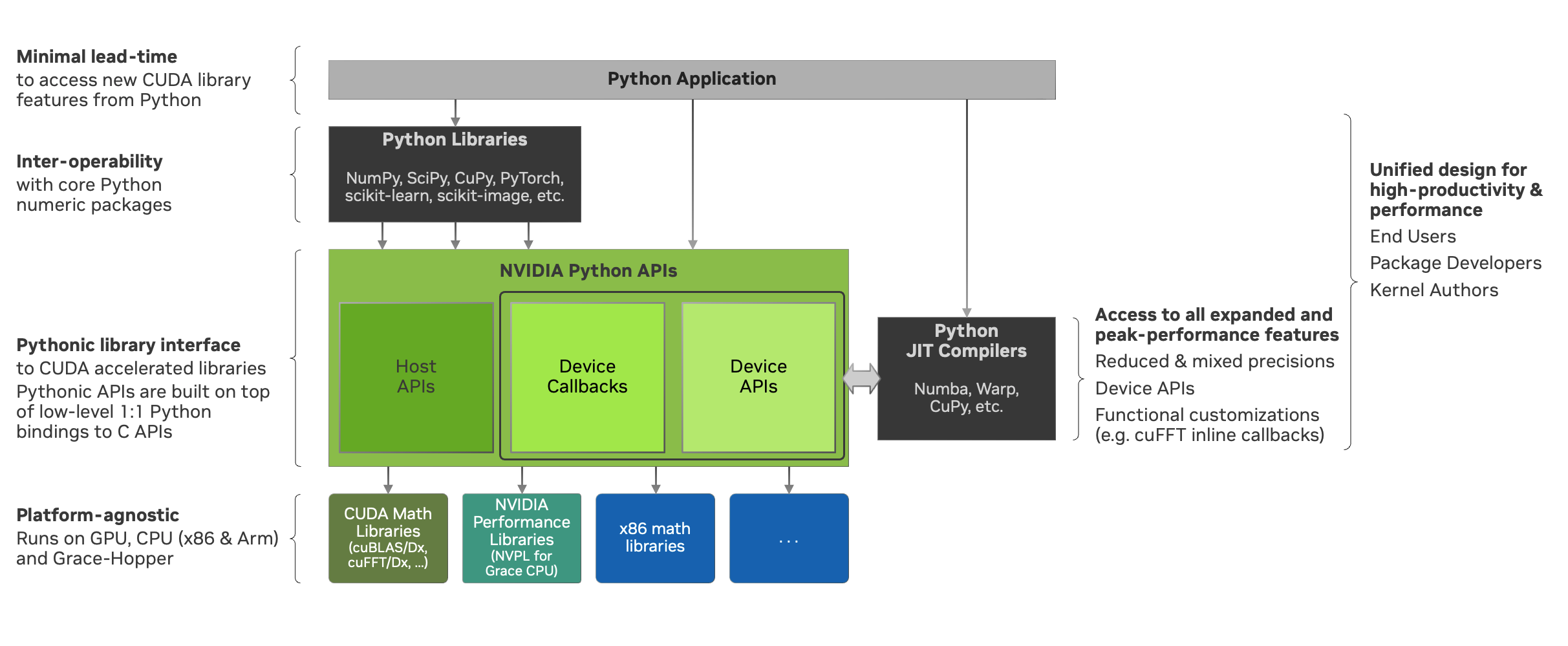
此外,我们提供 Python 绑定,它提供与 C API 的 1:1 映射。这些绑定充当包装器,其 API 签名与其 C 对应项类似,非常适合希望以自定义方式集成 NVIDIA 数学库功能的库开发者,以防 Pythonic API 不能满足他们的特定要求。相反,我们高级的 Pythonic API 提供了一个完全集成的解决方案,既适用于原生 Python 用户,也适用于库开发者,涵盖主机和设备 API。未来,选择的主机 API 将接受用 Python 编写并编译成受支持格式(如 LTO-IR)的回调函数,使用像 Numba 这样的编译器。
主机 API#
nvmath-python 提供了一系列可以直接从 CPU(主机)调用的 API。目前,这些 API 涵盖以下类别中的部分功能:
nvmath.中的快速傅里叶变换。有关详细信息,请参阅 快速傅里叶变换。fft nvmath.中的线性代数。有关详细信息,请参阅 线性代数。linalg
轻松互操作性#
所有主机 API 都支持来自 NumPy、CuPy 和 PyTorch 的输入数组/张量,同时使用相同的软件包返回输出操作数,从而提供与这些框架的轻松互操作性。下面显示了一个互操作性的示例:
import numpy as np
import nvmath
# Create a numpy.ndarray as input
a = np.random.random(128) + 1.j * np.random.random(128)
# Call nvmath-python pythonic APIs
b = nvmath.fft.fft(a)
# Verify that output is also a numpy.ndarray
assert isinstance(b, np.ndarray)
无状态和有状态 API#
nvmath-python 中的主机 API 通常可以分为两种类型:无状态函数形式的 API 和有状态类形式的 API。
函数形式的 API,例如 nvmath. 和 nvmath.,旨在通过单个函数调用提供快速的端到端结果。这些 API 非常适合用户需要执行单个计算而无需中间步骤、自定义算法选择或准备步骤的成本摊销的情况。相反,有状态类形式的 API,如 nvmath. 和 nvmath.,提供了更全面和灵活的方法。它们不仅包含其函数形式对应项中的功能,还允许摊销一次性成本,从而可能显着提高性能。
nvmath-python 中所有有状态 API 的设计模式包括几个关键阶段:
问题规范:此初始阶段涉及定义操作并设置影响其执行的选项。它旨在尽可能轻量级,确保问题得到良好定义并受当前实现支持。
准备:以 FFT 为例,此阶段包括一个规划步骤,以选择用于定义的 FFT 操作的最佳算法。可选的自动调优操作(如果可用)也属于准备阶段。准备阶段通常是资源最密集的阶段,可能包含用户指定的规划和自动调优选项。
执行:此阶段允许重复执行,其中操作数可以就地修改,也可以使用
reset_operand/reset_operands方法显式重置。因此,前两个阶段的成本在这些多次执行中摊销。资源释放:建议用户在上下文中使用状态对象,使用 with 语句,该语句会在退出时自动处理内部资源的释放。如果对象未使用
with作为上下文管理器,则必须显式调用free方法以确保所有资源都得到正确释放。
注意
根据设计,nvmath-python 不会使用无状态函数形式的 API 缓存计划。这是为了使库开发人员和其他人员能够将他们自己的缓存机制与 nvmath-python 一起使用。因此,用户应将状态对象 API 用于重复使用以及基准测试,以避免产生重复的准备成本,或者使用缓存的 API(有关示例实现,请参阅 caching.py)。
注意
需要显式调用 free 来释放资源的决定,是由于 Python 的垃圾回收器可能会延迟释放对象资源,当对象超出作用域或其引用计数降至零时。有关详细信息,请参阅 __del__ 方法 Python 文档。
通用和专用 API#
在 nvmath-python 中对主机 API 进行分类的另一种方法是根据其灵活性和功能范围将其分为通用 API 和专用 API
通用 API 旨在适应广泛的操作数,并且这些 API 的自定义仅限于普遍适用于所有受支持操作数类型的选项。例如,通用矩阵乘法 API 除了密集的完整矩阵外,还可以处理结构化矩阵(例如三角形矩阵和带状矩阵,以完整或压缩形式),但可用选项仅限于适用于所有这些矩阵类型的选项。
另一方面,专用 API 专为特定类型的操作数量身定制,允许对此类操作数进行完全自定义。一个主要的例子是用于密集矩阵的专用矩阵乘法 API,它提供了许多专门适用于密集矩阵的选项。
应该注意的是,通用 API 和专用 API 的概念与有状态 API 和无状态 API 的概念是正交的。目前,nvmath-python 为密集矩阵乘法提供了专用接口,形式为 stateful 和 stateless。
完全日志记录支持#
nvmath-python 与 Python 标准库记录器(来自 logging 模块)集成,以提供各个级别计算详细信息的完整日志记录,例如调试、信息、警告和错误。下面显示了一个说明如何使用全局 Python 记录器的示例
import logging
# Turn on logging with level set to "debug" and use a custom format for the log
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s %(levelname)-8s %(message)s',
datefmt='%m-%d %H:%M:%S'
)
# Call nvmath-python pythonic APIs
out = nvmath.linalg.advanced.matmul(...)
或者,对于包含 options 参数的 API,用户可以通过直接在字典中或作为相应的 Options 对象的一部分传递自定义记录器来设置自定义记录器,例如 nvmath. 用于 nvmath. 和 nvmath.。下面显示了一个基于 FFT 的示例
import logging
# Create a custom logger
logger = logging.getLogger('userlogger')
...
# Call nvmath-python pythonic APIs
out = nvmath.fft.fft(..., options={'logger': logger})
有关完整示例,请参阅 全局日志记录示例 和 自定义用户日志记录示例。
注意
Python 日志记录与某些 NVIDIA 数学库提供的日志记录是正交的,后者封装了低级实现细节,可以通过特定的环境变量(例如 CUBLASLT_LOG_LEVEL 用于 cuBLASLt)或通过 Python 绑定以编程方式激活(例如 nvmath. 用于 cuSOLVER)。
调用阻塞行为#
默认情况下,如果输入操作数驻留在设备上,则对所有需要 GPU 执行的 pythonic 主机 API 的调用都是非阻塞的。这意味着像 nvmath.、nvmath. 和 nvmath. 这样的函数将在操作在 GPU 上启动后立即返回,而无需等待其完成。因此,用户有责任在需要时正确同步流。可以通过将相关 Options 对象的 blocking 属性(默认 'auto')设置为 True 来修改默认行为。例如,用户可以将 nvmath. 设置为 True 并将此选项对象传递给相应的 FFT API 调用。如果输入操作数在主机上,则 pythonic API 调用将始终阻塞,因为计算会产生也将驻留在主机上的输出操作数。同时,在主机上执行的 API(例如 nvmath.)始终阻塞。
流语义#
流语义取决于执行 API 的行为是选择阻塞还是非阻塞(请参阅 调用阻塞行为)。
对于阻塞行为,流排序由 nvmath-python 高级 API 自动处理在包内执行的操作。可以出于两个原因提供流
当准备输入操作数的计算在调用执行 API 时尚未完成时。这是用户提供数据的正确性要求。
如果设备有足够的资源并且当前流(默认流)具有伴随操作,则可以实现跨多个流的并行计算。这样做可能是出于性能原因。
对于非阻塞行为,用户有责任确保执行 API 调用之间正确的流排序。
在任何情况下,执行 API 都在提供的流上启动。
有关流排序的示例,请参阅 使用多个流的 FFT。
内存管理#
默认情况下,主机 API 使用其操作数所属包的内存池。这确保了不会发生内存争用或虚假的内存不足错误。但是,如果用户选择这样做,他们也可以提供自己的内存分配器。在我们的 pythonic API 中,我们支持 EMM 类的接口,如 Numba 提出和支持的那样,供用户设置他们的 Python 内存池。以 FFT 为例,用户可以将选项 nvmath. 设置为符合 nvmath. 协议的 Python 对象,并将选项传递给高级 API,如 nvmath. 或 nvmath.。临时内存分配将通过此接口完成。在内部,我们使用相同的接口来使用 CuPy 或 PyTorch 的内存池,具体取决于操作数。
注意
nvmath 的 BaseCUDAMemoryManager 协议与 Numba 的 EMM 接口 (numba.cuda.BaseCUDAMemoryManager) 略有不同,但在运行时使用现有 EMM 实例(不是类型!)进行鸭子类型化应该是可能的。
带有回调的主机 API#
某些主机 API(例如 nvmath. 和 nvmath.)允许用户提供用 Python 编写的前言或后记函数,从而产生融合内核。这通过避免额外的全局内存往返并有效提高操作的算术强度来提高性能。
import cupy as cp
import nvmath
# Create the data for the batched 1-D FFT.
B, N = 256, 1024
a = cp.random.rand(B, N, dtype=cp.float64) + 1j * cp.random.rand(B, N, dtype=cp.float64)
# Compute the normalization factor.
scale = 1.0 / N
# Define the epilog function for the FFT.
def rescale(data_out, offset, data, user_info, unused):
data_out[offset] = data * scale
# Compile the epilog to LTO-IR (in the context of the execution space).
with a.device:
epilog = nvmath.fft.compile_epilog(rescale, "complex128", "complex128")
# Perform the forward FFT, applying the filter as an epilog...
r = nvmath.fft.fft(a, axes=[-1], epilog={"ltoir": epilog})
设备 API#
设备 API 使用户能够在他们的 Python CUDA 内核中调用核心数学运算,从而产生完全融合的内核。融合对于延迟主导情况下的性能至关重要,以减少内核启动次数,并且对于内存受限的操作,可以避免额外的全局内存往返。
我们目前提供在使用 Numba 编写的内核中调用 FFT、矩阵乘法和随机数生成 API 的支持,并计划在未来提供更多核心操作并支持其他编译器。设备 API 的设计密切模仿了来自相应的 NVIDIA 数学库的 C++ API(用于 FFT 和矩阵乘法的 MathDx 库 cuFFTDx 和 cuBLASDx,以及用于随机数生成的 cuRAND 设备 API)。
兼容性策略#
nvmath-python 与任何 Python 包没有什么不同,因为如果没有 Python 社区的依赖、协作和共同发展,我们就不会成功。考虑到这些因素,我们努力履行以下承诺
对于 低级 Python 绑定,
如果要绑定的库是 CUDA 工具包的一部分,我们支持来自最近两个 CUDA 主要版本(当前为 CUDA 11/12)的库
否则,我们在其主要版本内支持该库
请注意,所有绑定目前都是实验性的。
对于高级 pythonic API,我们在最大程度上保持向后兼容性。当必须进行重大更改时,我们会发出运行时警告,以提醒用户在下一个主要版本中即将发生的更改。这种做法确保了重大更改得到清晰的沟通并保留用于主要版本更新,使用户能够做好准备和适应,而不会感到意外。
我们遵守 NEP-29 并支持社区定义的核心依赖项集(CPython、NumPy 等)。
注意
向后兼容性策略将从 1.0.0 版本开始应用。