cuSPARSE
cuSPARSE 的 API 参考指南,CUDA 稀疏矩阵库。
1. 简介
cuSPARSE 库包含一组 GPU 加速的基本线性代数子程序,用于处理稀疏矩阵,其性能明显快于仅 CPU 的替代方案。根据具体操作,该库的目标矩阵的稀疏率在 70%-99.9% 之间。它基于 NVIDIA® CUDA™ 运行时(CUDA 工具包的一部分)实现,旨在从 C 和 C++ 中调用。
另请参阅 cuSPARSELt:用于稀疏矩阵-矩阵乘法的高性能 CUDA 库
cuSPARSE 发行说明: cuda-toolkit-release-notes
cuSPARSE GitHub 示例: CUDALibrarySamples
Nvidia 开发者论坛: GPU 加速库
提供反馈: Math-Libs-Feedback@nvidia.com
近期 cuSPARSE/cuSPARSELt 博客文章和 GTC 演示文稿:
库例程提供以下功能
稀疏向量和稠密向量之间的运算:求和、点积、scatter、gather
稠密矩阵和稀疏向量之间的运算:乘法
稀疏矩阵和稠密向量之间的运算:乘法、三角求解器、三对角线求解器、五对角线求解器
稀疏矩阵和稠密矩阵之间的运算:乘法、三角求解器、三对角线求解器、五对角线求解器
稀疏矩阵和稀疏矩阵之间的运算:求和、乘法
稠密矩阵之间的运算,输出为稀疏矩阵:乘法
稀疏矩阵预处理器:不完全 Cholesky 分解(level 0)、不完全 LU 分解(level 0)
不同稀疏矩阵存储格式之间的重排序和转换操作
1.1. 库组织和特性
cuSPARSE 库组织为两组 API
旧版 API,灵感来自稀疏 BLAS 标准,提供有限的功能集,在未来的版本中将不会改进,即使仍然确保标准维护。此类别中的某些例程可能会在短期内被弃用和删除。在弃用过程中,将为其中最重要的例程提供替代方案。
-
通用 API 提供 cuSPARSE 的标准接口层。它们允许以灵活的方式计算最常见的稀疏线性代数运算,例如稀疏矩阵-向量 (SpMV) 和稀疏矩阵-矩阵乘法 (SpMM)。新的 API 具有以下功能和特性
设置矩阵数据布局、批次数量和存储格式(例如,CSR、COO 等)。
设置输入/输出/计算数据类型。这也允许混合数据类型计算。
设置稀疏向量/矩阵索引的类型(例如,32 位、64 位)。
选择计算的算法。
为内部操作保证外部设备内存。
在输入矩阵和向量之间提供广泛的一致性检查。这包括验证大小、数据类型、布局、允许的操作等。
为向量和矩阵输入提供常量描述符,以支持 const 安全接口并保证 API 不会修改其输入。
1.2. 静态库支持
从 CUDA 6.5 开始,cuSPARSE 库也以静态形式作为 libcusparse_static.a 在 Linux 上交付。
例如,要使用 cuSPARSE 针对动态库编译一个小型应用程序,可以使用以下命令
nvcc my_cusparse_app.cu -lcusparse -o my_cusparse_app
而要针对静态库进行编译,则必须使用以下命令
nvcc my_cusparse_app.cu -lcusparse_static -o my_cusparse_app
也可以使用本机 Host C++ 编译器。根据 Host 操作系统,链接行可能需要一些额外的库,例如 pthread 或 dl。建议在 Linux 上使用以下命令
gcc my_cusparse_app.c -lcusparse_static -lcudart_static -lpthread -ldl -I <cuda-toolkit-path>/include -L <cuda-toolkit-path>/lib64 -o my_cusparse_app
请注意,在后一种情况下,不需要库 cuda。如果需要,CUDA 运行时将尝试显式打开 cuda 库。对于没有安装 CUDA 驱动程序的系统,这允许应用程序优雅地管理此问题,并在 CPU 专用路径可用时可能运行。
1.3. 库依赖项
从 CUDA 12.0 开始,cuSPARSE 将依赖 nvJitLink 库来实现 JIT(即时)LTO(链接时优化)功能;有关更多信息,请参阅 cusparseSpMMOp() API。
如果用户链接到动态库,则用于在运行时加载库的环境变量(例如 Linux 上的 LD_LIBRARY_PATH 和 Windows 上的 PATH)必须包含 libnvjitlink.so 所在的路径。如果它与 cuSPARSE 位于同一目录中,则用户无需执行任何操作。
如果链接到静态库,用户需要链接 -lnvjitlink 并相应地设置用于在编译时加载库的环境变量 LIBRARY_PATH/PATH。
2. 使用 cuSPARSE API
本章介绍如何使用 cuSPARSE 库 API。它不是 cuSPARSE API 数据类型和函数的参考;这在后续章节中提供。
2.1. API 用法说明
cuSPARSE 库允许开发人员访问 NVIDIA 图形处理单元 (GPU) 的计算资源。
cuSPARSE API 假定输入和输出数据(向量和矩阵)驻留在 GPU(设备)内存中.
输入和输出标量(例如 \(\alpha\) 和 \(\beta\))可以通过引用在主机或设备上传递,而不是仅允许通过值在主机上传递。这允许库函数使用流异步执行,即使它们是由先前的内核生成的,从而实现最大的并行性。
cuSPARSE 库上下文的句柄使用函数初始化,并显式传递给每个后续的库函数调用。这允许用户在使用多个主机线程和多个 GPU 时更好地控制库设置。
错误状态
cusparseStatus_t由所有 cuSPARSE 库函数调用返回。
开发人员有责任分配内存,并使用标准 CUDA 运行时 API 例程(例如 cudaMalloc()、cudaFree()、cudaMemcpy() 和 cudaMemcpyAsync())在 GPU 内存和 CPU 内存之间复制数据。
cuSPARSE 库函数相对于主机异步执行,并且可能会在结果准备就绪之前将控制权返回给主机上的应用程序。开发人员可以使用 cudaDeviceSynchronize() 函数来确保特定 cuSPARSE 库例程的执行已完成。
开发人员还可以使用 cudaMemcpy() 例程,分别使用 cudaMemcpyDeviceToHost 和 cudaMemcpyHostToDevice 参数将数据从设备复制到主机,反之亦然。在这种情况下,无需调用 cudaDeviceSynchronize(),因为调用带有上述参数的 cudaMemcpy() 是阻塞的,并且仅在主机上的结果准备就绪时才完成。
2.2. 已弃用的 API
cuSPARSE 库文档明确指出了一组已弃用的 API/枚举器/数据结构。已弃用 API 的库策略如下
-
API 在版本 X.Y(例如 11.2)上标记为
[[DEPRECATED]]文档索引了可用的替换项(如果有)
否则,该功能在未来将不会维护
API 将在版本 X+1.0(例如 12.0)中删除
即使对于已弃用的 API,仍然会解决正确性错误,但不一定保证性能问题。
除了文档之外,已弃用的 API 在使用时还会为大多数平台生成编译时警告。可以通过在包含 cusparse.h 之前定义宏 DISABLE_CUSPARSE_DEPRECATED 或将标志 -DDISABLE_CUSPARSE_DEPRECATED 传递给编译器来禁用弃用警告。
2.3. 线程安全
该库是线程安全的。可以随时从任何线程调用任何函数,只要它正在使用的任何数据不同时被另一个线程写入即可。cuSPARSE 函数是否写入对象通常通过 const 参数指示。
不建议在多个线程之间共享同一个 cuSPARSE 句柄。这样做是可能的,但对句柄的更改(例如 设置流 或 销毁)将影响所有线程并引入全局同步问题。
2.4. 结果可重现性
cuSPARSE 的设计优先考虑性能而不是按位可重现性。
使用转置或共轭转置 cusparseOperation_t 的操作没有可重现性保证。
对于其余操作,在同一台机器上使用完全相同的参数和相同的可执行文件执行相同的 API 调用两次将产生按位相同的结果。硬件、CUDA 驱动程序、cuSPARSE 版本、数据内存对齐或算法选择的更改可能会破坏这种按位可重现性。
2.5. NaN 和 Inf 传播
浮点数具有 NaN(非数字)和 Inf(无穷大)的特殊值。cuSPARSE 中的函数不保证 NaN 和 Inf 的传播。
cuSPARSE 算法评估假设所有有限浮点值。NaN 和 Inf 仅在算法恰好生成或传播它们时才会出现在输出中。由于算法会根据工具包版本和运行时考虑因素而发生变化,因此 NaN 和 Inf 的传播行为也会发生变化。
cuSPARSE 中的 NaN 传播与典型的稠密数值线性代数(例如 cuBLAS)不同。向量 [0, 1, 0] 和 [1, 1, NaN] 之间的点积在使用典型的稠密数值算法时为 NaN,但在典型的稀疏数值算法中将为 1.0。
2.6. 使用流的并行性
如果应用程序执行多个独立的小型计算,或者如果它在与计算并行进行数据传输,则可以使用 CUDA 流来重叠这些任务。
应用程序可以在概念上将流与每个任务关联起来。为了实现任务之间计算的重叠,开发人员应使用函数 cudaStreamCreate() 创建 CUDA 流,并通过在调用实际 cuSPARSE 例程之前调用 cusparseSetStream() 来设置每个单独的 cuSPARSE 库例程要使用的流。然后,在单独的流中执行的计算将在 GPU 上尽可能自动重叠。当单个任务执行的计算量相对较小并且不足以用工作填充 GPU 时,或者当存在可以与计算并行执行的数据传输时,此方法特别有用。
当使用流时,我们建议使用新的 cuSPARSE API,其中标量参数和结果通过设备内存中的引用传递,以实现最大的计算重叠。
尽管开发人员可以创建许多流,但在实践中,不可能同时执行超过 16 个并发内核。
2.7. 兼容性和版本控制
cuSPARSE API 旨在与未来的版本在源代码级别上向后兼容(除非在特定未来版本的发行说明中另有说明)。换句话说,如果程序使用 cuSPARSE,则它应该继续编译并在较新版本的 cuSPARSE 上正确工作,而无需更改源代码。cuSPARSE 不保证在二进制级别上向后兼容。不支持使用不同版本的 cusparse.h 头文件和共享库。不支持使用不同版本的 cuSPARSE 和 CUDA 运行时。
该库使用标准的 版本语义 约定来标识不同的版本。
版本采用四个字段的形式,字段之间用句点连接:MAJOR.MINOR.PATCH.BUILD
这些版本字段根据以下规则递增
MAJOR:API 破坏性更改或新的 CUDA 主要版本(较低级别的破坏性更改,例如驱动程序、编译器、库)MINOR:新的 API 和功能PATCH:错误修复或性能改进(或 * 新的 CUDA 版本)BUILD:内部构建号
* 不同的 CUDA 工具包版本确保了不同的库版本,即使库级别没有更改。
2.8. 优化说明
大多数 cuSPARSE 例程可以通过利用CUDA Graphs 捕获和硬件内存压缩功能进行优化。
更详细地说,单个 cuSPARSE 调用或一系列调用可以被 CUDA Graph 捕获,并在稍后执行。这最大限度地减少了内核启动开销,并允许 CUDA 运行时优化整个工作流程。应用于 cuSPARSE 例程的 CUDA 图形捕获的完整示例可以在 cuSPARSE 库示例 - CUDA Graph 中找到。
其次,cuSPARSE 中涉及的数据类型和功能适用于 Ampere GPU 设备(计算能力 8.0)或更高版本中可用的硬件内存压缩。该功能允许对具有足够零字节的数据进行内存压缩,而不会丢失信息。设备内存必须使用 CUDA 驱动程序 API 进行分配。应用于 cuSPARSE 例程的硬件内存压缩的完整示例可以在 cuSPARSE 库示例 - 内存压缩 中找到。
3. cuSPARSE 存储格式
cuSPARSE 库支持稠密和稀疏向量,以及稠密和稀疏矩阵格式。
3.1. 索引基
该库支持基于零和基于一的索引,以确保与 C/C++ 和 Fortran 语言的兼容性。索引基通过 cusparseIndexBase_t 类型选择。
3.2. 向量格式
本节介绍稠密和稀疏向量格式。
3.2.1. 稠密向量格式
稠密向量用单个数据数组表示,该数组在线性存储器中线性存储,例如以下 \(7 \times 1\) 稠密向量。
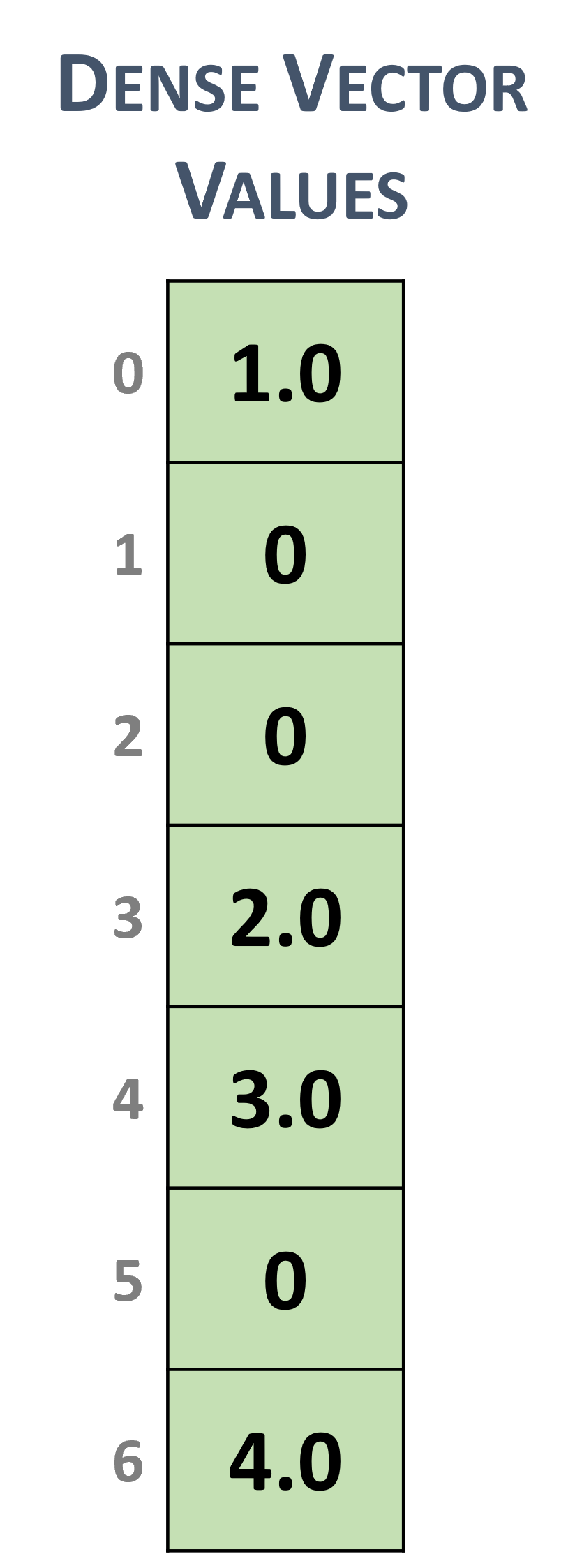
稠密向量表示
3.2.2. 稀疏向量格式
稀疏向量用两个数组表示。
values 数组存储稠密格式等效数组中的非零值。
indices 数组表示稠密格式等效数组中相应非零值的位置。
例如,第 3.2.1 节中的稠密向量可以存储为具有基于零或基于一索引的稀疏向量。

稀疏向量表示
注意
cuSPARSE 例程假定索引以递增顺序提供,并且每个索引仅出现一次。在相反的情况下,计算的正确性并不总是得到保证。
3.3. 矩阵格式
本节讨论稠密和几种稀疏矩阵格式。
3.3.1. 稠密矩阵格式
稠密矩阵可以以行优先和列优先内存布局(排序)存储,它由以下参数表示。
矩阵中的行数。
矩阵中的列数。
-
前导维度,必须是
在行优先布局中,大于或等于列数
在列优先布局中,大于或等于行数
-
指向长度为以下值的 values 数组的指针
在行优先布局中为 \(rows \times leading\; dimension\)
在列优先布局中为 \(columns \times leading\; dimension\)
下图表示具有两种内存布局的 \(5 \times 2\) 稠密矩阵
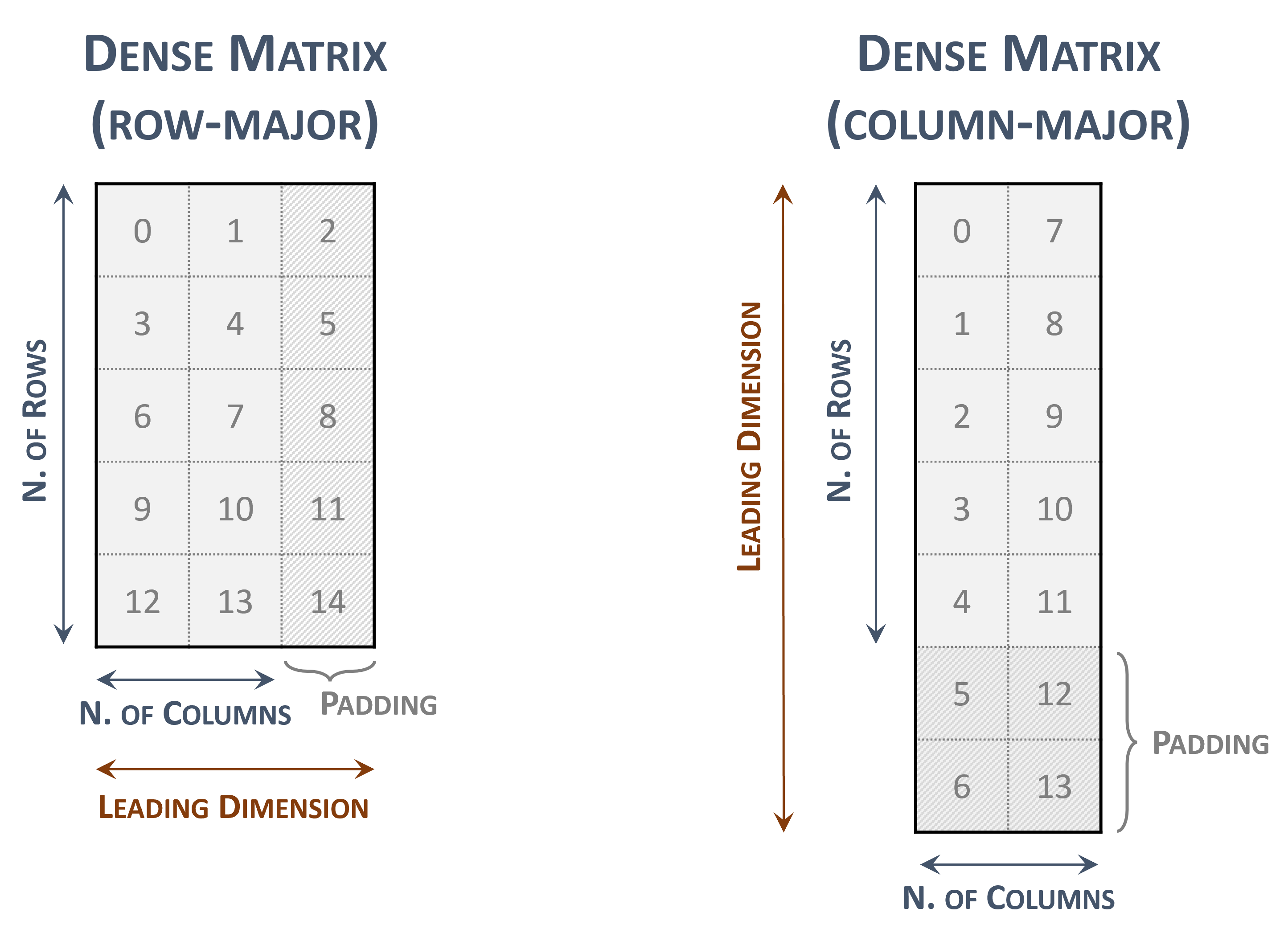
稠密矩阵表示
矩阵内的索引表示内存中的连续位置。
前导维度对于表示原始矩阵中的子矩阵很有用
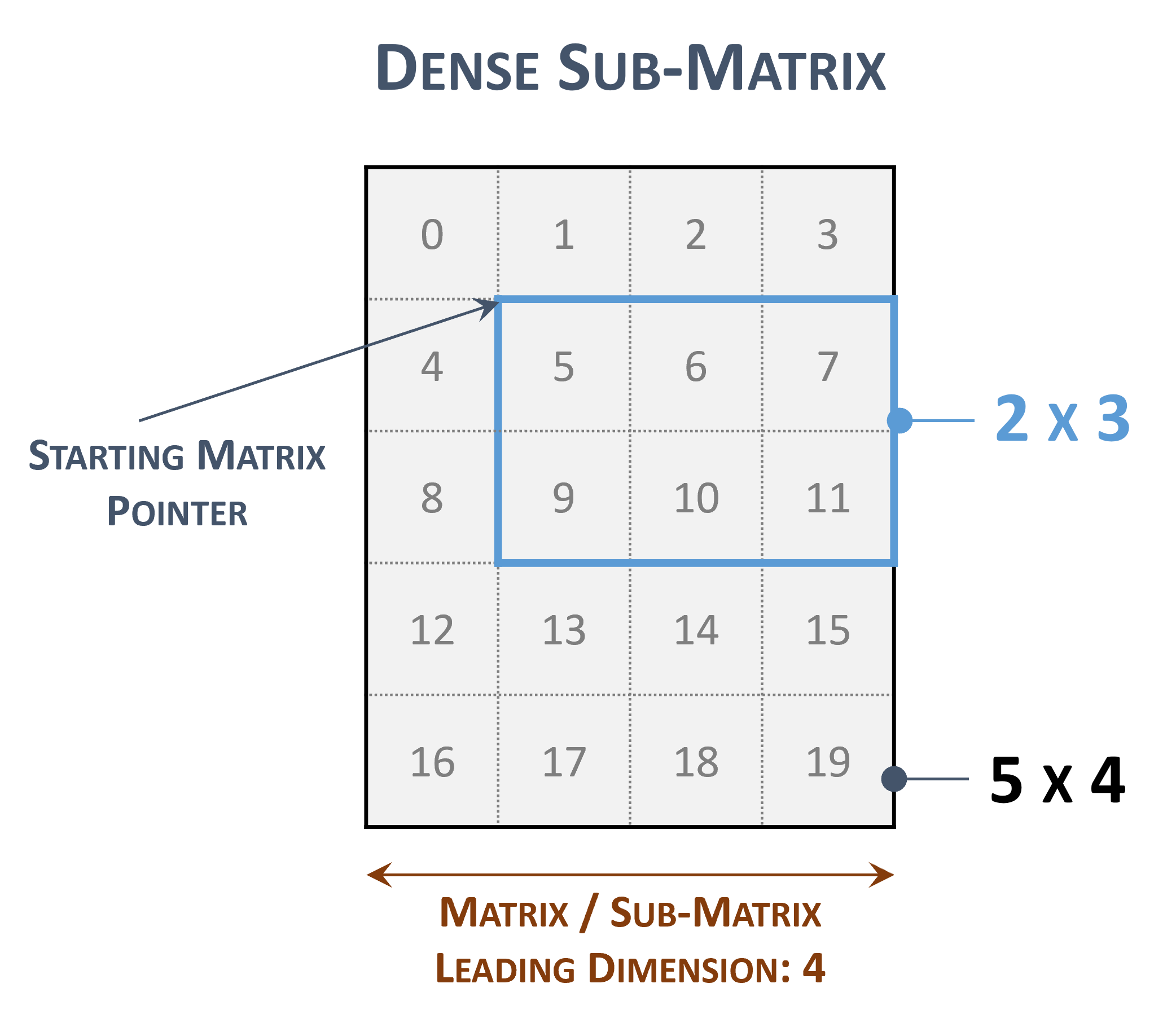
子矩阵表示
3.3.2. 坐标 (COO)
以 COO 格式存储的稀疏矩阵由以下参数表示。
矩阵中的行数。
矩阵中的列数。
矩阵中非零元素的数量 (
nnz)。指向长度为
nnz的 行索引 数组的指针,该数组包含 values 数组中相应元素的行索引。指向长度为
nnz的 列索引 数组的指针,该数组包含 values 数组中相应元素的列索引。指向长度为
nnz的 values 数组的指针,该数组以行优先顺序保存矩阵的所有非零值。COO 表示的每个条目都由
<row, column>对组成。COO 格式假定按行排序。
以下示例显示了以 COO 格式表示的 \(5 \times 4\) 矩阵。

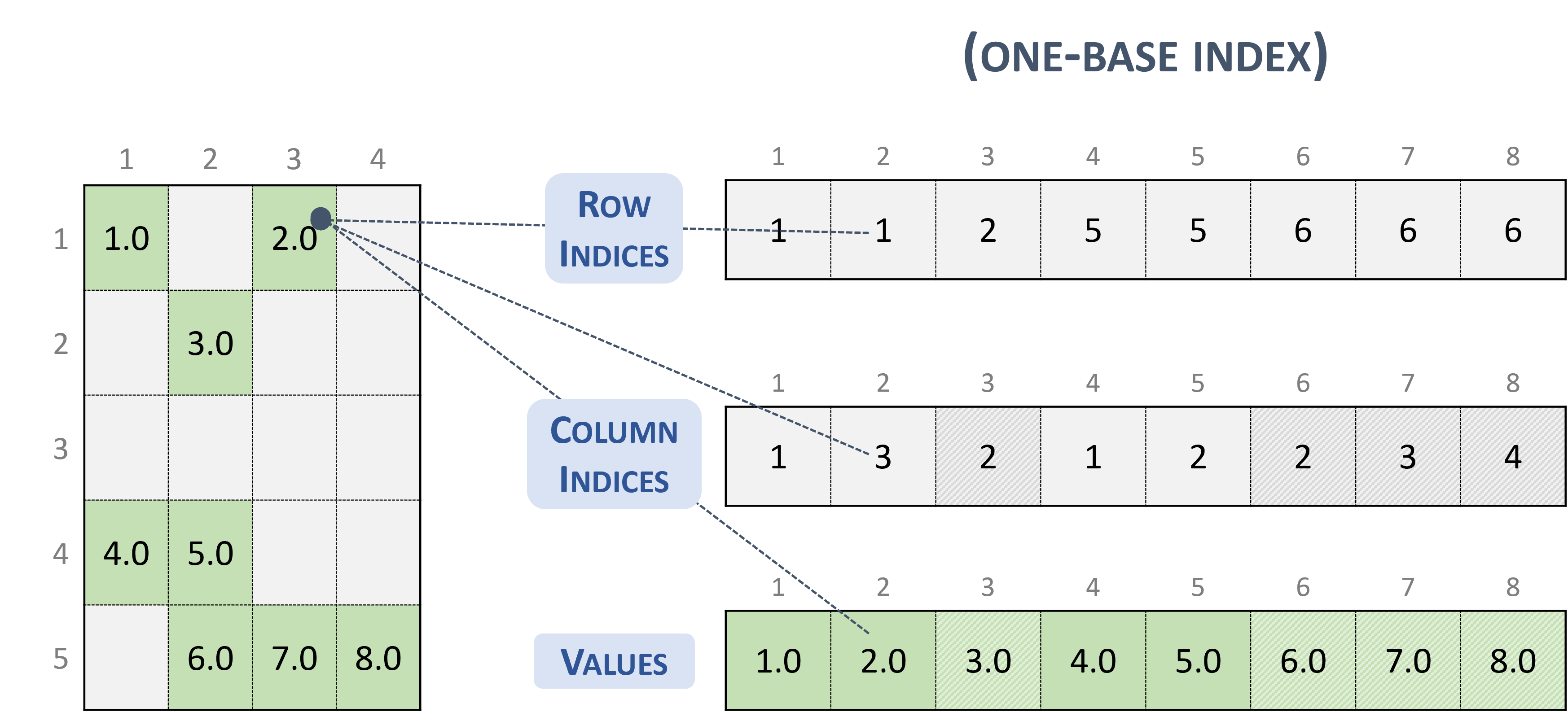
注意
cuSPARSE 支持给定行中已排序和未排序的列索引。
注意
如果给定行中的列索引不是唯一的,则计算的正确性并不总是得到保证。
给定 COO 格式(基于零)的条目,稠密矩阵中的相应位置计算为
// row-major
rows_indices[i] * leading_dimension + column_indices[i]
// column-major
column_indices[i] * leading_dimension + rows_indices[i]
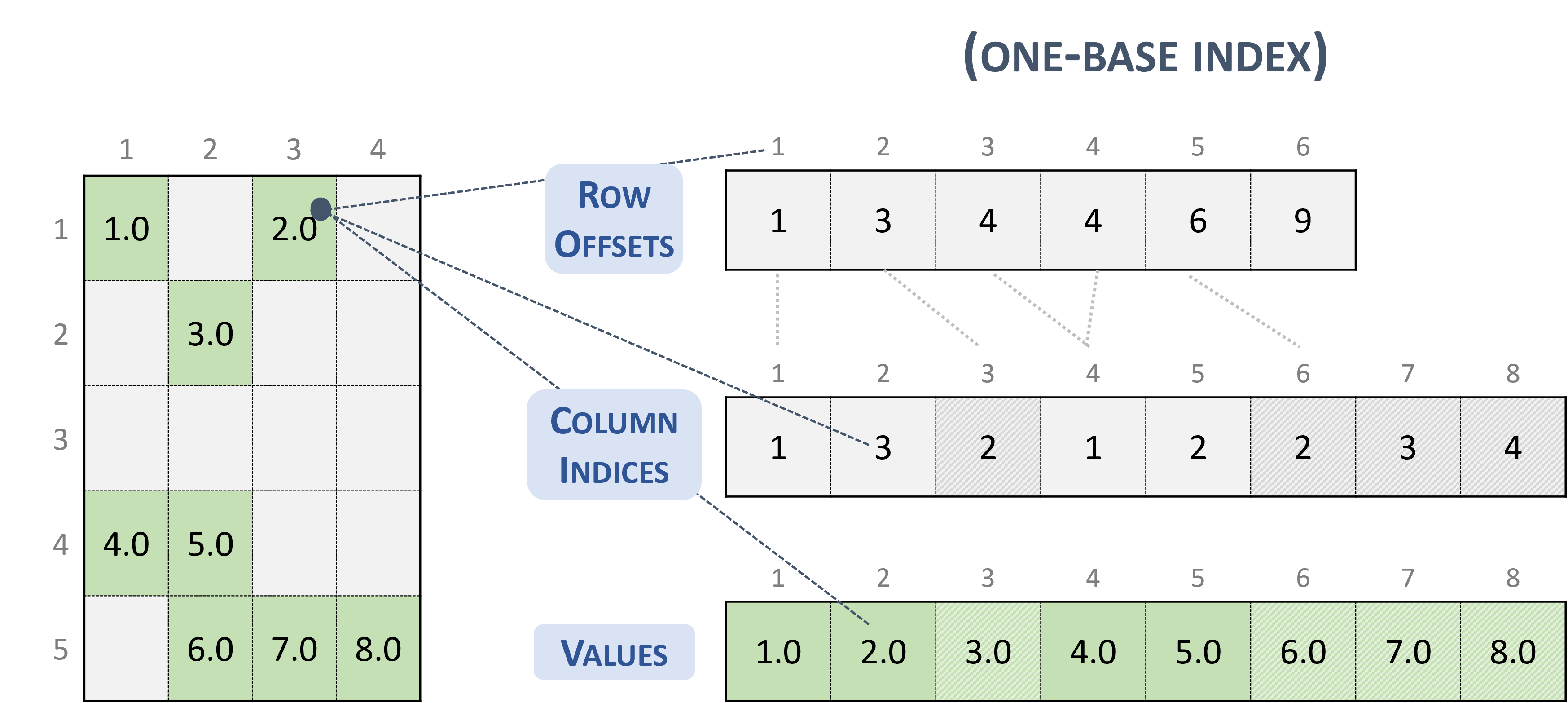
3.3.3. 压缩稀疏行 (CSR)
CSR 格式类似于 COO,其中行索引被压缩并替换为偏移量数组。
以 CSR 格式存储的稀疏矩阵由以下参数表示。
矩阵中的行数。
矩阵中的列数。
矩阵中非零元素的数量 (
nnz)。指向长度为行数 + 1 的 行偏移量 数组的指针,该数组表示 columns 和 values 数组中每一行的起始位置。
指向长度为
nnz的 列索引 数组的指针,该数组包含 values 数组中相应元素的列索引。指向长度为
nnz的 values 数组的指针,该数组以行优先顺序保存矩阵的所有非零值。
以下示例显示了以 CSR 格式表示的 \(5 \times 4\) 矩阵。

注意
cuSPARSE 支持给定行中已排序和未排序的列索引。
注意
如果给定行中的列索引不是唯一的,则计算的正确性并不总是得到保证。
给定 CSR 格式(基于零)的条目,稠密矩阵中的相应位置计算为
// row-major
row * leading_dimension + column_indices[row_offsets[row] + k]
// column-major
column_indices[row_offsets[row] + k] * leading_dimension + row
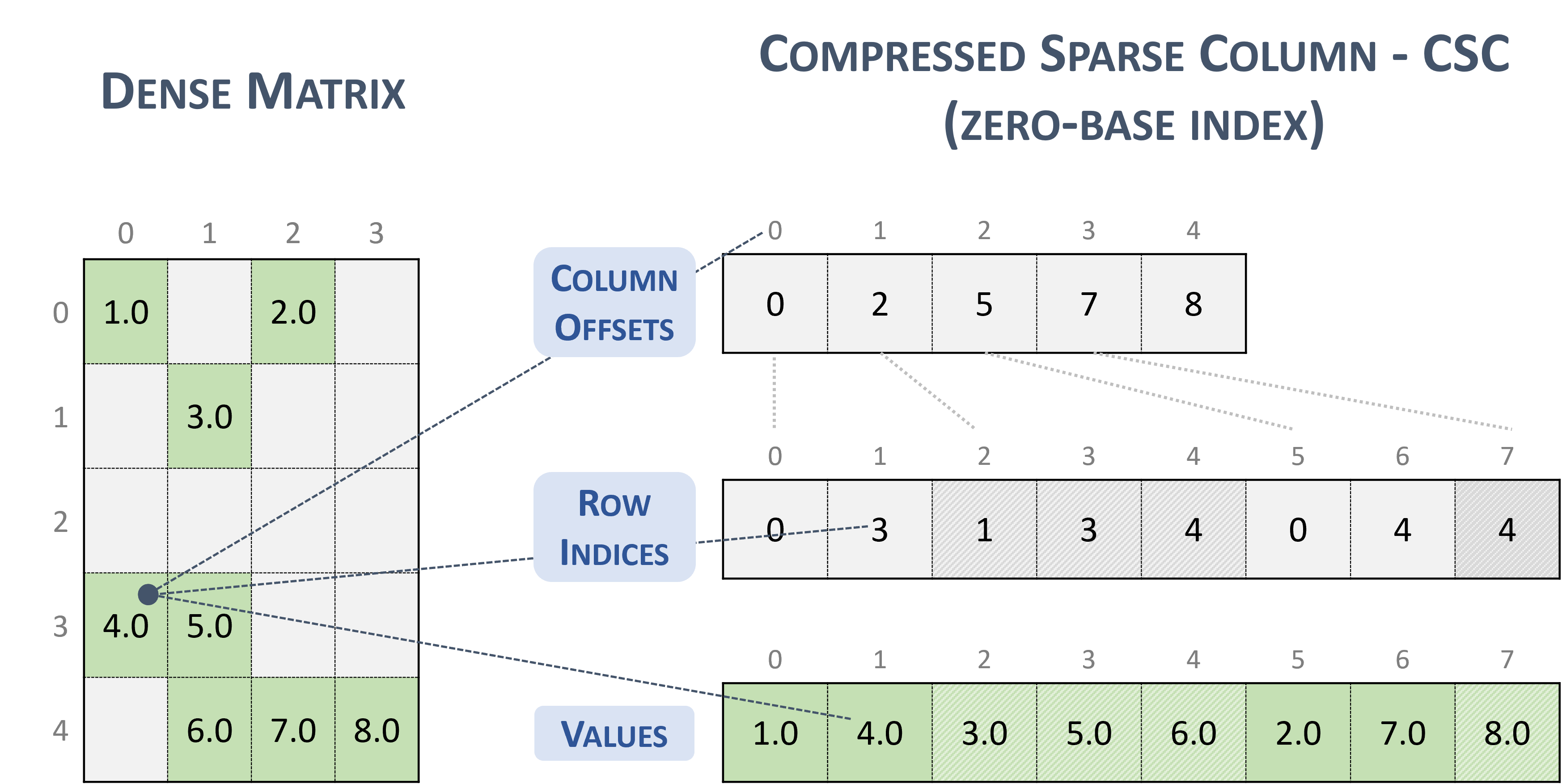
3.3.4. 压缩稀疏列 (CSC)
CSC 格式类似于 COO,其中列索引被压缩并替换为偏移量数组。
以 CSC 格式存储的稀疏矩阵由以下参数表示。
矩阵中的行数。
矩阵中的列数。
矩阵中非零元素的数量 (
nnz)。指向列偏移量数组的指针,该数组的长度为列数 + 1,表示 columns 和 values 数组中每列的起始位置。
指向行索引数组的指针,该数组的长度为
nnz,其中包含 values 数组中对应元素的行索引。指向 values 数组的指针,该数组的长度为
nnz,其中以列优先顺序保存矩阵的所有非零值。
以下示例显示了以 CSC 格式表示的 \(5 \times 4\) 矩阵。
注意
CSR 格式的内存布局与其转置在 CSC 格式中的内存布局完全相同(反之亦然)。
注意
cuSPARSE 支持给定列内的已排序和未排序的行索引。
注意
如果给定列内的行索引不是唯一的,则计算的正确性不总是得到保证。
给定 CSC 格式的条目(从零开始),则密集矩阵中的对应位置计算为
// row-major
column * leading_dimension + row_indices[column_offsets[column] + k]
// column-major
row_indices[column_offsets[column] + k] * leading_dimension + column
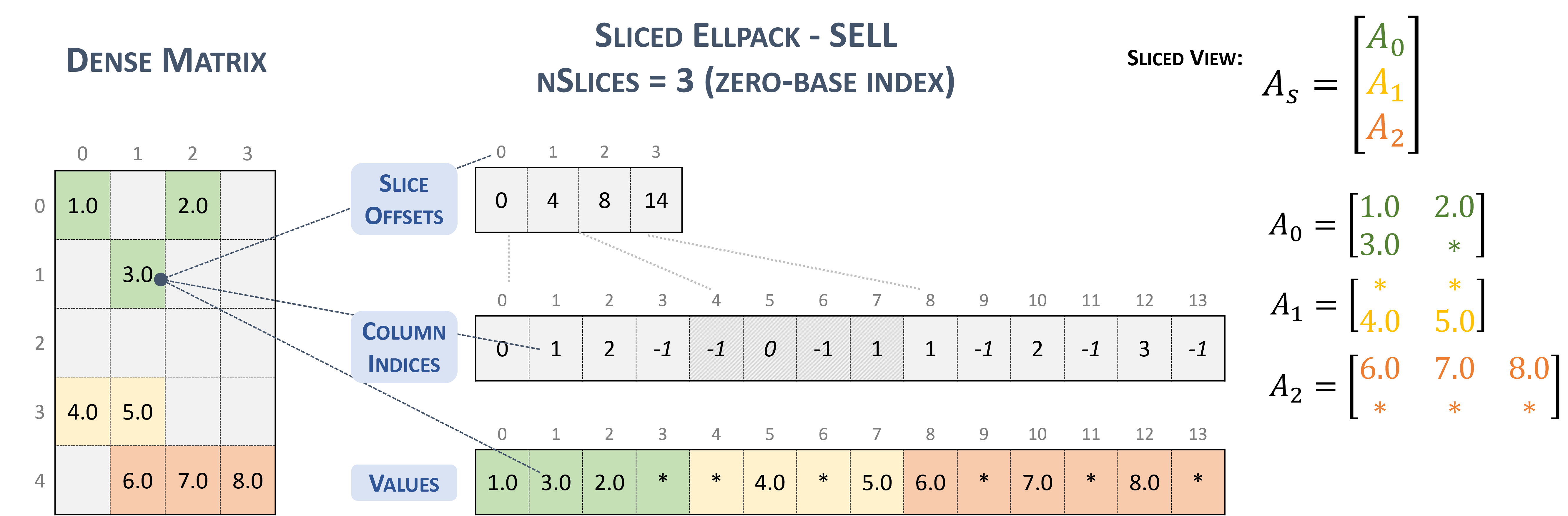
3.3.5. Sliced Ellpack (SELL)
Sliced Ellpack 格式是标准化的且众所周知的最先进技术。这种格式可以显著提高所有涉及每行非零元素数量低变异性问题的性能。
Sliced Ellpack 格式的矩阵被划分为切片,每个切片包含确切的行数 (\(sliceSize\)),由用户定义。为每个切片找到最大行长度(即,每行的最大非零元素数),并且切片中的每一行都被填充到最大行长度。值 -1 用于填充。
一个 \(m \times n\) 稀疏矩阵 \(A\) 等价于一个切片稀疏矩阵 \(A_{s}\),具有 \(nslices = \left \lceil{\frac{m}{sliceSize}}\right \rceil\) 个切片行和 \(n\) 列。为了提高内存合并和内存利用率,每个切片都以列优先顺序存储。
以 SELL 格式存储的稀疏矩阵由以下参数表示。
切片数量。
矩阵中的行数。
矩阵中的列数。
矩阵中非零元素的数量 (
nnz)。元素总数 (
sellValuesSize),包括非零值和填充元素。指向长度为 \(nslices + 1\) 的 slice offsets 的指针,它保存与 columns 和 values 数组对应的切片的偏移量。
指向长度为
sellValuesSize的 列索引 数组的指针,其中包含 values 数组中对应元素的列索引。列索引以列优先布局存储。值-1表示填充。指向长度为
sellValuesSize的 values 数组的指针,其中以列优先布局保存所有非零值和填充。
以下示例显示了以 SELL 格式表示的 \(5 \times 4\) 矩阵。

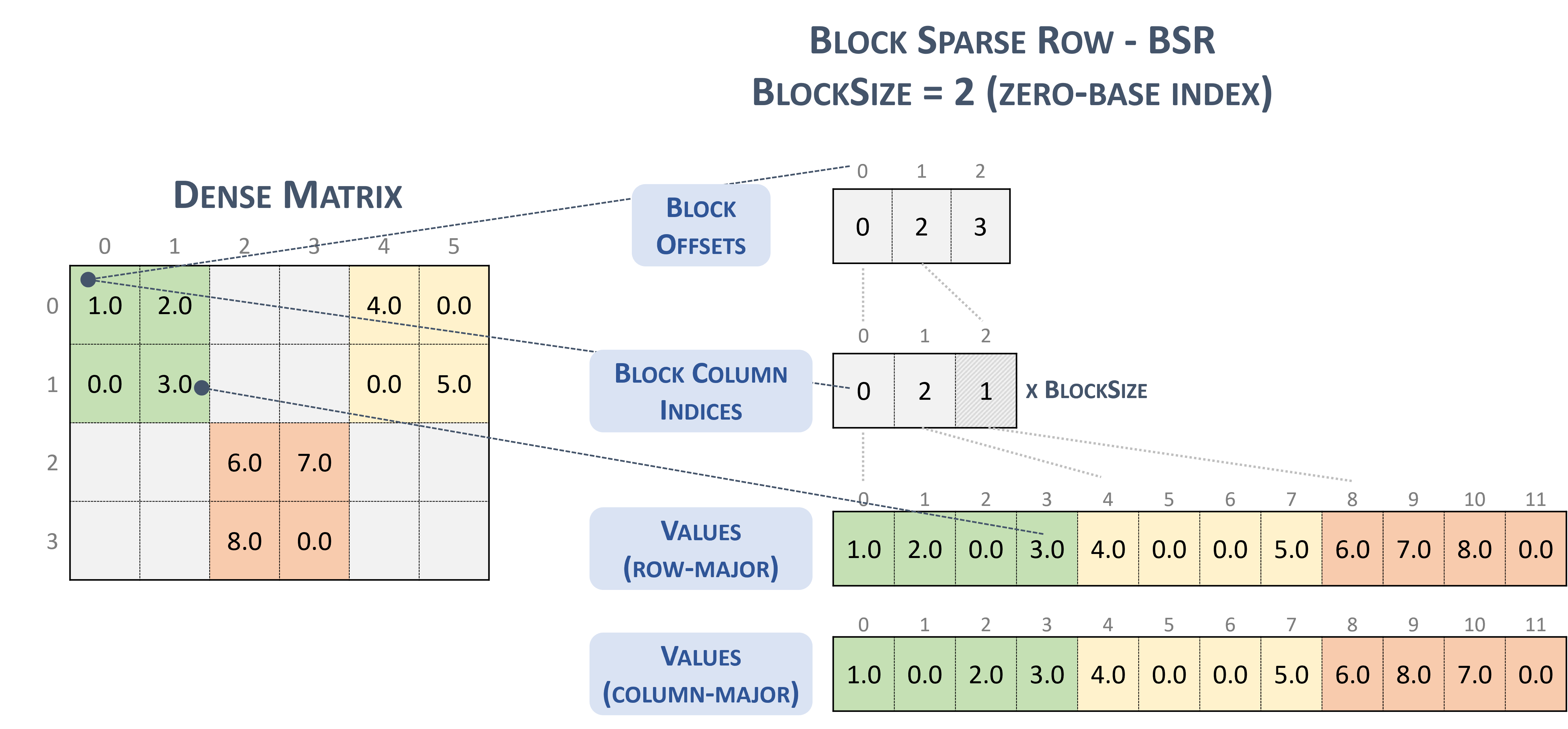
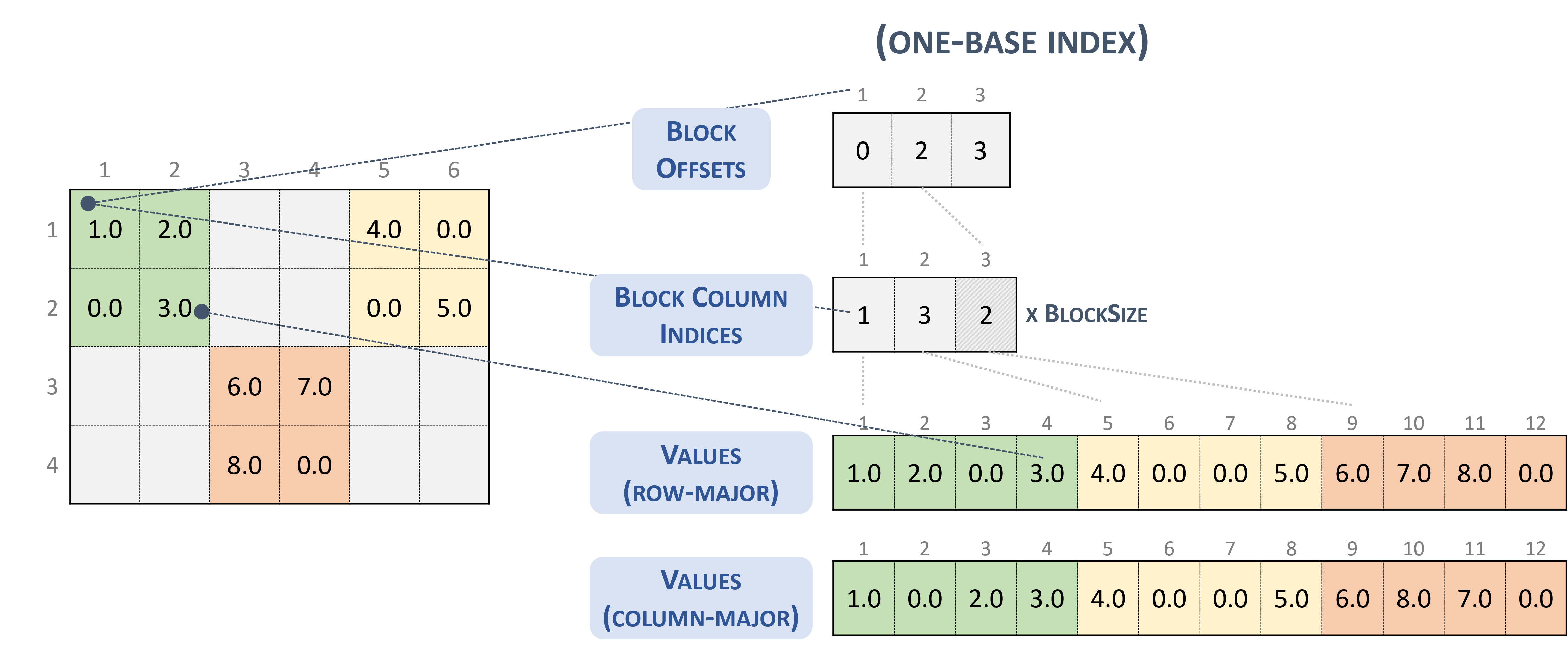
3.3.6. Block Sparse Row (BSR)
BSR 格式类似于 CSR,其中列索引表示二维块而不是单个矩阵条目。
块稀疏行格式的矩阵被组织成大小为 \(blockSize\) 的块,由用户定义。
一个 \(m \times n\) 稀疏矩阵 \(A\) 等价于一个块稀疏矩阵 \(A_{B}\):\(mb \times nb\),其中 \(mb = \frac{m}{blockSize}\) 块行,\(nb = \frac{n}{blockSize}\) 块列。如果 \(m\) 或 \(n\) 不是 \(blockSize\) 的倍数,则用户需要用零填充矩阵。
注意
cuSPARSE 当前仅支持正方形块。
BSR 格式以行优先顺序存储块。但是,块的内部存储格式可以是列优先 (cusparseDirection_t=CUSPARSE_DIRECTION_COLUMN) 或行优先 (cusparseDirection_t=CUSPARSE_DIRECTION_ROW),独立于基本索引。
以 BSR 格式存储的稀疏矩阵由以下参数表示。
块大小。
矩阵中的行块数。
矩阵中的列块数。
矩阵中的非零块数 (
nnzb)。指向长度为行块数 + 1的 行块偏移量 数组的指针,它表示 columns 和 values 数组中每个行块的起始位置。
指向长度为
nnzb的 列块索引 数组的指针,其中包含 values 数组中对应元素的位置。指向长度为
nnzb的 values 数组的指针,其中保存矩阵的所有非零值。
以下示例显示了以 BSR 格式表示的 \(4 \times 7\) 矩阵。
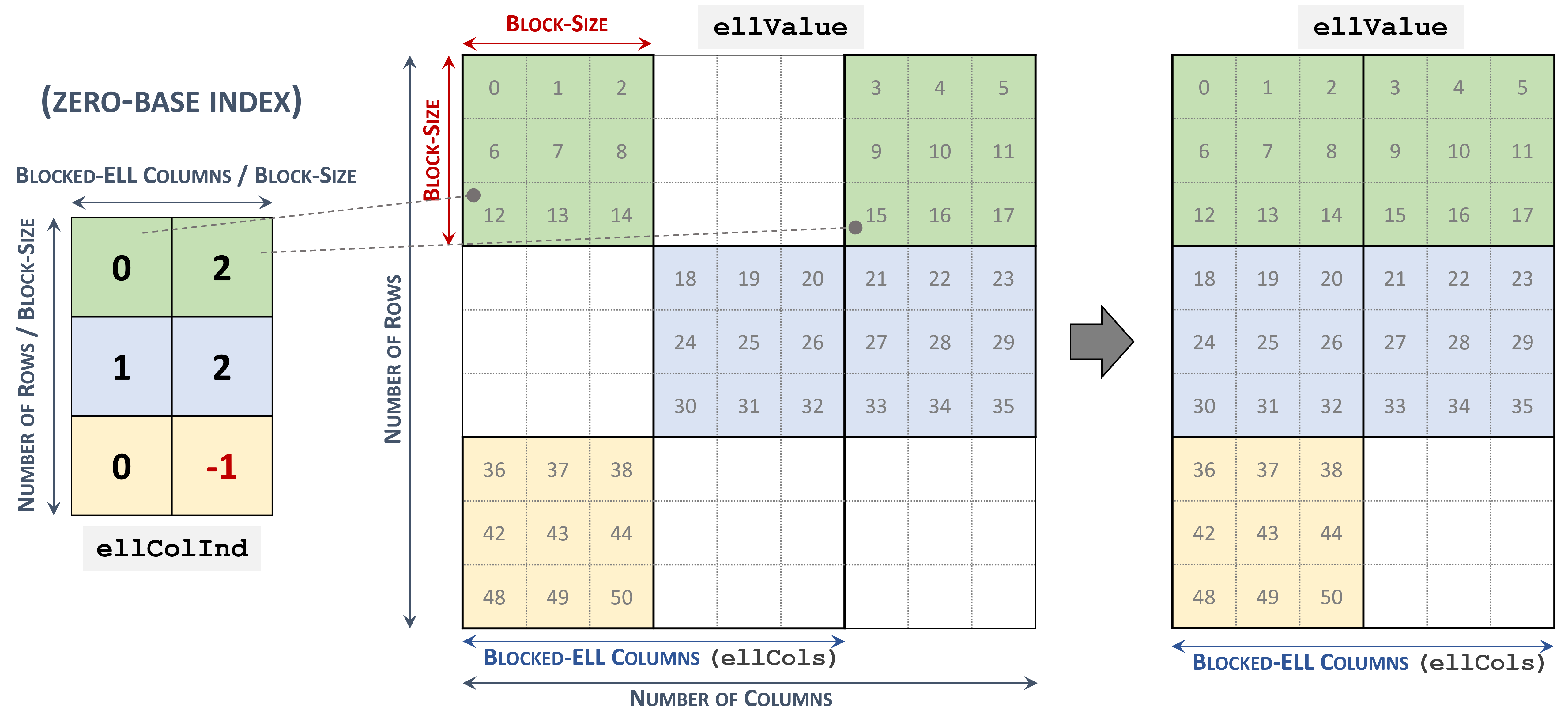
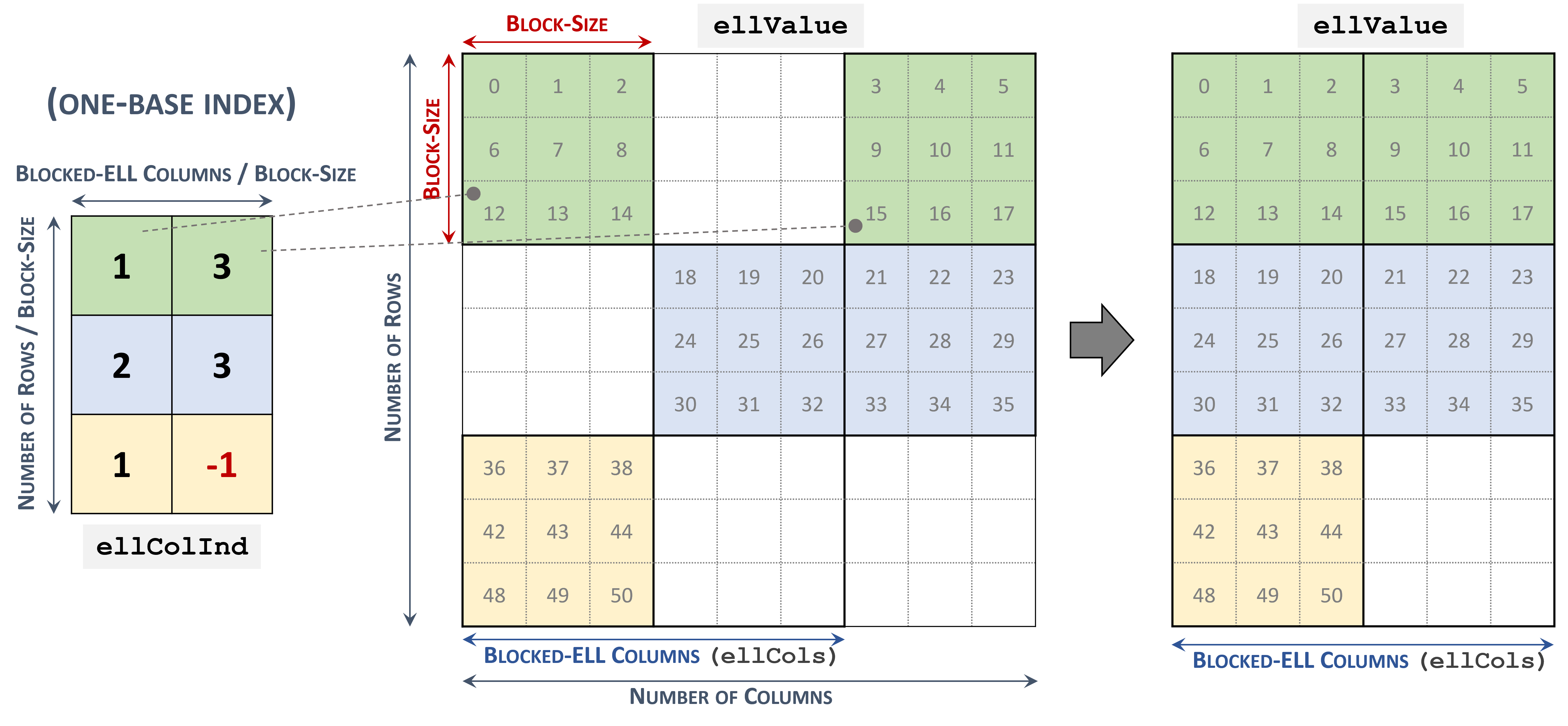
3.3.7. Blocked Ellpack (BLOCKED-ELL)
Blocked Ellpack 格式类似于标准 Ellpack,其中列索引表示二维块而不是单个矩阵条目。
Blocked Ellpack 格式的矩阵被组织成大小为 \(blockSize\) 的块,由用户定义。每行列数 \(nEllCols\) 也由用户定义 (\(nEllCols \le n\))。
一个 \(m \times n\) 稀疏矩阵 \(A\) 等价于一个 Blocked-ELL 矩阵 \(A_{B}\):\(mb \times nb\),其中 \(mb = \left \lceil{\frac{m}{blockSize}}\right \rceil\) 块行,\(nb = \left \lceil{\frac{nEllCols}{blockSize}}\right \rceil\) 块列。如果 \(m\) 或 \(n\) 不是 \(blockSize\) 的倍数,则剩余元素为零。
以 Blocked-ELL 格式存储的稀疏矩阵由以下参数表示。
块大小。
矩阵中的行数。
矩阵中的列数。
矩阵中每行列数 (
nEllCols)。指向长度为 \(mb \times nb\) 的 列块索引 数组的指针,其中包含 values 数组中对应元素的位置。空块可以用
-1索引表示。指向长度为 \(m \times nEllCols\) 的 values 数组的指针,其中以行优先顺序保存矩阵的所有非零值。
以下示例显示了以 Blocked-ELL 格式表示的 \(9 \times 9\) 矩阵。
3.3.8. Extended BSR Format (BSRX) [已弃用]
BSRX 与 BSR 格式相同,但数组 bsrRowPtrA 分为两个部分。每行第一个非零块仍然由数组 bsrRowPtrA 指定,这与 BSR 中的相同,但每行最后一个非零块旁边的位置由数组 bsrEndPtrA 指定。简而言之,BSRX 格式就像 BSR 格式的 4 向量变体。
矩阵 A 由以下 BSRX 格式的参数表示。
|
(整数) |
矩阵 |
|
(整数) |
|
|
(整数) |
|
|
(整数) |
矩阵 |
|
(指针) |
指向长度为 \(nnzb \ast blockDim^{2}\) 的数据数组的指针,其中保存 |
|
(指针) |
指向长度为 |
|
(指针) |
指向长度为 |
|
(指针) |
指向长度为 |
BSR 和 BSRX 之间的简单转换可以按如下方式完成。假设开发人员有一个 \(2 \times 3\) 块稀疏矩阵 \(A_{b}\),表示如下。
假设它具有此 BSR 格式
BSRX 格式的 bsrRowPtrA 只是 BSR 格式的 bsrRowPtrA 的前两个元素。BSRX 格式的 bsrEndPtrA 是 BSR 格式的 bsrRowPtrA 的最后两个元素。
BSRX 格式的优点是开发人员可以通过修改 bsrRowPtrA 和 bsrEndPtrA 来指定原始 BSR 格式中的子矩阵,同时保持 bsrColIndA 和 bsrValA 不变。
例如,要创建另一个与 \(A\) 略有不同的块矩阵 \(\widetilde{A} = \begin{bmatrix} O & O & O \\ O & A_{11} & O \\ \end{bmatrix}\),开发人员可以保留 bsrColIndA 和 bsrValA,但通过正确设置 bsrRowPtrA 和 bsrEndPtrA 来重建 \(\widetilde{A}\)。以下 4 向量描述了 \(\widetilde{A}\) 。
4. cuSPARSE 基本 API
4.1. cuSPARSE 类型参考
4.1.1. cudaDataType_t
本节介绍多个 CUDA 库共享并在头文件 library_types.h 中定义的类型。cudaDataType 类型是一个枚举器,用于指定数据精度。当数据引用本身不携带类型时(例如 void*),将使用它。例如,它在例程 cusparseSpMM() 中使用。
值 |
含义 |
数据类型 |
头文件 |
|
|---|---|---|---|---|
|
数据类型为 16 位 IEEE-754 浮点型 |
|
cuda_fp16.h |
|
|
数据类型为 16 位复数 IEEE-754 浮点型 |
|
cuda_fp16.h |
[已弃用] |
|
数据类型为 16 位 bfloat 浮点型 |
|
cuda_bf16.h |
|
|
数据类型为 16 位复数 bfloat 浮点型 |
|
cuda_bf16.h |
[已弃用] |
|
数据类型为 32 位 IEEE-754 浮点型 |
|
||
|
数据类型为 32 位复数 IEEE-754 浮点型 |
|
cuComplex.h |
|
|
数据类型为 64 位 IEEE-754 浮点型 |
|
||
|
数据类型为 64 位复数 IEEE-754 浮点型 |
|
cuComplex.h |
|
|
数据类型为 8 位整数 |
|
stdint.h |
|
|
数据类型为 32 位整数 |
|
stdint.h |
重要提示: 仅当 GPU 架构原生支持文档相应部分报告的所有数据类型时,通用 API 例程才允许使用这些数据类型。如果特定的 GPU 型号不提供给定数据类型的原生支持,则例程返回 CUSPARSE_STATUS_ARCH_MISMATCH 错误。
不支持的数据类型和计算能力 (CC)
在
CC < 53的 GPU 上(例如 Kepler)不支持__half在
CC < 80的 GPU 上(例如 Kepler、Maxwell、Pascal、Volta、Turing)不支持__nv_bfloat16
请参阅 https://developer.nvidia.com/cuda-gpus
4.1.2. cusparseStatus_t
此数据类型表示库函数返回的状态,它可以具有以下值
值 |
描述 |
|---|---|
|
操作成功完成 |
|
cuSPARSE 库未初始化。这通常是由于缺少先前的调用、cuSPARSE 例程调用的 CUDA 运行时 API 中的错误或硬件设置中的错误引起的 纠正措施: 在函数调用之前调用 该错误也适用于通用 API (cuSPARSE 通用 API),用于指示矩阵/向量描述符未初始化 |
|
cuSPARSE 库内部资源分配失败。这通常是由设备内存分配 ( 纠正措施: 在函数调用之前,尽可能多地释放先前分配的内存 |
|
将不支持的值或参数传递给函数(例如,负向量大小) 纠正措施: 确保传递的所有参数都具有有效值 |
|
该函数需要设备架构中缺少的功能 纠正措施: 在具有适当计算能力的设备上编译并运行应用程序 |
|
GPU 程序执行失败。这通常是由 GPU 上内核启动失败引起的,这可能是由多种原因造成的 纠正措施: 检查硬件、驱动程序的适当版本和 cuSPARSE 库是否已正确安装 |
|
内部 cuSPARSE 操作失败 纠正措施: 检查硬件、驱动程序的适当版本和 cuSPARSE 库是否已正确安装。此外,检查作为参数传递给例程的内存是否在例程完成之前被释放 |
|
此函数不支持矩阵类型。这通常是由于将无效的矩阵描述符传递给函数引起的 纠正措施: 检查 |
|
该函数当前不支持该操作或数据类型组合 |
|
用于计算的资源(例如 GPU 全局或共享内存)不足以完成操作。该错误也可能表明当前的计算模式(例如稀疏矩阵索引的位大小)不允许处理给定的输入 |
4.1.3. cusparseHandle_t
这是一种指向不透明 cuSPARSE 上下文的指针类型,用户必须通过在调用 cusparseCreate() 之前调用任何其他库函数来初始化它。cusparseCreate() 创建并返回的句柄必须传递给每个 cuSPARSE 函数。
4.1.4. cusparsePointerMode_t
此类型指示标量值是通过主机还是设备上的引用传递的。重要的是要指出,如果在函数调用中通过引用传递了多个标量值,则所有这些值都将符合相同的单个指针模式。可以使用 cusparseSetPointerMode() 和 cusparseGetPointerMode() 例程分别设置和检索指针模式。
值 |
含义 |
|---|---|
|
标量通过主机上的引用传递。 |
|
标量通过设备上的引用传递。 |
4.1.5. cusparseOperation_t
此类型指示应用于相关输入(例如,稀疏矩阵或向量)的操作。
值 |
含义 |
|---|---|
|
选择非转置操作。 |
|
选择转置操作。 |
|
选择共轭转置操作。 |
4.1.6. cusparseDiagType_t
此类型指示矩阵对角线项是否为单位值。始终假定对角线元素存在,但如果将 CUSPARSE_DIAG_TYPE_UNIT 传递给 API 例程,则该例程假定所有对角线项均为单位值,并且不会读取或修改这些项。请注意,在这种情况下,例程假定对角线项等于 1,而不管这些项在内存中实际设置为多少。
值 |
含义 |
|---|---|
|
矩阵对角线具有非单位元素。 |
|
矩阵对角线具有单位元素。 |
4.1.7. cusparseFillMode_t
此类型指示矩阵的下部还是上部以稀疏存储方式存储。
值 |
含义 |
|---|---|
|
存储下三角部分。 |
|
存储上三角部分。 |
4.1.8. cusparseIndexBase_t
此类型指示矩阵索引的基数是零还是一。
值 |
含义 |
|---|---|
|
基本索引为零(C 兼容性)。 |
|
基本索引为一(Fortran 兼容性)。 |
4.1.9. cusparseDirection_t
此类型指示在函数 cusparse[S|D|C|Z]nnz 中,应按行还是按列解析密集矩阵的元素(假设密集矩阵在内存中以列优先顺序存储)。此外,BSR 格式中块的存储格式也由此类型控制。
值 |
含义 |
|---|---|
|
应按行解析矩阵。 |
|
应按列解析矩阵。 |
4.2. cuSPARSE 管理 API
本节介绍用于管理库的 cuSPARSE 函数。
4.2.1. cusparseCreate()
cusparseStatus_t
cusparseCreate(cusparseHandle_t *handle)
此函数初始化 cuSPARSE 库并在 cuSPARSE 上下文上创建句柄。必须在调用任何其他 cuSPARSE API 函数之前调用它。它分配访问 GPU 所需的硬件资源。
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
指向 cuSPARSE 上下文句柄的指针 |
有关返回状态的描述,请参阅 cusparseStatus_t。
4.2.2. cusparseDestroy()
cusparseStatus_t
cusparseDestroy(cusparseHandle_t handle)
此函数释放 cuSPARSE 库使用的 CPU 端资源。GPU 端资源的释放可能会延迟到应用程序关闭时。
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
cuSPARSE 上下文的句柄 |
有关返回状态的描述,请参阅 cusparseStatus_t。
4.2.3. cusparseGetErrorName()
const char*
cusparseGetErrorString(cusparseStatus_t status)
该函数返回错误代码枚举名称的字符串表示形式。如果无法识别错误代码,则返回“unrecognized error code”。
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
要转换为字符串的错误代码 |
|
输出 |
指向 NULL 终止字符串的指针 |
4.2.4. cusparseGetErrorString()
const char*
cusparseGetErrorString(cusparseStatus_t status)
返回错误代码的描述字符串。如果无法识别错误代码,则返回“unrecognized error code”。
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
要转换为字符串的错误代码 |
|
输出 |
指向 NULL 终止字符串的指针 |
4.2.5. cusparseGetProperty()
cusparseStatus_t
cusparseGetProperty(libraryPropertyType type,
int* value)
该函数返回请求属性的值。有关支持的类型,请参阅 libraryPropertyType。
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
请求的属性 |
|
输出 |
请求属性的值 |
libraryPropertyType (在 library_types.h 中定义)
值 |
含义 |
|---|---|
|
用于查询主版本的枚举器 |
|
用于查询次要版本的枚举器 |
|
用于标识补丁级别的数字 |
有关返回状态的描述,请参阅 cusparseStatus_t。
4.2.6. cusparseGetVersion()
cusparseStatus_t
cusparseGetVersion(cusparseHandle_t handle,
int* version)
此函数返回 cuSPARSE 库的版本号。
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
cuSPARSE 句柄 |
|
输出 |
库的版本号 |
有关返回状态的描述,请参阅 cusparseStatus_t。
4.2.7. cusparseGetPointerMode()
cusparseStatus_t
cusparseGetPointerMode(cusparseHandlet handle,
cusparsePointerMode_t *mode)
此函数获取 cuSPARSE 库使用的指针模式。有关更多详细信息,请参阅有关 cusparsePointerMode_t 类型的章节。
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
cuSPARSE 上下文的句柄 |
|
输出 |
枚举指针模式类型之一 |
有关返回状态的描述,请参阅 cusparseStatus_t。
4.2.8. cusparseSetPointerMode()
cusparseStatus_t
cusparseSetPointerMode(cusparseHandle_t handle,
cusparsePointerMode_t mode)
此函数设置 cuSPARSE 库使用的指针模式。默认情况下,值通过主机上的引用传递。有关更多详细信息,请参阅有关 cublasPointerMode_t 类型的章节。
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
cuSPARSE 上下文的句柄 |
|
输入 |
枚举指针模式类型之一 |
有关返回状态的描述,请参阅 cusparseStatus_t。
4.2.9. cusparseGetStream()
cusparseStatus_t
cusparseGetStream(cusparseHandle_t handle, cudaStream_t *streamId)
此函数获取 cuSPARSE 库流,该流正用于执行对 cuSPARSE 库函数的所有调用。如果未设置 cuSPARSE 库流,则所有内核都使用默认的 NULL 流。
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
cuSPARSE 上下文的句柄 |
|
输出 |
库使用的流 |
有关返回状态的描述,请参阅 cusparseStatus_t。
4.2.10. cusparseSetStream()
cusparseStatus_t
cusparseSetStream(cusparseHandle_t handle, cudaStream_t streamId)
此函数设置 cuSPARSE 库用于执行其例程的流。
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
cuSPARSE 上下文的句柄 |
|
输入 |
库要使用的流 |
有关返回状态的描述,请参阅 cusparseStatus_t。
4.3. cuSPARSE 日志记录 API
可以通过在启动目标应用程序之前设置以下环境变量来启用 cuSPARSE 日志记录机制
CUSPARSE_LOG_LEVEL=<level> - level 是以下级别之一
0- 关闭 (Off) - 日志记录被禁用(默认)1- 错误 (Error) - 仅记录错误2- 跟踪 (Trace) - 启动 CUDA 内核的 API 调用将记录其参数和重要信息3- 提示 (Hints) - 可能提高应用程序性能的提示4- 信息 (Info) - 提供关于库执行的一般信息,可能包含关于启发式状态的详细信息5- API 跟踪 (API Trace) - API 调用将记录其参数和重要信息
CUSPARSE_LOG_MASK=<mask> - mask 是以下掩码的组合
0- 关闭 (Off)1- 错误 (Error)2- 跟踪 (Trace)4- 提示 (Hints)8- 信息 (Info)16- API 跟踪 (API Trace)
CUSPARSE_LOG_FILE=<file_name> - file name 是日志文件的路径。File name 可以包含 %i,它将被进程 ID 替换。例如 <file_name>_%i.log。
如果未定义 CUSPARSE_LOG_FILE,则日志消息将打印到 stdout。
从 CUDA 12.3 开始,还可以通过设置环境变量 CUSPARSE_STORE_INPUT_MATRIX 在创建期间将稀疏矩阵(CSR、CSC、COO、SELL、BSR)转储为二进制文件。之后,可以将二进制文件发送到 Math-Libs-Feedback@nvidia.com,用于调试和重现特定的正确性/性能问题。
另一种选择是使用实验性的 cuSPARSE 日志 API。请参考
注意
日志记录机制不适用于旧版 API。
4.3.1. cusparseLoggerSetCallback()
cusparseStatus_t
cusparseLoggerSetCallback(cusparseLoggerCallback_t callback)
实验性 (Experimental): 此函数设置日志记录回调函数。
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
指向回调函数的指针 |
其中 cusparseLoggerCallback_t 具有以下签名
void (*cusparseLoggerCallback_t)(int logLevel,
const char* functionName,
const char* message)
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
选定的日志级别 |
|
输入 |
记录此消息的 API 的名称 |
|
输入 |
日志消息 |
有关返回状态的描述,请参阅 cusparseStatus_t。
4.3.2. cusparseLoggerSetFile()
cusparseStatus_t
cusparseLoggerSetFile(FILE* file)
实验性 (Experimental): 此函数设置日志输出文件。注意:一旦使用此函数调用注册,除非再次调用该函数以切换到不同的文件句柄,否则提供的文件句柄不得关闭。
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
指向打开文件的指针。文件应具有写入权限 |
有关返回状态的描述,请参阅 cusparseStatus_t。
4.3.3. cusparseLoggerOpenFile()
cusparseStatus_t
cusparseLoggerOpenFile(const char* logFile)
实验性 (Experimental): 此函数在给定路径中打开日志输出文件。
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
日志输出文件的路径 |
有关返回状态的描述,请参阅 cusparseStatus_t。
4.3.4. cusparseLoggerSetLevel()
cusparseStatus_t
cusparseLoggerSetLevel(int level)
实验性 (Experimental): 此函数设置日志级别的路径值。
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
日志级别的值 |
有关返回状态的描述,请参阅 cusparseStatus_t
4.3.5. cusparseLoggerSetMask()
cusparseStatus_t
cusparseLoggerSetMask(int mask)
实验性 (Experimental): 此函数设置日志掩码的值。
参数。 |
输入/输出 |
含义 |
|---|---|---|
|
输入 |
日志掩码的值 |
有关返回状态的描述,请参阅 cusparseStatus_t
5. cuSPARSE 旧版 API (Legacy APIs)
5.1. 命名约定 (Naming Conventions)
cuSPARSE 旧版函数可用于数据类型 float、double、cuComplex 和 cuDoubleComplex。稀疏 Level 2 和 Level 3 函数遵循以下命名约定
cusparse<t>[<matrix data format>]<operation>[<output matrix data format>]
其中 <t> 可以是 S、D、C、Z 或 X,分别对应于数据类型 float、double、cuComplex、cuDoubleComplex 和通用类型。
<matrix data format> 可以是 dense、coo、csr 或 csc,分别对应于密集 (dense)、坐标 (coordinate)、压缩稀疏行 (compressed sparse row) 和压缩稀疏列 (compressed sparse column) 格式。
5.2. cuSPARSE 旧版类型参考 (Legacy Types Reference)
5.2.1. cusparseAction_t
此类型指示操作是仅对索引执行,还是对数据和索引执行。
值 |
含义 |
|---|---|
|
操作仅对索引执行。 |
|
操作对数据和索引执行。 |
5.2.2. cusparseMatDescr_t
此结构用于描述矩阵的形状和属性。
typedef struct {
cusparseMatrixType_t MatrixType;
cusparseFillMode_t FillMode;
cusparseDiagType_t DiagType;
cusparseIndexBase_t IndexBase;
} cusparseMatDescr_t;
5.2.3. cusparseMatrixType_t
此类型指示稀疏存储中存储的矩阵类型。请注意,对于对称 (symmetric)、埃尔米特 (Hermitian) 和三角 (triangular) 矩阵,仅假定存储其下半部分或上半部分。
矩阵类型和填充模式的全部想法是为对称/埃尔米特矩阵保持最小存储,并利用 SpMV(稀疏矩阵向量乘法)的对称属性。要计算 y=A*x,当 A 是对称矩阵且仅存储下三角部分时,需要两个步骤。第一步是计算 y=(L+D)*x,第二步是计算 y=L^T*x + y。鉴于转置运算 y=L^T*x 比非转置版本 y=L*x 慢 10 倍,对称属性不会显示任何性能提升。用户最好将对称矩阵扩展为一般矩阵,并使用矩阵类型 CUSPARSE_MATRIX_TYPE_GENERAL 应用 y=A*x。
通常,SpMV、预处理器(不完全 Cholesky 或不完全 LU)和三角求解器在迭代求解器(例如 PCG 和 GMRES)中组合在一起。如果用户始终使用一般矩阵(而不是对称矩阵),则无需在预处理器中支持一般矩阵以外的其他矩阵。因此,新的例程 [bsr|csr]sv2(三角求解器)、[bsr|csr]ilu02(不完全 LU)和 [bsr|csr]ic02(不完全 Cholesky)仅支持矩阵类型 CUSPARSE_MATRIX_TYPE_GENERAL。
值 |
含义 |
|---|---|
|
矩阵是一般矩阵 (general)。 |
|
矩阵是对称矩阵 (symmetric)。 |
|
矩阵是埃尔米特矩阵 (Hermitian)。 |
|
矩阵是三角矩阵 (triangular)。 |
5.2.4. cusparseColorInfo_t [已弃用 (DEPRECATED)]
这是指向不透明结构的指针类型,该结构保存 csrcolor() 中使用的信息。
5.2.5. cusparseSolvePolicy_t [已弃用 (DEPRECATED)]
此类型指示是否在 csrsv2、csric02、csrilu02、bsrsv2、bsric02 和 bsrilu02 中生成和使用级别信息。
值 |
含义 |
|---|---|
|
不生成和使用级别信息。 |
|
生成和使用级别信息。 |
5.2.6. bsric02Info_t [已弃用 (DEPRECATED)]
这是指向不透明结构的指针类型,该结构保存 bsric02_bufferSize()、bsric02_analysis() 和 bsric02() 中使用的信息。
5.2.7. bsrilu02Info_t [已弃用 (DEPRECATED)]
这是指向不透明结构的指针类型,该结构保存 bsrilu02_bufferSize()、bsrilu02_analysis() 和 bsrilu02() 中使用的信息。
5.2.8. bsrsm2Info_t [已弃用 (DEPRECATED)]
这是指向不透明结构的指针类型,该结构保存 bsrsm2_bufferSize()、bsrsm2_analysis() 和 bsrsm2_solve() 中使用的信息。
5.2.9. bsrsv2Info_t [已弃用 (DEPRECATED)]
这是指向不透明结构的指针类型,该结构保存 bsrsv2_bufferSize()、bsrsv2_analysis() 和 bsrsv2_solve() 中使用的信息。
5.2.10. csric02Info_t [已弃用 (DEPRECATED)]
这是指向不透明结构的指针类型,该结构保存 csric02_bufferSize()、csric02_analysis() 和 csric02() 中使用的信息。
5.2.11. csrilu02Info_t [已弃用 (DEPRECATED)]
这是指向不透明结构的指针类型,该结构保存 csrilu02_bufferSize()、csrilu02_analysis() 和 csrilu02() 中使用的信息。
5.3. cuSPARSE 辅助函数参考 (Helper Function Reference)
本节介绍 cuSPARSE 辅助函数。
5.3.1. cusparseCreateColorInfo() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseCreateColorInfo(cusparseColorInfo_t* info)
此函数创建 cusparseColorInfo_t 结构并将其初始化为默认值。
输入 (Input)
|
指向 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.2. cusparseCreateMatDescr()
cusparseStatus_t
cusparseCreateMatDescr(cusparseMatDescr_t *descrA)
此函数初始化矩阵描述符。它将字段 MatrixType 和 IndexBase 设置为默认值 CUSPARSE_MATRIX_TYPE_GENERAL 和 CUSPARSE_INDEX_BASE_ZERO,同时保持其他字段未初始化。
输入 (Input)
|
指向矩阵描述符的指针。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.3. cusparseDestroyColorInfo() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseDestroyColorInfo(cusparseColorInfo_t info)
此函数销毁并释放结构所需的任何内存。
输入 (Input)
|
指向 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.4. cusparseDestroyMatDescr()
cusparseStatus_t
cusparseDestroyMatDescr(cusparseMatDescr_t descrA)
此函数释放为矩阵描述符分配的内存。
输入 (Input)
|
矩阵描述符。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.5. cusparseGetMatDiagType()
cusparseDiagType_t
cusparseGetMatDiagType(const cusparseMatDescr_t descrA)
此函数返回矩阵描述符 descrA 的 DiagType 字段。
输入 (Input)
|
矩阵描述符。 |
返回 (Returned)
|
枚举的 diagType 类型之一。 |
5.3.6. cusparseGetMatFillMode()
cusparseFillMode_t
cusparseGetMatFillMode(const cusparseMatDescr_t descrA)
此函数返回矩阵描述符 descrA 的 FillMode 字段。
输入 (Input)
|
矩阵描述符。 |
返回 (Returned)
|
枚举的 fillMode 类型之一。 |
5.3.7. cusparseGetMatIndexBase()
cusparseIndexBase_t
cusparseGetMatIndexBase(const cusparseMatDescr_t descrA)
此函数返回矩阵描述符 descrA 的 IndexBase 字段。
输入 (Input)
|
矩阵描述符。 |
返回 (Returned)
|
枚举的 indexBase 类型之一。 |
5.3.8. cusparseGetMatType()
cusparseMatrixType_t
cusparseGetMatType(const cusparseMatDescr_t descrA)
此函数返回矩阵描述符 descrA 的 MatrixType 字段。
输入 (Input)
|
矩阵描述符。 |
返回 (Returned)
|
枚举的 matrix 类型之一。 |
5.3.9. cusparseSetMatDiagType()
cusparseStatus_t
cusparseSetMatDiagType(cusparseMatDescr_t descrA,
cusparseDiagType_t diagType)
此函数设置矩阵描述符 descrA 的 DiagType 字段。
输入 (Input)
|
枚举的 diagType 类型之一。 |
输出 (Output)
|
矩阵描述符。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.10. cusparseSetMatFillMode()
cusparseStatus_t
cusparseSetMatFillMode(cusparseMatDescr_t descrA,
cusparseFillMode_t fillMode)
此函数设置矩阵描述符 descrA 的 FillMode 字段。
输入 (Input)
|
枚举的 fillMode 类型之一。 |
输出 (Output)
|
矩阵描述符。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.11. cusparseSetMatIndexBase()
cusparseStatus_t
cusparseSetMatIndexBase(cusparseMatDescr_t descrA,
cusparseIndexBase_t base)
此函数设置矩阵描述符 descrA 的 IndexBase 字段。
输入 (Input)
|
枚举的 indexBase 类型之一。 |
输出 (Output)
|
矩阵描述符。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.12. cusparseSetMatType()
cusparseStatus_t
cusparseSetMatType(cusparseMatDescr_t descrA, cusparseMatrixType_t type)
此函数设置矩阵描述符 descrA 的 MatrixType 字段。
输入 (Input)
|
枚举的 matrix 类型之一。 |
输出 (Output)
|
矩阵描述符。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.13. cusparseCreateCsric02Info() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseCreateCsric02Info(csric02Info_t *info);
此函数创建不完全 Cholesky 的求解和分析结构,并将其初始化为默认值。
输入 (Input)
|
指向不完全 Cholesky 的求解和分析结构的指针。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.14. cusparseDestroyCsric02Info() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseDestroyCsric02Info(csric02Info_t info);
此函数销毁并释放结构所需的任何内存。
输入 (Input)
|
求解 ( |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.15. cusparseCreateCsrilu02Info() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseCreateCsrilu02Info(csrilu02Info_t *info);
此函数创建不完全 LU 的求解和分析结构,并将其初始化为默认值。
输入 (Input)
|
指向不完全 LU 的求解和分析结构的指针。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.16. cusparseDestroyCsrilu02Info() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseDestroyCsrilu02Info(csrilu02Info_t info);
此函数销毁并释放结构所需的任何内存。
输入 (Input)
|
求解 ( |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.17. cusparseCreateBsrsv2Info() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseCreateBsrsv2Info(bsrsv2Info_t *info);
此函数创建 bsrsv2 的求解和分析结构,并将其初始化为默认值。
输入 (Input)
|
指向 bsrsv2 的求解和分析结构的指针。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.18. cusparseDestroyBsrsv2Info() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseDestroyBsrsv2Info(bsrsv2Info_t info);
此函数销毁并释放结构所需的任何内存。
输入 (Input)
|
求解 ( |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.19. cusparseCreateBsrsm2Info() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseCreateBsrsm2Info(bsrsm2Info_t *info);
此函数创建 bsrsm2 的求解和分析结构,并将其初始化为默认值。
输入 (Input)
|
指向 bsrsm2 的求解和分析结构的指针。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.20. cusparseDestroyBsrsm2Info() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseDestroyBsrsm2Info(bsrsm2Info_t info);
此函数销毁并释放结构所需的任何内存。
输入 (Input)
|
求解 ( |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.21. cusparseCreateBsric02Info() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseCreateBsric02Info(bsric02Info_t *info);
此函数创建块不完全 Cholesky 的求解和分析结构,并将其初始化为默认值。
输入 (Input)
|
指向块不完全 Cholesky 的求解和分析结构的指针。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.22. cusparseDestroyBsric02Info() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseDestroyBsric02Info(bsric02Info_t info);
此函数销毁并释放结构所需的任何内存。
输入 (Input)
|
求解 ( |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.23. cusparseCreateBsrilu02Info() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseCreateBsrilu02Info(bsrilu02Info_t *info);
此函数创建块不完全 LU 的求解和分析结构,并将其初始化为默认值。
输入 (Input)
|
指向块不完全 LU 的求解和分析结构的指针。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.24. cusparseDestroyBsrilu02Info() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseDestroyBsrilu02Info(bsrilu02Info_t info);
此函数销毁并释放结构所需的任何内存。
输入 (Input)
|
求解 ( |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.25. cusparseCreatePruneInfo() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseCreatePruneInfo(pruneInfo_t *info);
此函数创建 prune 结构并将其初始化为默认值。
输入 (Input)
|
指向 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.3.26. cusparseDestroyPruneInfo() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseDestroyPruneInfo(pruneInfo_t info);
此函数销毁并释放结构所需的任何内存。
输入 (Input)
|
|
有关返回状态的描述,请参阅 cusparseStatus_t。
5.4. cuSPARSE Level 2 函数参考 (Function Reference)
本章介绍稀疏线性代数函数,这些函数执行稀疏矩阵和稠密向量之间的运算。
5.4.1. cusparse<t>bsrmv()
cusparseStatus_t
cusparseSbsrmv(cusparseHandle_t handle,
cusparseDirection_t dir,
cusparseOperation_t trans,
int mb,
int nb,
int nnzb,
const float* alpha,
const cusparseMatDescr_t descr,
const float* bsrVal,
const int* bsrRowPtr,
const int* bsrColInd,
int blockDim,
const float* x,
const float* beta,
float* y)
cusparseStatus_t
cusparseDbsrmv(cusparseHandle_t handle,
cusparseDirection_t dir,
cusparseOperation_t trans,
int mb,
int nb,
int nnzb,
const double* alpha,
const cusparseMatDescr_t descr,
const double* bsrVal,
const int* bsrRowPtr,
const int* bsrColInd,
int blockDim,
const double* x,
const double* beta,
double* y)
cusparseStatus_t
cusparseCbsrmv(cusparseHandle_t handle,
cusparseDirection_t dir,
cusparseOperation_t trans,
int mb,
int nb,
int nnzb,
const cuComplex* alpha,
const cusparseMatDescr_t descr,
const cuComplex* bsrVal,
const int* bsrRowPtr,
const int* bsrColInd,
int blockDim,
const cuComplex* x,
const cuComplex* beta,
cuComplex* y)
cusparseStatus_t
cusparseZbsrmv(cusparseHandle_t handle,
cusparseDirection_t dir,
cusparseOperation_t trans,
int mb,
int nb,
int nnzb,
const cuDoubleComplex* alpha,
const cusparseMatDescr_t descr,
const cuDoubleComplex* bsrVal,
const int* bsrRowPtr,
const int* bsrColInd,
int blockDim,
const cuDoubleComplex* x,
const cuDoubleComplex* beta,
cuDoubleComplex* y)
此函数执行矩阵-向量运算
其中 \(A\text{ 是一个 }(mb \ast blockDim) \times (nb \ast blockDim)\) 稀疏矩阵,该矩阵在 BSR 存储格式中由三个数组 bsrVal、bsrRowPtr 和 bsrColInd 定义;x 和 y 是向量;\(\alpha\text{ 和 }\beta\) 是标量;并且

bsrmv() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
关于 bsrmv() 的一些注释
仅支持
blockDim > 1仅支持
CUSPARSE_OPERATION_NON_TRANSPOSE,即
仅支持
CUSPARSE_MATRIX_TYPE_GENERAL。向量
x的大小应至少为 \((nb \ast blockDim)\),向量y的大小应至少为 \((mb \ast blockDim)\);否则,由于数组越界,内核可能会返回CUSPARSE_STATUS_EXECUTION_FAILED。
例如,假设用户具有 CSR 格式并想尝试 bsrmv(),以下代码演示了如何在单精度中使用 csr2bsr() 转换和 bsrmv() 乘法。
// Suppose that A is m x n sparse matrix represented by CSR format,
// hx is a host vector of size n, and hy is also a host vector of size m.
// m and n are not multiple of blockDim.
// step 1: transform CSR to BSR with column-major order
int base, nnz;
int nnzb;
cusparseDirection_t dirA = CUSPARSE_DIRECTION_COLUMN;
int mb = (m + blockDim-1)/blockDim;
int nb = (n + blockDim-1)/blockDim;
cudaMalloc((void**)&bsrRowPtrC, sizeof(int) *(mb+1));
cusparseXcsr2bsrNnz(handle, dirA, m, n,
descrA, csrRowPtrA, csrColIndA, blockDim,
descrC, bsrRowPtrC, &nnzb);
cudaMalloc((void**)&bsrColIndC, sizeof(int)*nnzb);
cudaMalloc((void**)&bsrValC, sizeof(float)*(blockDim*blockDim)*nnzb);
cusparseScsr2bsr(handle, dirA, m, n,
descrA, csrValA, csrRowPtrA, csrColIndA, blockDim,
descrC, bsrValC, bsrRowPtrC, bsrColIndC);
// step 2: allocate vector x and vector y large enough for bsrmv
cudaMalloc((void**)&x, sizeof(float)*(nb*blockDim));
cudaMalloc((void**)&y, sizeof(float)*(mb*blockDim));
cudaMemcpy(x, hx, sizeof(float)*n, cudaMemcpyHostToDevice);
cudaMemcpy(y, hy, sizeof(float)*m, cudaMemcpyHostToDevice);
// step 3: perform bsrmv
cusparseSbsrmv(handle, dirA, transA, mb, nb, nnzb, &alpha,
descrC, bsrValC, bsrRowPtrC, bsrColIndC, blockDim, x, &beta, y);
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
运算 \(\text{op}(A)\)。仅支持 |
|
矩阵 \(A\) 的块行数。 |
|
矩阵 \(A\) 的块列数。 |
|
矩阵 \(A\) 的非零块数。 |
|
<type> 用于乘法的标量。 |
|
矩阵 \(A\) 的描述符。支持的矩阵类型为 |
|
<type> 矩阵 \(A\) 的 |
|
包含每个块行的起始位置和最后一个块行的结束位置加一的 |
|
矩阵 \(A\) 的 |
|
稀疏矩阵 \(A\) 的块维度,大于零。 |
|
<type> \(nb \ast blockDim\) 个元素的向量。 |
|
<type> 用于乘法的标量。如果 |
|
<type> \(mb \ast blockDim\) 个元素的向量。 |
输出 (Output)
|
<type> 更新后的向量。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.4.2. cusparse<t>bsrxmv() [已弃用 (DEPRECATED)]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseSbsrxmv(cusparseHandle_t handle,
cusparseDirection_t dir,
cusparseOperation_t trans,
int sizeOfMask,
int mb,
int nb,
int nnzb,
const float* alpha,
const cusparseMatDescr_t descr,
const float* bsrVal,
const int* bsrMaskPtr,
const int* bsrRowPtr,
const int* bsrEndPtr,
const int* bsrColInd,
int blockDim,
const float* x,
const float* beta,
float* y)
cusparseStatus_t
cusparseDbsrxmv(cusparseHandle_t handle,
cusparseDirection_t dir,
cusparseOperation_t trans,
int sizeOfMask,
int mb,
int nb,
int nnzb,
const double* alpha,
const cusparseMatDescr_t descr,
const double* bsrVal,
const int* bsrMaskPtr,
const int* bsrRowPtr,
const int* bsrEndPtr,
const int* bsrColInd,
int blockDim,
const double* x,
const double* beta,
double* y)
cusparseStatus_t
cusparseCbsrxmv(cusparseHandle_t handle,
cusparseDirection_t dir,
cusparseOperation_t trans,
int sizeOfMask,
int mb,
int nb,
int nnzb,
const cuComplex* alpha,
const cusparseMatDescr_t descr,
const cuComplex* bsrVal,
const int* bsrMaskPtr,
const int* bsrRowPtr,
const int* bsrEndPtr,
const int* bsrColInd,
int blockDim,
const cuComplex* x,
const cuComplex* beta,
cuComplex* y)
cusparseStatus_t
cusparseZbsrxmv(cusparseHandle_t handle,
cusparseDirection_t dir,
cusparseOperation_t trans,
int sizeOfMask,
int mb,
int nb,
int nnzb,
const cuDoubleComplex* alpha,
const cusparseMatDescr_t descr,
const cuDoubleComplex* bsrVal,
const int* bsrMaskPtr,
const int* bsrRowPtr,
const int* bsrEndPtr,
const int* bsrColInd,
int blockDim,
const cuDoubleComplex* x,
const cuDoubleComplex* beta,
cuDoubleComplex* y)
此函数执行 bsrmv 和掩码运算
其中 \(A\text{ 是一个 }(mb \ast blockDim) \times (nb \ast blockDim)\) 稀疏矩阵,该矩阵在 BSRX 存储格式中由四个数组 bsrVal、bsrRowPtr、bsrEndPtr 和 bsrColInd 定义;x 和 y 是向量;\(\alpha\text{ 和 }\beta\) 是标量;并且
掩码运算由数组 bsrMaskPtr 定义,该数组包含 \(y\) 的更新块行索引。如果 bsrMaskPtr 中未指定行 \(i\),则 bsrxmv() 不会触及 \(A\) 和 \(y\) 的行块 \(i\)。
例如,考虑 \(2 \times 3\) 块矩阵 \(A\)
及其从 1 开始的 BSR 格式(三向量形式)为
假设我们想对矩阵 \(\bar{A}\) 执行以下 bsrmv 运算,该矩阵与 \(A\) 略有不同。
我们不需要为新矩阵 \(\bar{A}\) 创建另一个 BSR 格式,我们应该做的只是保持 bsrVal 和 bsrColInd 不变,但修改 bsrRowPtr 并添加一个额外的数组 bsrEndPtr,它指向 \(\bar{A}\) 的每行最后一个非零元素加 1。
例如,以下 bsrRowPtr 和 bsrEndPtr 可以表示矩阵 \(\bar{A}\)
此外,我们可以使用掩码算子(由数组 bsrMaskPtr 指定)仅更新 \(y\) 的特定块行索引,因为 \(y_{1}\) 永远不会更改。在这种情况下,bsrMaskPtr\(=\) [2],sizeOfMask=1。
掩码算子等效于以下操作
如果块行未出现在 bsrMaskPtr 中,则不会在该行上执行任何计算,并且 y 中的相应值保持不变。问号“?”用于指示不在 bsrMaskPtr 中的行块。
在这种情况下,第一个行块未出现在 bsrMaskPtr 中,因此 bsrRowPtr[0] 和 bsrEndPtr[0] 也不会被触及。
bsrxmv() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
关于 bsrxmv() 的一些注释
仅支持
blockDim > 1仅支持
CUSPARSE_OPERATION_NON_TRANSPOSE和CUSPARSE_MATRIX_TYPE_GENERAL。参数
bsrMaskPtr、bsrRowPtr、bsrEndPtr和bsrColInd与基本索引(从零开始或从一开始)一致。上面的例子是从一开始的索引。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
运算 \(\text{op}(A)\)。仅支持 |
|
\(y\) 中更新的块行数。 |
|
矩阵 \(A\) 的块行数。 |
|
矩阵 \(A\) 的块列数。 |
|
矩阵 \(A\) 的非零块数。 |
|
<type> 用于乘法的标量。 |
|
矩阵 \(A\) 的描述符。支持的矩阵类型为 |
|
<type> 矩阵 \(A\) 的 |
|
包含与更新的块行对应的索引的 |
|
包含每个块行起始位置的 |
|
包含每个块行结束位置加一的 |
|
矩阵 \(A\) 的非零块的 |
|
稀疏矩阵 \(A\) 的块维度,大于零。 |
|
<type> \(nb \ast blockDim\) 个元素的向量。 |
|
<type> 用于乘法的标量。如果 |
|
<type> \(mb \ast blockDim\) 个元素的向量。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.4.3. cusparse<t>bsrsv2_bufferSize() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseSbsrsv2_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
float* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrsv2Info_t info,
int* pBufferSizeInBytes)
cusparseStatus_t
cusparseDbsrsv2_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
double* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrsv2Info_t info,
int* pBufferSizeInBytes)
cusparseStatus_t
cusparseCbsrsv2_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
cuComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrsv2Info_t info,
int* pBufferSizeInBytes)
cusparseStatus_t
cusparseZbsrsv2_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
cuDoubleComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrsv2Info_t info,
int* pBufferSizeInBytes)
此函数返回 bsrsv2 中使用的缓冲区大小,这是一个新的稀疏三角线性系统 op(A)*y =\(\alpha\)x。
A 是一个 (mb*blockDim)x(mb*blockDim) 稀疏矩阵,由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 以 BSR 存储格式定义;x 和 y 是右侧向量和解向量;\(\alpha\) 是一个标量;并且
尽管在参数 trans 以及 A 的上(下)三角部分方面有六种组合,bsrsv2_bufferSize() 返回这些组合中的最大缓冲区大小。缓冲区大小取决于维度 mb、blockDim 和矩阵 nnzb 的非零块的数量。如果用户更改了矩阵,则必须再次调用 bsrsv2_bufferSize() 以获得正确的缓冲区大小;否则可能会发生段错误。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
操作 \(\text{op}(A)\) 。 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 矩阵 |
|
包含每个块行的起始位置和最后一个块行的结束位置加一的 |
|
|
|
稀疏矩阵 A 的块维度;必须大于零。 |
输出 (Output)
|
基于不同算法的内部状态记录。 |
|
在 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.4.4. cusparse<t>bsrsv2_analysis() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseSbsrsv2_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
const float* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrsv2Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseDbsrsv2_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
const double* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrsv2Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseDbsrsv2_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
const cuComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrsv2Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseZbsrsv2_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrsv2Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
此函数执行 bsrsv2 的分析阶段,这是一个新的稀疏三角线性系统 op(A)*y =\(\alpha\)x。
A 是一个 (mb*blockDim)x(mb*blockDim) 稀疏矩阵,由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 以 BSR 存储格式定义;x 和 y 是右侧向量和解向量;\(\alpha\) 是一个标量;并且
BSR 格式的块大小为 blockDim*blockDim,以列优先或行优先存储,由参数 dirA 确定,dirA 为 CUSPARSE_DIRECTION_COLUMN 或 CUSPARSE_DIRECTION_ROW。矩阵类型必须为 CUSPARSE_MATRIX_TYPE_GENERAL,并且忽略填充模式和对角线类型。
预计对于给定的矩阵和特定的操作类型,此函数将仅执行一次。
此函数需要 bsrsv2_bufferSize() 返回的缓冲区大小。 pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
函数 bsrsv2_analysis() 报告结构零并计算级别信息,这些信息存储在不透明结构 info 中。级别信息可以为三角求解器提取更多并行性。但是,即使没有级别信息,也可以完成 bsrsv2_solve()。要禁用级别信息,用户需要将三角求解器的策略指定为 CUSPARSE_SOLVE_POLICY_NO_LEVEL。
即使参数 policy 为 CUSPARSE_SOLVE_POLICY_NO_LEVEL,函数 bsrsv2_analysis() 始终报告第一个结构零。如果指定了 CUSPARSE_DIAG_TYPE_UNIT,即使对于某些 j 块 A(j,j) 缺失,也不会报告结构零。用户需要调用 cusparseXbsrsv2_zeroPivot() 以了解结构零的位置。
如果 bsrsv2_analysis() 报告结构零,则用户可以选择是否调用 bsrsv2_solve()。在这种情况下,用户仍然可以调用 bsrsv2_solve(),它将在与结构零相同的位置返回数值零。但是,结果 x 没有意义。
此函数需要内部分配的临时额外存储空间。
如果流有序内存分配器可用,则该例程支持异步执行。
如果流有序内存分配器可用,则该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
操作 \(\text{op}(A)\) 。 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 矩阵 |
|
包含每个块行的起始位置和最后一个块行的结束位置加一的 |
|
|
|
稀疏矩阵 A 的块维度,大于零。 |
|
使用 |
|
支持的策略为 |
|
用户分配的缓冲区,大小由 |
输出 (Output)
|
填充了分析阶段收集的信息的结构(应保持不变地传递到求解阶段)。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.4.5. cusparse<t>bsrsv2_solve() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseSbsrsv2_solve(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
int mb,
int nnzb,
const float* alpha,
const cusparseMatDescr_t descrA,
const float* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrsv2Info_t info,
const float* x,
float* y,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseDbsrsv2_solve(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
int mb,
int nnzb,
const double* alpha,
const cusparseMatDescr_t descrA,
const double* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrsv2Info_t info,
const double* x,
double* y,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseCbsrsv2_solve(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
int mb,
int nnzb,
const cuComplex* alpha,
const cusparseMatDescr_t descrA,
const cuComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrsv2Info_t info,
const cuComplex* x,
cuComplex* y,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseZbsrsv2_solve(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
int mb,
int nnzb,
const cuDoubleComplex* alpha,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrsv2Info_t info,
const cuDoubleComplex* x,
cuDoubleComplex* y,
cusparseSolvePolicy_t policy,
void* pBuffer)
此函数执行 bsrsv2 的求解阶段,这是一个新的稀疏三角线性系统 op(A)*y =\(\alpha\)x。
A 是一个 (mb*blockDim)x(mb*blockDim) 稀疏矩阵,由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 以 BSR 存储格式定义;x 和 y 是右侧向量和解向量;\(\alpha\) 是一个标量;并且
BSR 格式的块大小为 blockDim*blockDim,以列优先或行优先存储,由参数 dirA 确定,dirA 为 CUSPARSE_DIRECTION_COLUMN 或 CUSPARSE_DIRECTION_ROW。矩阵类型必须为 CUSPARSE_MATRIX_TYPE_GENERAL,并且忽略填充模式和对角线类型。函数 bsrsv02_solve() 可以支持任意 blockDim。
对于给定的矩阵和特定的操作类型,此函数可以多次执行。
此函数需要 bsrsv2_bufferSize() 返回的缓冲区大小。 pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
虽然 bsrsv2_solve() 可以在没有级别信息的情况下完成,但用户仍然需要注意一致性。如果使用策略 CUSPARSE_SOLVE_POLICY_USE_LEVEL 调用 bsrsv2_analysis(),则 bsrsv2_solve() 可以使用或不使用级别运行。另一方面,如果使用 CUSPARSE_SOLVE_POLICY_NO_LEVEL 调用 bsrsv2_analysis(),则 bsrsv2_solve() 只能接受 CUSPARSE_SOLVE_POLICY_NO_LEVEL;否则,将返回 CUSPARSE_STATUS_INVALID_VALUE。
级别信息可能不会提高性能,但可能会花费额外的分析时间。例如,三对角矩阵没有并行性。在这种情况下,CUSPARSE_SOLVE_POLICY_NO_LEVEL 比 CUSPARSE_SOLVE_POLICY_USE_LEVEL 性能更好。如果用户有迭代求解器,最好的方法是使用 CUSPARSE_SOLVE_POLICY_USE_LEVEL 执行一次 bsrsv2_analysis()。然后在第一次运行时使用 CUSPARSE_SOLVE_POLICY_NO_LEVEL 执行 bsrsv2_solve(),在第二次运行时使用 CUSPARSE_SOLVE_POLICY_USE_LEVEL 执行 bsrsv2_solve(),并选择最快的一个来执行剩余的迭代。
函数 bsrsv02_solve() 的行为与 csrsv02_solve() 相同。也就是说,bsr2csr(bsrsv02(A)) = csrsv02(bsr2csr(A))。csrsv02_solve() 的数值零表示存在一些零 A(j,j)。bsrsv02_solve() 的数值零表示存在一些不可逆的块 A(j,j)。
函数 bsrsv2_solve() 报告第一个数值零,包括结构零。如果指定了 CUSPARSE_DIAG_TYPE_UNIT,即使对于某些 j,A(j,j) 不可逆,也不会报告数值零。用户需要调用 cusparseXbsrsv2_zeroPivot() 以了解数值零的位置。
如果 pBuffer != NULL,则该函数支持以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
例如,假设 L 是具有单位对角线的下三角矩阵,则以下代码通过级别信息求解 L*y=x。
// Suppose that L is m x m sparse matrix represented by BSR format,
// The number of block rows/columns is mb, and
// the number of nonzero blocks is nnzb.
// L is lower triangular with unit diagonal.
// Assumption:
// - dimension of matrix L is m(=mb*blockDim),
// - matrix L has nnz(=nnzb*blockDim*blockDim) nonzero elements,
// - handle is already created by cusparseCreate(),
// - (d_bsrRowPtr, d_bsrColInd, d_bsrVal) is BSR of L on device memory,
// - d_x is right hand side vector on device memory.
// - d_y is solution vector on device memory.
// - d_x and d_y are of size m.
cusparseMatDescr_t descr = 0;
bsrsv2Info_t info = 0;
int pBufferSize;
void *pBuffer = 0;
int structural_zero;
int numerical_zero;
const double alpha = 1.;
const cusparseSolvePolicy_t policy = CUSPARSE_SOLVE_POLICY_USE_LEVEL;
const cusparseOperation_t trans = CUSPARSE_OPERATION_NON_TRANSPOSE;
const cusparseDirection_t dir = CUSPARSE_DIRECTION_COLUMN;
// step 1: create a descriptor which contains
// - matrix L is base-1
// - matrix L is lower triangular
// - matrix L has unit diagonal, specified by parameter CUSPARSE_DIAG_TYPE_UNIT
// (L may not have all diagonal elements.)
cusparseCreateMatDescr(&descr);
cusparseSetMatIndexBase(descr, CUSPARSE_INDEX_BASE_ONE);
cusparseSetMatFillMode(descr, CUSPARSE_FILL_MODE_LOWER);
cusparseSetMatDiagType(descr, CUSPARSE_DIAG_TYPE_UNIT);
// step 2: create a empty info structure
cusparseCreateBsrsv2Info(&info);
// step 3: query how much memory used in bsrsv2, and allocate the buffer
cusparseDbsrsv2_bufferSize(handle, dir, trans, mb, nnzb, descr,
d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, &pBufferSize);
// pBuffer returned by cudaMalloc is automatically aligned to 128 bytes.
cudaMalloc((void**)&pBuffer, pBufferSize);
// step 4: perform analysis
cusparseDbsrsv2_analysis(handle, dir, trans, mb, nnzb, descr,
d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim,
info, policy, pBuffer);
// L has unit diagonal, so no structural zero is reported.
status = cusparseXbsrsv2_zeroPivot(handle, info, &structural_zero);
if (CUSPARSE_STATUS_ZERO_PIVOT == status){
printf("L(%d,%d) is missing\n", structural_zero, structural_zero);
}
// step 5: solve L*y = x
cusparseDbsrsv2_solve(handle, dir, trans, mb, nnzb, &alpha, descr,
d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, info,
d_x, d_y, policy, pBuffer);
// L has unit diagonal, so no numerical zero is reported.
status = cusparseXbsrsv2_zeroPivot(handle, info, &numerical_zero);
if (CUSPARSE_STATUS_ZERO_PIVOT == status){
printf("L(%d,%d) is zero\n", numerical_zero, numerical_zero);
}
// step 6: free resources
cudaFree(pBuffer);
cusparseDestroyBsrsv2Info(info);
cusparseDestroyMatDescr(descr);
cusparseDestroy(handle);
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
操作 \(\text{op}(A)\)。 |
|
矩阵 |
|
<type> 用于乘法的标量。 |
|
矩阵 |
|
<type> 矩阵 |
|
包含每个块行的起始位置和最后一个块行的结束位置加一的 |
|
|
|
稀疏矩阵 |
|
包含分析阶段收集的信息的结构(应保持不变地传递到求解阶段)。 |
|
<type> 大小为 |
|
支持的策略为 |
|
用户分配的缓冲区,大小由 |
输出 (Output)
|
<type> 大小为 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.4.6. cusparseXbsrsv2_zeroPivot() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseXbsrsv2_zeroPivot(cusparseHandle_t handle,
bsrsv2Info_t info,
int* position)
如果返回的错误代码为 CUSPARSE_STATUS_ZERO_PIVOT,则 position=j 表示 A(j,j) 是结构零或数值零(奇异块)。否则 position=-1。
position 可以是基于 0 的或基于 1 的,与矩阵相同。
函数 cusparseXbsrsv2_zeroPivot() 是一个阻塞调用。它调用 cudaDeviceSynchronize() 以确保所有先前的内核都已完成。
position 可以在主机内存或设备内存中。用户可以使用 cusparseSetPointerMode() 设置正确的模式。
该例程不需要额外的存储空间。
如果流有序内存分配器可用,则该例程支持异步执行。
如果流有序内存分配器可用,则该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
如果用户已经调用了 |
输出 (Output)
|
如果没有结构零或数值零,则 |
有关返回状态的描述,请参阅 cusparseStatus_t
5.4.7. cusparse<t>gemvi() [已弃用]
> 此例程将在未来的主要版本中移除。
cusparseStatus_t
cusparseSgemvi_bufferSize(cusparseHandle_t handle,
cusparseOperation_t transA,
int m,
int n,
int nnz,
int* pBufferSize)
cusparseStatus_t
cusparseDgemvi_bufferSize(cusparseHandle_t handle,
cusparseOperation_t transA,
int m,
int n,
int nnz,
int* pBufferSize)
cusparseStatus_t
cusparseCgemvi_bufferSize(cusparseHandle_t handle,
cusparseOperation_t transA,
int m,
int n,
int nnz,
int* pBufferSize)
cusparseStatus_t
cusparseZgemvi_bufferSize(cusparseHandle_t handle,
cusparseOperation_t transA,
int m,
int n,
int nnz,
int* pBufferSize)
cusparseStatus_t
cusparseSgemvi(cusparseHandle_t handle,
cusparseOperation_t transA,
int m,
int n,
const float* alpha,
const float* A,
int lda,
int nnz,
const float* x,
const int* xInd,
const float* beta,
float* y,
cusparseIndexBase_t idxBase,
void* pBuffer)
cusparseStatus_t
cusparseDgemvi(cusparseHandle_t handle,
cusparseOperation_t transA,
int m,
int n,
const double* alpha,
const double* A,
int lda,
int nnz,
const double* x,
const int* xInd,
const double* beta,
double* y,
cusparseIndexBase_t idxBase,
void* pBuffer)
cusparseStatus_t
cusparseCgemvi(cusparseHandle_t handle,
cusparseOperation_t transA,
int m,
int n,
const cuComplex* alpha,
const cuComplex* A,
int lda,
int nnz,
const cuComplex* x,
const int* xInd,
const cuComplex* beta,
cuComplex* y,
cusparseIndexBase_t idxBase,
void* pBuffer)
cusparseStatus_t
cusparseZgemvi(cusparseHandle_t handle,
cusparseOperation_t transA,
int m,
int n,
const cuDoubleComplex* alpha,
const cuDoubleComplex* A,
int lda,
int nnz,
const cuDoubleComplex* x,
const int* xInd,
const cuDoubleComplex* beta,
cuDoubleComplex* y,
cusparseIndexBase_t idxBase,
void* pBuffer)
此函数执行矩阵-向量运算
A 是一个 \(m \times n\) 稠密矩阵和一个稀疏向量 x,该向量由长度为 nnz 的两个数组 xVal, xInd 定义,y 是一个稠密向量;\(\alpha \;\) 和 \(\beta \;\) 是标量;并且
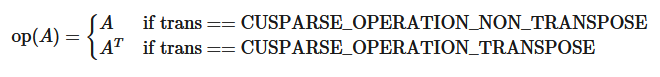
为了简化实现,我们尚未(还)优化转置乘法的情况。我们为对此情况感兴趣的用户推荐以下方法。
使用
csr2csc()函数之一将矩阵从 CSR 格式转换为 CSC 格式。请注意,通过交换结果的行和列,您隐式地转置了矩阵。-
调用
gemvi()函数,并将cusparseOperation_t参数设置为CUSPARSE_OPERATION_NON_TRANSPOSE,并将矩阵的交换行和列存储在 CSC 格式中。这(隐式地)将向量乘以原始 CSR 格式矩阵的转置。该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
函数 cusparse<t>gemvi_bufferSize() 返回 cusparse<t>gemvi() 中使用的缓冲区的大小。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
操作 \(\text{op}(A)\)。 |
|
矩阵 |
|
矩阵 |
|
<type> 用于乘法的标量。 |
|
指向稠密矩阵 |
|
|
|
向量 |
|
<type> 如果 \(\text{op}(A)=A\),则大小为 |
|
|
|
<type> 用于乘法的标量。如果 |
|
<type> 如果 \(\text{op}(A)=A\),则大小为 |
|
0 或 1,分别表示从 0 开始或从 1 开始的索引。 |
|
|
|
工作空间缓冲区。 |
输出 (Output)
|
<type> 更新后的稠密向量。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.5. cuSPARSE Level 3 函数参考
本章介绍稀疏线性代数函数,这些函数执行稀疏矩阵和(通常是高瘦)稠密矩阵之间的运算。
5.5.1. cusparse<t>bsrmm() [已弃用]
> 此例程将在未来的主要版本中移除。 请改用带有 BSR 矩阵的 cusparseSpMM()。
cusparseStatus_t
cusparseSbsrmm(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transB,
int mb,
int n,
int kb,
int nnzb,
const float* alpha,
const cusparseMatDescr_t descrA,
const float* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
const float* B,
int ldb,
const float* beta,
float* C,
int ldc)
cusparseStatus_t
cusparseDbsrmm(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transB,
int mb,
int n,
int kb,
int nnzb,
const double* alpha,
const cusparseMatDescr_t descrA,
const double* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
const double* B,
int ldb,
const double* beta,
double* C,
int ldc)
cusparseStatus_t
cusparseCbsrmm(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transB,
int mb,
int n,
int kb,
int nnzb,
const cuComplex* alpha,
const cusparseMatDescr_t descrA,
const cuComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
const cuComplex* B,
int ldb,
const cuComplex* beta,
cuComplex* C,
int ldc)
cusparseStatus_t
cusparseZbsrmm(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transB,
int mb,
int n,
int kb,
int nnzb,
const cuDoubleComplex* alpha,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
const cuDoubleComplex* B,
int ldb,
const cuDoubleComplex* beta,
cuDoubleComplex* C,
int ldc)
此函数执行以下矩阵-矩阵运算之一
A 是一个 \(mb \times kb\) 稀疏矩阵,由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 以 BSR 存储格式定义;B 和 C 是稠密矩阵;\(\alpha\text{~和~}\beta\) 是标量;并且

和

该函数具有以下限制
仅支持
CUSPARSE_MATRIX_TYPE_GENERAL矩阵类型。仅支持
blockDim > 1。如果
blockDim≤ 4,则 max(mb)/max(n) = 524,272。如果 4 <
blockDim≤ 8,则 max(mb) = 524,272,max(n) = 262,136。如果
blockDim> 8,则 m < 65,535 且 max(n) = 262,136。
transpose(B) 的动机是为了改善矩阵 B 的内存访问。A*transpose(B) 与列优先顺序的矩阵 B 的计算模式等效于行优先顺序的矩阵 B 的 A*B。
实际上,迭代求解器或特征值求解器中的任何操作都不使用 A*transpose(B)。但是,我们可以执行 A*transpose(transpose(B)),这与 A*B 相同。例如,假设 A 为 mb*kb,B 为 k*n,C 为 m*n,以下代码显示了 cusparseDbsrmm() 的用法。
// A is mb*kb, B is k*n and C is m*n
const int m = mb*blockSize;
const int k = kb*blockSize;
const int ldb_B = k; // leading dimension of B
const int ldc = m; // leading dimension of C
// perform C:=alpha*A*B + beta*C
cusparseSetMatType(descrA, CUSPARSE_MATRIX_TYPE_GENERAL );
cusparseDbsrmm(cusparse_handle,
CUSPARSE_DIRECTION_COLUMN,
CUSPARSE_OPERATION_NON_TRANSPOSE,
CUSPARSE_OPERATION_NON_TRANSPOSE,
mb, n, kb, nnzb, alpha,
descrA, bsrValA, bsrRowPtrA, bsrColIndA, blockSize,
B, ldb_B,
beta, C, ldc);
我们的建议是将 B 转置为 Bt,而不是使用 A*B,方法是首先调用 cublas<t>geam(),然后执行 A*transpose(Bt)。
// step 1: Bt := transpose(B)
const int m = mb*blockSize;
const int k = kb*blockSize;
double *Bt;
const int ldb_Bt = n; // leading dimension of Bt
cudaMalloc((void**)&Bt, sizeof(double)*ldb_Bt*k);
double one = 1.0;
double zero = 0.0;
cublasSetPointerMode(cublas_handle, CUBLAS_POINTER_MODE_HOST);
cublasDgeam(cublas_handle, CUBLAS_OP_T, CUBLAS_OP_T,
n, k, &one, B, int ldb_B, &zero, B, int ldb_B, Bt, ldb_Bt);
// step 2: perform C:=alpha*A*transpose(Bt) + beta*C
cusparseDbsrmm(cusparse_handle,
CUSPARSE_DIRECTION_COLUMN,
CUSPARSE_OPERATION_NON_TRANSPOSE,
CUSPARSE_OPERATION_TRANSPOSE,
mb, n, kb, nnzb, alpha,
descrA, bsrValA, bsrRowPtrA, bsrColIndA, blockSize,
Bt, ldb_Bt,
beta, C, ldc);
bsrmm() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
操作 |
|
操作 |
|
稀疏矩阵 |
|
稠密矩阵 |
|
稀疏矩阵 |
|
稀疏矩阵 |
|
<type> 用于乘法的标量。 |
|
矩阵 |
|
<type> 矩阵 |
|
包含每个块行的起始位置和最后一个块行的结束位置加一的 |
|
|
|
稀疏矩阵 |
|
如果 |
|
|
|
<type> 用于乘法的标量。如果 |
|
维度为 |
|
|
输出 (Output)
|
<type> 更新后的维度为 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.5.2. cusparse<t>bsrsm2_bufferSize() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseSbsrsm2_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transX,
int mb,
int n,
int nnzb,
const cusparseMatDescr_t descrA,
float* bsrSortedValA,
const int* bsrSortedRowPtrA,
const int* bsrSortedColIndA,
int blockDim,
bsrsm2Info_t info,
int* pBufferSizeInBytes)
cusparseStatus_t
cusparseDbsrsm2_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transX,
int mb,
int n,
int nnzb,
const cusparseMatDescr_t descrA,
double* bsrSortedValA,
const int* bsrSortedRowPtrA,
const int* bsrSortedColIndA,
int blockDim,
bsrsm2Info_t info,
int* pBufferSizeInBytes)
cusparseStatus_t
cusparseCbsrsm2_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transX,
int mb,
int n,
int nnzb,
const cusparseMatDescr_t descrA,
cuComplex* bsrSortedValA,
const int* bsrSortedRowPtrA,
const int* bsrSortedColIndA,
int blockDim,
bsrsm2Info_t info,
int* pBufferSizeInBytes)
cusparseStatus_t
cusparseZbsrsm2_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transX,
int mb,
int n,
int nnzb,
const cusparseMatDescr_t descrA,
cuDoubleComplex* bsrSortedValA,
const int* bsrSortedRowPtrA,
const int* bsrSortedColIndA,
int blockDim,
bsrsm2Info_t info,
int* pBufferSizeInBytes)
此函数返回 bsrsm2() 中使用的缓冲区大小,这是一个新的稀疏三角线性系统 op(A)*op(X)=\(\alpha\)op(B)。
A 是一个 (mb*blockDim)x(mb*blockDim) 稀疏矩阵,由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 以 BSR 存储格式定义;B 和 X 是右手侧矩阵和解矩阵;\(\alpha\) 是一个标量;并且
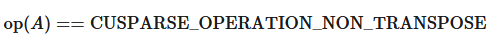
尽管在参数 trans 以及 A 的上(和下)三角部分方面有六种组合,bsrsm2_bufferSize() 返回这些组合中的最大缓冲区大小。缓冲区大小取决于维度 mb,blockDim 和矩阵的非零数 nnzb。如果用户更改了矩阵,则必须再次调用 bsrsm2_bufferSize() 以获得正确的缓冲区大小,否则可能会发生段错误。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
操作 |
|
操作 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 矩阵 |
|
包含每个块行的起始位置和最后一个块行的结束位置加一的 |
|
|
|
稀疏矩阵 |
输出 (Output)
|
基于不同算法的内部状态记录。 |
|
在 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.5.3. cusparse<t>bsrsm2_analysis() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseSbsrsm2_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transX,
int mb,
int n,
int nnzb,
const cusparseMatDescr_t descrA,
const float* bsrSortedVal,
const int* bsrSortedRowPtr,
const int* bsrSortedColInd,
int blockDim,
bsrsm2Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseDbsrsm2_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transX,
int mb,
int n,
int nnzb,
const cusparseMatDescr_t descrA,
const double* bsrSortedVal,
const int* bsrSortedRowPtr,
const int* bsrSortedColInd,
int blockDim,
bsrsm2Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseCbsrsm2_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transX,
int mb,
int n,
int nnzb,
const cusparseMatDescr_t descrA,
const cuComplex* bsrSortedVal,
const int* bsrSortedRowPtr,
const int* bsrSortedColInd,
int blockDim,
bsrsm2Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseZbsrsm2_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transX,
int mb,
int n,
int nnzb,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* bsrSortedVal,
const int* bsrSortedRowPtr,
const int* bsrSortedColInd,
int blockDim,
bsrsm2Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
此函数执行 bsrsm2() 的分析阶段,这是一个新的稀疏三角线性系统 op(A)*op(X) =\(\alpha\)op(B)。
A 是一个 (mb*blockDim)x(mb*blockDim) 稀疏矩阵,由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 以 BSR 存储格式定义;B 和 X 是右手侧矩阵和解矩阵;\(\alpha\) 是一个标量;并且
和

并且 op(B) 和 op(X) 相等。
BSR 格式的块大小为 blockDim*blockDim,以列优先或行优先存储,由参数 dirA 确定,dirA 为 CUSPARSE_DIRECTION_ROW 或 CUSPARSE_DIRECTION_COLUMN。矩阵类型必须为 CUSPARSE_MATRIX_TYPE_GENERAL,并且忽略填充模式和对角线类型。
预计对于给定的矩阵和特定的操作类型,此函数将仅执行一次。
此函数需要 bsrsm2_bufferSize() 返回的缓冲区大小。 pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
函数 bsrsm2_analysis() 报告结构零并计算存储在不透明结构 info 中的级别信息。级别信息可以在三角求解器期间提取更多并行性。但是,即使没有级别信息,也可以完成 bsrsm2_solve()。要禁用级别信息,用户需要将三角求解器的策略指定为 CUSPARSE_SOLVE_POLICY_NO_LEVEL。
即使参数 policy 为 CUSPARSE_SOLVE_POLICY_NO_LEVEL,函数 bsrsm2_analysis() 始终报告第一个结构零。此外,如果指定了 CUSPARSE_DIAG_TYPE_UNIT,即使对于某些 j 块 A(j,j) 缺失,也不会报告结构零。用户必须调用 cusparseXbsrsm2_query_zero_pivot() 以了解结构零的位置。
如果 bsrsm2_analysis() 报告结构零,则求解将返回与结构零相同位置的数值零,但此结果 X 没有意义。
此函数需要内部分配的临时额外存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
操作 |
|
操作 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 矩阵 |
|
包含每个块行的起始位置和最后一个块行的结束位置加一的 |
|
|
|
稀疏矩阵 |
|
使用 |
|
支持的策略为 |
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
填充了分析阶段收集的信息的结构(应保持不变地传递到求解阶段)。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.5.4. cusparse<t>bsrsm2_solve() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseSbsrsm2_solve(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transX,
int mb,
int n,
int nnzb,
const float* alpha,
const cusparseMatDescr_t descrA,
const float* bsrSortedVal,
const int* bsrSortedRowPtr,
const int* bsrSortedColInd,
int blockDim,
bsrsm2Info_t info,
const float* B,
int ldb,
float* X,
int ldx,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseDbsrsm2_solve(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transX,
int mb,
int n,
int nnzb,
const double* alpha,
const cusparseMatDescr_t descrA,
const double* bsrSortedVal,
const int* bsrSortedRowPtr,
const int* bsrSortedColInd,
int blockDim,
bsrsm2Info_t info,
const double* B,
int ldb,
double* X,
int ldx,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseCbsrsm2_solve(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transX,
int mb,
int n,
int nnzb,
const cuComplex* alpha,
const cusparseMatDescr_t descrA,
const cuComplex* bsrSortedVal,
const int* bsrSortedRowPtr,
const int* bsrSortedColInd,
int blockDim,
bsrsm2Info_t info,
const cuComplex* B,
int ldb,
cuComplex* X,
int ldx,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseZbsrsm2_solve(cusparseHandle_t handle,
cusparseDirection_t dirA,
cusparseOperation_t transA,
cusparseOperation_t transX,
int mb,
int n,
int nnzb,
const cuDoubleComplex* alpha,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* bsrSortedVal,
const int* bsrSortedRowPtr,
const int* bsrSortedColInd,
int blockDim,
bsrsm2Info_t info,
const cuDoubleComplex* B,
int ldb,
cuDoubleComplex* X,
int ldx,
cusparseSolvePolicy_t policy,
void* pBuffer)
此函数执行稀疏三角线性方程组解的求解阶段
A 是一个 (mb*blockDim)x(mb*blockDim) 稀疏矩阵,它由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 以 BSR 存储格式定义;B 和 X 是右侧矩阵和解矩阵;\(\alpha\) 是一个标量,并且
和
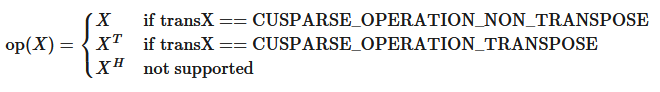
仅支持 op(A)=A。
op(B) 和 op(X) 必须以相同的方式执行。换句话说,如果 op(B)=B,则 op(X)=X。
BSR 格式的块大小为 blockDim*blockDim,以列优先或行优先方式存储,具体取决于参数 dirA,参数 dirA 为 CUSPARSE_DIRECTION_ROW 或 CUSPARSE_DIRECTION_COLUMN。矩阵类型必须为 CUSPARSE_MATRIX_TYPE_GENERAL,并且填充模式和对角线类型将被忽略。函数 bsrsm02_solve() 可以支持任意 blockDim。
对于给定的矩阵和特定的操作类型,此函数可以多次执行。
此函数需要 bsrsm2_bufferSize() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
尽管可以在没有级别信息的情况下完成 bsrsm2_solve(),但用户仍然需要注意一致性。如果使用策略 CUSPARSE_SOLVE_POLICY_USE_LEVEL 调用 bsrsm2_analysis(),则可以使用或不使用级别运行 bsrsm2_solve()。另一方面,如果使用 CUSPARSE_SOLVE_POLICY_NO_LEVEL 调用 bsrsm2_analysis(),则 bsrsm2_solve() 只能接受 CUSPARSE_SOLVE_POLICY_NO_LEVEL;否则,将返回 CUSPARSE_STATUS_INVALID_VALUE。
函数 bsrsm02_solve() 与 bsrsv02_solve() 具有相同的行为,报告第一个数值零,包括结构零。用户必须调用 cusparseXbsrsm2_query_zero_pivot() 以了解数值零的位置。
transpose(X) 的动机是改善矩阵 X 的内存访问。transpose(X) 与列优先顺序的矩阵 X 的计算模式等效于行优先顺序的矩阵 X 的 X。
支持就地操作,并且要求 B 和 X 指向相同的内存块,并且 ldb=ldx。
如果 pBuffer != NULL,则该函数支持以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
操作 |
|
操作 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 用于乘法的标量。 |
|
矩阵 |
|
<type> 数组,包含 |
|
包含每个块行的起始位置和最后一个块行的结束位置加一的 |
|
|
|
稀疏矩阵 |
|
使用 |
|
<type> 右侧数组。 |
|
|
|
|
|
支持的策略为 |
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
<type> 解数组,具有主维度 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.5.5. cusparseXbsrsm2_zeroPivot() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseXbsrsm2_zeroPivot(cusparseHandle_t handle,
bsrsm2Info_t info,
int* position)
如果返回的错误代码为 CUSPARSE_STATUS_ZERO_PIVOT,则 position=j 表示 A(j,j) 是结构零或数值零(奇异块)。否则 position=-1。
position 可以是 0 基或 1 基,与矩阵相同。
函数 cusparseXbsrsm2_zeroPivot() 是一个阻塞调用。它调用 cudaDeviceSynchronize() 以确保完成所有先前的内核。
position 可以在主机内存或设备内存中。用户可以使用 cusparseSetPointerMode() 设置正确的模式。
该例程不需要额外的存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
如果用户已调用 |
输出 (Output)
|
如果没有结构零或数值零,则 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.6. cuSPARSE 额外函数参考
本章介绍用于操作稀疏矩阵的额外例程。
5.6.1. cusparse<t>csrgeam2()
cusparseStatus_t
cusparseScsrgeam2_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const float* alpha,
const cusparseMatDescr_t descrA,
int nnzA,
const float* csrSortedValA,
const int* csrSortedRowPtrA,
const int* csrSortedColIndA,
const float* beta,
const cusparseMatDescr_t descrB,
int nnzB,
const float* csrSortedValB,
const int* csrSortedRowPtrB,
const int* csrSortedColIndB,
const cusparseMatDescr_t descrC,
const float* csrSortedValC,
const int* csrSortedRowPtrC,
const int* csrSortedColIndC,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseDcsrgeam2_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const double* alpha,
const cusparseMatDescr_t descrA,
int nnzA,
const double* csrSortedValA,
const int* csrSortedRowPtrA,
const int* csrSortedColIndA,
const double* beta,
const cusparseMatDescr_t descrB,
int nnzB,
const double* csrSortedValB,
const int* csrSortedRowPtrB,
const int* csrSortedColIndB,
const cusparseMatDescr_t descrC,
const double* csrSortedValC,
const int* csrSortedRowPtrC,
const int* csrSortedColIndC,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseCcsrgeam2_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const cuComplex* alpha,
const cusparseMatDescr_t descrA,
int nnzA,
const cuComplex* csrSortedValA,
const int* csrSortedRowPtrA,
const int* csrSortedColIndA,
const cuComplex* beta,
const cusparseMatDescr_t descrB,
int nnzB,
const cuComplex* csrSortedValB,
const int* csrSortedRowPtrB,
const int* csrSortedColIndB,
const cusparseMatDescr_t descrC,
const cuComplex* csrSortedValC,
const int* csrSortedRowPtrC,
const int* csrSortedColIndC,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseZcsrgeam2_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const cuDoubleComplex* alpha,
const cusparseMatDescr_t descrA,
int nnzA,
const cuDoubleComplex* csrSortedValA,
const int* csrSortedRowPtrA,
const int* csrSortedColIndA,
const cuDoubleComplex* beta,
const cusparseMatDescr_t descrB,
int nnzB,
const cuDoubleComplex* csrSortedValB,
const int* csrSortedRowPtrB,
const int* csrSortedColIndB,
const cusparseMatDescr_t descrC,
const cuDoubleComplex* csrSortedValC,
const int* csrSortedRowPtrC,
const int* csrSortedColIndC,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseXcsrgeam2Nnz(cusparseHandle_t handle,
int m,
int n,
const cusparseMatDescr_t descrA,
int nnzA,
const int* csrSortedRowPtrA,
const int* csrSortedColIndA,
const cusparseMatDescr_t descrB,
int nnzB,
const int* csrSortedRowPtrB,
const int* csrSortedColIndB,
const cusparseMatDescr_t descrC,
int* csrSortedRowPtrC,
int* nnzTotalDevHostPtr,
void* workspace)
cusparseStatus_t
cusparseScsrgeam2(cusparseHandle_t handle,
int m,
int n,
const float* alpha,
const cusparseMatDescr_t descrA,
int nnzA,
const float* csrSortedValA,
const int* csrSortedRowPtrA,
const int* csrSortedColIndA,
const float* beta,
const cusparseMatDescr_t descrB,
int nnzB,
const float* csrSortedValB,
const int* csrSortedRowPtrB,
const int* csrSortedColIndB,
const cusparseMatDescr_t descrC,
float* csrSortedValC,
int* csrSortedRowPtrC,
int* csrSortedColIndC,
void* pBuffer)
cusparseStatus_t
cusparseDcsrgeam2(cusparseHandle_t handle,
int m,
int n,
const double* alpha,
const cusparseMatDescr_t descrA,
int nnzA,
const double* csrSortedValA,
const int* csrSortedRowPtrA,
const int* csrSortedColIndA,
const double* beta,
const cusparseMatDescr_t descrB,
int nnzB,
const double* csrSortedValB,
const int* csrSortedRowPtrB,
const int* csrSortedColIndB,
const cusparseMatDescr_t descrC,
double* csrSortedValC,
int* csrSortedRowPtrC,
int* csrSortedColIndC,
void* pBuffer)
cusparseStatus_t
cusparseCcsrgeam2(cusparseHandle_t handle,
int m,
int n,
const cuComplex* alpha,
const cusparseMatDescr_t descrA,
int nnzA,
const cuComplex* csrSortedValA,
const int* csrSortedRowPtrA,
const int* csrSortedColIndA,
const cuComplex* beta,
const cusparseMatDescr_t descrB,
int nnzB,
const cuComplex* csrSortedValB,
const int* csrSortedRowPtrB,
const int* csrSortedColIndB,
const cusparseMatDescr_t descrC,
cuComplex* csrSortedValC,
int* csrSortedRowPtrC,
int* csrSortedColIndC,
void* pBuffer)
cusparseStatus_t
cusparseZcsrgeam2(cusparseHandle_t handle,
int m,
int n,
const cuDoubleComplex* alpha,
const cusparseMatDescr_t descrA,
int nnzA,
const cuDoubleComplex* csrSortedValA,
const int* csrSortedRowPtrA,
const int* csrSortedColIndA,
const cuDoubleComplex* beta,
const cusparseMatDescr_t descrB,
int nnzB,
const cuDoubleComplex* csrSortedValB,
const int* csrSortedRowPtrB,
const int* csrSortedColIndB,
const cusparseMatDescr_t descrC,
cuDoubleComplex* csrSortedValC,
int* csrSortedRowPtrC,
int* csrSortedColIndC,
void* pBuffer)
此函数执行以下矩阵-矩阵运算
其中 A、B 和 C 是 \(m \times n\) 稀疏矩阵(由三个数组 csrValA|csrValB|csrValC、csrRowPtrA|csrRowPtrB|csrRowPtrC 和 csrColIndA|csrColIndB|csrcolIndC 分别以 CSR 存储格式定义),并且 \(\alpha\text{~and~}\beta\) 是标量。由于 A 和 B 具有不同的稀疏模式,因此 cuSPARSE 采用两步方法来完成稀疏矩阵 C。在第一步中,用户分配 csrRowPtrC 的 m+1 个元素,并使用函数 cusparseXcsrgeam2Nnz() 来确定 csrRowPtrC 和非零元素的总数。在第二步中,用户从 nnzC(矩阵 C 的非零元素数)中收集 (nnzC=*nnzTotalDevHostPtr) 或 (nnzC=csrRowPtrC(m)-csrRowPtrC(0)),并分别分配 csrValC, csrColIndC 的 nnzC 个元素,然后最终调用函数 cusparse[S|D|C|Z]csrgeam2() 以完成矩阵 C。
一般步骤如下
int baseC, nnzC;
/* alpha, nnzTotalDevHostPtr points to host memory */
size_t BufferSizeInBytes;
char *buffer = NULL;
int *nnzTotalDevHostPtr = &nnzC;
cusparseSetPointerMode(handle, CUSPARSE_POINTER_MODE_HOST);
cudaMalloc((void**)&csrRowPtrC, sizeof(int)*(m+1));
/* prepare buffer */
cusparseScsrgeam2_bufferSizeExt(handle, m, n,
alpha,
descrA, nnzA,
csrValA, csrRowPtrA, csrColIndA,
beta,
descrB, nnzB,
csrValB, csrRowPtrB, csrColIndB,
descrC,
csrValC, csrRowPtrC, csrColIndC
&bufferSizeInBytes
);
cudaMalloc((void**)&buffer, sizeof(char)*bufferSizeInBytes);
cusparseXcsrgeam2Nnz(handle, m, n,
descrA, nnzA, csrRowPtrA, csrColIndA,
descrB, nnzB, csrRowPtrB, csrColIndB,
descrC, csrRowPtrC, nnzTotalDevHostPtr,
buffer);
if (NULL != nnzTotalDevHostPtr){
nnzC = *nnzTotalDevHostPtr;
}else{
cudaMemcpy(&nnzC, csrRowPtrC+m, sizeof(int), cudaMemcpyDeviceToHost);
cudaMemcpy(&baseC, csrRowPtrC, sizeof(int), cudaMemcpyDeviceToHost);
nnzC -= baseC;
}
cudaMalloc((void**)&csrColIndC, sizeof(int)*nnzC);
cudaMalloc((void**)&csrValC, sizeof(float)*nnzC);
cusparseScsrgeam2(handle, m, n,
alpha,
descrA, nnzA,
csrValA, csrRowPtrA, csrColIndA,
beta,
descrB, nnzB,
csrValB, csrRowPtrB, csrColIndB,
descrC,
csrValC, csrRowPtrC, csrColIndC
buffer);
关于 csrgeam2() 的几点说明
cuSPARSE 不支持其他三种组合 NT、TN 和 TT。为了执行这三种组合中的任何一种,用户应使用例程
csr2csc()将 \(A\) | \(B\) 转换为 \(A^{T}\) | \(B^{T}\) 。仅支持
CUSPARSE_MATRIX_TYPE_GENERAL。如果A或B是对称矩阵或 Hermitian 矩阵,则用户必须将矩阵扩展为完整矩阵,并将描述符的MatrixType字段重新配置为CUSPARSE_MATRIX_TYPE_GENERAL。如果已知矩阵
C的稀疏模式,则用户可以跳过对函数cusparseXcsrgeam2Nnz()的调用。例如,假设用户有一个迭代算法,该算法将迭代更新A和B,但保持稀疏模式。用户可以调用函数cusparseXcsrgeam2Nnz()一次以设置C的稀疏模式,然后仅在每次迭代时调用函数cusparse[S|D|C|Z]geam()。指针
alpha和beta必须有效。当
alpha或beta为零时,cuSPARSE 不会将其视为特殊情况。C的稀疏模式与alpha和beta的值无关。如果用户想要 \(C = 0 \times A + 1 \times B^{T}\) ,则csr2csc()比csrgeam2()更好。csrgeam2()与csrgeam()相同,除了csrgeam2()需要显式缓冲区,而csrgeam()在内部分配缓冲区。此函数需要内部分配的临时额外存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
稀疏矩阵 |
|
稀疏矩阵 |
|
<type> 用于乘法的标量。 |
|
矩阵 |
|
稀疏矩阵 |
|
<type> 数组,包含 |
|
整数数组,包含 |
|
整数数组,包含 |
|
<type> 用于乘法的标量。如果 |
|
矩阵 |
|
稀疏矩阵 |
|
<type> 数组,包含 |
|
整数数组,包含 |
|
整数数组,包含 |
|
矩阵 |
输出 (Output)
|
<type> 数组,包含 |
|
整数数组,包含 |
|
整数数组,包含 |
|
设备或主机内存中非零元素的总数。它等于 |
有关返回状态的描述,请参阅 cusparseStatus_t
5.7. cuSPARSE 预处理器参考
本章介绍实现不同预处理器的例程。
5.7.1. 不完全 Cholesky 分解:级别 0 [已弃用]
本节讨论 ic0 的不同算法。
5.7.1.1. cusparse<t>csric02_bufferSize() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseScsric02_bufferSize(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
float* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csric02Info_t info,
int* pBufferSizeInBytes)
cusparseStatus_t
cusparseDcsric02_bufferSize(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
double* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csric02Info_t info,
int* pBufferSizeInBytes)
cusparseStatus_t
cusparseCcsric02_bufferSize(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
cuComplex* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csric02Info_t info,
int* pBufferSizeInBytes)
cusparseStatus_t
cusparseZcsric02_bufferSize(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
cuDoubleComplex* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csric02Info_t info,
int* pBufferSizeInBytes)
此函数返回用于计算不完全 Cholesky 分解且 \(0\) 填充且无旋转的缓冲区大小
A 是一个 \(m \times m\) 稀疏矩阵,它由三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。
缓冲区大小取决于维度 m 和 nnz,即矩阵的非零数。如果用户更改矩阵,则必须再次调用 csric02_bufferSize() 以获得正确的缓冲区大小;否则,可能会发生段错误。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 数组,包含 |
|
整数数组,包含 |
|
整数数组,包含 |
输出 (Output)
|
基于不同算法记录内部状态 |
|
|
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.1.2. cusparse<t>csric02_analysis() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseScsric02_analysis(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const float* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseDcsric02_analysis(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const double* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseCcsric02_analysis(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const cuComplex* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseZcsric02_analysis(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
此函数执行不完全 Cholesky 分解的分析阶段,分解具有 \(0\) 填充且无旋转
A 是一个 \(m \times m\) 稀疏矩阵,它由三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。
此函数需要 csric02_bufferSize() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
函数 csric02_analysis() 报告结构零,并计算存储在不透明结构 info 中的级别信息。级别信息可以在不完全 Cholesky 分解期间提取更多并行性。但是,可以在没有级别信息的情况下完成 csric02()。要禁用级别信息,用户必须将 csric02_analysis() 和 csric02() 的策略指定为 CUSPARSE_SOLVE_POLICY_NO_LEVEL。
即使策略为 CUSPARSE_SOLVE_POLICY_NO_LEVEL,函数 csric02_analysis() 始终报告第一个结构零。用户需要调用 cusparseXcsric02_zeroPivot() 以了解结构零的位置。
如果 csric02_analysis() 报告结构零,用户可以选择是否调用 csric02()。在这种情况下,用户仍然可以调用 csric02(),这将返回与结构零相同位置的数值零。但是结果没有意义。
此函数需要内部分配的临时额外存储空间。
如果流有序内存分配器可用,则该例程支持异步执行。
如果流有序内存分配器可用,则该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 数组,包含 |
|
整数数组,包含 |
|
整数数组,包含 |
|
使用 |
|
支持的策略为 |
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
|
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.1.3. cusparse<t>csric02() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseScsric02(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
float* csrValA_valM,
const int* csrRowPtrA,
const int* csrColIndA,
csric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseDcsric02(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
double* csrValA_valM,
const int* csrRowPtrA,
const int* csrColIndA,
csric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseCcsric02(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
cuComplex* csrValA_valM,
const int* csrRowPtrA,
const int* csrColIndA,
csric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseZcsric02(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
cuDoubleComplex* csrValA_valM,
const int* csrRowPtrA,
const int* csrColIndA,
csric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
此函数执行计算不完全 Cholesky 分解的求解阶段,分解具有 \(0\) 填充且无旋转
此函数需要 csric02_bufferSize() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
尽管可以在没有级别信息的情况下完成 csric02(),但用户仍然需要注意一致性。如果使用策略 CUSPARSE_SOLVE_POLICY_USE_LEVEL 调用 csric02_analysis(),则可以使用或不使用级别运行 csric02()。另一方面,如果使用 CUSPARSE_SOLVE_POLICY_NO_LEVEL 调用 csric02_analysis(),则 csric02() 只能接受 CUSPARSE_SOLVE_POLICY_NO_LEVEL;否则,将返回 CUSPARSE_STATUS_INVALID_VALUE。
函数 csric02() 报告第一个数值零,包括结构零。用户必须调用 cusparseXcsric02_zeroPivot() 以了解数值零的位置。
函数 csric02() 仅采用矩阵 A 的下三角部分来执行分解。矩阵类型必须为 CUSPARSE_MATRIX_TYPE_GENERAL,填充模式和对角线类型将被忽略,并且严格的上三角部分将被忽略且永远不会被触及。 A 是否为 Hermitian 矩阵无关紧要。换句话说,从 csric02() 的角度来看,A 是 Hermitian 矩阵,并且仅提供下三角部分。
注意
在实践中,正定矩阵可能不具有不完全 Cholesky 分解。据我们所知,只有矩阵 M 可以保证不完全 Cholesky 分解的存在。如果 csric02() 不完全 Cholesky 分解失败并报告数值零,则不完全 Cholesky 分解可能不存在。
例如,假设 A 是一个实数 m times m 矩阵,以下代码解决了预处理系统 M*y = x,其中 M 是 Cholesky 分解 L 及其转置的乘积。
// Suppose that A is m x m sparse matrix represented by CSR format,
// Assumption:
// - handle is already created by cusparseCreate(),
// - (d_csrRowPtr, d_csrColInd, d_csrVal) is CSR of A on device memory,
// - d_x is right hand side vector on device memory,
// - d_y is solution vector on device memory.
// - d_z is intermediate result on device memory.
cusparseMatDescr_t descr_M = 0;
cusparseMatDescr_t descr_L = 0;
csric02Info_t info_M = 0;
csrsv2Info_t info_L = 0;
csrsv2Info_t info_Lt = 0;
int pBufferSize_M;
int pBufferSize_L;
int pBufferSize_Lt;
int pBufferSize;
void *pBuffer = 0;
int structural_zero;
int numerical_zero;
const double alpha = 1.;
const cusparseSolvePolicy_t policy_M = CUSPARSE_SOLVE_POLICY_NO_LEVEL;
const cusparseSolvePolicy_t policy_L = CUSPARSE_SOLVE_POLICY_NO_LEVEL;
const cusparseSolvePolicy_t policy_Lt = CUSPARSE_SOLVE_POLICY_USE_LEVEL;
const cusparseOperation_t trans_L = CUSPARSE_OPERATION_NON_TRANSPOSE;
const cusparseOperation_t trans_Lt = CUSPARSE_OPERATION_TRANSPOSE;
// step 1: create a descriptor which contains
// - matrix M is base-1
// - matrix L is base-1
// - matrix L is lower triangular
// - matrix L has non-unit diagonal
cusparseCreateMatDescr(&descr_M);
cusparseSetMatIndexBase(descr_M, CUSPARSE_INDEX_BASE_ONE);
cusparseSetMatType(descr_M, CUSPARSE_MATRIX_TYPE_GENERAL);
cusparseCreateMatDescr(&descr_L);
cusparseSetMatIndexBase(descr_L, CUSPARSE_INDEX_BASE_ONE);
cusparseSetMatType(descr_L, CUSPARSE_MATRIX_TYPE_GENERAL);
cusparseSetMatFillMode(descr_L, CUSPARSE_FILL_MODE_LOWER);
cusparseSetMatDiagType(descr_L, CUSPARSE_DIAG_TYPE_NON_UNIT);
// step 2: create a empty info structure
// we need one info for csric02 and two info's for csrsv2
cusparseCreateCsric02Info(&info_M);
cusparseCreateCsrsv2Info(&info_L);
cusparseCreateCsrsv2Info(&info_Lt);
// step 3: query how much memory used in csric02 and csrsv2, and allocate the buffer
cusparseDcsric02_bufferSize(handle, m, nnz,
descr_M, d_csrVal, d_csrRowPtr, d_csrColInd, info_M, &bufferSize_M);
cusparseDcsrsv2_bufferSize(handle, trans_L, m, nnz,
descr_L, d_csrVal, d_csrRowPtr, d_csrColInd, info_L, &pBufferSize_L);
cusparseDcsrsv2_bufferSize(handle, trans_Lt, m, nnz,
descr_L, d_csrVal, d_csrRowPtr, d_csrColInd, info_Lt,&pBufferSize_Lt);
pBufferSize = max(bufferSize_M, max(pBufferSize_L, pBufferSize_Lt));
// pBuffer returned by cudaMalloc is automatically aligned to 128 bytes.
cudaMalloc((void**)&pBuffer, pBufferSize);
// step 4: perform analysis of incomplete Cholesky on M
// perform analysis of triangular solve on L
// perform analysis of triangular solve on L'
// The lower triangular part of M has the same sparsity pattern as L, so
// we can do analysis of csric02 and csrsv2 simultaneously.
cusparseDcsric02_analysis(handle, m, nnz, descr_M,
d_csrVal, d_csrRowPtr, d_csrColInd, info_M,
policy_M, pBuffer);
status = cusparseXcsric02_zeroPivot(handle, info_M, &structural_zero);
if (CUSPARSE_STATUS_ZERO_PIVOT == status){
printf("A(%d,%d) is missing\n", structural_zero, structural_zero);
}
cusparseDcsrsv2_analysis(handle, trans_L, m, nnz, descr_L,
d_csrVal, d_csrRowPtr, d_csrColInd,
info_L, policy_L, pBuffer);
cusparseDcsrsv2_analysis(handle, trans_Lt, m, nnz, descr_L,
d_csrVal, d_csrRowPtr, d_csrColInd,
info_Lt, policy_Lt, pBuffer);
// step 5: M = L * L'
cusparseDcsric02(handle, m, nnz, descr_M,
d_csrVal, d_csrRowPtr, d_csrColInd, info_M, policy_M, pBuffer);
status = cusparseXcsric02_zeroPivot(handle, info_M, &numerical_zero);
if (CUSPARSE_STATUS_ZERO_PIVOT == status){
printf("L(%d,%d) is zero\n", numerical_zero, numerical_zero);
}
// step 6: solve L*z = x
cusparseDcsrsv2_solve(handle, trans_L, m, nnz, &alpha, descr_L, // replace with cusparseSpSV
d_csrVal, d_csrRowPtr, d_csrColInd, info_L,
d_x, d_z, policy_L, pBuffer);
// step 7: solve L'*y = z
cusparseDcsrsv2_solve(handle, trans_Lt, m, nnz, &alpha, descr_L, // replace with cusparseSpSV
d_csrVal, d_csrRowPtr, d_csrColInd, info_Lt,
d_z, d_y, policy_Lt, pBuffer);
// step 6: free resources
cudaFree(pBuffer);
cusparseDestroyMatDescr(descr_M);
cusparseDestroyMatDescr(descr_L);
cusparseDestroyCsric02Info(info_M);
cusparseDestroyCsrsv2Info(info_L);
cusparseDestroyCsrsv2Info(info_Lt);
cusparseDestroy(handle);
如果 pBuffer != NULL,则该函数支持以下属性
此函数需要内部分配的临时额外存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 数组,包含 |
|
整数数组,包含 |
|
整数数组,包含 |
|
包含分析阶段收集的信息的结构(应保持不变地传递到求解阶段)。 |
|
支持的策略为 |
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
<type> 矩阵,包含不完全 Cholesky 下三角因子。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.1.4. cusparseXcsric02_zeroPivot() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseXcsric02_zeroPivot(cusparseHandle_t handle,
csric02Info_t info,
int* position)
如果返回的错误代码为 CUSPARSE_STATUS_ZERO_PIVOT,则 position=j 表示 A(j,j) 具有结构零或数值零;否则,position=-1。
position 可以是基于 0 的或基于 1 的,与矩阵相同。
函数 cusparseXcsric02_zeroPivot() 是一个阻塞调用。它调用 cudaDeviceSynchronize() 以确保完成所有先前的内核。
position 可以位于主机内存或设备内存中。用户可以使用 cusparseSetPointerMode() 设置正确的模式。
该例程不需要额外的存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
如果用户已调用 |
输出 (Output)
|
如果没有结构零或数值零,则 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.1.5. cusparse<t>bsric02_bufferSize() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseSbsric02_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
float* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsric02Info_t info,
int* pBufferSizeInBytes)
cusparseStatus_t
cusparseDbsric02_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
double* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsric02Info_t info,
int* pBufferSizeInBytes)
cusparseStatus_t
cusparseCbsric02_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
cuComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsric02Info_t info,
int* pBufferSizeInBytes)
cusparseStatus_t
cusparseZbsric02_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
cuDoubleComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsric02Info_t info,
int* pBufferSizeInBytes)
此函数返回用于计算不完全 Cholesky 分解且 0 填充且无旋转的缓冲区大小
A 是一个 (mb*blockDim)*(mb*blockDim) 稀疏矩阵,它由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 以 BSR 存储格式定义。
缓冲区大小取决于 mb、blockDim 的维度以及矩阵 nnzb 的非零块数。如果用户更改矩阵,则必须再次调用 bsric02_bufferSize() 以获得正确的缓冲区大小;否则,可能会发生段错误。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 矩阵 |
|
包含每个块行的起始位置和最后一个块行的结束位置加一的 |
|
|
|
稀疏矩阵 A 的块维度,大于零。 |
输出 (Output)
|
基于不同算法的内部状态记录。 |
|
在 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.1.6. cusparse<t>bsric02_analysis() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseSbsric02_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
const float* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseDbsric02_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
const double* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseCbsric02_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
const cuComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseZbsric02_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
此函数执行不完全 Cholesky 分解的分析阶段,分解具有 0 填充且无旋转
A 是一个 (mb*blockDim)x(mb*blockDim) 稀疏矩阵,它由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 以 BSR 存储格式定义。BSR 格式的块大小为 blockDim*blockDim,以列优先或行优先方式存储,具体取决于参数 dirA,参数 dirA 为 CUSPARSE_DIRECTION_COLUMN 或 CUSPARSE_DIRECTION_ROW。矩阵类型必须为 CUSPARSE_MATRIX_TYPE_GENERAL,并且填充模式和对角线类型将被忽略。
此函数需要 bsric02_bufferSize90 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
函数 bsric02_analysis() 报告结构零,并计算存储在不透明结构 info 中的级别信息。级别信息可以在不完全 Cholesky 分解期间提取更多并行性。但是,可以在没有级别信息的情况下完成 bsric02()。要禁用级别信息,用户需要将 bsric02[_analysis| ] 的参数 policy 指定为 CUSPARSE_SOLVE_POLICY_NO_LEVEL。
即使当参数 policy 为 CUSPARSE_SOLVE_POLICY_NO_LEVEL 时,函数 bsric02_analysis 始终报告第一个结构零。用户必须调用 cusparseXbsric02_zeroPivot() 才能知道结构零的位置。
如果 bsric02_analysis() 报告结构零,用户可以选择是否调用 bsric02()。在这种情况下,用户仍然可以调用 bsric02(),它将在与结构零相同的位置返回数值零。但是,结果是无意义的。
此函数需要内部分配的临时额外存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 矩阵 |
|
包含每个块行的起始位置和最后一个块行的结束位置加一的 |
|
|
|
稀疏矩阵 A 的块维度;必须大于零。 |
|
使用 |
|
支持的策略为 |
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
结构填充了在分析阶段收集的信息(应在求解阶段保持不变地传递)。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.1.7. cusparse<t>bsric02() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseSbsric02(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
float* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseDbsric02(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
double* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseCbsric02(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
cuComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseZbsric02(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
cuDoubleComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsric02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
此函数执行不完全 Cholesky 分解的求解阶段,其中填充量为 0 且不进行旋转。
A 是一个 (mb*blockDim)x(mb*blockDim) 稀疏矩阵,它由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 以 BSR 存储格式定义。BSR 格式的块大小为 blockDim*blockDim,以列优先或行优先方式存储,具体取决于参数 dirA,参数 dirA 为 CUSPARSE_DIRECTION_COLUMN 或 CUSPARSE_DIRECTION_ROW。矩阵类型必须为 CUSPARSE_MATRIX_TYPE_GENERAL,并且填充模式和对角线类型将被忽略。
此函数需要由 bsric02_bufferSize() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
虽然可以在没有级别信息的情况下完成 bsric02(),但用户必须注意一致性。如果使用策略 CUSPARSE_SOLVE_POLICY_USE_LEVEL 调用 bsric02_analysis(),则 bsric02() 可以使用或不使用级别运行。另一方面,如果使用 CUSPARSE_SOLVE_POLICY_NO_LEVEL 调用 bsric02_analysis(),则 bsric02() 只能接受 CUSPARSE_SOLVE_POLICY_NO_LEVEL;否则,将返回 CUSPARSE_STATUS_INVALID_VALUE。
函数 bsric02() 的行为与 csric02() 相同。也就是说,bsr2csr(bsric02(A)) = csric02(bsr2csr(A))。csric02() 的数值零表示存在某个零 L(j,j)。bsric02() 的数值零表示存在某个不可逆的块 Lj,j)。
函数 bsric02 报告第一个数值零,包括结构零。用户必须调用 cusparseXbsric02_zeroPivot() 才能知道数值零的位置。
bsric02() 函数仅采用矩阵 A 的下三角部分进行分解。严格上三角部分将被忽略且永远不会被触及。A 是否为 Hermitian 矩阵无关紧要。换句话说,从 bsric02() 的角度来看,A 是 Hermitian 矩阵,并且仅提供下三角部分。此外,对角块的对角元素的虚部将被忽略。
例如,假设 A 是一个实数 m×m 矩阵,其中 m=mb*blockDim。以下代码求解预处理系统 M*y = x,其中 M 是 Cholesky 分解 L 及其转置的乘积。
// Suppose that A is m x m sparse matrix represented by BSR format,
// The number of block rows/columns is mb, and
// the number of nonzero blocks is nnzb.
// Assumption:
// - handle is already created by cusparseCreate(),
// - (d_bsrRowPtr, d_bsrColInd, d_bsrVal) is BSR of A on device memory,
// - d_x is right hand side vector on device memory,
// - d_y is solution vector on device memory.
// - d_z is intermediate result on device memory.
// - d_x, d_y and d_z are of size m.
cusparseMatDescr_t descr_M = 0;
cusparseMatDescr_t descr_L = 0;
bsric02Info_t info_M = 0;
bsrsv2Info_t info_L = 0;
bsrsv2Info_t info_Lt = 0;
int pBufferSize_M;
int pBufferSize_L;
int pBufferSize_Lt;
int pBufferSize;
void *pBuffer = 0;
int structural_zero;
int numerical_zero;
const double alpha = 1.;
const cusparseSolvePolicy_t policy_M = CUSPARSE_SOLVE_POLICY_NO_LEVEL;
const cusparseSolvePolicy_t policy_L = CUSPARSE_SOLVE_POLICY_NO_LEVEL;
const cusparseSolvePolicy_t policy_Lt = CUSPARSE_SOLVE_POLICY_USE_LEVEL;
const cusparseOperation_t trans_L = CUSPARSE_OPERATION_NON_TRANSPOSE;
const cusparseOperation_t trans_Lt = CUSPARSE_OPERATION_TRANSPOSE;
const cusparseDirection_t dir = CUSPARSE_DIRECTION_COLUMN;
// step 1: create a descriptor which contains
// - matrix M is base-1
// - matrix L is base-1
// - matrix L is lower triangular
// - matrix L has non-unit diagonal
cusparseCreateMatDescr(&descr_M);
cusparseSetMatIndexBase(descr_M, CUSPARSE_INDEX_BASE_ONE);
cusparseSetMatType(descr_M, CUSPARSE_MATRIX_TYPE_GENERAL);
cusparseCreateMatDescr(&descr_L);
cusparseSetMatIndexBase(descr_L, CUSPARSE_INDEX_BASE_ONE);
cusparseSetMatType(descr_L, CUSPARSE_MATRIX_TYPE_GENERAL);
cusparseSetMatFillMode(descr_L, CUSPARSE_FILL_MODE_LOWER);
cusparseSetMatDiagType(descr_L, CUSPARSE_DIAG_TYPE_NON_UNIT);
// step 2: create a empty info structure
// we need one info for bsric02 and two info's for bsrsv2
cusparseCreateBsric02Info(&info_M);
cusparseCreateBsrsv2Info(&info_L);
cusparseCreateBsrsv2Info(&info_Lt);
// step 3: query how much memory used in bsric02 and bsrsv2, and allocate the buffer
cusparseDbsric02_bufferSize(handle, dir, mb, nnzb,
descr_M, d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, info_M, &bufferSize_M);
cusparseDbsrsv2_bufferSize(handle, dir, trans_L, mb, nnzb,
descr_L, d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, info_L, &pBufferSize_L);
cusparseDbsrsv2_bufferSize(handle, dir, trans_Lt, mb, nnzb,
descr_L, d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, info_Lt, &pBufferSize_Lt);
pBufferSize = max(bufferSize_M, max(pBufferSize_L, pBufferSize_Lt));
// pBuffer returned by cudaMalloc is automatically aligned to 128 bytes.
cudaMalloc((void**)&pBuffer, pBufferSize);
// step 4: perform analysis of incomplete Cholesky on M
// perform analysis of triangular solve on L
// perform analysis of triangular solve on L'
// The lower triangular part of M has the same sparsity pattern as L, so
// we can do analysis of bsric02 and bsrsv2 simultaneously.
cusparseDbsric02_analysis(handle, dir, mb, nnzb, descr_M,
d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, info_M,
policy_M, pBuffer);
status = cusparseXbsric02_zeroPivot(handle, info_M, &structural_zero);
if (CUSPARSE_STATUS_ZERO_PIVOT == status){
printf("A(%d,%d) is missing\n", structural_zero, structural_zero);
}
cusparseDbsrsv2_analysis(handle, dir, trans_L, mb, nnzb, descr_L,
d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim,
info_L, policy_L, pBuffer);
cusparseDbsrsv2_analysis(handle, dir, trans_Lt, mb, nnzb, descr_L,
d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim,
info_Lt, policy_Lt, pBuffer);
// step 5: M = L * L'
cusparseDbsric02_solve(handle, dir, mb, nnzb, descr_M,
d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, info_M, policy_M, pBuffer);
status = cusparseXbsric02_zeroPivot(handle, info_M, &numerical_zero);
if (CUSPARSE_STATUS_ZERO_PIVOT == status){
printf("L(%d,%d) is not positive definite\n", numerical_zero, numerical_zero);
}
// step 6: solve L*z = x
cusparseDbsrsv2_solve(handle, dir, trans_L, mb, nnzb, &alpha, descr_L,
d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, info_L,
d_x, d_z, policy_L, pBuffer);
// step 7: solve L'*y = z
cusparseDbsrsv2_solve(handle, dir, trans_Lt, mb, nnzb, &alpha, descr_L,
d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, info_Lt,
d_z, d_y, policy_Lt, pBuffer);
// step 6: free resources
cudaFree(pBuffer);
cusparseDestroyMatDescr(descr_M);
cusparseDestroyMatDescr(descr_L);
cusparseDestroyBsric02Info(info_M);
cusparseDestroyBsrsv2Info(info_L);
cusparseDestroyBsrsv2Info(info_Lt);
cusparseDestroy(handle);
如果 pBuffer != NULL,则该函数支持以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 矩阵 |
|
包含每个块行的起始位置和最后一个块行的结束位置加一的 |
|
|
|
稀疏矩阵 A 的块维度,大于零。 |
|
包含分析阶段收集的信息的结构(应保持不变地传递到求解阶段)。 |
|
支持的策略为 |
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
<type> 矩阵,包含不完全 Cholesky 下三角因子。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.1.8. cusparseXbsric02_zeroPivot() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseXbsric02_zeroPivot(cusparseHandle_t handle,
bsric02Info_t info,
int* position)
如果返回的错误代码是 CUSPARSE_STATUS_ZERO_PIVOT,则 position=j 表示 A(j,j) 具有结构零或数值零(该块不是正定的)。否则 position=-1。
position 可以是基于 0 的或基于 1 的,与矩阵相同。
函数 cusparseXbsric02_zeroPivot() 是一个阻塞调用。它调用 cudaDeviceSynchronize() 以确保所有先前的内核都已完成。
position 可以在主机内存或设备内存中。用户可以使用 cusparseSetPointerMode() 设置正确的模式。
该例程不需要额外的存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
如果用户已经调用了 |
输出 (Output)
|
如果没有结构零或数值零,则 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.2. 不完全 LU 分解:级别 0 [已弃用]
本节讨论 ilu0 的不同算法。
5.7.2.1. cusparse<t>csrilu02_numericBoost() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseScsrilu02_numericBoost(cusparseHandle_t handle,
csrilu02Info_t info,
int enable_boost,
double* tol,
float* boost_val)
cusparseStatus_t
cusparseDcsrilu02_numericBoost(cusparseHandle_t handle,
csrilu02Info_t info,
int enable_boost,
double* tol,
double* boost_val)
cusparseStatus_t
cusparseCcsrilu02_numericBoost(cusparseHandle_t handle,
csrilu02Info_t info,
int enable_boost,
double* tol,
cuComplex* boost_val)
cusparseStatus_t
cusparseZcsrilu02_numericBoost(cusparseHandle_t handle,
csrilu02Info_t info,
int enable_boost,
double* tol,
cuDoubleComplex* boost_val)
用户可以使用提升值来替换不完全 LU 分解中的数值。tol 用于确定数值零,而 boost_val 用于替换数值零。行为如下:
如果 tol >= fabs(A(j,j)),则 A(j,j)=boost_val。
要启用提升值,用户必须在调用 csrilu02() 之前将参数 enable_boost 设置为 1。要禁用提升值,用户可以再次调用 csrilu02_numericBoost(),并将参数 enable_boost=0。
如果 enable_boost=0,则 tol 和 boost_val 将被忽略。
tol 和 boost_val 都可以位于主机内存或设备内存中。用户可以使用 cusparseSetPointerMode() 设置正确的模式。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄 |
|
使用 |
|
通过 |
|
确定数值零的容差 |
|
用于替换数值零的提升值 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.2.2. cusparse<t>csrilu02_bufferSize() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseScsrilu02_bufferSize(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
float* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csrilu02Info_t info,
int* pBufferSizeInBytes)
cusparseStatus_t
cusparseDcsrilu02_bufferSize(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
double* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csrilu02Info_t info,
int* pBufferSizeInBytes)
cusparseStatus_t
cusparseCcsrilu02_bufferSize(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
cuComplex* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csrilu02Info_t info,
int* pBufferSizeInBytes)
cusparseStatus_t
cusparseZcsrilu02_bufferSize(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
cuDoubleComplex* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csrilu02Info_t info,
int* pBufferSizeInBytes)
此函数返回用于计算不完全 LU 分解的缓冲区大小,其中填充量为 \(0\) 且不进行旋转
A 是一个 \(m \times m\) 稀疏矩阵,它由三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。
缓冲区大小取决于维度 m 和 nnz,即矩阵的非零元素数。如果用户更改了矩阵,则必须再次调用 csrilu02_bufferSize() 以获得正确的缓冲区大小;否则,可能会发生段错误。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 数组,包含 |
|
整数数组,包含 |
|
整数数组,包含 |
输出 (Output)
|
基于不同算法记录内部状态 |
|
|
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.2.3. cusparse<t>csrilu02_analysis() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseScsrilu02_analysis(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const float* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseDcsrilu02_analysis(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const double* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseCcsrilu02_analysis(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const cuComplex* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseZcsrilu02_analysis(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
csrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
此函数执行不完全 LU 分解的分析阶段,其中填充量为 \(0\) 且不进行旋转
A 是一个 \(m \times m\) 稀疏矩阵,它由三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。
此函数需要由 csrilu02_bufferSize() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
函数 csrilu02_analysis() 报告结构零,并计算存储在不透明结构 info 中的级别信息。级别信息可以在不完全 LU 分解期间提取更多并行性;但是,可以在没有级别信息的情况下完成 csrilu02()。要禁用级别信息,用户必须将 csrilu02() 的策略指定为 CUSPARSE_SOLVE_POLICY_NO_LEVEL。
如果 csrilu02_analysis() 报告结构零,用户可以选择是否调用 csrilu02()。在这种情况下,用户仍然可以调用 csrilu02(),它将在与结构零相同的位置返回数值零。但是,结果是无意义的。
此函数需要内部分配的临时额外存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 数组,包含 |
|
整数数组,包含 |
|
整数数组,包含 |
|
使用 |
|
支持的策略为 |
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
结构填充了在分析阶段收集的信息(应在求解阶段保持不变地传递)。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.2.4. cusparse<t>csrilu02() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseScsrilu02(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
float* csrValA_valM,
const int* csrRowPtrA,
const int* csrColIndA,
csrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseDcsrilu02(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
double* csrValA_valM,
const int* csrRowPtrA,
const int* csrColIndA,
csrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseCcsrilu02(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
cuComplex* csrValA_valM,
const int* csrRowPtrA,
const int* csrColIndA,
csrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseZcsrilu02(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
cuDoubleComplex* csrValA_valM,
const int* csrRowPtrA,
const int* csrColIndA,
csrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
此函数执行不完全 LU 分解的求解阶段,其中填充量为 \(0\) 且不进行旋转
A 是一个 \(m \times m\) 稀疏矩阵,它由三个数组 csrValA_valM、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。
此函数需要由 csrilu02_bufferSize() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
矩阵类型必须为 CUSPARSE_MATRIX_TYPE_GENERAL。填充模式和对角线类型将被忽略。
虽然可以在没有级别信息的情况下完成 csrilu02(),但用户仍然需要注意一致性。如果使用策略 CUSPARSE_SOLVE_POLICY_USE_LEVEL 调用 csrilu02_analysis(),则 csrilu02() 可以使用或不使用级别运行。另一方面,如果使用 CUSPARSE_SOLVE_POLICY_NO_LEVEL 调用 csrilu02_analysis(),则 csrilu02() 只能接受 CUSPARSE_SOLVE_POLICY_NO_LEVEL;否则,将返回 CUSPARSE_STATUS_INVALID_VALUE。
函数 csrilu02() 报告第一个数值零,包括结构零。用户必须调用 cusparseXcsrilu02_zeroPivot() 才能知道数值零的位置。
例如,假设 A 是一个实数 \(m \times m\) 矩阵,以下代码求解预处理系统 M*y = x,其中 M 是 LU 因子 L 和 U 的乘积。
// Suppose that A is m x m sparse matrix represented by CSR format,
// Assumption:
// - handle is already created by cusparseCreate(),
// - (d_csrRowPtr, d_csrColInd, d_csrVal) is CSR of A on device memory,
// - d_x is right hand side vector on device memory,
// - d_y is solution vector on device memory.
// - d_z is intermediate result on device memory.
cusparseMatDescr_t descr_M = 0;
cusparseMatDescr_t descr_L = 0;
cusparseMatDescr_t descr_U = 0;
csrilu02Info_t info_M = 0;
csrsv2Info_t info_L = 0;
csrsv2Info_t info_U = 0;
int pBufferSize_M;
int pBufferSize_L;
int pBufferSize_U;
int pBufferSize;
void *pBuffer = 0;
int structural_zero;
int numerical_zero;
const double alpha = 1.;
const cusparseSolvePolicy_t policy_M = CUSPARSE_SOLVE_POLICY_NO_LEVEL;
const cusparseSolvePolicy_t policy_L = CUSPARSE_SOLVE_POLICY_NO_LEVEL;
const cusparseSolvePolicy_t policy_U = CUSPARSE_SOLVE_POLICY_USE_LEVEL;
const cusparseOperation_t trans_L = CUSPARSE_OPERATION_NON_TRANSPOSE;
const cusparseOperation_t trans_U = CUSPARSE_OPERATION_NON_TRANSPOSE;
// step 1: create a descriptor which contains
// - matrix M is base-1
// - matrix L is base-1
// - matrix L is lower triangular
// - matrix L has unit diagonal
// - matrix U is base-1
// - matrix U is upper triangular
// - matrix U has non-unit diagonal
cusparseCreateMatDescr(&descr_M);
cusparseSetMatIndexBase(descr_M, CUSPARSE_INDEX_BASE_ONE);
cusparseSetMatType(descr_M, CUSPARSE_MATRIX_TYPE_GENERAL);
cusparseCreateMatDescr(&descr_L);
cusparseSetMatIndexBase(descr_L, CUSPARSE_INDEX_BASE_ONE);
cusparseSetMatType(descr_L, CUSPARSE_MATRIX_TYPE_GENERAL);
cusparseSetMatFillMode(descr_L, CUSPARSE_FILL_MODE_LOWER);
cusparseSetMatDiagType(descr_L, CUSPARSE_DIAG_TYPE_UNIT);
cusparseCreateMatDescr(&descr_U);
cusparseSetMatIndexBase(descr_U, CUSPARSE_INDEX_BASE_ONE);
cusparseSetMatType(descr_U, CUSPARSE_MATRIX_TYPE_GENERAL);
cusparseSetMatFillMode(descr_U, CUSPARSE_FILL_MODE_UPPER);
cusparseSetMatDiagType(descr_U, CUSPARSE_DIAG_TYPE_NON_UNIT);
// step 2: create a empty info structure
// we need one info for csrilu02 and two info's for csrsv2
cusparseCreateCsrilu02Info(&info_M);
cusparseCreateCsrsv2Info(&info_L);
cusparseCreateCsrsv2Info(&info_U);
// step 3: query how much memory used in csrilu02 and csrsv2, and allocate the buffer
cusparseDcsrilu02_bufferSize(handle, m, nnz,
descr_M, d_csrVal, d_csrRowPtr, d_csrColInd, info_M, &pBufferSize_M);
cusparseDcsrsv2_bufferSize(handle, trans_L, m, nnz,
descr_L, d_csrVal, d_csrRowPtr, d_csrColInd, info_L, &pBufferSize_L);
cusparseDcsrsv2_bufferSize(handle, trans_U, m, nnz,
descr_U, d_csrVal, d_csrRowPtr, d_csrColInd, info_U, &pBufferSize_U);
pBufferSize = max(pBufferSize_M, max(pBufferSize_L, pBufferSize_U));
// pBuffer returned by cudaMalloc is automatically aligned to 128 bytes.
cudaMalloc((void**)&pBuffer, pBufferSize);
// step 4: perform analysis of incomplete Cholesky on M
// perform analysis of triangular solve on L
// perform analysis of triangular solve on U
// The lower(upper) triangular part of M has the same sparsity pattern as L(U),
// we can do analysis of csrilu0 and csrsv2 simultaneously.
cusparseDcsrilu02_analysis(handle, m, nnz, descr_M,
d_csrVal, d_csrRowPtr, d_csrColInd, info_M,
policy_M, pBuffer);
status = cusparseXcsrilu02_zeroPivot(handle, info_M, &structural_zero);
if (CUSPARSE_STATUS_ZERO_PIVOT == status){
printf("A(%d,%d) is missing\n", structural_zero, structural_zero);
}
cusparseDcsrsv2_analysis(handle, trans_L, m, nnz, descr_L,
d_csrVal, d_csrRowPtr, d_csrColInd,
info_L, policy_L, pBuffer);
cusparseDcsrsv2_analysis(handle, trans_U, m, nnz, descr_U,
d_csrVal, d_csrRowPtr, d_csrColInd,
info_U, policy_U, pBuffer);
// step 5: M = L * U
cusparseDcsrilu02(handle, m, nnz, descr_M,
d_csrVal, d_csrRowPtr, d_csrColInd, info_M, policy_M, pBuffer);
status = cusparseXcsrilu02_zeroPivot(handle, info_M, &numerical_zero);
if (CUSPARSE_STATUS_ZERO_PIVOT == status){
printf("U(%d,%d) is zero\n", numerical_zero, numerical_zero);
}
// step 6: solve L*z = x
cusparseDcsrsv2_solve(handle, trans_L, m, nnz, &alpha, descr_L, // replace with cusparseSpSV
d_csrVal, d_csrRowPtr, d_csrColInd, info_L,
d_x, d_z, policy_L, pBuffer);
// step 7: solve U*y = z
cusparseDcsrsv2_solve(handle, trans_U, m, nnz, &alpha, descr_U, // replace with cusparseSpSV
d_csrVal, d_csrRowPtr, d_csrColInd, info_U,
d_z, d_y, policy_U, pBuffer);
// step 6: free resources
cudaFree(pBuffer);
cusparseDestroyMatDescr(descr_M);
cusparseDestroyMatDescr(descr_L);
cusparseDestroyMatDescr(descr_U);
cusparseDestroyCsrilu02Info(info_M);
cusparseDestroyCsrsv2Info(info_L);
cusparseDestroyCsrsv2Info(info_U);
cusparseDestroy(handle);
如果 pBuffer != NULL,则该函数支持以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 数组,包含 |
|
整数数组,包含 |
|
整数数组,包含 |
|
包含分析阶段收集的信息的结构(应保持不变地传递到求解阶段)。 |
|
支持的策略为 |
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
<类型> 包含不完全 LU 下三角和上三角因子的矩阵。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.2.5. cusparseXcsrilu02_zeroPivot() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseXcsrilu02_zeroPivot(cusparseHandle_t handle,
csrilu02Info_t info,
int* position)
如果返回的错误代码为 CUSPARSE_STATUS_ZERO_PIVOT,则 position=j 表示 A(j,j) 具有结构零或数值零;否则,position=-1。
position 可以是基于 0 的或基于 1 的,与矩阵相同。
函数 cusparseXcsrilu02_zeroPivot() 是一个阻塞调用。它调用 cudaDeviceSynchronize()` 以确保所有先前的内核都已完成。
position 可以位于主机内存或设备内存中。用户可以使用 cusparseSetPointerMode() 设置正确的模式。
该例程不需要额外的存储空间。
如果流有序内存分配器可用,则该例程支持异步执行。
如果流有序内存分配器可用,则该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
如果用户已经调用了 |
输出 (Output)
|
如果没有结构零或数值零,则 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.2.6. cusparse<t>bsrilu02_numericBoost() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseSbsrilu02_numericBoost(cusparseHandle_t handle,
bsrilu02Info_t info,
int enable_boost,
double* tol,
float* boost_val)
cusparseStatus_t
cusparseDbsrilu02_numericBoost(cusparseHandle_t handle,
bsrilu02Info_t info,
int enable_boost,
double* tol,
double* boost_val)
cusparseStatus_t
cusparseCbsrilu02_numericBoost(cusparseHandle_t handle,
bsrilu02Info_t info,
int enable_boost,
double* tol,
cuComplex* boost_val)
cusparseStatus_t
cusparseZbsrilu02_numericBoost(cusparseHandle_t handle,
bsrilu02Info_t info,
int enable_boost,
double* tol,
cuDoubleComplex* boost_val)
用户可以使用提升值来替换不完全 LU 分解中的数值。参数 tol 用于确定数值零,而 boost_val 用于替换数值零。行为如下:
如果 tol >= fabs(A(j,j)),则将块 A(j,j) 的每个对角线元素重置为 boost_val。
要启用提升值,用户需要在调用 bsrilu02() 之前将参数 enable_boost 设置为 1。要禁用提升值,用户可以调用 bsrilu02_numericBoost(),并将参数 enable_boost=0。
如果 enable_boost=0,则 tol 和 boost_val 将被忽略。
tol 和 boost_val 都可以位于主机内存或设备内存中。用户可以使用 cusparseSetPointerMode() 设置正确的模式。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
使用 |
|
通过设置 |
|
确定数值零的容差。 |
|
用于替换数值零的提升值。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.2.7. cusparse<t>bsrilu02_bufferSize() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseSbsrilu02_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
float *bsrValA,
const int *bsrRowPtrA,
const int *bsrColIndA,
int blockDim,
bsrilu02Info_t info,
int *pBufferSizeInBytes);
cusparseStatus_t
cusparseDbsrilu02_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
double *bsrValA,
const int *bsrRowPtrA,
const int *bsrColIndA,
int blockDim,
bsrilu02Info_t info,
int *pBufferSizeInBytes);
cusparseStatus_t
cusparseCbsrilu02_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
cuComplex *bsrValA,
const int *bsrRowPtrA,
const int *bsrColIndA,
int blockDim,
bsrilu02Info_t info,
int *pBufferSizeInBytes);
cusparseStatus_t
cusparseZbsrilu02_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
cuDoubleComplex *bsrValA,
const int *bsrRowPtrA,
const int *bsrColIndA,
int blockDim,
bsrilu02Info_t info,
int *pBufferSizeInBytes);
此函数返回用于计算不完全 LU 分解的缓冲区大小,其中填充量为 0 且不进行旋转。
A 是一个 (mb*blockDim)x(mb*blockDim) 稀疏矩阵,它由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 以 BSR 存储格式定义。
缓冲区大小取决于 mb、blockDim 的维度以及矩阵 nnzb 的非零块数。如果用户更改了矩阵,则必须再次调用 bsrilu02_bufferSize() 以获得正确的缓冲区大小;否则,可能会发生段错误。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 矩阵 |
|
包含每个块行的起始位置和最后一个块行的结束位置加一的 |
|
|
|
稀疏矩阵 A 的块维度,大于零。 |
输出 (Output)
|
基于不同算法的内部状态记录。 |
|
|
返回状态
|
操作成功完成。 |
|
库未初始化。 |
|
资源无法分配。 |
|
传递了无效参数 ( |
|
该设备仅支持计算能力 2.0 及更高版本。 |
|
内部操作失败。 |
|
不支持的矩阵类型。 |
5.7.2.8. cusparse<t>bsrilu02_analysis() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseSbsrilu02_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
float* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseDbsrilu02_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
double* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseCbsrilu02_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
cuComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseZbsrilu02_analysis(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descrA,
cuDoubleComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
此函数执行不完全 LU 分解的分析阶段,其中填充量为 0 且不进行旋转。
\(A \approx LU\) |
A 是一个 (mb*blockDim)×(mb*blockDim) 稀疏矩阵,它由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 以 BSR 存储格式定义。BSR 格式的块大小为 blockDim*blockDim,根据参数 dirA 确定以列优先或行优先存储,dirA 可以是 CUSPARSE_DIRECTION_COLUMN 或 CUSPARSE_DIRECTION_ROW。矩阵类型必须为 CUSPARSE_MATRIX_TYPE_GENERAL,填充模式和对角线类型将被忽略。
此函数需要由 bsrilu02_bufferSize() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
函数 bsrilu02_analysis() 报告结构零,并计算存储在不透明结构 info 中的级别信息。级别信息可以在不完全 LU 分解期间提取更多并行性。但是,可以在没有级别信息的情况下完成 bsrilu02()。要禁用级别信息,用户需要将 bsrilu02[_analysis| ] 的参数 policy 指定为 CUSPARSE_SOLVE_POLICY_NO_LEVEL。
即使参数 policy 为 CUSPARSE_SOLVE_POLICY_NO_LEVEL 时,函数 bsrilu02_analysis() 始终报告第一个结构零。用户必须调用 cusparseXbsrilu02_zeroPivot() 才能知道结构零的位置。
如果 bsrilu02_analysis() 报告结构零,用户可以选择是否调用 bsrilu02()。在这种情况下,用户仍然可以调用 bsrilu02(),它将在与结构零相同的位置返回数值零。但是,结果是无意义的。
此函数需要内部分配的临时额外存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 矩阵 |
|
包含每个块行的起始位置和最后一个块行的结束位置加一的 |
|
|
|
稀疏矩阵 A 的块维度,大于零。 |
|
使用 |
|
支持的策略为 |
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
结构填充了在分析阶段收集的信息(应在求解阶段保持不变地传递) |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.2.9. cusparse<t>bsrilu02() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseSbsrilu02(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descry,
float* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseDbsrilu02(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descry,
double* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseCbsrilu02(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descry,
cuComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
cusparseStatus_t
cusparseZbsrilu02(cusparseHandle_t handle,
cusparseDirection_t dirA,
int mb,
int nnzb,
const cusparseMatDescr_t descry,
cuDoubleComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
bsrilu02Info_t info,
cusparseSolvePolicy_t policy,
void* pBuffer)
此函数执行不完全 LU 分解的求解阶段,其中填充量为 0 且不进行旋转。
A 是一个 (mb*blockDim)×(mb*blockDim) 稀疏矩阵,它由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 以 BSR 存储格式定义。BSR 格式的块大小为 blockDim*blockDim,根据参数 dirA 确定以列优先或行优先存储,dirA 可以是 CUSPARSE_DIRECTION_COLUMN 或 CUSPARSE_DIRECTION_ROW。矩阵类型必须为 CUSPARSE_MATRIX_TYPE_GENERAL,填充模式和对角线类型将被忽略。函数 bsrilu02() 支持任意 blockDim。
此函数需要由 bsrilu02_bufferSize() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
虽然可以在没有级别信息的情况下使用 bsrilu02(),但用户必须注意一致性。如果使用策略 CUSPARSE_SOLVE_POLICY_USE_LEVEL 调用 bsrilu02_analysis(),则 bsrilu02() 可以使用或不使用级别运行。另一方面,如果使用 CUSPARSE_SOLVE_POLICY_NO_LEVEL 调用 bsrilu02_analysis(),则 bsrilu02() 只能接受 CUSPARSE_SOLVE_POLICY_NO_LEVEL;否则,将返回 CUSPARSE_STATUS_INVALID_VALUE。
函数 bsrilu02() 的行为与 csrilu02() 相同。也就是说,bsr2csr(bsrilu02(A)) = csrilu02(bsr2csr(A))。csrilu02() 的数值零表示存在某个零 U(j,j)。bsrilu02() 的数值零表示存在某个不可逆的块 U(j,j)。
函数 bsrilu02 报告第一个数值零,包括结构零。用户必须调用 cusparseXbsrilu02_zeroPivot() 才能知道数值零的位置。
例如,假设 A 是一个实数 m×m 矩阵,其中 m=mb*blockDim。以下代码求解预处理系统 M*y = x,其中 M 是 LU 因子 L 和 U 的乘积。
// Suppose that A is m x m sparse matrix represented by BSR format,
// The number of block rows/columns is mb, and
// the number of nonzero blocks is nnzb.
// Assumption:
// - handle is already created by cusparseCreate(),
// - (d_bsrRowPtr, d_bsrColInd, d_bsrVal) is BSR of A on device memory,
// - d_x is right hand side vector on device memory.
// - d_y is solution vector on device memory.
// - d_z is intermediate result on device memory.
// - d_x, d_y and d_z are of size m.
cusparseMatDescr_t descr_M = 0;
cusparseMatDescr_t descr_L = 0;
cusparseMatDescr_t descr_U = 0;
bsrilu02Info_t info_M = 0;
bsrsv2Info_t info_L = 0;
bsrsv2Info_t info_U = 0;
int pBufferSize_M;
int pBufferSize_L;
int pBufferSize_U;
int pBufferSize;
void *pBuffer = 0;
int structural_zero;
int numerical_zero;
const double alpha = 1.;
const cusparseSolvePolicy_t policy_M = CUSPARSE_SOLVE_POLICY_NO_LEVEL;
const cusparseSolvePolicy_t policy_L = CUSPARSE_SOLVE_POLICY_NO_LEVEL;
const cusparseSolvePolicy_t policy_U = CUSPARSE_SOLVE_POLICY_USE_LEVEL;
const cusparseOperation_t trans_L = CUSPARSE_OPERATION_NON_TRANSPOSE;
const cusparseOperation_t trans_U = CUSPARSE_OPERATION_NON_TRANSPOSE;
const cusparseDirection_t dir = CUSPARSE_DIRECTION_COLUMN;
// step 1: create a descriptor which contains
// - matrix M is base-1
// - matrix L is base-1
// - matrix L is lower triangular
// - matrix L has unit diagonal
// - matrix U is base-1
// - matrix U is upper triangular
// - matrix U has non-unit diagonal
cusparseCreateMatDescr(&descr_M);
cusparseSetMatIndexBase(descr_M, CUSPARSE_INDEX_BASE_ONE);
cusparseSetMatType(descr_M, CUSPARSE_MATRIX_TYPE_GENERAL);
cusparseCreateMatDescr(&descr_L);
cusparseSetMatIndexBase(descr_L, CUSPARSE_INDEX_BASE_ONE);
cusparseSetMatType(descr_L, CUSPARSE_MATRIX_TYPE_GENERAL);
cusparseSetMatFillMode(descr_L, CUSPARSE_FILL_MODE_LOWER);
cusparseSetMatDiagType(descr_L, CUSPARSE_DIAG_TYPE_UNIT);
cusparseCreateMatDescr(&descr_U);
cusparseSetMatIndexBase(descr_U, CUSPARSE_INDEX_BASE_ONE);
cusparseSetMatType(descr_U, CUSPARSE_MATRIX_TYPE_GENERAL);
cusparseSetMatFillMode(descr_U, CUSPARSE_FILL_MODE_UPPER);
cusparseSetMatDiagType(descr_U, CUSPARSE_DIAG_TYPE_NON_UNIT);
// step 2: create a empty info structure
// we need one info for bsrilu02 and two info's for bsrsv2
cusparseCreateBsrilu02Info(&info_M);
cusparseCreateBsrsv2Info(&info_L);
cusparseCreateBsrsv2Info(&info_U);
// step 3: query how much memory used in bsrilu02 and bsrsv2, and allocate the buffer
cusparseDbsrilu02_bufferSize(handle, dir, mb, nnzb,
descr_M, d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, info_M, &pBufferSize_M);
cusparseDbsrsv2_bufferSize(handle, dir, trans_L, mb, nnzb,
descr_L, d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, info_L, &pBufferSize_L);
cusparseDbsrsv2_bufferSize(handle, dir, trans_U, mb, nnzb,
descr_U, d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, info_U, &pBufferSize_U);
pBufferSize = max(pBufferSize_M, max(pBufferSize_L, pBufferSize_U));
// pBuffer returned by cudaMalloc is automatically aligned to 128 bytes.
cudaMalloc((void**)&pBuffer, pBufferSize);
// step 4: perform analysis of incomplete LU factorization on M
// perform analysis of triangular solve on L
// perform analysis of triangular solve on U
// The lower(upper) triangular part of M has the same sparsity pattern as L(U),
// we can do analysis of bsrilu0 and bsrsv2 simultaneously.
cusparseDbsrilu02_analysis(handle, dir, mb, nnzb, descr_M,
d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, info_M,
policy_M, pBuffer);
status = cusparseXbsrilu02_zeroPivot(handle, info_M, &structural_zero);
if (CUSPARSE_STATUS_ZERO_PIVOT == statuss){
printf("A(%d,%d) is missing\n", structural_zero, structural_zero);
}
cusparseDbsrsv2_analysis(handle, dir, trans_L, mb, nnzb, descr_L,
d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim,
info_L, policy_L, pBuffer);
cusparseDbsrsv2_analysis(handle, dir, trans_U, mb, nnzb, descr_U,
d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim,
info_U, policy_U, pBuffer);
// step 5: M = L * U
cusparseDbsrilu02(handle, dir, mb, nnzb, descr_M,
d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, info_M, policy_M, pBuffer);
status = cusparseXbsrilu02_zeroPivot(handle, info_M, &numerical_zero);
if (CUSPARSE_STATUS_ZERO_PIVOT == statuss){
printf("block U(%d,%d) is not invertible\n", numerical_zero, numerical_zero);
}
// step 6: solve L*z = x
cusparseDbsrsv2_solve(handle, dir, trans_L, mb, nnzb, &alpha, descr_L,
d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, info_L,
d_x, d_z, policy_L, pBuffer);
// step 7: solve U*y = z
cusparseDbsrsv2_solve(handle, dir, trans_U, mb, nnzb, &alpha, descr_U,
d_bsrVal, d_bsrRowPtr, d_bsrColInd, blockDim, info_U,
d_z, d_y, policy_U, pBuffer);
// step 6: free resources
cudaFree(pBuffer);
cusparseDestroyMatDescr(descr_M);
cusparseDestroyMatDescr(descr_L);
cusparseDestroyMatDescr(descr_U);
cusparseDestroyBsrilu02Info(info_M);
cusparseDestroyBsrsv2Info(info_L);
cusparseDestroyBsrsv2Info(info_U);
cusparseDestroy(handle);
如果 pBuffer != NULL,则该函数支持以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式: |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 矩阵 |
|
包含每个块行的起始位置和最后一个块行的结束位置加一的 |
|
|
|
稀疏矩阵 A 的块维度;必须大于零。 |
|
包含分析阶段收集的信息的结构(应保持不变地传递到求解阶段)。 |
|
支持的策略为 |
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
<类型> 包含不完全 LU 下三角和上三角因子的矩阵 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.2.10. cusparseXbsrilu02_zeroPivot() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseXbsrilu02_zeroPivot(cusparseHandle_t handle,
bsrilu02Info_t info,
int* position)
如果返回的错误代码是 CUSPARSE_STATUS_ZERO_PIVOT,则 position=j 表示 A(j,j) 具有结构零或数值零(该块不可逆)。否则 position=-1。
position 可以是基于 0 的或基于 1 的,与矩阵相同。
函数 cusparseXbsrilu02_zeroPivot() 是一个阻塞调用。它调用 cudaDeviceSynchronize() 以确保所有先前的内核都已完成。
position 可以位于主机内存或设备内存中。用户可以使用 cusparseSetPointerMode() 设置正确的模式。
该例程不需要额外的存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
如果用户已经调用了 |
输出 (Output)
|
如果没有结构零或数值零,则 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.3. 三对角线求解
本节讨论三对角线求解的不同算法。
5.7.3.1. cusparse<t>gtsv2_buffSizeExt()
cusparseStatus_t
cusparseSgtsv2_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const float* dl,
const float* d,
const float* du,
const float* B,
int ldb,
size_t* bufferSizeInBytes)
cusparseStatus_t
cusparseDgtsv2_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const double* dl,
const double* d,
const double* du,
const double* B,
int ldb,
size_t* bufferSizeInBytes)
cusparseStatus_t
cusparseCgtsv2_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const cuComplex* dl,
const cuComplex* d,
const cuComplex* du,
const cuComplex* B,
int ldb,
size_t* bufferSizeInBytes)
cusparseStatus_t
cusparseZgtsv2_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const cuDoubleComplex* dl,
const cuDoubleComplex* d,
const cuDoubleComplex* du,
const cuDoubleComplex* B,
int ldb,
size_t* bufferSizeInBytes)
此函数返回 gtsv2 中使用的缓冲区大小,该函数计算具有多个右侧的三对角线性系统的解。
这些三对角线性系统中每一个的系数矩阵 A 由三个向量定义,这些向量对应于其下对角线(dl)、主对角线(d)和上对角线(du);右侧存储在稠密矩阵 B 中。请注意,解 X 在退出时会覆盖右侧矩阵 B。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
线性系统的大小(必须 ≥ 3)。 |
|
右侧的数量,矩阵 |
|
<类型> 包含三对角线性系统下对角线的稠密数组。每个下对角线的第一个元素必须为零。 |
|
<类型> 包含三对角线性系统主对角线的稠密数组。 |
|
<类型> 包含三对角线性系统上对角线的稠密数组。每个上对角线的最后一个元素必须为零。 |
|
<类型> 维度为 |
|
|
输出 (Output)
|
|
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.3.2. cusparse<t>gtsv2()
cusparseStatus_t
cusparseSgtsv2(cusparseHandle_t handle,
int m,
int n,
const float* dl,
const float* d,
const float* du,
float* B,
int ldb,
void* pBuffer)
cusparseStatus_t
cusparseDgtsv2(cusparseHandle_t handle,
int m,
int n,
const double* dl,
const double* d,
const double* du,
double* B,
int ldb,
void* pBuffer)
cusparseStatus_t
cusparseCgtsv2(cusparseHandle_t handle,
int m,
int n,
const cuComplex* dl,
const cuComplex* d,
const cuComplex* du,
cuComplex* B,
int ldb,
void* pBuffer)
cusparseStatus_t
cusparseZgtsv2(cusparseHandle_t handle,
int m,
int n,
const cuDoubleComplex* dl,
const cuDoubleComplex* d,
const cuDoubleComplex* du,
cuDoubleComplex* B,
int ldb,
void* pBuffer)
此函数计算具有多个右侧的三对角线性系统的解
这些三对角线性系统中每一个的系数矩阵 A 由三个向量定义,这些向量对应于其下对角线(dl)、主对角线(d)和上对角线(du);右侧存储在稠密矩阵 B 中。请注意,解 X 在退出时会覆盖右侧矩阵 B。
假设 A 的大小为 m 且基数为 1,则 dl、d 和 du 由以下公式定义:
dl(i) := A(i, i-1),对于 i=1,2,...,m
dl 的第一个元素越界(dl(1) := A(1,0)),因此 dl(1) = 0。
d(i) = A(i,i),对于 i=1,2,...,m
du(i) = A(i,i+1),对于 i=1,2,...,m
du 的最后一个元素越界(du(m) := A(m,m+1)),因此 du(m) = 0。
该例程执行旋转,这通常比 cusparse<t>gtsv_nopivot() 或 cusparse<t>gtsv2_nopivot() 产生更准确和更稳定的结果,但会牺牲一些执行时间。
此函数需要由 gtsv2_bufferSizeExt() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
线性系统的大小(必须 ≥ 3)。 |
|
右侧的数量,矩阵 |
|
<类型> 包含三对角线性系统下对角线的稠密数组。每个下对角线的第一个元素必须为零。 |
|
<类型> 包含三对角线性系统主对角线的稠密数组。 |
|
<类型> 包含三对角线性系统上对角线的稠密数组。每个上对角线的最后一个元素必须为零。 |
|
<类型> 维度为 |
|
|
|
用户分配的缓冲区,大小由 |
输出 (Output)
|
<类型> 维度为 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.3.3. cusparse<t>gtsv2_nopivot_bufferSizeExt()
cusparseStatus_t
cusparseSgtsv2_nopivot_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const float* dl,
const float* d,
const float* du,
const float* B,
int ldb,
size_t* bufferSizeInBytes)
cusparseStatus_t
cusparseDgtsv2_nopivot_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const double* dl,
const double* d,
const double* du,
const double* B,
int ldb,
size_t* bufferSizeInBytes)
cusparseStatus_t
cusparseCgtsv2_nopivot_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const cuComplex* dl,
const cuComplex* d,
const cuComplex* du,
const cuComplex* B,
int ldb,
size_t* bufferSizeInBytes)
cusparseStatus_t
cusparseZgtsv2_nopivot_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const cuDoubleComplex* dl,
const cuDoubleComplex* d,
const cuDoubleComplex* du,
const cuDoubleComplex* B,
int ldb,
size_t* bufferSizeInBytes)
此函数返回 gtsv2_nopivot 中使用的缓冲区大小,该函数计算具有多个右侧的三对角线性系统的解。
这些三对角线性系统中每一个的系数矩阵 A 由三个向量定义,这些向量对应于其下对角线(dl)、主对角线(d)和上对角线(du);右侧存储在稠密矩阵 B 中。请注意,解 X 在退出时会覆盖右侧矩阵 B。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
线性系统的大小(必须 ≥ 3)。 |
|
右侧的数量,矩阵 |
|
<类型> 包含三对角线性系统下对角线的稠密数组。每个下对角线的第一个元素必须为零。 |
|
<类型> 包含三对角线性系统主对角线的稠密数组。 |
|
<类型> 包含三对角线性系统上对角线的稠密数组。每个上对角线的最后一个元素必须为零。 |
|
<类型> 维度为 |
|
|
输出 (Output)
|
|
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.3.4. cusparse<t>gtsv2_nopivot()
cusparseStatus_t
cusparseSgtsv2_nopivot(cusparseHandle_t handle,
int m,
int n,
const float* dl,
const float* d,
const float* du,
float* B,
int ldb,
void* pBuffer)
cusparseStatus_t
cusparseDgtsv2_nopivot(cusparseHandle_t handle,
int m,
int n,
const double* dl,
const double* d,
const double* du,
double* B,
int ldb,
void* pBuffer)
cusparseStatus_t
cusparseCgtsv2_nopivot(cusparseHandle_t handle,
int m,
int n,
const cuComplex* dl,
const cuComplex* d,
const cuComplex* du,
cuComplex* B,
int ldb,
void* pBuffer)
cusparseStatus_t
cusparseZgtsv2_nopivot(cusparseHandle_t handle,
int m,
int n,
const cuDoubleComplex* dl,
const cuDoubleComplex* d,
const cuDoubleComplex* du,
cuDoubleComplex* B,
int ldb,
void* pBuffer)
此函数计算具有多个右侧的三对角线性系统的解
这些三对角线性系统中每一个的系数矩阵 A 由三个向量定义,这些向量对应于其下对角线(dl)、主对角线(d)和上对角线(du);右侧存储在稠密矩阵 B 中。请注意,解 X 在退出时会覆盖右侧矩阵 B。
该例程不执行任何旋转,并使用循环约简 (CR) 和并行循环约简 (PCR) 算法的组合来找到解。当 m 是 2 的幂时,它可以获得更好的性能。
此函数需要由 gtsv2_nopivot_bufferSizeExt() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
线性系统的大小(必须 ≥ 3)。 |
|
右侧的数量,矩阵 |
|
<类型> 包含三对角线性系统下对角线的稠密数组。每个下对角线的第一个元素必须为零。 |
|
<类型> 包含三对角线性系统主对角线的稠密数组。 |
|
<类型> 包含三对角线性系统上对角线的稠密数组。每个上对角线的最后一个元素必须为零。 |
|
<类型> 维度为 |
|
|
|
用户分配的缓冲区,大小由 |
输出 (Output)
|
<类型> 维度为 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.4. 批量三对角求解
本节讨论了用于批量三对角求解的不同算法。
5.7.4.1. cusparse<t>gtsv2StridedBatch_bufferSizeExt()
cusparseStatus_t
cusparseSgtsv2StridedBatch_bufferSizeExt(cusparseHandle_t handle,
int m,
const float* dl,
const float* d,
const float* du,
const float* x,
int batchCount,
int batchStride,
size_t* bufferSizeInBytes)
cusparseStatus_t
cusparseDgtsv2StridedBatch_bufferSizeExt(cusparseHandle_t handle,
int m,
const double* dl,
const double* d,
const double* du,
const double* x,
int batchCount,
int batchStride,
size_t* bufferSizeInBytes)
cusparseStatus_t
cusparseCgtsv2StridedBatch_bufferSizeExt(cusparseHandle_t handle,
int m,
const cuComplex* dl,
const cuComplex* d,
const cuComplex* du,
const cuComplex* x,
int batchCount,
int batchStride,
size_t* bufferSizeInBytes)
cusparseStatus_t
cusparseZgtsv2StridedBatch_bufferSizeExt(cusparseHandle_t handle,
int m,
const cuDoubleComplex* dl,
const cuDoubleComplex* d,
const cuDoubleComplex* du,
const cuDoubleComplex* x,
int batchCount,
int batchStride,
size_t* bufferSizeInBytes)
此函数返回 gtsv2StridedBatch 中使用的缓冲区大小,该函数计算 i=0,…,batchCount 的多个三对角线性系统的解
每个三对角线性系统的系数矩阵 A 由三个向量定义,分别对应于其下对角线 (dl)、主对角线 (d) 和上对角线 (du);右侧项存储在稠密矩阵 X 中。请注意,解 Y 在退出时会覆盖右侧项矩阵 X。假定不同的矩阵大小相同,并以固定的 batchStride 存储在内存中。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
线性系统的大小(必须 ≥ 3)。 |
|
<type> 包含三对角线性系统下对角线的稠密数组。与第 i 个线性系统对应的下对角线 \(dl^{(i)}\) 从内存中的位置 |
|
<type> 包含三对角线性系统主对角线的稠密数组。与第 i 个线性系统对应的主对角线 \(d^{(i)}\) 从内存中的位置 |
|
<type> 包含三对角线性系统上对角线的稠密数组。与第 i 个线性系统对应的上对角线 \(du^{(i)}\) 从内存中的位置 |
|
<type> 包含三对角线性系统右侧项的稠密数组。与第 i 个线性系统对应的右侧项 \(x^{(i)}\) 从内存中的位置 |
|
要解的系统数量。 |
|
分隔每个系统向量的步幅(元素数量)(必须至少为 |
输出 (Output)
|
|
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.4.2. cusparse<t>gtsv2StridedBatch()
cusparseStatus_t
cusparseSgtsv2StridedBatch(cusparseHandle_t handle,
int m,
const float* dl,
const float* d,
const float* du,
float* x,
int batchCount,
int batchStride,
void* pBuffer)
cusparseStatus_t
cusparseDgtsv2StridedBatch(cusparseHandle_t handle,
int m,
const double* dl,
const double* d,
const double* du,
double* x,
int batchCount,
int batchStride,
void* pBuffer)
cusparseStatus_t
cusparseCgtsv2StridedBatch(cusparseHandle_t handle,
int m,
const cuComplex* dl,
const cuComplex* d,
const cuComplex* du,
cuComplex* x,
int batchCount,
int batchStride,
void* pBuffer)
cusparseStatus_t
cusparseZgtsv2StridedBatch(cusparseHandle_t handle,
int m,
const cuDoubleComplex* dl,
const cuDoubleComplex* d,
const cuDoubleComplex* du,
cuDoubleComplex* x,
int batchCount,
int batchStride,
void* pBuffer)
此函数计算 i=0,…,batchCount 的多个三对角线性系统的解
每个三对角线性系统的系数矩阵 A 由三个向量定义,分别对应于其下对角线 (dl)、主对角线 (d) 和上对角线 (du);右侧项存储在稠密矩阵 X 中。请注意,解 Y 在退出时会覆盖右侧项矩阵 X。假定不同的矩阵大小相同,并以固定的 batchStride 存储在内存中。
该例程不执行任何旋转,并使用循环约简 (CR) 和并行循环约简 (PCR) 算法的组合来找到解。当 m 是 2 的幂时,它可以获得更好的性能。
此函数需要由 gtsv2StridedBatch_bufferSizeExt() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
线性系统的大小(必须 ≥ 3)。 |
|
<type> 包含三对角线性系统下对角线的稠密数组。与第 i 个线性系统对应的下对角线 \(dl^{(i)}\) 从内存中的位置 |
|
<type> 包含三对角线性系统主对角线的稠密数组。与第 i 个线性系统对应的主对角线 \(d^{(i)}\) 从内存中的位置 |
|
<type> 包含三对角线性系统上对角线的稠密数组。与第 i 个线性系统对应的上对角线 \(du^{(i)}\) 从内存中的位置 |
|
<type> 包含三对角线性系统右侧项的稠密数组。与第 i 个线性系统对应的右侧项 \(x^{(i)}\) 从内存中的位置 |
|
要解的系统数量。 |
|
分隔每个系统向量的步幅(元素数量)(必须至少为 |
|
用户分配的缓冲区,大小由 |
输出 (Output)
|
<type> 包含三对角线性系统解的稠密数组。与第 i 个线性系统对应的解 \(x^{(i)}\) 从内存中的位置 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.4.3. cusparse<t>gtsvInterleavedBatch()
cusparseStatus_t
cusparseSgtsvInterleavedBatch_bufferSizeExt(cusparseHandle_t handle,
int algo,
int m,
const float* dl,
const float* d,
const float* du,
const float* x,
int batchCount,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseDgtsvInterleavedBatch_bufferSizeExt(cusparseHandle_t handle,
int algo,
int m,
const double* dl,
const double* d,
const double* du,
const double* x,
int batchCount,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseCgtsvInterleavedBatch_bufferSizeExt(cusparseHandle_t handle,
int algo,
int m,
const cuComplex* dl,
const cuComplex* d,
const cuComplex* du,
const cuComplex* x,
int batchCount,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseZgtsvInterleavedBatch_bufferSizeExt(cusparseHandle_t handle,
int algo,
int m,
const cuDoubleComplex* dl,
const cuDoubleComplex* d,
const cuDoubleComplex* du,
const cuDoubleComplex* x,
int batchCount,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseSgtsvInterleavedBatch(cusparseHandle_t handle,
int algo,
int m,
float* dl,
float* d,
float* du,
float* x,
int batchCount,
void* pBuffer)
cusparseStatus_t
cusparseDgtsvInterleavedBatch(cusparseHandle_t handle,
int algo,
int m,
double* dl,
double* d,
double* du,
double* x,
int batchCount,
void* pBuffer)
cusparseStatus_t
cusparseCgtsvInterleavedBatch(cusparseHandle_t handle,
int algo,
int m,
cuComplex* dl,
cuComplex* d,
cuComplex* du,
cuComplex* x,
int batchCount,
void* pBuffer)
cusparseStatus_t
cusparseZgtsvInterleavedBatch(cusparseHandle_t handle,
int algo,
int m,
cuDoubleComplex* dl,
cuDoubleComplex* d,
cuDoubleComplex* du,
cuDoubleComplex* x,
int batchCount,
void* pBuffer)
此函数计算 i=0,…,batchCount 的多个三对角线性系统的解
这些三对角线性系统中每一个的系数矩阵 A 由三个向量定义,这些向量对应于其下对角线(dl)、主对角线(d)和上对角线(du);右侧存储在稠密矩阵 B 中。请注意,解 X 在退出时会覆盖右侧矩阵 B。
假设 A 的大小为 m 且基数为 1,则 dl、d 和 du 由以下公式定义:
dl(i) := A(i, i-1),对于 i=1,2,...,m
dl 的第一个元素越界(dl(1) := A(1,0)),因此 dl(1) = 0。
d(i) = A(i,i),对于 i=1,2,...,m
du(i) = A(i,i+1),对于 i=1,2,...,m
du 的最后一个元素越界(du(m) := A(m,m+1)),因此 du(m) = 0。
数据布局与 gtsvStridedBatch 不同,后者将所有矩阵一个接一个地聚合。相反,gtsvInterleavedBatch 以连续方式收集相同元素的不同矩阵。如果将 dl 视为大小为 m-by-batchCount 的二维数组,则 dl(:,j) 存储第 j 个矩阵。gtsvStridedBatch 使用列优先,而 gtsvInterleavedBatch 使用行优先。
该例程提供三种不同的算法,由参数 algo 选择。第一种算法是由 Barcelona Supercomputing Center 提供的 cuThomas。第二种算法是带部分选主元的 LU 分解,最后一种算法是 QR 分解。从稳定性角度来看,cuThomas 在数值上不稳定,因为它没有选主元。带部分选主元的 LU 分解和 QR 分解是稳定的。从性能角度来看,带部分选主元的 LU 分解和 QR 分解比 cuThomas 慢约 10% 到 20%。
此函数需要由 gtsvInterleavedBatch_bufferSizeExt() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
如果用户准备聚合格式,则可以使用 cublasXgeam 获取交错格式。但是,这种转换所花费的时间与求解器本身相当。为了获得最佳性能,用户必须显式准备交错格式。
此函数需要内部分配的临时额外存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
algo = 0:cuThomas(不稳定算法);algo = 1:带选主元的 LU 分解(稳定算法);algo = 2:QR 分解(稳定算法) |
|
线性系统的大小。 |
|
<类型> 包含三对角线性系统下对角线的稠密数组。每个下对角线的第一个元素必须为零。 |
|
<类型> 包含三对角线性系统主对角线的稠密数组。 |
|
<类型> 包含三对角线性系统上对角线的稠密数组。每个上对角线的最后一个元素必须为零。 |
|
<type> 维度为 |
|
用户分配的缓冲区,大小由 |
输出 (Output)
|
<type> 维度为 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.7.5. 批量五对角求解
本节讨论了用于批量五对角求解的不同算法。
5.7.5.1. cusparse<t>gpsvInterleavedBatch()
cusparseStatus_t
cusparseSgpsvInterleavedBatch_bufferSizeExt(cusparseHandle_t handle,
int algo,
int m,
const float* ds,
const float* dl,
const float* d,
const float* du,
const float* dw,
const float* x,
int batchCount,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseDgpsvInterleavedBatch_bufferSizeExt(cusparseHandle_t handle,
int algo,
int m,
const double* ds,
const double* dl,
const double* d,
const double* du,
const double* dw,
const double* x,
int batchCount,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseCgpsvInterleavedBatch_bufferSizeExt(cusparseHandle_t handle,
int algo,
int m,
const cuComplex* ds,
const cuComplex* dl,
const cuComplex* d,
const cuComplex* du,
const cuComplex* dw,
const cuComplex* x,
int batchCount,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseZgpsvInterleavedBatch_bufferSizeExt(cusparseHandle_t handle,
int algo,
int m,
const cuDoubleComplex* ds,
const cuDoubleComplex* dl,
const cuDoubleComplex* d,
const cuDoubleComplex* du,
const cuDoubleComplex* dw,
const cuDoubleComplex* x,
int batchCount,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseSgpsvInterleavedBatch(cusparseHandle_t handle,
int algo,
int m,
float* ds,
float* dl,
float* d,
float* du,
float* dw,
float* x,
int batchCount,
void* pBuffer)
cusparseStatus_t
cusparseDgpsvInterleavedBatch(cusparseHandle_t handle,
int algo,
int m,
double* ds,
double* dl,
double* d,
double* du,
double* dw,
double* x,
int batchCount,
void* pBuffer)
cusparseStatus_t
cusparseCgpsvInterleavedBatch(cusparseHandle_t handle,
int algo,
int m,
cuComplex* ds,
cuComplex* dl,
cuComplex* d,
cuComplex* du,
cuComplex* dw,
cuComplex* x,
int batchCount,
void* pBuffer)
cusparseStatus_t
cusparseZgpsvInterleavedBatch(cusparseHandle_t handle,
int algo,
int m,
cuDoubleComplex* ds,
cuDoubleComplex* dl,
cuDoubleComplex* d,
cuDoubleComplex* du,
cuDoubleComplex* dw,
cuDoubleComplex* x,
int batchCount,
void* pBuffer)
此函数计算 i=0,…,batchCount 的多个五对角线性系统的解
每个五对角线性系统的系数矩阵 A 由五个向量定义,分别对应于其下对角线 (ds, dl)、主对角线 (d) 和上对角线 (du, dw);右侧项存储在稠密矩阵 B 中。请注意,解 X 在退出时会覆盖右侧项矩阵 B。
假设 A 的大小为 m 且从 1 开始索引,ds、dl、d、du 和 dw 由以下公式定义
ds(i) := A(i, i-2) 对于 i=1,2,...,m
ds 的前两个元素越界 (ds(1) := A(1,-1), ds(2) := A(2,0)),因此 ds(1) = 0 且 ds(2) = 0。
dl(i) := A(i, i-1),对于 i=1,2,...,m
dl 的第一个元素越界(dl(1) := A(1,0)),因此 dl(1) = 0。
d(i) = A(i,i),对于 i=1,2,...,m
du(i) = A(i,i+1),对于 i=1,2,...,m
du 的最后一个元素越界(du(m) := A(m,m+1)),因此 du(m) = 0。
dw(i) = A(i,i+2) 对于 i=1,2,...,m
dw 的最后两个元素越界 (dw(m-1) := A(m-1,m+1), dw(m) := A(m,m+2)),因此 dw(m-1) = 0 且 dw(m) = 0。
数据布局与 gtsvStridedBatch 相同。
该例程在数值上是稳定的,因为它使用 QR 分解来求解线性系统。
此函数需要由 gpsvInterleavedBatch_bufferSizeExt() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSPARSE_STATUS_INVALID_VALUE。
如果 pBuffer != NULL,则该函数支持以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
仅支持 algo = 0 (QR) |
|
线性系统的大小。 |
|
<type> 包含五对角线性系统的下对角线(距离对角线 2)的稠密数组。前两个元素必须为零。 |
|
<type> 包含五对角线性系统的下对角线(距离对角线 1)的稠密数组。第一个元素必须为零。 |
|
<type> 包含五对角线性系统主对角线的稠密数组。 |
|
<type> 包含五对角线性系统的上对角线(距离对角线 1)的稠密数组。最后一个元素必须为零。 |
|
<type> 包含五对角线性系统的上对角线(距离对角线 2)的稠密数组。最后两个元素必须为零。 |
|
<type> 维度为 |
|
用户分配的缓冲区,大小由 |
输出 (Output)
|
<type> 维度为 |
有关返回状态的描述,请参阅 cusparseStatus_t。
请访问 cuSPARSE 库示例 - cusparseSgpsvInterleavedBatch 获取代码示例。
5.8. cuSPARSE 重新排序参考
本章介绍了用于操作稀疏矩阵的重新排序例程。
5.8.1. cusparse<t>csrcolor() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseScsrcolor(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const float* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const float* fractionToColor,
int* ncolors,
int* coloring,
int* reordering,
cusparseColorInfo_t info)
cusparseStatus_t
cusparseDcsrcolor(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const double* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const double* fractionToColor,
int* ncolors,
int* coloring,
int* reordering,
cusparseColorInfo_t info)
cusparseStatus_t
cusparseCcsrcolor(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const cuComplex* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const cuComplex* fractionToColor,
int* ncolors,
int* coloring,
int* reordering,
cusparseColorInfo_t info)
cusparseStatus_t
cusparseZcsrcolor(cusparseHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const cuDoubleComplex* fractionToColor,
int* ncolors,
int* coloring,
int* reordering,
cusparseColorInfo_t info)
此函数对与以 CSR 格式存储的矩阵 A 关联的邻接图执行着色。着色是将颜色(整数)分配给节点,以便相邻节点具有不同的颜色。此例程中使用近似着色算法,并在对一定百分比的节点进行着色后停止。其余节点被分配不同的颜色(从先前使用的最后一个整数开始的递增整数序列)。最后两个辅助例程可用于提取生成的颜色数、其分配和关联的重新排序。重新排序使得已被分配相同颜色的节点被重新排序为彼此相邻。
传递给此例程的矩阵 A 必须存储为通用矩阵,并具有对称稀疏模式。如果矩阵是非对称的,用户应将 A+A^T 作为参数传递给此例程。
此函数需要内部分配的临时额外存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 数组,包含 |
|
包含每行起始和最后一行末尾加一的 |
|
整数数组,包含 |
|
要着色的节点比例,应在 [0.0,1.0] 区间内,例如 0.8 表示将对 80% 的节点进行着色。 |
|
包含要传递给着色过程的信息的结构。 |
输出 (Output)
|
使用的不同颜色的数量(最多为矩阵的大小,但可能小得多)。 |
|
生成的着色排列 |
|
生成的重新排序排列(如果为 NULL 则保持不变) |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9. cuSPARSE 格式转换参考
本章介绍了不同稀疏和稠密存储格式之间的转换例程。
coosort、csrsort、cscsort 和 csru2csr 是内部没有 malloc 的排序例程,下表估算了缓冲区大小。
|
|
|
|
|
125M |
|
|
100M |
|
|
‘d’ 为 71M,‘z’ 为 55M |
5.9.1. cusparse<t>bsr2csr() [已弃用]
> 此例程将在未来的主要版本中移除。
cusparseStatus_t
cusparseSbsr2csr(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
const cusparseMatDescr_t descrA,
const float* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
const cusparseMatDescr_t descrC,
float* csrValC,
int* csrRowPtrC,
int* csrColIndC)
cusparseStatus_t
cusparseDbsr2csr(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
const cusparseMatDescr_t descrA,
const double* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
const cusparseMatDescr_t descrC,
double* csrValC,
int* csrRowPtrC,
int* csrColIndC)
cusparseStatus_t
cusparseCbsr2csr(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
const cusparseMatDescr_t descrA,
const cuComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
const cusparseMatDescr_t descrC,
cuComplex* csrValC,
int* csrRowPtrC,
int* csrColIndC)
cusparseStatus_t
cusparseZbsr2csr(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int blockDim,
const cusparseMatDescr_t descrC,
cuDoubleComplex* csrValC,
int* csrRowPtrC,
int* csrColIndC)
此函数将以 BSR 格式(由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 定义)存储的稀疏矩阵转换为以 CSR 格式(由数组 csrValC、csrRowPtrC 和 csrColIndC 定义)存储的稀疏矩阵。
设 m(=mb*blockDim) 为 A 的行数,n(=nb*blockDim) 为 A 的列数,则 A 和 C 是 m*n 稀疏矩阵。A 的 BSR 格式包含 nnzb(=bsrRowPtrA[mb] - bsrRowPtrA[0]) 个非零块,而稀疏矩阵 A 包含 nnz(=nnzb*blockDim*blockDim) 个元素。用户必须为数组 csrRowPtrC、csrColIndC 和 csrValC 分配足够的空间。要求如下
csrRowPtrC 包含 m+1 个元素
csrValC 包含 nnz 个元素
csrColIndC 包含 nnz 个元素
一般步骤如下
// Given BSR format (bsrRowPtrA, bsrcolIndA, bsrValA) and
// blocks of BSR format are stored in column-major order.
cusparseDirection_t dir = CUSPARSE_DIRECTION_COLUMN;
int m = mb*blockDim;
int nnzb = bsrRowPtrA[mb] - bsrRowPtrA[0]; // number of blocks
int nnz = nnzb * blockDim * blockDim; // number of elements
cudaMalloc((void**)&csrRowPtrC, sizeof(int)*(m+1));
cudaMalloc((void**)&csrColIndC, sizeof(int)*nnz);
cudaMalloc((void**)&csrValC, sizeof(float)*nnz);
cusparseSbsr2csr(handle, dir, mb, nb,
descrA,
bsrValA, bsrRowPtrA, bsrColIndA,
blockDim,
descrC,
csrValC, csrRowPtrC, csrColIndC);
该例程不需要额外的存储空间。
如果
blockDim != 1或流有序内存分配器可用,则例程支持异步执行如果
blockDim != 1或流有序内存分配器可用,则例程支持 CUDA 图捕获
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
稀疏矩阵 |
|
稀疏矩阵 |
|
矩阵 |
|
<type> 包含矩阵 |
|
包含矩阵 |
|
包含矩阵 |
|
稀疏矩阵 |
|
矩阵 |
输出 (Output)
|
<type> 包含矩阵 |
|
包含矩阵 |
|
包含矩阵 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.2. cusparse<t>gebsr2gebsc()
cusparseStatus_t
cusparseSgebsr2gebsc_bufferSize(cusparseHandle_t handle,
int mb,
int nb,
int nnzb,
const float* bsrVal,
const int* bsrRowPtr,
const int* bsrColInd,
int rowBlockDim,
int colBlockDim,
int* pBufferSize)
cusparseStatus_t
cusparseDgebsr2gebsc_bufferSize(cusparseHandle_t handle,
int mb,
int nb,
int nnzb,
const double* bsrVal,
const int* bsrRowPtr,
const int* bsrColInd,
int rowBlockDim,
int colBlockDim,
int* pBufferSize)
cusparseStatus_t
cusparseCgebsr2gebsc_bufferSize(cusparseHandle_t handle,
int mb,
int nb,
int nnzb,
const cuComplex* bsrVal,
const int* bsrRowPtr,
const int* bsrColInd,
int rowBlockDim,
int colBlockDim,
int* pBufferSize)
cusparseStatus_t
cusparseZgebsr2gebsc_bufferSize(cusparseHandle_t handle,
int mb,
int nb,
int nnzb,
const cuDoubleComplex* bsrVal,
const int* bsrRowPtr,
const int* bsrColInd,
int rowBlockDim,
int colBlockDim,
int* pBufferSize)
cusparseStatus_t
cusparseSgebsr2gebsc(cusparseHandle_t handle,
int mb,
int nb,
int nnzb,
const float* bsrVal,
const int* bsrRowPtr,
const int* bsrColInd,
int rowBlockDim,
int colBlockDim,
float* bscVal,
int* bscRowInd,
int* bscColPtr,
cusparseAction_t copyValues,
cusparseIndexBase_t baseIdx,
void* pBuffer)
cusparseStatus_t
cusparseDgebsr2gebsc(cusparseHandle_t handle,
int mb,
int nb,
int nnzb,
const double* bsrVal,
const int* bsrRowPtr,
const int* bsrColInd,
int rowBlockDim,
int colBlockDim,
double* bscVal,
int* bscRowInd,
int* bscColPtr,
cusparseAction_t copyValues,
cusparseIndexBase_t baseIdx,
void* pBuffer)
cusparseStatus_t
cusparseCgebsr2gebsc(cusparseHandle_t handle,
int mb,
int nb,
int nnzb,
const cuComplex* bsrVal,
const int* bsrRowPtr,
const int* bsrColInd,
int rowBlockDim,
int colBlockDim,
cuComplex* bscVal,
int* bscRowInd,
int* bscColPtr,
cusparseAction_t copyValues,
cusparseIndexBase_t baseIdx,
void* pBuffer)
cusparseStatus_t
cusparseZgebsr2gebsc(cusparseHandle_t handle,
int mb,
int nb,
int nnzb,
const cuDoubleComplex* bsrVal,
const int* bsrRowPtr,
const int* bsrColInd,
int rowBlockDim,
int colBlockDim,
cuDoubleComplex* bscVal,
int* bscRowInd,
int* bscColPtr,
cusparseAction_t copyValues,
cusparseIndexBase_t baseIdx,
void* pBuffer)
当大小为 rowBlockDim*colBlockDim 的每个块被视为标量时,此函数可以看作与 csr2csc() 相同。
结果矩阵的稀疏模式也可以看作是原始稀疏矩阵的转置,但块的内存布局不会改变。
用户必须调用 gebsr2gebsc_bufferSize() 来确定 gebsr2gebsc() 所需的缓冲区大小,分配缓冲区,并将缓冲区指针传递给 gebsr2gebsc()。
如果
pBuffer != NULL,则例程不需要额外的存储空间如果流有序内存分配器可用,则该例程支持异步执行。
如果流有序内存分配器可用,则该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
稀疏矩阵 |
|
稀疏矩阵 |
|
矩阵 |
|
<type> 包含矩阵 |
|
包含矩阵 |
|
包含矩阵 |
|
矩阵 |
|
矩阵 |
|
|
|
|
|
包含 |
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
<type> 包含矩阵 |
|
包含矩阵 |
|
包含每个块列起始和最后一个块列末尾加一的 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.3. cusparse<t>gebsr2gebsr() [已弃用]
> 此例程将在未来的主要版本中移除。
cusparseStatus_t
cusparseSgebsr2gebsr_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
int nnzb,
const cusparseMatDescr_t descrA,
const float* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int rowBlockDimA,
int colBlockDimA,
int rowBlockDimC,
int colBlockDimC,
int* pBufferSize)
cusparseStatus_t
cusparseDgebsr2gebsr_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
int nnzb,
const cusparseMatDescr_t descrA,
const double* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int rowBlockDimA,
int colBlockDimA,
int rowBlockDimC,
int colBlockDimC,
int* pBufferSize)
cusparseStatus_t
cusparseCgebsr2gebsr_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
int nnzb,
const cusparseMatDescr_t descrA,
const cuComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int rowBlockDimA,
int colBlockDimA,
int rowBlockDimC,
int colBlockDimC,
int* pBufferSize)
cusparseStatus_t
cusparseZgebsr2gebsr_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
int nnzb,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int rowBlockDimA,
int colBlockDimA,
int rowBlockDimC,
int colBlockDimC,
int* pBufferSize)
cusparseStatus_t
cusparseXgebsr2gebsrNnz(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
int nnzb,
const cusparseMatDescr_t descrA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int rowBlockDimA,
int colBlockDimA,
const cusparseMatDescr_t descrC,
int* bsrRowPtrC,
int rowBlockDimC,
int colBlockDimC,
int* nnzTotalDevHostPtr,
void* pBuffer)
cusparseStatus_t
cusparseSgebsr2gebsr(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
int nnzb,
const cusparseMatDescr_t descrA,
const float* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int rowBlockDimA,
int colBlockDimA,
const cusparseMatDescr_t descrC,
float* bsrValC,
int* bsrRowPtrC,
int* bsrColIndC,
int rowBlockDimC,
int colBlockDimC,
void* pBuffer)
cusparseStatus_t
cusparseDgebsr2gebsr(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
int nnzb,
const cusparseMatDescr_t descrA,
const double* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int rowBlockDimA,
int colBlockDimA,
const cusparseMatDescr_t descrC,
double* bsrValC,
int* bsrRowPtrC,
int* bsrColIndC,
int rowBlockDimC,
int colBlockDimC,
void* pBuffer)
cusparseStatus_t
cusparseCgebsr2gebsr(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
int nnzb,
const cusparseMatDescr_t descrA,
const cuComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int rowBlockDimA,
int colBlockDimA,
const cusparseMatDescr_t descrC,
cuComplex* bsrValC,
int* bsrRowPtrC,
int* bsrColIndC,
int rowBlockDimC,
int colBlockDimC,
void* pBuffer)
cusparseStatus_t
cusparseZgebsr2gebsr(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
int nnzb,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int rowBlockDimA,
int colBlockDimA,
const cusparseMatDescr_t descrC,
cuDoubleComplex* bsrValC,
int* bsrRowPtrC,
int* bsrColIndC,
int rowBlockDimC,
int colBlockDimC,
void* pBuffer)
此函数将以通用 BSR 格式(由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 定义)存储的稀疏矩阵转换为以另一种通用 BSR 格式(由数组 bsrValC、bsrRowPtrC 和 bsrColIndC 定义)存储的稀疏矩阵。
如果 rowBlockDimA=1 且 colBlockDimA=1,则 cusparse[S|D|C|Z]gebsr2gebsr() 与 cusparse[S|D|C|Z]csr2gebsr() 相同。
如果 rowBlockDimC=1 且 colBlockDimC=1,则 cusparse[S|D|C|Z]gebsr2gebsr() 与 cusparse[S|D|C|Z]gebsr2csr() 相同。
A 是一个 m*n 稀疏矩阵,其中 m(=mb*rowBlockDim) 是 A 的行数,n(=nb*colBlockDim) 是 A 的列数。A 的通用 BSR 格式包含 nnzb(=bsrRowPtrA[mb] - bsrRowPtrA[0]) 个非零块。矩阵 C 也是通用 BSR 格式,但块大小不同,为 rowBlockDimC*colBlockDimC。如果 m 不是 rowBlockDimC 的倍数,或者 n 不是 colBlockDimC 的倍数,则会填充零。C 的块行数为 mc(=(m+rowBlockDimC-1)/rowBlockDimC)。C 的块列数为 nc(=(n+colBlockDimC-1)/colBlockDimC)。C 的非零块数为 nnzc。
该实现采用两步方法进行转换。首先,用户分配 mc+1 个元素的 bsrRowPtrC,并使用函数 cusparseXgebsr2gebsrNnz() 来确定矩阵 C 的每个块行的非零块列数。其次,用户从 (nnzc=*nnzTotalDevHostPtr) 或 (nnzc=bsrRowPtrC[mc]-bsrRowPtrC[0]) 获取 nnzc(矩阵 C 的非零块列数),并分配 nnzc*rowBlockDimC*colBlockDimC 个元素的 bsrValC 和 nnzc 个整数的 bsrColIndC。最后,调用函数 cusparse[S|D|C|Z]gebsr2gebsr() 以完成转换。
用户必须调用 gebsr2gebsr_bufferSize() 以了解 gebsr2gebsr() 所需的缓冲区大小,分配缓冲区,并将缓冲区指针传递给 gebsr2gebsr()。
一般步骤如下
// Given general BSR format (bsrRowPtrA, bsrColIndA, bsrValA) and
// blocks of BSR format are stored in column-major order.
cusparseDirection_t dir = CUSPARSE_DIRECTION_COLUMN;
int base, nnzc;
int m = mb*rowBlockDimA;
int n = nb*colBlockDimA;
int mc = (m+rowBlockDimC-1)/rowBlockDimC;
int nc = (n+colBlockDimC-1)/colBlockDimC;
int bufferSize;
void *pBuffer;
cusparseSgebsr2gebsr_bufferSize(handle, dir, mb, nb, nnzb,
descrA, bsrValA, bsrRowPtrA, bsrColIndA,
rowBlockDimA, colBlockDimA,
rowBlockDimC, colBlockDimC,
&bufferSize);
cudaMalloc((void**)&pBuffer, bufferSize);
cudaMalloc((void**)&bsrRowPtrC, sizeof(int)*(mc+1));
// nnzTotalDevHostPtr points to host memory
int *nnzTotalDevHostPtr = &nnzc;
cusparseXgebsr2gebsrNnz(handle, dir, mb, nb, nnzb,
descrA, bsrRowPtrA, bsrColIndA,
rowBlockDimA, colBlockDimA,
descrC, bsrRowPtrC,
rowBlockDimC, colBlockDimC,
nnzTotalDevHostPtr,
pBuffer);
if (NULL != nnzTotalDevHostPtr){
nnzc = *nnzTotalDevHostPtr;
}else{
cudaMemcpy(&nnzc, bsrRowPtrC+mc, sizeof(int), cudaMemcpyDeviceToHost);
cudaMemcpy(&base, bsrRowPtrC, sizeof(int), cudaMemcpyDeviceToHost);
nnzc -= base;
}
cudaMalloc((void**)&bsrColIndC, sizeof(int)*nnzc);
cudaMalloc((void**)&bsrValC, sizeof(float)*(rowBlockDimC*colBlockDimC)*nnzc);
cusparseSgebsr2gebsr(handle, dir, mb, nb, nnzb,
descrA, bsrValA, bsrRowPtrA, bsrColIndA,
rowBlockDimA, colBlockDimA,
descrC, bsrValC, bsrRowPtrC, bsrColIndC,
rowBlockDimC, colBlockDimC,
pBuffer);
如果
pBuffer != NULL,则例程不需要额外的存储空间如果流有序内存分配器可用,则该例程支持异步执行。
这些例程不支持 CUDA 图捕获
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
稀疏矩阵 |
|
稀疏矩阵 |
|
矩阵 |
|
矩阵 |
|
<type> 包含矩阵 |
|
包含矩阵 |
|
包含矩阵 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
包含 |
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
<type> 包含矩阵 |
|
包含矩阵 |
|
包含矩阵 |
|
矩阵 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.4. cusparse<t>gebsr2csr() [已弃用]
> 此例程将在未来的主要版本中移除。
cusparseStatus_t
cusparseSgebsr2csr(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
const cusparseMatDescr_t descrA,
const float* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int rowBlockDim,
int colBlockDim,
const cusparseMatDescr_t descrC,
float* csrValC,
int* csrRowPtrC,
int* csrColIndC)
cusparseStatus_t
cusparseDgebsr2csr(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
const cusparseMatDescr_t descrA,
const double* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int rowBlockDim,
int colBlockDim,
const cusparseMatDescr_t descrC,
double* csrValC,
int* csrRowPtrC,
int* csrColIndC)
cusparseStatus_t
cusparseCgebsr2csr(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
const cusparseMatDescr_t descrA,
const cuComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int rowBlockDim,
int colBlockDim,
const cusparseMatDescr_t descrC,
cuComplex* csrValC,
int* csrRowPtrC,
int* csrColIndC)
cusparseStatus_t
cusparseZgebsr2csr(cusparseHandle_t handle,
cusparseDirection_t dir,
int mb,
int nb,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* bsrValA,
const int* bsrRowPtrA,
const int* bsrColIndA,
int rowBlockDim,
int colBlockDim,
const cusparseMatDescr_t descrC,
cuDoubleComplex* csrValC,
int* csrRowPtrC,
int* csrColIndC)
此函数将以通用 BSR 格式(由三个数组 bsrValA、bsrRowPtrA 和 bsrColIndA 定义)存储的稀疏矩阵转换为以 CSR 格式(由数组 csrValC、csrRowPtrC 和 csrColIndC 定义)存储的稀疏矩阵。
设 m(=mb*rowBlockDim) 为 A 的行数,n(=nb*colBlockDim) 为 A 的列数,则 A 和 C 是 m*n 稀疏矩阵。A 的通用 BSR 格式包含 nnzb(=bsrRowPtrA[mb] - bsrRowPtrA[0]) 个非零块,而稀疏矩阵 A 包含 nnz(=nnzb*rowBlockDim*colBlockDim) 个元素。用户必须为数组 csrRowPtrC、csrColIndC 和 csrValC 分配足够的空间。要求如下
csrRowPtrC 包含 m+1 个元素
csrValC 包含 nnz 个元素
csrColIndC 包含 nnz 个元素
一般步骤如下
// Given general BSR format (bsrRowPtrA, bsrColIndA, bsrValA) and
// blocks of BSR format are stored in column-major order.
cusparseDirection_t dir = CUSPARSE_DIRECTION_COLUMN;
int m = mb*rowBlockDim;
int n = nb*colBlockDim;
int nnzb = bsrRowPtrA[mb] - bsrRowPtrA[0]; // number of blocks
int nnz = nnzb * rowBlockDim * colBlockDim; // number of elements
cudaMalloc((void**)&csrRowPtrC, sizeof(int)*(m+1));
cudaMalloc((void**)&csrColIndC, sizeof(int)*nnz);
cudaMalloc((void**)&csrValC, sizeof(float)*nnz);
cusparseSgebsr2csr(handle, dir, mb, nb,
descrA,
bsrValA, bsrRowPtrA, bsrColIndA,
rowBlockDim, colBlockDim,
descrC,
csrValC, csrRowPtrC, csrColIndC);
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
稀疏矩阵 |
|
稀疏矩阵 |
|
矩阵 |
|
<type> 包含矩阵 |
|
包含矩阵 |
|
包含矩阵 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
输出 (Output)
|
<type> 包含矩阵 |
|
包含矩阵 |
|
包含矩阵 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.5. cusparse<t>csr2gebsr()
cusparseStatus_t
cusparseScsr2gebsr_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dir,
int m,
int n,
const cusparseMatDescr_t descrA,
const float* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
int rowBlockDim,
int colBlockDim,
int* pBufferSize)
cusparseStatus_t
cusparseDcsr2gebsr_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dir,
int m,
int n,
const cusparseMatDescr_t descrA,
const double* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
int rowBlockDim,
int colBlockDim,
int* pBufferSize)
cusparseStatus_t
cusparseCcsr2gebsr_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dir,
int m,
int n,
const cusparseMatDescr_t descrA,
const cuComplex* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
int rowBlockDim,
int colBlockDim,
int* pBufferSize)
cusparseStatus_t
cusparseZcsr2gebsr_bufferSize(cusparseHandle_t handle,
cusparseDirection_t dir,
int m,
int n,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
int rowBlockDim,
int colBlockDim,
int* pBufferSize)
cusparseStatus_t
cusparseXcsr2gebsrNnz(cusparseHandle_t handle,
cusparseDirection_t dir,
int m,
int n,
const cusparseMatDescr_t descrA,
const int* csrRowPtrA,
const int* csrColIndA,
const cusparseMatDescr_t descrC,
int* bsrRowPtrC,
int rowBlockDim,
int colBlockDim,
int* nnzTotalDevHostPtr,
void* pBuffer)
cusparseStatus_t
cusparseScsr2gebsr(cusparseHandle_t handle,
cusparseDirection_t dir,
int m,
int n,
const cusparseMatDescr_t descrA,
const float* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const cusparseMatDescr_t descrC,
float* bsrValC,
int* bsrRowPtrC,
int* bsrColIndC,
int rowBlockDim,
int colBlockDim,
void* pBuffer)
cusparseStatus_t
cusparseDcsr2gebsr(cusparseHandle_t handle,
cusparseDirection_t dir,
int m,
int n,
const cusparseMatDescr_t descrA,
const double* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const cusparseMatDescr_t descrC,
double* bsrValC,
int* bsrRowPtrC,
int* bsrColIndC,
int rowBlockDim,
int colBlockDim,
void* pBuffer)
cusparseStatus_t
cusparseCcsr2gebsr(cusparseHandle_t handle,
cusparseDirection_t dir,
int m,
int n,
const cusparseMatDescr_t descrA,
const cuComplex* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const cusparseMatDescr_t descrC,
cuComplex* bsrValC,
int* bsrRowPtrC,
int* bsrColIndC,
int rowBlockDim,
int colBlockDim,
void* pBuffer)
cusparseStatus_t
cusparseZcsr2gebsr(cusparseHandle_t handle,
cusparseDirection_t dir,
int m,
int n,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const cusparseMatDescr_t descrC,
cuDoubleComplex* bsrValC,
int* bsrRowPtrC,
int* bsrColIndC,
int rowBlockDim,
int colBlockDim,
void* pBuffer)
此函数将 CSR 格式的稀疏矩阵 A(由数组 csrValA、csrRowPtrA 和 csrColIndA 定义)转换为通用 BSR 格式的稀疏矩阵 C(由三个数组 bsrValC、bsrRowPtrC 和 bsrColIndC 定义)。
矩阵 A 是 :math: m times n 稀疏矩阵,矩阵 C 是 (mb*rowBlockDim)*(nb*colBlockDim) 稀疏矩阵,其中 mb(=(m+rowBlockDim-1)/rowBlockDim) 是 C 的块行数,nb(=(n+colBlockDim-1)/colBlockDim) 是 C 的块列数。
矩阵 C 的块大小为 rowBlockDim*colBlockDim。如果 m 不是 rowBlockDim 的倍数,或者 n 不是 colBlockDim 的倍数,则会填充零。
该实现采用两步法进行转换。首先,用户分配 mb+1 个元素的 bsrRowPtrC,并使用函数 cusparseXcsr2gebsrNnz() 来确定每个块行的非零块列数。其次,用户从 (nnzb=*nnzTotalDevHostPtr) 或 (nnzb=bsrRowPtrC[mb]-bsrRowPtrC[0]) 中获取 nnzb (矩阵 C 的非零块列数),并分配 nnzb*rowBlockDim*colBlockDim 个元素的 bsrValC 和 nnzb 个整数的 bsrColIndC。最后,调用函数 cusparse[S|D|C|Z]csr2gebsr() 完成转换。
用户必须通过调用 csr2gebsr_bufferSize() 获取 csr2gebsr() 所需缓冲区的大小,分配缓冲区,并将缓冲区指针传递给 csr2gebsr()。
一般步骤如下
// Given CSR format (csrRowPtrA, csrColIndA, csrValA) and
// blocks of BSR format are stored in column-major order.
cusparseDirection_t dir = CUSPARSE_DIRECTION_COLUMN;
int base, nnzb;
int mb = (m + rowBlockDim-1)/rowBlockDim;
int nb = (n + colBlockDim-1)/colBlockDim;
int bufferSize;
void *pBuffer;
cusparseScsr2gebsr_bufferSize(handle, dir, m, n,
descrA, csrValA, csrRowPtrA, csrColIndA,
rowBlockDim, colBlockDim,
&bufferSize);
cudaMalloc((void**)&pBuffer, bufferSize);
cudaMalloc((void**)&bsrRowPtrC, sizeof(int) *(mb+1));
// nnzTotalDevHostPtr points to host memory
int *nnzTotalDevHostPtr = &nnzb;
cusparseXcsr2gebsrNnz(handle, dir, m, n,
descrA, csrRowPtrA, csrColIndA,
descrC, bsrRowPtrC, rowBlockDim, colBlockDim,
nnzTotalDevHostPtr,
pBuffer);
if (NULL != nnzTotalDevHostPtr){
nnzb = *nnzTotalDevHostPtr;
}else{
cudaMemcpy(&nnzb, bsrRowPtrC+mb, sizeof(int), cudaMemcpyDeviceToHost);
cudaMemcpy(&base, bsrRowPtrC, sizeof(int), cudaMemcpyDeviceToHost);
nnzb -= base;
}
cudaMalloc((void**)&bsrColIndC, sizeof(int)*nnzb);
cudaMalloc((void**)&bsrValC, sizeof(float)*(rowBlockDim*colBlockDim)*nnzb);
cusparseScsr2gebsr(handle, dir, m, n,
descrA,
csrValA, csrRowPtrA, csrColIndA,
descrC,
bsrValC, bsrRowPtrC, bsrColIndC,
rowBlockDim, colBlockDim,
pBuffer);
例程 cusparseXcsr2gebsrNnz() 具有以下属性
该例程不需要额外的存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
例程 cusparse<t>csr2gebsr() 具有以下属性
如果
pBuffer != NULL,则该例程不需要额外的存储空间。该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
块的存储格式,可以是 |
|
稀疏矩阵 |
|
稀疏矩阵 |
|
矩阵 |
|
|
|
整数数组,包含 |
|
整数数组,包含矩阵 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
用户分配的缓冲区,其大小由 |
输出 (Output)
|
|
|
整数数组,包含 |
|
整数数组,包含矩阵 |
|
矩阵 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.6. cusparse<t>coo2csr()
cusparseStatus_t
cusparseXcoo2csr(cusparseHandle_t handle,
const int* cooRowInd,
int nnz,
int m,
int* csrRowPtr,
cusparseIndexBase_t idxBase)
此函数将包含未压缩行索引(对应于 COO 格式)的数组转换为压缩行指针数组(对应于 CSR 格式)。
它也可以用于将包含未压缩列索引(对应于 COO 格式)的数组转换为列指针数组(对应于 CSC 格式)。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
整数数组,包含 |
|
稀疏矩阵的非零元素数量(也是数组 |
|
矩阵 |
|
|
输出 (Output)
|
包含每行起始和最后一行末尾加一的 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.7. cusparse<t>csr2coo()
cusparseStatus_t
cusparseXcsr2coo(cusparseHandle_t handle,
const int* csrRowPtr,
int nnz,
int m,
int* cooRowInd,
cusparseIndexBase_t idxBase)
此函数将包含压缩行指针(对应于 CSR 格式)的数组转换为未压缩行索引数组(对应于 COO 格式)。
它也可以用于将包含压缩列索引(对应于 CSC 格式)的数组转换为未压缩列索引数组(对应于 COO 格式)。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
包含每行起始和最后一行末尾加一的 |
|
稀疏矩阵的非零元素数量(也是数组 |
|
矩阵 |
|
|
输出 (Output)
|
整数数组,包含 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.8. cusparseCsr2cscEx2()
cusparseStatus_t
cusparseCsr2cscEx2_bufferSize(cusparseHandle_t handle,
int m,
int n,
int nnz,
const void* csrVal,
const int* csrRowPtr,
const int* csrColInd,
void* cscVal,
int* cscColPtr,
int* cscRowInd,
cudaDataType valType,
cusparseAction_t copyValues,
cusparseIndexBase_t idxBase,
cusparseCsr2CscAlg_t alg,
size_t* bufferSize)
cusparseStatus_t
cusparseCsr2cscEx2(cusparseHandle_t handle,
int m,
int n,
int nnz,
const void* csrVal,
const int* csrRowPtr,
const int* csrColInd,
void* cscVal,
int* cscColPtr,
int* cscRowInd,
cudaDataType valType,
cusparseAction_t copyValues,
cusparseIndexBase_t idxBase,
cusparseCsr2CscAlg_t alg,
void* buffer)
此函数将 CSR 格式(由三个数组 csrVal、csrRowPtr 和 csrColInd 定义)的稀疏矩阵转换为 CSC 格式(由数组 cscVal、cscRowInd 和 cscColPtr 定义)的稀疏矩阵。结果矩阵也可以看作是原始稀疏矩阵的转置。请注意,此例程也可用于将 CSC 格式的矩阵转换为 CSR 格式的矩阵。
该例程需要额外的存储空间,其大小与非零值 nnz 的数量成正比。它始终提供相同的矩阵输出。
它相对于主机异步执行,并且可能在结果准备就绪之前将控制权返回给主机上的应用程序。
函数 cusparseCsr2cscEx2_bufferSize() 返回 cusparseCsr2cscEx2() 所需的工作空间大小。用户需要分配此大小的缓冲区,并将该缓冲区作为参数提供给 cusparseCsr2cscEx2()。
如果 nnz == 0,则 csrColInd、csrVal、cscVal 和 cscRowInd 可以具有 NULL 值。在这种情况下,cscColPtr 将所有值设置为 idxBase。
如果 m == 0 或 n == 0,则不检查指针,并且例程返回 CUSPARSE_STATUS_SUCCESS。
输入 (Input)
|
cuSPARSE 库上下文的句柄 |
|
CSR 输入矩阵的行数;CSC 输出矩阵的列数 |
|
CSR 输入矩阵的列数;CSC 输出矩阵的行数 |
|
CSR 和 CSC 矩阵的非零元素数量 |
|
CSR 矩阵的大小为 |
|
大小为 |
|
大小为 |
|
CSC 矩阵的大小为 |
|
大小为 |
|
大小为 |
|
CSR 和 CSC 矩阵的值类型 |
|
|
|
索引基 |
|
算法实现。有关可能的值,请参见 |
|
|
|
指向工作空间缓冲区的指针 |
cusparseCsr2cscEx2() 支持以下数据类型
|
|---|
|
|
|
|
|
|
|
|
|
cusparseCsr2cscEx2() 支持以下算法 (cusparseCsr2CscAlg_t)
算法 |
注释 |
|---|---|
|
默认算法 |
操作 |
注释 |
|---|---|
|
计算 CSC 输出矩阵的“结构”(偏移量、行索引) |
|
计算 CSC 输出矩阵的“结构”并复制值 |
cusparseCsr2cscEx2() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
cusparseCsr2cscEx2() 支持以下优化
CUDA 图捕获
硬件内存压缩
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.9. cusparse<t>nnz()
cusparseStatus_t
cusparseSnnz(cusparseHandle_t handle,
cusparseDirection_t dirA,
int m,
int n,
const cusparseMatDescr_t descrA,
const float* A,
int lda,
int* nnzPerRowColumn,
int* nnzTotalDevHostPtr)
cusparseStatus_t
cusparseDnnz(cusparseHandle_t handle,
cusparseDirection_t dirA,
int m,
int n,
const cusparseMatDescr_t descrA,
const double* A,
int lda,
int* nnzPerRowColumn,
int* nnzTotalDevHostPtr)
cusparseStatus_t
cusparseCnnz(cusparseHandle_t handle,
cusparseDirection_t dirA,
int m,
int n,
const cusparseMatDescr_t descrA,
const cuComplex* A,
int lda,
int* nnzPerRowColumn,
int* nnzTotalDevHostPtr)
cusparseStatus_t
cusparseZnnz(cusparseHandle_t handle,
cusparseDirection_t dirA,
int m,
int n,
const cusparseMatDescr_t descrA,
const cuDoubleComplex* A,
int lda,
int* nnzPerRowColumn,
int* nnzTotalDevHostPtr)
此函数计算稠密矩阵中每行或每列的非零元素数量以及非零元素总数。
此函数需要内部分配的临时额外存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
指定是按 |
|
矩阵 |
|
矩阵 |
|
矩阵 |
|
维度为 |
|
稠密数组 |
输出 (Output)
|
大小为 |
|
设备或主机内存中的非零元素总数 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.10. cusparseCreateIdentityPermutation() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseCreateIdentityPermutation(cusparseHandle_t handle,
int n,
int* p);
此函数创建恒等映射。输出参数 p 通过 p = 0:1:(n-1) 表示此类映射。
此函数通常与 coosort、csrsort、cscsort 一起使用。
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
|
|
|
|
cuSPARSE 库上下文的句柄。 |
|
|
映射的大小。 |
输出 (Output)
|
|
|
|
|
维度为 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.11. cusparseXcoosort()
cusparseStatus_t
cusparseXcoosort_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
int nnz,
const int* cooRows,
const int* cooCols,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseXcoosortByRow(cusparseHandle_t handle,
int m,
int n,
int nnz,
int* cooRows,
int* cooCols,
int* P,
void* pBuffer)
cusparseStatus_t
cusparseXcoosortByColumn(cusparseHandle_t handle,
int m,
int n,
int nnz,
int* cooRows,
int* cooCols,
int* P,
void* pBuffer);
此函数对 COO 格式进行排序。排序是就地进行的。用户也可以按行或按列排序。
A 是一个 \(m \times n\) 稀疏矩阵,它由三个数组 cooVals、cooRows 和 cooCols 以 COO 存储格式定义。
矩阵的基索引没有假设。coosort 对有符号整数使用稳定排序,因此 cooRows 或 cooCols 的值可以为负数。
此函数 coosort() 需要 coosort_bufferSizeExt() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。否则,将返回 CUSPARSE_STATUS_INVALID_VALUE。
参数 P 既是输入又是输出。如果用户想要计算排序后的 cooVal,则必须在 coosort() 之前将 P 设置为 0:1:(nnz-1),并且在 coosort() 之后,新的排序后的值数组满足 cooVal_sorted = cooVal(P)。
备注:不使用维度 m 和 n。如果用户不知道 m 或 n 的值,只需传递一个正值即可。如果用户只读取 COO 数组,并且需要稍后确定维度 m 或 n,则通常会发生这种情况。
如果
pBuffer != NULL,则例程不需要额外的存储空间如果流有序内存分配器可用,则该例程支持异步执行。
如果流有序内存分配器可用,则该例程支持 CUDA 图捕获。
输入 (Input)
|
|
|
|
|
cuSPARSE 库上下文的句柄。 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
整数数组,包含 |
|
|
整数数组,包含 |
|
|
整数数组,包含 |
|
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
|
|
|
|
整数数组,包含 |
|
|
整数数组,包含 |
|
|
整数数组,包含 |
|
|
缓冲区的字节数。 |
有关返回状态的描述,请参阅 cusparseStatus_t
请访问 cuSPARSE 库示例 - cusparseXcoosortByRow 以获取代码示例。
5.9.12. cusparseXcsrsort()
cusparseStatus_t
cusparseXcsrsort_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
int nnz,
const int* csrRowPtr,
const int* csrColInd,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseXcsrsort(cusparseHandle_t handle,
int m,
int n,
int nnz,
const cusparseMatDescr_t descrA,
const int* csrRowPtr,
int* csrColInd,
int* P,
void* pBuffer)
此函数对 CSR 格式进行排序。稳定排序是就地进行的。
矩阵类型被隐式视为 CUSPARSE_MATRIX_TYPE_GENERAL。换句话说,任何对称属性都将被忽略。
此函数 csrsort() 需要 csrsort_bufferSizeExt() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。否则,将返回 CUSPARSE_STATUS_INVALID_VALUE。
参数 P 既是输入又是输出。如果用户想要计算排序后的 csrVal,则必须在 csrsort() 之前将 P 设置为 0:1:(nnz-1),并且在 csrsort() 之后,新的排序后的值数组满足 csrVal_sorted = csrVal(P)。
一般步骤如下
// A is a 3x3 sparse matrix, base-0
// | 1 2 3 |
// A = | 4 5 6 |
// | 7 8 9 |
const int m = 3;
const int n = 3;
const int nnz = 9;
csrRowPtr[m+1] = { 0, 3, 6, 9}; // on device
csrColInd[nnz] = { 2, 1, 0, 0, 2,1, 1, 2, 0}; // on device
csrVal[nnz] = { 3, 2, 1, 4, 6, 5, 8, 9, 7}; // on device
size_t pBufferSizeInBytes = 0;
void *pBuffer = NULL;
int *P = NULL;
// step 1: allocate buffer
cusparseXcsrsort_bufferSizeExt(handle, m, n, nnz, csrRowPtr, csrColInd, &pBufferSizeInBytes);
cudaMalloc( &pBuffer, sizeof(char)* pBufferSizeInBytes);
// step 2: setup permutation vector P to identity
cudaMalloc( (void**)&P, sizeof(int)*nnz);
cusparseCreateIdentityPermutation(handle, nnz, P);
// step 3: sort CSR format
cusparseXcsrsort(handle, m, n, nnz, descrA, csrRowPtr, csrColInd, P, pBuffer);
// step 4: gather sorted csrVal
cusparseDgthr(handle, nnz, csrVal, csrVal_sorted, P, CUSPARSE_INDEX_BASE_ZERO);
如果
pBuffer != NULL,则例程不需要额外的存储空间如果流有序内存分配器可用,则该例程支持异步执行。
如果流有序内存分配器可用,则该例程支持 CUDA 图捕获。
输入 (Input)
|
|
|
|
|
cuSPARSE 库上下文的句柄。 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
包含每行起始和最后一行末尾加一的 |
|
|
整数数组,包含 |
|
|
整数数组,包含 |
|
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
|
|
|
|
整数数组,包含 |
|
|
整数数组,包含 |
|
|
缓冲区的字节数。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.13. cusparseXcscsort()
cusparseStatus_t
cusparseXcscsort_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
int nnz,
const int* cscColPtr,
const int* cscRowInd,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseXcscsort(cusparseHandle_t handle,
int m,
int n,
int nnz,
const cusparseMatDescr_t descrA,
const int* cscColPtr,
int* cscRowInd,
int* P,
void* pBuffer)
此函数对 CSC 格式进行排序。稳定排序是就地进行的。
矩阵类型被隐式视为 CUSPARSE_MATRIX_TYPE_GENERAL。换句话说,任何对称属性都将被忽略。
此函数 cscsort() 需要 cscsort_bufferSizeExt() 返回的缓冲区大小。pBuffer 的地址必须是 128 字节的倍数。否则,将返回 CUSPARSE_STATUS_INVALID_VALUE。
参数 P 既是输入又是输出。如果用户想要计算排序后的 cscVal,则必须在 cscsort() 之前将 P 设置为 0:1:(nnz-1),并且在 cscsort() 之后,新的排序后的值数组满足 cscVal_sorted = cscVal(P)。
一般步骤如下
// A is a 3x3 sparse matrix, base-0
// | 1 2 |
// A = | 4 0 |
// | 0 8 |
const int m = 3;
const int n = 2;
const int nnz = 4;
cscColPtr[n+1] = { 0, 2, 4}; // on device
cscRowInd[nnz] = { 1, 0, 2, 0}; // on device
cscVal[nnz] = { 4.0, 1.0, 8.0, 2.0 }; // on device
size_t pBufferSizeInBytes = 0;
void *pBuffer = NULL;
int *P = NULL;
// step 1: allocate buffer
cusparseXcscsort_bufferSizeExt(handle, m, n, nnz, cscColPtr, cscRowInd, &pBufferSizeInBytes);
cudaMalloc( &pBuffer, sizeof(char)* pBufferSizeInBytes);
// step 2: setup permutation vector P to identity
cudaMalloc( (void**)&P, sizeof(int)*nnz);
cusparseCreateIdentityPermutation(handle, nnz, P);
// step 3: sort CSC format
cusparseXcscsort(handle, m, n, nnz, descrA, cscColPtr, cscRowInd, P, pBuffer);
// step 4: gather sorted cscVal
cusparseDgthr(handle, nnz, cscVal, cscVal_sorted, P, CUSPARSE_INDEX_BASE_ZERO);
如果
pBuffer != NULL,则例程不需要额外的存储空间如果流有序内存分配器可用,则该例程支持异步执行。
如果流有序内存分配器可用,则该例程支持 CUDA 图捕获。
输入 (Input)
|
|
|
|
|
cuSPARSE 库上下文的句柄。 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
整数数组,包含 |
|
|
整数数组,包含 |
|
|
整数数组,包含 |
|
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
|
|
|
|
整数数组,包含 |
|
|
整数数组,包含 |
|
|
缓冲区的字节数。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.14. cusparseXcsru2csr() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseCreateCsru2csrInfo(csru2csrInfo_t *info);
cusparseStatus_t
cusparseDestroyCsru2csrInfo(csru2csrInfo_t info);
cusparseStatus_t
cusparseScsru2csr_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
int nnz,
float* csrVal,
const int* csrRowPtr,
int* csrColInd,
csru2csrInfo_t info,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseDcsru2csr_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
int nnz,
double* csrVal,
const int* csrRowPtr,
int* csrColInd,
csru2csrInfo_t info,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseCcsru2csr_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
int nnz,
cuComplex* csrVal,
const int* csrRowPtr,
int* csrColInd,
csru2csrInfo_t info,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseZcsru2csr_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
int nnz,
cuDoubleComplex* csrVal,
const int* csrRowPtr,
int* csrColInd,
csru2csrInfo_t info,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseScsru2csr(cusparseHandle_t handle,
int m,
int n,
int nnz,
const cusparseMatDescr_t descrA,
float* csrVal,
const int* csrRowPtr,
int* csrColInd,
csru2csrInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseDcsru2csr(cusparseHandle_t handle,
int m,
int n,
int nnz,
const cusparseMatDescr_t descrA,
double* csrVal,
const int* csrRowPtr,
int* csrColInd,
csru2csrInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseCcsru2csr(cusparseHandle_t handle,
int m,
int n,
int nnz,
const cusparseMatDescr_t descrA,
cuComplex* csrVal,
const int* csrRowPtr,
int* csrColInd,
csru2csrInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseZcsru2csr(cusparseHandle_t handle,
int m,
int n,
int nnz,
const cusparseMatDescr_t descrA,
cuDoubleComplex* csrVal,
const int* csrRowPtr,
int* csrColInd,
csru2csrInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseScsr2csru(cusparseHandle_t handle,
int m,
int n,
int nnz,
const cusparseMatDescr_t descrA,
float* csrVal,
const int* csrRowPtr,
int* csrColInd,
csru2csrInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseDcsr2csru(cusparseHandle_t handle,
int m,
int n,
int nnz,
const cusparseMatDescr_t descrA,
double* csrVal,
const int* csrRowPtr,
int* csrColInd,
csru2csrInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseCcsr2csru(cusparseHandle_t handle,
int m,
int n,
int nnz,
const cusparseMatDescr_t descrA,
cuComplex* csrVal,
const int* csrRowPtr,
int* csrColInd,
csru2csrInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseZcsr2csru(cusparseHandle_t handle,
int m,
int n,
int nnz,
const cusparseMatDescr_t descrA,
cuDoubleComplex* csrVal,
const int* csrRowPtr,
int* csrColInd,
csru2csrInfo_t info,
void* pBuffer)
此函数将未排序的 CSR 格式转换为 CSR 格式,反之亦然。该操作是就地进行的。
此函数是 csrsort 和 gthr 的包装器。用例是以下场景。
如果用户有一个 CSR 格式的矩阵 A,它是未排序的,并基于此特殊顺序(例如,先对角线,然后下三角,然后上三角)实现自己的代码(可以是 CPU 或 GPU 内核),并且在调用 CUSPARSE 库时想要将其转换为 CSR 格式,然后在他的/她的内核上执行其他操作时将其转换回来。例如,假设用户想要通过以下迭代方案求解线性系统 Ax=b
该代码大量使用 SpMV 和三角求解。假设用户对基于 A 的特殊顺序的 SpMV(稀疏矩阵-向量乘法)进行了内部设计。但是,用户想要使用 cuSPARSE 库进行三角求解器。那么以下代码可以工作
do |
步骤 1:计算残差向量 |
\(r = b - A x^k\) 通过内部 SpMV |
|
步骤 2:B := sort(A),L 是 B 的下三角部分 (仅对 A 排序一次并保留置换向量) |
||
步骤 3:求解 |
\(z = L (-1) * ( b - A x^k )\) 通过 cusparseXcsrsv |
|
步骤 4:添加校正 |
\(x^{k+1} = x^k+z\) |
|
|
步骤 5:A := unsort(B) (使用置换向量返回未排序的 CSR) |
||
直到收敛 |
||
步骤 2 和步骤 5 的要求是
就地操作。
置换向量
P隐藏在不透明结构中。转换例程内部没有
cudaMalloc。相反,用户必须显式提供缓冲区。未排序的 CSR 和排序的 CSR 之间的转换可能需要多次,但该函数仅生成一次置换向量
P。该函数基于
csrsort、gather和scatter操作。
该操作称为 csru2csr,表示未排序的 CSR 到排序的 CSR。我们还提供逆操作,称为 csr2csru。
为了保持置换向量不可见,我们需要一个名为 csru2csrInfo 的不透明结构。然后,使用两个函数 (cusparseCreateCsru2csrInfo, cusparseDestroyCsru2csrInfo) 初始化和销毁不透明结构。
cusparse[S|D|C|Z]csru2csr_bufferSizeExt 返回缓冲区的大小。置换向量 P 也分配在 csru2csrInfo 内部。置换向量的生命周期与 csru2csrInfo 的生命周期相同。
cusparse[S|D|C|Z]csru2csr 执行从未排序的 CSR 到排序的 CSR 的正向转换。第一次调用使用 csrsort 生成置换向量 P,后续调用使用 P 进行转换。
cusparse[S|D|C|Z]csr2csru 执行从排序的 CSR 到未排序的 CSR 的反向转换。P 用于返回未排序的形式。
例程 cusparse<t>csru2csr() 具有以下属性
如果
pBuffer != NULL,则例程不需要额外的存储空间如果流有序内存分配器可用,则该例程支持异步执行。
如果流有序内存分配器可用,则该例程支持 CUDA 图捕获。
如果 pBuffer != NULL,则例程 cusparse<t>csr2csru() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
下表描述了 csr2csru_bufferSizeExt 和 csr2csru 的参数。
输入 (Input)
|
|
|
|
|
cuSPARSE 库上下文的句柄。 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
|
|
|
包含每行起始和最后一行末尾加一的 |
|
|
整数数组,包含 |
|
|
使用 |
|
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
|
|
|
|
|
|
|
整数数组,包含 |
|
|
缓冲区的字节数。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.15. cusparseXpruneDense2csr() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseHpruneDense2csr_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const __half* A,
int lda,
const __half* threshold,
const cusparseMatDescr_t descrC,
const __half* csrValC,
const int* csrRowPtrC,
const int* csrColIndC,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseSpruneDense2csr_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const float* A,
int lda,
const float* threshold,
const cusparseMatDescr_t descrC,
const float* csrValC,
const int* csrRowPtrC,
const int* csrColIndC,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseDpruneDense2csr_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const double* A,
int lda,
const double* threshold,
const cusparseMatDescr_t descrC,
const double* csrValC,
const int* csrRowPtrC,
const int* csrColIndC,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseHpruneDense2csrNnz(cusparseHandle_t handle,
int m,
int n,
const __half* A,
int lda,
const __half* threshold,
const cusparseMatDescr_t descrC,
int* csrRowPtrC,
int* nnzTotalDevHostPtr,
void* pBuffer)
cusparseStatus_t
cusparseSpruneDense2csrNnz(cusparseHandle_t handle,
int m,
int n,
const float* A,
int lda,
const float* threshold,
const cusparseMatDescr_t descrC,
int* csrRowPtrC,
int* nnzTotalDevHostPtr,
void* pBuffer)
cusparseStatus_t
cusparseDpruneDense2csrNnz(cusparseHandle_t handle,
int m,
int n,
const double* A,
int lda,
const double* threshold,
const cusparseMatDescr_t descrC,
int* csrRowPtrC,
int* nnzTotalDevHostPtr,
void* pBuffer)
cusparseStatus_t
cusparseHpruneDense2csr(cusparseHandle_t handle,
int m,
int n,
const __half* A,
int lda,
const __half* threshold,
const cusparseMatDescr_t descrC,
__half* csrValC,
const int* csrRowPtrC,
int* csrColIndC,
void* pBuffer)
cusparseStatus_t
cusparseSpruneDense2csr(cusparseHandle_t handle,
int m,
int n,
const float* A,
int lda,
const float* threshold,
const cusparseMatDescr_t descrC,
float* csrValC,
const int* csrRowPtrC,
int* csrColIndC,
void* pBuffer)
cusparseStatus_t
cusparseDpruneDense2csr(cusparseHandle_t handle,
int m,
int n,
const double* A,
int lda,
const double* threshold,
const cusparseMatDescr_t descrC,
double* csrValC,
const int* csrRowPtrC,
int* csrColIndC,
void* pBuffer)
此函数将稠密矩阵裁剪为 CSR 格式的稀疏矩阵。
给定一个稠密矩阵 A 和一个非负值 threshold,该函数返回一个稀疏矩阵 C,其定义为
该实现采用两步法进行转换。首先,用户分配 m+1 个元素的 csrRowPtrC,并使用函数 pruneDense2csrNnz() 来确定每行的非零列数。其次,用户从 (nnzC=*nnzTotalDevHostPtr) 或 (nnzC=csrRowPtrC[m]-csrRowPtrC[0]) 中获取 nnzC (矩阵 C 的非零元素数量),并分配 nnzC 个元素的 csrValC 和 nnzC 个整数的 csrColIndC。最后,调用函数 pruneDense2csr() 完成转换。
用户必须通过调用 pruneDense2csr_bufferSizeExt() 获取 pruneDense2csr() 所需缓冲区的大小,分配缓冲区,并将缓冲区指针传递给 pruneDense2csr()。
例程 cusparse<t>pruneDense2csrNnz() 具有以下属性
此函数需要内部分配的临时额外存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
例程 cusparse<t>DpruneDense2csr() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
|
|
|
|
cuSPARSE 库上下文的句柄。 |
|
|
矩阵 |
|
|
矩阵 |
|
|
维度为 (lda, n) 的数组。 |
|
|
|
|
|
一个用于删除 A 条目的值。 |
|
|
矩阵 |
|
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
|
|
|
|
矩阵 |
|
|
<type> 矩阵 |
|
|
包含每行起始和最后一行末尾加一的 |
|
|
矩阵 |
|
|
缓冲区的字节数。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.16. cusparseXpruneCsr2csr() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseHpruneCsr2csr_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const __half* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const __half* threshold,
const cusparseMatDescr_t descrC,
const __half* csrValC,
const int* csrRowPtrC,
const int* csrColIndC,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseSpruneCsr2csr_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const float* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const float* threshold,
const cusparseMatDescr_t descrC,
const float* csrValC,
const int* csrRowPtrC,
const int* csrColIndC,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseDpruneCsr2csr_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const double* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const double* threshold,
const cusparseMatDescr_t descrC,
const double* csrValC,
const int* csrRowPtrC,
const int* csrColIndC,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseHpruneCsr2csrNnz(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const __half* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const __half* threshold,
const cusparseMatDescr_t descrC,
int* csrRowPtrC,
int* nnzTotalDevHostPtr,
void* pBuffer)
cusparseStatus_t
cusparseSpruneCsr2csrNnz(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const float* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const float* threshold,
const cusparseMatDescr_t descrC,
int* csrRowPtrC,
int* nnzTotalDevHostPtr,
void* pBuffer)
cusparseStatus_t
cusparseDpruneCsr2csrNnz(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const double* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const double* threshold,
const cusparseMatDescr_t descrC,
int* csrRowPtrC,
int* nnzTotalDevHostPtr,
void* pBuffer)
cusparseStatus_t
cusparseHpruneCsr2csr(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const __half* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const __half* threshold,
const cusparseMatDescr_t descrC,
__half* csrValC,
const int* csrRowPtrC,
int* csrColIndC,
void* pBuffer)
cusparseStatus_t
cusparseSpruneCsr2csr(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const float* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const float* threshold,
const cusparseMatDescr_t descrC,
float* csrValC,
const int* csrRowPtrC,
int* csrColIndC,
void* pBuffer)
cusparseStatus_t
cusparseDpruneCsr2csr(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const double* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
const double* threshold,
const cusparseMatDescr_t descrC,
double* csrValC,
const int* csrRowPtrC,
int* csrColIndC,
void* pBuffer)
此函数将稀疏矩阵裁剪为 CSR 格式的稀疏矩阵。
给定一个稀疏矩阵 A 和一个非负值 threshold,此函数返回一个稀疏矩阵 C,其定义为
该实现采用两步法进行转换。首先,用户分配 m+1 个元素的 csrRowPtrC,并使用函数 pruneCsr2csrNnz() 来确定每行的非零列数。其次,用户从 (nnzC=*nnzTotalDevHostPtr) 或 (nnzC=csrRowPtrC[m]-csrRowPtrC[0]) 获取 nnzC(矩阵 C 的非零数),并分配 nnzC 个元素的 csrValC 和 nnzC 个整数的 csrColIndC。最后,调用函数 pruneCsr2csr() 以完成转换。
用户必须通过调用 pruneCsr2csr_bufferSizeExt() 来获取 pruneCsr2csr() 所需缓冲区的大小,分配缓冲区,并将缓冲区指针传递给 pruneCsr2csr()。
例程 cusparse<t>pruneCsr2csrNnz() 具有以下属性
此函数需要内部分配的临时额外存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
例程 cusparse<t>pruneCsr2csr() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
|
|
|
|
cuSPARSE 库上下文的句柄。 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
<type> 矩阵 |
|
|
包含每行起始和最后一行末尾加一的 |
|
|
矩阵 |
|
|
一个用于删除 A 条目的值。 |
|
|
矩阵 |
|
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
|
|
|
|
矩阵 |
|
|
<type> 矩阵 |
|
|
包含每行起始和最后一行末尾加一的 |
|
|
矩阵 |
|
|
缓冲区的字节数。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.17. cusparseXpruneDense2csrPercentage() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseHpruneDense2csrByPercentage_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const __half* A,
int lda,
float percentage,
const cusparseMatDescr_t descrC,
const __half* csrValC,
const int* csrRowPtrC,
const int* csrColIndC,
pruneInfo_t info,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseSpruneDense2csrByPercentage_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const float* A,
int lda,
float percentage,
const cusparseMatDescr_t descrC,
const float* csrValC,
const int* csrRowPtrC,
const int* csrColIndC,
pruneInfo_t info,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseDpruneDense2csrByPercentage_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
const double* A,
int lda,
float percentage,
const cusparseMatDescr_t descrC,
const double* csrValC,
const int* csrRowPtrC,
const int* csrColIndC,
pruneInfo_t info,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseHpruneDense2csrNnzByPercentage(cusparseHandle_t handle,
int m,
int n,
const __half* A,
int lda,
float percentage,
const cusparseMatDescr_t descrC,
int* csrRowPtrC,
int* nnzTotalDevHostPtr,
pruneInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseSpruneDense2csrNnzByPercentage(cusparseHandle_t handle,
int m,
int n,
const float* A,
int lda,
float percentage,
const cusparseMatDescr_t descrC,
int* csrRowPtrC,
int* nnzTotalDevHostPtr,
pruneInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseDpruneDense2csrNnzByPercentage(cusparseHandle_t handle,
int m,
int n,
const double* A,
int lda,
float percentage,
const cusparseMatDescr_t descrC,
int* csrRowPtrC,
int* nnzTotalDevHostPtr,
pruneInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseHpruneDense2csrByPercentage(cusparseHandle_t handle,
int m,
int n,
const __half* A,
int lda,
float percentage,
const cusparseMatDescr_t descrC,
__half* csrValC,
const int* csrRowPtrC,
int* csrColIndC,
pruneInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseSpruneDense2csrByPercentage(cusparseHandle_t handle,
int m,
int n,
const float* A,
int lda,
float percentage,
const cusparseMatDescr_t descrC,
float* csrValC,
const int* csrRowPtrC,
int* csrColIndC,
pruneInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseDpruneDense2csrByPercentage(cusparseHandle_t handle,
int m,
int n,
const double* A,
int lda,
float percentage,
const cusparseMatDescr_t descrC,
double* csrValC,
const int* csrRowPtrC,
int* csrColIndC,
pruneInfo_t info,
void* pBuffer)
此函数通过百分比将稠密矩阵裁剪为稀疏矩阵。
给定一个稠密矩阵 A 和一个非负值 percentage,此函数通过以下三个步骤计算稀疏矩阵 C
步骤 1:按升序对 A 的绝对值进行排序。
步骤 2:通过参数 percentage 选择阈值
步骤 3:使用参数 threshold 调用 pruneDense2csr()。
该实现采用两步法进行转换。首先,用户分配 m+1 个元素的 csrRowPtrC,并使用函数 pruneDense2csrNnzByPercentage() 来确定每行的非零列数。其次,用户从 (nnzC=*nnzTotalDevHostPtr) 或 (nnzC=csrRowPtrC[m]-csrRowPtrC[0]) 获取 nnzC(矩阵 C 的非零数),并分配 nnzC 个元素的 csrValC 和 nnzC 个整数的 csrColIndC。最后,调用函数 pruneDense2csrByPercentage() 以完成转换。
用户必须通过调用 pruneDense2csrByPercentage_bufferSizeExt() 来获取 pruneDense2csrByPercentage() 所需缓冲区的大小,分配缓冲区,并将缓冲区指针传递给 pruneDense2csrByPercentage()。
备注 1:percentage 的值必须不大于 100。否则,将返回 CUSPARSE_STATUS_INVALID_VALUE。
备注 2:A 的零值不会被忽略。所有条目都会被排序,包括零值。这与 pruneCsr2csrByPercentage() 不同
例程 cusparse<t>pruneDense2csrNnzByPercentage() 具有以下属性
此函数需要内部分配的临时额外存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
例程 cusparse<t>pruneDense2csrByPercentage() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
|
|
|
|
cuSPARSE 库上下文的句柄。 |
|
|
矩阵 |
|
|
矩阵 |
|
|
维度为 (lda, n) 的数组。 |
|
|
|
|
|
percentage <=100 且 percentage >= 0 |
|
|
矩阵 |
|
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
|
|
|
|
矩阵 |
|
|
<type> 矩阵 |
|
|
包含每行起始和最后一行末尾加一的 |
|
|
矩阵 |
|
|
缓冲区的字节数。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.18. cusparseXpruneCsr2csrByPercentage() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseHpruneCsr2csrByPercentage_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const __half* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
float percentage,
const cusparseMatDescr_t descrC,
const __half* csrValC,
const int* csrRowPtrC,
const int* csrColIndC,
pruneInfo_t info,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseSpruneCsr2csrByPercentage_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const float* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
float percentage,
const cusparseMatDescr_t descrC,
const float* csrValC,
const int* csrRowPtrC,
const int* csrColIndC,
pruneInfo_t info,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseDpruneCsr2csrByPercentage_bufferSizeExt(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const double* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
float percentage,
const cusparseMatDescr_t descrC,
const double* csrValC,
const int* csrRowPtrC,
const int* csrColIndC,
pruneInfo_t info,
size_t* pBufferSizeInBytes)
cusparseStatus_t
cusparseHpruneCsr2csrNnzByPercentage(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const __half* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
float percentage,
const cusparseMatDescr_t descrC,
int* csrRowPtrC,
int* nnzTotalDevHostPtr,
pruneInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseSpruneCsr2csrNnzByPercentage(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const float* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
float percentage,
const cusparseMatDescr_t descrC,
int* csrRowPtrC,
int* nnzTotalDevHostPtr,
pruneInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseDpruneCsr2csrNnzByPercentage(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const double* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
float percentage,
const cusparseMatDescr_t descrC,
int* csrRowPtrC,
int* nnzTotalDevHostPtr,
pruneInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseHpruneCsr2csrByPercentage(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const __half* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
float percentage,
const cusparseMatDescr_t descrC,
__half* csrValC,
const int* csrRowPtrC,
int* csrColIndC,
pruneInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseSpruneCsr2csrByPercentage(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const float* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
float percentage,
const cusparseMatDescr_t descrC,
float* csrValC,
const int* csrRowPtrC,
int* csrColIndC,
pruneInfo_t info,
void* pBuffer)
cusparseStatus_t
cusparseDpruneCsr2csrByPercentage(cusparseHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const double* csrValA,
const int* csrRowPtrA,
const int* csrColIndA,
float percentage,
const cusparseMatDescr_t descrC,
double* csrValC,
const int* csrRowPtrC,
int* csrColIndC,
pruneInfo_t info,
void* pBuffer)
此函数通过百分比将稀疏矩阵裁剪为稀疏矩阵。
给定一个稀疏矩阵 A 和一个非负值 percentage,此函数通过以下三个步骤计算稀疏矩阵 C
步骤 1:按升序对 A 的绝对值进行排序
步骤 2:通过参数 percentage 选择阈值
步骤 3:使用参数 threshold 调用 pruneCsr2csr()。
该实现采用两步法进行转换。首先,用户分配 m+1 个元素的 csrRowPtrC,并使用函数 pruneCsr2csrNnzByPercentage() 来确定每行的非零列数。其次,用户从 (nnzC=*nnzTotalDevHostPtr) 或 (nnzC=csrRowPtrC[m]-csrRowPtrC[0]) 获取 nnzC(矩阵 C 的非零数),并分配 nnzC 个元素的 csrValC 和 nnzC 个整数的 csrColIndC。最后,调用函数 pruneCsr2csrByPercentage() 以完成转换。
用户必须通过调用 pruneCsr2csrByPercentage_bufferSizeExt() 来获取 pruneCsr2csrByPercentage() 所需缓冲区的大小,分配缓冲区,并将缓冲区指针传递给 pruneCsr2csrByPercentage()。
备注 1:percentage 的值必须不大于 100。否则,将返回 CUSPARSE_STATUS_INVALID_VALUE。
例程 cusparse<t>pruneCsr2csrNnzByPercentage() 具有以下属性
此函数需要内部分配的临时额外存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
例程 cusparse<t>pruneCsr2csrByPercentage() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程支持 CUDA 图捕获。
输入 (Input)
|
|
|
|
|
cuSPARSE 库上下文的句柄。 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
<type> 矩阵 |
|
|
包含每行起始和最后一行末尾加一的 |
|
|
矩阵 |
|
|
percentage <=100 且 percentage >= 0 |
|
|
矩阵 |
|
|
用户分配的缓冲区;大小由 |
输出 (Output)
|
|
|
|
|
矩阵 |
|
|
<type> 矩阵 |
|
|
包含每行起始位置和最后一行结束位置加一的 |
|
|
矩阵 |
|
|
缓冲区的字节数 |
有关返回状态的描述,请参阅 cusparseStatus_t。
5.9.19. cusparse<t>nnz_compress() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseSnnz_compress(cusparseHandle_t handle,
int m,
const cusparseMatDescr_t descr,
const float* csrValA,
const int* csrRowPtrA,
int* nnzPerRow,
int* nnzC,
float tol)
cusparseStatus_t
cusparseDnnz_compress(cusparseHandle_t handle,
int m,
const cusparseMatDescr_t descr,
const double* csrValA,
const int* csrRowPtrA,
int* nnzPerRow,
int* nnzC,
double tol)
cusparseStatus_t
cusparseCnnz_compress(cusparseHandle_t handle,
int m,
const cusparseMatDescr_t descr,
const cuComplex* csrValA,
const int* csrRowPtrA,
int* nnzPerRow,
int* nnzC,
cuComplex tol)
cusparseStatus_t
cusparseZnnz_compress(cusparseHandle_t handle,
int m,
const cusparseMatDescr_t descr,
const cuDoubleComplex* csrValA,
const int* csrRowPtrA,
int* nnzPerRow,
int* nnzC,
cuDoubleComplex tol)
此函数是将 CSR 格式转换为压缩 CSR 格式的第一步。
给定一个稀疏矩阵 A 和一个非负值阈值,此函数返回稀疏矩阵 C 的 nnzPerRow(每行的非零列数)和 nnzC(非零总数),其定义为
对于 cuComplex 和 cuDoubleComplex 情况,一个关键的假设是此容差以实部给出。例如,tol = 1e-8 + 0*i,我们提取 cureal,即此结构的 x 分量。
此函数需要内部分配的临时额外存储空间。
该例程在流序内存分配器可用时支持异步执行。
该例程在流序内存分配器可用时支持 CUDA 图捕获。
输入 (Input)
|
cuSPARSE 库上下文的句柄。 |
|
矩阵 |
|
矩阵 |
|
CSR 非压缩值数组 |
|
对应的输入非压缩行指针。 |
|
非负容差,用于确定数字是否小于或等于它。 |
输出 (Output)
|
此数组包含每行绝对值大于 tol 的元素数量。 |
|
绝对值大于 tol 的元素总数的主机/设备指针。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6. cuSPARSE 通用 API
cuSPARSE 通用 API 允许以灵活的方式计算最常见的稀疏线性代数运算,例如稀疏矩阵-向量乘法 (SpMV) 和稀疏矩阵-矩阵乘法 (SpMM)。新的 API 具有以下功能和特性
设置矩阵数据布局、批次数和存储格式(例如,CSR、COO 等)。
设置输入/输出/计算数据类型。这也允许混合数据类型计算。
设置稀疏向量/矩阵索引的类型(例如,32 位、64 位)。
选择计算的算法。
为内部操作保证外部设备内存。
提供跨输入矩阵和向量的广泛一致性检查。这包括尺寸、数据类型、布局、允许的操作等的验证。
为向量和矩阵输入提供常量描述符,以支持 const 安全接口并保证 API 不会修改其输入。
6.1. 通用类型参考
本节介绍 cuSPARSE 通用类型参考。
6.1.1. cusparseFormat_t
此类型指示稀疏矩阵的格式。有关其描述,请参见 cuSPARSE 存储格式。
值 |
含义 |
|---|---|
|
矩阵以坐标 (COO) 格式存储,并以结构数组 (SoA) 布局组织 |
|
矩阵以压缩稀疏行 (CSR) 格式存储 |
|
矩阵以压缩稀疏列 (CSC) 格式存储 |
|
矩阵以分块 Ellpack (Blocked-ELL) 格式存储 |
|
矩阵以切片 Ellpack (Sliced-ELL) 格式存储 |
|
矩阵以块稀疏行 (BSR) 格式存储 |
6.1.2. cusparseOrder_t
此类型指示稠密矩阵的内存布局。
值 |
含义 |
|---|---|
|
矩阵以行优先存储 |
|
矩阵以列优先存储 |
6.1.3. cusparseIndexType_t
此类型指示用于表示稀疏矩阵索引的索引类型。
值 |
含义 |
|---|---|
|
32 位有符号整数 [0, 2^31 - 1] |
|
64 位有符号整数 [0, 2^63 - 1] |
6.2. 稠密向量 API
本节介绍用于稠密向量描述符的 cuSPARSE 辅助函数。
有关存储格式的详细描述,请参见 稠密向量格式 部分。
6.2.1. cusparseCreateDnVec()
cusparseStatus_t
cusparseCreateDnVec(cusparseDnVecDescr_t* dnVecDescr,
int64_t size,
void* values,
cudaDataType valueType)
cusparseStatus_t
cusparseCreateConstDnVec(cusparseConstDnVecDescr_t* dnVecDescr,
int64_t size,
const void* values,
cudaDataType valueType)
此函数初始化稠密向量描述符 dnVecDescr。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输出 |
稠密向量描述符 |
|
主机 |
输入 |
稠密向量的大小 |
|
设备 |
输入 |
稠密向量的值。具有 |
|
主机 |
输入 |
枚举器,指定 |
cusparseCreateDnVec() 具有以下约束
values必须与valueType指定的数据类型的大小对齐。有关数据类型的描述,请参阅 cudaDataType_t。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.2.2. cusparseDestroyDnVec()
cusparseStatus_t
cusparseDestroyDnVec(cusparseConstDnVecDescr_t dnVecDescr) // non-const descriptor supported
此函数释放为稠密向量描述符 dnVecDescr 分配的主机内存。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稠密向量描述符 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.2.3. cusparseDnVecGet()
cusparseStatus_t
cusparseDnVecGet(cusparseDnVecDescr_t dnVecDescr,
int64_t* size,
void** values,
cudaDataType* valueType)
cusparseStatus_t
cusparseConstDnVecGet(cusparseConstDnVecDescr_t dnVecDescr,
int64_t* size,
const void** values,
cudaDataType* valueType)
此函数返回稠密向量描述符 dnVecDescr 的字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稠密向量描述符 |
|
主机 |
输出 |
稠密向量的大小 |
|
设备 |
输出 |
稠密向量的值。具有 |
|
主机 |
输出 |
枚举器,指定 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.2.4. cusparseDnVecGetValues()
cusparseStatus_t
cusparseDnVecGetValues(cusparseDnVecDescr_t dnVecDescr,
void** values)
cusparseStatus_t
cusparseConstDnVecGetValues(cusparseConstDnVecDescr_t dnVecDescr,
const void** values)
此函数返回稠密向量描述符 dnVecDescr 的 values 字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稠密向量描述符 |
|
设备 |
输出 |
稠密向量的值 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.2.5. cusparseDnVecSetValues()
cusparseStatus_t
cusparseDnVecSetValues(cusparseDnVecDescr_t dnVecDescr,
void* values)
此函数设置稠密向量描述符 dnVecDescr 的 values 字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稠密向量描述符 |
|
设备 |
输入 |
稠密向量的值。具有 |
cusparseDnVecSetValues() 具有以下约束
values必须与dnVecDescr中指定的数据类型的大小对齐。有关数据类型的描述,请参阅 cudaDataType_t。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.3. 稀疏向量 API
本节介绍用于稀疏向量描述符的 cuSPARSE 辅助函数。
有关存储格式的详细描述,请参见 稀疏向量格式 部分。
6.3.1. cusparseCreateSpVec()
cusparseStatus_t
cusparseCreateSpVec(cusparseSpVecDescr_t* spVecDescr,
int64_t size,
int64_t nnz,
void* indices,
void* values,
cusparseIndexType_t idxType,
cusparseIndexBase_t idxBase,
cudaDataType valueType)
cusparseStatus_t
cusparseCreateConstSpVec(cusparseConstSpVecDescr_t* spVecDescr,
int64_t size,
int64_t nnz,
const void* indices,
const void* values,
cusparseIndexType_t idxType,
cusparseIndexBase_t idxBase,
cudaDataType valueType)
此函数初始化稀疏矩阵描述符 spVecDescr。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输出 |
稀疏向量描述符 |
|
主机 |
输入 |
稀疏向量的大小 |
|
主机 |
输入 |
稀疏向量的非零条目数 |
|
设备 |
输入 |
稀疏向量的索引。具有 |
|
设备 |
输入 |
稀疏向量的值。具有 |
|
主机 |
输入 |
枚举器,指定 |
|
主机 |
输入 |
枚举器,指定 |
|
主机 |
输入 |
枚举器,指定 |
cusparseCreateSpVec() 具有以下约束
indices和values必须分别与idxType和valueType指定的数据类型的大小对齐。有关数据类型的描述,请参阅 cudaDataType_t。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.3.2. cusparseDestroySpVec()
cusparseStatus_t
cusparseDestroySpVec(cusparseConstSpVecDescr_t spVecDescr) // non-const descriptor supported
此函数释放为稀疏向量描述符 spVecDescr 分配的主机内存。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏向量描述符 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.3.3. cusparseSpVecGet()
cusparseStatus_t
cusparseSpVecGet(cusparseSpVecDescr_t spVecDescr,
int64_t* size,
int64_t* nnz,
void** indices,
void** values,
cusparseIndexType_t* idxType,
cusparseIndexBase_t* idxBase,
cudaDataType* valueType)
cusparseStatus_t
cusparseConstSpVecGet(cusparseConstSpVecDescr_t spVecDescr,
int64_t* size,
int64_t* nnz,
const void** indices,
const void** values,
cusparseIndexType_t* idxType,
cusparseIndexBase_t* idxBase,
cudaDataType* valueType)
此函数返回稀疏向量描述符 spVecDescr 的字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏向量描述符 |
|
主机 |
输出 |
稀疏向量的大小 |
|
主机 |
输出 |
稀疏向量的非零条目数 |
|
设备 |
输出 |
稀疏向量的索引。具有 |
|
设备 |
输出 |
稀疏向量的值。具有 |
|
主机 |
输出 |
枚举器,指定 |
|
主机 |
输出 |
枚举器,指定 |
|
主机 |
输出 |
枚举器,指定 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.3.4. cusparseSpVecGetIndexBase()
cusparseStatus_t
cusparseSpVecGetIndexBase(cusparseConstSpVecDescr_t spVecDescr, // non-const descriptor supported
cusparseIndexBase_t* idxBase)
此函数返回稀疏向量描述符 spVecDescr 的 idxBase 字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏向量描述符 |
|
主机 |
输出 |
枚举器,指定 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.3.5. cusparseSpVecGetValues()
cusparseStatus_t
cusparseSpVecGetValues(cusparseSpVecDescr_t spVecDescr,
void** values)
cusparseStatus_t
cusparseConstSpVecGetValues(cusparseConstSpVecDescr_t spVecDescr,
const void** values)
此函数返回稀疏向量描述符 spVecDescr 的 values 字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏向量描述符 |
|
设备 |
输出 |
稀疏向量的值。具有 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.3.6. cusparseSpVecSetValues()
cusparseStatus_t
cusparseSpVecSetValues(cusparseSpVecDescr_t spVecDescr,
void* values)
此函数设置稀疏向量描述符 spVecDescr 的 values 字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏向量描述符 |
|
设备 |
输入 |
稀疏向量的值。具有 |
cusparseDnVecSetValues() 具有以下约束
values必须与spVecDescr中指定的数据类型的大小对齐。有关数据类型的描述,请参阅 cudaDataType_t。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.4. 稠密矩阵 API
本节介绍用于稠密矩阵描述符的 cuSPARSE 辅助函数。
有关存储格式的详细描述,请参见 稠密矩阵格式 部分。
6.4.1. cusparseCreateDnMat()
cusparseStatus_t
cusparseCreateDnMat(cusparseDnMatDescr_t* dnMatDescr,
int64_t rows,
int64_t cols,
int64_t ld,
void* values,
cudaDataType valueType,
cusparseOrder_t order)
cusparseStatus_t
cusparseCreateConstDnMat(cusparseConstDnMatDescr_t* dnMatDescr,
int64_t rows,
int64_t cols,
int64_t ld,
const void* values,
cudaDataType valueType,
cusparseOrder_t order)
此函数初始化稠密矩阵描述符 dnMatDescr。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输出 |
稠密矩阵描述符 |
|
主机 |
输入 |
稠密矩阵的行数 |
|
主机 |
输入 |
稠密矩阵的列数 |
|
主机 |
输入 |
稠密矩阵的引导维度 |
|
设备 |
输入 |
稠密矩阵的值。具有 |
|
主机 |
输入 |
枚举器,指定 |
|
主机 |
输入 |
枚举器,指定稠密矩阵的内存布局 |
cusparseCreateDnMat() 具有以下约束
values必须与valueType指定的数据类型的大小对齐。有关数据类型的描述,请参阅 cudaDataType_t。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.4.2. cusparseDestroyDnMat()
cusparseStatus_t
cusparseDestroyDnMat(cusparseConstDnMatDescr_t dnMatDescr) // non-const descriptor supported
此函数释放为稠密矩阵描述符 dnMatDescr 分配的主机内存。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稠密矩阵描述符 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.4.3. cusparseDnMatGet()
cusparseStatus_t
cusparseDnMatGet(cusparseDnMatDescr_t dnMatDescr,
int64_t* rows,
int64_t* cols,
int64_t* ld,
void** values,
cudaDataType* type,
cusparseOrder_t* order)
cusparseStatus_t
cusparseConstDnMatGet(cusparseConstDnMatDescr_t dnMatDescr,
int64_t* rows,
int64_t* cols,
int64_t* ld,
const void** values,
cudaDataType* type,
cusparseOrder_t* order)
此函数返回稠密矩阵描述符 dnMatDescr 的字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稠密矩阵描述符 |
|
主机 |
输出 |
稠密矩阵的行数 |
|
主机 |
输出 |
稠密矩阵的列数 |
|
主机 |
输出 |
稠密矩阵的引导维度 |
|
设备 |
输出 |
稠密矩阵的值。具有 |
|
主机 |
输出 |
枚举器,指定 |
|
主机 |
输出 |
枚举器,指定稠密矩阵的内存布局 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.4.4. cusparseDnMatGetValues()
cusparseStatus_t
cusparseDnMatGetValues(cusparseDnMatDescr_t dnMatDescr,
void** values)
cusparseStatus_t
cusparseConstDnMatGetValues(cusparseConstDnMatDescr_t dnMatDescr,
const void** values)
此函数返回稠密矩阵描述符 dnMatDescr 的 values 字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稠密矩阵描述符 |
|
设备 |
输出 |
稠密矩阵的值。具有 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.4.5. cusparseDnMatSetValues()
cusparseStatus_t
cusparseDnMatSetValues(cusparseDnMatDescr_t dnMatDescr,
void* values)
此函数设置稠密矩阵描述符 dnMatDescr 的 values 字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稠密矩阵描述符 |
|
设备 |
输入 |
稠密矩阵的值。具有 |
cusparseDnMatSetValues() 具有以下约束
values必须与dnMatDescr中指定的数据类型的大小对齐。有关数据类型的描述,请参阅 cudaDataType_t。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.4.6. cusparseDnMatGetStridedBatch()
cusparseStatus_t
cusparseDnMatGetStridedBatch(cusparseConstDnMatDescr_t dnMatDescr, // non-const descriptor supported
int* batchCount,
int64_t* batchStride)
此函数返回稠密矩阵描述符 dnMatDescr 的批次数和批次步幅。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稠密矩阵描述符 |
|
主机 |
输出 |
稠密矩阵的批次数 |
|
主机 |
输出 |
批次中一个矩阵与下一个矩阵之间的地址偏移量 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.4.7. cusparseDnMatSetStridedBatch()
cusparseStatus_t
cusparseDnMatSetStridedBatch(cusparseDnMatDescr_t dnMatDescr,
int batchCount,
int64_t batchStride)
此函数设置稠密矩阵描述符 dnMatDescr 的批次数和批次步幅。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稠密矩阵描述符 |
|
主机 |
输入 |
稠密矩阵的批次数 |
|
主机 |
输入 |
批次中一个矩阵与下一个矩阵之间的地址偏移量。 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5. 稀疏矩阵 API
本节介绍用于稀疏矩阵描述符的 cuSPARSE 辅助函数。
有关存储格式的详细描述,请参见 COO、CSR、CSC、SELL、BSR、Blocked-Ell 部分。
6.5.1. 坐标 (COO)
6.5.1.1. cusparseCreateCoo()
cusparseStatus_t
cusparseCreateCoo(cusparseSpMatDescr_t* spMatDescr,
int64_t rows,
int64_t cols,
int64_t nnz,
void* cooRowInd,
void* cooColInd,
void* cooValues,
cusparseIndexType_t cooIdxType,
cusparseIndexBase_t idxBase,
cudaDataType valueType)
cusparseStatus_t
cusparseCreateConstCoo(cusparseConstSpMatDescr_t* spMatDescr,
int64_t rows,
int64_t cols,
int64_t nnz,
const void* cooRowInd,
const void* cooColInd,
const void* cooValues,
cusparseIndexType_t cooIdxType,
cusparseIndexBase_t idxBase,
cudaDataType valueType)
此函数初始化 COO 格式(结构数组布局)的稀疏矩阵描述符 spMatDescr。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输出 |
稀疏矩阵描述符 |
|
主机 |
输入 |
稀疏矩阵的行数 |
|
主机 |
输入 |
稀疏矩阵的列数 |
|
主机 |
输入 |
稀疏矩阵的非零条目数 |
|
设备 |
输入 |
稀疏矩阵的行索引。具有 |
|
设备 |
输入 |
稀疏矩阵的列索引。具有 |
|
设备 |
输入 |
稀疏矩阵的值。具有 |
|
主机 |
输入 |
|
|
主机 |
输入 |
|
|
主机 |
输入 |
|
cusparseCreateCoo() 具有以下约束
cooRowInd、cooColInd和cooValues必须分别与cooIdxType、cooIdxType和valueType指定的数据类型的大小对齐。有关数据类型的描述,请参阅 cudaDataType_t。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.1.2. cusparseCooGet()
cusparseStatus_t
cusparseCooGet(cusparseSpMatDescr_t spMatDescr,
int64_t* rows,
int64_t* cols,
int64_t* nnz,
void** cooRowInd,
void** cooColInd,
void** cooValues,
cusparseIndexType_t* idxType,
cusparseIndexBase_t* idxBase,
cudaDataType* valueType)
cusparseStatus_t
cusparseConstCooGet(cusparseConstSpMatDescr_t spMatDescr,
int64_t* rows,
int64_t* cols,
int64_t* nnz,
const void** cooRowInd,
const void** cooColInd,
const void** cooValues,
cusparseIndexType_t* idxType,
cusparseIndexBase_t* idxBase,
cudaDataType* valueType)
此函数返回以 COO 格式(结构数组布局)存储的稀疏矩阵描述符 spMatDescr 的字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
主机 |
输出 |
稀疏矩阵的行数 |
|
主机 |
输出 |
稀疏矩阵的列数 |
|
主机 |
输出 |
稀疏矩阵的非零条目数 |
|
设备 |
输出 |
稀疏矩阵的行索引。数组 |
|
设备 |
输出 |
稀疏矩阵的列索引。数组 |
|
设备 |
输出 |
稀疏矩阵的值。 数组包含 |
|
主机 |
输出 |
|
|
主机 |
输出 |
|
|
主机 |
输出 |
|
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.1.3. cusparseCooSetPointers()
cusparseStatus_t
cusparseCooSetPointers(cusparseSpMatDescr_t spMatDescr,
void* cooRows,
void* cooColumns,
void* cooValues)
此函数设置稀疏矩阵描述符 spMatDescr 的指针。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
设备 |
输入 |
稀疏矩阵的行索引。具有 |
|
设备 |
输入 |
稀疏矩阵的列索引。具有 |
|
设备 |
输入 |
稀疏矩阵的值。具有 |
cusparseCooSetPointers() 具有以下约束
cooRows、cooColumns和cooValues必须与其在spMatDescr中指定的相应数据类型对齐。 有关数据类型的描述,请参阅 cudaDataType_t。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.1.4. cusparseCooSetStridedBatch()
cusparseStatus_t
cusparseCooSetStridedBatch(cusparseSpMatDescr_t spMatDescr,
int batchCount,
int64_t batchStride)
此函数设置稀疏矩阵描述符 spMatDescr 的 batchCount 和 batchStride 字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
主机 |
输入 |
稀疏矩阵的批次数 |
|
主机 |
输入 |
连续批次之间的地址偏移量 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.2. 压缩稀疏行 (CSR)
6.5.2.1. cusparseCreateCsr()
cusparseStatus_t
cusparseCreateCsr(cusparseSpMatDescr_t* spMatDescr,
int64_t rows,
int64_t cols,
int64_t nnz,
void* csrRowOffsets,
void* csrColInd,
void* csrValues,
cusparseIndexType_t csrRowOffsetsType,
cusparseIndexType_t csrColIndType,
cusparseIndexBase_t idxBase,
cudaDataType valueType)
cusparseStatus_t
cusparseCreateConstCsr(cusparseConstSpMatDescr_t* spMatDescr,
int64_t rows,
int64_t cols,
int64_t nnz,
const void* csrRowOffsets,
const void* csrColInd,
const void* csrValues,
cusparseIndexType_t csrRowOffsetsType,
cusparseIndexType_t csrColIndType,
cusparseIndexBase_t idxBase,
cudaDataType valueType)
此函数初始化 CSR 格式的稀疏矩阵描述符 spMatDescr。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输出 |
稀疏矩阵描述符 |
|
主机 |
输入 |
稀疏矩阵的行数 |
|
主机 |
输入 |
稀疏矩阵的列数 |
|
主机 |
输入 |
稀疏矩阵的非零条目数 |
|
设备 |
输入 |
稀疏矩阵的行偏移量。 数组包含 |
|
设备 |
输入 |
稀疏矩阵的列索引。具有 |
|
设备 |
输入 |
稀疏矩阵的值。具有 |
|
主机 |
输入 |
|
|
主机 |
输入 |
|
|
主机 |
输入 |
|
|
主机 |
输入 |
|
cusparseCreateCsr() 具有以下约束
csrRowOffsets、csrColInd和csrValues必须分别与其在csrRowOffsetsType、csrColIndType和valueType中指定的数据类型的大小对齐。 有关数据类型的描述,请参阅 cudaDataType_t。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.2.2. cusparseCsrGet()
cusparseStatus_t
cusparseCsrGet(cusparseSpMatDescr_t spMatDescr,
int64_t* rows,
int64_t* cols,
int64_t* nnz,
void** csrRowOffsets,
void** csrColInd,
void** csrValues,
cusparseIndexType_t* csrRowOffsetsType,
cusparseIndexType_t* csrColIndType,
cusparseIndexBase_t* idxBase,
cudaDataType* valueType)
cusparseStatus_t
cusparseConstCsrGet(cusparseConstSpMatDescr_t spMatDescr,
int64_t* rows,
int64_t* cols,
int64_t* nnz,
const void** csrRowOffsets,
const void** csrColInd,
const void** csrValues,
cusparseIndexType_t* csrRowOffsetsType,
cusparseIndexType_t* csrColIndType,
cusparseIndexBase_t* idxBase,
cudaDataType* valueType)
此函数返回以 CSR 格式存储的稀疏矩阵描述符 spMatDescr 的字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
主机 |
输出 |
稀疏矩阵的行数 |
|
主机 |
输出 |
稀疏矩阵的列数 |
|
主机 |
输出 |
稀疏矩阵的非零条目数 |
|
设备 |
输出 |
稀疏矩阵的行偏移量。 数组包含 |
|
设备 |
输出 |
稀疏矩阵的列索引。具有 |
|
设备 |
输出 |
稀疏矩阵的值。具有 |
|
主机 |
输出 |
|
|
主机 |
输出 |
|
|
主机 |
输出 |
|
|
主机 |
输出 |
|
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.2.3. cusparseCsrSetPointers()
cusparseStatus_t
cusparseCsrSetPointers(cusparseSpMatDescr_t spMatDescr,
void* csrRowOffsets,
void* csrColInd,
void* csrValues)
此函数设置稀疏矩阵描述符 spMatDescr 的指针。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
设备 |
输入 |
稀疏矩阵的行偏移量。 数组包含 |
|
设备 |
输入 |
稀疏矩阵的列索引。具有 |
|
设备 |
输入 |
稀疏矩阵的值。具有 |
cusparseCsrSetPointers() 具有以下约束
csrRowOffsets、csrColInd和csrValues必须与其在spMatDescr中指定的相应数据类型对齐。 有关数据类型的描述,请参阅 cudaDataType_t。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.2.4. cusparseCsrSetStridedBatch()
cusparseStatus_t
cusparseCsrSetStridedBatch(cusparseSpMatDescr_t spMatDescr,
int batchCount,
int64_t offsetsBatchStride,
int64_t columnsValuesBatchStride)
此函数设置稀疏矩阵描述符 spMatDescr 的 batchCount 和 batchStride 字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
主机 |
输入 |
稀疏矩阵的批次数 |
|
主机 |
输入 |
行偏移数组的连续批次之间的地址偏移量 |
|
主机 |
输入 |
列和值数组的连续批次之间的地址偏移量 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.3. 压缩稀疏列 (CSC)
6.5.3.1. cusparseCreateCsc()
cusparseStatus_t
cusparseCreateCsc(cusparseSpMatDescr_t* spMatDescr,
int64_t rows,
int64_t cols,
int64_t nnz,
void* cscColOffsets,
void* cscRowInd,
void* cscValues,
cusparseIndexType_t cscColOffsetsType,
cusparseIndexType_t cscRowIndType,
cusparseIndexBase_t idxBase,
cudaDataType valueType)
cusparseStatus_t
cusparseCreateConstCsc(cusparseConstSpMatDescr_t* spMatDescr,
int64_t rows,
int64_t cols,
int64_t nnz,
const void* cscColOffsets,
const void* cscRowInd,
const void* cscValues,
cusparseIndexType_t cscColOffsetsType,
cusparseIndexType_t cscRowIndType,
cusparseIndexBase_t idxBase,
cudaDataType valueType)
此函数初始化 CSC 格式的稀疏矩阵描述符 spMatDescr。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输出 |
稀疏矩阵描述符 |
|
主机 |
输入 |
稀疏矩阵的行数 |
|
主机 |
输入 |
稀疏矩阵的列数 |
|
主机 |
输入 |
稀疏矩阵的非零条目数 |
|
设备 |
输入 |
稀疏矩阵的列偏移量。 数组包含 |
|
设备 |
输入 |
稀疏矩阵的行索引。具有 |
|
设备 |
输入 |
稀疏矩阵的值。具有 |
|
主机 |
输入 |
|
|
主机 |
输入 |
|
|
主机 |
输入 |
|
|
主机 |
输入 |
|
cusparseCreateCsc() 具有以下约束
cscColOffsets、cscRowInd和cscValues必须分别与其在cscColOffsetsType、cscRowIndType和valueType中指定的数据类型的大小对齐。 有关数据类型的描述,请参阅 cudaDataType_t。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.3.2. cusparseCscGet()
cusparseStatus_t
cusparseCscGet(cusparseSpMatDescr_t spMatDescr,
int64_t* rows,
int64_t* cols,
int64_t* nnz,
void** cscColOffsets,
void** cscRowInd,
void** cscValues,
cusparseIndexType_t* cscColOffsetsType,
cusparseIndexType_t* cscRowIndType,
cusparseIndexBase_t* idxBase,
cudaDataType* valueType)
cusparseStatus_t
cusparseConstCscGet(cusparseConstSpMatDescr_t spMatDescr,
int64_t* rows,
int64_t* cols,
int64_t* nnz,
const void** cscColOffsets,
const void** cscRowInd,
const void** cscValues,
cusparseIndexType_t* cscColOffsetsType,
cusparseIndexType_t* cscRowIndType,
cusparseIndexBase_t* idxBase,
cudaDataType* valueType)
此函数返回以 CSC 格式存储的稀疏矩阵描述符 spMatDescr 的字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
主机 |
输出 |
稀疏矩阵的行数 |
|
主机 |
输出 |
稀疏矩阵的列数 |
|
主机 |
输出 |
稀疏矩阵的非零条目数 |
|
设备 |
输出 |
稀疏矩阵的列偏移量。 数组包含 |
|
设备 |
输出 |
稀疏矩阵的行索引。具有 |
|
设备 |
输出 |
稀疏矩阵的值。具有 |
|
主机 |
输出 |
|
|
主机 |
输出 |
|
|
主机 |
输出 |
|
|
主机 |
输出 |
|
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.3.3. cusparseCscSetPointers()
cusparseStatus_t
cusparseCscSetPointers(cusparseSpMatDescr_t spMatDescr,
void* cscColOffsets,
void* cscRowInd,
void* cscValues)
此函数设置稀疏矩阵描述符 spMatDescr 的指针。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
设备 |
输入 |
稀疏矩阵的列偏移量。 数组包含 |
|
设备 |
输入 |
稀疏矩阵的行索引。具有 |
|
设备 |
输入 |
稀疏矩阵的值。具有 |
cusparseCscSetPointers() 具有以下约束
cscColOffsets、cscRowInd和cscValues必须与其在spMatDescr中指定的相应数据类型对齐。 有关数据类型的描述,请参阅 cudaDataType_t。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.4. 块-ELLPACK (Blocked-ELL)
6.5.4.1. cusparseCreateBlockedEll()
cusparseStatus_t
cusparseCreateBlockedEll(cusparseSpMatDescr_t* spMatDescr,
int64_t rows,
int64_t cols,
int64_t ellBlockSize,
int64_t ellCols,
void* ellColInd,
void* ellValue,
cusparseIndexType_t ellIdxType,
cusparseIndexBase_t idxBase,
cudaDataType valueType)
cusparseStatus_t
cusparseCreateConstBlockedEll(cusparseConstSpMatDescr_t* spMatDescr,
int64_t rows,
int64_t cols,
int64_t ellBlockSize,
int64_t ellCols,
const void* ellColInd,
const void* ellValue,
cusparseIndexType_t ellIdxType,
cusparseIndexBase_t idxBase,
cudaDataType valueType)
此函数初始化 Blocked-Ellpack (ELL) 格式的稀疏矩阵描述符 spMatDescr。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输出 |
稀疏矩阵描述符 |
|
主机 |
输入 |
稀疏矩阵的行数 |
|
主机 |
输入 |
稀疏矩阵的列数 |
|
主机 |
输入 |
ELL-Block 的大小 |
|
主机 |
输入 |
Blocked-Ellpack 格式的实际列数( |
|
设备 |
输入 |
Blocked-ELL 列索引。 数组包含 |
|
设备 |
输入 |
稀疏矩阵的值。 数组包含 |
|
主机 |
输入 |
|
|
主机 |
输入 |
|
|
主机 |
输入 |
|
Blocked-ELL 列索引 (ellColInd) 的范围为 [0, cols / ellBlockSize -1]。 该数组可以包含 -1 值,以指示空块。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.4.2. cusparseBlockedEllGet()
cusparseStatus_t
cusparseBlockedEllGet(cusparseSpMatDescr_t spMatDescr,
int64_t* rows,
int64_t* cols,
int64_t* ellBlockSize,
int64_t* ellCols,
void** ellColInd,
void** ellValue,
cusparseIndexType_t* ellIdxType,
cusparseIndexBase_t* idxBase,
cudaDataType* valueType)
cusparseStatus_t
cusparseConstBlockedEllGet(cusparseConstSpMatDescr_t spMatDescr,
int64_t* rows,
int64_t* cols,
int64_t* ellBlockSize,
int64_t* ellCols,
const void** ellColInd,
const void** ellValue,
cusparseIndexType_t* ellIdxType,
cusparseIndexBase_t* idxBase,
cudaDataType* valueType)
此函数返回以 Blocked-Ellpack (ELL) 格式存储的稀疏矩阵描述符 spMatDescr 的字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
主机 |
输出 |
稀疏矩阵的行数 |
|
主机 |
输出 |
稀疏矩阵的列数 |
|
主机 |
输出 |
ELL-Block 的大小 |
|
主机 |
输出 |
Blocked-Ellpack 格式的实际列数 |
|
设备 |
输出 |
ELL-Block 的列索引。 数组包含 |
|
设备 |
输出 |
稀疏矩阵的值。 数组包含 |
|
主机 |
输出 |
|
|
主机 |
输出 |
|
|
主机 |
输出 |
|
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.5. 切片-ELLPACK (SELL)
6.5.5.1. cusparseCreateSlicedEll()
cusparseStatus_t
cusparseCreateSlicedEll(cusparseSpMatDescr_t* spMatDescr,
int64_t rows,
int64_t cols,
int64_t nnz,
int64_t sellValuesSize,
int64_t sliceSize,
void* sellSliceOffsets,
void* sellColInd,
void* sellValues,
cusparseIndexType_t sellSliceOffsetsType,
cusparseIndexType_t sellColIndType,
cusparseIndexBase_t idxBase,
cudaDataType valueType)
cusparseStatus_t
cusparseCreateConstSlicedEll(cusparseConstSpMatDescr_t* spMatDescr,
int64_t rows,
int64_t cols,
int64_t nnz,
int64_t sellValuesSize,
int64_t sliceSize,
const void* sellSliceOffsets,
const void* sellColInd,
const void* sellValues,
cusparseIndexType_t sellSliceOffsetsType,
cusparseIndexType_t sellColIndType,
cusparseIndexBase_t idxBase,
cudaDataType valueType)
此函数初始化 Sliced Ellpack (SELL) 格式的稀疏矩阵描述符 spMatDescr。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输出 |
稀疏矩阵描述符 |
|
主机 |
输入 |
稀疏矩阵的行数 |
|
主机 |
输入 |
稀疏矩阵的列数 |
|
主机 |
输入 |
稀疏矩阵中非零元素的数量 |
|
主机 |
输入 |
|
|
主机 |
输入 |
每个切片的行数 |
|
设备 |
输入 |
稀疏矩阵的切片偏移量。 大小为 \(\left \lceil{\frac{rows}{sliceSize}}\right \rceil + 1\) 的数组 |
|
设备 |
输入 |
稀疏矩阵的列索引。 大小为 |
|
设备 |
输入 |
稀疏矩阵的值。 大小为 |
|
主机 |
输入 |
|
|
主机 |
输入 |
|
|
主机 |
输入 |
|
|
主机 |
输入 |
|
注意
Sliced Ellpack 列数组 sellColInd 包含 -1 值,以指示填充条目。
cusparseCreateSlicedEll() 具有以下约束
sellSliceOffsets、sellColInd和sellValues必须分别与其在sellSliceOffsetsType、sellColIndType和valueType中指定的数据类型的大小对齐。 有关数据类型的描述,请参阅 cudaDataType_t。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.6. 块稀疏行 (BSR)
6.5.6.1. cusparseCreateBsr()
cusparseStatus_t
cusparseCreateBsr(cusparseSpMatDescr_t* spMatDescr,
int64_t brows,
int64_t bcols,
int64_t bnnz,
int64_t rowBlockSize,
int64_t colBlockSize,
void* bsrRowOffsets,
void* bsrColInd,
void* bsrValues,
cusparseIndexType_t bsrRowOffsetsType,
cusparseIndexType_t bsrColIndType,
cusparseIndexBase_t idxBase,
cudaDataType valueType,
cusparseOrder_t order)
cusparseStatus_t
cusparseCreateConstBsr(cusparseConstSpMatDescr_t* spMatDescr,
int64_t brows,
int64_t bcols,
int64_t bnnz,
int64_t rowBlockSize,
int64_t colBlockSize,
const void* bsrRowOffsets,
const void* bsrColInd,
const void* bsrValues,
cusparseIndexType_t bsrRowOffsetsType,
cusparseIndexType_t bsrColIndType,
cusparseIndexBase_t idxBase,
cudaDataType valueType,
cusparseOrder_t order)
此函数初始化块压缩行 (BSR) 格式的稀疏矩阵描述符 spMatDescr。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输出 |
稀疏矩阵描述符 |
|
主机 |
输入 |
稀疏矩阵的块行数 |
|
主机 |
输入 |
稀疏矩阵的块列数 |
|
主机 |
输入 |
稀疏矩阵的块数 |
|
主机 |
输入 |
每个块的行数 |
|
主机 |
输入 |
每个块的列数 |
|
设备 |
输入 |
稀疏矩阵的块行偏移量。 大小为 |
|
设备 |
输入 |
稀疏矩阵的块列索引。 大小为 |
|
设备 |
输入 |
稀疏矩阵的值。 大小为 |
|
主机 |
输入 |
|
|
主机 |
输入 |
|
|
主机 |
输入 |
|
|
主机 |
输入 |
|
|
主机 |
输入 |
枚举器,指定每个块中值的内存布局 |
cusparseCreateBsr() 具有以下约束
bsrRowOffsets、bsrColInd和bsrValues必须分别与其在bsrRowOffsetsType、bsrColIndType和valueType中指定的数据类型的大小对齐。 有关数据类型的描述,请参阅 cudaDataType_t。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.6.2. cusparseBsrSetStridedBatch()
cusparseStatus_t
cusparseBsrSetStridedBatch(cusparseSpMatDescr_t spMatDescr,
int batchCount,
int64_t offsetsBatchStride,
int64_t columnsBatchStride,
int64_t valuesBatchStride)
此函数设置稀疏矩阵描述符 spMatDescr 的 batchCount 和 batchStride 字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
主机 |
输入 |
稀疏矩阵的批次数 |
|
主机 |
输入 |
行偏移数组的连续批次之间的地址偏移量 |
|
主机 |
输入 |
列数组的连续批次之间的地址偏移量 |
|
主机 |
输入 |
值数组的连续批次之间的地址偏移量 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.7. 所有稀疏格式
6.5.7.1. cusparseDestroySpMat()
cusparseStatus_t
cusparseDestroySpMat(cusparseConstSpMatDescr_t spMatDescr) // non-const descriptor supported
此函数释放为主机内存分配的稀疏矩阵描述符 spMatDescr。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.7.2. cusparseSpMatGetSize()
cusparseStatus_t
cusparseSpMatGetSize(cusparseConstSpMatDescr_t spMatDescr, // non-const descriptor supported
int64_t* rows,
int64_t* cols,
int64_t* nnz)
此函数返回稀疏矩阵 spMatDescr 的大小。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
主机 |
输出 |
稀疏矩阵的行数 |
|
主机 |
输出 |
稀疏矩阵的列数 |
|
主机 |
输出 |
稀疏矩阵的非零条目数 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.7.3. cusparseSpMatGetFormat()
cusparseStatus_t
cusparseSpMatGetFormat(cusparseConstSpMatDescr_t spMatDescr, // non-const descriptor supported
cusparseFormat_t* format)
此函数返回稀疏矩阵描述符 spMatDescr 的 format 字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
主机 |
输出 |
稀疏矩阵的存储格式 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.7.4. cusparseSpMatGetIndexBase()
cusparseStatus_t
cusparseSpMatGetIndexBase(cusparseConstSpMatDescr_t spMatDescr, // non-const descriptor supported
cusparseIndexBase_t* idxBase)
此函数返回稀疏矩阵描述符 spMatDescr 的 idxBase 字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
主机 |
输出 |
稀疏矩阵的索引基 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.7.5. cusparseSpMatGetValues()
cusparseStatus_t
cusparseSpMatGetValues(cusparseSpMatDescr_t spMatDescr,
void** values)
cusparseStatus_t
cusparseConstSpMatGetValues(cusparseConstSpMatDescr_t spMatDescr,
const void** values)
此函数返回稀疏矩阵描述符 spMatDescr 的 values 字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
设备 |
输出 |
稀疏矩阵的值。具有 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.7.6. cusparseSpMatSetValues()
cusparseStatus_t
cusparseSpMatSetValues(cusparseSpMatDescr_t spMatDescr,
void* values)
此函数设置稀疏矩阵描述符 spMatDescr 的 values 字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
设备 |
输入 |
稀疏矩阵的值。具有 |
cusparseSpMatSetValues() 具有以下约束
values必须与其在spMatDescr中指定的相应数据类型的大小对齐。 有关数据类型的描述,请参阅 cudaDataType_t。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.7.7. cusparseSpMatGetStridedBatch()
cusparseStatus_t
cusparseSpMatGetStridedBatch(cusparseConstSpMatDescr_t spMatDescr, // non-const descriptor supported
int* batchCount)
此函数返回稀疏矩阵描述符 spMatDescr 的 batchCount 字段。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
主机 |
输出 |
稀疏矩阵的批次数 |
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.7.8. cusparseSpMatGetAttribute()
cusparseStatus_t
cusparseSpMatGetAttribute(cusparseConstSpMatDescr_t spMatDescr, // non-const descriptor supported
cusparseSpMatAttribute_t attribute,
void* data,
size_t dataSize)
此函数获取稀疏矩阵描述符 spMatDescr 的属性。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
稀疏矩阵描述符 |
|
主机 |
输入 |
属性枚举器 |
|
主机 |
输出 |
属性值 |
|
主机 |
输入 |
为了安全起见,属性的大小(以字节为单位) |
Attribute |
含义 |
Possible Values |
|---|---|---|
|
指示矩阵的下半部分或上半部分是否存储在稀疏存储中 |
|
|
指示矩阵对角线项是否为单位值 |
|
有关返回状态的描述,请参阅 cusparseStatus_t。
6.5.7.9. cusparseSpMatSetAttribute()
cusparseStatus_t
cusparseSpMatSetAttribute(cusparseSpMatDescr_t spMatDescr,
cusparseSpMatAttribute_t attribute,
const void* data,
size_t dataSize)
此函数设置稀疏矩阵描述符 spMatDescr 的属性
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输出 |
稀疏矩阵描述符 |
|
主机 |
输入 |
属性枚举器 |
|
主机 |
输入 |
属性值 |
|
主机 |
输入 |
为了安全起见,属性的大小(以字节为单位) |
Attribute |
含义 |
Possible Values |
|---|---|---|
|
指示矩阵的下半部分或上半部分是否存储在稀疏存储中 |
|
|
指示矩阵对角线项是否为单位值 |
|
有关返回状态的描述,请参阅 cusparseStatus_t。
6.6. 通用 API 函数
6.6.1. cusparseAxpby() [已弃用]
> 此例程将在未来的主要版本中移除。
cusparseStatus_t
cusparseAxpby(cusparseHandle_t handle,
const void* alpha,
cusparseConstSpVecDescr_t vecX, // non-const descriptor supported
const void* beta,
cusparseDnVecDescr_t vecY)
此函数计算稀疏向量 vecX 和稠密向量 vecY 的和。
换句话说,
for i=0 to n-1
Y[i] = beta * Y[i]
for i=0 to nnz-1
Y[X_indices[i]] += alpha * X_values[i]
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
cuSPARSE 库上下文的句柄 |
|
HOST 或 DEVICE |
输入 |
\(\alpha\) 用于计算类型乘法的标量 |
|
主机 |
输入 |
稀疏向量 |
|
HOST 或 DEVICE |
输入 |
\(\beta\) 用于计算类型乘法的标量 |
|
主机 |
输入/输出 |
稠密向量 |
cusparseAxpby 支持以下索引类型来表示稀疏向量 vecX
32 位索引 (
CUSPARSE_INDEX_32I)64 位索引 (
CUSPARSE_INDEX_64I)
cusparseAxpby 支持以下数据类型
单精度计算
|
|---|
|
|
|
|
混合精度计算
|
|
|
|---|---|---|
|
|
|
|
||
|
|
[已弃用] |
|
[已弃用] |
cusparseAxpby() 具有以下约束
表示稀疏向量
vecX的数组必须与 16 字节对齐
cusparseAxpby() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
如果稀疏向量
vecX索引是不同的,则为每次运行提供确定性(按位)结果该例程允许
vecX的indices是未排序的
cusparseAxpby() 支持以下 优化
CUDA 图捕获
硬件内存压缩
有关返回状态的描述,请参阅 cusparseStatus_t。
请访问 cuSPARSE Library Samples - cusparseAxpby 以获取代码示例。
6.6.2. cusparseGather()
cusparseStatus_t
cusparseGather(cusparseHandle_t handle,
cusparseConstDnVecDescr_t vecY, // non-const descriptor supported
cusparseSpVecDescr_t vecX)
此函数将稠密向量 vecY 的元素收集到稀疏向量 vecX 中
换句话说,
for i=0 to nnz-1
X_values[i] = Y[X_indices[i]]
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
cuSPARSE 库上下文的句柄 |
|
主机 |
输出 |
稀疏向量 |
|
主机 |
输入 |
稠密向量 |
cusparseGather 支持以下索引类型来表示稀疏向量 vecX
32 位索引 (
CUSPARSE_INDEX_32I)64 位索引 (
CUSPARSE_INDEX_64I)
cusparseGather 支持以下数据类型
|
|---|
|
|
|
|
|
|
|
|
cusparseGather() 具有以下约束
表示稀疏向量
vecX的数组必须与 16 字节对齐
cusparseGather() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
如果稀疏向量
vecX索引是不同的,则为每次运行提供确定性(按位)结果该例程允许
vecX的indices是未排序的
cusparseGather() 支持以下 优化
CUDA 图捕获
硬件内存压缩
有关返回状态的描述,请参阅 cusparseStatus_t。
请访问 cuSPARSE Library Samples - cusparseGather 以获取代码示例。
6.6.3. cusparseScatter()
cusparseStatus_t
cusparseScatter(cusparseHandle_t handle,
cusparseConstSpVecDescr_t vecX, // non-const descriptor supported
cusparseDnVecDescr_t vecY)
此函数将稀疏向量 vecX 的元素分散到稠密向量 vecY 中
换句话说,
for i=0 to nnz-1
Y[X_indices[i]] = X_values[i]
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
cuSPARSE 库上下文的句柄 |
|
主机 |
输入 |
稀疏向量 |
|
主机 |
输出 |
稠密向量 |
cusparseScatter 支持以下索引类型来表示稀疏向量 vecX
32 位索引 (
CUSPARSE_INDEX_32I)64 位索引 (
CUSPARSE_INDEX_64I)
cusparseScatter 支持以下数据类型
|
|---|
|
|
|
|
|
|
|
|
|
cusparseScatter() 具有以下约束
表示稀疏向量
vecX的数组必须与 16 字节对齐
cusparseScatter() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
如果稀疏向量
vecX索引是不同的,则为每次运行提供确定性(按位)结果该例程允许
vecX的indices是未排序的
cusparseScatter() 支持以下 优化
CUDA 图捕获
硬件内存压缩
有关返回状态的描述,请参阅 cusparseStatus_t。
请访问 cuSPARSE Library Samples - cusparseScatter 以获取代码示例。
6.6.4. cusparseRot() [已弃用]
> 该例程将在下一个主要版本中删除
cusparseStatus_t
cusparseRot(cusparseHandle_t handle,
const void* c_coeff,
const void* s_coeff,
cusparseSpVecDescr_t vecX,
cusparseDnVecDescr_t vecY)
此函数计算 Givens 旋转矩阵
应用于稀疏向量 vecX 和稠密向量 vecY
换句话说,
for i=0 to nnz-1
Y[X_indices[i]] = c * Y[X_indices[i]] - s * X_values[i]
X_values[i] = c * X_values[i] + s * Y[X_indices[i]]
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
cuSPARSE 库上下文的句柄 |
|
HOST 或 DEVICE |
输入 |
旋转矩阵的余弦元素 |
|
主机 |
输入/输出 |
稀疏向量 |
|
HOST 或 DEVICE |
输入 |
旋转矩阵的正弦元素 |
|
主机 |
输入/输出 |
稠密向量 |
cusparseRot 支持以下索引类型来表示稀疏向量 vecX
32 位索引 (
CUSPARSE_INDEX_32I)64 位索引 (
CUSPARSE_INDEX_64I)
cusparseRot 支持以下数据类型
单精度计算
|
|---|
|
|
|
|
混合精度计算
|
|
|
|---|---|---|
|
|
|
|
||
|
|
[已弃用] |
|
[已弃用] |
cusparseRot() 具有以下约束
表示稀疏向量
vecX的数组必须与 16 字节对齐
cusparseRot() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
如果稀疏向量
vecX索引是不同的,则为每次运行提供确定性(按位)结果
cusparseRot() 支持以下 优化
CUDA 图捕获
硬件内存压缩
有关返回状态的描述,请参阅 cusparseStatus_t。
请访问 cuSPARSE Library Samples - cusparseRot 以获取代码示例。
6.6.5. cusparseSpVV() [已弃用]
> 此例程将在未来的主要版本中移除。
cusparseStatus_t
cusparseSpVV_bufferSize(cusparseHandle_t handle,
cusparseOperation_t opX,
cusparseConstSpVecDescr_t vecX, // non-const descriptor supported
cusparseConstDnVecDescr_t vecY, // non-const descriptor supported
void* result,
cudaDataType computeType,
size_t* bufferSize)
cusparseStatus_t
cusparseSpVV(cusparseHandle_t handle,
cusparseOperation_t opX,
cusparseConstSpVecDescr_t vecX, // non-const descriptor supported
cusparseConstDnVecDescr_t vecY, // non-const descriptor supported
void* result,
cudaDataType computeType,
void* externalBuffer)
此函数计算稀疏向量 vecX 和稠密向量 vecY 的内积。
换句话说,
result = 0;
for i=0 to nnz-1
result += op(X_values[i]) * Y[X_indices[i]]

函数 cusparseSpVV_bufferSize() 返回 cusparseSpVV() 所需的工作空间大小
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
cuSPARSE 库上下文的句柄 |
|
主机 |
输入 |
非转置或共轭转置运算 |
|
主机 |
输入 |
稀疏向量 |
|
主机 |
输入 |
稠密向量 |
|
HOST 或 DEVICE |
输出 |
结果内积 |
|
主机 |
输入 |
执行计算的数据类型 |
|
主机 |
输出 |
|
|
设备 |
输入 |
指向至少 |
cusparseSpVV 支持以下索引类型来表示稀疏向量 vecX
32 位索引 (
CUSPARSE_INDEX_32I)64 位索引 (
CUSPARSE_INDEX_64I)
下面列出了当前 cusparseSpVV 支持的数据类型组合
单精度计算
|
|---|
|
|
|
|
混合精度计算
|
|
注释 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
[已弃用] |
|
|
[已弃用] |
cusparseSpVV() 具有以下约束
表示稀疏向量
vecX的数组必须与 16 字节对齐
cusparseSpVV() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
如果稀疏向量
vecX索引是不同的,则为每次运行提供确定性(按位)结果该例程允许
vecX的indices是未排序的
cusparseSpVV() 支持以下 优化
CUDA 图捕获
硬件内存压缩
有关返回状态的描述,请参阅 cusparseStatus_t。
请访问 cuSPARSE Library Samples - cusparseSpVV 以获取代码示例。
6.6.6. cusparseSpMV()
cusparseStatus_t
cusparseSpMV_bufferSize(cusparseHandle_t handle,
cusparseOperation_t opA,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstDnVecDescr_t vecX, // non-const descriptor supported
const void* beta,
cusparseDnVecDescr_t vecY,
cudaDataType computeType,
cusparseSpMVAlg_t alg,
size_t* bufferSize)
cusparseStatus_t
cusparseSpMV_preprocess(cusparseHandle_t handle,
cusparseOperation_t opA,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstDnVecDescr_t vecX, // non-const descriptor supported
const void* beta,
cusparseDnVecDescr_t vecY,
cudaDataType computeType,
cusparseSpMVAlg_t alg,
void* externalBuffer)
cusparseStatus_t
cusparseSpMV(cusparseHandle_t handle,
cusparseOperation_t opA,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstDnVecDescr_t vecX, // non-const descriptor supported
const void* beta,
cusparseDnVecDescr_t vecY,
cudaDataType computeType,
cusparseSpMVAlg_t alg,
void* externalBuffer)
此函数执行稀疏矩阵 matA 和稠密向量 vecX 的乘法运算
其中
op(A)是大小为 \(m \times k\) 的稀疏矩阵X是大小为 \(k\) 的稠密向量Y是大小为 \(m\) 的稠密向量\(\alpha\) 和 \(\beta\) 是标量
此外,对于矩阵 A

函数 cusparseSpMV_bufferSize() 返回 cusparseSpMV_preprocess() 和 cusparseSpMV() 所需的工作空间大小
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
cuSPARSE 库上下文的句柄 |
|
主机 |
输入 |
运算 |
|
HOST 或 DEVICE |
输入 |
\(\alpha\) 用于类型为 |
|
主机 |
输入 |
稀疏矩阵 |
|
主机 |
输入 |
稠密向量 |
|
HOST 或 DEVICE |
输入 |
\(\beta\) 用于类型为 |
|
主机 |
输入/输出 |
稠密向量 |
|
主机 |
输入 |
执行计算的数据类型 |
|
主机 |
输入 |
计算的算法 |
|
主机 |
输出 |
|
|
设备 |
输入 |
指向至少 |
下面列出了当前支持的稀疏矩阵格式
CUSPARSE_FORMAT_COOCUSPARSE_FORMAT_CSRCUSPARSE_FORMAT_CSCCUSPARSE_FORMAT_SLICED_ELL
cusparseSpMV 支持以下索引类型来表示稀疏矩阵 matA
32 位索引 (
CUSPARSE_INDEX_32I)64 位索引 (
CUSPARSE_INDEX_64I)
cusparseSpMV 支持以下数据类型
单精度计算
|
|---|
|
|
|
|
混合精度计算
|
|
|
注释 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|||
|
|||
|
|
||
|
|
||
|
|
|
|
|
|
[已弃用] |
|
|
|
[已弃用] |
|
|
|---|---|
|
|
混合常规/复数计算
|
|
|---|---|
|
|
|
|
注意:CUDA_R_16F、CUDA_R_16BF、CUDA_C_16F 和 CUDA_C_16BF 数据类型始终意味着混合精度计算。
cusparseSpMV() 支持以下算法
算法 |
注释 |
|---|---|
|
任何稀疏矩阵格式的默认算法。 |
|
COO 稀疏矩阵格式的默认算法。 在使用相同输入参数的不同运行中,可能会产生略有不同的结果。 |
|
为每次运行提供确定性(位级)结果。如果 |
|
CSR/CSC 稀疏矩阵格式的默认算法。在使用相同输入参数的不同运行中,可能会产生略微不同的结果。 |
|
为每次运行提供确定性(位级)结果。如果 |
|
分片 Ellpack 稀疏矩阵格式的默认算法。为每次运行提供确定性(位级)结果。 |
调用 cusparseSpMV_preprocess() 是可选的。它可以加速后续对 cusparseSpMV() 的调用。当使用相同的稀疏模式 (matA) 多次调用 cusparseSpMV() 时,它非常有用。
使用 buffer 调用 cusparseSpMV_preprocess() 会使该缓冲区对于 matA SpMV 调用变为“活动”状态。后续使用 matA 和活动缓冲区调用 cusparseSpMV() 时,必须使用与调用 cusparseSpMV_preprocess() 相同的参数值。例外情况是:alpha、beta、vecX、vecY,以及 matA 的值(但不是索引)可能不同。重要的是,自调用 cusparseSpMV_preprocess() 以来,缓冲区内容必须保持未修改。当使用 matA 及其活动缓冲区调用 cusparseSpMV() 时,它可以从缓冲区读取加速数据。
再次使用 matA 和新缓冲区调用 cusparseSpMV_preprocess() 将使新缓冲区变为活动状态,从而遗忘先前活动的缓冲区并使其变为非活动状态。对于 cusparseSpMV(),每个稀疏矩阵一次只能有一个活动缓冲区。要获得单个稀疏矩阵的多个活动缓冲区的效果,请创建多个矩阵句柄,这些句柄都指向相同的索引和值缓冲区,并为每个句柄使用不同的工作区缓冲区调用一次 cusparseSpMV_preprocess()。
始终允许使用非活动缓冲区调用 cusparseSpMV()。但是,在这种情况下,可能无法从预处理获得加速。
出于 线程安全 的目的,cusparseSpMV_preprocess() 正在写入 matA 内部状态。
性能注意事项
CUSPARSE_SPMV_COO_ALG1和CUSPARSE_SPMV_CSR_ALG1提供比CUSPARSE_SPMV_COO_ALG2和CUSPARSE_SPMV_CSR_ALG2更高的性能。通常,
opA == CUSPARSE_OPERATION_NON_TRANSPOSE比opA != CUSPARSE_OPERATION_NON_TRANSPOSE快 3 倍。使用
cusparseSpMV_preprocess()有助于提高 CSR 中cusparseSpMV()的性能。当我们使用相同的矩阵 (cusparseSpMV_preprocess()只执行一次) 多次运行cusparseSpMV()时,它很有益。
cusparseSpMV() 具有以下属性
该例程需要额外的存储空间,用于 CSR/CSC 格式(所有算法)和使用
CUSPARSE_SPMV_COO_ALG2算法的 COO 格式。仅对于
CUSPARSE_SPMV_COO_ALG2和CUSPARSE_SPMV_CSR_ALG2算法以及opA == CUSPARSE_OPERATION_NON_TRANSPOSE,为每次运行提供确定性(位级)结果。该例程支持异步执行。
当
beta == 0时,compute-sanitizer 可能会报告此例程的错误竞争条件。这是为了优化目的,不会影响计算的正确性。该例程允许
matA的索引是未排序的。
cusparseSpMV() 支持以下 优化
CUDA 图捕获
硬件内存压缩
有关返回状态的描述,请参阅 cusparseStatus_t。
请访问 cuSPARSE 库示例 - cusparseSpMV CSR 和 cusparseSpMV COO 以获取代码示例。
6.6.7. cusparseSpSV()
cusparseStatus_t
cusparseSpSV_createDescr(cusparseSpSVDescr_t* spsvDescr);
cusparseStatus_t
cusparseSpSV_destroyDescr(cusparseSpSVDescr_t spsvDescr);
cusparseStatus_t
cusparseSpSV_bufferSize(cusparseHandle_t handle,
cusparseOperation_t opA,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstDnVecDescr_t vecX, // non-const descriptor supported
cusparseDnVecDescr_t vecY,
cudaDataType computeType,
cusparseSpSVAlg_t alg,
cusparseSpSVDescr_t spsvDescr,
size_t* bufferSize)
cusparseStatus_t
cusparseSpSV_analysis(cusparseHandle_t handle,
cusparseOperation_t opA,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstDnVecDescr_t vecX, // non-const descriptor supported
cusparseDnVecDescr_t vecY,
cudaDataType computeType,
cusparseSpSVAlg_t alg,
cusparseSpSVDescr_t spsvDescr
void* externalBuffer)
cusparseStatus_t
cusparseSpSV_solve(cusparseHandle_t handle,
cusparseOperation_t opA,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstDnVecDescr_t vecX, // non-const descriptor supported
cusparseDnVecDescr_t vecY,
cudaDataType computeType,
cusparseSpSVAlg_t alg,
cusparseSpSVDescr_t spsvDescr)
cusparseStatus_t
cusparseSpSV_updateMatrix(cusparseHandle_t handle,
cusparseSpSVDescr_t spsvDescr,
void* newValues,
cusparseSpSVUpdate_t updatePart)
此函数求解线性方程组,其系数以稀疏三角矩阵表示
其中
op(A)是大小为 \(m \times m\) 的稀疏方阵X是大小为 \(m\) 的稠密向量Y是大小为 \(m\) 的稠密向量\(\alpha\) 是标量
此外,对于矩阵 A
函数 cusparseSpSV_bufferSize() 返回 cusparseSpSV_analysis() 和 cusparseSpSV_solve() 所需的工作空间大小。函数 cusparseSpSV_analysis() 执行分析阶段,而 cusparseSpSV_solve() 执行稀疏三角线性系统的求解阶段。不透明数据结构 spsvDescr 用于在所有函数之间共享信息。函数 cusparseSpSV_updateMatrix() 使用新的矩阵值更新 spsvDescr。
该例程支持输入矩阵的任意稀疏性,但在计算中仅考虑上三角或下三角部分。
注意: 所有参数在 cusparseSpSV API 调用中必须保持一致,并且矩阵描述和 externalBuffer 在 cusparseSpSV_analysis() 和 cusparseSpSV_solve() 之间不得修改。函数 cusparseSpSV_updateMatrix() 可用于更新存储在不透明数据结构 spsvDescr 内部的稀疏矩阵上的值
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
cuSPARSE 库上下文的句柄 |
|
主机 |
输入 |
运算 |
|
HOST 或 DEVICE |
输入 |
\(\alpha\) 用于类型为 |
|
主机 |
输入 |
稀疏矩阵 |
|
主机 |
输入 |
稠密向量 |
|
主机 |
输入/输出 |
稠密向量 |
|
主机 |
输入 |
执行计算的数据类型 |
|
主机 |
输入 |
计算的算法 |
|
主机 |
输出 |
|
|
设备 |
输入/输出 |
指向至少 |
|
主机 |
输入/输出 |
用于存储三个步骤中使用的内部数据的不透明描述符 |
下面列出了当前支持的稀疏矩阵格式
CUSPARSE_FORMAT_CSRCUSPARSE_FORMAT_COOCUSPARSE_FORMAT_SLICED_ELL
cusparseSpSV() 支持以下形状和属性
CUSPARSE_FILL_MODE_LOWER和CUSPARSE_FILL_MODE_UPPER填充模式CUSPARSE_DIAG_TYPE_NON_UNIT和CUSPARSE_DIAG_TYPE_UNIT对角线类型
填充模式和对角线类型可以通过 cusparseSpMatSetAttribute() 设置。
cusparseSpSV() 支持以下索引类型来表示稀疏矩阵 matA
32 位索引 (
CUSPARSE_INDEX_32I)64 位索引 (
CUSPARSE_INDEX_64I)
cusparseSpSV() 支持以下数据类型
单精度计算
|
|---|
|
|
|
|
cusparseSpSV() 支持以下算法
算法 |
注释 |
|---|---|
|
默认算法 |
cusparseSpSV() 具有以下属性
该例程需要额外的存储空间用于分析阶段,该存储空间与稀疏矩阵的非零条目数成正比
为求解阶段
cusparseSpSV_solve()的每次运行提供确定性(位级)结果该例程支持原地操作
cusparseSpSV_solve()例程支持异步执行cusparseSpSV_bufferSize()和cusparseSpSV_analysis()例程接受NULL用于vecX和vecY该例程允许
matA的索引是未排序的
cusparseSpSV() 支持以下 优化
CUDA 图捕获
硬件内存压缩
cusparseSpSV_updateMatrix() 在调用分析阶段后更新稀疏矩阵。此函数支持以下更新策略 (updatePart)
策略 |
注释 |
|---|---|
|
使用 |
|
使用存储在 |
有关返回状态的描述,请参阅 cusparseStatus_t。
请访问 cuSPARSE 库示例 - cusparseSpSV CSR 和 cusparseSpSV COO 以获取代码示例。
6.6.8. cusparseSpMM()
cusparseStatus_t
cusparseSpMM_bufferSize(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstDnMatDescr_t matB, // non-const descriptor supported
const void* beta,
cusparseDnMatDescr_t matC,
cudaDataType computeType,
cusparseSpMMAlg_t alg,
size_t* bufferSize)
cusparseStatus_t
cusparseSpMM_preprocess(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstDnMatDescr_t matB, // non-const descriptor supported
const void* beta,
cusparseDnMatDescr_t matC,
cudaDataType computeType,
cusparseSpMMAlg_t alg,
void* externalBuffer)
cusparseStatus_t
cusparseSpMM(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstDnMatDescr_t matB, // non-const descriptor supported
const void* beta,
cusparseDnMatDescr_t matC,
cudaDataType computeType,
cusparseSpMMAlg_t alg,
void* externalBuffer)
此函数执行稀疏矩阵 matA 和稠密矩阵 matB 的乘法。
其中
op(A)是大小为 \(m \times k\) 的稀疏矩阵op(B)是大小为 \(k \times n\) 的稠密矩阵C是大小为 \(m \times n\) 的稠密矩阵\(\alpha\) 和 \(\beta\) 是标量
通过切换稠密矩阵布局,该例程也可用于执行稠密矩阵和稀疏矩阵的乘法
其中 \(\mathbf{B}_{C}\) , \(\mathbf{C}_{C}\) 表示列优先布局,而 \(\mathbf{B}_{R}\) , \(\mathbf{C}_{R}\) 指的是行优先布局
同样,对于矩阵 A 和 B

当使用稀疏矩阵 A 的(共轭)转置时,此例程在使用相同输入参数的不同运行中可能会产生略微不同的结果。
函数 cusparseSpMM_bufferSize() 返回 cusparseSpMM() 所需的工作空间大小
调用 cusparseSpMM_preprocess() 是可选的。它可以加速后续对 cusparseSpMM() 的调用。当使用相同的稀疏模式 (matA) 多次调用 cusparseSpMM() 时,它非常有用。它为 CUSPARSE_SPMM_CSR_ALG1 或 CUSPARSE_SPMM_CSR_ALG3 提供了性能优势。对于所有其他格式和算法,它没有效果。
使用 buffer 调用 cusparseSpMM_preprocess() 会使该缓冲区对于 matA SpMM 调用变为“活动”状态。后续使用 matA 和活动缓冲区调用 cusparseSpMM() 时,必须使用与调用 cusparseSpMM_preprocess() 相同的参数值。例外情况是:alpha、beta、matX、matY,以及 matA 的值(但不是索引)可能不同。重要的是,自调用 cusparseSpMM_preprocess() 以来,缓冲区内容必须保持未修改。当使用 matA 及其活动缓冲区调用 cusparseSpMM() 时,它可以从缓冲区读取加速数据。
再次使用 matA 和新缓冲区调用 cusparseSpMM_preprocess() 将使新缓冲区变为活动状态,从而遗忘先前活动的缓冲区并使其变为非活动状态。对于 cusparseSpMM(),每个稀疏矩阵一次只能有一个活动缓冲区。要获得单个稀疏矩阵的多个活动缓冲区的效果,请创建多个矩阵句柄,这些句柄都指向相同的索引和值缓冲区,并为每个句柄使用不同的工作区缓冲区调用一次 cusparseSpMM_preprocess()。
始终允许使用非活动缓冲区调用 cusparseSpMM()。但是,在这种情况下,可能无法从预处理获得加速。
出于 线程安全 的目的,cusparseSpMM_preprocess() 正在写入 matA 内部状态。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
cuSPARSE 库上下文的句柄 |
|
主机 |
输入 |
运算 |
|
主机 |
输入 |
运算 |
|
HOST 或 DEVICE |
输入 |
\(\alpha\) 用于类型为 |
|
主机 |
输入 |
稀疏矩阵 |
|
主机 |
输入 |
稠密矩阵 |
|
HOST 或 DEVICE |
输入 |
\(\beta\) 用于类型为 |
|
主机 |
输入/输出 |
稠密矩阵 |
|
主机 |
输入 |
执行计算的数据类型 |
|
主机 |
输入 |
计算的算法 |
|
主机 |
输出 |
|
|
设备 |
输入 |
指向至少 |
cusparseSpMM 支持以下稀疏矩阵格式
CUSPARSE_FORMAT_COOCUSPARSE_FORMAT_CSRCUSPARSE_FORMAT_CSCCUSPARSE_FORMAT_BSRCUSPARSE_FORMAT_BLOCKED_ELL
(1) |
COO/CSR/CSC/BSR 格式 |
cusparseSpMM 支持以下索引类型来表示稀疏矩阵 matA
32 位索引 (
CUSPARSE_INDEX_32I)64 位索引 (
CUSPARSE_INDEX_64I)
cusparseSpMM 支持以下数据类型
单精度计算
|
|---|
|
|
|
|
混合精度计算
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|||
|
|||
|
|
||
|
|
||
|
|
|
[已弃用] |
|
|
[已弃用] |
注意:CUDA_R_16F、CUDA_R_16BF、CUDA_C_16F 和 CUDA_C_16BF 数据类型始终意味着混合精度计算。
cusparseSpMM 支持以下算法
算法 |
注释 |
|---|---|
|
任何稀疏矩阵格式的默认算法 |
|
COO 稀疏矩阵格式的算法 1
|
|
COO 稀疏矩阵格式的算法 2
|
|
COO 稀疏矩阵格式的算法 3
|
|
COO 稀疏矩阵格式的算法 4
|
|
CSR/CSC 稀疏矩阵格式的算法 1
|
|
CSR/CSC 稀疏矩阵格式的算法 2
|
|
CSR/CSC 稀疏矩阵格式的算法 3
|
|
BSR 稀疏矩阵格式的算法 1
|
性能注意事项
行优先布局提供比列优先更高的性能
CUSPARSE_SPMM_COO_ALG4和CUSPARSE_SPMM_CSR_ALG2应与行优先布局一起使用,而CUSPARSE_SPMM_COO_ALG1、CUSPARSE_SPMM_COO_ALG2、CUSPARSE_SPMM_COO_ALG3和CUSPARSE_SPMM_CSR_ALG1与列优先布局一起使用对于
beta != 1,大多数算法在主计算之前缩放输出矩阵对于
n == 1,该例程可以使用cusparseSpMV()
除了 CUSPARSE_SPMM_CSR_ALG3 之外,cusparseSpMM() 与所有算法都支持以下批处理模式
\(C_{i} = A \cdot B_{i}\)
\(C_{i} = A_{i} \cdot B\)
\(C_{i} = A_{i} \cdot B_{i}\)
批处理的数量及其步幅可以使用 cusparseCooSetStridedBatch、cusparseCsrSetStridedBatch 和 cusparseDnMatSetStridedBatch 设置。cusparseSpMM() 的最大批处理数量为 65,535。
cusparseSpMM() 具有以下属性
对于
CUSPARSE_SPMM_COO_ALG1、CUSPARSE_SPMM_COO_ALG3、CUSPARSE_SPMM_COO_ALG4、CUSPARSE_SPMM_BSR_ALG1,该例程不需要额外的存储空间该例程支持异步执行。
仅为
CUSPARSE_SPMM_COO_ALG2、CUSPARSE_SPMM_CSR_ALG3和CUSPARSE_SPMM_BSR_ALG1算法的每次运行提供确定性(位级)结果compute-sanitizer可能会报告此例程的错误竞争条件。这是为了优化目的,不会影响计算的正确性该例程允许
matA的索引是未排序的
cusparseSpMM() 支持以下 优化
CUDA 图捕获
硬件内存压缩
请访问 cuSPARSE 库示例 - cusparseSpMM CSR 和 cusparseSpMM COO 以获取代码示例。对于批量计算,请访问 cusparseSpMM CSR Batched 和 cusparseSpMM COO Batched。
(2) |
BLOCKED-ELLPACK 格式 |
cusparseSpMM 支持 CUSPARSE_FORMAT_BLOCKED_ELL 格式的以下数据类型以及以下 GPU 架构,以利用 NVIDIA Tensor Core
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
cusparseSpMM 支持 CUSPARSE_FORMAT_BLOCKED_ELL 格式的以下算法
算法 |
注释 |
|---|---|
|
任何稀疏矩阵格式的默认算法 |
|
Blocked-ELL 格式的默认算法 |
性能注意事项
Blocked-ELL SpMM 在 2 的幂次方块大小时提供最佳性能。
较大的块大小(例如 ≥ 64)提供最佳性能。
该函数具有以下限制
指针模式必须等于
CUSPARSE_POINTER_MODE_HOST仅支持
opA == CUSPARSE_OPERATION_NON_TRANSPOSE。不支持
opB == CUSPARSE_OPERATION_CONJUGATE_TRANSPOSE。仅支持
CUSPARSE_INDEX_32I。
请访问 cuSPARSE 库示例 - cusparseSpMM Blocked-ELL 以获取代码示例。
有关返回状态的描述,请参阅 cusparseStatus_t。
6.6.9. cusparseSpMMOp()
cusparseStatus_t CUSPARSEAPI
cusparseSpMMOp_createPlan(cusparseHandle_t handle,
cusparseSpMMOpPlan_t* plan,
cusparseOperation_t opA,
cusparseOperation_t opB,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstDnMatDescr_t matB, // non-const descriptor supported
cusparseDnMatDescr_t matC,
cudaDataType computeType,
cusparseSpMMOpAlg_t alg,
const void* addOperationNvvmBuffer,
size_t addOperationBufferSize,
const void* mulOperationNvvmBuffer,
size_t mulOperationBufferSize,
const void* epilogueNvvmBuffer,
size_t epilogueBufferSize,
size_t* SpMMWorkspaceSize)
cusparseStatus_t
cusparseSpMMOp_destroyPlan(cusparseSpMMOpPlan_t plan)
cusparseStatus_t
cusparseSpMMOp(cusparseSpMMOpPlan_t plan,
void* externalBuffer)
注意 1: NVRTC 和 nvJitLink 当前在 Arm64 Android 平台上不可用。
注意 2: 除了 Judy (sm87) 平台外,该例程不支持 Android 和 Tegra 平台。
实验性:此函数使用自定义运算符执行稀疏矩阵 matA 和稠密矩阵 matB 的乘法。
其中
op(A)是大小为 \(m \times k\) 的稀疏矩阵op(B)是大小为 \(k \times n\) 的稠密矩阵C是大小为 \(m \times n\) 的稠密矩阵\(\oplus\) 、 \(\otimes\) 和 \(\text{epilogue}\) 分别是自定义的 add、mul 和 epilogue 运算符。
同样,对于矩阵 A 和 B
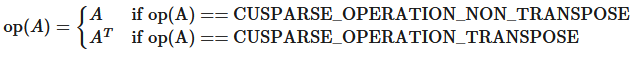
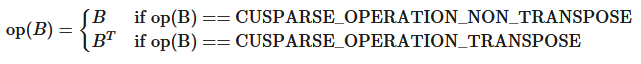
目前仅支持 opA == CUSPARSE_OPERATION_NON_TRANSPOSE
函数 cusparseSpMMOp_createPlan() 返回 cusparseSpMMOp() 所需的工作空间大小和编译后的内核
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
cuSPARSE 库上下文的句柄 |
|
主机 |
输入 |
运算 |
|
主机 |
输入 |
运算 |
|
主机 |
输入 |
稀疏矩阵 |
|
主机 |
输入 |
稠密矩阵 |
|
主机 |
输入/输出 |
稠密矩阵 |
|
主机 |
输入 |
执行计算的数据类型 |
|
主机 |
输入 |
计算的算法 |
|
主机 |
输入 |
指向包含自定义 add 运算符的 NVVM 缓冲区的指针 |
|
主机 |
输入 |
|
|
主机 |
输入 |
指向包含自定义 mul 运算符的 NVVM 缓冲区的指针 |
|
主机 |
输入 |
|
|
主机 |
输入 |
指向包含自定义 epilogue 运算符的 NVVM 缓冲区的指针 |
|
主机 |
输入 |
|
|
主机 |
输出 |
|
运算符必须具有以下签名和返回类型
__device__ <computetype> add_op(<computetype> value1, <computetype> value2);
__device__ <computetype> mul_op(<computetype> value1, <computetype> value2);
__device__ <computetype> epilogue(<computetype> value1, <computetype> value2);
<computetype> 是 float、double、cuComplex、cuDoubleComplex 或 int 之一,
cusparseSpMMOp 支持以下稀疏矩阵格式
CUSPARSE_FORMAT_CSR
cusparseSpMMOp 支持以下索引类型来表示稀疏矩阵 matA
32 位索引 (
CUSPARSE_INDEX_32I)64 位索引 (
CUSPARSE_INDEX_64I)
cusparseSpMMOp 支持以下数据类型
单精度计算
|
|---|
|
|
|
|
混合精度计算
|
|
|
|---|---|---|
|
|
|
|
|
|
|
||
|
||
|
|
|
|
|
cusparseSpMMOp 支持以下算法
算法 |
注释 |
|---|---|
|
任何稀疏矩阵格式的默认算法 |
性能注意事项
行优先布局提供比列优先更高的性能。
cusparseSpMMOp() 具有以下属性
该例程需要额外的存储空间
该例程支持异步执行。
为每次运行提供确定性(位级)结果
该例程允许
matA的索引是未排序的
cusparseSpMMOp() 支持以下 优化
CUDA 图捕获
硬件内存压缩
请访问 cuSPARSE 库示例 - cusparseSpMMOp
有关返回状态的描述,请参阅 cusparseStatus_t。
6.6.10. cusparseSpSM()
cusparseStatus_t
cusparseSpSM_createDescr(cusparseSpSMDescr_t* spsmDescr);
cusparseStatus_t
cusparseSpSM_destroyDescr(cusparseSpSMDescr_t spsmDescr);
cusparseStatus_t
cusparseSpSM_bufferSize(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstDnMatDescr_t matB, // non-const descriptor supported
cusparseDnMatDescr_t matC,
cudaDataType computeType,
cusparseSpSMAlg_t alg,
cusparseSpSMDescr_t spsmDescr,
size_t* bufferSize)
cusparseStatus_t
cusparseSpSM_analysis(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstDnMatDescr_t matB, // non-const descriptor supported
cusparseDnMatDescr_t matC,
cudaDataType computeType,
cusparseSpSMAlg_t alg,
cusparseSpSMDescr_t spsmDescr,
void* externalBuffer)
cusparseStatus_t
cusparseSpSM_solve(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstDnMatDescr_t matB, // non-const descriptor supported
cusparseDnMatDescr_t matC,
cudaDataType computeType,
cusparseSpSMAlg_t alg,
cusparseSpSMDescr_t spsmDescr)
cusparseStatus_t
cusparseSpSM_updateMatrix(cusparseHandle_t handle,
cusparseSpSMDescr_t spsmDescr,
void* newValues,
cusparseSpSMUpdate_t updatePart)
此函数求解线性方程组,其系数以稀疏三角矩阵表示
其中
op(A)是大小为 \(m \times m\) 的稀疏方阵op(B)是大小为 \(m \times n\) 的稠密矩阵C是大小为 \(m \times n\) 的稠密矩阵\(\alpha\) 是标量
此外,对于矩阵 A

函数 cusparseSpSM_bufferSize() 返回 cusparseSpSM_analysis() 和 cusparseSpSM_solve() 所需的工作空间大小。函数 cusparseSpSM_analysis() 执行分析阶段,而 cusparseSpSM_solve() 执行稀疏三角线性系统的求解阶段。不透明数据结构 spsmDescr 用于在所有函数之间共享信息。函数 cusparseSpSM_updateMatrix() 使用新的矩阵值更新 spsmDescr。
该例程支持输入矩阵的任意稀疏性,但在计算中仅考虑上三角或下三角部分。
cusparseSpSM_bufferSize() 需要一个缓冲区大小,用于分析阶段,该大小与稀疏矩阵的非零条目数成正比
The externalBuffer 存储到 spsmDescr 中,并由 cusparseSpSM_solve() 使用。因此,设备内存缓冲区必须仅在 cusparseSpSM_solve() 之后才可释放分配
NOTE: 所有参数在 cusparseSpSM API 调用中必须保持一致,并且矩阵描述和 externalBuffer 不得在 cusparseSpSM_analysis() 和 cusparseSpSM_solve() 之间修改
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
cuSPARSE 库上下文的句柄 |
|
主机 |
输入 |
运算 |
|
主机 |
输入 |
运算 |
|
HOST 或 DEVICE |
输入 |
\(\alpha\) 用于类型为 |
|
主机 |
输入 |
稀疏矩阵 |
|
主机 |
输入 |
稠密矩阵 |
|
主机 |
输入/输出 |
稠密矩阵 |
|
主机 |
输入 |
执行计算的数据类型 |
|
主机 |
输入 |
计算的算法 |
|
主机 |
输出 |
|
|
设备 |
输入/输出 |
指向至少 |
|
主机 |
输入/输出 |
用于存储三个步骤中使用的内部数据的不透明描述符 |
下面列出了当前支持的稀疏矩阵格式
CUSPARSE_FORMAT_CSRCUSPARSE_FORMAT_COO
cusparseSpSM() 支持以下形状和属性
CUSPARSE_FILL_MODE_LOWER和CUSPARSE_FILL_MODE_UPPER填充模式CUSPARSE_DIAG_TYPE_NON_UNIT和CUSPARSE_DIAG_TYPE_UNIT对角线类型
填充模式和对角线类型可以通过 cusparseSpMatSetAttribute() 设置。
cusparseSpSM() 支持以下索引类型来表示稀疏矩阵 matA
32 位索引 (
CUSPARSE_INDEX_32I)64 位索引 (
CUSPARSE_INDEX_64I)
cusparseSpSM() 支持以下数据类型
单精度计算
|
|---|
|
|
|
|
cusparseSpSM() 支持以下算法
算法 |
注释 |
|---|---|
|
默认算法 |
cusparseSpSM() 具有以下属性
该例程不需要额外的存储空间。
为求解阶段
cusparseSpSM_solve()的每次运行提供确定性(按位)结果cusparseSpSM_solve()例程支持异步执行该例程支持就地操作。必须为稠密矩阵
matB和matC的values参数提供相同的设备指针。所有其他稠密矩阵描述符参数(例如,order)都可以独立设置cusparseSpSM_bufferSize()和cusparseSpSM_analysis()例程接受matB和matC的NULL值的描述符。这两个例程不接受NULL描述符该例程允许
matA的索引是未排序的
cusparseSpSM() 支持以下 优化
CUDA 图捕获
硬件内存压缩
cusparseSpSM_updateMatrix() 在调用分析阶段后更新稀疏矩阵。此函数支持以下更新策略 (updatePart)
策略 |
注释 |
|---|---|
|
使用 |
|
使用存储在 |
有关返回状态的描述,请参阅 cusparseStatus_t。
请访问 cuSPARSE 库示例 - cusparseSpSM CSR 和 cuSPARSE 库示例 - cusparseSpSM COO 以获取代码示例。
6.6.11. cusparseSDDMM()
cusparseStatus_t
cusparseSDDMM_bufferSize(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
const void* alpha,
cusparseConstDnMatDescr_t matA, // non-const descriptor supported
cusparseConstDnMatDescr_t matB, // non-const descriptor supported
const void* beta,
cusparseSpMatDescr_t matC,
cudaDataType computeType,
cusparseSDDMMAlg_t alg,
size_t* bufferSize)
cusparseStatus_t
cusparseSDDMM_preprocess(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
const void* alpha,
cusparseConstDnMatDescr_t matA, // non-const descriptor supported
cusparseConstDnMatDescr_t matB, // non-const descriptor supported
const void* beta,
cusparseSpMatDescr_t matC,
cudaDataType computeType,
cusparseSDDMMAlg_t alg,
void* externalBuffer)
cusparseStatus_t
cusparseSDDMM(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
const void* alpha,
cusparseConstDnMatDescr_t matA, // non-const descriptor supported
cusparseConstDnMatDescr_t matB, // non-const descriptor supported
const void* beta,
cusparseSpMatDescr_t matC,
cudaDataType computeType,
cusparseSDDMMAlg_t alg,
void* externalBuffer)
此函数执行 matA 和 matB 的乘法,然后与 matC 的稀疏模式进行逐元素乘法。形式上,它执行以下操作
其中
op(A)是大小为 \(m \times k\) 的稠密矩阵op(B)是大小为 \(k \times n\) 的稠密矩阵C是大小为 \(m \times n\) 的稀疏矩阵\(\alpha\) 和 \(\beta\) 是标量
\(\circ\) 表示 Hadamard(逐元素)矩阵乘积,而 \({spy}\left( \mathbf{C} \right)\) 是
C的结构稀疏模式矩阵,定义为
同样,对于矩阵 A 和 B
函数 cusparseSDDMM_bufferSize() 返回 cusparseSDDMM 或 cusparseSDDMM_preprocess 所需的工作区大小。
调用 cusparseSDDMM_preprocess() 是可选的。它可以加速后续对 cusparseSDDMM() 的调用。当 cusparseSDDMM() 使用相同的稀疏模式 (matC) 多次调用时,它非常有用。
使用 buffer 调用 cusparseSDDMM_preprocess() 使该缓冲区对于 matC SDDMM 调用变为“活动”状态。后续使用 matC 和活动缓冲区调用 cusparseSDDMM() 时,必须对所有参数使用与调用 cusparseSDDMM_preprocess() 时相同的值。例外情况是:alpha、beta、matA、matB 以及 matC 的值(但不是索引)可能不同。重要的是,自调用 cusparseSDDMM_preprocess() 以来,缓冲区内容必须未修改。当使用 matC 及其活动缓冲区调用 cusparseSDDMM() 时,它可能会从缓冲区读取加速数据。
再次使用 matC 和新缓冲区调用 cusparseSDDMM_preprocess() 将使新缓冲区变为活动状态,从而忘记先前活动的缓冲区并使其变为非活动状态。对于 cusparseSDDMM(),每个稀疏矩阵一次只能有一个活动缓冲区。要获得单个稀疏矩阵的多个活动缓冲区的效果,请创建多个矩阵句柄,这些句柄都指向相同的索引和值缓冲区,并使用不同的工作区缓冲区为每个句柄调用一次 cusparseSDDMM_preprocess()。
始终允许使用非活动缓冲区调用 cusparseSDDMM()。但是,在这种情况下,可能没有来自预处理的加速。
出于 线程安全 的目的,cusparseSDDMM_preprocess() 正在写入 matC 内部状态。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
cuSPARSE 库上下文的句柄 |
|
主机 |
输入 |
运算 |
|
主机 |
输入 |
运算 |
|
HOST 或 DEVICE |
输入 |
\(\alpha\) 用于类型为 |
|
主机 |
输入 |
稠密矩阵 |
|
主机 |
输入 |
稠密矩阵 |
|
HOST 或 DEVICE |
输入 |
\(\beta\) 用于类型为 |
|
主机 |
输入/输出 |
稀疏矩阵 |
|
主机 |
输入 |
执行计算的数据类型 |
|
主机 |
输入 |
计算的算法 |
|
主机 |
输出 |
|
|
设备 |
输入 |
指向至少 |
当前支持的稀疏矩阵格式
CUSPARSE_FORMAT_CSRCUSPARSE_FORMAT_BSR
cusparseSDDMM() 支持以下索引类型来表示稀疏矩阵 matA
32 位索引 (
CUSPARSE_INDEX_32I)64 位索引 (
CUSPARSE_INDEX_64I)
下面列出了 cusparseSDDMM 当前支持的数据类型组合
单精度计算
|
|---|
|
|
|
|
混合精度计算
|
|
|
|---|---|---|
|
|
|
|
|
用于 CUSPARSE_FORMAT_BSR 的 cusparseSDDMM 还支持以下混合精度计算
|
|
|
|---|---|---|
|
|
|
|
|
注意:CUDA_R_16F、CUDA_R_16BF 数据类型始终意味着混合精度计算。
用于 CUSPASRE_FORMAT_BSR 的 cusparseSDDMM() 支持 2、4、8、16、32、64 和 128 的块大小。
cusparseSDDMM() 支持以下算法
算法 |
注释 |
|---|---|
|
默认算法。它支持批量计算。 |
性能说明:当 matA 和 matB 满足以下条件时,用于 CUSPARSE_FORMAT_CSR 的 cuspaseSDDMM() 提供最佳性能
-
matA:matA以行优先顺序排列,并且opA为CUSPARSE_OPERATION_NON_TRANSPOSE,或者matA以列优先顺序排列,并且opA不是CUSPARSE_OPERATION_NON_TRANSPOSE
-
matB:matB以列优先顺序排列,并且opB为CUSPARSE_OPERATION_NON_TRANSPOSE,或者matB以行优先顺序排列,并且opB不是CUSPARSE_OPERATION_NON_TRANSPOSE
当 matA 和 matB 满足以下条件时,用于 CUSPARSE_FORMAT_BSR 的 cusparseSDDMM() 提供最佳性能
-
matA:matA以行优先顺序排列,并且opA为CUSPARSE_OPERATION_NON_TRANSPOSE,或者matA以列优先顺序排列,并且opA不是CUSPARSE_OPERATION_NON_TRANSPOSE
-
matB:matB以行优先顺序排列,并且opB为CUSPARSE_OPERATION_NON_TRANSPOSE,或者matB以列优先顺序排列,并且opB不是CUSPARSE_OPERATION_NON_TRANSPOSE
cusparseSDDMM() 支持以下批量模式
\(C_{i} = (A \cdot B) \circ C_{i}\)
\(C_{i} = \left( A_{i} \cdot B \right) \circ C_{i}\)
\(C_{i} = \left( A \cdot B_{i} \right) \circ C_{i}\)
\(C_{i} = \left( A_{i} \cdot B_{i} \right) \circ C_{i}\)
批次数量及其步幅可以使用 cusparseCsrSetStridedBatch 和 cusparseDnMatSetStridedBatch 设置。 cusparseSDDMM() 的最大批次数量为 65,535。
cusparseSDDMM() 具有以下属性
该例程不需要额外的存储空间。
为每次运行提供确定性(位级)结果
该例程支持异步执行。
该例程允许
matC的索引未排序
cusparseSDDMM() 支持以下 优化
CUDA 图捕获
硬件内存压缩
有关返回状态的描述,请参阅 cusparseStatus_t。
请访问 cuSPARSE 库示例 - cusparseSDDMM 以获取代码示例。对于批量计算,请访问 cusparseSDDMM CSR 批量。
6.6.12. cusparseSpGEMM()
cusparseStatus_t
cusparseSpGEMM_createDescr(cusparseSpGEMMDescr_t* descr)
cusparseStatus_t
cusparseSpGEMM_destroyDescr(cusparseSpGEMMDescr_t descr)
cusparseStatus_t
cusparseSpGEMM_workEstimation(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstSpMatDescr_t matB, // non-const descriptor supported
const void* beta,
cusparseSpMatDescr_t matC,
cudaDataType computeType,
cusparseSpGEMMAlg_t alg,
cusparseSpGEMMDescr_t spgemmDescr,
size_t* bufferSize1,
void* externalBuffer1)
cusparseStatus_t
cusparseSpGEMM_getNumProducts(cusparseSpGEMMDescr_t spgemmDescr,
int64_t* num_prods)
cusparseStatus_t
cusparseSpGEMM_estimateMemory(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstSpMatDescr_t matB, // non-const descriptor supported
const void* beta,
cusparseSpMatDescr_t matC,
cudaDataType computeType,
cusparseSpGEMMAlg_t alg,
cusparseSpGEMMDescr_t spgemmDescr,
float chunk_fraction,
size_t* bufferSize3,
void* externalBuffer3,
size_t* bufferSize2)
cusparseStatus_t
cusparseSpGEMM_compute(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstSpMatDescr_t matB, // non-const descriptor supported
const void* beta,
cusparseSpMatDescr_t matC,
cudaDataType computeType,
cusparseSpGEMMAlg_t alg,
cusparseSpGEMMDescr_t spgemmDescr,
size_t* bufferSize2,
void* externalBuffer2)
cusparseStatus_t
cusparseSpGEMM_copy(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
const void* alpha,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseConstSpMatDescr_t matB, // non-const descriptor supported
const void* beta,
cusparseSpMatDescr_t matC,
cudaDataType computeType,
cusparseSpGEMMAlg_t alg,
cusparseSpGEMMDescr_t spgemmDescr)
此函数执行两个稀疏矩阵 matA 和 matB 的乘法。
其中 \(\alpha,\) \(\beta\) 是标量,而 \(\mathbf{C},\) \(\mathbf{C^{\prime}}\) 具有相同的稀疏模式。
函数 cusparseSpGEMM_workEstimation()、cusparseSpGEMM_estimateMemory() 和 cusparseSpGEMM_compute() 用于确定缓冲区大小和执行实际计算。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
cuSPARSE 库上下文的句柄 |
|
主机 |
输入 |
运算 |
|
主机 |
输入 |
运算 |
|
HOST 或 DEVICE |
输入 |
\(\alpha\) 用于乘法的标量 |
|
主机 |
输入 |
稀疏矩阵 |
|
主机 |
输入 |
稀疏矩阵 |
|
HOST 或 DEVICE |
输入 |
\(\beta\) 用于乘法的标量 |
|
主机 |
输入/输出 |
稀疏矩阵 |
|
主机 |
输入 |
枚举器,指定执行计算的数据类型 |
|
主机 |
输入 |
枚举器,指定计算的算法 |
|
主机 |
输入/输出 |
用于存储三个步骤中使用的内部数据的不透明描述符 |
|
主机 |
输出 |
指向 64 位整数的指针,该整数存储 |
|
主机 |
输入 |
在一个块中计算的总中间乘积的分数。仅由 |
|
主机 |
输入/输出 |
|
|
主机 |
输入/输出 |
|
|
主机 |
输入/输出 |
|
|
设备 |
输入 |
|
|
设备 |
输入 |
|
|
设备 |
输入 |
|
目前,该函数具有以下限制
仅支持 32 位索引
CUSPARSE_INDEX_32I仅支持 CSR 格式
CUSPARSE_FORMAT_CSR仅支持等于
CUSPARSE_OPERATION_NON_TRANSPOSE的opA、opB
下面列出了 cusparseSpGEMM 当前支持的数据类型组合
单精度计算
|
|---|
|
|
|
|
|
|
|
|
cusparseSpGEMM 例程针对以下算法运行
算法 |
注释 |
|---|---|
|
默认算法。目前,它是 |
|
算法 1
|
|
算法 2
|
|
算法 3
|
cusparseSpGEMM() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程允许
matA和matB的索引未排序该例程保证
matC的索引已排序
cusparseSpGEMM() 支持以下 优化
CUDA 图捕获
硬件内存压缩
有关返回状态的描述,请参阅 cusparseStatus_t。
请访问 cuSPARSE 库示例 - cusparseSpGEMM 以获取 CUSPARSE_SPGEMM_DEFAULT 和 CUSPARSE_SPGEMM_ALG1 的代码示例,并访问 cuSPARSE 库示例 - 内存优化 cusparseSpGEMM 以获取 CUSPARSE_SPGEMM_ALG2 和 CUSPARSE_SPGEMM_ALG3 的代码示例。
6.6.13. cusparseSpGEMMreuse()
cusparseStatus_t
cusparseSpGEMM_createDescr(cusparseSpGEMMDescr_t* descr)
cusparseStatus_t
cusparseSpGEMM_destroyDescr(cusparseSpGEMMDescr_t descr)
cusparseStatus_t
cusparseSpGEMMreuse_workEstimation(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
cusparseSpMatDescr_t matA, // non-const descriptor supported
cusparseSpMatDescr_t matB, // non-const descriptor supported
cusparseSpMatDescr_t matC,
cusparseSpGEMMAlg_t alg,
cusparseSpGEMMDescr_t spgemmDescr,
size_t* bufferSize1,
void* externalBuffer1)
cusparseStatus_t
cusparseSpGEMMreuse_nnz(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
cusparseSpMatDescr_t matA, // non-const descriptor supported
cusparseSpMatDescr_t matB, // non-const descriptor supported
cusparseSpMatDescr_t matC,
cusparseSpGEMMAlg_t alg,
cusparseSpGEMMDescr_t spgemmDescr,
size_t* bufferSize2,
void* externalBuffer2,
size_t* bufferSize3,
void* externalBuffer3,
size_t* bufferSize4,
void* externalBuffer4)
cusparseStatus_t CUSPARSEAPI
cusparseSpGEMMreuse_copy(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
cusparseSpMatDescr_t matA, // non-const descriptor supported
cusparseSpMatDescr_t matB, // non-const descriptor supported
cusparseSpMatDescr_t matC,
cusparseSpGEMMAlg_t alg,
cusparseSpGEMMDescr_t spgemmDescr,
size_t* bufferSize5,
void* externalBuffer5)
cusparseStatus_t CUSPARSEAPI
cusparseSpGEMMreuse_compute(cusparseHandle_t handle,
cusparseOperation_t opA,
cusparseOperation_t opB,
const void* alpha,
cusparseSpMatDescr_t matA, // non-const descriptor supported
cusparseSpMatDescr_t matB, // non-const descriptor supported
const void* beta,
cusparseSpMatDescr_t matC,
cudaDataType computeType,
cusparseSpGEMMAlg_t alg,
cusparseSpGEMMDescr_t spgemmDescr)
此函数执行两个稀疏矩阵 matA 和 matB 的乘法,其中输出矩阵 matC 的结构可以重复用于具有不同值的多次计算。
其中 \(\alpha\) 和 \(\beta\) 是标量。
函数 cusparseSpGEMMreuse_workEstimation()、cusparseSpGEMMreuse_nnz() 和 cusparseSpGEMMreuse_copy() 用于确定缓冲区大小和执行实际计算。
注意:cusparseSpGEMMreuse() 输出 CSR 矩阵 (matC) 按列索引排序。
内存要求:cusparseSpGEMMreuse 需要将所有中间乘积保存在内存中,以重用输出矩阵的结构。另一方面,中间乘积的数量通常比非零条目的数量高出几个数量级。为了最大限度地减少内存需求,该例程使用多个缓冲区,这些缓冲区在不再需要后可以释放分配。如果中间乘积的数量超过 2^31-1,则例程将返回 CUSPARSE_STATUS_INSUFFICIENT_RESOURCES 状态。
目前,该函数具有以下限制
仅支持 32 位索引
CUSPARSE_INDEX_32I仅支持 CSR 格式
CUSPARSE_FORMAT_CSR仅支持等于
CUSPARSE_OPERATION_NON_TRANSPOSE的opA、opB
下面列出了 cusparseSpGEMMreuse 当前支持的数据类型组合。
单精度计算
|
|---|
|
|
|
|
|
|
混合精度计算:[已弃用]
|
|
|
|---|---|---|
|
|
|
|
|
|
cusparseSpGEMMreuse 例程针对以下算法运行
算法 |
注释 |
|---|---|
|
|
默认算法。为每次运行的输出矩阵提供确定性(按位)结构,而值计算是不确定的。 |
|
为每次运行的输出矩阵和值计算提供确定性(按位)结构。 |
cusparseSpGEMMreuse() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
该例程允许
matA和matB的索引未排序该例程保证
matC的索引已排序
cusparseSpGEMMreuse() 支持以下 优化
CUDA 图捕获
硬件内存压缩
有关返回状态的描述,请参阅 cusparseStatus_t。
请访问 cuSPARSE 库示例 - cusparseSpGEMMreuse 以获取代码示例。
6.6.14. cusparseSparseToDense()
cusparseStatus_t
cusparseSparseToDense_bufferSize(cusparseHandle_t handle,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseDnMatDescr_t matB,
cusparseSparseToDenseAlg_t alg,
size_t* bufferSize)
cusparseStatus_t
cusparseSparseToDense(cusparseHandle_t handle,
cusparseConstSpMatDescr_t matA, // non-const descriptor supported
cusparseDnMatDescr_t matB,
cusparseSparseToDenseAlg_t alg,
void* buffer)
该函数将 CSR、CSC 或 COO 格式的稀疏矩阵 matA 转换为其稠密表示 matB。目前不支持 Blocked-ELL。
函数 cusparseSparseToDense_bufferSize() 返回 cusparseSparseToDense() 所需的工作区大小。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
cuSPARSE 库上下文的句柄 |
|
主机 |
输入 |
稀疏矩阵 |
|
主机 |
输出 |
稠密矩阵 |
|
主机 |
输入 |
计算的算法 |
|
主机 |
输出 |
|
|
设备 |
输入 |
指向工作空间缓冲区的指针 |
cusparseSparseToDense() 支持以下索引类型来表示稀疏矩阵 matA
32 位索引 (
CUSPARSE_INDEX_32I)64 位索引 (
CUSPARSE_INDEX_64I)
cusparseSparseToDense() 支持以下数据类型
|
|---|
|
|
|
|
|
|
|
|
|
cusparseSparse2Dense() 支持以下算法
算法 |
注释 |
|---|---|
|
默认算法 |
cusparseSparseToDense() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
为每次运行提供确定性(位级)结果
该例程允许
matA的索引是未排序的
cusparseSparseToDense() 支持以下 优化
CUDA 图捕获
硬件内存压缩
有关返回状态的描述,请参阅 cusparseStatus_t。
请访问 cuSPARSE 库示例 - cusparseSparseToDense 以获取代码示例。
6.6.15. cusparseDenseToSparse()
cusparseStatus_t
cusparseDenseToSparse_bufferSize(cusparseHandle_t handle,
cusparseConstDnMatDescr_t matA, // non-const descriptor supported
cusparseSpMatDescr_t matB,
cusparseDenseToSparseAlg_t alg,
size_t* bufferSize)
cusparseStatus_t
cusparseDenseToSparse_analysis(cusparseHandle_t handle,
cusparseConstDnMatDescr_t matA, // non-const descriptor supported
cusparseSpMatDescr_t matB,
cusparseDenseToSparseAlg_t alg,
void* buffer)
cusparseStatus_t
cusparseDenseToSparse_convert(cusparseHandle_t handle,
cusparseConstDnMatDescr_t matA, // non-const descriptor supported
cusparseSpMatDescr_t matB,
cusparseDenseToSparseAlg_t alg,
void* buffer)
该函数将稠密矩阵 matA 转换为 CSR、CSC、COO 或 Blocked-ELL 格式的稀疏矩阵 matB。
函数 cusparseDenseToSparse_bufferSize() 返回 cusparseDenseToSparse_analysis() 所需的工作区大小。
函数 cusparseDenseToSparse_analysis() 更新稀疏矩阵描述符 matB 中非零元素的数量。用户负责分配稀疏矩阵所需的内存
CSC 和 CSR 分别对应的行/列索引和值数组
COO 的行、列、值数组
Blocked-ELL 的列 (
ellColInd)、值 (ellValue) 数组
最后,我们调用 cusparseDenseToSparse_convert() 来填充上一步中分配的数组。
参数。 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
主机 |
输入 |
cuSPARSE 库上下文的句柄 |
|
主机 |
输入 |
稠密矩阵 |
|
主机 |
输出 |
稀疏矩阵 |
|
主机 |
输入 |
计算的算法 |
|
主机 |
输出 |
|
|
设备 |
输入 |
指向工作空间缓冲区的指针 |
cusparseDenseToSparse() 支持以下索引类型来表示稀疏向量 matB
32 位索引 (
CUSPARSE_INDEX_32I)64 位索引 (
CUSPARSE_INDEX_64I)
cusparseDenseToSparse() 支持以下数据类型
|
|---|
|
|
|
|
|
|
|
|
|
cusparseDense2Sparse() 支持以下算法
算法 |
注释 |
|---|---|
|
默认算法 |
cusparseDenseToSparse() 具有以下属性
该例程不需要额外的存储空间。
该例程支持异步执行。
为每次运行提供确定性(位级)结果
该例程不保证
matB的索引已排序
cusparseDenseToSparse() 支持以下 优化
CUDA 图捕获
硬件内存压缩
有关返回状态的描述,请参阅 cusparseStatus_t。
请访问 cuSPARSE 库示例 - cusparseDenseToSparse (CSR) 和 cuSPARSE 库示例 - cusparseDenseToSparse (Blocked-ELL) 以获取代码示例。
7. cuSPARSE Fortran 绑定
cuSPARSE 库是使用基于 C 的 CUDA 工具链实现的,因此它提供了 C 风格的 API,使得与用 C 或 C++ 编写的应用程序的接口变得非常简单。还有许多用 Fortran 实现的应用程序将受益于使用 cuSPARSE,因此开发了 cuSPARSE Fortran 接口。
不幸的是,Fortran 到 C 的调用约定未标准化,并且因平台和工具链而异。特别是,以下领域可能存在差异
符号名称(大小写,名称修饰)
参数传递(按值或引用)
传递指针参数(指针的大小)
为了在解决这些差异时提供最大的灵活性,cuSPARSE Fortran 接口以包装函数的形式提供,这些包装函数用 C 编写,位于文件 cusparse_fortran.c 中。此文件还包含一些额外的包装函数(用于 cudaMalloc()、cudaMemset 等),可用于在 GPU 上分配内存。
cuSPARSE Fortran 包装器代码仅作为示例提供,需要编译到应用程序中才能调用 cuSPARSE API 函数。提供此源代码允许用户对特定平台和工具链进行任何必要的更改。
cuSPARSE Fortran 包装器代码已用于演示与编译器 g95 0.91(在 32 位和 64 位 Linux 上)和 g95 0.92(在 32 位和 64 位 Mac OS X 上)的互操作性。为了使用其他编译器,用户必须对可能需要的包装器代码进行任何更改。
直接包装器旨在用于生产代码,用设备指针替换所有 cuSPARSE 函数中的向量和矩阵参数。为了使用这些接口,需要稍微修改现有应用程序,以在 GPU 内存空间中分配和释放数据结构(使用 CUDA_MALLOC() 和 CUDA_FREE())以及在 GPU 和 CPU 内存空间之间复制数据(使用 CUDA_MEMCPY() 例程)。cusparse_fortran.c 中提供的示例包装器将设备指针映射到 OS 相关的类型 size_t,在 32 位平台上为 32 位宽,在 64 位平台上为 64 位宽。
在 Fortran 代码中处理设备指针上的索引算术的一种方法是使用 C 风格的宏,并使用 C 预处理器来扩展它们。在 Linux 和 Mac OS X 上,可以使用选项 '-cpp' 与 g95 或 gfortran 进行预处理。与 cuSPARSE Fortran 包装器一起提供的函数 GET_SHIFTED_ADDRESS() 也可以使用,如示例 B 所示。
示例 B 显示了在主机上用 Fortran 77 实现的示例 A 的 C++ 代码。此示例应使用 ARCH_64 编译,在 64 位操作系统系统上定义为 1,在 32 位操作系统系统上未定义。例如,在 g95 或 gfortran 上,可以直接在命令行中使用选项 -cpp -DARCH_64=1 完成。
7.1. Fortran 应用程序
c #define ARCH_64 0
c #define ARCH_64 1
program cusparse_fortran_example
implicit none
integer cuda_malloc
external cuda_free
integer cuda_memcpy_c2fort_int
integer cuda_memcpy_c2fort_real
integer cuda_memcpy_fort2c_int
integer cuda_memcpy_fort2c_real
integer cuda_memset
integer cusparse_create
external cusparse_destroy
integer cusparse_get_version
integer cusparse_create_mat_descr
external cusparse_destroy_mat_descr
integer cusparse_set_mat_type
integer cusparse_get_mat_type
integer cusparse_get_mat_fill_mode
integer cusparse_get_mat_diag_type
integer cusparse_set_mat_index_base
integer cusparse_get_mat_index_base
integer cusparse_xcoo2csr
integer cusparse_dsctr
integer cusparse_dcsrmv
integer cusparse_dcsrmm
external get_shifted_address
#if ARCH_64
integer*8 handle
integer*8 descrA
integer*8 cooRowIndex
integer*8 cooColIndex
integer*8 cooVal
integer*8 xInd
integer*8 xVal
integer*8 y
integer*8 z
integer*8 csrRowPtr
integer*8 ynp1
#else
integer*4 handle
integer*4 descrA
integer*4 cooRowIndex
integer*4 cooColIndex
integer*4 cooVal
integer*4 xInd
integer*4 xVal
integer*4 y
integer*4 z
integer*4 csrRowPtr
integer*4 ynp1
#endif
integer status
integer cudaStat1,cudaStat2,cudaStat3
integer cudaStat4,cudaStat5,cudaStat6
integer n, nnz, nnz_vector
parameter (n=4, nnz=9, nnz_vector=3)
integer cooRowIndexHostPtr(nnz)
integer cooColIndexHostPtr(nnz)
real*8 cooValHostPtr(nnz)
integer xIndHostPtr(nnz_vector)
real*8 xValHostPtr(nnz_vector)
real*8 yHostPtr(2*n)
real*8 zHostPtr(2*(n+1))
integer i, j
integer version, mtype, fmode, dtype, ibase
real*8 dzero,dtwo,dthree,dfive
real*8 epsilon
write(*,*) "testing fortran example"
c predefined constants (need to be careful with them)
dzero = 0.0
dtwo = 2.0
dthree= 3.0
dfive = 5.0
c create the following sparse test matrix in COO format
c (notice one-based indexing)
c |1.0 2.0 3.0|
c | 4.0 |
c |5.0 6.0 7.0|
c | 8.0 9.0|
cooRowIndexHostPtr(1)=1
cooColIndexHostPtr(1)=1
cooValHostPtr(1) =1.0
cooRowIndexHostPtr(2)=1
cooColIndexHostPtr(2)=3
cooValHostPtr(2) =2.0
cooRowIndexHostPtr(3)=1
cooColIndexHostPtr(3)=4
cooValHostPtr(3) =3.0
cooRowIndexHostPtr(4)=2
cooColIndexHostPtr(4)=2
cooValHostPtr(4) =4.0
cooRowIndexHostPtr(5)=3
cooColIndexHostPtr(5)=1
cooValHostPtr(5) =5.0
cooRowIndexHostPtr(6)=3
cooColIndexHostPtr(6)=3
cooValHostPtr(6) =6.0
cooRowIndexHostPtr(7)=3
cooColIndexHostPtr(7)=4
cooValHostPtr(7) =7.0
cooRowIndexHostPtr(8)=4
cooColIndexHostPtr(8)=2
cooValHostPtr(8) =8.0
cooRowIndexHostPtr(9)=4
cooColIndexHostPtr(9)=4
cooValHostPtr(9) =9.0
c print the matrix
write(*,*) "Input data:"
do i=1,nnz
write(*,*) "cooRowIndexHostPtr[",i,"]=",cooRowIndexHostPtr(i)
write(*,*) "cooColIndexHostPtr[",i,"]=",cooColIndexHostPtr(i)
write(*,*) "cooValHostPtr[", i,"]=",cooValHostPtr(i)
enddo
c create a sparse and dense vector
c xVal= [100.0 200.0 400.0] (sparse)
c xInd= [0 1 3 ]
c y = [10.0 20.0 30.0 40.0 | 50.0 60.0 70.0 80.0] (dense)
c (notice one-based indexing)
yHostPtr(1) = 10.0
yHostPtr(2) = 20.0
yHostPtr(3) = 30.0
yHostPtr(4) = 40.0
yHostPtr(5) = 50.0
yHostPtr(6) = 60.0
yHostPtr(7) = 70.0
yHostPtr(8) = 80.0
xIndHostPtr(1)=1
xValHostPtr(1)=100.0
xIndHostPtr(2)=2
xValHostPtr(2)=200.0
xIndHostPtr(3)=4
xValHostPtr(3)=400.0
c print the vectors
do j=1,2
do i=1,n
write(*,*) "yHostPtr[",i,",",j,"]=",yHostPtr(i+n*(j-1))
enddo
enddo
do i=1,nnz_vector
write(*,*) "xIndHostPtr[",i,"]=",xIndHostPtr(i)
write(*,*) "xValHostPtr[",i,"]=",xValHostPtr(i)
enddo
c allocate GPU memory and copy the matrix and vectors into it
c cudaSuccess=0
c cudaMemcpyHostToDevice=1
cudaStat1 = cuda_malloc(cooRowIndex,nnz*4)
cudaStat2 = cuda_malloc(cooColIndex,nnz*4)
cudaStat3 = cuda_malloc(cooVal, nnz*8)
cudaStat4 = cuda_malloc(y, 2*n*8)
cudaStat5 = cuda_malloc(xInd,nnz_vector*4)
cudaStat6 = cuda_malloc(xVal,nnz_vector*8)
if ((cudaStat1 /= 0) .OR.
$ (cudaStat2 /= 0) .OR.
$ (cudaStat3 /= 0) .OR.
$ (cudaStat4 /= 0) .OR.
$ (cudaStat5 /= 0) .OR.
$ (cudaStat6 /= 0)) then
write(*,*) "Device malloc failed"
write(*,*) "cudaStat1=",cudaStat1
write(*,*) "cudaStat2=",cudaStat2
write(*,*) "cudaStat3=",cudaStat3
write(*,*) "cudaStat4=",cudaStat4
write(*,*) "cudaStat5=",cudaStat5
write(*,*) "cudaStat6=",cudaStat6
stop 2
endif
cudaStat1 = cuda_memcpy_fort2c_int(cooRowIndex,cooRowIndexHostPtr,
$ nnz*4,1)
cudaStat2 = cuda_memcpy_fort2c_int(cooColIndex,cooColIndexHostPtr,
$ nnz*4,1)
cudaStat3 = cuda_memcpy_fort2c_real(cooVal, cooValHostPtr,
$ nnz*8,1)
cudaStat4 = cuda_memcpy_fort2c_real(y, yHostPtr,
$ 2*n*8,1)
cudaStat5 = cuda_memcpy_fort2c_int(xInd, xIndHostPtr,
$ nnz_vector*4,1)
cudaStat6 = cuda_memcpy_fort2c_real(xVal, xValHostPtr,
$ nnz_vector*8,1)
if ((cudaStat1 /= 0) .OR.
$ (cudaStat2 /= 0) .OR.
$ (cudaStat3 /= 0) .OR.
$ (cudaStat4 /= 0) .OR.
$ (cudaStat5 /= 0) .OR.
$ (cudaStat6 /= 0)) then
write(*,*) "Memcpy from Host to Device failed"
write(*,*) "cudaStat1=",cudaStat1
write(*,*) "cudaStat2=",cudaStat2
write(*,*) "cudaStat3=",cudaStat3
write(*,*) "cudaStat4=",cudaStat4
write(*,*) "cudaStat5=",cudaStat5
write(*,*) "cudaStat6=",cudaStat6
call cuda_free(cooRowIndex)
call cuda_free(cooColIndex)
call cuda_free(cooVal)
call cuda_free(xInd)
call cuda_free(xVal)
call cuda_free(y)
stop 1
endif
c initialize cusparse library
c CUSPARSE_STATUS_SUCCESS=0
status = cusparse_create(handle)
if (status /= 0) then
write(*,*) "CUSPARSE Library initialization failed"
call cuda_free(cooRowIndex)
call cuda_free(cooColIndex)
call cuda_free(cooVal)
call cuda_free(xInd)
call cuda_free(xVal)
call cuda_free(y)
stop 1
endif
c get version
c CUSPARSE_STATUS_SUCCESS=0
status = cusparse_get_version(handle,version)
if (status /= 0) then
write(*,*) "CUSPARSE Library initialization failed"
call cuda_free(cooRowIndex)
call cuda_free(cooColIndex)
call cuda_free(cooVal)
call cuda_free(xInd)
call cuda_free(xVal)
call cuda_free(y)
call cusparse_destroy(handle)
stop 1
endif
write(*,*) "CUSPARSE Library version",version
c create and setup the matrix descriptor
c CUSPARSE_STATUS_SUCCESS=0
c CUSPARSE_MATRIX_TYPE_GENERAL=0
c CUSPARSE_INDEX_BASE_ONE=1
status= cusparse_create_mat_descr(descrA)
if (status /= 0) then
write(*,*) "Creating matrix descriptor failed"
call cuda_free(cooRowIndex)
call cuda_free(cooColIndex)
call cuda_free(cooVal)
call cuda_free(xInd)
call cuda_free(xVal)
call cuda_free(y)
call cusparse_destroy(handle)
stop 1
endif
status = cusparse_set_mat_type(descrA,0)
status = cusparse_set_mat_index_base(descrA,1)
c print the matrix descriptor
mtype = cusparse_get_mat_type(descrA)
fmode = cusparse_get_mat_fill_mode(descrA)
dtype = cusparse_get_mat_diag_type(descrA)
ibase = cusparse_get_mat_index_base(descrA)
write (*,*) "matrix descriptor:"
write (*,*) "t=",mtype,"m=",fmode,"d=",dtype,"b=",ibase
c exercise conversion routines (convert matrix from COO 2 CSR format)
c cudaSuccess=0
c CUSPARSE_STATUS_SUCCESS=0
c CUSPARSE_INDEX_BASE_ONE=1
cudaStat1 = cuda_malloc(csrRowPtr,(n+1)*4)
if (cudaStat1 /= 0) then
call cuda_free(cooRowIndex)
call cuda_free(cooColIndex)
call cuda_free(cooVal)
call cuda_free(xInd)
call cuda_free(xVal)
call cuda_free(y)
call cusparse_destroy_mat_descr(descrA)
call cusparse_destroy(handle)
write(*,*) "Device malloc failed (csrRowPtr)"
stop 2
endif
status= cusparse_xcoo2csr(handle,cooRowIndex,nnz,n,
$ csrRowPtr,1)
if (status /= 0) then
call cuda_free(cooRowIndex)
call cuda_free(cooColIndex)
call cuda_free(cooVal)
call cuda_free(xInd)
call cuda_free(xVal)
call cuda_free(y)
call cuda_free(csrRowPtr)
call cusparse_destroy_mat_descr(descrA)
call cusparse_destroy(handle)
write(*,*) "Conversion from COO to CSR format failed"
stop 1
endif
c csrRowPtr = [0 3 4 7 9]
c exercise Level 1 routines (scatter vector elements)
c CUSPARSE_STATUS_SUCCESS=0
c CUSPARSE_INDEX_BASE_ONE=1
call get_shifted_address(y,n*8,ynp1)
status= cusparse_dsctr(handle, nnz_vector, xVal, xInd,
$ ynp1, 1)
if (status /= 0) then
call cuda_free(cooRowIndex)
call cuda_free(cooColIndex)
call cuda_free(cooVal)
call cuda_free(xInd)
call cuda_free(xVal)
call cuda_free(y)
call cuda_free(csrRowPtr)
call cusparse_destroy_mat_descr(descrA)
call cusparse_destroy(handle)
write(*,*) "Scatter from sparse to dense vector failed"
stop 1
endif
c y = [10 20 30 40 | 100 200 70 400]
c exercise Level 2 routines (csrmv)
c CUSPARSE_STATUS_SUCCESS=0
c CUSPARSE_OPERATION_NON_TRANSPOSE=0
status= cusparse_dcsrmv(handle, 0, n, n, nnz, dtwo,
$ descrA, cooVal, csrRowPtr, cooColIndex,
$ y, dthree, ynp1)
if (status /= 0) then
call cuda_free(cooRowIndex)
call cuda_free(cooColIndex)
call cuda_free(cooVal)
call cuda_free(xInd)
call cuda_free(xVal)
call cuda_free(y)
call cuda_free(csrRowPtr)
call cusparse_destroy_mat_descr(descrA)
call cusparse_destroy(handle)
write(*,*) "Matrix-vector multiplication failed"
stop 1
endif
c print intermediate results (y)
c y = [10 20 30 40 | 680 760 1230 2240]
c cudaSuccess=0
c cudaMemcpyDeviceToHost=2
cudaStat1 = cuda_memcpy_c2fort_real(yHostPtr, y, 2*n*8, 2)
if (cudaStat1 /= 0) then
call cuda_free(cooRowIndex)
call cuda_free(cooColIndex)
call cuda_free(cooVal)
call cuda_free(xInd)
call cuda_free(xVal)
call cuda_free(y)
call cuda_free(csrRowPtr)
call cusparse_destroy_mat_descr(descrA)
call cusparse_destroy(handle)
write(*,*) "Memcpy from Device to Host failed"
stop 1
endif
write(*,*) "Intermediate results:"
do j=1,2
do i=1,n
write(*,*) "yHostPtr[",i,",",j,"]=",yHostPtr(i+n*(j-1))
enddo
enddo
c exercise Level 3 routines (csrmm)
c cudaSuccess=0
c CUSPARSE_STATUS_SUCCESS=0
c CUSPARSE_OPERATION_NON_TRANSPOSE=0
cudaStat1 = cuda_malloc(z, 2*(n+1)*8)
if (cudaStat1 /= 0) then
call cuda_free(cooRowIndex)
call cuda_free(cooColIndex)
call cuda_free(cooVal)
call cuda_free(xInd)
call cuda_free(xVal)
call cuda_free(y)
call cuda_free(csrRowPtr)
call cusparse_destroy_mat_descr(descrA)
call cusparse_destroy(handle)
write(*,*) "Device malloc failed (z)"
stop 2
endif
cudaStat1 = cuda_memset(z, 0, 2*(n+1)*8)
if (cudaStat1 /= 0) then
call cuda_free(cooRowIndex)
call cuda_free(cooColIndex)
call cuda_free(cooVal)
call cuda_free(xInd)
call cuda_free(xVal)
call cuda_free(y)
call cuda_free(z)
call cuda_free(csrRowPtr)
call cusparse_destroy_mat_descr(descrA)
call cusparse_destroy(handle)
write(*,*) "Memset on Device failed"
stop 1
endif
status= cusparse_dcsrmm(handle, 0, n, 2, n, nnz, dfive,
$ descrA, cooVal, csrRowPtr, cooColIndex,
$ y, n, dzero, z, n+1)
if (status /= 0) then
call cuda_free(cooRowIndex)
call cuda_free(cooColIndex)
call cuda_free(cooVal)
call cuda_free(xInd)
call cuda_free(xVal)
call cuda_free(y)
call cuda_free(z)
call cuda_free(csrRowPtr)
call cusparse_destroy_mat_descr(descrA)
call cusparse_destroy(handle)
write(*,*) "Matrix-matrix multiplication failed"
stop 1
endif
c print final results (z)
c cudaSuccess=0
c cudaMemcpyDeviceToHost=2
cudaStat1 = cuda_memcpy_c2fort_real(zHostPtr, z, 2*(n+1)*8, 2)
if (cudaStat1 /= 0) then
call cuda_free(cooRowIndex)
call cuda_free(cooColIndex)
call cuda_free(cooVal)
call cuda_free(xInd)
call cuda_free(xVal)
call cuda_free(y)
call cuda_free(z)
call cuda_free(csrRowPtr)
call cusparse_destroy_mat_descr(descrA)
call cusparse_destroy(handle)
write(*,*) "Memcpy from Device to Host failed"
stop 1
endif
c z = [950 400 2550 2600 0 | 49300 15200 132300 131200 0]
write(*,*) "Final results:"
do j=1,2
do i=1,n+1
write(*,*) "z[",i,",",j,"]=",zHostPtr(i+(n+1)*(j-1))
enddo
enddo
c check the results
epsilon = 0.00000000000001
if ((DABS(zHostPtr(1) - 950.0) .GT. epsilon) .OR.
$ (DABS(zHostPtr(2) - 400.0) .GT. epsilon) .OR.
$ (DABS(zHostPtr(3) - 2550.0) .GT. epsilon) .OR.
$ (DABS(zHostPtr(4) - 2600.0) .GT. epsilon) .OR.
$ (DABS(zHostPtr(5) - 0.0) .GT. epsilon) .OR.
$ (DABS(zHostPtr(6) - 49300.0) .GT. epsilon) .OR.
$ (DABS(zHostPtr(7) - 15200.0) .GT. epsilon) .OR.
$ (DABS(zHostPtr(8) - 132300.0).GT. epsilon) .OR.
$ (DABS(zHostPtr(9) - 131200.0).GT. epsilon) .OR.
$ (DABS(zHostPtr(10) - 0.0) .GT. epsilon) .OR.
$ (DABS(yHostPtr(1) - 10.0) .GT. epsilon) .OR.
$ (DABS(yHostPtr(2) - 20.0) .GT. epsilon) .OR.
$ (DABS(yHostPtr(3) - 30.0) .GT. epsilon) .OR.
$ (DABS(yHostPtr(4) - 40.0) .GT. epsilon) .OR.
$ (DABS(yHostPtr(5) - 680.0) .GT. epsilon) .OR.
$ (DABS(yHostPtr(6) - 760.0) .GT. epsilon) .OR.
$ (DABS(yHostPtr(7) - 1230.0) .GT. epsilon) .OR.
$ (DABS(yHostPtr(8) - 2240.0) .GT. epsilon)) then
write(*,*) "fortran example test FAILED"
else
write(*,*) "fortran example test PASSED"
endif
c deallocate GPU memory and exit
call cuda_free(cooRowIndex)
call cuda_free(cooColIndex)
call cuda_free(cooVal)
call cuda_free(xInd)
call cuda_free(xVal)
call cuda_free(y)
call cuda_free(z)
call cuda_free(csrRowPtr)
call cusparse_destroy_mat_descr(descrA)
call cusparse_destroy(handle)
stop 0
end
8. 致谢
NVIDIA 感谢以下个人和机构的贡献
cusparse<t>gtsv 实现源自伊利诺伊大学 Li-Wen Chang 开发的版本。
cusparse<t>gtsvInterleavedBatch 采用了巴塞罗那超级计算中心和 BSC/UPC NVIDIA GPU 卓越中心的 Pedro Valero-Lara 和 Ivan Martínez-Pérez 开发的 cuThomasBatch。
本产品包含 {fmt} - 现代格式化库 https://fmt.dev 版权所有 (c) 2012 - 至今,Victor Zverovich。
9. 参考书目
[1] N. Bell 和 M. Garland,《在面向吞吐量的处理器上实现稀疏矩阵-向量乘法》,超级计算,2009 年。
[2] R. Grimes、D. Kincaid 和 D. Young,《ITPACK 2.0 用户指南》,技术报告 CNA-150,德克萨斯大学数值分析中心,1979 年。
[3] M. Naumov,《使用 cuSPARSE 和 cuBLAS 的不完全 LU 和 Cholesky 预处理迭代方法》,技术报告和白皮书,2011 年。
[4] Pedro Valero-Lara、Ivan Martínez-Pérez、Raül Sirvent、Xavier Martorell 和 Antonio J. Peña。 NVIDIA GPU 可扩展性以解决多个(批量)三对角线系统。 cuThomasBatch 的实现。并行处理和应用数学 - 第 12 届国际会议 (PPAM),2017 年。
10. 声明
10.1. 声明
本文档仅供参考,不应被视为对产品的特定功能、条件或质量的保证。 NVIDIA Corporation(“NVIDIA”)不对本文档中包含的信息的准确性或完整性做出任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。 NVIDIA 对使用此类信息或因使用此类信息而可能导致的侵犯第三方专利或其他权利的后果或使用不承担任何责任。 本文档不是开发、发布或交付任何材料(如下定义)、代码或功能的承诺。
NVIDIA 保留随时对此文档进行更正、修改、增强、改进和任何其他更改的权利,恕不另行通知。
客户在下订单前应获取最新的相关信息,并应验证此类信息是否为最新且完整。
NVIDIA 产品的销售受订单确认时提供的 NVIDIA 标准销售条款和条件的约束,除非 NVIDIA 和客户的授权代表签署的个别销售协议(“销售条款”)另有约定。 NVIDIA 在此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。 本文档不直接或间接地构成任何合同义务。
NVIDIA 产品并非设计、授权或担保适用于医疗、军事、航空、航天或生命维持设备,也不适用于因 NVIDIA 产品故障或失灵可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在上述设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,包含和/或使用 NVIDIA 产品由客户自行承担风险。
NVIDIA 不保证或声明基于本文档的产品将适用于任何特定用途。NVIDIA 不一定会对每种产品的全部参数进行测试。客户全权负责评估和确定本文档中任何信息的适用性,确保产品适合并满足客户计划的应用,并为该应用执行必要的测试,以避免应用或产品发生故障。客户产品设计的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档所含内容的其他或不同的条件和/或要求。对于因以下原因引起或归因于以下原因的任何故障、损坏、成本或问题,NVIDIA 不承担任何责任:(i) 以任何违反本文档的方式使用 NVIDIA 产品或 (ii) 客户产品设计。
本文档未授予任何明示或暗示的许可,以使用任何 NVIDIA 专利权、版权或其他 NVIDIA 知识产权。NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予的使用此类产品或服务的许可,也不构成 NVIDIA 对其的保证或认可。使用此类信息可能需要获得第三方的专利或其他知识产权许可,或获得 NVIDIA 的专利或其他知识产权许可。
只有在事先获得 NVIDIA 书面批准的情况下,才可以复制本文档中的信息,且复制时不得进行更改,并应完全遵守所有适用的出口法律法规,并附带所有相关的条件、限制和声明。
本文档以及所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”,单独或合并)均“按现状”提供。NVIDIA 不对这些材料作任何明示、暗示、法定或其他形式的保证,并且明确声明不承担所有关于不侵权、适销性和针对特定用途适用性的暗示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对因使用本文档而引起的任何损害(包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害,无论因何种原因造成,也无论基于何种责任理论)承担责任,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因遭受任何损害,NVIDIA 对本文所述产品的累积总责任应根据产品的销售条款进行限制。
10.2. OpenCL
OpenCL 是 Apple Inc. 的商标,已授权 Khronos Group Inc. 使用。
10.3. 商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其各自公司相关的商标。