即时链接时优化¶
什么是 JIT LTO?¶
链接时优化 (LTO) 是一个强大的工具,它为使用单独编译构建的应用程序带来全程序优化。对于 CUDA 应用程序,LTO 首次在 CUDA 11.2 中引入。当 LTO 作为使用 nvcc 编译器构建应用程序过程的一部分应用时,我们称之为 离线 LTO。
我们还可以在运行时(当应用程序执行时)应用 LTO 优化。我们将此过程称为 即时 (JIT) LTO。JIT LTO 允许库仅在运行时最终确定用户请求的内核,而不是所有可能的内核。
JIT LTO 是使用 nvJitLink 库 实现的,该库是 在 CUDA 12.0 中引入的。
cuFFT LTO EA 中的 JIT LTO¶
在此预览版中,我们决定将 JIT LTO 应用于自 CUDA 6.5 以来一直是 cuFFT 一部分的回调内核。与非 LTO 回调相比,目前 cuFFT 中启用 LTO 的回调有两个主要优势。
首先,JIT LTO 允许我们将用户回调代码内联到 cuFFT 内核中。一旦回调被内联,优化过程将在完全内核可见性的情况下进行。在没有 JIT LTO 的情况下,用户回调是单独编译的,并使用函数指针从 cuFFT 内核内部间接调用。使用 LTO 的结果是,由于消除了回调的间接函数调用开销,某些回调用例的性能得到了显着提高。
换句话说,JIT LTO 允许我们在运行时将用户代码与库代码无缝结合。
其次,JIT LTO 的运行时方面意味着我们不需要预先构建所有可能的内核来随库一起发布;只需要最终确定用户在计划时请求的内核。cuFFT 将在未来的版本中扩展这个想法,以带来额外的功能和“光速”性能,这些功能和性能以前在不影响二进制大小的情况下是不可能发布的。
cuFFT LTO EA 包含 LTO 回调内核的这种额外性能的示例
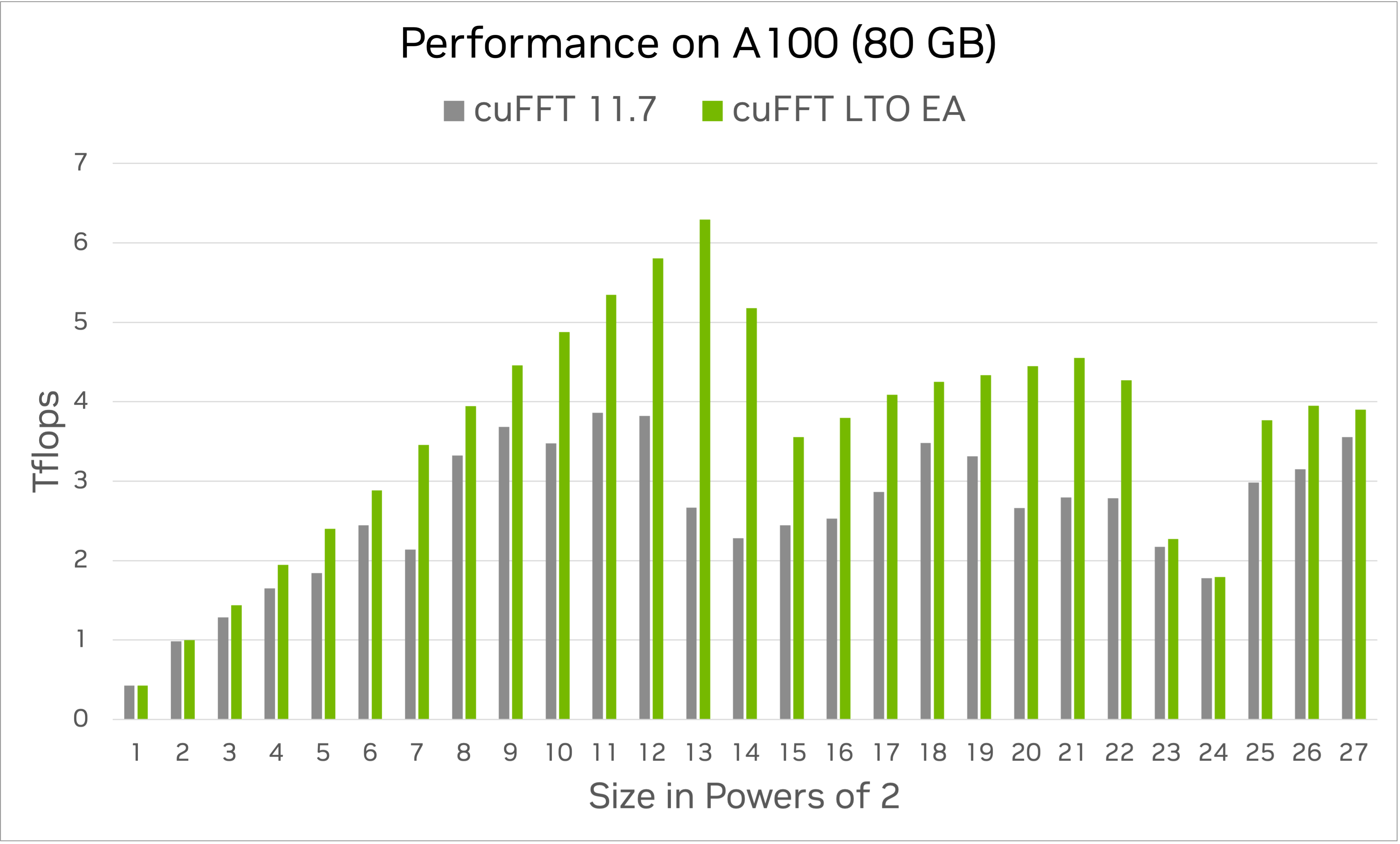
上面的图表说明了在 CUDA Toolkit 11.7 中分发的 cuFFT 中,使用 LTO 回调与非 LTO 回调相比的性能提升。该基准测试在 Ampere GPU (配备 80 GB 显存的 A100) 上以单精度运行复数到复数 (C2C) FFT,并使用最少的加载和存储回调。
JIT LTO 的成本¶
当使用 JIT LTO 时,内核最终确定发生在运行时,而不是在构建库时。与离线 LTO 相比,这个运行时组件是一个巨大的优势:因为使用离线 LTO 我们不知道哪些内核将被运行,所以我们需要将整个库与用户回调代码链接起来,这是一个缓慢而精细的过程。
在运行时最终确定内核的缺点是在计划时内核最终确定的开销。我们已测量到大多数情况下每个内核在计划时有 50 到 500 毫秒的开销。相比之下,由于 PTX JIT,CUDA 10.X 中发布的旧版本 cuFFT 的库初始化时间约为 250 毫秒,CUDA 11.X 及更高版本中每个内核的库初始化时间不到 200 毫秒。
请记住,这些时间是估计值,实际时间会因用于运行应用程序的系统的特性而异,例如 CPU 功率。另请注意,从 CUDA 12.1 开始,nvJitLink 使用缓存来大大减少跨多次运行的内核的运行时链接开销。