Base Command Platform
在 Base Command Platform 上运行 NeMo 框架
简介
训练大型语言模型 (LLM) 需要大量的计算能力、数据和代码库。LLM 训练作业可能需要数小时到数月才能运行完成,并且需要一个强大的平台来支持用户完成端到端的训练过程。
NVIDIA NeMo 框架 提供了一个工具包,用于开发、训练和定制 LLM 以及其他生成式 AI 工作负载。NVIDIA Base Command Platform (BCP) 为在复杂硬件上部署和管理 NeMo 框架带来了强大的用户界面。
本文档介绍了如何在 BCP 上使用 NeMo 框架
如何在 Jupyter Notebook 中启动 NeMo 框架
如何启动长时间运行的训练作业
如何管理训练作业的数据和结果
使用 BCP 运行、管理和调整使用 NeMo 框架的 LLM 的最佳实践
有关 NeMo 框架的更多详细信息,请访问 生成式 AI。
Base Command Platform 关键概念
本节介绍了 Base Command Platform 中使用的关键概念和术语。有关 Base Command Platform 的更多信息,请参阅 Base Command Platform 用户指南。
作业
作业是 BCP 上的计算单元。
作业示例包括
一个容器,其中 JupyterLab 作为端点公开
一个容器,用于下载和预处理用于训练的数据集
指定的容器镜像和一组 Python 脚本,这些脚本在运行时可在多个副本(计算节点)上训练 LLM
工作空间
工作空间是可共享的读写持久存储,可以挂载到作业中以供并发使用。在作业中以读写模式(默认模式)挂载工作空间非常适合用作检查点文件夹。工作空间也可以以只读模式挂载到作业中,使其成为配置/代码/输入用例的理想选择,让您确信作业不会损坏/修改任何这些数据。数据在作业完成后仍然存在,并且对于每个副本都是相同的。请注意,工作空间内没有文件锁定机制,因此共享工作空间中的同一文件可能会被两个作业同时写入,从而导致损坏。
数据集
数据集是作业的数据输入,以只读方式挂载到作业中指定的位置。它们可以包含数据或代码。与工作空间一样,数据集在作业完成后仍然存在,并且对于每个副本都是相同的。
结果
结果是由作业指定的读写挂载点,并由系统捕获。写入结果的所有数据在作业完成后以及 stdout 和 stderr 的内容都可用。结果在作业完成后仍然存在,并且对于每个副本都是唯一的 - 它们不在多节点作业的节点之间共享。
先决条件
要在 BCP 上运行 NeMo 工作负载,您需要以下条件
访问 DGX Cloud 上的 BCP
在 BCP 内创建工作空间的权限
本地机器上安装并配置的最新版本的 NGC CLI,该机器必须来自“允许”的 IP。本指南已使用 NGC 版本 3.33.0 进行测试
如果您希望按照本文档中的示例进行操作,您还需要以下条件
访问 DGX Cloud 中至少具有 4 个 DGX A100 或 DGX H100 节点的 ACE
至少 1.5TB 的存储配额
在 Base Command Platform 上使用 NeMo
在 BCP 上运行 NeMo 框架作业主要有两种方法。第一种是启动 JupyterLab 环境,并从 Jupyter 笔记本与 NeMo 框架进行交互。第二种是启动批处理作业,运行脚本以进行非交互式工作。
JupyterLab 方法通常用于学习环境和准备代码和启动脚本。一旦您准备好启动脚本,运行持久训练作业的首选方法是启动批处理作业 - 这意味着您的 BCP 组织或团队中的其他人可以重复使用您的启动命令,获得可重复的结果。
在 BCP 上以批处理作业方式运行 NeMo 框架
您可以在 BCP 上以批处理作业方式运行大多数 LLM 训练作业。这些作业可以运行多天,并且需要大量的资源。
在本节中,我们将逐步介绍如何在 Base Command Platform 上使用 NeMo 框架训练 LLM 的过程。在整个过程中,我们将在一个具体示例的上下文中工作。我们将使用 8B 参数 GPT 模型。但是,我们将指出您可以在何处个性化工作流程以使用您自己的模型和数据。
训练 LLM 有三个主要阶段
设置
数据准备
模型预训练
以下各节将逐步介绍每个步骤。
设置
首先,确定您要在其上训练 LLM 的 ACE 的组织 ID。这将是每个集群独有的。
您可以通过在安装了 NGC CLI 的本地机器上运行 ngc org list 来查找您的组织 ID。此命令列出您当前有权访问的所有组织。输出可能类似于以下内容
+--------+---------------------------------+----------------+------------+ | Id | Name | Description | Type | +--------+---------------------------------+----------------+------------+ | 123456 | nv-dgx-cloud-org (abcdefghijkl) | | ENTERPRISE | +--------+---------------------------------+----------------+------------+
在上面的示例中,组织 ID 将是 abcdefghijkl。请注意,您的组织 ID 将在整个文档中被引用为 <ORG ID>。
为了缩短 NGC 命令,请在本地机器上运行 ngc config set,您将在该机器上启动命令并指定您的 NGC 密钥、ACE 和组织 ID。通过设置默认值,您无需在每个命令中都指定 --org、--team 和 --ace 标志。本文档的其余部分假设已在本地使用 ngc config set 设置了配置。
创建工作空间
需要工作空间来存储动态代码和中间数据。NeMo 框架要求启动器存储库被复制到工作空间并在作业期间挂载。工作空间将包含启动代码、模型配置、数据集和检查点。
要创建工作空间,请从本地计算机上的终端运行以下命令
ngc workspace create --name nemo-framework
其中
nemo-framework 是工作空间的名称。(您可以随意在此处替换工作空间名称,但
nemo-framework将在本文档的其余部分用作工作空间名称。)
要验证工作空间是否已成功创建,请运行 ngc workspace list | grep nemo-framework (根据需要替换工作空间名称),其中应包含新创建的工作空间。
在本地挂载工作空间(可选)
要查看和更新您的配置文件和任何训练检查点,您可以将工作空间挂载到本地机器上。
要挂载工作空间,请运行以下命令
ngc workspace mount \ --mode RW \ nemo-framework \ <LOCAL-MOUNT-DIRECTORY>
其中
<本地挂载目录> 是在本地计算机上挂载工作空间的路径
挂载工作空间后,cd 进入该目录并查看内容。此时,它应该是空的,因为尚未向其中写入任何文件。
如果您选择不在本地挂载工作空间,则一旦 NeMo 作业启动,就可以通过使用 NGC CLI 的 exec 功能与您的配置文件和检查点进行交互,或者只是查看作业的 日志 选项卡(如果您只想观察基本的作业进度)来完成作业监控。
数据准备
为了在 BCP 上使用 NeMo 框架训练 LLM,我们需要确保训练数据可以通过 BCP 访问,并且已经过预处理,以便 NeMo 框架能够最佳地摄取。
上传数据集
以下是将数据导入 Base Command Platform 的建议
如果您希望将生成的模型与数据集共同定位,请使用工作空间来存放数据
如果模型位置不需要与数据集共同定位,并且数据集是完全静态的,请考虑使用数据集代替
如果您可以使用数据集,请尽可能使用 NGC CLI 的数据集导入功能来迁移数据
对于本指南,数据集将通过批处理作业下载,数据不会直接通过工作空间或数据集上传。
配置文件
如果您需要进行更改,请将配置文件从默认配置文件复制到工作空间中(如果需要,您可以使用用于其他用途的工作空间中的目录,或者为配置文件创建一个完全独立的工作空间。)
对工作空间中复制的配置文件进行所需的更改。
启动 NeMo FW 作业时,请确保将保存配置文件修改的工作空间挂载到作业,并将 NeMo FW 配置文件路径设置为指向新修改的配置文件。
预处理数据集
NeMo 框架支持处理自定义的基于文本的数据集,用于预训练新模型。数据预处理器要求数据集经过清理,排除任何敏感或格式不正确的数据,这些数据不适合在预训练期间使用。数据集中的每个文件都需要是 .json 格式,或者理想情况下是 .jsonl 格式。数据集可以从外部来源下载,也可以直接上传到工作空间。
以下示例逐步介绍了下载、提取、连接和预处理 SlimPajama 数据集的过程。虽然本文档的其余部分将基于 SlimPajama 数据集,但此通用过程可以用于大多数自定义数据集,并将提供有关如何根据需要进行调整的指导。
首先,必须将几个脚本写入工作空间,以下载、提取和连接文件。在安装了 NGC CLI 的本地机器上,创建一个名为“slim-pajama-scripts”的新目录,并将以下文件保存在新目录中。这些文件将在下一节中解释。
注意: 对于 download.py 文件,脚本顶部的 CHUNKS = 10 变量可以减少为 CHUNKS = 1,以便仅拉取数据集的前 6,000 个文件,从而加快数据准备速度。这对于不依赖完整数据集的快速工作负载验证非常有用。本文档的其余部分将假设拉取所有十个块,但如果使用较少的块,这些步骤仍然有效。
download.py
import os import requests import time CHUNKS = 10 SHARDS = 6000 wrank = int(os.environ.get('RANK', 0)) wsize = int(os.environ.get('WORLD_SIZE', 0)) def download(url, filename, retry=False): if os.path.exists(filename): return response = requests.get(url) # In case of getting rate-limited, wait 3 seconds and retry the # download once. if response.status_code == 429 and not retry: time.sleep(3) download(url, filename, retry=True) if response.status_code != 200: return with open(filename, 'wb') as fn: fn.write(response.content) def split_shards(wsize): shards = [] shards_to_download = list(range(SHARDS)) for shard in range(wsize): idx_start = (shard * SHARDS) // wsize idx_end = ((shard + 1) * SHARDS) // wsize shards.append(shards_to_download[idx_start:idx_end]) return shards for chunk in range(1, CHUNKS + 1): shards_to_download = split_shards(wsize) for shard in shards_to_download[wrank]: filename = f'example_train_chunk{chunk}_shard{shard}.jsonl.zst' url = f'https://hugging-face.cn/datasets/cerebras/SlimPajama-627B/resolve/main/train/chunk{chunk}/example_train_{shard}.jsonl.zst' download(url, filename)
extract.py
import os import requests import subprocess from glob import glob wrank = int(os.environ.get('RANK', 0)) wsize = int(os.environ.get('WORLD_SIZE', 0)) def split_shards(wsize, dataset): shards = [] for shard in range(wsize): idx_start = (shard * len(dataset)) // wsize idx_end = ((shard + 1) * len(dataset)) // wsize shards.append(dataset[idx_start:idx_end]) return shards dataset = glob('example_train*') shards_to_extract = split_shards(wsize, dataset) for shard in shards_to_extract[wrank]: subprocess.run([f"unzstd --rm {shard}"], shell=True)
concat.sh
#!/bin/bash shards_per_file=800 num_files=`ls example_train_chunk*.jsonl | wc -l` files=(example_train_chunk*.jsonl) # Find the ceiling of the result shards=$(((num_files+shards_per_file-1)/shards_per_file )) echo "Creating ${shards} combined chunks comprising ${shards_per_file} files each" for ((i=0; i<$shards; i++)); do file_start=$((i*shards_per_file)) if [[ $(((i+1)*shards_per_file)) -ge ${#files[@]} ]]; then file_stop=$((${#files[@]}-1)) else file_stop=$(((i+1)*shards_per_file)) fi echo " Building chunk $i with files $file_start to $file_stop" cat ${files[@]:$file_start:$shards_per_file} > train_chunk_${i}.jsonl done
文件保存后,使用以下命令将其上传到工作空间
ngc workspace upload \ --source slim-pajama-scripts \ --destination /scripts nemo-framework
这会将这三个脚本上传到工作空间内的 /scripts 目录。
SlimPajama 数据集 托管在 HuggingFace 上,作为近 60,000 个独立的 jsonl.zst 文件的集合,每个文件大小约为 16MB。download.py 脚本(先前已保存到工作空间)并行下载所有文件,并将它们保存到工作空间。虽然可以使用 HuggingFace Python 库加载文件,但这将花费几个数量级的时间才能完全下载,建议按照脚本直接下载每个分片。
要启动下载过程,请运行以下批处理作业
ngc base-command job run \ --name slim-pajama-download \ --priority NORMAL \ --order 50 \ --preempt RUNONCE \ --min-timeslice 10h \ --total-runtime 10h \ --instance dgxa100.80g.8.norm \ --workspace nemo-framework:/mount_workspace:RW \ --image nvcr.io/nvaie/nemo-framework-training:23.11 \ --result /results \ --array-type "PYTORCH" \ --replicas 2 \ --commandline "mkdir -p /mount_workspace/data && \ bcprun --nnodes 2 \ --npernode=48 \ --no_redirect \ --cmd 'cd /mount_workspace/data && python3 ../scripts/download.py'"
根据网络流量,这可以在两节点上仅用 15 分钟完成。完成后,工作空间中应有 59,165 个数据集分片,可以通过运行以下作业进行验证
ngc base-command job run \ --name slim-pajama-download-verification \ --priority NORMAL \ --order 50 \ --preempt RUNONCE \ --min-timeslice 1h \ --instance dgxa100.80g.1.norm \ --workspace nemo-framework:/mount_workspace:RW \ --image nvcr.io/nvaie/nemo-framework-training:23.11 \ --result /results \ --commandline "echo 'Number of files:' \`ls /mount_workspace/data/*zst | wc -l\`"
这将使用最小的 GPU 实例类型针对工作空间启动一个短作业,并显示下载到工作空间的文件数。结果可以通过登录 BCP Web UI 并导航到 slim-pajama-download-verification 作业的日志页面来查看。如果成功,输出应显示 Number of files: 59166。
数据集中的每个分片都使用 .zst 格式压缩,这在基于文本的数据集中很常见。所有分片都需要解压缩才能开始预处理。已上传到工作空间的 extract.py 脚本并行提取工作空间内的所有分片。请注意,NeMo 框架训练容器中不需要 zstd 包来提取文件。以下命令使用 apt 安装此软件包。
要启动提取过程,请运行以下批处理作业
ngc base-command job run \ --name slim-pajama-extract \ --priority NORMAL \ --order 50 \ --preempt RUNONCE \ --min-timeslice 10h \ --total-runtime 10h \ --instance dgxa100.80g.8.norm \ --workspace nemo-framework:/mount_workspace:RW \ --image nvcr.io/nvaie/nemo-framework-training:23.11 \ --result /results \ --array-type "PYTORCH" \ --replicas 2 \ --commandline "bcprun --nnodes 2 \ --npernode=1 \ --no_redirect \ --cmd 'apt update && apt install -y zstd' && \ bcprun --nnodes 2 \ --npernode=48 \ --no_redirect \ --cmd 'cd /mount_workspace/data && python3 ../scripts/extract.py'"
这可能需要长达一小时的时间才能在两个节点上完成。完成后,工作空间中应有 59,165 个扩展名为 .jsonl 的已提取数据集分片,并且没有压缩文件,这可以通过以下作业进行验证
ngc base-command job run \ --name slim-pajama-extract-verification \ --priority NORMAL \ --order 50 \ --preempt RUNONCE \ --min-timeslice 1h \ --instance dgxa100.80g.1.norm \ --workspace nemo-framework:/mount_workspace:RW \ --image nvcr.io/nvaie/nemo-framework-training:23.11 \ --result /results \ --commandline "echo 'Number of files:' \`ls /mount_workspace/data/*jsonl | wc -l\`"
这将使用最小的 GPU 实例类型针对工作空间启动一个短作业,并显示下载到工作空间的文件数。结果可以通过登录 BCP Web UI 并导航到 slim-pajama-extract-verification 作业的日志页面来查看。如果成功,输出中应显示 Number of files: 59166。
为了获得最佳的预训练吞吐量,建议最大限度地减少数据集中的文件总数,以减少磁盘和 CPU I/O 操作。由于 SlimPajama 包含近 60,000 个文件,每个文件大约 43MB,因此应将这些文件合并为更少、更大的文件。对于文件应该有多大没有硬性规定,但建议保持合并后的文件小于 45GB,因为更大的文件可能会抛出内存不足错误。
上传的 concat.sh 脚本一次获取 800 个单独的文件,并将它们连接成一个大约 34GB 的文件,总共 74 个合并后的文件。鉴于分片是 .jsonl 格式,所有文件中的每一行都是有效的 JSON 结构,可以安全地连接,而无需担心结构。如果文件只是 .json 格式,则应检查它们的结构,以查看连接是否会改变格式。
要将所有文件连接成更大的块,请启动以下批处理作业
ngc base-command job run \ --name "slim-pajama-concat" \ --priority NORMAL \ --order 50 \ --preempt RUNONCE \ --min-timeslice 10h \ --total-runtime 10h \ --instance dgxa100.80g.8.norm \ --workspace nemo-framework:/mount_workspace:RW \ --image nvcr.io/nvaie/nemo-framework-training:23.11 \ --result /results \ --commandline "cd /mount_workspace/data && \ bash ../scripts/concat.sh && \ rm example_train_chunk*.jsonl"
这可能需要四个或更多小时才能完成。完成后,应该有 74 个更大的块 (0-73),每个块 34GB,最后一个文件除外,它只有 29GB。这可以通过以下作业进行验证
ngc base-command job run \ --name slim-pajama-concat-verification \ --priority NORMAL \ --order 50 \ --preempt RUNONCE \ --min-timeslice 1h \ --instance dgxa100.80g.1.norm \ --workspace nemo-framework:/mount_workspace:RW \ --image nvcr.io/nvaie/nemo-framework-training:23.11 \ --result /results \ --commandline "echo 'Number of files:' \`ls /mount_workspace/data/*jsonl | wc -l\`"
这将使用最小的 GPU 实例类型针对工作空间启动一个短作业,并显示下载到工作空间的文件数。结果可以通过登录 BCP Web UI 并导航到 slim-pajama-concat-verification 作业的日志页面来查看。如果成功,输出中应显示 Number of files: 74。
一旦将各个分片合并成更大的文件,数据集就可以进行预处理了。预处理包括标记化数据集,并将每个文件转换为大型二进制文件和小型索引文件,以实现最佳的 I/O 操作。NeMo 框架包含将 .jsonl 文件转换为预期格式的脚本。可以使用各种分词器,也可以在预处理期间训练自定义 SentencePiece 分词器。在本例中,使用了用于 GPT 模型的 BPE 分词器。
要预处理连接的分片,请启动以下批处理作业
ngc base-command job run \ --name "preprocess-slim-pajama" \ --priority NORMAL \ --order 50 \ --preempt RUNONCE \ --min-timeslice 10h \ --total-runtime 10h \ --instance dgxa100.80g.8.norm \ --replicas 2 \ --array-type "PYTORCH" \ --result /results \ --image "nvcr.io/nvaie/nemo-framework-training:23.11" \ --workspace nemo-framework:/mount_workspace:RW \ --commandline "cd /opt/NeMo-Megatron-Launcher/launcher_scripts && \ bcprun \ --nnodes=1 \ --npernode=1 \ --no_redirect \ --cmd 'mkdir -p /mount_workspace/data/bpe && \ cd /mount_workspace/data/bpe && \ wget https://hugging-face.cn/gpt2/resolve/main/vocab.json && \ wget https://hugging-face.cn/gpt2/resolve/main/merges.txt' && \ python3 main.py \ launcher_scripts_path=/opt/NeMo-Megatron-Launcher/launcher_scripts \ data_dir=/mount_workspace/data \ base_results_dir=/mount_workspace/results \ cluster_type=bcp \ stages=[data_preparation] \ data_preparation=generic/custom_dataset \ data_preparation.run.node_array_size=\${NGC_ARRAY_SIZE} \ data_preparation.run.cpus_per_node=512 \ data_preparation.train_tokenizer=False \ data_preparation.custom_dataset_dir=/mount_workspace/data \ data_preparation.raw_dataset_files=/mount_workspace/data \ data_preparation.tokenizer_library=megatron \ data_preparation.tokenizer_model=null \ data_preparation.tokenizer_type=GPT2BPETokenizer \ data_preparation.vocab_file=/mount_workspace/data/bpe/vocab.json \ data_preparation.merges_file=/mount_workspace/data/bpe/merges.txt && \ rm -rf /mount_workspace/data/train_chunk*jsonl && \ mv /mount_workspace/data/preprocessed/* /mount_workspace/data/"
在两个节点上,这可能需要六个小时或更长时间才能完成。完成后,在工作空间内的 data/custom_dataset/preprocessed 目录中,将有 74 个单独的 .bin 文件(每个文件约 16GB)和 74 个 .idx 文件(每个文件约 165MB)。这可以通过以下作业进行验证
ngc base-command job run \ --name slim-pajama-preprocess-verification \ --priority NORMAL \ --order 50 \ --preempt RUNONCE \ --min-timeslice 1h \ --instance dgxa100.80g.1.norm \ --workspace nemo-framework:/mount_workspace:RW \ --image nvcr.io/nvaie/nemo-framework-training:23.11 \ --result /results \ --commandline "echo 'Number of binary files:' \`ls /mount_workspace/data/*bin | wc -l\` && \ echo 'Number of index files:' \`ls /mount_workspace/data/*idx | wc -l\` && \ echo 'File sizes:' \`du -sh /mount_workspace/data/*\`"
这将使用最小的 GPU 实例类型针对工作空间启动一个短作业,并显示下载到工作空间的文件数。结果可以通过登录 BCP Web UI 并导航到 slim-pajama-preprocess-verification 作业的日志页面来查看。如果成功,它应该显示
Number of binary files: 74 Number of index files: 74 File sizes: 16G /mount_workspace/data/train_chunk_0.jsonl_text_document.bin 153M /mount_workspace/data/train_chunk_0.jsonl_text_document.idx 16G /mount_workspace/data/train_chunk_1.jsonl_text_document.bin 153M /mount_workspace/data/train_chunk_1.jsonl_text_document.idx ...
模型训练
数据准备完成后,就可以训练模型了。NeMo 框架包含许多预定义的配置文件,用于各种模型,包括 80 亿参数 GPT 模型。本节将演示如何在可变数量的节点上启动 8B 模型的训练。
ngc base-command job run \ --name "gpt-training-8b-bf16" \ --instance dgxa100.80g.8.norm \ --image "nvcr.io/nvaie/nemo-framework-training:23.11" \ --result /results \ --workspace nemo-framework:/mount_workspace:RW \ --total-runtime 5D \ --replicas 8 \ --array-type PYTORCH \ --commandline "\ set -x && \ python3 /opt/NeMo-Megatron-Launcher/launcher_scripts/main.py \ cluster_type=bcp \ stages=[training] \ training=gpt3/7b_improved \ launcher_scripts_path=/opt/NeMo-Megatron-Launcher/launcher_scripts \ data_dir=/mount_workspace/data \ base_results_dir=/mount_workspace/results \ training.run.name=\"gpt_8b\" \ training.run.time_limit=\"5-00:00:00\" \ training.trainer.max_time=\"4:23:30:00\" \ training.trainer.num_nodes=\${NGC_ARRAY_SIZE} \ training.model.tokenizer.vocab_file=/mount_workspace/data/bpe/vocab.json \ training.model.tokenizer.merge_file=/mount_workspace/data/bpe/merges.txt \ training.model.data.data_prefix=[0.0135,'/mount_workspace/data/train_chunk_0.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_1.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_2.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_3.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_4.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_5.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_6.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_7.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_8.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_9.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_10.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_11.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_12.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_13.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_14.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_15.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_16.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_17.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_18.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_19.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_20.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_21.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_22.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_23.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_24.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_25.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_26.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_27.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_28.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_29.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_30.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_31.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_32.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_33.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_34.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_35.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_36.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_37.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_38.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_39.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_40.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_41.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_42.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_43.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_44.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_45.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_46.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_47.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_48.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_49.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_50.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_51.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_52.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_53.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_54.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_55.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_56.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_57.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_58.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_59.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_60.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_61.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_62.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_63.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_64.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_65.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_66.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_67.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_68.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_69.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_70.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_71.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_72.jsonl_text_document',0.0135,'/mount_workspace/data/train_chunk_73.jsonl_text_document'] \ > >(tee -a /results/train_log.log) \ 2> >(tee -a /results/train_stderr.log >&2) && \ rsync -P -rvh /mount_workspace/results /results"
其中
总运行时间 指定了时间限制,在此时间之后,BCP 将终止作业。指定的此作业将在 5 天后自动终止。如果需要不同的时间限制(即,如果作业应仅运行 24 小时),请在此处指定。
副本数 应根据要测试的节点数进行更新。请注意,虽然可以调整数量,但它需要能够被全局批大小 (GBS)、微批大小 (MBS)、张量并行 (TP) 和流水线并行 (PP) 整除,其中
GBS % (MBS * num GPUs) / (PP * TP)。对于 8B 模型,默认 GBS 为 512,MBS 为 1,TP 为 4,PP 为 1。因此,副本数为 8 是有效的,因为512 % (1 * (8 * 8)) / (1 * 4) == 0。training.run.time_limit:是 NeMo 框架将自动关闭自身的时间。这与上面的总运行时间不同,因为这并非由 BCP 实现,理论上应该涉及干净的退出,而 BCP 终止将强制终止,而不管状态如何。如果首选干净的退出,则可以将其设置为低于上面的总运行时间。training.trainer.max_time:是 NeMo 框架将完成当前前向传递(如果需要)并开始保存检查点的时间。建议将其设置为比总时间限制提前 30-60 分钟,以便为保存反映模型最终状态的检查点提供额外的回旋余地。保存检查点后,训练过程将干净地退出。training.model.data.data_prefix:指向已预处理的自定义数据集。training=gpt3/7b_improved:是要训练的模型。7b_improved模型尤其等同于 8B 模型。要训练不同的模型,请指定要使用的配置。这些选项可以在/opt/NeMo-Megatron-Launcher/launcher_scripts/conf/目录中找到。
注意:8B 模型需要几天时间才能在较小的集群上训练到收敛。如果需要快速验证,可以使用 gpt3/126m 配置,该配置可以在 4 个 DGX A100 上在不到两天的时间内训练到完全收敛。
如前所述,训练过程会利用集群中涉及的许多硬件组件。作业开始后,您可以在 BCP Web UI 中查看遥测数据。以下屏幕截图是在 8 个节点上运行的 GPT 8B 训练会话的前 24 小时的示例。
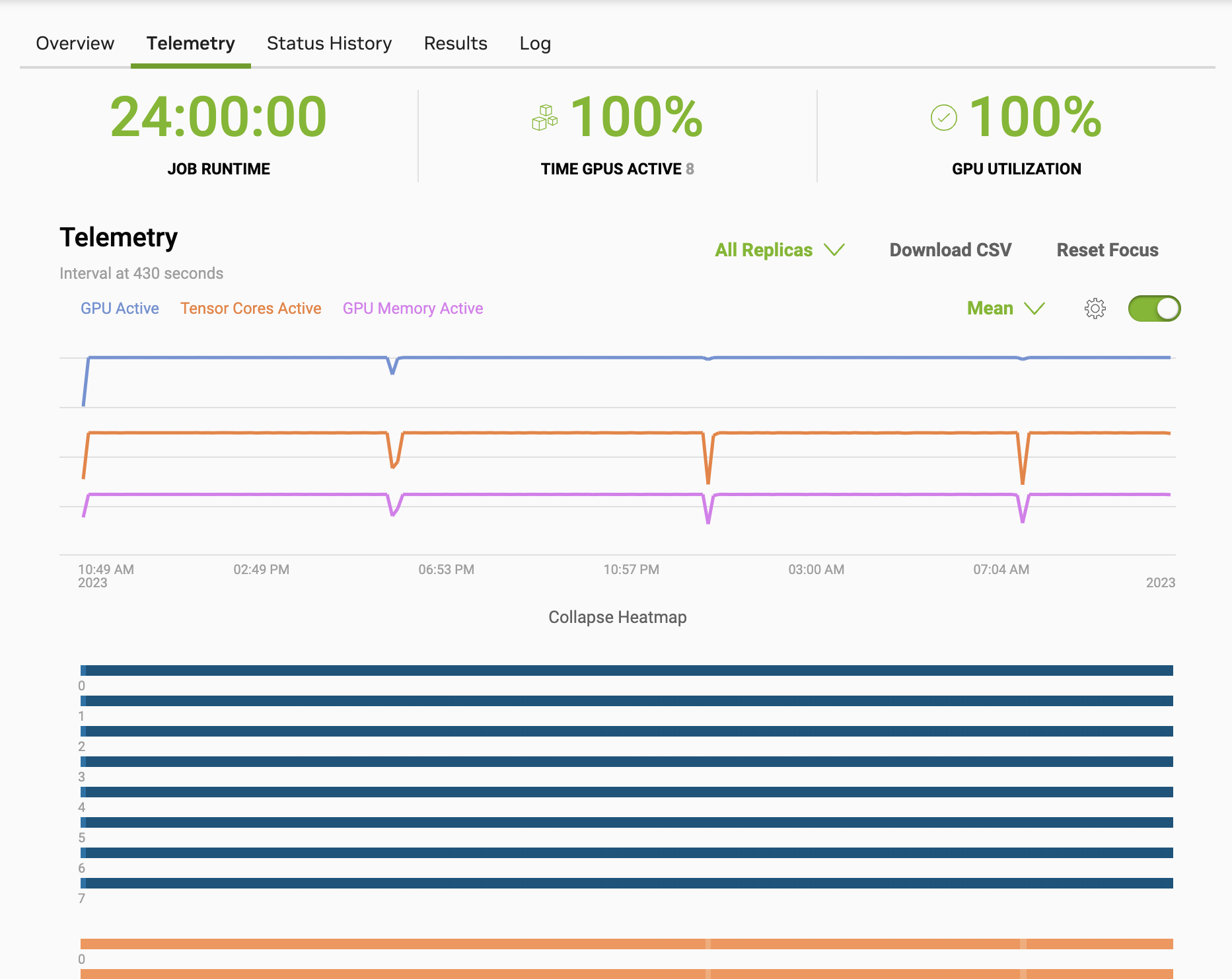
可以在作业页面的“日志”部分查看训练进度。这将显示完成百分比以及训练模型剩余的估计时间。请注意,作业可能会在模型完成训练之前终止,具体取决于指定的时间限制。这仍然很有价值,因为模型应具有确定性的损失曲线,并且可以进行准确性比较,如果作业运行足够长的时间,则可以用于验证硬件是否仍然健康。
默认情况下,在 2000 个全局步骤后,将根据当前模型状态保存一个检查点。对于使用最新训练容器的 8B 模型,每个分布式检查点将保存为大约 90GB 大小的分布式目录。如果本地挂载了工作空间,则可以在工作空间中查看检查点
du -sh results/gpt_8b/results/checkpoints/* 90G results/gpt_8b/results/checkpoints/megatron_gpt--val_loss=1.76-step=50000-consumed_samples=25600000.0 90G results/gpt_8b/results/checkpoints/megatron_gpt--val_loss=1.76-step=50000-consumed_samples=25600000.0-last 90G results/gpt_8b/results/checkpoints/megatron_gpt--val_loss=1.76-step=48000-consumed_samples=24576000.0 90G results/gpt_8b/results/checkpoints/megatron_gpt--val_loss=1.76-step=46000-consumed_samples=23552000.0 90G results/gpt_8b/results/checkpoints/megatron_gpt--val_loss=1.77-step=44000-consumed_samples=22528000.0 90G results/gpt_8b/results/checkpoints/megatron_gpt--val_loss=1.77-step=42000-consumed_samples=21504000.0 90G results/gpt_8b/results/checkpoints/megatron_gpt--val_loss=1.78-step=40000-consumed_samples=20480000.0
上面的命令指示已保存六个检查点,以及最新检查点的附加副本,名称中包含 -last.ckpt。在本例中,验证损失随着每个检查点而改善,表明模型按预期进行。默认情况下,最多保存十个具有较低 val_loss 分数的检查点,一旦达到该限制,较低的分数将替换较高的分数。
在每次验证传递之后,最新的检查点将始终根据当前模型进行覆盖,而与 val_loss 分数无关。因此,在某些情况下,如果 val_loss 分数没有降低,则 -last.ckpt 文件可能不具有最低的 val_loss 分数。
在 JupyterLab 中运行 NeMo 框架
您可以使用 BCP 启动一个作业,该作业在 NeMo 框架训练容器内部署 JupyterLab。这非常适合使用 NeMo 框架测试和开发模型和工作流程。
要从 Base Command Platform UI 执行此操作
从 Base Command 仪表板中,选择 作业,然后选择 创建作业。您将进入作业创建页面。
选择您的加速计算环境和特定的计算实例。建议从单节点 8-GPU 实例开始。
选择要挂载到作业的任何数据集或工作空间。
从
容器选择部分从“选择容器”下拉菜单中选择
nvaie/nemo-framework-training从“选择标签”下拉菜单中选择最新标签
在 运行命令 框中添加
jupyter lab --ip=0.0.0.0 --allow-root --no-browser --NotebookApp.token='' --notebook-dir=/ --NotebookApp.allow_origin='*'选择 HTTPS 协议端口,并在端口
8888上公开它(务必单击 添加 以添加端口)。
单击页面右上角的 启动作业 按钮以启动您的 JupyterLab NeMo 作业。
这将在指定计算实例上的训练容器内启动 JupyterLab,它将在端口 8888 上公开,端点将公开访问。作业运行后,在作业页面中,您可以通过单击 Web UI 作业详细信息“概述”选项卡中“URL / 主机名”下显示的 URL 来启动 JupyterLab。
在 JupyterLab 中,启动一个 Python 笔记本,并在单元格中运行 import nemo 以在笔记本中使用 NeMo,或使用容器内 /opt/NeMo 目录中的现有笔记本之一。
声明
声明
本文档仅供参考,不得视为对产品的特定功能、条件或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含的信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对使用此类信息或因使用此类信息而可能导致的侵犯第三方专利或其他权利的后果或使用不承担任何责任。本文档不构成开发、发布或交付任何材料(如下定义)、代码或功能的承诺。
NVIDIA 保留随时对此文档进行更正、修改、增强、改进和任何其他更改的权利,恕不另行通知。
客户在下订单前应获取最新的相关信息,并应验证此类信息是否为最新和完整。
NVIDIA 产品根据订单确认时提供的 NVIDIA 标准销售条款和条件进行销售,除非 NVIDIA 和客户的授权代表签署的个别销售协议(“销售条款”)另有约定。NVIDIA 特此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档不直接或间接地形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命维持设备,也不适用于 NVIDIA 产品的故障或故障可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对 NVIDIA 产品包含和/或用于此类设备或应用不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不保证基于本文档的产品将适用于任何特定用途。NVIDIA 不一定执行每个产品的所有参数的测试。客户有责任评估和确定本文档中包含的任何信息的适用性,确保产品适合并符合客户计划的应用,并为该应用执行必要的测试,以避免应用或产品的默认设置。客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同的条件和/或要求。NVIDIA 对因以下原因可能引起的或可归因于以下原因的任何默认设置、损坏、成本或问题不承担任何责任:(i) 以任何与本文档相悖的方式使用 NVIDIA 产品,或 (ii) 客户产品设计。
根据本文档,未授予任何 NVIDIA 专利权、版权或其他 NVIDIA 知识产权的明示或暗示许可。 NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予的使用此类产品或服务的许可,也不构成 NVIDIA 对其的担保或认可。 使用此类信息可能需要获得第三方专利或其它知识产权的许可,或者获得 NVIDIA 专利或其它知识产权的许可。
只有在事先获得 NVIDIA 书面批准的情况下才允许复制本文档中的信息,并且复制时不得进行任何修改,并且必须完全遵守所有适用的出口法律法规,并随附所有相关的条件、限制和声明。
本文件以及所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”,且以下分别称为“材料”)均按“现状”提供。 NVIDIA 对这些材料不作任何明示、暗示、法定或其他形式的保证,并明确声明不承担任何关于不侵权、适销性和针对特定用途适用性的默示保证责任。 在法律允许的最大范围内,NVIDIA 在任何情况下均不对因使用本文档而导致的任何损害承担责任,包括但不限于任何直接、间接、特殊、偶然、惩罚性或后果性损害,无论何种原因造成,也无论基于何种责任理论,即使 NVIDIA 已被告知可能发生此类损害。 尽管客户可能因任何原因遭受任何损害,但 NVIDIA 对客户承担的与本文所述产品相关的总体和累积责任应根据产品的销售条款进行限制。
商标
NVIDIA、NVIDIA 徽标和 Base Command 是 NVIDIA Corporation 在美国和其他国家/地区的商标和/或注册商标。 其他公司和产品名称可能是与其各自公司相关的商标。
版权
© 2023-2024 NVIDIA Corporation 和附属公司。 保留所有权利。