使用 NVSHMEM¶
NVSHMEM 作业由多个操作系统进程组成,这些进程称为处理元素 (PE),并在 GPU 集群中的一个或多个节点上执行。NVSHMEM 作业由进程管理器启动,NVSHMEM 作业中的每个进程都运行同一可执行程序的副本。
NVSHMEM 作业代表单程序多数据 (SPMD) 并行执行。每个 PE 都被分配一个整数标识符 (ID),范围从零到小于 PE 总数的数值。PE ID 用于标识 OpenSHMEM 操作中的源或目标进程,应用程序开发人员也使用 PE ID 在 NVSHMEM 作业中为特定进程分配工作。
NVSHMEM 作业中的所有 PE 必须同时(即集体地)调用 NVSHMEM 初始化例程,然后才能执行 NVSHMEM 操作。同样,在退出之前,PE 也必须集体调用 NVSHMEM 最终化函数。初始化后,可以查询 PE 的 ID 和正在运行的 PE 总数。PE 通过对称内存进行通信和共享数据,对称内存是从位于 GPU 内存中的对称堆分配的。此内存通过使用 CPU 侧 NVSHMEM 分配 API 分配。使用任何其他方法分配的内存被视为分配 PE 的私有内存,其他 PE 无法访问。
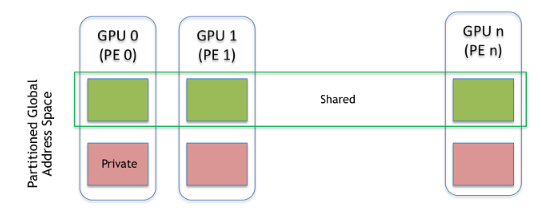
每个 PE 上的共享和私有内存区域。所有 PE 的共享内存段的聚合称为分区全局地址空间 (PGAS)。
NVSHMEM 中的对称内存分配是一种集体操作,它要求每个 PE 在给定分配的大小参数中传递相同的值。生成的内存分配是对称的;指定大小的线性内存区域从每个 PE 的对称堆中分配,随后可以使用 PE ID 和 NVSHMEM 分配例程返回的对称地址的组合进行访问。作业中的所有其他 PE 都可以通过 CUDA 内核和 CPU 上的 NVSHMEM API 访问对称内存。此外,NVSHMEM 分配例程返回的对称地址也是调用 PE 上本地 GPU 内存的有效指针,并且可以被该 PE 用于通过使用 CUDA API 和 GPU 上的加载/存储操作直接访问其对称分配部分。
与所有 PGAS 模型类似,全局地址空间中数据的位置是 NVSHMEM 寻址模型的固有组成部分。NVSHMEM 操作以 <symmetric_address, destination_PE> 元组的形式访问对称对象。对称地址可以通过对 NVSHMEM 分配例程返回的地址执行指针运算来生成,例如 &X[10] 或 &ptr->x。对称地址仅在 NVSHMEM 分配例程返回它们的 PE 上有效,并且不能与其他 PE 共享。在 NVSHMEM 运行时中,对称地址被转换为实际的远程地址,并使用高级 CUDA 内存映射技术来确保可以以最小的开销完成此转换。
NVSHMEM 示例程序¶
以下代码片段展示了 CUDA 内核中 NVSHMEM 的简单用法示例,其中 PE 形成通信环。
#include <stdio.h>
#include <cuda.h>
#include <nvshmem.h>
#include <nvshmemx.h>
__global__ void simple_shift(int *destination) {
int mype = nvshmem_my_pe();
int npes = nvshmem_n_pes();
int peer = (mype + 1) % npes;
nvshmem_int_p(destination, mype, peer);
}
int main(void) {
int mype_node, msg;
cudaStream_t stream;
nvshmem_init();
mype_node = nvshmem_team_my_pe(NVSHMEMX_TEAM_NODE);
cudaSetDevice(mype_node);
cudaStreamCreate(&stream);
int *destination = (int *) nvshmem_malloc(sizeof(int));
simple_shift<<<1, 1, 0, stream>>>(destination);
nvshmemx_barrier_all_on_stream(stream);
cudaMemcpyAsync(&msg, destination, sizeof(int), cudaMemcpyDeviceToHost, stream);
cudaStreamSynchronize(stream);
printf("%d: received message %d\n", nvshmem_my_pe(), msg);
nvshmem_free(destination);
nvshmem_finalize();
return 0;
}
此示例从 main 开始,首先初始化 NVSHMEM 库,查询节点上团队中 PE 的 ID,并使用节点上 ID 设置 CUDA 设备。必须先设置设备,然后才能分配内存或启动内核。创建一个流,并在每个 PE 上分配一个名为 destination 的对称整数。最后,使用指向此对称对象的指针作为其参数,在一个线程上启动 simple_shift kernel。
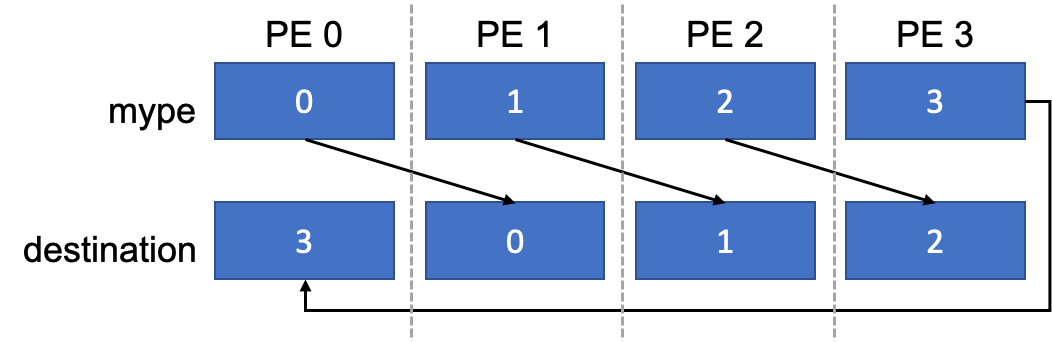
simple_shift 内核执行的通信图示。
此内核查询全局 PE ID 和正在执行的 PE 数量。然后,它执行单元素整数放置操作,将调用 PE 的 ID 写入到 ID 次高的 PE(如果 PE 的 ID 最高,则为 0)上的 destination 中。内核在流上异步启动,然后在流上执行 NVSHMEM 屏障,以确保所有更新都已完成,并执行异步复制,将更新后的 destination 值复制到主机。同步流并打印结果。以下是包含 8 个 PE 的示例输出
0: received message 7
1: received message 0
2: received message 1
4: received message 3
6: received message 5
7: received message 6
3: received message 2
5: received message 4
最后,释放 destination 缓冲区,并在程序退出之前最终化 NVSHMEM 库。
使用 NVSHMEM InfiniBand GPUDirect Async 传输¶
NVSHMEM 支持完全在 GPU 中实现 InfiniBand 网络通信的控制平面和数据平面,从而无需反向代理设备发起的通信。此功能集通过 InfiniBand GPUDirect Async (IBGDA) 远程传输公开。
IBGDA 传输具有以下先决条件
- 仅限 Mellanox HCA 和 NIC。
- Mellanox OFED 5.0 或更高版本。
- nvidia.ko >= 510.40.3
- nvidia_peermem >= 510.40.3 或 nv_peer_mem >= 1.3
有关 IBGDA 和影响该传输的环境变量的更多信息,请参阅本文档的环境变量部分。
将 NVSHMEM 与 MPI 或 OpenSHMEM 一起使用¶
NVSHMEM 可以与 OpenSHMEM 或 MPI 一起使用,这使得现有的 OpenSHMEM 和 MPI 应用程序可以更轻松地逐步移植到使用 NVSHMEM。以下代码片段展示了如何在 MPI 程序中初始化 NVSHMEM。在此程序中,我们假设每个 MPI 进程也是一个 NVSHMEM PE,其中每个进程都具有 MPI 秩和 NVSHMEM 秩。
#include <cuda.h>
#include <nvshmem.h>
#include <nvshmemx.h>
#include <mpi.h>
int main(int argc, char *argv[]) {
int rank, ndevices;
nvshmemx_init_attr_t attr;
MPI_Comm comm = MPI_COMM_WORLD;
attr.mpi_comm = &comm;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
cudaGetDeviceCount(&ndevices);
cudaSetDevice(rank % ndevices);
nvshmemx_init_attr(NVSHMEMX_INIT_WITH_MPI_COMM, &attr);
// ...
nvshmem_finalize();
MPI_Finalize();
return 0;
}
如本示例所示,应首先初始化 MPI(或 OpenSHMEM)库。MPI 初始化后,可以查询 MPI 秩并将其用于设置 CUDA 设备。创建一个 nvshmemx_init_attr_t 结构,并将 mpi_comm 字段分配给 MPI 通信器句柄的引用。要启用 MPI 兼容模式,请使用 nvshmemx_init_attr 操作而不是 nvshmem_init。有关更多详细信息,请参阅 nvshmemx_init_attr。
编译 NVSHMEM 程序¶
编写应用程序后,可以使用 nvcc 编译该应用程序并将其链接到 NVSHMEM。
NVSHMEM 还在所有已安装软件包的默认位置提供 cmake 配置文件。Cmake 工具链可以使用 cmake find_package() 实用程序在配置模式下与 nvshmem 一起构建。
有关更复杂的构建环境的一些参考资料,请参阅故障排除和常见问题解答。
NVSHMEM 库安装包含两个目录:lib 和 include。lib 包含静态库 libnvshmem.a 和 libnvshmem_device.a;共享库 libnvshmem_host.so;以及 NVSHMEM 引导模块。include 目录包含所有 NVSHMEM 头文件。可以使用以下命令编译并静态链接包含上述第一个示例的示例,假设源文件为 nvshmem_hello.cu,NVSHMEM 库安装路径为 NVSHMEM_HOME。
nvcc -rdc=true -ccbin g++ -gencode=$NVCC_GENCODE -I $NVSHMEM_HOME/include nvshmem_hello.cu -o nvshmem_hello.out -L $NVSHMEM_HOME/lib -lnvshmem -lnvidia-ml -lcuda -lcudart
可以使用以下命令通过动态链接主机 NVSHMEM 库来编译此示例。
nvcc -rdc=true -ccbin g++ -gencode=$NVCC_GENCODE -I $NVSHMEM_HOME/include nvshmem_hello.cu -o nvshmem_hello.out -L $NVSHMEM_HOME/lib -lnvshmem_host -lnvshmem_device
NVCC_GENCODE 是一个 nvcc 选项,用于指定要为其构建代码的 GPU 架构。有关该选项的更多信息,请访问 http://docs.nvda.net.cn/cuda/cuda-compiler-driver-nvcc/index.html。
如果 NVSHMEM 是使用 UCX 支持构建的,则需要以下附加标志。
-L$(UCX_HOME)/lib -lucs -lucp
如果 NVSHMEM 是使用 IBDEVX 或 IBGDA 支持构建的,则需要以下附加标志。
-L$(NON_STANDARD_MLX5_LOCATION) -lmlx5
运行 NVSHMEM 程序¶
默认情况下,NVSHMEM 库在编译时支持 PMI 和 PMI-2 接口。但是,它也可以编译为支持 PMIx。有关编译 NVSHMEM 库的更多信息,请参阅安装指南。
NVSHMEM 应用程序可以直接由 mpirun 启动器执行。没有 NVSHMEM 特定的选项或配置文件。例如,以下两个命令都是启动 NVSHMEM 应用程序的有效方法。
mpirun -n 4 -ppn 2 -hosts hostname1,hostname2 /path/to/nvshmem/app/binary
mpirun -n 2 /path/to/nvshmem/app/binary
NVSHMEM 应用程序也可以直接由 srun 启动,而无需任何其他配置。
默认情况下,NVSHMEM 应用程序将尝试使用 PMI-1 进行通信。但是,应用程序使用的 PMI 接口可以在运行时通过设置 NVSHMEM_BOOTSTRAP_PMI 环境变量进行修改。这使得同一个 NVSHMEM 二进制文件可以使用不同的 PMI 通信接口由多个启动器运行。有关 NVSHMEM_BOOTSTRAP_PMI 接口的更多信息,请参阅环境变量
NVSHMEM 在 scripts/install_hydra.sh 处为 Hydra 进程管理器打包了一个安装脚本,以实现独立的 NVSHMEM 应用程序开发。这消除了对安装外部 MPI 以使用 NVSHMEM 的任何依赖性。具体来说,您可以编写一个 NVSHMEM 程序,并使用提供的 Hydra 进程管理器运行多进程作业。从 scripts/install_hydra.sh 安装的 Hydra 启动器称为 nvshmrun.hydra,并安装了一个符号链接 nvshmrun 以方便访问。安装后运行 nvshmrun.hydra -h 以获取帮助信息。
通信模型¶
NVSHMEM 提供 get 和 put API,分别用于从对称对象复制数据和将数据复制到对称对象。提供了这些 API 的批量传输、标量传输和交错版本。此外,还提供了原子内存操作 (AMO),可用于对对称变量执行原子更新。借助这些 API,NVSHMEM 提供了从 CUDA 内核对 PGAS 中存储的数据进行细粒度和低开销的访问。通过从内核内部执行通信,NVSHMEM 还允许应用程序从 GPU warp 调度硬件的固有延迟隐藏功能中受益。
除了 put、get 和 AMO 库例程之外,应用程序还可以使用 nvshmem_ptr 例程来查询指向位于其他 PE 上的 PGAS 分区中的数据的直接指针。当指定 PE 上的内存可以直接访问时,此函数返回有效指针。否则,它返回空指针。这允许应用程序向全局内存发出直接加载和存储。NVSHMEM API 和加载/存储(在硬件允许的情况下)可用于访问本地和远程数据,这允许一个代码路径处理本地和远程数据。同样,应用程序还可以使用 nvshmemx_mc_ptr 例程来查询任何团队的直接多播指针,以指向位于 PGAS 分区中的数据。当指定 TEAM 的内存在支持 CU_DEVICE_ATTRIBUTE_MULTICAST_SUPPORTED 的平台上可以直接访问时,此函数返回有效指针。否则,它返回空指针。这允许应用程序向全局多播内存发出直接多媒体加载归约和存储广播。有关分配、发布和订阅多播内存的更多信息,请参阅多播内存编程指南。
NVSHMEM 为 OpenSHMEM 接口提供了以下值得注意的扩展
- 使用 NVSHMEM 分配 API 分配的所有对称内存都是固定的 GPU 设备内存。
- NVSHMEM 支持 GPU 侧和 CPU 侧的通信和同步 API,前提是涉及的内存是由 NVSHMEM 分配的 GPU 设备内存。在其他 OpenSHMEM 实现中,这些 API 只能从 CPU 调用。
NVSHMEM 是一个有状态的库,当 PE 调用 NVSHMEM 初始化例程时,它会检测 PE 正在使用的 GPU。此信息存储在 NVSHMEM 运行时中。PE 进行的所有对称分配调用都返回所选 GPU 的设备内存。PE 进行的所有 NVSHMEM 调用都假定是相对于所选 GPU 或从在此 GPU 上启动的内核内部进行的。当使用 NVSHMEM 时,这需要在应用程序中的 PE 到 GPU 映射上施加某些限制。
NVSHMEM 程序应遵守以下规则
- PE 在首次分配、同步、通信、集体内核 API 启动调用或设备上的 NVSHMEM API 调用之前选择其 GPU(例如,使用 cudaSetDevice)。
- 必须在设备上的第一个 NVSHMEM API 调用之前,在主机上执行 NVSHMEM 分配或同步。
- PE 在 NVSHMEM 作业的整个生命周期中只使用一个 GPU。
- 一个 GPU 不能被多个 PE 使用。
当使用数据访问 API 时,NVSHMEM 依赖于 GPU 硬件中的数据合并功能来提高网络效率。应用程序开发人员在使用 NVSHMEM 中的细粒度通信 API 时,必须遵循 CUDA 编程最佳实践,以促进数据合并。
NVSHMEM 还允许作业中的任何两个 CUDA 线程通过使用 OpenSHMEM 点对点同步 API nvshmem_wait_until 或集体同步 API(如 nvshmem_barrier)在全局内存中的位置上进行同步。
注意:使用同步或集合通信 API 的 CUDA 内核必须使用集合启动 API 启动,以保证无死锁的进度和完成。
不使用 NVSHMEM 同步或集合通信 API,但使用其他 NVSHMEM 通信 API 的 CUDA 内核可以使用正常的 CUDA 启动接口或集合启动 API 启动。这些内核仍然可以使用其他 NVSHMEM 设备端 API,例如单边数据移动 API。
使用集合启动和 CUDA 内核侧同步 API 的 NVSHMEM 程序应遵守以下正确性准则,并且所有 NVSHMEM 程序都应遵守以下性能可预测性准则
- 多个 PE 不应共享同一个 GPU。
- NVSHMEM PE 应独占访问 GPU。GPU 不能用于驱动显示器或用于其他计算作业。
数据一致性¶
OpenSHMEM 根据操作顺序和对称对象更新的可见性来定义全局地址空间中数据的一致性。
NVSHMEM 遵循 OpenSHMEM 内存模型。但是,对 OpenSHMEM 进行了一些重要的例外处理,以使 OpenSHMEM 适应 GPU 架构提供的弱一致性内存模型,如NVSHMEM 和 OpenSHMEM 之间的差异中所述。
NVSHMEM 提供以下方法来访问本地或远程对称内存
- 远程内存访问 (RMA: PUT/GET)
- 原子内存操作 (AMO)
- 信号操作
- 直接加载和存储操作(例如,使用
nvshmem_ptr返回的指针)- 直接多媒体加载归约和存储广播操作(例如,使用
nvshmemx_mc_ptr返回的指针)- 集合函数(广播、归约和其他函数)
- 等待和测试函数(仅限本地对称内存)
由同一 PE 或不同 PE 发出的且并行访问同一内存位置的两个操作,当一个或多个操作执行写入时,会发生冲突。这些冲突会导致 OpenSHMEM 内存模型中未定义的行为。当操作是 AMO 或 AMO 和等待/测试操作的组合时,会进行例外处理。当操作是信号更新和等待/测试操作的组合时,会进行第二次例外处理。
对全局可访问对象的更新是无序的。PE 可以使用 nvshmem_fence 操作强制执行其更新相对于目标 PE 执行的访问的顺序。当 PE 执行的更新必须排序或对目标 PE 以外的 PE 可见时,请使用 nvshmem_quiet 操作。虽然更新是无序的,但保证使用 NVSHMEM API 进行的更新最终会完成,而无需源 PE 或目标 PE 执行任何其他操作。因此,NVSHMEM 保证更新最终将通过 NVSHMEM API 对其他 PE 可见。更新也是稳定的,因为在更新对另一个 API 调用可见后,更新将保持不变,直到被另一个更新替换。这保证了如上所述的同步在有限的时间内完成。
默认情况下,所有 OpenSHMEM 操作都是无序的,程序员必须通过使用 nvshmem_fence 和 nvshmem_quiet 操作对内存更新进行排序,并使用等待/测试操作对内存读取进行排序来确保顺序。屏障操作也可用于对更新和读取进行排序。以下列表提供了有关保证同一 PE 的两个内存访问按顺序发生的场景的更多详细信息
- 访问是按程序顺序发生的不同的集合函数调用的结果。
- 第一次访问是等待或测试调用,后跟读取操作,并且两个操作都以本地对称内存为目标。
- 访问是两个不同的 API 调用或 LD/ST 操作的结果,并通过基于下表的适当排序操作分隔
| 首次访问的类型 | 同一目标 PE | 不同目标 PE |
| 阻塞 | Fence/quiet/barrier | Quiet/barrier |
| 非阻塞 | Quiet/barrier | Quiet/barrier |
nvshmem_quiet 操作用于完成挂起的操作,并提供以下保证
- 调用 PE 发出的所有非阻塞操作都已完成。
- 对所有 PE 的访问(例如,对 PGAS 中的任何位置的访问)都是有序的,因此 quiet 操作之前发生的访问可以被所有 PE 观察为发生在 quiet 操作之后的访问之前。PE 必须使用适当的同步操作(例如,等待/测试操作)来观察在执行 quiet 操作的 PE 上强制执行的排序。
- 保证所有 OpenSHMEM API 和直接存储操作的排序。
nvshmem_fence 操作提供以下较弱的保证,并用于确保操作的点对点排序
- 对每个 PE 的访问(例如,对 PGAS 分区的访问)都是有序的,因此 fence 操作之前发生的访问可以被本地于 PGAS 相应分区的 PE 观察为发生在 fence 操作之后的访问之前。PE 必须使用适当的同步操作(例如,等待/测试操作)来观察在执行 quiet 操作的 PE 上强制执行的排序。
- 保证所有 OpenSHMEM API 和直接存储操作的排序。
多进程 GPU 支持¶
在 NVSHMEM 2.2.1 版本之前,NVSHMEM 每个 GPU 仅支持一个 PE。自 NVSHMEM 2.4.1 以来,有限的多 PE 每 GPU (MPG) 支持可用。MPG 支持取决于应用程序是在有还是没有 CUDA MPS(多进程服务)的情况下运行。MPS 文档可在此处获取。对于 MPG 支持,可以考虑三种情况。
没有 MPS 的 MPG
多个 PE 可以通过时间共享使用同一个 GPU。每个 PE 都有一个与其关联的 CUDA 上下文。GPU 必须切换上下文才能运行来自不同 PE 的 CUDA 任务。由于多个 PE 不能同时在同一个 GPU 上运行,因此点对点同步 API 和集合通信 API 的支持不可用。在此场景中,以下 API 支持可用
- 点对点 RMA API
nvshmem_barrier_all()主机 APInvshmemx_barrier_all_on_stream()nvshmem_sync_all()主机 APInvshmemx_sync_all_on_stream()
带有 MPS 的 MPG
多进程服务 (MPS) 允许在同一个 GPU 上同时运行多个 CUDA 上下文。这使得可以支持 NVSHMEM 的同步和集合通信 API,前提是运行在同一个 GPU 上的所有 PE 的活动线程百分比之和小于 100。在此场景中,所有 NVSHMEM API 的支持都可用。有关如何设置 MPS 客户端进程的活动线程百分比的详细信息,请参阅 MPS 文档。
带有 MPS 和超额订阅的 MPG
当运行在同一个 GPU 上的 PE 的活动线程百分比之和大于 100 时,仅 MPG 中没有 MPS 场景中的有限 API 支持可用。这是因为在这种情况下,CUDA 无法保证分配给同一个 GPU 的所有 PE 都可以同时在 GPU 上运行,因此可能会导致点对点同步和集合通信 API 中的死锁。
构建 NVSHMEM 应用程序/库¶
NVSHMEM 构建为两个库 - libnvshmem_host.so 和 libnvshmem_device.a。即使应用程序仅使用主机 API 或设备 API,也必须链接这两个库。
在构建使用 NVSHMEM 的共享库时,静态库 libnvshmem_device.a 将集成到共享库中。使用此库的应用程序反过来也可能使用 NVSHMEM 或链接另一个使用 NVSHMEM 的库。这可能导致多个设备库实例,从而导致符号冲突。因此,共享库必须通过仅公开其自己的 API 来隐藏 NVSHMEM 符号。它可以使用链接器脚本来实现此目的。