内存模型¶
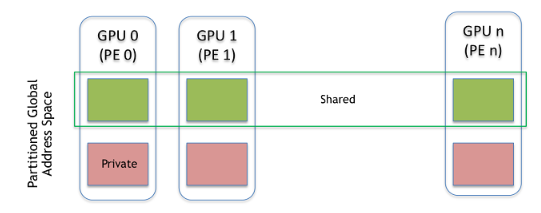
NVSHMEM 内存模型
NVSHMEM 程序由每个 PE 私有的数据对象和所有 PE 远程可访问的数据对象组成。私有数据对象存储在每个 PE 的本地内存中,并且只能由 PE 本身访问;这些数据对象不能通过 NVSHMEM 例程被其他 PE 访问。私有数据对象遵循 C 的内存模型。然而,远程可访问的对象可以被远程 PE 使用 NVSHMEM 例程访问。远程可访问的数据对象称为对称数据对象。每个对称数据对象在所有 PE 上都有一个对应的对象,具有相同的名称、类型和大小,可以通过 NVSHMEM API [1] 访问。
在 NVSHMEM 中,由 NVSHMEM 内存管理例程分配的 GPU 内存是对称的。有关分配对称内存的信息,请参阅第 内存管理 节。
NVSHMEM 动态内存分配例程(例如,nvshmem_malloc)允许在称为对称堆的特殊内存区域上集体分配对称数据对象。对称堆在程序执行期间在由 NVSHMEM 库确定的内存位置创建。对称堆可能驻留在不同 PE 上的不同内存区域中。图 NVSHMEM 内存模型 显示了一个 NVSHMEM 内存布局示例,说明了远程可访问的对称对象和私有数据对象的位置。
对称对象的指针¶
对称数据对象在 NVSHMEM 操作中通过指向所需远程可访问对象的本地指针来引用。此指针中包含的地址称为对称地址。每个对称地址也是一个本地地址,它对于直接内存访问是有效的;然而,并非所有本地地址都是对称的。允许操作传递给 NVSHMEM 例程的对称地址,包括指针算术、数组索引以及结构或联合成员的访问,只要生成的本地指针保持在相同的对称分配或对象内。对称地址仅在其生成的 PE 上有效;使用由不同 PE 生成的对称地址进行直接内存访问或作为 NVSHMEM 例程的参数会导致未定义的行为。
提供给类型化接口的对称地址必须根据其类型和底层架构的任何要求自然对齐。提供给固定大小 NVSHMEM 接口(例如,nvshmem_put32)的对称地址也必须与给定的大小对齐。提供给固定大小 NVSHMEM 接口的对称对象必须具有等于给定操作的位宽的存储大小 [2]。由于 C/C++ 结构可能包含实现定义的填充,因此固定大小的接口不应与 C/C++ 结构一起使用。“mem”接口(例如,nvshmem_putmem)没有对齐要求。
nvshmem_ptr 例程允许程序员查询指定 PE 上远程可访问数据对象的本地地址。生成的指针对于直接内存访问是有效的;但是,将此地址作为需要对称地址的 NVSHMEM 例程的参数提供会导致未定义的行为。
操作顺序¶
NVSHMEM 中读取数据的阻塞操作(例如,get 或原子 fetch-and-add)应根据操作执行的顺序返回数据。例如,考虑一个程序,该程序对 PE 0 上的对称变量 \(x\) 执行原子 fetch-and-add 操作,值为 \(1\)。
a = nvshmem_int_fadd(x, 1, 0);
b = nvshmem_int_fadd(x, 1, 0);
在此示例中,OpenSHMEM 规范保证 \(b > a\)。然而,这种强排序可能会在弱序架构上产生显著的开销,因为它需要在任何此类操作返回之前执行内存屏障。NVSHMEM 放宽了此要求,以便在 NVIDIA GPU 上提供更高效的实现。因此,NVSHMEM 不保证 \(b > a\)。
如果需要这种排序,程序员可以使用 nvshmem_fence 操作来强制阻塞操作的排序(例如,在上面的两个语句之间)。非阻塞操作不受调用 nvshmem_fence 排序。相反,它们必须使用 nvshmem_quiet 操作完成。获取操作的完成语义与 OpenSHMEM 规范保持不变:get 或 AMO 的结果可用于程序顺序中出现在它之后的任何依赖操作。
原子性保证¶
NVSHMEM 包含许多对对称数据对象执行原子操作的例程,这些例程在第 原子内存操作 节中定义。原子例程保证,使用相同数据类型(在表 标准 AMO 类型和名称 和 扩展 AMO 类型和名称 中指定)的任何这些例程对同一位置的并发访问将是互斥的。当目标 PE 对与一个或多个原子操作相同的位置和相同数据类型执行等待或测试操作时,也保证互斥性。
在以下所有会导致未定义行为的情况下,NVSHMEM 原子操作不保证互斥性。
- 当使用不同数据类型的 NVSHMEM 原子操作对同一位置执行并发访问时。
- 当原子和非原子 NVSHMEM 操作用于并发访问同一位置时。
- 当 NVSHMEM 原子操作和非 NVSHMEM 操作(例如,加载和存储操作)用于并发访问同一位置时。
NVSHMEM 和 OpenSHMEM 之间的差异¶
阻塞式获取操作的顺序¶
OpenSHMEM 中读取数据的阻塞操作,例如 get 或原子 fetch-and-add,应根据操作执行的顺序返回数据。例如,考虑一个程序,该程序执行原子设置操作以更新 PE 0 上的对称变量 x 和 y
// Let: v_N represent symmetric variable v at PE N
// Input: x_0 = 0, y_0 = 0, i = 0, j = 0
if (nvshmem_my_pe() == 0) {
a = nvshmem_int_atomic_set(x, 1, 0);
nvshmem_quiet();
b = nvshmem_int_atomic_set(y, 1, 0);
}
i = nvshmem_int_atomic_fetch(y, 0);
j = nvshmem_int_atomic_fetch(x, 0);
// Allowed output: i = 1, j = 0
在此示例中,OpenSHMEM 规范保证 如果 i == 1 则 j == 1。然而,这种强排序可能会在弱序架构上产生显著的开销,因为它需要在任何获取操作返回之前执行内存屏障。NVSHMEM 放宽了此要求,以提供与 NVIDIA GPU 内存模型对齐的更高效的实现。因此,NVSHMEM 不保证 如果 i == 1 则 j == 1。
如果需要这种排序,程序员可以使用 nvshmem_fence 操作来强制阻塞操作的排序(例如,在上面的两个 nvshmem_int_atomic_fetch 语句之间)。非阻塞操作不受调用 nvshmem_fence 排序。相反,这些操作必须通过使用 nvshmem_quiet 操作完成。获取操作的完成语义与规范保持不变,即 get 或 AMO 的结果可用于程序顺序中出现在它之后的任何依赖操作。
可见性保证¶
在同时具有 NVLink 和 InfiniBand 的系统上,NVSHMEM 同步操作(包括 nvshmem_barrier、nvshmem_barrier_all、nvshmem_quiet、nvshmem_wait_until_* 和 nvshmem_test_*)仅保证对本地 PE 的对称对象更新的可见性。然而,在仅具有 NVLink 的系统上,这些操作保证对对称对象的全局更新可见性。
| [1] | 出于效率原因,对称数据对象的相同偏移量(来自任意内存地址)可能在所有 PE 上使用。有关对称堆布局和实现效率的更多讨论,请参见第 NVSHMEM_MALLOC、NVSHMEM_FREE、NVSHMEM_ALIGN 节 |
| [2] | 字节的位宽在 C 中是实现定义的。limits.h 中的 CHAR_BIT 常量可用于可移植地计算 C 对象的位宽。 |