简介#
NVIDIA NIM for NV-CLIP (NV-CLIP NIM) 将最先进的嵌入模型的强大功能带入企业应用,提供无与伦比的自然语言和多模态理解能力。
借助 NIM,IT 和 DevOps 团队可以轻松地在他们自己管理的环境中自托管 NV-CLIP NIM,同时仍然为开发人员提供行业标准的 API,使他们能够构建强大的副驾驶、聊天机器人和 AI 助手,从而转型其业务。NIM 利用 NVIDIA 的尖端 GPU 加速和可扩展部署,为推理提供最快的路径和无与伦比的性能。
NV-CLIP NIM 将最先进的文本和图像嵌入模型的强大功能带到您的应用程序中,提供无与伦比的自然语言处理和理解能力。您可以将 NV-CLIP NIM 用于语义搜索、检索增强生成 (RAG),或任何使用文本和图像嵌入的应用程序。它构建于 NVIDIA 软件平台之上,整合了 CUDA、TensorRT 和 Triton,可提供开箱即用的 GPU 加速。
企业级功能#
NIM 抽象化了模型推理的内部机制,例如执行引擎和运行时操作。无论使用 TensorRT 还是 ONNX,它们都是性能最优的选择。NIM 提供以下高性能功能:
高性能 NV-CLIP NIM 针对高性能深度学习推理进行了优化,采用 NVIDIA TensorRT^TM^ 和 NVIDIA Triton^TM^ 推理服务器。
可扩展部署,性能卓越,可以快速无缝地从少量用户扩展到数百万用户。
灵活集成,可轻松将微服务集成到现有工作流程和应用程序中。为开发人员提供 OpenAI API 兼容的编程模型和自定义 NVIDIA 扩展,以实现额外的功能。
企业级安全,通过使用 safetensors、持续监控和修补我们堆栈中的 CVE 以及进行内部渗透测试来强调安全性。
架构#
NIM 以容器镜像的形式按模型/模型系列进行打包。每个 NIM 都是其自己的 Docker 容器,其中包含一个模型,例如“nvidia/nvclip-vit-h-14”。这些容器包含一个运行时,该运行时可在任何具有足够 GPU 内存的 NVIDIA GPU 上运行,但某些模型/GPU 组合经过了优化。NIM 自动从 NGC 下载模型,如果本地文件系统缓存可用,则会利用该缓存。每个 NIM 都是从一个通用基础构建的,因此一旦下载了一个 NIM,就可以快速下载其他 NIM。
对于 支持矩阵 中列出的 NVIDIA GPU,NIM 下载优化的 TensorRT 引擎,并使用 TensorRT 库运行推理。对于所有其他 NVIDIA GPU,NIM 下载非优化模型。
NIM 通过 NVIDIA NGC 目录作为 NGC 容器镜像分发。NGC 目录中的每个容器都有一个安全扫描报告,其中提供了该镜像的安全评级、按软件包划分的 CVE 严重程度细分以及指向 CVE 详细信息的链接。
应用场景#
多模态检索增强生成#
在多模态检索增强生成 (RAG) 应用程序中,我们使用嵌入模型将图像和文本的知识库(离线)和用户问题(在线)编码为上下文嵌入,以便 LLM 可以检索最相关的上下文并为用户提供正确的答案。我们需要高质量的嵌入模型来确保检索到的上下文具有高相关性。
1. 编码知识库(离线):给定一个包含文本、PDF、HTML 或其他格式的文档和图像的知识库,我们首先将文档知识库拆分为块,然后使用嵌入模型将每个块编码为密集向量表示,也称为嵌入。我们还使用嵌入模型将每个图像编码为嵌入。生成的嵌入及其相应的文档和其他元数据保存在向量数据库中。下图说明了知识库编码过程。
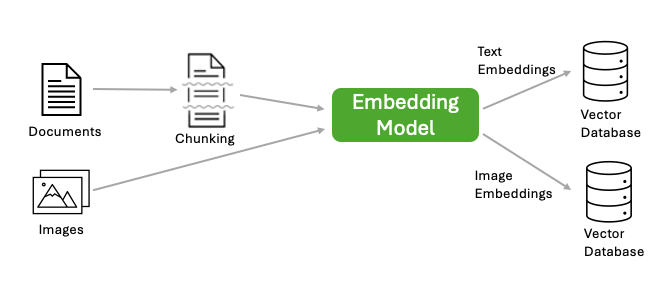
2. 部署(在线):部署后,RAG 应用程序可以访问向量数据库并实时回答问题。为了回答用户问题,RAG 应用程序首先从向量数据库中查找相关块,然后使用检索到的块作为上下文来生成响应。
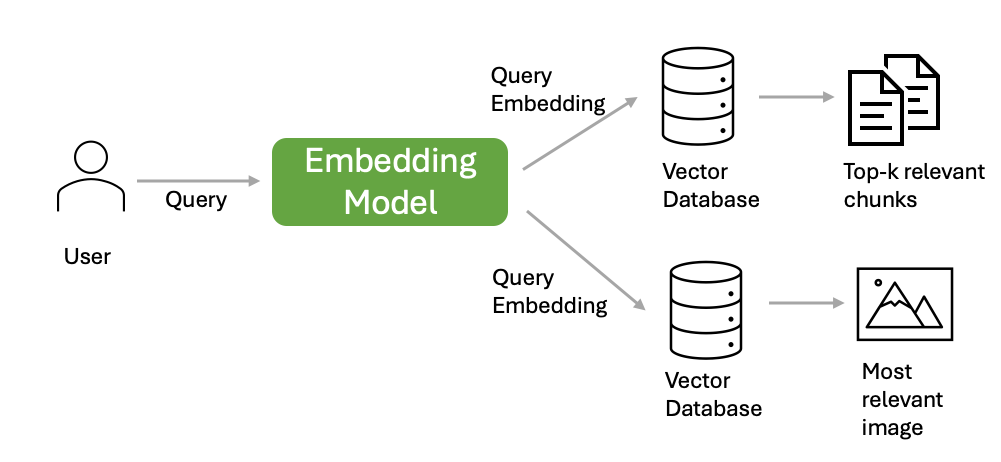
- 阶段 1:根据用户查询从向量数据库中检索
用户的查询首先使用嵌入模型嵌入为密集向量。然后,查询嵌入用于在向量数据库中搜索与用户查询最相关的文档块和最相关的图像。下图说明了检索过程。
- 阶段 2:使用 LLM 生成利用检索到的上下文的响应
最相关的块被连接起来,形成用户查询的上下文。LLM 结合上下文和用户查询来生成响应。下图说明了响应生成过程。

图像分类和检索#
零样本图像分类:NV-CLIP NIM 可以通过将图像与自然语言描述相关联来分类图像,而无需特定的训练数据。
语义图像搜索:用户可以输入自然语言查询来检索与文本描述匹配的图像,从而提高搜索的精确度和相关性。
文本分类和聚类#
文本嵌入可用于文本分类任务,例如情感分析和主题分类。它们还可用于聚类任务,例如主题发现和推荐系统。高质量的嵌入模型通过捕获密集向量表示中的上下文信息来提高这些任务的性能。
自定义应用#
NV-CLIP NIM API 旨在实现多功能性。开发人员可以根据其特定用例利用文本和图像嵌入进行各种应用、实验,并将 API 无缝集成到他们的项目中。一些示例工作流程可以在我们存储库的 多模态搜索 部分找到。