NVIDIA Earth-2 Correction Diffusion NIM 快速入门指南#
使用本文档开始使用 NVIDIA Earth-2 Correction Diffusion (CorrDiff) NIM。
重要提示
在使用本文档之前,您必须满足所有前提条件。
警告
本快速入门指南旨在与 Nvidia 的 A100 或 H100 GPU 一起使用。VRAM 和/或计算能力较低的 GPU 可能需要降低 EARTH2NIM_TARGET_BATCHSIZE 或增加 post 请求中的超时时间。有关不同部署选项,请参阅配置页面。
启动 NIM#
使用以下命令拉取 NIM 容器。
注意
容器大小约为 26GB(未压缩),下载时间取决于互联网连接速度。
docker pull nvcr.io/nim/nvidia/corrdiff:1.0.0
使用以下命令运行 NIM 容器。此命令启动 NIM 容器并公开端口 8000,供用户与 NIM 交互。它从本地文件系统拉取模型。
注意
模型大小约为 4GB,下载时间取决于互联网连接速度。
export NGC_API_KEY=<NGC API Key>
docker run --rm --runtime=nvidia --gpus all --shm-size 2g \
-p 8000:8000 \
-e NGC_API_KEY \
-t nvcr.io/nim/nvidia/corrdiff:1.0.0
NIM 运行后,您将看到类似于以下的输出
I0829 05:18:42.152983 108 grpc_server.cc:2466] "Started GRPCInferenceService at 0.0.0.0:8001"
I0829 05:18:42.153277 108 http_server.cc:4638] "Started HTTPService at 0.0.0.0:8090"
I0829 05:18:42.222628 108 http_server.cc:320] "Started Metrics Service at 0.0.0.0:8002"
检查 NIM 健康状况#
打开一个新的终端,保持当前终端打开并运行服务。
等待健康检查端点返回
{"status":"ready"}后再继续。这可能需要几分钟时间。使用以下方法查询健康检查。
Bash#
curl -X 'GET' \
'http://127.0.0.1:8000/v1/health/ready' \
-H 'accept: application/json'
Python#
import requests
r = requests.get("http://127.0.0.1:8000/v1/health/ready")
if r.status_code == 200:
print("NIM is healthy!")
else:
print("NIM is not ready!")
获取输入数据#
CorrDiff NIM 启动时使用针对美国本土降尺度训练的默认模型配置文件。此模型的输入是来自 NOAA 的 0.25 度(约 25 公里)分辨率的 GEFS 天气数据(美国上空)。CorrDiff 使用此输入数据生成 3 公里分辨率的降尺度天气场,类似于 NOAA 的 HRRR 模型。有关更多详细信息,请参阅模型卡。
为了简化数据准备,我们使用 Earth2Studio 来获取和格式化输入数据,如下所示
获取一组在经纬度网格上分辨率为 0.25 度的选定 GEFS 变量。
获取一组分辨率为 0.5 度的常规 GEFS 变量,并插值到经纬度网格上 0.25 度的网格。
将两个变量裁剪到美国上空的边界框。
连接两组变量以及表示输入所代表的预报提前期的整数字段。
使用以下脚本下载和构建数据
from datetime import datetime, timedelta
import numpy as np
import torch
from earth2studio.data import GEFS_FX, HRRR, GEFS_FX_721x1440
GEFS_SELECT_VARIABLES = [
"u10m",
"v10m",
"t2m",
"r2m",
"sp",
"msl",
"tcwv",
]
GEFS_VARIABLES = [
"u1000",
"u925",
"u850",
"u700",
"u500",
"u250",
"v1000",
"v925",
"v850",
"v700",
"v500",
"v250",
"z1000",
"z925",
"z850",
"z700",
"z500",
"z200",
"t1000",
"t925",
"t850",
"t700",
"t500",
"t100",
"r1000",
"r925",
"r850",
"r700",
"r500",
"r100",
]
ds_gefs = GEFS_FX(cache=True)
ds_gefs_select = GEFS_FX_721x1440(cache=True, product="gec00")
def fetch_input_gefs(
time: datetime, lead_time: timedelta, content_dtype: str = "float32"
):
"""Fetch input GEFS data and place into a single numpy array
Parameters
----------
time : datetime
Time stamp to fetch
lead_time : timedelta
Lead time to fetch
filename : str
File name to save input array to
content_dtype : str
Numpy dtype to save numpy
"""
dtype = np.dtype(getattr(np, content_dtype))
# Fetch high-res select GEFS input data
select_data = ds_gefs_select(time, lead_time, GEFS_SELECT_VARIABLES)
select_data = select_data.values
# Crop to bounding box [225, 21, 300, 53]
select_data = select_data[:, 0, :, 148:277, 900:1201].astype(dtype)
assert select_data.shape == (1, len(GEFS_SELECT_VARIABLES), 129, 301)
# Fetch GEFS input data
pressure_data = ds_gefs(time, lead_time, GEFS_VARIABLES)
# Interpolate to 0.25 grid
pressure_data = torch.nn.functional.interpolate(
torch.Tensor(pressure_data.values),
(len(GEFS_VARIABLES), 721, 1440),
mode="nearest",
)
pressure_data = pressure_data.numpy()
# Crop to bounding box [225, 21, 300, 53]
pressure_data = pressure_data[:, 0, :, 148:277, 900:1201].astype(dtype)
assert pressure_data.shape == (1, len(GEFS_VARIABLES), 129, 301)
# Create lead time field
lead_hour = int(lead_time.total_seconds() // (3 * 60 * 60)) * np.ones(
(1, 1, 129, 301)
).astype(dtype)
input_data = np.concatenate([select_data, pressure_data, lead_hour], axis=1)[None]
return input_data
input_array = fetch_input_gefs(datetime(2023, 1, 1), timedelta(hours=0))
np.save("corrdiff_inputs.npy", input_array)
运行脚本将生成 NumPy 数组 corrdiff_inputs.npy,现在可以与模型一起使用。
推理请求#
使用此 CorrDiff US 模型的预处理输入,现在可以按如下方式使用 NIM 的 API。NumPy 数组作为文件发送到 NIM,同时还发送其他几个参数,这些参数可用于控制底层扩散模型。有关 NIM API 规范的完整文档,请访问 API 文档页面。
Bash#
curl -X POST \
-F "input_array=@corrdiff_inputs.npy" \
-F "samples=2" \
-F "steps=12" \
-o output.tar \
http://127.0.0.1:8000/v1/infer
Python#
import requests
url = "http://127.0.0.1:8000/v1/infer"
files = {
"input_array": ("input_array", open("corrdiff_inputs.npy", "rb")),
}
data = {
"samples": 2,
"steps": 14,
"seed": 0,
}
headers = {
"accept": "application/x-tar",
}
print("Sending post request to NIM")
# Adjust time out (seconds) below
r = requests.post(url, headers=headers, data=data, files=files, timeout=180)
if r.status_code != 200:
raise Exception(r.content)
else:
# Dump response to file
with open("output.tar", "wb") as tar:
tar.write(r.content)
结果#
结果位于 tar 文件中,可以使用以下命令进行浏览
tar -tvf output.tar
-rw-r--r-- 0/0 60555392 1970-01-01 00:00 000_000.npy
-rw-r--r-- 0/0 60555392 1970-01-01 00:00 001_000.npy
提示
tar 存档填充了 NumPy 数组,其命名约定为 {sample index}_{batch index}.npy。
重要提示
对于大多数推理调用,指定更长的请求超时时间对于此 NIM 非常重要。有关不同 GPU 型号的估计推理速度,请参阅性能数据。
流式响应#
当客户端请求的样本大小大于 NIM 的推理批处理大小时,可以使用 CorrDiff NIM 流式传输回生成的样本。当创建在每个时间步运行后续进程的管道时,这非常有用。以下代码段可用于从 NIM 访问内存中生成的每个时间步。
注意
环境变量 EARTH2NIM_TARGET_BATCHSIZE 控制 NIM 内部使用的批处理大小。当此值低于请求的样本大小时,流式传输回结果可能很有用。有关此参数的更多详细信息,请参阅配置指南。
import io
import tarfile
from pathlib import Path
import numpy as np
import requests
import tqdm
url = f"http://127.0.0.1:8000/v1/infer"
files = {
"input_array": ("input_array", open("corrdiff_inputs.npy", "rb")),
}
data = {
"samples": 16,
"steps": 8,
"seed": 0,
}
headers = {
"accept": "application/x-tar",
}
pbar = tqdm.tqdm(range(data["samples"]), desc="CorrDiff samples")
with (
requests.post(
url,
headers=headers,
files=files,
data=data,
timeout=300,
stream=True,
)
) as resp:
resp.raise_for_status()
with tarfile.open(fileobj=resp.raw, mode="r|") as tar_stream:
# Loop over file members from tar stream
for member in tar_stream:
arr_file = io.BytesIO()
arr_file.write(tar_stream.extractfile(member).read())
arr_file.seek(0)
data = np.load(arr_file)
# Array names are in the form <BATCH_IDX>_<SAMPLE_IDX>.npy
arr_sample_idx, _ = (
int(x) for x in Path(member.name).stem.split("_", maxsplit=1)
)
pbar.write(f"Received data for sample {arr_sample_idx}")
pbar.write(f"Output numpy {member.name} with shape {data.shape}")
pbar.update(1)
后处理#
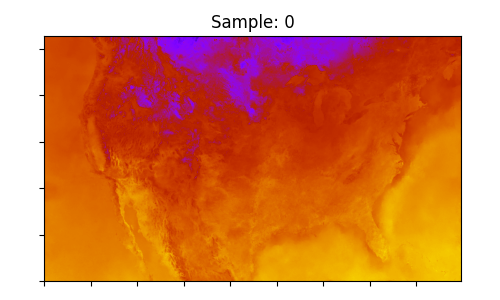
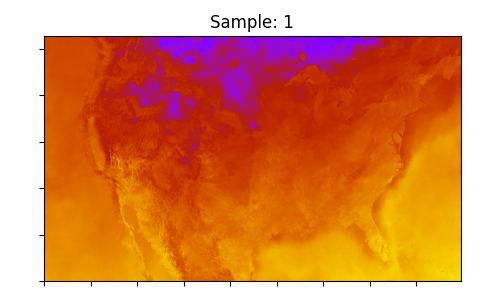
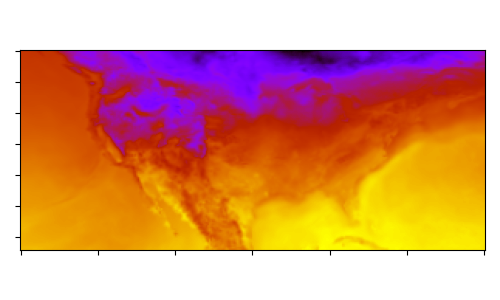
最后一步是对结果进行一些基本可视化。绘制输入和输出数组中的地表温度。
注意
CorrDiff NIM 返回原始输出数据数组。必须使用模型卡中的信息在客户端处理其他元数据。纬度和经度坐标值可以从模型包中的 corrdiff_output_lat.npy 和 corrdiff_output_lon.npy 文件中获得。
import matplotlib.pyplot as plt
import numpy as np
import tarfile
import io
# Output variables: [u10m, v10m, t2m, tp, csnow, cicep, cfrzr, crain]
variable = 2
input = np.load("corrdiff_inputs.npy")
fig, ax = plt.subplots(1,1, figsize=(5,3))
ax.imshow(input[0,0,variable], cmap="gnuplot")
ax.set_yticklabels([])
ax.set_xticklabels([])
fig.tight_layout()
plt.savefig("input_t2m.png")
with tarfile.open("output.tar") as tar:
for i, member in enumerate(tar.getmembers()):
arr_file = io.BytesIO()
arr_file.write(tar.extractfile(member).read())
arr_file.seek(0)
data = np.load(arr_file)
plt.close("all")
fig, ax = plt.subplots(1,1, figsize=(5,3))
ax.set_title(f"Sample: {i}")
ax.imshow(data[0,0,variable], origin='lower', cmap="gnuplot")
ax.set_yticklabels([])
ax.set_xticklabels([])
fig.tight_layout()
plt.savefig(f"output_t2m_sample_{i}.png")
~25 公里分辨率的输入地表温度等值线
使用 CorrDiff 降尺度到 3 公里分辨率的输出地表温度样本