DGX-2 KVM 性能调优
NVIDIA DGX-2 虚拟化支持 Guest GPU VM,如 NVIDIA DGX-2 系统用户指南的 KVM 章节所述。Guest VM 使用默认数量的资源(如 vCPU、GPU 和内存)进行静态资源配置。默认值考虑了 PCIe 拓扑、CPU 亲缘性和 NVLink 拓扑,以提供最佳性能。
可以覆盖这些默认设置以提供额外的性能优化。本章讨论这些性能优化。
背景
Guest GPU VM 作为简单的用户空间 Linux 进程在 KVM 主机中运行,而 vCPU 是在主机中运行的 POSIX 线程。KVM 主机上运行的 Linux 内核使用内置调度器来处理这些进程和线程。默认设置提供通用功能,但您可能需要应用一定程度的性能调优以获得更好的性能。由于性能设置不够通用,无法满足每个应用程序的需求,因此您应将性能调优视为一个迭代过程 - 更改设置,运行测试,然后评估结果,重复该过程,直到为特定应用程序或一组应用程序实现最佳性能。使用裸机值作为可实现性能的基准,然后将 Guest VM 结果与裸机结果进行比较,以便逐步改进结果。
使用半虚拟化驱动程序进行性能调优
下图显示了 hypervisor 和 Guest 之间的 I/O 流。
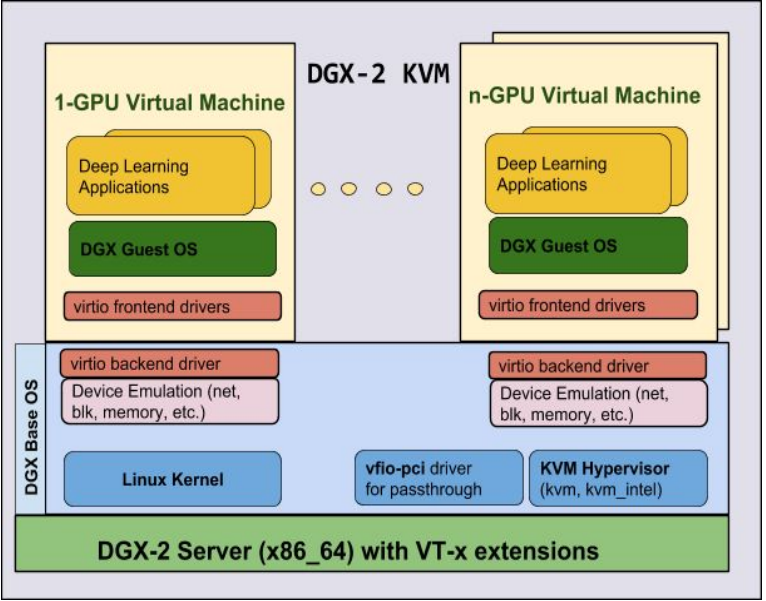
DGX-2 KVM 使用以下半虚拟化驱动程序 (virtio) 来帮助提高 DGX-2 KVM 性能。
- virtio-net:virtio-net 驱动程序支持虚拟网络设备。
- virtio-blk:virtio-blk 驱动程序支持虚拟块设备(OS 驱动器、数据驱动器)。
- virtio-balloon:virtio 内存气球驱动程序管理 Guest 内存。
- virtio-console:virtio-console 驱动程序管理 Guest 和 KVM 主机之间的数据流
您可以使用更改这些驱动程序的默认设置来提高性能。
本章介绍以下性能调优领域。
- CPU 调优
- 使用巨页进行内存调优
- NUMA 调优
- I/O 调优
CPU 调优
尽管 KVM 支持过度分配虚拟化 CPU,但 DGX-2 实现将 vCPU 限制为与可用超线程数量 1:1 匹配。如前所述,vCPU 实际上是 KVM 主机中的 POSIX 线程;它们受 DGX-2 系统策略上运行的调度器的约束,该策略为每个 vCPU 分配相同的优先级。
为了获得最佳性能,软件会将 vCPU 绑定到超线程,如下节所述。由于 vCPU 作为用户空间任务在主机操作系统上运行,因此绑定提高了缓存效率。
vCPU 绑定
NVIDIA DGX-2 系统是 NUMA 感知的系统;通过将 vCPU 绑定到超线程物理 CPU 核心,应用程序可以提高 CPU 缓存命中率并减少昂贵的上下文切换次数。vCPU 绑定的另一个优点是应用程序可以避免对远程 NUMA 节点的慢速内存访问,因为所有 vCPU 都绑定到单个 NUMA 节点。通过 vCPU 绑定,可以在没有已知负面影响的情况下获得巨大的性能提升。
默认情况下,DGX-2 Guest GPU VM 支持 vCPU 绑定,无需额外步骤。默认 vCPU 绑定基于 DGX-2 的 NUMA 拓扑。
如何验证是否启用了 vCPU 绑定
以下输出显示了 vCPU 绑定:第一个 VM 中已启用,第二个 VM 中已禁用。启用 vCPU 绑定后,‘virsh vcpuinfo’ CPU 亲缘性输出对于绑定的 vCPU 显示 'y',对于所有其他超线程物理 CPU 核心显示 '-'。禁用 vCPU 绑定后,'virsh vcpuinfo' CPU 亲缘性输出对于所有超线程物理 CPU 核心显示 'y'。
获取系统上 VM 的 ID 号。
lab@xpl-dvt-64:~$ virsh list Id Name State ---------------------------------------------------- 14 dgx2vm-labThu1726-8g0-7 running 15 dgx2vm-labThu1733 running
在本示例中,有两个 VM ID - 14 和 15。以下输出显示 VM #14 已启用 vCPU 绑定,每个 CPU 亲缘性行都包含单个 'y' 表示已启用。
lab@xpl-dvt-64:~$ virsh vcpuinfo 14 VCPU: 0 CPU: 0 State: running CPU time: 54.9s CPU Affinity: y----------------------------------------------- VCPU: 1 CPU: 1 State: running CPU time: 6.8s CPU Affinity: -y---------------------------------------------- VCPU: 2 CPU: 2 State: running CPU time: 8.3s CPU Affinity: --y--------------------------------------------- VCPU: 3 CPU: 3 State: running CPU time: 3.5s CPU Affinity: ---y-------------------------------------------- VCPU: 4 CPU: 4 State: running CPU time: 7.6s CPU Affinity: ----y------------------------------------------- ... VCPU: 22 CPU: 22 State: running CPU time: 2.6s CPU Affinity: ----------------------y------------------------- VCPU: 23 CPU: 48 State: running CPU time: 2.9s CPU Affinity: ------------------------------------------------y----------------------------------------------- VCPU: 24 CPU: 49 State: running CPU time: 2.5s CPU Affinity: -------------------------------------------------y---------------------------------------------- ... VCPU: 44 CPU: 69 State: running CPU time: 4.6s CPU Affinity: ---------------------------------------------------------------------y-------------------------- VCPU: 45 CPU: 70 State: running CPU time: 5.6s CPU Affinity: ----------------------------------------------------------------------y-------------------------以下示例显示 VM #15 已禁用 vCPU 绑定,每个 CPU 亲缘性都填充了 y 表示已禁用。
lab@xpl-dvt-64:~$ virsh vcpuinfo 15 VCPU: 0 CPU: 5 State: running CPU time: 11.0s CPU Affinity: yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy VCPU: 1 CPU: 11 State: running CPU time: 9.2s CPU Affinity: yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy lab@xpl-dvt-64:~$
验证每个“CPU 亲缘性:”行上是否只有一个 ‘y’。对于未启用 vCPU 绑定的 VM,亲缘性行上有多个 ‘y’。
如何禁用 vCPU 绑定
vCPU 绑定在 DGX-2 KVM 上始终默认启用。以下描述了如何禁用 vCPU 绑定。
- 启动 GPU VM。
- 使用 ‘virsh shutdown’ 关闭 VM。
- 使用 ‘virsh edit <vm-name>’ 编辑 VM XML 文件。
- 删除 vCPU 绑定条目。 以下示例显示了 2-GPU VM 的 XML 文件中的 vCPU 条目。这些是禁用 vCPU 绑定需要删除的行。
lab@dgx2~$ virsh edit 2gpu-vm-2g0-1 <vcpupin vcpu='0' cpuset='0'/> <vcpupin vcpu='1' cpuset='1'/> <vcpupin vcpu='2' cpuset='2'/> <vcpupin vcpu='3' cpuset='3'/> <vcpupin vcpu='4' cpuset='4'/> <vcpupin vcpu='5' cpuset='5'/> <vcpupin vcpu='6' cpuset='48'/> <vcpupin vcpu='7' cpuset='49'/> <vcpupin vcpu='8' cpuset='50'/> <vcpupin vcpu='9' cpuset='51'/> <vcpupin vcpu='10' cpuset='52'/> - 使用 ‘virsh start <vm-name>’ 重新启动 VM
核心亲缘性优化
NVIDIA DGX-2 系统启用了超线程,这意味着 Linux 内核为每个物理核心显示两个线程(或 pCPU)。Guest VM 需要将其 vCPU 绑定到匹配的物理 CPU ID 值。这些物理 CPU 或线程将不会用于调度来自其他 Guest 的作业,前提是其他 Guest 将其 vCPU 绑定到不同的 pCPU。
核心亲缘性优化的优势
核心亲缘性优化的优势是双重的。首先,核心不会在 Guest 之间拆分,因此核心的缓存利用率得到提高。这是因为核心的 L1/L2 缓存不会在 Guest 之间共享。其次,Guest VM 对核心和线程的概念与真实核心和线程完全匹配 - 允许操作系统任务调度器更有效地在底层处理器上调度作业。简而言之,核心亲缘性是将 Guest vCPU 绑定到主机 pCPU 的一种方式,这种方式将 Guest VM 的核心和线程概念映射到实际的 pCPU 核心和线程。
NVIDIA DGX-2 上的核心亲缘性优化
NVIDIA DGX-2 使用双 Intel CPU(2 个插槽),每个 CPU 有 24 个核心/48 个线程,总共 48 个核心/96 个线程,并启用了超线程。内核在枚举线程同级之前,先跨两个插槽枚举 pCPU。
- 在 Intel 系统的第一个插槽上:pCPU 编号为 0 - 23。
- 在 Intel 系统的第二个插槽上:pCPU 编号为 24 - 47。
- 在 Intel 系统的第一个插槽上:线程同级编号为 48 - 71。
这些与第一个插槽上首先枚举的 pCPU 形成线程对 - (0, 48), (1, 49), (2, 50).....(23, 71),每对共享一个公共核心。
- 在 Intel 系统的第二个插槽上:线程同级编号为 72 - 95。
这些与第二个插槽上首先枚举的 pCPU 形成线程对 - (24, 72), (25, 73), (26, 74).....(47, 95),每对共享一个公共核心。
可以从 sysfs 文件中读取哪些线程共享核心之间的关系:/sys/devices/system/cpu/cpuX/topology/thread_siblings_list,其中 X 是主机内核枚举的 pCPU 编号。
出于性能原因,最好不要在 Guest VM 之间拆分公共核心中的线程。由于共享核心的 pCPU 也共享 L1/L2 缓存,因此在此类拆分核心场景中,在不同 Guest 上运行的进程将争用相同的缓存资源,从而可能影响性能。此外,Guest VM 对超线程的视图需要映射到共享核心的实际物理线程。
为了获得最佳性能,请为每个 KVM Guest 分配偶数个 vCPU。
当 Guest 内核调度作业时,它将假定每对连续的 vCPU 属于同一个物理核心 - 正如您所看到的,当域 XML 文件以上述方式指定 CPU 绑定时,情况确实如此。
在 DGX 系统上创建 Guest 时,根据每个插槽的实际核心数(例如,DGX-2 每个插槽有 24 个核心,总共 96 个线程),需要调整实际映射。
启用核心亲缘性优化
- 使用 nvidia-vm 创建 Guest VM。
- 关闭 VM。
- 编辑位于 /etc/libvirt/qemu/ 的 VM XML 文件。
在进行任何修改之前,先备份 XML 文件,以便在需要时可以轻松恢复原始设置。
根据 VM 的 GPU 大小以及使用的插槽数量编辑文件,如下节所述。
- 使用 virsh start 命令启动 Guest。
1-GPU VM
最好不要尝试对使用一个 GPU 的 Guest VM 使用核心亲缘性优化,因为它使用奇数个 vCPU。
目前,nvidia-vm 为每个单 GPU Guest VM 分配奇数个 CPU。为了最大限度地利用超线程调度,Guest 应具有偶数个 vCPU。虽然可以通过编辑域 XML 文件来添加或删除 Guest 的 vCPU 来为这类 VM 启用核心亲缘性优化,但这样做可能会与其他 nvidia-vm 操作(例如分配给其他 Guest 的 pCPU)冲突。
2、4 或 8 GPU VM
- 指定仅使用一个插槽。
<cpu> ... <topology sockets='1' cores='23' threads='2'/>
- 根据上一节中概述的编号,将每个 vCPU 绑定到 pCPU。
16-GPU VM
在 2-GPU VM 上启用核心亲缘性优化的示例
为 2-GPU VM 分配了十个 vCPU。
- 指定 vCPU 绑定。
绑定到第一个插槽上的 pCPU 的示例。
<cputune> <vcpupin vcpu='0' cpuset='0'/> <vcpupin vcpu='1' cpuset='48'/> <vcpupin vcpu='2' cpuset='1'/> <vcpupin vcpu='3' cpuset='49'/> <vcpupin vcpu='4' cpuset='2'/> <vcpupin vcpu='5' cpuset='50'/> <vcpupin vcpu='6' cpuset='3'/> <vcpupin vcpu='7' cpuset='51'/> <vcpupin vcpu='8' cpuset='4'/> <vcpupin vcpu='9' cpuset='52'/>
绑定到第二个插槽上的 pCPU 的示例。
<cputune> <vcpupin vcpu='0' cpuset='24'/> <vcpupin vcpu='1' cpuset='72'/> <vcpupin vcpu='2' cpuset='25'/> <vcpupin vcpu='3' cpuset='73'/> <vcpupin vcpu='4' cpuset='26'/> <vcpupin vcpu='5' cpuset='74'/> <vcpupin vcpu='6' cpuset='27'/> <vcpupin vcpu='7' cpuset='75'/> <vcpupin vcpu='8' cpuset='28'/> <vcpupin vcpu='9' cpuset='76'/>
- 指定仅使用一个插槽。
<topology sockets='1' cores='23' threads='2'/>
内存调优
默认情况下,DGX-2 Guest VM 根据分配给 Guest 的 GPU 数量接收主机内存分配。始终可以通过编辑 Guest VM 模板来覆盖此静态分配。
巨页支持
NVIDIA DGX-2 KVM 主机和 Guest 操作系统支持巨页,这有助于提高内存管理性能。
Linux 内核以页面粒度管理内存,默认大小为 4 KB。Linux 内核还支持更大的页面大小,从 2 MB 到 1 GB。这些称为巨页。巨页通过增加 CPU 缓存命中翻译后备缓冲区 (TLB) 的次数,显着提高性能。
所有页面都由 CPU 中内置的内存管理单元 (MMU) 管理。您可以使用 2MB 页面处理具有多个 GB 内存的系统,并使用 1GB 页面处理具有 TB 内存的系统(如 NVIDIA DGX-2)。
- 透明巨页 (THP)
THP 支持多种配置。在默认的 Linux 配置中,Linux 内核尝试自动分配 THP 巨页。无需特殊配置。
- 持久巨页 (Huge TLB)
使用 Huge TLB 需要特殊配置。有关详细信息,请参见下文。
如何在运行时设置巨页
- 停止 16-GPU VM。
$ virsh list
Id Name State ---------------------------------------------------- 4 dgx2vm-labMon1906-16g0-15 running
$ virsh shutdown dgx2vm-labMon1906-16g0-15
- 在此 VM 上使用 2MB 巨页设置巨页。
- 查看 VM 正在使用的 RAM 量。
$ virsh edit dgx2vm-labMon1906-16g0-15
<memory unit='KiB'>1516912640</memory> <currentMemory unit='KiB'>1516912640</currentMemory>
- 通过除以 2024 将此内存值转换为 2 MB 单位。 这将产生 740680 个 2MB 巨页。
- 将 VM 设置为使用 740680 个 2MB 巨页。
$ echo 740680 | sudo tee /etc/sysctl.conf
$ sudo sysctl vm.nr_hugepages=740680
- 验证更改是否到位
$ cat /proc/meminfo | grep -i huge
AnonHugePages: 0 kB ShmemHugePages: 0 kB HugePages_Total: 740680 HugePages_Free: 740680 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB
- 查看 VM 正在使用的 RAM 量。
- 重新启动 libvirtd 以使上述更改生效。
$ sudo systemctl restart libvirtd
- 修改 Guest VM。
$ virsh edit dgx2vm-labMon1906-16g0-15
将以下行添加到 XML 文件的开头。<domain type='kvm'> <name>dgx2vm-labMon1906-16g0-15</name> <uuid>0c9296c6-2d8f-4712-8883-dac654e6bc69</uuid> <memory unit='KiB'>1516912640</memory> <memoryBacking> <hugepages/> </memoryBacking> <currentMemory unit='KiB'>1516912640</currentMemory> - 重新启动 GPU VM
$ time virsh start dgx2vm-labMon1906-16g0-15
Domain dgx2vm-labMon1906-16g0-15 started real5m32.559s user0m0.016s sys0m0.010s
如何仅在启动时设置巨页
- 关闭 Guest VM。
$ virsh shutdown dgx2vm-labMon1906-16g0-1
- 计算 16-GPU VM 所需的最大 1 GB 巨页数量。
- 确定分配给 16-GPU VM 或由其使用的内存量。
$ virsh edit dgx2vm-labMon1906-16g0-15
示例输出:<domain type='kvm'> <name>dgx2vm-labMon1906-16g0-15</name> <uuid>0c9296c6-2d8f-4712-8883-dac654e6bc69</uuid> <memory unit='KiB'>1516912640</memory>
在本示例中,为 VM 分配了 1516912640 KB (1,517 GB) 的内存。 - 使用以下公式计算所需的 1 GB 巨页数量: 1 GB 巨页数量 =(分配的内存 (KB))/(1024*1024) 使用示例,1516912640/(1024*1024)=1446,因此需要 1446 个巨页,每个巨页 1 GB。
- 确定分配给 16-GPU VM 或由其使用的内存量。
- 设置启动时要分配的巨页数量。
编辑 /etc/default/grub 并更改以下行以指定启动时为 16-GPU VM 分配的巨页数量
GRUB_CMDLINE_LINUX=""
示例GRUB_CMDLINE_LINUX=”default_hugepagesz=1G hugepages=1446”
- 修改 GRUB 后,运行以下命令以使更改生效。
$ sudo update-grub
- 重新启动 KVM 主机。
$ sudo reboot
- 修改 Guest VM。
$ virsh edit dgx2vm-labMon1906-16g0-15
- 将以下行添加到 XML 文件
<memoryBacking> <hugepages/> </memoryBacking> - 将以下行添加到 XML 文件的开头。
<domain type='kvm'> <name>dgx2vm-labMon1906-16g0-15</name> <uuid>0c9296c6-2d8f-4712-8883-dac654e6bc69</uuid> <memory unit='KiB'>1516912640</memory> <memoryBacking> <hugepages/> </memoryBacking> <currentMemory unit='KiB'>1516912640</currentMemory>
- 将以下行添加到 XML 文件
- 重新启动 Guest VM。
$ time virsh start dgx2vm-labMon1906-16g0-15
Domain dgx2vm-labMon1906-16g0-15 started real5m32.559s user0m0.016s sys0m0.010s
如何在主机中禁用巨页
- 停止任何正在运行的 Guest。
- 禁用巨页支持
$ echo 0 | sudo tee /etc/sysctl.conf
$ sudo sysctl vm.nr_hugepages=0
- 重新启动 libvirtd。
$ sudo systemctl restart libvirtd
- 在重新启动 VM 之前,请确保从 XML 文件中删除巨页条目。
$ sudo virsh edit dgx2vm-labMon1906-16g0-15
<memoryBacking> <hugepages/> </memoryBacking> - 保存文件并重新启动 VM。注意: 启动时间的影响不会很显着,因为大部分时间都用于为 Guest 分配 RAM。因此,此处未发布任何数字。
NUMA 调优
非统一内存访问 (NUMA) 允许将系统内存划分为区域(节点)。NUMA 节点分配给特定的 CPU 或插槽。与传统单片内存方法(其中每个 CPU/核心都可以访问所有内存,而不管其位置如何,通常会导致更大的延迟)相比,NUMA 绑定的进程可以访问位于其执行 CPU 本地的内存。在大多数情况下,这比访问连接到系统上远程 CPU 的内存要快得多。
DGX-2 使用 NUMA 架构将其内存划分为可由其 Skylake 处理器(节点)平等访问。这意味着特定的 Skylake 处理器组对系统 RAM 的本地子集具有相同的访问延迟。对于虚拟化环境,需要进行一些调整才能充分利用 NUMA 架构。
自动 NUMA 平衡
- 要检查和启用自动 NUMA 平衡,请输入以下内容。
# cat /proc/sys/kernel/numa_balancing
这应返回 1。 - 如果未返回 1,则输入以下内容。
# echo 1 > /proc/sys/kernel/numa_balancing
启用 NUMA 调优
DGX-2 节点显示它总共支持 2 个节点(通过运行 virsh capabilities)。对于支持高达 1.5TB 内存的 16-GPU VM,将内存均匀地分成两个单元,以便每个单元获得内存局部性。
设置 NUMA 调优
- 停止 16-GPU VM。
$ virsh list Id Name State ---------------------------------------------------- 2 dgx2vm-labFri2209-16g0-15 running $ virsh shutdown 2 Domain 2 is being shutdown
- 通过添加指示的行来编辑 XML 文件。
$ virsh edit dgx2vm-labFri2209-16g0-15
<cpu> <numa> <cell id="0" cpus="0-45" memory="758456320" unit="KiB"/> <cell id="1" cpus="46-91" memory="758456320" unit="KiB"/> </numa> </cpu>这定义了两个 vNUMA 节点,每个节点具有 739 GiB 内存,并且核心 0-45 可以低延迟访问其中一个 739GB 集,而 46-91 可以低延迟访问另一个集。可以针对 NUMA 进行优化的应用程序将能够考虑到这一点,以便它们尝试限制它们进行的远程内存访问次数。 - 定义 vNUMA 单元后,使用 numatune 元素来分配物理 NUMA 节点,这些单元将从中分配内存。
<numatune> <memnode cellid="0" mode="strict" nodeset="0"/> <memnode cellid="1" mode="strict" nodeset="1"/> </numatune> - 重新启动 VM。
$ virsh start dgx2vm-labFri2209-16g0-15 Domain dgx2vm-labFri2209-16g0-15started
启用 NUMA 调优的效果
启用 NUMA 调优没有副作用。启用 NUMA 调优已显示出 16-GPU VM 的性能提升,但在很大程度上取决于工作负载和应用程序。
对于较小的 VM,也建议添加 NUMA 元素,以确保从其关联的物理 NUMA 节点分配内存。以下示例显示了物理节点 0 上的 1-GPU VM
<cpu>
...
<numa> <cell id='0' memory='10485760' unit='KiB' cpus='0-4' /> </numa></cpu>
...
<numatune>
<memnode cellid="0" mode="strict" nodeset="0"/>
</numatune>以及物理节点 1 上的 1-GPU VM
<cpu>
...
<numa> <cell id='0' memory='10485760' unit='KiB' cpus='0-4' /> </numa></cpu>
...
<numatune>
<memnode cellid="0" mode="strict" nodeset="1"/>
</numatune>Emulatorpin
Guest VM 作为 KVM 主机中的进程运行。进程本身可以在 DGX-2 上的任何核心上运行。此 Linux Guest VM 进程(emulator)也可以绑定到某些物理 CPU 上运行。如果未绑定,则 emulator 默认情况下会利用所有物理 CPU,而与 VM 的 NUMA 亲缘性无关。
通过使用可选的 emulatorpin 元素,您可以实现将 “emulator” 绑定到物理 CPU。当前的建议是将 emulator 绑定到 VM 使用的同一 CPU 插槽上的空闲物理 CPU。将 emulator 绑定到与 VM 相同的 CPU 插槽可消除 NUMA 跳跃和 QPI 消息。以下是如何为 1-GPU VM 执行此操作的示例
<cputune> ... <emulatorpin cpuset='50,53,56,59,62,65,68,71'/> </cputune>
I/O 调优
将多队列与逻辑卷结合使用
默认情况下,每个 VM 都会获得一个使用基于文件的存储创建的数据驱动器,并创建一个基于 QCOW2 的逻辑卷。
$ nvidia-vm create --domain testme --gpu-count 8 --gpu-index 8 testme-8g8-15: create start mac: 52:54:00:d8:ec:20 ip: 192.168.122.26
$ virsh dumpxml testme-8g8-15
<snip> ..
<disk type='file' device='disk'>
<driver name='qemu' type='vmdk'/>
<source file='/raid/dgx-kvm/vol-testme-8g8-15'/>
<backingStore/>
<target dev='vdb' bus='virtio'/>
<alias name='virtio-disk1'/>
<address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x0'/>
</disk>
<snip> ..
Login VM machine
nvidia@testme-8g8-15:~$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 252:0 0 50G 0 disk
└─vda1 252:1 0 50G 0 part /
vdb 252:16 0 13.9T 0 disk
└─vdb1 252:17 0 13.9T 0 part /raid
nvidia@testme-8g8-15:~$ 数据驱动器性能不是最佳的,但您可以设置以下功能(默认情况下未启用)来提高数据驱动器性能。
- 使用 ‘raw’ 驱动器类型而不是 QCOW2
- QEMU Copy on Write 版本 2.0 (QCOW2) 通过在逻辑块和物理块之间添加映射,将物理存储层与虚拟层分离。每个逻辑块都映射到其物理偏移量。
- RAW 格式不使用格式化,并将写入的 I/O 直接映射到后备文件中的相同偏移量,从而提供最佳性能。
- 禁用缓存
- 绕过主机页面缓存,并且 I/O 直接发生在 hypervisor 用户空间缓冲区和后备存储之间。这相当于直接访问主机的驱动器。
- 缺点:禁用缓存可能会影响数据完整性。
- 启用多队列
- 多队列在 virtio-blk 驱动程序中提供改进的存储性能和可扩展性。它使每个虚拟 CPU 都可以拥有一个单独的队列和中断以供使用,而不会影响其他 vCPU。理想情况下,队列的数量应少于属于组的 vCPU 总数,并且是最接近的 2 的幂。例如,对于 92-vCPU VM,理想设置为 64。
启用这三项已显示出巨大的数据驱动器性能提升。
I/O 线程
I/O 线程是专用的事件循环线程。这些线程允许磁盘设备执行块 I/O 请求,以提高可扩展性,尤其是在 SMP 主机/Guest 上。这是一个仅限 QEMU 的选项,可以通过 XML 文件架构以下列两种方式指定。
- iothreads
此可选元素定义要分配给域供支持的目标存储设备使用的 IOThreads 的数量。
<domain> ... <iothreads>4</iothreads> ... </domain>
- iothreadids
可选的 iothreadids 元素提供了为域专门定义 IOThread ID 的功能。这些 ID 从 1 开始顺序编号,直到为域定义的 iothreads 的数量。 id 属性用于定义 IOThread ID,并且是一个大于 0 的正整数。
<domain> ... <iothreadids> <iothread id="2"/> <iothread id="4"/> <iothread id="6"/> <iothread id="8"/> </iothreadids> ... </domain>
如何设置 I/O 调优
在域 XML 文件中,进行以下更改
添加 "<iothreads>46</iothreads>" 行。- 8-GPU VM 通常使用 46 个 vCPU 启动
- 更改此数字以匹配您的 xGPU VM 的 vCPU 数量
- 队列的数量可能不超过可用的 vCPU 总数
- 关闭 VM,然后编辑 XML 文件。
$ virsh list
Id Name State ---------------------------------------------------- 1 testme-8g8-15 running
$ virsh shutdown testme-8g8-15 Domain testme-8g8-15 is being shutdown
$ virsh edit testme-8g8-15
<domain type='kvm'> <name>testme-8g8-15</name> <uuid>056f1635-d510-4d06-9e05-879e46479c08</uuid> <iothreads>46</iothreads> <snip> .. <disk type='file' device='disk'> <driver name='qemu' type=qcow2 cache='none' io='native' queues='32'/> <source file='/raid/dgx-kvm/vol-testme-8g8-15'/> <target dev='vdb' bus='virtio'/> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x0'/> </disk> <snip> .. - 保存 XML 文件并重新启动 VM。
$ virsh start testme-8g8-15
在数据驱动器上运行标准文件系统性能测试工具(例如 fio)显示性能提升了 3 倍到 4 倍。
NVMe 驱动器作为 PCI 直通设备
默认情况下,DGX-2 Guest GPU VM 在启动时支持两个驱动器。
- OS 驱动器:/dev/vda(大小固定为 50 GB)
- 数据驱动器:/dev/vdb(大小因 VM 中的 GPU 数量而异,从 1.9 TB 到 27 TB)
OS 驱动器和数据驱动器是主机 NVMe 驱动器上的逻辑卷,因此可能无法提供最佳性能。为了提高性能,您可以使用 PCI 直通来公开 VM 内部的所有物理 NVMe 驱动器。
本节介绍如何使用 PCI 直通将 NVMe SSD 直通到 16-GPU Guest VM。
如何为 NVME 驱动器设置 PCI 直通
在 KVM 主机上执行以下操作。
- 停止 KVM 主机上正在运行的 RAID-0。
$ sudo cat /proc/mdstat Personalities : [raid1] [raid0] [linear] [multipath] [raid6] [raid5] [raid4] [raid10] md1 : active raid0 nvme2n1[2] nvme9n1[0] nvme4n1[3] nvme8n1[5] nvme3n1[4] nvme5n1[7] nvme7n1[1] nvme6n1[6] 30004846592 blocks super 1.2 512k chunks md0 : active raid1 nvme0n1p2[0] nvme1n1p2[1] 937034752 blocks super 1.2 [2/2] [UU] bitmap: 1/7 pages [4KB], 65536KB chunk unused devices: <none> $ sudo umount /raid $ sudo mdadm --stop /dev/md1 mdadm: stopped /dev/md1
- 将 NVMe 设备传递到 Guest。 对于 NVMe 设备的每个 PCI 总线:设备:功能,通过运行此脚本创建一个 XML 文件
#! /bin/bash lspci | awk '{dev=0} /Micron/ {dev="nvme"} { if (dev!=0) { gsub(":.*","",$1); printf("%s %s\n", dev, $1); }}' | \ while read DEV PCID; do echo "<hostdev mode='subsystem' type='pci' managed='yes'> <source> <address domain='0x0000' bus='0x${PCID}' slot='0x0' function='0x0'/> </source> </hostdev>" > hw-${DEV}-${PCID}.xml; done这将创建以下文件$ ls hw*
hw-nvme-2e.xml hw-nvme-2f.xml hw-nvme-51.xml hw-nvme-52.xml hw-nvme-b1.xml hw-nvme-b2.xml hw-nvme-da.xml hw-nvme-db.xml
以下是其中一个文件的示例。$ cat hw-nvme-2f.xml
<hostdev mode='subsystem' type='pci' managed='yes'> <source> <address domain='0x0000' bus='0x2f' slot='0x0' function='0x0'/> </source> </hostdev>
. - 将其中一个设备作为 NVMe 直通传递到 Guest VM
- 创建没有数据驱动器的 GPU Guest VM。
$ nvidia-vm create --domain nvme-passthrough --gpu-index 0 --gpu-count 16 nvme-passthrough-16g0-15: create start mac: 52:54:00:46:f3:34 ip: 192.168.122.91
$ virsh list -all
Id Name State ---------------------------------------------------- 1 nvme-passthrough-16g0-15 running
- 将 NVMe 驱动器传递到 VM。
$ virsh attach-device nvme-passthrough-16g0-15 hw-nvme-2e.xml --live
Device attached successfully
- 验证 VM 内部的 NVMe 设备。
$ virsh console nvme-passthrough-16g0-15
nvidia@nvme-passthrough-16g0-15:~$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 252:0 0 50G 0 disk └─vda1 252:1 0 50G 0 part / nvme0n1 259:0 0 3.5T 0 disk nvidia@nvme-passthrough-16g0-15:~$
- 创建没有数据驱动器的 GPU Guest VM。
执行 NVMe 直通没有副作用。启用 NVMe 直通已显示出具有各种工作负载和应用程序的 GPU VM 的巨大性能提升。
如何还原 NVMe 驱动器的 PCI 直通
这些步骤描述了如何撤消之前的更改,并且从 KVM 主机执行。
- 销毁 VM
$ sudo nvidia-vm delete --domain nvme-passthrough-16g0-15 --force
- 在 KVM 主机上重新创建 RAID-0
$ sudo mdadm --create --verbose /dev/md1 --level=0 --raid-devices=8 /dev/nvme2n1 /dev/nvme3n1 /dev/nvme4n1 /dev/nvme5n1 /dev/nvme6n1 /dev/nvme7n1 /dev/nvme8n1 /dev/nvme9n1
mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md1 started.
$ sudo mkfs.ext4 /dev/md1
mke2fs 1.44.1 (24-Mar-2018) Discarding device blocks: done Creating filesystem with 7501211648 4k blocks and 468826112 inodes Filesystem UUID: 0e1d6cb6-020e-47d3-80a1-d2c93b259ff7 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968, 102400000, 214990848, 512000000, 550731776, 644972544, 1934917632, 2560000000, 3855122432, 5804752896 Allocating group tables: done Writing inode tables: done Creating journal (262144 blocks): done Writing superblocks and filesystem accounting information: done
- 在 KVM 主机内部挂载 RAID-0。
$ sudo mount /dev/md1 /raid
$ sudo mdadm --detail --scan | sudo tee -a /etc/mdadm/mdadm.conf
ARRAY /dev/md/0 metadata=1.2 name=dgx-18-04:0 UUID=1740dd3f:6c26bdc1:c6ed2395:690d0707 ARRAY /dev/md1 metadata=1.2 name=xpl-dvt-34:1 UUID=dfa7e422:430a396b:89fc4b74:9a5d8c3c
注意: 确保这些条目显示在 /etc/mdadm/mdadm.conf 中,并且它们替换任何先前存在的条目。在替换 /etc/dmadm/mdadm.conf 中的条目后;确保仅显示上面的两行。例如,$ grep ARRAY /etc/mdadm/mdadm.conf ARRAY /dev/md/0 metadata=1.2 name=dgx-18-04:0 UUID=1740dd3f:6c26bdc1:c6ed2395:690d0707 ARRAY /dev/md1 metadata=1.2 name=xpl-dvt-34:1 UUID=dfa7e422:430a396b:89fc4b74:9a5d8c3c
物理驱动器直通
本节介绍如何将驱动器直通到 GPU Guest VM。
初步步骤
在为物理驱动器设置直通之前,请务必执行以下操作。
- 确保 mdadm raid 未在 NVMe 驱动器上运行。
$ sudo ls /dev/md* /dev/md0 /dev/md: 0
- 如果您还看到“md1”,请停止它。
$ sudo umount /raid $ sudo mdadm --stop /dev/md1 mdadm: stopped /dev/md1
- 使用 parted 创建一个大分区。
$ sudo parted /dev/nvme4n1 GNU Parted 3.2 Using /dev/nvme4n1 Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) p Error: /dev/nvme4n1: unrecognised disk label Model: NVMe Device (nvme) Disk /dev/nvme4n1: 3841GB Sector size (logical/physical): 512B/512B Partition Table: unknown Disk Flags: (parted) mklabel gpt (parted) unit GB (parted) mkpart 1 0 3841 (parted) quit
如何设置驱动器直通
- 在驱动器的分区上放置一个文件系统(此处使用 nvme4n1)
$ sudo mkfs.ext4 /dev/nvme4n1p1
mke2fs 1.44.1 (24-Mar-2018) Discarding device blocks: done Creating filesystem with 937684224 4k blocks and 234422272 inodes Filesystem UUID: d3853f33-5241-478f-8a06-5010db70543d Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968, 102400000, 214990848, 512000000, 550731776, 644972544 Allocating group tables: done Writing inode tables: done Creating journal (262144 blocks): done Writing superblocks and filesystem accounting information: done
- 启动 GPU VM,将其关闭,并且不传递数据驱动器
$ nvidia-vm create --domain disk-passthrough --gpu-count 1 --gpu-index 8 --volGB 0 WARNING: Host Data volume not setup, no VM data volume will be created disk-passthrough-1g8: create start mac: 52:54:00:50:c3:95 ip: 192.168.122.198
- 将这些行添加到 XML
$ virsh shutdown disk-passthrough-1g8 $ virsh edit disk-passthrough-1g8 <disk type='block' device='disk'> <driver name='qemu' type='raw'/> <source dev='/dev/nvme4n1'/> <target dev='vdb' bus='virtio'/> </disk>
- 保存并重新启动 Guest VM
$ virsh start disk-passthrough-1g8
- 验证驱动器是否在 Guest VM 内部显示
$ virsh console disk-passthrough-1g8 nvidia@disk-passthrough-1g8:~$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 252:0 0 50G 0 disk └─vda1 252:1 0 50G 0 part / vdb 252:16 0 3.5T 0 disk └─vdb1 252:17 0 3.5T 0 part /raid
如何还原驱动器直通
这些步骤说明了如何撤消之前的更改以设置驱动器直通。在 KVM 主机上执行这些步骤。
- 销毁 VM。
$ sudo nvidia-vm delete --domain disk-passthrough-1g8 --force
- 在 KVM 主机上重新创建 RAID-0。
$ sudo mdadm --create --verbose /dev/md1 --level=0 --raid-devices=8 /dev/nvme2n1 /dev/nvme3n1 /dev/nvme4n1 /dev/nvme5n1 /dev/nvme6n1 /dev/nvme7n1 /dev/nvme8n1 /dev/nvme9n1 mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started. $ sudo mkfs.ext4 /dev/md1 mke2fs 1.44.1 (24-Mar-2018) Discarding device blocks: done Creating filesystem with 7501211648 4k blocks and 468826112 inodes Filesystem UUID: 0e1d6cb6-020e-47d3-80a1-d2c93b259ff7 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968, 102400000, 214990848, 512000000, 550731776, 644972544, 1934917632, 2560000000, 3855122432, 5804752896 Allocating group tables: done Writing inode tables: done Creating journal (262144 blocks): done Writing superblocks and filesystem accounting information: done
- 在 KVM 主机内部挂载 RAID-0
$ sudo mount /dev/md1 /raid $ sudo mdadm --detail --scan | sudo tee -a /etc/mdadm/mdadm.conf ARRAY /dev/md/0 metadata=1.2 name=dgx-18-04:0 UUID=1740dd3f:6c26bdc1:c6ed2395:690d0707 ARRAY /dev/md1 metadata=1.2 name=xpl-dvt-34:1 UUID=dfa7e422:430a396b:89fc4b74:9a5d8c3c
注意: 确保这些条目显示在 /etc/mdadm/mdadm.conf 中并替换现有条目。在替换 /etc/dmadm/mdadm.conf 中的条目后;确保仅显示上面的两行。$ grep ARRAY /etc/mdadm/mdadm.conf ARRAY /dev/md/0 metadata=1.2 name=dgx-18-04:0 UUID=1740dd3f:6c26bdc1:c6ed2395:690d0707 ARRAY /dev/md1 metadata=1.2 name=xpl-dvt-34:1 UUID=dfa7e422:430a396b:89fc4b74:9a5d8c3c
驱动器分区直通
如果驱动器不足以支持需要创建的 VM 数量,则可以在磁盘上创建多个分区,然后将每个分区直通到 VM。本节介绍如何将驱动器分区直通到 Guest VM。
- 停止 /dev/md1 上的 RAID,有关示例,请参见前面的章节。
- 使用 fdisk 创建两个驱动器分区(此处使用 nvme5n1)。
$ fdisk /dev/nvme5n1 Welcome to fdisk (util-linux 2.31.1). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. The size of this disk is 3.5 TiB (3840755982336 bytes). DOS partition table format cannot be used on drives for volumes larger than 2199023255040 bytes for 512-byte sectors. Use GUID partition table format (GPT). Command (m for help): d Selected partition 1 Partition 1 has been deleted. Command (m for help): n Partition type p primary (0 primary, 0 extended, 4 free) e extended (container for logical partitions) Select (default p): p Partition number (1-4, default 1): First sector (2048-4294967295, default 2048): Last sector, +sectors or +size{K,M,G,T,P} (2048-4294967294, default 4294967294): 2147485695 Created a new partition 1 of type 'Linux' and of size 1 TiB. Command (m for help): n Partition type p primary (1 primary, 0 extended, 3 free) e extended (container for logical partitions) Select (default p): p Partition number (2-4, default 2): First sector (2147485696-4294967295, default 2147485696): Last sector, +sectors or +size{K,M,G,T,P} (2147485696-4294967294, default 4294967294): Created a new partition 2 of type 'Linux' and of size 1024 GiB. Command (m for help): wq The partition table has been altered. Calling ioctl() to re-read partition table. Syncing disks. - 验证两个分区是否存在。
$ sudo fdisk -l /dev/nvme5n1
Disk /dev/nvme5n1: 3.5 TiB, 3840755982336 bytes, 7501476528 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0xb1dc316c Device Boot Start End Sectors Size Id Type /dev/nvme5n1p1 2048 2147485695 2147483648 1T 83 Linux /dev/nvme5n1p2 2147485696 4294967294 2147481599 1024G 83 Linux
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 1024M 0 rom nvme0n1 259:0 0 894.3G 0 disk ├─nvme0n1p1 259:1 0 512M 0 part /boot/efi └─nvme0n1p2 259:2 0 893.8G 0 part └─md0 9:0 0 893.6G 0 raid1 / nvme1n1 259:3 0 894.3G 0 disk ├─nvme1n1p1 259:4 0 512M 0 part └─nvme1n1p2 259:5 0 893.8G 0 part └─md0 9:0 0 893.6G 0 raid1 / nvme3n1 259:6 0 3.5T 0 disk nvme4n1 259:7 0 3.5T 0 disk nvme5n1 259:9 0 3.5T 0 disk ├─nvme5n1p1 259:8 0 1T 0 part └─nvme5n1p2 259:17 0 1024G 0 part nvme6n1 259:10 0 3.5T 0 disk nvme2n1 259:11 0 3.5T 0 disk nvme9n1 259:12 0 3.5T 0 disk nvme8n1 259:13 0 3.5T 0 disk nvme7n1 259:14 0 3.5T 0 disk
该示例显示了两个分区,目的是将第二个分区传递到 Guest VM。 - 在驱动器的分区上放置一个文件系统(此处使用 nvme5n1p1)。
$ mkfs.ext4 /dev/nvme5n1p1
mke2fs 1.44.1 (24-Mar-2018) Discarding device blocks: done Creating filesystem with 268435456 4k blocks and 67108864 inodes Filesystem UUID: 7fa91b82-51db-4953-87d5-4364958951e5 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968, 102400000, 214990848 Allocating group tables: done Writing inode tables: done Creating journal (262144 blocks): done Writing superblocks and filesystem accounting information: done
- 找出磁盘分区的路径(通过 UUID)。
$ ls -l /dev/disk/by-partuuid/ | grep 5n1p1
lrwxrwxrwx 1 root root 15 Sep 26 08:35 b1dc316c-01 -> ../../nvme5n1p1
- 启动 GPU VM,将其关闭,并且不传递数据驱动器。
$ nvidia-vm create --domain disk-passthrough --gpu-count 1 --gpu-index 9 --volGB 0
WARNING: Host Data volume not setup, no VM data volume will be created disk-passthrough-1g9: create start mac: 52:54:00:96:6c:38 ip: 192.168.122.140
- 首先捕获 VM 中可见的设备数量。
nvidia@disk-passthrough-1g9:~$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 252:0 0 50G 0 disk └─vda1 252:1 0 50G 0 part /
nvidia@disk-passthrough-1g9:~$
$ virsh shutdown disk-passthrough-1g9
- 将这些行添加到 XML 中现有 <disk> 条目的旁边
$ virsh edit disk-passthrough-1g9
<disk type='block' device='disk'> <driver name='qemu' type='raw'/> <source dev='/dev/disk/by-partuuid/b1dc316c-01'/> <target dev='vdb' bus='virtio'/> </disk>注意: 确保 UUID 与先前步骤中的 UUID 匹配. - 保存并重新启动 Guest VM。
$ virsh start disk-passthrough-1g9
- 验证驱动器是否在 Guest VM 内部显示。
$ virsh console disk-passthrough-1g9
nvidia@disk-passthrough-1g8:~$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 252:0 0 50G 0 disk └─vda1 252:1 0 50G 0 part / vdb 252:16 0 1024G 0 disk └─vdb1 252:17 0 1024G 0 part /raid
如何设置驱动器分区直通
如何将驱动器分区传递到 GPU Guest VM。
- 停止 /dev/md1 上的 RAID。 有关示例,请参见前面的章节。
- 使用 fdisk 创建两个驱动器分区(此处使用 nvme5n1)。
$ fdisk /dev/nvme5n1 Welcome to fdisk (util-linux 2.31.1). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. The size of this disk is 3.5 TiB (3840755982336 bytes). DOS partition table format cannot be used on drives for volumes larger than 2199023255040 bytes for 512-byte sectors. Use GUID partition table format (GPT). Command (m for help): d Selected partition 1 Partition 1 has been deleted. Command (m for help): n Partition type p primary (0 primary, 0 extended, 4 free) e extended (container for logical partitions) Select (default p): p Partition number (1-4, default 1): First sector (2048-4294967295, default 2048): Last sector, +sectors or +size{K,M,G,T,P} (2048-4294967294, default 4294967294): 2147485695 Created a new partition 1 of type 'Linux' and of size 1 TiB. Command (m for help): n Partition type p primary (1 primary, 0 extended, 3 free) e extended (container for logical partitions) Select (default p): p Partition number (2-4, default 2): First sector (2147485696-4294967295, default 2147485696): Last sector, +sectors or +size{K,M,G,T,P} (2147485696-4294967294, default 4294967294): Created a new partition 2 of type 'Linux' and of size 1024 GiB. Command (m for help): wq The partition table has been altered. Calling ioctl() to re-read partition table. Syncing disks. - 验证两个分区是否存在。
$ sudo fdisk -l /dev/nvme5n1 Disk /dev/nvme5n1: 3.5 TiB, 3840755982336 bytes, 7501476528 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0xb1dc316c Device Boot Start End Sectors Size Id Type /dev/nvme5n1p1 2048 2147485695 2147483648 1T 83 Linux /dev/nvme5n1p2 2147485696 4294967294 2147481599 1024G 83 Linux $ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 1024M 0 rom nvme0n1 259:0 0 894.3G 0 disk ├─nvme0n1p1 259:1 0 512M 0 part /boot/efi └─nvme0n1p2 259:2 0 893.8G 0 part └─md0 9:0 0 893.6G 0 raid1 / nvme1n1 259:3 0 894.3G 0 disk ├─nvme1n1p1 259:4 0 512M 0 part └─nvme1n1p2 259:5 0 893.8G 0 part └─md0 9:0 0 893.6G 0 raid1 / nvme3n1 259:6 0 3.5T 0 disk nvme4n1 259:7 0 3.5T 0 disk nvme5n1 259:9 0 3.5T 0 disk ├─nvme5n1p1 259:8 0 1T 0 part └─nvme5n1p2 259:17 0 1024G 0 part nvme6n1 259:10 0 3.5T 0 disk nvme2n1 259:11 0 3.5T 0 disk nvme9n1 259:12 0 3.5T 0 disk nvme8n1 259:13 0 3.5T 0 disk nvme7n1 259:14 0 3.5T 0 disk
本示例显示了两个分区,目的是将第二个分区传递到 Guest VM。 - 在驱动器的分区上放置一个文件系统(此处使用 nvme5n1p1)。
$ mkfs.ext4 /dev/nvme5n1p1 mke2fs 1.44.1 (24-Mar-2018) Discarding device blocks: done Creating filesystem with 268435456 4k blocks and 67108864 inodes Filesystem UUID: 7fa91b82-51db-4953-87d5-4364958951e5 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968, 102400000, 214990848 Allocating group tables: done Writing inode tables: done Creating journal (262144 blocks): done Writing superblocks and filesystem accounting information: done
- 找出磁盘分区的路径(通过 UUID)。
$ ls -l /dev/disk/by-partuuid/ | grep 5n1p1 lrwxrwxrwx 1 root root 15 Sep 26 08:35 b1dc316c-01 -> ../../nvme5n1p1
- 启动 GPU VM,将其关闭,并且不传递数据驱动器。
$ nvidia-vm create --domain disk-passthrough --gpu-count 1 --gpu-index 9 --volGB 0 WARNING: Host Data volume not setup, no VM data volume will be created disk-passthrough-1g9: create start mac: 52:54:00:96:6c:38 ip: 192.168.122.140
- 捕获 VM 中可见的设备数量。
nvidia@disk-passthrough-1g9:~$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 252:0 0 50G 0 disk └─vda1 252:1 0 50G 0 part / nvidia@disk-passthrough-1g9:~$ $ virsh shutdown disk-passthrough-1g9
- 将这些行添加到 XML 中现有 <disk> 条目的旁边。
$ virsh edit disk-passthrough-1g9 <disk type='block' device='disk'> <driver name='qemu' type='raw'/> <source dev='/dev/disk/by-partuuid/b1dc316c-01'/> <target dev='vdb' bus='virtio'/> </disk>注意: 确保 UUID 与先前步骤中的 UUID 匹配。 - 保存并重新启动 Guest VM。
$ virsh start disk-passthrough-1g9
- 验证驱动器是否在 Guest VM 内部显示。
$ virsh console disk-passthrough-1g9 nvidia@disk-passthrough-1g8:~$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 252:0 0 50G 0 disk └─vda1 252:1 0 50G 0 part / vdb 252:16 0 1024G 0 disk └─vdb1 252:17 0 1024G 0 part /raid