多进程服务
多进程服务 (MPS) 是 CUDA 应用程序编程接口 (API) 的另一种二进制兼容的实现。MPS 运行时架构旨在透明地支持协作式多进程 CUDA 应用程序(通常是 MPI 作业),以利用最新的 NVIDIA(基于 Kepler 架构)Tesla 和 Quadro GPU 上的 Hyper-Q 功能。
1. 简介#
1.1. 概览#
1.1.1. MPS#
多进程服务 (MPS) 是 CUDA 应用程序编程接口 (API) 的另一种二进制兼容的实现。MPS 运行时架构旨在透明地支持协作式多进程 CUDA 应用程序(通常是 MPI 作业),以利用最新的 NVIDIA(Kepler 及更高版本)GPU 上的 Hyper-Q 功能。Hyper-Q 允许 CUDA 内核在同一 GPU 上并发处理;当单个应用程序进程未充分利用 GPU 计算能力时,这可以提高性能。
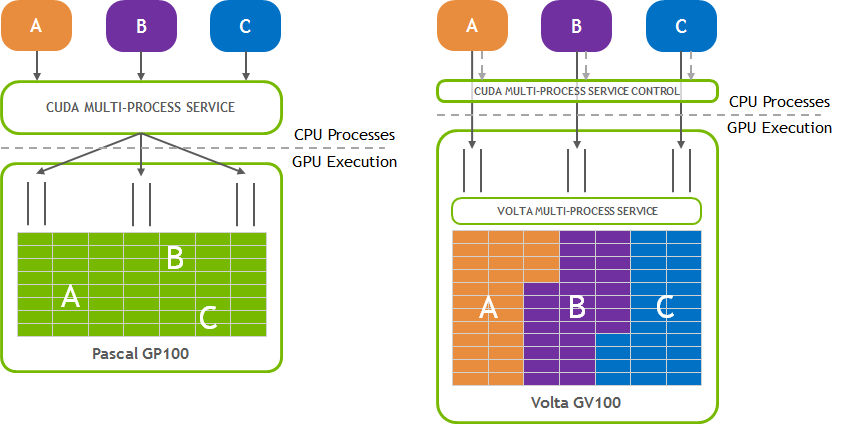
1.1.2. Volta MPS#
Volta 架构引入了新的 MPS 功能。与 pre-Volta GPU 上的 MPS 相比,Volta MPS 提供了一些关键改进
Volta MPS 客户端直接将工作提交到 GPU,而无需通过 MPS 服务器。
每个 Volta MPS 客户端都拥有自己的 GPU 地址空间,而不是与所有其他 MPS 客户端共享 GPU 地址空间。
Volta MPS 支持有限的执行资源调配,以实现服务质量 (QoS)。
本文档将介绍新功能,并指出 Volta MPS 与 pre-Volta GPU 上的 MPS 之间的差异。在 Volta 上运行 MPS 将自动启用新功能。
1.1.3. 目标受众#
本文档是 MPS 功能和用法的综合指南。它旨在供应用程序开发人员和用户阅读,这些开发人员和用户将运行 GPU 计算并旨在获得最高级别的执行性能。它也旨在供系统管理员阅读,他们将以用户友好的方式启用 MPS 功能,通常在多节点集群上。
1.1.4. 本文档的组织结构#
演示顺序如下
简介和概念 – 描述了为什么需要 MPS 以及它如何为多进程应用程序启用 Hyper-Q。
何时使用 MPS – 描述了在选择使用 MPS 运行应用程序或为用户部署 MPS 时需要考虑哪些因素。
架构 – 详细描述了 MPS 的客户端-服务器架构,以及它如何将客户端多路复用到 GPU 上。
附录 – MPS 系统使用的工具和接口的参考信息,以及常见用例的指导。
1.2. 前提条件#
本文档的某些部分假设您已经熟悉
CUDA 应用程序的结构以及它们如何通过 CUDA 运行时和 CUDA 驱动程序软件库利用 GPU
现代操作系统的概念,例如进程和线程如何调度以及进程间通信通常如何工作
Linux 命令行 shell 环境
通过命令行界面配置和运行 MPI 程序
1.3. 概念#
1.3.1. 为什么需要 MPS#
为了平衡 CPU 和 GPU 任务之间的工作负载,MPI 进程通常在多核 CPU 机器中分配单独的 CPU 核心,以提供潜在 Amdahl 瓶颈的 CPU 核心并行化。因此,当使用 CUDA 内核加速 MPI 进程时,分配给每个 MPI 进程的工作量可能会未充分利用 GPU。虽然每个 MPI 进程最终可能会运行得更快,但 GPU 的使用效率低下。多进程服务利用 MPI 进程间并行性,提高了整体 GPU 利用率。
1.3.2. MPS 是什么#
MPS 是 CUDA API 的二进制兼容的客户端-服务器运行时实现,它由几个组件组成
控制守护进程 – 控制守护进程负责启动和停止服务器,以及协调客户端和服务器之间的连接。
客户端运行时 – MPS 客户端运行时内置于 CUDA 驱动程序库中,并且可以被任何 CUDA 应用程序透明地使用。
服务器进程 – 服务器是客户端与 GPU 的共享连接,并在客户端之间提供并发性。
1.4. 另请参阅#
nvidia-smi (1)的手册页
2. 何时使用 MPS#
2.1. MPS 的优势#
2.1.1. GPU 利用率#
单个进程可能无法利用 GPU 上可用的所有计算和内存带宽容量。MPS 允许来自不同进程的内核和内存复制操作在 GPU 上重叠,从而实现更高的利用率和更短的运行时间。
2.1.2. 减少 GPU 上下文存储#
在没有 MPS 的情况下,每个使用 GPU 的 CUDA 进程都会在 GPU 上分配单独的存储和调度资源。相比之下,MPS 服务器分配 GPU 存储和调度资源的一个副本,供其所有客户端共享。Volta MPS 支持 MPS 客户端之间更高的隔离度,因此资源减少的程度要小得多。
2.1.3. 减少 GPU 上下文切换#
在没有 MPS 的情况下,当进程共享 GPU 时,它们的调度资源必须在 GPU 上来回交换。MPS 服务器在其所有客户端之间共享一组调度资源,从而消除了在 GPU 在这些客户端之间进行调度时进行交换的开销。
2.2. 识别候选应用程序#
当每个应用程序进程生成的工作不足以使 GPU 饱和时,MPS 非常有用。可以使用 MPS 在每个节点上运行多个进程,以实现更高的并发性。像这样的应用程序可以通过具有少量块/网格来识别。
此外,如果应用程序由于每个网格的线程数较少而显示出较低的 GPU 占用率,则可以通过 MPS 实现性能改进。建议在内核调用中使用较少的块/网格,并使用更多的线程/块来增加每个块的占用率。MPS 允许剩余的 GPU 容量被来自其他进程的 CUDA 内核占用。
这些情况出现在强扩展情况下,其中计算能力(节点、CPU 核心和/或 GPU 计数)增加,而问题规模保持不变。虽然计算工作的总量保持不变,但每个进程的工作量减少,并且在应用程序运行时可能未充分利用可用的计算能力。使用 MPS,GPU 将允许来自不同进程的内核启动并发运行,并消除计算中不必要的序列化点。
2.3. 注意事项#
2.3.1. 系统注意事项#
2.3.1.1. 局限性#
MPS 仅在 Linux 和 QNX 操作系统上受支持。当在 Linux 以外的操作系统上启动时,MPS 服务器将无法启动。
Tegra 平台仅支持 Volta MPS。
MPS 需要计算能力版本为 3.5 或更高的 GPU。如果应用
CUDA_VISIBLE_DEVICES后可见的 GPU 之一的计算能力不为 3.5 或更高,则 MPS 服务器将无法启动。CUDA 的统一虚拟寻址 (UVA) 功能必须可用,这对于在计算能力版本为 2.0 或更高的 GPU 上运行的任何 64 位 CUDA 程序都是默认设置。如果 UVA 不可用,则 MPS 服务器将无法启动。
MPS 客户端可以分配的页面锁定主机内存量受 tmpfs 文件系统(Linux 的
/dev/shm和 QNX 的/dev/shmem)大小的限制。独占模式限制应用于 MPS 服务器,而不是 MPS 客户端。GPU 计算模式在 Tegra 平台上不受支持。
系统上只有一个用户可以拥有活动的 MPS 服务器。
MPS 控制守护进程将对来自不同用户的 MPS 服务器激活请求进行排队,从而导致用户之间 GPU 的串行独占访问,而与 GPU 独占设置无关。
所有 MPS 客户端行为都将归因于系统监控和计费工具的 MPS 服务器进程(例如,
nvidia-smi、NVML API)。
2.3.1.2. GPU 计算模式#
通过 nvidia-smi 中可访问的设置支持三种计算模式
PROHIBITED– GPU 不可用于计算应用程序。EXCLUSIVE_PROCESS— GPU 一次仅分配给一个进程,并且单个进程线程可以并发地向 GPU 提交工作。DEFAULT– 多个进程可以同时使用 GPU。每个进程的单个线程可以同时向 GPU 提交工作。
有效使用 MPS 会使 EXCLUSIVE_PROCESS 模式的行为类似于所有 MPS 客户端的 DEFAULT 模式。MPS 将始终允许多个客户端通过 MPS 服务器使用 GPU。
使用 MPS 时,建议使用 EXCLUSIVE_PROCESS 模式以确保只有一个 MPS 服务器正在使用 GPU,这提供了额外的保证,即 MPS 服务器是该 GPU 的所有 CUDA 进程之间唯一的仲裁点。
2.3.2. 应用程序注意事项#
NVIDIA Codec SDK:https://developer.nvidia.com/nvidia-video-codec-sdk 在 pre-Volta MPS 客户端上的 MPS 下不受支持。
仅支持 64 位应用程序。如果 CUDA 应用程序不是 64 位的,则 MPS 服务器将无法启动。MPS 客户端将无法进行 CUDA 初始化。
如果应用程序使用 CUDA 驱动程序 API,则它必须使用来自 CUDA 4.0 或更高版本的标头(即,它一定不能通过将
CUDA_FORCE_API_VERSION设置为早期版本来构建)。如果上下文版本早于 4.0,则客户端中的上下文创建将失败。不支持动态并行。如果模块使用动态并行功能,则 CUDA 模块加载将失败。
MPS 服务器仅支持与服务器运行在相同 UID 下的客户端。如果服务器未在相同的 UID 下运行,则客户端应用程序将无法初始化。Volta MPS 可以在
-multiuser-server模式下启动,以允许不同 UID 下的客户端连接到在 root 用户下启动的单个 MPS 服务器,同时删除用户之间的隔离。有关-multiuser-server模式的详细信息,请参阅 服务器。pre-Volta MPS 客户端不支持流回调。调用任何流回调 API 将返回错误。
在 pre-Volta MPS 客户端上的 MPS 下不支持带有主机节点的 CUDA 图。
pre-Volta MPS 客户端应用程序可以分配的页面锁定主机内存量受 tmpfs 文件系统(Linux 的
/dev/shm和 QNX 的/dev/shmem)大小的限制。尝试使用任何相关的 CUDA API 分配超过允许大小的页面锁定内存将失败。在未与所有未完成的 GPU 工作同步的情况下终止 MPS 客户端(通过 Ctrl-C / 程序异常(例如段错误)/ 信号等)可能会使 MPS 服务器和其他 MPS 客户端处于未定义状态,这可能会导致挂起、意外故障或损坏。
Volta MPS 支持由作为 MPS 客户端运行的进程创建的 CUDA 上下文与由不作为 MPS 客户端运行的进程创建的 CUDA 上下文之间的 CUDA IPC。Tegra 平台不支持 CUDA IPC。
Tegra 平台上不支持使用 MPS 启动协同组内核。
2.3.3. 内存保护和错误遏制#
MPS 仅建议用于有效地充当单个应用程序的协作进程,例如同一 MPI 作业的多个 ranks,这样以下内存保护和错误遏制限制的严重性是可接受的。
2.3.3.1. 内存保护#
Volta MPS 客户端进程具有完全隔离的 GPU 地址空间。
Pre-Volta MPS 客户端进程从同一 GPU 虚拟地址空间的不同分区分配内存。因此
CUDA 内核中的越界写入可能会修改另一个进程的 CUDA 可访问内存状态,并且不会触发错误。
CUDA 内核中的越界读取可以访问由另一个进程修改的 CUDA 可访问内存,并且不会触发错误,从而导致未定义的行为。
此 pre-Volta MPS 行为仅限于来自 CUDA 内核中指针的内存访问。任何 CUDA API 都限制 MPS 客户端访问该 MPS 客户端内存分区之外的任何资源。例如,不可能使用 cudaMemcpy() API 覆盖另一个 MPS 客户端的内存。
2.3.3.2. 错误遏制#
Volta MPS 支持有限的错误遏制
由 Volta MPS 客户端进程生成的致命 GPU 故障将遏制在所有客户端之间共享的 GPU 子集中,其中包含导致致命故障的 GPU。
由 Volta MPS 客户端进程生成的致命 GPU 故障将报告给在包含致命故障的 GPU 子集上运行的所有客户端,但不指示哪个客户端生成了错误。请注意,受影响的客户端有责任在被告知致命 GPU 故障后退出。
在其他 GPU 上运行的客户端不受致命故障的影响,并将正常运行直到完成。
一旦观察到致命故障,MPS 服务器将等待与受影响 GPU 关联的所有客户端退出,禁止新客户端连接到这些 GPU 加入。MPS 服务器的状态从
ACTIVE更改为FAULT。当与受影响 GPU 关联的所有现有客户端都退出后,MPS 服务器将在受影响的 GPU 上重新创建 GPU 上下文,并恢复处理对这些 GPU 的客户端请求。MPS 服务器状态更改回ACTIVE,表示它能够处理新客户端。
例如,如果您的系统有设备 0、1 和 2,并且如果有四个客户端客户端 A、客户端 B、客户端 C 和客户端 D 连接到 MPS 服务器:客户端 A 在设备 0 上运行,客户端 B 在设备 0 和 1 上运行,客户端 C 在设备 1 上运行,客户端 D 在设备 2 上运行。如果客户端 A 触发致命 GPU 故障
由于设备 0 和设备 1 共享一个公共客户端客户端 B,因此致命 GPU 故障遏制在设备 0 和 1 内。
致命 GPU 故障将报告给在设备 0 和 1 上运行的所有客户端,即客户端 A、客户端 B 和客户端 C。
在设备 2 上运行的客户端 D 不受致命故障的影响,并继续正常运行。
MPS 服务器将等待客户端 A、客户端 B 和客户端 C 退出,并且任何新的客户端请求都将被拒绝并显示错误
CUDA_ERROR_MPS_SERVER_NOT_READY,而服务器状态为FAULT。在客户端 A、客户端 B 和客户端 C 退出后,服务器会在设备 0 和设备 1 上重新创建 GPU 上下文,然后恢复接受所有设备上的客户端请求。服务器状态再次变为ACTIVE。
有关致命 GPU 故障遏制的信息将被记录,包括
如果致命 GPU 故障是致命内存故障,则触发致命 GPU 内存故障的客户端的 PID。
受此致命 GPU 故障影响的设备的设备 ID。
受此致命 GPU 故障影响的客户端的 PID。每个受影响客户端的状态变为
INACTIVE,MPS 服务器的状态变为FAULT。指示在所有受影响客户端退出后成功重新创建受影响设备的消息。
Pre-Volta MPS 客户端进程共享 GPU 上的调度和错误报告资源。因此
任何客户端生成的 GPU 故障都将报告给所有客户端,但不指示哪个客户端生成了错误。
由一个客户端触发的致命 GPU 故障将终止 MPS 服务器和所有客户端的 GPU 活动。
在 CUDA 运行时或 CUDA 驱动程序中 CPU 上生成的 CUDA API 错误仅传递给调用客户端。
2.3.4. 多 GPU 系统上的 MPS#
MPS 服务器支持使用多个 GPU。在具有多个 GPU 的系统上,您可以使用 CUDA_VISIBLE_DEVICES 枚举您想要使用的 GPU。有关更多详细信息,请参阅 环境变量。
在混合使用 Volta / pre-Volta GPU 的系统上,如果 MPS 服务器设置为枚举任何 Volta GPU,它将丢弃所有 pre-Volta GPU。换句话说,MPS 服务器将仅在 Volta GPU 上运行并公开 Volta 功能,或者仅在 pre-Volta GPU 上运行。
2.3.5. 性能#
2.3.5.1. 客户端-服务器连接限制#
pre-Volta MPS 服务器每个设备并发支持最多 16 个客户端 CUDA 上下文。Volta MPS 服务器每个设备支持 48 个客户端 CUDA 上下文。这些上下文可以分布在多个进程中。如果超过连接限制,CUDA 应用程序将无法创建 CUDA 上下文,并从 cuCtxCreate() 或触发上下文创建的第一个 CUDA 运行时 API 调用返回 API 错误。MPS 服务器将记录失败的连接尝试。
2.3.5.2. Volta MPS 执行资源调配#
Volta MPS 支持有限的执行资源调配。可以将客户端上下文设置为仅使用可用线程的一部分。调配功能通常用于实现两个目标
减少客户端内存占用: 由于每个 MPS 客户端进程都具有完全隔离的地址空间,因此每个客户端上下文都会分配独立的上下文存储和调度资源。这些资源会随着客户端可用的线程数量而扩展。默认情况下,每个 MPS 客户端都拥有所有可用的线程。由于 MPS 通常与同时运行的多个进程一起使用,因此使每个客户端都可以访问所有线程通常是不必要的,因此分配完整的上下文存储是浪费的。减少可用线程数将有效地减少上下文存储分配大小。
提高 QoS: 调配机制可以用作经典的 QoS 机制来限制可用的计算带宽。减少可用线程的比例也将客户端提交的工作集中到一组 SM 上,从而减少对其他客户端提交工作的破坏性干扰。
设置限制不会为任何 MPS 客户端上下文保留专用资源。它只是限制了客户端上下文可以使用的资源量。来自不同 MPS 客户端上下文的内核启动可能会在同一 SM 上执行,具体取决于负载平衡。
默认情况下,每个客户端都配置为可以访问所有可用线程。这将允许最大程度的调度自由度,但代价是由于浪费的执行资源分配而导致更高的内存占用。可以通过 nvidia-smi 查询每个客户端进程的内存使用情况。
可以通过几种不同的机制设置调配限制,以获得不同的效果。这些机制分为两种机制:活动线程百分比和编程接口。特别是,通过活动线程百分比进行分区分为两种策略:均匀分区和非均匀分区。
为客户端进程配置均匀活动线程百分比限制,该限制在客户端进程启动时配置,之后无法为客户端进程更改。执行的限制通过设备属性 cudaDevAttrMultiProcessorCount 反映,该属性的值在整个客户端进程中保持不变。
MPS 控制实用程序提供 2 组命令来设置/查询所有未来 MPS 客户端的限制。有关更多详细信息,请参阅 nvidia-cuda-mps-control。
或者,可以通过为 MPS 控制进程设置环境变量
CUDA_MPS_ACTIVE_THREAD_PERCENTAGE来设置所有未来 MPS 客户端的限制。有关更多详细信息,请参阅 MPS 控制守护进程级别。可以通过仅为客户端进程设置环境变量
CUDA_MPS_ACTIVE_THREAD_PERCENTAGE来进一步限制新客户端的限制。有关更多详细信息,请参阅 客户端进程级别。
为每个客户端 CUDA 上下文配置非均匀活动线程百分比限制,并且可以在整个客户端进程中更改该限制。执行的限制通过设备属性 cudaDevAttrMultiProcessorCount 反映,该属性的值返回客户端 CUDA 上下文当前调用线程可以使用的可用线程部分。
可以通过结合使用环境变量
CUDA_MPS_ACTIVE_THREAD_PERCENTAGE和环境变量CUDA_MPS_ENABLE_PER_CTX_DEVICE_MULTIPROCESSOR_PARTITIONING来进一步限制通过均匀分区机制限制的新客户端 CUDA 上下文。有关更多详细信息,请参阅 客户端 CUDA 上下文级别 和 CUDA_MPS_ENABLE_PER_CTX_DEVICE_MULTIPROCESSOR_PARTITIONING。
通过编程分区限制为通过 cuCtxCreate_v3() 创建的客户端 CUDA 上下文配置,执行关联性 CUexecAffinityParam 指定上下文限制使用的 SM 数量。可以通过 cuCtxGetExecAffinity() 查询上下文的执行限制。有关更多详细信息,请参阅 SM 分区的最佳实践。
常见的调配策略是将可用线程均匀地分配给每个 MPS 客户端进程(即,对于 n 个预期的 MPS 客户端进程,将活动线程百分比设置为 100% / n)。此策略将分配接近最小数量的执行资源,但可能会限制偶尔可以使用空闲资源的客户端的性能。
更优化的策略是将部分均匀地划分为预期客户端数量的一半(即,将活动线程百分比设置为 100% / 0.5n),以便在存在空闲资源时,负载均衡器可以更自由地重叠客户端之间的执行。
接近最优的调配策略是基于每个 MPS 客户端的工作负载非均匀地分区可用线程(即,如果客户端 1 工作负载和客户端 2 工作负载的比率为 30%: 70%,则将客户端 1 的活动线程百分比设置为 30%,将客户端 2 的活动线程百分比设置为 70%)。此策略将不同客户端提交的工作集中到不相交的 SM 集,并有效地最大限度地减少不同客户端提交工作之间的干扰。
最合适的调配策略是在知道每个客户端的执行资源需求的情况下,精确地限制每个 MPS 客户端使用的 SM 数量(即,在具有 84 个 SM 的设备上,客户端 1 为 24 个 SM,客户端 2 为 60 个 SM)。与活动线程百分比相比,此策略提供对工作将运行的 SM 集更精细和更灵活的控制。
如果活动线程百分比用于分区,则限制将在内部向下舍入到最接近的硬件支持的线程计数限制。如果编程接口用于分区,则限制将在内部向上舍入到最接近的硬件支持的 SM 计数限制。
2.3.5.3. 线程和 Linux 调度#
在 pre-Volta GPU 上,启动的 MPS 客户端数量超过机器上可用的逻辑核心数量将导致启动延迟增加,并且通常会由于 Linux CFS(完全公平调度器)如何调度线程而减慢客户端-服务器通信速度。对于每个 GPU 启动 MPS 控制守护进程和服务器的使用多个 GPU 的设置,我们建议将每个 MPS 服务器绑定到不同的核心。这可以通过使用实用程序 taskset 来完成,该实用程序允许将正在运行的程序绑定到多个核心或在这些核心上启动新程序。为了使用 MPS 完成此操作,请启动绑定到特定核心的控制守护进程,例如,taskset -c 0 nvidia-cuda-mps-control -d。进程关联性将在 MPS 服务器启动时被继承。
2.3.5.4. Volta MPS 设备内存限制#
在 Volta MPS 上,用户可以强制客户端遵守分配设备内存,直到达到预设限制。此机制提供了一种在特定 GPU 上运行的 MPS 客户端之间对 GPU 内存进行部分化的工具,这使调度和部署系统能够根据客户端的内存使用情况做出决策。如果客户端尝试分配超出预设限制的内存,则 CUDA 内存分配调用将返回内存不足错误。内存限制特定也将考虑 CUDA 内部设备分配,这将帮助用户为优化 GPU 利用率做出调度决策。这可以通过控制机制层次结构来完成,用户可以使用该层次结构来限制 MPS 客户端上的固定设备内存。default 限制设置将在所有生成的未来 MPS 服务器的所有 MPS 客户端上强制执行设备内存限制。per server 限制设置允许对内存资源限制进行更精细的控制,用户可以选择使用服务器 PID 有选择地设置内存限制,从而限制服务器的所有客户端。此外,MPS 客户端可以使用 CUDA_MPS_PINNED_DEVICE_MEM_LIMIT 环境变量进一步限制来自服务器的内存限制设置。
2.3.6. 与工具的交互#
2.3.6.1. 调试和 CUDA-GDB#
在 Volta MPS 上,可以使用 CUDA-GDB 生成和调试 GPU 核心转储。有关使用说明,请参阅 CUDA-GDB 文档 <http://docs.nvda.net.cn/cuda/cuda-gdb/index.html>`__。
在某些情况下,从 CUDA-GDB(或任何 CUDA 兼容的调试器,例如 Allinea DDT)中调用的应用程序即使在 MPS 自动调配处于活动状态时,也可能在不使用 MPS 的情况下自动运行。为了利用此自动回退,此时不得运行其他 MPS 客户端应用程序。这使得可以调试 CUDA 应用程序,而无需修改系统的 MPS 配置。
以下是它的工作原理
CUDA-GDB 尝试运行应用程序,并识别出它将成为 MPS 客户端。
在 CUDA-GDB 下运行的应用程序在
cuInit()中阻止,并等待所有活动的 MPS 客户端进程退出(如果有任何进程正在运行)。一旦所有客户端进程终止,MPS 服务器将允许 CUDA-GDB 和正在调试的应用程序继续运行。
任何新的客户端进程尝试连接到 MPS 守护进程都将正常调配服务器。
2.3.6.2. memcheck#
memcheck 工具在 MPS 上受支持。有关用法说明,请参阅 memcheck 文档。
2.3.6.3. 性能分析#
MPS 下支持 CUDA 性能分析工具(例如 nvprof 和 Nvidia Visual Profiler)以及基于 CUPTI 的性能分析器。
有关更多详细信息,请参阅 从 Visual Profiler 和 nvprof 迁移到 Nsight Tools。
2.3.7. 客户端提前终止#
不支持通过 CTRL-C 或信号终止 MPS 客户端,这将导致未定义的行为。用户必须保证 MPS 客户端处于空闲状态,方法是在终止 MPS 客户端之前,在所有流上调用 cudaDeviceSynchronize 或 cudaStreamSynchronize。在未同步所有未完成的 GPU 工作的情况下提前终止 MPS 客户端可能会使 MPS 服务器处于未定义状态,并导致意外的故障、损坏或挂起;因此,必须重启受影响的 MPS 服务器及其所有客户端。
在 Volta MPS 上,用户可以使用控制命令 terminate_client <服务器 PID> <客户端 PID> 指示 MPS 服务器终止 MPS 客户端进程的 CUDA 上下文,无论 CUDA 上下文是否空闲。此机制使用户能够终止给定 MPS 客户端进程的 CUDA 上下文,即使 CUDA 上下文处于非空闲状态,也不会影响 MPS 服务器或其他 MPS 客户端。控制命令 terminate_client 向 MPS 服务器发送请求,MPS 服务器代表用户终止目标 MPS 客户端进程的 CUDA 上下文,并在 MPS 服务器完成请求后返回。如果目标 MPS 客户端进程的 CUDA 上下文已成功终止,则返回值为 CUDA_SUCCESS;否则,返回描述故障状态的 CUDA 错误。当 MPS 服务器开始处理请求时,在目标 MPS 客户端进程中运行的每个 MPS 客户端上下文都将变为 INACTIVE;MPS 服务器将记录状态更改。成功完成客户端终止后,目标 MPS 客户端进程将观察到粘滞错误 CUDA_ERROR_MPS_CLIENT_TERMINATED,并且可以使用诸如 SIGKILL 之类的信号安全地终止目标 MPS 客户端进程,而不会影响 MPS 服务器的其余部分及其 MPS 客户端。请注意,MPS 服务器不负责在设置粘滞错误后终止目标 MPS 客户端进程,因为目标 MPS 客户端进程可能想要
执行其 GPU 或 CPU 状态的清理工作。 这可能包括设备重置。 继续剩余的 CPU 工作。
继续剩余的 CPU 工作。
如果用户想要终止在与 MPS 控制的 PID 命名空间不同的 PID 命名空间(例如容器内的 MPS 客户端进程)内运行的 MPS 客户端进程的 GPU 工作,则用户必须使用转换为 MPS 控制的 PID 命名空间的目标 MPS 客户端进程的 PID。例如,容器内的 MPS 客户端进程的 PID 为 6,而此 MPS 客户端进程在主机 PID 命名空间中的 PID 为 1024;用户必须使用 1024 来终止目标 MPS 客户端进程的 GPU 工作。
终止客户端应用程序 nbody 的常用工作流程
使用控制命令 ps 获取当前活动的 MPS 客户端的状态。
$ echo "ps" | nvidia-cuda-mps-control
PID ID SERVER DEVICE NAMESPACE COMMAND
9741 0 6472 GPU-cb1213a3-d6a4-be7f 4026531836 ./nbody
9743 0 6472 GPU-cb1213a3-d6a4-be7f 4026531836 ./matrixMul
使用 ps 报告的主机 PID 命名空间中 nbody 的 PID 进行终止
$ echo "terminate_client 6472 9741" | nvidia-cuda-mps-control
#wait until terminate_client to return
#upon successful termination 0 is returned
0
现在可以安全地终止 nbody
$ kill -9 9741
Tegra 平台上不支持 MPS 客户端终止。
2.3.8. 客户端优先级控制#
通常,用户只能在使用 cudaStreamCreateWithPriority() API 编写程序时控制其内核的 GPU 优先级。在 Volta MPS 上,用户可以使用控制命令 set_default_client_priority <优先级级别> 将给定客户端的流优先级映射到不同的内部 CUDA 优先级范围。对此设置的更改在下次客户端连接到服务器时才会生效。用户还可以在启动控制守护程序或任何给定客户端进程之前设置 CUDA_MPS_CLIENT_PRIORITY 环境变量来设置此值。
在此版本中,允许的优先级级别值为 0(正常)和 1(低于正常)。较低的数字映射到较高的优先级,以匹配 Linux 内核调度程序的行为。
注意
CUDA 优先级级别不能保证执行顺序,它们只是 CUDA 驱动程序的性能提示。
例如
进程 A 以正常优先级启动,并且仅使用默认 CUDA 流,该流的优先级最低,为 0。
进程 B 以低于正常优先级启动,并使用具有自定义流优先级值(例如 -3)的流。
如果没有此功能,CUDA 驱动程序将首先执行来自进程 B 的流。但是,借助客户端优先级级别功能,来自进程 A 的流将优先执行。
3. 架构#
3.1. 背景#
CUDA 是一个通用的并行计算平台和编程模型,它利用 NVIDIA GPU 中的并行计算引擎来解决许多复杂的计算问题,其效率比在 CPU 上更高。
CUDA 程序首先为特定的 GPU 创建 CUDA 上下文,可以使用驱动程序 API 显式创建,也可以使用运行时 API 隐式创建。上下文封装了程序能够管理内存并在该 GPU 上启动工作所需的所有硬件资源。
在 GPU 上启动工作通常涉及将数据复制到先前在 GPU 内存中分配的区域,运行对该数据进行操作的 CUDA 内核,然后将结果从 GPU 内存复制回系统内存。CUDA 内核由线程组的层次结构组成,这些线程组在 GPU 的计算引擎上并行执行。
所有使用 CUDA 启动到 GPU 上的工作都显式启动到 CUDA 流中,或者隐式使用默认流。流是一个软件抽象,表示命令序列(可能是内核、复制和其他命令的混合),这些命令按顺序执行。在两个不同流中启动的工作可以同时执行,从而实现粗粒度的并行性。
CUDA 流通过驱动程序别名到一个或多个 GPU 上的“工作队列”。工作队列是硬件资源,表示流中要由 GPU 上特定引擎(例如内核执行或内存复制)执行的命令子集的有序序列。具有 Hyper-Q 的 GPU 具有并发调度程序,用于调度来自属于单个 CUDA 上下文的工作队列的工作。从属于同一 CUDA 上下文的工作队列启动到计算引擎的工作可以在 GPU 上并发执行。
GPU 还具有分时调度程序,用于调度来自属于不同 CUDA 上下文的工作队列的工作。从属于不同 CUDA 上下文的工作队列启动到计算引擎的工作不能并发执行。如果从单个 CUDA 上下文启动的工作不足以用尽可用的所有资源,则可能导致 GPU 计算资源利用率不足。
此外,在软件层中,为了接收来自操作系统的异步通知并代表应用程序执行异步 CPU 工作,CUDA 驱动程序可能会创建内部线程:一个 upcall 处理程序线程和一个潜在的用户回调执行程序线程。
3.2. 客户端-服务器架构#
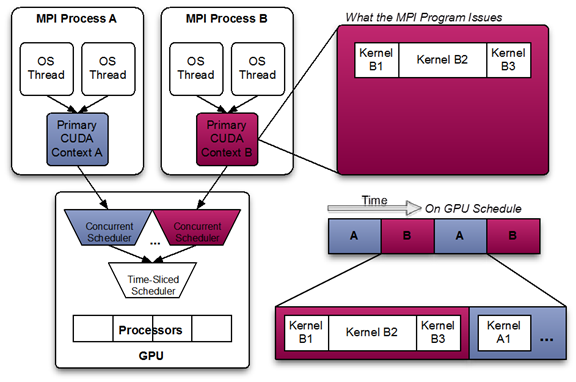
此图显示了在运行由多个 OS 进程组成的 MPI 应用程序且不使用 MPS 时,CUDA 内核的可能调度。请注意,虽然来自每个 MPI 进程内的 CUDA 内核可以并发调度,但每个 MPI 进程都在整个 GPU 上分配了串行调度的时隙。
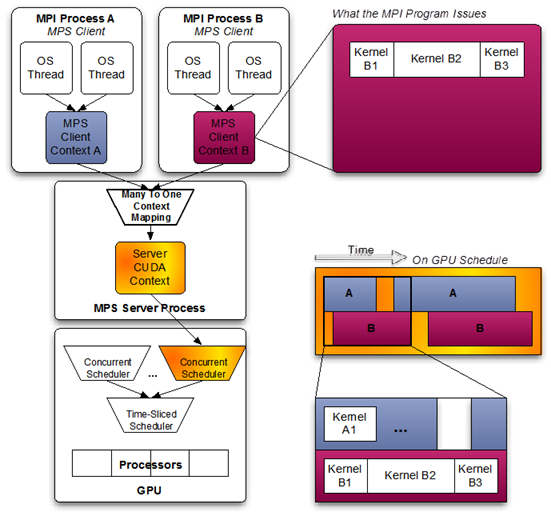
当使用 pre-Volta MPS 时,服务器管理与单个 CUDA 上下文关联的硬件资源。属于 MPS 客户端的 CUDA 上下文通过 MPS 服务器传递其工作。这允许客户端 CUDA 上下文绕过与分时调度相关的硬件限制,并允许其 CUDA 内核同时执行。
Volta 提供了新的硬件功能,以减少 MPS 服务器必须管理的硬件资源类型。客户端 CUDA 上下文管理 Volta 上的大多数硬件资源,并将工作直接提交给硬件。Volta MPS 服务器调解剩余的共享资源,以确保同时调度各个客户端提交的工作,并保持在关键执行路径之外。
MPS 客户端和 MPS 服务器之间的通信完全封装在 CUDA API 后面的 CUDA 驱动程序中。因此,MPS 对于 MPI 程序是透明的。
MPS 客户端 CUDA 上下文保留其 upcall 处理程序线程和任何异步执行程序线程。MPS 服务器创建一个额外的 upcall 处理程序线程,并为每个客户端创建一个工作线程。
3.3. 配置顺序#
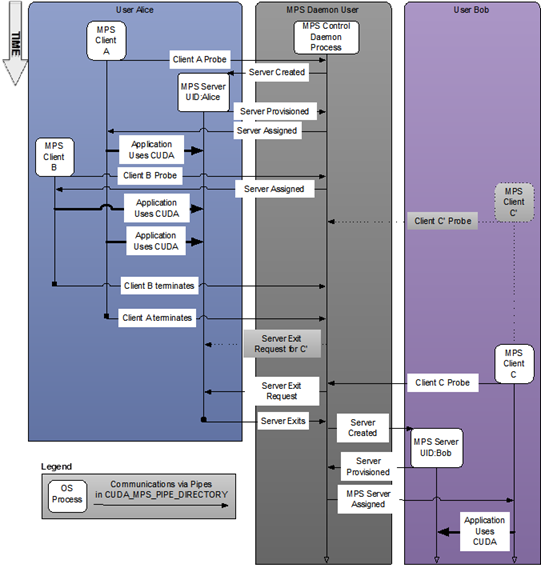
图 1 具有多个用户的系统范围配置。#
3.3.1. 服务器#
MPS 控制守护程序负责 MPS 服务器的启动和关闭。控制守护程序最多允许一个 MPS 服务器同时处于活动状态。当 MPS 客户端连接到控制守护程序时,如果没有活动的服务器,则守护程序会启动 MPS 服务器。MPS 服务器以与 MPS 客户端相同的用户 ID 启动。
如果已经有一个活动的 MPS 服务器,并且服务器和客户端的用户 ID 匹配,则控制守护程序允许客户端继续连接到服务器。如果已经有一个活动的 MPS 服务器,但服务器和客户端使用不同的用户 ID 启动,则控制守护程序请求现有服务器在所有客户端断开连接后关闭。一旦现有服务器关闭,控制守护程序将使用与新用户的客户端进程相同的用户 ID 启动新服务器。上图显示了用户 Bob 在服务器可用之前启动客户端 C' 的情况。只有在用户 Alice 的客户端退出后,才会为用户 Bob 和客户端 C' 创建服务器。
如果没有挂起的客户端请求,MPS 控制守护程序不会关闭活动的服务器。这意味着即使所有活动的客户端都退出,活动的 MPS 服务器进程也会持续存在。当使用与活动的 MPS 服务器不同的用户 ID 启动的新 MPS 客户端连接到控制守护程序时,或者当客户端启动的工作导致故障时,活动服务器将关闭。如上例所示,即使 Alice 的所有客户端都已退出,控制守护程序也仅在用户 Bob 启动客户端 C 时才向 Alice 的服务器发出服务器退出请求。
在 Volta MPS 上,每个 MPS 服务器一个 Linux 用户的限制可能会放宽,以避免在每个新用户请求时重新配置 MPS 服务器。在此模式下,来自所有 Linux 用户的客户端将显示为来自 root 用户的客户端,并连接到 root MPS 服务器。在启用此模式之前,务必确保可以安全地忽略不同用户(包括 root 用户)之间的隔离。来自所有用户的客户端将共享相同的 MPS 日志文件。相同的错误遏制规则(请参阅 内存保护和错误遏制)也适用于此模式下来自所有用户的客户端。例如,来自一个客户端的致命故障可能会导致与故障客户端共享任何 GPU 的不同用户的客户端崩溃。要允许多个 Linux 用户共享一个 MPS 服务器,请使用 -multiuser-server 选项以超级用户身份启动控制守护程序。Tegra 平台上不支持此选项。
MPS 服务器可能处于以下状态之一:INITIALIZING、ACTIVE 或 FAULT。INITIALIZING 状态表示 MPS 服务器正忙于初始化,MPS 控制将新客户端请求保留在其队列中。ACTIVE 状态表示 MPS 服务器能够处理新的客户端请求。FAULT 状态表示 MPS 服务器因客户端导致的致命故障而被阻止。任何新的客户端请求都将被拒绝,并显示错误 CUDA_ERROR_MPS_SERVER_NOT_READY。
新启动的 MPS 服务器将首先处于 INITIALIZING 状态。成功初始化后,MPS 服务器将进入 ACTIVE 状态。当客户端遇到致命故障时,MPS 服务器将从 ACTIVE 转换为 FAULT。在 pre-Volta MPS 上,MPS 服务器在遇到致命故障后会关闭。在 Volta MPS 上,在所有故障客户端断开连接后,MPS 服务器将再次变为 ACTIVE。
控制守护程序可执行文件还支持交互模式,具有足够权限的用户可以在其中发出命令,例如查看当前服务器和客户端列表或手动启动和关闭服务器。
3.3.2. 客户端连接/断开连接#
当程序中首次初始化 CUDA 时,CUDA 驱动程序会尝试连接到 MPS 控制守护程序。如果连接尝试失败,程序将继续像往常一样运行,而无需 MPS。但是,如果连接尝试成功,则 MPS 控制守护程序将继续确保在返回客户端之前,以与连接客户端相同的用户 ID 启动的 MPS 服务器处于活动状态。然后,MPS 客户端继续连接到服务器。
MPS 客户端、MPS 控制守护程序和 MPS 服务器之间的所有通信都是使用命名管道和 UNIX 域套接字完成的。MPS 服务器启动一个工作线程来接收来自客户端的命令。客户端成功连接后,MPS 服务器将记录日志,客户端状态变为 ACTIVE。客户端进程退出时,服务器会销毁客户端进程未显式释放的任何资源,并终止工作线程。MPS 服务器将记录客户端退出事件。
4. 附录:工具和接口参考#
以下实用程序和环境变量用于管理 MPS 执行环境。它们在下面以及标准 CUDA 编程环境的其他相关部分中进行描述。
4.1. 实用程序和守护程序#
4.1.1. nvidia-cuda-mps-control#
此控制守护程序通常存储在 Linux 和 QNX 系统的 /usr/bin 下,并且通常以超级用户权限运行,用于管理下一节中描述的 nvidia-cuda-mps-server。以下是相关的用例
man nvidia-cuda-mps-control # Describes usage of this utility.
nvidia-cuda-mps-control -d # Start daemon in background process.
ps -ef | grep mps # Check if the MPS daemon is running, for Linux.
pidin | grep mps # See if the MPS daemon is running, for QNX.
echo quit | nvidia-cuda-mps-control # Shut the daemon down.
nvidia-cuda-mps-control -f # Start daemon in foreground.
nvidia-cuda-mps-control -v # Print version of control daemon executable (applicable on Tegra platforms only).
控制守护程序创建一个 nvidia-cuda-mps-control.pid 文件,该文件包含 CUDA_MPS_PIPE_DIRECTORY 中的控制守护程序进程的 PID。当并行运行控制守护程序的多个实例时,可以通过在相应的 CUDA_MPS_PIPE_DIRECTORY 中查找其 PID 来定位特定实例。如果未设置 CUDA_MPS_PIPE_DIRECTORY,则 nvidia-cuda-mps-control.pid 文件将在默认管道目录 /tmp/nvidia-mps 中创建。
在交互模式下使用时,可用的命令为
get_server_list– 打印所有服务器实例的 PID 列表。get_server_status <PID>– 这将打印出给定 <PID> 的服务器的状态。start_server - uid <用户 ID>– 手动启动具有给定用户 ID 的 nvidia-cuda-mps-server 的新实例。get_client_list <PID>– 列出连接到分配给给定 PID 的服务器实例的客户端应用程序的 PID。quit– 终止nvidia-cuda-mps-control守护程序。
Volta MPS 控制可用的命令
get_device_client_list [<PID>]– 列出枚举此设备的设备和客户端应用程序的 PID。它可选地接受服务器实例 PID。set_default_active_thread_percentage <百分比>– 覆盖 MPS 服务器的默认活动线程百分比。如果已生成服务器,则此命令仅影响下一个服务器。如果执行quit命令,则设置的值将丢失。默认值为 100。get_default_active_thread_percentage– 查询当前默认可用线程百分比。set_active_thread_percentage <PID> <百分比>– 覆盖给定 PID 的 MPS 服务器实例的活动线程百分比。之后使用该服务器创建的所有客户端都将观察到新的限制。现有客户端不受影响。get_active_thread_percentage <PID>– 查询给定 PID 的 MPS 服务器实例的当前可用线程百分比。set_default_device_pinned_mem_limit <dev> <value>– 设置每个 MPS 客户端的默认设备固定内存限制。如果已生成服务器,则此命令仅影响下一个服务器。如果执行quit命令,则设置的值将丢失。dev 参数可以是设备 UUID 字符串或整数序号。该值必须采用整数形式,后跟限定符“G”或“M”,分别指定以千兆字节或兆字节为单位的值。例如,要为设备 0 设置 10 千兆字节的限制,请使用以下命令set_default_device_pinned_mem_limit 0 10G默认情况下,未设置内存限制。
请注意,对于此命令,dev 参数未针对 MPS 服务器中的可用设备进行验证。因此,可以为同一设备设置两个内存限制:一个通过设备 UUID,另一个通过序号。启动 MPS 服务器时,最后设置的限制将生效。使用无效设备 UUID 或序号设置的限制在启动 MPS 服务器时将被忽略。
get_default_device_pinned_mem_limit <dev>– 查询设备的当前默认固定内存限制。dev参数可以是设备 UUID 字符串或整数序号。请注意,此命令不会在设备 UUID 或序号之间进行转换,并且将返回通过
set_default_device_pinned_mem_limit命令为每个设备标识符设置的限制。set_device_pinned_mem_limit <PID> <dev> <value>- 覆盖 MPS 服务器的设备固定内存限制。这将为给定 PID 的 MPS 服务器实例的每个客户端设置设备 dev 的设备固定内存限制。之后使用该服务器创建的所有客户端都将观察到新的限制。现有客户端不受影响。dev参数可以是设备 UUID 字符串或整数序号。例如,要为 pid 为 1024 的服务器的设备 0 设置 900MB 的限制,请使用以下命令set_device_pinned_mem_limit 1024 0 900Mget_device_pinned_mem_limit <PID> <dev>– 查询给定 PID 的 MPS 服务器实例的设备dev的当前设备固定内存限制。dev参数可以是设备 UUID 字符串或整数序号。terminate_client <服务器 PID> <客户端 PID>– 终止在<服务器 PID>表示的 MPS 服务器上运行的 MPS 客户端进程<客户端 PID>的所有未完成的 GPU 工作。例如,要终止在 PID 为 123 的 MPS 服务器上运行的 PID 为 1024 的 MPS 客户端进程的未完成的 GPU 工作,请使用以下命令terminate_client 123 1024ps [-p PID]– 报告当前客户端进程的快照。它可选地接受服务器实例 PID。它显示 PID、服务器分配的唯一标识符、关联设备的 UUID 的一部分、连接服务器的 PID、命名空间 PID 和客户端的命令行。set_default_client_priority [priority]– 设置将用于新客户端的默认客户端优先级。该值不适用于现有客户端。优先级值应被视为 CUDA 驱动程序的提示,而不是保证。允许的值为0 [NORMAL]和 1[BELOW NORMAL]。如果执行quit命令,则设置的值将丢失。默认值为0 [NORMAL]。get_default_client_priority– 查询将用于新客户端的当前优先级值。
4.1.2. nvidia-cuda-mps-server#
此守护程序通常存储在 Linux 和 QNX 系统的 /usr/bin 下,并在与节点上运行的客户端应用程序相同的 $UID 下运行。nvidia-cuda-mps-server 实例在客户端应用程序连接到控制守护程序时按需创建。服务器二进制文件不应直接调用,而应使用控制守护程序来管理服务器的启动和关闭。
nvidia-cuda-mps-server 进程拥有 GPU 上的 CUDA 上下文,并使用它为其客户端应用程序进程执行 GPU 操作。因此,当通过 nvidia-smi(或任何基于 NVML 的应用程序)查询活动进程时,nvidia-cuda-mps-server 将显示为活动的 CUDA 进程,而不是任何客户端进程。
可以使用以下命令打印 nvidia-cuda-mps-server 可执行文件的版本
nvidia-cuda-mps-server -v
4.1.3. nvidia-smi#
此实用程序通常存储在 Linux 系统的 /usr/bin 下,用于配置节点上的 GPU。以下用例与管理 MPS 相关
man nvidia-smi # Describes usage of this utility.
nvidia-smi -L # List the GPU's on node.
nvidia-smi -q # List GPU state and configuration information.
nvidia-smi -q -d compute # Show the compute mode of each GPU.
nvidia-smi -i 0 -c EXCLUSIVE_PROCESS # Set GPU 0 to exclusive mode, run as root.
nvidia-smi -i 0 -c DEFAULT # Set GPU 0 to default mode, run as root. (SHARED_PROCESS)
nvidia-smi -i 0 -r # Reboot GPU 0 with the new setting.
4.2. 环境变量#
4.2.1. CUDA_VISIBLE_DEVICES#
CUDA_VISIBLE_DEVICES 用于指定哪些 GPU 应该对 CUDA 应用程序可见。只有索引或 UUID 存在于序列中的设备才对 CUDA 应用程序可见,并且它们按照序列的顺序枚举。
如果在启动控制守护程序之前设置了 CUDA_VISIBLE_DEVICES,则设备将由 MPS 服务器重新映射。这意味着,如果您的系统具有设备 0、1 和 2,并且如果 CUDA_VISIBLE_DEVICES 设置为 0,2,则当客户端连接到服务器时,它将看到重新映射的设备 – 设备 0 和设备 1。因此,在启动客户端时将 CUDA_VISIBLE_DEVICES 设置为 0,2 将导致错误。
如果任何可见设备是 Volta+,MPS 控制守护程序将进一步过滤掉任何 pre-Volta 设备。
为避免这种歧义,我们建议使用 UUID 而不是索引。可以通过启动 nvidia-smi -q 来查看这些 UUID。启动服务器或应用程序时,您可以将 CUDA_VISIBLE_DEVICES 设置为 UUID_1,UUID_2,其中 UUID_1 和 UUID_2 是 GPU UUID。当您指定 UUID 的前几个字符(包括 GPU-)而不是完整的 UUID 时,它也同样有效。
如果在应用 CUDA_VISIBLE_DEVICES 后,仍然存在不兼容的设备可见,MPS 服务器将无法启动。
4.2.2. CUDA_MPS_PIPE_DIRECTORY#
MPS 控制守护程序、MPS 服务器和相关的 MPS 客户端通过命名管道和 UNIX 域套接字相互通信。这些管道和套接字的默认目录是 /tmp/nvidia-mps。环境变量 CUDA_MPS_PIPE_DIRECTORY 可用于覆盖这些管道和套接字的位置。对于共享同一 MPS 服务器和 MPS 控制守护程序的所有 MPS 客户端,此环境变量的值应保持一致。
包含这些命名管道和域套接字的目录的推荐位置是本地文件夹,例如 /tmp。如果指定的位置存在于共享的多节点文件系统中,则每个节点的路径必须是唯一的,以防止多个 MPS 服务器或 MPS 控制守护程序使用相同的管道和套接字。当基于每个用户配置 MPS 时,应将目录设置为不同的用户不会最终使用同一目录的位置。
在 Tegra 平台上,管道和套接字没有默认目录设置。用户必须设置此环境变量,以便只有预期的用户才能访问此位置。
4.2.3. CUDA_MPS_LOG_DIRECTORY#
MPS 控制守护程序维护一个 control.log 文件,其中包含其 MPS 服务器的状态、已发布的用户命令及其结果,以及守护程序的启动和关闭通知。MPS 服务器维护一个 server.log 文件,其中包含其启动和关闭信息以及客户端的状态。
默认情况下,这些日志文件存储在目录 /var/log/nvidia-mps 中。可以使用 CUDA_MPS_LOG_DIRECTORY 环境变量来覆盖默认值。此环境变量应在 MPS 控制守护程序的环境中设置,并且由该控制守护程序启动的任何 MPS 服务器自动继承。
在 Tegra 平台上,没有用于存储日志文件的默认目录设置。MPS 将在用户不设置此环境变量的情况下保持运行;但是,在这种情况下,MPS 日志将不可用。如果需要捕获日志,则用户必须设置此环境变量,以便只有预期的用户才能访问此位置。
4.2.4. CUDA_DEVICE_MAX_CONNECTIONS#
当在 MPS 客户端的环境中遇到 CUDA_DEVICE_MAX_CONNECTIONS 时,它会为该客户端设置从主机到设备的计算和复制引擎并发连接(工作队列)的首选数量。驱动程序实际分配的数量可能与请求的数量不同,这取决于硬件资源限制或其他考虑因素。在 MPS 下,每个服务器的客户端共享一个连接池,而在没有 MPS 的情况下,每个 CUDA 上下文都将分配其自己独立的连接池。Volta MPS 客户端独占为共享池中的客户端预留的连接,因此在 Volta MPS 下设置此环境变量可能会减少可用客户端的数量。对于 Volta MPS 客户端,默认值为 2。
4.2.5. CUDA_MPS_ACTIVE_THREAD_PERCENTAGE#
在 Volta GPU 上,此环境变量设置客户端上下文可以使用的可用线程部分。可以在不同级别配置此限制。
4.2.5.1. MPS 控制守护程序级别#
在 MPS 控制守护程序的环境中设置此环境变量将在 MPS 控制守护程序启动时配置默认的活动线程百分比。
由 MPS 控制守护程序生成的所有 MPS 服务器都将遵守此限制。一旦 MPS 控制守护程序启动,更改此环境变量将无法影响 MPS 服务器。
4.2.5.2. 客户端进程级别#
在 MPS 客户端的环境中设置此环境变量将在客户端进程启动时配置活动线程百分比。新限制只会进一步约束控制守护程序设置的限制(通过 set_default_active_thread_percentage 或 set_active_thread_percentage 控制守护程序命令,或 MPS 控制守护程序级别的此环境变量)。如果控制守护程序的设置较低,则客户端进程将遵守控制守护程序的设置。
在客户端进程中创建的所有客户端 CUDA 上下文都将遵守新限制。一旦客户端进程启动,更改此环境变量的值将无法影响客户端 CUDA 上下文。
4.2.5.3. 客户端 CUDA 上下文级别#
默认情况下,在客户端 CUDA 上下文级别配置活动线程百分比是禁用的。用户必须通过环境变量 CUDA_MPS_ENABLE_PER_CTX_DEVICE_MULTIPROCESSOR_PARTITIONING 显式选择启用。有关更多详细信息,请参阅 CUDA_MPS_ENABLE_PER_CTX_DEVICE_MULTIPROCESSOR_PARTITIONING。
在客户端进程中设置此环境变量将在创建新的客户端 CUDA 上下文时配置活动线程百分比。新限制只会进一步约束控制守护程序级别和客户端进程级别设置的限制。如果控制守护程序或客户端进程具有较低的设置,则客户端 CUDA 上下文将遵守较低的设置。之后创建的所有客户端 CUDA 上下文都将遵守新限制。现有的客户端 CUDA 上下文不受影响。
4.2.6. CUDA_MPS_ENABLE_PER_CTX_DEVICE_MULTIPROCESSOR_PARTITIONING#
默认情况下,用户只能均匀地划分可用线程。需要通过此环境变量显式选择启用非均匀分区功能。要启用非均匀分区功能,必须在客户端进程启动之前设置此环境变量。
当在 MPS 客户端的环境中启用非均匀分区功能时,客户端 CUDA 上下文可以在同一客户端进程中具有不同的活动线程百分比,方法是在创建上下文之前设置 CUDA_MPS_ACTIVE_THREAD_PERCENTAGE。设备属性 cudaDevAttrMultiProcessorCount 将反映活动线程百分比,并返回可供调用线程的客户端 CUDA 上下文使用的可用 SM 的部分。
4.2.7. CUDA_MPS_PINNED_DEVICE_MEM_LIMIT#
固定内存限制控制限制客户端进程可通过 CUDA API 分配的 GPU 内存量。在 Volta GPU 上,此环境变量设置客户端上下文可以分配的固定设备内存的限制。在 MPS 客户端的环境中设置此环境变量将在客户端进程启动时设置设备的固定内存限制。新限制只会进一步约束控制守护程序设置的限制(通过 set_default_device_pinned_mem_limit 或 set_device_pinned_mem_limit control 守护程序命令,或 MPS 控制守护程序级别的此环境变量)。如果控制守护程序具有较低的值,则客户端进程将遵守控制守护程序的设置。此环境变量将具有与 CUDA_VISIBLE_DEVICES 相同的语义,即值字符串可以包含逗号分隔的设备序号和/或设备 UUID,每个设备的内存限制用等号分隔。用法示例
$ export CUDA_MPS_PINNED_DEVICE_MEM_LIMIT=''0=1G,1=512MB''
以下示例重点介绍了 MPS 内存限制功能的层次结构和用法。
# Set the default device pinned mem limit to 3G for device 0. The default limit constrains the memory allocation limit of all the MPS clients of future MPS servers to 3G on device 0.
$ nvidia-cuda-mps-control set_default_device_pinned_mem_limit 0 3G
# Start daemon in background process
$ nvidia-cuda-mps-control -d
# Set device pinned mem limit to 2G for device 0 for the server instance of the
# given PID. All the MPS clients on this server will observe this new limit of 2G
# instead of the default limit of 3G when allocating pinned device memory on device 0.
# Note -- users are allowed to specify a server limit (via set_device_pinned_mem_limit)
# greater than the default limit previously set by set_default_device_pinned_mem_limit.
$ nvidia-cuda-mps-control set_device_pinned_mem_limit <pid> 0 2G
# Further constrain the device pinned mem limit for a particular MPS client to 1G for
# device 0. This ensures the maximum amount of memory allocated by this client is capped
# at 1G.
# Note - setting this environment variable to a value greater than value observed by the
# server for its clients (through set_default_device_pinned_mem_limit/ set_device_pinned_mem_limit)
* will not set the limit to the higher value and thus will be ineffective and the eventual
# limit observed by the client will be that observed by the server.
$ export CUDA_MPS_DEVICE_MEM_LIMIT="0=1G"
4.2.8. CUDA_MPS_CLIENT_PRIORITY#
客户端优先级级别变量控制 MPS 控制守护程序的初始默认服务器值(如果用于启动该守护程序),或者客户端的客户端优先级级别值(如果用于客户端启动)。以下示例演示了这两种用法。
# Set the default client priority level for new servers and clients to Below Normal
$ export CUDA_MPS_CLIENT_PRIORITY=1
$ nvidia-cuda-mps-control -d
# Set the client priority level for a single program to Normal without changing the priority level for future clients
$ CUDA_MPS_CLIENT_PRIORITY=0 <program>
注意
CUDA 优先级级别并非执行顺序的保证,它们仅是 CUDA 驱动程序的性能提示。
4.3. MPS 日志记录格式#
4.3.1. 控制日志#
控制守护程序记录的一些示例消息
由其进程 ID 和启动它们的用户 ID 标识的 MPS 服务器的启动和关闭。
[2013-08-05 12:50:23.347 Control 13894] Starting new server 13929 for user 500[2013-08-05 12:50:24.870 Control 13894] NEW SERVER 13929: Ready[2013-08-05 13:02:26.226 Control 13894] Server 13929 exited with status 0由客户端进程 ID 和启动客户端进程的用户的用户 ID 标识的新 MPS 客户端连接。
[2013-08-05 13:02:10.866 Control 13894] NEW CLIENT 19276 from user 500: Server already exists[2013-08-05 13:02:10.961 Control 13894] Accepting connection...用户向控制守护程序发出的命令及其结果。
[2013-08-05 12:50:23.347 Control 13894] Starting new server 13929 for user 500[2013-08-05 12:50:24.870 Control 13894] NEW SERVER 13929: Ready错误信息,例如未能与客户端建立连接。
[2013-08-05 13:02:10.961 Control 13894] Accepting connection...[2013-08-05 13:02:10.961 Control 13894] Unable to read new connection type information
4.3.2. 服务器日志#
MPS 服务器记录的一些示例消息
由客户端进程 ID 标识的新 MPS 客户端连接和断开连接。
[2013-08-05 13:00:09.269 Server 13929] New client 14781 connected[2013-08-05 13:00:09.270 Server 13929] Client 14777 disconnected错误信息,例如 MPS 服务器因系统要求未满足而无法启动。
[2013-08-06 10:51:31.706 Server 29489] MPS server failed to start[2013-08-06 10:51:31.706 Server 29489] MPS is only supported on 64-bit Linux platforms, with an SM 3.5 or higher GPU.关于 Volta+ MPS 上致命 GPU 错误遏制的信息
[2022-04-28 15:56:07.410 Other 11570] Volta MPS: status of client {11661, 1} is ACTIVE[2022-04-28 15:56:07.468 Other 11570] Volta MPS: status of client {11663, 1} is ACTIVE[2022-04-28 15:56:07.518 Other 11570] Volta MPS: status of client {11643, 2} is ACTIVE[2022-04-28 15:56:08.906 Other 11570] Volta MPS: Server is handling a fatal GPU error.[2022-04-28 15:56:08.906 Other 11570] Volta MPS: status of client {11641, 1} is INACTIVE[2022-04-28 15:56:08.906 Other 11570] Volta MPS: status of client {11643, 1} is INACTIVE[2022-04-28 15:56:08.906 Other 11570] Volta MPS: status of client {11643, 2} is INACTIVE[2022-04-28 15:56:08.906 Other 11570] Volta MPS: The following devices[2022-04-28 15:56:08.906 Other 11570] 0[2022-04-28 15:56:08.907 Other 11570] 1[2022-04-28 15:56:08.907 Other 11570] Volta MPS: The following clients have a sticky error set:[2022-04-28 15:56:08.907 Other 11570] 11641[2022-04-28 15:56:08.907 Other 11570] 11643[2022-04-28 15:56:09.200 Other 11570] Client {11641, 1} exit[2022-04-28 15:56:09.244 Other 11570] Client {11643, 1} exit[2022-04-28 15:56:09.244 Other 11570] Client {11643, 2} exit[2022-04-28 15:56:09.245 Other 11570] Volta MPS: Destroy server context on device 0[2022-04-28 15:56:09.269 Other 11570] Volta MPS: Destroy server context on device 1[2022-04-28 15:56:10.310 Other 11570] Volta MPS: Creating server context on device 0[2022-04-28 15:56:10.397 Other 11570] Volta MPS: Creating server context on device 1
4.4. MPS 已知问题#
即使客户端上下文的数量少于 16 个的硬性限制,客户端也可能无法启动,并在创建第一个 CUDA 上下文时返回
ERROR_OUT_OF_MEMORY。评论:在创建上下文时,客户端会尝试为统一虚拟寻址内存范围保留虚拟地址空间。在某些系统上,这可能会与系统链接器及其加载的动态共享库冲突。确保 CUDA 初始化(例如,
cuInit()或任何cuda*()运行时 API 函数)是您的代码中调用的首批函数之一。为了向链接器和 Linux 内核提供提示,表明您希望您的动态共享库在 VA 空间中更高(在那里它不会与 CUDA 的 UVA 范围冲突),请将您的代码编译为 PIC(位置无关代码)和 PIE(位置无关可执行文件)。有关如何实现此目的的说明,请参阅您的编译器手册。内存分配 API 调用(包括上下文创建)可能会失败,并在服务器日志中显示以下消息:MPS Server failed to create/open SHM segment。(MPS 服务器无法创建/打开 SHM 段。)
评论:这很可能是由于系统上的文件描述符限制耗尽所致。检查系统上允许的最大打开文件描述符数,并在必要时增加。我们建议将其设置为 16384 或更高。通常,可以通过命令
ulimit -n检查此信息;有关如何更改限制,请参阅您的操作系统说明。
5. 附录:常用任务#
使用 MPS 的约定因系统环境而异。例如,Cray 环境以用户几乎不可见的方式管理 MPS,而其他基于 Linux 的系统可能需要用户自己管理激活控制守护程序。作为用户,您需要了解哪一组约定适合您正在运行的系统。本节介绍了一些情况。
5.1. 在 Linux 上启动和停止 MPS#
5.1.1. 在多用户系统上#
要使系统的所有用户都通过 MPS 运行 CUDA 应用程序,您需要设置 MPS 控制守护程序在系统启动时运行。
5.1.1.1. 启动 MPS 控制守护程序#
以 root 用户身份,运行以下命令
export CUDA_VISIBLE_DEVICES=0 # Select GPU 0.
nvidia-smi -i 0 -c EXCLUSIVE_PROCESS # Set GPU 0 to exclusive mode.
nvidia-cuda-mps-control -d # Start the daemon.
这将启动 MPS 控制守护程序,该守护程序将为任何启动应用程序的 $UID 生成新的 MPS 服务器实例,并将其与控制守护程序可见的 GPU 相关联。每个节点应仅运行一个 nvidia-cuda-mps-control 守护程序实例。请注意,不应在客户端进程的环境中设置 CUDA_VISIBLE_DEVICES。
5.1.1.2. 关闭 MPS 控制守护程序#
要关闭守护程序,以 root 用户身份运行
echo quit | nvidia-cuda-mps-control
5.1.1.3. 日志文件#
您可以通过查看以下位置的日志文件来查看守护程序的状态
/var/log/nvidia-mps/control.log
/var/log/nvidia-mps/server.log
这些通常仅对具有管理权限的用户可见。
5.1.2. 在单用户系统上#
以单用户身份运行时,必须使用与客户端进程相同的用户 ID 启动控制守护程序。
5.1.2.1. 启动 MPS 控制守护程序#
以 $UID 身份,运行以下命令
export CUDA_VISIBLE_DEVICES=0 # 选择 GPU 0。
export CUDA_MPS_PIPE_DIRECTORY=/tmp/nvidia-mps # 选择给定 $UID 可以访问的位置
export CUDA_MPS_LOG_DIRECTORY=/tmp/nvidia-log # 选择给定 $UID 可以访问的位置
nvidia-cuda-mps-control -d # 启动守护程序。
这将启动 MPS 控制守护程序,该守护程序将为启动应用程序的 $UID 生成新的 MPS 服务器实例,并将其与控制守护程序可见的 GPU 相关联。
5.1.2.2. 启动 MPS 客户端应用程序#
在客户端进程的环境中设置以下变量。请注意,不应在客户端的环境中设置 CUDA_VISIBLE_DEVICES。
export CUDA_MPS_PIPE_DIRECTORY=/tmp/nvidia-mps # 设置为与 MPS 控制守护程序相同的位置
export CUDA_MPS_LOG_DIRECTORY=/tmp/nvidia-log # 设置为与 MPS 控制守护程序相同的位置
5.1.2.3. 关闭 MPS#
要关闭守护程序,以 $UID 身份运行
echo quit | nvidia-cuda-mps-control
5.1.2.4. 日志文件#
您可以通过查看以下位置的日志文件来查看守护程序的状态
$CUDA_MPS_LOG_DIRECTORY/control.log
$CUDA_MPS_LOG_DIRECTORY/server.log
5.1.3. 编写批处理排队系统的脚本#
5.1.3.1. 基本原则#
第 3 章和第 4 章介绍了 MPS 组件、软件实用程序以及控制它们的环境变量。但是,在此级别使用 MPS 会给用户带来负担,因为
在应用程序级别,用户只关心是否启用了 MPS,而不必了解环境设置等细节,因为他们不太可能偏离固定配置。
可能存在需要系统本身强制执行的一致性条件,例如在应用程序运行之间清除 CPU 和 GPU 内存,或在作业完成时删除僵尸进程。
需要 root 访问权限(或等效权限)才能更改 GPU 的模式。
我们建议您通过在基本 MPS 组件之上构建某种自动配置抽象来管理这些细节。本节讨论如何在 PBS/Torque 排队环境中实现批处理提交标志,并讨论 MPS 集成到批处理排队系统中。
5.1.3.2. 按作业 MPS 控制:Torque/PBS 示例#
注意
Torque 安装是高度自定义的。指定作业资源的约定因站点而异,我们预计,类似地,启用 MPS 的约定也可能因站点而异。请咨询您的系统管理员,以了解他们是否已经有代表您配置 MPS 的方法。
通常不鼓励在排队约定之外修改节点,因为作业通常在节点由完成的作业释放时分派。可以通过使用 Torque prologue 和 epilogue 脚本来启动和停止 nvidia-cuda-mps-control 守护程序,从而在每个作业的基础上启用 MPS。在本示例中,我们重用 account 参数来为作业请求 MPS,因此以下命令
qsub -A "MPS=true" ...
将导致 prologue 脚本启动 MPS,如下所示
# Activate MPS if requested by user
USER=$2
ACCTSTR=$7
echo $ACCTSTR | grep -i "MPS=true"
if [ $? -eq 0 ]; then
nvidia-smi -c 3
USERID=`id -u $USER`
export CUDA_VISIBLE_DEVICES=0
nvidia-cuda-mps-control -d && echo "MPS control daemon started"
sleep 1
echo "start_server -uid $USERID" | nvidia-cuda-mps-control && echo "MPS server started for $USER"
fi
epilogue 脚本停止 MPS,如下所示
# Reset compute mode to default
nvidia-smi -c 0
# Quit cuda MPS if it's running
ps aux | grep nvidia-cuda-mps-control | grep -v grep > /dev/null
if [ $? -eq 0 ]; then
echo quit | nvidia-cuda-mps-control
fi
# Test for presence of MPS zombie
ps aux | grep nvidia-cuda-mps | grep -v grep > /dev/null
if [ $? -eq 0 ]; then
logger "`hostname` epilogue: MPS refused to quit! Marking offline"
pbsnodes -o -N "Epilogue check: MPS did not quit" `hostname`
fi
# Check GPU sanity, simple check
nvidia-smi > /dev/null
if [ $? -ne 0 ]; then
logger "`hostname` epilogue: GPUs not sane! Marking `hostname` offline"
pbsnodes -o -N "Epilogue check: nvidia-smi failed" `hostname`
fi
5.2. SM 分区的最佳实践#
创建上下文在时间、内存和硬件资源方面都是一项成本高昂的操作。
如果在内核启动时创建具有执行亲缘性的上下文,用户将观察到由于上下文创建而导致的延迟和内存占用突然增加。为了避免支付上下文创建的延迟以及内核启动时内存使用量的突然增加,建议用户预先创建具有不同 SM 分区的上下文池,并在内核启动时选择具有合适 SM 分区的上下文
int device = 0;
cudaDeviceProp prop;
const Int CONTEXT_POOL_SIZE = 4;
CUcontext contextPool[CONTEXT_POOL_SIZE];
int smCounts[CONTEXT_POOL_SIZE];
cudaSetDevice(device);
cudaGetDeviceProperties(&prop, device);
smCounts[0] = 1; smCounts[1] = 2;
smCounts[3] = (prop. multiProcessorCount - 3) / 3;
smCounts[4] = (prop. multiProcessorCount - 3) / 3 * 2;
for (int i = 0; i < CONTEXT_POOL_SIZE; i++) {
CUexecAffinityParam affinity;
affinity.type = CU_EXEC_AFFINITY_TYPE_SM_COUNT;
affinity.param.smCount.val = smCounts[i];
cuCtxCreate_v3(&contextPool[i], affinity, 1, 0, deviceOrdinal);
}
for (int i = 0; i < CONTEXT_POOL_SIZE; i++) {
std::thread([i]() {
int numSms = 0;
int numBlocksPerSm = 0;
int numThreads = 128;
CUexecAffinityParam affinity;
cuCtxSetCurrent(contextPool[i]);
cuCtxGetExecAffinity(&affinity, CU_EXEC_AFFINITY_TYPE_SM_COUNT);
numSms = affinity.param.smCount.val;
cudaOccupancyMaxActiveBlocksPerMultiprocessor(
&numBlocksPerSm, kernel, numThreads, 0);
void *kernelArgs[] = { /* add kernel args */ };
dim3 dimBlock(numThreads, 1, 1);
dim3 dimGrid(numSms * numBlocksPerSm, 1, 1);
cudaLaunchCooperativeKernel((void*)my_kernel, dimGrid, dimBlock, kernelArgs);
};
}
客户端 CUDA 上下文所需的硬件资源是有限的,并且在 Volta MPS 上每个设备最多支持 48 个客户端 CUDA 上下文。每个设备的上下文池大小受每个设备支持的 CUDA 客户端上下文数量的限制。每个客户端 CUDA 上下文的内存占用空间和 CUDA_DEVICE_MAX_CONNECTIONS 的值可能会进一步减少可用客户端的数量。因此,应谨慎创建具有不同 SM 分区的 CUDA 客户端上下文。
6. 声明#
本文档仅供参考,不应被视为对产品的特定功能、状况或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对因使用此类信息或因使用此类信息而可能导致的任何专利或第三方其他权利的侵权行为的后果或使用不承担任何责任。本文档不构成开发、发布或交付任何材料(如下定义)、代码或功能的承诺。
NVIDIA 保留随时对此文档进行更正、修改、增强、改进和任何其他更改的权利,恕不另行通知。
客户在下订单前应获取最新的相关信息,并应验证此类信息是最新且完整的。
NVIDIA 产品根据订单确认时提供的 NVIDIA 标准销售条款和条件进行销售,除非 NVIDIA 和客户的授权代表签署的个别销售协议(“销售条款”)另有约定。NVIDIA 特此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档未直接或间接形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命支持设备,也不适用于 NVIDIA 产品的故障或失灵可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在上述设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不保证或声明基于本文档的产品适用于任何特定用途。NVIDIA 不一定会对每个产品的所有参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合且符合客户计划的应用,并为该应用执行必要的测试,以避免应用或产品的默认设置。客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同的条件和/或要求。对于可能基于或归因于以下原因的任何默认设置、损坏、成本或问题,NVIDIA 不承担任何责任:(i)以任何违反本文档的方式使用 NVIDIA 产品或(ii)客户产品设计。
本文档未授予任何 NVIDIA 专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予的使用此类产品或服务的许可,也不构成对其的保证或认可。使用此类信息可能需要获得第三方专利或其他知识产权下的第三方许可,或获得 NVIDIA 专利或其他知识产权下的 NVIDIA 许可。
仅当事先获得 NVIDIA 书面批准,在未更改且完全符合所有适用的出口法律和法规的情况下复制,并附带所有相关的条件、限制和声明,才允许复制本文档中的信息。
本文档和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均“按原样”提供。NVIDIA 对材料不作任何明示、暗示、法定或其他形式的保证,并且明确声明不承担任何关于不侵权、适销性和适用于特定用途的暗示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对因使用本文档而引起的任何损害(包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害,无论如何造成,也无论责任理论如何)承担责任,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因而遭受任何损害,NVIDIA 对本文所述产品的客户的累计总责任应根据产品的销售条款进行限制。
6.1. 商标#
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。