Compute Sanitizer
简介
关于 Compute Sanitizer
Compute Sanitizer 是 CUDA 工具包中包含的功能正确性检查套件。此套件包含多个可以执行不同类型检查的工具。memcheck 工具能够精确检测和归因 CUDA 应用程序中越界和未对齐的内存访问错误。该工具还可以报告 GPU 遇到的硬件异常。racecheck 工具可以报告可能导致数据竞争的共享内存数据访问危害。initcheck 工具可以报告 GPU 执行对全局内存的未初始化访问的情况。synccheck 工具可以报告应用程序尝试无效使用同步原语的情况。本文档介绍了这些工具的用法。
为何使用 Compute Sanitizer
NVIDIA 允许开发者轻松利用 GPU 的强大功能,使用 CUDA 并行解决问题。CUDA 应用程序通常并行运行数千个线程。每个程序员都不可避免地会遇到内存访问错误和线程排序危害,这些问题难以检测且调试耗时。当处理数千个线程时,此类错误的数量会大幅增加。Compute Sanitizer 套件旨在检测 CUDA 应用程序中的这些问题。
如何获取 Compute Sanitizer
Compute Sanitizer 作为 CUDA 工具包的一部分安装。
Compute Sanitizer 工具
Compute Sanitizer 通过不同的工具提供不同的检查机制。目前支持的工具有
Memcheck – 内存访问错误和泄漏检测工具。请参阅 Memcheck 工具
Racecheck – 共享内存数据访问危害检测工具。请参阅 Racecheck 工具
Initcheck – 未初始化的设备全局内存访问检测工具。请参阅 Initcheck 工具
Synccheck – 线程同步危害检测工具。请参阅 Synccheck 工具
Compute Sanitizer
可以通过运行 compute-sanitizer 可执行文件来调用 Compute Sanitizer 工具,如下所示
compute-sanitizer [options] app_name [app_options]
有关可以为 compute-sanitizer 指定的选项及其默认值的完整列表,请参阅 命令行选项
命令行选项
可以为 compute-sanitizer 指定命令行选项。除了一些例外,这些选项通常采用 --option value 的形式。选项列表可以通过指定 -- 终止。所有后续单词都被视为正在运行的应用程序及其参数。
下表详细描述了支持的选项。第一列是传递给 compute-sanitizer 的选项名称。某些选项有一个字符的简短形式,在括号中给出。这些选项可以使用单个连字符调用。例如,help 选项可以作为 -h 调用。具有简短形式的选项不接受值。
第二列包含选项的允许值。如果该值是用户定义的,则在花括号 {} 中显示。可以接受任何数值的选项表示为 {number}。
第三列包含选项的默认值。某些选项根据其运行的架构具有不同的默认值。
选项 |
值 |
默认值 |
描述 |
|---|---|---|---|
check-device-heap |
yes, no |
yes |
启用设备堆分配的检查。这适用于错误检查和泄漏检查。 |
check-bulk-copy |
yes, no |
yes |
启用与 Hopper 上的 PTX cp.async.bulk 指令相关的检查。 |
check-exit-code |
yes, no |
yes |
检查应用程序退出代码,如果代码不是 0,则打印错误。 |
check-optix-leaks |
N/A |
disabled |
检测并报告在 OptixDeviceContextDestroy 时间创建但未销毁的 OptiX 资源。有关更多信息,请参阅 OptiX 支持。 |
check-warpgroup-mma |
yes, no |
yes |
为 PTX |
coredump-behavior |
full, exit |
full |
控制在生成 CUDA coredump 后目标应用程序的行为。
|
coredump-name |
{filename} |
N/A |
用于生成的 coredump 文件的名称。 |
demangle |
full, simple, no |
full |
启用设备函数名称的反解。有关更多信息,请参阅 名称反解。 |
destroy-on-device-error |
context, kernel |
context |
这控制应用程序在遇到内存访问错误时如何继续。有关更多信息,请参阅 错误操作。 |
error-exitcode |
{number} |
0 |
如果原始应用程序成功,但工具检测到存在错误,则 Compute Sanitizer 将返回此退出代码。这旨在允许将 Compute Sanitizer 集成到自动化测试套件中。 |
force-blocking-launches |
N/A |
disabled |
强制所有主机内核启动顺序执行。启用后,报告错误的数量和精度将降低。 |
force-synchronization-limit |
{number} |
0 |
强制在流达到给定数量的未同步启动后进行同步。这旨在减少 Compute Sanitizer 工具的内存使用量,但可能会影响性能。 |
generate-coredump |
N/A |
disabled |
设置此选项后,将为遇到的第一个错误生成 coredump,并且程序执行将停止。有关更多信息,请参阅 Coredump 支持。 |
help (h) |
N/A |
N/A |
显示帮助消息 |
ignore-getprocaddress-notfound |
N/A |
disabled |
忽略 cuGetProcAddress 的 CUDA_ERROR_NOT_FOUND API 错误。 |
injection-path |
N/A |
N/A |
设置注入库的路径。 |
injection-path32 |
N/A |
N/A |
设置 32 位注入库的路径。 |
kernel-name |
{key1=val1}[{,key2=val2}] |
N/A |
控制 Compute Sanitizer 工具运行时将检查哪些应用程序内核。有关更多信息,请参阅 指定过滤器。 |
kernel-name-exclude |
{key1=val1}[{,key2=val2}] |
N/A |
控制 Compute Sanitizer 工具运行时将检查哪些应用程序内核。有关更多信息,请参阅 指定过滤器。 |
language |
c, fortran |
c |
这控制 Compute Sanitizer 工具中特定于应用程序源语言的行为。有关 fortran 特定行为,请参阅 CUDA Fortran 特定行为。 |
launch-count (c) |
{number} |
0 |
限制要检查的内核启动次数。计数仅针对与内核过滤器匹配的启动递增。使用 0 表示无限制。 |
launch-skip (s) |
{number} |
0 |
设置在开始检查之前要跳过的内核启动次数。计数仅针对与内核过滤器匹配的启动递增。 |
launch-timeout |
{number} |
单进程 10 秒,多进程 60 秒 |
连接到目标进程的超时时间(秒)。值为零会强制 compute-sanitizer 无限期等待。 |
log-file |
{filename} |
N/A |
这是 Compute Sanitizer 将所有文本输出写入的文件。默认情况下,Compute Sanitizer 会将所有输出打印到 stdout。有关更多信息,请参阅 转义序列。 |
max-connections |
{number} |
10 |
用于连接到目标应用程序的最大端口数。 |
kill |
N/A |
disabled |
使 compute-sanitizer 在遇到通信错误时终止目标应用程序。默认情况下,compute-sanitizer 将等待程序正常完成,而不报告潜在错误。 |
mode |
launch-and-attach, launch, attach |
launch-and-attach |
选择与目标应用程序交互的模式
|
num-callers-device |
{number} |
0 |
设置设备堆栈跟踪中要打印的调用者数量。使用 0 表示无限制。 |
num-callers-host |
{number} |
0 |
设置主机堆栈跟踪中要打印的调用者数量。使用 0 表示无限制。 |
num-cuda-barriers |
{number} |
0 |
设置目标应用程序每个块将使用的 cuda::barriers 数量。使用 0 表示自动检测。 |
nvtx |
true,false |
true |
启用 NVTX 支持。 |
port |
{number} |
49152 |
用于连接到目标应用程序的基本端口。 |
prefix |
{string} |
======== |
前置于 Compute Sanitizer 输出行的字符串。 |
preload-library |
{lib1}[{,lib2}] |
N/A |
前置一个或多个共享库,以便应用程序在注入库之前加载它们。 |
print-level |
info, warn, error, fatal |
warn |
来自 Compute Sanitizer 的消息的最小打印级别。 |
print-limit |
{number} |
100 |
设置此选项后,Compute Sanitizer 将在达到给定错误数后停止打印错误。使用 0 表示无限制打印。 |
print-session-details |
N/A |
disabled |
打印有关每个目标应用程序的 sanitizer 会话的详细信息,例如进程 ID、命令行、目标系统等。 |
quiet (q) |
N/A |
disabled |
控制是否静默运行,仅打印错误消息。 |
read |
{filename} |
N/A |
要从中读取数据的输入 Compute Sanitizer 文件。这可以与 –save 选项结合使用,以便在运行后处理记录。 |
require-cuda-init |
yes, no |
yes |
控制如果目标应用程序未使用 CUDA,Compute Sanitizer 是否应返回错误。 |
save |
{filename} |
N/A |
Compute Sanitizer 将在其中保存当前运行输出的文件名。有关更多信息,请参阅 转义序列。 |
save-session-details |
N/A |
disabled |
将有关每个目标应用程序的 sanitizer 会话的详细信息保存在 |
strip-paths |
yes, no |
disabled |
仅打印文件名,而不是完整路径。 |
support-32bit |
N/A |
disabled |
此选项仅在 Linux x86_64 上存在。启用对包含 32 位进程的应用程序的跟踪支持。在 Windows 上,如果找到 32 位注入库,则始终启用该支持。注意:仅支持 64 位进程进行实际检查,该选项的目的是允许跟踪 32 位进程的子进程。 |
suppressions |
{filename} |
N/A |
输入 XML 文件,其中包含应在检测到时被工具过滤掉的报告列表。有关更多信息,请参阅 错误抑制。 |
target-processes |
application-only, all |
all |
选择要由 compute-sanitizer 跟踪的进程:根应用程序进程,或根应用程序及其所有子进程。 |
target-processes-filter |
{string} |
N/A |
设置逗号分隔的表达式以过滤要跟踪的进程。
可执行文件名将被视为要匹配的进程名称。如果进程名称或提供的表达式匹配,则将跟踪该进程。示例
|
tool |
memcheck, racecheck, initcheck, synccheck |
memcheck |
控制哪个 Compute Sanitizer 工具正在主动运行。 |
version (v) |
N/A |
N/A |
打印 Compute Sanitizer 的版本。 |
xml |
N/A |
disabled |
以 XML 格式将错误输出发送到文件。使用时,还必须设置 –save 以指定要保存到的文件。 |
选项 |
值 |
默认值 |
描述 |
|---|---|---|---|
show-backtrace |
yes, host, device, no |
yes |
为大多数类型的错误显示回溯。“no”禁用所有回溯,“yes”启用所有回溯。“host”仅启用主机端回溯。“device”仅启用设备端回溯。有关更多信息,请参阅 堆栈回溯。 |
backtrace-short |
yes, no |
yes |
使用回溯的简短版本。不打印 CUDART 帧和 main() 下方的帧。 |
选项 |
值 |
默认值 |
描述 |
|---|---|---|---|
check-cache-control |
N/A |
disabled |
检查缓存控制内存访问。 |
detect-missing-module-unload |
N/A |
disabled |
检测由缺少模块卸载调用引起的泄漏。如果应用程序使用 CUDA 运行时,则此选项可能会报告误报,因为它取决于应用程序退出时运行时和驱动程序之间的销毁顺序,而这是无法保证的。 |
leak-check |
full, no |
no |
打印有关所有分配的信息,这些分配在上下文销毁时未通过 cudaFree 释放。有关更多信息,请参阅 内存泄漏检查。 |
padding |
{number} |
0 |
使 compute-sanitizer 在每次 CUDA 分配后分配填充缓冲区。number 是填充缓冲区的大小(以字节为单位)。有关更多信息,请参阅 填充。 |
report-api-errors |
all, explicit, no |
explicit |
如果任何 CUDA API 调用失败,则报告错误。有关更多信息,请参阅 CUDA API 错误检查。 |
track-stream-ordered-races |
all, use-before-alloc, use-after-free, no |
no |
跟踪 CUDA 流序分配竞争。有关更多信息,请参阅 流序竞争检测。 |
选项 |
值 |
默认值 |
描述 |
|---|---|---|---|
racecheck-detect-level |
info, warn, error |
warn |
设置要检测的竞争条件的最低级别。 |
racecheck-memcpy-async |
yes, no |
yes |
启用异步内存复制操作的检查。有关更多信息,请参阅 Racecheck 对异步复制的支持。 |
racecheck-num-workers |
{number} |
0 |
工具使用的 CPU 工作线程数。使用 0 表示自动。 |
racecheck-report |
hazard, analysis, all |
analysis |
控制 racecheck 如何报告信息。有关更多信息,请参阅 Racecheck 报告模式。 |
选项 |
值 |
默认值 |
描述 |
|---|---|---|---|
check-api-memory-access |
yes,no |
yes |
启用 cudaMemcpy/cudaMemset 的检查 |
check-optix |
N/A |
disabled |
使用 initcheck 检查 OptiX 内核启动。有关更多信息,请参阅 OptiX 支持。 |
track-unused-memory |
N/A |
disabled |
检查未使用的内存分配。 |
unused-memory-threshold |
{number} |
0 |
未使用的内存报告被静音的阈值百分比。该值必须是介于 0 到 100 之间的数字。 |
选项 |
值 |
默认值 |
描述 |
|---|---|---|---|
missing-barrier-init-is-fatal |
yes, no |
yes |
控制缺少 |
编译选项
Compute Sanitizer 工具不需要任何特殊的编译标志即可运行。
使用一些额外的编译器标志,Compute Sanitizer 工具显示的输出会更有用。nvcc 的 -G 选项强制编译器为 CUDA 应用程序生成调试信息。要为应用程序生成行号信息,而不影响输出的优化级别,可以使用 -lineinfo nvcc 选项。Compute Sanitizer 工具完全支持这两个选项,并且可以为使用行信息编译的应用程序显示错误源归属。
当应用程序包含函数符号名称时,Compute Sanitizer 工具的堆栈回溯功能会更有用。对于主机回溯,这因主机操作系统而异。在 Linux 上,必须为主机编译器提供 -rdynamic 选项以保留函数符号。在 Windows 上,应用程序必须编译为调试,即 /Zi 选项。使用 nvcc 时,可以使用 -Xcompiler 选项指定主机编译器的标志。对于设备回溯,仅当应用程序使用设备调试信息编译时,才能获得完整的帧信息。使用优化进行构建时,编译器可以跳过帧信息的生成。
在 Linux 上使用函数符号和设备端行号信息构建的示例命令行
nvcc -Xcompiler -rdynamic -lineinfo -o out in.cu
环境变量
可以在启动 compute-sanitizer 工具之前设置以下环境变量。
名称 |
描述 |
默认值/值 |
|---|---|---|
NV_COMPUTE_SANITIZER_BINARY_PATCHING |
控制 compute-sanitizer 是否会检测用户内核代码。 此选项旨在用于调试,不应由普通用户使用。 |
如果未设置,则默认为:启用。 有效值:0 到 |
NV_COMPUTE_SANITIZER_LOCAL_CONNECTION_OVERRIDE |
覆盖前端和目标进程之间的默认本地连接机制。默认机制取决于平台。仅当本地启动中前端和目标进程之间存在连接问题时,才应使用此选项。 |
默认值:未设置(使用默认机制)
|
NV_COMPUTE_SANITIZER_MAX_RACECHECK_CLUSTER_RECORDS |
覆盖用于提前退出竞争检测的最大 racecheck 集群访问记录数。此选项可用于增加工具可以检测到的竞争数,或抑制提前退出竞争(0 将不显示提前退出竞争)。 |
如果未设置,则默认为:100。 有效值:0 到 |
NV_COMPUTE_SANITIZER_MAX_RACECHECK_HAZARDS |
覆盖 racecheck 危害工具将处理的最大危害数。此选项可用于增加工具可以检测到的竞争数,或减少竞争数并节省主机内存。 |
如果未设置,则默认为:10,000,000。 有效值:0 到 |
NV_COMPUTE_SANITIZER_SHARED_ADDRESSING_SUPPORT |
覆盖共享内存寻址支持。 |
如果未设置,则默认为:
|
NV_COMPUTE_SANITIZER_RACECHECK_INDIRECT_BARRIER_TRACKING |
覆盖 racecheck 间接 barrier 依赖项跟踪。 此选项适用于间接 barrier 跟踪可能会严重影响性能的情况。 |
如果未设置,则默认为:启用。 有效值:0 到 |
Memcheck 工具
什么是 Memcheck?
memcheck 工具是 CUDA 应用程序的运行时错误检测工具。该工具可以精确检测和报告 CUDA 应用程序中全局内存、本地内存和共享内存的越界和未对齐的内存访问。它还可以检测和报告硬件报告的错误信息。此外,memcheck 工具可以检测和报告用户应用程序中的内存泄漏。
支持的错误检测
下表总结了 memcheck 工具可以报告的错误。位置列指示报告是来自主机还是来自设备。下段解释了错误的精度。
名称 |
描述 |
位置 |
精度 |
另请参阅 |
|---|---|---|---|---|
内存访问错误 |
由于全局、本地、共享或全局原子访问对内存的越界或未对齐访问而导致的错误。 |
设备 |
精确 |
|
硬件异常 |
由硬件错误报告机制报告的错误。 |
设备 |
不精确 |
|
Malloc/Free 错误 |
由于在 CUDA 内核中不正确使用 |
设备 |
精确 |
|
CUDA API 错误 |
当应用程序中的 CUDA API 调用返回失败时报告。 |
主机 |
精确 |
|
cudaMalloc 内存泄漏 |
使用 |
主机 |
精确 |
|
设备堆内存泄漏 |
在设备代码中使用 |
设备 |
不精确 |
memcheck 工具报告两种类型的错误:精确错误和不精确错误。
memcheck 中的精确错误是指工具可以唯一识别并收集所有信息的错误。对于这些错误,memcheck 可以报告导致失败的线程的块和线程坐标、执行访问的指令的程序计数器 (PC),以及正在访问的地址及其大小和类型。如果 CUDA 应用程序包含行号信息(通过使用设备端调试信息或行信息进行编译),则该工具还将打印错误访问的源文件和行号。
不精确错误是由硬件错误报告机制报告的错误,这些错误无法精确归因于特定线程。错误的精度因错误类型而异,在许多情况下,memcheck 可能无法将错误原因追溯到源文件和行。
使用 Memcheck
运行 Compute Sanitizer 应用程序时,默认启用 memcheck 工具。也可以使用 --tool memcheck 选项显式启用它。
compute-sanitizer --tool memcheck [sanitizer_options] app_name [app_options]
以这种方式运行时,memcheck 工具将查找精确错误、不精确错误、malloc/free 错误和 CUDA API 错误。设备泄漏的报告必须显式启用。memcheck 工具识别的错误在应用程序完成执行后显示在屏幕上。请参阅 了解 Memcheck 错误,以获取有关如何解释工具打印的消息的更多信息。
了解 Memcheck 错误
memcheck 工具可以产生各种不同的错误。这是一个简短指南,显示了一些错误示例,并解释了如何解释每个错误报告中的信息。
内存访问错误:内存访问错误是为 memcheck 工具可以正确归因和识别错误指令的错误而生成的。以下是精确内存访问错误的示例。
========= Invalid __global__ write of size 4 bytes ========= at unaligned_kernel():0x160 in memcheck_demo.cu:6 ========= by thread (0,0,0) in block (0,0,0) ========= Address 0x7f6510c00001 is misaligned
让我们逐行检查这个错误
Invalid __global__ write of size 4 bytes
第一行显示了正在访问的内存段、类型和大小。内存段是以下之一
__global__ : 用于设备全局内存
__shared__ : 用于每个块的共享内存
__local__ : 用于每个线程的本地内存
在这种情况下,访问是设备全局内存。下一个字段包含有关访问类型的信息,是读取还是写入。在这种情况下,访问是写入。最后,最后一个项目是以字节为单位的访问大小。在这个例子中,访问大小为 4 字节。
at unaligned_kernel():0x160 in memcheck_demo.cu:6
第二行包含 CUDA 内核名称、指令偏移量、源文件和行号(如果可用)。在本例中,导致访问的指令位于
unaligned_kernelCUDA 内核内的偏移量 0x160 处。此外,由于应用程序是使用行号信息编译的,因此该指令对应于 memcheck_demo.cu 源文件中的第 6 行。by thread (0,0,0) in block (0,0,0)
第三行包含发生错误的线程的线程索引和块索引。在本例中,执行错误访问的线程属于第一个块中的第一个线程。
Address 0x7f6510c00001 is misaligned
第四行包含正在访问的内存地址和访问错误的类型。访问错误的类型可以是越界访问或未对齐访问。在本例中,访问的地址是 0x7f6510c00001,访问错误是因为该地址未正确对齐。
硬件异常:不精确的错误是为硬件报告给 memcheck 工具的错误而生成的。硬件异常具有多种格式和消息。通常,第一行将提供有关遇到的错误类型的一些信息。
Malloc/free 错误:Malloc/free 错误指的是在 CUDA 内核中调用设备端
malloc()/free()时发生的错误。以下是一个 malloc/free 错误的示例========= Malloc/Free error encountered : Double free ========= at 0x79d8 ========= by thread (0,0,0) in block (0,0,0) ========= Address 0x400aff920
我们可以逐行检查这一行。
Malloc/Free error encountered : Double free
第一行指示这是一个 malloc/free 错误,并包含错误类型。此类型可以是
Double free – 这表示线程对已释放的分配调用了
free()。Invalid pointer to free – 这表示对不是由
malloc()返回的指针调用了free。堆损坏:这表示广义的堆损坏,或者堆的状态以 memcheck 未预期的方式被修改的情况。
在本例中,错误是由于对已释放的指针调用
free()引起的。at 0x79d8
第二行给出了 GPU 上报告错误的 PC。此 PC 通常位于系统代码内部,用户对此不感兴趣。设备帧回溯将包含用户代码中进行
malloc()/free()调用的位置。by thread (0,0,0) in block (0,0,0)
第三行包含导致此错误的线程的线程和块索引。在本例中,线程的 threadIdx = (0,0,0),blockIdx = (0,0,0)
Address 0x400aff920
此行包含传递给
free()或由malloc()返回的指针的值泄漏错误:对于使用 cudaMalloc 创建的分配以及设备堆上在关联的 CUDA 上下文被销毁之前(即程序退出、
cudaDeviceReset()或 CUDA 驱动程序 API 调用cuCtxDestroy())未释放的分配,会报告错误。以下是一个 cudaMalloc 分配泄漏报告的示例========= Leaked 64 bytes at 0x400200200
错误消息报告有关泄漏的分配大小以及设备上分配地址的信息。
设备堆泄漏消息将被明确标识为如此
========= Leaked 16 bytes at 0x4012ffff6 on the device heap
CUDA API 错误:对于返回错误值的 CUDA API 调用,会报告 CUDA API 错误。以下是一个 CUDA API 错误的示例
========= Program hit invalid copy direction for memcpy (error 21) on CUDA API call to cudaMemcpy.该消息包含 CUDA API 调用的返回值,以及被调用的 API 函数的名称。
CUDA API 错误检查
如果用户程序发出的 CUDA API 调用返回错误,memcheck 工具支持报告错误。该工具支持对 CUDA 运行时和 CUDA 驱动程序 API 调用的检测。在所有情况下,如果 API 函数调用具有非零返回值,Compute Sanitizer 将打印一条错误消息,其中包含失败的 API 调用的名称和 API 调用的返回值。
CUDA API 错误报告不会终止应用程序,它们仅提供额外的信息。由应用程序检查 CUDA API 调用的返回状态并适当处理错误条件。
以下 API 错误不会报告
cudaErrorNotReady用于cudaEventQuery和cudaStreamQueryAPI。cudaErrorPeerAccessAlreadyEnabled用于cudaDeviceEnablePeerAccessAPI。cudaErrorPeerAccessNotEnabled用于cudaDeviceDisablePeerAccessAPI。
设备端分配检查
memcheck 工具检查对设备堆中分配的访问。
这些分配是通过在内核内部调用 malloc() 创建的。此功能默认启用,可以通过指定 --check-device-heap no 选项禁用。此功能仅针对应用程序中调用 malloc() 的内核激活。
如果应用程序对同一分配调用两次 free(),或者在无效指针上调用 free(),则该工具将报告错误。
注意
注意:请务必查看设备端回溯,以查找应用程序中进行 malloc()/free() 调用的位置。
泄漏检查
memcheck 工具可以检测已分配内存的泄漏。
内存泄漏是在上下文被销毁时未释放的设备端分配。memcheck 工具跟踪使用 CUDA 驱动程序或运行时 API 创建的设备内存分配。
必须指定 --leak-check full 选项才能启用泄漏检查。
填充
memcheck 工具可以自动向内存分配添加填充,以提高全局内存的越界错误检测。
默认情况下,全局内存缓冲区可以在虚拟地址空间中背靠背分配。当发生这种情况时,对第一个缓冲区的溢出访问将简单地发生在第二个缓冲区中,并且不会被检测为越界。

使用 --padding 选项将自动扩展分配大小,从而在每次分配后有效地创建一个填充缓冲区。这提高了越界错误检测,因为对填充区域的访问将始终被视为无效。下面的示例显示了使用 --padding 32 时可能的缓冲区地址。每个分配后都跟随一个 32 字节的填充缓冲区。写入或读取此缓冲区将导致报告越界访问。

此选项支持通过 cudaMalloc API、cudaHostAlloc 和 cudaMallocHost 创建的分配。
此选项不支持通过 cudaHostRegister 或 CUDA 虚拟内存管理 API 创建的分配。
请注意,使用此选项将导致设备内存压力增加,可能导致额外的 CUDA 内存不足错误。
流序竞争检测
memcheck 工具可以使用 --track-stream-ordered-races all 选项检测流序分配竞争。它将报告在其生命周期之外使用的流序分配的访问。
该工具能够检测 2 种类型的竞争
Use-before-alloc 竞争 (
--track-stream-ordered-races use-before-alloc)当分配在使用之前可用时,会发生这种竞争:在流上使用
cudaMallocAsync创建的分配不能在另一个流上使用,除非在分配后有先前的同步事件。它还包括使用
cudaFreeAsync在分配可用之前释放分配的情况。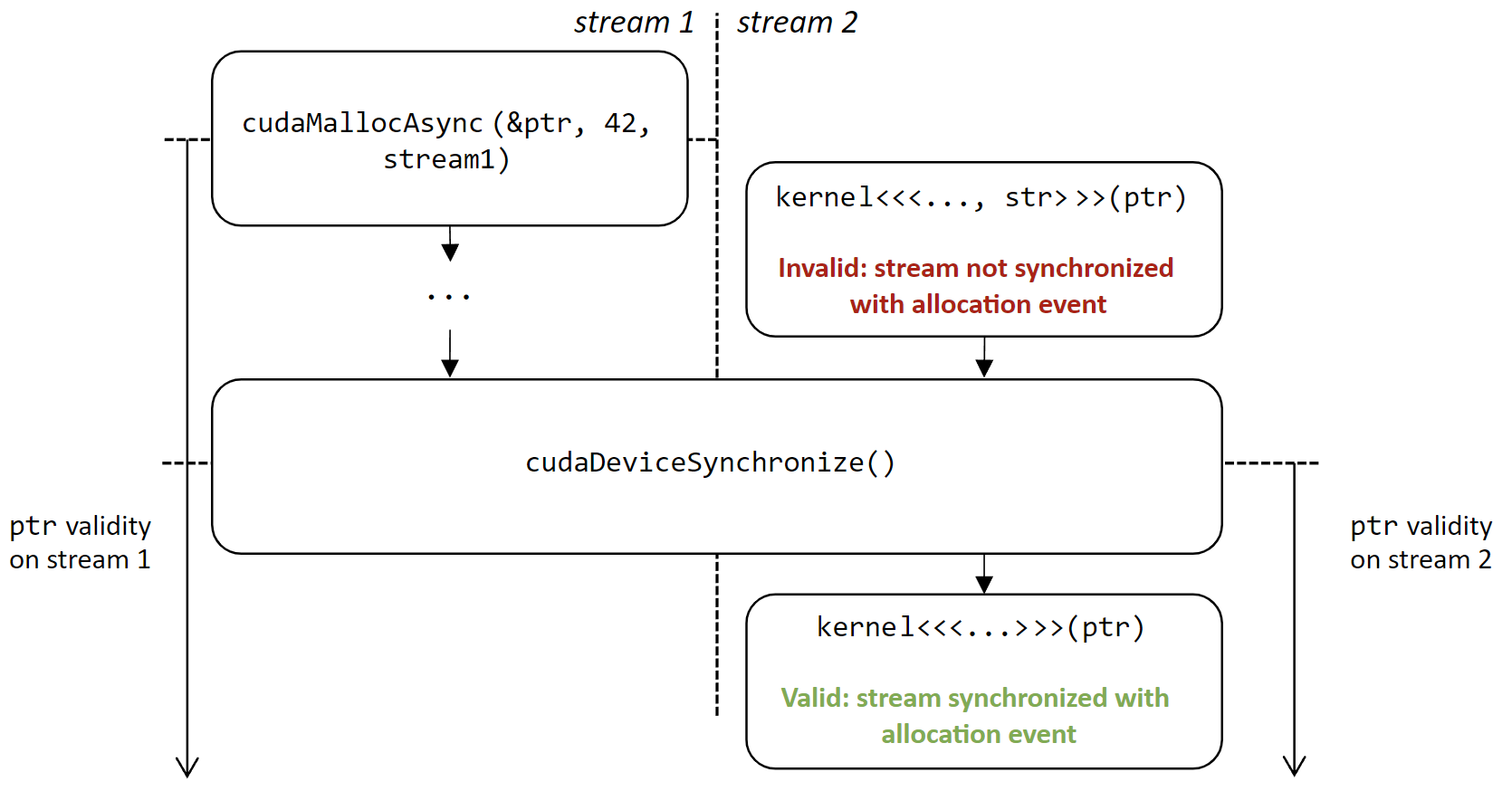
Use-after-free 竞争 (
--track-stream-ordered-races use-after-free)当分配在释放后使用时,会发生这种竞争:在流上使用
cudaFreeAsync释放的分配不能在另一个流上使用,除非在释放之前有后续的同步事件。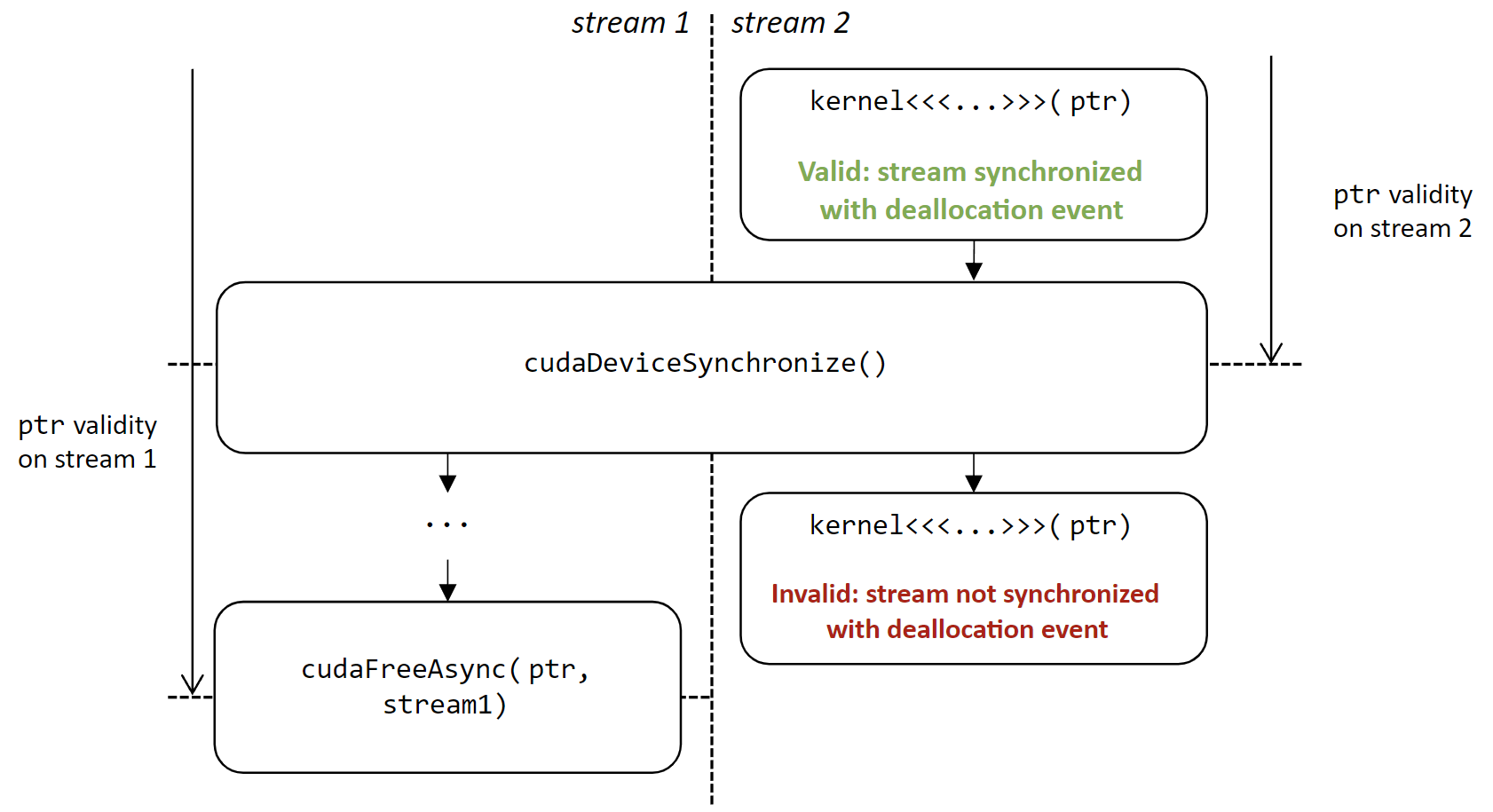
Tensor Core MMA 防护栏
在 Blackwell GPU 上,如果程序正在使用 PTX Tensor Core 第五代系列指令 (tcgen05.*),则可以指示 PTX 优化汇编器使用 PTXAS 标志 -g-tmem-access-check 在 TCMMA 指令周围插入防护栏。
在 compute-sanitizer 的 memcheck 下运行启用 TCMMA 防护栏的程序将导致该工具报告任何无效的 TCMMA 操作,例如对张量内存的越界或未对齐访问,或在调用 relinquish 后进行分配。
memcheck 报告的 TCMMA 错误示例
========= Tensor Memory column 32 being accessed by instruction tcgen05.ld is not allocated. Columns allocated are: 0-31.
========= at $__internal_8_$__cuda_sm10x_tcgen05_guardrail_trap_unallocated_columns_access+0x1250 in TcmmaGuardrails.cu:99
========= by thread (0,0,0) in block (0,0,0)
Racecheck 工具
什么是 Racecheck?
racecheck 工具是一个运行时共享内存数据访问危害检测器。此工具的主要用途是帮助识别使用共享内存的 CUDA 应用程序中的内存访问竞争条件。
在 CUDA 应用程序中,使用 __shared__ 限定符声明的存储位于片上共享内存中。线程块中的所有线程都可以访问此每个块的共享内存。当线程块完成执行时,共享内存超出范围。由于共享内存在芯片上,因此经常用于线程间通信,并用作保存正在处理的数据的临时缓冲区。由于此数据正在由多个线程并行访问,因此不正确的程序假设可能会导致数据竞争。Racecheck 是一个旨在识别这些危害并帮助用户编写没有共享内存竞争的程序的工具。
目前,此工具仅支持检测对片上共享内存的访问。
什么是危害?
数据访问危害是指两个线程尝试访问内存中的同一位置,从而导致不确定性行为的情况,这取决于两次访问的相对顺序。这些危害会导致数据竞争,其中应用程序的行为或输出取决于硬件执行所有并行线程的顺序。竞争条件表现为间歇性应用程序故障,或在尝试在不同的 GPU 上运行工作应用程序时出现故障。
racecheck 工具识别程序中的三种规范危害。这些是
写后写 (WAW) 危害
当两个线程尝试将数据写入同一内存位置时,会发生此危害。该位置的最终值取决于两次访问的相对顺序。
写后读 (WAR) 危害
当两个线程访问同一内存位置时,会发生此危害,其中一个线程执行读取,另一个线程执行写入。在这种情况下,写入线程排在读取线程之前,并且返回给读取线程的值不是内存位置的原始值。
读后写 (RAW) 危害
当两个线程访问同一内存位置时,会发生此危害,其中一个线程执行读取,另一个线程执行写入。在这种情况下,读取线程在写入线程提交值之前读取该值。
使用 Racecheck
通过使用 --tool racecheck 选项运行 Compute Sanitizer 应用程序来启用 racecheck 工具。
compute-sanitizer --tool racecheck [sanitizer_options] app_name [app_options]
一旦 racecheck 识别出危害,用户可以进行程序修改以确保不再存在此危害。在写后写危害的情况下,应修改程序,以便不会在同一位置发生多次写入。在读后写和写后读危害的情况下,读取和写入位置应按确定性顺序排列。在 CUDA 内核中,这可以通过在两次访问之间插入 __syncthreads() 调用来实现。为了避免单个 warp 中线程之间的竞争,可以使用 __syncwarp()。
注意
注意:racecheck 工具不执行任何内存访问错误检查。建议用户首先运行 memcheck 工具以确保应用程序没有错误。
Racecheck 报告模式
racecheck 工具可以生成两种类型的输出
危害报告
这些报告包含有关特定危害的详细信息。每个危害报告都是字节精确的,并表示有关影响共享内存的此字节的两个线程之间冲突访问的信息。
分析报告
这些报告包含一组后分析报告。这些报告由 racecheck 工具通过分析多个危害报告和检查活动设备状态来生成。有关分析报告的示例用法,请参阅 了解 Racecheck 分析报告。
了解 Racecheck 分析报告
在分析报告中,racecheck 工具生成一系列高级消息,这些消息基于观察到的危害和其他机器状态来识别特定竞争的源位置。
下面是一个 racecheck 分析报告示例
========= WARNING: Race reported between Write access at RAW()+0xf0 in raceGroupBasic.cu:40
========= and Read access at RAW()+0x280 in raceGroupBasic:46 [4 hazards]
分析记录包含有关传达给最终用户的危害的高级信息。每一行都包含有关参与竞争的应用程序中唯一位置的信息。
第一行上的第一个词表示此报告的严重程度。在本例中,消息的严重程度为 WARNING 级别。有关不同严重程度级别的更多信息,请参阅 Racecheck 严重程度级别。分析报告由一个或多个 racecheck 危害组成,报告的严重程度级别是严重程度最高的危害的级别。
第一行还包含访问类型。访问可以是
读取
写入
该行上的下一个项目是发出访问的内核的名称以及发生访问的位置的偏移量。在本例中,偏移量是 RAW() 内核中的 0xf0。如果应用程序是使用行号信息编译的,则此行还包含访问的文件名和行号。
接下来的几行包含参与竞争条件的其他偏移量的位置。在本例中,只有一个其他位置,即偏移量为 0x280 的 RAW() 内核。与第一行类似,如果应用程序是使用行号信息编译的,则会打印文件名和行号。最后,该行还包含为此特定竞争条件检测到的危害数量。
给定的分析报告将始终包含至少一行执行写入访问的行。消除仅包含写入访问的竞争的常见策略是确保写入访问仅由一个线程执行。对于具有多个读取器和一个写入器的竞争,通过 __syncthreads() 调用引入显式程序排序可以避免竞争条件。对于同一 warp 内线程之间的竞争,可以使用 __syncwarp() intrinsic 来避免危害。
了解 Racecheck 危害报告
在危害报告模式下,racecheck 工具生成一系列消息,详细说明应用程序中危害的信息。该工具是字节精确的,并为检测到危害的每个字节生成一条消息。此外,启用后,还将显示内核启动的主机回溯。
下面是一个 racecheck 危害示例
========= ERROR: Potential WAW hazard detected at __shared__ 0x0 in block (0,0,0) :
========= Write Thread (0,0,0) at WAW()+0x2f0 in raceWAW.cu:20
========= Write Thread (1,0,0) at WAW()+0x2f0 in raceWAW.cu:20
========= Current Value : 1, Incoming Value : 2
危害记录是密集的,并捕获了许多有趣的信息。一般来说,第一行包含有关危害严重程度、类型和地址的信息,以及有关发生危害的线程块的信息。接下来的 2 行包含有关发生竞争的两个线程的详细信息。这两行按时间顺序排列,因此第一个条目是关于较早发生的访问,第二个条目是关于较晚发生的访问。最后一行针对某些危害类型打印,并捕获正在写入的实际数据。
逐行检查,我们有
ERROR: Potential WAW hazard detected at __shared__ 0x0 in block (0, 0, 0)
此行上的第一个词表示此危害的严重程度。在本例中,消息的严重程度为 ERROR 级别。有关不同严重程度级别的更多信息,请参阅 Racecheck 严重程度级别。
此处的下一个信息是危害类型。racecheck 工具检测到三种类型的危害
WAW 或写后写危害
WAR 或写后读危害
RAW 或读后写危害
危害类型指示发生竞争的两个线程的访问类型。在本例中,危害类型为写后写。
下一个信息是正在访问的共享内存中的地址。这是两个线程正在访问的每个块共享内存中的偏移量。由于 racecheck 工具是字节精确的,因此消息仅针对给定地址的内存字节。在本例中,正在访问的字节是共享内存中的字节 0x0。
最后,第一行包含两个竞争线程所属的线程块的块索引。
第二行包含有关第一个写入此位置的线程的信息。
Write Thread (0, 0, 0) at WAW()+0x2f0 in raceWAW.cu:20(void)
此行上的第一个项目指示此线程对共享内存地址执行的访问类型。在本例中,线程正在写入位置。下一个组件是线程块的索引。在本例中,线程的索引为 (0,0,0)。接下来,我们有内核的名称和指令的字节偏移量,该指令在内核中执行了访问。在本例中,偏移量为 0x2f0。接下来是源文件和行号(如果行号信息可用)。
第三行包含有关导致此危害的第二个线程的类似信息。此行的格式与前一行相同。
第四行包含有关两次访问中数据的信息。
Current Value : 1, Incoming Value : 2
如果危害中的第二个线程正在执行写入访问,即危害是写后写 (WAW) 或写后读 (WAR),则此行包含第一个线程访问后的值作为当前值,以及第二个访问将写入的值作为传入值。在本例中,第一个线程将值 1 写入共享内存位置。第二个线程正在尝试写入值 2。
Racecheck 严重程度级别
racecheck 报告的问题可能具有不同的严重程度级别。根据级别,开发人员需要采取不同的操作。默认情况下,仅显示严重程度级别为 WARNING 和 ERROR 的问题。可以使用命令行选项 --print-level 来设置应报告的最低严重程度级别。
Racecheck 报告具有以下严重程度级别之一
INFO:最低的严重程度级别。这适用于对程序执行没有影响的危害,因此不会导致数据访问危害。找到并消除此类危害仍然是一个好主意。
WARNING:此严重程度级别的危害被确定为编程模型危害,但可能是程序员有意创建的。这方面的一个例子是由于 warp 级别编程而产生的危害,warp 级别编程假设线程以组的形式进行。此类危害通常仅由高级程序员遇到。在初级程序员遇到此类错误的情况下,他应将其视为危害的来源。
从 Volta 架构开始,程序员不能再依赖 warp 内的线程无条件地以锁步方式执行的假设。因此,在将应用程序从早期架构开发或移植到 Volta 及更高版本时,必须修复由于没有显式同步的 warp 同步编程而引起的警告。开发人员可以使用
__syncwarp()intrinsic 或 Cooperative Groups API。ERROR:最高的严重程度级别。这对应于极有可能导致数据访问竞争的危害。强烈建议程序员检查此严重程度级别的错误。
Racecheck 对 cuda::barrier 的支持
Racecheck 支持在 Ampere GPU 和更新的 GPU 上通过 cuda::barrier 进行同步。
该工具跟踪的 barrier 数量基于编译器信息报告的源代码中存在的 barrier 数量。在某些情况下,编译器可能会低估此数量。如果使用的 barrier 多于预期,Racecheck 将报告以下警告
========= Warning: Detected overflow of tracked cuda::barrier structures. Results might be incorrect. Try using --num-cuda-barriers to fix the issue
可以使用 --num-cuda-barriers 选项来指示源代码中预期的 barrier 数量并解决此问题。
Racecheck 对异步复制的支持
Racecheck 支持对共享内存进行竞争检测,以用于计算能力 8.0 中引入的从全局内存到共享内存的异步内存复制操作。这些操作可以采用 CUDA C++ cuda::memcpy_async 或 PTX cp.async 的形式。具体而言,racecheck 能够检测到何时在保证其完成所需的 commit/wait 之前访问了管道 (CUDA C++) 或 async-group (PTX) 跟踪的异步复制的目标。在这些情况下,使用 --racecheck-report hazard 时的各个危害将带有 (invalid memcpy_async synchronization) 的提示。可以使用 --racecheck-memcpy-async no 禁用这些检查。
Racecheck 集群进入和退出竞争检测
Racecheck 支持对远程共享内存访问进行竞争检测,而无需适当的集群范围同步。当内核从一个块到另一个块(在同一集群中)进行远程共享内存访问时,它需要保证目标块存在,否则会引发错误 cudaErrorLaunchFailure。实现此目的的一种方法是使用 Cluster Group API 中的 cluster.sync()。有关更多信息,请参阅有关分布式共享内存的 CUDA 文档。
在 Racecheck 下运行程序时,该工具不会失败,而是会报告以下两种类型的非法访问
延迟进入竞争检测:一个块正在尝试从集群中的另一个块访问共享内存,而事先没有适当的集群范围同步。
提前退出竞争检测:一个块正在尝试从集群中的另一个块访问共享内存,而在目标块退出之前没有适当的集群范围同步。
下面是两种竞争的示例报告
========= Potential invalid __shared__ read of size 4 bytes
========= at RemoteAccess(int *, int)+0x170 in RaceCluster.cu:10
========= by thread (0,0,0) in block (0,0,0)
========= Address 0x1000400 is located in a block that might not have entered yet
=========
========= Potential invalid __shared__ read of size 4 bytes
========= at RemoteAccess(int *, int)+0x170 in RaceCluster.cu:10
========= by thread (0,0,0) in block (0,0,0)
========= Address 0x1000400 is located in a block that might have already exited
=========
Initcheck 工具
什么是 Initcheck?
initcheck 工具是一个运行时未初始化设备全局内存访问检测器。此工具可以识别何时在设备全局内存未经设备端写入或通过 CUDA memcpy 和 memset API 调用初始化的情况下被访问。
目前,此工具仅支持检测对设备全局内存的访问。
使用 Initcheck
通过使用 --tool initcheck 选项运行 Compute Sanitizer 应用程序来启用 initcheck 工具。
compute-sanitizer --tool initcheck [sanitizer_options] app_name [app_options]
注意
initcheck 工具不执行任何内存访问错误检查。建议用户首先运行 memcheck 工具以确保应用程序没有错误。
未使用内存检测
initcheck 工具还可以通过使用 --track-unused-memory 选项来检测未使用的内存。
compute-sanitizer --tool initcheck --track-unused-memory app_name [app_options]
下面是一个未使用的内存报告示例
========= Unused memory in allocation 0x7fed9f400000 of size 100 bytes
========= Not written 80 bytes at offset 0x14 (0x7fed9f400014)
========= 80% of allocation were unused.
此报告包含分配的地址和大小、未使用的字节数及其位置。如果所有未使用的字节不连续,则位置可以是范围。
可以使用 --unused-memory-threshold 选项调整此功能的行为,该选项采用应打印报告的最低百分比。例如,使用 81 或更高的值将使上面的示例报告静音。
Synccheck 工具
什么是 Synccheck?
synccheck 工具是一个运行时工具,可以识别 CUDA 应用程序是否正确使用同步原语,特别是 __syncthreads() 和 __syncwarp() intrinsic 及其 Cooperative Groups API 对等项。
使用 Synccheck
通过使用 --tool synccheck 选项运行 Compute Sanitizer 应用程序来启用 synccheck 工具。
compute-sanitizer --tool synccheck [sanitizer_options] app_name [app_options]
注意
synccheck 工具不执行任何内存访问错误检查。建议用户首先运行 memcheck 工具以确保应用程序没有错误。
了解 Synccheck 报告
对于每个违规,synccheck 工具都会生成一条报告消息,用于标识违规的源位置及其分类。
下面是一个 synccheck 报告示例
========= Barrier error detected. Divergent thread(s) in warp
========= at ThreadDivergence(int *, int)+0xf0 in divergence.cu:79
========= by thread (37,0,0) in block (0,0,0)
每个报告都以“Barrier error detected.”开头。在大多数情况下,接下来是对检测到的 barrier 错误的分类。在此消息中,发现了一个具有发散线程的 CUDA 块。可以报告以下错误类别
块中的发散线程:对于当前架构上不支持此功能的 barrier,检测到块内线程之间的发散。例如,当在条件代码中使用
__syncthreads()但条件在块中的所有线程之间评估不相等时,就会发生这种情况。Warp 中的发散线程:对于当前架构上不支持此功能的 barrier,检测到单个 warp 内线程之间的发散。
无效参数:barrier 指令或原语与无效参数一起使用。例如,如果并非所有到达
__syncwarp()的线程都在 mask 参数中声明自己,则可能会发生这种情况。但是,synccheck 不会检测到并非所有在 mask 参数中声明的线程都到达__syncwarp()的情况。
下一行说明了函数内发生访问的位置的偏移量。在本例中,偏移量为 0xf0。如果应用程序是使用行号信息编译的,则此行还将包含访问的文件名和行号,后跟发出访问的内核的名称。
第三行包含有关检测到此违规的线程和块的信息。在本例中,它是块 0 中的线程 37。
Synccheck 对 cuda::barrier 的支持
Synccheck 支持在 Ampere GPU 和更新的 GPU 上通过 cuda::barrier 进行同步。
该工具跟踪的 barrier 数量基于编译器信息报告的源代码中存在的 barrier 数量。在某些情况下,编译器可能会低估此数量。如果使用的 barrier 多于预期,Synccheck 将报告以下警告
========= Warning: Detected overflow of tracked cuda::barrier structures. Results might be incorrect. Try using --num-cuda-barriers to fix the issue
可以使用 --num-cuda-barriers 选项来指示源代码中预期的 barrier 数量并解决此问题。
Synccheck 对 wgmma 的支持
Synccheck 支持与 Hopper sm_90a 架构的 PTX wgmma 指令相关的其他检查。
`wgmma <http://docs.nvda.net.cn/cuda/parallel-thread-execution/index.html#asynchronous-warpgroup-level-matrix-instructions>`__ 指令在 warpgroup 中执行。warpgroup 中的每个 warp 都应以相同的谓词按相同顺序执行相同的 wgmma 指令,所有线程都处于活动状态或都不处于活动状态。Synccheck 可以检测并报告不遵守这些规则的情况,并在检测到时退出整个 warpgroup。在这种情况下,报告将以“Warpgroup MMA sequence error detected”而不是“Barrier error detected”开头,后跟对遇到的特定错误的描述。每个遇到错误的 warp 报告一次错误。
可以使用 --check-warpgroup-mma 选项来启用或禁用这些检查。
Compute Sanitizer 功能
非阻塞模式
默认情况下,独立的 Compute Sanitizer 工具将在非阻塞模式下启动内核。这允许该工具在运行并发内核的应用程序中支持错误报告。
要强制内核串行执行,用户可以使用 --force-blocking-launches 选项。一个副作用是,当处于阻塞模式时,只会报告内核中第一个遇到错误的线程。此外,使用此选项或 --force-synchronization-limit 将禁用 CUDA 简化 API 序列化。
堆栈回溯
当给定 --show-backtrace 选项时,Compute Sanitizer 可以生成回溯。回溯通常由两个部分组成——一个保存的主机回溯,它指向 CUDA 驱动程序调用站点,以及错误发生时的设备回溯。每个回溯都包含一个帧列表,显示创建回溯时堆栈的状态。
要在主机回溯中获取函数名称,用户应用程序必须在构建时支持主机应用程序中的符号信息。有关更多信息,请参阅 编译选项
回溯会为大多数 Compute Sanitizer 工具输出打印,并且生成的信息因输出类型而异。下表解释了在不同条件下看到的主机和设备回溯类型。
输出类型 |
主机回溯 |
设备回溯 |
|---|---|---|
内存访问错误 |
主机上的内核启动 |
设备上的精确回溯 |
硬件异常 |
主机上的内核启动 |
设备上的不精确回溯 1 |
Malloc/Free 错误 |
主机上的内核启动 |
设备上的精确回溯 |
cudaMalloc 分配泄漏 |
cudaMalloc 的调用站点 |
N/A |
CUDA API 错误 |
CUDA API 调用的调用站点 |
N/A |
Compute Sanitizer 内部错误 |
导致内部错误的调用站点 |
N/A |
设备堆分配泄漏 |
N/A |
N/A |
共享内存冲突 |
主机上的内核启动 |
N/A |
请注意,对于 OptiX 应用程序,OptiX 内部设备函数的名称将显示为 “NVIDIA Internal”。
- 1
在某些情况下,可能没有设备回溯
名称反解
Compute Sanitizer 套件支持显示 CUDA 内核和 CUDA 设备函数的 mangled 和 demangled 名称。默认情况下,工具显示完全 demangled 的名称,其中包含内核的名称及其原型信息。在简单 demangle 模式下,工具只会显示名称的第一部分。如果禁用 demangle,工具将显示内核的完整 mangled 名称。
动态并行
Compute Sanitizer 工具套件支持动态并行。memcheck 工具支持对使用动态并行的应用程序的全局、本地和共享内存访问以及全局原子指令进行越界和未对齐访问的精确错误报告。此外,也不完全支持不精确的硬件异常报告机制。在使用动态并行的应用程序上进行错误检测需要设备上更多的内存;因此,在内存受限的环境中,memcheck 可能因内部内存不足错误而无法初始化。
有关限制,请参阅发行说明部分中的已知限制。
错误操作
当遇到错误时,Compute Sanitizer 的行为取决于错误的类型。Compute Sanitizer 的默认行为是在纯主机端错误上继续执行。memcheck 工具检测到的硬件异常会导致 CUDA 上下文被销毁。memcheck 工具检测到的精确错误(例如内存访问和 malloc/free 错误)会导致内核终止。这将终止内核,而不会运行任何后续指令,并且应用程序继续在 CUDA 上下文中启动其他内核。可以使用 --destroy-on-device-error 选项更改 memcheck 工具检测到的内存访问和 malloc/free 错误的处理方式。
Maxwell GPU 不支持 --destroy-on-device-error kernel 选项。
对于 racecheck 检测到的冲突,将报告冲突,但执行不受影响。
有关基于错误类型的错误操作的完整摘要,请参见下表。错误操作“终止内核”指的是内核提前终止,并且不运行任何后续指令的情况。在这种情况下,CUDA 上下文不会被销毁,其他内核继续执行,并且仍然可以进行 CUDA API 调用。
注意
当内核执行提前终止时,应用程序可能尚未完成对数据的计算。任何依赖于此数据的后续内核都将具有未定义的行为。
操作“终止 CUDA 上下文”指的是强制终止 CUDA 上下文的情况。在这种情况下,上下文的所有未完成工作都将被终止,并且后续的 CUDA API 调用将失败。操作“继续应用程序”指的是应用程序执行不受影响,并且内核继续执行指令的情况。
错误类型 |
位置 |
操作 |
评论 |
|---|---|---|---|
内存访问错误 |
设备 |
终止 CUDA 上下文 |
用户可以选择改为终止内核 |
硬件异常 |
设备 |
终止 CUDA 上下文 |
CUDA 上下文的后续调用将失败 |
Malloc/Free 错误 |
设备 |
终止 CUDA 上下文 |
用户可以选择改为终止内核 |
cudaMalloc 分配泄漏 |
主机 |
继续应用程序 |
报告错误。不采取其他操作。 |
CUDA API 错误 |
主机 |
继续应用程序 |
报告错误。不采取其他操作。 |
设备堆分配泄漏 |
设备 |
继续应用程序 |
报告错误。不采取其他操作。 |
共享内存冲突 |
设备 |
继续应用程序 |
报告错误。不采取其他操作。 |
同步错误 |
设备 |
终止 CUDA 上下文 |
用户可以选择改为终止内核 |
Compute Sanitizer 内部错误 |
主机 |
未定义 |
应用程序的行为可能以未定义的方式进行 |
转义序列
Compute Sanitizer 的 --save 和 --log-file 选项接受文件名中的以下转义序列。
%%: 替换为文字 %。%p: 替换为 Compute Sanitizer 前端应用程序的 PID。%q{ENVVAR}: 替换为环境变量ENVVAR的内容。如果变量不存在,则替换为空字符串。百分号 (%) 后面的任何其他字符都会导致错误。
指定过滤器
Compute Sanitizer 工具支持过滤应检查的内核的选择。当指定过滤器时,只会检查与过滤器匹配的内核。过滤器使用 --kernel-name 和 --kernel-name-exclude 选项指定。默认情况下,Compute Sanitizer 工具将检查应用程序中的所有内核。
可以多次指定 --kernel-name 和 --kernel-name-exclude 选项。如果内核满足任何过滤器,它将被运行的 Compute Sanitizer 工具检查。
--kernel-name 和 --kernel-name-exclude 选项接受过滤器规范,该规范由逗号分隔的键值对列表组成,指定为 key=value。当使用 regex 过滤器键时,需要通过多次使用该选项来指定多个键值对。为了使过滤器匹配,必须满足过滤器规范的所有组件。如果任何组件中错误地指定了过滤器,则整个过滤器将被忽略。有关有效键值的完整摘要,请参见下表。如果一个键有多个字符串,则可以使用任何字符串来指定该过滤器组件。
名称 |
键字符串 |
值 |
评论 |
|---|---|---|---|
内核名称 |
kernel_name, kne |
完整的 mangled 内核名称 |
用户指定完整的 mangled 内核名称。 |
内核子字符串 |
kernel_substring, kns |
mangled 内核名称中的任何子字符串 |
用户指定 mangled 内核名称中的子字符串。 |
正则表达式 |
regex |
可以在 mangled 内核名称的子字符串中匹配的任何正则表达式 |
用户指定在 mangled 内核名称中搜索的正则表达式。 |
当使用 kernel-name 过滤器时,Compute Sanitizer 工具将检查内核进行的所有 device 函数调用。当使用 CUDA 动态并行 (CDP) 时,Compute Sanitizer 工具将不检查从已检查内核启动的子内核,除非子内核与过滤器匹配。如果 GPU 启动的内核不匹配过滤器,但调用了可从匹配过滤器的内核访问的设备函数,则该设备函数的行为就像已被检查一样。在某些工具的情况下,这可能会导致未定义的行为。
过滤器使用示例
我们考虑一个应用程序,它启动了以下声明的三个不同的内核。
__global__ void gamma(int *bufer);
__global__ void delta(int *bufer);
__global__ void epsilon(int *bufer);
它们各自的 mangled 名称是 _Z5gammaPi、_Z5deltaPi 和 _Z7epsilonPi。我们只想检查内核 epsilon 的启动。以下是实现它的不同方法
compute-sanitizer --kernel-name kne=_Z7epsilonPi只有 epsilon 匹配指定的过滤器,因此只会检查 epsilon 的内核启动。compute-sanitizer --kernel-name kns=epsilon由于 “epsilon” 是 “_Z7epsilonPi” 的子字符串,并且恰好是唯一在其 mangled 名称中具有此子字符串的内核,因此只有 epsilon 将被匹配和检查。compute-sanitizer --kernel-name-exclude kns=delta,kne=_Z5gammaPi这次,我们使用排除选项。只有 epsilon 不匹配此场景中的排除选项,这意味着它将是唯一被检查的内核。我们使用逗号分隔指定了多个过滤器:这可以与kernel-name和kernel-name-exclude一起使用。compute-sanitizer --kernel-name-exclude kns=delta --kernel-name-exclude kne=_Z5gammaPi与上面相同,除了我们使用了两次排除选项来指定多个过滤器,而不是一次指定所有过滤器。如果需要,可以同时使用kernel-name和kernel-name-exclude。compute-sanitizer --kernel-name regex='[a-z]{7}'对于此示例,我们正在使用 regex 过滤器。它匹配正则表达式可以在 mangle 名称内的任何位置匹配的任何内核。指定的 regex 匹配任何 7 个连续的小写字母。_Z7epsilonPi是唯一具有 7 个连续小写字母的内核,因此是--kernel-name匹配的唯一内核。
Coredump 支持
从 CUDA 11.6 开始,compute-sanitizer 工具可以在检测到错误后使用 --generate-coredump 选项生成 CUDA coredump。生成 coredump 后,目标应用程序将中止。
在 Linux 上,可以使用以下选项在 cuda-gdb 中加载 coredump 文件
(cuda-gdb) target cudacore core.name.nvcudmp
有关更多信息,请参见 cuda-gdb 文档。
在 Windows 上,可以使用 文件 > 打开 菜单在 NVIDIA Nsight Visual Studio Edition 中加载 coredump 文件,或者通过将文件拖放到 Visual Studio 中。有关更多信息,请参见 NVIDIA Nsight Visual Studio Edition 文档。
可以使用 --coredump-name 选项指定 coredump 的文件名。有关模板说明符和默认名称的更多信息,请参见 cuda-gdb 文档的“GPU 核心转储文件命名”部分。
coredump 功能具有以下限制
只能在生成的 coredump 中检查遇到错误的线程
不支持 Maxwell GPU
不支持 racecheck 工具。
错误抑制
compute-sanitizer 工具有时可能会生成误报。在这些情况下,可以提供抑制文件作为工具的输入,以抑制这些误报的报告。
可以使用目标应用程序上 compute-sanitizer 工具的 --xml 选项生成抑制文件。生成后,可以手动编辑 XML 文件使其更通用。
在后续使用工具时,可以使用 --suppressions 选项提供抑制文件作为输入。
在检查是否应抑制检测到的报告时,将应用以下规则
报告的类型必须匹配。
如果在抑制文件中提供,则整数字段必须完全匹配。
如果在抑制文件中提供,则字符串字段可以是正则表达式。
在比较堆栈跟踪时,抑制跟踪需要具有与报告跟踪相同或更少的帧数。
堆栈帧比较包括以下字段(如果在抑制中提供):函数名称、文件名和模块名称。
可以抑制以下类型的错误
OptiX 支持
从 CUDA 11.6 开始,compute-sanitizer 工具支持带有 memcheck 和 initcheck 的 OptiX 7 应用程序。需要设置 --check-optix 选项才能使用 initcheck 跟踪 optix 启动。要获得完整的设备回溯信息,请确保您的 OptiX 模块在 OptixModuleCompileOptions 结构的 debugLevel 字段中设置了 OPTIX_COMPILE_DEBUG_LEVEL_FULL 进行编译。
当在 OptiX 应用程序上使用 compute-sanitizer 时,某些或所有设备帧可能位于 OptiX 内部代码中。此类帧的名称显示为 NVIDIA Internal。请参见以下示例,该示例显示了从内部 OptiX 函数调用的用户代码中报告的错误
========= Invalid __global__ write of size 1 bytes
========= at __raygen__placeholder_0x67b9a77bb7822a34+0x19b0 in /home/cuda/optixApp.cu:70
========= by thread (0,0,0) in block (0,0,0)
========= Address 0x7f91edf00403 is out of bounds
========= and is 262,132 bytes after the nearest allocation at 0x7f91edec0400 of size 16 bytes
========= Device Frame:NVIDIA Internal [0x520]
========= Saved host backtrace up to driver entry point at kernel launch time
[...]
从 CUDA 11.7 开始,可以使用 compute-sanitizer 检测 OptixModule、optixPipeline、optixProgramGroup 和 optixDenoiser 的泄漏。这需要使用 --check-optix-leaks 选项。只有在通过调用 OptixDeviceContextDestroy 销毁 OptixDeviceContext 时才会报告泄漏。泄漏的 OptixDeviceContext 将使用常规的 --leak-check full 报告其关联的 CUDA 缓冲区。请参见以下示例,该示例显示了未销毁的 optixProgramGroup 的报告
========= Leaked an OptixProgramGroup with handle 0x55dbffbd9840
========= Saved host backtrace up to driver entry point at allocation time
[...]
以下功能集按 OptiX API 版本受支持
OptiX API 版本 |
内核检查 |
资源泄漏检查 |
7.0 - 8.1 |
是 |
是 |
使用指南
内存占用
Compute Sanitizer 工具由于其跟踪数据而可能具有较大的内存占用。这可能会导致在执行大量并发内核启动的应用程序上出现内存不足错误。
========= Internal Sanitizer Error: The Sanitizer encountered an error while launching kernel_name and didn't track the launch. Errors might go undetected. (Unable to allocate enough memory to perform the requested operation)
这些工具还可能导致主机内存分配失败,从而导致应用程序崩溃。
========= Error: process didn't terminate successfully
========= Target application returned an error
可以使用以下命令行选项之一解决此问题
--force-synchronization-limit {number}强制在流达到给定的未同步启动次数后进行流同步。--force-blocking-launches强制序列化每个内核启动。此选项等效于--force-synchronization-limit 1。
使用 CUDA 延迟模块加载 也有助于降低工具的内存占用,包括主机和设备内存。
操作系统特定行为
本节介绍操作系统特定行为。
Windows 特定行为
调试接口
注册表项
HKEY_LOCAL_MACHINE\SOFTWARE\NVIDIA Corporation\GPUDebugger\EnableInterface必须设置为(DWORD) 1。这是启用 Compute Sanitizer 工具的调试接口所必需的。超时检测和恢复 (TDR)
在 Windows 上,GPU 具有与其关联的超时。运行时间超过阈值(默认为 2 秒)的 GPU 应用程序将被操作系统杀死。由于 Compute Sanitizer 工具会增加内核的运行时,因此 CUDA 内核可能会超过超时,并因此由于 TDR 机制而被终止。
为了调试目的,可以通过在 DWORD 注册表项
TdrDelay中设置超时值(以秒为单位)来修改超时之前的秒数,位置在HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\GraphicsDrivers
有关控制超时检测和恢复机制的注册表项的更多信息,请从 MSDN 获取,网址为 http://msdn.microsoft.com/en-us/library/windows/hardware/ff569918%28v=vs.85%29.aspx。
在 Jetson 和 Tegra 设备上使用 Compute Sanitizer
默认情况下,在 Jetson 和 Drive Tegra 设备上,仅当 compute-sanitizer 由 debug 组的成员用户启动时,才支持 GPU 调试。
要将当前用户添加到 debug 组,请运行此命令
sudo usermod -a -G debug $USER
CUDA Fortran 支持
本节介绍对 CUDA Fortran 的支持。
CUDA Fortran 特定行为
默认情况下,Compute Sanitizer 打印的错误报告包含线程索引 (threadIdx) 和块索引 (blockIdx) 的从 0 开始的 C 样式值。为了使 Compute Sanitizer 工具使用 Fortran 样式的从 1 开始的偏移量,请使用
--language fortran选项。CUDA Fortran 编译器可能会在共享内存中插入额外的填充。访问此额外填充可能不会报告为错误。
Compute Sanitizer 工具示例
Memcheck 的示例用法
本节介绍在名为 memcheck_demo 的简单应用程序上运行 Compute Sanitizer 中的 memcheck 工具的步骤。
注意
根据 GPU 的 SM 类型,您的系统输出可能会有所不同。
该应用程序可以在 compute-sanitizer github 存储库 中找到
可以使用提供的 Makefile 编译此应用程序
make
memcheck_demo 输出
当 CUDA 应用程序导致访问冲突时,内核启动可能会报告非法内存访问或未对齐的地址。所有后续内核启动都将报告粘滞错误。
此示例应用程序导致两个故障,但无法检测到未对齐的地址访问发生的位置。第二个内核也无法运行,如下面的输出所示
$ ./memcheck_demo
Mallocing memory
Running unaligned_kernel: misaligned address
Running out_of_bounds_kernel: misaligned address
memcheck_demo 使用 Memcheck 的输出(发布版本)
在这种情况下,由于应用程序以发布模式构建,因此 Compute Sanitizer 输出仅包含应用程序中导致访问冲突的内核名称。虽然检测到内核名称和错误类型,但失败内核上没有行号信息。输出中还包括启动函数的调用站点的主机和设备回溯
现在使用 Compute Sanitizer 运行此应用程序并检查输出。默认情况下,应用程序将运行,以便在发生内存访问错误时终止内核,但 CUDA 上下文中的其他工作仍然可以继续进行。
在下面的输出中,第一个内核不再报告未指定的启动失败,因为在 Compute Sanitizer 检测到错误后,其执行已提前终止。应用程序继续运行第二个内核。在第二个内核中检测到的错误导致其提前终止。
$ make run_memcheck
/usr/local/cuda/compute-sanitizer/compute-sanitizer --destroy-on-device-error kernel memcheck_demo
========= COMPUTE-SANITIZER
Mallocing memory
========= Invalid __global__ write of size 4 bytes
========= at unaligned_kernel()+0x50
========= by thread (0,0,0) in block (0,0,0)
========= Address 0x710fdca00001 is misaligned
========= and is inside the nearest allocation at 0x710fdca00000 of size 4 bytes
========= Saved host backtrace up to driver entry point at kernel launch time
========= Host Frame: run_unaligned() [0xacd4] in memcheck_demo
========= Host Frame: main [0xae61] in memcheck_demo
=========
Running unaligned_kernel: no error
========= Invalid __global__ write of size 4 bytes
========= at out_of_bounds_kernel()+0x90
========= by thread (0,0,0) in block (0,0,0)
========= Address 0x87654320 is out of bounds
========= and is 124,310,666,263,776 bytes before the nearest allocation at 0x710fdc800000 of size 1,024 bytes
========= Saved host backtrace up to driver entry point at kernel launch time
========= Host Frame: run_out_of_bounds() [0xadb6] in memcheck_demo
========= Host Frame: main [0xae66] in memcheck_demo
=========
Running out_of_bounds_kernel: no error
========= ERROR SUMMARY: 2 errors
memcheck_demo 使用 Memcheck 的输出(调试版本)
可以使用设备端调试信息和函数符号构建应用程序,如下所示
make dbg=1
错误的源位置现在在 compute-sanitizer 输出中报告
$ make run_memcheck
========= COMPUTE-SANITIZER
Mallocing memory
========= Invalid __global__ write of size 4 bytes
========= at unaligned_kernel()+0x100 in memcheck_demo.cu:34
========= by thread (0,0,0) in block (0,0,0)
========= Address 0x7cc43aa00001 is misaligned
========= and is inside the nearest allocation at 0x7cc43aa00000 of size 4 bytes
========= Saved host backtrace up to driver entry point at kernel launch time
========= Host Frame: run_unaligned() [0xacd4] in memcheck_demo
========= Host Frame: main [0xae61] in memcheck_demo
=========
Running unaligned_kernel: no error
========= Invalid __global__ write of size 4 bytes
========= at out_of_bounds_function()+0xb0 in memcheck_demo.cu:39
========= by thread (0,0,0) in block (0,0,0)
========= Address 0x87654320 is out of bounds
========= and is 137,179,965,340,896 bytes before the nearest allocation at 0x7cc43a800000 of size 1,024 bytes
========= Device Frame: out_of_bounds_kernel()+0x30 in memcheck_demo.cu:44
========= Saved host backtrace up to driver entry point at kernel launch time
========= Host Frame: run_out_of_bounds() [0xadb6] in memcheck_demo
========= Host Frame: main [0xae66] in memcheck_demo
=========
Running out_of_bounds_kernel: no error
========= ERROR SUMMARY: 2 errors
Compute Sanitizer 中的泄漏检查
要在 CUDA 上下文销毁时打印有关尚未释放的分配的信息,我们可以为 Compute Sanitizer 指定 --leak-check full 选项。
当使用泄漏检查选项运行程序时,用户将看到未销毁的分配列表,以及分配的大小和设备上分配的地址。对于在主机上进行的分配,每个泄漏报告还将打印与首次进行分配时保存的主机堆栈相对应的回溯。还提供了泄漏的总字节数和相应分配数的摘要。
在此示例中,程序使用 cudaMalloc() 创建了一个分配,但尚未调用 cudaFree() 来释放它,从而导致内存泄漏。请注意,Compute Sanitizer 仍然会打印在运行应用程序时遇到的错误。为了清晰起见,它们在下面的输出中被省略。
$ make run_leakcheck
========= COMPUTE-SANITIZER
...
========= Leaked 1,024 bytes at 0x7879c0800000
========= Saved host backtrace up to driver entry point at allocation time
========= Host Frame: cudaMalloc [0x56624] in memcheck_demo
========= Host Frame: main [0xae5c] in memcheck_demo
=========
========= LEAK SUMMARY: 1024 bytes leaked in 1 allocations
========= ERROR SUMMARY: 3 errors
Racecheck 的示例用法
本节介绍 Compute Sanitizer 中 racecheck 工具的两个示例用法。第一个示例使用名为 block_error 的应用程序,该应用程序在块级别具有共享内存冲突。第二个示例使用名为 warp_error 的应用程序,该应用程序在 warp 级别具有共享内存冲突。
注意
根据 GPU 的 SM 类型,您的系统输出可能会有所不同。
块级冲突
该应用程序可以在 compute-sanitizer github 存储库 中找到
可以使用提供的 Makefile 编译此应用程序
make dbg=1
每个内核线程都在共享内存中写入一些元素。之后,线程 0 计算共享内存中所有元素的总和,并将结果存储在全局内存变量 sum_out 中。
在 racecheck 工具下使用 --racecheck-report analysis 选项运行此应用程序,将报告以下错误
$ make run_block_error
========= COMPUTE-SANITIZER
========= Error: Race reported between Write access at sumKernel(int *, int *)+0x90 in /home/cuda/github/compute-sanitizer-samples/Racecheck/block_error.cu:41
========= and Read access at sumKernel(int *, int *)+0x100 in /home/cuda/github/compute-sanitizer-samples/Racecheck/block_error.cu:51 [508 hazards]
=========
========= RACECHECK SUMMARY: 1 hazard displayed (1 error, 0 warnings)
Racecheck 报告了线程 0 在第 51 行读取所有共享内存元素,与每个单独的线程在第 41 行写入其共享内存条目之间的冲突。多个线程之间对共享内存的访问,其中至少一个访问是写入,可能会相互冲突。由于冲突发生在不同 warp 的线程之间,因此第 42 行需要块级同步屏障 __syncthreads()。
请注意,总共报告了 508 个冲突:内核使用一个包含 128 个线程的块。每个线程写入或读取的数据大小分别为四个字节(一个 int),并且冲突在字节级别报告。除线程 0 本身的四个写入之外,所有线程的写入都与线程 0 的读取发生冲突。
Warp 级冲突
该应用程序可以在 compute-sanitizer github 存储库 中找到
可以使用提供的 Makefile 编译此应用程序
make dbg=1
内核分两个阶段计算共享内存中所有单个元素的总和。首先,每个线程在 smem_first 中计算其本地共享内存值。其次,选择每个 warp 的单个线程,使用 if (tx % WARP_SIZE == 0) 对其 warp 写入的所有元素(索引为 wx)求和,并将结果存储在 smem_second 中。最后,内核的线程 0 计算 smem_second 中元素的总和,并将该值写入全局内存。
在 racecheck 工具下使用 --racecheck-report hazard 选项运行此应用程序,将报告多个严重性为 WARNING 的冲突
========= Warning: (Warp Level Programming) Potential RAW hazard detected at __shared__ 0x8c in block (0,0,0) :
========= Write Thread (35,0,0) at sumKernel(int *, int *)+0x90 in /home/cuda/github/compute-sanitizer-samples/Racecheck/warp_error.cu:44
========= Read Thread (32,0,0) at sumKernel(int *, int *)+0x120 in /home/cuda/github/compute-sanitizer-samples/Racecheck/warp_error.cu:56
========= Current Value : 35
为了避免 块级冲突 示例中演示的错误,内核在第 60 行使用了块级屏障 __syncthreads()。但是,racecheck 仍然报告同一 warp 内线程之间的读后写 (RAW) 冲突,严重性为 WARNING。在 SM 7.0 (Volta) 之前的架构上,程序员通常依赖于 warp 内的线程以锁步方式执行代码的假设(warp 级编程)。从 CUDA 9.0 开始,程序员可以使用新的 __syncwarp() warp 范围屏障(而不是之前的 __syncthreads())来避免此类冲突。此屏障应插入在第 45 行。
Initcheck 的示例用法
本节介绍 Compute Sanitizer 中 initcheck 工具的用法。该示例使用名为 memset_error 的应用程序。
Memset 错误
该应用程序可以在 compute-sanitizer github 存储库 中找到
可以使用提供的 Makefile 编译此应用程序
make dbg=1
该示例实现了一个非常简单的向量加法,其中线程索引被添加到每个向量元素。向量包含 NumBlocks * NumThreads 个类型为 int 的元素。向量在设备上分配,然后在内核启动之前使用 cudaMemset 初始化为 0。
在 initcheck 工具下运行此应用程序会报告多个如下所示的错误
$ make run_initcheck
========= Uninitialized __global__ memory read of size 4 bytes
========= at vectorAdd(int *)+0x70 in /home/cuda/github/compute-sanitizer-samples/Initcheck/memset_error.cu:41
========= by thread (31,0,0) in block (1,0,0)
========= Address 0x7f3c7ec000fc
问题在于对 cudaMemset 的调用期望以字节为单位设置内存的大小。但是,大小是以元素为单位给出的,因为在计算参数时缺少 sizeof(int) 的因子。因此,在向量加法期间,3/4 的内存将具有未定义的值。
Synccheck 的示例用法
本节介绍 Compute Sanitizer 中 synccheck 工具的两个示例用法。第一个示例使用名为 divergent_threads 的应用程序。第二个示例使用名为 illegal_syncwarp 的应用程序。
注意
根据 GPU 的 SM 类型,您的系统输出可能会有所不同。
发散线程
divergent_threads 应用程序可以在 compute-sanitizer github 存储库 中找到
可以使用提供的 Makefile 编译此应用程序
make dbg=1
在此示例中,我们启动一个具有 64 个线程的单个块的内核。内核循环遍历 DataBlocks 个输入数据块 data_in。在每次迭代中,NumThreads 个元素在共享内存中并发添加。最后,单个线程 0 计算共享内存中所有值的总和,并将其写入 sum_out。
在 synccheck 工具下运行此应用程序时,将报告 16 个如下所示的错误
$ make run_divergent_threads
========= Barrier error detected. Divergent thread(s) in warp
========= at myKernel(int*, int*, int)+0x578 in divergent_thread.cu:54
========= by thread (32,0,0) in block (0,0,0)
问题在于将最后一个数据块读入共享内存时,第 20 行的 __syncthreads()。请注意,最后一个数据块只有 48 个元素(而所有其他块为 64 个元素)。因此,第二个 warp 并非所有线程都按要求同步执行此语句。
注意
在 SM 7.0 及更高版本上,允许在不同步的情况下调用 __syncthreads()。Synccheck 不会报告这些架构上此示例的任何错误。
非法 Syncwarp
illegal_syncwarp 应用程序可以在 compute-sanitizer github 存储库 中找到
可以使用提供的 Makefile 编译此应用程序
make dbg=1
此示例仅适用于计算能力为 7.0 (Volta) 及以上的设备。内核使用单个 warp(32 个线程)启动,但只有线程 0-15 参与计算。这些线程中的每一个都使用其线程索引初始化一个共享内存元素。赋值后,使用 __syncwarp() 以确保 warp 同步,并且所有写入对其他线程可见。传递给 __syncwarp() 的掩码是使用 __ballot_sync() 计算的,它在 mask 中启用前 16 个线程的位。最后,第一个线程(索引 0)计算所有初始化的共享内存元素的总和,并将其写入全局内存。
使用 -G 构建应用程序以启用调试信息,并在 SM 7.0 及更高版本上的 synccheck 工具下运行它,会报告如下多个错误
$ make run_illegal_syncwarp
========= Barrier error detected. Invalid arguments
========= at __cuda_sm70_warpsync+0x30
========= by thread (0,0,0) in block (0,0,0)
========= Device Frame:__syncwarp(unsigned int)+0xf0 in /usr/local/cuda/include/sm_30_intrinsics.hpp:110
========= Device Frame:myKernel(int *)+0x3c0 in /home/cuda/github/compute-sanitizer-samples/Synccheck/illegal_syncwarp.cu:48
问题在于第 48 行的 __syncwarp(mask)。掩码中启用了所有满足 tx < (NumThreads / 2) 的线程,即线程 0-15。但是,if 条件对于线程 0-16 评估为真。因此,线程 16 执行了 __syncwarp(mask),但没有按要求在掩码参数中声明自己。
抑制的示例用法
本节介绍 Compute Sanitizer 抑制功能的两个示例用法。第一个示例显示 API 抑制(在 memcheck 工具中)。第二个示例显示 initcheck 报告抑制。
API 错误抑制
API 错误应用程序可以在 compute-sanitizer github 存储库 </xref> 中找到
可以使用提供的 Makefile 编译此应用程序
make
在此示例中,我们有一个简单的循环,应用程序尝试分配一个不断减小的大尺寸。我们可以预期 cudaMalloc API 在尺寸足够小以适应 GPU 之前会多次失败。
$ make run_memcheck
/usr/local/cuda/compute-sanitizer/compute-sanitizer suppressions_demo
========= COMPUTE-SANITIZER
========= Program hit cudaErrorMemoryAllocation (error 2) due to "out of memory" on CUDA API call to cudaMalloc.
为了生成抑制文件,我们需要使用 --xml 选项与用于输出文件名的 --save 选项结合使用。运行该命令仍然像以前一样打印错误,但它还会创建一个 XML 文件,并在其中填充输出记录。
$ make gen_supp
/usr/local/cuda/compute-sanitizer/compute-sanitizer --save supp.xml --xml suppressions_demo
========= COMPUTE-SANITIZER
========= Program hit cudaErrorMemoryAllocation (error 2) due to "out of memory" on CUDA API call to cudaMalloc.
[...]
$ cat supp.xml
<![CDATA[
<?xml version="1.0" encoding="utf-8"?>
<ComputeSanitizerOutput>
<record>
<kind>Api</kind>
<what>
<text>Program hit cudaErrorMemoryAllocation (error 2) due to out of memory on CUDA API call to cudaMalloc.</text>
<api>cudaMalloc</api>
<error>cudaErrorMemoryAllocation</error>
<message>out of memory</message>
<result>2</result>
</what>
<hostStack>
[...]
</hostStack>
]]>
现在,我们可以使用该文件作为输入来运行该工具,并使用 --suppressions 选项来忽略该错误。
$ make run_memcheck_with_supp
/usr/local/cuda/compute-sanitizer/compute-sanitizer --suppressions supp.xml suppressions_demo
========= COMPUTE-SANITIZER
========= ERROR SUMMARY: 0 errors
可以编辑 XML 文件以更改要忽略的错误。例如,可以在 api 标记中使用正则表达式来抑制一系列 API 调用。例如,cuda.* 将忽略与以 cuda 开头的 API 相关的任何错误。
可以编辑的其他标记是 result 和 hoststack 标记。请注意,主机堆栈以相反的顺序出现,并且抑制功能将比较记录的每个堆栈帧。
Initcheck 错误抑制
API 错误应用程序可以在 compute-sanitizer github 存储库 </xref> 中找到
make
在此示例中,我们有一个简单的乘法内核。调用 <codeph>cudaMemset</codeph> 用于将设备内存初始化为 0。但是,它不会初始化数组的最后一个字节。initcheck 工具检测到未初始化的访问
$ make run_initcheck
/usr/local/cuda/compute-sanitizer/compute-sanitizer --tool initcheck suppressions_initcheck_demo
========= COMPUTE-SANITIZER
========= Uninitialized __global__ memory read of size 4 bytes
========= at mult(int *, int *, int)+0x60
========= by thread (122,0,0) in block (0,0,0)
========= Address 0x7f936fa001e8
[...]
========= ERROR SUMMARY: 1 error
与之前的示例类似,我们可以使用 <codeph>–xml</codeph> 选项来生成抑制文件。
$ make initcheck_gen_supp
/usr/local/cuda/compute-sanitizer/compute-sanitizer --tool initcheck --save supp.xml --xml suppressions_initcheck_demo
========= COMPUTE-SANITIZER
========= Uninitialized __global__ memory read of size 4 bytes
[...]
现在,可以使用 XML 文件作为抑制功能的输入来忽略该错误。
$ make run_initcheck_with_supp
/usr/local/cuda/compute-sanitizer/compute-sanitizer --tool initcheck --suppressions supp.xml suppressions_initcheck_demo
========= COMPUTE-SANITIZER
========= ERROR SUMMARY: 0 errors
与 API 抑制一样,可以编辑 XML 文件,通过编辑或删除 threadId、blockId、size 和 device stack 标记,使抑制检测更通用。
声明
声明
所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均“按原样”提供。NVIDIA 不对这些材料做出任何明示、暗示、法定或其他方面的保证,并且明确声明不承担任何关于不侵权、适销性和针对特定用途适用性的暗示保证。
所提供的信息据信是准确可靠的。但是,NVIDIA 公司对使用此类信息造成的后果或因使用此类信息而可能导致的侵犯第三方专利或其他权利不承担任何责任。未以暗示或其他方式授予 NVIDIA 公司专利权项下的任何许可。本出版物中提及的规格如有更改,恕不另行通知。本出版物取代并替换之前提供的所有其他信息。未经 NVIDIA 公司明确书面批准,NVIDIA 公司产品未被授权用作生命维持设备或系统中的关键组件。
商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA 公司在美国和其他国家/地区的商标和/或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。