NVIDIA GPU 调试指南
本文档提供 GPU 错误调试和诊断指南,旨在帮助系统管理员、开发人员和 FAE 尽快恢复服务器运行。
1. 概述
本文档提供了一个流程图和相关详细信息,说明如何开始调试 GPU 服务器上的一般问题。它旨在涵盖在数据中心 GPU 运行中可能看到的最常见问题,但并非旨在面面俱到。以下信息是关于调试 GPU 系统问题的若干不同文档和最佳实践的摘要。
此调试过程旨在通用,可能与您的系统供应商的特定分类指南不一致。请尽早而不是稍后与您的系统供应商联系,以确保您的系统尽快恢复到完全健康状态。但是,通过使用此过程,基础设施团队应该能够完成调试过程的最初步骤,以收集尽可能多的数据,或完全避免提交帮助请求的需要。
2. 初始事件报告
在管理 GPU 系统事件时,与所有系统事件一样,拥有精心设计的流程可以帮助更快地诊断事件,并使系统更快地恢复生产。在任何事件开始时(无论是系统检测到的还是用户报告的),请尝试记录以下问题
观察到事件的哪些方面?
何时观察到事件?
如何观察到的?
在多个系统或组件上是否观察到此行为?
如果是,有多少,频率如何?
系统、驱动程序或应用程序行为最近是否发生任何变化?
收集有关这些问题的信息以启动调试过程非常重要,因为它提供了对问题的最佳理解,并且通过记录此信息,可以将其与其他事件关联起来,从而更好地了解整体系统行为和健康状况。
3. GPU 节点分类
系统支持团队可以通过多种方式收到有关基于 GPU 的系统的潜在问题的通知。这些通知可能来自错误报告、监控系统事件和诊断指标。虽然这些事件可能会影响 GPU 系统的运行,但并非所有事件都需要系统供应商进行干预才能解决。此外,还有一些常用工具可用于在系统问题发生后收集数据,这些工具对本地系统支持团队和供应商进行节点分类都很有用。
图 1 至图 3 是流程图,说明应如何根据提供的信息开始节点分类,表明可能存在节点问题。
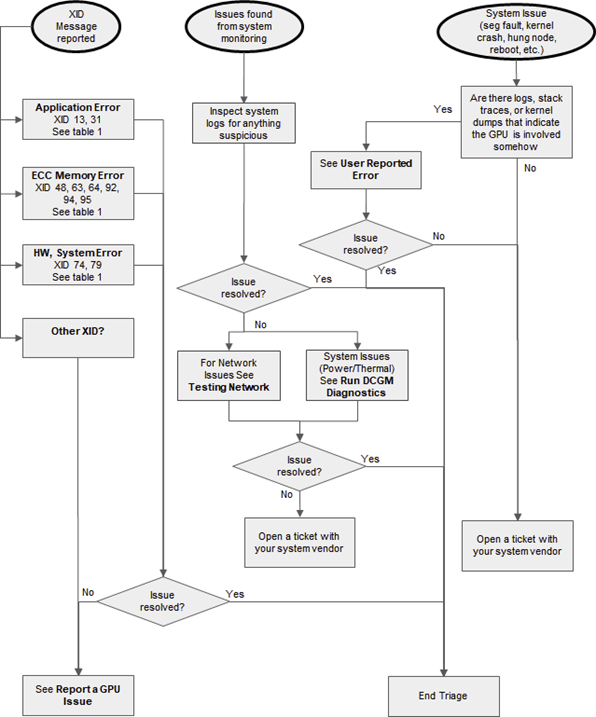
图 1 GPU 分类流程图
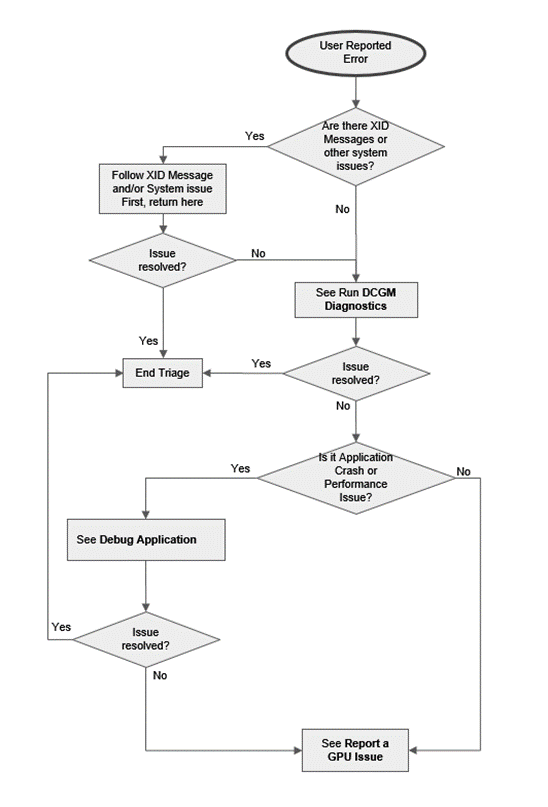
图 2 GPU 分类流程图(用户报告的错误)
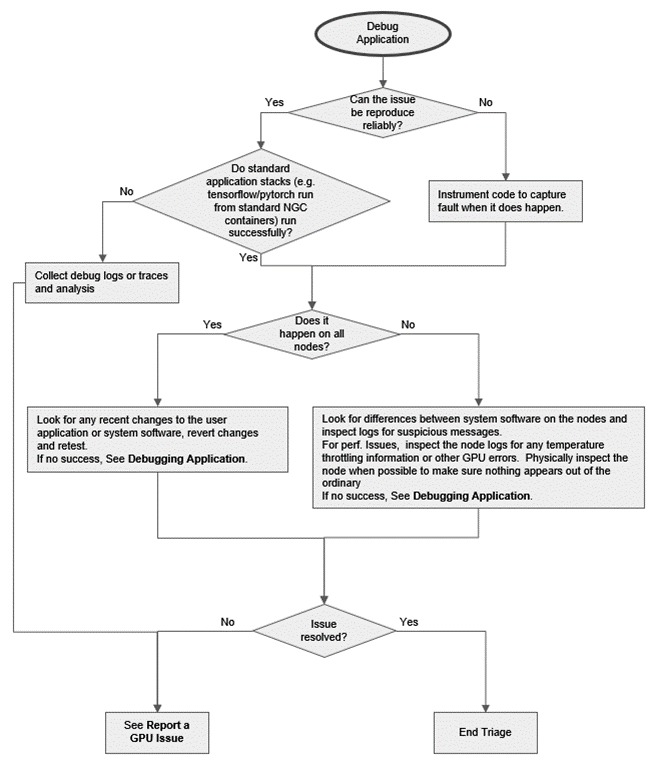
图 3 GPU 分类流程图(调试应用程序)
3.1. 报告 GPU 问题
为您的系统供应商收集数据时,您应包括以下内容
基本系统配置,例如操作系统和驱动程序信息。
问题的清晰描述,包括描述问题的任何关键日志消息。
已采取的调试步骤列表。
用于上述关键消息的日志的完整列表。
nvidia-bug-report.sh的输出。HGX 系统的 Fabric Manager 日志文件。
DCGM 诊断日志。
如果与用户应用程序相关联,您可以提供的有关应用程序性质的任何详细信息(ISV 代码、框架、版本号等)以及指向源代码的链接(如果可能)。
向您的系统供应商提交工单。
3.2. 理解 Xid 消息
XID 错误文档列出了 XID 错误和潜在原因。在文档末尾,它还提供了有关一些常见 XID 错误的更多信息和建议的操作。有关详细信息,请参阅 http://docs.nvda.net.cn/deploy/xid-errors/index.html。
表 1 列出了数据中心部署中最常见的 XID 消息和建议的步骤。
Xid |
描述 |
操作 |
|---|---|---|
13 |
图形引擎异常 |
运行 DCGM 和现场诊断,以确认问题是否与硬件相关。如果不是,请使用 http://docs.nvda.net.cn/deploy/xid-errors/index.html 中的指南调试用户应用程序。如果是后者,请参阅 报告 GPU 问题。 |
31 |
疑似硬件问题 |
联系硬件供应商。他们可以完成其硬件诊断流程。 |
45 |
稳健通道抢占式移除 |
无需操作,仅供参考。指示受另一个故障影响的通道。在 A100 上,当 FM 与 GPU 在同一操作系统环境中运行时,可能会单独看到此错误,原因是 Fabric Manager 意外关闭。否则,此错误可以安全地忽略,因为它只是信息性消息。 |
48 |
双位 ECC 错误 |
如果 Xid 48 后跟 Xid 63 或 64:排空/隔离节点,等待所有工作完成,然后重置报告 XID 的 GPU(请参阅下面的 GPU 重置功能/限制部分)。如果 Xid 48 后未跟 Xid 63 或 64:请参阅运行现场诊断以收集其他调试信息。有关何时根据过多错误退回 RMA GPU 的指南,请参见下文。 |
61 |
PMU 断点 |
报告 GPU 问题并重置报告 XID 的 GPU(请参阅下面的 GPU 重置功能/限制部分)。 |
62 |
PMU 停止错误 |
报告 GPU 问题并重置报告 XID 的 GPU(请参阅下面的 GPU 重置功能/限制部分)。 |
63 |
旧版 GPU: ECC 页面停用记录事件 |
如果与 XID 48 相关联,则排空/隔离节点,等待所有工作完成,然后重置报告 XID 的 GPU(请参阅下面的 GPU 重置功能/限制部分)。如果不是,则它来自单位错误,系统可以保持原样运行,直到有方便的时间重新启动它。有关何时根据过多错误退回 RMA GPU 的指南,请参见下文。 |
A100: 行重映射记录事件 |
如果与 XID 94 相关联,则需要重新启动遇到错误的应用程序。系统上的所有其他应用程序都可以保持原样运行,直到有方便的时间重置 GPU(请参阅下面的 GPU 重置功能/限制部分)或重新启动以激活行重映射。有关何时根据行重映射故障退回 RMA GPU 的指南,请参见下文。 |
|
64 |
旧版 GPU: ECC 页面停用记录失败 |
请参见上文,但是应密切监控节点。如果没有关联的 XID 48 错误,则这些错误与单位错误相关。必须立即重置报告错误的 GPU(请参阅下面的 GPU 重置功能/限制部分),因为存在记录失败。如果错误继续发生,请排空、分类并参阅 报告 GPU 问题。有关何时根据过多错误退回 RMA GPU 的指南,请参见下文。 |
A100: 行重映射记录失败 |
应立即重新启动节点,因为存在记录失败。如果错误继续发生,请排空、分类并参阅 报告 GPU 问题。有关何时根据行重映射故障退回 RMA GPU 的指南,请参见下文。 |
|
74 |
NVLink 错误 |
从 XID 错误消息中提取十六进制字符串。例如:(0x12345678, 0x12345678, 0x12345678, 0x12345678, 0x12345678, 0x12345678, 0x12345678) 查看加粗的 DWORD(第一个),如果设置了特定位(从 LSB 侧计数),则采用以下路径。位 4 或 5:可能是 ECC/奇偶校验的硬件问题 –> 如果在同一链路上看到超过 2 次,请报告错误。位 21 或 22:边缘通道 SI 问题。检查链路机械连接。如果伴随其他错误,请遵循这些错误的解决方案。位 8、9、12、16、17、24、28:可能是硬件问题;检查链路机械连接,如果需要现场解决,请重新拔插。如果问题仍然存在,请运行诊断程序。 |
79 |
GPU 已从总线上掉线 |
排空并参阅 报告 GPU 问题。 |
92 |
高单位 ECC 错误率 |
请参阅 运行现场诊断 以收集其他调试信息。有关何时根据过多错误退回 RMA GPU 的指南,请参见下文。 |
94 |
发生包含的 ECC 错误(仅限 A100) |
需要重新启动遇到错误的应用程序。系统上的所有其他应用程序都可以保持原样运行,直到有方便的时间重置 GPU(请参阅下面的 GPU 重置功能/限制部分)或重新启动以激活行重映射。有关何时根据行重映射故障退回 RMA GPU 的指南,请参见下文。 |
95 |
发生未包含的 ECC 错误(仅限 A100) |
如果启用 MIG,请排空其他 GPU 实例上的所有工作,等待所有工作完成,然后重置报告 XID 的 GPU(请参阅下面的 GPU 重置功能/限制部分)。如果禁用 MIG,则应立即重新启动节点,因为存在无法纠正的未包含的 ECC 错误。如果错误继续发生,请排空、分类并参阅 报告 GPU 问题。有关何时根据行重映射故障退回 RMA GPU 的指南,请参见下文。 |
123 |
SPI PMU RPC 写入失败 |
报告 GPU 问题并重置报告 XID 的 GPU(请参阅 FM 用户指南中提供的 GPU 重置功能/限制部分)。 |
XID 消息 48、63、64、92、94 和 95 与 GPU 内存错误相关。A100 之前的 NVIDIA GPU 支持动态页面停用。有关动态页面停用的详细信息,请参阅 http://docs.nvda.net.cn/deploy/dynamic-page-retirement/index.html。
NVIDIA A100 GPU 引入了新的内存错误恢复功能,这些功能提高了弹性,并避免影响未受影响的应用程序。有关 A100 GPU 内存错误管理的详细信息,请参阅 http://docs.nvda.net.cn/deploy/a100-gpu-mem-error-mgmt/index.html。
此外,还有 SXID 消息,用于指示 NVSwitch 的问题。根据严重程度(致命与非致命)和受影响的端口,这些错误可能会中止现有的 CUDA 作业并阻止新的 CUDA 作业启动。有关详细信息,请参阅 http://docs.nvda.net.cn/datacenter/tesla/fabric-manager-user-guide/index.html。
GPU/VM/系统重置功能/限制
请参阅以下摘自 nvidia-smi 手册页的摘录
触发一个或多个 GPU 的重置。可用于清除 GPU 硬件和软件状态,否则需要重新启动计算机。通常在发生双位 ECC 错误时很有用。可选的 -i 开关可用于定位一个或多个特定设备。如果不使用此选项,则会重置所有 GPU。需要 root 权限。不能有任何应用程序正在使用这些设备(例如,CUDA 应用程序、X 服务器等图形应用程序、其他 nvidia-smi 实例等监控应用程序)。
FM 状态 |
裸机 |
虚拟化 - 同一 VM 中的所有设备 |
共享 NVSwitch 虚拟化 - 不同 VM 中的 GPU 和交换机 |
|
|---|---|---|---|---|
NVIDIA Ampere 架构及更高版本,具有直接 NVLink 连接 |
不适用 |
可以单独重置 GPU。此外,可以重置所有 GPU,而无需指定 -i(如上所述)。 |
VM 中不支持 GPU 重置。重新启动 VM。 |
不适用 |
NVIDIA Ampere 架构 + NVSwitch |
正在运行 |
可以单独重置 GPU。作为 GPU 重置操作的一部分,FM 也会自动重置相应的 NVSwitch 侧链路。 |
VM 中不支持 GPU 重置。重新启动 VM。 |
重新启动仅 GPU VM。服务 VM 流程应确保通过与 FM 通信来正确重置 NVSwitch 链路。 |
未运行 |
不支持单独的 GPU 重置。重置通过 NVLink 连接在一起的所有 GPU 和 NVSwitch。 |
VM 中不支持 GPU 重置。重新启动 VM。 |
||
Hopper 及更高版本 + NVSwitch |
不适用 |
无论 FM 依赖性如何,都可以单独重置 GPU。此外,可以重置所有 GPU 和 NVSwitch,而无需指定 -i(如上所述)。 |
GPU 重置能力取决于虚拟机监控程序允许 VM 的权限。如果不允许,请重新启动 VM。 |
GPU 重置能力取决于虚拟机监控程序允许 VM 的权限。如果不允许,请重新启动 VM。 |
3.3. 运行 DCGM 诊断
- DCGM 是一种系统级工具,为生产环境提供诊断测试,以评估节点运行状况和集群就绪情况。有关详细信息,请参阅
http://docs.nvda.net.cn/datacenter/dcgm/latest/dcgm-user-guide/dcgm-diagnostics.html.
有许多选项可用于运行测试,以及一些应在大多数系统上工作的默认配置,使用 --run (-r) 选项指定。可用的测试套件为 1(短)、2(中)和 3(长)。为了充分地对系统施加压力,请使用长 (3) 选项。
# dcgmi diag -r 3
长时间测试大约需要 30 分钟。其他选项可以用作预检或在系统序言中使用,以在启动作业之前验证节点。
当 DCGM 诊断发现问题时,请尝试解决它。配置问题可以使用 IT 命令处理,DCGM 可能会提供有关从哪里开始的建议。如果诊断测试发现 GPU 或 NVSwitch Fabric(如果存在)的运行存在问题,请检查节点和节点配置是否存在任何异常。
3.4. 运行现场诊断
现场诊断是 NVIDIA 用于确定 GPU 运行状况的权威且全面的工具。通常在可以启动 RMA 之前需要它。请联系您的系统供应商,以获取有关何时、是否以及如何运行此工具的说明。
3.5. 网络测试
可以使用 NCCL 性能测试 (https://github.com/NVIDIA/nccl-tests) 测试网络性能和延迟。特别是,all_reduce_perf 测试是建立节点组之间网络性能的绝佳测试。节点的成对测试应产生相同的性能。当识别出速度较慢的节点对时,请使用这些节点和不同的节点重新测试以隔离问题。在多轨网络拓扑中,测试也可以隔离到特定轨道,以确定哪个网络接口存在问题。有关更多信息,请访问 https://developer.nvidia.com/nccl。
建议在将系统投入生产之前运行网络测试并记录实现的性能。这将帮助您了解网络的性能,并为将来的比较提供基准。节点组的性能可能会因系统网络拓扑而异。与您的网络供应商/架构师协调,以帮助了解应实现哪些性能。
3.6. 调试应用程序
调试应用程序通常需要将调试器附加到用户应用程序,并收集尽可能多的数据,直到应用程序崩溃。导致应用程序崩溃的问题可能与系统软件有关,但调试过程是了解崩溃位置以及是否可以从应用程序端解决的最快方法。从调试器收集的数据可供 NVIDIA 用于开始调试系统软件问题。
CUDA-GDB 是 NVIDIA 用于调试在 Linux 和 QNX 上运行的 CUDA 应用程序的工具。这使开发人员能够调试应用程序,而不会受到模拟和仿真环境引入的潜在变化的影响。有关详细信息,请参阅 https://developer.nvidia.com/cuda-gdb 和 http://docs.nvda.net.cn/cuda/cuda-gdb/index.html。
如果问题与性能有关,则可以使用性能分析器(例如 Nsight Systems 或 Nsight Compute)来了解应用程序中的性能和瓶颈。系统软件的更改可能会导致应用程序性能的变化,因此即使应用程序没有更改,分析应用程序也是一个重要的步骤。分析器数据可以突出显示 CPU、存储或 GPU 中的性能问题,从而帮助了解性能问题可能源自何处。
4. 最佳实践
调试应用程序通常需要将调试器附加到用户应用程序,并收集尽可能多的数据,直到应用程序崩溃。导致应用程序崩溃的问题可能与系统软件有关,但调试过程是了解崩溃位置以及是否可以从应用程序端解决的最快方法。从调试器收集的数据可供 NVIDIA 用于开始调试系统软件问题。
CUDA-GDB 是 NVIDIA 用于调试在 Linux 和 QNX 上运行的 CUDA 应用程序的工具。这使开发人员能够调试应用程序,而不会受到模拟和仿真环境引入的潜在变化的影响。有关详细信息,请参阅 https://developer.nvidia.com/cuda-gdb 和 http://docs.nvda.net.cn/cuda/cuda-gdb/index.html。
如果问题与性能有关,则可以使用性能分析器(例如 Nsight Systems 或 Nsight Compute)来了解应用程序中的性能和瓶颈。系统软件的更改可能会导致应用程序性能的变化,因此即使应用程序没有更改,分析应用程序也是一个重要的步骤。分析器数据可以突出显示 CPU、存储或 GPU 中的性能问题,从而帮助了解性能问题可能源自何处。
4.1. 收集节点指标
节点性能和运行可以通过系统指标推断出来。收集系统指标的时间序列数据可以让管理员检测到节点何时开始运行不正常,或者用于主动系统维护。
指标可以通过带内工具(如 DCGM Prometheus 插件)和带外工具(如 IPMI)收集。有关 DCGM Prometheus 插件的详细信息,请参阅 http://docs.nvda.net.cn/datacenter/cloud-native/gpu-telemetry/latest/kube-prometheus.html。
为 Kubernetes 部署提供了容器化的 DCGM 版本。有关详细信息,请参阅 使用 DCGM 监控 Kubernetes 中的 GPU。
应在基于 GPU 的系统上收集的关键指标包括
每个电源的功耗
PDU 的功耗
PDU 功率因数
CPU 功耗和 CPU 温度
GPU 功耗、GPU 温度、GPU 内存温度和 GPU 时钟
NVLink 指标(仅限 A100)
节点风扇速度
入口温度
其他指标可能有用,具体取决于数据中心的具体情况。
数据可以存储在时间序列或其他 NoSQL 数据库中,并根据需要进行调用。此外,还可以创建警报以检测可能对系统和应用程序性能产生负面影响的条件。这些条件包括
入口温度升高可能是数据中心冷却问题或其他碎屑阻塞气流的指标。
高 GPU 和 GPU 内存温度将导致 GPU 节流和性能下降。
4.2. 在错误发生前捕获错误
本文档的目标是帮助管理员找到最常见的系统问题,并提供理解或快速解决问题的途径。但是,最好在系统问题影响用户作业之前捕获它们。执行此操作的最佳时间是在作业开始时通过 init 容器或序言脚本,或者在作业结束时通过尾声脚本。以下是一些关于包含在测试中的建议,以帮助在系统错误影响用户作业之前捕获它们。
GPU 特定检查
确认关键软件已加载
GPU 驱动程序
nv-peer-mem`(对于 GPUDirect RDMA,https://developer.nvidia.com/gpudirect)Gdrdrv(对于 GDRCopy,https://github.com/NVIDIA/gdrcopy)
HGX 系统的 Fabric Manager
确认节点的特定 GPU 功能是否正确(GPU 计数、PCIe 链路速度、VBIOS 等)
确认驱动程序持久性设置是否正确。驱动程序持久性应通过持久性守护程序控制。(<http://docs.nvda.net.cn/deploy/driver-persistence/index.html)
对于基于 NVSwitch 的系统
确认 Fabric Manager 正在运行
确认 NVLink Fabric 拓扑是否正确
检查是否有任何最近的 XID 错误
运行 dcgmi diag -r 2 以快速检查系统软件和 GPU 功能
要包含的其他非 GPU 检查
检查所有网络链路是否处于活动状态
这可以是一个简单的检查,看看它是否处于活动状态,或者是一个更强大的检查,验证预期的链路速度、固件、PCIe 链路宽度等。
检查所有预期的文件系统挂载是否存在
通过运行一些 CUDA 工作负载来检查以确保节点设置正确。有关详细信息,请参阅 http://docs.nvda.net.cn/datacenter/tesla/hgx-software-guide/index.html 和 http://docs.nvda.net.cn/datacenter/tesla/driver-installation-guide/index.html
5. 通知
本文档仅供参考,不应视为对产品的特定功能、状况或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含的信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对因使用此类信息而造成的后果或使用,或因其使用而可能导致的侵犯第三方专利或其他权利的行为概不负责。本文档不构成开发、发布或交付任何材料(定义如下)、代码或功能的承诺。
NVIDIA 保留随时修改、增强、改进和对本文档进行任何其他更改的权利,恕不另行通知。
客户应在下订单前获取最新的相关信息,并应验证此类信息是否为最新和完整。
NVIDIA 产品根据订单确认时提供的 NVIDIA 标准销售条款和条件进行销售,除非 NVIDIA 和客户的授权代表签署的个别销售协议(“销售条款”)另有约定。NVIDIA 在此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档既不直接也不间接地形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命支持设备,也不适用于 NVIDIA 产品的故障或失灵可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在上述设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不保证或声明基于本文档的产品将适用于任何特定用途。NVIDIA 不一定会执行每个产品的所有参数的测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适用于客户计划的应用并适合该应用,并为该应用执行必要的测试,以避免应用或产品的默认设置。客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的额外或不同条件和/或要求。对于可能基于以下原因或归因于以下原因的任何默认设置、损坏、成本或问题,NVIDIA 概不负责:(i) 以任何违反本文档的方式使用 NVIDIA 产品或 (ii) 客户产品设计。
本文档未授予 NVIDIA 专利权、版权或其他 NVIDIA 知识产权项下的任何明示或暗示的许可。NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成对其的保证或认可。使用此类信息可能需要获得第三方的专利或其他知识产权项下的许可,或获得 NVIDIA 的专利或其他知识产权项下的许可。
只有在事先获得 NVIDIA 书面批准的情况下,才允许复制本文档中的信息,复制时不得进行更改,并且必须完全遵守所有适用的出口法律和法规,并附带所有相关的条件、限制和通知。
本文档以及所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均按“原样”提供。NVIDIA 不对材料作出任何明示、暗示、法定或其他方面的保证,并且明确否认所有关于不侵权、适销性和特定用途适用性的暗示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对因使用本文档而引起的任何损害(包括但不限于任何直接、间接、特殊、偶然、惩罚性或后果性损害,无论因何种原因造成,也无论责任理论如何)承担责任,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因而遭受任何损害,但 NVIDIA 对本文所述产品的客户的累计责任应根据产品的销售条款进行限制。
5.1. 商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其关联的各自公司的商标。