使用混合精度训练
混合精度 训练通过以半精度格式执行操作来提供显著的计算加速,同时以单精度存储最少的信息,以在网络的关键部分保留尽可能多的信息。自从 Volta 和 Turing 架构中引入 张量核心 以来,切换到混合精度后,训练速度显著提高——在大多数计算密集型模型架构上,总体速度提高高达 3 倍。使用混合精度训练需要两个步骤
- 将模型移植为在适当的地方使用 FP16 数据类型。
- 添加损失缩放以保留小梯度值。
在 Pascal 架构中引入了使用较低精度训练深度学习网络的能力,并在 NVIDIA 深度学习 SDK 的 CUDA 8 中首次支持。
混合精度 是在计算方法中组合使用不同的数值精度。
半精度(也称为 FP16)数据与更高精度的 FP32 与 FP64 相比,减少了神经网络的内存使用量,从而允许训练和部署更大的网络,并且 FP16 数据传输比 FP32 或 FP64 传输花费的时间更少。
单精度(也称为 32 位)是一种常见的浮点格式(C 派生编程语言中的 float),而 64 位则称为双精度(double)。深度神经网络 (DNN) 在许多领域取得了突破,包括:
- 图像处理和理解
- 语言建模
- 语言翻译
- 语音处理
- 游戏和许多其他领域。
DNN 复杂性不断增加以实现这些结果,这反过来又增加了训练这些网络所需的计算资源。降低所需资源的一种方法是使用较低精度的算术,这具有以下好处。
- 半精度浮点格式 (FP16) 使用 16 位,而单精度 (FP32) 使用 32 位。降低所需的内存使得可以训练更大的模型或使用更大的小批量进行训练。
- 执行时间可能对内存或算术带宽敏感。半精度使访问的字节数减半,从而减少了在内存受限层中花费的时间。与单精度相比,NVIDIA GPU 提供高达 8 倍的半精度算术吞吐量,从而加速了计算受限层。
图 1. 用于 bigLSTM 英语语言模型的训练曲线显示了混合精度训练技术的好处。Y 轴是训练损失。没有损失缩放的混合精度(灰色)在一段时间后会发散,而使用损失缩放的混合精度(绿色)与单精度模型(黑色)相匹配。

由于 DNN 训练传统上依赖于 IEEE 单精度格式,因此本指南将重点介绍如何在保持单精度实现的网络精度的同时使用半精度进行训练(如 图 1)。这种技术称为混合精度训练,因为它同时使用单精度和半精度表示。
2.1. 半精度格式
IEEE 754 标准定义了以下 16 位半精度浮点格式:1 个符号位、5 个指数位和 10 个小数位。
指数以 15 作为偏差进行编码,从而产生 [-14, 15] 指数范围(两个指数值 0 和 31 保留用于特殊值)。对于归一化值,假定一个隐式前导位 1,就像在其他 IEEE 浮点格式中一样。半精度格式导致以下动态范围和精度
- 2-14 至 215,11 位尾数
- 2-24 至 2-15,尾数位随着指数变小而减少。[-24, -15] 范围内的指数 k 导致 (25 - k) 位尾数精度。
一些示例量级
- 65,504
- 2-14= ~6.10e-5
- 2-24= ~5.96e-8
半精度动态范围(包括非归一化值)为 2 的 40 次幂。相比之下,单精度动态范围(包括非归一化值)为 2 的 264 次幂。
2.2. 张量核心数学
Volta 一代 GPU 引入了张量核心,它提供的吞吐量是单精度数学管道的 8 倍。每个张量核心执行 D = A x B + C,其中 A、B、C 和 D 是矩阵。A 和 B 是半精度 4x4 矩阵,而 D 和 C 可以是半精度或单精度 4x4 矩阵。换句话说,张量核心数学可以将半精度乘积累积到单精度或半精度输出中。
在实践中,当 A 和 B 维度是 8 的倍数时,可以实现更高的性能。cuDNN v7 和 cuBLAS 9 包含一些调用张量核心操作的函数,出于性能原因,这些函数要求输入和输出特征图大小是 8 的倍数。有关更多信息,请参阅 NVIDIA cuDNN 开发者指南。
半精度如此吸引人的原因是 V100 GPU 具有 640 个张量核心,因此它们可以同时执行 4x4 乘法。V100 上张量核心的理论峰值性能约为 120 TFLOPS。这比双精度 (FP64) 快大约一个数量级 (10 倍),比单精度 (FP32) 快大约四倍。
矩阵乘法是卷积神经网络 (CNN) 的核心。CNN 在许多网络的深度学习中非常常见。从 CUDA 9 和 cuDNN 7 开始,卷积运算在可能的情况下使用张量核心完成。这可以大大提高 CNN 或包含卷积的模型的训练速度以及推理速度。
2.3. 考虑何时使用混合精度训练
假设框架支持张量核心数学,只需在框架中启用张量核心路径即可更快地训练许多网络。您可以为张量和/或卷积/全连接层选择 FP16 格式,并保留 FP32 训练会话的所有超参数。有关更多详细信息,请参阅 框架。
但是,某些网络需要将其梯度值移入 FP16 可表示范围,以匹配 FP32 训练会话的精度。下图说明了这样一种情况。
图 2. Multibox SSD 网络的 FP32 训练中激活梯度幅度的直方图。x 轴是对数的,零条目除外。例如,66.8% 的值为 0,4% 的值幅度在 (2-32 , 2-30) 范围内。

但是,情况并非总是如此。您可能必须进行一些缩放和归一化才能在训练期间使用 FP16。
图 3. Multibox SSD 网络的 FP32 训练中激活梯度幅度的直方图。x 轴和 y 轴均为对数。

考虑激活梯度值的直方图(在上面的线性和对数 y 尺度中显示),这些值是在 Multibox SSD 检测器网络(VGG-D 主干)的 FP32 训练期间跨所有层收集的。当转换为 FP16 时,这些值中有 31% 变为零,仅留下 5.3% 为非零值,对于此网络,这会导致训练期间的发散。
FP16 可表示范围的大部分未被梯度值使用。因此,如果我们移动梯度值以占用该范围的更多部分,我们可以保留许多原本会丢失为 0 的值。
对于此特定网络,移动三个指数值(乘以 8)足以通过恢复丢失为 0 的相关值来匹配使用 FP32 训练实现的精度。移动 15 个指数值(乘以 32K)将恢复除 0.1% 以外的所有丢失为 0 的值(在转换为 FP16 时),并且仍然避免溢出。换句话说,FP16 动态范围足以进行训练,但可能必须缩放梯度以将其移动到该范围,以防止它们在 FP16 中变为零。
2.3.1. 损失缩放以保留小梯度幅度
如上一节所示,成功训练某些网络需要梯度值缩放,以防止它们在 FP16 中变为零。这可以通过单次乘法来实现。您可以在开始反向传播之前,缩放前向传播中计算的损失值。根据链式法则,反向传播确保所有相同数量级的梯度值都被缩放。这在反向传播期间不需要额外的操作,并防止相关的梯度值变为零并丢失该梯度信息。
权重梯度必须在权重更新之前取消缩放,以保持更新幅度与 FP32 训练中的幅度相同。最简单的方法是在反向传播之后但在梯度裁剪或任何其他与梯度相关的计算之前立即执行此反缩放。这确保了不必调整任何超参数(例如梯度裁剪阈值、权重衰减等)。
虽然当所有张量都以 FP16 存储时,许多网络都与 FP32 训练结果相匹配,但有些网络需要更新权重的 FP32 副本。此外,大型归约计算的值应保留在 FP32 中。这方面的示例包括批量归一化、SoftMax 计算的统计信息(均值和方差)。批量归一化仍然可以接受 FP16 输入和输出,与 FP32 相比,节省了一半的带宽,只是统计信息和值调整应在 FP32 中完成。这导致以下高级训练过程:
2.3.2. 选择缩放因子
上一节中描述的过程要求您选择一个损失缩放因子来调整梯度幅度。您可以选择一个大的缩放因子,只要它不会在反向传播期间导致溢出即可。这将导致权重梯度包含无穷大或 NaN,这反过来会在更新期间不可逆转地损坏权重。这些溢出可以通过检查计算出的权重梯度轻松有效地检测到,例如,在上一节中将权重梯度乘以 1/S 的步骤。
有几种选项可以选择损失缩放因子。最简单的方法是选择一个恒定的缩放因子。我们使用张量核心数学针对各种任务训练了许多前馈和循环网络。网络的缩放因子范围从 8 到 32K(许多网络不需要缩放因子)。网络精度是通过 FP32 训练实现的。但是,由于所需的最小缩放因子可能取决于网络、框架、小批量大小等,因此在选择缩放值时可能需要进行一些试验和错误。如果梯度统计信息可用,则可以更直接地选择恒定的缩放因子。选择一个值,使其与最大绝对梯度值的乘积低于 65,504(FP16 中可表示的最大值)。更稳健的方法是动态选择损失缩放因子。基本思想是以一个大的缩放因子开始,然后在每次训练迭代中重新考虑它。如果选择的迭代次数 N 没有发生溢出,则增加缩放因子。如果发生溢出,则跳过权重更新并减小缩放因子。我们发现,只要不频繁地跳过更新,就不必调整训练计划即可达到与 FP32 训练相同的精度。请注意,N 有效地限制了我们可能溢出和跳过更新的频率。缩放因子更新的速率可以通过选择增加/减少乘数以及 N(增加之前的非溢出迭代次数)来调整。我们已成功地使用 N = 2000、缩放因子增加 2 倍、缩放因子减少 0.5 倍训练了网络,许多其他设置也有效。动态损失缩放方法导致以下高级训练过程:
- 在可能的情况下,将模型转换为使用 float16 数据类型。
- 保留 float32 主权重以累积每次迭代的权重更新。
- 使用损失缩放来保留小梯度值。
- 集成到优化器类中的自动损失缩放和主权重
- float16 和 float32 之间的自动转换,以最大限度地提高速度,同时确保特定于任务的精度不会损失
在那些具有自动支持的框架中,使用混合精度可以像添加一行代码或启用单个环境变量一样简单。目前,支持自动混合精度的框架是 TensorFlow、PyTorch 和 MXNet。有关更多信息,请参阅 NVIDIA 深度学习自动混合精度,以及下面的 框架 部分。
NVIDIA 张量核心为混合精度训练提供硬件加速。在 V100 GPU 上,张量核心可以将 float16 中的矩阵乘法和卷积运算加速高达 8 倍,超过其 float32 等效项。
充分利用张量核心可能需要更改模型代码。本节介绍您可以采取的三个步骤,以最大限度地提高张量核心提供的优势:
上述好处按复杂性递增排序,特别是,第一步(满足形状约束)通常以较小的努力提供最大的好处。
4.1. 满足张量核心形状约束
- 在 FP16 输入上,所有三个维度(M、N、K)都必须是 8 的倍数。
- 在 INT8 输入上(仅限 Turing),所有三个维度都必须是 16 的倍数。
- 在 FP16 输入上,输入和输出通道必须是 8 的倍数。
- 在 INT8 输入上(仅限 Turing),输入和输出通道必须是 16 的倍数。
- 选择小批量大小为 8 的倍数
- 选择线性层维度为 8 的倍数
- 选择卷积层通道计数为 8 的倍数
- 对于分类问题,将词汇表填充为 8 的倍数
- 对于序列问题,将序列长度填充为 8 的倍数
4.2. 增加算术强度
算术强度是衡量每个输入字节在内核中执行多少计算工作的指标。例如,V100 GPU 具有 125 TFLOP 的数学吞吐量和 900 GB/s 的内存带宽。取两者的比率,我们看到任何内核,如果每个输入字节的 FLOP 少于 ~140 个,都将是内存受限的。也就是说,张量核心无法以全吞吐量运行,因为内存带宽将是限制因素。具有足够的算术强度以允许全张量核心吞吐量的内核是计算受限的。
可以在模型实现和模型架构中增加算术强度。为了增加模型实现中的算术强度:
- 在循环单元中连接权重和门激活。
- 在序列模型中跨时间连接激活。
4.3. 减少非张量核心工作量
深度神经网络中的许多运算未被张量核心加速,了解这对端到端加速的影响非常重要。例如,假设模型在张量核心加速运算(矩阵乘法和卷积)中花费了总训练时间的一半。如果张量核心为这些运算提供 5 倍的加速,则总加速将为 1. / (0.5 + (0.5 / 5.)) = 1.67 倍。
一般来说,随着张量核心运算占总工作量的比例越来越小,优化非张量核心运算就变得越来越重要。可以通过手动使用自定义 CUDA 实现以及框架集成来加速这些运算。此外,框架开始提供支持,以使用编译器工具自动加速非张量核心运算。示例包括 TensorFlow 的 XLA 和 PyTorch JIT。
步骤
- 在 Volta 或 Turing 架构上运行。
- 安装 NVIDIA 驱动程序。当前支持 CUDA 10.1,这需要 NVIDIA 驱动程序版本 418.xx+。但是,如果您在 Tesla(Tesla V100、Tesla P4、Tesla P40 或 Tesla P100)上运行,则可以使用 NVIDIA 驱动程序版本 384.111+ 或 410。CUDA 驱动程序的兼容性包仅支持特定的驱动程序。有关支持的驱动程序的完整列表,请参阅 CUDA 应用程序兼容性 主题。有关更多信息,请参阅 CUDA 兼容性和升级。
- 安装 CUDA® 工具包™ 。
- 安装 cuDNN。注意
如果使用从 NGC 容器注册表提取的 NVIDIA 优化框架容器,您仍然需要在基本操作系统上安装 NVIDIA 驱动程序。但是,CUDA 和 cuDNN 将包含在容器中。有关更多信息,请参阅 框架支持矩阵。
大多数主要的深度学习框架已经开始合并对半精度训练技术的支持,这些技术利用 Volta 和 Turing 中的张量核心计算。其他优化拉取请求正处于不同的阶段,并在各自的部分中列出。
对于 NVCaffe、Caffe2、MXNet、Microsoft Cognitive Toolkit、PyTorch、TensorFlow 和 Theano,如果启用 FP16 存储,则会自动启用张量核心加速。
虽然像 Torch 这样的框架可以容忍最新的架构,但它目前没有利用张量核心功能。
PyTorch
PyTorch 包括对 FP16 存储和张量核心数学的支持。为了获得最佳性能,您可以使用张量核心数学和混合精度来训练模型。
7.1.1. PyTorch 中的自动混合精度训练
自动混合精度功能从 NVIDIA NGC PyTorch 19.03+ 容器内部开始提供。
要开始使用,我们建议使用 AMP(自动混合精度),它只需 3 行 Python 代码即可启用混合精度。AMP 通过 NVIDIA 的 Apex 存储库 提供,该存储库包含混合精度和分布式训练工具。AMP API 在 此处 详细记录。
7.1.2. 成功案例
| 模型 | 加速 |
|---|---|
| NVIDIA 情感分析 | 4.5 倍加速 |
| FAIRSeq | 3.5 倍加速 |
| GNMT | 2 倍加速 |
7.1.3. PyTorch 的张量核心优化模型脚本
GitHub 中提供的张量核心示例 侧重于使用 NVIDIA Volta 张量核心实现最佳性能和收敛。它使用最新的 深度学习示例 网络和 模型脚本 进行训练。
这些示例侧重于通过使用最新的深度学习示例网络进行训练,从 NVIDIA Volta 张量核心实现最佳性能和收敛。每个示例模型都使用 Volta 上的混合精度张量核心进行训练,因此您可以比不使用张量核心进行训练更快地获得结果。此模型针对每个 NGC 每月容器版本进行测试,以确保长期保持一致的精度和性能。此容器包括以下张量核心示例。
7.1.4. 在 PyTorch 中手动转换为混合精度
我们建议使用 AMP 在您的模型中实现混合精度。但是,如果您希望自行实现混合精度,请参考我们在 GTC 上关于手动混合精度的演讲(视频,幻灯片)。
TensorFlow
TensorFlow 支持 FP16 存储和 Tensor Core 数学运算。包含使用 tf.float16 数据类型的卷积或矩阵乘法的模型将尽可能自动利用 Tensor Core 硬件。
为了利用 Tensor Core,FP32 模型需要转换为使用 FP32 和 FP16 的混合精度。这可以通过自动混合精度 (AMP) 或手动完成。
7.2.1. TensorFlow 中的自动混合精度训练
对于已经使用 tf.train.Optimizer 或 tf.keras.optimizers.Optimizer 进行 compute_gradients() 和 apply_gradients() 操作的模型(例如,通过调用 optimizer.minimize() 或 model.fit()),可以通过使用 tf.train.experimental.enable_mixed_precision_graph_rewrite() 包装优化器来启用自动混合精度。
基于图的示例
opt = tf.train.AdamOptimizer()
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt)
train_op = opt.miminize(loss)
基于 Keras 的示例
opt = tf.keras.optimizers.Adam()
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt)
model.compile(loss=loss, optimizer=opt)
model.fit(...)
您还可以在 TensorFlow Python 脚本内部设置环境变量。在脚本开头发出以下代码
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
- 在您的 TensorFlow 图中插入适当的类型转换操作,以在适当的位置使用 float16 执行和存储。这使得能够使用 Tensor Core 以及内存存储和带宽节省。
- 在训练优化器对象内部启用 自动损失缩放。
有关自动混合精度的更多信息,请参阅 NVIDIA TensorFlow 用户指南。
7.2.2. 成功案例
| 模型 | 加速 |
|---|---|
| BERT 问答 | 3.3 倍加速 |
| GNMT | 1.7 倍加速 |
| NCF | 2.6 倍加速 |
| SSD-RN50-FPN-640 | 2.5 倍加速 |
7.2.3. TensorFlow 的 Tensor Core 优化模型脚本
GitHub 中提供的张量核心示例 侧重于使用 NVIDIA Volta 张量核心实现最佳性能和收敛。它使用最新的 深度学习示例 网络和 模型脚本 进行训练。
每个示例模型都使用 Volta 上的混合精度 Tensor Cores 进行训练,因此您可以比不使用 Tensor Cores 进行训练更快地获得结果。此模型针对每个 NGC 月度容器版本进行测试,以确保长期保持一致的准确性和性能。此容器包含以下 Tensor Core 示例。
7.2.4. 在 TensorFlow 中手动转换为混合精度训练
步骤
- 从 NVIDIA GPU Cloud (NGC) 容器注册表 中拉取最新的 TensorFlow 容器。该容器已构建、测试、调整和准备运行。TensorFlow 容器包括最新的 CUDA 版本、FP16 支持,并针对最新的架构进行了优化。有关分步拉取说明,请参阅 NVIDIA 深度学习框架用户指南。
- 在包含卷积或矩阵乘法的模型上使用
tf.float16数据类型。此数据类型尽可能自动利用 Tensor Core 硬件,换句话说,为了增加 Tensor Core 加速的机会,请尽可能选择线性层矩阵维度和卷积通道计数的八倍数。例如dtype = tf.float16 data = tf.placeholder(dtype, shape=(nbatch, nin)) weights = tf.get_variable('weights', (nin, nout), dtype) biases = tf.get_variable('biases', nout, dtype, initializer=tf.zeros_initializer()) logits = tf.matmul(data, weights) + biases
- 确保可训练变量采用 float32 精度,并在模型中使用它们之前将其转换为 float16。例如
tf.cast(tf.get_variable(..., dtype=tf.float32), tf.float16)
float32_variable_storage_getter来实现。 - 确保 SoftMax 计算采用 float32 精度。例如
tf.losses.softmax_cross_entropy(target, tf.cast(logits, tf.float32))
- 应用先前部分中概述的损失缩放。损失缩放涉及在计算梯度之前将损失乘以比例因子,然后再次将得到的梯度除以相同的比例来重新归一化它们。例如,要应用恒定的损失缩放因子 128
loss, params = ... scale = 128 grads = [grad / scale for grad in tf.gradients(loss * scale, params)]
MXNet
MXNet 包括对 FP16 存储和 Tensor Core 数学运算的支持。为了获得最佳性能,您需要在 MXNet 上使用 Tensor Core 数学运算和 FP16 模式训练模型。
以下过程是当您想要在 FP16 中拥有整个网络时的典型过程。或者,您可以从任何层获取输出并将其转换为 FP16。后续层将采用 FP16,并将使用 Tensor Core 数学运算(如果适用)。
7.3.1. MXNet 中的自动混合精度训练
自动混合精度功能从 NVIDIA NGC MXNet 19.04+ 容器 开始提供。
训练深度学习网络是一项计算量非常大的任务。新型模型架构往往具有越来越多的层和参数,这会减慢训练速度。幸运的是,新一代训练硬件以及软件优化使训练这些新模型成为一项可行的任务。
大多数硬件和软件训练优化机会都涉及利用较低的精度(如 FP16),以便利用在新的 Volta 和 Turing GPU 上可用的 Tensor Cores。虽然以 FP16 进行训练在图像分类任务中取得了巨大成功,但由于在应用确保适当模型训练所需的 FP16 训练指南方面存在困难,其他更复杂的神经网络通常仍停留在 FP32 中。
这就是 AMP(自动混合精度)发挥作用的地方 - 它自动应用 FP16 训练的指南,在提供最大益处的地方使用 FP16 精度,同时保守地保持在 FP32 精度操作中不安全的操作。
MXNet AMP 教程位于此容器内的 /opt/mxnet/nvidia-examples/AMP/AMP_tutorial.md 中,通过 GluonCV 中的 SSD 网络示例,展示了如何开始使用 AMP for MXNet 进行混合精度训练。
7.3.2. MXNet 的 Tensor Core 优化模型脚本
GitHub 中提供的 Tensor Core 示例 侧重于使用 NVIDIA Volta Tensor Cores 实现最佳性能和收敛。它还使用了最新的 深度学习示例 网络和 模型脚本 进行训练。
每个示例模型都从 Volta 架构开始使用混合精度 Tensor Cores 进行训练,因此您可以比不使用 Tensor Cores 进行训练更快地获得结果。此模型针对每个 NGC 月度容器版本进行测试,以确保长期保持一致的准确性和性能。MXNet 容器包括以下 MXNet Tensor Core 示例:
7.3.3. 在 MXNet 中手动转换为混合精度训练
步骤
- 从 NVIDIA GPU Cloud (NGC) 容器注册表 中拉取最新的 MXNet 容器。该容器已构建、测试、调整和准备运行。MXNet 容器包括最新的 CUDA 版本、FP16 支持,并针对最新的架构进行了优化。有关分步拉取说明,请参阅 NVIDIA 深度学习框架用户指南。
- 要使用 IO 管道,请使用
IndexedRecordIO输入格式。它与旧版RecordIO格式不同,它包含一个带有.idx扩展名的附加索引文件。使用im2rec.py工具生成新的RecordIO文件时,会自动生成.idx文件。如果您已经拥有没有相应.idx文件的.rec文件,则可以使用tools/rec2idx.py工具生成索引文件python tools/rec2idx.py <path to .rec file> <path to newly created .idx file>
- 要将 FP16 训练与 MXNet 结合使用,请将数据(网络的输入)转换为 FP16。
mxnet.sym.Cast(data=input_data, dtype=numpy.float16)
- 在 SoftMax 层之前转换回 FP32。
- 如果您遇到精度问题,最好将损失放大 128 倍,并将梯度的应用缩小 128 倍。这确保了反向传递计算期间的更高梯度,但仍会正确更新权重。例如,如果您的最后一层是
mx.sym.SoftmaxOutput(交叉熵损失),并且初始学习率为 0.1,请添加grad_scale参数mxnet.sym.SoftmaxOutput(other_args, grad_scale=128.0)
mxnet.optimizer.SGD(other_args, rescale_grad=1.0/128)
提示在 FP16 中训练时,最好使用多精度优化器,该优化器将权重保持在 FP32 中并在 FP16 中执行反向传递。例如,对于具有动量的 SGD,您将发出以下命令
mxnet.optimizer.SGD(other_args, momentum=0.9, multi_precision=True)
或者,您可以将
'multi_precision': True传递给model.fit方法中的optimizer_params选项。
Caffe2
Caffe2 包括对 FP16 存储和 Tensor Core 数学运算的支持。为了获得最佳性能,您可以在 Caffe2 上使用 Tensor Core 数学运算和 FP16 模式训练模型。
在 Caffe2 上使用 Tensor Core 数学运算和 FP16 训练模型时,需要执行以下操作:
- 准备您的数据。您可以生成 FP32 中的数据,然后将其转换为 FP16。
ImageInput操作的 GPU 转换路径可以以融合方式执行此转换。 - 前向传递。由于数据以 FP16 形式提供给网络,因此所有后续操作都将在 FP16 模式下运行,因此:
- 梯度缩放。
- 要缩放,请将损失乘以缩放因子。
- 要取消缩放,请将
LR和weight_decay除以缩放因子。
7.4.1. 在 Caffe2 上运行 FP16 训练
步骤
- 从 NVIDIA GPU Cloud (NGC) 容器注册表 中拉取最新的 Caffe2 容器。该容器已构建、测试、调整和准备运行。Caffe2 容器包括最新的 CUDA 版本、FP16 支持,并针对 Volta 架构进行了优化。有关分步拉取说明,请参阅 NVIDIA 深度学习框架用户指南。
- 使用适当的命令行参数运行以下 Python 脚本。您可以使用 Caffe2 中包含的 ResNet-50 图像分类训练脚本进行测试。
python caffe2/python/examples/resnet50_trainer.py --train_data <path> --test_data <path> --num-gpus <int> --batch-size <int> --dtype float16 --enable-tensor-core --cudnn_workspace_limit_mb 1024 --image_size 224
caffe2/python/examples/resnet50_trainer.py --help
为了提高性能,必须进行以下更改:caffe2/python/models/resnet.py中的网络定义必须更改为反映网络版本 1,方法是将残差块步幅从 3x3 卷积更改为第一个 1x1 卷积运算符。- 通过将
use_nccl=True和broadcast_computed_params=False标志添加到caffe2/python/examples/resnet50_trainer.py中的 data_parallel_model.Parallelize 调用中,启用优化的通信运算符并禁用某些通信操作。 - 将
decode_threads=3和use_gpu_transform=True添加到 brew.image_input 调用中。这调整了用于数据解码和增强的 CPU 线程数量(值是每个 GPU),并启用了 GPU 用于某些数据增强工作。 - 通过在调用
data_parallel_model.Parallelize后添加train_model.net.Proto().num_workers = 4 * len(gpus),增加用于在 GPU 上调度运算符的主机线程数。
Microsoft Cognitive Toolkit
Microsoft Cognitive Toolkit 包括对 FP16 存储和 Tensor Core 数学运算的支持。为了获得最佳性能,您需要在 Microsoft Cognitive Toolkit 上使用 Tensor Core 数学运算和 FP16 模式训练模型。
7.5.1. 在 Microsoft Cognitive Toolkit 上运行 FP16 训练
在您训练了神经网络之后,您可以使用 TensorRT™ 优化和部署模型以进行 GPU 推理。有关使用 TensorRT 进行优化和部署的更多信息,请参阅 NVIDIA TensorRT 文档。
Tensor Core 数学运算在 FP16 中默认开启。以下过程是 Microsoft Cognitive Toolkit 在多层感知器 MNIST 示例中使用 FP16 的典型过程。
import cntk as C
import numpy as np
input_dim = 784
num_output_classes = 10
num_hidden_layers = 1
hidden_layers_dim = 200
# Input variables denoting the features and label data
feature = C.input_variable(input_dim, np.float32)
label = C.input_variable(num_output_classes, np.float32)
feature16 = C.cast(feature, np.float16)
label16 = C.cast(label, np.float16)
with C.default_options(dtype=np.float16):
# Instantiate the feedforward classification model
scaled_input16 = C.element_times(C.constant(0.00390625, dtype=np.float16), feature16)
z16 = C.layers.Sequential([C.layers.For(range(num_hidden_layers),
lambda i: C.layers.Dense(hidden_layers_dim, activation=C.relu)),
C.layers.Dense(num_output_classes)])(scaled_input16)
ce16 = C.cross_entropy_with_softmax(z16, label16)
pe16 = C.classification_error(z16, label16)
z = C.cast(z16, np.float32)
ce = C.cast(ce16, np.float32)
pe = C.cast(pe16, np.float32)
# fake data with batch_size = 5
batch_size = 5
feature_data = np.random.randint(0, 256, (batch_size,784)).astype(np.float32)
label_data = np.eye(num_output_classes)[np.random.randint(0, num_output_classes, batch_size)]
ce.eval({feature:feature_data, label:label_data})
7.5.2. Microsoft Cognitive Toolkit FP16 示例
有关使用分布式训练的 ResNet-50 的更完整示例,请参阅 TrainResNet_ImageNet_Distributed.py 示例。
NVCaffe
NVCaffe 包括对 FP16 存储和 Tensor Core 数学运算的支持。为了获得最佳性能,您可以在 NVCaffe 上使用 Tensor Core 数学运算和 FP16 模式训练模型。
7.6.1. 在 NVCaffe 上运行 FP16 训练
步骤
- 从 NVIDIA GPU Cloud (NGC) 容器注册表 中拉取最新的 NVCaffe 容器。该容器已构建、测试、调整和准备运行。NVCaffe 容器包括最新的 CUDA 版本、FP16 支持,并针对最新的架构进行了优化。有关分步拉取说明,如果您有 DGX-1,请参阅 NVIDIA 深度学习框架用户指南,否则请参阅 将 NGC 与您的 NVIDIA TITAN 或 Quadro PC 设置指南结合使用。
- 尝试以下训练参数:
- 在运行以下训练脚本之前,请调整批处理大小以获得更好的性能。为此,请使用您选择的编辑器打开训练设置,例如 vim
caffe$ vim models/resnet50/train_val_fp16.prototxt
并将
batch_size: 32设置值更改为[64...128] * <安装的 GPU 数量>。 - 通过设置来试验纯 FP16 模式
default_forward_type: FLOAT16 default_backward_type: FLOAT16 default_forward_math: FLOAT16 default_backward_math: FLOAT16
并通过将
solver_data_type: FLOAT16添加到文件models/resnet50/solver_fp16.prototxt中。 - 如果您获得 NaN 或 INF 值,请尝试自适应缩放
global_grad_scale_adaptive: true
- 在运行以下训练脚本之前,请调整批处理大小以获得更好的性能。为此,请使用您选择的编辑器打开训练设置,例如 vim
- 训练 ResNet-50。打开
caffe$ ./models/resnet50/train_resnet50_fp16.sh
I0806 06:54:20.037241 276 parallel.cpp:79] Overall multi-GPU performance: 5268.04 img/sec*
注意5268 img/秒的性能数字是在 8-GPU 系统上训练的。对于单 GPU 系统,您可以预期使用 NVCaffe 进行约 750 img/秒的训练。
- 查看输出。发出以下命令
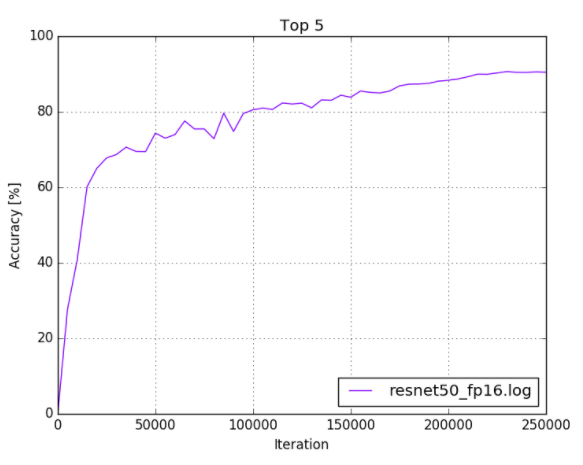
caffe$ python plot_top5.py -s models/resnet50/logs/resnet50_fp16.log
您的输出应类似于以下内容
图 4. ResNet-50 FP16 训练日志

7.6.2. NVCaffe FP16 示例
有关优化的示例,请参阅 models/resnet50/train_val_fp16.prototxt 文件。
在您训练了神经网络之后,您可以使用 TensorRT™ 优化和部署模型以进行 GPU 推理。有关使用 TensorRT 进行优化和部署的更多信息,请参阅 NVIDIA TensorRT 文档。
9.1. 常规常见问题解答
问:关于如何使用混合精度,还有哪些其他可用资源?
- 混合精度训练 (ICLR 2018)。
- 深度神经网络的混合精度训练 (NVIDIA 开发者博客)。
问:什么是自动混合精度 (AMP),它如何帮助训练我的模型?
答:自动混合精度 (AMP) 进行了所有必要的调整,以使用混合精度训练模型,与手动操作相比,它提供了两个好处:
- 开发人员无需修改网络模型代码,从而减少了开发和维护工作。
- 使用 AMP 保持了与所有用于定义和运行模型的 API 的向前和向后兼容性。
- 通过使用 Tensor Cores,加速数学密集型操作,例如线性层和卷积层。
- 通过访问单精度一半的字节数,加速内存受限的操作。
- 减少训练模型的内存需求,从而能够使用更大的模型或更大的小批量。
有关更多信息,请参阅 深度学习的自动混合精度。
问:AMP 如何自动化混合精度?
答:使用 混合精度训练 需要两个步骤:
- 将模型移植为在适当的地方使用 FP16 数据类型。
- 使用损失缩放来保留小梯度值。
AMP 自动化了这两个步骤。特别是在 TF-AMP 中,这通过单个环境变量来控制。
问:动态缩放如何工作?
答:动态损失缩放基本上尝试在不引起梯度溢出的情况下尽可能使用最高的损失比例,以充分利用 FP16 动态范围。
它通过从高损失比例值(例如,2^24)开始,然后在每次迭代中检查梯度是否溢出(infs/NaNs)来实现这一点。如果没有任何梯度溢出,则梯度被取消缩放(在 FP32 中),并且像往常一样应用 optimizer.step()。如果检测到溢出,则修补 optimizer.step 以跳过实际的权重更新(以便 inf/NaN 梯度不会污染权重),并且损失比例减小某个因子 F(默认情况下 F=2)。这负责将损失比例降低到不会产生溢出的范围。但这只是故事的一半。
如果稍后训练稳定,并且允许更高的损失比例会怎么样? 例如,在训练后期,梯度幅度往往较小,可能需要更高的损失比例来防止下溢。 因此,动态损失缩放也尝试每 N 次迭代(默认情况下 N=2000)将损失比例增加 F 倍。 如果增加损失比例再次导致溢出,则跳过该步骤,并将损失比例像往常一样减小回增加前的值。 这样,通过:在遇到梯度溢出时减小损失比例,以及间歇性地尝试增加损失比例,就(大致)实现了尽可能使用不会引起溢出的最高损失比例的目标。
问:启用 AMP 后,如何增加批量大小? 只是将批量大小增加 2 倍吗?
答:这取决于您节省了多少内存,而这取决于模型。 一个快速的方法是在启动运行时,从单独的终端监视 -n 0.5 nvidia-smi,以查看您正在使用的设备内存量。 一般来说,只要您遵守允许 Tensor Core 使用的指南(有关更多信息,请参阅 Issue #221),每个 GPU 使用更大的批量往往会提高利用率。
问:AllowList/DenyList/InferList 是如何确定的? 每个列表中包含哪些对应的操作?
答:我们根据我们在研究中获得的数值稳定性经验来确定这些列表。 AllowList 操作是利用我们的 GPU Tensor Core 的操作。 DenyList 操作是可能溢出 FP16 范围或需要更高 FP32 精度的操作。 InferList 操作是在 FP32 或 FP16 中都能安全完成的操作。 每个列表中包含的典型操作如下:
- AllowList:卷积、全连接层
- DenyList:大型归约、交叉熵损失、L1 损失、指数
- InferList:逐元素操作(加法、乘以常数)
要查看/审查、修改和重新编译以进行实验,或使用容器中的环境变量来修改 AllowList/DenyList,请参阅:
问:使用 AMP 的最低硬件和软件要求是什么?
答:为了有效地运行 AMP,您的 GPU 需要 Tensor Core; 对于训练,我们建议使用 V100; 对于推理,我们建议使用 T4。 您可以通过云服务提供商(AWS、Azure 或 Google Cloud)访问此硬件。
当使用框架时,TensorFlow 1.14 原生支持 AMP,或者使用 NVIDIA 的容器 19.07+ 可以支持 AMP。 在 PyTorch 中,1.0 AMP 通过 APEX 提供。
问:如何为我的深度学习训练启用 AMP?
- 在 TensorFlow 中,AMP 由包装优化器来控制,如下所示
tf.train.experimental.enable_mixed_precision_graph_rewrite(opt)
- 在 PyTorch 中,AMP 通过 APEX 扩展提供
model, optimizer = amp.initialize(model, optimizer, opt_level="O1") with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward()
- 在 MXNET 中,AMP 通过 contrib 库提供
amp.init() amp.init_trainer(trainer) with amp.scale_loss(loss, trainer) as scaled_loss: autograd.backward(scaled_loss)
问:哪些模型适合 AMP? 我可以期望获得什么样的加速?
答:所有模型都适合 AMP,尽管加速效果可能因模型而异。 下表提供了一些不同模型的加速示例:
| 模型脚本 | 框架 | 数据集 | FP32 精度 | 混合精度精度 | FP32 吞吐量 | 混合精度吞吐量 | 加速 |
|---|---|---|---|---|---|---|---|
| BERT 问答 | TensorFlow | SQuAD | 90.83 前 1% |
90.99 前 1% |
66.65 句/秒 | 129.16 句/秒 | 1.94 |
| SSD w/RN50 | TensorFlow | COCO 2017 | 0.268 mAP |
0.269 mAP |
569 图像/秒 | 752 图像/秒 | 1.32 |
| GNMT | PyTorch | WMT16 英语到德语 | 24.16 BLEU |
24.22 BLEU |
314,831 tokens/秒 | 738,521 tokens/秒 | 2.35 |
| 神经协同过滤 | PyTorch | MovieLens 20M | 0.959 HR |
0.960 HR |
55,004,590 样本/秒 | 99,332,230 样本/秒 | 1.81 |
| U-Net 工业 | TensorFlow | DAGM 2007 | 0.965-0.988 | 0.960-0.988 | 445 图像/秒 | 491 图像/秒 | 1.10 |
| ResNet-50 v1.5 | MXNet | ImageNet | 76.67 前 1% |
76.49 前 1% |
2,957 图像/秒 | 10,263 图像/秒 | 3.47 |
| Tacotron 2 / WaveGlow 1.0 | PyTorch | LJ 语音数据集 | 0.3629/-6.1087 | 0.3645/-6.0258 | 10,843 tok/s 257,687 smp/s |
12,742 tok/s 500,375 smp/s |
1.18/1.94 |
这些值是在 DGX-1V 8GPU 16G、DGX-1V 8GPU 32G 或 DGX-2V 16GPU 32G 上运行模型时测量的。
启用 AMP 时,还有其他方面需要考虑,例如内存减少以及训练混合精度模型所需的带宽减少。
问:使用 AMP 后,我的模型运行速度会快多少?
- 在矩阵乘法(线性层)或卷积中花费的时间越多,Tensor Core 就越能加速模型。 这意味着“更大”的模型通常会看到更大的加速。
- 特别是,非常小的线性和卷积层从 AMP 中获得的好处有限,因为没有足够的数学运算来充分利用 Tensor Core。
- 混合精度模型比 FP32 使用更少的内存,因此在使用 AMP 运行时可以增加批量大小。 因此,在启用 AMP 后,您通常可以通过增加批量大小来提高加速效果。
问:如何查看内存消耗的减少?
答:在 TensorFlow 中,设置 allow_growth 标志,使其仅分配所需的内存,并在 nvidia-smi 中查看。 对于 PyTorch,nvidia-smi 可以显示内存利用率。 最好的测试方法是尝试更大的批量大小,否则在未启用 AMP 时会导致内存不足。
问:如果我已经实现了手动混合精度,AMP 将如何进一步提高我的模型性能? 我应该从 AMP 中期待什么好处?
答:如果代码的编写方式已经遵循 NVIDIA 混合精度训练指南,那么 AMP 将保持原样。
问:为什么我打开 AMP 后只观察到一点点加速?
答:首先,您需要确定工作流程中的瓶颈,是数据 I/O 还是计算受限? 要找出限制工作流程性能的原因,请使用 DLProf 对其进行分析。
如果工作流程中最慢的部分在 GPU 中,请检查模型的层是否实际使用了混合精度。 这可以在使用 DLProf 分析网络后在 TensorBoard 扩展中完成,或者手动通过使用 Nsight Systems 或 nvprof 进行分析并查找包含字符串 [i|s|h]884 或 [i|s|h]1688 的内核名称(例如,volta_h884gemm_… 或 turing_fp16_s1688cudnn_fp16_…)。 网络的某些层被列入 DenyList,这意味着出于精度原因,它们不能使用混合精度。 DenyList 取决于框架。 有关更多信息,请参阅以下资源:
此外,Tensor Core 正在优化 GEMM(广义(密集)矩阵-矩阵乘法)操作,为了有效地优化此类操作,对矩阵的维度存在限制:
- 对于 A x B,其中 A 的大小为 (M, K),B 的大小为 (K, N):
- N、M、K 应为 8 的倍数
- 全连接层中的 GEMM:
- 批量大小、输入特征、输出特征应为 8 的倍数
- RNN 中的 GEMM:
- 批量大小、隐藏层大小、嵌入大小和字典大小应为 8 的倍数
问:启用 AMP 后,精度会变差吗?
答:AMP 旨在使精度与 FP32 训练相比保持不变。 并且,在实践中,我们在使用 AMP 训练时从未观察到明显的精度下降。
问:如果启用 AMP 后模型代码崩溃了怎么办?
答:首先,确保您的模型在不使用 AMP 的情况下不会崩溃。 然后,如果您在启用 AMP 后遇到此类问题,请提交错误报告。
问:如何知道 AMP 是否对我有效或 Tensor Core 是否已启用?
答:日志输出 AMP 是否有效,并且特定于框架。 例如,在 TensorFlow 中,您将看到类似于以下的日志消息
TF AMP log messages are of the form ‘Converted 405/4897 nodes to float16 precision using
2 cast(s) to float16 (excluding Const and Variable casts)
9.2. TensorFlow 常见问题解答
问:自动混合精度 (AMP) 是否依赖于 TensorFlow 版本,还是任何 TensorFlow 版本都可以启用 AMP?
答:AMP 在 NGC TensorFlow 容器中从 19.03 版本开始提供,并且可以使用 TF_ENABLE_AUTO_MIXED_PRECISION=1 环境变量启用。 现在可以通过包装优化器对象来启用,如下所示
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt)
以下网络研讨会中提供了更多信息。 从 TensorFlow 1.14 开始,AMP 将在框架中原生提供。
问:TensorFlow 如何决定将哪些操作转换为 FP16(图的哪个级别或在哪里决定)? TensorFlow 是否也像 PyTorch 一样保留 DenyList 和 AllowList?
答:我们的 GTC 硅谷会议 S91029,TensorFlow 训练的自动混合精度工具讨论了这是如何工作的。 TensorFlow 也使用 DenyList 和 AllowList 概念,但有一些细微的差异,因为 TensorFlow 具有静态图的优势,可以进行分析和转换。
问:什么是 TF-AMP,其目标是什么?
答:首要目标是使用 TensorFlow 在 V100 上进行训练的客户能够获得出色的混合精度训练体验,并利用硬件提供的所有加速功能。 这意味着精度与 FP32 匹配,并且在无需太多手动操作的情况下实现真正的加速。 在实践中,实现该目标需要发生以下几件事:
- 正确地将模型移植到混合精度。 意味着更新代码中的
dtypes为 FP16,并确保数值“不安全”的操作保持在 FP32 中。 - 使用损失缩放以避免梯度刷新为零(对精度很重要)。
- 相关操作存在快速的 FP16 内核,以及从用户到内核的软件堆栈,确保正确调用这些内核。
问:TF-AMP 是如何实现的?
- 在您的 TensorFlow 图中插入适当的强制转换操作,以便在适当的情况下使用 FP16 执行和存储; 这既可以利用 Tensor Core,又可以节省内存存储和带宽。
- 在优化器对象内部启用自动损失缩放。
可以分别启用自动插入强制转换操作和自动损失缩放。 有关更多详细信息,请参阅此NVIDIA TensorFlow 用户指南。
必须强调的是,这只是使混合精度成功的一部分,最重要的是确保这些更改不会降低精度。
问:AMP 是否依赖于 TensorFlow 版本,还是任何 TensorFlow 版本都可以启用 AMP?
答:AMP 在 NGC TensorFlow 容器中提供:
- 用于启用 TF-AMP 的环境变量方法从 19.03 版本开始提供。
- 用于启用 TF-AMP 的优化器包装器方法从 19.06 容器开始提供。
此外,AMP 在 TensorFlow 的官方发行版中从 1.14 版本开始提供。 以下网络研讨会中提供了更多信息。
问:AMP 如何知道要优化模型的哪一层?
- AllowList:将所有内容转换为 FP16
- DenyList:将所有内容转换为 FP32
- 其他所有内容:将所有内容转换为与最宽的输入类型匹配(不允许类型不匹配)
TensorFlow 列表位于此处。 与其他框架相比,TensorFlow 具有静态图的优势,可以进行分析和转换。
我们的 GTC 硅谷会议 S91029,TensorFlow 训练的自动混合精度工具更详细地讨论了这是如何工作的。
问:如何查看自动混合精度对我的模型所做的更改?
答:由于自动混合精度在 TensorFlow 图的级别上运行,因此快速掌握它所做的更改可能具有挑战性:它通常会调整数千个 TensorFlow 操作,但这些操作对应于更少的逻辑层。 您可以设置环境变量 TF_CPP_VMODULE="auto_mixed_precision=2" 以查看自动混合精度所做决定的完整日志(请注意,这可能会生成大量输出)。
问:为什么我在保存的模型 GraphDef 中只看到 FP32 数据类型?
答:当您保存模型图或使用 Session.graph 或 Session.graph_def 检查图时,TensorFlow 返回图的未优化版本。 TF-AMP 作为原始图的优化过程运行,因此其更改未包含在未优化的图中。 您可以设置环境变量 TF_AMP_LOG_PATH=some_directory,TF-AMP 会将它处理的每个图的优化前和优化后副本保存到该目录。
将会有许多难以区分的图形文件,因为 TensorFlow 将初始化(例如)作为不相交的图形进行处理。
问:为什么在使用 TF-AMP 训练时多次重复看到 step=0 ?
答:TF-AMP 启用的自动损失缩放算法可以选择“跳过”训练迭代,因为它会搜索最佳损失比例。 当它这样做时,它不会增加全局步数计数。 由于大多数跳过发生在训练开始时(通常少于十次迭代),因此此行为表现为步数计数器保持为零的多次迭代。
问:用户定义的自定义 TF 操作如何处理?
答:默认情况下,TF-AMP 将保留任何它不了解的操作类型,包括自定义操作。 这意味着操作的输入和输出的类型不会更改,并且 TF-AMP 将根据需要插入强制转换,以便与(可能已更改的)图的其余部分互操作。 如果您希望 TF-AMP 了解自定义操作类型,可以使用三个环境变量
-
TF_AMP_ALLOWLIST_ADD - 这些操作值得将输入强制转换为 FP16 以获得 FP16 执行。 主要是,它们是可以利用 Tensor Core 的操作。
-
TF_AMP_INFERLIST_ADD - 这些操作可以使用 FP16 执行,因此如果输入恰好已经是 FP16(因为上游 AllowList 操作),则它们可以使用 FP16。
-
TF_AMP_DENYLIST_ADD - 这些操作需要 FP32 才能获得数值精度,并且输出不能安全地强制转换回 FP16。 示例操作包括 Exp 和 Log。
这些环境变量中的每一个都采用逗号分隔的字符串操作名称列表。 例如,您可以设置 export TF_AMP_ALLOWLIST_ADD=MyOp1,MyOp2。 操作名称是在调用 REGISTER_OP 时使用的字符串名称,它对应于操作的 OpDef 上的名称属性。
问:我可以更改自动混合精度的算法行为吗?
答:控制自动混合精度行为的主要手段是操作 AllowList、InferList 和 DenyList 中的哪些操作。 您可以使用上面的三个环境变量将操作添加到每个列表,并且有一个相应的变量 TF_AUTO_MIXED_PRECISION_GRAPH_REWRITE_{ALLOWLIST,INFERLIST,DENYLIST}_REMOVE 可以从每个列表中删除内置操作。
问:为什么当我启用 AMP 时,我的模型无法达到完全精度?
答:最可能的解释是在梯度评估期间未应用损失缩放。 如果优化器未由 tf.trian.experimental.enable_mixed_precision_graph_rewrite() 包装,或者梯度是直接使用 tf.gradients() 而不是 Optimizer.minimize() 或 Optimizer.compute_gradients() 计算的,则可能会发生这种情况。
问:我们是否有示例或文档说明如何将 AMP 与 tf.gradients() 以及静态和/或动态损失缩放一起使用?
答:对于静态损失缩放,这很简单
loss = some_loss()
loss *= loss_scale # Scale by the loss scale
scaled_grads = tf.gradients(loss, …) # Compute gradients
# Now unscale, handling sparse grads
grads = []
for scaled_grad in scaled_grads:
if scaled_grad is not None:
if isinstance(scaled_grad, tf.IndexedSlices):
grads.append(tf.IndexedSlices(
scaled_grad.values * (1. / loss_scale),
scaled_grad.indices,
scaled_grad.dense_shape))
else:
grads.append(scaled_grad * (1. / loss_scale))
else:
grads.append(None)
# Now use `grads` as you would normally
9.3. PyTorch 常见问题解答
问:自动混合精度 (AMP) 是否依赖于 PyTorch 版本,还是任何 PyTorch 版本都可以启用 AMP?
答:带有 CUDA 和 CPP 扩展的 AMP 需要 PyTorch 1.0 或更高版本。 纯 Python 构建可能能够与 PyTorch 0.4 一起使用,但是,强烈建议使用 1.0+。
问:动态缩放如何选择合适的缩放因子?
答:动态损失缩放基本上尝试在不引起梯度溢出的情况下尽可能使用最高的损失比例,以充分利用 FP16 动态范围。
它通过从高损失比例值(例如,2^24)开始来实现这一点,然后在每次迭代中,检查梯度是否溢出(infs/NaNs)。 如果没有梯度溢出,则梯度被取消缩放(在 FP32 中),并且像往常一样应用 optimizer.step()。 如果检测到溢出,则修补 optimizer.step 以跳过实际的权重更新(以便 inf/NaN 梯度不会污染权重),并且损失比例会按某个因子 F(默认情况下 F=2)减小。 这负责将损失比例减小到不会产生溢出的范围。 然而,这只是故事的一半。 如果稍后训练稳定,并且允许更高的损失比例会怎么样? 例如,在训练后期,梯度幅度往往较小,可能需要更高的损失比例来防止下溢。 因此,动态损失缩放也尝试每 N 次迭代(默认情况下 N=2000)将损失比例增加 F 倍。 如果增加损失比例再次导致溢出,则跳过该步骤,并将损失比例像往常一样减小回增加前的值。 这样,通过:
- 在遇到梯度溢出时减小损失比例,以及
- 间歇性地尝试增加损失比例,就(大致)实现了尽可能使用不会引起溢出的最高损失比例的目标。
问:启用 AMP 后,如何增加批量大小? 只是将批量大小增加 8 倍吗?
答:这取决于您节省了多少内存,而这取决于模型。 一个快速而简便的方法是在启动运行时,从单独的终端 watch -n 0.5 nvidia-smi,以查看您正在使用的设备内存量。 一般来说,只要您遵守允许 Tensor Core 使用的指南(有关更多信息,请参阅 Issue #221),每个 GPU 使用更大的批量往往会提高利用率。
问:AMP 是否依赖于 PyTorch 版本,还是任何 PyTorch 版本都可以启用 AMP?
答:带有 CUDA 和 CPP 扩展的 AMP 需要 PyTorch 1.0 或更高版本。 纯 Python 构建可能能够与 PyTorch 0.4 一起使用,但是,强烈建议使用 1.0+。
问:如何使用 O0、O1、O2、O3? 哪个推荐用于 AMP? 有什么区别?
- 使用 O0 作为基线 FP32。
- 使用 O1 作为 AMP。注意
将来,AMP O1 功能将向上游移动。
- O2 稍快,但可能更难收敛/稳定,或者可能无法收敛到 FP32 结果。 在 O2 中,所有操作都在 FP16 中,因此通常不建议使用。
- 对于 FP16 中的所有内容,请使用 O3,没有主权重。 O3 旨在进行性能比较,以查看 AMP 开销。
问:AMP 可以将模型的检查点保存在 FP32 中吗?
答:模型的 O1 检查点将以 FP32 格式保存,而模型的 O2 检查点将不会以 FP32 格式保存,并且优化器主权重必须单独保存。 最佳实践始终是使用 O1 保存检查点。
9.4. MXNet 常见问题解答
问:自动混合精度 (AMP) 是否依赖于 MXNet 版本,还是任何 MXNet 版本都可以启用 AMP?
答:AMP 在 NGC MXNet 容器中从 19.04 版本开始提供。 从 MXNet 1.5 开始,AMP 将在上游框架中原生提供。
声明
本文档仅供参考,不得视为对产品的特定功能、条件或质量的保证。 NVIDIA Corporation(“NVIDIA”)对本文档中包含的信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。 NVIDIA 对因使用此类信息而造成的后果或使用,或因其使用而可能导致的侵犯第三方专利或其他权利的行为不承担任何责任。 本文档不构成开发、发布或交付任何材料(如下定义)、代码或功能的承诺。
NVIDIA 保留随时对本文档进行更正、修改、增强、改进和任何其他更改的权利,恕不另行通知。
客户应在下订单前获取最新的相关信息,并应验证此类信息是否为最新且完整。
NVIDIA 产品的销售受 NVIDIA 订单确认时提供的标准销售条款和条件的约束,除非 NVIDIA 和客户的授权代表签署的个别销售协议(“销售条款”)另有约定。 NVIDIA 在此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。 本文档不直接或间接地构成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命维持设备,也不适用于 NVIDIA 产品的故障或失灵可能会合理预期导致人身伤害、死亡或财产或环境损害的应用。 NVIDIA 对在上述设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不保证基于本文档的产品适用于任何特定用途。 NVIDIA 不一定会对每个产品的所有参数进行测试。 客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合并满足客户计划的应用,并为该应用执行必要的测试,以避免应用或产品的默认设置。 客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同的条件和/或要求。 NVIDIA 对可能基于或归因于以下原因的任何默认设置、损坏、成本或问题不承担任何责任:(i) 以任何违反本文档的方式使用 NVIDIA 产品,或 (ii) 客户产品设计。
本文档未授予 NVIDIA 专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。 NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成 NVIDIA 对其的保证或认可。 使用此类信息可能需要获得第三方在其专利或其他知识产权下的许可,或获得 NVIDIA 在其专利或其他 NVIDIA 知识产权下的许可。
只有在事先获得 NVIDIA 书面批准的情况下,才可以复制本文档中的信息,并且复制时不得进行更改,必须完全遵守所有适用的出口法律和法规,并附带所有相关的条件、限制和声明。
本文档和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”,单独称为“材料”)均按“原样”提供。 NVIDIA 不对材料作出任何明示、暗示、法定或其他方面的保证,并且明确声明不承担所有关于不侵权、适销性和特定用途适用性的默示保证。 在法律未禁止的范围内,在任何情况下,NVIDIA 均不对因使用本文档而引起的任何损害(包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害,无论如何造成,也无论责任理论如何)承担责任,即使 NVIDIA 已被告知可能发生此类损害。 尽管客户可能因任何原因遭受任何损害,但 NVIDIA 对本文所述产品的客户承担的总体和累积责任应根据产品的销售条款进行限制。
Android、Android TV、Google Play 和 Google Play 徽标是 Google, Inc. 的商标。
商标
NVIDIA、NVIDIA 徽标、CUDA、Merlin、RAPIDS、Triton Inference Server、Turing 和 Volta 是 NVIDIA Corporation 在美国和其他国家/地区的商标和/或注册商标。 其他公司和产品名称可能是与其相关的各自公司的商标。