步骤 4:运行工作流程#
数字指纹
训练管道#
在首次运行 AI 管道之前,必须使用以下命令运行初始训练作业
kubectl -n $NAMESPACE create job train --from=cronjob/$APP_NAME-training
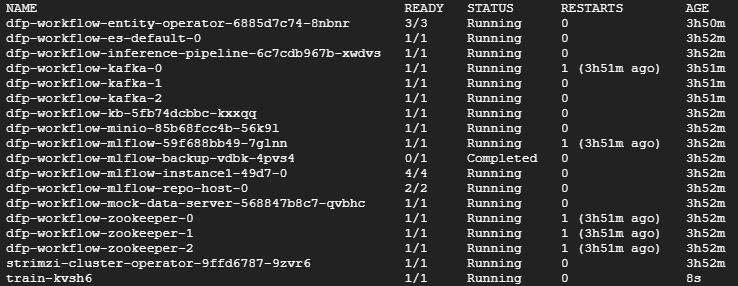
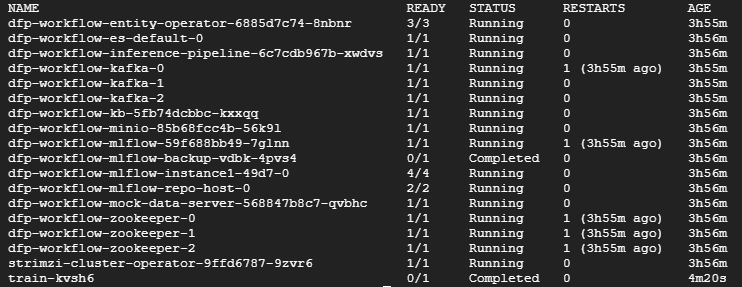
然后您应该看到一个名为 train-XXXXX 的 pod 在命名空间中运行。在下面的示例中,它是列出的最后一个 pod。等待此训练 pod 显示 Completed 状态后再继续。这应该只需要几分钟。
kubectl -n $NAMESPACE get pods
在此初始命令之后,训练作业会作为 cronjob 定期提交,默认设置为每周日凌晨 3 点。此值可以在工作流程的 helm chart 的 values.yaml 中修改。
此训练会话包含两个并行运行的管道。一个管道训练每个用户的模型,其中为每个检测到的用户 ID 训练自定义模型。另一个管道训练通用模型,用于处理以前未见过的用户。这些管道使用来自身份验证日志的各种特征列,例如时间戳、IP 地址和浏览器版本,来开发用户的指纹模型。训练后的模型和相关信息可以在 MLflow 中找到;URL 在下一节中提供。
推理管道#
在继续之前,请确保已通过上述说明提交至少一个训练作业。
AI 应用程序包括为此管道设置的示例仪表板和组件。可以使用提供的命令提取的凭据,通过以下 URL 访问它们
Grafana: https://dashboards.my-cluster.my-domain.com
用户: admin
密码
kubectl get secret grafana-admin-credentials -n nvidia-monitoring -o jsonpath='{.data.GF_SECURITY_ADMIN_PASSWORD}' | base64 -d
Kibana: https://kibana-<APP_NAME>-<NAMESPACE>.my-cluster.my-domain.com
用户: elastic
密码
kubectl -n $NAMESPACE get secret $APP_NAME-es-elastic-user -o jsonpath='{.data.elastic}' | base64 -d
MinIO: https://minio-<APP_NAME>-<NAMESPACE>.my-cluster.my-domain.com
用户: minioadmin
密码
kubectl -n $NAMESPACE get secret s3-admin -o jsonpath='{.data.MINIO_ROOT_PASSWORD}' | base64 -d
MLflow: https://mlflow-<APP_NAME>-<NAMESPACE>.my-cluster.my-domain.com
此信息也可以通过以下命令在 Helm 版本的 notes.txt 中找到
helm status $APP_NAME -n $NAMESPACE
这些组件支持管道的功能,允许用户与管道和数据的活动进行交互和监控。
例如,Grafana 的仪表板显示有关 AI 应用程序管道性能和功能以及管道检测到的异常日志的相关数据。最初,此仪表板将是空白的,因为管道尚未收到任何流数据。
此解决方案包含一个模拟 Azure AD Active Directory 日志的模拟数据生成器。要开始将数据流式传输到管道中,您需要使用以下命令将此数据生成器扩展到至少一个实例
kubectl -n $NAMESPACE scale deploy/$APP_NAME-mock-data-producer --replicas=1
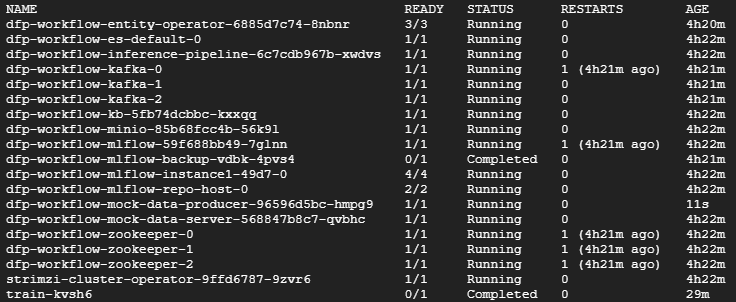
每个数据生成器实例大约发送 10 条消息/秒。扩展后,您应该看到一个新的 data-producer pod 在命名空间中运行
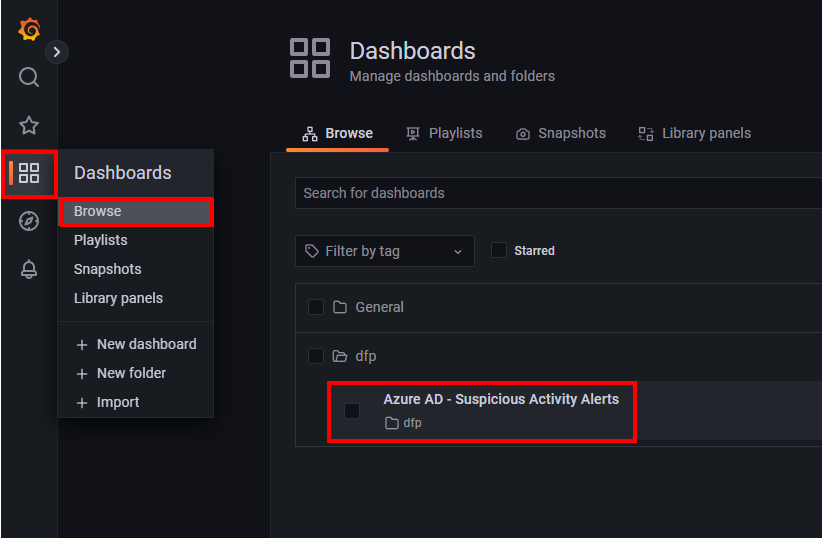
一旦数据生成器运行并流式传输数据,您现在应该看到信息填充到 Grafana 仪表板中。您可以通过使用上面检索到的凭据登录、选择左侧导航窗格中的 Dashboards 图标、选择 browse,然后双击 **Azure AD - Suspicious Activity Alerts dashboard** 来打开仪表板。
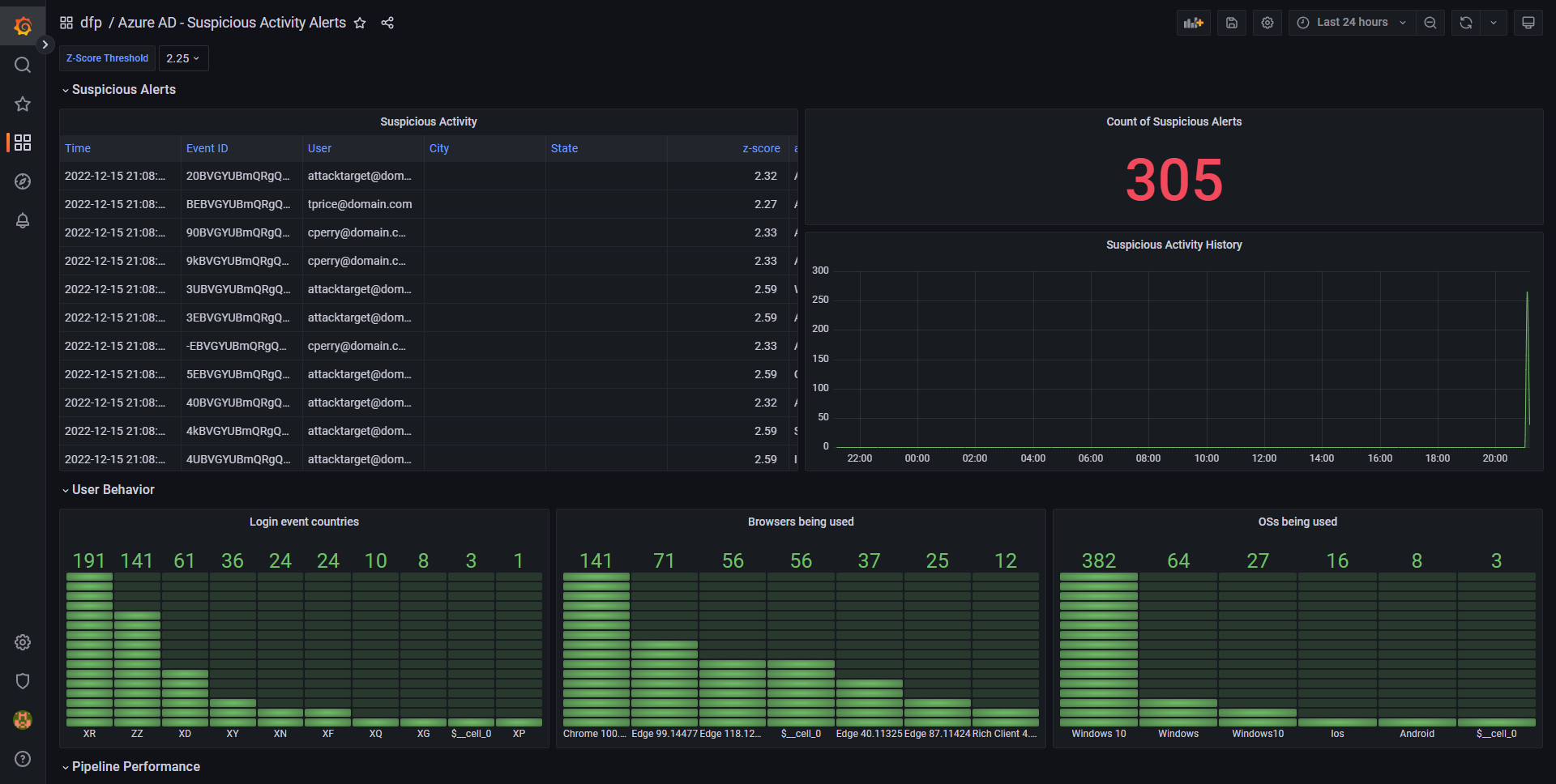
Kibana 也可用于查看通过管道运行的数据,以进行分析和调查。您可以使用之前检索到的凭据登录 Kibana 仪表板,按照以下步骤查看数据
打开左上角的菜单,然后选择 **Analytics 下的 Discover**。
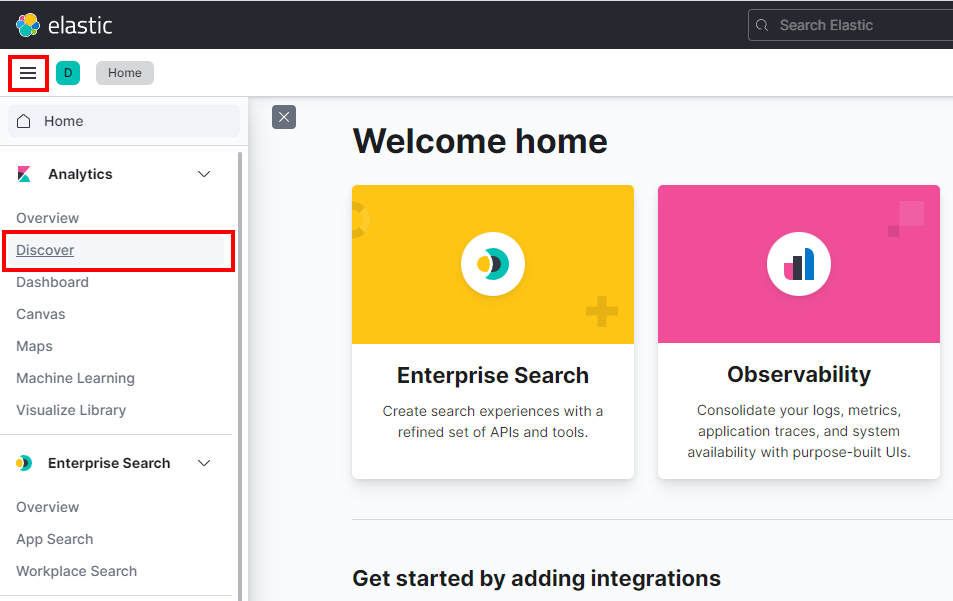
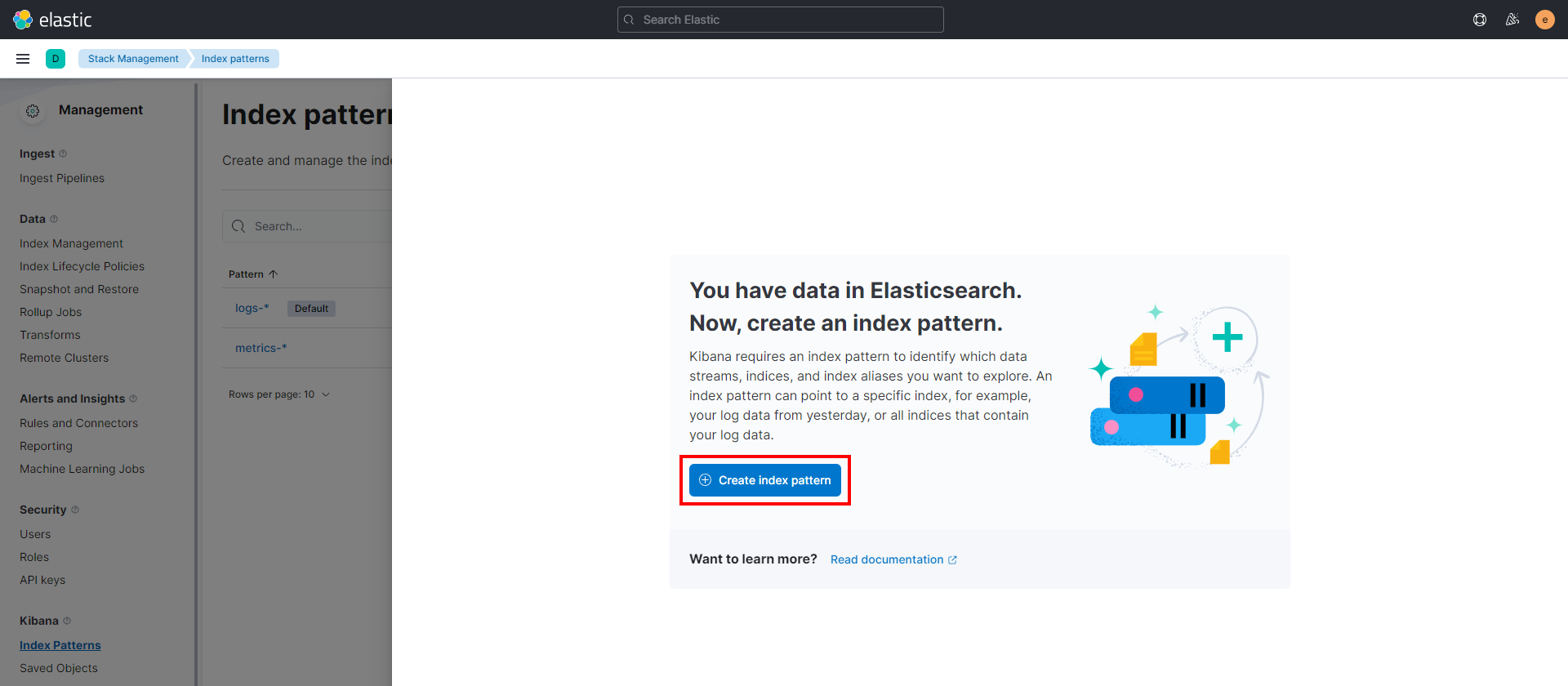
单击 **创建索引模式**。
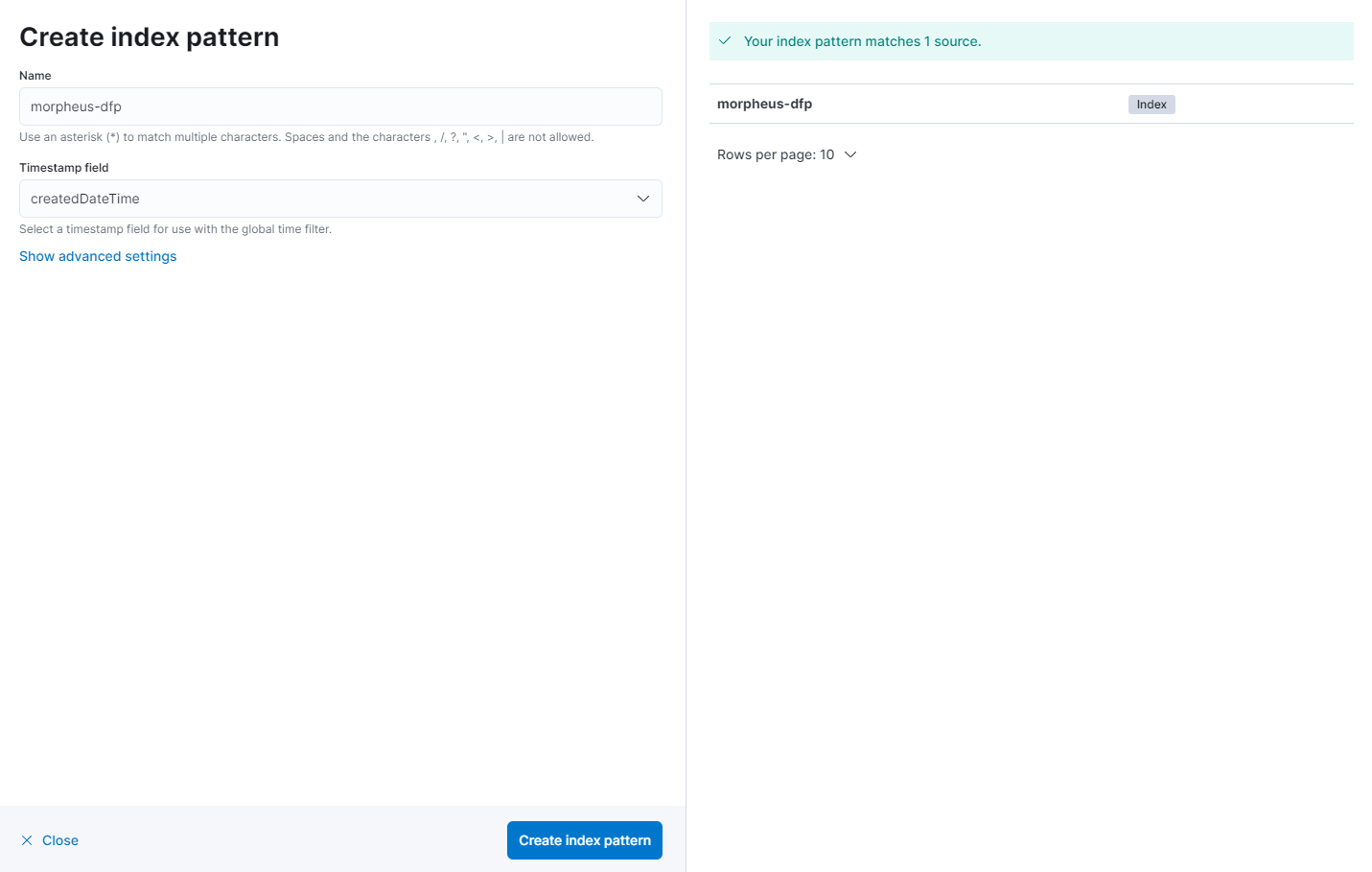
在 Name 字段下输入 morpheus-dfp,然后在 **Timestamp** 字段下选择 createdDateTime。然后单击 **创建索引模式**。
再次打开左上角的菜单,然后选择 Analytics 下的 **Discover**。
将过滤器从 logs-* 更改为 morpheus-dfp。
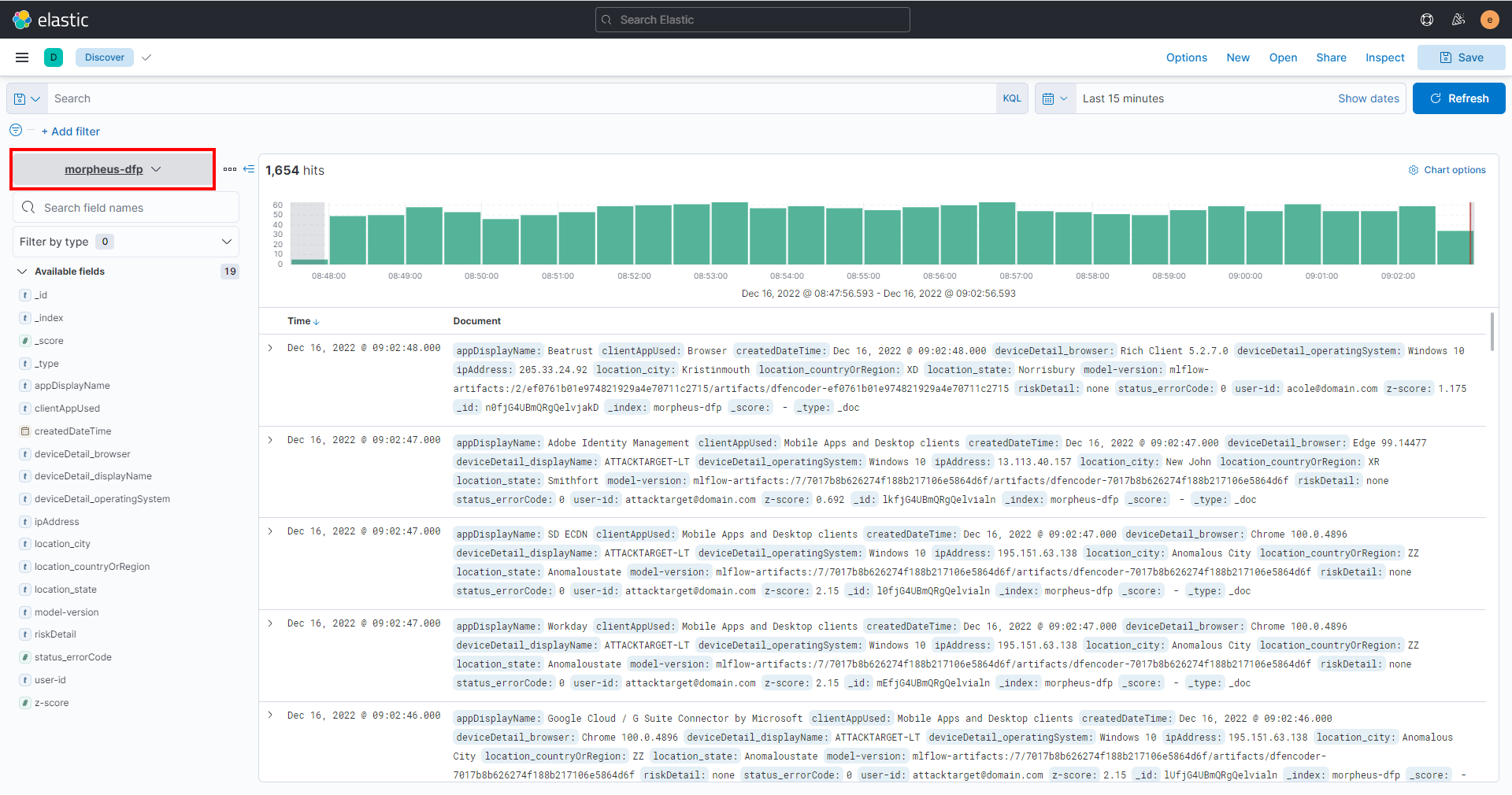
您现在应该看到所有通过管道流式传输后的数据。
整体管道功能如下
数据从模拟数据生成器流式传输到 Kafka 中。
数据被摄取到管道中,经过预处理、推理和后处理。
来自管道的结果聚合到 Prometheus 中,并通过 Grafana 呈现。
数据通过管道运行后,将保存在 Elasticsearch 中,以便稍后通过 Kibana 查看和分析。
对于更大量的数据,可以使用以下命令并行扩展数据生成器 pod
kubectl -n $NAMESPACE scale deploy/$APP_NAME-mock-data-producer --replicas=3
完成此操作后,管道也可以扩展到在多个 GPU 上运行的多个实例,以支持增加的吞吐量,使用以下命令
首先,我们将重新配置 Kafka 主题以允许更多侦听器。通过运行以下命令编辑 Kafka 主题
kubectl edit kafkatopic -n $NAMESPACE $APP_NAME-inbox
然后,将分区数从 1 更改为更高的数字,例如 5。这决定了此主题的最大侦听器数量。
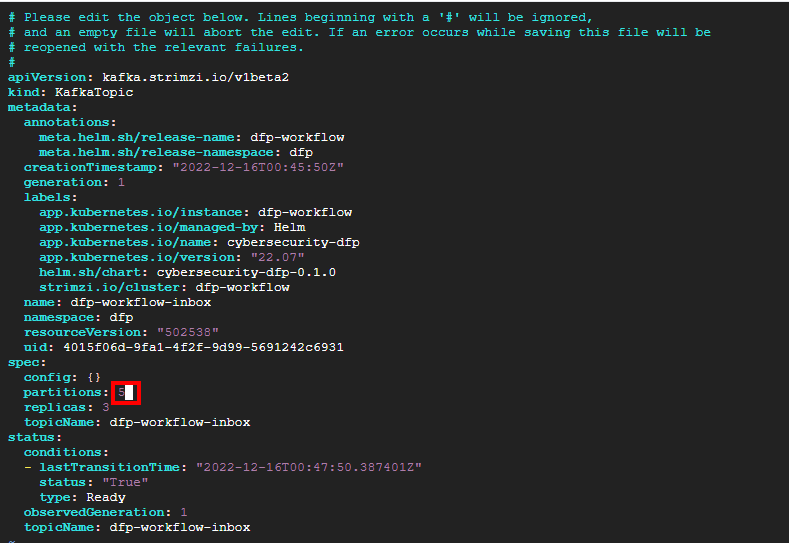
进行此更改后,保存并退出编辑器。
现在,我们将使用以下命令扩展管道 pod 的数量
kubectl -n $NAMESPACE scale deploy/$APP_NAME-inference-pipeline --replicas=2
您应该注意到,随着每秒消息数量的增加,仪表板中的吞吐量也会增加。
这就是运行数字指纹 AI 工作流程的全部内容。您可以随意探索作为解决方案一部分部署的其他组件。您还可以查看 NGC 上数字指纹集合中包含的源代码,以确定此工作流程是如何构建的,以及如何根据您的特定用例和环境对其进行自定义。例如,可以使用真实的流数据连接到此管道,替换此工作流程中包含的模拟数据生成器。