简介#
在 2.0 版本中添加。
Red Hat OpenShift#
Red Hat 和 NVIDIA 合作,通过交付针对 AI 工作负载优化的端到端企业平台,为每家企业释放 AI 的力量。这个集成平台提供一流的 AI 软件 NVIDIA AI Enterprise 套件,该套件针对行业领先的容器和 Kubernetes 平台 Red Hat OpenShift 进行了优化和认证。该平台在 NVIDIA 认证系统™(行业领先的加速服务器)上运行,加速了开发人员构建 AI 和高性能数据分析的速度,使组织能够在他们已经投资的基础设施上扩展现代工作负载,并提供企业级的可管理性、安全性和可用性。此外,借助 Red Hat OpenShift,企业可以灵活地在裸机或 VMware vSphere 虚拟化环境中进行部署。
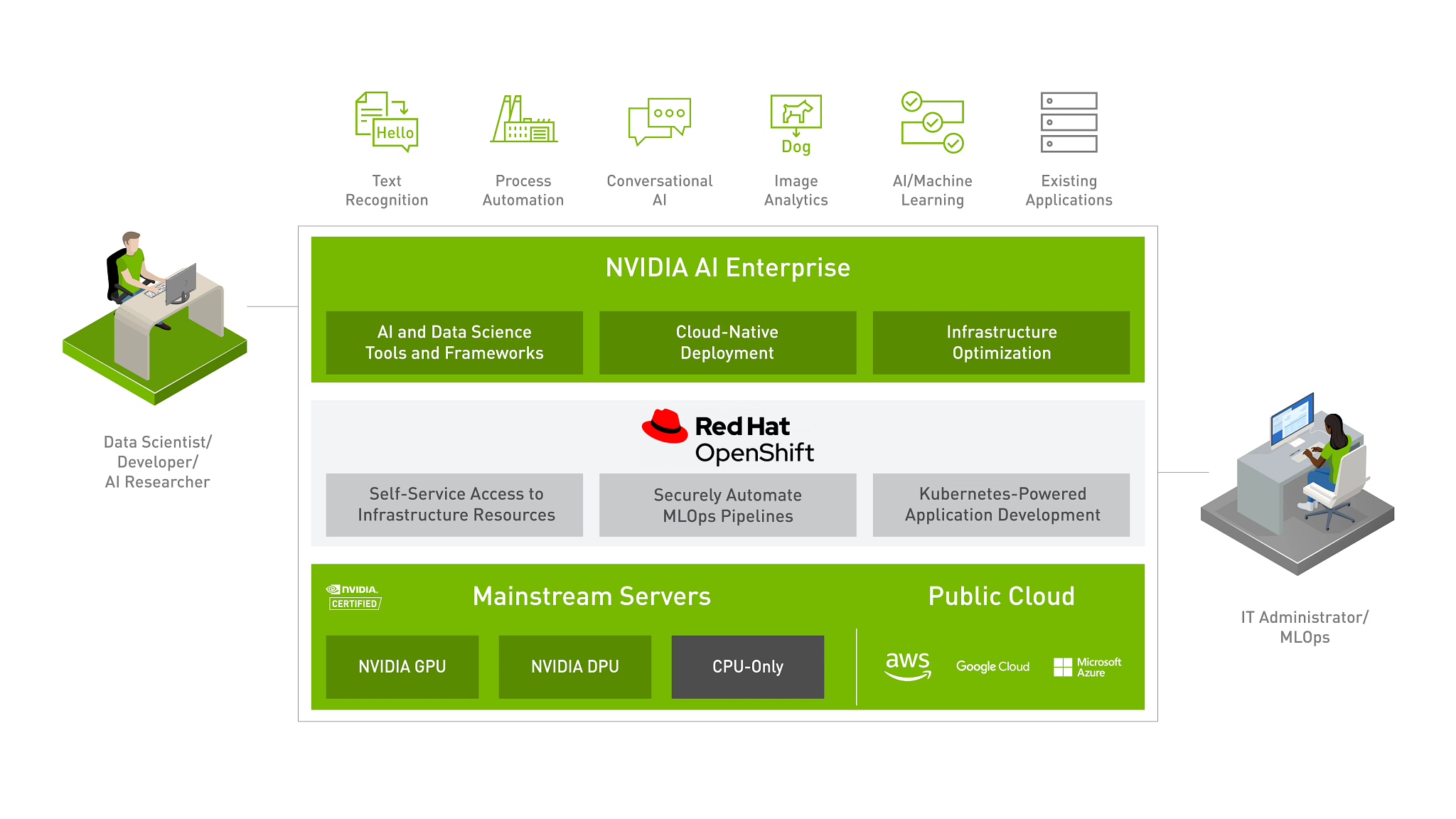
此 NVIDIA 和 Red Hat 联合 AI 就绪平台解决方案的优势在于
易于部署和扩展
企业可以放心地在 NVIDIA 认证系统上部署和扩展由 NVIDIA 和 Red Hat 认证的端到端 AI 解决方案。这包括在 Red Hat OpenShift 上、裸机或跨数据中心和边缘的现有 VMware vSphere 上一致地部署 NVIDIA AI Enterprise 和数据分析软件的灵活性。Red Hat OpenShift 与 NVIDIA GPU 的集成(使用经过认证的 Kubernetes 运算符和容器化 AI 软件)降低了部署风险,并实现了无缝扩展。
支持自助访问 AI 工具和基础设施
Red Hat OpenShift 上的 NVIDIA AI Enterprise 为数据科学家、ML 工程师和开发人员实现了自助式、一致的、类似云的体验,他们可以灵活且可移植地使用容器化的 AI 工具和基础设施资源。这使他们能够在生产部署之前快速构建、扩展、复制和共享模型。他们还可以访问开箱即用的、可信赖的、经过试验和测试的 AI 工具,以提高生产力并加快实现价值的时间。
通过集成的 MLOps 安全交付智能应用程序
将 OpenShift DevOps 和 GitOps 自动化功能扩展到整个 AI 生命周期,可以改善数据科学家、ML 工程师、软件开发人员和 IT 运营之间的协作。这使组织能够自动化和简化将模型集成到软件开发流程、生产部署、监控、再培训和重新部署的迭代过程,以确保持续的预测准确性。
NVIDIA 虚拟架构#
当 NVIDIA AI Enterprise 在虚拟化基础设施上运行时,一个关键组件是 NVIDIA 虚拟 GPU。下图说明了启用 NVIDIA 虚拟 GPU 的环境的高级架构。在这里,服务器中有 GPU,并且安装在主机服务器上的是打包为 vSphere 安装包 (VIB) 的 NVIDIA AI Enterprise 主机软件。
注意
Red Hat OpenShift 可以在 VMware vSphere 上以直通模式运行 GPU,这不需要 VIB。
该软件使多个 VM 可以共享单个 GPU,或者如果服务器中有多个 GPU,则可以将它们聚合,以便单个 VM 可以访问多个 GPU。物理 NVIDIA GPU 可以支持多个虚拟 GPU (vGPU),并在运行在 hypervisor 中的 NVIDIA AI Enterprise Host Software 的控制下直接分配给 guest VM。Guest VM 以与 hypervisor 直通的物理 GPU 相同的方式使用 NVIDIA vGPU。在 VM 本身中,安装了 vGPU 驱动程序,这些驱动程序支持可用的不同许可证级别。
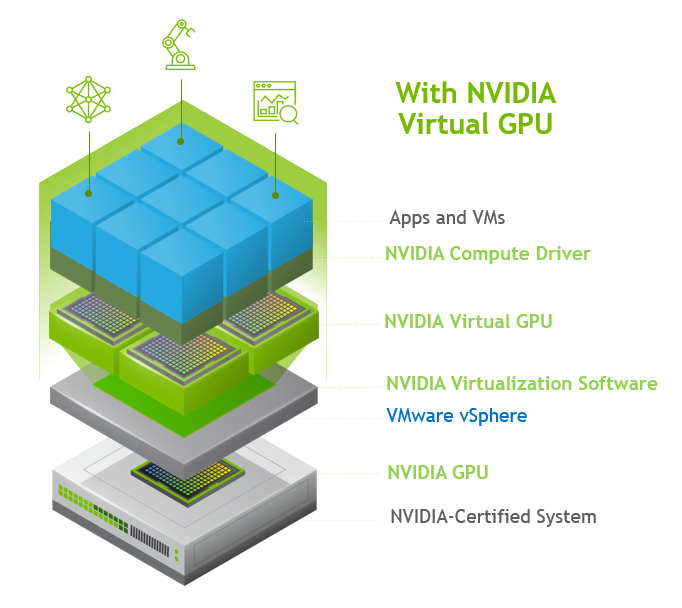
NVIDIA AI Enterprise 主机软件 (VIB)#
NVIDIA AI Enterprise 主机软件主机驱动程序是安装在 hypervisor 主机上的软件驱动程序,它负责与安装在 guest VM 上的 NVIDIA vGPU guest 驱动程序进行通信。
NVIDIA GPU 运算符#
GPU 运算符使 DevOps 团队能够在集群级别管理与 Red Hat OpenShift 一起使用时的 GPU 生命周期。无需单独管理每个节点。当 GPU 运算符与 Red Hat OpenShift 一起使用时,基础设施团队可以从单个管理平台轻松管理 GPU 和 CPU 节点。GPU 运算符还允许客户在不可变的操作系统上运行 GPU 加速应用程序。由于 GPU 运算符的构建方式使其可以检测新添加的 GPU 加速 Kubernetes 工作节点,因此可以实现更快的节点配置。然后自动安装运行 GPU 加速应用程序所需的所有软件组件。GPU 运算符是管理所有 Kubernetes 组件(GPU 设备插件、GPU 功能发现、GPU 监控工具、NVIDIA 运行时)的单个工具。重要的是要注意,GPU 运算符也安装 NVIDIA AI Enterprise Guest Driver。
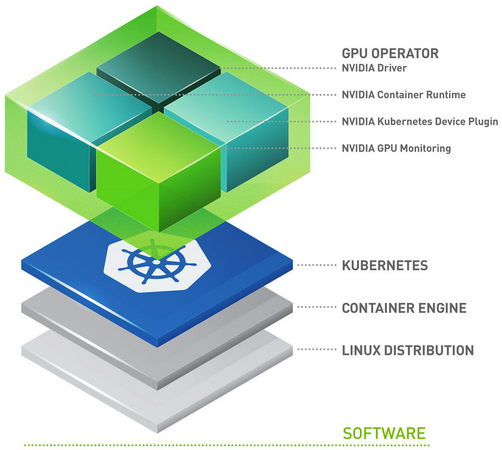
组件如下
GPU 功能发现,它根据 GPU 规格标记工作节点。这使客户能够更精细地选择其应用程序所需的 GPU 资源。
NVIDIA AI Enterprise Guest Driver
Kubernetes 设备插件,它向 Kubernetes 调度器通告 GPU
NVIDIA 容器工具包 - 允许用户构建和运行 GPU 加速容器。该工具包包括一个容器运行时库和实用程序,用于自动配置容器以利用 NVIDIA GPU。
数据中心 GPU 管理器 (DCGM) 监控 - 允许监控 Kubernetes 上的 GPU。
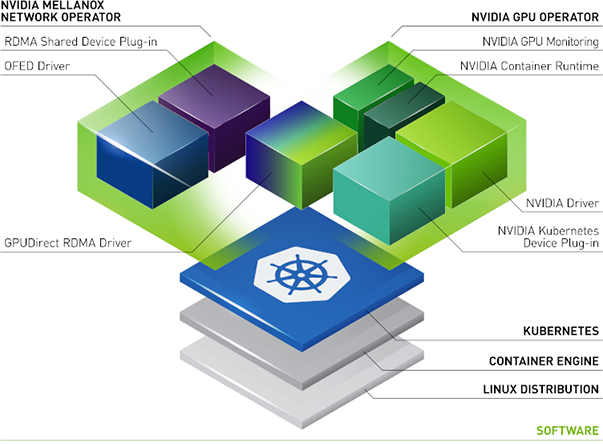
NVIDIA 网络运算符#
NVIDIA 网络运算符利用 Kubernetes 自定义资源和运算符框架来配置快速网络、RDMA 和 GPUDirect。
安装 NGC Catalog CLI#
要访问 NVIDIA AI Enterprise 主机软件 (VIB),您必须首先下载并安装 NGC Catalog CLI。安装 NGC Catalog CLI 后,您需要启动命令窗口,然后运行命令以下载软件。建议将 NGC CLI 安装在可用于与 OpenShift 集群或 ESXi 主机交互的同一台计算机上。
要安装 NGC Catalog CLI
在右上角,单击Welcome,然后从菜单中选择Setup。
从“Setup”页面中,单击“Install NGC CLI”下的 Downloads。
在“CLI Install”页面中,根据您将运行 NGC Catalog CLI 的平台,单击“Windows”、“Linux”或“MacOS”选项卡。
按照说明安装 CLI。
打开终端或命令提示符
通过输入
ngc--version验证安装。输出应为NGC Catalog CLI x.y.z,其中 x.y.z 表示版本。您必须配置 NGC CLI 才能使用,以便可以运行命令。输入以下命令,然后在提示时输入您的 API 密钥
1$ ngc config set
2Enter API key [no-apikey]. Choices: [<VALID_APIKEY>, 'no-apikey']: (COPY/PASTE API KEY)
3
4Enter CLI output format type [ascii]. Choices: [ascii, csv, json]: ascii
5
6Enter org [no-org]. Choices: ['no-org']: nvlp-aienterprise
7
8Enter team [no-team]. Choices: ['no-team']: no-team
9
10Enter ace [no-ace]. Choices: ['no-ace']: no-ace
NVIDIA AI Enterprise 主机软件 VIB#
安装 NGC Catalog CLI 后,您需要启动命令窗口并运行以下命令以下载 NVIDIA AI Enterprise 主机软件 (VIB)。
ngc registry resource download-version "nvaie/vgpu_host_driver_2_0:510.47"
为您的 ESXi 版本选择正确的 vib
对于 vSphere 7.0 U2 或更高版本
NVIDIA-AIE_ESXi_7.0.2_Driver_510.47-1OEM.702.0.0.17630552.vib对于 vSphere 6.7
NVIDIA-AIE_ESXi_6.7.0_Driver_510.47-1OEM.670.0.0.8169922.vib