创建集群策略实例#
在 2.0 版本中添加。
接下来,我们将创建集群策略,它负责维护策略资源以在集群中创建 Pod。
在 OpenShift 容器平台 Web 控制台中,从侧边菜单中选择 **Operators** > **已安装的 Operators**,然后单击 **NVIDIA GPU Operator**。
选择 **ClusterPolicy** 选项卡,然后单击 **创建 ClusterPolicy**。
注意
平台分配默认名称 *gpu-cluster-policy*。
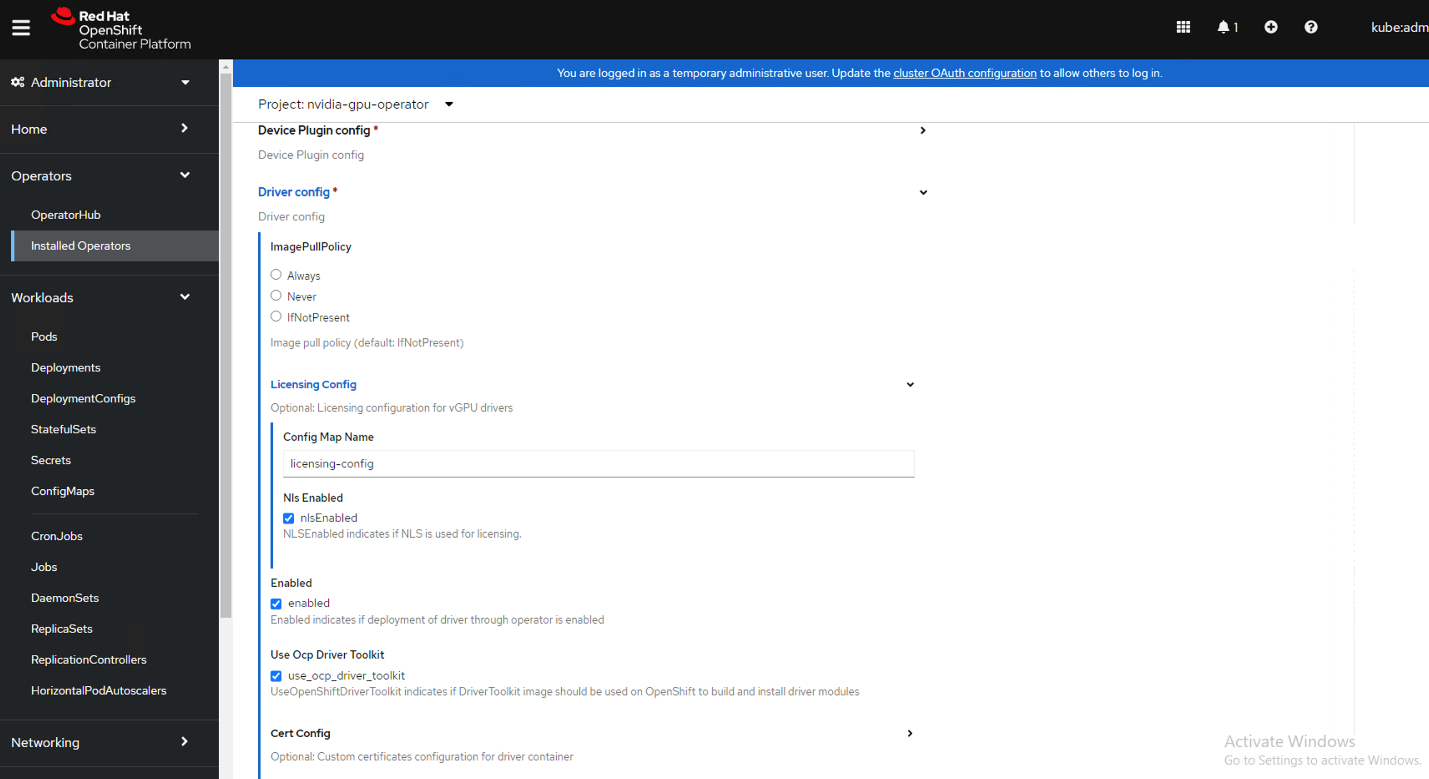
展开 **Driver config** 和 **Licensing Config** 的下拉菜单。在标记为 **Config Map Name** 的文本框中,输入先前创建的许可证配置映射的名称(例如:licensing-config)。选中 **NLS Enabled** 复选框。请参考以下屏幕截图中的参数示例,并相应地修改值。
重要提示
这在 创建 CLS 许可证配置映射 的步骤 2 中已创建。
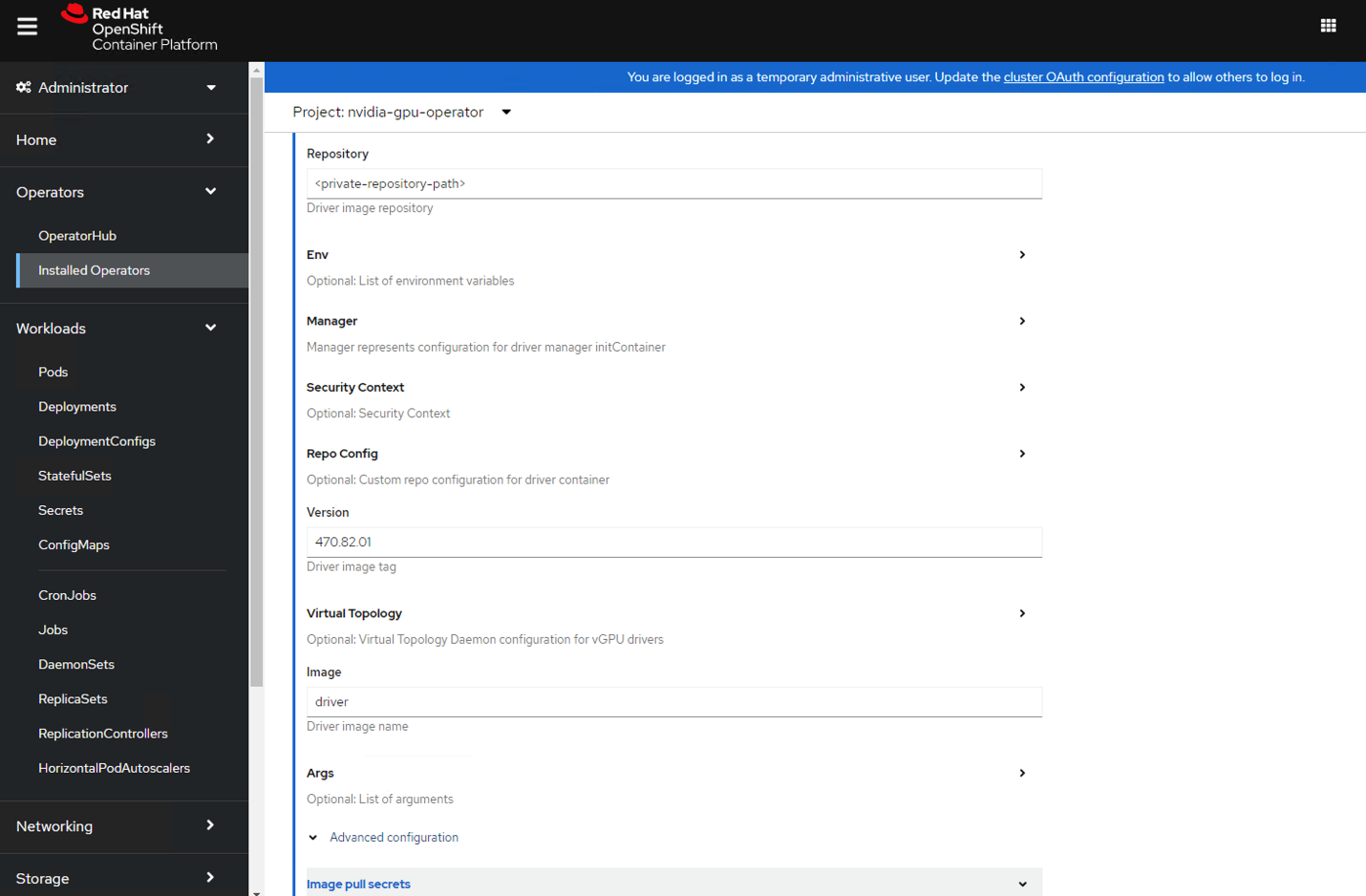
向下滚动以在 **Driver** 部分下指定
repository路径、image``name 和 NVIDIA vGPU driver ``version。请参考以下屏幕截图中的参数示例,并相应地修改值。
展开 **高级配置** 菜单并指定
imagePullSecret。(例如:gpu-operator-secret)重要提示
这在 创建 CLS 许可证配置映射 的步骤 3 中已创建。
单击 **创建**。
验证集群策略#
GPU 运算符将继续安装所有必需的组件,以在 OpenShift 集群中设置 NVIDIA GPU。
当安装成功时,新部署的 NVIDIA GPU 运算符的 ClusterPolicy gpu-cluster-policy 的状态将更改为 State:ready。
要从 CLI 验证 ClusterPolicy 安装,请使用
$ oc get nodes -o=custom-columns='Node:metadata.name,GPUs:status.capacity.nvidia\.com/gpu'
这将列出每个节点及其可供 Kubernetes 使用的 GPU 数量。
示例输出
1$ oc get nodes -o=custom-columns='Node:metadata.name,GPUs:status.capacity.nvidia\.com/gpu' 2Node GPUs 3nvaie-ocp-7rfr8-master-0 <none> 4nvaie-ocp-7rfr8-master-1 <none> 5nvaie-ocp-7rfr8-master-2 <none> 6nvaie-ocp-7rfr8-worker-7x5km 1 7nvaie-ocp-7rfr8-worker-9jgmk <none> 8nvaie-ocp-7rfr8-worker-jntsp 1