EKS (Elastic Kubernetes Service)#
概述#
在 3.1 版本中添加。
Amazon EKS 是一种托管的 Kubernetes 服务,用于在 AWS 云中运行 Kubernetes。NVIDIA AI Enterprise 是 NVIDIA AI 平台的端到端软件,支持在 EKS 上运行。在云中,Amazon EKS 自动管理 Kubernetes 控制平面节点的可用性和可扩展性,这些节点负责调度容器、管理应用程序可用性、存储集群数据以及其他关键任务。本指南详细介绍了如何在具有 GPU 加速节点的 EKS 集群上部署和运行 NVIDIA AI Enterprise。
注意
NVIDIA Terraform 模块提供了一种简便的方法来部署托管的 Kubernetes 集群,当与受支持的操作系统和 GPU Operator 版本一起使用时,这些集群可以受到 NVIDIA AI Enterprise 的支持。
先决条件#
NVIDIA AI Enterprise 许可证,通过自带许可证 (BYOL) 或私有报价获得
安装 AWS CLI
安装 EKS CLI
AWS IAM 角色,用于创建具有以下权限的 EKS 集群
Administrator Access(管理员访问权限)
AmazonEKSClusterPolicy
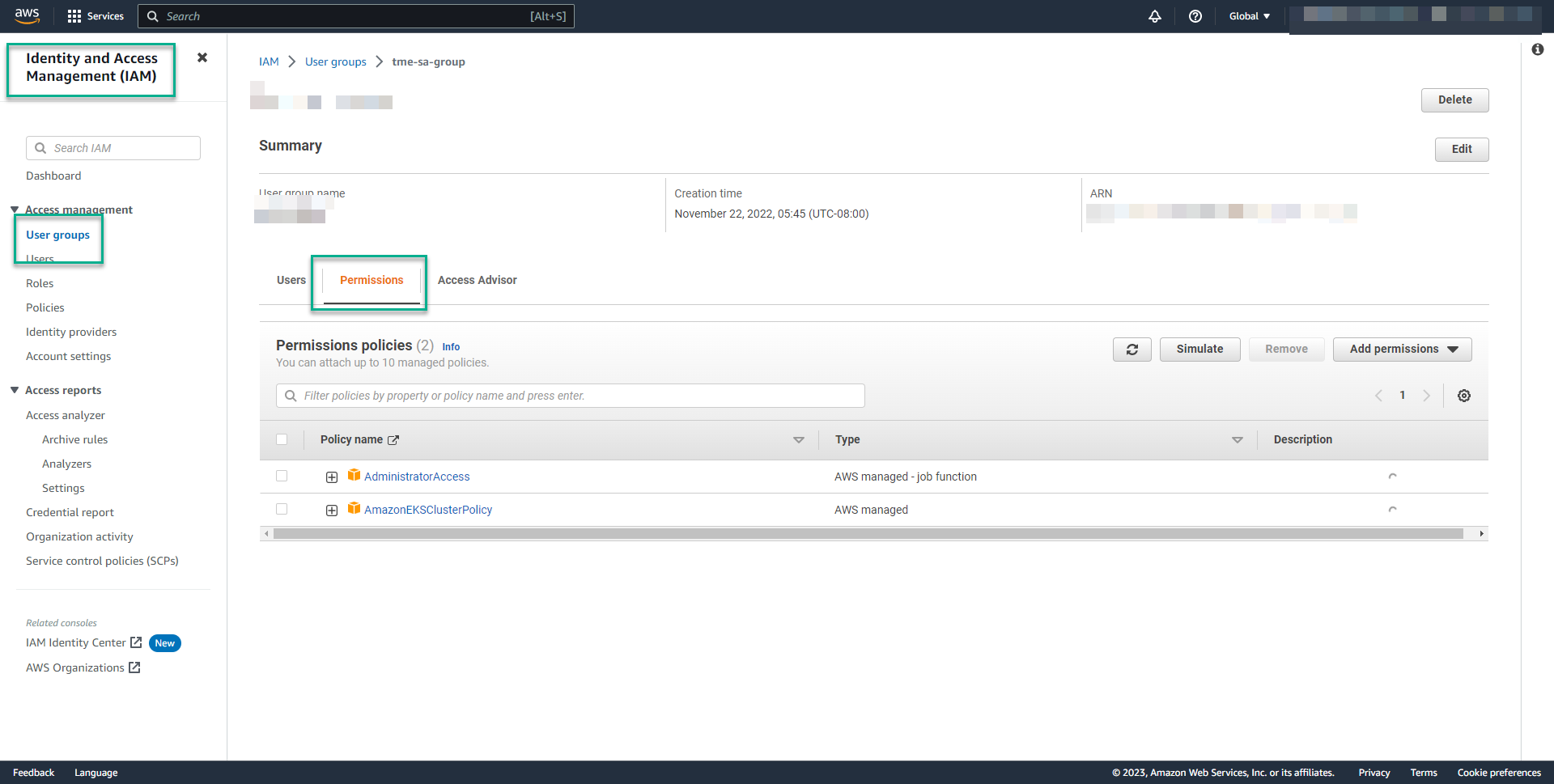
AWS EKS 集群 先决条件
重要提示
请注意,发布版本在您的本地环境中会有所不同。截至本文档发布时,已使用并验证了 eksctl 版本 0.133.0。有关发行说明历史记录以及本文档范围未涵盖的任何主题,请参阅 Amazon EKS 入门。
创建 EKS 集群#
AWS 配置#
首先,我们将按照以下步骤从 AWS 控制台获取 AWS 凭证,单击“Access keys”(访问密钥)并继续
选择“Command Line Interface”(命令行界面)并继续“Next”(下一步)
下载 .csv 文件以供将来参考,并使用 AWS CLI 在您的系统上配置凭证。
aws configure
以下是示例输出
1AWS Access Key ID [None]:
2AWS Secret Access Key [None]:
3Default region name [None]:
4Default output format [None]:
重要提示
根据您组织的安全实践,您可能需要使用临时安全凭证。有关使用 AWS STS 的更多详细信息,请参阅 IAM 文档中的临时安全凭证。
创建一个 cluster-config.yaml 文件,并按照以下说明填写详细信息。
重要提示
从此处替换 ami 和 amiFamily,使用适当的值:https://cloud-images.ubuntu.com/aws-eks/
1apiVersion: eksctl.io/v1alpha5
2kind: ClusterConfig
3metadata:
4 name: <eks-cluster-name>
5 region: us-west-1
6 version: "1.25"
7nodeGroups:
8- name: gpu-nodegroup
9 # grab AMI ID for Ubuntu EKS AMI here: https://cloud-images.ubuntu.com/aws-eks/
10 # using AMI ID for us-west-1 region: ami-00687acd80b7a620a
11 ami: ami-00687acd80b7a620a
12 amiFamily: Ubuntu2004
13 instanceType: g4dn.xlarge
14 minSize: 1
15 maxSize: 1
16 volumeSize: 100
17 desiredCapacity: 1
18 overrideBootstrapCommand: |
19 #!/bin/bash
20 source /var/lib/cloud/scripts/eksctl/bootstrap.helper.sh
21 /etc/eks/bootstrap.sh ${CLUSTER_NAME} --container-runtime containerd --use-max-pods false --kubelet-extra-args "--max-pods=60" "--node-labels=${NODE_LABELS}"
选择区域并根据区域更新 AMI。确保用户提供的 <eks-cluster-name> 在 .yaml 文件的两个部分中都相同。选择专为 EKS 集群设计的 AMI,您可以从 此处获取 AMI 的信息。
运行以下命令以创建 EKS 集群。
eksctl create cluster -f cluster-config.yaml --install-nvidia-plugin=false
注意
集群的创建将需要一些时间才能完成。
运行以下命令以验证节点信息
kubectl get nodes -o wide
示例输出结果
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
eks-<eks-cluster-name>-db9e3df9-r0jf Ready <none> 5m15s v1.25.6 192.168.50.108 13.57.187.63 Ubuntu 20.04.6 LTS 5.15.0-1033-aws containerd://1.6.12
部署 GPU Operator#
现在集群和适当的资源已创建,可以安装 NVIDIA GPU Operator
首先,我们将访问我们的 NGC API 密钥。
登录您的 NGC 帐户并生成新的 API 密钥或找到您现有的 API 密钥。请参阅附录的 访问 NGC 部分。
生成用于访问目录的 API 密钥
接下来,您必须生成一个 API 密钥,该密钥将使您能够访问 NGC Catalog。
导航到右上角的用户帐户图标,然后选择 Setup(设置)。
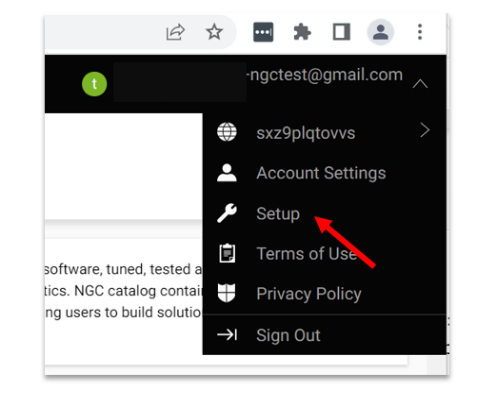
选择 Get API key(获取 API 密钥)以打开“Setup > API Key”(设置 > API 密钥)页面。
选择 Generate API Key(生成 API 密钥)以生成您的 API 密钥。
选择 Confirm(确认)以生成密钥,并从页面底部复制它。NGC 不会保存您的密钥,因此请将其存储在安全的地方。

注意
生成新的 API 密钥会使先前生成的密钥失效。
添加 Helm repo 并使用以下命令更新。
1helm repo add nvidia https://helm.ngc.nvidia.com/nvaie --username='$oauthtoken' --password=<YOUR API KEY>
2helm repo update
在“gpu-operator”命名空间中使用您的 NGC API 密钥创建一个 NGC Secret,如下所示。
1$ kubectl create ns gpu-operator
2
3$ kubectl create secret docker-registry ngc-secret \
4--docker-server=nvcr.io/nvaie --docker-username=\$oauthtoken \
5 --docker-password=<NGC-API-KEY> \
6--docker-email=<NGC-email> -n gpu-operator
创建一个空的 gridd.conf 文件,然后使用 NVIDIA vGPU 许可证令牌文件创建一个 configmap,如下所示
kubectl create configmap licensing-config -n gpu-operator --from-file=./client_configuration_token.tok --from-file=./gridd.conf
注意
configmap 将查找文件 client_configuration_token.tok,如果您的令牌采用不同的形式,例如 client_configuration_token_date_xx_xx.tok,请运行以下命令
mv client_configuration_token_date_xx_xx.tok client_configuration_token.tok
从 NGC Catalog 安装 GPU Operator,其中包含许可证令牌和 NVIDIA AI Enterprise 驱动程序 repo。
警告
如果使用低于 1.25 的 K8s 版本,则使用通过参数选项 --psp.enabled=true 启用的 PSP 选项部署 GPU operator。如果使用大于或等于 1.25 的 K8s 版本,则部署 GPU operator 时不启用 PSP 选项
helm install gpu-operator nvidia/gpu-operator-3-0 --set driver.repository=nvcr.io/nvaie,driver.licensingConfig.configMapName=licensing-config --namespace gpu-operator
重要提示
确保您具有正确的角色。如果您缺少所需的权限,请参阅 AWS IAM 角色 文档。
安装完成后,请等待至少 5 分钟,并验证所有 Pod 是否都在运行或已完成,如下所示。
1kubectl get pods -n gpu-operator
2NAME READY STATUS RESTARTS AGE
3gpu-feature-discovery-fzgv9 1/1 Running 0 6m1s
4gpu-operator-69f476f875-w4hwr 1/1 Running 0 6m29s
5gpu-operator-node-feature-discovery-master-84c7c7c6cf-hxlk4 1/1 Running 0 6m29s
6gpu-operator-node-feature-discovery-worker-86bbx 1/1 Running 0 6m29s
7nvidia-container-toolkit-daemonset-c7k5p 1/1 Running 0 6m
8nvidia-cuda-validator-qjcsf 0/1 Completed 0 59s
9nvidia-dcgm-exporter-9tggn 1/1 Running 0 6m
10nvidia-device-plugin-daemonset-tpx9z 1/1 Running 0 6m
11nvidia-device-plugin-validator-gz85d 0/1 Completed 0 44s
12nvidia-driver-daemonset-jwzx8 1/1 Running 0 6m9s
13nvidia-operator-validator-qj57n 1/1 Running 0 6m
验证 GPU Operator 安装#
使用以下命令验证 NVIDIA GPU 驱动程序是否已加载。
kubectl exec -it nvidia-driver-daemonset-jwzx8 -n gpu-operator -- nvidia-smi
1Defaulted container "nvidia-driver-ctr" out of: nvidia-driver-ctr, k8s-driver-manager (init)
2Tue Feb 14 22:24:31 2023
3+-----------------------------------------------------------------------------+
4| NVIDIA-SMI 520.60.13 Driver Version: 520.60.13 CUDA Version: 12.0 |
5|-------------------------------+----------------------+----------------------+
6| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
7| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
8| | | MIG M. |
9|===============================+======================+======================|
10| 0 Tesla T4 On | 00000000:00:04.0 Off | 0 |
11| N/A 51C P8 17W / 70W | 0MiB / 15360MiB | 0% Default |
12| | | N/A |
13+-------------------------------+----------------------+----------------------+
14
15+-----------------------------------------------------------------------------+
16| Processes: |
17| GPU GI CI PID Type Process name GPU Memory |
18| ID ID Usage |
19|=============================================================================|
20| No running processes found |
21+-----------------------------------------------------------------------------+
注意
nvidia-driver-daemonset-xxxxx 在您自己的环境中会有所不同,上述命令用于验证 NVIDIA vGPU 驱动程序。
使用以下命令验证 NVIDIA vGPU 许可证信息
kubectl exec -it nvidia-driver-daemonset-jwzx8 -n gpu-operator -- nvidia-smi -q
检查验证器 Pod 日志以确保 GPU 已暴露并被利用。
Kubectl logs nvidia-cuda-validator-vkr14 -n nvidia-gpu-operator
Kubectl logs nvidia-device-plugin-validator-lsmnc -n nvidia-gpu-operator
运行示例 NVIDIA AI Enterprise 容器#
创建一个 docker-registry Secret。这将用于自定义 yaml 文件中,以从 NGC Catalog 拉取容器。
1kubectl create secret docker-registry regcred --docker-server=nvcr.io/nvaie --docker-username=\$oauthtoken --docker-password=<YOUR_NGC_KEY> --docker-email=<your_email_id> -n default
创建一个自定义 yaml 文件以部署 NVIDIA AI Enterprise 容器并运行示例训练代码。
nano pytoch-mnist.yaml
将以下内容粘贴到文件中并保存
1---
2apiVersion: apps/v1
3kind: Deployment
4metadata:
5 name: pytorch-mnist
6 labels:
7 app: pytorch-mnist
8spec:
9 replicas: 1
10 selector:
11 matchLabels:
12 app: pytorch-mnist
13 template:
14 metadata:
15 labels:
16 app: pytorch-mnist
17 spec:
18 containers:
19 - name: pytorch-container
20 image: nvcr.io/nvaie/pytorch-2-0:22.02-nvaie-2.0-py3
21 command:
22 - python
23 args:
24 - /workspace/examples/upstream/mnist/main.py
25 resources:
26 requests:
27 nvidia.com/gpu: 1
28 limits:
29 nvidia.com/gpu: 1
30 imagePullSecrets:
31 - name: regcred
检查 Pod 的状态。
1kubectl get pods
查看示例 mnist 训练作业的输出。
1kubectl logs -l app=pytorch-mnist
输出将类似于这样。
1~$ kubectl logs -l app=pytorch-mnist
2Train Epoch: 7 [55680/60000 (93%)] Loss: 0.040756
3Train Epoch: 7 [56320/60000 (94%)] Loss: 0.028230
4Train Epoch: 7 [56960/60000 (95%)] Loss: 0.019917
5Train Epoch: 7 [57600/60000 (96%)] Loss: 0.005957
6Train Epoch: 7 [58240/60000 (97%)] Loss: 0.003768
7Train Epoch: 7 [58880/60000 (98%)] Loss: 0.277371
8Train Epoch: 7 [59520/60000 (99%)] Loss: 0.115487
9
10
11Test set: Average loss: 0.0270, Accuracy: 9913/10000 (99%)
删除 EKS 集群#
运行以下命令以删除 EKS 集群。
eksctl delete cluster -f cluster_config.yaml