概述#
在 2.0 版本中添加。
通过利用 Kubernetes,IT 管理员可以自动化部署、扩展和管理容器化的 AI 应用程序和框架。
什么是 Kubernetes?#
Kubernetes 是一个开源的容器编排平台,可以简化 DevOps 工程师的工作。应用程序可以作为逻辑单元部署在 Kubernetes 上,这些逻辑单元易于管理、升级和部署,具有零停机时间(滚动升级)和使用复制实现的高可用性。在 Kubernetes 上部署 Triton Inference Server 为企业中的 AI 提供了相同的优势。为了在 Kubernetes 集群中轻松管理 GPU 资源,使用了 NVIDIA GPU Operator。
什么是 Helm?#
Helm 是一个运行在 Kubernetes 之上的应用程序包管理器。Helm 非常类似于 Linux 的 Debian/RPM,或者 Java 应用程序的 JAR/WAR。Helm charts 帮助您定义、安装和升级即使是最复杂的 Kubernetes 应用程序。
什么是 NVIDIA Network Operator?#
NVIDIA Network Operator 利用 Kubernetes 自定义资源和 Operator 框架来配置快速网络、RDMA 和 GPUDirect。Network Operator 的目标是安装在 Kubernetes 集群中启用 RDMA 和 GPUDirect 所需的主机网络组件。它通过在每个集群节点中的辅助网络上为 IO 密集型工作负载配置高速数据路径来实现这一点。
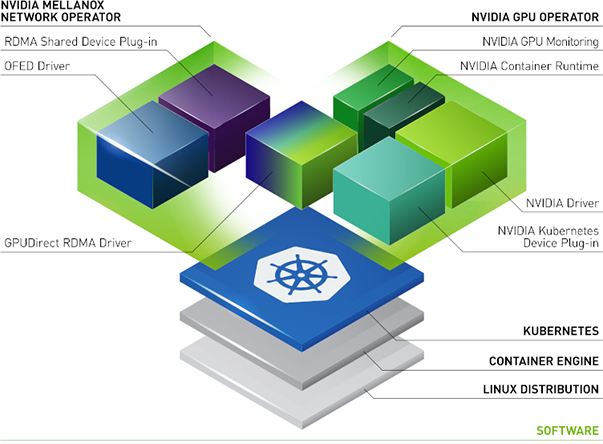
什么是 NVIDIA GPU Operator?#
GPU Operator 允许 Kubernetes 集群的 DevOps 工程师像管理集群中的 CPU 节点一样管理 GPU 节点。管理员无需为 GPU 节点提供特殊的操作系统镜像,而是可以为 CPU 和 GPU 节点部署标准的操作系统镜像,然后依靠 GPU Operator 为 GPU 提供所需的软件组件。
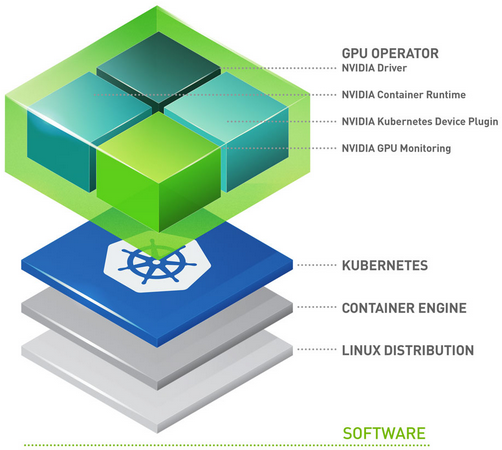
GPU Operator 以 Helm Chart 的形式打包。它安装和管理软件组件的生命周期,以便在 Kubernetes 上运行 GPU 加速的应用程序。
组件如下:
GPU Feature Discovery,它根据 GPU 规格标记工作节点。这使客户能够更精细地选择其应用程序所需的 GPU 资源。
NVIDIA AI Enterprise Guest Driver
Kubernetes Device Plugin,它向 Kubernetes 调度器通告 GPU
NVIDIA Container Toolkit – 允许用户构建和运行 GPU 加速的容器。该工具包包括一个容器运行时库和实用程序,用于自动配置容器以利用 NVIDIA GPU。
DCGM 监控 – 允许监控 Kubernetes 上的 GPU。
GPU Operator 如何帮助 IT 基础设施团队?#
GPU Operator 使 DevOps 团队能够在集群级别使用 Kubernetes 时管理 GPU 的生命周期。无需单独管理每个节点。在没有 GPU Operator 的情况下,基础设施团队必须管理两个操作系统镜像,一个用于 GPU 节点,另一个用于 CPU 节点。当使用 GPU Operator 时,基础设施团队可以使用带有 GPU 工作节点的 CPU 镜像。它还允许客户在不可变的操作系统上运行 GPU 加速的应用程序。更快的节点配置是可实现的,因为 GPU Operator 的构建方式使其能够检测新添加的 GPU 加速 Kubernetes 工作节点。然后自动安装运行 GPU 加速应用程序所需的所有软件组件。GPU Operator 是一个管理所有 K8s 组件(GPU Device Plugin、GPU Feature Discovery、GPU Monitoring Tools、NVIDIA Runtime)的单一工具。重要的是要注意,GPU Operator 也安装 NVIDIA AI Enterprise Guest Driver。