性能对比
在本节中,我们将 VPI 的性能与其他知名的计算机视觉库进行比较。性能数据是按照基准测试方法中描述的方法收集的。
基准测试是在 NVIDIA® Jetson AGX Orin™ 设备上完成的,时钟频率已最大化。
数据表明,VPI 在许多用例中提供了显著的速度提升。
OpenCV
与内置 NVIDIA® CUDA® 支持的 OpenCV 4.5.4 版本进行比较。此版本与 NVIDIA® JetPack™ 附带的 OpenCV 版本相匹配。
由于不同算法性能数据之间存在巨大差异,所有绘图均使用对数刻度。
CPU 性能
OpenCV 和 VPI 的测量均使用一个调度线程完成。许多 OpenCV 算法一旦调度,就会在执行期间使用多个 CPU 核心,但有些可能不会。这与 VPI 形成对比,在 VPI 中,始终使用所有可用的 CPU 核心。
主要的含义是,仅使用一个核心的 OpenCV 算法可以并行运行多个实例,最多可达 CPU 核心数,而不会影响其性能。另一方面,VPI CPU 算法性能随着并行实例数量线性扩展。在这种情况下,VPI 的优势在于性能随着添加的额外核心数量线性增加,而 OpenCV 的单线程算法性能将保持不变。
Jetson AGX Orin CPU 具有十二个核心。
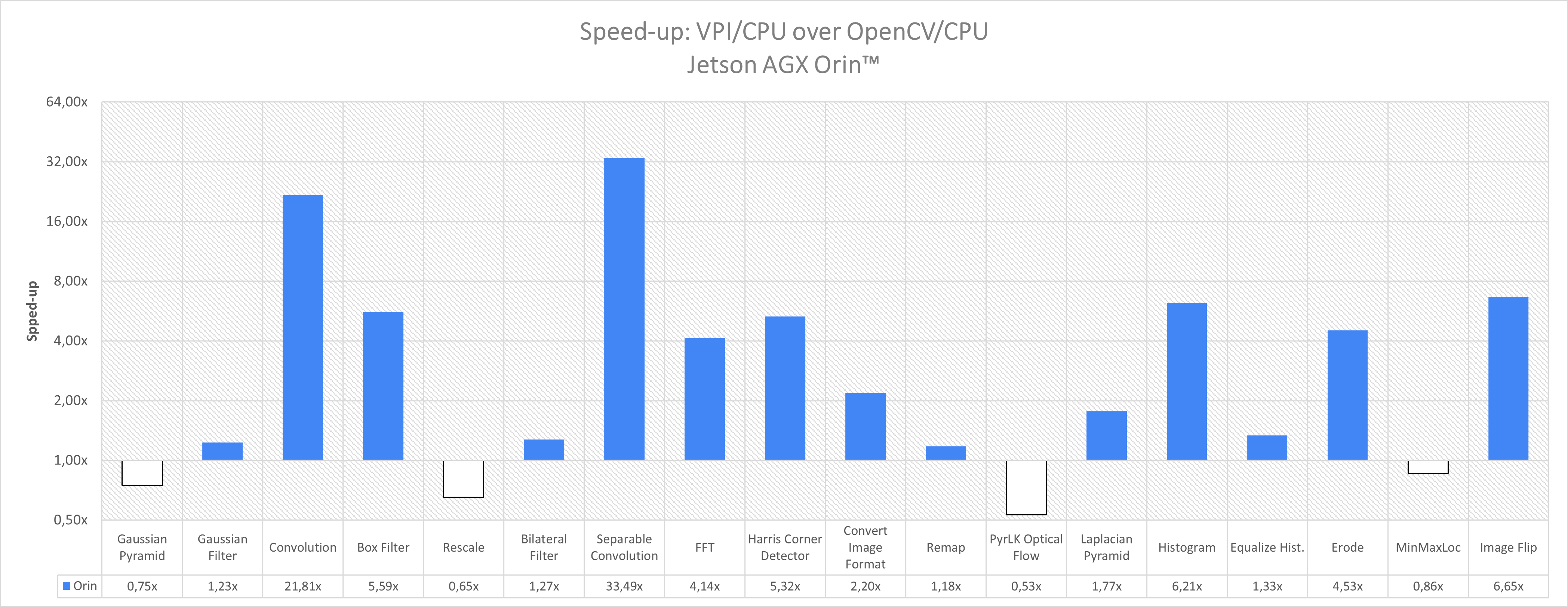
| 算法 | 参数 | OpenCV 4.5.4 CPU | VPI 2.0 CPU | 加速 |
|---|---|---|---|---|
| 高斯金字塔 | 1920x1080 U8 scale=0.5, nlevels=5 | 0.299 毫秒 | 0.399 毫秒 | 0.75 倍 |
| 高斯滤波器 | 1920x1080 U8 3x3 | 0.251 毫秒 | 0.204 毫秒 | 1.23 倍 |
| 卷积 | 1920x1080 U8 3x3 | 6.871 毫秒 | 0.315 毫秒 | 21.81 倍 |
| 方框滤波器 | 1920x1080 U8 3x3 clamp | 1.520 毫秒 | 0.272 毫秒 | 5.59 倍 |
| 重缩放 | 1280x720 到 1920x1080, RGBA8 线性插值 | 4.260 毫秒 | 6.542 毫秒 | 0.65 倍 |
| 双边滤波器 | 1920x1080 U8 3x3 | 2.012 毫秒 | 1.579 毫秒 | 1.27 倍 |
| 可分离卷积 | 1920x1080 U8 11x11 | 18.250 毫秒 | 0.545 毫秒 | 33.49 倍 |
| FFT | 626x626 Real->Complex | 81.060 毫秒 | 19.560 毫秒 | 4.14 倍 |
| Harris 角点检测器 | 1920x1080 U8 grad=3x3, win=3x3 | 39.400 毫秒 | 7.410 毫秒 | 5.32 倍 |
| 转换图像格式 | 1920x1080 NV12_ER 到 RGBA8 | 1.866 毫秒 | 0.850 毫秒 | 2.20 倍 |
| 重映射 | 1920x1080 RGBA8 dense, 线性插值 | 6.280 毫秒 | 5.320 毫秒 | 1.18 倍 |
| 金字塔 LK 光流 | 1920x1080 U8 3x3, 3 级, win=11x11 | 1.610 毫秒 | 3.030 毫秒 | 0.53 倍 |
| 拉普拉斯金字塔 | 1920x1080 U8 -> S16, scale=0.5, 5 级 | 5.100 毫秒 | 2.880 毫秒 | 1.77 倍 |
| 直方图 | 1920x1080 U8, [0,256) 范围, 256 bins | 1.35 毫秒 | 3.3 毫秒 | 0.4 倍 |
| 直方图均衡化 | 1920x1080 U8 | 0.452 毫秒 | 0.339 毫秒 | 1.33 倍 |
| 腐蚀 | 1920x1080 U8 3x3 | 0.530 毫秒 | 0.117 毫秒 | 4.54 倍 |
| 最小值/最大值位置 | 1920x1080 U8 2 个位置, 最小值+最大值 | 0.241 毫秒 | 0.280 毫秒 | 0.86 倍 |
| 图像翻转 | 1920x1080 RGBA8 both | 1.630 毫秒 | 0.245 毫秒 | 6.65 倍 |
CUDA 性能
OpenCV 和 VPI 基准测试均使用一个流进行算法执行。
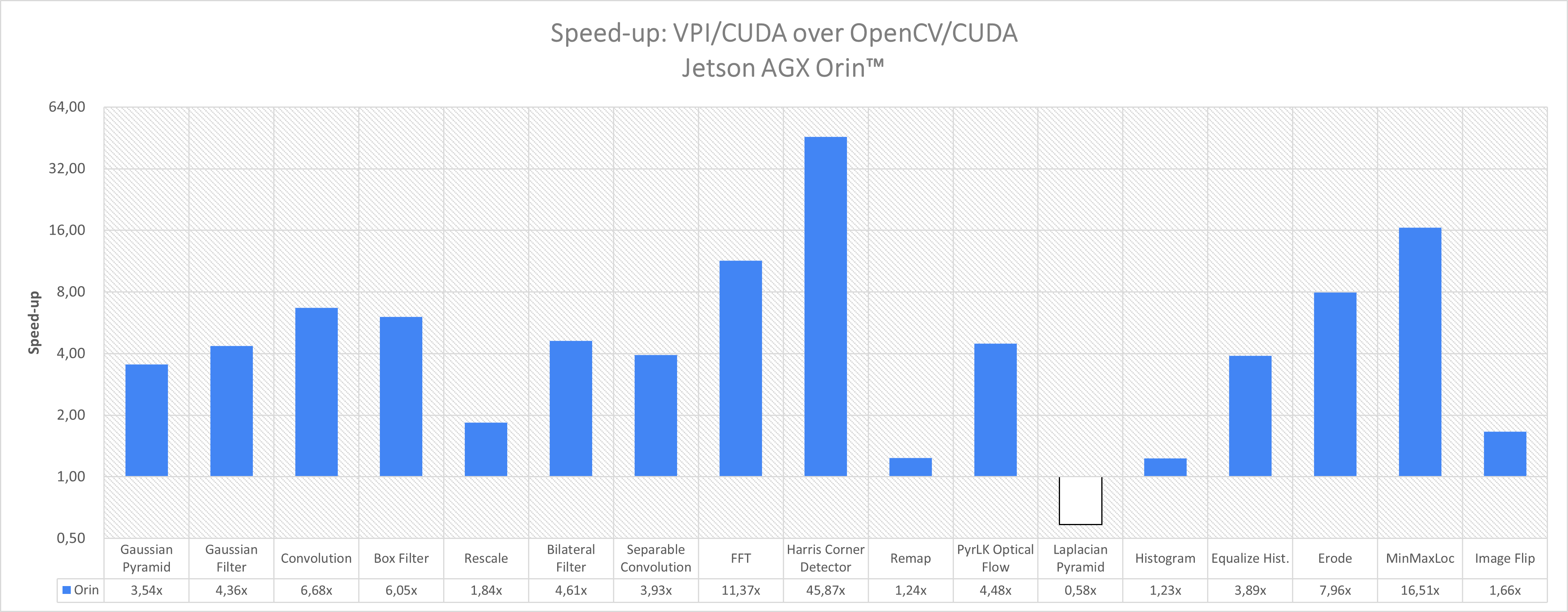
| 算法 | 参数 | OpenCV 4.5.4 CUDA | VPI 2.0 CUDA | 加速 |
|---|---|---|---|---|
| 高斯金字塔 | 1920x1080 U8 scale=0.5, 5 levels | 0.143 毫秒 | 0.040 毫秒 | 3.54 倍 |
| 高斯滤波器 | 1920x1080 U8 3x3 | 0.141 毫秒 | 0.035 毫秒 | 4.36 倍 |
| 卷积 | 1920x1080 U8 3x3 | 0.228 毫秒 | 0.034 毫秒 | 6.68 倍 |
| 方框滤波器 | 1920x1080 U8 3x3 clamp | 0.205 毫秒 | 0.045 毫秒 | 6.06 倍 |
| 重缩放 | 1280x720 -> 1920x1080 RGBA8, 线性插值 | 0.114 毫秒 | 0.078 毫秒 | 1.84 倍 |
| 双边滤波器 | 1920x1080 U8 3x3 | 0.295 毫秒 | 0.064 毫秒 | 4.61 倍 |
| 可分离卷积 | 1920x1080 U8 11x11 | 0.220 毫秒 | 0.056 毫秒 | 3.93 倍 |
| FFT | 626x626 Real->Complex | 2.162 毫秒 | 0.190 毫秒 | 11.37 倍 |
| Harris 角点检测 | 1920x1080 U8 grad=3x3, win=3x3 | 19.480 毫秒 | 0.425 毫秒 | 45.87 倍 |
| 重映射 | 1920x1080 RGBA8, dense, 线性插值 | 0.246 毫秒 | 0.199 毫秒 | 1.24 倍 |
| 金字塔 LK 光流 | 1920x1080 RGBA8 dense, 线性插值 | 0.949 毫秒 | 0.212 毫秒 | 4.48 倍 |
| 拉普拉斯金字塔 | 1920x1080 U8 -> S16, scale=0.5, 5 级 | 0.355 毫秒 | 0.608 毫秒 | 0.58 倍 |
| 直方图 | 1920x1080 U8, [0,256) 范围, 256 bins | 0.041 毫秒 | 0.033 毫秒 | 1.23 倍 |
| 直方图均衡化 | 1920x1080 U8 | 0.350 毫秒 | 0.090 毫秒 | 3.89 倍 |
| 腐蚀 | 1920x1080 U8 3x3 | 0.246 毫秒 | 0.031 毫秒 | 7.96 倍 |
| 最小值/最大值位置 | 1920x1080 U8 2 个位置, 最小值+最大值 | 0.700 毫秒 | 0.042 毫秒 | 16.51 倍 |
| 图像翻转 | 1920x1080 RGBA8 both | 0.155 毫秒 | 0.093 毫秒 | 1.66 倍 |