文本重排序 NIM 概述#
NeMo 文本检索器 NIM (Text Retriever NIM) API 提供对最先进模型的轻松访问,这些模型是企业语义搜索应用的基础构建模块,能够快速且大规模地提供准确的答案。开发人员可以使用这些 API 从头到尾创建强大的副驾驶、聊天机器人和 AI 助手。Text Retriever NIM 模型构建于 NVIDIA 软件平台之上,集成了 CUDA、TensorRT 和 Triton,以提供开箱即用的 GPU 加速。
NeMo Retriever 文本嵌入 NIM - 提升文本问答检索性能,为许多下游 NLP 任务提供高质量的嵌入。有关更多信息,请参阅《文本嵌入 NIM 文档》。
NeMo Retriever 文本重排序 NIM - 包含一个微调的重排序器并提升检索过程,找到最相关的段落,以便在查询 LLM 时作为上下文提供。
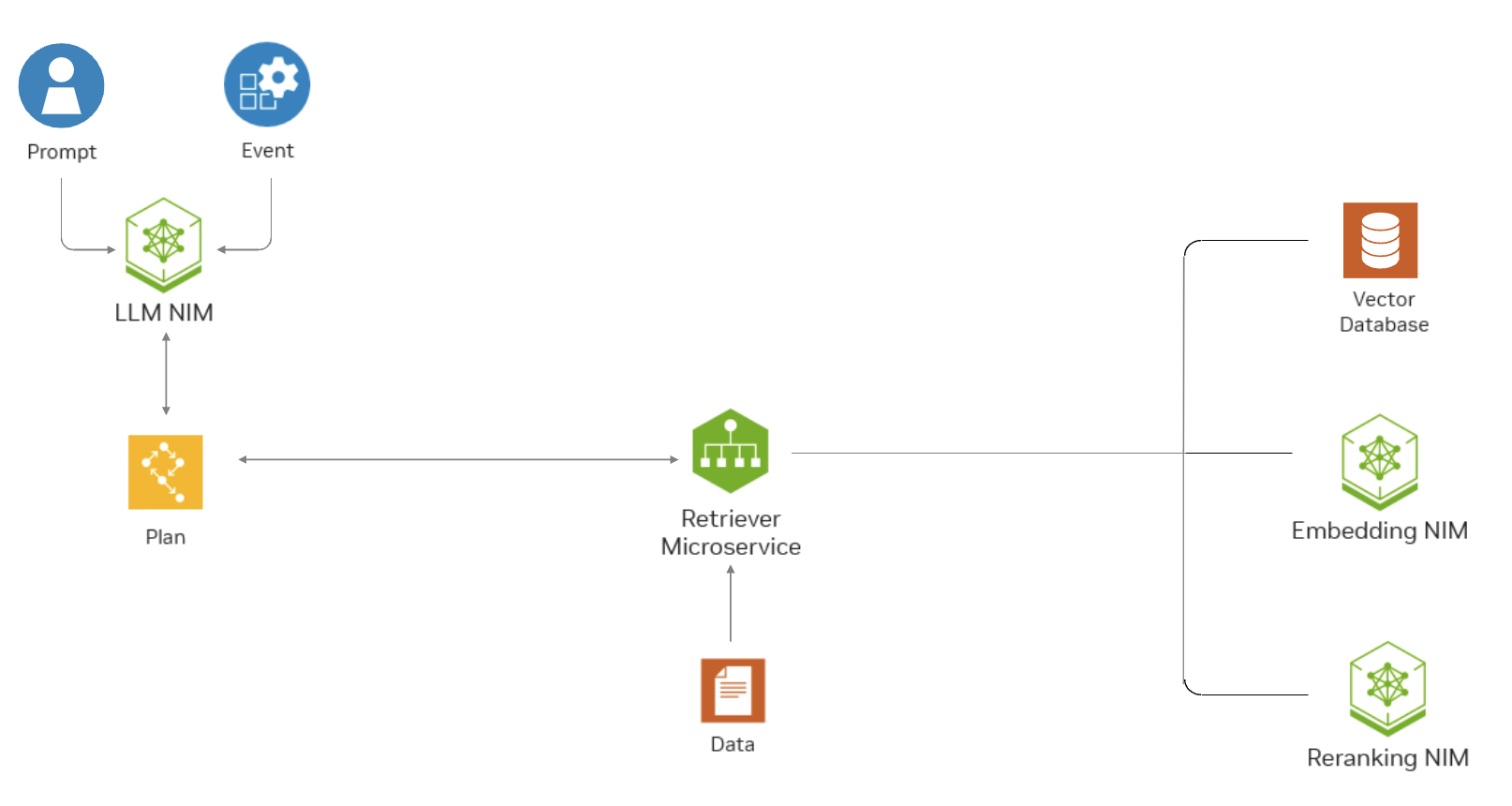
此图表显示了 Text Retriever NIM API 如何帮助基于 RAG 的应用程序根据企业目的的问答查找相关数据。
文本重排序 NIM#
NeMo Retriever 文本重排序 NIM (Text Reranking NIM) 根据引文与查询的匹配程度对其进行重新排序。这是检索过程中的关键步骤,尤其是在检索管道涉及来自不同数据存储的引文时,每个数据存储都有自己衡量相似度的算法。
架构#
每个 Text Reranking NIM 将重排序模型(例如 NV-RerankQA-Mistral4B-v3)打包到 Docker 容器镜像中。所有 Text Reranking NIM Docker 容器均通过 NVIDIA TritonTM Inference Server 加速,并公开与 OpenAI API 标准兼容的 API。Text Reranking NIM 提供基于 Mistral 7B 的微调、即用型重排序器,通过仅使用一半的权重,将尺寸减小到 3.5B 参数。有关受支持模型的完整列表,请参阅支持矩阵。
注意
在我们的命名约定中,我们向上舍入到最接近的整数,因此您可能会在其他文档以及 URL 和文件名中看到提及 Mistral4B。
企业级功能#
Text Reranking NIM 具有企业级功能,例如高性能推理服务器、灵活的集成和企业级安全性。
高性能:Text Reranking NIM 针对使用 NVIDIA TensorRTTM 和 NVIDIA TritonTM Inference Server 的高性能深度学习推理进行了优化。
可扩展部署:Text Reranking NIM 可以从少量用户无缝扩展到数百万用户。
灵活集成:Text Reranking NIM 可以轻松集成到现有的数据管道和应用程序中。除了自定义 NVIDIA 扩展之外,还为开发人员提供了与 OpenAI 兼容的 API。
企业级安全性:Text Reranking NIM 具有安全功能,例如使用 safetensors、持续修补 CVE 以及通过内部渗透测试进行持续监控。
权衡#
重排序在混合检索情况下至关重要,因为它有助于在没有简单方法合并来自不同数据源的结果时将它们组合起来。在具有多个检索文档源的混合管道中,这一点变得很明显,因为密集最近邻搜索使用诸如余弦相似度之类的分数,而稀疏检索器(如 Elasticsearch)可能使用 BM25 分数。考虑到评分量表的差异,仅基于它们进行简单的重新排序不足以确保最佳相关性。
管道 |
平均 recall@5 |
|---|---|
密集 |
0.5699 |
密集 + 重排序 |
0.7070 |
密集 + 稀疏 |
0.5856 |
密集 + 稀疏 + 重排序 |
0.7137 |
上表显示,重排序不仅在组合数据源时提高了 recall,而且在仅使用单个数据存储时也提高了 recall。对于这些实验,数据存储的 top_k 为 100。平均 recall@5 是 FiQA、HotpotQA、BEIR、NQ 和 TechQA 的平均分数。
为了换取这种改进,权衡是成本和延迟的增加。在 H100 上,重排序 500 个段落将花费约 1,750 毫秒。