等价多路径负载分担
Cumulus Linux 默认启用 ECMP。对于具有多个已安装下一跳的 IPv4 和 IPv6 路由,负载分担会自动进行。硬件或路由协议配置决定了负载分担发生的最大路由数。
ECMP 仅在 RIB 中的等价路由上运行。为了使 Cumulus Linux 将路由视为等价路由,这些路由必须
- 源自相同的路由协议。来自不同来源的路由不被视为等价路由。例如,静态路由和 OSPF 路由不被考虑用于 ECMP 负载分担。
- 具有相同的开销。如果来自相同协议的两个路由开销不相等,则只有最佳路由会被安装到路由表中。
当路由表中存在多个路由时,哈希算法决定数据包所走的路径。为了防止数据包乱序,ECMP 基于每流进行哈希;所有具有相同源和目标 IP 地址以及相同源和目标端口的数据包始终哈希到相同的下一跳。ECMP 哈希不会记录哈希到每个下一跳的数据包,也不保证到每个下一跳的流量是均等的。
Cumulus Linux 默认启用 BGP `maximum-paths` 设置并安装多个路由。请参阅 BGP 和 ECMP。
下一跳组
ECMP 路由解析为下一跳组,这些组标识一个或多个下一跳。要查看下一跳信息,请运行 NVUE `nv show router nexthop rib` 或 `nv show router nexthop rib <id>` 命令,或者 `ip nexthop show` 或 `ip nexthop show <id>` 内核命令。
cumulus@leaf01:mgmt:~$ nv show router nexthop rib
Installed - Install state
ID Installed Uptime Vrf Valid Via ViaIntf ViaVrf Depends
--- --------- -------------------- ------- ----- ------------------------- ------------- ------- -------
12 2024-10-22T18:35:53Z default on swp53 default
13 2024-10-22T18:35:53Z default on swp51 default
14 on 2024-10-22T18:35:53Z default on swp54 default
15 on 2024-10-22T18:36:00Z default on lo default
16 on 2024-10-22T18:35:53Z default on eth0 mgmt
17 on 2024-10-22T18:35:53Z default on eth0 mgmt
18 2024-10-22T18:36:00Z default on
19 on 2024-10-22T18:36:00Z default on 192.168.200.1 eth0 mgmt
20 on 2024-10-22T18:36:00Z default on
21 on 2024-10-22T18:36:00Z default on
22 on 2024-10-22T18:36:00Z default on
24 2024-10-22T18:35:53Z default on swp52 default
52 2024-10-22T18:35:55Z default on peerlink.4094 default
62 on 2024-10-22T18:36:02Z default on fe80::4ab0:2dff:feb5:3daa peerlink.4094 default
74 2024-10-22T18:35:59Z default on br_default default
75 2024-10-22T18:35:59Z default on vlan10v0 RED
76 on 2024-10-22T18:35:59Z default on vlan10 RED
77 2024-10-22T18:35:59Z default on vlan10v0 RED
78 2024-10-22T18:35:59Z default on vlan4063_l3 RED
79 2024-10-22T18:35:59Z default on vlan20 RED
80 on 2024-10-22T18:35:59Z default on vlan10 RED
81 on 2024-10-22T18:35:59Z default on vlan20 RED
82 on 2024-10-22T18:35:59Z default on vlan30 BLUE
83 2024-10-22T18:35:59Z default on vlan4006_l3 BLUE
84 on 2024-10-22T18:35:59Z default on vlan30 BLUE
91 2024-10-22T18:35:59Z default on vlan20v0 RED
92 2024-10-22T18:35:59Z default on vlan4063_l3v0 RED
93 2024-10-22T18:35:59Z default on vlan20v0 RED
94 2024-10-22T18:35:59Z default on vlan30v0 BLUE
95 2024-10-22T18:35:59Z default on vlan4006_l3v0 BLUE
96 2024-10-22T18:35:59Z default on vlan30v0 BLUE
100 2024-10-22T18:36:01Z default on vxlan48 default
107 on 2024-10-22T18:36:04Z default on fe80::4ab0:2dff:fe32:2a3f swp52 default
110 on 2024-10-22T18:36:04Z default on 10.10.10.63 vlan4063_l3 RED
111 on 2024-10-22T18:36:04Z default on 10.10.10.63 vlan4006_l3 BLUE
115 on 2024-10-22T18:36:04Z default on fe80::4ab0:2dff:fe41:6b79 swp51 default
125 on 2024-10-22T18:42:21Z default on 107
115
126 on 2024-10-22T18:36:04Z default on 111
127
127 on 2024-10-22T18:36:04Z default on 10.10.10.64 vlan4006_l3 BLUE
128 on 2024-10-22T18:36:04Z default on 110
129
129 on 2024-10-22T18:36:04Z default on 10.10.10.64 vlan4063_l3 RED
140 on 2024-10-22T18:42:34Z default on 10.0.1.34 vlan4006_l3 BLUE
142 on 2024-10-22T18:42:36Z default on 10.0.1.34 vlan4063_l3 RED
...
以下示例显示了下一跳组 108 的信息
cumulus@leaf01:mgmt:~$ nv show router nexthop rib 129
operational
--------------- --------------------
type zebra
ref-count 2
vrf default
valid on
installed on
interface-index 74
uptime 2024-10-22T18:36:04Z
Via
======
Flags - u - unreachable, r - recursive, o - onlink, i - installed, d -
duplicate, c - connected, A - active, Type - Type of nexthop, Weight - Weight to
be used by the nexthop for purposes of ECMP, VRF - VRF to use for egress.
Nexthop Flags Type Weight VRF Interface
----------- ----- ---------- ------ --- -----------
10.10.10.64 oA ip-address 1 RED vlan4063_l3
Via BackupNexthops
=====================
No Data
Depends
==========
No Data
Dependents
=============
Nexthop-group
-------------
128
ECMP 哈希
您可以配置自定义哈希,以指定在以下两者之间的负载均衡期间,哈希计算中包含的内容
- 第 3 层路由的多个下一跳(ECMP 哈希)。
- 属于同一链路聚合组的多个接口(链路聚合或 LAG 哈希)。有关链路聚合哈希,请参阅 链路聚合 - 链路聚合。
对于第 3 层路由的多个下一跳之间的 ECMP 负载均衡,您可以基于以下字段进行哈希
字段 | 默认设置 | NVUE 命令 | traffic.conf |
|---|---|---|---|
| IP 协议 | 开启 | nv set system forwarding ecmp-hash ip-protocol onnv set system forwarding ecmp-hash ip-protocol off | hash_config.ip_prot |
| 源 IP 地址 | 开启 | nv set system forwarding ecmp-hash source-ip onnv set system forwarding ecmp-hash source-ip off | hash_config.sip |
| 目标 IP 地址 | 开启 | nv set system forwarding ecmp-hash destination-ip onnv set system forwarding ecmp-hash destination-ip off | hash_config.dip |
| 源端口 | 开启 | nv set system forwarding ecmp-hash source-port onnv set system forwarding ecmp-hash source-port off | hash_config.sport |
| 目标端口 | 开启 | nv set system forwarding ecmp-hash destination-port onnv set system forwarding ecmp-hash destination-port off | hash_config.dport |
| IPv6 流标签 | 开启 | nv set system forwarding ecmp-hash ipv6-label onnv set system forwarding ecmp-hash ipv6-label off | hash_config.ip6_label |
| 入口接口 | 关闭 | nv set system forwarding ecmp-hash ingress-interface onnv set system forwarding ecmp-hash ingress-interface off | hash_config.ing_intf |
| TEID(请参阅 GTP 哈希) | 关闭 | nv set system forwarding ecmp-hash gtp-teid onnv set system forwarding ecmp-hash gtp-teid off | hash_config.gtp_teid |
| 内部 IP 协议 | 关闭 | nv set system forwarding ecmp-hash inner-ip-protocol onnv set system forwarding ecmp-hash inner-ip-protocol off | hash_config.inner_ip_prot |
| 内部源 IP 地址 | 关闭 | nv set system forwarding ecmp-hash inner-source-ip onnv set system forwarding ecmp-hash inner-source-ip off | hash_config.inner_sip |
| 内部目标 IP 地址 | 关闭 | nv set system forwarding ecmp-hash inner-destination-ip onnv set system forwarding ecmp-hash inner-destination-ip off | hash_config.inner_dip |
| 内部源端口 | 关闭 | nv set system forwarding ecmp-hash inner-source-port onnv set system forwarding ecmp-hash inner-source-port off | hash_config.inner-sport |
| 内部目标端口 | 关闭 | nv set system forwarding ecmp-hash inner-destination-port onnv set system forwarding ecmp-hash inner-destination-port off | hash_config.inner_dport |
| 内部 IPv6 流标签 | 关闭 | nv set system forwarding ecmp-hash inner-ipv6-label onnv set system forwarding ecmp-hash inner-ipv6-label off | hash_config.inner_ip6_label |
以下示例命令从哈希计算中省略了源端口和目标端口
cumulus@switch:~$ nv set system forwarding ecmp-hash source-port off
cumulus@switch:~$ nv set system forwarding ecmp-hash destination-port off
cumulus@switch:~$ nv config apply
当 NVUE 未启用时,请使用以下说明。如果您正在使用 NVUE 配置交换机,则 NVUE 命令会更改 /etc/cumulus/datapath/nvue_traffic.conf 中的设置,这些设置优先于 /etc/cumulus/datapath/traffic.conf 中的设置。
- 编辑
/etc/cumulus/datapath/traffic.conf文件- 取消注释
hash_config.enable = true选项。 - 将
hash_config.sport和hash_config.dport选项设置为false。
- 取消注释
cumulus@switch:~$ sudo nano /etc/cumulus/datapath/traffic.conf
...
# HASH config for ECMP to enable custom fields
# Fields will be applicable for ECMP hash
# calculation
#Note : Currently supported only for MLX platform
# Uncomment to enable custom fields configured below
hash_config.enable = true
#hash Fields available ( assign true to enable)
#ip protocol
hash_config.ip_prot = true
#source ip
hash_config.sip = true
#destination ip
hash_config.dip = true
#source port
hash_config.sport = false
#destination port
hash_config.dport = false
...
运行
echo 1 > /cumulus/switchd/ctrl/hash_config_reload命令。此命令不会导致任何流量中断。cumulus@switch:~$ echo 1 > /cumulus/switchd/ctrl/hash_config_reload
Cumulus Linux 默认启用对称哈希。请确保源 IP 和目标 IP 字段的设置匹配,并且源端口和目标端口字段的设置匹配;否则 Cumulus Linux 会自动禁用对称哈希。如有必要,您可以在 /etc/cumulus/datapath/traffic.conf 文件中手动禁用对称哈希,方法是将 symmetric_hash_enable = FALSE 设置为 FALSE。
GTP 哈希
GTP 在移动运营商网络的核心内传输移动数据。从蜂窝站点到计算节点的 5G 移动核心集群中的流量具有相同的源和目标 IP 地址。识别单个流的唯一方法是使用 GTP TEID。启用 GTP 哈希会将 TEID 添加为哈希参数,并帮助网络中的 Cumulus Linux 交换机在 ECMP 路由上均匀分配移动数据流量。
Cumulus Linux 支持基于 TEID 的 ECMP 哈希,用于
有关链路聚合组上流量的基于 TEID 的负载均衡,请参阅 链路聚合 - 链路聚合。
仅当从端口出口的外部标头是 GTP 封装的,并且入口数据包是 GTP-U 数据包或 VXLAN 封装的 GTP-U 数据包时,GTP 基于 TEID 的 ECMP 哈希才适用。
- Cumulus Linux 在 NVIDIA Spectrum-2 及更高版本上支持 GTP 哈希。
- GTP-C 数据包不属于 GTP 哈希的一部分。
要启用基于 TEID 的 ECMP 哈希
cumulus@switch:~$ nv set system forwarding ecmp-hash gtp-teid on
cumulus@switch:~$ nv config apply
要禁用基于 TEID 的 ECMP 哈希,请运行 nv set system forwarding ecmp-hash gtp-teid off 命令。
当 NVUE 未启用时,请使用以下说明。如果您正在使用 NVUE 配置交换机,则 NVUE 命令会更改 /etc/cumulus/datapath/nvue_traffic.conf 中的设置,这些设置优先于 /etc/cumulus/datapath/traffic.conf 中的设置。
编辑
/etc/cumulus/datapath/traffic.conf文件,并将hash_config.gtp_teid参数更改为truecumulus@switch:~$ sudo nano /etc/cumulus/datapath/traffic.conf ... #GTP-U teid hash_config.gtp_teid = true运行
echo 1 > /cumulus/switchd/ctrl/hash_config_reload命令。此命令不会导致任何流量中断。cumulus@switch:~$ echo 1 > /cumulus/switchd/ctrl/hash_config_reload
要禁用基于 TEID 的 ECMP 哈希,请将 hash_config.gtp_teid 参数设置为 false,然后重新加载配置。
要显示基于 TEID 的 ECMP 哈希已启用,请运行以下命令
cumulus@switch:~$ nv show system forwarding ecmp-hash
applied description
----------------- ------- -----------------------------------
destination-ip on Destination IPv4/IPv6 Address
destination-port on TCP/UDP destination port
gtp-teid on GTP-U TEID
...
ECMP 哈希桶
当路由表中存在多个路由时,Cumulus Linux 会将每个路由分配到一个 ECMP 桶。当 ECMP 哈希执行时,哈希结果决定了要使用的桶。
在以下示例中,存在四个下一跳。三个不同的流哈希到不同的哈希桶。每个下一跳都到一个唯一的哈希桶。
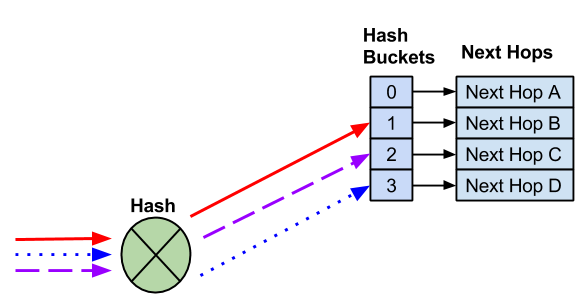
添加下一跳会创建一个新的哈希桶。下一跳到哈希桶的分配以及哈希结果有时会随着下一跳的添加而改变。
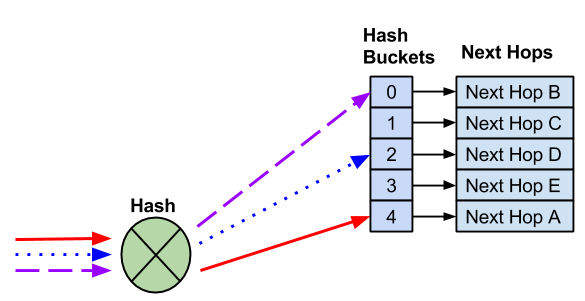
添加新的下一跳后,会出现一个新的哈希桶。因此,哈希和哈希桶分配会发生变化,因此现有流会转到不同的下一跳。
当您删除下一跳时,剩余的哈希桶分配可能会更改,这也可能更改为现有流选择的下一跳。
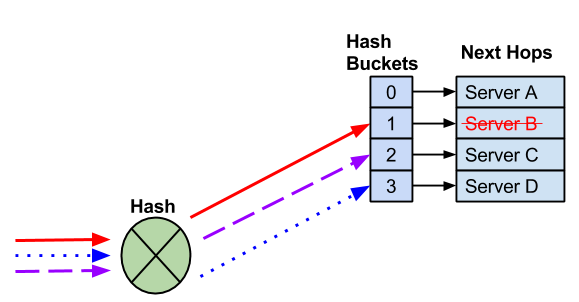
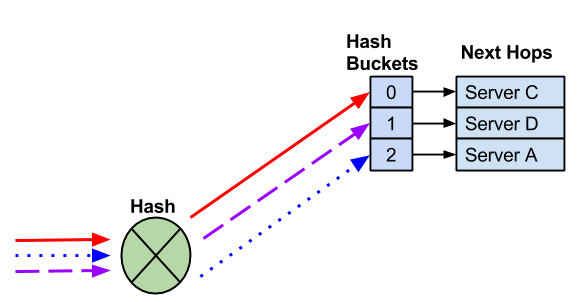
下一跳失败,这将删除下一跳和哈希桶。Cumulus Linux 可能会重新分配剩余的下一跳。
在大多数情况下,修改哈希桶对流量流没有影响,因为交换机将流量转发到单个终端主机。在多个终端主机使用相同 IP 地址(任播)的部署中,您必须使用弹性哈希。
唯一哈希种子
您可以为每个交换机配置唯一的哈希种子,以防止哈希极化,这是一种网络拥塞,当多个数据流尝试使用相同的交换机端口到达交换机时会发生这种情况。
您可以设置介于 0 和 4294967295 之间的哈希种子值。如果您不指定值,switchd 会创建一个随机生成的种子。
要配置哈希种子
cumulus@switch:~$ nv set system forwarding hash-seed 50
cumulus@switch:~$ nv config apply
如果您未启用 NVUE,请使用以下说明。如果您正在使用 NVUE 配置交换机,则 NVUE 命令会更改 /etc/cumulus/datapath/nvue_traffic.conf 中的设置,这些设置优先于 /etc/cumulus/datapath/traffic.conf 中的设置。
编辑 /etc/cumulus/datapath/traffic.conf 文件以更改 ecmp_hash_seed 参数,然后重启 switchd。
cumulus@switch:~$ sudo nano /etc/cumulus/datapath/traffic.conf
...
#Specify the hash seed for Equal cost multipath entries
# and for custom ecmp and lag hash
# Default value: random
# Value Range: {0..4294967295}
ecmp_hash_seed = 50
...
cumulus@switch:~$ sudo systemctl restart switchd.service
重启 switchd 服务会导致所有网络端口重置,中断网络服务,并重置交换机硬件配置。
cl-ecmpcalc
运行 cl-ecmpcalc 命令以确定硬件哈希结果。例如,您可以查看流在网络中采用的路径。您必须提供哈希中的所有字段,包括入口接口、第 3 层源 IP、第 3 层目标 IP、第 4 层源端口和第 4 层目标端口。
cl-ecmpcalc 仅支持在端口选项卡文件中转换为单个物理端口的输入接口,例如物理交换机端口 (swp)。您不能指定虚拟接口,如桥接器、链路聚合或子接口。
cumulus@switch:~$ sudo cl-ecmpcalc -i swp1 -s 10.0.0.1 -d 10.0.0.1 -p tcp --sport 20000 --dport 80
ecmpcalc: will query hardware
swp3
如果您省略一个字段,cl-ecmpcalc 将会失败。
cumulus@switch:~$ sudo cl-ecmpcalc -i swp1 -s 10.0.0.1 -d 10.0.0.1 -p tcp
ecmpcalc: will query hardware
usage: cl-ecmpcalc [-h] [-v] [-p PROTOCOL] [-s SRC] [--sport SPORT] [-d DST]
[--dport DPORT] [--vid VID] [-i IN_INTERFACE]
[--sportid SPORTID] [--smodid SMODID] [-o OUT_INTERFACE]
[--dportid DPORTID] [--dmodid DMODID] [--hardware]
[--nohardware] [-hs HASHSEED]
[-hf HASHFIELDS [HASHFIELDS ...]]
[--hashfunction {crc16-ccitt,crc16-bisync}] [-e EGRESS]
[-c MCOUNT]
cl-ecmpcalc: error: --sport and --dport required for TCP and UDP frames
弹性哈希
在 Cumulus Linux 中,当下一跳失败或您从 ECMP 池中删除下一跳时,哈希或哈希桶分配可能会更改。弹性哈希是管理 ECMP 组的另一种方法。Cumulus Linux 使用下一跳的哈希标头字段将下一跳分配到桶,并使用生成的哈希值索引到 2^n 哈希桶表中。由于给定流中的所有数据包都具有相同的标头哈希值,因此它们都使用相同的流桶。
- 弹性哈希同时支持 IPv4 和 IPv6 路由。
- 弹性哈希在您删除下一跳时防止中断,但在您添加下一跳时不能防止中断。
NVIDIA Spectrum ASIC 将数据包分配到哈希桶,并将哈希桶分配到下一跳。ASIC 还运行一个后台线程,用于监视桶,并可以在下一跳之间迁移桶以重新平衡负载。
- 当您删除下一跳时,Cumulus Linux 会将分配的桶分发给剩余的下一跳。
- 当您添加下一跳时,在后台线程重新平衡负载之前,Cumulus Linux 不会将任何桶分配给新的下一跳。
- 仅当存在可用的非活动哈希桶时,负载才会在活动流计时器到期时重新平衡;新的下一跳可能会保持未填充状态,直到活动流计时器中设置的期间到期。
- 当不平衡计时器到期且负载未平衡时,线程会将桶迁移到不同的下一跳以重新平衡负载。
任何流都可以迁移到任何下一跳,具体取决于流活动和负载均衡条件。随着时间的推移,流可能会被固定,这是默认设置和行为。
当您启用弹性哈希时,Cumulus Linux 会以轮询方式将下一跳分配到固定数量的桶。在本示例中,有 12 个桶和四个下一跳。
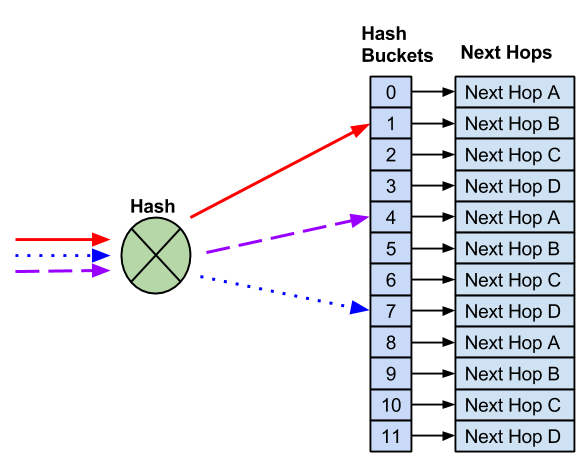
与默认 ECMP 哈希不同,当您需要删除下一跳时,哈希桶的数量不会改变。
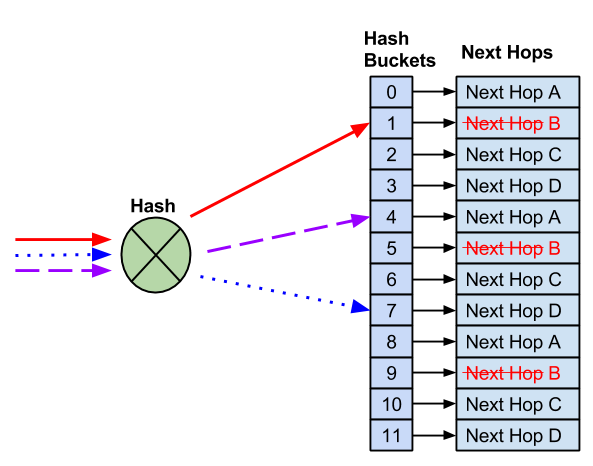
使用 12 个桶和四个下一跳,剩余的下一跳会替换失败的下一跳,而不是减少桶的数量,这会影响到已知良好主机的流。
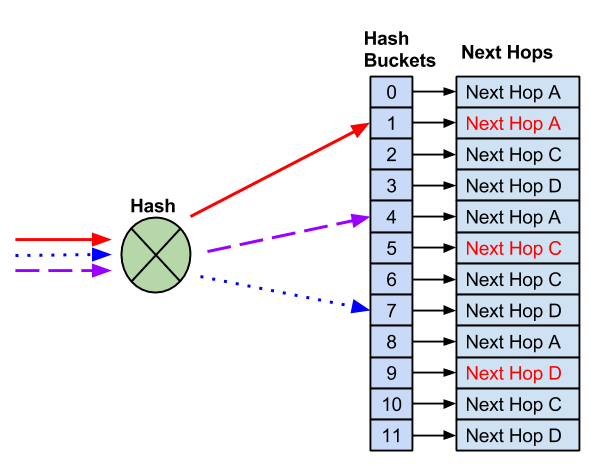
在您删除失败的下一跳后,剩余的下一跳会替换它。这可以防止对任何哈希到工作下一跳的流产生影响。
当您添加新的下一跳时,弹性哈希不能防止对现有流的可能影响。因为桶的数量是固定的,所以新的下一跳需要将下一跳重新分配到桶。
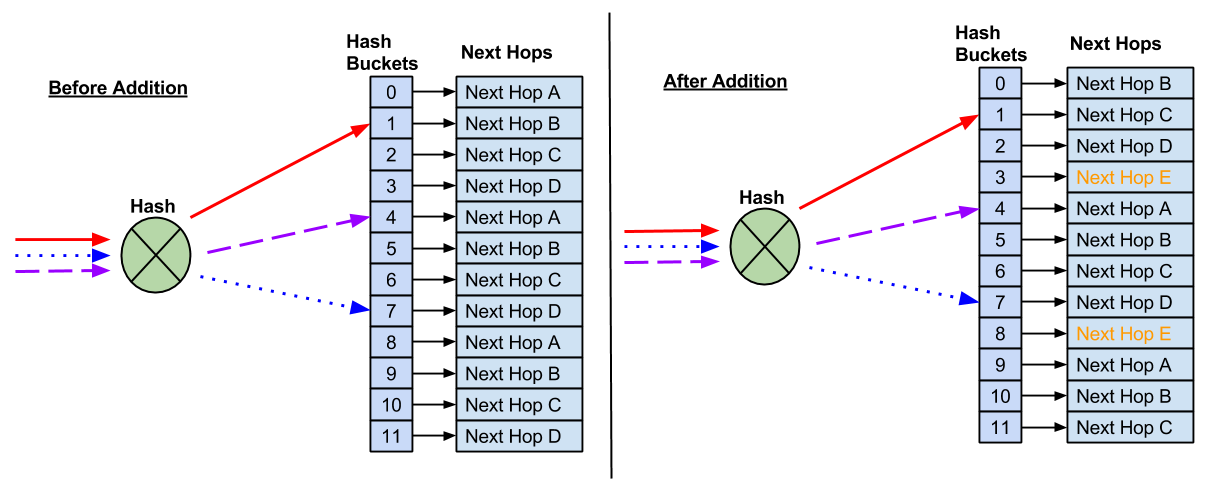
因此,某些流哈希到新的下一跳,这可能会影响任播部署。
Cumulus Linux 默认情况下不启用弹性哈希。当您启用弹性哈希时,所有 ECMP 组共享 65,536 个桶。ECMP 组是多个 ECMP 路由引用的唯一下一跳列表。
一个 ECMP 路由被视为具有多个下一跳的单个路由。
所有 ECMP 路由必须使用相同数量的桶(您无法配置每个 ECMP 路由的桶数)。
更大数量的 ECMP 桶减少了向 ECMP 路由添加新下一跳的影响。但是,系统支持的 ECMP 路由较少。如果您安装了最大数量的 ECMP 路由,则新的 ECMP 路由会记录错误并且不会安装。
您可以根据 ECMP 桶大小的变化配置路由和 MAC 地址硬件资源。请参阅 NVIDIA Spectrum 路由资源。
要启用弹性哈希
编辑
/etc/cumulus/datapath/traffic.conf文件以取消注释并将resilient_hash_enable参数设置为TRUE。您还可以将
resilient_hash_entries_ecmp参数设置为用于所有 ECMP 路由的哈希桶数量。在 Spectrum 交换机上,您可以将桶数设置为 64、512、1024、2048 或 4096。在 NVIDIA Spectrum-2 及更高版本上,您可以将桶数设置为 64、128、256、512、1024、2048 或 4096。默认值为 64。# Enable resilient hashing resilient_hash_enable = TRUE # Resilient hashing flowset entries per ECMP group # # Mellanox Spectrum platforms: # Valid values - 64, 512, 1024, 2048, 4096 # # Mellanox Spectrum2/3 platforms # Valid values - 64, 128, 256, 512, 1024, 2048, 4096 # # resilient_hash_entries_ecmp = 64重启
switchd服务
cumulus@switch:~$ sudo systemctl restart switchd.service
重启 switchd 服务会导致所有网络端口重置,中断网络服务,并重置交换机硬件配置。
- 硬件中的弹性哈希不适用于下一跳组;当下一跳集更改时,交换机会将流重新映射到新的下一跳。要解决此问题,请配置 zebra 不要使用以下 vtysh 命令在内核中安装下一跳 ID
cumulus@switch:~$ sudo vtysh
switch# configure terminal
switch(config)# zebra nexthop proto only
switch(config)# exit
switch# write memory
switch# exit
cumulus@switch:~$
注意事项
当路由器添加或删除 ECMP 路径,或者当下一跳 IP 地址、接口或隧道发生变化时,IPv6 前缀的下一跳信息可能会发生变化。FRR 从内核中删除到该前缀的现有路由,然后添加包含所有相关新信息的新的路由。在某些情况下,Cumulus Linux 不会为 IPv6 流维护弹性哈希。
要解决此问题,您可以启用 IPv6 路由替换。
对于某些配置,IPv6 路由替换可能会导致不正确的转发决策和流量丢失。例如,对于某个目标,可能存在具有网关值(带有出站接口)的下一跳,或者仅存在出站接口本身,而没有网关地址的下一跳。如果同一目标的两种类型的下一跳都存在,则路由替换无法正常运行;Cumulus Linux 会添加一个额外的路由条目和下一跳,但不会删除之前的路由条目和下一跳。
要启用 IPv6 路由替换选项
在
/etc/frr/daemons文件中,将配置选项--v6-rr-semantics添加到 zebra 守护程序定义中。例如cumulus@switch:~$ sudo nano /etc/frr/daemons ... vtysh_enable=yes zebra_options=" -M cumulus_mlag -M snmp -A 127.0.0.1 --v6-rr-semantics -s 90000000" bgpd_options=" -M snmp -A 127.0.0.1" ospfd_options=" -M snmp -A 127.0.0.1" ...
使用此命令重启 FRR
cumulus@switch:~$ sudo systemctl restart frr.service
重启 FRR 会重启所有已启用并正在运行的路由协议守护程序。
要验证 IPv6 路由替换,请运行 systemctl status frr 命令
cumulus@switch:~$ systemctl status frr
● frr.service - FRRouting
Loaded: loaded (/lib/systemd/system/frr.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2020-02-03 20:02:33 UTC; 3min 8s ago
Docs: https://frrouting.readthedocs.io/en/latest/setup.html
Process: 4675 ExecStart=/usr/lib/frr/frrinit.sh start (code=exited, status=0/SUCCESS)
Memory: 14.4M
CGroup: /system.slice/frr.service
├─4685 /usr/lib/frr/watchfrr -d zebra bgpd staticd
├─4701 /usr/lib/frr/zebra -d -M snmp -A 127.0.0.1 --v6-rr-semantics -s 90000000
├─4705 /usr/lib/frr/bgpd -d -M snmp -A 127.0.0.1
└─4711 /usr/lib/frr/staticd -d -A 127.0.0.1
自适应路由
自适应路由是一种负载均衡功能,它通过基于交换机的状态(例如队列占用率和端口利用率)动态选择转发路径,来提高符合条件的 IP 数据包的网络利用率。
使用自适应路由的好处包括
- 交换机可以将符合自适应路由条件的 IP 数据包通过所有可用的 ECMP 成员端口转发,以最大化总流量吞吐量,同时消除潜在的 ECMP 流冲突。
- 交换机在可用的 IP 下一跳之间平均分配(或根据其权重)传入流量,这有助于最大限度地减少延迟和网络拥塞。
- 如果一个或多个流的累积速率超过了单个上行链路端口的链路带宽,则自适应路由可以在多个上行链路端口之间动态分配流量;这些流的可用带宽不限于单个上行链路端口的链路带宽。
使用自适应路由,交换机基于每个数据包将数据包转发到负载较轻的路径,以最佳地利用结构资源并避免拥塞。端口选择的更改决策设置为一微秒;您无法更改它。
Cumulus Linux 支持用于自适应路由的 ECMP 资源优化,这解决了瞬态场景中路由协议收敛期间大量 ECMP 组的需求。
Cumulus Linux 支持以下自适应路由
- 具有 Spectrum-4 ASIC 的交换机,速度为 400G 和 200G。
- RoCE2 单播流量。
- VXLAN 封装的 RoCE 流量。
- 第 3 层接口。
- 默认 VRF 中的下一跳路由器接口。
- NVIDIA Spectrum-X 网络平台,可加速 AI 网络性能。有关 NVIDIA Spectrum-X 的信息,请参阅 NVIDIA Spectrum-X 网络平台。
- 自适应路由不使用弹性哈希。
- Cumulus Linux 不支持在第 3 层子接口、SVI、bond 或 bond 成员上使用自适应路由。
- Spectrum-4 交换机不支持在 800G 链路上使用自适应路由。
Cumulus Linux 还支持带有自适应路由的 BGP W-ECMP;请参阅 BGP 加权等价多路径。
启用自适应路由
要启用自适应路由
在属于同一 ECMP 路由的所有端口上运行 nv set interface <interface> router adaptive-routing enable on 命令。NVUE 在端口上设置自适应路由并启用自适应路由功能。
cumulus@switch:~$ nv set interface swp51 router adaptive-routing enable on
cumulus@switch:~$ nv set interface swp52 router adaptive-routing enable on
cumulus@switch:~$ nv config apply
要禁用自适应路由,请运行 nv set router adaptive-routing enable off 命令。要在特定端口上禁用自适应路由,请运行 nv set interface <interface> router adaptive-routing enable off 命令。
启用或禁用自适应路由会重启 switchd 服务,这将导致所有网络端口重置、中断网络服务并重置交换机硬件配置。
编辑 /etc/cumulus/switchd.d/adaptive_routing.conf 文件
- 将
adaptive_routing.enable参数设置为TRUE以启用自适应路由功能。 - 在
Per-port configuration部分中,将interface.<port>.adaptive_routing.enable参数设置为TRUE,以在属于同一 ECMP 路由的所有端口上启用自适应路由。
cumulus@switch:~$ sudo nano /etc/cumulus/switchd.d/adaptive_routing.conf
## Global adaptive-routing enable/disable setting
adaptive_routing.enable = TRUE
...
## Per-port configuration
interface.swp51.adaptive_routing.enable = TRUE
interface.swp51.adaptive_routing.link_util_thresh = 70
interface.swp52.adaptive_routing.enable = TRUE
interface.swp52.adaptive_routing.link_util_thresh = 70
...
使用 sudo systemctl restart switchd.service 命令重启 switchd。
- 要禁用自适应路由,请在
/etc/cumulus/switchd.d/adaptive_routing.conf文件中将adaptive_routing.enable参数设置为FALSE。 - 要在特定端口上禁用自适应路由,请在
/etc/cumulus/switchd.d/adaptive_routing.conf文件中将interface.<port>.adaptive_routing.enable参数设置为FALSE。
当您启用自适应路由时,Cumulus Linux 会为您的交换机 ASIC 类型使用默认配置文件设置。您无法更改默认配置文件设置。如果您需要调整设置,请联系 NVIDIA 客户支持。
链路利用率
链路利用率是自适应路由决策中的参数之一,当链路利用率超过阈值时会触发自适应路由。接口上的默认链路利用率阈值百分比为 70。您可以将该百分比更改为介于 1 到 100 之间的值。
默认情况下,链路利用率处于关闭状态;您必须启用全局链路利用率设置才能使用在自适应路由接口上设置的链路利用率阈值。您无法按接口启用或禁用链路利用率。
在 Cumulus Linux 5.5 及更早版本中,链路利用率默认处于开启状态。如果您在之前的版本中配置了链路利用率,请务必在升级后启用链路利用率。
以下示例启用链路利用率并使用默认链路利用率阈值百分比 70
cumulus@switch:~$ nv set router adaptive-routing link-utilization-threshold on
cumulus@switch:~$ nv config apply
以下示例将 swp51 上的链路利用率阈值百分比更改为 100,并启用链路利用率
cumulus@switch:~$ nv set interface swp51 router adaptive-routing link-utilization-threshold 100
cumulus@switch:~$ nv set router adaptive-routing link-utilization-threshold on
cumulus@switch:~$ nv config apply
启用或禁用链路利用率会重新加载 switchd 服务。
编辑 /etc/cumulus/switchd.d/adaptive_routing.conf 文件以设置
interface.<interface>.adaptive_routing.link_util_thresh为介于 1 和 100 之间的值。adaptive_routing.link_util_threshold_disabled为 FALSE。
cumulus@switch:~$ sudo nano /etc/cumulus/switchd.d/adaptive_routing.conf
## Global adaptive-routing enable/disable setting
adaptive_routing.enable = TRUE
## Global Link-utilization-threshold on/off
adaptive_routing.link_utilization_threshold_disabled = FALSE
## Per-port configuration
interface.swp51.adaptive_routing.enable = TRUE
interface.swp51.adaptive_routing.link_util_thresh = 100
使用 sudo systemctl reload switchd.service 命令重新加载 switchd。
配置示例
以下示例在 swp1 和 swp2 上启用自适应路由。全局链路利用率处于关闭状态(默认设置)。
cumulus@switch:~$ nv set interface swp51 router adaptive-routing enable on
cumulus@switch:~$ nv set interface swp52 router adaptive-routing enable on
cumulus@switch:~$ nv config apply
以下示例在 swp51 和 swp52 上启用自适应路由,将 swp51 和 swp52 上的链路利用率阈值百分比设置为 100,并启用全局链路利用率
cumulus@switch:~$ nv set interface swp51 router adaptive-routing enable on
cumulus@switch:~$ nv set interface swp52 router adaptive-routing enable on
cumulus@switch:~$ nv set interface swp51 router adaptive-routing link-utilization-threshold 100
cumulus@switch:~$ nv set interface swp52 router adaptive-routing link-utilization-threshold 100
cumulus@switch:~$ nv set router adaptive-routing link-utilization-threshold on
cumulus@switch:~$ nv config apply
以下示例在 swp51 和 swp52 上启用自适应路由。全局链路利用率处于关闭状态(默认设置)。
cumulus@switch:~$ sudo nano /etc/cumulus/switchd.d/ad.aptive_routing.conf
## Global adaptive-routing enable/disable setting
adaptive_routing.enable = TRUE
## Global Link-utilization-threshold on/off
adaptive_routing.link_utilization_threshold_disabled = TRUE
## Per-port configuration
interface.swp51.adaptive_routing.enable = TRUE
interface.swp51.adaptive_routing.link_util_thresh = 0
interface.swp52.adaptive_routing.enable = TRUE
interface.swp52.adaptive_routing.link_util_thresh = 0
...
使用 sudo systemctl reload switchd.service 命令重新加载 switchd。
以下示例在 swp51 和 swp52 上启用自适应路由,将 swp51 和 swp52 上的链路利用率阈值百分比设置为 100,并启用全局链路利用率。
cumulus@switch:~$ sudo nano /etc/cumulus/switchd.d/adaptive_routing.conf
## Global adaptive-routing enable/disable setting
adaptive_routing.enable = TRUE
## Global Link-utilization-threshold on/off
adaptive_routing.link_utilization_threshold_disabled = FALSE
## Per-port configuration
interface.swp51.adaptive_routing.enable = TRUE
interface.swp51.adaptive_routing.link_util_thresh = 100
interface.swp52.adaptive_routing.enable = TRUE
interface.swp52.adaptive_routing.link_util_thresh = 100
使用 sudo systemctl reload switchd.service 命令重新加载 switchd。
显示自适应路由设置
要显示自适应路由设置,请运行 nv show router adaptive-routing 命令
cumulus@leaf01:mgmt:~$ nv show router adaptive-routing
operational applied
-------------------------- ------------ -------
enable on off
要显示接口的自适应路由配置,请运行 nv show interface <interface> router adaptive-routing。
注意事项
IPv6 下一跳首选项
当接收到同时具有链路本地和全局下一跳的路由时,Cumulus Linux 使用 IPv6 链路本地地址作为 BGP 下一跳。要配置 BGP 对等以优先选择全局下一跳地址,请在应用于对等方的入站路由映射中配置 ipv6-nexthop-prefer-global 选项。当与同一路由器建立多个启用了自适应路由的 BGP 对等连接,或与共享同一 MAC 地址或物理接口的接口上的同一路由器建立多个对等连接时,请使用此配置。请参阅 设置 IPv6 优先全局。