核心 Colang 概念
本指南建立在Hello World 指南的基础上,并介绍了您应该理解的核心 Colang 概念,以便开始使用 NeMo Guardrails。
前提条件
此“Hello World” guardrails 配置使用 OpenAI gpt-3.5-turbo-instruct 模型。
安装
openai包
pip install openai
设置
OPENAI_API_KEY环境变量
export OPENAI_API_KEY=$OPENAI_API_KEY # Replace with your own key
如果您在 notebook 中运行此代码,请修补 AsyncIO 循环。
import nest_asyncio
nest_asyncio.apply()
什么是 Colang?
Colang 是一种用于会话应用程序的建模语言。使用 Colang 设计用户和机器人之间对话应如何进行。
注意:在本指南中,机器人指的是整个基于 LLM 的会话应用程序。
核心概念
在 Colang 中,两个核心概念是消息和流程。
消息
在 Colang 中,对话被建模为用户和机器人之间消息的交换。交换的消息具有话语,例如“你能做什么?”,以及规范形式,例如 ask about capabilities。规范形式是将话语意译为标准形式(通常更短的形式)。
使用 Colang,您可以定义对您的基于 LLM 的应用程序重要的用户消息。例如,在“Hello World”示例中,express greeting 用户消息定义为
define user express greeting
"Hello"
"Hi"
"Wassup?"
express greeting 代表规范形式,“Hello”、“Hi”和“Wassup?”代表示例话语。示例话语的作用是教导机器人已定义规范形式的含义。
您还可以定义机器人消息,例如机器人应如何与用户交谈。例如,在“Hello World”示例中,express greeting 和 ask how are you 机器人消息定义为
define bot express greeting
"Hey there!"
define bot ask how are you
"How are you doing?"
如果为规范形式提供了多个话语,则当使用该消息时,机器人会使用随机话语。
如果您想知道用户消息规范形式是否与经典意图相同,答案是肯定的。您可以将它们视为意图。但是,当使用它们时,机器人不受限于仅使用预定义的列表。
流程
在 Colang 中,流程表示用户和机器人之间交互的模式。在最简单的形式中,它们是用户和机器人消息的序列。在“Hello World”示例中,greeting 流程定义为
define flow greeting
user express greeting
bot express greeting
bot ask how are you
此流程指示机器人在每次用户向机器人问候时,都以问候语回应并询问用户的感受。
Guardrails(护栏)
消息和流程为定义 guardrails(或简称为 rails)提供了核心构建块。先前的 greeting 流程实际上是一个 rail,用于指导 LLM 如何响应问候语。
它是如何工作的?
本节解答以下问题
用户和机器人消息定义是如何使用的?
LLM 如何被提示以及进行了多少次调用?
我可以使用没有示例话语的机器人消息吗?
让我们使用以下问候语作为示例。
from nemoguardrails import RailsConfig, LLMRails
config = RailsConfig.from_path("./config")
rails = LLMRails(config)
response = rails.generate(messages=[{
"role": "user",
"content": "Hello!"
}])
print(response["content"])
Hello World!
How are you doing?
ExplainInfo 类
要获取有关 LLM 调用的信息,请调用 LLMRails 类的 explain 函数。
# Fetch the `ExplainInfo` object.
info = rails.explain()
Colang 历史记录
使用 colang_history 函数检索 Colang 格式的对话历史记录。这向我们展示了确切的消息及其规范形式
print(info.colang_history)
user "Hello!"
express greeting
bot express greeting
"Hello World!"
bot ask how are you
"How are you doing?"
LLM 调用
使用 print_llm_calls_summary 函数列出已进行的 LLM 调用的摘要
info.print_llm_calls_summary()
Summary: 1 LLM call(s) took 0.48 seconds and used 524 tokens.
1. Task `generate_user_intent` took 0.48 seconds and used 524 tokens.
info 对象还包含一个 info.llm_calls 属性,其中包含有关每次 LLM 调用的详细信息。该属性在后续指南中描述。
过程
一旦收到来自用户的输入消息,多步骤过程就开始了。
步骤 1:计算用户消息的规范形式
在从用户收到话语(例如,先前示例中的“Hello!”)后,guardrails 实例使用 LLM 计算相应的规范形式。
注意:NeMo Guardrails 使用面向任务的交互模型与 LLM。每次调用 LLM 时,它都会使用特定的任务提示模板,例如
generate_user_intent、generate_next_step、generate_bot_message。有关详细信息,请参阅默认模板提示。
在“Hello!”消息的情况下,使用 generate_user_intent 任务提示模板进行单次 LLM 调用。提示看起来像这样
print(info.llm_calls[0].prompt)
"""
Below is a conversation between a helpful AI assistant and a user. The bot is designed to generate human-like text based on the input that it receives. The bot is talkative and provides lots of specific details. If the bot does not know the answer to a question, it truthfully says it does not know.
"""
# This is how a conversation between a user and the bot can go:
user "Hello there!"
express greeting
bot express greeting
"Hello! How can I assist you today?"
user "What can you do for me?"
ask about capabilities
bot respond about capabilities
"As an AI assistant, I can help you with a wide range of tasks. This includes question answering on various topics, generating text for various purposes and providing suggestions based on your preferences."
user "Tell me a bit about the history of NVIDIA."
ask general question
bot response for general question
"NVIDIA is a technology company that specializes in designing and manufacturing graphics processing units (GPUs) and other computer hardware. The company was founded in 1993 by Jen-Hsun Huang, Chris Malachowsky, and Curtis Priem."
user "tell me more"
request more information
bot provide more information
"Initially, the company focused on developing 3D graphics processing technology for the PC gaming market. In 1999, NVIDIA released the GeForce 256, the world's first GPU, which was a major breakthrough for the gaming industry. The company continued to innovate in the GPU space, releasing new products and expanding into other markets such as professional graphics, mobile devices, and artificial intelligence."
user "thanks"
express appreciation
bot express appreciation and offer additional help
"You're welcome. If you have any more questions or if there's anything else I can help you with, please don't hesitate to ask."
# This is how the user talks:
user "Wassup?"
express greeting
user "Hi"
express greeting
user "Hello"
express greeting
# This is the current conversation between the user and the bot:
# Choose intent from this list: express greeting
user "Hello there!"
express greeting
bot express greeting
"Hello! How can I assist you today?"
user "What can you do for me?"
ask about capabilities
bot respond about capabilities
"As an AI assistant, I can help you with a wide range of tasks. This includes question answering on various topics, generating text for various purposes and providing suggestions based on your preferences."
user "Hello!"
提示具有四个逻辑部分
一组通用指令。可以使用 config.yml 中的
instructions键配置这些指令。一个示例对话,也可以使用 config.yml 中的
sample_conversation键配置。一组用于将用户话语转换为规范形式的示例。通过对所有用户消息示例执行向量搜索来选择前五个最相关的示例。有关更多详细信息,请参阅 ABC Bot。
当前对话,前面是示例对话的前两个回合。
对于 generate_user_intent 任务,LLM 必须预测最后一个用户话语的规范形式。
print(info.llm_calls[0].completion)
express greeting
正如我们所见,LLM 正确预测了 express greeting 规范形式。它甚至进一步预测了机器人应该做什么,即 bot express greeting,以及应该使用的话语。但是,对于 generate_user_intent 任务,仅使用第一个预测行。如果您希望 LLM 在单次调用中预测所有内容,您可以通过将 config.yml 中的 rails.dialog.single_call 键设置为 True 来启用单次 LLM 调用选项。
步骤 2:确定下一步
在计算出用户消息的规范形式后,guardrails 实例需要决定接下来应该发生什么。有两种情况
如果存在与规范形式匹配的流程,则使用该流程。该流程可以决定机器人应该用特定消息响应,或执行操作。
如果没有流程,则使用
generate_next_step任务提示 LLM 进行下一步操作。
在我们的示例中,greeting 流程中存在匹配项,下一步是
bot express greeting
bot ask how are you
步骤 3:生成机器人消息
一旦确定了机器人应该说什么的规范形式,就必须生成消息。有两种情况
如果找到预定义的消息,则使用确切的话语。如果多个示例话语与同一规范形式关联,则使用随机一个。
如果预定义消息不存在,则提示 LLM 使用
generate_bot_message任务生成消息。
在我们的“Hello World”示例中,使用了预定义消息“Hello world!”和“How are you doing?”。
后续问题
在前面的示例中,LLM 被提示了一次。下图提供了概述步骤序列的摘要
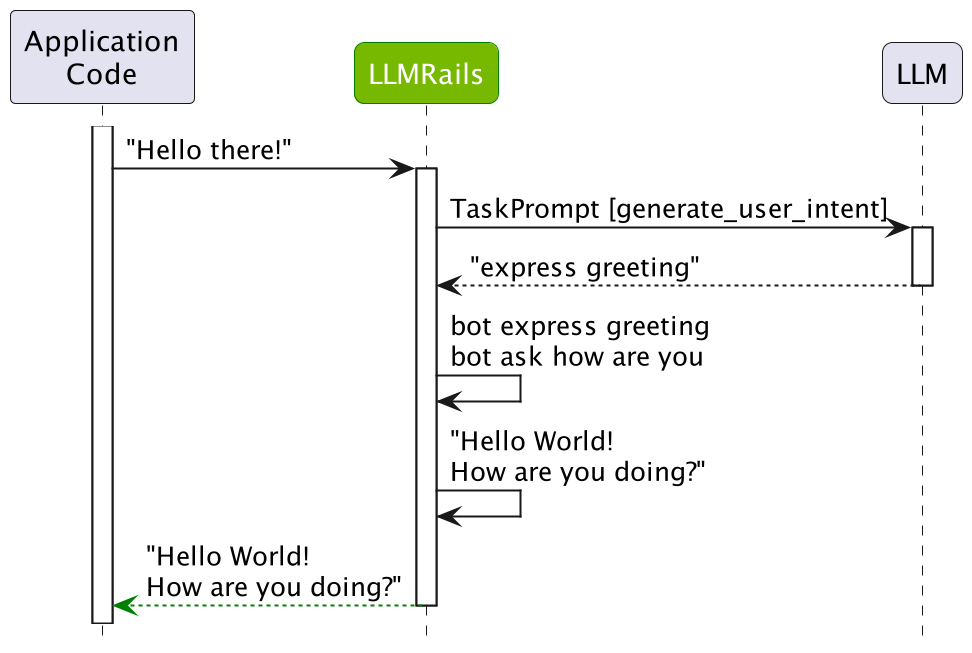
让我们检查一下后续问题“法国的首都是哪里?”的相同过程。
response = rails.generate(messages=[{
"role": "user",
"content": "What is the capital of France?"
}])
print(response["content"])
The capital of France is Paris.
让我们检查一下 colang 历史记录
info = rails.explain()
print(info.colang_history)
user "What is the capital of France?"
ask general question
bot response for general question
"The capital of France is Paris."
以及 LLM 调用
info.print_llm_calls_summary()
Summary: 3 LLM call(s) took 1.79 seconds and used 1374 tokens.
1. Task `generate_user_intent` took 0.63 seconds and used 546 tokens.
2. Task `generate_next_steps` took 0.64 seconds and used 216 tokens.
3. Task `generate_bot_message` took 0.53 seconds and used 612 tokens.
基于这些步骤,我们可以看到为用户话语“法国的首都是哪里?”预测了 ask general question 规范形式。由于没有与它匹配的流程,因此要求 LLM 预测下一步,在本例中为 bot response for general question。此外,由于没有预定义的响应,因此第三次要求 LLM 预测最终消息。
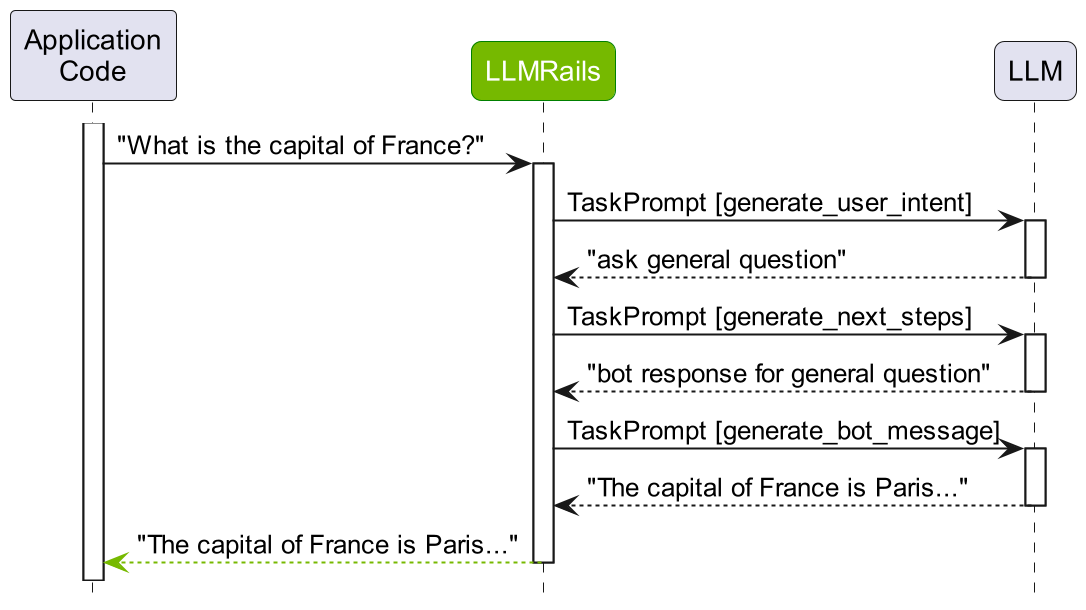
总结
本指南详细概述了两个核心 Colang 概念:消息和流程。它还研究了消息和流程定义在幕后是如何使用的,以及如何提示 LLM。有关更多详细信息,请参阅Python API 和 Colang 语言语法的参考文档。
下一步
下一个指南,演示用例,将指导您选择一个演示用例,以实现不同类型的 rails,例如用于输入、输出或对话的 rails。