概述
此应用程序实现了一个典型的设备,用于执行智能视频分析。应用领域包括公共安全、智慧城市和自主机器。此示例演示了四个 (4) 并发视频流,这些视频流通过使用片上解码器的解码过程、使用片上缩放器的视频缩放和 GPU 计算。为了演示的简洁性,只有一个通道使用 NVIDIA® TensorRT™ 来执行对象识别并在识别的对象周围生成边界框。此示例还使用视频转换器功能进行各种格式转换。它还使用 EGLImage 来演示缓冲区共享和图像显示。
在此示例中,对象检测仅限于识别分辨率为 960 x 540 的视频流中的汽车,帧率高达 14 FPS。该网络基于 GoogleNet。推理逐帧执行,不涉及对象跟踪。请注意,此网络旨在作为一个示例,展示如何使用 TensorRT 快速构建计算管线。该示例包含经过训练的 GoogleNet,该 GoogleNet 使用 NVIDIA 深度学习 GPU 训练系统 (DIGITS) 进行训练。训练使用了大约 3000 帧,拍摄高度为 5-10 英尺。根据输入的视频样本,预计检测精度会有所不同。鉴于此示例锁定在低于 10 FPS 的半高清分辨率下执行,因此对于推理而言,较高 FPS 的视频源将在播放期间出现卡顿。
此示例不需要摄像头。
构建和运行
前提条件
- 您已按照《构建和运行》中的步骤 1-3 进行操作。
- 您已安装
- CUDA 工具包
- OpenCV
- (可选)您已安装 NVIDIA® TensorRT™(以前称为 GPU 推理引擎 (GIE))
安装 TensorRT
- 在文本编辑器中打开 apt 源配置文件
$ sudo vi /etc/apt/sources.list.d/nvidia-l4t-apt-source.list
在下面显示的 deb 命令中更改存储库名称和下载 URL
deb https://repo.download.nvidia.com/jetson/common <release> main deb https://repo.download.nvidia.com/jetson/<platform> <release> main
<release> 是版本号。例如:r32.5。
<platform> 标识平台的处理器
- t194 用于 Jetson AGX Xavier 系列或 Jetson Xavier NX
- t186 用于 Jetson TX2 系列
- t210 用于 Jetson Nano 或 Jetson TX1
- 输入
$ sudo apt-get update $ sudo apt-get install tensorrt
构建
- 如果您想在不使用 TensorRT 的情况下运行示例,请在 Makefile 中设置以下内容
ENABLE_TRT := 0
- 输入
$ cd backend $ make
运行
- 输入
$ ./backend 1 ../../data/Video/sample_outdoor_car_1080p_10fps.h264 H264 \ --trt-deployfile ../../data/Model/GoogleNet_one_class/GoogleNet_modified_oneClass_halfHD.prototxt \ --trt-modelfile ../../data/Model/GoogleNet_one_class/GoogleNet_modified_oneClass_halfHD.caffemodel \ --trt-mode 0 --trt-proc-interval 1 -fps 10
退出
- 输入
q。
查看命令行选项
- 输入
$ cd backend $ ./backend -h
流程
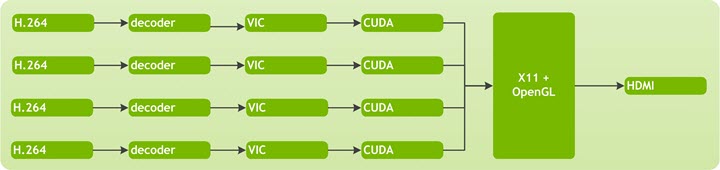
下图显示了在未启用 TensorRT 时数据在示例中的流动。
下图显示了使用 TensorRT 的通道的数据流详细信息。
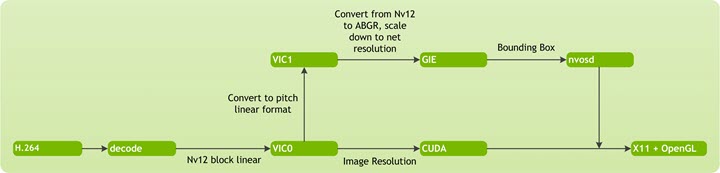
NvEGLImageFromFd 是一个 NVIDIA API,它从通过 Tegra 机制分配的文件描述符缓冲区返回一个 EGLImage 指针。然后,TensorRT 使用 EGLImage 缓冲区将边界框渲染到图像上。
X11 详细信息
有关 X11 技术详细信息,请参阅
http://www.x.org/docs/X11/xlib.pdf
关键结构和类
context_t 结构 (backend/v4l2_backend_test.h) 管理示例应用程序中的所有资源。
| 元素 | 描述 |
|---|---|
| NvVideoDecoder | 包含所有视频解码相关的元素和函数。 |
| NvVideoConverter | 包含用于视频格式转换的元素和函数。 |
| NvEglRenderer | 包含所有 EGL 显示渲染相关的功能。 |
| EGLImageKHR | 用于 CUDA 处理的 EGLImage。此类型来自 EGL 开源图形库。 |
%NvVideoDecoder
NvVideoDecoder 类创建一个新的 V4L2 视频解码器。下表描述了此示例使用的关键 NvVideoDecoder 成员。
| 成员 | 描述 |
|---|---|
| NvV4l2Element::output_plane | 持有 V4L2 输出平面。 |
| NvV4l2Element::capture_plane | 持有 V4L2 捕获平面。 |
| NvVideoDecoder::createVideoDecoder | 用于创建视频解码对象的静态函数。 |
| NvV4l2Element::subscribeEvent | 订阅事件。 |
| NvVideoDecoder::setExtControls | 设置 V4L2 设备的外部控制。 |
| NvVideoDecoder::setOutputPlaneFormat | 设置输出平面格式。 |
| NvVideoDecoder::setCapturePlaneFormat | 设置捕获平面格式。 |
| NvV4l2Element::getControl | 获取控制设置的值。 |
| NvV4l2Element::dqEvent | 将 V4L2 设备报告的 devent 出队。 |
| NvV4l2Element::isInError | 检查是否处于错误状态。 |
%NvVideoConverter
NvVideoConverter 类封装了所有视频转换相关的元素和函数。它执行颜色空间转换、缩放以及硬件缓冲区内存和软件缓冲区内存之间的转换。下表描述了此示例使用的关键 NvVideoConverter 成员。
| 成员 | 描述 |
|---|---|
| NvV4l2Element::output_plane | 持有输出平面。 |
| NvV4l2Element::capture_plane | 持有捕获平面。 |
| NvVideoConverter::waitForIdle | 等待直到输出平面上排队的所有缓冲区都已转换并从捕获平面出队。这是一种阻塞方法。 |
| NvVideoConverter::setCapturePlaneFormat | 在转换器捕获平面上设置格式。 |
| NvVideoConverter::setOutputPlaneFormat | 在转换器输出平面上设置格式。 |
NvVideoDecoder 和 NvVideoConverter 包含两个关键元素:output_plane 和 capture_plane。这些对象是从 NvV4l2ElementPlane 类类型实例化的。
%NvV4l2ElementPlane
NvV4l2ElementPlane 创建一个 NVv4l2Element 平面。下表描述了此示例中使用的关键 NvV4l2ElementPlane 成员。v4l2_buf 是 NvV4l2ElementPlane::dqThreadCallback 函数内部的局部变量,因此,作用域仅存在于回调函数内部。如果示例的其他函数必须访问此缓冲区,则需要在回调函数内部事先复制缓冲区。
| 成员 | 描述 |
|---|---|
| NvV4l2ElementPlane::setupPlane | 设置 V4l2 元素的平面。 |
| NvV4l2ElementPlane::deinitPlane | 销毁 V4l2 元素的平面。 |
| NvV4l2ElementPlane::setStreamStatus | 启动/停止流。 |
| NvV4l2ElementPlane::setDQThreadCallback | 设置 dqueue 缓冲区线程的回调函数。 |
| NvV4l2ElementPlane::startDQThread | 启动 dqueue 缓冲区的线程。 |
| NvV4l2ElementPlane::stopDQThread | 停止 dqueue 缓冲区的线程。 |
| NvV4l2ElementPlane::qBuffer | 从平面上排队一个 V4l2 缓冲区。 |
| NvV4l2ElementPlane::dqBuffer | 从平面上出队一个 V4l2 缓冲区。 |
| NvV4l2ElementPlane::getNumBuffers | 获取 V4l2 缓冲区的数量。 |
| NvV4l2ElementPlane::getNumQueuedBuffers | 获取队列中 V4l2 缓冲区的数量。 |
| NvV4l2ElementPlane::getNthBuffer | 获取索引 N 处的 NvBuffer 队列对象。 |
%TRT_Context
TRT_Context 提供了一系列接口来加载 Caffe 模型并执行推理。下表描述了此示例中使用的关键 TRT_Context 成员。
| TRT_Context | 描述 |
|---|---|
| TRT_Context::destroyTrtContext | 销毁 TRT_context。 |
| TRT_Context::getNumTrtInstances | 获取 TRT_context 实例的数量。 |
| TRT_Context::doInference | 加载 TensorRT 模型后进行推理的接口。 |
创建/销毁 EGLImage 的函数
该示例使用 2 个全局函数来从 dmabuf 文件描述符创建和销毁 EGLImage。这些函数在 nvbuf_utils.h 中定义。
| 全局函数 | 描述 |
|---|---|
| NvEGLImageFromFd() | 从 dmabuf fd 创建 EGLImage。 |
| NvDestroyEGLImage() | 销毁 EGLImage。 |