NVIDIA HPC 编译器参考指南
前言
本指南是描述如何使用 NVIDIA HPC Fortran、C++ 和 C 编译器的一组手册的一部分。这些编译器包括 NVFORTRAN、NVC++ 和 NVC 编译器。它们与目标系统上的汇编器、链接器、库和头文件协同工作,并包括用于 GPU 计算的 CUDA 工具链、库和头文件。您可以使用 NVIDIA HPC 编译器为 NVIDIA GPU 以及 x86-64 和 Arm 服务器多核 CPU 开发、优化和并行化应用程序。
NVIDIA HPC 编译器用户指南提供了 NVIDIA HPC 编译器命令行开发环境的操作说明。NVIDIA HPC 编译器参考指南包含有关 NVIDIA 编译器对 Fortran、C++ 和 C 语言标准的解释、语言扩展的实现以及命令行编译的详细信息。用户应具有 Fortran、C++ 和 C 编程语言的先前经验或知识。这些指南不教授 Fortran、C++ 或 C 编程语言。
受众描述
本手册适用于使用 NVIDIA HPC 编译器的科学家和工程师。要使用这些编译器,您应该了解高级语言(如 Fortran、C++ 和 C)以及并行编程模型(如 CUDA、OpenACC 和 OpenMP)在软件开发过程中的作用,并且您应该对编程有一定的了解。NVIDIA HPC 编译器可在各种 NVIDIA GPU 以及基于 x86-64 和 Arm CPU 的平台和操作系统上使用。您需要熟悉系统上可用的基本命令。
兼容性和标准一致性
您的系统需要运行正确安装和配置的 NVIDIA HPC 编译器版本。有关安装 NVIDIA HPC 编译器的信息,请参阅软件随附的发行说明和安装指南。
有关更多信息,请参阅以下内容
美国国家标准编程语言 FORTRAN,ANSI X3. -1978 (1978)。
ISO/IEC 1539-1 : 1991,信息技术 – 编程语言 – Fortran,日内瓦,1991 (Fortran 90)。
ISO/IEC 1539-1 : 1997,信息技术 – 编程语言 – Fortran,日内瓦,1997 (Fortran 95)。
ISO/IEC 1539-1 : 2004,信息技术 – 编程语言 – Fortran,日内瓦,2004 (Fortran 2003)。
ISO/IEC 1539-1 : 2010,信息技术 – 编程语言 – Fortran,日内瓦,2010 (Fortran 2008)。
ISO/IEC 1539-1 : 2018,信息技术 – 编程语言 – Fortran,日内瓦,2018 (Fortran 2018)。
Fortran 95 手册完整 ISO/ANSI 参考,Adams 等人,MIT 出版社,剑桥,马萨诸塞州,1997 年。
Fortran 2003 手册,Adams 等人,Springer,2009 年。
OpenACC 应用程序编程接口,版本 2.7,2018 年 11 月,http://www.openacc.org。
OpenMP 应用程序编程接口,版本 5.0,2018 年 11 月,http://www.openmp.org。
VAX Fortran 编程,版本 4.0,数字设备公司(1984 年 9 月)。
IBM VS Fortran,IBM 公司,修订版 GC26-4119。
军事标准,Fortran,美国国家标准编程语言 Fortran 的 DOD 补充,ANSI x.3-1978,MIL-STD-1753(1978 年 11 月 9 日)。
美国国家标准编程语言 C,ANSI X3.159-1989。
ISO/IEC 9899:1990,信息技术 – 编程语言 – C,日内瓦,1990 (C90)。
ISO/IEC 9899:1999,信息技术 – 编程语言 – C,日内瓦,1999 (C99)。
ISO/IEC 9899:2011,信息技术 – 编程语言 – C,日内瓦,2011 (C11)。
ISO/IEC 14882:2011,信息技术 – 编程语言 – C++,日内瓦,2011 (C++11)。
ISO/IEC 14882:2014,信息技术 – 编程语言 – C++,日内瓦,2014 (C++14)。
ISO/IEC 14882:2017,信息技术 – 编程语言 – C++,日内瓦,2017 (C++17)。
组织
本手册包含有关编译器特定方面的详细参考信息,例如编译器选项、指令、支持的数据类型等的详细信息。它包含以下章节
Fortran、C++ 和 C 数据类型 描述了 NVIDIA HPC Fortran、C++ 和 C 编译器支持的数据类型。
命令行选项参考 提供了大多数命令行选项的详细描述。
C++ 名称修饰 描述了名称修饰工具,并解释了实体名称到包含实体类型和完全限定名称方面信息的名称的转换。
运行时环境 描述了与编译器代码生成相关的详细信息,包括 Linux/x86-64 和 Linux/Arm 处理器系统的寄存器约定和调用约定。
支持的 C++ 方言 列出了 NVC++ 支持的 C++ 语言版本的更多详细信息。
x86-64 C++ 和 C MMX/SSE/AVX 内联函数 提供了表格,列出了 C++ 和 C 程序中支持的 MMX 和 SSE/SSE2/SSE3/SSSE3/SSE4a/ABM/AVX 内联函数。
消息 提供了 Fortran 编译器错误消息的列表。
硬件和软件约束
本指南描述了面向 NVIDIA GPU 以及 x86-64 和 Arm CPU 的 NVIDIA HPC 编译器版本。有关特定于环境的值和默认值以及特定于系统的特性或限制的详细信息,请参阅 NVIDIA HPC 编译器随附的发行说明。
约定
本指南使用以下约定
- italic
用于强调。
Constant Width用于文件名、目录、参数、选项、示例以及文本中的语言语句,包括汇编语言语句。
- Bold
用于命令。
- [ item1 ]
一般来说,方括号表示可选项目。在本例中,item1 是可选的。在 p/t 集的上下文中,方括号是指定 p/t 集所必需的。
- { item2 | item 3 }
花括号表示需要选择。在本例中,您必须选择 item2 或 item3。
- filename …
省略号表示重复。可以出现零个或多个前面的项目。在本例中,允许多个文件名。
FORTRANFortran 语言语句在本指南的文本中使用缩小的固定点大小显示。
C++ 和 CC++ 和 C 语言语句在本指南的测试中使用缩小的固定点大小显示。
术语
本指南通篇使用了许多与系统、处理器、编译器和工具有关的术语。例如
加速器 |
FMA |
-mcmodel=medium |
共享库 |
AVX |
主机 |
-mcmodel=small |
SIMD |
CUDA |
超线程 (HT) |
MPI |
SSE |
设备 |
大型数组 |
MPICH |
静态链接 |
驱动程序 |
linux86-64 |
NUMA |
x86-64 |
DWARF |
LLVM |
OpenPOWER |
Arm |
动态库 |
多核 |
ppc64le |
Aarch64 |
下表列出了 NVIDIA HPC 编译器及其对应的命令
编译器或工具 |
语言或功能 |
命令 |
|---|---|---|
NVFORTRAN |
ISO/ANSI Fortran 2003 |
nvfortran |
NVC++ |
ISO/ANSI C++17 与 GNU 兼容 |
nvc++ |
NVC |
ISO/ANSI C11 |
nvc |
一般来说,NVFORTRAN 的名称用于指代 NVIDIA Fortran 编译器,而 nvfortran 用于指代调用编译器的命令。每个 NVIDIA HPC 编译器都使用类似的约定。
为简单起见,编译器的命令行调用的示例通常引用 nvfortran 命令,并且大多数源代码示例都用 Fortran 编写。NVC++ 和 NVC 的使用与 NVFORTRAN 一致,尽管这些编译器的一些命令行选项和功能不适用于 NVFORTRAN,反之亦然。
正在使用各种各样的 x86-64 CPU。这些 CPU 大多向前兼容,但不向后兼容,这意味着为目标处理器编译的代码不一定在上一代处理器上正确执行。
发行说明中提供了 NVIDIA HPC 编译器支持的处理器选项表。该表还包括编译器使用的特性,这些特性从兼容性角度区分了它们。
在本手册中,约定使用“x86-64”来指定与 x86 兼容、启用 64 位并运行 64 位操作系统的 CPU 组。x86-64 处理器在对各种预取、SSE 和 AVX 指令的支持方面可能有所不同。如果这些区别对于给定的编译器选项或功能很重要,则在本手册中明确指出。
1. Fortran、C++ 和 C 数据类型
本节介绍 NVIDIA Fortran、C++ 和 C 编译器识别的标量和聚合数据类型、每种类型在内存中的格式和对齐方式,以及每种类型在 64 位操作系统上可以具有的值范围。
1.1. Fortran 数据类型
1.1.1. Fortran 标量
标量数据类型保存单个值,例如整数值 42 或实数值 112.6。下表列出了 Fortran 标量数据类型、它们的大小、格式和范围。表 3 显示了 Fortran 实数数据类型的范围和近似精度。表 4 显示了不同标量数据类型的对齐方式。对齐方式适用于所有标量,无论它们是独立的还是包含在数组、结构或联合中。
Fortran 数据类型 |
格式 |
范围 |
|---|---|---|
INTEGER |
2 的补码整数 |
-231 到 231-1 |
INTEGER*2 |
2 的补码整数 |
-32768 到 32767 |
INTEGER*4 |
2 的补码整数 |
-231 到 231-1 |
INTEGER*8 |
2 的补码整数 |
-263 到 263-1 |
LOGICAL |
32 位值 |
true 或 false |
LOGICAL*1 |
8 位值 |
true 或 false |
LOGICAL*2 |
16 位值 |
true 或 false |
LOGICAL*4 |
32 位值 |
true 或 false |
LOGICAL*8 |
64 位值 |
true 或 false |
BYTE |
2 的补码 |
-128 到 127 |
REAL |
单精度浮点 |
10-37 到 1038(1) |
REAL*2 |
半精度浮点 (binary16) |
10-4 到 10 5(1) |
REAL*4 |
单精度浮点 |
10-37 到 10 38(1) |
REAL*8 |
双精度浮点 |
10-307 到 10 308(1) |
DOUBLE PRECISION |
双精度浮点 |
10-307 到 10308(1) |
COMPLEX |
单精度浮点 |
10-37 到 1038(1) |
DOUBLE COMPLEX |
双精度浮点 |
10-307 到 10308(1) |
COMPLEX*16 |
双精度浮点 |
10-307 到 10308(1) |
CHARACTER*n |
n 字节序列 |
(1) 近似值
逻辑常量 .TRUE. 和 .FALSE. 分别是全 1 和全 0。在内部,如果最低有效位为 1,则逻辑变量的值为真,否则为假。当设置选项 -Munixlogical 时,非零值的逻辑变量为真,零值的逻辑变量为假。
注意
逻辑类型的变量可以出现在算术上下文中,并且逻辑类型然后被视为相同大小的整数。
数据类型 |
二进制范围 |
十进制范围 |
精度位数 |
|---|---|---|---|
REAL |
-2-126 到 2128 |
10-37 到 1038(1) |
7–8 |
REAL*2 |
-2-14 到 216 |
10-4 到 105(1) |
3–4 |
REAL*8 |
-2-1022 到 21024 |
10-307 到 10308(1) |
15–16 |
此类型… |
…在此大小边界上对齐 |
|---|---|
LOGICAL*1 |
1 字节 |
LOGICAL*2 |
2 字节 |
LOGICAL*4 |
4 字节 |
LOGICAL*8 |
8 字节 |
BYTE |
1 字节 |
INTEGER*2 |
2 字节 |
INTEGER*4 |
4 字节 |
INTEGER*8 |
8 字节 |
REAL*2 |
2 字节 |
REAL*4 |
4 字节 |
REAL*8 |
8 字节 |
COMPLEX*8 |
4 字节 |
COMPLEX*16 |
8 字节 |
1.1.2. FORTRAN real(2)
NVFORTRAN 编译器支持 real(2) 数据类型,这使得以半精度浮点声明和使用数据成为可能。显式要求在 real 数据类型上使用值为 2 的 kind 属性以利用此支持。此数据类型支持以下运算符:+ , -, *, /, .lt., .le., .gt., .ge., .eq.,.ne.。
有几种创建 real(2) 常量的方法
! Using kind attribute of 2 by appending _2 to the floating point value:
real(2) :: val1 = 2.0_2
! Using a hexadecimal constant:
real(2) :: val2 = z'4000'
! Explicitly calling real() intrinsic with the value to be converted:
real(2) :: val3 = real(2, kind=2)
! Implicitly relying on compiler to convert value to real(2):
real(2) :: val4 = 2d0
并非 NVFORTRAN 支持的所有架构目标都提供半精度原生支持。仍然可以使用此类型,但请注意,实现依赖于转换为 real(4),在 real(4) 中处理操作,然后转换回 real(2)。支持 CUDA 计算能力 6.0 及更高版本的 NVIDIA GPU 本机实现操作,不依赖于转换。
半精度表示为 IEEE 754 binary16。在表示浮点值的 16 位中,一位用于符号,五位用于指数,十位用于有效数。当遇到无法以格式精确表示的值时,例如当添加两个 real(2) 数字时,IEEE 754 定义了舍入规则。对于 real(2),默认规则是就近舍入, ties-to-even 属性,这在 IEEE 754-2008 标准的 4.3.1 节中详细描述。此格式的动态范围很小,因此大于 65520 的值将四舍五入为无穷大。
1.1.3. FORTRAN 77 聚合数据类型扩展
NVFORTRAN 编译器支持 FORTRAN 77 的事实标准扩展,允许使用聚合数据类型。聚合数据类型由一个或多个标量数据类型对象组成。您可以声明以下聚合数据类型
数组由一个或多个单一数据类型的元素组成,这些元素从第一个到最后一个连续排列。
结构可以包含不同的数据类型。成员按照它们在定义中出现的顺序分配,但可能不占用连续的位置。
联合是单个位置,可以包含一组指定的标量或聚合数据类型中的任何一种。联合一次只能有一个值。分配数据的联合成员的数据类型决定了该分配后联合的数据类型。
数组、结构或联合(聚合)的对齐方式会影响对象占用的空间大小以及处理器寻址成员的效率。数组使用其成员的对齐方式。
- 数组类型
根据数组元素的对齐方式对齐。例如,
INTEGER*2数据数组在 2 字节边界上对齐。此规则的例外是REAL*2数组的对齐在 4 字节边界上。- 结构和联合
根据结构或联合的最严格数据类型的对齐方式对齐。在下一个示例中,联合在 4 字节边界上对齐,因为最严格的元素 c 的对齐方式为 4。
STRUCTURE /astr/
UNION
MAP
INTEGER*2 a ! 2 bytes
END MAP
MAP
BYTE b ! 1 byte
END MAP
MAP
INTEGER*4 c ! 4 bytes
END MAP
END UNION
END STRUCTURE
结构对齐可能会导致未使用的空间,称为填充。结构成员之间的填充称为内部填充。最后一个成员和空间末尾之间的填充称为尾部填充。
结构成员从结构开头算起的偏移量是成员对齐方式的倍数。例如,由于 INTEGER*2 在 2 字节边界上对齐,因此 INTEGER*2 成员从结构开头算起的偏移量是两字节的倍数。
1.1.4. Fortran 90 聚合数据类型(派生类型)
Fortran 90 标准增加了对聚合数据类型的正式支持。TYPE 语句开始派生类型数据规范或声明指定用户定义类型的变量。例如,以下代码将定义派生类型 ATTENDEE
TYPE ATTENDEE
CHARACTER(LEN=30) NAME
CHARACTER(LEN=30) ORGANIZATION
CHARACTER (LEN=30) EMAIL
END TYPE ATTENDEE
为了声明 ATTENDEE 类型的变量并访问此类变量的内容,将使用如下代码
TYPE (ATTENDEE) ATTLIST(100)
. . .
ATTLIST(1)%NAME = ‘JOHN DOE’
1.2. C 和 C++ 数据类型
1.2.1. C 和 C++ 标量
表 5 列出了 C 和 C++ 标量数据类型,提供了它们的大小和格式。标量数据类型的对齐方式等于其大小。表 6 显示了适用于单个标量以及作为数组元素或结构或联合成员的标量的标量对齐方式。支持宽字符(以 L 为前缀的字符常量)。每个宽字符的大小为 4 字节。
数据类型 |
大小(字节) |
格式 |
范围 |
|---|---|---|---|
unsigned char |
1 |
ordinal |
0 到 255 |
signed char |
1 |
2 的补码整数 |
-128 到 127 |
char |
1 |
2 的补码整数 |
-128 到 127 |
char |
1 |
ordinal |
0 到 255 |
unsigned short |
2 |
ordinal |
0 到 65535 |
[signed] short |
2 |
2 的补码整数 |
-32768 到 32767 |
unsigned int |
4 |
ordinal |
0 到 232 -1 |
[signed] int |
4 |
2 的补码整数 |
-231 到 231-1 |
[signed] long [int] (win64) |
4 |
2 的补码整数 |
-231 到 231-1 |
[signed] long [int] (linux86-64) |
8 |
2 的补码整数 |
-263 到 263-1 |
unsigned long [int] (win64) |
4 |
ordinal |
0 到 232-1 |
unsigned long [int] (linux86-64) |
8 |
ordinal |
0 到 264-1 |
[signed] long long [int] |
8 |
2 的补码整数 |
-263 到 263-1 |
unsigned long long [int] |
8 |
ordinal |
0 到 264-1 |
[signed] __int128 |
16 |
2 的补码整数 |
-2127 到 2127-1 |
unsigned __int128 |
16 |
ordinal |
0 到 2128-1 |
float |
4 |
IEEE 单精度浮点 |
10-37 到 1038(1) |
double |
8 |
IEEE 双精度浮点 |
10-307 到 10308(1) |
long double |
16 |
IEEE 扩展精度浮点 |
10-4931 到 104932(1) |
long double |
16 |
IBM double-double |
10-307 到 10308(1) |
位字段(2)(无符号值) |
1 到 32 位 |
ordinal |
0 到 2size-1,其中 size 是位字段中的位数 |
位字段(2)(有符号值) |
1 到 32 位 |
2 的补码整数 |
-2size-1 到 2size-1-1,其中 size 是位字段中的位数 |
指针(32 位操作系统) |
4 |
地址 |
0 到 232-1 |
指针 |
8 |
地址 |
0 到 264-1 |
enum |
4 |
2 的补码整数 |
-231 到 231-1 |
(1) 近似值
(2) 位字段占用的位数与您分配给它们的位数一样多,最多 4 个字节,并且它们的长度不必是 8 位(1 字节)的倍数
数据类型 |
在此大小边界上对齐 |
|---|---|
char |
1 字节边界,有符号或无符号。 |
short |
2 字节边界,有符号或无符号。 |
int |
4 字节边界,有符号或无符号。 |
enum |
float |
指针 |
double |
float |
float |
double |
double |
long double |
double |
long double(64 位操作系统) |
16 字节边界。 |
long [int] linux86-64 |
8 字节边界,有符号或无符号。 |
long long [int] |
8 字节边界,有符号或无符号。 |
1.2.2. C 和 C++ 聚合数据类型
聚合数据类型由一个或多个标量数据类型对象组成。您可以声明以下聚合数据类型
- 数组
由一个或多个单一数据类型的元素组成,这些元素从第一个到最后一个连续排列。
- 类
(仅限 C++)是一个类,它定义了一个对象及其成员函数。该对象可以包含基本数据类型或其他聚合,包括其他类。类成员按照它们在定义中出现的顺序分配,但可能不占用连续的位置。
- 结构
是一个可以包含不同数据类型的结构。成员按照它们在定义中出现的顺序分配,但可能不占用连续的位置。当使用成员函数定义结构时,其对齐规则与类的对齐规则相同。
- 联合
是单个位置,可以包含一组指定的标量或聚合数据类型中的任何一种。联合一次只能有一个值。分配数据的联合成员的数据类型决定了该分配后联合的数据类型。
1.2.3. 类和对象数据布局
没有虚拟实体且没有基类的类和结构对象(即仅是直接数据字段成员)的布局方式与 C 结构相同。以下部分描述了这些类 C 结构的对齐方式和大小。C++ 类(以及作为类特殊情况的结构)更难描述。它们的对齐方式和大小由编译器生成的字段以及用户指定的字段决定。以下段落描述了更通用类的存储布局方式。警告用户,类(或结构)的对齐方式和大小取决于直接和虚拟基类以及虚拟函数信息的存在和位置。以下信息仅供参考,反映了当前的实现,并且可能会更改。不要对复杂类或结构的布局做出假设。
所有类的布局方式大致相同,使用以下模式(按指示的顺序)
首先,所有直接基类的存储空间(隐式包括非虚拟间接基类的存储空间)
当直接基类也是虚拟的时,仅为指向实际存储空间的指针预留足够的空间,实际存储空间稍后出现。
在非虚拟直接基类的情况下,为其自身的非虚拟基类、其虚拟基类指针、其自身的字段及其虚拟函数信息预留了足够的存储空间,但未为其虚拟基类分配空间。
接下来,是类自身字段的存储空间。
接下来,是虚拟函数信息的存储空间(通常是指向虚拟函数表的指针)。
最后,是其虚拟基类的存储空间,在每种情况下都为自身的非虚拟基类、虚拟基类指针、字段和虚拟函数信息预留了足够的空间。
1.2.4. 聚合对齐
数组、结构或联合(聚合)的对齐方式会影响对象占用的空间大小以及处理器寻址成员的效率。
- 数组
根据数组元素的对齐方式对齐。例如,short 数据类型数组在 2 字节边界上对齐。
- 结构和联合
根据封闭成员的最严格对齐方式对齐。在以下示例中,联合 un1 在 4 字节边界上对齐,因为最严格的元素 c 的对齐方式为 4
union un1 { short a; /* 2 bytes */ char b; /* 1 byte */ int c; /* 4 bytes */ };
结构对齐可能会导致未使用的空间,称为填充。结构成员之间的填充称为内部填充。最后一个成员和结构占用的空间末尾之间的填充称为尾部填充。图 1 说明了结构对齐。考虑以下结构
struct strc1 {
char a; /* occupies byte 0 */
short b; /* occupies bytes 2 and 3 */
char c; /* occupies byte 4 */
int d; /* occupies bytes 8 through 11 */
};
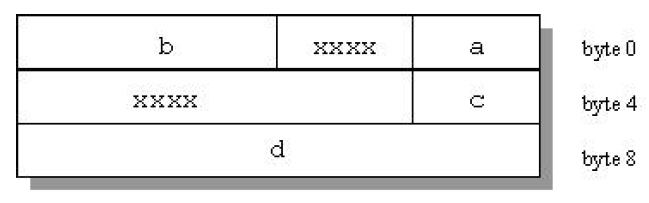
图 1. 结构中的内部填充
图 2 显示了如何将尾部填充应用于在双字(8 字节)边界上对齐的结构。
struct strc2{
int m1[4]; /* occupies bytes
0 through 15 */
double m2; /* occupies bytes 16 through 23 */
short m3; /* occupies bytes 24 and 25 */
} st;
1.2.5. 位字段对齐
位字段具有与其他聚合相同的大小和对齐规则,但这些规则有几个补充
位字段从右向左分配。
位字段必须完全驻留在适合其类型的存储单元中。位字段永远不会跨越单元边界。
位字段可以与其他结构/联合成员共享存储单元,包括不是位字段的成员。
未命名的位字段的类型不影响结构或联合的对齐方式。
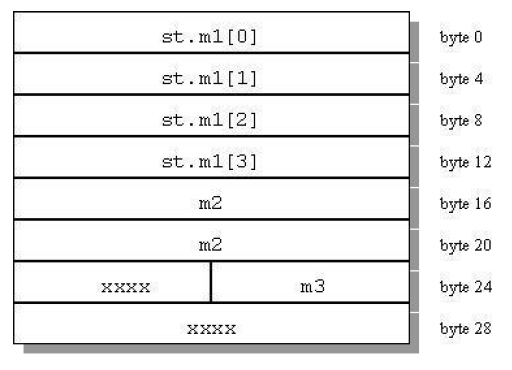
图 2. 结构中的尾部填充
1.2.6. C 和 C++ 中的其他类型关键字
void 数据类型既不是标量也不是聚合类型。你可以使用 void 或 void* 作为函数的返回类型,以表明函数不返回值;或者分别作为指向未指定数据类型的指针。
const 和 volatile 类型限定符本身并不定义数据类型,而是将属性与其他类型关联。使用 const 指定标识符是常量且不可更改。使用 volatile 防止程序外部可以更改的数据(例如内存映射的 I/O 缓冲区)的优化问题。
NVC 和 NVC++ 现在支持扩展整数类型 __int128 和 unsigned __int128。可以使用 -Mint128 标志启用 128 位整数支持。请注意,OpenMP、OpenACC 和 CUDA 不支持 128 位整数支持。
2. 命令行选项参考
命令行选项允许你在编译和链接程序时指定特定行为。编译器选项执行各种功能,例如设置编译器特性、描述要生成的对象代码、控制发出的诊断消息以及执行一些预处理器功能。大多数未显式设置的选项都采用默认设置。本参考部分描述了每个编译器选项的语法和操作。为了便于参考,这些选项按字母顺序排列。
有关选项用法的概述和技巧,以及哪些选项最适合哪些任务,请参阅HPC 编译器用户指南的“使用命令行选项”部分,该部分还提供了不同选项的摘要表。
本节使用以下符号
- [item]
方括号表示括起来的项目是可选的。
- {item | item}
花括号表示你必须选择且仅选择一个括起来的项目。竖线 (|) 分隔选项。
- ...
水平省略号表示前面的项目可以出现零次或多次。
2.1. HPC 编译器选项摘要
下表包含所有非特定于语言的 HPC 编译器选项。这些选项按类别分隔,以便于参考。
有关每个选项的完整描述,请参阅本节后面的详细信息。
生成代码,该代码支持 64 位 Linux 环境中的中等内存模型。
-nvmalloc
链接到自定义主机内存分配器库。
-shared
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
-Xlinker <option>
将选项传递给链接器。
2.2. 通用编译器选项
$ nvfortran -# prog.f
描述
以下描述适用于 NVIDIA HPC Fortran、C++ 和 C 编译器通用的编译器选项。为了便于参考,这些选项按字母顺序排列。有关按任务列出的选项列表,请参阅本节开头的表格。
2.2.1. -#
显示编译器、汇编器和链接器的调用。
默认
编译器不显示各个阶段的调用。
用法以下命令行请求详细的调用信息。
主机-# 选项显示编译器、汇编器和链接器的调用。这些调用是由驱动程序根据你的命令行输入和默认值创建的命令行。
多核相关选项
-Minfo[=option [,option,…]], -V[release_number], -v2.2.2. -[no]acc
启用 [禁用] OpenACC 指令。以下子选项可以在等号 (“=”) 后使用,多个子选项用逗号分隔gpu
OpenACC 指令仅针对 GPU 执行进行编译。host
为在主机 CPU 上串行执行进行编译。multicore
为在主机 CPU 上并行执行进行编译。legacy
禁止显示关于已弃用的 NVIDIA 加速器指令的警告。[no]autopar
在 acc parallel 中启用 [禁用] 循环自动并行化。默认设置为自动并行化,即启用循环自动并行化。[no]routineseq
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
为 devicee 编译每个例程。默认行为是不将每个例程视为 seq 指令。
将选项传递给链接器。
strict
$ nvfortran -acc=verystrict prog.f
指示编译器为非 OpenACC 加速器指令发出警告。
sync
忽略 async 子句
verystrict
指示编译器对于任何非 OpenACC 加速器指令都失败并报错。
[no]wait
等待每个设备内核完成。除非使用 async 子句,否则默认情况下内核启动被阻止。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
默认情况下,OpenACC 指令针对 GPU 和顺序 CPU 主机执行进行编译(即,等效于显式设置 -acc=gpu,host)。
将选项传递给链接器。
% nvfortran -Bdynamic myprogram.f
以下命令行请求启用 OpenACC 指令,并为任何非 OpenACC 加速器指令发出错误。
2.2.1. -#
预定义宏
将隐式添加与编译目标对应的以下宏
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
__NVCOMPILER_OPENACC_GPU 当 OpenACC 指令针对 GPU 编译时。
将选项传递给链接器。
__NVCOMPILER_OPENACC_MULTICORE 当 OpenACC 指令针对多核 CPU 编译时。
$ nvfortran -byteswapio myprog.f
描述
__NVCOMPILER_OPENACC_HOST 当 OpenACC 指令针对 CPU 上的串行执行编译时。
2.2.3. -Bdynamic
编译并链接到 NVIDIA HPC 编译器运行时库的共享对象版本。
2.2.1. -#
动态链接是 Linux 的默认行为。
当你使用 NVIDIA HPC 编译器标志 -Bdynamic 创建链接到运行时共享对象形式的可执行文件时,构建的可执行文件比不使用 -Bdynamic 构建的可执行文件小。但是,NVIDIA HPC 编译器运行时共享对象必须在运行可执行文件的系统上可用。当可执行文件链接到由 NVIDIA HPC 编译器构建的共享对象时,必须使用 -Bdynamic 标志。
-C
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
2.2.4. -byteswapio
将选项传递给链接器。
在输入/输出时,交换未格式化 Fortran 数据文件中的数据字节顺序。
$ nvfortran -C myprog.f
描述
默认
2.2.1. -#
用法
以下命令行请求在输入/输出时执行字节交换。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
使用 -byteswapio 选项来交换未格式化 Fortran 数据文件在输入/输出时的数据字节顺序。当使用此选项时,数据和记录控制字中的字节顺序都会被交换;后者发生在未格式化的顺序文件中。
将选项传递给链接器。
你可以使用此选项将大多数旧式 RISC 工作站生成的大端格式数据文件转换为在文件读取/写入期间动态使用的现代 Linux 系统上的小端格式。
$ nvfortran -c myprog.f
描述
此选项假定未格式化的顺序访问和直接访问文件的记录布局在系统上是相同的。它进一步假定 IEEE 表示用于浮点数。特别是,NVIDIA HPC Fortran 编译器生成的未格式化数据文件的格式与 Sun 和 SGI 工作站上使用的格式相同;此格式允许你从使用 -byteswapio 选项为现代 Linux 平台编译的程序中读取和写入在这些平台上生成的未格式化 Fortran 数据文件。
2.2.1. -#
相关选项
无。
2.2.5. -C
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
默认
将选项传递给链接器。
编译器不启用数组边界检查。
$ nvfortran main.f90 mycpp.o -c++libs
描述
用法
2.2.1. -#
在此示例中,编译器检测从 myprog.f 生成的可执行文件,以在运行时执行数组边界检查
使用此选项启用数组边界检查。如果数组是假定大小的数组,则边界检查仅适用于下限。如果在执行期间发生数组边界违规,则会打印描述错误的错误消息,并且程序终止。错误消息的文本包括数组的名称、错误发生的位置(源文件和源文件中的行号)以及有关越界下标的信息(其值、其下限和上限及其维度)。
相关选项-M[no]bounds
2.2.6. -c停止汇编阶段后的编译过程,并将目标代码写入文件。
将选项传递给链接器。
默认
$ nvfortran -cuda myprog.f
编译器生成可执行文件,并且不使用 -c 选项。
用法
在此示例中,编译器在当前目录中生成目标文件myprog.o。使用 -c 选项停止汇编阶段后的编译过程,并将目标代码写入文件。如果输入文件是
filename.f,则输出文件是filename.o。相关选项2.2.7. -c++libs指示编译器将 C++ 运行时库附加到使用 NVFORTRAN 构建的程序的链接行。
默认NVFORTRAN 编译器不将 C++ 运行时库附加到链接行。
用法在以下示例中,C++ 运行时库与使用 NVFORTRAN 编译的目标文件链接
使用此选项指示 NVIDIA Fortran 编译器将 C++ 运行时库附加到链接行。2.2.8. -cuda
启用 CUDA;请参考-gpu获取特定于目标的选项。以下子选项可以在等号 (“=”) 后使用,多个子选项用逗号分隔charstring
启用对 GPU 内核中字符字符串的有限支持。madconst
将模块数组描述符放在 CUDA 常量内存中用法
以下命令行请求启用 CUDA 互操作性,并在所有 Fortran 文件中识别和处理 CUDA Fortran 语法。2.2.9. -cudalib
将 CUDA 优化的库添加到链接行。当未指定子选项时,编译器将链接所有必要的 CUDA 优化库。-cudalib 将使用适合正在使用的 CUDA 版本的库版本。以下库可以在等号 (“=”) 后指定,多个库用逗号分隔cublas
将选项传递给链接器。
链接 cuBLAS 库。
$ nvfortran -acc -cudalib myprog.cpp
cufft
链接 cuFFT 库。
注意
cufftw
链接 cuFFTW 库。
-Dname[=value]
curand
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
链接 cuRAND 库。
将选项传递给链接器。
cusolver
$ nvfortran -DPATHLENGTH=256 myprog.F
链接 cuSOLVER 库。
#ifndef PATHLENGTH
#define PATHLENGTH 128
#endif SUBROUTINE SUB CHARACTER*PATHLENGTH path
...
END
描述
cusparse
链接 cuSPARSE 库。
2.2.1. -#
链接 cuTENSOR 库。
nvblas
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
链接 NVBLAS 库。
链接 cuFFTW 库。
-d[D|I|M|N]
nccl链接 NCCL 库。
nvlamath链接 NVLAmath 库。
nvshmem链接 NVSHMEM 库。
用法以下命令行链接所有必要的 CUDA 库。
将选项传递给链接器。
2.2.10. -D
$ nvc -dN myprog.f
描述
创建具有给定值的预处理器宏。
2.2.1. -#
你可以在编译器命令行上多次使用 -D 选项。活动宏定义的数量仅受可用内存的限制。
语法
-D<name>[=<value>]
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
-Xlinker <option>
将选项传递给链接器。
其中 name 是符号名称,value 是整数值或字符串。
$ nvfortran -dryrun myprog.f
描述
如果你定义宏名称而不指定值,则预处理器将字符串 1 分配给宏名称。
2.2.1. -#
用法
在以下示例中,宏 PATHLENGTH 的值为 256,直到后续编译。如果未使用 -D 选项,则 PATHLENGTH 设置为 128。
-drystdinc
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
在 myprog.F 中的源代码是
将选项传递给链接器。
使用 -D 选项创建具有给定值的预处理器宏。该值必须是整数或字符串。
$ nvc -drystdinc myprog.c
描述
你可以将宏与条件编译一起使用,以在预处理期间选择源代码文本。在编译器调用中定义的宏对于命令行上的每个模块都保持有效,除非你使用 #undef 预处理器指令或 -U 选项删除宏。编译器在处理 -D 选项后处理命令行中的所有 -U 选项。
2.2.1. -#
动态链接是 Linux 的默认行为。
相关选项
-U
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
2.2.11. -d<arg>
将选项传递给链接器。
打印来自预处理器的其他信息。[仅对 C 编译器 (nvc) 有效]
$ nvc -E myprog.c
描述
默认
2.2.1. -#
不从预处理器打印其他信息。
子选项
-dD
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
2.2.11. -d<arg>
将选项传递给链接器。
打印来自源文件的宏和值。
$ nvfortran -F myprog.F
描述
-dI
2.2.1. -#
打印包含文件名。
-dM
打印宏和值,包括预定义宏和命令行宏。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
-dN
将选项传递给链接器。
打印来自源文件的宏名称。
$ nvfortran -fast vadd.f95
描述
用法
注意
在以下示例中,编译器打印来自源文件的宏名称。
注意
使用 -d<arg> 选项打印来自预处理器的其他信息。
2.2.1. -#
相关选项
-E, -D, -U
2.2.12. -dryrun
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
显示编译器、汇编器和链接器的调用,但不执行它们。
用法
2.2.1. -#
以下命令行请求详细的调用信息。
使用 -dryrun 选项显示编译器、汇编器和链接器的调用,但不执行它们。这些调用是由编译器驱动程序从 rc 文件和与 -dryrun 一起提供的命令行创建的命令行。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
相关选项
将选项传递给链接器。
-Minfo[=option [,option,…]], -V[release_number]
$ nvfortran --flagcheck myprog.f
描述
2.2.13. -drystdinc
2.2.1. -#
动态链接是 Linux 的默认行为。
默认
编译器不显示标准包含目录。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
用法
将选项传递给链接器。
在以下示例中,.c 主程序与使用 nvfortran 编译的目标文件链接。
$ nvc main.c myfort.o -fortranlibs
描述
使用此选项指示 C++ 或 C 编译器将 NVFORTRAN 运行时库附加到链接行。
2.2.1. -#
2.2.20. -fpic
生成位置无关代码,适用于包含在共享对象(动态链接库)文件中。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不生成位置无关代码。
将选项传递给链接器。
在以下示例中,生成的目标文件 myprog.o 可用于生成共享对象。
$ nvfortran -fpic myprog.f
使用 -fpic 选项生成位置无关代码,适用于包含在共享对象(动态链接库)文件中。
2.2.1. -#
2.2.21. -fPIC
等同于 -fpic。为与其他编译器兼容而提供。
2.2.22. -g
指示编译器在目标模块中包含符号调试信息;除非命令行中存在 -O 选项,否则将优化级别设置为零。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不会将调试信息放入目标模块中。
将选项传递给链接器。
在以下示例中,目标文件 myprog.o 包含符号调试信息。
$ nvfortran -c -g myprog.f
描述
使用 -g 选项指示编译器在目标模块中包含符号调试信息。调试器需要在目标模块中包含符号调试信息,以显示和操作程序变量和源代码。
如果在命令行上指定 -g 选项,则编译器会将优化级别设置为 -O0(零),除非您指定 -O 选项。有关 -g 和 -O 选项之间交互的更多信息,请参阅 -O 条目。如果选择的优化级别不是零,符号调试可能会给出令人困惑的结果。
注意
注意:包含符号调试信息会增加目标模块的大小。
2.2.1. -#
2.2.23. -g77libs
在链接行中使用时,此选项指示 nvfortran 驱动程序搜索必要的 g77 或 gfortran 支持库,以解析特定于 g77 或 gfortran 编译的程序单元的引用。
注意
g77 或 gfortran 编译器必须安装在执行链接的系统上,此选项才能正常工作。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不会搜索 g77 或 gfortran 支持库以解析链接时的引用。
将选项传递给链接器。
以下命令行请求在链接时搜索 g77 和 gfortran 支持库
$ nvfortran -g77libs myprog.f g77_object.o
描述
如果将 g77 或 gfortran 编译的程序单元链接到使用 nvfortran 驱动程序编译的 nvfortran 主程序中,请在链接行中使用 -g77libs 选项。当此选项存在时,nvfortran 驱动程序将搜索必要的 g77 和 gfortran 支持库,以解析特定于 g77 或 gfortran 编译的程序单元的引用。
2.2.1. -#
2.2.24. –gcc-toolchain=<path>
指定 gcc 工具链位置,以在编译期间使用。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
使用默认的 gcc 工具链位置(在安装期间选择)进行编译。
将选项传递给链接器。
以下示例使用指定的 gcc 9.3.0 工具链进行编译。
$ nvc++ --gcc-toolchain=~/gcc/gcc-9.3.0/ myprog.cpp
$ nvc++ --gcc-toolchain=~/gcc/gcc-9.3.0/bin/ myprog.cpp
$ nvc++ --gcc-toolchain=~/gcc/gcc-9.3.0/bin/gcc myprog.cpp
描述
参数可以是 gcc 根目录、<根目录>/bin 或 gcc 可执行文件本身。
2.2.1. -#
动态链接是 Linux 的默认行为。
2.2.25. -gopt
指示编译器在目标文件中包含符号调试信息,并生成与未指定 -g 时生成的优化代码相同的代码。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不会将调试信息放入目标模块中。
将选项传递给链接器。
在以下示例中,目标文件 myprog.o 包含符号调试信息。
$ nvfortran -c -gopt myprog.f
描述
使用 -g 会改变优化代码的生成方式,旨在启用或改进优化代码的调试。-gopt 选项指示编译器在目标文件中包含符号调试信息,并生成与未指定 -g 时生成的优化代码相同的代码。
2.2.1. -#
2.2.26. -gpu
与 -acc、-cuda、-mp 和 -stdpar 标志结合使用,以指定 GPU 代码生成的选项。以下子选项可以在等号 (“=”) 后使用,多个子选项用逗号分隔
autocompare在执行时自动比较 CPU 与 GPU 的结果:暗示 redundant
ccXY为计算能力为 X.Y 的设备生成代码。可以指定多个计算能力,并将为每个计算能力生成一个版本。默认情况下,编译器将检测每个已安装 GPU 的计算能力。使用 -help -gpu 查看您的安装的有效计算能力。
ccall为本平台以及选定的或默认的 CUDA 工具包支持的所有计算能力生成代码。
ccall-major为所有主要支持的计算能力编译。
ccnative检测系统上可见的 GPU,并为其生成代码。如果没有设备可用,将使用与 NVCC 默认值匹配的计算能力。
cudaX.Y使用 CUDA X.Y 工具包兼容性,如果已安装
[no]debug在设备代码中启用 [禁用] 调试信息生成
deepcopy在 OpenACC 中启用聚合数据结构的完整深拷贝;仅限 Fortran
fastmath使用快速数学库中的例程
[no]flushz为 GPU 上的浮点计算启用 [禁用] 刷新为零模式
[no]fma生成 [不生成] 融合乘加指令;在
-O1时为默认值。这是 -M[no]fma 的别名。[no]implicitsections将数据子句中的数组元素引用更改 [不更改] 为数组切片。在 C++ 中,
implicitsections选项会将update device(a[n])更改为update device(a[0:n])。在 Fortran 中,它会将enter data copyin(a(n))更改为enter data copyin(a(:n))。默认行为noimplicitsections也可以使用 rcfile 更改;例如,可以添加set IMPLICITSECTIONS=0;到 siterc 或另一个 rcfile。[no]interceptdeallocations拦截 [不拦截] 对标准库内存释放的调用(例如
free),如果地址在固定内存或托管内存中,则调用相应的 CUDA 内存释放版本,否则调用常规版本。keep保留内核文件(.cubin、.ptx、source)
[no]lineinfo启用 [禁用] GPU 行信息生成
loadcache:{L1|L2}选择用于全局内存加载的硬件级别缓存;选项包括默认值
L1或L2[no]managed在 CUDA 托管内存中分配 [不分配] 任何动态分配的数据。将
-gpu=nomanaged与-stdpar一起使用,以防止该标志在检测到 CUDA 托管内存功能时隐式使用-gpu=managed。此选项已弃用。maxregcount:n指定要在 GPU 上使用的最大寄存器数;留空表示没有限制
mem:{separate|managed|unified}为生成的二进制文件选择 GPU 内存模式。这控制要使用的 CUDA 内存功能,例如仅独立的 GPU 内存 (
separate)、用于动态分配数据的 GPU 托管内存 (managed) 或系统内存(也称为完全 CUDA 统一内存)(unified)。使用托管内存或统一内存可以通过消除检测所有要复制到 GPU 上执行的代码区域内和代码区域外的数据的需求,从而简化编程。pinned使用 CUDA 固定内存。此选项已弃用。
ptxinfo打印 PTX 信息
[no]rdc生成 [不生成] 可重定位设备代码。
redundant冗余 CPU/GPU 执行
safecache允许缓存指令中使用可变大小的数组切片;编译器假定它们适合 CUDA 共享内存
sm_XY为计算能力为 X.Y 的设备生成代码。可以指定多个计算能力,并将为每个计算能力生成一个版本。默认情况下,编译器将检测每个已安装 GPU 的计算能力。使用 -help -gpu 查看您的安装的有效计算能力。
stacklimit:<l>nostacklimit设置过程或内核中堆栈变量的限制 (l),以 KB 为单位。此选项已弃用。
[no]unified为 CUDA 统一内存功能编译 [不编译],其中系统内存可从 GPU 访问。除非通过
-gpu=[no]managed设置显式行为,否则此模式将系统内存和托管内存用于动态分配的数据。将-gpu=nounified与-stdpar一起使用,以防止该标志在检测到 CUDA 统一内存功能时隐式使用-gpu=unified。此选项必须同时出现在编译和链接行中。此选项已弃用。[no]unroll启用 [禁用] 自动内部循环展开;在
-O3时为默认值zeroinit使用零初始化分配的设备内存
将选项传递给链接器。
在以下示例中,编译器为计算能力为 6.0 和 7.0 的 NVIDIA GPU 生成代码。
$ nvfortran -acc -gpu=cc60,cc70 myprog.f
编译器自动调用必要的软件工具来创建内核代码,并将内核嵌入到目标文件中。
要链接到相应的 GPU 库,您必须使用 -acc 标志链接 OpenACC 程序,对于 -cuda、-mp 或 -stdpar 也是如此。
DWARF 调试格式
使用 -g 选项可以在主机和设备上启用完整 DWARF 信息的生成;在没有其他优化标志的情况下,-g 将优化级别设置为零。如果 -O 选项将优化级别提高到 1 或更高,即使指定了 -g,也只会在设备代码中生成 GPU 行信息。要在高于零的优化级别强制为设备代码生成完整 DWARF,请使用 -gpu 的 debug 子选项。相反,要阻止为设备代码生成 dwarf 信息,请使用 -gpu 的 nodebug 子选项。debug 和 nodebug 都可以独立于 -g 使用。
2.2.27. -help
在没有其他选项的情况下使用 -help,会在标准输出上显示驱动程序识别的选项。当与一个或多个附加选项组合使用时,会将这些选项的用法信息显示到标准输出。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不显示用法信息。
将选项传递给链接器。
在以下示例中,-Minline 的用法信息会打印到标准输出。
$ nvc -help -Minline
-Minline[=lib:<inlib>|<maxsize>|<func>|except:<func>|name:<func>|maxsize:<n>|
totalsize:<n>|smallsize:<n>|reshape]
Enable function inlining
lib:<inlib> Use extracted functions from inlib
<maxsize> Set maximum function size to inline
<func> Inline function func
except:<func> Do not inline function func
name:<func> Inline function func
maxsize:<n> Inline only functions smaller than n
totalsize:<n> Limit inlining to total size of n
smallsize:<n> Always inline functions smaller than n
reshape Allow inlining in Fortran even when array shapes do not
match
-Minline Inline all functions that were extracted
在以下示例中,-help 的用法信息显示了如何根据功能列出或检查选项组。
$ nvc -help -help
-help[=groups|asm|debug|language|linker|opt|other|
overall|phase|prepro|suffix|switch|target|variable]
描述
使用 -help 选项获取有关可用选项及其语法的信息。您可以使用以下三种方式之一使用 -help
使用不带参数的
-help获取所有可用选项的列表,以及每个选项的简短单行描述。向 -help 添加参数以将输出限制为有关特定选项的信息。此用法的语法如下
-help <command line option>
向 -help 添加参数以将输出限制为一组特定的选项或构建过程。此用法的语法如下
-help=<subgroup>
下表列出并描述了 -help 可用的子组。
使用此 -help 选项 |
以获取此信息… |
|---|---|
|
特定于汇编阶段的选项列表。 |
|
与调试信息生成相关的选项列表。 |
|
可用开关分类的列表。 |
|
特定于语言的选项列表。 |
|
特定于链接阶段的选项列表。 |
|
特定于优化阶段的选项列表。 |
|
其他选项的列表,例如 C 的 ANSI 一致性指针别名。 |
|
任何 NVIDIA HPC 编译器通用的选项列表。 |
|
构建过程阶段及其应用编译器的列表。 |
|
特定于预处理阶段的选项列表。 |
|
已知文件后缀及其应用阶段的列表。 |
|
所有已知选项的列表;这等效于不带任何参数使用 -help。 |
|
特定于目标处理器的选项列表。 |
|
所有变量及其当前值的列表。可以使用语法 VAR=VALUE 在命令行上重新定义它们。 |
有关 -help 的更多示例,请参阅“命令行选项帮助”。
2.2.1. -#
2.2.28. -I
将目录添加到搜索路径,以查找使用 INCLUDE 语句或预处理器指令 #include 包含的文件。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器仅在某些目录中搜索包含的文件。
对于 gcc-lib 包含:
/usr/lib64/gcc-lib对于系统包含:
/usr/include
链接 cuFFTW 库。
-Idirectory
其中 directory 是添加到包含文件的标准搜索路径的目录名称。
将选项传递给链接器。
在以下示例中,编译器首先搜索目录 mydir,然后搜索默认目录以查找包含文件。
$ nvfortran -Imydir
描述
将目录添加到搜索路径,以查找使用 INCLUDE 语句或预处理器指令 #include 包含的文件。使用 -I 选项将目录添加到搜索包含文件的位置列表。编译器在默认目录之前搜索 -I 选项指定的目录。
Fortran INCLUDE 语句指示编译器开始从另一个文件读取。编译器使用两条规则来定位文件
如果 INCLUDE 语句中指定的文件名包含路径名,则编译器开始从其指定的文件读取。
如果在 INCLUDE 语句中未提供路径名,则编译器按顺序搜索
使用 -I 选项指定的任何目录(按指定的顺序)
包含源文件的目录
当前目录
例如,编译器将规则 (1) 应用于以下语句
INCLUDE '/bob/include/file1' (absolute path name) INCLUDE '../../file1' (relative path name)
并将规则 (2) 应用于此语句
INCLUDE 'file1'
2.2.1. -#
2.2.29. -i2, -i4, -i8
(仅限 Fortran)将 INTEGER 和 LOGICAL 变量视为两个、四个或八个字节。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器将 INTERGER 和 LOGICAL 变量视为四个字节。
将选项传递给链接器。
在以下示例中,使用 -i8 开关会导致整数变量被视为 64 位。
$ nvfortran -i8 int.f
int.f 是类似于此的函数
int.f
print *, "Integer size:", bit_size(i)
end
描述
使用此选项将 INTEGER 和 LOGICAL 变量视为两个、四个或八个字节。INTEGER*8 值不仅占用 8 字节的存储空间,而且操作使用 64 位,而不是 32 位。
-i2:将 INTEGER 变量视为 2 个字节。
-i4:将 INTEGER 变量视为 4 个字节。
-i8:将 INTEGER 和 LOGICAL 变量视为 8 个字节,并将 64 位用于 INTEGER*8 操作。
2.2.1. -#
动态链接是 Linux 的默认行为。
2.2.30. -K<flag>
请求编译器提供关于符合 IEEE 754 的特殊编译语义。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
默认值为 -Knoieee,编译器不提供特殊编译语义。
链接 cuFFTW 库。
将 INTEGER 和 LOGICAL 变量视为 8 字节,并对 INTEGER*8 操作使用 64 位。
其中 flag 是以下之一
ieee严格按照 IEEE 754 标准执行浮点运算。某些优化被禁用,并且在某些系统上,如果在链接步骤期间使用
-Kieee,则会链接更精确的数学库。noieee默认标志。使用最快可用的方法执行浮点运算,如果可用,则链接更快的非 IEEE 库,并禁用下溢陷阱。
PIC或pic生成位置无关代码。等同于
-fpic。为与其他编译器兼容而提供。trap=option[,option]...控制处理器在发生浮点异常时的行为。可能的选项包括
fpalign(已忽略)invdenormdivzovfunfinexactnone
注意
与 -Ktrap=option[,option] 相同的浮点异常功能可以使用运行时环境变量 NVCOMPILER_FPU_STATE 实现
将选项传递给链接器。
在以下示例中,编译器严格按照 IEEE 754 标准执行浮点运算
$ nvfortran -Kieee myprog.f
描述
使用 -K 指示编译器提供特殊编译语义。
-Ktrap 仅在编译主函数或程序时由编译器处理。选项 inv、denorm、divz、ovf、unf 和 inexact 对应于处理器的异常掩码位:无效操作、非规范化操作数、除零、溢出、下溢和精度。
通常,处理器的异常掩码位是开启的,这意味着浮点异常被屏蔽 - 处理器从异常中恢复并继续。如果发生浮点异常,并且其对应的掩码位是关闭的,或“未屏蔽”,则执行会因算术异常(C 的 SIGFPE 信号)而终止。
-Ktrap=fp 等同于 -Ktrap=inv,divz,ovf。
注意
NVIDIA HPC 编译器不支持 -Ktrap=inexact 的无异常执行。此硬件支持的目的是为那些对其执行有特定用途的人以及用于处理其产生的异常的适当信号处理程序。它并非设计用于正常的浮点运算代码支持。
2.2.1. -#
动态链接是 Linux 的默认行为。
2.2.31. -L
-L<dirname>
注意
多个 -L 选项有效。但是,多个 -L 选项的位置相对于提供的 -l 选项很重要。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器搜索标准库目录。
链接 cuFFTW 库。
-Ldirectory
其中 directory 是库目录的名称。
将选项传递给链接器。
在以下示例中,库目录是 /lib,链接器从此目录链接 NVFORTRAN 所需的标准库。
$ nvfortran -L/lib myprog.f
在以下示例中,在库目录 /lib 中搜索库文件 libx.a,并在目录 /lib 和 /libz 中搜索 liby.a。
$ nvfortran -L/lib -lx -L/libz -ly myprog.f
描述
使用 -L 选项指定要搜索库的目录。使用 -L 允许您将目录添加到库文件的搜索路径。
2.2.1. -#
2.2.32. -l<library>
指示链接器加载指定的库。链接器除了标准库之外,还会搜索 <library>。
注意
链接器在搜索标准库之前,按出现顺序搜索使用 -l 指定的库。
链接 cuFFTW 库。
-llibrary
其中 library 是要搜索的库的名称。
用法:在以下示例中,如果标准库目录是 /lib,则链接器除了标准库之外,还会加载库 /lib/libmylib.a。
$ nvfortran myprog.f -lmylib
描述
使用此选项指示链接器加载指定的库。编译器将字符 lib 添加到库名称的前面,并在库名称后添加 .a 扩展名。链接器在搜索标准库之前,会搜索每个指定的库。
2.2.1. -#
2.2.33. -M
生成 make 依赖关系列表。您可以(仅限 nvc++)使用 -MD,filename 生成 make 依赖关系列表并将其打印到指定的文件。
2.2.34. -M<nvflag>
选择代码生成的选项。这些选项分为以下几类
代码生成 |
Fortran 语言控制 |
优化 |
环境 |
C/C++ 语言控制 |
杂项 |
内联 |
下表按字母顺序列出并简要描述了这些选项,并包含一个字段显示类别。有关与这些类别相关的选项的更多详细信息,请参阅“-M 选项按类别”。
nvflag |
描述 |
类别 |
|---|---|---|
|
控制在可分配数组赋值中是使用 Fortran 95 还是 Fortran 2003 语义。 |
Fortran 语言 |
|
使用源代码注释汇编代码。 |
杂项 |
|
当使用 inline 关键字声明 C/C++ 函数时,在 -O2 级别内联它。 |
内联 |
|
指定编译器是否允许在 C/C++ 源文件中使用 asm 关键字(仅限 nvc 和 nvc++)。 |
C/C++ 语言 |
|
确定如何在带引号的字符串中处理反斜杠字符(仅限 nvfortran)。 |
Fortran 语言 |
|
指定是否启用或禁用数组边界检查。 |
杂项 |
|
是否使用数学子例程内置支持进行编译,这将导致选定的数学库例程被内联(仅限 nvc 和 nvc++)。 |
优化 |
|
在 Fortran 无格式数据的 I/O 期间交换字节顺序(大端到小端或反之亦然)。 |
杂项 |
|
在可能的情况下,将大小大于或等于 16 字节的数据对象对齐到缓存行边界。 |
优化 |
|
检查 NULL 指针(仅限 nvfortran)。 |
杂项 |
|
在进入并行区域时和在并行区域开始之前,检查堆栈是否有可用空间。当声明了许多私有变量时很有用。 |
杂项 |
|
启用循环的自动并发化。多个处理器或核心将用于执行可并行化的循环。 |
优化 |
|
运行 NVIDIA 类 cpp 预处理器,而不执行后续编译步骤。 |
杂项 |
|
强制 Cray Fortran (CF77) 兼容性(仅限 nvfortran)。 |
优化 |
|
启用 CUDA Fortran。 |
Fortran 语言 |
|
是否将非规范化操作数视为零(默认)。 |
代码生成 |
|
确定是否必须声明所有程序变量(仅限 nvfortran)。 |
Fortran 语言 |
|
确定如何处理星号 (“*”) 字符与标准输入和标准输出的关系,而与 I/O 单元 5 和 6 的状态无关。(仅限 nvfortran)。 |
Fortran 语言 |
|
检查潜在的数据依赖性。 |
优化 |
|
为大量使用函数内联的程序启用 [禁用] 死存储消除阶段。 |
优化 |
|
确定编译器是否将第一列包含字母“D”的行视为可执行语句 (仅限 nvfortran)。 |
Fortran 语言 |
|
指定编译器将美元符号 ($) 映射到的字符 (char) (仅限 nvfortran)。 |
Fortran 语言 |
|
指定[不]添加 DWARF 调试信息。 |
代码生成 |
|
与 -g 一起使用时,生成 DWARF2 格式的调试信息。 |
代码生成 |
|
与 -g 一起使用时,生成 DWARF3 格式的调试信息。 |
代码生成 |
|
指示编译器接受 132 列的源代码;否则它接受 72 列的代码 (仅限 nvfortran)。 |
Fortran 语言 |
|
调用函数提取器。 |
内联 |
|
使用放宽的精度执行某些浮点固有函数。 |
优化 |
|
指示编译器假定 F77 样式的固定格式源代码 (仅限 nvfortran)。 |
Fortran 语言 |
|
将非规格化结果视为零 [不视为零](默认)。 |
代码生成 |
|
指定不使用低精度 fp 近似运算。 |
优化 |
|
指示编译器假定 F90 样式的自由格式源代码 (仅限 nvfortran)。 |
Fortran 语言 |
|
编译器将所有函数对齐到 32 字节边界。 |
代码生成 |
|
匹配某些 gcc 错误的行为 |
杂项 |
|
在编译进行时,将关于优化和代码生成的信息性消息打印到标准输出。 |
杂项 |
|
指定编译器显示的最低错误严重级别。 |
杂项 |
|
调用函数内联器。 |
内联 |
|
生成额外的代码以启用函数检测。 |
代码生成 |
|
确定是否在 Fortran I/O 调用周围生成临界区 (仅限 nvfortran)。 |
Fortran 语言 |
|
调用过程间分析和优化。 |
优化 |
|
保留中间汇编语言文件。 |
杂项 |
|
启用对大于 2GB 的 64 位索引和单个静态数据对象的支持。 |
代码生成 |
|
指定编译器是否创建列表文件。 |
杂项 |
|
将最内层循环对齐 [不对齐] 到 32 字节边界。 |
代码生成 |
|
启用 [禁用] 循环携带冗余消除。 |
优化 |
|
识别 [忽略] __m128、__m128d 和 __m128i 数据类型。(仅限 nvc) |
代码生成 |
|
指示编译器将浮点常量视为 float 数据类型,而不是默认的 double 数据类型(仅限 nvc 和 nvc++)。 |
C/C++ 语言 |
|
指示编译器生成关于为什么不执行某些优化的信息。 |
杂项 |
|
消除为函数设置真实堆栈帧指针的操作。 |
优化 |
|
[不]将 INTEGER 变量和常量视为 INTEGER(KIND=4)。 |
优化 |
|
当调用链接步骤时,不要包含调用 Fortran 主程序的对象文件。(仅限 nvfortran)。 |
代码生成 |
|
在 Linux 上,不要将 -rpath 路径添加到链接行。 |
杂项 |
|
指示编译器不识别标准预处理器宏。 |
环境 |
|
指示编译器不搜索包含文件的标准位置。 |
环境 |
|
指示链接器不链接标准库。 |
环境 |
|
确定每个 DO 循环是否至少执行一次 (仅限 nvfortran)。 |
Language |
|
禁用成语识别和生成对优化向量函数的调用。 |
优化 |
|
对汇编语言和 Fortran 输入源文件执行类似 cpp 的预处理。 |
杂项 |
|
[不]将 REAL 变量和常量视为 REAL(KIND=8)(仅限 nvfortran)。 |
优化 |
|
确定编译器如何处理内在函数 CMPLX 和 REAL(仅限 nvfortran)。 |
优化 |
|
在堆栈上分配 [不分配] 局部变量;这允许递归。SAVEd、数据初始化或 namelist 成员始终静态分配,无论此开关的设置如何(仅限 nvfortran)。 |
代码生成 |
|
指定编译器是否避免可能阻止代码成为可重入代码的优化。 |
代码生成 |
|
[不]强制引用出现在 EXTERNAL 语句中的名称(仅限 nvfortran)。 |
代码生成 |
|
指示编译器覆盖指针和数组之间的数据依赖性(仅限 nvc 和 nvc++)。 |
优化 |
|
如果在循环之后使用标量,但未在循环的每次迭代中定义标量,则编译器默认情况下不会并行化循环。但是,此选项告诉编译器并行化循环是安全的。对于给定的循环,为所有标量计算的最后一个值使其可以安全地并行化循环。 |
代码生成 |
|
确定编译器是否假定所有局部变量都受 SAVE 语句的约束 (仅限 nvfortran)。 |
Fortran 语言 |
|
为字符指定 signed char(仅限 nvc 和 nvc++ – 另请参见 uchar)。 |
C/C++ 语言 |
|
如果 Fortran 全局变量的名称已包含下划线,则添加 [不添加] 第二个下划线到其名称(仅限 nvfortran)。 |
代码生成 |
|
扩展 [不扩展] 符号位(如果已设置)。 |
代码生成 |
|
将 float 参数转换为 double 参数字符 [不转换](仅限 nvc 和 nvc++)。 |
C/C++ 语言 |
|
导致编译器标记不符合 ANSI 标准的源代码 (仅限 nvfortran)。 |
Fortran 语言 |
|
为包含增量可能为零的归纳变量的循环生成 [不生成] 备用代码(仅限 nvfortran)。 |
代码生成 |
|
为字符指定 unsigned char(仅限 nvc 和 nvc++ – 另请参见 schar)。 |
C/C++ 语言 |
|
[不]将任何非零逻辑变量视为 .TRUE. 。(仅限 nvfortran)。 |
Fortran 语言 |
|
控制循环展开。 |
优化 |
|
确定编译器是否保留标识符中的大写字母。Fortran 关键字必须为小写 (仅限 nvfortran)。 |
Fortran 语言 |
|
强制 Fortran 程序单元假定调用的是具有 varargs 类型接口的 C 函数 (仅限 nvfortran) |
代码生成 |
|
调用 [不调用] 代码向量化器。 |
优化 |
2.2.35. -m
-m
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不显示链接映射。
将选项传递给链接器。
当执行以下示例时,nvfortran 将链接映射写入 stdout。
$ nvfortran -m myprog.f
描述
使用此选项可显示链接映射。
在 Linux 上,映射将写入
stdout。
2.2.1. -#
2.2.36. -march=<target>
是 -mcpu=<target>[<+extension…>] 的别名。请参阅 -mcpu=<target>[<+extension…>] 了解详细信息。
2.2.1. -#
-tp <target>、 -mcpu=<target>[<+extension…>]、 -mtune=<target> 以及所有控制环境的 -M<nvflag> 选项,如 环境控制 中所列。
2.2.37. -mcmodel=<size>
在 Linux 执行环境中为请求的内存模型生成代码。
默认值:编译器为 Arm 和 x86-64 目标上的小型内存模型生成代码。
将选项传递给链接器。
以下命令行请求中等内存模型
$ nvfortran -mcmodel=medium myprog.f
Arm 描述
tiny 内存模型将用户的对象或可执行文件的组合区域限制为 1MB。最大代码大小为 1MB。
small 内存模型将用户的对象或可执行文件的组合区域限制为 4GB。最大代码大小为 2GB。
Arm 上不支持 medium 内存模型。这将自动选择 large 内存模型。
large 内存模型允许不受限制的数据大小。最大代码大小为 2GB。-mcmodel=large 在 Arm 系统上与 -fPIC 不兼容。
x86-64 描述
x86-64 上不支持 tiny 内存模型。
small 内存模型将用户的对象或可执行文件的组合区域限制为 2GB。在 x86-64 目标上暗示 -Mlarge_arrays。
medium 内存模型允许不受限制的数据大小。最大代码大小为 2GB。
Linux 环境提供 static libxxx.a 存档库,这些库使用和不使用 -fpic 构建,以及使用 -fpic 编译的 dynamic libxxx.so 共享对象库。使用链接开关 -mcmodel=medium 意味着 -fpic 开关并默认使用共享库。
x86-64 上不支持大型内存模型。
详细信息
tiny 和 small 代码模型是最快的,应该适合大多数程序。medium 和 large 代码模型允许更大的代码和数据大小,但代价是额外的指令。请参阅各自的 SysV ABI 文档以获取更多详细信息。
2.2.1. -#
2.2.38. -mcpu=<target>[<+extension…>]
设置目标处理器。目标处理器后面可以跟一个可选的架构扩展列表。通过在扩展名称前加上 no 来禁用架构扩展。例如,+nocrypto。扩展按从左到右的顺序处理。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
NVIDIA HPC 编译器生成专门针对执行编译的处理器类型的代码。特别是,默认情况下,在给定系统上编译时尽可能使用所有支持的指令。
默认目标处理器根据执行编译的处理器自动选择。您可以指定与自动选择的默认值不同的目标处理器,但该目标必须与执行编译的处理器属于同一 CPU 系列。NVIDIA HPC 编译器支持 2 个不同的 CPU 系列:x86_64 和 64 位 Arm 服务器 CPU。
在给定系统上创建的没有 -mcpu= 标志的可执行文件可能无法在以前的系统上使用。例如,在 Intel Skylake 处理器上创建的可执行文件可能使用 AVX-512 或其他在早期 Intel 处理器或某些 AMD 处理器上不可用的指令。
将选项传递给链接器。
在以下示例中,nvfortran 将目标处理器设置为支持 Crypto 的 Arm Neoverse-v2
$ nvfortran -mcpu=neoverse-v2+crypto myprog.f
描述
使用此选项可设置目标架构。默认情况下,NVIDIA HPC 编译器在给定系统上编译时尽可能使用所有支持的指令。
可以使用 -mcpu 选项显式指定或限制特定于处理器的优化。因此,可以创建可在上一代系统上使用的可执行文件。
以下列表包含 -mcpu 的可能子选项以及每个子选项旨在针对的处理器。
x86-64
px生成可在任何基于 x86-64 处理器的系统上使用的代码。
主机生成针对主机处理器的代码。链接 HPC SDK cpu 数学库的本机版本。
native生成针对主机处理器的代码。-tp host 的别名。
x86-64-v2生成用于 x86-64 微架构级别的代码,包括 SSE。
x86-64-v3生成用于 x86-64 微架构级别的代码,包括 AVX2。
x86-64-v4生成用于 x86-64 微架构级别的代码,包括一些 AVX512 扩展。
bulldozer为 AMD Bulldozer 和兼容处理器生成代码。
piledriver生成可在任何基于 AMD Piledriver 处理器的系统上使用的代码。
bdver3为 AMD Steamroller 和兼容处理器生成代码。
bdver4为 AMD Excavator 和兼容处理器生成代码。
zen生成可在任何基于 AMD Zen 处理器的系统(例如 Naples、Ryzen)上使用的代码。
zen2生成可在任何基于 AMD Zen 2 处理器的系统(例如 Rome、第 3 代 Ryzen)上使用的代码。
zen3生成可在任何基于 AMD Zen 3 处理器的系统(例如 Milan、Ryzen 5000)上使用的代码。
zen4生成可在任何基于 AMD Zen 4 处理器的系统(例如 Genoa)上使用的代码。
sandybridge为 Intel Sandy Bridge 和兼容处理器生成代码。
haswell生成可在任何基于 Intel Haswell 处理器的系统上使用的代码。
skylake生成可在基于 Intel Skylake Xeon 处理器的系统上使用的代码。
icelake生成可在基于 Intel Ice Lake Xeon 处理器的系统上使用的代码。
cannonlake生成可在基于 Intel Cannon Lake Xeon 处理器的系统上使用的代码。
cascadelake生成可在基于 Intel Cascade Lake Xeon 处理器的系统上使用的代码。
cooperlake生成可在基于 Intel Cooper Lake Xeon 处理器的系统上使用的代码。
tigerlake生成可在基于 Intel Tiger Lake Xeon 处理器的系统上使用的代码。
alderlake生成可在基于 Intel Alder Lake Xeon 处理器的系统上使用的代码。
rocketlake生成可在基于 Intel Rocket Lake Xeon 处理器的系统上使用的代码。
sapphirerapids生成可在基于 Intel Sapphire Rapids Xeon 处理器的系统上使用的代码。
graniterapids生成可在基于 Intel Granite Rapids Xeon 处理器的系统上使用的代码。
Arm
px生成可在任何基于 Arm 处理器的系统上使用的代码。
主机生成针对主机处理器的代码。链接 HPC SDK cpu 数学库的本机版本。
native生成针对主机处理器的代码。-tp host 的别名。
a64fx生成可在基于 Fujitsu A64fx 处理器的系统(SVE x 512)上使用的代码。
neoverse-n1生成可在任何基于 Arm Neoverse-N1 处理器的系统上使用的代码。
neoverse-v1生成可在任何基于 Arm Neoverse-V1 处理器的系统(SVE x 256)上使用的代码。
neoverse-v2生成可在任何基于 Arm Neoverse-V2 处理器的系统(SVE x 128)上使用的代码。
grace生成可在基于 NVIDIA Grace 处理器的系统(SVE x 128)上使用的代码。
graviton3生成可在基于 AWS Graviton3 处理器的系统(SVE x 256)上使用的代码。
graviton4生成可在基于 AWS Graviton4 处理器的系统(SVE x 128)上使用的代码。
thunderx2t99生成可在基于 Cavium Vulcan 处理器的系统上使用的代码。
2.2.1. -#
-tp <target>、 -march=<target>、 -mcpu=<target>[<+extension…>] 以及所有控制环境的 -M<nvflag> 选项,如 环境控制 中所列。
2.2.39. -module <moduledir>
允许您指定一个特定的目录,在其中放置生成的中间 .mod 文件。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器将 .mod 文件放置在当前工作目录中,并且仅在当前工作目录中搜索预编译的中间 .mod 文件。
将选项传递给链接器。
以下命令行请求将编译 myprog.f 期间生成的任何中间模块文件放置在目录 mymods 中;具体来说,将使用文件 ./mymods/myprog.mod。
$ nvfortran -module mymods myprog.f
描述
使用 -module 选项来指定应在其中放置生成的中间 .mod 文件的特定目录。如果存在 -module <moduledir> 选项,并且在已编译的程序单元中存在 USE 语句,则在默认本地目录中搜索之前,将在 *<moduledir>* 中搜索 .mod 中间文件。
2.2.1. -#
动态链接是 Linux 的默认行为。
2.2.40. -[no]mp
启用 [禁用] OpenMP 指令。启用后,它指示编译器解释用户插入的 OpenMP 并行编程指令和编译指示,并生成一个可执行文件,该文件将在并行系统中使用多个处理器。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不解释用户插入的 OpenMP 并行编程指令和编译指示。
将选项传递给链接器。
以下命令行请求处理 myprog.f 中存在的任何 OpenMP 指令
$ nvfortran -mp myprog.f
描述
使用 -mp 选项指示编译器解释用户插入的 OpenMP 并行编程指令,并生成一个可执行文件,该文件将在并行系统中使用多个处理器。
子选项是以下一项或多项
[no]align强制使用算法将循环迭代分配给 OpenMP 进程,该算法最大程度地提高了并行化和 SIMD 向量化的循环中向量子节的对齐。此分配可以提高包含许多此类循环的程序单元的性能。它还可能导致负载平衡问题,从而显着降低程序单元的性能,这些程序单元具有相对较短的循环,但在每次迭代中包含大量工作。
启用 [禁用] OpenACC 指令。以下子选项可以在等号 (“=”) 后使用,多个子选项用逗号分隔默认情况下启用
omp loop中循环的自动并行化。要禁用此优化,请使用noautopar子选项。用法OpenMP 指令被编译用于 GPU 执行以及主机回退到 CPU。有关特定于目标的选项,请参阅
-gpu的文档。多核OpenMP 指令仅针对多核 CPU 执行进行编译;此子选项是默认选项。
ompt链接到启用 OMPT 的 OpenMP 运行时库。OMPT 是一个接口,可帮助第一方工具监视 OpenMP 程序的执行。
有关 HPC 编译器如何支持 OpenMP 的更多信息,请参阅 HPC 编译器用户指南的“使用 OpenMP”部分。
2.2.1. -#
-Mconcur[=option [,option,…]]、 -M[no]vect[=option [,option,…]]
2.2.41. -mtune=<target>
-mtune= 提供了兼容性。它不执行任何操作。
2.2.1. -#
-tp、 -march=<target>、 -mcpu=<target>[<+extension…>] 以及所有控制环境的 -M<nvflag 选项,如 环境控制 中所列。
2.2.42. -noswitcherror
对于未知开关,发出警告而不是错误。在打印警告消息后,忽略未知的命令行开关。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器打印错误消息然后停止。
将选项传递给链接器。
在以下示例中,编译器在打印警告消息后忽略未知的命令行开关。
$ nvfortran -noswitcherror myprog.f
描述
使用此选项指示编译器在打印警告消息后忽略未知的命令行开关。
提示
您可以在 siterc 文件中通过添加以下内容来配置此行为:set NOSWITCHERROR=1。
2.2.1. -#
动态链接是 Linux 的默认行为。
2.2.43. -nvmalloc
与包含客户内存分配器的库链接。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器链接到用于动态分配的系统库。
将选项传递给链接器。
在以下示例中,编译器使用自定义主机内存分配器代替系统库。
$ nvc main.c -nvmalloc
描述
使用此选项可使用备用内存分配器库。在某些情况下,用户可能会通过使用此库看到性能提升。
2.2.1. -#
动态链接是 Linux 的默认行为。
2.2.44. -O<level>
以指定的级别调用代码优化。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器启用经典全局优化。
链接 cuFFTW 库。
-O [level]
其中 level 是从 0 到 4 或 “fast” 的整数。
将选项传递给链接器。
在以下示例中,由于未指定 -O 选项,因此编译器将优化设置为级别 1。
$ nvfortran myprog.f
在以下示例中,由于未指定优化级别并且指定了 -O 选项,因此编译器启用经典全局优化。
$ nvfortran -O myprog.f
描述
使用此选项可调用代码优化。将 NVIDIA 编译器命令与 -Olevel 选项(大写 O 代表 Optimize)结合使用,您可以指定以下任何优化级别
-O0级别零指定不进行优化。为每个语言语句生成一个基本块。
-O1级别一指定局部优化。执行基本块的调度。执行寄存器分配。
-O当未指定级别时,将执行级别全局优化,包括传统的标量优化、归纳识别和循环不变式移动。未启用 SIMD 向量化。
-O2级别二指定所有级别 1 和全局优化,并启用更高级的优化,例如 SIMD 代码生成、缓存对齐和部分冗余消除。
-O3级别三指定激进的全局优化。此级别执行所有级别一和级别二的全局优化,并启用可能盈利也可能不盈利的更激进的提升和标量替换优化。
-Ofast启用
-O3、-Mfprelaxed、-Mstack_arrays、-Mno-nan、-Mno-inf和-fcx-limited-range。注意
当同时启用命令行选项
-Ofast和-stdpar时,-Mstack_array被禁用。-O4级别四执行所有级别一、级别二和级别三的优化,并启用受保护的不变浮点表达式的提升。
下表显示了 -O 选项、-g 选项、-Mvect 和 -Mconcur 选项之间的交互。
优化选项 |
调试选项 |
-M 选项 |
优化级别 |
|---|---|---|---|
none |
none |
none |
1 |
none |
none |
-Mvect |
2 |
none |
none |
-Mconcur |
2 |
none |
(仅限 Fortran)生成代码以检查数组边界。 |
none |
0 |
-O |
none 或 -g |
none |
2 |
-Olevel |
none 或 -g |
none |
level |
-Olevel < 2 |
none 或 -g |
-Mvect |
2 |
-Olevel < 2 |
none 或 -g |
-Mconcur |
2 |
使用 -O0 选项编译的未优化代码可能比在其他优化级别生成的代码慢得多。与 -Mvect 选项一样,如果未提供 -O 或 -g 选项,则 -Munroll 选项会将优化级别设置为级别 2。-gopt 选项建议用于生成具有优化代码的调试信息。有关优化的更多信息,请参阅 HPC 编译器用户指南的“多核 CPU 优化”部分。
2.2.1. -#
2.2.45. -o
命名可执行文件。使用 -o 选项指定编译器对象文件的文件名。最终输出是链接的结果。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器根据需要创建可执行文件名。如果您未指定 -o 选项,则默认文件名为链接器输出文件 a.out。
链接 cuFFTW 库。
-o filename
其中 filename 是编译输出文件的名称。filename 不应具有 .f 扩展名。
将选项传递给链接器。
在以下示例中,可执行文件是 myprog 而不是默认的 a.out。
$ nvfortran myprog.f -o myprog
2.2.1. -#
2.2.46. -pg
指示编译器检测生成的用于 gprof 样式 gmon.out 基于采样的性能分析跟踪文件的可执行文件。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不检测生成的用于 gprof 样式性能分析的可执行文件。
将选项传递给链接器。
在以下示例中,程序已编译为使用 gprof 进行性能分析。
$ nvfortran -pg myprog.c
描述
使用此选项指示编译器检测生成的用于 gprof 样式基于采样的性能分析的可执行文件。您必须在编译和链接步骤都使用此选项。当执行生成的程序时,将生成 gmon.out 样式的跟踪,并且可以使用 gprof 进行分析。
2.2.1. -#
动态链接是 Linux 的默认行为。
2.2.47. -R<directory>
指示链接器将路径名 <directory> 硬编码到生成的共享对象(动态链接库)文件的搜索路径中。
注意
R 和 <directory> 之间不能有空格。
将选项传递给链接器。
在以下示例中,在运行时,a.out 可执行文件在指定目录(在本例中为 /home/Joe/myso)中搜索共享对象。
$ nvfortran -R/home/Joe/myso myprog.f
描述
使用此选项指示编译器将信息传递给链接器,以将路径名 <directory> 硬编码到共享对象(动态链接库)文件的搜索路径中。
2.2.1. -#
2.2.48. -r
-r
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不会创建可重定位的目标文件,也不使用 -r 选项。
将选项传递给链接器。
在此示例中,nvfortran 创建了一个可重定位的目标文件。
$ nvfortran -r myprog.f
描述
使用此选项创建可重定位的目标文件。
2.2.1. -#
2.2.49. -r4 和 -r8
(仅限 Fortran) 将 DOUBLE PRECISION 变量解释为 REAL (-r4),或将 REAL 变量解释为 DOUBLE PRECISION (-r8)。 请注意,这些选项不会覆盖明确声明类型名称中字节数的实际标准类型声明 (REAL*4 和 REAL*8)。
将选项传递给链接器。
在此示例中,双精度变量被解释为 REAL。
$ nvfortran -r4 myprog.f
描述
将 DOUBLE PRECISION 变量解释为 REAL (-r4) 或将 REAL 变量解释为 DOUBLE PRECISION (-r8)。
2.2.1. -#
2.2.50. -rc
指定驱动程序启动配置文件的名称。 如果提供的文件或路径名不是完整路径名,则加载的配置文件的路径相对于 $DRIVER 路径(当前正在执行的驱动程序的路径)。 如果提供完整路径名,则该文件将用作驱动程序配置文件。
链接 cuFFTW 库。
-rc [path] filename
其中 path 是相对于 $DRIVER 值的相对路径名,或者是以外 “/” 开头的完整路径名。 Filename 是驱动程序配置文件。
将选项传递给链接器。
在以下示例中,文件 .nvfortranrctest 相对于 /opt/hpc_sdk/<target>/<release>/compilers/bin,$DRIVER 的值,是驱动程序配置文件。
$ nvfortran -rc .nvfortranrctest myprog.f
描述
使用此选项指定编译器驱动程序启动配置文件的名称。 如果提供的文件或路径名不是完整路径名,则加载的配置文件的路径相对于 $DRIVER 路径——当前正在执行的编译器驱动程序的路径。 如果提供完整路径名,则该文件将用作编译器驱动程序配置文件。
2.2.1. -#
2.2.51. -S
在编译阶段之后停止编译,并将汇编语言输出写入文件。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不保留 .s 文件。
将选项传递给链接器。
在此示例中,nvfortran 在当前目录中生成文件 myprog.s。
$ nvfortran -S myprog.f
描述
使用此选项在编译阶段之后停止编译,然后将汇编语言输出写入文件。 如果输入文件是 filename.f,则输出文件为 filename.s。
2.2.1. -#
2.2.52. -s
从可执行文件中剥离符号表信息。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器包含所有符号表信息,并且不使用 -s 选项。
将选项传递给链接器。
在此示例中,nvfortran 从 a.out 可执行文件中剥离符号表信息。
$ nvfortran -s myprog.f
描述
使用此选项从可执行文件中剥离符号表信息。
2.2.1. -#
2.2.53. -shared
指示编译器将信息传递给链接器,以生成共享对象(动态链接库)文件。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不会将信息传递给链接器以生成共享对象文件。
将选项传递给链接器。
在以下示例中,编译器将信息传递给链接器以生成共享对象文件:myso.so。
$ nvfortran -shared myprog.f -o myso.so
描述
使用此选项指示编译器将信息传递给链接器,以生成共享对象(动态链接库)文件。
2.2.1. -#
2.2.54. -show
生成描述当前驱动程序配置的驱动程序帮助信息。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不显示驱动程序帮助信息。
将选项传递给链接器。
在以下示例中,驱动程序在处理驱动程序配置文件后,将配置信息显示到标准输出。
$ nvfortran -show myprog.f
描述
使用此选项生成描述当前驱动程序配置的驱动程序帮助信息。
2.2.1. -#
2.2.55. -silent
-silent
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器打印警告消息。
将选项传递给链接器。
在以下示例中,驱动程序不显示警告消息。
$ nvfortran -silent myprog.f
描述
使用此选项抑制警告消息。
2.2.1. -#
2.2.56. -soname
编译器识别 -soname 选项并将其传递给链接器。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不识别 -soname 选项。
将选项传递给链接器。
在以下示例中,驱动程序将 soname 选项及其参数传递给链接器。
$ nvfortran -soname library.so myprog.f
描述
使用此选项指示编译器识别 -soname 选项并将其传递给链接器。
2.2.1. -#
动态链接是 Linux 的默认行为。
2.2.57. -static
静态链接所有库,包括 NVIDIA HPC 编译器运行时库。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
动态链接是 Linux 的默认行为。
将选项传递给链接器。
以下命令行显式编译并链接到 NVIDIA HPC 编译器运行时库的静态版本。
% nvfortran -static -c object1.f
描述
您可以使用此选项显式编译并链接到系统库和 NVIDIA HPC 编译器运行时库的静态版本。
2.2.1. -#
2.2.58. -static-nvidia
仅限 Linux。 编译并仅静态链接到 NVIDIA HPC 编译器运行时库。 其他库是动态链接的。 隐含 -Mnorpath。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器使用静态库。
将选项传递给链接器。
以下命令行显式编译并链接到 NVIDIA HPC 编译器运行时库的静态版本。
% nvfortran -static-nvidia -c object1.f
描述
您可以使用此选项显式编译并链接到 NVIDIA HPC 编译器运行时库的静态版本。
注意
在 Linux 上,-static-nvidia 会生成可在大多数 Linux 系统上运行的代码,而无需可移植性包。
2.2.1. -#
2.2.59. -stdpar
启用 ISO C++17 并行算法行为;有关特定于目标的选项,请参阅 -gpu。 支持的子选项可以在等号 (“=”) 后使用,多个子选项用逗号分隔。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
如果没有子选项,-stdpar 请求生成用于在 GPU 上执行 C++ 并行算法的代码。
子选项
用法在 GPU 上执行 C++ 并行算法;默认设置。
多核在 CPU 上并行执行 C++ 并行算法。
将选项传递给链接器。
以下命令行启用 C++ 并行算法的并行化,以便卸载到 GPU。
$ nvc++ -stdpar myprog.cpp
2.2.60. -target
为所有使用的并行编程范例(OpenACC、OpenMP、标准语言)选择目标设备。 以下子选项可以在等号 (“=”) 后使用,多个子选项用逗号分隔。
用法全局设置目标设备为 NVIDIA GPU。
多核全局设置目标设备为多核 CPU。
将选项传递给链接器。
以下命令行启用 C++17 并行算法和 OpenACC 的并行化,并将目标设备全局指定为 NVIDIA GPU。
$ nvc++ -stdpar -acc -target=gpu myprog.cpp
2.2.61. -time
打印各个编译步骤的执行时间。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不打印编译步骤的执行时间。
将选项传递给链接器。
在以下示例中,nvfortran 打印各个编译步骤的执行时间。
$ nvfortran -time myprog.f
描述
使用此选项打印各个编译步骤的执行时间。
2.2.1. -#
2.2.62. -tp <target>
设置目标处理器。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
NVIDIA HPC 编译器生成专门针对执行编译的处理器类型的代码。特别是,默认情况下,在给定系统上编译时尽可能使用所有支持的指令。
默认目标处理器根据执行编译的处理器自动选择。您可以指定与自动选择的默认值不同的目标处理器,但该目标必须与执行编译的处理器属于同一 CPU 系列。NVIDIA HPC 编译器支持 2 个不同的 CPU 系列:x86_64 和 64 位 Arm 服务器 CPU。
在给定系统上创建的、未使用 -tp 标志的可执行文件可能无法在上一代系统上使用。 例如,在 Intel Skylake 处理器上创建的可执行文件可能使用 AVX-512 或其他在早期 Intel 处理器或某些 AMD 处理器上不可用的指令。
将选项传递给链接器。
在以下示例中,nvfortran 将目标处理器设置为 Intel Skylake Xeon 处理器。
$ nvfortran -tp=skylake myprog.f
描述
使用此选项可设置目标架构。默认情况下,NVIDIA HPC 编译器在给定系统上编译时尽可能使用所有支持的指令。
可以使用 -tp 选项显式指定或限制特定于处理器的优化。 因此,可以创建可在上一代系统上使用的可执行文件。
以下列表包含 -tp 的可能子选项以及每个子选项旨在针对的处理器。
px生成可在任何基于 x86-64 处理器的系统上使用的代码。
主机生成针对主机处理器的代码。链接 HPC SDK cpu 数学库的本机版本。
native生成针对主机处理器的代码。-tp host 的别名。
x86-64-v2生成用于 x86-64 微架构级别的代码,包括 SSE。
x86-64-v3生成用于 x86-64 微架构级别的代码,包括 AVX2。
x86-64-v4生成用于 x86-64 微架构级别的代码,包括一些 AVX512 扩展。
bulldozer为 AMD Bulldozer 和兼容处理器生成代码。
piledriver生成可在任何基于 AMD Piledriver 处理器的系统上使用的代码。
bdver3为 AMD Steamroller 和兼容处理器生成代码。
bdver4为 AMD Excavator 和兼容处理器生成代码。
zen生成可在任何基于 AMD Zen 处理器的系统(例如 Naples、Ryzen)上使用的代码。
zen2生成可在任何基于 AMD Zen 2 处理器的系统(例如 Rome、第 3 代 Ryzen)上使用的代码。
zen3生成可在任何基于 AMD Zen 3 处理器的系统(例如 Milan、Ryzen 5000)上使用的代码。
zen4生成可在任何基于 AMD Zen 4 处理器的系统(例如 Genoa)上使用的代码。
sandybridge为 Intel Sandy Bridge 和兼容处理器生成代码。
haswell生成可在任何基于 Intel Haswell 处理器的系统上使用的代码。
skylake生成可在基于 Intel Skylake Xeon 处理器的系统上使用的代码。
icelake生成可在基于 Intel Ice Lake Xeon 处理器的系统上使用的代码。
cannonlake生成可在基于 Intel Cannon Lake Xeon 处理器的系统上使用的代码。
cascadelake生成可在基于 Intel Cascade Lake Xeon 处理器的系统上使用的代码。
cooperlake生成可在基于 Intel Cooper Lake Xeon 处理器的系统上使用的代码。
tigerlake生成可在基于 Intel Tiger Lake Xeon 处理器的系统上使用的代码。
alderlake生成可在基于 Intel Alder Lake Xeon 处理器的系统上使用的代码。
rocketlake生成可在基于 Intel Rocket Lake Xeon 处理器的系统上使用的代码。
sapphirerapids生成可在基于 Intel Sapphire Rapids Xeon 处理器的系统上使用的代码。
graniterapids生成可在基于 Intel Granite Rapids Xeon 处理器的系统上使用的代码。
主机生成针对主机处理器的代码。链接 HPC SDK cpu 数学库的本机版本。
native生成针对主机处理器的代码。-tp host 的别名。
a64fx生成可在基于 Fujitsu A64fx 处理器的系统(SVE x 512)上使用的代码。
neoverse-n1生成可在任何基于 Arm Neoverse-N1 处理器的系统上使用的代码。
neoverse-v1生成可在任何基于 Arm Neoverse-V1 处理器的系统(SVE x 256)上使用的代码。
neoverse-v2生成可在任何基于 Arm Neoverse-V2 处理器的系统(SVE x 128)上使用的代码。
grace生成可在基于 NVIDIA Grace 处理器的系统(SVE x 128)上使用的代码。
graviton3生成可在基于 AWS Graviton3 处理器的系统(SVE x 256)上使用的代码。
graviton4生成可在基于 AWS Graviton4 处理器的系统(SVE x 128)上使用的代码。
thunderx2t99生成可在基于 Cavium Vulcan 处理器的系统上使用的代码。
2.2.1. -#
所有控制环境的 -M<nvflag> 选项,如 环境控制 中所列。
2.2.63. -[no]traceback
-[no]traceback
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器为 FORTRAN 启用回溯,并为 C 和 C++ 禁用回溯。
链接 cuFFTW 库。
-traceback
将选项传递给链接器。
在此示例中,nvfortran 为程序 myprog.f 启用回溯。
$ nvfortran -traceback myprog.f
描述
使用此选项启用或禁用运行时回溯信息,以便与环境变量 NVCOMPILER_TERM 一起使用。
在 siterc 或 .mynv*rc 中设置 set TRACEBACK=OFF; 也会禁用默认回溯。
使用 ON 而不是 OFF 会启用默认回溯。
2.2.1. -#
动态链接是 Linux 的默认行为。
2.2.64. -U
取消定义预处理器宏。
链接 cuFFTW 库。
-Usymbol
其中 symbol 是符号名称。
将选项传递给链接器。
以下示例取消定义宏 test。
$ nvfortran -Utest myprog.F
$ nvfortran -Dtest -Utest myprog.F
描述
使用此选项取消定义预处理器宏。 您还可以使用 #undef 预处理器指令来取消定义宏。
2.2.1. -#
2.2.65. -u
使用 <symbol> 初始化符号表,该符号对于链接器是未定义的。 未定义的符号会触发加载归档库的第一个成员。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不使用 -u 选项。
链接 cuFFTW 库。
-usymbol
其中 symbol 是符号名称。
将选项传递给链接器。
在此示例中,nvfortran 使用 test 初始化符号表。
$ nvfortran -utest myprog.f
描述
使用此选项使用 <symbol> 初始化符号表,该符号对于链接器是未定义的。 未定义的符号会触发加载归档库的第一个成员。
2.2.1. -#
2.2.66. -V[release_number]
显示其他信息,包括版本消息。 此外,如果附加了 release_number,编译器驱动程序将尝试使用指定的版本而不是默认版本进行编译。
注意
-V 和 release_number 之间不能有空格。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不显示版本信息,并使用您的路径指定的版本进行编译。
将选项传递给链接器。
以下命令行显示使用 -V 选项的输出。
% nvfortran -V myprog.f
以下命令行使 nvc 使用 20.7 版本而不是默认版本进行编译。
% nvc -V20.7 myprog.c
描述
使用此选项显示其他信息,包括版本消息;或者,如果附加了 release_number,则指示编译器驱动程序尝试使用指定的版本而不是默认版本进行编译。
指定的版本必须与默认版本共同安装。
2.2.1. -#
2.2.67. -v
显示编译器、汇编器和链接器的调用。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
-Xlinker <option>
将选项传递给链接器。
在以下示例中,您使用 -v 查看发送到编译器工具、汇编器和链接器的命令。
$ nvfortran -v myprog.f90
描述
使用 -v 选项显示编译器、汇编器和链接器的调用。 这些调用是由编译器驱动程序根据文件和您在编译器命令行上指定的 -W 选项创建的命令行。
2.2.1. -#
-dryrun, -Minfo[=option [,option,…]], -V[release_number], -W
2.2.68. -W
-W
链接 cuFFTW 库。
-W{0 | a | l },option[,option...]
注意
在 -W 和单字母传递标识符之间、标识符和逗号之间,或逗号和选项之间不能有空格。
0(数字零) 指定编译器。
a指定汇编器。
l(小写字母 l) 指定链接器。
option是一个字符串,它被传递给编译器、汇编器或链接器并由其解释。 以逗号分隔的选项作为单独的命令行参数传递。
将选项传递给链接器。
在以下示例中,链接器在地址 0xffc00000 加载文本段,并在地址 0xffe00000 加载数据段。
$ nvfortran -Wl,-k,-t,0xffc00000,-d,0xffe00000 myprog.f
描述
使用此选项将参数传递到特定阶段。 您可以使用 -W 选项为汇编器、编译器或链接器指定选项。
给定的 NVIDIA HPC 编译器命令调用编译器驱动程序,该驱动程序解析命令行,并为编译器、汇编器和链接器生成相应的命令。
2.2.1. -#
显示编译器、汇编器和链接器的调用。
2.2.69. -w
-silent
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器打印警告消息。
将选项传递给链接器。
在以下示例中,不打印任何警告消息。
$ nvfortran -w myprog.f
描述
使用 -w 选项抑制警告消息。
2.2.1. -#
2.2.70. -Xs
对 C 和 C++ 使用旧版标准模式。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
动态链接是 Linux 的默认行为。
将选项传递给链接器。
在以下示例中,编译器使用旧版标准模式。
$ nvc -Xs myprog.c
描述
使用此选项对 C 和 C++ 使用旧版标准模式。 此外,此选项隐含 -alias=traditional。
2.2.1. -#
2.2.71. -Xt
对 C 和 C++ 使用旧版过渡模式。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
动态链接是 Linux 的默认行为。
将选项传递给链接器。
在以下示例中,编译器使用旧版过渡模式。
$ nvc -Xt myprog.c
描述
使用此选项对 C 和 C++ 使用旧版过渡模式。 此外,此选项隐含 -alias=traditional。
2.2.1. -#
2.2.72. -Xlinker
-Mlarge_model
链接 cuFFTW 库。
-Xlinker option[,option...]
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
动态链接是 Linux 的默认行为。
将选项传递给链接器。
在以下示例中,选项 –trace-symbol=foo 被传递给链接器,这将导致 Linux 链接器列出引用符号 foo 的所有文件。
$ nvc -Xlinker --trace-symbol=foo myprog.c
描述
使用此选项将选项传递给链接器。 当链接步骤需要自定义但编译器不理解必要的链接器选项时,这非常有用。 链接器支持的选项取决于平台,此处未列出。 此选项具有与 -Wl 相同的效果。
2.2.1. -#
2.3. C++ 和 C 特定的编译器选项
有大量特定于 NVC++ 和 NVC 编译器(尤其是 NVC++)的编译器选项。 本节提供了其中几个选项的详细信息,但并非详尽无遗。 有关可用选项的完整列表,包括 NVC++ 选项的详尽列表,请使用 -help 命令行选项。 有关给定选项的更多详细信息,请使用 -help 并显式指定选项,如 -help 中所述。
2.3.1. -A
(仅限 nvc++) 指示 NVC++ 编译器接受符合 ISO C++ 标准的代码,并为不符合标准的代码发出错误。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
默认情况下,编译器接受符合标准 C++ 注释参考手册的代码。
将选项传递给链接器。
以下命令行请求符合 ISO 标准的 C++。
$ nvc++ -A hello.cc
描述
使用此选项指示 NVC++ 编译器接受符合 ISO C++ 标准的代码,并为不符合标准的代码发出错误。
2.2.1. -#
2.3.2. -a
(仅限 nvc++) 指示 NVC++ 编译器接受符合 ISO C++ 标准的代码,并为不符合标准的代码发出警告。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
默认情况下,编译器接受符合标准 C++ 注释参考手册的代码。
将选项传递给链接器。
以下命令行请求符合 ISO 标准的 C++,并为不符合标准的代码发出警告。
$ nvc++ -a hello.cc
描述
使用此选项指示 NVC++ 编译器接受符合 ISO C++ 标准的代码,并为不符合标准的代码发出警告。
2.2.1. -#
2.3.3. -alias
在 C 和 C++ 中,根据基于类型的指针别名规则选择优化。
链接 cuFFTW 库。
-alias=[ansi|traditional]
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
动态链接是 Linux 的默认行为。
将选项传递给链接器。
以下命令行启用优化。
$ nvc++ -alias=ansi hello.cc
描述
使用此选项在 C 和 C++ 中,根据基于类型的指针别名规则选择优化。
- ansi
使用 ANSI C 基于类型的指针消除歧义启用优化。
- traditional
禁用基于类型的指针消除歧义。
2.2.1. -#
2.3.4. –[no_]alternative_tokens
(仅限 nvc++) 启用或禁用对备用标记的识别。 这些标记使编写 C++ 代码时无需使用逗号 (,)、[, ]、#、&、^ 和字符。 备用标记包括运算符关键字(例如,and、bitand 等)和二合字母。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
默认行为是 –no_alternative_tokens,即禁用对备用标记的识别。
将选项传递给链接器。
以下命令行启用备用标记识别。
$ nvc++ --alternative_tokens hello.cc
2.2.1. -#
动态链接是 Linux 的默认行为。
2.3.5. -B
(nvc 和 nvc++) 在 C 程序单元中启用以 // 开头的 C++ 样式注释的使用。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
NVC C 编译器不允许 C++ 样式注释。
将选项传递给链接器。
在以下示例中,编译器接受 C++ 样式注释。
$ nvc -B myprog.cc
描述
使用此选项在 C 程序单元中启用以 // 开头的 C++ 样式注释的使用。
2.2.1. -#
2.3.6. –[no_]bool
(仅限 nvc++) 启用或禁用对 bool 的识别。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器识别 bool:–bool。
将选项传递给链接器。
在以下示例中,编译器不识别 bool。
$ nvc++ --no_bool myprog.cc
描述
使用此选项启用或禁用对 bool 的识别。
2.2.1. -#
动态链接是 Linux 的默认行为。
2.3.7. –[no_]builtin
编译时是否启用数学子例程内置支持。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
默认设置为启用数学子例程支持进行编译:–builtin。
将选项传递给链接器。
在以下示例中,编译器在构建时不启用数学子例程支持。
$ nvc++ --no_builtin myprog.cc
描述
使用此选项启用或禁用使用数学子例程内置支持进行编译。 当您使用数学子例程内置支持进行编译时,选定的数学库例程将被内联。
2.2.1. -#
动态链接是 Linux 的默认行为。
2.3.8. –[no_]compress_names
压缩文件中的长函数名称。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不压缩名称:–no_compress_names。
将选项传递给链接器。
在以下示例中,编译器压缩长函数名称。
$ nvc++ --compress_names myprog.cc
描述
使用此选项指定压缩长函数名称。 高度嵌套的模板参数可能会导致非常长的函数名称。 这些长名称可能会给旧版本的汇编器带来问题。 遇到这些问题的用户应使用 --compress_names 编译所有 C++ 代码,包括库代码。 NVIDIA 提供的库与 –compress_names 配合使用。
2.2.1. -#
动态链接是 Linux 的默认行为。
2.3.9. –diag_error <number>
(仅限 nvc++) 覆盖指定诊断消息的正常严重性。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不覆盖正常诊断严重性。
描述
使用此选项覆盖指定诊断消息的正常严重性,并将它们视为错误。 消息可以使用助记符标记或诊断编号来指定。
2.2.1. -#
–diag_remark <number>, –diag_suppress <number>, –diag_warning <number>, –display_error_number
2.3.10. –diag_remark <number>
(仅限 nvc++) 覆盖指定诊断消息的正常严重性。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不覆盖正常诊断严重性。
描述
使用此选项覆盖指定诊断消息的正常严重性,并将它们视为备注。 消息可以使用助记符标记或诊断编号来指定。
2.2.1. -#
–diag_error <number>, –diag_suppress <number>, –diag_warning <number>, –display_error_number
2.3.11. –diag_suppress <number>
(仅限 nvc++) 覆盖指定诊断消息的正常严重性。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不覆盖正常诊断严重性。
将选项传递给链接器。
在以下示例中,编译器抑制指定的诊断消息。
$ nvc++ --diag_suppress error_tag prog.cc
描述
使用此选项覆盖指定诊断消息的正常严重性,并抑制它们。 消息可以使用助记符标记或诊断编号来指定。
2.2.1. -#
–diag_error <number>, –diag_remark <number>, –diag_warning <number>, –display_error_number
2.3.12. –diag_warning <number>
(仅限 nvc++) 覆盖指定诊断消息的正常严重性。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不覆盖正常诊断严重性。
将选项传递给链接器。
在以下示例中,编译器覆盖指定诊断消息的严重性,并将它们视为警告。
$ nvc++ --diag_warning an_error_tag myprog.cc
描述
使用此选项覆盖指定诊断消息的正常严重性,并将它们视为警告。 消息可以使用助记符标记或诊断编号来指定。
2.2.1. -#
–diag_error <number>, –diag_remark <number>, –diag_suppress <number>, –display_error_number
2.3.13. –display_error_number
(仅限 nvc++) 在生成的任何诊断消息中显示错误消息编号。 此选项可用于确定在覆盖诊断消息的严重性时要使用的错误编号。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不显示生成的诊断消息的错误消息编号。
将选项传递给链接器。
在以下示例中,编译器显示任何生成的诊断消息的错误消息编号。
$ nvc++ --display_error_number myprog.cc
描述
使用此选项在生成的任何诊断消息中显示错误消息编号。 您可以使用此选项确定在覆盖诊断消息的严重性时要使用的错误编号。
2.2.1. -#
–diag_error <number>, –diag_remark <number>, –diag_suppress <number>, –diag_warning <number>
2.3.14. -e<number>
(仅限 nvc++) 将 C++ 前端错误限制设置为指定的 <number>。
2.3.15. –no_exceptions
(仅限 nvc++) 禁用异常处理支持。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
异常处理支持已启用。
将选项传递给链接器。
在以下示例中,编译器不提供异常处理支持。
$ nvc++ --no_exceptions myprog.cc
描述
使用此选项禁用异常处理支持。 关闭异常处理后,代码中的任何 try/catch 块或 throw 表达式都将导致编译错误,并且任何异常规范都将被忽略。
2.3.16. -fvisibility=<visibility>
(仅限 nvc++) 设置 ELF 符号的可见性。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
设置 ELF 符号的可见性。
将选项传递给链接器。
所有符号都标记为全局可见,除非使用此开关或 visibility 属性覆盖。
$ nvc++ -fvisibility=default hello.cp
描述
visibility 参数可以采用四个值之一:default、internal、hidden 或 protected。
2.3.17. –gnu_version <num>
(仅限 nvc++) 设置 GNU C++ 兼容性版本。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器使用编译执行所在系统上安装的最新版本。
将选项传递给链接器。
在以下示例中,编译器将 GNU 版本设置为 4.3.4。
$ nvc++ --gnu_version 4.3.4 myprog.cc
描述
使用此选项设置编译时要使用的 GNU C++ 兼容性版本。
2.3.18. –[no]llalign
(仅限 nvc++) 启用或禁用 long long 整数在 long long 边界上的对齐。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器在 long long 边界上对齐 long long 整数:–llalign。
将选项传递给链接器。
在以下示例中,编译器不在 long long 边界上对齐 long long 整数。
$ nvc++ --nollalign myprog.cc
描述
使用此选项允许启用或禁用 long long 整数在 long long 边界上的对齐。
2.2.1. -#
动态链接是 Linux 的默认行为。
2.3.19. -M
生成 make 依赖项列表并将其打印到 stdout。
注意
注意:编译在预处理阶段后停止。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不生成 make 依赖项列表。
将选项传递给链接器。
在以下示例中,编译器生成 make 依赖项列表。
$ nvc++ -M myprog.cc
描述
使用此选项生成 make 依赖项列表并将其打印到 stdout。
2.2.1. -#
2.3.20. -MD[<dfile>]
生成 make 依赖项列表并将其打印到文件。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不生成 make 依赖项列表。
将选项传递给链接器。
在以下示例中,编译器生成 make 依赖项列表并将其打印到文件 myprog.d。
$ nvc++ -MD myprog.cc
描述
使用此选项生成 make 依赖项列表并将其打印到文件。 文件名由正在编译的文件名确定,或者使用可选的 <dfile> 参数指定。
2.2.1. -#
2.3.21. –optk_allow_dollar_in_id_chars
(仅限 nvc++) 接受标识符中的美元符号 ($)。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不接受标识符中的美元符号 ($)。
将选项传递给链接器。
在以下示例中,编译器允许标识符中使用美元符号 ($)。
$ nvc++ --optk_allow_dollar_in_id_chars myprog.cc
描述
使用此选项指示编译器接受标识符中的美元符号 ($)。
2.3.22. -P
在预处理后停止编译过程,并将预处理后的输出写入文件。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
2.2.11. -d<arg>
将选项传递给链接器。
在以下示例中,编译器在当前目录中生成预处理文件 myprog.i。
$ nvc++ -P myprog.cc
描述
使用此选项在预处理后停止编译过程,并将预处理后的输出写入文件。 如果输入文件是 filename.c 或 filename.cc.,则输出文件为 filename.i。
2.2.1. -#
2.3.23. –pedantic
打印来自包含的 <system header files> 的警告信息。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不打印来自包含的系统头文件的警告信息。
将选项传递给链接器。
在以下示例中,编译器打印来自包含的系统头文件的警告信息。
$ nvc++ --pedantic myprog.cc
2.2.1. -#
动态链接是 Linux 的默认行为。
2.3.24. –preinclude=<filename>
(仅限 nvc++) 指定要在编译开始时包含的文件的名称。
在以下示例中,编译器在编译开始时包含文件 incl_file.c。我
$ nvc++ --preinclude=incl_file.c myprog.cc
描述
使用此选项可指定要在编译开始时包含的文件的名称。例如,您可以使用此选项来设置系统相关的宏和类型。
2.2.1. -#
动态链接是 Linux 的默认行为。
2.3.25. –[no_]using_std
(仅限 nvc++) 启用或禁用在包含标准头文件时隐式使用 std 命名空间。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
当包含标准头文件时,编译器使用 std 命名空间:–using_std。
将选项传递给链接器。
以下命令行禁用隐式使用 std 命名空间
$ nvc++ --no_using_std hello.cc
描述
当编译中包含标准头文件时,使用此选项启用或禁用隐式使用 std 命名空间。
2.2.1. -#
2.3.26. -Xfilename
(仅限 nvc++) 生成交叉引用信息并将输出放置在指定的文件中。
链接 cuFFTW 库。
-Xfoo
其中 foo 是交叉引用信息的指定文件。
传递给链接器。指示链接器生成共享对象文件。暗示 -fpic。
编译器不生成交叉引用信息。
将选项传递给链接器。
在以下示例中,编译器生成交叉引用信息,并将其放置在文件 xreffile 中。
$ nvc++ -Xxreffile myprog.cc
描述
使用此选项可生成交叉引用信息并将输出放置在指定的文件中。这是一个 EDG 选项。
2.2.1. -#
动态链接是 Linux 的默认行为。
2.4. -M 选项按类别
本节按类别描述了 -M 可用的每个选项
代码生成 |
Fortran 语言控制 |
优化 |
环境 |
C/C++ 语言控制 |
内联 |
杂项 |
以下各节详细描述了几个(但不是全部)-M<nvflag> 选项。 有关所有选项的完整字母列表,请参阅 表 12。 这些选项按类别分组,并列出了确切的语法、默认值以及关于相似或相关选项的注释。
有关给定选项的最新信息和描述,或查看所有可用选项,请使用 -help 命令行选项,在 -help 中进行了描述。
2.4.1. 代码生成控制
本节描述了控制代码生成的 -M<nvflag> 选项。
默认值: 对于您未指定的参数,默认的代码生成控制如下:
daz |
norecursive |
nosecond_underscore |
flushz |
noreentrant |
nostride0 |
noref_externals |
signextend |
相关选项: -D、-I、-L、-l、-U。
以下列表提供了每个控制代码生成的 -M<nvflag> 选项的语法。 每个选项都有一个描述,如果适用,还有任何相关选项。
-Mdaz将 IEEE 反常化浮点操作数设置为零;这会带来性能优势,但可能会出现误导性的结果,例如当用小的归一化数除以反常化数时。 要生效,必须在编译主程序/函数时设置此选项。[默认 - x86_64 和 aarch64]
注意
使用运行时环境变量
NVCOMPILER_FPU_STATE可以实现相同的功能-Mnodaz不要将反常化数视为零。 要生效,必须为主程序设置此选项。
注意
使用运行时环境变量
NVCOMPILER_FPU_STATE可以实现相同的功能-Mnodwarf指定不添加 DWARF 调试信息。
-Mdwarf2生成 DWARF2 格式的调试信息。 要生效,必须将此选项与
-g结合使用。-Mdwarf3生成 DWARF3 格式的调试信息。 要生效,必须将此选项与
-g结合使用。-Mflushz将浮点控制寄存器设置为 flush-to-zero 模式;如果发生浮点下溢,则结果设置为零。 要生效,必须在编译主程序/函数时设置此选项。[默认 - x86_64 和 aarch64]
注意
使用运行时环境变量
NVCOMPILER_FPU_STATE可以实现相同的功能-Mnoflushz不设置 flush-to-zero 模式;生成下溢。 要生效,必须为主程序设置此选项。
注意
使用运行时环境变量
NVCOMPILER_FPU_STATE可以实现相同的功能-Mfma在 CPU 和 GPU 上启用 FMA(融合乘加)生成;在
-O1时为默认值。注意
全局
-Mfma选项可以与-gpu=[no]fma结合使用,以显式地在 CPU 或 GPU 上启用/禁用 FMA。示例
-Mfma // Enable CPU and GPU FMAs. -Mfma -gpu=nofma // Enable CPU FMAs and disable GPU FMAs. -Mnofma -gpu=fma // Disable CPU FMAs and enable GPU FMAs. -Mnofma // Disable CPU and GPU FMAs.
-Mnofma在 CPU 和 GPU 上禁用 FMA(融合乘加)生成。
注意
全局
-Mnofma选项可以与-gpu=[no]fma结合使用,以显式地在 CPU 或 GPU 上启用/禁用 FMA。-Mfunc32在 32 字节边界上对齐函数。
-Minstrument [=functions]生成额外的代码以启用函数检测。
注意
选项
-Minstrument=functions与-Minstrument相同。在函数入口之后和函数出口之前,将使用当前函数的地址及其调用站点调用以下分析函数。
void __cyg_profile_func_enter (void *this_fn, void *call_site); void __cyg_profile_func_exit (void *this_fn, void *call_site);
注意
在这些调用中,第一个参数是当前函数开始的地址。
暗示
-Mframe。-Minstrument-exclude-file-list=<filelist>指示编译器不要检测路径包含 <filelist> 的文件中的函数。 与
-Minstrument[=functions]结合使用-Minstrument-exclude-func-list=<functions>指示编译器不要检测包含子字符串 <functions> 的函数。 与
-Minstrument[=functions]结合使用
-Mlarge_arrays启用对 64 位索引和大于 2 GB 的单个静态数据对象的支持。 在 x86-64 目标上,在存在
-mcmodel=medium的情况下,此选项是默认选项。 它可以与默认的小内存模型一起单独使用,用于管理自身内存空间的某些 64 位应用程序。 有关更多信息,请参阅 HPC 编译器用户指南 的 “64 位环境的编程注意事项” 部分-Mnolarge_arrays禁用对 64 位索引和大于 2 GB 的单个静态数据对象的支持。 在 x86-64 目标上,当此选项在命令行上的
-mcmodel=medium之后放置时,它将禁用对没有大于 2 GB 的单个数据对象的应用程序使用 64 位索引。 有关更多信息,请参阅 HPC 编译器用户指南 的 “64 位环境的编程注意事项” 部分。-Mnomain指示编译器不要包含调用 Fortran 主程序的目标文件作为链接步骤的一部分。 此选项对于链接主程序用 C/C++ 编写,一个或多个子例程用 Fortran 编写的程序很有用(仅限 Fortran)。
-M[no]pre启用 [禁用] 部分冗余消除。
-Mrecursive指示编译器允许递归调用 Fortran 子程序。
-MnorecursiveFortran 子程序不能被递归调用。
-Mref_externals强制引用出现在
EXTERNAL语句中的名称(仅限 Fortran)。-Mnoref_externals不强制引用出现在
EXTERNAL语句中的名称(仅限 Fortran)。-Mreentrant指示编译器避免可能阻止代码成为可重入的代码的优化。
-Mnoreentrant指示编译器不要避免可能阻止代码成为可重入的代码的优化。
-Msecond_underscore指示编译器如果 Fortran 全局符号的名称已包含下划线,则向其名称添加第二个下划线。 此选项对于保持与使用 gfortran 编译的目标代码的兼容性很有用,gfortran 默认使用此约定(仅限 Fortran)。
-Mnosecond_underscore指示编译器如果 Fortran 全局符号的名称已包含下划线,则不要向其名称添加第二个下划线(仅限 Fortran)。
-Msafe_lastval当在循环之后使用标量,但并非在循环的每次迭代中都定义时,编译器默认情况下不会并行化循环。 但是,此选项告诉编译器并行化循环是安全的。 对于给定的循环,为所有标量计算的最后一个值使其可以安全地并行化循环。
-Msignextend指示编译器扩展符号位,该符号位是通过将一种数据类型的对象转换为更大的有符号数据类型的对象而设置的。
-Mnosignextend指示编译器不要扩展符号位,该符号位是通过将一种数据类型的对象转换为更大的数据类型的对象而设置的。
-Mstack_arrays将自动数组放置在堆栈上。
-Mnostack_arrays在堆上分配自动数组。
-Mnostack_arrays是默认值,也是传统上使用的方法。-Mstride0指示编译器禁止某些优化,并允许步幅为 0 的数组引用。 此选项可能会降低性能,只有在零步幅归纳变量可能的情况下才应使用。
-Mnostride0指示编译器执行某些优化,并禁止步幅为 0 的数组引用。
-Mvarargs强制 Fortran 程序单元假定过程调用是对具有 varargs 类型接口的 C 函数的调用(仅限 nvfortran)。
2.4.2. C/C++ 语言控制
本节描述了影响 NVC++ 和 NVC 编译器对 C++ 和 C 语言解释的 -M<nvflag> 选项。 这些选项仅对 nvc++ 和 nvc 编译器驱动程序有效。
默认值: 对于您未指定的参数,默认值如下:
noasmkeyword |
nosingle |
dollar,_ |
schar |
将选项传递给链接器。
在此示例中,编译器允许源文件中的 asm 关键字。
$ nvc -Masmkeyword myprog.c
在以下示例中,编译器将美元符号映射到点字符。
$ nvc -Mdollar,. myprog.c
在以下示例中,编译器将浮点常量视为 float 值,而不是默认的 double 值。
$ nvc -Mfcon myprog.c
在以下示例中,编译器不会将 float 参数转换为 double 参数。
$ nvc -Msingle myprog.c
如果没有 -Muchar 或使用 -Mschar,则变量 ch 是有符号字符
char ch;
signed char sch;
如果在命令行上指定了 -Muchar
$ nvc -Muchar myprog.c
前面声明中的 char ch 等效于
unsigned char ch;
以下列表提供了每个控制 C++ 和 C 代码生成的 -M<nvflag> 选项的语法。 每个选项都有一个描述,如果适用,还有任何相关选项。
-Masmkeyword指示编译器允许 C 源文件中的 asm 关键字。 asm 语句的语法如下:
asm("statement");其中 statement 是合法的汇编语言语句。 引号是必需的。
注意
当前的默认设置是支持 gcc 的扩展 asm,其中扩展 asm 的语法包括 asm 字符串。 只有当目标设备是 Pentium 3 或更旧的 cpu 类型 (-tp piii|p6|k7|athlon|athlonxp|px) 时,
-M[no]asmkeyword开关才有用。-Mnoasmkeyword指示编译器不允许 C 源文件中的 asm 关键字。 如果您使用此选项并且您的程序包含 asm 关键字,则会生成未解析的引用
-Mdollar,charchar 指定编译器将美元符号 ($) 映射到的字符。 NVC 编译器允许名称中使用美元符号; ANSI C 不允许名称中使用美元符号。
-M[no]eh_frame指示链接器将 eh_frame 调用帧节保留在可执行文件中。
注意
eh_frame 选项仅在提供系统 unwind 库的较新 Linux 系统上可用。
-Mfcon指示编译器将浮点常量视为 float 数据类型,而不是 double 数据类型。 此选项可以提高单精度代码的性能。
-M[no]m128指示编译器识别 [忽略] __m128、__m128d 和 __m128i 数据类型。
-Mschar指定有符号 char 字符。 编译器将 “plain” char 声明视为有符号 char。
-Msingle在非原型函数中,不要将 float 参数转换为 double 参数。 如果您的程序仅使用 float 参数,则此选项可以提高代码速度。 但是,由于 ANSI C 规定例程必须在非原型函数中将 float 参数转换为 double 参数,因此此选项会导致不符合 ANSI 标准的代码。
-Mnosingle指示编译器在非原型函数中将 float 参数转换为 double 参数。
-Muchar指示编译器将 “plain” char 声明视为无符号 char。
2.4.3. 环境控制
本节描述了控制环境的 -M<nvflag> 选项。
默认值: 对于您未指定的参数,默认环境选项取决于您的配置。
以下列表提供了每个控制环境的 -M<nvflag> 选项的语法。 每个选项都有一个描述,如果适用,还有任何相关选项的列表。
-Mnostartup指示链接器不要链接包含程序入口点 (_start) 的标准启动例程。
注意
如果您使用 -Mnostartup 选项并且不提供入口点,则链接器会发出以下错误消息:Warning: cannot find entry symbol _start
-M[no]hugetlb链接到巨页运行时库。 启用分配大型 2 兆字节页面。 效果是减少执行程序所需的 TLB 条目数。 此选项在较新的架构上最有效; 较旧的架构没有足够的 TLB 条目来使此选项受益。 就其本身而言,huge 子选项尝试分配尽可能多的巨页。 您还可以使用环境变量
NVCOMPILER_HUGE_PAGES限制分配的页面。
-M[no]stddef指示编译器在编译 C 程序时不要为预处理器预定义任何宏。
-Mnostdinc指示编译器不要搜索包含文件的标准位置。
-Mnostdlib指示链接器不要链接标准目录
lib内库目录lib中的标准库libnvf.a、libm.a、libc.a和libnvc.a。 您可以使用 -l 选项链接您自己的库,或使用 -L 选项指定库目录。
2.4.4. Fortran 语言控制
本节描述了影响 NVIDIA Fortran 编译器对 Fortran 语言解释的 -M<nvflag> 选项。 这些选项仅对 nvfortran 编译器驱动程序有效。
默认值: 在查看所有选项之前,让我们先看一下默认值。 对于您未指定的参数,默认值如下:
nobackslash |
nodefaultunit |
dollar,_ |
noonetrip |
nounixlogical |
nodclchk |
nodlines |
noiomutex |
nosave |
noupcase |
以下列表提供了每个影响 Fortran 语言解释的 -M<nvflag> 选项的语法。 每个选项都有一个描述,如果适用,还有任何相关选项的列表。
-Mallocatable=95|03控制在可分配数组赋值中使用 Fortran 95 还是 Fortran 2003 语义。 默认行为是使用 Fortran 95 语义;
03选项指示编译器使用 Fortran 2003 语义。-Mbackslash指示编译器将反斜杠视为普通字符,而不是带引号的字符串中的转义字符。
-Mnobackslash指示编译器将反斜杠识别为带引号的字符串中的转义字符(符合标准 C 用法)。
-Mdclchk指示编译器要求声明所有程序变量。
-Mnodclchk指示编译器不要求声明所有程序变量。
-Mdefaultunit指示编译器将 “
*” 视为读取的标准输入和写入的标准输出的同义词。-Mnodefaultunit指示编译器将 “
*” 视为输入的单元 5 和输出的单元 6 的同义词。-Mdlines指示编译器将第 1 列中包含 “
D” 的行视为可执行语句(忽略 “D”)。-Mnodlines指示编译器不要将第 1 列中包含 “
D” 的行视为可执行语句。 编译器不忽略 “D”。-Mdollar,charchar 指定编译器将美元符号映射到的字符。 编译器允许名称中使用美元符号。
-Mextend指示编译器接受 132 列的源代码;否则,它接受 72 列的代码。
-Mfixed指示编译器假定输入源文件采用 FORTRAN 77 风格的固定格式。
-Mfree指示编译器假定输入源文件采用 Fortran 90/95 自由格式。
-Miomutex指示编译器在 Fortran I/O 语句周围生成临界区调用。
-Mnoiomutex指示编译器不要在 Fortran I/O 语句周围生成临界区调用。
-Monetrip指示编译器强制每个
DO循环至少执行一次。 此选项对于为早期版本的 Fortran 编写的程序很有用。-Mnoonetrip指示编译器不要强制每个
DO循环至少执行一次。-Msave指示编译器假定所有局部变量都受
SAVE语句的约束。 这可能允许较旧的 Fortran 程序运行,但会大大降低性能。-Mnosave指示编译器不要假定所有局部变量都受
SAVE语句的约束。-Mstandard指示编译器标记不符合 ANSI 标准的源代码。
-Munixlogical指示编译器将逻辑值视为:如果值非零则为真,如果值为零则为假 (UNIX F77 约定)。 启用
-Munixlogical后,非零的逻辑值或测试为.TRUE.,零值或测试为.FALSE.。 此外,当结果为.TRUE.时,逻辑表达式的值保证为一 (1)。-Mnounixlogical指示编译器对 true 和 false 的逻辑值使用 VMS 约定。 偶数值为 true,奇数值为 false。
-Mupcase指示编译器保留标识符中的大写字母。 使用
-Mupcase,标识符X和x是不同的。 关键字必须为小写。 此选择会影响链接过程。 如果您在一种情况下使用-Mupcase编译和链接相同的源代码,而在另一种情况下使用-Mnoupcase,您可能会得到两个不同的可执行文件 - 具体取决于源是否包含大写字母。 标准库是使用默认的-Mnoupcase编译的。-Mnoupcase指示编译器将所有标识符转换为小写。 此选择会影响链接过程。 如果您在一种情况下使用
-Mupcase编译和链接相同的源代码,而在另一种情况下使用-Mnoupcase,您可能会得到两个不同的可执行文件,具体取决于源是否包含大写字母。 标准库是使用-Mnoupcase编译的。
2.4.5. 内联控制
本节描述了控制函数内联的 -M<nvflag> 选项。
用法: 在查看所有选项之前,让我们先看几个示例。 在以下示例中,编译器从源文件 myprog.f 中提取语句数少于或等于 500 的函数,并将它们保存在文件 extract.il 中。
$ nvfortran -Mextract=500 -o extract.il myprog.f
在以下示例中,编译器内联源文件 myprog.f 中语句数少于大约 100 个的函数。
$ nvfortran -Minline=maxsize:100 myprog.f
相关选项: -o, -Mextract
以下列表提供了每个控制函数内联的 -M<nvflag> 选项的语法。 每个选项都有一个描述,如果适用,还有任何相关选项的列表。
-M[no]autoinline[=option[,option,...]]指示编译器在 -O2 级别内联 [不内联] C++ 和 C 函数,其中 option 可以是以下任何一项
maxsize:n指示编译器不要内联大小 > n 的函数。 默认大小为 100。
nostatic不内联没有 inline 关键字的静态函数
totalsize:n指示编译器在大小等于 n 时停止内联。 默认大小为 800。
-Mextract[=option[,option,...]]从命令行上指示的文件中提取函数,并创建或附加到指定的提取目录,其中 option 可以是以下任何一项
name:func指示提取器从文件中提取函数 func。
size:number指示提取器从文件中提取语句数少于或等于 number 的函数。
lib:filename.ext指示提取器使用目录
filename.ext作为提取目录,这是保存和重用内联库所必需的。
如果您同时指定 name 和 size,则编译器会提取与 func 匹配或语句数少于或等于 number 的函数。 有关提取函数的示例,请参阅 HPC 编译器用户指南 的 “使用函数内联” 部分。
-Minline[=option[,option,...]]指示编译器将选项传递给函数内联器,其中 option 可以是以下任何一项
except:func内联除
func(源代码中的函数)之外的所有符合条件的函数。 您可以使用逗号分隔列表来指定多个函数。[name:]func内联源代码中名称与
func匹配的所有函数。 您可以使用逗号分隔列表来指定多个函数。函数名称应为不包含句点的非数字字符串。 您还可以使用
name:前缀,后跟函数名称。 如果指定了name:,则后面的内容始终是函数名称。[maxsize:]number数字选项被假定为大小。 大小小于或等于
number的函数将被内联。 如果同时指定了number和function,则会内联与给定名称匹配或满足大小要求的函数。大小 number 不需要完全等于所选函数中的语句数; 大小参数只是一个粗略的衡量标准。
[no]reshape指示内联器允许 [不允许] 在 Fortran 中进行内联,即使数组形状不匹配也是如此。 默认值为
-Minline=noreshape,但在-Mconcur或-mp的情况下,默认值为-Minline=reshape。smallsize:number始终内联大小小于
number的函数,而与其他大小限制无关。totalsize:number当函数的总内联大小达到指定的
number时,停止在函数中进行内联。[lib:]filename.ext指示内联器内联库文件
filename.ext中的函数。 编译器假定包含句点的filename.ext选项是库文件。提示
使用
-Mextract选项创建库文件。 您还可以使用lib:前缀,后跟库名称。如果指定了
lib:,则库名称中不需要句点。 将内联指定库中的函数。如果未指定库,则从提取预传递期间创建的临时库中提取函数。
如果您同时指定了
func和number,则编译器会内联与函数名称匹配或语句数少于或等于number的函数。可以使用
-Mnoinline禁用内联。有关内联函数的示例,请参阅 HPC 编译器用户指南 的 “使用函数内联” 部分。
2.4.6. 优化控制
本节描述了控制优化的 -M<nvflag> 选项。
默认值: 在查看所有选项之前,让我们先看一下默认值。 对于您未指定的参数,默认的优化控制选项如下:
depchk |
noipa |
nounroll |
nor8 |
i4 |
nolre |
novect |
nor8intrinsics |
nofprelaxed |
noprefetch |
用法: 在此示例中,编译器调用向量化器,并启用打包 SIMD 指令的使用。
$ nvfortran -Mvect=simd -Mcache_align myprog.f
注意
如果您没有为 -Mvect 提供任何子选项,则编译器将使用取决于目标系统的默认值。 并非所有子选项在所有目标系统上都有效。
相关选项: -g, -O
以下列表提供了每个控制优化的 -M<nvflag> 选项的语法。 每个选项都有一个描述,如果适用,还有任何相关选项的列表。
-Mcache_align将长度大于等于 16 字节的无约束对象在缓存行边界上对齐。无约束对象是指不是聚合结构或公共块成员的数据对象。此选项不影响可分配或自动数组的对齐方式。要实现基于堆栈的局部变量的缓存行对齐,必须使用
-Mcache_align编译主程序或函数。
-Mconcur[=选项 [,选项,...]]指示编译器启用多核 CPU 的循环自动并行化。如果指定
-Mconcur,则将使用多个 CPU 核心来执行编译器确定为可并行化的循环。选项是以下之一allcores指示编译器使用所有可用的核心。在链接时使用此选项。
[no]altcode:n指示并行化器为并行化循环生成备用串行代码。
如果指定了
altcode但没有参数,则并行化器会确定一个合适的截止长度,并生成串行代码,以便在循环计数小于或等于该长度时执行。如果指定了
altcode:n,则当循环计数小于或等于 n 时,将执行串行备用代码。如果指定了
noaltcode,则始终执行循环的并行化版本,而与循环计数无关。
cncall指示并行循环中的调用可以安全地并行化。此外,在发生并行化之前,不必满足最小循环计数阈值,并且假定标量的最后值是安全的。
[no]innermost指示并行化器启用最内层循环的并行化。默认情况下,不并行化最内层循环,因为在双核处理器上通常没有效益。
levels:n并行化最多嵌套 n 层的循环。
noassoc指示并行化器禁用具有归约的循环的并行化。
链接时,必须指定
-Mconcur开关,否则会导致未解析的引用。注意
此选项仅适用于共享内存多处理器 (SMP) 或多核 CPU 的系统。
-Mcray[=选项[,选项,...]](仅限 Fortran) 强制 Cray Fortran 兼容性,并考虑列出的选项。选项的可能值包括
指针为了优化目的,假定基于指针的变量不会覆盖任何其他变量的存储。
-Mdepchk指示编译器假定未解析的数据依赖性实际上会冲突。
-Mnodepchk指示编译器假定潜在的数据依赖性不会冲突。但是,如果存在数据依赖性,则此选项可能会生成不正确的代码。
-Mdse启用死存储消除阶段,这对于依赖于大量使用内联函数调用以提高性能的程序非常有用。默认情况下禁用此功能。
-Mnodse禁用死存储消除阶段。这是默认设置。
-M[no]fpapprox [=选项]使用低精度近似执行某些浮点运算。
-Mnofpapprox指定不使用低精度 fp 近似运算。默认情况下不使用-Mfpapprox。如果使用-Mfpapprox但没有子选项,则默认使用近似的div、sqrt和rsqrt。可用的子选项如下:div近似浮点除法
sqrt近似浮点平方根
rsqrt近似浮点倒数平方根
-M[no]fpmisalign指示编译器允许(不允许)内存操作数未在 16 字节边界上对齐的向量算术指令。默认情况下,所有处理器都为
-Mnofpmisalign。-M[no]fprelaxed[=选项]指示编译器在计算某些内部函数时使用[不使用]放宽的精度。可能会提高性能,但会牺牲数值精度。选项的可能值包括:
div使用放宽的精度执行除法。
intrinsic启用使用放宽精度的内部函数。
noorder不允许表达式重新排序或因式分解。
order允许表达式重新排序,包括因式分解。
recip使用放宽的精度执行倒数。
rsqrtrsqrt
sqrt使用放宽的精度执行倒数平方根 (1/sqrt)。
sqrt
使用放宽的精度执行平方根。没有选项时,
-Mfprelaxed为那些产生显著性能提升的操作生成放宽精度的代码,具体取决于目标处理器。默认值为-Mnofprelaxed,它指示编译器在计算内部函数时不使用放宽的精度。-Mi4(仅限 Fortran) 指示编译器将
INTEGER变量视为INTEGER*4。-Mlre[=array \| assoc \| noassoc]启用循环携带冗余消除,这是一种优化,可以减少循环中算术运算和内存引用的数量。可用的子选项包括:
noassocassoc
允许表达式重新关联。指定此子选项可以增加循环携带冗余消除的机会,但可能会改变数值结果。noassoc
不允许表达式重新关联。-Mnolre
禁用循环携带冗余消除。-Mnoframe
消除为每个函数设置真实堆栈帧指针的操作。启用此选项后,您无法对生成的代码执行回溯,也无法访问局部变量。-Mnoi4
(仅限 Fortran) 指示编译器将INTEGER变量视为INTEGER*2。-Mpre
启用部分冗余消除。-Mprefetch[=选项 [,选项...]]
在支持预取指令的处理器上启用预取指令的生成。选项的可能值包括:d:m
将预取指令的预取距离设置为m个缓存行。n:p
将给定循环要生成的最大预取指令数设置为p。nta
使用预取指令。plain
使用预取指令(默认)。t0
使用 prefetcht0 指令。w
使用特定于 AMD 的 prefetchw 指令。-Mnoprefetch
禁用预取指令的生成。-M[no]propcond
启用或禁用从等式条件导出的断言进行常量传播。默认情况下启用。-Mr8
(仅限 Fortran) 编译器将 REAL 变量和常量分别提升为 DOUBLE PRECISION 变量和常量。DOUBLE PRECISION元素长度为 8 字节。-Mnor8
(仅限 Fortran) 编译器不会将 REAL 变量和常量提升为DOUBLE PRECISION。REAL变量将为单精度(长度为 4 字节)。-Mr8intrinsics
(仅限 Fortran) 编译器将内部函数CMPLX和REAL分别视为DCMPLX和DBLE。-Mnor8intrinsics
(仅限 Fortran) 编译器不会将内部函数CMPLX和REAL分别提升为DCMPLX和DBLE。-Msafeptr[=选项[,选项,...]]
(仅限 C++ 和 C) 指示 C++ 或 C 编译器覆盖给定存储类指针之间的数据依赖性。选项的可能值包括:all
假定所有指针和数组都是独立的,并且对于积极的优化是安全的,特别是没有指针或数组相互重叠或冲突。arg
- 指示编译器将具有与 Fortran 哑元相同的
copyin和copyout语义的数组和指针进行处理。 global
指示编译器全局或外部指针和数组不会相互重叠或冲突,并且是独立的。local/auto
指示编译器局部指针和数组不会相互重叠或冲突,并且是独立的。static
指示编译器静态指针和数组不会相互重叠或冲突,并且是独立的。-M[no]target_temps
指示编译器启用[禁用]在使用目标属性传递假定形状变量的数组给被调用者时使用临时变量。-Munroll[=选项 [,选项...]]
调用循环展开器以在每次迭代期间执行循环的多个实例。如果优化级别设置为小于 2,或者如果未提供-O或-g选项,则此选项还会将优化级别设置为 2。选项是以下之一:c:m
指示编译器完全展开循环计数小于或等于m的常量循环,其中m是提供的常量。如果未提供此值,则 m 计数设置为 1。m:<n>
指示编译器将多块循环展开n次。此选项对于具有条件语句的循环很有用。如果未提供n,则默认值为 1。默认设置是不启用-Munroll=m。n:<n>
指示编译器将单块循环展开n次,即未完全展开或具有非常量循环计数的循环。如果未提供n,则展开器会计算候选循环展开的次数。-Mnounroll
指示编译器不要展开循环。-M[no]vect[=选项 [,选项,...]]
启用[禁用]代码向量化器,其中选项是以下之一:[no]altcode
在适当时启用[禁用]为向量化循环生成备用代码 (altcode)。对于每个向量化循环,编译器都会决定是否生成备用代码以及要生成的一种或多种类型,可以是以下任何一种或全部:没有迭代剥离的备用代码、具有非临时存储和其他数据缓存优化的备用代码,以及基于在运行时动态计算的数组对齐方式的备用代码。编译器还会确定用于执行备用代码的合适的循环计数和数组对齐条件。默认情况下启用此选项。[no]assoc
启用[禁用]某些关联性转换,这些转换可能会由于舍入误差而更改计算结果。一种典型的优化是将算术运算更改为数学上正确但由于舍入误差而在计算上可能不同的算术运算。cachesize:n
指示向量化器在执行缓存平铺优化时,假定缓存大小为 n。默认值是根据处理器类型设置的,可以使用-tp开关或从主机自动检测。[no]fuse
sum = 0.d0 do k=d(j),d(j+1)-1 sum = sum + a(k)*b(c(k)) enddo启用[禁用]向量化器的自动循环融合。
[no]gather启用[禁用]包含间接数组引用的循环的向量化,例如以下循环:
levels:n默认值为 gather。
[no]idiom启用[禁用]向量化器的惯用法识别。
levels:<n>要优化的循环的最大嵌套级别
nocond禁用带有条件语句的循环的向量化。
[no]partial通过最内层循环分发启用[禁用]部分循环向量化。
prefetch指示向量化器搜索可向量化的循环,并在可能的情况下使用预取指令。
[no]short启用[禁用]短向量运算。
-Mvect=short启用为循环外部或循环迭代体内的标量代码产生的短向量运算生成打包 SIMD 指令。[no]simd[:{128|256|512}]在可以选择的处理器上,启用[禁用]使用 SIMD 指令和数据进行向量化,指令和数据宽度可以是 128 位、256 位或 512 位。
[no]simdresidual启用[禁用]使用 SIMD 指令向量化向量化循环的剩余迭代。
注意
[no]sizelimit:n
指示向量化器为所有可能的循环生成向量代码,而不管循环中语句的数量。这会覆盖向量化器中的启发式方法,该方法通常会阻止向量化语句数量超过特定阈值的循环。默认值为 nosizelimit。[no]uniform
指示向量化器在向量化循环和剩余循环中执行相同的优化。
此选项可能会影响剩余循环的性能。
-Mnovintr
inform |
指示编译器不执行惯用法识别或引入对手工优化的向量函数的调用。 |
2.4.7. 其他控制 |
本节介绍不方便归入其他 -M<nvflag> 选项类别的 -M<nvflag> 选项。 |
默认值: 在查看所有选项之前,让我们先看看默认值。对于您未指定的参数,默认的其他选项如下:
nobounds
$ nvfortran -Manno -S myprog.f
nolist
$ nvfortran -Mkeepasm myprog.f
warn
$ nvfortran -Minfo=inline -Minline=20 myprog.f
相关选项: -m、-S、-V、-v
$ nvfortran -Mlist myprog.f
用法: 在以下示例中,编译器将 Fortran 源代码包含在汇编代码中。
$ nvfortran -Mbounds myprog.f
在以下示例中,汇编器在汇编过程之后不会删除汇编文件 myprog.s。
在以下示例中,编译器显示有关源代码行数少于约 20 行的内联函数的信息,源文件为myprog.f。在以下示例中,编译器创建列表文件
myprog.lst。
编译器在输入/输出时不进行字节交换。在以下示例中,启用了数组边界检查。
以下列表提供了每个其他 -M<nvflag> 选项的语法。每个选项都有一个描述,并在适当的情况下,列出任何相关选项。
-Manno
使用源代码注释生成的汇编代码。暗示
-Mkeepasm。NVFTN-F-Subscript out of range for array a (a.f: 2) subscript=3, lower bound=1, upper bound=2, dimension=2
-Mbounds启用[禁用]数组边界检查。
-Mnobounds如果数组是假定大小的数组,则边界检查仅适用于下限。
如果在执行期间发生数组边界违规,则会打印描述错误的错误消息,并且程序终止。错误消息的文本包括数组的名称、错误发生的位置(源文件和源文件中的行号)以及有关越界下标的信息(其值、其下限和上限及其维度)。以下是示例错误消息:
-Mbyteswapio在 Fortran 无格式数据文件的输入/输出时,交换字节顺序,从大端到小端或反之亦然。
注意
-Mchkptr
指示编译器检查在初始化为 NULL 时被解引用的指针(仅限 Fortran)。
-Mchkstk指示编译器在函数的序言中以及在并行区域开始之前检查堆栈的可用空间。如果堆栈空间不足,则打印警告消息并优雅地中止程序。当 OpenMP 程序中声明了许多局部变量和私有变量时,此选项很有用。
-Mcpp[=选项 [,选项,...]]运行类似 cpp 的预处理器,而不执行任何后续编译步骤。此选项对于生成要包含在 makefile 中的依赖信息很有用。
m、md、mm 或 mmd 选项中只能存在一个;如果列出了多个这些选项,则接受最后一个列出的选项,而忽略其他选项。选项是以下一个或多个:
m运行类似 cpp 的预处理器,而不执行任何后续编译步骤。此选项对于生成要包含在 makefile 中的依赖信息很有用。
将 makefile 依赖关系打印到 stdout。md
将 makefile 依赖关系打印到filename.d,其中 filename 是正在处理的输入文件的根名称,忽略系统包含文件。mm
将 makefile 依赖关系打印到 stdout,忽略系统包含文件。mmd
将 makefile 依赖关系打印到filename.d,其中 filename 是正在处理的源文件的根名称,忽略系统包含文件。[no]comment
在输出中保留[不保留]注释。[suffix:]<suff>
使用 <suff> 作为包含 makefile 依赖关系的输出文件的后缀。-Mgccbug[s]
指示编译器匹配某些 gcc 错误的行为。-Miface[=选项]
调整 Fortran 的调用约定,其中选项是以下之一:cref
(仅限 Fortran) 编译器不会将内部函数CMPLX和REAL分别提升为DCMPLX和DBLE。使用 CREF 调用约定,没有尾随下划线。
-Minfo=accel,inline,ipa,loop,lre,mp,opt,par,vect,stdpar
mixed_str_len_arg将字符参数的长度紧跟在其对应的参数之后。仅在 CREF 调用约定中有效。
nomixed_str_len_arg将字符参数的长度放在参数列表的末尾。仅在 CREF 调用约定中有效。
inline-Minfo[=选项 [,选项,...]]
指示编译器在标准错误输出中生成信息,其中选项是以下之一:all
指示编译器生成所有可用的
-Minfo信息。暗示许多子选项:accel
指示编译器启用加速器信息。
ftn指示编译器启用特定于 Fortran 的信息。
inline指示编译器显示有关提取或内联函数的信息。如果没有
-Mextract或-Minline选项,则此选项无用。intensity指示编译器提供有关循环强度的信息性消息。指定 <n> 以获取有关嵌套循环的消息。
对于浮点循环,强度定义为浮点运算的数量除以浮点加载和存储的数量。对于整数循环,循环强度定义为整数算术运算的总数(可能包括循环计数和地址的更新)除以整数加载和存储的总数。
默认情况下,消息仅适用于最内层循环。loop
指示编译器显示有关循环的信息,例如有关向量化的信息。lre
指示编译器启用 LRE(循环携带冗余消除)信息。mp
指示编译器显示有关并行化的信息。opt
指示编译器显示有关优化的信息。par
指示编译器启用并行化器信息。stdpar
指示编译器发出有关 C++ 并行算法和 Fortran DO CONCURRENT 循环并行化的信息。time
指示编译器显示编译统计信息。unroll
inform指示编译器显示有关循环展开的信息。
vect指示编译器启用向量化器信息。
本节介绍不方便归入其他 -M<nvflag> 选项类别的 -M<nvflag> 选项。-Minform=level
指示编译器显示指定级别及更高级别的错误消息,其中level是以下之一:fatal
指示编译器显示致命错误消息。[no]file
指示编译器打印或不打印正在编译的源文件名。默认设置为打印名称:-Minform=file。inform
指示编译器显示所有错误消息(inform、warn、severe 和 fatal)。
severe
指示编译器显示严重错误和致命错误消息。cref
(仅限 Fortran) 编译器不会将内部函数CMPLX和REAL分别提升为DCMPLX和DBLE。warn
mixed_str_len_arg将字符参数的长度紧跟在其对应的参数之后。仅在 CREF 调用约定中有效。
concur指示编译器显示警告、严重错误和致命错误消息。
nomixed_str_len_arg将字符参数的长度放在参数列表的末尾。仅在 CREF 调用约定中有效。
inline-Minfo[=选项 [,选项,...]]
ftn指示编译器启用特定于 Fortran 的信息。
inline指示编译器显示有关提取或内联函数的信息。如果没有
-Mextract或-Minline选项,则此选项无用。intensity指示编译器提供有关循环强度的信息性消息。指定 <n> 以获取有关嵌套循环的消息。
对于浮点循环,强度定义为浮点运算的数量除以浮点加载和存储的数量。对于整数循环,循环强度定义为整数算术运算的总数(可能包括循环计数和地址的更新)除以整数加载和存储的总数。
默认情况下,消息仅适用于最内层循环。loop
指示编译器显示有关优化的信息。par
-Mkeepasm指示编译器在编译继续时保留汇编文件。通常,汇编器在完成时会删除此文件。汇编文件与源文件具有相同的文件名,但扩展名为 .s。
-Mlist指示编译器创建列表文件。列表文件为
filename.lst,其中源文件的名称为filename.f。-Mnames={lowercase|uppercase}指定 Fortran 外部名称的大小写。
注意
lowercase - 对 Fortran 外部名称使用小写。
uppercase - 对 Fortran 外部名称使用大写。
-Mneginfo[=选项[,选项,...]]指示编译器生成有关为什么未执行各种优化的所有可用信息。
par指示编译器生成有关为什么循环未自动并行化的所有可用信息。特别是,如果由于潜在的数据依赖性而未并行化循环,则导致潜在依赖性的变量将列在使用
-Mneginfo选项时看到的消息中。-Mnolist编译器不创建列表文件。这是默认设置。
-Mnorpath不要将 -rpath 添加到链接行。
-Mnvpl[=选项, [选项, ...]]指示编译器将 NVIDIA 性能库 (NVPL) 链接到应用程序中。使用不带子选项的此选项链接到 NVPL 中的所有库,或使用子选项仅链接到指定的 NVPL 库。要使用 NVPL ScaLAPACK 库,请使用
-Mscalapack -Mnvpl。有关此选项的更多信息,请参阅有关-Mscalapack的部分。NVPL 库仅适用于 Arm CPU。有关 NVPL 的更多信息,请访问 https://docs.nvda.net.cn/nvpl/此标志的有效选项包括:
blas链接到 NVPL BLAS 库。
fft链接到 NVPL FFT 库。
注意
lapack
链接到 NVPL LAPACK 库。此选项还将导致链接到 NVPL BLAS 库,因为 BLAS 是 LAPACK 的依赖项。rand
链接到 NVPL RAND 库。
sparse
链接到 NVPL Sparse 库。
tensor
链接到 NVPL Tensor 库。
-Mpreprocess
指示编译器对汇编和 Fortran 输入源文件执行类似 cpp 的预处理。
-Mwritable_strings
将字符串常量存储在可写数据段中。
选项 -Xs 和 -Xst 包含 -Mwritable_strings。
-Mscalapack
prompt> nvdecode
_ZN1A1gEf
A::g(float)
指示编译器链接到 ScaLAPACK 库。ScaLAPACK 是用于并行分布式内存机器的高性能线性代数例程库,它使用 MPI 作为底层通信机制。如果在命令行中也指定了 -Mnvpl,则此标志会将 NVPL ScaLAPACK 库链接到应用程序中。否则,将使用 Netlib ScaLAPACK 库。
3. C++ 名称修饰
名称修饰转换实体的名称,以便名称包含有关实体类型和完全限定名称方面的信息。此功能是必要的,因为程序被翻译成的中间语言包含比 C++ 语言中更少更简单的命名空间;具体来说:
#define __NVCOMPILER_MAJOR__ 25 #define __NVCOMPILER_MINOR__ 1 #define __NVCOMPILER_PATCHLEVEL__ 0 #define __NVCOMPILER_CLANG_SSE_INTRINSICS_VERSION__ 60000 #define __NVCOMPILER 1 #define __NVCOMPILER_LLVM__ 1
中间语言中不允许重载函数名称。
类在 C++ 中有自己的作用域,但在生成的中间语言中没有。例如,来自类内部的实体 x 不得与来自文件作用域的实体 x 冲突。
注意
对象代码中的外部名称形成一个完全扁平的命名空间。具有外部链接的实体的名称必须投影到该命名空间上,以便它们彼此不冲突。例如,来自类 A 的函数 f 不得与来自类 B 的函数 f 具有相同的外部名称。
有些名称不是传统意义上的名称,它们不是字母数字字符的字符串,例如:operator=。
这里有两个主要问题:
生成不会冲突的外部名称。
为 C++ 中具有奇怪名称的实体生成字母数字名称。
名称修饰通过生成不会冲突的外部名称以及为 C++ 中具有奇怪名称的实体生成字母数字名称来解决这些问题。它还解决了为某些幕后语言支持生成隐藏名称的问题,以便它们在单独的编译中匹配。
如果您查看由 NVC++ 或 NVC 翻译的文件,并且您不使用解修饰 C++ 名称的工具,您会看到修饰后的名称。使用修饰名称的中间文件包括 NVC++ 命令创建的汇编文件和目标文件。要查看解修饰的名称,请使用工具 nvdecode,它从 stdin 获取输入。nvdecode 解修饰 NVC++ 名称。
4. 预定义的编译器宏 |
HPC 编译器将预定义某些编译器宏。宏定义如下: |
5. 运行时环境 |
|---|---|---|
本节介绍与编译器代码生成相关的详细信息,包括基于 x86-64 和 OpenPOWER 处理器的系统的寄存器约定和调用约定。它解决了运行 Linux 操作系统的处理器的这些约定。 |
在本节中,我们有时会提到字、半字和双字。等效的字节信息是字(4 字节)、半字(2 字节)和双字(8 字节)。 |
5.1. Linux 编程模型 |
本节定义了编译器和汇编语言约定,用于在运行 Linux 操作系统的 x86-64 或 OpenPOWER 处理器上使用某些方面。必须遵循这些标准,以确保不同人员和组织编写的编译器、应用程序和操作系统能够协同工作。NVC ISO/ANSI C 编译器支持的约定实现了应用程序二进制接口 (ABI),如 System V Application Binary Interface: AMD64 Architecture Processor Supplement 和 Preface 中列出的 OpenPOWER for Linux Supplement, Power Architecture 64-Bit ELF V2 ABI Specification 中所定义。 |
5.1.1. x86-64 函数调用序列 |
|
本节介绍标准函数调用序列,包括堆栈帧、寄存器使用和参数传递。 |
x86-64 寄存器使用约定 |
|
下表定义了寄存器分配的标准。x86-64 架构提供了各种寄存器。所有通用寄存器、x87 寄存器、XMM 寄存器、SSE 寄存器和 AVX 寄存器对于运行程序中的所有过程都是可见的。 |
表 14. x86-64 寄存器分配 |
|
类型 |
名称 |
|
用途 |
通用 |
|
%rax |
第一个返回值寄存器。当被调用者具有可变数量的参数时,%al 指定传递的向量寄存器的数量。 |
|
%rbx |
被调用者保存;可选基指针 |
|
%rcx |
将第 4 个参数传递给函数 |
|
%rdx |
将第 3 个参数传递给函数;第二个返回值寄存器 |
|
%rsp |
堆栈指针 |
|
%rbp |
被调用者保存;可选堆栈帧指针 |
|
%rsi |
将第 2 个参数传递给函数 |
|
%rdi |
将第 1 个参数传递给函数 |
%r8 |
将第 5 个参数传递给函数 |
%r9 |
|
将第 6 个参数传递给函数 |
%r10 |
|
临时寄存器;传递函数的静态链指针 |
%r11 |
临时寄存器 |
%r12-r15 |
临时寄存器 |
|
被调用者保存的寄存器 |
%r10 |
XMM
%xmm0-%xmm1
%xmm2-%xmm7 |
传递浮点参数 |
%xmm8-%xmm15 |
|---|---|---|
临时寄存器 |
x87 |
%st(0) |
临时寄存器;返回 long double 参数 |
%st(1) |
|
%st(2) - %st(7) |
x86-64 堆栈帧组织 |
除了寄存器之外,每个函数在运行时堆栈上都有一个帧。此堆栈从高地址向下增长。表 15 显示了堆栈帧组织。 |
表 15. 标准堆栈帧 |
位置 |
除了寄存器之外,每个函数在运行时堆栈上都有一个帧。此堆栈从高地址向下增长。表 15 显示了堆栈帧组织。 |
内容 |
帧 |
|
8n+16 (%rbp) |
参数 eightbyte n … |
|
上一个 |
16 (%rbp) |
参数 eightbyte 0
8 (%rbp)
返回地址
在 %rsp 寄存器所指位置之外的 128 字节区域称为红色区域,可用于临时本地数据存储。该区域不会被信号或中断处理程序修改。
call 指令将下一条指令的地址(返回地址)压入堆栈。return 指令从堆栈中弹出地址,并有效地在 call 指令之后的下一条指令处继续执行。函数必须保存非易失性寄存器,即其内容必须在子例程调用中保留的寄存器。此外,被调用的函数必须从堆栈中移除返回地址,使堆栈指针 (%rsp) 的值恢复到执行 call 指令之前的值。
x86-64 系统上的所有寄存器对于调用函数和被调用函数都是可见的。寄存器 %rbx、%rsp、%rbp、%r12、%r13、%r14 和 %r15 在函数调用之间是非易失性的。因此,函数必须为其调用者保留这些寄存器的值。其余寄存器是易失性(暂存)寄存器,即其内容不必在子例程调用中保留的寄存器。如果调用函数想要在函数调用之间保留此类寄存器值,则必须显式保存其值。
寄存器在标准调用序列中被广泛使用。前六个整数和指针参数通过以下寄存器传递(按顺序排列):%rdi、%rsi、%rdx、%rcx、%r8、%r9。前八个浮点参数通过前八个 XMM 寄存器传递:%xmm0、%xmm1、…、%xmm7。寄存器 %rax 和 %rdx 用于返回整数和指针值。寄存器 %xmm0 和 %xmm1 用于返回浮点数值。
标准调用序列中具有指定角色的其他寄存器
- 类型
堆栈指针保存当前堆栈帧的界限,即堆栈最底部有效字的地址。堆栈必须是 16 字节对齐的。
- 用途
帧指针保存当前堆栈帧的基地址。因此,一个函数拥有指向其帧两端的寄存器。传入的参数位于前一个帧中,作为相对于 %rbp 的正偏移量引用,而局部变量位于当前帧中,作为相对于 %rbp 的负偏移量引用。函数必须为其调用者保留此寄存器值。
- RFLAGS
标志寄存器包含系统标志,例如方向标志和进位标志。在进入和退出函数之前,方向标志必须设置为“向前”(即零)方向。其他用户标志在标准调用序列中没有指定角色,并且不会被保留。
- 浮点控制字
控制字包含浮点标志,例如舍入模式和异常屏蔽。此寄存器在进程初始化时初始化,其值必须被保留。
信号可以中断进程。在信号处理期间调用的函数对其寄存器的使用没有不寻常的限制。此外,如果信号处理函数返回,则进程将恢复其原始执行路径,并且寄存器恢复为其原始值。因此,程序和编译器可以自由使用所有寄存器,而无需担心信号处理程序更改其值。
x86-64 函数返回标量或无返回值
返回整数或指针值的函数将其结果放置在序列 %rax、%rdx 的下一个可用寄存器中。
返回可以容纳在 XMM 寄存器中的浮点数值的函数将其值返回到序列 %xmm0、%xmm1 的下一个可用 XMM 寄存器中。
X87 浮点返回值以 80 位 X87 数字的形式出现在浮点堆栈的顶部 %st(0) 中。如果此 X87 返回值是复数,则该值的实部在 %st(0) 中返回,虚部在 %st(1) 中返回。
返回内存中值的函数还在 %rax 中返回此内存的地址。
不返回值的函数(也称为过程或 void 函数)不会在任何寄存器中放置特定的值。
x86-64 函数返回结构体或联合体
函数可以使用寄存器或内存来返回结构体或联合体。结构体或联合体的大小和类型决定了其返回方式。如果结构体或联合体大于 16 字节,则在调用者分配的内存中返回。
要确定是否可以在一个或多个返回寄存器中返回 16 字节或更小的结构体或联合体,请检查结构体或联合体的前八个字节。构成这八个字节的结构体或联合体字段的类型决定了这八个字节的返回方式。如果这八个字节包含至少一个整数类型,即使这八个字节中也存在非整数类型,这八个字节也将在 %rax 中返回。如果这八个字节仅包含浮点类型,则这八个字节将在 %xmm0 中返回。
如果结构体或联合体大于八个字节但小于 17 个字节,请检查构成结构体或联合体的第二个八个字节的字段的类型。如果这八个字节包含至少一个整数类型,即使这八个字节中也存在非整数类型,这八个字节也将在 %rdx 中返回。如果这八个字节仅包含浮点类型,则这八个字节将在 %xmm1 中返回。
如果结构体或联合体在内存中返回,则调用者提供返回值的空间,并将其地址作为“隐藏”的第一个参数在 %rdi 中传递给函数。此地址也将在 %rax 中返回。
x86-64 整数和指针参数
整数和指针参数使用序列 %rdi、%rsi、%rdx、%rcx、%r8、%r9 的下一个可用寄存器传递给函数。在此寄存器列表耗尽后,所有剩余的整数和指针参数都通过堆栈传递给函数。
x86-64 浮点参数
float 和 double 参数使用从 %xmm0 到 %xmm7 顺序的下一个可用 XMM 寄存器传递给函数。在此寄存器列表耗尽后,所有剩余的 float 和 double 参数都通过堆栈传递给函数。
x86-64 结构体和联合体参数
结构体和联合体参数可以通过寄存器或堆栈传递给函数。结构体或联合体的大小和类型决定了其传递方式。如果结构体或联合体大于 16 字节,则在内存中传递给函数。
要确定是否可以在一个或两个寄存器中将 16 字节或更小的结构体或联合体传递给函数,请检查结构体或联合体的前八个字节。构成这八个字节的结构体或联合体字段的类型决定了这八个字节的传递方式。如果这八个字节包含至少一个整数类型,即使这八个字节中也存在非整数类型,这八个字节也将在序列 %rdi、%rsi、%rdx、%rcx、%r8、%r9 的第一个可用通用寄存器中传递。如果这八个字节仅包含浮点类型,则这八个字节将在从 %xmm0 到 %xmm7 的序列的第一个可用 XMM 寄存器中传递。
如果结构体或联合体大于八个字节但小于 17 个字节,请检查构成结构体或联合体的第二个八个字节的字段的类型。如果这八个字节包含至少一个整数类型,即使这八个字节中也存在非整数类型,这八个字节也将在序列 %rdi、%rsi、%rdx、%rcx、%r8、%r9 的下一个可用通用寄存器中传递。如果这八个字节仅包含浮点类型,则这八个字节将在从 %xmm0 到 %xmm7 的序列的下一个可用 XMM 寄存器中传递。
如果由于某种原因,结构体或联合体的第一个或第二个八个字节无法在寄存器中传递,则必须在内存中传递整个结构体或联合体。
x86-64 通过堆栈传递参数
如果在分配完每个参数寄存器后还有剩余的参数,则剩余的参数通过堆栈传递给函数。未分配的参数以相反的顺序压入堆栈,最后一个参数首先压入。
x86-64 参数传递
表 16 显示了以下示例中所示的函数声明和调用的寄存器分配和堆栈帧偏移量。表和示例均改编自 System V Application Binary Interface: AMD64 Architecture Processor Supplement。
typedef struct {
int a, b;
double d;
}
structparam;
structparam s;
int e, f, g, h, i, j, k;
float flt;
double m, n;
extern void func(int e, int f, structparam s, int g, int h,
float flt, double m, double n, int i, int j, int k);
void func2()
{
func(e, f, s, g, h, flt, m, n, i, j, k);
}
通用寄存器 |
浮点寄存器 |
堆栈帧偏移量 |
|---|---|---|
%rdi: e |
%xmm0: s.d |
0: j |
%rsi: f |
%xmm1: flt |
8: k |
%rdx: s.a,s.b |
%xmm2: m |
|
%rcx: g |
%xmm3: n |
|
%r8: h |
||
%r9: i |
x86-64 实现堆栈
通常,编译器和程序员必须维护一个软件堆栈。堆栈指针,寄存器 %rsp,在程序启动时由操作系统为应用程序设置。堆栈必须从高地址向下增长。
单独的帧指针允许调用在运行时更改堆栈指针以在堆栈上分配空间的例程(例如 alloca)。某些语言还可以从低于原始堆栈顶指针的堆栈空间上分配的例程返回值。这样的例程阻止调用函数将 %rsp 相对寻址用于堆栈上的值。如果编译器不调用在返回时将 %rsp 留在更改状态的例程,则不需要帧指针,并且如果指定了编译器选项 -Mnoframe,则可能不会使用帧指针。
堆栈必须保持在 16 字节边界上对齐。
x86-64 变长参数列表
寄存器中的参数传递可以处理可变数量的参数。C 语言使用一种特殊的方法来访问可变计数参数。stdarg.h 和 varargs.h 文件定义了几个函数来访问这些参数。带有可变参数的 C 例程必须使用 va_start 宏来设置数据结构,然后才能使用参数。va_arg 宏必须用于访问后续参数。
对于使用 varargs 或 stdargs 的调用,寄存器 %rax 充当隐藏参数,其值是在调用中使用的 XMM 寄存器的数量。
x86-64 C 参数转换
在 C 语言中,对于调用的原型函数,被调用函数中的参数类型必须与调用函数中的参数类型匹配。如果被调用函数没有原型,则调用约定使用参数的类型,但将 char 或 short 提升为 int,并将 unsigned char 或 unsigned short 提升为 unsigned int,并将 float 提升为 double,除非您使用 -Msingle 选项。有关 -Msingle 选项的更多信息,请参阅 -M 选项按类别。
x86-64 调用汇编语言程序
以下示例显示了一个 C 程序调用汇编语言例程 sum_3。
调用汇编语言例程的 C 程序
/* File: testmain.c */
#include <stdio.h>
int
main() {
long l_para1 = 2;
float f_para2 = 1.0;
double d_para3 = 0.5;
float f_return;
extern float sum_3(long para1, float para2, double para3);
f_return = sum_3(l_para1, f_para2, d_para3);
printf("Parameter one, type long = %ld\n", l_para1);
printf("Parameter two, type float = %f\n", f_para2);
printf("Parameter three, type double = %f\n", d_para3);
printf("The sum after conversion = %f\n", f_return);
return 0;
}
# File: sum_3.s
# Computes ( para1 + para2 ) + para3
.text
.align 16
.globl sum_3
sum_3:
pushq %rbp
movq %rsp, %rbp
cvtsi2ssq %rdi, %xmm2
addss %xmm0, %xmm2
cvtss2sd %xmm2,%xmm2
addsd %xmm1, %xmm2
cvtsd2ss %xmm2, %xmm2
movaps %xmm2, %xmm0
popq %rbp
ret
.type sum_3, @function
.size sum_3,.-sum_3
5.1.2. OpenPOWER 函数调用序列
OpenPOWER 寄存器使用约定
下表定义了寄存器分配的标准。OpenPOWER 架构提供了多种寄存器。所有通用寄存器、向量标量寄存器和向量寄存器对于正在运行的程序中的所有过程都是可见的。
在 64 位 OpenPOWER 架构中,始终有 32 个通用寄存器,每个寄存器 64 位宽。在本文档中,符号 rN 用于指代通用寄存器 N,其中 N 是寄存器号。
4. 预定义的编译器宏 |
HPC 编译器将预定义某些编译器宏。宏定义如下: |
保存规则 |
5. 运行时环境 |
|---|---|---|---|
本节介绍与编译器代码生成相关的详细信息,包括基于 x86-64 和 OpenPOWER 处理器的系统的寄存器约定和调用约定。它解决了运行 Linux 操作系统的处理器的这些约定。 |
r0 |
易失性 |
在函数链接中的可选使用。在函数序言中使用。 |
r1 |
非易失性 |
堆栈帧指针。 |
|
r2 |
非易失性(1) |
TOC 指针。 |
|
r3–r10 |
易失性 |
参数和返回值。 |
|
r11 |
易失性 |
在函数链接中的可选使用。在需要环境指针的语言中用作环境指针。 |
|
r12 |
易失性 |
在函数链接中的可选使用。全局入口点处的函数入口地址。 |
|
r13 |
保留 |
线程指针。 |
|
r14–r31(2) |
非易失性 |
局部变量。 |
|
浮点 |
f0 |
易失性 |
局部变量。 |
f1–f13 |
易失性 |
用于二进制浮点类型的参数传递和返回值。 |
|
f14–f31 |
非易失性 |
局部变量。 |
|
向量 |
v0–v1 |
易失性 |
局部变量。 |
v2–v13 |
易失性 |
用于参数传递和返回值。 |
|
v14–v19 |
易失性 |
局部变量。 |
|
v20–v31 |
非易失性 |
局部变量。 |
(1) 寄存器 r2 对于同一编译单元中函数之间的调用是非易失性的。它由链接器插入的代码保存和恢复,以解析对外部函数的调用。
(2) 如果函数需要帧指针,建议将 r31 分配为帧指针的角色。
在符合 OpenPOWER 标准的处理器中,浮点和向量函数使用统一的向量标量模型实现。如图 图 3 和 图 4 所示,有 64 个向量标量寄存器;每个寄存器 128 位宽。
向量标量寄存器可以使用向量标量指令进行寻址,用于所有 64 个寄存器的向量和标量处理,或者使用“经典”Power 浮点指令来引用每个寄存器 64 位的 32 个寄存器子集。它们也可以使用 VMX 指令进行寻址,以引用 128 位宽寄存器的 32 个寄存器子集。

图 3. 作为向量标量寄存器一部分的浮点寄存器
图 4. 作为向量标量寄存器一部分的向量寄存器
经典的浮点指令集包含 32 个浮点寄存器,每个寄存器 64 位宽,以及一个关联的专用寄存器,用于提供浮点状态和控制。在本文档中,符号 fN 用于指代浮点寄存器 N,其中 N 是寄存器号。
出于函数调用的目的,VSX 寄存器的右半部分,对应于经典的浮点寄存器(即 vsr0–vsr31),是易失性的。
单精度和双精度应在浮点寄存器中传递。单精度十进制浮点数应占用浮点寄存器的下半部分。当在输入参数分配期间跳过浮点寄存器时,参数列表中相应的 GPR 或内存双字中的字不会被跳过。
OpenPOWER 向量类别指令集提供了引用向量标量寄存器文件的 32 个向量寄存器(每个寄存器 128 位宽)和一个专用寄存器 VSCR 的能力。在本文档中,符号 vN 用于指代向量寄存器 N,其中 N 是寄存器号。
具有一对双精度浮点值的 long double 格式的参数应在两个连续的浮点寄存器中传递。
如果只能在一个浮点寄存器中传递一个值,则第二个参数将根据结构体聚合的参数传递规则在 GPR 或内存中传递。
OpenPOWER 堆栈帧组织
图 5. 堆栈帧组织
OpenPOWER 堆栈使用约定
堆栈应为四字对齐。
最小堆栈帧大小应为 32 字节。最小堆栈帧由前 4 个双字(后向链双字、CR 保存字和保留字、LR 保存双字和 TOC 指针双字)组成,并填充以满足 16 字节对齐要求。
未定义最大堆栈帧大小。
应将填充添加到堆栈帧的局部变量空间,以保持定义的堆栈帧对齐。
堆栈指针 r1 应始终指向最近分配的堆栈帧的最低地址双字。
堆栈应从高地址开始并向下增长到较低地址。
当存在后向链时,最低地址双字(图 5 中的后向链字)应指向先前分配的堆栈帧。作为例外,第一个堆栈帧应具有值 0 (NULL)。
如果需要,堆栈指针应在被调用函数的序言中递减,并在被调用函数的尾声中恢复。
堆栈指针应以原子方式更新,以便在任何时候,如果维护后向链,它都指向有效的后向链双字。
在函数调用任何其他函数之前,它应将 LR 寄存器的值保存到调用者堆栈帧的 LR 保存双字中。
后向链双字
当不存在后向链时,编译器必须为所有语言提供与 ABI 展开框架兼容的替代信息,以展开堆栈,而与语言功能无关。不提供此类系统兼容的展开信息的编译器必须生成后向链。所有编译器都应默认生成后向链信息,并且默认库应包含后向链。
CR 保存字
如果函数更改了条件寄存器的任何非易失性字段中的值,它应首先保存至少条件寄存器的那些非易失性字段的值,以便在函数退出之前恢复。调用者帧 CR 保存字可以用作保存位置。当前帧中的此位置可以用作临时存储,该存储在函数调用中是易失性的。
保留字
此字保留供系统函数使用。除非未来的 ABI 修订明确允许,否则禁止修改此字中包含的值。
LR 保存双字
如果函数更改了链接寄存器的值,它必须首先保存旧值,以便在函数退出之前恢复。调用者帧 LR 保存双字可以用作保存位置。当前帧中的此位置可以用作临时存储,该存储在函数调用中是易失性的。
TOC 指针双字
如果函数更改了 TOC 指针寄存器的值,它应首先将其保存在 TOC 指针双字中。
OpenPOWER 可选保存区域
此 ABI 提供了一个带有多个可选保存区域的堆栈帧。这些区域始终存在,但大小可能为 0。本节指示这些保存区域相对于彼此以及堆栈帧的主要元素的位置。
由于堆栈帧的后向链字必须保持四字对齐,因此在 CR 保存字上方引入了一个保留字,以提供四字对齐的最小堆栈帧,并将固定堆栈帧部分内的双字在双字边界处对齐。
在向量寄存器保存区域上方可能需要可选的对齐填充到四字边界元素,以提供 16 字节对齐,如 图 5 所示。
浮点寄存器保存区域
如果函数更改了任何非易失性浮点寄存器 fN 中的值,它应首先将 fN 中的值保存在浮点寄存器保存区域中,并在函数退出时恢复寄存器。
浮点寄存器保存区域始终是双字对齐的。浮点寄存器保存区域的大小取决于必须保存的浮点寄存器的数量。如果不需要保存浮点寄存器,则浮点寄存器保存区域的大小为零。
通用寄存器保存区域
如果函数更改了任何非易失性通用寄存器 rN 中的值,它应首先将 rN 中的值保存在通用寄存器保存区域中,并在函数退出时恢复寄存器。
通用寄存器保存区域始终是双字对齐的。通用寄存器保存区域的大小取决于必须保存的通用寄存器的数量。如果不需要保存通用寄存器,则通用寄存器保存区域的大小为零。
向量寄存器保存区域
如果函数更改了任何非易失性向量寄存器 vN 中的值,它应首先将 vN 中的值保存在向量寄存器保存区域中,并在函数退出时恢复寄存器。
向量寄存器保存区域始终是四字对齐的。如果需要确保向量保存区域的适当对齐,则可以在向量寄存器和通用寄存器保存区域之间引入填充双字,和/或可以将局部变量空间扩展到下一个四字边界。向量寄存器保存区域的大小取决于必须保存的向量寄存器的数量。范围从 0 字节到最大 192 字节(12 × 16)。如果不需要保存向量寄存器,则向量寄存器保存区域的大小为零。
局部变量空间
局部变量空间用于分配局部变量。局部变量空间位于参数保存区域的正上方,地址较高。对此区域的大小没有限制。
注意
有时需要寄存器溢出区域。它通常位于局部变量空间上方。
当函数的参数列表不需要调用者分配保存区域时,局部变量空间还包含任何需要分配内存地址的参数。
参数保存区域
除非为被调用者提供了原型,指示所有参数都可以在寄存器中传递,否则参数保存区域应由调用者为函数调用分配。(这需要为以下函数创建参数保存区域:参数的数量和类型超过可用于在寄存器中传递参数的寄存器的函数、原型包含省略号以指示可变参数函数的函数,以及在没有原型声明的情况下声明的函数。)
当调用者分配参数保存区域时,它将始终自动进行四字对齐,因为它必须始终从 SP + 32 开始。它应至少为 8 个双字长。如果函数需要传递超过 8 个双字的参数,则参数保存区域应足够大,以溢出所有基于寄存器的参数并包含调用者存储在其中的参数。
调用函数不能期望此保存区域的内容在从被调用者返回时有效。
参数保存区域位于距堆栈指针固定偏移量 32 字节处,在每个堆栈帧中保留,用作需要内存中参数列表时的参数列表。例如,当调用具有以下特征的函数时,调用者必须分配参数保存区域
原型函数,其中参数不能包含在参数寄存器中
具有可变参数的原型函数
调用者无法获得合适的声明以确定被调用函数的特征的函数(例如,C 语言中没有作用域原型的函数)。
在这些情况下,始终保留至少 8 个双字。此区域的大小必须足以容纳拥有堆栈帧的函数传递的最长参数列表。尽管特定调用的并非所有参数都位于存储中,但当需要内存中参数列表时,请将参数视为在此区域中形成列表。每个参数占用一个或多个双字。
可能会传递比可以存储在参数寄存器中更多的参数。在这种情况下,剩余的参数存储在参数保存区域中。堆栈上传递的值与放置在寄存器中的值相同。因此,堆栈包含未放置到寄存器中的值的寄存器映像。
此 ABI 使用简单的 va_list 类型用于可变列表,以指向下一个参数的内存位置。因此,无论类型如何,可变参数都必须始终位于同一位置,以便可以在运行时找到它们。前 8 个双字位于通用寄存器 r3–r10 中。任何其他双字都位于堆栈参数保存区域中。向量类型等对齐要求可能需要首先对齐 va_list 指针,然后才能访问值。
遵循以下参数传递规则
将每个参数映射到参数保存区域中足够的双字以保存其值。
将单精度浮点值映射到单个双字中的最低有效字。
将双精度浮点值映射到单个双字。
将简单整数类型(char、short、int、long、enum)映射到单个双字。根据源数据类型是有符号还是无符号,将短于双字的值进行符号扩展或零扩展为双字。
当按值传递 128 位整数类型时,将每个类型映射到两个连续的 GPR、两个连续的双字或一个 GPR 和一个双字。int128 数据类型的必需对齐为 16 字节。因此,当传入参数未在 16 字节边界对齐时,按值参数必须复制到被调用者堆栈帧的局部变量区域中的新位置,然后才能提供类型的地址(例如,使用地址运算符,或者当变量要按引用传递时)。
将 long double 映射到两个连续的双字。long double 数据类型的必需对齐为 16 字节。因此,当传入参数未在 16 字节边界对齐时,按值参数必须复制到被调用者堆栈帧的局部变量区域中的新位置,然后才能提供类型的地址(例如,使用地址运算符,或者当变量要按引用传递时)。
将复数浮点类型和复数整数类型映射为参数被指定为单独的实部和虚部。
将指针映射到单个双字。
将向量映射到单个四字,四字对齐。这可能会导致参数保存区域中跳过双字。
将按值传递的固定大小的聚合和联合映射到参数保存区域中值在内存中使用的双字数量。按如下方式对齐聚合和联合
包含限定浮点或向量参数的聚合通常按照其基本类型的对齐方式对齐。有关限定参数的更多信息,请参阅 OpenPOWER 寄存器中的参数传递。
其他聚合通常按照聚合的已定义对齐方式对齐。
对齐永远不会大于堆栈帧对齐(16 字节)。
这可能会导致为了对齐而跳过双字。当参数保存区域(或其 GPR 副本)中的双字包含结构的至少一部分时,该双字必须包含映射到同一双字的所有其他部分。(也就是说,双字可以是完全有效的,也可以是完全无效的,但不能是部分有效和无效的,除非在最后一个双字中可能存在无效填充。)
填充小于一个双字大小的聚合或联合,使其位于双字的最低有效位中。如有必要,在其尾部填充所有其他聚合或联合。可变大小的聚合或联合按引用传递。
将其他标量值映射到其大小所需的双字数。
未来具有架构定义的四字所需对齐的数据类型将在四字边界处对齐。
如果被调用者具有已知的原型,则当参数加载到其参数寄存器中或映射到参数保存区域中时,参数将转换为相应参数的类型。例如,如果将 long 用作 float double 参数的参数,则该值将转换为双精度并映射到参数保存区域中的双字。
OpenPOWER 保护区
堆栈指针下方的 288 字节可用作易失性程序存储,在函数调用之间不会保留。中断处理程序和任何其他可能在没有显式调用的情况下运行的函数必须注意保留一个保护区,也称为红色区域,为 512 字节,包括
用于保存寄存器和局部变量的 288 字节易失性程序存储区域
易失性程序存储区域下方的另外 224 字节,设置为系统函数的易失性系统存储区域
如果函数不调用其他函数,并且不需要比易失性程序存储区域(即 288 字节)中可用的堆栈空间更多的堆栈空间,则它不需要具有堆栈帧。224 字节的易失性系统存储区域不可供编译器分配给保存的寄存器和局部变量。
OpenPOWER 寄存器中的参数传递
对于 OpenPOWER 架构,在寄存器中而不是通过内存传递参数更有效。有关通过内存传递参数的更多信息,请参阅 参数保存区域 下的 OpenPOWER 可选保存区域。对于 OpenPOWER ABI,以下参数可以在寄存器中传递
最多可以在通用寄存器 r3–r10 中传递八个参数。
最多可以在浮点寄存器 f1–f13 中传递十三个限定浮点参数,或者在向量寄存器 v2–v13 中传递最多十二个限定浮点参数。
最多可以在浮点寄存器 f1–f13 中传递十三个单精度或双精度十进制浮点参数。
最多可以在偶奇浮点寄存器对 f2–f13 中传递六个四精度十进制浮点参数。
最多可以在 v2–v13 中传递 12 个限定向量参数。
限定浮点参数对应于
标量浮点数据类型
复数浮点类型的每个成员
同构聚合的成员,其中多个类似数据类型在最多八个浮点寄存器中传递
同构聚合可以由各种嵌套结构组成,包括结构体、联合体和数组元素,应遍历这些结构以确定基本浮点类型的成员的类型和数量。(复数浮点数据类型被视为传递了两个单独的基本类型标量值。)
同构浮点聚合最多可以有四个 long double 成员或八个浮点类型成员。(联合体被视为其最大的成员。对于同构联合体,不同的联合体备选项可能具有不同的大小,前提是所有联合体成员彼此同构。)如果该类型的参数将在浮点寄存器中传递,则它们将在浮点寄存器中传递。如果该类型的参数将在向量寄存器中传递,则它们将在向量寄存器中传递。它们的传递方式就好像每个成员都被指定为单独的参数一样。
限定向量参数对应于
向量数据类型
同构聚合的成员,其中多个类似数据类型在最多八个向量寄存器中传递
任何未来需要 16 字节对齐的类型(请参阅 OpenPOWER 可选保存区域)或在向量寄存器中处理的类型
同类聚合可以包含各种嵌套结构,包括结构体、联合体和数组元素,这些结构将被遍历以确定基本向量类型的成员类型和数量。最多包含八个成员的同类向量聚合会像每个成员都被指定为单独的参数一样,通过最多八个向量寄存器传递。(联合体被视为其最大的成员。对于同类联合体,不同的联合体备选项可能具有不同的大小,前提是所有联合体成员彼此之间都是同类的。)
注意
包含填充字和宽度为 0 的整数字段的浮点和向量聚合不应被视为同类聚合。
同类聚合要么是同类浮点聚合,要么是同类向量聚合。此 ABI 未指定整数类型的同类聚合。
long double 类型的数字使用两个连续的浮点寄存器传递。在必要时,可能会跳过一个浮点寄存器以分配一个偶数/奇数寄存器对。当跳过浮点寄存器时,自然宿主位置不会跳过相应的内存字;也就是说,参数列表中的相应 GPR 或内存双字。
所有其他聚合都在连续的 GPR 中、GPR 和内存中或内存中传递。
当参数在浮点或向量寄存器中传递时,将跳过一些 GPR,跳过的数量与传递的参数类型在内存中的表示大小相称,并按分配顺序进行。
每个参数至少分配到一个双字。
完整双字规则
当参数保存区(或其 GPR 副本)中的一个双字至少包含结构的一部分时,该双字必须包含映射到同一双字的所有其他部分。(也就是说,一个双字可以完全有效,也可以完全无效,但不能部分有效和部分无效,除非在最后一个双字中可能存在无效的填充。)
长双精度浮点数 (Long Double)
长双精度浮点数参数的传递方式与由单独的双精度浮点数参数组成的结构体相同。
对于同类聚合的确定,长双精度浮点数参数应被视为一种不同的类型。
如果需要的参数较少,则先前定义的未使用的寄存器将在被调用函数的入口处包含未定义的值。
如果参数多于寄存器,或者未提供函数原型,则函数必须在其堆栈帧中为所有参数提供空间。在这种情况下,只需要在堆栈帧中分配包含所有参数所需的最小存储空间(包括为在寄存器中传递的参数分配空间)。
通用寄存器 r3–r10 对应于参数到参数保存区前 8 个双字的分配。具体而言,这需要跳过适当数量的通用寄存器,以对应于在浮点和向量寄存器中传递的参数。
如果参数对应于与省略号对应的未命名参数,则调用者应将 float 值提升为 double。如果参数对应于与省略号对应的未命名参数,则该参数应在 GPR 中或参数保存区中传递。
如果没有可用的函数原型,调用者应将 float 值提升为 double,并在可用的浮点寄存器和参数保存区中传递浮点参数。如果没有可用的函数原型,调用者应在可用的向量寄存器和参数保存区中传递向量参数。(如果被调用者期望一个 float 参数,则结果将不正确。)
被调用者有责任在局部变量区中为存储的数据分配存储空间。当被调用者的参数列表指示调用者必须分配参数保存区(因为至少一个参数必须在内存中传递,或者原型中存在省略号)时,被调用者可以使用预先分配的参数保存区来保存传入的参数。
OpenPOWER 参数传递寄存器选择算法
以下算法描述了 C 语言的参数传递位置。在此算法中,假定参数从左(第一个参数)到右排序。参数的实际评估顺序未指定。
gr 包含下一个可用通用寄存器的编号。
fr 包含下一个可用浮点寄存器的编号。
vr 包含下一个可用向量寄存器的编号。
注意
以下类型指的是函数原型声明的参数类型。参数值在传递给被调用函数之前会转换为原型参数的类型(如果需要)。
如果不存在原型,或者它是可变参数原型,并且参数在省略号之后,则类型指的是传递给被调用函数的数据对象的类型。
初始化:如果函数返回类型需要存储缓冲区,则设置 gr = 4;否则设置 gr = 3。
Set fr = 1 Set vr = 2
扫描:如果没有更多参数,则终止。否则,根据函数参数的类别按如下方式分配
switch(class(argument)) integer: pointer: if gr > 10 goto mem_argument pass (GPR, gr, argument); gr++ break; aggregate: if (homogeneous(argument,float) and regs_needed(members(argument)) <= 8) n_fregs = n_fregs_for_type(member_type(argument,0)) agg_size = members(argument * n_fregs reg_size = min(agg_size, 15-fr) pass(FPR,fr,first_n_DW(argument,reg_size) fr += reg_size; gr += size_in_DW (first_n_DW(argument,reg_size)) if remaining_members argument = after_n_DW(argument,reg_size)) goto gpr_struct break; if (homogeneous(argument,vector) and members(argument) <= 8) use_vrs: agg_size = members(argument) reg_size = min(agg_size, 14-vr) if (gr&1 = 0) // align vector in memory gr++ pass(VR,vr,first_n_elements(argument,reg_size); vr += reg_size gr += size_in_DW (first_n_elements(argument,reg_size) if remaining_members argument = after_n_elements(argument,reg_size)) goto gpr_struct break; if gr > 10 goto mem_argument size = size_in_DW(argument) gpr_struct: reg_size = min(size, 11-gr) pass (GPR, gr, first_n_DW (argument, reg_size)); gr += size_in_DW (first_n_DW (argument, reg_size)) if remaining_members argument = after_n_DW(argument,reg_size)) goto mem_argument break; float: // float is passed in one FPR. // double is passed in one FPR. if (register_type_used (type (argument)) == vr) goto use_vr; if fr > 14 goto mem_argument n_fregs = n_fregs_for_type(argument) // Assumes n_fregs_for_type == 2 // for long double == 1 for float // or double pass(FPR,fr,argument) fr += n_fregs gr += size_in_DW(argument) break; vector: Use vr: if vr > 13 goto mem_argument if (gr&1 = 0) // align vector in memory gr++ pass(VR,vr,argument) vr ++ gr += 2 break; next argument; mem_argument: need_save_area = TRUE pass (stack, gr, argument) gr += size_in_DW(argument) next argument;
所有复杂数据类型都按如下方式处理:如同两个基类型的标量值作为单独的参数传递。
如果被调用者获取其任何参数的地址,则在寄存器中传递的值将存储到内存中。被调用者有责任在局部变量区中为存储的数据分配存储空间。当被调用者的参数列表指示调用者必须分配参数保存区(因为至少一个参数必须在内存中传递,或者原型中存在省略号)时,被调用者可以使用预先分配的参数保存区来保存传入的参数。(如果存在省略号,则使用预先分配的参数保存区可确保所有参数都是连续的。)如果调用者的编译单元包含函数原型,但被调用者具有不匹配的定义,则可能会导致存储错误的值。
注意
如果调用者使用的函数的声明与被调用函数的定义不匹配,则可能发生调用者堆栈空间的损坏。
OpenPOWER 可变参数列表
旨在跨不同编译器和架构移植的 C 程序必须使用头文件 <stdarg.h> 来处理可变参数列表。此头文件包含一组宏定义,这些宏定义定义了如何逐步遍历参数列表。此头文件的实现可能因不同的架构而异,但接口是相同的。
对于可变参数列表,不使用此头文件并假定所有参数都按堆栈上的递增顺序传递到堆栈上的 C 程序是不可移植的,尤其是在某些参数在寄存器中传递的架构上。OpenPOWER 架构是在寄存器中传递某些参数的架构之一。
参数列表的长度可能为零,并且仅当参数溢出、函数具有未命名参数或未提供原型时才分配。当参数保存区被分配时,参数保存区必须足够大以容纳所有参数,包括在寄存器中传递的参数。
OpenPOWER 返回值
返回值的函数应将结果放置在与返回值作为函数的第一个命名输入参数时相同的寄存器中,除非返回值是非同类聚合(大于 2 个双字)或同类聚合(具有超过八个寄存器)。有关同类聚合的定义,请参见 OpenPOWER 寄存器中的参数传递。(同类聚合是同类浮点或向量类型以及已知固定大小的数组、结构体或联合体。)因此,long double 函数在 f1:f2 中返回。
由最多八个寄存器组成的同类浮点或向量聚合返回值,最多包含八个元素,将在浮点或向量寄存器中返回,这些寄存器对应于如果返回值类型是函数的第一个输入参数时将使用的参数寄存器。
不是按值返回的聚合在调用者提供的存储缓冲区中返回。地址作为隐藏的第一个输入参数在通用寄存器 r3 中提供。
返回以下类型值的函数应将结果放置在寄存器 r3 中,作为有符号或无符号整数(视情况而定),并在必要时进行符号扩展或零扩展到 64 位
char
enum
short
int
long
指向任何类型的指针
_Bool
5.1.3. Linux Fortran 补充
Linux ABI 的 A2.4.1 到 A2.4.4 节定义了 Fortran 补充。该文档中规定的寄存器使用约定对于 Fortran 保持不变。
Fortran 基本类型
Fortran 类型 |
大小(字节) |
对齐(字节) |
|---|---|---|
INTEGER |
4 |
4 |
INTEGER*1 |
1 |
1 |
INTEGER*2 |
2 |
2 |
INTEGER*4 |
4 |
4 |
INTEGER*8 |
8 |
8 |
LOGICAL |
4 |
4 |
LOGICAL*1 |
1 |
1 |
LOGICAL*2 |
2 |
2 |
LOGICAL*4 |
4 |
4 |
LOGICAL*8 |
8 |
8 |
BYTE |
1 |
1 |
CHARACTER*n |
n |
1 |
REAL |
4 |
4 |
REAL*4 |
4 |
4 |
REAL*8 |
8 |
8 |
DOUBLE PRECISION |
8 |
8 |
COMPLEX |
8 |
4 |
COMPLEX*8 |
8 |
4 |
COMPLEX*16 |
16 |
8 |
DOUBLE COMPLEX |
16 |
8 |
逻辑常量是以下之一
.TRUE.
.FALSE.
逻辑常量 .TRUE. 和 .FALSE. 分别定义为四字节值 -1 和 0。如果逻辑表达式的最低有效位为 1,则定义为 .TRUE.;否则定义为 .FALSE.
请注意,字符的值不会自动以 NULL 结尾。
命名约定
默认情况下,所有全局可见的 Fortran 符号名称(子例程、函数、公共块)都转换为小写。此外,Fortran 全局名称会附加一个下划线,以区分 Fortran 命名空间与 C/C++ 命名空间。
参数传递和返回约定
参数通过引用传递(即,传递参数的地址,而不是参数本身)。相比之下,C/C++ 参数通过值传递。
当传递声明为 Fortran 类型 CHARACTER 的参数时,还向函数传递一个表示 CHARACTER 参数长度的参数。此长度参数是一个四字节整数,按值传递,并在参数列表的末尾、其他形式参数之后传递。每个 CHARACTER 参数都会传递一个长度参数;长度参数的传递顺序与其各自的 CHARACTER 参数相同。
返回 CHARACTER 类型值的 Fortran 函数会在其参数列表的开头添加两个参数。第一个附加参数是由调用者为返回值创建的区域的地址;第二个附加参数是返回值的长度。如果 Fortran 函数声明为返回固定长度的字符值,例如 CHARACTER*4 FUNCTION CHF(),则仍必须提供表示返回值长度的第二个额外参数。
在 Linux86-64 系统上,Fortran complex 函数在内存中返回其值。调用者为返回值提供空间,并将此存储空间的地址作为函数的第一个参数传递。在 OpenPOWER 系统上,Fortran complex 函数以与 complex 函数相同的方式返回其值。
Fortran 函数的备用返回说明符不会作为参数由调用者传递。备用返回函数将适当的返回值传递回 Linux86-64 上的 %rax 和 OpenPOWER 上的 r1 中的调用者。
以下 Fortran 90 功能的处理是实现定义的:内部过程、指针参数、假定形状参数、返回数组的函数以及返回派生类型的函数。
跨语言调用
如果函数/子例程参数和返回值匹配类型,则可以在 Fortran 和 C/C++ 之间进行跨语言调用。
如果 C/C++ 函数返回值,则从 Fortran 中将其作为函数调用,否则,将其作为子例程调用。
如果 Fortran 函数的类型为 CHARACTER(或 Linux86-64 上的 COMPLEX),则从 C/C++ 中将其作为 void 函数调用。
如果 Fortran 子例程具有备用返回,则从 C/C++ 中将其作为返回 int 的函数调用;此类子例程的值是在备用 RETURN 语句中指定的整数表达式的值。
如果 Fortran 子例程不包含备用返回,则从 C/C++ 中将其作为 void 函数调用。
Fortran 2003 还提供了一种机制来支持与 C 的互操作性。此机制包括 ISO_C_BINDING 本征模块、绑定标签和 BIND 属性。
表 19 提供了与每个 Fortran 数据类型对应的 C/C++ 数据类型。
Fortran 类型 |
C/C++ 类型 |
大小(字节) |
|---|---|---|
CHARACTER*n x |
char x[n] |
n |
REAL x |
float x |
4 |
REAL*4 x |
float x |
4 |
REAL*8 x |
double x |
8 |
DOUBLE PRECISION x |
double x |
8 |
INTEGER x |
int x |
4 |
INTEGER*1 x |
signed char x |
1 |
INTEGER*2 x |
short x |
2 |
INTEGER*4 x |
int x |
4 |
INTEGER*8 x |
long x, 或 long long x |
8 |
LOGICAL x |
int x |
4 |
LOGICAL*1 x |
char x |
1 |
LOGICAL*2 x |
short x |
2 |
LOGICAL*4 x |
int x |
4 |
LOGICAL*8 x |
long x, 或 long long x |
8 |
Fortran 类型(小写) |
C/C++ 类型 |
大小(字节) |
|---|---|---|
complex x |
struct {float r,i;} x; float complex x; |
8 |
complex*8 x |
struct {float r,i;} x; float complex x; |
8 8 |
double complex x |
struct {double dr,di;} x; double complex x; |
16 16 |
complex *16 x |
struct {double dr,di;} x; double complex x; |
16 16 |
注意
对于 C/C++,complex 类型表示 C99 或更高版本。
数组
C/C++ 数组和 Fortran 数组使用不同的默认初始数组索引值。默认情况下,C/C++ 数组从 0 开始,而 Fortran 数组从 1 开始。可以将 Fortran 数组声明为从零开始。
Fortran 和 C/C++ 数组之间的另一个区别是使用的存储方法。Fortran 使用列优先顺序,而 C/C++ 使用行优先顺序。对于一维数组,这不会造成任何问题。对于二维数组(其中行和列的数量相等),可以简单地反转行和列索引。不建议对除一维数组和正方形二维数组之外的数组进行跨语言函数混合。
结构体、联合体、映射和派生类型
Fortran 结构体和派生类型中的字段,以及 Fortran 联合体中的多个映射声明,都符合 C 结构体使用的相同对齐要求。
公共块
命名的 Fortran 公共块可以在 C/C++ 中用结构体表示,其成员对应于公共块的成员。C/C++ 中结构体的名称必须添加下划线。
例如,Fortran 公共块
INTEGER I, J
COMPLEX C
DOUBLE COMPLEX CD
DOUBLE PRECISION D
COMMON /COM/ i, j, c, cd, d
在 C 中用以下等效项表示
extern struct {
int i;
int j;
struct {float real, imag;} c;
struct {double real, imag;} cd;
double d;
} com_;
在 C++ 中用以下等效项表示
extern "C" struct {
int i;
int j;
struct {float real, imag;} c;
struct {double real, imag;} cd;
double d;
} com_;
注意
编译器提供的 BLANK COMMON 块的名称是特定于实现的。
从 C/C++ 调用 Fortran COMPLEX 和 CHARACTER 函数不如调用其他类型的 Fortran 函数那么直接。C/C++ 调用者必须将额外的参数传递给 Fortran 函数。Fortran COMPLEX 函数在内存中返回其值;传递给函数的第一个参数必须包含此值存储空间的地址。Fortran CHARACTER 函数在其参数列表的开头添加两个参数。以下从 C/C++ 调用 Fortran CHARACTER 函数的示例说明了这些调用者提供的额外参数
CHARACTER*(*) FUNCTION CHF(C1, I)
CHARACTER*(*) C1
INTEGER I
END
extern void chf_();
char tmp[10];
char c1[9];
int i;
chf_(tmp, 10, c1, &i, 9);
额外的参数 tmp 和 10 是为返回值提供的,而 9 是作为 c1 的长度提供的。
6. C++ 方言支持
NVC++ 编译器接受 ISO/IEC 标准(最高到并包括 14882:2017 标准)的 C++ 语言,以及几乎所有的 GNU C++ 扩展。
命令行选项提供对许多 C++ 变体的完全支持,包括严格的标准一致性。NVC++ 提供 --c++XY 命令行选项,使用户能够指定接受的 C++ 版本,其中 XY 是 {17 \| 14 \| 11 \| 03} 之一。默认情况下接受的 C++ 版本由用于编译的 GCC 工具链的版本确定并与之匹配。
6.1. C++17 语言特性接受
NVC++ 编译器包含对 C++17 语言标准的支持。通过使用 --c++17 或 -std=c++17 进行编译来启用此支持。
在使用 GCC 7 或更高版本工具链的 Linux 系统上,可以使用受支持的 C++17 核心语言特性。
支持以下 C++17 语言特性
结构化绑定
带有初始值设定项的选择语句
编译时条件语句,也称为
constexpr if折叠表达式
内联变量
Constexpr lambda
按值捕获 *this 的 Lambda
类模板推导
自动非类型模板参数
保证复制省略
NVC++ 编译器安装不包括 C++ 标准库,因此对 C++17 添加到标准库的支持取决于系统上提供的 C++ 库。在 Linux 上,GCC 7 是第一个具有重要 C++17 支持的 GCC 版本。
当针对 GCC 7 或更高版本构建时,支持以下 C++ 库更改
std::string_view
std::optional
std::variant
std::any
用于元函数的变量模板
当针对 GCC 9 或更高版本构建时,支持以下 C++ 库更改
并行算法
文件系统支持
多态分配器和内存资源
7. x86-64 C++ 和 C MMX/SSE/AVX 内联函数
内联函数是给定语言中可用的函数,其实现由编译器专门处理。通常,内联函数用自动生成的指令序列替换原始函数调用。由于编译器对内联函数非常了解,因此可以更好地集成和优化它以适应具体情况。
NVIDIA 在 C++ 和 C 程序中提供对 MMX 和 SSE/SSE2/SSE3/SSSE3/SSE4a/ABM/AVX 内联函数的支持。
内联函数使处理器特定增强功能的使用更加容易,因为它们为汇编指令提供了 C++ 和 C 语言接口。通过这样做,编译器可以管理用户通常必须关心的事情,例如寄存器名称、寄存器分配和数据内存位置。
本节包含与内联函数关联的以下表格
MMX 内联函数表 (mmintrin.h)
SSE 内联函数表 (xmmintrin.h)
SSE2 内联函数表 (emmintrin.h)
SSE3 内联函数表 (pmmintrin.h)
SSSE3 内联函数表 (tmmintrin.h)
SSE4a 内联函数表 (ammintrin.h)
ABM 内联函数表 (intrin.h)
AVX 内联函数表 (immintrin.h)
7.1. 使用内联函数
内联函数的定义在相应的头文件中提供。
7.1.1. 必需的头文件
要从 C/C++ 源代码调用这些内联函数,您必须包含相应的头文件 – 以下文件之一
|
|
7.1.2. 内联函数数据类型
下表描述了为内联函数定义的数据类型
数据类型 |
在…中定义 |
描述 |
|---|---|---|
__m64 |
|
|
__m128 |
|
|
__m128d |
|
|
__ m128i |
|
|
__m256 |
|
|
__m256d |
|
|
__m256i |
|
|
7.1.3. 内联函数示例
MMX/SSE 内联函数包括用于初始化前面表格中定义的类型变量的函数。以下示例程序 example.c 说明了 SSE 内联函数 _mm_add_ps 和 _mm_set_ps 的用法。
#include<xmmintrin.h>
int main(){
__m128 A, B, result;
A = _mm_set_ps(23.3, 43.7, 234.234, 98.746); /* initialize A */
B = _mm_set_ps(15.4, 34.3, 4.1, 8.6); /* initialize B */
result = _mm_add_ps(A, B);
return 0;
}
要编译此程序,请使用以下命令
$ nvc example.c -o myprog
7.2. x86-64 MMX 内联函数
NVC++ 和 NVC 支持一组 MMX 内联函数,这些函数允许直接从 C++ 和 C 代码中使用 MMX 指令,而无需编写汇编指令。下表列出了支持的 MMX 内联函数。
注意
带有 * 的内联函数仅在 64 位系统上可用。
_mm_empty |
_m_paddd |
_m_psllw |
_m_pand |
_m_empty |
_mm_add_si64 |
_mm_slli_pi16 |
_mm_andnot_si64 |
_mm_cvtsi32_si64 |
_mm_adds_pi8 |
_m_psllwi |
_m_pandn |
_m_from_int |
_m_paddsb |
_mm_sll_pi32 |
_mm_or_si64 |
_mm_cvtsi64x_si64* |
_mm_adds_pi16 |
_m_pslld |
_m_por |
_mm_set_pi64x* |
_m_paddsw |
_mm_slli_pi32 |
_mm_xor_si64 |
_mm_cvtsi64_si32 |
_mm_adds_pu8 |
_m_pslldi |
_m_pxor |
_m_to_int |
_m_paddusb |
_mm_sll_si64 |
_mm_cmpeq_pi8 |
_mm_cvtsi64_si64x* |
_mm_adds_pu16 |
_m_psllq |
_m_pcmpeqb |
_mm_packs_pi16* |
_m_paddusw |
_mm_slli_si64 |
_mm_cmpgt_pi8 |
_m_packsswb |
_mm_sub_pi8 |
_m_psllqi |
_m_pcmpgtb |
_mm_packs_pi32 |
_m_psubb |
_mm_sra_pi16 |
_mm_cmpeq_pi16 |
_m_packssdw |
_mm_sub_pi16 |
_m_psraw |
_m_pcmpeqw |
_mm_packs_pu16 |
_m_psubw |
_mm_srai_pi16 |
_mm_cmpgt_pi16 |
_m_packuswb |
_mm_sub_pi32 |
_m_psrawi |
_m_pcmpgtw |
_mm_unpackhi_pi8 |
_m_psubd |
_mm_sra_pi32 |
_mm_cmpeq_pi32 |
_m_punpckhbw |
_mm_sub_si64 |
_m_psrad |
_m_pcmpeqd |
_mm_unpackhi_pi16 |
_mm_subs_pi8 |
_mm_srai_pi32 |
_mm_cmpgt_pi32 |
_m_punpckhwd |
_m_psubsb |
_m_psradi |
_m_pcmpgtd |
_mm_unpackhi_pi32 |
_mm_subs_pi16 |
_mm_srl_pi16 |
_mm_setzero_si64 |
_m_punpckhdq |
_m_psubsw |
_m_psrlw |
_mm_set_pi32 |
_mm_unpacklo_pi8 |
_mm_subs_pu8 |
_mm_srli_pi16 |
_mm_set_pi16 |
_m_punpcklbw |
_m_psubusb |
_m_psrlwi |
_mm_set_pi8 |
_mm_unpacklo_pi16 |
_mm_subs_pu16 |
_mm_srl_pi32 |
_mm_setr_pi32 |
_m_punpcklwd |
_m_psubusw |
_m_psrld |
_mm_setr_pi16 |
_mm_unpacklo_pi32 |
_mm_madd_pi16 |
_mm_srli_pi32 |
_mm_setr_pi8 |
_m_punpckldq |
_m_pmaddwd |
_m_psrldi |
_mm_set1_pi32 |
_mm_add_pi8 |
_mm_mulhi_pi16 |
_mm_srl_si64 |
_mm_set1_pi16 |
_m_paddb |
_m_pmulhw |
_m_psrlq |
_mm_set1_pi8 |
_mm_add_pi16 |
_mm_mullo_pi16 |
_mm_srli_si64 |
|
_m_paddw |
_m_pmullw |
_m_psrlqi |
|
_mm_add_pi32 |
_mm_sll_pi16 |
_mm_and_si64 |
7.3. x86-64 SSE 内联函数
NVC++ 和 NVC 支持一组 SSE 内联函数,这些函数允许直接从 C++ 和 C 代码中使用 SSE 指令,而无需编写汇编指令。下表列出了支持的 SSE 内联函数。
注意
带有 * 的内联函数仅在 64 位系统上可用。
_mm_add_ss |
_mm_comige_ss |
_mm_load_ss |
_mm_sub_ss |
_mm_comineq_ss |
_mm_load1_ps |
_mm_mul_ss |
_mm_ucomieq_ss |
_mm_load_ps1 |
_mm_div_ss |
_mm_ucomilt_ss |
_mm_load_ps |
_mm_sqrt_ss |
_mm_ucomile_ss |
_mm_loadu_ps |
_mm_rcp_ss |
_mm_ucomigt_ss |
_mm_loadr_ps |
_mm_rsqrt_ss |
_mm_ucomige_ss |
_mm_set_ss |
_mm_min_ss |
_mm_ucomineq_ss |
_mm_set1_ps |
_mm_max_ss |
_mm_cvtss_si32 |
_mm_set_ps1 |
_mm_add_ps |
_mm_cvt_ss2si |
_mm_set_ps |
_mm_sub_ps |
_mm_cvtss_si64x* |
_mm_setr_ps |
_mm_mul_ps |
_mm_cvtps_pi32 |
_mm_store_ss |
_mm_div_ps |
_mm_cvt_ps2pi |
_mm_store_ps |
_mm_sqrt_ps |
_mm_cvttss_si32 |
_mm_store1_ps |
_mm_rcp_ps |
_mm_cvtt_ss2si |
_mm_store_ps1 |
_mm_rsqrt_ps |
_mm_cvttss_si64x* |
_mm_storeu_ps |
_mm_min_ps |
_mm_cvttps_pi32 |
_mm_storer_ps |
_mm_max_ps |
_mm_cvtt_ps2pi |
_mm_move_ss |
_mm_and_ps |
_mm_cvtsi32_ss |
_mm_extract_pi16 |
_mm_andnot_ps |
_mm_cvt_si2ss |
_m_pextrw |
_mm_or_ps |
_mm_cvtsi64x_ss* |
_mm_insert_pi16 |
_mm_xor_ps |
_mm_cvtpi32_ps |
_m_pinsrw |
_mm_cmpeq_ss |
_mm_cvt_pi2ps |
_mm_max_pi16 |
_mm_cmplt_ss |
_mm_movelh_ps |
_m_pmaxsw |
_mm_cmple_ss |
_mm_setzero_ps |
_mm_max_pu8 |
_mm_cmpgt_ss |
_mm_cvtpi16_ps |
_m_pmaxub |
_mm_cmpge_ss |
_mm_cvtpu16_ps |
_mm_min_pi16 |
_mm_cmpneq_ss |
_mm_cvtpi8_ps |
_m_pminsw |
_mm_cmpnlt_ss |
_mm_cvtpu8_ps |
_mm_min_pu8 |
_mm_cmpnle_ss |
_mm_cvtpi32x2_ps |
_m_pminub |
_mm_cmpngt_ss |
_mm_movehl_ps |
_mm_movemask_pi8 |
_mm_cmpnge_ss |
_mm_cvtps_pi16 |
_m_pmovmskb |
_mm_cmpord_ss |
_mm_cvtps_pi8 |
_mm_mulhi_pu16 |
_mm_cmpunord_ss |
_mm_shuffle_ps |
_m_pmulhuw |
_mm_cmpeq_ps |
_mm_unpackhi_ps |
_mm_shuffle_pi16 |
_mm_cmplt_ps |
_mm_unpacklo_ps |
_m_pshufw |
_mm_cmple_ps |
_mm_loadh_pi |
_mm_maskmove_si64 |
_mm_cmpgt_ps |
_mm_storeh_pi |
_m_maskmovq |
_mm_cmpge_ps |
_mm_loadl_pi |
_mm_avg_pu8 |
_mm_cmpneq_ps |
_mm_storel_pi |
_m_pavgb |
_mm_cmpnlt_ps |
_mm_movemask_ps |
_mm_avg_pu16 |
_mm_cmpnle_ps |
_mm_getcsr |
_m_pavgw |
_mm_cmpngt_ps |
_MM_GET_EXCEPTION_STATE |
_mm_sad_pu8 |
_mm_cmpnge_ps |
_MM_GET_EXCEPTION_MASK |
_m_psadbw |
_mm_cmpord_ps |
_MM_GET_ROUNDING_MODE |
_mm_prefetch |
_mm_cmpunord_ps |
_MM_GET_FLUSH_ZERO_MODE |
_mm_stream_pi |
_mm_comieq_ss |
_mm_setcsr |
_mm_stream_ps |
_mm_comilt_ss |
_MM_SET_EXCEPTION_STATE |
_mm_sfence |
_mm_comile_ss |
_MM_SET_EXCEPTION_MASK |
_mm_pause |
_mm_comigt_ss |
_MM_SET_ROUNDING_MODE _MM_SET_FLUSH_ZERO_MODE |
_MM_TRANSPOSE4_PS |
表 23 列出了 emmintrin.h 中支持和可用的 SSE2 intrinsics。
_mm_load_sd |
_mm_cmpge_sd |
_mm_cvtps_pd |
_mm_srl_epi32 |
_mm_load1_pd |
_mm_cmpneq_sd |
_mm_cvtsd_si32 |
_mm_srl_epi64 |
_mm_load_pd1 |
_mm_cmpnlt_sd |
_mm_cvtsd_si64x* |
_mm_slli_epi16 |
_mm_load_pd |
_mm_cmpnle_sd |
_mm_cvttsd_si32 |
_mm_slli_epi32 |
_mm_loadu_pd |
_mm_cmpngt_sd |
_mm_cvttsd_si64x* |
_mm_slli_epi64 |
_mm_loadr_pd |
_mm_cmpnge_sd |
_mm_cvtsd_ss |
_mm_srai_epi16 |
_mm_set_sd |
_mm_cmpord_sd |
_mm_cvtsi32_sd |
_mm_srai_epi32 |
_mm_set1_pd |
_mm_cmpunord_sd |
_mm_cvtsi64x_sd* |
_mm_srli_epi16 |
_mm_set_pd1 |
_mm_comieq_sd |
_mm_cvtss_sd |
_mm_srli_epi32 |
_mm_set_pd |
_mm_comilt_sd |
_mm_unpackhi_pd |
_mm_srli_epi64 |
_mm_setr_pd |
_mm_comile_sd |
_mm_unpacklo_pd |
_mm_and_si128 |
_mm_setzero_pd |
_mm_comigt_sd |
_mm_loadh_pd |
_mm_andnot_si128 |
_mm_store_sd |
_mm_comige_sd |
_mm_storeh_pd |
_mm_or_si128 |
_mm_store_pd |
_mm_comineq_sd |
_mm_loadl_pd |
_mm_xor_si128 |
_mm_store1_pd |
_mm_ucomieq_sd |
_mm_storel_pd |
_mm_cmpeq_epi8 |
_mm_store_pd1 |
_mm_ucomilt_sd |
_mm_movemask_pd |
_mm_cmpeq_epi16 |
_mm_storeu_pd |
_mm_ucomile_sd |
_mm_packs_epi16 |
_mm_cmpeq_epi32 |
_mm_storer_pd |
_mm_ucomigt_sd |
_mm_packs_epi32 |
_mm_cmplt_epi8 |
_mm_move_sd |
_mm_ucomige_sd |
_mm_packus_epi16 |
_mm_cmplt_epi16 |
_mm_add_pd |
_mm_ucomineq_sd |
_mm_unpackhi_epi8 |
_mm_cmplt_epi32 |
_mm_add_sd |
_mm_load_si128 |
_mm_unpackhi_epi16 |
_mm_cmpgt_epi8 |
_mm_sub_pd |
_mm_loadu_si128 |
_mm_unpackhi_epi32 |
_mm_cmpgt_epi16 |
_mm_sub_sd |
_mm_loadl_epi64 |
_mm_unpackhi_epi64 |
_mm_srl_epi16 |
_mm_mul_pd |
_mm_store_si128 |
_mm_unpacklo_epi8 |
_mm_cmpgt_epi32 |
_mm_mul_sd |
_mm_storeu_si128 |
_mm_unpacklo_epi16 |
_mm_max_epi16 |
_mm_div_pd |
_mm_storel_epi64 |
_mm_unpacklo_epi32 |
_mm_max_epu8 |
_mm_div_sd |
_mm_movepi64_pi64 |
_mm_unpacklo_epi64 |
_mm_min_epi16 |
_mm_sqrt_pd |
_mm_move_epi64 |
_mm_add_epi8 |
_mm_min_epu8 |
_mm_sqrt_sd |
_mm_setzero_si128 |
_mm_add_epi16 |
_mm_movemask_epi8 |
_mm_min_pd |
_mm_set_epi64 |
_mm_add_epi32 |
_mm_mulhi_epu16 |
_mm_min_sd |
_mm_set_epi32 |
_mm_add_epi64 |
_mm_maskmoveu_si128 |
_mm_max_pd |
_mm_set_epi64x* |
_mm_adds_epi8 |
_mm_avg_epu8 |
_mm_max_sd |
_mm_set_epi16 |
_mm_adds_epi16 |
_mm_avg_epu16 |
_mm_and_pd |
_mm_set_epi8 |
_mm_adds_epu8 |
_mm_sad_epu8 |
_mm_andnot_pd |
_mm_set1_epi64 |
_mm_adds_epu16 |
_mm_stream_si32 |
_mm_or_pd |
_mm_set1_epi32 |
_mm_sub_epi8 |
_mm_stream_si128 |
_mm_xor_pd |
_mm_set1_epi64x* |
_mm_sub_epi16 |
_mm_stream_pd |
_mm_cmpeq_pd |
_mm_set1_epi16 |
_mm_sub_epi32 |
_mm_movpi64_epi64 |
_mm_cmplt_pd |
_mm_set1_epi8 |
_mm_sub_epi64 |
_mm_lfence |
_mm_cmple_pd |
_mm_setr_epi64 |
_mm_subs_epi8 |
_mm_mfence |
_mm_cmpgt_pd |
_mm_setr_epi32 |
_mm_subs_epi16 |
_mm_cvtsi32_si128 |
_mm_cmpge_pd |
_mm_setr_epi16 |
_mm_subs_epu8 |
_mm_cvtsi64x_si128* |
_mm_cmpneq_pd |
_mm_setr_epi8 |
_mm_subs_epu16 |
_mm_cvtsi128_si32 |
_mm_cmpnlt_pd |
_mm_cvtepi32_pd |
_mm_madd_epi16 |
_mm_cvtsi128_si64x* |
_mm_cmpnle_pd |
_mm_cvtepi32_ps |
_mm_mulhi_epi16 |
_mm_srli_si128 |
_mm_cmpngt_pd |
_mm_cvtpd_epi32 |
_mm_mullo_epi16 |
_mm_slli_si128 |
_mm_cmpnge_pd |
_mm_cvtpd_pi32 |
_mm_mul_su32 |
_mm_shuffle_pd |
_mm_cmpord_pd |
_mm_cvtpd_ps |
_mm_mul_epu32 |
_mm_shufflehi_epi16 |
_mm_cmpunord_pd |
_mm_cvttpd_epi32 |
_mm_sll_epi16 |
_mm_shufflelo_epi16 |
_mm_cmpeq_sd |
_mm_cvttpd_pi32 |
_mm_sll_epi32 |
_mm_shuffle_epi32 |
_mm_cmplt_sd |
_mm_cvtpi32_pd |
_mm_sll_epi64 |
_mm_extract_epi16 |
_mm_cmple_sd |
_mm_cvtps_epi32 |
_mm_sra_epi16 |
_mm_insert_epi16 |
_mm_cmpgt_sd |
_mm_cvttps_epi32 |
_mm_sra_epi32 |
表 24 列出了 pmmintrin.h 中支持和可用的 SSE3 intrinsics。
_mm_addsub_ps |
_mm_moveldup_ps |
_mm_loaddup_pd |
_mm_mwait |
_mm_hadd_ps |
_mm_addsub_pd |
_mm_movedup_pd |
|
_mm_hsub_ps |
_mm_hadd_pd |
_mm_lddqu_si128 |
|
_mm_movehdup_ps |
_mm_hsub_pd |
_mm_monitor |
表 25 列出了 tmmintrin.h 中支持和可用的 SSSE3 intrinsics。
_mm_hadd_epi16 |
_mm_hsubs_pi16 |
_mm_sign_pi16 |
_mm_hadd_epi32 |
_mm_maddubs_epi16 |
_mm_sign_pi32 |
_mm_hadds_epi16 |
_mm_maddubs_pi16 |
_mm_alignr_epi8 |
_mm_hadd_pi16 |
_mm_mulhrs_epi16 |
_mm_alignr_pi8 |
_mm_hadd_pi32 |
_mm_mulhrs_pi16 |
_mm_abs_epi8 |
_mm_hadds_pi16 |
_mm_shuffle_epi8 |
_mm_abs_epi16 |
_mm_hsub_epi16 |
_mm_shuffle_pi8 |
_mm_abs_epi32 |
_mm_hsub_epi32 |
_mm_sign_epi8 |
_mm_abs_pi8 |
_mm_hsubs_epi16 |
_mm_sign_epi16 |
_mm_abs_pi16 |
_mm_hsub_pi16 |
_mm_sign_epi32 |
_mm_abs_pi32 |
_mm_hsub_pi32 |
_mm_sign_pi8 |
表 26 列出了 ammintrin.h 中支持和可用的 SSE4a intrinsics。
_mm_stream_sd |
_mm_extract_si64 |
_mm_insert_si64 |
_mm_stream_ss |
_mm_extracti_si64 |
_mm_inserti_si64 |
7.4. x86-64 ABM 指令集
NVC++ 和 NVC 支持一组 ABM Intrinsics,这些 intrinsics 允许直接从 C++ 和 C 代码中使用 ABM 指令,而无需编写汇编指令。下表列出了支持的 ABM intrinsics。
__lzcnt16 |
__lzcnt64 |
__popcnt |
__rdtscp |
__lzcnt |
__popcnt16 |
__popcnt64 |
7.5. x86-64 AVX 指令集
下表列出了 NVC++ 和 NVC 支持的 AVX intrinsics。
_mm256_add_pd |
_mm256_add_ps |
_mm256_addsub_pd |
_mm256_addsub_ps |
_mm256_and_pd |
_mm256_and_ps |
_mm256_andnot_pd |
_mm256_andnot_ps |
_mm256_blendv_pd |
_mm256_blendv_ps |
_mm256_broadcast_pd |
_mm256_broadcast_ps |
_mm256_broadcast_sd |
_mm256_broadcast_ss |
_mm256_castpd_si256 |
_mm256_castps_si256 |
_mm256_castpd_ps |
_mm256_castps_pd |
_mm256_castpd128_pd256 |
_mm256_castpd256_pd128 |
_mm256_castsi256_pd |
_mm256_castsi256_ps |
_mm256_cvtepi32_pd |
_mm256_cvtepi32_ps |
_mm256_cvtpd_epi32 |
_mm256_cvtps_epi32 |
_mm256_cvtpd_ps |
_mm256_cvtps_pd |
_mm256_cvttpd_epi32 |
_mm256_cvttps_epi32 |
_mm256_div_pd |
_mm256_div_ps |
_mm256_hadd_pd |
_mm256_hadd_ps |
_mm256_hsub_pd |
_mm256_hsub_ps |
_mm256_load_pd |
_mm256_load_ps |
_mm256_loadu_pd |
_mm256_loadu_ps |
_mm256_maskload_pd |
_mm256_maskload_ps |
_mm256_maskstore_pd |
_mm256_maskstore_ps |
_mm256_max_pd |
_mm256_max_ps |
_mm256_min_pd |
_mm256_min_ps |
_mm256_movemask_pd |
_mm256_movemask_ps |
_mm256_mul_pd |
_mm256_mul_ps |
_mm256_or_pd |
_mm256_or_ps |
_mm256_rcp_ps |
_mm256_rsqrt_ps |
_mm256_set_pd |
_mm256_set_ps |
_mm256_setr_pd |
_mm256_setr_ps |
_mm256_set1_pd |
_mm256_set1_ps |
_mm256_set_epi32 |
_mm256_set_epi64x |
_mm256_setzero_pd |
_mm256_setzero_ps |
_mm256_sqrt_pd |
_mm256_sqrt_ps |
_mm256_store_pd |
_mm256_store_ps |
_mm256_storeu_pd |
_mm256_storeu_ps |
_mm256_stream_pd |
_mm256_stream_ps |
_mm256_stream_si256 |
_mm256_sub_pd |
_mm256_sub_ps |
_mm256_testz_pd |
_mm256_testz_ps |
_mm256_testc_pd |
_mm256_testc_ps |
_mm256_testnzc_pd |
_mm256_testnzc_ps |
_mm256_unpackhi_pd |
_mm256_unpackhi_ps |
_mm256_unpacklo_pd |
_mm256_unpacklo_ps |
_mm256_xor_pd |
_mm256_xor_ps |
_mm256_zeroupper |
_mm256_macc_pd |
_mm256_macc_ps |
_mm256_msub_pd |
_mm256_msub_ps |
_mm256_nmacc_pd |
_mm256_nmacc_ps |
_mm256_nmsub_pd |
_mm256_nmsub_ps |
_mm256_maddsub_pd |
_mm256_maddsub_ps |
_mm256_msubadd_pd |
_mm256_msubadd_ps |
_mm_macc_pd |
_mm_macc_ps |
_mm_msub_pd |
_mm_msub_ps |
_mm_nmacc_pd |
_mm_nmacc_ps |
_mm_nmsub_pd |
_mm_nmsub_ps |
_mm_maddsub_pd |
_mm_maddsub_ps |
_mm_msubadd_pd |
_mm_msubadd_ps |
_mm_macc_sd |
_mm_macc_ss |
_mm_msub_sd |
_mm_msub_ss |
_mm_nmacc_sd |
_mm_nmacc_ss |
_mm_nmsub_sd |
_mm_nmsub_ss |
_mm256_extractf128_pd |
_mm256_extractf128_ps |
_mm256_extractf128_si256 |
_mm256_permute_pd |
_mm256_permute_ps |
_mm256_permute2f128_pd |
_mm256_permute2f128_ps |
_mm256_permute2f128_si256 |
_mm256_blend_pd |
_mm256_blend_ps |
_mm256_shuffle_pd |
_mm256_shuffle_ps |
_mm256_cmp_pd |
_mm256_cmp_ps |
_mm256_round_pd |
_mm256_round_ps |
_mm256_insertf128_pd |
_mm256_insertf128_ps |
_mm256_insertf128_si256 |
_mm256_dp_ps |
8. 消息
本节描述编译器生成的各种消息。这些消息包括注册消息和关于备注、警告和错误的诊断消息。编译器始终在屏幕上显示任何错误消息以及错误的源代码行。如果您指定 -Mlist 选项,编译器会将任何错误消息放在列表文件中。您还可以使用 -v 选项来显示有关编译器、汇编器和链接器调用以及主机系统的更多信息。有关 -Mlist 和 -v 选项的更多信息,请参阅 HPC Compiler User Guide 中的“使用命令行选项”。
8.1. 诊断消息
诊断消息提供关于您源代码文本的句法和语义信息。句法信息包括诸如语法错误之类的信息。语义信息包括诸如无法访问的代码、为例程调用指定的参数数量不正确、非法数据类型使用等信息。
您可以使用 -Minform 选项指定编译器显示特定级别的错误消息。
编译器消息引用严重性级别、消息编号以及发生错误的行号。
编译器还可以在标准错误上显示内部错误消息。
如果您使用列表文件选项 -Mlist,编译器会将诊断消息放在列表文件中的源代码行之后,格式如下:
NVFORTRAN-etype-enum-message (filename: line)
其中
- etype
是表示严重性级别的字符
- enum
是错误编号
- message
是错误消息
- filename
是源文件名
- line
是编译器检测到错误的行号。
8.2. 阶段调用消息
您可以使用 -v 命令行选项显示编译器、汇编器和链接器阶段调用。有关此选项的更多信息,请参阅 HPC Compilers User Guide 的“使用命令行选项”部分。
8.3. Fortran 编译器错误消息
本节介绍 NVFORTRAN 编译器生成的错误消息。编译器在程序列表和标准输出上显示错误消息。它们还可以在标准错误上显示内部编译器错误消息。
8.3.1. 消息格式
每个消息都有编号。每个消息还列出了错误发生的行号和列号。消息中的美元符号 ($) 表示每个消息实例特定的信息。
8.3.2. 消息列表
错误消息严重性
- I
informative (信息性)
- W
warning (警告)
- S
severe error (严重错误)
- F
fatal error (致命错误)
- V
variable (变量)
V000 Internal compiler error. $ $
此消息指示编译器中的错误,而不是用户错误——尽管用户错误可能导致内部错误。严重性可能有所不同;如果是信息性或警告,则可能生成了正确的对象代码,但依赖于此是不安全的。
F001 Source input file name not specified
在命令行中,源文件名应在所有开关之前或之后指定。
F002 Unable to open source input file: $
源文件名拼写错误、文件不在当前工作目录中,或者文件是只读保护的。
F003 Unable to open listing file
此消息通常在用户对当前工作目录没有写入权限时发生。
F004 $ $
文件错误的通用消息。
F005 Unable to open temporary file
编译器使用目录“/usr/tmp”或“/tmp”来创建临时文件。如果这些目录在正在使用编译器的节点上都不可用,则会发生此错误。
S006 Input file empty
源输入文件不包含任何 Fortran 语句,除了注释或编译器指令。
F007 Subprogram too large to compile at this optimization level $
内部编译器数据结构溢出、工作存储耗尽,或与子程序大小相关的其他一些不可恢复的问题。如果此错误发生在优化级别 2,则将优化级别降低到 1 可能会解决问题。将正在编译的子程序移动到其自己的源文件可能会消除问题。
F008 Error limit exceeded
由于发出了太多严重错误,编译器放弃;错误限制可以在命令行上重置。
F009 Unable to open assembly file
此消息通常在用户对当前工作目录没有写入权限时发生。
F010 File write error occurred $
文件系统可能已满。
S011 Unrecognized command line switch: $
有关允许的编译器开关列表,请参阅 HPC Compiler User Guide。
S012 Value required for command line switch: $
某些开关需要紧随其后的值,例如“-opt 2”。
S013 Unrecognized value specified for command line switch: $
S014 Ambiguous command line switch: $
其中一个开关使用了过短的缩写。
W015 Hexadecimal or octal constant truncated to fit data type
I016 Identifier, $, truncated to 63 chars
标识符的最大长度为 63 个字符;第 63 个字符之后的字符将被忽略。
S017 Unable to open include file: $
文件丢失、只读保护或超出最大包含深度 (10)。请记住,文件名应该用引号括起来。
S018 Illegal label $ $
用于标签“字段”错误或非法值。例如,在固定源格式中,指示行的标签字段(前五个字符)包含非数字字符。
S019 Illegally placed continuation line
续行不跟随初始行,或者指定了超过 99 行续行。
S020 Unrecognized compiler directive
S021 Label field of continuation line is not blank
续行的前五个字符必须为空格。
S022 Unexpected end of file - missing END statement
源文件缺少 END 语句,或者文件被截断。
S023 Syntax error - unbalanced $
括号或方括号不平衡。
W024 CHARACTER or Hollerith constant truncated to fit data type
字符或 hollerith 常量被转换为数据类型,该数据类型不足以包含常量中的所有字符。当常量在算术表达式中使用或分配给非字符变量时,会发生此类型转换。字符或 hollerith 常量在右侧被截断,也就是说,如果需要 4 个字符,则使用前 4 个字符,其余字符将被丢弃。
W025 Illegal character ($) - ignored
当前行包含一个字符,可能是非打印字符,它不是合法的 Fortran 字符(字符或 Hollerith 常量内的字符不会导致此错误)。作为一般规则,所有非打印字符都视为空格字符(空格和制表符);发生这种情况时不会生成错误消息。如果由于某种原因,非打印字符未被视为空格字符,则其十六进制表示形式将以 dd 形式打印,其中每个 d 都是十六进制数字。
S026 Unmatched quote
字符常量缺少结束引号,或者源文件被截断。
S027 Illegal integer constant: $
整数常量对于 32 位字来说太大。
S028 Illegal real or double precision constant: $
S029 Illegal $ constant: $
非法十六进制、八进制或二进制常量。十六进制常量由数字 0..9 和字母 A..F 或 a..f 组成;十六进制常量中的任何其他字符都是非法的。八进制常量由数字 0..7 组成;八进制常量中的任何其他数字或字符都是非法的。二进制常量由数字 0 或 1 组成;二进制常量中的任何其他数字或字符都是非法的。
S030 Explicit shape must be specified for $
数组表达式的形状在此上下文中受到影响。
S031 Illegal data type length specifier for $
数据类型长度说明符(例如 INTEGER*4 中的 4)不是常量表达式,它不是此特定数据类型允许值集合的成员。
W032 Data type length specifier not allowed for $
在给定的语法中不允许使用数据类型长度说明符(例如 INTEGER*4 中的 4)(例如 DIMENSION A(10)*4)。
S033 Illegal use of constant $
常量在非法上下文中使用,例如在赋值语句的左侧或作为数据初始化语句的目标。
S034 Syntax error at or near $
指定了非法命令。
I035 Predefined intrinsic $ loses intrinsic property
intrinsic 名称的使用方式与该 intrinsic 的语言定义不一致。编译器将根据上下文将名称视为变量或外部函数。
S036 Illegal implicit character range
第一个字符在字母顺序上必须在第二个字符之前。
S037 Contradictory data type specified for $
指示的标识符出现在多个类型规范语句中,并且为其指定了不同的数据类型。
S038 Symbol, $, has not been explicitly declared
指示的标识符必须在类型语句中声明;当子程序中出现 IMPLICIT NONE 语句时,这是必需的。
W039 Symbol, $, appears illegally in a SAVE statement $
出现在 SAVE 语句中的标识符必须是局部变量或数组。
S040 Illegal common variable $
指示的标识符是哑变量,已在公共块中,或者先前已定义为变量或数组以外的其他内容。
W041 Illegal use of dummy argument $
此错误可能在多种情况下发生。如果在 PROGRAM 语句上指定了哑参数,则可能会发生这种情况。如果哑参数名称出现在 DATA、COMMON、SAVE 或 EQUIVALENCE 语句中,也可能发生这种情况。程序语句必须具有空的参数列表。
S042 $ is a duplicate dummy argument
每个哑参数必须具有唯一的名称。
S043 Illegal attempt to redefine $ $
尝试以与同一符号的早期定义不一致的方式定义符号。这可能是由于多种原因造成的。该消息尝试指示发生的情况。
intrinsic – 尝试重新定义 intrinsic 函数。如果表示 intrinsic 函数的符号先前未被验证为 intrinsic 函数,则可以重新定义该符号。例如,intrinsic sin 可以定义为整数数组。如果通过 INTRINSIC 语句或通过 intrinsic 函数引用验证符号为 intrinsic 函数,则在程序单元的其余部分中,它必须被称为 intrinsic 函数。
symbol – 尝试重新定义先前定义的符号。一个例子是将符号声明为 PARAMETER,该符号先前已声明为子程序参数。
S044 Multiple declaration for symbol $
发生了符号的冗余声明。例如,尝试将符号声明为 ENTRY,而该符号先前已声明为 ENTRY。
S045 Data type of entry point $ disagrees with function $
当前函数的入口点的数据类型与当前函数的数据类型不一致。例如,函数返回字符类型,而入口点返回复数类型。
S046 Data type length specifier in wrong position
CHARACTER 数据类型说明符的长度说明符的位置与其他数据类型不同。假设我们要声明数组 ARRAYA 和 ARRAYB 具有 8 个元素,每个元素的长度为 4 个字节。不同之处在于 ARRAYA 是字符,ARRAYB 是整数。声明将是 CHARACTER ARRAYA(8)*4 和 INTEGER ARRAYB*4(8)。
S047 More than seven dimensions specified for array
编译器当前最多支持七个数组维度。
S048 Illegal use of '*' in declaration of array $
星号只能用作最后一个维度的上限。
S049 Illegal use of '*' in non-subroutine subprogram
备用返回说明符“*”仅在 subroutine 语句中合法。程序、函数和块数据不允许具有备用返回说明符。
S050 Assumed size array, $, is not a dummy argument
维度中带有“*”的数组只能声明为哑参数。
S051 Unrecognized built-in % function
允许的内置函数是 %VAL、%REF、%LOC 和 %FILL。遇到一个与这些允许的形式之一不匹配的函数。
S052 Illegal argument to %VAL or %LOC
S053 %REF or %VAL not legal in this context
内置函数 %REF 和 %VAL 只能用作过程调用中的实际参数。
W054 Implicit character $ used in a previous implicit statement
隐式字符已被赋予多次隐式数据类型。无论如何,隐式字符的隐式数据类型都会更改。
W055 Multiple implicit none statements
IMPLICIT NONE 语句在一个子程序中只能出现一次。
W056 Implicit type declaration
-Mdclchk 开关和 IMPLICIT NONE 语句之后的隐式声明将为 IMPLICIT 语句生成警告消息。
S057 Illegal equivalence of dummy variable, $
哑参数不得出现在 EQUIVALENCE 语句中。
S058 Equivalenced variables $ and $ not in same common block
公共块变量不得与另一个公共块中的变量等效。
S059 Conflicting equivalence between $ and $
指示的等效性暗示存储布局与其他等效性不一致。
S060 Illegal equivalence of structure variable, $
STRUCTURE 和 UNION 变量不得出现在 EQUIVALENCE 语句中。
S061 Equivalence of $ and $ extends common block backwards
W062 Equivalence forces $ to be unaligned
EQUIVALENCE 语句已为变量定义了一个地址,该地址的对齐方式对于其数据类型的变量来说不是最佳的。例如,当 INTEGER 和 CHARACTER 数据等效时,可能会发生这种情况。
I063 Gap in common block $ before $
S064 Illegal use of $ in DATA statement implied DO loop
指示的变量在其不是活动的隐式 DO 索引变量的地方被引用。
S065 Repeat factor less than zero
S066 Too few data constants in initialization statement
S067 Too many data constants in initialization statement
S068 Numeric initializer for CHARACTER $ out of range 0 through 255
如果常量在 0 到 255 的范围内,则 CHARACTER*1 变量或字符数组元素可以初始化为整数、八进制或十六进制常量。
S069 Illegal implied DO expression
隐式 DO 表达式中唯一允许的操作是整数 +, -, *, 和 /。
S070 Incorrect sequence of statements $
语句顺序不正确。例如,IMPLICIT NONE 语句必须在规范语句之前,而规范语句又必须在可执行语句之前。
S071 Executable statements not allowed in block data
S072 Assignment operation illegal to $ $
赋值操作的目标必须是变量、数组引用或向量引用。赋值操作可以通过赋值语句、数据语句或隐式 DO 循环的索引变量进行。编译器已确定用作目标的标识符不是存储位置。错误消息尝试指示使用的实体的类型。
entry point (入口点) – 尝试对不是函数过程的入口点进行赋值。
external procedure (外部过程) – 尝试对外部过程或 Fortran intrinsic 名称进行赋值。如果标识符是不作为函数的入口点的名称,则为外部过程。
S073 Intrinsic or predeclared, $, cannot be passed as an argument
S074 Illegal number or type of arguments to $ $
指示的符号是 intrinsic 或通用函数,或预声明的 subroutine 或 function,需要一定数量的固定数据类型的参数。
S075 Subscript, substring, or argument illegal in this context for $
如果您尝试双重索引数组(例如 ra(2)(3)),则可能会发生这种情况。这也适用于子字符串和函数引用。
S076 Subscripts specified for non-array variable $
S077 Subscripts omitted from array $
S078 Wrong number of subscripts specified for $
S079 Keyword form of argument illegal in this context for $
S080 Subscript for array $ is out of bounds
S081 Illegal selector $ $
S082 Illegal substring expression for variable $
子字符串表达式必须是整数类型,如果为常量,则必须大于零。
S083 Vector expression used where scalar expression required
向量表达式在非法上下文中使用。例如,iscalar = iarray,其中标量被赋值为数组的值。此外,字符和记录引用不可向量化。
S084 Illegal use of symbol $ $
此消息用于许多不同的错误。
S085 Incorrect number of arguments to statement function $
S086 Dummy argument to statement function must be a variable
S087 Non-constant expression where constant expression required
S088 Recursive subroutine or function call of $
函数不得调用自身。
S089 Illegal use of symbol, $, with character length = *
类型为 CHARACTER*(*) 的符号必须是哑变量,并且不得用作语句函数哑参数和语句函数名称。此外,类型为 CHARACTER*(*) 的哑变量不能用作函数。
S090 Hollerith constant more than 4 characters
在某些上下文中,Hollerith 常量的长度不得超过 4 个字符。
S091 Constant expression of wrong data type
S092 Illegal use of variable length character expression
用作实际参数或在 I/O 语句中某些上下文中使用的字符表达式,不得包含涉及传递长度字符变量的连接。
W093 Type conversion of expression performed
某种数据类型的表达式出现在需要某种其他数据类型的表达式的上下文中。编译器生成代码以将表达式转换为所需的类型。
S094 Variable $ is of wrong data type $
指示的变量在需要某种其他数据类型的变量的上下文中使用。
S095 Expression has wrong data type
某种数据类型的表达式出现在需要某种其他数据类型的表达式的上下文中。
S096 Illegal complex comparison
关系 .LT.、.GT.、.GE. 和 .LE. 不允许用于复数值。
S097 Statement label $ has been defined more than once
在子程序中,具有指示语句编号的语句不止一个。
S098 Divide by zero
S099 Illegal use of $
聚合记录引用只能出现在聚合赋值语句、未格式化 I/O 语句中,以及作为子程序的参数。例如,它们可能不会出现在表达式中。此外,结构类型不同的记录不能相互赋值。
S100 Expression cannot be promoted to a vector
使用的表达式需要非法地将标量量提升为向量。例如,将字符常量字符串赋值给字符数组。记录也不能提升为向量。
S101 Vector operation not allowed on $
记录和字符类型实体只能作为标量量引用。
S102 Arithmetic IF expression has wrong data type
算术 if 语句的括号表达式必须是整数、实数或双精度标量表达式。
S103 Type conversion of subscript expression for $
下标表达式的数据类型必须是整数。如果不是,则会进行转换。
S104 Illegal control structure $
此消息针对许多涉及 IF-THEN 语句、DO 循环和指令的错误发出。您可能会看到以下消息之一:
NVFORTRAN-S-0104-Illegal control structure - unterminated PARALLEL directive
NVFORTRAN-S-0104-Illegal control structure - unterminated block IF
如果指定的行号是子程序的最后一行(END 语句),则错误可能是未终止的 DO 循环或 IF-THEN 语句。如果消息包含 unterminated PARALLEL directive (未终止的 PARALLEL 指令),则很可能您缺少必需的 !$omp end parallel 指令。
S105 Unmatched ELSEIF, ELSE or ENDIF statement
ELSEIF、ELSE 或 ENDIF 语句无法与之前的 IF-THEN 语句匹配。
S106 DO index variable must be a scalar variable
DO 索引变量不能是数组名称、下标变量、PARAMETER 名称、函数名称、结构名称等。
S107 Illegal assigned goto variable $
S108 Illegal variable, $, in NAMELIST group $
NAMELIST 组只能由数组和标量组成。
I109 Overflow in $ constant $, constant truncated at left
需要超过 64 位的非十进制(十六进制、八进制或二进制)常量会产生溢出。常量在左侧被截断(例如,‘1234567890abcdef1’x 将变为 ‘234567890abcdef1’x)。
I110 <reserved message number>
I111 Underflow of real or double precision constant
I112 Overflow of real or double precision constant
S113 Label $ is referenced but never defined
S114 Cannot initialize $
W115 Assignment to DO variable $ in loop
S116 Illegal use of pointer-based variable $ $
S117 Statement not allowed within a $ definition
该语句不得出现在 STRUCTURE 或派生类型定义中。
S118 Statement not allowed in DO, IF, or WHERE block
I119 Redundant specification for $
指示符号的数据类型被多次指定。
I120 Label $ is defined but never referenced
I121 Operation requires logical or integer data types
表达式中的操作尝试作用于数据类型与该操作不兼容的数据。例如,逻辑表达式只能包含整数或逻辑类型的逻辑元素。实数数据将无效。
I122 Character string truncated
出现在 DATA 语句或 PARAMETER 语句中的字符串或 Hollerith 常量已被截断,以适应相应标识符的声明大小。
W123 Hollerith length specification too big, reduced
Hollerith 常量的长度说明符字段指定的字符数多于 Hollerith 常量的字符字段中存在的字符数。长度说明符已减少以与存在的字符数一致。
S124 Relational expression mixes character with numeric data
关系表达式用于比较两个算术表达式或两个字符表达式。字符表达式不能与算术表达式进行比较。
I125 Dummy procedure $ not declared EXTERNAL
未在 EXTERNAL 语句中声明的哑元被用作 CALL 语句中的子程序名称,或被调用为函数,因此被假定为哑过程。此消息可能是由于未能声明哑数组而导致的。
I126 Name $ is not an intrinsic function
I127 Optimization level for $ changed to opt 1 $
W128 Integer constant truncated to fit data type: $
当将整数常量赋值给小于 32 位的数据类型(例如 BYTE)时,整数常量将被截断。
I129 Floating point overflow. Check constants and constant expressions
I130 Floating point underflow. Check constants and constant expressions
I131 Integer overflow. Check floating point expressions cast to integer
I132 Floating pt. invalid oprnd. Check constants and constant expressions
I133 Divide by 0.0. Check constants and constant expressions
S134 Illegal attribute $ $
W135 Missing STRUCTURE name field
最外层结构需要 STRUCTURE 名称字段。
W136 Field-namelist not allowed
STRUCTURE 语句的字段名列表字段在最外层结构上是不允许的。
W137 Field-namelist is required in nested structures
W138 Multiply defined STRUCTURE member name $
在结构中,成员名称被多次使用。
W139 Structure $ in RECORD statement not defined
RECORD 语句包含对尚未定义的 STRUCTURE 的引用。
S140 Variable $ is not a RECORD
S141 RECORD required on left of $
S142 $ is not a member of this RECORD
S143 $ requires initializer
W144 NEED ERROR MESSAGE $ $
这被用作编译器开发的临时消息。
W145 %FILL only valid within STRUCTURE block
%FILL 特殊名称在 STRUCTURE 多行语句之外使用。即使它被忽略,它也仅在 STRUCTURE 多行语句中使用时才有效。
S146 Expression must be character type
S147 Character expression not allowed in this context
S148 Reference to $ required
在语句编译期间,预期聚合记录引用,但却找到了另一种数据类型。
S149 Record where arithmetic value required
当预期算术表达式时,遇到了聚合记录引用。
S150 Structure, Record, derived type, or member $ not allowed in this context
在不支持的上下文中找到了结构、记录或成员引用。
S151 Empty TYPE, STRUCTURE, UNION, or MAP
TYPE - ENDTYPE、STRUCTURE - ENDSTRUCTURE、UNION - ENDUNION 或 MAP - ENDMAP 声明不包含任何成员。
S152 All dimension specifiers must be ':'
S153 Array objects are not conformable $
S154 DISTRIBUTE target, $, must be a processor
S155 $ $
S156 Number of colons and triplets must be equal in ALIGN $ with $
S157 Illegal subscript use of ALIGN dummy $ - $
S158 Alternate return not specified in SUBROUTINE or ENTRY
只有当在 SUBROUTINE 或 ENTRY 语句中出现备用返回说明符时,才能使用备用返回。
S159 Alternate return illegal in FUNCTION subprogram
备用返回不能在 FUNCTION 中使用。
S160 ENDSTRUCTURE, ENDUNION, or ENDMAP does not match top
S161 Vector subscript must be rank-one array
W162 Not equal test of loop control variable $ replaced with < or > test.
S163 <reserved message number>
S164 Overlapping data initializations of $
尝试对已初始化的变量或数组元素进行数据初始化。
S165 $ appeared more than once as a subprogram
子程序名称在源文件中出现多次。此消息仅在汇编文件是编译器的输出时适用。
S166 $ cannot be a common block and a subprogram
名称同时作为公共块名称和子程序名称出现。此消息仅在汇编文件是编译器的输出时适用。
I167 Inconsistent size of common block $
公共块在源文件的多个子程序中出现,并且其大小不相同。将选择最大大小。此消息仅在汇编文件是编译器的输出时适用。
S168 Incompatible size of common block $
公共块在源文件的多个子程序中出现,并在一个子程序中初始化。发现其初始化大小小于其在其他子程序中的大小。此消息仅在汇编文件是编译器的输出时适用。
W169 Multiple data initializations of common block $
公共块在源文件的多个子程序中初始化。仅应用第一组初始化。此消息仅在汇编文件是编译器的输出时适用。
W170 NVIDIA Fortran extension: $ $
使用了非标准功能。提供了该功能的描述。
W171 NVIDIA Fortran extension: nonstandard statement type $
W172 NVIDIA Fortran extension: numeric initialization of CHARACTER $
CHARACTER*1 变量或数组元素已使用数值初始化。
W173 NVIDIA Fortran extension: nonstandard use of data type length specifier
W174 NVIDIA Fortran extension: type declaration contains data initialization
W175 NVIDIA Fortran extension: IMPLICIT range contains nonalpha characters
W176 NVIDIA Fortran extension: nonstandard operator $
W177 NVIDIA Fortran extension: nonstandard use of keyword argument $
W178 <reserved message number>
W179 NVIDIA Fortran extension: use of structure field reference $
W180 NVIDIA Fortran extension: nonstandard form of constant
W181 NVIDIA Fortran extension: & alternate return
W182 NVIDIA Fortran extension: mixed non-character and character elements in COMMON $
W183 NVIDIA Fortran extension: mixed non-character and character EQUIVALENCE ($,$)
W184 Mixed type elements (numeric and/or character types) in COMMON $
W185 Mixed numeric and/or character type EQUIVALENCE ($,$)
S186 Argument missing for formal argument $
S187 Too many arguments specified for $
S188 Argument number $ to $: type mismatch
S189 Argument number $ to $: association of scalar actual argument to array dummy argument
S190 Argument number $ to $: non-conformable arrays
S191 Argument number $ to $ cannot be an assumed-size array
S192 Argument number $ to $ must be a label
W193 Argument number $ to $ does not match INTENT (OUT)
W194 INTENT(IN) argument cannot be defined - $
S195 Statement may not appear in an INTERFACE block $
S196 Deferred-shape specifiers are required for $
S197 Invalid qualifier or qualifier value (/$) in OPTIONS statement
找到了非法限定符,或者为不需要值的限定符指定了值。在任何一种情况下,错误消息中都会指示发生错误的限定符。
S198 $ $ in ALLOCATE/DEALLOCATE
W199 Unaligned memory reference
发生了内存引用,其地址不符合其数据对齐要求。
S200 Missing UNIT/FILE specifier
S201 Illegal I/O specifier - $
S202 Repeated I/O specifier - $
S203 FORMAT statement has no label
S204 $ $
其他 I/O 错误。
S205 Illegal specification of scale factor
省略了 + 或 - 后面的整数,或者 P 没有跟在整数值后面。
S206 Repeat count is zero
S207 Integer constant expected in edit descriptor
S208 Period expected in edit descriptor
S209 Illegal edit descriptor
S210 Exponent width not used in the Ew.dEe or Gw.dEe edit descriptors
S211 Internal I/O not allowed in this I/O statement
S212 Illegal NAMELIST I/O
命名列表 I/O 不能与内部、非格式化、格式化和列表定向 I/O 一起执行。此外,I/O 列表不得存在。
S213 $ is not a NAMELIST group name
S214 Input item is not a variable reference
S215 Assumed sized array name cannot be used as an I/O item or specifier
假定大小的数组被用作要读取或写入的项目,或用作 I/O 说明符(即,FMT = 数组名)。在这些上下文中,数组的大小必须是已知的。
S216 STRUCTURE/UNION cannot be used as an I/O item
S217 ENCODE/DECODE buffer must be a variable, array, or array element
S218 Statement labeled $ $
S219 <reserved message number>
S220 Redefining predefined macro $
S221 #elif after #else
在 #else 指令之后找到了预处理器 #elif 指令;在这种上下文中只允许使用 #endif。
S222 #else after #else
在 #else 指令之后找到了预处理器 #else 指令;在这种上下文中只允许使用 #endif。
S223 #if-directives too deeply nested
预处理器 #if 指令嵌套超过了允许的最大值(当前为 10)。
S224 Actual parameters too long for $
对指示宏的宏调用中参数的总长度超过了允许的最大值(当前为 2048)。
W225 Argument mismatch for $
在对指示宏的调用中提供的参数数量与宏定义中的参数数量不一致。
F226 Can't find include file $
无法打开指示的包含文件。
S227 Definition too long for $
指示宏的宏定义的长度超过了允许的最大值(当前为 2048)。
S228 EOF in comment
在处理注释时遇到了文件结尾。
S229 EOF in macro call to $
在处理对指示宏的调用时遇到了文件结尾。
S230 EOF in string
在处理带引号的字符串时遇到了文件结尾。
S231 Formal parameters too long for $
指示宏的定义中参数的总长度超过了允许的最大值(当前为 2048)。
S232 Identifier too long
标识符的长度超过了允许的最大值(当前为 2048)。
S233 <reserved message number>
W234 Illegal directive name
# 符号后面的字符序列不是标识符。
W235 Illegal macro name
宏名称不是标识符。
S236 Illegal number $
指示的数字包含语法错误。
F237 Line too long
输入源行长度超过了允许的最大值(当前为 2048)。
W238 Missing #endif
在找到必需的 #endif 指令之前遇到了文件结尾。
W239 Missing argument list for $
对指示宏的调用没有参数列表。
S240 Number too long
数字的长度超过了允许的最大值(当前为 2048)。
W241 Redefinition of symbol $
指示的宏名称被重新定义。
I242 Redundant definition for symbol $
找到了指示的宏名称的定义,该定义与之前的定义相同。
F243 String too long
带引号的字符串的长度超过了允许的最大值(当前为 2048)。
S244 Syntax error in #define, formal $ not identifier
在宏定义中使用了不是标识符的形式参数。
W245 Syntax error in #define, missing blank after name or arglist
宏名称或参数列表与宏定义之间没有空格或制表符。
S246 Syntax error in #if
在解析 #if 或 #elif 指令后面的表达式时发现了语法错误。
S247 Syntax error in #include
#include 指令的格式不正确。
W248 Syntax error in #line
#line 指令的格式不正确。
W249 Syntax error in #module
#module 指令的格式不正确。
W250 Syntax error in #undef
#undef 指令的格式不正确。
W251 Token after #ifdef must be identifier
#ifdef 指令后面没有跟标识符。
W252 Token after #ifndef must be identifier
#ifndef 指令后面没有跟标识符。
S253 Too many actual parameters to $
指示宏的实际参数数量超过了允许的最大值(当前为 31)。
S254 Too many formal parameters to $
指示宏的形式参数数量超过了允许的最大值(当前为 31)。
F255 Too much pushback
预处理器在处理宏展开时空间不足。该宏可能是递归的。
W256 Undefined directive $
# 后面的标识符不是指令名称。
F257 POS value must be positive.
遇到了 POS <= 0 的值。负值和 0 值对于文件中的位置是非法的。
S257 EOF in #include directive
在处理 #include 指令时遇到了文件结尾。
S258 Unmatched #elif
遇到了 #elif 指令,但前面没有 #if 或 #elif 指令。
S259 Unmatched #else
遇到了 #else 指令,但前面没有 #if 或 #elif 指令。
S260 Unmatched #endif
遇到了 #endif 指令,但前面没有 #if、#ifdef 或 #ifndef 指令。
S261 Include files nested too deeply
#include 指令的嵌套深度超过了最大值(当前为 20)。
S262 Unterminated macro definition for $
在指示宏的形式参数列表中遇到了换行符。
S263 Unterminated string or character constant
在带引号的字符串中找到了没有前导反斜杠的换行符。
I264 Possible nested comment
在注释中找到了字符 /*。
S265 <reserved message number>
S266 <reserved message number>
S267 <reserved message number>
W268 Cannot inline subprogram; common block mismatch
W269 Cannot inline subprogram; argument type mismatch
如果编译过程进行得太远而无法撤消内联过程,则此消息可能是严重的。
F270 Missing -exlib option
W271 Can't inline $ - wrong number of arguments
I272 Argument of inlined function not used
S273 Inline library not specified on command line (-inlib switch)
F274 Unable to access file $/TOC
S275 Unable to open file $ while extracting or inlining
F276 Assignment to constant actual parameter in inlined subprogram
I277 Inlining of function $ may result in recursion
S278 <reserved message number>
W279 Possible use of $ before definition in $
优化器检测到变量可能在使用前已被赋值。列出了变量的名称和使用该变量的函数。如果指定了行号,则该行号是包含变量使用的基本块的行号。
W280 Syntax error in directive $
消息 280-300 保留用于指令处理
W281 Directive ignored - $ $
S300 Too few data constants in initialization of derived type $
S301 $ must be TEMPLATE or PROCESSOR
S302 Unmatched END$ statement
S303 END statement for $ required in an interface block
S304 EXIT/CYCLE statement must appear in a DO/DOWHILE loop$
S305 $ cannot be named, $
S306 $ names more than one construct
S307 $ must have the construct name $
S308 DO may not terminate at an EXIT, CYCLE, RETURN, STOP, GOTO, or arithmetic IF
S309 Incorrect name, $, specified in END statement
S310 $ $
MODULE 错误的通用消息。
W311 Non-replicated mapping for $ array, $, ignored
W312 <reserved message number>
W313 <reserved message number>
E314 IPA: actual argument $ is a label, but dummy argument $ is not an asterisk
调用将标签传递给子程序;子程序中相应的哑元应为星号,以将其声明为备用返回。
I315 IPA: routine $, $ constant dummy arguments
由于过程间分析,这么多哑元正在被常量替换。
I316 IPA: routine $, $ INTENT(IN) dummy arguments
由于过程间分析,这么多哑元被标记为 INTENT(IN)。
I317 <reserved message number>
I318 <reserved message number>
I319 <reserved message number>
I320 IPA: routine $, $ common blocks optimized
通过过程间分析优化了这么多映射的公共块。
I321 IPA: routine $, $ common blocks not optimized
由于过程间分析未优化这么多映射的公共块,原因可能是它们在不同的例程中声明不同,或者它们没有出现在主程序中。
I322 IPA: analyzing main program $
过程间分析正在构建调用图并使用指定的main程序传播信息。
I323 IPA: collecting information for $
过程间分析正在保存当前子程序的信息,以供后续分析和传播。
W324 IPA file $ appears to be out of date
W325 IPA file $ is for wrong subprogram: $
W326 Unable to open file $ to propagate IPA information to $
I327 IPA: $ subprograms analyzed
I328 IPA: $ dummy arguments replaced by constants
I329 IPA: $ INTENT(IN) dummy arguments should be INTENT(INOUT)
I330 IPA: $ dummy arguments changed to INTENT(IN)
I331 <reserved message number>
I332 <reserved message number>
I333 <reserved message number>
I334 <reserved message number>
I335 <reserved message number>
I336 <reserved message number>
I337 IPA: $ common blocks optimized
I338 IPA: $ common blocks not optimized
S339 Bad IPA contents file: $
S340 Bad IPA file format: $
S341 Unable to create file $ while analyzing IPA information
S342 Unable to open file $ while analyzing IPA information
S343 Unable to open IPA contents file $
S344 Unable to create file $ while collecting IPA information
F345 Internal error in $: table overflow
由于表超出其最大大小,分析失败。
W346 Subprogram $ appears twice
子程序在同一源文件中出现两次;IPA 将忽略第一次出现。
F347 Missing -ipalib option
通过 -ipacollect、-ipaanalyze 或 -ipapropagate 选项启用的过程间分析,需要 -ipalib 选项来指定库目录。
W348 <reserved message number>
W349 <reserved message number>
W350 <reserved message number>
W351 Wrong number of arguments passed to $
给定子程序的子例程或函数语句具有与调用中出现的哑元数量不同的哑元数量。
W352 Wrong number of arguments passed to $ when bound to $
给定子程序的子例程或函数语句具有与对给定 EXTERNAL 名称的调用中出现的哑元数量不同的哑元数量。
W353 Subprogram $ is missing
出现了对此名称的子例程或函数的调用,但无法找到或分析它。
I354 Subprogram $ is not called
程序中的任何位置都没有出现对给定子例程或函数的调用。
W355 Missing argument in call to $
在对给定子程序的调用中缺少非可选参数。
I356 Array section analysis incomplete
数组切片参数的过程间分析不完整;某些信息可能无法用于优化。
I357 Expression analysis incomplete
表达式参数的过程间分析不完整;某些信息可能无法用于优化。
W358 Dummy argument $ is EXTERNAL, but actual is not subprogram
CALL 语句将标量或数组传递给声明为 EXTERNAL 的哑元。
W359 SUBROUTINE $ passed to FUNCTION dummy argument $
CALL 语句将子例程名称传递给用作函数的哑元。
W360 FUNCTION $ passed to FUNCTION dummy argument $ with different result type
CALL 语句将函数参数传递给函数哑元,但哑元具有不同的结果类型。
W361 FUNCTION $ passed to SUBROUTINE dummy argument $
CALL 语句将函数名称传递给用作子例程的哑元。
W362 Argument $ has a different type than dummy argument $
实参的类型与相应的哑元的类型不同。
W363 Dummy argument $ is a POINTER but actual argument $ is not
哑元是指针,因此实参也必须是指针。
W364 Array or array expression passed to scalar dummy argument $
实参是数组,但哑元是标量变量。
W365 Scalar or scalar expression passed to array dummy argument $
实参是标量变量,但哑元是数组。
F366 Internal error: interprocedural analysis fails
过程间分析期间发生内部错误;请向编译器维护组报告此错误。如果在收集 IPA 信息或在 IPA 分析期间报告了用户错误,则纠正这些错误可能会避免此错误。
I367 Array $ bounds cannot be matched to formal argument
将非顺序数组传递给顺序哑元可能需要将数组复制到顺序存储。最常见的原因是将 ALLOCATABLE 数组或数组表达式传递给使用显式边界声明的哑元。将哑元声明为假定形状,边界为 (:,:,:),将消除此警告。
W368 Array-valued expression passed to scalar dummy argument $
实参是数组值表达式,但哑元是标量变量。
W369 Dummy argument $ has different rank than actual argument
实参是数组或数组值表达式,其秩与哑元的秩不同。
W370 Dummy argument $ has different shape than actual argument
实参是数组或数组值表达式,其形状与哑元的形状不同;这可能需要将实参复制到顺序存储中。
W371 Dummy argument $ is INTENT(IN) but may be modified
哑元被声明为 INTENT(IN),但分析发现该参数可能被修改;应更改 INTENT(IN) 声明。
W372 <reserved message number>
I373 <reserved message number>
I374 <reserved message number>
I375 <reserved message number>
I376 <reserved message number>
I377 <reserved message number>
I378 <reserved message number>
I379 <reserved message number>
I380 <reserved message number>
I381 <reserved message number>
I382 IPA: $ subprograms analyzed
过程间分析成功地在整个程序中找到并分析了这么多子程序。
I383 IPA: $ dummy arguments replaced by constants
过程间分析在整个程序中找到了这么多可以被常量替换的哑元。
I384 IPA: $ dummy arguments changed to INTENT(IN)
过程间分析在整个程序中找到了这么多未被修改并且可以声明为 INTENT(IN) 的哑元。
W385 IPA: $ INTENT(IN) dummy arguments should be INTENT(INOUT)
过程间分析在整个程序中找到了这么多被声明为 INTENT(IN) 但应为 INTENT(INOUT) 的哑元。
I386 <reserved message number>
I387 <reserved message number>
I388 <reserved message number>
I389 <reserved message number>
I390 <reserved message number>
I391 <reserved message number>
I392 IPA: $ common blocks optimized
过程间分析找到了这么多可以优化的公共块。
I393 IPA: $ common blocks not optimized
过程间分析找到了这么多无法优化的公共块,原因可能是公共块未在主程序中声明,或者因为它在不同的子程序中声明不同。
I394 IPA: $ replaced by constant value
根据过程间分析,哑元被常量替换。
I395 IPA: $ changed to INTENT(IN)
根据过程间分析,哑元已更改为 INTENT(IN)。
I396 <reserved message number>
I397 <reserved message number>
I398 <reserved message number>
I399 IPA: common block $ not optimized
给定的公共块未通过过程间分析进行优化,原因可能是它未在主程序中声明,或者因为它在不同的子程序中声明不同。
E400 IPA: dummy argument $ is an asterisk, but actual argument is not a label
子程序期望此参数的备用返回标签。
E401 Actual argument $ is a subprogram, but Dummy argument $ is not declared EXTERNAL
CALL 语句将函数或子例程名称传递给作为标量变量或数组的哑元。
E402 Actual argument $ is illegal
E403 <reserved message number>
E404 <reserved message number>
E405 <reserved message number>
E406 <reserved message number>
W407 Argument $ has a different character length than dummy argument $
实参的字符长度与为相应的哑元指定的长度不同。
W408 Specified main program $ is not a PROGRAM
命令行上指定的主程序是子例程、函数或块数据子程序。
W409 More than one main program in IPA directory: $ and $
在显示的 IPA 目录中分析了多个主程序。将使用找到的第一个。
W410 No main program found; IPA analysis fails.
主程序必须出现在 IPA 目录中才能继续进行分析。
W411 Formal argument $ is DYNAMIC but actual argument is an expression
W412 Formal argument $ is DYNAMIC but actual argument $ is not
I413 Formal argument $ has two reaching distributions and may be a candidate for cloning
I414 $ and $ may be aliased and one of them is assigned
过程间分析已确定两个形式参数可能是别名,因为同一个变量在两个参数位置都被传递;或者一个形式参数和全局或 COMMON 变量可能是别名,因为全局或 COMMON 变量作为实参传递。如果在子例程中分配了任何别名,则可能会发生意外结果;此消息提醒用户,Fortran 标准不允许这种情况。
F415 IPA fails: incorrect IPA file
过程间分析将其信息保存在指定 IPA 目录中的特殊 IPA 文件中。其中一个文件已重命名或损坏。当有两个具有相同前缀的文件时,可能会发生这种情况,例如 a.hpf 和 a.f90。
E416 Argument $ has the SEQUENCE attribute, but the dummy parameter $ does not
当实参是具有 SEQUENCE 属性的数组时,哑参数必须具有 SEQUENCE 属性,或者必须使用 INTERFACE 块。
E417 Interface block for $ is a SUBROUTINE but should be a FUNCTION
E418 Interface block for $ is a FUNCTION but should be a SUBROUTINE
E419 Interface block for $ is a FUNCTION has wrong result type
W420 Earlier $ directive overrides $ directive
W421 $ directive can only appear in a function or subroutine
E422 Nonconstant DIM= argument is not supported
E423 Constant DIM= argument is out of range
E424 Equivalence using substring or vector triplets is not allowed
E425 A record is not allowed in this context
E426 WORD type cannot be converted
E427 Interface block for $ has wrong number of arguments
E428 Interface block for $ should have $
E429 Interface block for $ should not have $
E430 Interface block for $ has wrong $
W431 Program is too large for Interprocedural Analysis to complete
W432 Illegal type conversion $
E433 <reserved message number>
W434 Incorrect home array specification ignored
W435 Array declared with zero size
声明数组时使用了零或负维度边界,例如 ‘real a(-1)’,或者上界小于下界,例如 ‘real a(4:2)’。
W436 Independent loop not parallelized$
W437 Type $ will be mapped to $
在不支持 DOUBLE PRECISION 的情况下,它被映射到 REAL,COMPLEX(16) 或 COMPLEX*32 也类似。
E438 $ $ not supported on this platform
编译器不支持此目标架构的此构造。
S439 An internal subprogram cannot be passed as argument - $
S440 Defined assignment statements may not appear in WHERE statement or WHERE block
S441 $ may not appear in a FORALL block
E442 Adjustable-length character type not supported on this host - $ $
S443 EQUIVALENCE of derived types not supported on this host - $
S444 Derived type in EQUIVALENCE statement must have SEQUENCE attribute - $
派生类型的变量或数组出现在 EQUIVALENCE 语句中。派生类型必须具有 SEQUENCE 属性,但没有。
E445 Array bounds must be integer $ $
数组边界中的表达式必须是整数。
S446 Argument number $ to $: rank mismatch
数组或数组表达式中的维度数与哑元中的维度数不匹配。
S447 Argument number $ to $ must be a subroutine or function name
S448 Argument number $ to $ must be a subroutine name
S449 Argument number $ to $ must be a function name
S450 Argument number $ to $: kind mismatch
S451 Arrays of derived type with a distributed member are not supported
S452 Assumed length character, $, is not a dummy argument
S453 Derived type variable with pointer member not allowed in IO - $ $
S454 Subprogram $ is not a module procedure
只有在此模块中声明或通过 USE 关联访问的模块过程的名称才能出现在 MODULE PROCEDURE 语句中。
S455 A derived type array section cannot appear with a member array section - $
不允许像 A(:)%B(:) 这样的引用,其中 ‘A’ 是派生类型数组,‘B’ 是成员数组;切片下标可以出现在 ‘A’ 或 ‘B’ 之后,但不能同时出现在两者之后。
S456 Unimplemented for data type for MATMUL
S457 Illegal expression in initialization
S458 Argument to NULL() must be a pointer
S459 Target of NULL() assignment must be a pointer
S460 ELEMENTAL procedures cannot be RECURSIVE
S461 Dummy arguments of ELEMENTAL procedures must be scalar
S462 Arguments and return values of ELEMENTAL procedures cannot have the POINTER attribute
S463 Arguments of ELEMENTAL procedures cannot be procedures
S464 An ELEMENTAL procedure cannot be passed as argument - $
S465 Functions returning a POINTER require an explicit interface
S466 Member $ of derived type $ has PRIVATE type
S467 Target of NULL() assignment must have the ALLOCATABLE attribute
W468 Argument to ISO_C_BINDING intrinsic must have TARGET attribute set
W469 Character argument to C_LOC intrinsic must have length of one
W470 <reserved message number>
W471 <reserved message number>
E472 A Scalar element of a nonsequential array cannot be passed to a dummy array argument - $
如果数组 ‘A’ 不是顺序的,则子例程或函数调用可能不会将数组的元素(如 ‘A(N)’)传递给哑数组参数。如果数组是顺序的,则 Fortran 顺序和存储关联规则会将哑元视为等效于从传递的元素开始的实参的新数组。如果数组不是顺序的,则 Fortran 顺序和存储关联规则不适用。
W473 $ must have the PURE attribute
F474 <reserved message number>
E475 <reserved message number>
E476 <reserved message number>
E477 The device array section actual argument was not stride-1 in the leading dimension - $
作为数组切片传递给假定形状哑元的设备(device、shared 或 constant 属性)数组在主导维度中必须是步长为 1。
E478 Invalid actual argument to REFLECTED dummy argument - $
具有 Accelerator REFLECTED 属性的哑元的实参符号或表达式必须是具有可见设备副本的符号。不允许使用表达式。
E479 The dummy argument $ is REFLECTED; the actual argument $ must have a visible device copy
如果哑元具有 Accelerator REFLECTED 属性,则实参必须是具有可见设备副本的符号。这可能是因为该符号出现在 MIRROR、REFLECTED、COPYIN、COPYOUT、COPY 或 LOCAL 声明性 Accelerator 指令中,或者因为它出现在围绕过程调用的 Accelerator DATA REGION 或 REGION 的 COPYIN、COPYOUT、COPY 或 LOCAL 子句中。
E480 Argument $ is passed to dummy argument $, which is REFLECTED; the actual argument must not require runtime reshaping
当实参是数组切片或指针数组切片时,有时必须将实参复制到临时数组。如果哑元不是假定形状,因此必须在内存中是连续的,或者如果实参在最左侧(第一个)维度中不是步长为 1,则可能会发生这种情况。在这些情况下,不支持 REFLECTED 参数。
F481 An ENTRY name must not appear as a dummy argument - $
子程序的名称或子程序的 ENTRY 不得作为子程序的哑元出现。
E482 <reserved message number>
E483 <reserved message number>
E484 <reserved message number>
E485 <reserved message number>
E486 The dummy argument $ is REFLECTED; an array element cannot be passed to a REFLECTED argument
作为数组元素的实参不能传递给 REFLECTED 哑元。
E487 Index variable $ does not appear in a subscript on the left hand side of the FORALL assignment
在 FORALL 语句中,FORALL 中的每个索引变量都必须出现在 FORALL 赋值左侧的某个下标中。否则,对于该索引的不同值,FORALL 将赋值相同的左侧元素。
I489 <reserved message number>
E488 The function call in the FORALL does not have the PURE attribute - $
在 FORALL 语句中,所有使用的函数都必须是 PURE 或 ELEMENTAL。否则,它们无法并行调用。
E490 An array section of $ is passed to the REFLECTED argument $, which is not supported
当实参是数组切片时,哑元不得具有 REFLECTED 属性。
W491 <reserved message number>
E492 <reserved message number>
E493 <reserved message number>
E494 <reserved message number>
W495 <reserved message number>
I496 <reserved message number>
E497 <reserved message number>
E498 <reserved message number>
W499 <reserved message number>
E500 MODULE $ uses (directly or indirectly) MODULE $, which causes a USE cycle
如果 MODULE A 具有对 MODULE B 的 USE 语句,我们说 MODULE A 直接使用 MODULE B。如果 MODULE B 具有对 MODULE C 的 USE 语句,我们说 MODULE A 间接使用 MODULE C。如果 MODULE C 随后具有对 MODULE A 的 USE 语句,则 MODULE A 间接使用自身,这是一个 USE 循环,是不允许的。
E504 DIM argument out of range for this symbol - $
此转换内部函数(CSHIFT、EOSHIFT、...)的 DIM 参数必须介于 1 和要转换的数组或表达式的秩之间。
E505 DIM argument out of range for this reduction - $
此归约内部函数(SUM、PRODUCT、...)的 DIM 参数必须介于 1 和要归约的表达式的秩之间。
E506 The argument to ASSOCIATED must be a pointer - $
ASSOCIATED 内部函数的参数必须是具有 POINTER 属性的变量或数组。
E507 The arguments to MOVE_ALLOC must be ALLOCATABLE - $
MOVE_ALLOC 过程的参数必须具有 ALLOCATABLE 属性。
E508 The array objects in a call to an elemental function are not conformable - $
调用 elemental 函数时,参数必须是标量或符合形状的数组或数组表达式。
E509 Variables in a PURE subprogram may not have the SAVE attribute - $
PURE 子程序不能引用外部数据、模块数据或 COMMON 数据,并且不能在 SAVEd 变量中保存状态。
E510 Only assignment statements are allowed in a WHERE construct
WHERE 构造是 WHERE 语句以及直到匹配的 ENDWHERE 的所有语句。WHERE 构造的主体只能包含赋值语句。
E511 The WHERE mask expression and the array assignment do not conform
在 WHERE 掩码控制下的赋值必须具有与 WHERE 掩码相同的形状。
E512 The WHERE mask is not an array expression
WHERE 掩码表达式必须是逻辑数组表达式。
E513 <reserved message number>
E514 <reserved message number>
E515 <reserved message number>
E516 <reserved message number>
E517 <reserved message number>
W518 <reserved message number>
E519 More than one device-resident object in assignment
赋值中只允许一个驻留在设备上的变量或数组。
E520 Host MODULE data cannot be used in a DEVICE or GLOBAL subprogram - $
CUDA Fortran DEVICE 或 GLOBAL 子程序无法直接访问主机数据。
E521 MODULE data cannot be used in a DEVICE or GLOBAL subprogram unless compiling for compute capability >= 2.0 - $
CUDA Fortran DEVICE 或 GLOBAL 子程序无法访问任何 MODULE 中的数据,除非是包含该子程序的 MODULE,除非它们是为计算能力 2.0 或更高版本编译的。此功能需要计算能力 2.0 中提供的统一内存系统。
E522 MODULE data cannot be used in a DEVICE or GLOBAL subprogram unless compiling with CUDA Toolkit 3.0 or later - $
CUDA Fortran DEVICE 或 GLOBAL 子程序无法访问任何 MODULE 中的数据,除非是包含该子程序的 MODULE,除非它们是为计算能力 2.0 或更高版本以及 CUDA Toolkit 3.0 或更高版本编译的。
此功能需要计算能力 2.0 中提供的统一内存系统。
W523 MODULE data used in a DEVICE or GLOBAL subprogram forces compute capability >= 2.0 only - $
CUDA Fortran DEVICE 或 GLOBAL 子程序只能在为计算能力 2.0 或更高版本编译时才能访问 MODULE 数据。
E524 Dependency in assignment causes allocation of a temporary which is not supported in DEVICE or GLOBAL subprograms
编译器已在赋值语句中识别出可能的依赖关系,这需要分配临时存储才能生成正确的结果。在设备上运行的子程序中不支持动态内存分配。
E525 Array reshaping is not supported for device subprogram calls: argument $ to subprogram $
在全球或设备子程序中,不支持将数组切片或假定形状数组传递给非假定形状哑元。这将需要运行时测试以及可能在运行时复制到动态分配的临时数组。
W526 SHARED attribute ignored on dummy argument $
当应用于哑元时,SHARED 属性没有意义。
E527 Argument number $ requires allocation of a temporary which is not supported in DEVICE or GLOBAL subprograms
指定参数的求值需要分配临时存储,以便将结果传递给正在调用的子程序。在设备上运行的子程序中不支持动态内存分配。
E528 Argument number $ to $: device attribute mismatch
实参和形参的设备属性不相同。
E529 PRINT and WRITE statements in device subprograms are only supported when compiling with CUDA Toolkit 4.0 or later
在 CUDA Fortran 设备子程序中支持 PRINT * 或 WRITE(*,*) 语句需要 CUDA Toolkit 4.0 或更高版本以及计算能力 2.0 或更高版本。
E530 PRINT and WRITE statements in device subprograms are only supported with compute capability 2.0 or higher
在 CUDA Fortran 设备子程序中支持 PRINT * 或 WRITE(*,*) 语句需要 CUDA Toolkit 4.0 或更高版本以及计算能力 2.0 或更高版本。
W531 NVIDIA extension to OpenACC: $
此程序正在使用 NVIDIA OpenACC 的扩展。
W532 OpenACC feature not yet implemented: $
此 OpenACC 功能尚未实现。此程序正在使用 NVIDIA OpenACC 的扩展。
E533 Clause $ not allowed in $ directive
指定的指令不允许使用此子句。
E534 A loop scheduling directive may not appear within a KERNEL loop
指定调度的加速器或 OpenACC 循环指令(例如 PARALLEL、VECTOR、WORKER 或 GANG)可能不会出现在具有带有 KERNEL 子句的加速器循环指令的循环内部。指定的指令不允许使用此子句。
E535 Undeclared symbol $ used in directive
OpenACC 指令中使用的符号必须声明。
S901 #elif after #else
在 #else 指令之后找到了预处理器 #elif 指令;在这种上下文中只允许使用 #endif。
S902 #else after #else
在 #else 指令之后找到了预处理器 #else 指令;在这种上下文中只允许使用 #endif。
W905 Argument mismatch for $
在对指示宏的调用中提供的参数数量与宏定义中的参数数量不一致。
F906 Can't find include file $
无法打开指示的包含文件。
S908 EOFin comment
在处理注释时遇到了文件结尾。
S909 EOFin macro call to $
在处理对指示宏的调用时遇到了文件结尾。
S912 Identifier too long
标识符的长度超过了允许的最大值(当前为 2048)。
W914 Illegal directive name
# 符号后面的字符序列不是标识符。
W915 Illegal macro name
宏名称不是标识符。
W918 Missing #endif
在找到必需的 #endif 指令之前遇到了文件结尾。
W919 Missing argument list for $
对指示宏的调用没有参数列表。
S920 Number too long
数字的长度超过了允许的最大值(当前为 2048)。
W921 Redefinition of symbol $
指示的宏名称被重新定义。
I922 Redundant definition for symbol $
找到了指示的宏名称的定义,该定义与之前的定义相同。
F923 String too long
带引号的字符串的长度超过了允许的最大值(当前为 2048)。
S924 Syntax error in #define, formal $ not identifier
在宏定义中使用了不是标识符的形式参数。
S926 Syntax error in #if
在解析 #if 或 #elif 指令后面的表达式时发现了语法错误。
S927 Syntax error in #include
#include 指令的格式不正确。
W928 Syntax error in #line
#line 指令的格式不正确。
W929 Syntax error in #module
#module 指令的格式不正确。
W930 Syntax error in #undef
#undef 指令的格式不正确。
W931 Token after #ifdef must be identifier
#ifdef 指令后面没有跟标识符。
W932 Token after #ifndef must be identifier
#ifndef 指令后面没有跟标识符。
S933 Too many actual parameters to $
指示宏的实际参数数量超过了允许的最大值(当前为 31)。
S934 Too many formal parameters to $
指示宏的形式参数数量超过了允许的最大值(当前为 31)。
S935 Illegal context for __VA_ARGS__
W936 Undefined directive $
# 后面的标识符不是指令名称。
S937 EOFin #include directive
在处理 #include 指令时遇到了文件结尾。
S938 Unmatched #elif
遇到了 #elif 指令,但前面没有 #if 或 #elif 指令。
S939 Unmatched #else
遇到了 #else 指令,但前面没有 #if 或 #elif 指令。
S940 Unmatched #endif
遇到了 #endif 指令,但前面没有 #if、#ifdef 或 #ifndef 指令。
W941 Illegal token in directive, $
指令令牌包含非法字符。
S942 Unterminated macro definition for $
在指示宏的形式参数列表中遇到了换行符。
S943 Unterminated string or character constant
在带引号的字符串中找到了没有前导反斜杠的换行符。
I944 Possible nested comment
在注释中找到了字符 /*。
I945 Redefining predefined macro $
I946 Undefining predefined macro $
W947 Can't redefine predefined macro $
W948 Can't undefine predefined macro $
F949 #error -- $
用户定义的预处理器错误消息。
W950 #ident not followed by quoted string
W951 Extraneous tokens ignored following # directive
F952 Unexpected EOF following #directive
W953 Unexpected # ignored in #if expression
S954 Illegal number in directive
S955 Illegal token in #if expression
S956 Missing > in #include
W957 Arguments in macro $ are not unique
S959 ## directive occurs at beginning or end of macro definition
S960 $ is not an argument
W961 No macro replacement within a character constant
W962 Macro replacement within a character constant
W964 Macro replacement within a string literal
F965 Recursive include file $
W966 Null argument to macro
宏的参数为空值。
F967 #warning -- $
用户定义的预处理器警告消息。
S969 _Pragma $
Pragma 运算符错误。
W972 The directive !$acc mirror is deprecated; use !$acc declare create instead
W973 The directive !$acc reflected is deprecated; use !$acc declare present
W974 The directive !$acc region is deprecated; use !$acc kernels instead
W975 The directive !$acc data region is deprecated; use !$acc data instead
W976 The directive !$acc do is deprecated; use !$acc loop instead
W977 The directive !$acc do kernel is deprecated; use !$acc loop instead
W978 The directive !$acc loop parallel is deprecated; use !$acc loop gang instead
W979 The directive !$acc region do is deprecated; use !$acc kernels loop instead
W980 The directive !$acc region loop is deprecated; use !$acc kernels loop instead
W981 The directive !$acc kernels do is deprecated; use !$acc kernels loop instead
W982 <reserved message number>
W983 The directive !$acc parallel do is deprecated; use !$acc parallel loop instead
W984 The directive !$acc scalar region is deprecated; use !$acc serial instead
W985 The clause local is deprecated; use clause create instead
W986 The clause cache is deprecated; use directive !$acc cache instead
W987 The clause update host is deprecated; use separate update host directive after the region instead
W988 The clause update device is deprecated; use separate update device directive before the region instead
W989 The clause update in is deprecated; use separate update device directeve before the region instead
W990 The clause update out is deprecated; use update self instead
W991 The clause pnot is deprecated; use no_create instead
W992 The clause updatein is deprecated; use update device instead
W993 The clause updateout is deprecated; use update self instead
W994 The directive !$acc copy is deprecated; use !$acc declare copy instead
W995 The directive !$acc copyin is deprecated; use !$acc declare copyin instead
W996 The directive !$acc copyout is deprecated; use !$acc declare copyout instead
W997 The directive !$acc device_resident is deprecated; use !$acc declare device_resident instead
W998 The directive !$acc do host is deprecated; no OpenACC equivalent
W999 The directive !$acc loop kernel is deprecated; no OpenACC equivalent
S1000 Call in OpenACC region to procedure '$' which has no acc routine information
S1001 All selected compute capabilities were disabled (see -Minfo)
S1002 Reduction type not supported for this variable datatype - $
W1003 Lambda capture by reference not supported in Accellerated region
W1004 Lambda capture 'this' by reference not supported in Accellerated region
W1005 The clause unroll is deprecated; no OpenACC equivalent
W1006 The clause mirror is deprecated; no OpenACC equivalent
W1007 The clause host is deprecated; no OpenACC equivalent
S1011 Device variable cannot be THREADPRIVATE - $
S1012 Threadprivate variables are not supported in acc routine - $
S1013 Static Threadprivate variables are not supported - $
S1014 Global Threadprivate variables are not supported - $
F1015 No shape directive is defined in structure $
F1016 No shape name $ is defined in structure $
F1017 arrays/pointers appearing in the OpenACC shape and policy directives must be a member of current aggregate type
F1018 Only one unnamed Shape directive is allowed in one aggregate type (struct/union)
F1019 Type clause must be used to specified structure type when Shape/Policy is defined outside (struct/union/class) definition
F1020 Data-Type appearing in type clause cannot be found
F1021 Data-Type appearing in type clause must be struct/union type
F1022 Duplicated shape names $ are defined for structure/union/class $
F1023 Duplicated policy names $ are defined for structure/union/class $
F1024 Type clause is not allowed within structure/union/class definition
F1025 The number of dimension section descriptions doesn't match member $ which requires $ dimensions
F1026 Pointers appearing within relative clause must be their sibling members
F1027 As motion clauses, only create, copyin, copyout, copy, update, and deviceptr are allowed in policy directive
F1028 The variable $ doesn't have predefined policy $ available
F1029 The variable $ using policy $ is not a structure-based type
F1030 Policy motion $ is not allowed in $ directive
W1031 The directive !$acc create is deprecated; use !$acc declare create instead
W1032 The directive !$acc present is deprecated; use !$acc declare present instead
W1033 The directive !$acc link is deprecated; use !$acc declare link instead
F1034 Only signed/unsigned 32 bits and 64 bits integer variables are allowed in bound expression. $ is is not such variable
F1035 Only integer sibling members and global variables are allowed in bound expression. $ is is neither of them.
F1036 No global variable named $ has been defined
F1037 Default clause can only contain include and exclude keyword.
F1038 Var $ used in array region cannot be found
F1039 Var $ used is not an integer type. It has to be int4 and int8.
F1040 In Fortran, the default option is full deep copy. A shape directive must be given a shape name.
F1041 Shape and policy directives cannot be declared within routine/subroutine.
S1042 $ mask expression must be scalar
DO CONCURRENT 或 FORALL 掩码表达式必须是标量。
S1043 DO CONCURRENT $ references construct variable $
DO CONCURRENT 限制或步长控制表达式可能不会引用索引名称或 LOCAL 名称。DO CONCURRENT 掩码表达式可能不会引用 LOCAL 名称。
S1044 Invalid DO CONCURRENT locality spec variable $
DO CONCURRENT 局部性规范中的名称必须是包含作用域中的有效变量名称。
S1045 DO CONCURRENT index name $ may not appear in a locality spec
S1046 Variable $ has multiple DO CONCURRENT locality spec references
S1047 Multiple DO CONCURRENT DEFAULT(NONE) locality specs
S1048 LOCAL/LOCAL_INIT variable $ $
DO CONCURRENT LOCAL 或 LOCAL_INIT 变量不得具有 ALLOCATABLE、INTENT (IN) 或 OPTIONAL 属性,不得为可终结类型,不得为非指针多态哑元,不得为假定大小的数组,并且必须允许出现在变量定义上下文中。
S1049 Variable $ is not in a DO CONCURRENT locality list
当为 DO CONCURRENT 循环指定 DEFAULT(NONE) 时,构造变量和来自包含作用域的变量必须出现在局部性规范中。
S1050 $ DO CONCURRENT construct
DO CONCURRENT 构造可能不包含 RETURN、EXIT、GOTO 或其他跳出构造的分支。允许使用 CYCLE 语句。
S1051 DO CONCURRENT polymorphic variable deallocation - $
DO CONCURRENT 构造不得包含可能导致多态变量释放分配的语句。
S1052 $ call in DO CONCURRENT construct
DO CONCURRENT 构造可能不包含对来自内部模块 IEEE_EXCEPTIONS 的 IEEE_GET_FLAG、IEEE_SET_HALTING_MODE 或 IEEE_GET_HALTING_MODE 的调用。
S1053 Duplicate $ index name
DO CONCURRENT 或 FORALL 构造或语句不得多次指定索引名称。
W1054 Duplicate subprogram prefix $ is used
S1055 MODULE prefix cannot be inside an abstract interface
S1056 MODULE prefix is only allowed for subprograms that were declared as separate module procedures
S1057 Definition argument name $ does not match declaration argument name $
S1058 The type of definition argument $ does not match its declaration type
S1059 The definition of subprogram $ does not have the same number of arguments as its declaration
S1060 The $ of the definition and declaration of subprogram $ must match
S1061 The definition of function return type of $ does not match its declaration type
S1062 LOCAL_INIT variable does not have an outside variable of the same name - $
具有 LOCAL_INIT 局部性的 DO CONCURRENT 变量必须具有相同名称的主机变量。
W1063 Data construct ignored in compute construct or acc routine
S1065 Unsupported nested compute construct in compute construct or acc routine
S1066 The -cuda flag should be used with CUDA DEVICE variable - $
S1067 Cannot determine bounds for array - $
S1068 Cannot determine start offset for array - $
S1069 Data clause required with default(none) - $
W1070 Data clause required in OpenACC 2.7 with default(none) - $; a future release will enforce this
S1071 Host array used in CUF kernel - $
S1100 Cannot collapse non-tightly-nested loops
S1207 ERROR STOP stop-code requires either a character or integer expression.
S1208 QUIET requires a logical expression.
S1209 ERROR STOP stop-code integer expression must be an integer of default kind.
S1210 Parent module $ must declare a separate module procedure.
S1211 Submodule's ancestor module $ must be a nonintrinsic module.
S1212 $ was previously declared to be a module procedure.
S1213 OpenACC $ data clause may not follow a device_type clause.
S1214 PGI Accelerator $ data clause may not follow a device_type clause.
S1215 OpenACC data clause expected after $.
S1216 Expression in assignment statement contains type bound procedure name $. This may be a function call that's missing parentheses.
S1217 Left hand side of polymorphic assignment must be allocatable - $
S1218 $ statement may not appear in a BLOCK construct.
S1219 Unimplemented feature: $.
S1220 PUBLIC namelist /$/ has a PRIVATE namelist object ($)
S1221 Interface $ is not declared.
S1222 Invalid module. Interface $ referenced in module $ is not declared.
8.4. Fortran 运行时错误消息
本节介绍由运行时系统生成的错误消息。运行时系统在标准输出上显示错误消息。
8.4.1. 消息格式
这些消息已编号,但没有严重性指示符,因为它们都会终止程序执行。
8.4.2. 消息列表
以下是运行时错误消息
201 specifier 的 非法 值
不正确的说明符值已传递给 I/O 运行时例程。示例:在 OPEN 语句中,form=’unknown’。
202 冲突的 specifier
冲突的说明符已传递给 I/O 运行时例程。示例:在 OPEN 语句中,form=’unformatted’, blank=’null’。
203 必须 指定 记录 长度
未传递 I/O 运行时例程所需的 recl 说明符。示例:在 OPEN 语句中,已传递 access=’direct’,但未指定记录长度(recl=specifier)。
204 非法 使用 只读 文件
不言自明。检查文件和目录模式的只读状态。
205 同时指定了 'SCRATCH' 和 'SAVE'/'KEEP'
在 OPEN 语句中,发生了文件处置冲突。示例:在 OPEN 语句中,status=’scratch’ 和 dispose=’keep’ 都已传递。
206 尝试 将 命名 文件 打开为 'SCRATCH'
207 文件 已 连接 到 另一个 单元
208 为 已 存在 的文件 指定了 'NEW'
209 为 不 存在 的文件 指定了 'OLD'
210 动态 内存 分配 失败
内存分配操作仅与命名列表 I/O 结合发生。固定缓冲区溢出的最可能原因是超过了同时打开的文件单元的最大数量。
211 无效的 文件 名
212 无效的 单元 号
已指定小于或等于零的文件单元号。
215 格式化/非格式化 文件 冲突
格式化/非格式化文件操作冲突。
217 尝试 读取 超过 文件 结尾
219 attempt to read/write past end of record
对于直接访问,要读取/写入的记录超出了指定的记录长度。
220 write after last internal record
221 syntax error in format string
运行时编码的格式包含词法或语法错误。
222 unbalanced parentheses in format string
223 illegal P or T edit descriptor - value missing
224 illegal Hollerith or character string in format
在运行时编码的格式中发现未知令牌类型。
225 lexical error -- unknown token type
226 unrecognized edit descriptor letter in format
在运行时格式项中发现意外的 Fortran 编辑描述符 (FED)。
228 end of file reached without finding group
229 end of file reached while processing group
230 scale factor out of range -128 to 127
Fortran P 编辑描述符比例因子不在 -128 到 127 的范围内。
231 error on data conversion
233 too many constants to initialize group item
234 invalid edit descriptor
在 format 语句中发现无效的编辑描述符。
235 edit descriptor does not match item type
I/O 列表项和相应编辑描述符指定的数据类型冲突。
236 formatted record longer than 2000 characters
237 quad precision type unsupported
238 tab value out of range
指定的制表符值小于 1。
239 entity name is not member of group
240 no initial left parenthesis in format string
241 unexpected end of format string
242 illegal operation on direct access file
243 format parentheses nesting depth too great
244 syntax error - entity name expected
245 syntax error within group definition
246 infinite format scan for edit descriptor
248 illegal subscript or substring specification
249 error in format - illegal E, F, G or D descriptor
250 error in format - number missing after '.', '-', or '+'
251 illegal character in format string
252 operation attempted after end of file
253 attempt to read non-existent record (direct access)
254 illegal repeat count in format
255 illegal asynchronous I/O operation
256 POS can only be specified for a 'STREAM' file
257 POS value must be positive
258 NEWUNIT requires FILE or STATUS=SCRATCH
通知
注意
所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称和单独称为“材料”)均“按原样”提供。NVIDIA 对这些材料不作任何明示、暗示、法定或其他方面的保证,并且明确声明不承担所有关于不侵权、适销性和特定用途适用性的暗示保证。
所提供的信息据信是准确且可靠的。但是,NVIDIA Corporation 对使用此类信息造成的后果,或因使用此类信息而可能导致的侵犯第三方专利或其他权利的行为不承担任何责任。未通过暗示或其他方式授予 NVIDIA Corporation 任何专利权下的许可。本出版物中提及的规格如有更改,恕不另行通知。本出版物取代并替换之前提供的所有其他信息。未经 NVIDIA Corporation 明确书面批准,NVIDIA Corporation 产品不得用作生命支持设备或系统中的关键组件。
商标
NVIDIA、NVIDIA 徽标、CUDA、CUDA-X、GPUDirect、HPC SDK、NGC、NVIDIA Volta、NVIDIA DGX、NVIDIA Nsight、NVLink、NVSwitch 和 Tesla 是 NVIDIA Corporation 在美国和其他国家/地区的商标和/或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。