使用硬件性能计数器测量工作负载性能#
许多软件性能分析工具依赖于来自硬件性能监控单元 (PMU) 的事件计数来表征工作负载性能。本章提供有关如何收集和组合来自 PMU 的数据以形成性能优化指标的信息。为简单起见,使用了 Linux perf 工具,但相同的指标可以用于任何从 PMU 收集硬件性能事件的工具,例如 NVIDIA Nsight Systems。
Linux perf 简介#
Linux perf 工具是一种广泛可用的开源工具,用于收集应用程序级和系统级性能数据。 perf 可以监控来自不同来源的大量软件和硬件性能事件,并且在许多情况下,不需要管理员权限(例如,root 权限)。
perf 的安装取决于发行版
Ubuntu:
apt install linux-tools-$(uname -r)Red Hat:
dnf install perf-$(uname -r)SLES:
zypper install perf
perf 通过使用 Linux 内核提供的 perf_event 系统从 PMU 收集数据。可以为进程的生命周期或特定时间段收集数据。
perf 支持以下测量类型
性能摘要 (
perf stat):perf 收集工作负载的总 PMU 事件计数,并提供基本性能特征的高级摘要。这是首次性能分析的好方法。
基于事件的采样 (
perf record):perf 定期收集 PMU 事件计数器,并将此数据与源代码位置关联起来。当特别配置的事件计数器溢出时,会收集事件计数,这会导致包含指令指针地址和寄存器信息的 中断。 perf 使用此信息构建堆栈跟踪和函数级注释,以表征特定调用路径上感兴趣的函数的性能。从高层次上讲,这是一种在初始工作负载表征之后进行详细性能表征的好方法。在使用
perf record命令收集数据后,要分析数据,请使用perf report或perf annotate命令。
配置 Perf#
默认情况下,非特权用户只能收集有关上下文切换事件的信息,其中包括大多数预定义的 CPU 核心事件,例如周期计数、指令计数和一些软件事件。为了给非特权用户提供对所有 PMU 和全局测量的访问权限,需要配置以下系统设置
注意
要配置这些设置,您必须具有 root 访问权限。
perf_event_paranoid:此设置控制内核中的特权检查。将其设置为 -1 或 0 允许非 root 用户执行按进程和系统范围的性能监控(有关更多信息,请参阅 非特权用户)。
kptr_restrict:此设置影响内核地址的公开方式。将其设置为 0 有助于内核符号解析。
例如
$ echo -1 | sudo tee /proc/sys/kernel/perf_event_paranoid
$ echo 0 | sudo tee /proc/sys/kernel/kptr_restrict
要使这些设置在重启后仍然有效,请按照您的 Linux 发行版的说明配置系统参数。通常,您需要编辑 /etc/sysctl.conf 或在 /etc/sysctl.d/ 文件夹中创建一个包含以下行的文件
kernel.perf_event_paranoid=-1
kernel.kptr_restrict=0
警告
如上例所示配置这些设置存在安全隐患。您必须阅读并理解相关的 Linux 内核文档,并咨询您的系统管理员。
要访问 PMU,请配置以下内核驱动程序模块
核心 PMU
CONFIG_ARM_PMU_ACPICONFIG_ARM_PMUV3
统计分析扩展 PMU
CONFIG_ARM_SPE_PMU
Coresight 系统 PMU
CONFIG_ARM_CORESIGHT_PMU_ARCH_SYSTEM_PMUCONFIG_NVIDIA_CORESIGHT_PMU_ARCH_SYSTEM_PMU
使用 Perf 收集硬件性能数据#
要生成事件计数的高级报告,请运行 perf stat 命令。例如,要计数缓存未命中事件、CPU 周期和 CPU 指令 10 秒钟
$ perf stat -a -e cache-misses,cycles,instructions sleep 10
您还可以收集特定进程的信息
$ perf stat -e cycles,stalled-cycles-backend ./stream.exe
这会计算在 stream.exe 执行时,CPU 停顿在前端或后端的总 CPU 周期和周期数。
-e 标志接受以逗号分隔的性能事件列表,可以是预定义的事件,也可以是原始事件。要查看预定义的事件,请键入 perf list。原始事件指定为 rXXXX,其中 XXXX 是十六进制事件编号。有关事件编号的更多信息,请参阅 Arm Neoverse V2 Core Technical Reference Manual。
为了进行更详细的分析,并在基于事件的采样模式下收集,请运行 perf record 命令
$ perf record -e cycles,instructions,dTLB-loads,dTLB-load-misses ./xhpl.exe
$ perf report
$ perf annotate
有关 perf 基本用法的更多信息,请参见 perf 手册页。
Grace CPU 性能指标#
本节提供有用的性能指标的公式,这些公式是硬件事件计数的函数,可以更充分地表达系统的性能特征。例如,简单的指令计数不如每周期指令数的比率有意义,后者表征了处理器的使用率。这些指标可以与任何从 Grace PMU 收集硬件性能事件数据的工具一起使用。
计数器按名称而不是事件编号提供,因为大多数性能分析工具都为常见事件提供名称。如果您的工具没有以下事件之一的命名计数器,请使用 Arm Neoverse V2 Core Technical Reference Manual 中的转换表将以下事件名称转换为原始事件编号。例如,FP_SCALE_OPS_SPEC 的事件编号为 0x80C0,FP_FIXED_OPS_SPEC 的事件编号为 0x80C1,因此可以使用 perf 通过测量原始事件 0x80C0 和 0x80C1 来收集 FLOPS 计算强度指标的数据
perf record -e r80C0 -e r80C1 ./a.out
周期和指令核算#
每周期指令数:每个周期完成的指令数。
INST_RETIRED/CPU_CYCLES
完成率:已完成操作的总槽位百分比,指示 CPU 的高效使用率。
100 * (OP_RETIRED/OP_SPEC) * (1 - (STALL_SLOT/(CPU_CYCLES*8)))错误推测:由于流水线刷新而未完成执行操作的总槽位百分比。
100 * ((1-OP_RETIRED/OP_SPEC) * (1-STALL_SLOT/(CPU_CYCLES * 8)) + BR_MIS_PRED * 4 / CPU_CYCLES)后端停顿周期:由于处理器后端单元中的资源限制而停顿的周期百分比。
(STALL_BACKEND/CPU_CYCLES)*100前端停顿周期: 由于处理器前端单元中的资源限制而停顿的周期百分比。
(STALL_FRONTEND/CPU_CYCLES)*100
计算强度#
SVE FLOPS:SVE 指令执行的任何精度下的每秒浮点运算次数。
融合指令计为两次运算,例如,融合乘加指令将计数增加两倍的活动 SVE 向量通道数。这些运算不计为标量或 NEON 指令执行的浮点运算。
FP_SCALE_OPS_SPEC/TIME非 SVE FLOPS:非 SVE 指令执行的任何精度下的每秒浮点运算次数。
融合指令计为两次运算,例如,标量融合乘加指令将计数增加 2,而融合乘加 NEON 指令将计数增加两倍的向量通道数。这些运算不计为 SVE 指令执行的浮点运算。
FP_FIXED_OPS_SPEC/TIMEFLOPS:任何指令执行的任何精度下的每秒浮点运算次数。
融合指令计为两次运算。
(FP_SCALE_OPS_SPEC + FP_FIXED_OPS_SPEC)/TIME
运算组合#
加载运算百分比:推测执行为加载运算的总运算百分比。
(LD_SPEC/INST_SPEC)*100存储运算百分比:推测执行为存储运算的总运算百分比。
(ST_SPEC/INST_SPEC)*100分支运算百分比:推测执行为分支运算的总运算百分比。
((BR_IMMED_SPEC + BR_INDIRECT_SPEC)/INST_SPEC)*100整数运算百分比:推测执行为标量整数运算的总运算百分比。
(DP_SPEC/INST_SPEC)*100注意
DP_SPEC 中的 DP 代表数据处理。
浮点运算百分比:推测执行为标量浮点运算的总运算百分比。指令。
(VFP_SPEC/INST_SPEC)*100同步百分比:推测执行为同步运算的总运算百分比。
((ISB_SPEC + DSB_SPEC + DMB_SPEC)/INST_SPEC)*100加密运算百分比:推测执行为加密运算的总运算百分比。
(CRYPTO_SPEC/INST_SPEC)*100SVE 运算(包括加载/存储)百分比:推测执行为可伸缩向量运算(包括加载和存储)的总运算百分比。
(SVE_INST_SPEC/INST_SPEC)*100高级 SIMD 运算百分比:推测执行为高级 SIMD (NEON) 运算的总运算百分比。
(ASE_INST_SPEC/INST_SPEC)*100SIMD 百分比:推测执行为整数或浮点向量/SIMD 运算的总运算百分比。
((SVE_INST_SPEC + ASE_INST_SPEC)/INST_SPEC)*100FP16 百分比:推测执行为半精度浮点运算的总运算百分比。
包括标量、融合和 SIMD 指令,不能用于测量计算强度。
(FP_HP_SPEC/INST_SPEC)*100FP32 百分比:推测执行为单精度浮点运算的总运算百分比。
包括标量、融合和 SIMD 指令,不能用于测量计算强度。
(FP_SP_SPEC/INST_SPEC)*100FP64 百分比:推测执行为双精度浮点运算的总运算百分比。
包括标量、融合和 SIMD 指令,不能用于测量计算强度。
(FP_DP_SPEC/INST_SPEC)*100
SVE 谓词#
完整 SVE 运算百分比:推测执行为所有活动谓词的 SVE SIMD 运算的总运算百分比。
(SVE_PRED_FULL_SPEC/INST_SPEC)*100部分 SVE 运算百分比:推测执行为至少一个元素为 FALSE 的 SVE SIMD 运算的总运算百分比。
(SVE_PRED_PARTIAL_SPEC/INST_SPEC)*100空 SVE 运算百分比:推测执行为没有活动谓词的 SVE SIMD 运算的总运算百分比。
(SVE_PRED_EMPTY_SPEC/INST_SPEC)*100
缓存效率#
L1 数据缓存未命中率:总共一级数据缓存读取或写入访问未命中的比率。
L1D_CACHE 包括读取和写入,是 L1D_CACHE_RD 和 L1D_CACHE_WR 的总和。
L1D_CACHE_REFILL/L1D_CACHEL1D 缓存 MPKI:每执行一千条指令,一级数据缓存访问未命中的次数。
(L1D_CACHE_REFILL/INST_RETIRED) * 1000L1I 缓存未命中率:一级指令缓存访问未命中次数与一级指令缓存访问总次数的比率。
L1I_CACHE 不测量缓存维护指令或不可缓存的访问。
L1I_CACHE_REFILL/L1I_CACHEL1I 缓存 MPKI:每执行一千条指令,一级指令缓存访问未命中的次数。
(L1I_CACHE_REFILL/INST_RETIRED) * 1000L2 缓存未命中率:二级缓存访问未命中次数与二级缓存访问总次数的比率。
L2D_CACHE 不计算缓存维护操作或来自核心外部的窥探。
L2D_CACHE_REFILL/L2D_CACHEL2 缓存 MPKI:每执行一千条指令,二级统一缓存访问未命中的次数。
(L2D_CACHE_REFILL/INST_RETIRED) * 1000LL 缓存读取命中率:最后一级缓存读取访问命中缓存次数与最后一级缓存访问总次数的比率。
(LL_CACHE_RD - LL_CACHE_MISS_RD) / LL_CACHE_RDLL 缓存读取未命中率:最后一级缓存读取访问未命中次数与最后一级缓存访问总次数的比率。
LL_CACHE_MISS_RD / LL_CACHE_RDLL 缓存读取 MPKI:每执行一千条指令,最后一级缓存读取访问未命中的次数。
(LL_CACHE_MISS_RD/INST_RETIRED) * 1000
TLB 效率#
L1 数据 TLB 未命中率:一级数据 TLB 访问未命中次数与一级数据 TLB 访问总次数的比率。
不计算 TLB 维护指令。
L1D_TLB_REFILL/L1D_TLBL1 数据 TLB MPKI:每执行一千条指令,一级数据 TLB 访问未命中的次数。
(L1D_TLB_REFILL/INST_RETIRED) * 1000L1 指令 TLB 未命中率:一级指令 TLB 访问未命中次数与一级指令 TLB 访问总次数的比率。
不计算 TLB 维护指令。
L1I_TLB_REFILL/L1I_TLBL1 指令 TLB MPKI:每执行一千条指令,一级指令 TLB 访问未命中的次数。
(L1I_TLB_REFILL/INST_RETIRED) * 1000DTLB MPKI:每执行一千条指令,数据 TLB 步行的次数。
(DTLB_WALK/INST_RETIRED) * 1000DTLB 步行率:数据 TLB 步行次数与数据 TLB 访问总次数的比率。
DTLB_WALK / L1D_TLBITLB MPKI:每执行一千条指令,指令 TLB 步行的次数。
(ITLB_WALK/INST_RETIRED) * 1000ITLB 步行率:指令 TLB 步行次数与指令 TLB 访问总次数的比率。
ITLB_WALK / L1I_TLBL2 统一 TLB 未命中率:二级统一 TLB 访问未命中次数与二级统一 TLB 访问总次数的比率。
L2D_TLB_REFILL / L2D_TLBL2 统一 TLB MPKI:每执行一千条指令,二级统一 TLB 访问未命中的次数。
(L2D_TLB_REFILL/INST_RETIRED) * 1000
分支#
分支误预测率:误预测分支数与架构执行的分支总数的比率。
BR_MIS_PRED_RETIRED/BR_RETIRED分支 MPKI:每执行一千条指令,分支误预测的次数。
(BR_MIS_PRED_RETIRED/INST_RETIRED) * 1000
统计分析扩展#
Arm 的统计分析扩展 (SPE) 旨在通过提供详细的分析功能来增强软件性能分析。此扩展允许您收集有关软件执行的统计数据,并记录关键执行数据,包括程序计数器、数据地址和 PMU 事件。 SPE 增强了分支、内存访问等的性能分析,使其对软件优化非常有用。 有关 SPE 的更多信息,请参阅 Statistical Profiling Extension。
Grace Coresight 系统 PMU 单元#
Grace 包括下表中的 Coresight 系统 PMU,这些 PMU 由 PMU 驱动程序使用指定的命名约定注册。
系统 |
Coresight 系统 PMU 名称 |
|---|---|
可扩展一致性互连 (SCF) |
nvidia_scf_pmu_<socket-id> |
NVLINK-C2C0 |
nvidia_nvlink_c2c0_pmu_<socket-id> |
NVLINK-C2C1(仅限 Grace-Hopper) |
nvidia_nvlink_c2c1_pmu_<socket-id> |
PCIe |
nvidia_pcie_pmu_<socket-id> |
CNVLINK(仅限多路 Grace-Hopper) |
nvidia_cnvlink_pmu_<socket-id> |
Coresight 系统 PMU 事件不可归因于核心,因此 perf 工具必须在系统范围模式下运行。如果测量需要测量多个事件,perf 工具支持来自同一 PMU 的事件分组。例如,要监控套接字 0 的 SCF PMU 的 SCF CYCLES、CMEM_WB_ACCESS 和 CMEM_WR_ACCESS 事件
$ perf stat -a -e
duration_time,'{nvidia_scf_pmu_0/event=cycles/,nvidia_scf_pmu_0/cmem_wb_access/,nvidia_scf_pmu_0/cmem_wr_access/}'
cmem_write_test
Performance counter stats for 'system wide':
168225760 ns duration_time
10515321 nvidia_scf_pmu_0/event=cycles/
191567 nvidia_scf_pmu_0/cmem_wb_access/
0 nvidia_scf_pmu_0/cmem_wr_access/
0.168225760 seconds time elapsed
Coresight 系统 PMU 流量覆盖范围#
流量模式决定了哪个 PMU 用于测量不同的访问类型,这可能会因芯片配置而异。
Grace CPU Superchip#
下表包含 Coresight 系统 PMU 事件的摘要,这些事件可用于监控 Grace CPU Superchip 中的不同内存流量类型。
PMU |
事件 |
流量 |
|---|---|---|
SCF PMU |
*SCF _CACHE* |
访问最后一级缓存。 |
CMEM* |
来自所有 CPU(本地和远程套接字)到本地内存的内存流量。例如,使用套接字 0 PMU 进行测量会计算来自套接字 0 和套接字 1 中的 CPU 到套接字 0 中的内存的流量。 |
|
SOCKET* 或 REMOTE* |
来自本地套接字中的 CPU 到远程内存(通过 C2C)的内存流量。 |
|
PCIe PMU |
*LOC |
来自 PCIe 根端口到本地内存的内存流量。 |
*REM |
来自 PCIe 根端口到远程内存的内存流量。 |
|
NVLINK-C2C0 PMU |
*LOC |
来自远程套接字的 PCIe 到本地内存(通过 C2C)的内存流量。例如,使用套接字 0 PMU 进行测量会计算来自套接字 1 的 PCIe 的流量。 注意: 写入流量仅限于 PCIe 宽松排序写入。 |
NVLINK-C2C1 PMU |
未使用。对此 PMU 的测量将返回零计数。 |
|
CNVLINK PMU |
未使用。对此 PMU 的测量将返回零计数。 |
*PMU 事件名称的前缀或后缀。
CPU 流量测量#
本节提供有关测量 CPU 流量的信息。
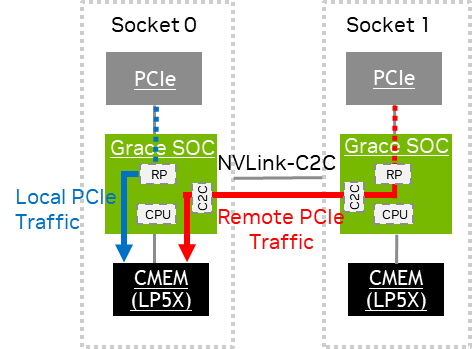
CPU 流量测量#
本地 CPU 流量在源套接字的 SCF PMU 上生成 CMEM 事件。远程 CPU 流量生成以下事件
源套接字的 SCF PMU 上的
REMOTE*或SOCKET*事件。目标套接字的 SCF PMU 上的
CMEM*事件。
可扩展一致性互连 PMU 核算 包含可以从这些事件中导出的性能指标。
以下是一些 CPU 流量测量示例,这些示例捕获了写入大小(以字节为单位)和读取大小(以数据节拍为单位),其中每个数据节拍最多传输 32 字节。
# Local traffic: Socket-0 CPU write to socket-0 DRAM.
# The workload performs a 1 GB write and the CPU and memory are pinned to socket-0.
# The result from SCF PMU in socket-0 shows 1,009,299,148 bytes of CPU writes to socket-0
# memory.
nvidia@localhost:~$ sudo perf stat -a -e
duration_time,'{nvidia_scf_pmu_0/cmem_wr_total_bytes/,nvidia_scf_pmu_0/cmem_rd_data/}','{nvidia_scf_pmu_1/remote_socket_wr_total_bytes/,nvidia_scf_pmu_1/remote_socket_rd_data/}'
numactl --cpunodebind=0 --membind=0 dd if=/dev/zero of=/tmp/node0 bs=1M
count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.125672 s, 8.5 GB/s
Performance counter stats for 'system wide':
27,496,157 ns duration_time
1,009,299,148 nvidia_scf_pmu_0/cmem_wr_total_bytes/
1,213,938 nvidia_scf_pmu_0/cmem_rd_data/
1,355,223 nvidia_scf_pmu_1/remote_socket_wr_total_bytes/
7,960 nvidia_scf_pmu_1/remote_socket_rd_data/
0.127496157 seconds time elapsed
# Local traffic: Socket-0 CPU read from socket-0 DRAM
# The workload performs a 1 GB read and the CPU and memory are pinned to socket-0.
# The result from SCF PMU in socket-0 shows 35,572,420 data beats of CPU reads from socket-0
# memory. Converting it to bytes: 35,572,420 x 32 bytes = 1,138,317,440 bytes.**
nvidia@localhost:~$ sudo perf stat -a -e duration_time,'{nvidia_scf_pmu_0/cmem_wr_total_bytes/,nvidia_scf_pmu_0/cmem_rd_data/}','{nvidia_scf_pmu_1/remote_socket_wr_total_bytes/,nvidia_scf_pmu_1/remote_socket_rd_data/}' numactl --cpunodebind=0 --membind=0 dd of=/dev/null if=/tmp/node0 bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.0872731 s, 12.3 GB/s
Performance counter stats for 'system wide':
88,826,372 ns duration_time
36,057,808 nvidia_scf_pmu_0/cmem_wr_total_bytes/
35,572,420 nvidia_scf_pmu_0/cmem_rd_data/**
24,173 nvidia_scf_pmu_1/remote_socket_wr_total_bytes/
4,728 nvidia_scf_pmu_1/remote_socket_rd_data/
0.088826372 seconds time elapsed
# Remote traffic: Socket-1 CPU write to socket-0 DRAM
# The workload performs a 1 GB write. The CPU is pinned to socket-1 and memory is pinned to socket-0.
# The result from SCF PMU in socket-1 shows 961,728,219 bytes of remote writes to socket-0**
# memory. The remote writes are also captured by the destination (socket-0) SCF PMU that shows
# 993,278,696 bytes of any CPU writes to socket-0 memory.
nvidia@localhost:~$ sudo perf stat -a -e duration_time,'{nvidia_scf_pmu_0/cmem_wr_total_bytes/,nvidia_scf_pmu_0/cmem_rd_data/}','{nvidia_scf_pmu_1/remote_socket_wr_total_bytes/,nvidia_scf_pmu_1/remote_socket_rd_data/}'
numactl --cpunodebind=1 --membind=0 dd if=/dev/zero of=/tmp/node0 bs=1M
count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.171349 s, 6.3 GB/s
Performance counter stats for 'system wide':
172,847,464 ns duration_time
993,278,696 nvidia_scf_pmu_0/cmem_wr_total_bytes/
1,040,902 nvidia_scf_pmu_0/cmem_rd_data/
961,728,219 nvidia_scf_pmu_1/remote_socket_wr_total_bytes/**
1,065,136 nvidia_scf_pmu_1/remote_socket_rd_data/
0.172847464 seconds time elapsed
# Remote traffic: Socket-1 CPU read from socket-0 DRAM**
# The workload performs a 1 GB read. The CPU is pinned to socket-1 and memory is pinned to socket-0.
# The result from SCF PMU in socket-1 shows 36,189,087 data beats of remote reads from socket-0
# memory. The remote reads are also captured by the destination (socket-0) SCF PMU that shows
# 33,542,984 data beats of any CPU read from socket-0 memory.**
# Converting it to bytes:
# - Socket-1 CPU remote read: 36,189,087 x 32 bytes = 1,158,050,784 bytes.
# - Any CPU read from socket-0 memory = 33,542,984 x 32 bytes = 1,073,375,488 bytes.
nvidia@localhost:~$ sudo perf stat -a -e
duration_time,'{nvidia_scf_pmu_0/cmem_wr_total_bytes/,nvidia_scf_pmu_0/cmem_rd_data/}','{nvidia_scf_pmu_1/remote_socket_wr_total_bytes/,nvidia_scf_pmu_1/remote_socket_rd_data/}'
numactl --cpunodebind=1 --membind=0 dd of=/dev/null if=/tmp/node0 bs=1M
count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.133185 s, 8.1 GB/s
Performance counter stats for 'system wide':
134,526,031 ns duration_time
19,588,224 nvidia_scf_pmu_0/cmem_wr_total_bytes/
33,542,984 nvidia_scf_pmu_0/cmem_rd_data/
18,771,438 nvidia_scf_pmu_1/remote_socket_wr_total_bytes/
36,189,087 nvidia_scf_pmu_1/remote_socket_rd_data/**
0.134526031 seconds time elapsed
PCIe 流量测量#
本节提供有关测量 PCIe 流量的信息。
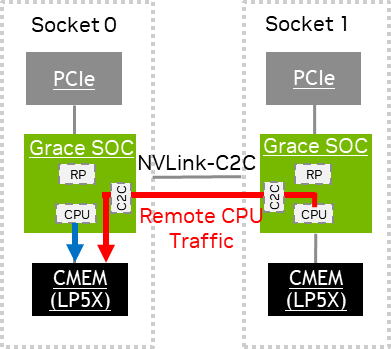
PCIe 流量测量#
本地 PCIe 流量在源套接字的 PCIe PMU 上生成 *LOC 事件,远程 PCIe 流量生成以下事件
源套接字的 PCIe PMU 上的
*REM事件。目标套接字的 NVLINK-C2C0 PMU 上的
*LOC事件。
PCIe PMU 核算 包含可以从这些事件中导出的性能指标。
PCIe PMU 监控来自 PCIe 根端口到本地/远程内存的流量。 Grace SOC 最多支持 10 个 PCIe 根端口。至少需要在 perf 工具中使用 root_port 位图过滤器指定这些根端口之一。例如,root_port=0xF 过滤器对应于根端口 0 到 3。
示例:要计数套接字 0 的 PCIe 根端口 0 和 1 的 rd_bytes_loc 事件
$ perf stat -a -e nvidia_pcie_pmu_0/rd_bytes_loc,root_port=0x3/
示例:要计数套接字 1 中 PCIe 根端口 2 的 rd_bytes_rem 事件并测量测试持续时间(以纳秒为单位)
$ perf stat -a -e duration_time,'{nvidia_pcie_pmu_1/rd_bytes_rem,root_port=0x4/}'
以下是查找 PCIe 设备的根端口号的示例。
# Find the root port number of the NVLINK drive on each socket.
# nvme0 is attached to domain number 0018, which corresponds to socket-1 root port 0x8.
# nvme1 is attached to domain number 0008, which corresponds to socket-0 root port 0x8.
nvidia@localhost:~$ readlink -f /sys/class/nvme/nvme*
/sys/devices/pci0018:00/**0018**:00:00.0/0018:01:00.0/nvme/nvme0
/sys/devices/pci0008:00/**0008**:00:00.0/0008:01:00.0/0008:02:00.0/0008:03:00.0/nvme/nvme1
# Query the mount point of each nvme drive to get the path for the workloads below.
nvidia@localhost:~$ df -H | grep nvme0
/dev/**nvme0n1p2** 983G 625G 309G 67% /
nvidia@localhost:~$ df -H | grep nvme1
/dev/**nvme1n1** 472G 1.1G 447G 1% /var/data0
以下是一些从 DRAM 读取数据并将结果存储到 NVME 驱动器时的 PCIe 流量测量示例。 这些示例捕获了读取/写入本地/远程内存的大小(以字节为单位)。
# Local traffic: Socket-0 PCIE read from socket-0 DRAM.
# The workload copies data from socket-0 DRAM to socket-0 NVME in root port 0x8. The NVME would
# perform a read request to DRAM.
# The root_port filter value: 1 << root port number = 1 << 8 = 0x100
# The result from PCIe PMU in socket-0 shows 1,168,472,064 bytes of PCIe read from socket-0 memory.
nvidia@localhost:~$ sudo perf stat -a -e
duration_time,'{nvidia_pcie_pmu_0/rd_bytes_loc,root_port=0x100/,nvidia_pcie_pmu_0/wr_bytes_loc,root_port=0x100/,nvidia_pcie_pmu_0/rd_bytes_rem,root_port=0x100/,nvidia_pcie_pmu_0/wr_bytes_rem,root_port=0x100/}'
numactl --cpunodebind=0 --membind=0 dd if=/dev/zero of=/var/data0/pcie_test_0 bs=16M count=64 oflag=direct conv=fdatasync
64+0 records in
64+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 1.96463 s, 547 MB/s
Performance counter stats for 'system wide':
1,966,391,711 ns duration_time
1,168,472,064 nvidia_pcie_pmu_0/rd_bytes_loc,root_port=0x100/
31,250,176 nvidia_pcie_pmu_0/wr_bytes_loc,root_port=0x100/
49,152 nvidia_pcie_pmu_0/rd_bytes_rem,root_port=0x100/
0 nvidia_pcie_pmu_0/wr_bytes_rem,root_port=0x100/
1.966391711 seconds time elapsed
# Remote traffic: Socket-1 PCIE read from socket-0 DRAM.
# The workload copies data from socket-0 DRAM to socket-1 NVME in root port 0x8. The NVME would perform a read request to DRAM.
# The root_port filter value: 1 << root port number = 1 << 8 = 0x100
# The result from PCIe PMU in socket-1 shows 1,073,762,304 bytes of PCIe read from socket-0 memory.
# The remote reads are also captured by the destination (socket-0) NVLINK C2C0 PMU that shows 1,074,057,216 bytes of reads.
nvidia@localhost:~$ sudo perf stat -a -e
duration_time,'{nvidia_pcie_pmu_1/rd_bytes_loc,root_port=0x100/,nvidia_pcie_pmu_1/wr_bytes_loc,root_port=0x100/,nvidia_pcie_pmu_1/rd_bytes_rem,root_port=0x100/,nvidia_pcie_pmu_1/wr_bytes_rem,root_port=0x100/}','{nvidia_nvlink_c2c0_pmu_0/rd_bytes_loc/,nvidia_nvlink_c2c0_pmu_0/wr_bytes_loc/}' numactl --membind=0 dd if=/dev/zero of=/home/nvidia/pcie_test_0 bs=16M count=64 oflag=direct conv=fdatasync
64+0 records in
64+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.73373 s, 1.5 GB/s
Performance counter stats for 'system wide':
735,201,612 ns duration_time
6,398,720 nvidia_pcie_pmu_1/rd_bytes_loc,root_port=0x100/
164,096 nvidia_pcie_pmu_1/wr_bytes_loc,root_port=0x100/
1,073,762,304 nvidia_pcie_pmu_1/rd_bytes_rem,root_port=0x100/**
0 nvidia_pcie_pmu_1/wr_bytes_rem,root_port=0x100/
1,074,057,216 nvidia_nvlink_c2c0_pmu_0/rd_bytes_loc/
32,768 nvidia_nvlink_c2c0_pmu_0/wr_bytes_loc/
0.735201612 seconds time elapsed
Grace Hopper Superchip#
下表包含 Coresight 系统 PMU 事件的摘要,这些事件可用于监控 Grace Hopper Superchip 中的不同内存流量类型。
PMU |
事件 |
流量 |
|---|---|---|
SCF PMU |
*SCF_CACHE* |
访问最后一级缓存。 |
CMEM* |
从 CPU 到 CPU 内存的内存流量。 |
|
GMEM* |
从 CPU 到 GPU 内存(通过 C2C)的内存流量。 |
|
PCIe PMU |
*LOC |
从 PCIe 根端口到 CPU 或 GPU 内存的内存流量。 |
NVLINK-C2C0 PMU |
*LOC |
来自 GPU 到 CPU 内存(通过 C2C)的 ATS 转换或 EGM 内存流量。 |
NVLINK-C2C1 PMU |
*LOC |
来自 GPU 到 CPU 或 GPU 内存(通过 C2C)的非 ATS 转换内存流量。 |
CNVLINK PMU |
未使用。对此 PMU 的测量将返回零计数。 |
* PMU 事件名称的前缀或后缀。
有关 CPU 和 PCIe 流量测量的更多信息,请参阅 Grace CPU Superchip。
GPU 流量测量#
本节提供有关测量 GPU 流量的信息。
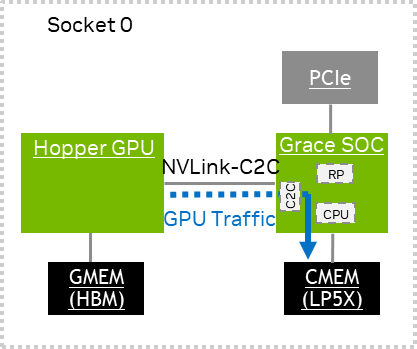
GPU 流量测量#
GPU 流量在 Grace Coresight 系统 C2C PMU 上生成 *LOC 事件,NVLINK-C2C0 PMU 捕获 ATS 转换或 EGM 内存流量。 NVLINK-C2C1 PMU 捕获非 ATS 转换流量。实线仅表示已捕获从 SOC 到内存的路径。 C2C PMU 不捕获 C2C 互连的延迟效应。 有关可以从这些事件中导出的性能指标的更多信息,请参阅 NVLink C2C PMU 核算。
以下是一些 GPU 流量测量示例,这些示例捕获了读取/写入大小(以字节为单位)。
# GPU write to CPU DRAM.
# The workload performs a write by GPU copy engine to CPU DRAM.
# The result from NVLINK-C2C0 PMU shows 4,026,531,840 bytes of writes to DRAM.
nvidia@localhost:/home/nvidia/nvbandwidth$ sudo perf stat -a -e '{nvidia_nvlink_c2c0_pmu_0/total_bytes_loc/,nvidia_nvlink_c2c0_pmu_0/rd_bytes_loc/,nvidia_nvlink_c2c0_pmu_0/wr_bytes_loc/}','{nvidia_nvlink_c2c1_pmu_0/total_bytes_loc/,nvidia_nvlink_c2c1_pmu_0/rd_bytes_loc/,nvidia_nvlink_c2c1_pmu_0/wr_bytes_loc/}'
./nvbandwidth -t 1
nvbandwidth Version: v0.4
Built from Git version: v0.4
NOTE: This tool reports current measured bandwidth on your system.
Additional system-specific tuning may be required to achieve maximal peak bandwidth.
CUDA Runtime Version: 12050
CUDA Driver Version: 12050
Driver Version: 555.42.02
Device 0: NVIDIA GH200 120GB
Running device_to_host_memcpy_ce.memcpy CE CPU(row) <- GPU(column) bandwidth (GB/s)
0
0 295.07
SUM **device_to_host_memcpy_ce** 295.07
Performance counter stats for 'system wide':
4,234,950,656 nvidia_nvlink_c2c0_pmu_0/total_bytes_loc/
208,418,816 nvidia_nvlink_c2c0_pmu_0/rd_bytes_loc/
**4,026,531,840 nvidia_nvlink_c2c0_pmu_0/wr_bytes_loc/**
26,981,632 nvidia_nvlink_c2c1_pmu_0/total_bytes_loc/
6,337,792 nvidia_nvlink_c2c1_pmu_0/rd_bytes_loc/
20,643,840 nvidia_nvlink_c2c1_pmu_0/wr_bytes_loc/
0.777059774 seconds time elapsed
**# GPU read from CPU DRAM.**
**# The workload performs a read by GPU copy engine from CPU DRAM.**
**# The result from NVLINK-C2C0 PMU shows 4,234,927,104 bytes of reads from DRAM.**
nvidia@localhost:/home/nvidia/nvbandwidth$ sudo perf stat -a -e'{nvidia_nvlink_c2c0_pmu_0/total_bytes_loc/,nvidia_nvlink_c2c0_pmu_0/rd_bytes_loc/,nvidia_nvlink_c2c0_pmu_0/wr_bytes_loc/}','{nvidia_nvlink_c2c1_pmu_0/total_bytes_loc/,nvidia_nvlink_c2c1_pmu_0/rd_bytes_loc/,nvidia_nvlink_c2c1_pmu_0/wr_bytes_loc/}'
./nvbandwidth -t 0
nvbandwidth Version: v0.4
Built from Git version: v0.4
NOTE: This tool reports current measured bandwidth on your system.
Additional system-specific tuning may be required to achieve maximal peak bandwidth.
CUDA Runtime Version: 12050
CUDA Driver Version: 12050
Driver Version: 555.42.02
Device 0: NVIDIA GH200 120GB
Running host_to_device_memcpy_ce.memcpy CE CPU(row) -> GPU(column) bandwidth (GB/s)
0
0 408.42
SUM **host_to_device_memcpy_ce** 408.42
Performance counter stats for 'system wide':
4,436,253,696 nvidia_nvlink_c2c0_pmu_0/total_bytes_loc/
**4,234,927,104 nvidia_nvlink_c2c0_pmu_0/rd_bytes_loc/**
201,326,592 nvidia_nvlink_c2c0_pmu_0/wr_bytes_loc/
26,949,888 nvidia_nvlink_c2c1_pmu_0/total_bytes_loc/
6,356,480 nvidia_nvlink_c2c1_pmu_0/rd_bytes_loc/
20,593,408 nvidia_nvlink_c2c1_pmu_0/wr_bytes_loc/
0.771266524 seconds time elapsed
可扩展一致性互连 PMU 核算#
SCF PMU 事件#
下表提供了 PMU 驱动程序和 perf 工具公开的事件。
事件名称 |
ID |
描述 |
|---|---|---|
CYCLES |
0x100000000 |
SCF 时钟周期。 |
BUS_CYCLES |
0x1d |
与周期相同 |
事件名称 |
ID |
描述 |
|---|---|---|
SCF_CACHE_ALLOCATE |
0xf0 |
在 LL 缓存中分配的读取/写入/原子/预取请求。 |
SCF_CACHE_REFILL |
0xf1 |
最后一级缓存和内部缓存中未命中,导致请求下一级内存层次结构的读取/原子/ StashOnce 请求(CTAG 和 DIR 中未命中并从 L4 获取数据的读取请求数)。 |
SCF_CACHE |
0xf2 |
未导致解码错误的 LL 缓存读取/写入/原子/窥探/预取请求。 |
SCF_CACHE_WB |
0xf3 |
来自 LL 缓存的容量驱逐数。 |
事件名称 |
ID |
描述 |
|---|---|---|
CMEM_RD_DATA |
0x1a5 |
计数从本地 Grace DRAM 传输到本地或远程 CPU 的 SCF 读取数据节拍总数。每个数据节拍最多传输 32 字节。 |
CMEM_RD_ACCESS |
0x1a6 |
计数从本地或远程 CPU 到本地 Grace DRAM 的 SCF 读取访问次数。每个周期按新的读取访问总数递增。 |
CMEM_RD_OUTSTANDING |
0x1a7 |
计数从本地或远程 CPU 到本地套接字 Grace DRAM 的未完成 SCF 读取访问总数。每个周期按未完成计数总数递增。 |
CMEM_WB_DATA |
0x1ab |
计数从本地或远程 CPU 传输到本地 Grace DRAM 的 SCF 写回数据节拍总数(干净/脏)(不包括写唯一/非一致性写入)。每个 wb_data 节拍传输 32 字节数据。 |
CMEM_WB_ACCESS |
0x1ac |
计数从本地或远程 CPU 到本地 Grace DRAM 的 SCF 写回访问次数(干净/脏)(不包括写唯一/非一致性写入)。每个周期按新的写入访问总数递增。每个写回访问是 64 字节传输。 |
CMEM_WR_DATA |
0x1b1 |
计数基于大小字段传输的字节数,用于从本地或远程 CPU 到本地 Grace DRAM 的 SCF 写唯一和非一致性写入(包括 WriteZeros,其计数为 64 字节)。 |
CMEM_WR_TOTAL_BYTES |
0x1db |
计数从本地或远程 CPU 通过写回、写唯一和非一致性写入传输到本地 Grace DRAM 的总字节数。 |
CMEM_WR_ACCESS |
0x1ca |
计数从本地或远程 CPU 到本地 Grace DRAM 的 SCF 写唯一和非一致性写入(包括 WriteZeros)请求的总数。 |
事件名称 |
ID |
描述 |
|---|---|---|
GMEM_RD_DATA |
0x16d |
计数从本地相干 GPU DRAM 传输到本地或远程 CPU 的读取数据节拍总数。每个数据节拍最多传输 32 字节。 |
GMEM_RD_ACCESS |
0x16e |
统计从本地或远程 CPU 到本地一致性 GPU DRAM 的 SCF 读取访问次数。每个周期按新的读取访问总数递增。 |
GMEM_RD_OUTSTANDING |
0x16f |
指示从本地或远程 CPU 到一致性 GPU DRAM 的未完成读取请求总数。每个周期按未完成读取请求计数递增。 |
GMEM_WB_DATA |
0x173 |
统计从本地或远程 CPU 传输到本地一致性 GPU DRAM 的 SCF 写回数据节拍总数(不包括写独占/非一致性写入)。每个 wb_data 节拍传输 32 字节数据。 |
GMEM_WB_ACCESS |
0x174 |
统计从本地或远程 CPU 到本地一致性 GPU DRAM 的 SCF 写回访问次数(clean 和 dirty)(不包括写独占/非一致性写入)。每个周期按新的写入访问总数递增。每次写回访问是 64 字节的传输。 |
GMEM_WR_DATA |
0x179 |
根据大小字段统计从本地或远程 CPU 到本地一致性 GPU DRAM 的 SCF 写独占和非一致性写入传输的字节数。 |
GMEM_WR_ACCESS |
0x17b |
统计从本地或远程 CPU 到本地一致性 GPU DRAM 的 SCF 写独占和非一致性写入请求总数。 |
GMEM_WR_TOTAL_BYTES |
0x1a0 |
统计通过写回、写独占和非一致性写入传输到本地一致性 GPU DRAM 的总字节数。 |
事件名称 |
ID |
描述 |
|---|---|---|
SOCKET_0_RD_DATA |
0x101 |
统计从 CNVLINK Socket 0 内存或 NVLINK-C2C socket 0 内存传输到本地 CPU 的 SCF 读取数据节拍总数。每个数据节拍传输最多 32 字节。 |
SOCKET_1_RD_DATA |
0x102 |
统计从 CNVLINK Socket 1 内存或 NVLINK-C2C socket 1 内存传输到本地 CPU 的 SCF 读取数据节拍总数。每个数据节拍传输最多 32 字节。 |
SOCKET_2_RD_DATA |
0x103 |
统计从 CNVLINK Socket 2 内存传输到本地 CPU 的 SCF 读取数据节拍总数。每个数据节拍传输最多 32 字节。 |
SOCKET_3_RD_DATA |
0x104 |
统计从 CNVLINK Socket 3 内存传输到本地 CPU 的 SCF 读取数据节拍总数。每个数据节拍传输最多 32 字节。 |
SOCKET_0_WB_DATA |
0x109 |
统计从本地 CPU 传输到 CNVLINK socket 0 内存或 NVLINK-C2C socket 0 内存的 SCF 写回数据节拍总数(不包括写独占/非一致性写入)。每个 wb_data 节拍传输 32 字节数据。 |
SOCKET_1_WB_DATA |
0x10a |
统计从本地 CPU 传输到 CNVLINK socket 1 内存或 NVLINK-C2C socket 1 内存的 SCF 写回数据节拍总数(不包括写独占/非一致性写入)。每个 wb_data 节拍传输 32 字节数据。 |
SOCKET_2_WB_DATA |
0x10b |
统计从本地 CPU 传输到 CNVLINK socket 2 内存的 SCF 写回数据节拍总数(不包括写独占/非一致性写入)。每个 wb_data 节拍传输 32 字节数据。 |
SOCKET_3_WB_DATA |
0x10c |
统计从本地 CPU 传输到 CNVLINK socket 3 内存的 SCF 写回数据节拍总数(不包括写独占/非一致性写入)。每个 wb_data 节拍传输 32 字节数据。 |
SOCKET_0_WR_DATA |
0x17c |
根据大小字段统计从本地 CPU 到 CNVLINK socket 0 内存或 NVLINK-C2C socket 0 内存的 SCF 写独占和非一致性写入传输的字节总数。 |
SOCKET_1_WR_DATA |
0x17d |
根据大小字段统计从本地 CPU 到 CNVLINK socket 1 内存或 NVLINK-C2C socket 1 内存的 SCF 写独占和非一致性写入传输的字节总数。 |
SOCKET_2_WR_DATA |
0x17e |
根据大小字段统计从本地 CPU 到 CNVLINK socket 2 内存的 SCF 写独占和非一致性写入传输的字节总数。 |
SOCKET_3_WR_DATA |
0x17f |
根据大小字段统计从本地 CPU 到 CNVLINK socket 3 内存的 SCF 写独占和非一致性写入传输的字节总数。 |
SOCKET_0_RD_OUTSTANDING |
0x115 |
统计从本地 CPU 到 CNVLINK socket 0 内存或 NVLINK-C2C socket 0 内存的未完成 SCF 读取访问总数。每个周期按未完成计数总数递增。 |
SOCKET_1_RD_OUTSTANDING |
0x116 |
统计从本地 CPU 到 CNVLINK socket 1 内存或 NVLINK-C2C socket 1 内存的未完成 SCF 读取访问总数。每个周期按未完成计数总数递增。 |
SOCKET_2_RD_OUTSTANDING |
0x117 |
统计从本地 CPU 到 CNVLINK socket 2 内存的未完成 SCF 读取访问总数。每个周期按未完成计数总数递增。 |
SOCKET_3_RD_OUTSTANDING |
0x118 |
统计从本地 CPU 到 CNVLINK socket 3 内存的未完成 SCF 读取访问总数。每个周期按未完成计数总数递增。 |
SOCKET_0_RD_ACCESS |
0x12d |
统计从本地 CPU 到 CNVLINK Socket 0 内存或 NVLINK-C2C socket 0 内存的 SCF 读取访问次数。每个周期按新的读取访问总数递增。 |
SOCKET_1_RD_ACCESS |
0x12e |
统计从本地 CPU 到 CNVLINK Socket 1 内存或 NVLINK-C2C socket 1 内存的 SCF 读取访问次数。每个周期按新的读取访问总数递增。 |
SOCKET_2_RD_ACCESS |
0x12f |
统计从本地 CPU 到 CNVLINK Socket 2 内存的 SCF 读取访问次数。每个周期按新的读取访问总数递增。 |
SOCKET_3_RD_ACCESS |
0x130 |
统计从本地 CPU 到 CNVLINK Socket 3 内存的 SCF 读取访问次数。每个周期按新的读取访问总数递增。 |
SOCKET_0_WB_ACCESS |
0x135 |
统计从本地 CPU 到 CNVLINK socket 0 内存或 NVLINK-C2C socket 0 内存的所有写回(clean 和 dirty)访问次数。 |
SOCKET_1_WB_ACCESS |
0x136 |
统计从本地 CPU 到 CNVLINK socket 1 内存或 NVLINK-C2C socket 1 内存的所有写回(clean 和 dirty)访问次数。 |
SOCKET_2_WB_ACCESS |
0x137 |
统计从本地 CPU 到 CNVLINK socket 2 内存的所有写回(clean 和 dirty)访问次数。 |
SOCKET_3_WB_ACCESS |
0x138 |
统计从本地 CPU 到 CNVLINK socket 3 内存的所有写回(clean 和 dirty)访问次数。 |
SOCKET_0_WR_ACCESS |
0x139 |
统计从本地 CPU 到 CNVLINK socket 0 内存或 NVLINK-C2C socket 0 内存的写独占和非一致性写入访问次数。 |
SOCKET_1_WR_ACCESS |
0x13a |
统计从本地 CPU 到 CNVLINK socket 1 内存或 NVLINK-C2C socket 1 内存的写独占和非一致性写入访问次数。 |
SOCKET_2_WR_ACCESS |
0x13b |
统计从本地 CPU 到 CNVLINK socket 2 内存的写独占和非一致性写入访问次数。 |
SOCKET_3_WR_ACCESS |
0x13c |
统计从本地 CPU 到 CNVLINK socket 3 内存的写独占和非一致性写入访问次数。 |
REMOTE_SOCKET_WR_TOTAL_BYTES |
0x1a1 |
统计通过写回、写独占、非一致性写入和所有原子操作传输到远程 socket 内存的总字节数。对于非一致性写入,字节数基于大小字段。 |
REMOTE_SOCKET_RD_DATA |
0x1a2 |
统计从所有 CNVLINK 远程 socket 内存或 NVLINK-C2C 远程 socket 内存传输的读取数据节拍总数。每个数据节拍传输最多 32 字节。 |
REMOTE_SOCKET_RD_OUTSTANDING |
0x1a3 |
统计到所有 CNVLINK 远程 socket 内存或 NVLINK-C2C 远程 socket 内存的未完成读取访问总数。每个周期按未完成计数总数递增。 |
REMOTE_SOCKET_RD_ACCESS |
0x1a4 |
统计到所有 CNVLINK 远程 socket 内存或 NVLINK-C2C 远程 socket 内存的读取访问次数。每个周期按新的读取访问总数递增。 |
SCF 最大传输请求利用率#
目标 |
每个周期的最大读取请求数 |
每个周期的最大写入请求数 |
|---|---|---|
CMEM |
8 (RD_ACCESS) |
8 (WR_ACCESS 或 WB_ACCESS) |
GMEM |
4 (RD_ACCESS) |
4 (WR_ACCESS 或 WB_ACCESS) |
REMOTE |
2 (RD_ACCESS) |
2 (WR_ACCESS 或 WB_ACCESS) |
SCF PMU 指标#
本节提供了基于可扩展一致性 Fabric (SCF) PMU 提供的事件的有用性能指标的附加公式。
持续时间:以纳秒为单位的测量持续时间。
事件:
DURATION_TIME
周期数:SCF 周期计数
事件:
CYCLES
SCF 频率: SCF 周期的频率,单位为 GHz
指标公式:
CYCLES/DURATION_TIME
本地 CPU 内存写入带宽: 到本地 CPU 内存的写入带宽,单位为 GBps。
来源
Grace CPU Superchip:本地和远程 CPU
单 socket Grace Hopper Superchip:本地 CPU
目标:本地 CPU 内存
指标公式:
CMEM_WR_TOTAL_BYTES/DURATION_TIME
本地 CPU 内存读取带宽: 从本地 CPU 内存的读取带宽,单位为 GBps。
来源
Grace CPU Superchip:本地和远程 CPU
单 socket Grace Hopper Superchip:本地 CPU
目标:本地 CPU 内存
指标公式:
CMEM_RD_DATA*32/DURATION_TIME
本地 GPU 内存写入带宽: 到本地 GPU 内存的写入带宽,单位为 GBps。
来源:本地 CPU
目标
Grace CPU Superchip:不适用
单 socket Grace Hopper Superchip:本地 GPU 内存
指标公式:
GMEM_WR_TOTAL_BYTES/DURATION_TIME
本地 GPU 内存读取带宽: 从本地 GPU 内存的读取带宽,单位为 GBps。
来源:本地 CPU
目标
Grace CPU Superchip:不适用
单 socket Grace Hopper Superchip:本地 GPU 内存
指标公式:
GMEM_RD_DATA*32/DURATION_TIME
远程内存写入带宽:到远程 socket 内存的写入带宽,单位为 GBps。
来源:本地 CPU
目标
Grace CPU Superchip:远程 CPU 内存
单 socket Grace Hopper Superchip:不适用
指标公式:
REMOTE_SOCKET_WR_TOTAL_BYTES/DURATION_TIME
远程内存读取带宽:从远程 socket 内存的读取带宽,单位为 GBps。
来源:本地 CPU
目标
Grace CPU Superchip:远程 CPU 内存
单 socket Grace Hopper Superchip:不适用
指标公式:
REMOTE_SOCKET_RD_DATA*32/DURATION_TIME
本地 CPU 内存写入利用率百分比: 本地 CPU 内存写入的百分比使用率。
来源
Grace CPU Superchip:本地和远程 CPU
单 socket Grace Hopper Superchip:本地 CPU
目标:本地 CPU 内存
指标公式:
((CMEM_WB_ACCESS + CMEM_WR_ACCESS)/(8*CYCLES)) * 100.0
本地 GPU 内存写入利用率百分比: 本地 GPU 内存写入的百分比使用率。
来源:本地 CPU
目标
Grace CPU Superchip:不适用
单 socket Grace Hopper Superchip:本地 GPU 内存
指标公式:
((GMEM_WB_ACCESS + GMEM_WR_ACCESS)/(4*CYCLES)) * 100.0
远程内存写入利用率百分比: 远程 socket 内存写入的百分比使用率。
来源:本地 CPU
目标
Grace CPU Superchip:远程 CPU 内存
单 socket Grace Hopper Superchip:不适用
指标公式
Socket 0 访问 socket 1 内存(在 socket 0 中测量):
((SOCKET_1_WB_ACCESS + SOCKET_1_WR_ACCESS)/(2*CYCLES)) * 100.0Socket 1 访问 socket 0 内存(在 socket 1 中测量):
((SOCKET_0_WB_ACCESS + SOCKET_0_WR_ACCESS)/(2*CYCLES)) * 100.0
本地 CPU 内存读取利用率百分比: 本地 CPU 内存读取的百分比使用率。
来源
Grace CPU Superchip:本地和远程 CPU
单 socket Grace Hopper Superchip:本地 CPU
目标:本地 CPU 内存
指标公式:
((CMEM_RD_ACCESS)/(8*CYCLES)) * 100.0
本地 GPU 内存读取利用率百分比:本地 GPU 内存读取的百分比使用率。
来源:本地 CPU
目标
Grace CPU Superchip:不适用
单 socket Grace Hopper Superchip:本地 GPU 内存
指标公式:
((GMEM_RD_ACCESS)/(4*CYCLES)) * 100.0
远程内存读取利用率百分比: 远程 socket 内存读取的百分比使用率。
来源:本地 CPU
目标
Grace CPU Superchip:远程 CPU 内存
单 socket Grace Hopper Superchip:不适用
指标公式
Socket 0 访问 socket 1 内存(在 socket 0 中测量):
((SOCKET_1_RD_ACCESS)/(2*CYCLES)) * 100.0Socket 1 访问 socket 0 内存(在 socket 1 中测量):
((SOCKET_0_RD_ACCESS)/(2 * CYCLES)) * 100.0
本地 CPU 内存读取延迟: 从本地 CPU 内存读取的平均延迟,单位为纳秒。
来源
Grace CPU Superchip:本地和远程 CPU
单 socket Grace Hopper Superchip:本地 CPU
目标:本地 CPU 内存
指标公式:
(CMEM_RD_OUTSTANDING/CMEM_RD_ACCESS)/(CYCLES/DURATION)
本地 GPU 内存读取延迟: 从本地 GPU 内存读取的平均延迟,单位为纳秒。
来源:本地 CPU
目标
Grace CPU Superchip:不适用
单 socket Grace Hopper Superchip:本地 GPU 内存
指标公式:
(GMEM_RD_OUTSTANDING/GMEM_RD_ACCESS)/(CYCLES/DURATION)
远程内存读取延迟: 从远程内存读取的平均延迟,单位为纳秒。
来源:本地 CPU
目标
Grace CPU Superchip:远程 CPU 内存
单 socket Grace Hopper Superchip:不适用
指标公式
Socket 0 访问 socket 1 内存(在 socket 0 中测量):
(SOCKET_1_RD_OUTSTANDING/SOCKET_1_RD_ACCESS)/(CYCLES/DURATION)Socket 1 访问 socket 0 内存(在 socket 1 中测量):
(SOCKET_0_RD_OUTSTANDING/SOCKET_0_RD_ACCESS)/(CYCLES/DURATION)
PCIe PMU 记账#
PCIe PMU 事件#
下表提供了 PMU 驱动程序和 perf 工具公开的事件。
事件名称 |
ID |
描述 |
|---|---|---|
CYCLES |
0x100000000 |
PCIe PMU 周期计数器。 |
WR_REQ_LOC |
0x8 |
统计到本地 CMEM 或 GMEM 的 PCIe 写入请求数。 |
RD_REQ_LOC |
0x6 |
统计到本地 CMEM 或 GMEM 的 PCIe 读取请求数。 |
TOTAL_REQ_LOC |
0xa |
统计到本地 CMEM 或 GMEM 的 PCIe 读取/写入请求数。 |
WR_BYTES_LOC |
0x2 |
统计到本地 CMEM 或 GMEM 的 PCIe 写入字节数。 |
RD_BYTES_LOC |
0x0 |
统计到本地 CMEM 或 GMEM 的 PCIe 读取字节数。 |
TOTAL_BYTES_LOC |
0x4 |
统计到本地 CMEM 或 GMEM 的 PCIe 读取/写入字节数。 |
RD_CUM_OUTS_LOC |
0xc |
累积到本地 CMEM 或 GMEM 的 PCIe 未完成读取请求周期数。 |
WR_REQ_REM |
0x9 |
统计到远程 CMEM 或 GMEM 的 PCIe 写入请求数。 |
RD_REQ_REM |
0x7 |
统计到远程 CMEM 或 GMEM 的 PCIe 读取请求数。 |
TOTAL_REQ_REM |
0xb |
统计到远程 CMEM 或 GMEM 的 PCIe 读取/写入请求数。 |
WR_BYTES_REM |
0x3 |
统计到远程 CMEM 或 GMEM 的 PCIe 写入字节数。 |
RD_BYTES_REM |
0x1 |
统计到远程 CMEM 或 GMEM 的 PCIe 读取字节数。 |
TOTAL_BYTES_REM |
0x5 |
统计到远程 CMEM 或 GMEM 的 PCIe 读取/写入字节数。 |
RD_CUM_OUTS_REM |
0xd |
累积到远程 CMEM 或 GMEM 的 PCIe 未完成读取请求周期数 |
PCIe 最大传输请求利用率#
来源(目标:本地/远程) |
每个周期的最大读取请求数 |
每个周期的最大写入请求数 |
|---|---|---|
Root Ports 0-9 |
每个端口 1 个。 |
每个端口 1 个 32B 请求。 |
PCIe PMU 指标#
本节提供了基于 PCIe PMU 提供的事件的有用性能指标的附加公式。
注意
以下所有 PCIe 指标都受 root port 过滤器的影响。如果您未定义 root port 过滤器,则指标结果将为零(有关更多信息,请参阅 PCIe 流量管理)。
PCIe RP 频率: PCIe RP 内存客户端接口周期的频率,单位为 GHz。
指标公式:
CYCLES/DURATION_TIME
PCIe RP 读取带宽: PCIe root port 读取带宽,单位为 GBps。
来源:本地 PCIe root port
目标:本地和远程内存
指标公式:
(RD_BYTES_LOC + RD_BYTES_REM)/DURATION_TIME
PCIe RP 写入带宽: PCIe root port 写入带宽,单位为 GBps。
来源:本地 PCIe root port
目标:本地和远程内存
指标公式:
(WR_BYTES_LOC + WR_BYTES_REM)/DURATION_TIME
PCIe RP 双向带宽: PCIe root port 读取和写入带宽,单位为 GBps。
来源:本地 PCIe root port
目标:本地和远程内存
指标公式:
(RD_BYTES_LOC + RD_BYTES_REM + WR_BYTES_LOC + WR_BYTES_REM)/DURATION_TIME
PCIe RP 读取利用率百分比: PCIe root port 读取的平均百分比利用率。
来源:本地 PCIe root port
目标:本地和远程内存
指标公式:
((RD_REQ_LOC + RD_REQ_REM)/(10 * CYCLES) ) * 100.0
PCIe RP 写入利用率百分比: PCIe root port 写入的平均百分比利用率。
来源:本地 PCIe root port
目标:本地和远程内存
指标公式:
( (WR_REQ_LOC + WR_REQ_REM)/(10 * CYCLES) ) * 100.0
PCIE RP 本地内存读取延迟: PCIe root port 读取到本地内存的平均延迟,单位为纳秒。
注意
此指标不包括 PCIe 互连的延迟。
来源:本地 PCIe root port
目标:本地内存
指标公式:
(RD_CUM_OUTS_LOC/RD_REQ_LOC)/(CYCLES/DURATION_TIME)
PCIE RP 远程内存读取延迟: PCIe root port 读取到远程内存的平均延迟,单位为纳秒。
注意
此指标不包括 PCIe 互连的延迟。
来源:本地 PCIe root port
目标:远程内存
指标公式:
(RD_CUM_OUTS_REM/RD_REQ_REM)/(CYCLES/DURATION_TIME)
NVLink C2C PMU 记账#
注意
此 PMU 不监控 CPU 流量。用户应使用 SCF PMU 来捕获远程 CPU 流量。
来自此 PMU 的计数不包括互连延迟。
NVLink C2C PMU 监控从 NVLink 芯片到芯片 (C2C) 互连到本地内存的流量。此 PMU 捕获的流量仅限于以下流量
来自 Grace CPU Superchip 系统中远程 PCIe 设备的请求。
来自 Grace Hopper Superchip 系统中一致性 GPU 的请求。
有两个 C2C PMU,NVLINK-C2C0 和 NVLINK-C2C1 可用,并涵盖不同类型的流量。有关每个 PMU 涵盖的流量模式的更多信息,请参阅上面的Grace Superchip 上的访问模式的 PMU 记账和Grace Hopper Superchip 上的访问模式的 PMU 记账表格。NVLINK-C2C1 PMU 在 Grace Superchip 上未使用。
NVLink C2C PMU 事件#
下表提供了 PMU 驱动程序和 perf 工具公开的事件。
事件名称 |
ID |
描述 |
|---|---|---|
CYCLES |
0x100000000 |
NVLink-C2C0 PMU 周期计数器。 |
WR_REQ_LOC |
0x8 |
统计 Grace 一致性 GPU 中的 GPU ATS 转换的写入请求数或 Grace CPU Superchip 中远程 PCIe 宽松顺序写入请求数到本地 CMEM 或 GMEM 的次数。 |
RD_REQ_LOC |
0x6 |
统计 Grace 一致性 GPU 中的 GPU ATS 转换的读取请求数或 Super Grace 中远程 PCIe 读取请求数到本地 CMEM 或 GMEM 的次数。 |
TOTAL_REQ_LOC |
0xa |
统计 Grace 一致性 GPU 中的 GPU ATS 转换的读取/写入请求数或 Grace CPU Superchip 中远程 PCIe 读取/宽松顺序写入请求数到本地 CMEM 或 GMEM 的次数。 |
WR_BYTES_LOC |
0x2 |
统计 Grace 一致性 GPU 中的 GPU ATS 转换的写入字节数或 Grace CPU Superchip 中远程 PCIe 宽松顺序写入字节数到本地 CMEM 或 GMEM 的次数。 |
RD_BYTES_LOC |
0x0 |
统计 Grace 一致性 GPU 中的 GPU ATS 转换的读取字节数或 Grace CPU Superchip 中远程 PCIe 读取字节数到本地 CMEM 或 GMEM 的次数。 |
TOTAL_BYTES_LOC |
0x4 |
统计 Grace 一致性 GPU 中的 GPU ATS 转换的读取/写入字节数或 Grace CPU Superchip 中远程 PCIe 读取/宽松顺序写入字节数到本地 CMEM 或 GMEM 的次数。 |
RD_CUM_OUTS_LOC |
0xc |
累积 Grace 一致性 GPU 中 GPU ATS 转换的未完成读取请求周期数或 Grace CPU Superchip 周期中远程 PCIe 读取未完成读取请求周期数到本地 CMEM 或 GMEM 的次数。 |
WR_REQ_REM |
0x9 |
统计 Grace 一致性 GPU 中 GPU ATS 转换的写入请求数到远程 CMEM 或 GMEM 的次数。 |
RD_REQ_REM |
0x7 |
统计 Grace 一致性 GPU 中 GPU ATS 转换的读取请求数到远程 CMEM 或 GMEM 的次数。 |
TOTAL_REQ_REM |
0xb |
统计 Grace 一致性 GPU 中 GPU ATS 转换的读取/写入请求数到远程 CMEM 或 GMEM 的次数。 |
WR_BYTES_REM |
0x3 |
统计 Grace 一致性 GPU 中 GPU ATS 转换的写入字节数到远程 CMEM 或 GMEM 的次数。 |
RD_BYTES_REM |
0x1 |
统计 Grace 一致性 GPU 中 GPU ATS 转换的读取字节数到远程 CMEM 或 GMEM 的次数。 |
TOTAL_BYTES_REM |
0x5 |
统计 Grace 一致性 GPU 中 GPU ATS 转换的读取/写入字节数到远程 CMEM 或 GMEM 的次数。 |
RD_CUM_OUTS_REM |
0xd |
累积 Grace 一致性 GPU 中 GPU ATS 转换的未完成读取请求周期数到远程 CMEM 或 GMEM 的次数。 |
事件名称 |
ID |
描述 |
|---|---|---|
CYCLES |
0x100000000 |
NVLink-C2C1 PMU 周期计数器。 |
WR_REQ_LOC |
0x8 |
统计 Grace 一致性 GPU 中 GPU 非 ATS 转换的写入请求数到本地 CMEM 或 GMEM 的次数。 |
RD_REQ_LOC |
0x6 |
统计 Grace 一致性 GPU 中 GPU 非 ATS 转换的读取请求数到本地 CMEM 或 GMEM 的次数。 |
TOTAL_REQ_LOC |
0xa |
统计 Grace 一致性 GPU 中 GPU 非 ATS 转换的读取/写入请求数到本地 CMEM 或 GMEM 的次数。 |
WR_BYTES_LOC |
0x2 |
统计 Grace 一致性 GPU 中 GPU 非 ATS 转换的写入字节数到本地 CMEM 或 GMEM 的次数。 |
RD_BYTES_LOC |
0x0 |
统计 Grace 一致性 GPU 中 GPU 非 ATS 转换的读取字节数到本地 CMEM 或 GMEM 的次数。 |
TOTAL_BYTES_LOC |
0x4 |
统计 Grace 一致性 GPU 中 GPU 非 ATS 转换的读取/写入字节数到本地 CMEM 或 GMEM 的次数。 |
RD_CUM_OUTS_LOC |
0xc |
累积 Grace 一致性 GPU 周期中 GPU 非 ATS 转换的未完成读取请求周期数到本地 CMEM 或 GMEM 的次数。 |
WR_REQ_REM |
0x9 |
统计 Grace 一致性 GPU 中 GPU 非 ATS 转换的写入请求数到远程 CMEM 或 GMEM 的次数。 |
RD_REQ_REM |
0x7 |
统计 Grace 一致性 GPU 中 GPU 非 ATS 转换的读取请求数到远程 CMEM 或 GMEM 的次数。 |
TOTAL_REQ_REM |
0xb |
统计 Grace 一致性 GPU 中 GPU 非 ATS 转换的读取/写入请求数到远程 CMEM 或 GMEM 的次数。 |
WR_BYTES_REM |
0x3 |
统计 Grace 一致性 GPU 中 GPU 非 ATS 转换的写入字节数到远程 CMEM 或 GMEM 的次数。 |
RD_BYTES_REM |
0x1 |
统计 Grace 一致性 GPU 中 GPU 非 ATS 转换的读取字节数到远程 CMEM 或 GMEM 的次数。 |
TOTAL_BYTES_REM |
0x5 |
统计 Grace 一致性 GPU 中 GPU 非 ATS 转换的读取/写入字节数到远程 CMEM 或 GMEM 的次数。 |
RD_CUM_OUTS_REM |
0xd |
累积 Grace 一致性 GPU 中 GPU 非 ATS 转换的未完成读取请求周期数到远程 CMEM 或 GMEM 的次数。 |
NVLink C2C 最大传输请求利用率#
来源(目标:本地/远程) |
每个周期的最大读取请求数 |
每个周期的最大写入请求数 |
|---|---|---|
Grace Hopper Superchip 在单 GPU 模式下:每个 GPU 10 个 C2C 端口 |
每个端口 1 个。 |
每个端口 1 个 32B 请求。 |
NVLink C2C PMU 指标#
本节提供了基于 NVLINK-C2C PMU 提供的事件的有用性能指标的附加公式。
NVLink C2C 客户端接口频率: NVLink C2C 内存客户端接口周期的频率,单位为 GHz。
指标公式:
CYCLES/DURATION_TIME
GPU 或远程 PCIe 流量读取带宽: 读取流量的带宽,单位为 GBps。
来源:GPU 或远程 socket 的 PCIe
目标:本地内存
指标公式:
(RD_BYTES_LOC)/DURATION_TIME
GPU 或远程 PCIe 流量写入带宽: 写入流量的带宽,单位为 GBps。
来源:GPU 或远程 socket 的 PCIe
目标:本地内存
指标公式:
(WR_BYTES_LOC)/DURATION_TIME
GPU 或远程 PCIe 流量双向带宽: 读取和写入流量的带宽,单位为 GBps。
来源:GPU 或远程 socket 的 PCIe
目标:本地内存
指标公式:
(RD_BYTES_LOC + WR_BYTES_LOC )/DURATION_TIME
GPU 或远程 PCIe 流量读取利用率百分比: NVLink-C2C 客户端接口读取的平均百分比使用率。
来源:GPU 或远程 socket 的 PCIe
目标:本地内存
指标公式:
((RD_REQ_LOC)/(10 * CYCLES) ) * 100.0
GPU 或远程 PCIe 流量写入利用率百分比: NVLink-C2C 客户端接口写入的平均使用率。
来源:GPU 或远程 socket 的 PCIe
目标:本地内存
指标公式:
((WR_REQ_LOC)/(10 * CYCLES) ) * 100.0
GPU 或远程 PCIe 到本地内存读取延迟: 读取到本地内存的平均延迟,单位为纳秒。
注意
此指标不包含 NVLink-C2C 互连的延迟(更多信息请参考 GPU 流量测量)。
来源:GPU 或远程 socket 的 PCIe
目标:本地内存
指标公式:
(RD_CUM_OUTS_LOC/RD_REQ_LOC)/(CYCLES/DURATION_TIME)
使用 Nsight Systems 分析 CPU 行为#
Nsight Systems 工具(也称为 nsys)分析系统的计算单元,包括 CPU 和 GPU(更多信息请参考 Nsight Systems)。该工具可以追踪超过 25 个 API,包括 CUDA API,采样 CPU 指令指针/回溯,采样 CPU 和 SoC 事件计数,以及采样 GPU 硬件事件计数,以提供工作负载行为的系统级视图。
nsys 可以采样 CPU 和 SoC 事件,并在 nsys UI 时间线上绘制其速率图。它可以生成 Grace CPU 性能指标 到 NVLink C2C 计数 中描述的指标,并在 nsys UI 时间线上绘制它们。如果同时收集 CPU IP/回溯数据,用户可以确定 CPU 和 SoC 事件何时非常活跃(或不活跃),并将该信息与 IP/回溯数据相关联,以确定当时哪个工作负载方面正在积极运行。
下图显示了 nsys 配置文件时间线的示例。在本例中,除了每个 CPU 上的 IPC(每周期指令数)核心指标外,还收集了两个 Grace C2C0 插槽指标。C2C0 指标(C2C0 读取和写入利用率百分比)显示 GPU 对 CPU 内存的访问。IPC 指标显示线程 2965407(在 CPU 146 上运行)在 C2C0 活动之前是内存受限的(IPC 值约为 0.05)。线程 2965407 下方的橙黄色刻度线表示单个指令指针/回溯样本。用户可以将鼠标悬停在这些样本上以获取回溯,该回溯表示线程当时正在执行的代码。此数据可用于了解工作负载当时正在做什么。

Nsight Systems 时间线示例#
使用 --cpu-core-metrics、--cpu-socket-metrics 和 --sample nsys CLI 开关来收集上述数据。另请参阅用于分析 CPU 和/或 SoC 性能问题的 --cpu-core-events、--cpu-socket-events 和 --cpuctxsw nsys CLI 开关。有关更多信息,请运行 nsys profile --help 命令。
重要提示
--cpu-socket-metrics 需要 nsys 2024.4 或更高版本。