NVIDIA DGX SuperPOD 常见问题解答#
简介#
在哪里可以找到关于 NVIDIA DGX SuperPOD 的最新信息?
NVIDIA DGX SuperPOD 登陆页面提供了关于 DGX SuperPOD 优势的数据表和高级参考。更多详细信息可以在NVIDIA DGX SuperPOD 文档中找到。大多数客户认为 NVIDIA DGX SuperPOD 参考架构 - DGX H100 和 NVIDIA DGX SuperPOD:数据中心设计 - DGX H100 文档尤其有用。
重要提示
这些文档会频繁更新,所以请务必查看上述网站上的最新版本!
什么是 NVIDIA DGX SuperPOD 解决方案(产品)?
NVIDIA DGX SuperPOD 解决方案(产品)是一种统包式硬件、软件、服务和支持产品,消除了构建和部署 AI 基础设施时的猜测。对于需要可靠且经过验证的大规模 AI 创新方法的客户,我们将内部部署系统“Eos”封装成全面的解决方案、服务和支持产品。NVIDIA DGX SuperPOD 解决方案提供全面的服务体验,可在数周而不是数月内为每个需要领先级基础设施的组织交付行业验证的结果,并通过与您的业务智能集成的白手套实施,使您的团队能够更快地交付成果。DGX SuperPOD 可从 31 个扩展到 1,023 个 DGX 系统节点。
NVIDIA DGX SuperPOD 支持哪些 DGX 系统?
NVIDIA DGX SuperPOD 支持 DGX H100 系统。采用 DGX H100 的 SuperPOD 基于 NVIDIA Quantum 2 网络,其计算结构速度高达 400 Gb/s,采用 NDR400。
数据中心架构#
NVIDIA 针对 DGX SuperPOD 建议的参考架构是什么?
DGX SuperPOD 设计引入了称为可扩展单元 (SU) 的计算构建块。SuperPOD H100 设计的 SU 大小为每个 SU 32 个 DGX H100 节点。DGX SuperPOD 设计包括 NVIDIA 网络交换机和软件、DGX SuperPOD 认证的存储以及NVIDIA NGC™优化软件。参考架构文档列举了 NVIDIA DGX SuperPOD 的所有组件和配置。
针对 DGX SuperPOD,数据中心托管提供商有哪些注意事项?
DGX SuperPOD 将多个 DGX 系统、高速网络、存储和管理服务器集成到一个解决方案中。这种集成解决方案具有复杂的电源和散热要求。数据中心设计指南中讨论了这些要求。请参阅本文档以了解 DGX SuperPOD 的数据中心要求和规划细节。
硬件#
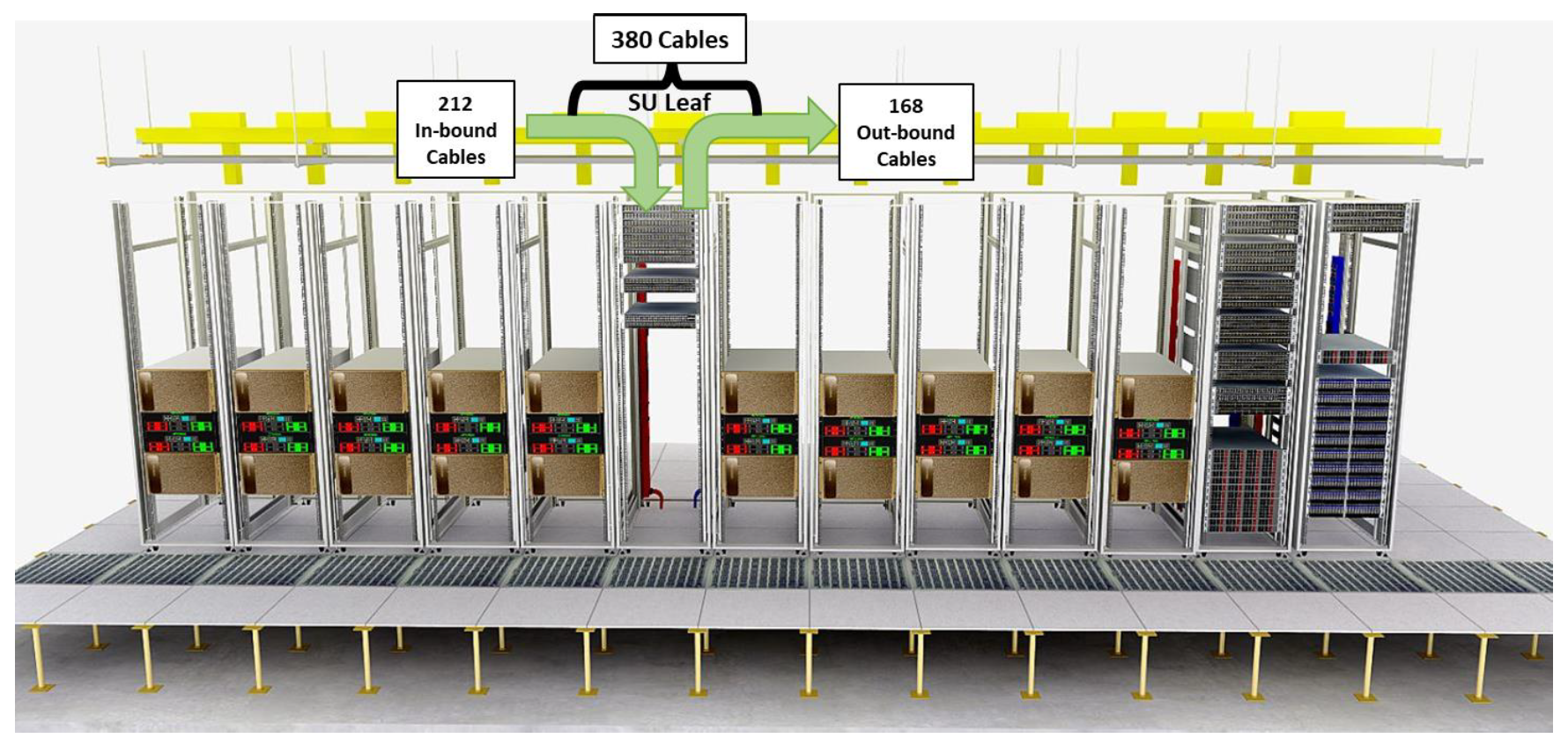
单个 SU 是什么样的?
以下是单个 SU 的示例图。根据数据中心的不同,机架的配置可能会因当地数据中心的要求而异,包括每个机架的最大功率和冷却基础设施。

NVIDIA DGX BasePOD 和 NVIDIA DGX SuperPOD 之间有什么区别?
DGX SuperPOD 是 NVIDIA 向市场提供的产品。DGX SuperPOD 是一个完整的统包解决方案,具有特定的物料清单、安装服务、支持服务和有保障的性能。DGX BasePOD 是一种更灵活的解决方案,主要由 NVIDIA 认证的存储供应商驱动。NVIDIA 为 DGX BasePOD 提供参考架构和规范,但存储供应商可以根据客户需求对其进行定制。NVIDIA DGX BasePOD 基本上包含 NVIDIA DGX、NVIDIA 网络和 NVIDIA 软件,包括 Base Command Manager (BCM) 和经过认证的第三方存储。虽然建议使用参考架构,但要被视为 DGX BasePOD,这不是必需的。
NVIDIA DGX SuperPOD/DGX BasePOD 和大型 DGX 节点集群之间有什么区别?
DGX SuperPOD 是一个完整的统包解决方案,具有特定的物料清单、安装服务、支持服务和有保障的性能。大型集群部署是指未使用 DGX SuperPOD 或 DGX BasePOD 的核心组件之一的情况。例如,如果客户有自己的集群管理解决方案,或者客户想要使用未认证的存储或其他供应商的网络设备。这将被**不**视为 SuperPOD 或 BasePOD。
允许对 DGX SuperPOD 设计进行哪些更改?
NVIDIA DGX SuperPOD 是一种镜像 NVIDIA 内部运营的解决方案,这使得 NVIDIA 能够提供最佳的客户体验。允许进行小的调整以与特定环境集成,例如调整每个机架的 DGX 系统数量、更改电缆长度或选择替代机架或 PDU 以符合目标数据中心的标准。
可能会影响 NVIDIA DGX SuperPOD 的性能或功能的更改,例如使用备用集群管理器或作业调度器(例如,Kubernetes 而不是 Slurm)、在集群上运行不同的操作系统(例如,Red Hat 而不是 Ubuntu/DGX OS)、使用非 DGX SuperPOD 认证的存储,或更改计算、存储或带内管理结构拓扑,通常会使系统失去成为 NVIDIA DGX SuperPOD 的资格。在许多情况下,该系统仍然是 NVIDIA DGX BasePOD,并将作为 DGX BasePOD 进行安装、支持和操作。
SuperPOD 能否在 SU 之间通过 VLAN 进行逻辑拆分?
否,SuperPOD 只能在物理上拆分为完全独立的计算结构
要成为 NVIDIA DGX SuperPOD,必须安装多少个 DGX 系统?
尺寸大小不是决定某物是否为 NVIDIA DGX SuperPOD 的因素。
如之前的问题所述,NVIDIA DGX SuperPOD 的重点是部署和运营与 NVIDIA 自身镜像的解决方案,以便最容易利用 NVIDIA 对其自身 DGX SuperPOD 部署所做的经验和持续改进 - 而不是系统数量。虽然 1SU DGX SuperPOD 配置是起点,但即使该 SU 中的所有 DGX 系统最初都未安装,它仍然可能是 NVIDIA DGX SuperPOD。相反,一个集群可能安装了数百个 DGX 系统,但由于它包含使其成为 NVIDIA DGX BasePOD 或大型自定义 DGX 集群的变体,因此它可能不是 NVIDIA DGX SuperPOD。
DGX SuperPOD 中使用什么网络?
根据 NVIDIA DGX SuperPOD H100 参考架构中的定义,DGX SuperPOD 需要多个网络。这些网络包括明确定义的计算、存储、带内和带外结构。DGX SuperPOD 仅支持 NVIDIA 网络。所有支持的交换机都在 RA 中定义。
DGX SuperPOD 使用什么高性能(内环)存储?
目前,唯一经过认证的存储是 DDN AI400X、Dell PowerScale、IBM Storage Scale、NetApp BeeGFS (E-Series)、WEKA 和 VAST。
DGX SuperPOD 需要哪些其他存储,但不包含在内?
用于 $HOME 的基于 NFS 的存储系统和作为外环存储的对象存储/数据湖。此外,还应考虑云爆发能力。客户负责确定范围并采购独立于 DGX SuperPOD 的此存储。
NVIDIA SuperPOD 始终是前后冷却吗?
是的。选择 NVIDIA SuperPOD 组件是为了从 DGX H100 面板侧吸入冷空气。
在风冷数据中心中,您见过的每个机架部署的 DGX 系统最多是多少个?一个机架上没有液冷的?
对于 DGX H100,除非数据中心是专门为显着更高的功率和冷却密度而设计的,否则两个是实际的最大值。然后,每个机架可能可以容纳三到四个 H100 节点。问题在于风冷数据中心和每个机架可用的功率。请注意,DGX 部署的可扩展性在于创建多个 SU 的能力,所有这些 SU 都连接回公共的 Infiniband 脊柱和核心,具体取决于系统的总大小。这与您可以在机架中放置多少个 DGX 系统无关,而与您可以在数据中心中引入多少个 SU 有关。
DGX 系统在 GPU 满载时的运行温度范围应该是多少?
DGX H100 的运行温度为 5–30 ºC (41–86 ºF)。
后门会改变我的气流要求吗?
如果管道可以容纳进入后门的供水解决方案,则后门热交换器可以在您的数据中心中提供更高的冷却密度。这使您可以通过将冷冻水更靠近 IT 机柜来增强数据中心的冷却能力。请确保您了解添加后门的任何限制 - 您的机柜后部空间、电缆部署和机架 PDU (rPDU) 也必须与后门相适应。
您不必担心冷却后门产生的背压吗?
如果您担心背压,请考虑使用带有风扇组件的有源后门来辅助气流。有源后门通常具有压力和温度监控器,可控制门风扇,因此您可以获得最佳气流以避免背压问题。如果您一直运行高密度、高性能工作负载,则有源后门可能是一种可以设计为满足冷却要求的选项。
这些电路是否必须是三相电路?
要使用单个公用电路及其冗余合作伙伴达到功率密度,如果我们试图支持每个机架多个 DGX H100 系统,则必须使用三相电源。可以使用多个单相 208V 电路来适应这种情况,但这需要在每个机架中引入许多电路。NVIDIA DGX SuperPOD:数据中心设计 - DGX H100 文档提供了各种推荐的数据中心电源配置示例,以实现最佳的 NVIDIA DGX SuperPOD 运行。
DGX H100 系统的功耗和物理尺寸是多少?
DGX H100 系统的功率为 10.2 kW,8U。
NVIDIA 是否指定了某些机柜尺寸或参数?
是的。虽然 NVIDIA 未指定要使用的机架的特定品牌或型号,但确实指定了机架必须符合 EIA-310 标准,用于带有 19 英寸 EIA 安装的封闭式机架。机柜的尺寸必须至少为 24 英寸 x 44 英寸(600 毫米 × 1100 毫米),并且高度至少为 42 RU。NVIDIA 建议使用 30 英寸 x 48 英寸 x 52 RU(700 毫米 × 1200 毫米)的机架。
是否可以使用配线面板或架顶式交换机来延长 InfiniBand 电缆长度限制?您对布线有什么建议吗?
否。InfiniBand 是一种极高性能的架构,其电缆长度限制基于整个信号路径的信号衰减和延迟,而不仅仅是电缆的一段。配线面板会加剧信号衰减,而中间的架顶式交换机会增加延迟。
此外,我们建议将电缆按相关性分组捆绑在一起(即,交换机间链路、到核心设备的上行链路),以简化管理和故障排除。此外,请使用正确的电缆长度。在每一端只留一点松弛。保持电缆运行距离低于有源光缆 (AOC) 支持的最大距离的 90%。提前安装和间隔电缆,以便将来更换损坏的电缆。最后,使用电缆扎带的颜色编码来指示端点,并在两端和沿途贴上适当的标签。
NVIDIA 是否指定了某些 rPDU 类型?
由于 rPDU 必须符合每个数据中心可用的电力供应以及每个市场区域可用的品牌,因此 NVIDIA 未指定特定的品牌或型号。但是,我们建议 SuperPOD 设计包括 rPDU,它们具有集成智能模块、网络接口、SNMP 接口、RestAPI 接口、用于温度和传感器探头的端口、锁定插座、PDU 级别计量、每个插座的远程插座切换以及可选的红色和蓝色外观颜色。
我可以部署多少个 SU?
一个 SuperPOD 最多可以包含四个 SU(经过测试的配置)。
如果我想部署超过四个 SU 怎么办?
标准的 SuperPOD 尺寸为 4 个 SU,可以在DGX SuperPOD 和 BasePOD BOM 配置器中进行配置。DGX SuperPOD H100 RA列出了对最多 64 个 SU 的支持。请使用SuperPOD ARB并将您对大于 4 个 SU 的咨询发送给 ARB。
请联系您的 NVIDIA 代表讨论更大的系统选项。
我是否可以利用 DGX (SU) 机架中的空闲空间来放置其他 IT 设备?
否。DGX SU 是一种工程解决方案,不应与共享机架中不相关的设备共存。
软件#
DGX SuperPOD 包含哪些软件?
每个 DGX 都预装了 DGX OS。NVIDIA DGX OS 提供了 Ubuntu Linux 的定制安装,其中包含特定于系统的优化和配置、附加驱动程序以及诊断和监控工具。它提供了一个稳定、经过全面测试和支持的操作系统,用于在 DGX 超级计算机上运行 AI、机器学习和分析应用程序。
NVIDIA Base Command Manager 为 DGX SuperPOD 提供全面的管理。它对于 DGX SuperPOD 体验至关重要,提供了最大化性能和利用率所需的工具和规范性配置信息。Base Command Manager 是 NVIDIA 用于管理数千个系统以供我们屡获殊荣的数据科学家使用的相同技术,并为需要最佳性能的组织提供了通往 TOP500 超级计算机的直接途径。完整数据表
调度/管理/ML Ops(SuperPOD 部署是否使用了 DGX-Ready SW 或 Slurm/K8s/Singularity 的组合?
DGX SuperPOD 针对多用户、大型 DL/AI 训练和 HPC 工作流程进行了优化。SLURM 是指定的调度和资源管理工具。SLURM 是一种经过企业验证、高效的工作负载调度器,可处理多 GPU 多节点批处理。SuperPOD 使用两个 NVIDIA 开发的开源工具 enroot 和 pyxis,以支持使用 SLURM 进行无根容器化多 GPU 和多节点工作负载管理。
可以使用 Kubernetes 等替代资源管理器,但这超出了当前 DGX SuperPOD 产品的范围。NVIDIA DGX SuperPOD 部署和性能验证将始终在 SLURM 环境中执行,即使最终用例旨在与不同的软件一起使用。一旦软件堆栈发生更改,NVIDIA 将无法将整个解决方案作为 DGX SuperPOD 提供支持。相反,它将被视为 DGX BasePOD,如先前问题中所述。
运营 - 人员配备#
共享环境的治理最佳实践是什么?
共享环境是托管设施、运营团队以及主要研究和科学团队领导者的共同责任。SuperPOD 参考架构未明确涵盖远程访问解决方案,因为它们依赖于站点。SuperPOD 作为一个统一系统运行,仅向外部环境公开管理节点。此架构创建了对 SuperPOD 资源的受控访问。它与符合 GDPR 和其他隐私标准的远程访问解决方案非常匹配,这些标准对于任何共享环境都是重要的考虑因素。
DGX SuperPOD 和 BasePOD 明确地**不是**为多租户环境设计的。
业务 - 预算和策略#
对于 DGX SuperPOD 的各个系统,标准三年企业支持服务是否是强制性的?
是的,对于 DGX SuperPOD 的各个系统,标准三年企业支持服务是强制性的。
每个 NVIDIA DGX SuperPOD 部署是否都需要高级 TAM?
作为 DGX SuperPOD 的一部分,每次部署都必须配备高级技术客户经理。
高级 TAM 服务的主要优势是什么?
高级 TAM 服务的目标客户是必须管理由包括 NVIDIA 在内的多家供应商提供的各种硬件和软件系统的 DGX SuperPOD 客户。高级 TAM 将在 SuperPOD 交付后开始与客户互动。高级
TAM 的可交付成果包括
制定和维护 DGX SuperPOD 的联合支持计划,并定义目标和成功指标
在 NVIDIA 内部路由和管理 DGX SuperPOD 的技术支持案例,并与第三方供应商协调
作为管理技术支持案例的一部分,高级 TAM 将协调软件更新和多供应商问题,包括识别根本原因并与供应商合作以促进问题解决的工作。
DGX SuperPOD 还提供哪些其他服务?
NVIDIA 专业服务安装和部署是 DGX SuperPOD 的必需项。
部署约定是什么样的?
对于每个 DGX SuperPOD 部署,NVIDIA 将提供技术项目管理,以支持成功交付、安装、测试和运营交接。一旦预订销售,指定的项目经理将与客户联系,开始制定每个客户部署的工作说明书。
支持#
DGX SuperPOD 包含哪些支持条款?
DGX SuperPOD 的支持期限或支持期间的长度等于 PTAM 和 DGX H100 企业支持服务、NVIDIA 网络支持条款以及 NVIDIA AI Enterprise 条款和条件的期限。第三方产品必须具有各自供应商的支持服务覆盖范围,以确保可以及时解决非 NVIDIA 技术问题。
NVIDIA 是否支持/建议客户应用程序(例如,深度学习模型扩展问题)
DGX SuperPOD 包含 NVIDIA AI Enterprise,因为它们构建在 NVIDIA DGX H100 系统之上。NVIDIA 企业支持可以解决 NVIDIA AI Enterprise 深度学习容器和框架的问题。
DGXperts 计划允许与 NVIDIA 解决方案架构和工程团队建立首选联系,以便在常规业务支持服务之上进行教育和扩展、尽力而为的支持。
DGX SuperPOD 的关键产品 DGX H100 系统包含哪些支持服务?
DGX H100 系统支持服务可交付成果包括
硬件支持服务 – 远程硬件支持;现场硬件支持和更换,包括下一个工作日的提前 RMA
软件支持服务 – 针对 NGC 以及与 DGX 系统上的基本操作系统(Ubuntu 或 Red Hat)、SBIOS、BMC 和固件相关的问题的远程软件支持
24/7 接受远程支持案例(电子邮件、电话或企业支持门户)
在客户当地工作时间内(上午 9 点至下午 5 点,周一至周五)的升级支持
与 NVIDIA 企业支持部门(由工程部门支持)直接沟通
访问最新的软件更新和升级
访问企业支持门户(案例启动、案例状态、软件/固件存储库和知识库)
访问私有 NGC 注册表
对于包含敏感信息的工作负载,有哪些选项可用于不必将驱动器送出数据中心?
在无法退回故障 SSD 的情况下,可以使用购买 SSD 介质保留服务 (SDMR) 服务。这允许在发生故障和 RMA 时保留物理介质。SDMR 的期限必须与 DGX H100 支持服务相匹配。
在安装和维护期间,如何适应气隙环境?
在气隙环境中部署 NVIDIA DGX SuperPOD 提出了一个重大的挑战,需要在部署前以及每次维护窗口期间进行密切协调和准备。虽然 NVIDIA DGX SuperPOD 在运行期间不需要互联网连接,但如果在部署和持续维护期间没有连接,则可能会带来挑战。在购买 NVIDIA DGX SuperPOD 之前,请与 NVIDIA DGX 团队合作,以确保部署适合预期的环境。