监控集群设备#
集群管理器监控允许集群管理员监控集群中可以监控的任何内容。 大部分监控由预定义的采样配置组成。 如果有任何未配置的内容,但可以对其基于的数据进行采样,则管理员也可以为其配置监控。
监控数据可以按历史记录查看,也可以按需查看。 历史监控数据可以原始格式存储,也可以选择以汇总数据(一种数据摘要方式)存储。
数据可以原始方式处理并在外部处理,也可以在 Base View 中以可自定义图表的形式可视化。 可视化有助于管理员发现趋势和异常行为,并有助于为管理人员提供摘要报告。
监控可以配置为根据触发器设置警报,并且可以根据触发器自动执行预定义或自定义的操作。 可以根据用户定义的条件表达式自定义触发器。
在为触发器设置自动执行操作后,意味着监控系统可以将管理员从执行这些琐事中解放出来。
在本章中,将通过以下方法解释监控系统
首先介绍一个基本示例,其中进程在节点上运行。 这些进程受到监控,并在超过阈值时触发操作。
以这个易于理解的示例作为基本模型,然后更深入地描述和讨论集群管理器监控系统的各种特性和相关功能。 这些包括数据可视化、概念、配置、监控自定义和 cmsh 使用。
基本监控示例和操作#
本节中的示例旨在基本说明监控系统能够处理的内容。 此示例描述了一个结构,在本章的其余部分中,将围绕该结构填充更多细节。
基本监控示例概要#
在本示例中,用户在通常负载很轻的头节点上运行一个人工 CPU 密集型进程。 管理员可以监控整个集群的用户模式 CPU 负载使用情况,并注意到此使用峰值。 在让用户停止浪费 CPU 周期后,管理员可能会决定自动阻止此类进程是一个好主意。 管理员可以设置一个操作,该操作在检测到高负载时触发。 触发后采取的操作是停止进程(图 9)。
图 9. CPU 密集型进程启动、检测和停止
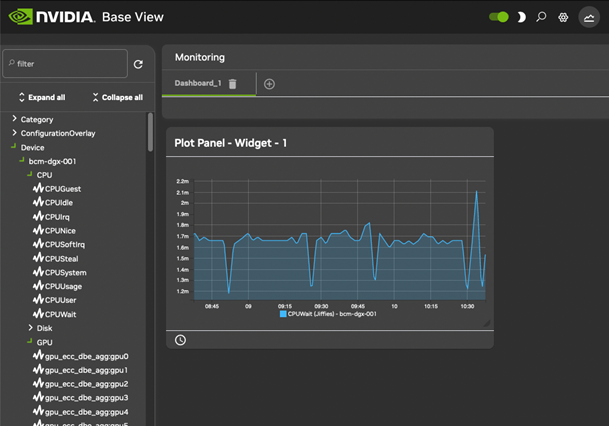
设置组件#
运行人工负载#
模拟用户运行 CPU 密集型进程的一种方法是运行多个标准 unix 实用程序 yes 的实例。 yes 命令发送无数行的 y 文本。 它通常在脚本中用于回答对话提示以进行确认。 管理员可以从头节点上的 CLI 在后台运行八个子 shell 进程,并将 yes 输出发送到 /dev/null
1for i in {1..8}; do ( yes > /dev/null &); done
运行 mpstat 2 显示每个处理器的使用情况统计信息,每两秒更新一次。 它显示,当八个子 shell 进程运行时,在八核或更少核的头节点上,%user(即用户模式 CPU 使用率百分比)接近 90%。
设置 Kill 操作#
要停止人工 CPU 密集型 yes 进程,可以使用 killall yes 命令。 管理员可以将其作为脚本 killallyes 的一部分
1#!/bin/bash killall yes
并使用 chmod 700 killallyes 使脚本可执行。 为了方便起见,可以将其放置在 /cm/local/apps/cmd/scripts/actions 目录中,其中也驻留着其他一些操作脚本。
使用基本监控示例#
现在组件已就位,管理员可以使用 Base View 将 killallyesaction 操作添加到其操作列表,然后为该操作设置触发器。
将操作添加到操作列表#
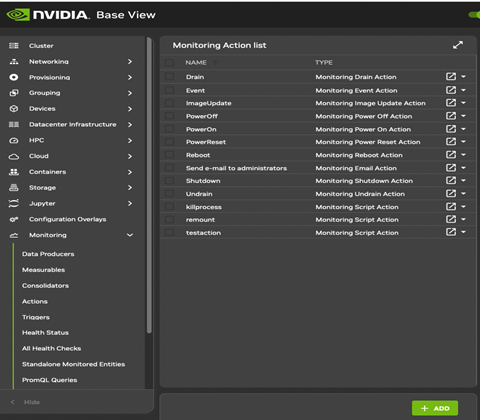
点击路径 监控>操作>监控操作>killprocess>克隆 用于克隆现有操作的结构。 killprocess 操作很方便,因为它有望以类似的方式运行,因此其选项不应进行太多修改。 但是,可以克隆任何操作,并在适当的位置修改克隆。
更改克隆操作的名称。 也就是说,管理员将名称设置为 killallyesaction。 文件名是任意的。
脚本设置为路径 /cm/local/apps/cmd/scripts/actions/killallyes,这是之前放置脚本的位置。
保存后,killallyesaction 操作将成为监控操作列表的一部分(图 10)。
图 10. Base View 监控配置:添加操作
使用登录节点上的 CPUUser 设置触发器#
点击路径 监控>触发器>失败的健康检查>克隆 可用于通过克隆现有触发器来配置监控触发器。 触发器是运行操作的采样状态条件。 在本例中,采样状态条件可能是指标(第 6.2.1.8 节)CPUUser 不得超过 50。 如果超过 50,则运行一个操作 (killallyesaction),该操作应终止 yes 进程。
CPUUser 是每秒在用户模式 CPU 使用率中花费的时间的度量,以每秒节拍间隔来衡量。
节拍间隔是每个平台为内核开发人员预定义的某种任意时间间隔。 它是进程在内核可以切换到另一个任务之前访问 CPU 的最短时间。
与 top 命令中的 %user 不同,节拍间隔不是百分比。
要配置触发器属性
转到监控触发器列表屏幕。 点击路径 监控>触发器>失败的健康检查
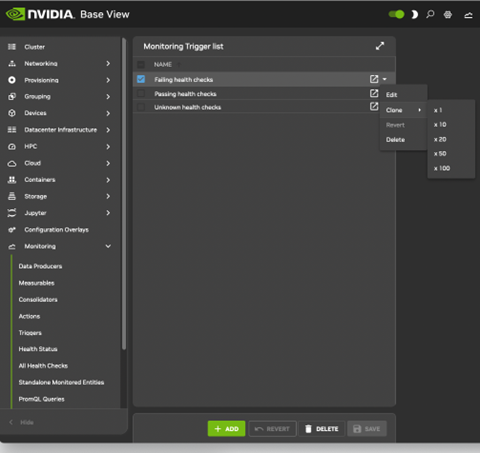
为触发器设置名称。 名称是任意的。 在本示例中使用 killallyestrigger。
配置 进入操作,以便触发器可以在采样状态跨越到满足触发器条件的状态时运行操作脚本。
配置运行 进入操作 操作脚本的条件。 可以通过在表达式子窗口中设置表达式来设置条件。 例如,当头节点上的 CPUUser 高于 50 时。
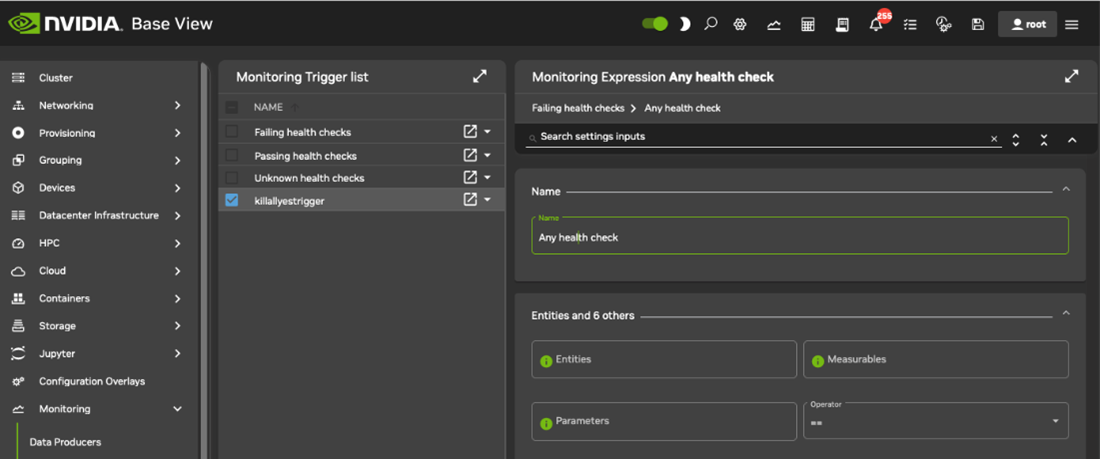
为触发器设置名称。 名称是任意的,在本示例中使用 killallyestrigger。
为表达式设置名称。 名称是任意的,在本示例中使用 killallyesregex。
设置实体。 在本例中,被监控的实体是头节点。 如果在本示例中头节点称为 headnode,则 headnode 是为实体设置的值。 实体通常只是一个设备,但它可以是 CMDaemon 存储的任何对象。
设置可测量项。 在本例中,使用 CPUUser。
设置运算符和阈值。 在本例中,GT(即大于运算符)和 50(即以节拍/秒为单位的 CPUUser 时间的显著量)分别设置为运算符和值。
启用触发器以激活它。
保存配置后,killallyesregex 正则表达式将评估为触发器采样的数据。 如果表达式为 TRUE,则触发器启动 killallyesaction 操作。
结果#
在上一节中,添加了一个操作,并使用监控表达式设置了触发器。 对于新安装的集群上的默认安装,CPUUser 的测量每 120 秒完成一次(可以在 Base View 的数据生产者窗口中修改周期,如 Bright Cluster Manager 管理员手册的 图 12.9 所示)。 因此,使用默认值配置的基本示例会监控头节点上的 CPUUser 是否每 120 秒跨越 50 节拍/秒的界限。
如果发现 CPUUser 已进入,即从低于该值跨越到超过 50 节拍的区域,则 killallyesregex 正则表达式会注意到这一点。 然后,为其配置的触发器 killallyestrigger 触发器运行 killallyesaction 操作,该操作运行 killallyes 脚本。 killallyes 脚本终止所有正在运行的 yes 进程。 假设系统负载很小,除了这些 yes 进程之外,CPUUser 指标值将降至 50 节拍以下。
为了澄清上一段中“发现已进入”的含义
对于某个样本,在满足 进入 触发器条件后,紧随其后的第一个样本永远不会满足 进入 触发器条件,因为 进入 阈值跨越条件要求前一个样本低于阈值。
只有在满足 进入 触发器条件且前一个样本低于阈值时,第二个样本才能启动操作。
在头节点上运行的其他非 yes CPU 密集型进程也可能触发 killallyes 脚本。 由于该脚本仅终止 yes 进程,而让任何非 yes 进程保持原样,因此在这种情况下,它将不必要地运行。 这是由于此处说明的基本示例是人为的和简单的性质所致的缺陷。 在生产案例中,操作脚本有望具有更复杂的设计。
本章的以下部分更详细地介绍了集群管理器监控的概念和特性。
监控概念和定义#
此时讨论监控的概念以及所用术语的定义是合适的。 稍后在本章中介绍的集群管理器中监控系统的特性将更容易理解。
可测量项#
可测量项是使用数据生产者 (6.2.8) CMDaemon 监控系统获得的测量值(样本值)。 可以对节点、头节点、其他设备或其他实体进行测量。
可测量项的类型#
可测量项可以是
enummetrics:具有少量状态的测量值。 这些状态可以是预定义的,也可以是用户定义的。 这些在 6.2.1.7 中介绍。
metrics:具有数值和无数据的测量值,作为可能的值。 例如,诸如:-13113143234.5、24、9234131299 之类的值。 这些在
健康检查:具有 PASS、FAIL 和 UNKNOWN 状态作为可能状态的测量值,以及当未设置任何其他状态时,无数据作为另一种可能状态。 这些在 6.2.2 中介绍。
无数据和可测量项#
如果未执行任何测量,但必须保存样本值,则可测量项的样本值设置为无数据。 这是一个定义的值,而不是空数据值。 因此,metrics 和 enummetrics 也可以采用无数据值。
实体和可测量项#
通常,设备、类别或某些类似的分组是方便的想法,可以作为实体来记住,以获得具体性。
集群管理器的全新安装中的默认实体是
设备 类别 分区[基础] 软件镜像
但是,更一般而言,实体可以是来自 cmsh 以下顶级模式的对象
类别 ceph 云 cmjob 配置 覆盖 设备 edgesight etcd fspart 组 作业队列 作业 kubernetes 网络 节点组 分区 配置文件 机架 软件镜像 用户
例如,要配置到节点的软件镜像对象是一个实体,该实体的某些可能属性是镜像的名称、内核版本、创建时间或锁定属性
1[root©headnode ~]# cmsh -c "software image use default-image; show"
2Parameter Value
3-------------------------------- -----------------------------------------------
4Creation time Thu, 08 Jun 2017 18:15:13 CEST
5Enable SOL no
6Kernel modules <44 in submode> Kernel parameters
7Kernel version 3.10.0-327.3.1.el7.x86_64
8Locked no
9Name default-image
10...
由于可以对如此多种实体进行测量,这意味着可以在集群管理器集群上执行的监控和条件操作可以非常多样化。 这使得实体成为集群管理器的监控系统中用于管理集群的强大而通用的概念。
列出实体使用的可测量项#
在 cmsh 中,对于实体,例如设备模式下的设备,可以使用 measurables 命令查看该设备使用的可测量项列表。
1[headnode->device]% measurables dgx001
2Type Name Parameter Class Producer
3------------ ------------------- ---------- --------- ---------------
4Enum DeviceStatus Internal DeviceState
5HealthCheck ManagedServicesOk Internal CMDaemonState
6HealthCheck default gateway Network default gateway
7HealthCheck diskspace Disk diskspace
8HealthCheck dmesg OS dmesg
9...
可以使用 list enum (6.2.1.7)、list metric (6.2.1.8) 和 list healthcheck (6.2.2) 列出这些可测量项的子集。
在 Base View 中,等效于列出可测量项的操作可以使用点击路径 监控>所有健康检查 来执行。
从监控模式列出可测量项#
类似地,在监控模式下,在 measurable 子模式下,可以使用 list 命令查看可以使用的可测量对象列表
1[headnode->monitoring]% measurable list
2Type Name (key) Parameter Class Producer
3------------ ------------------- ---------- ---------------------------- ------------------
4Enum DeviceStatus Internal DeviceState
5HealthCheck ManagedServicesOk Internal CMDaemonState
6HealthCheck Mon::Storage Internal/Monitoring/Storage MonitoringSystem
7HealthCheck chrootprocess OS chrootprocess
8HealthCheck cmsh Internal cmsh
9...
可以使用 list enum、list metric 和 list healthcheck 列出这些可测量项的子集。
在 Base View 中,等效于列出可测量项的操作可以通过点击路径 监控>可测量项 来执行,并且可以使用列过滤来列出可测量项的子集。
在监控模式下查看可测量项的参数#
在 measurable 子模式下,可以使用 show 命令查看特定可测量项的参数。
1[headnode->monitoring->measurable]% use devicestatus [headnode->monitoring->measurable[DeviceStatus]]% show
2Parameter Value
3-------------------------------- ----------------------
4Class Internal
5Consolidator none
6Description The device status
7Disabled no (DeviceState)
8Maximal age 0s (DeviceState)
9Maximal samples 4,096 (DeviceState)
10Name DeviceStatus
11Parameter
12Producer DeviceState
13Revision
14Type Enum
Enummetrics#
Enummetric 是实体的可测量项,只能采用有限的一组值。 DeviceStatus 是唯一的 enummetric。 这可能会在集群管理器的未来版本中更改。 enummetric DeviceStatus 的完整可能值列表为:up、down、closed、installing、installer_failed、installer_rebooting、installer_callinginit、installer_unreachable、installer_burning、burning、unknown、opening、going_down、pending 和 no data。
可以从监控模式的 measurable 子模式中列出可用的 enummetrics
1[headnode->monitoring->measurable]% list enum
2Type Name (key) Parameter Class Producer
3------ ------------------------ ------------------- --------- -------------------
4Enum DeviceStatus Internal DeviceState
5[headnode->monitoring->measurable]%
可以使用实体(例如设备)的 enummetrics 命令查看由实体配置的 enummetrics 列表
1[headnode->device]% enummetrics dgx001
2Type Name Parameter Class Producer
3------ ------------------------ ------------------- --------- -------------------
4Enum DeviceStatus Internal DeviceState
5[headnode->device]%
可以使用 dumpmonitoringdata 命令查看实体经历过的状态
1[headnode->device]% dumpmonitoringdata -99d now devicestatus dgx001
2Timestamp Value Info
3-------------------------- ----------- ----------
42017/07/03 16:07:00.001 down
52017/07/03 16:09:00.001 installing
62017/07/03 16:09:29.655 no data
72017/07/03 16:11:00 up
82017/07/12 16:05:00 up
可以从监控模式下的 measurable 子模式 (6.2.1.6) 查看和设置 enummetric(例如 devicestatus)的参数。
Metrics#
实体的 metric 通常是实体的数值。 该值可以具有与其关联的单位。
在 6.1 的示例中,考虑的 metric 值是 CPUUser,以 120 秒的默认规则时间间隔测量。
该值也可以定义为无数据。 当样本没有响应时,无数据将替换为空值。 一旦设置了无数据,它就不是空值。 这意味着对于监控数据,不会存储空值。
metrics 的其他示例包括
LoadOne(值为数字,例如:1.23)。
WriteTime(值以 ms/s 为单位,例如:5 ms/s)。
MemoryFree(值以可读单位表示,例如:930 MiB 或 10.0 GiB)。
metric 可以是内置的,这意味着它作为集成代码与 CMDaemon 一起提供给集群管理器。 这是基于 c++ 的,因此比替代方案快得多。 替代方案是 metric 可以是独立脚本,这意味着管理员通常可以使用脚本技能更轻松地修改它。
单词 metric 通常用于表示与 metric 关联的脚本或对象以及 metric 值。 上下文清楚地表明了含义。
可以使用 cmsh 从监控模式使用 list 命令查看正在使用的 metrics
1[headnode->monitoring]% measurable list metric
2Type Name (key) Parameter Class Producer
3------- ------------------------ -------------- ------------------ -------------
4Metric AlertLevel count Internal AlertLevel
5Metric AlertLevel maximum Internal AlertLevel
6...
在 Base View 中,可以使用点击路径 监控>可测量项,然后单击过滤器小部件以选择 Metric 来查看 metrics。 可以使用 cmsh 中的 metrics 命令查看实体正在使用的 metrics 列表。
例如,对于设备模式下的实体 dgx001
1[headnode->devices]% metrics dgx001
2Type Name Parameter Class Producer
3------- ------------------------ -------------- --------- --------------
4Metric AlertLevel count Internal AlertLevel
5Metric AlertLevel maximum Internal AlertLevel
6...
可以从监控模式下的 measurable 子模式中查看和设置 metric(例如 AlertLevel:count)的参数,就像其他可测量项一样
1[headnode->monitoring->measurable]% use alert level:count
2[headnode->monitoring->measurable[AlertLevel:count]]% show
3Parameter Value
4-------------------------------- ----------------------
5Class Internal
6Consolidator default
7Cumulative no
8Description Number of active triggers
9Disabled no
10Maximal age 0s
11Maximal samples 0
12Maximum 0
13Minimum 0
14Name AlertLevel
15Parameter count
16Producer AlertLevel
17Revision
18Type Metric
等效的 Base View 点击路径是 监控>可测量项>编辑。
健康检查#
健康检查值是对实体执行的检查的响应。 响应指示该检查的实体的健康状况。 例如,ssh2node 健康检查,它在头节点上运行以检查是否可以访问到常规节点的 SSH 端口 22 无密码访问。 健康检查以规则的时间间隔运行,并且可以具有以下可能的值
PASS:健康检查成功。 例如,如果 ssh2node 成功,则表明与节点的 ssh 连接正常。
FAIL:健康检查失败。 例如,如果 ssh2node 被拒绝。 这表明与节点的 ssh 连接失败。
UNKNOWN:健康检查具有未知响应。 例如,如果 ssh2node 由于路由或其他问题而超时,则意味着未知连接是否正常或失败。 管理员应进一步调查。
无数据:健康检查未运行,因此未获得数据。 例如,如果 ssh2node 在一段时间内被禁用,则在此期间未获得无数据值。 由于健康检查被禁用,这意味着 ssh2node 在此期间无法记录无数据。 但是,由于在这种情况下在监控数据中具有无数据值是一个好主意——明确知道具有无数据对于各种原因很有帮助——因此 CMDaemon 可以为没有数据的样本设置无数据值。
健康检查的其他示例包括
diskspace:检查硬盘驱动器上是否仍有足够的剩余空间。
mounts:检查挂载是否可访问。
mysql:检查 MySQL 的状态和配置是否正确。
hpraid:检查某些 HP RAID 硬件的 RAID 和健康状态
这些和其他内容可以在目录中看到:/cm/local/apps/cmd/scripts/healthchecks
健康检查#
在 Base View 中,可以使用点击路径 监控>可测量项,然后单击过滤器小部件以选择 健康检查 来查看可以为所有实体配置的健康检查。 可以通过单击 编辑 按钮来设置每个健康检查的选项。
所有已配置的健康检查#
可以使用点击路径 监控>所有健康检查 来查看所有已配置的健康检查。 可以按列过滤视图。
实体的已配置健康检查#
可以使用点击路径 监控>健康状态>实体>显示 来查看特定实体 <entity> 的概述。
健康检查的严重性级别以及覆盖它们#
健康检查具有可设置的严重性 (6.2.5),该严重性与其触发器选项中定义的响应相关联。 对于独立健康检查,脚本定义的严重性级别将覆盖触发器中的值。 例如,FAIL 40 或 UNKNOWN 10,如 hpraid 健康检查 (/cm/local/apps/cmd/scripts/healthchecks/hpraid) 中设置的那样。 当健康检查运行时,将处理严重性值以用于 AlertLevel 指标 (6.2.6)。
健康检查和触发器的默认模板#
健康检查还可以根据任何响应值启动操作。
监控触发器具有以下默认模板
严重性级别是相应健康检查的默认参数之一。 也可以修改这些默认值,以便在触发器运行时启动操作,例如,每当任何健康检查失败时发送电子邮件通知。
使用默认模板,默认情况下为所有健康检查设置操作。 但是,可以配置为特定可测量项而不是为所有健康检查启动的特定操作。 为此,可以克隆其中一个模板,可以重命名触发器,并且可以设置从触发器启动操作。
触发器#
触发器是为采样的可测量项设置的阈值条件。 当样本跨越阈值条件时,它会进入或离开由阈值划分的区域。 触发器区域还具有与其关联的可设置严重性 (6.2.5)。 此值在阈值事件触发操作时为 AlertLevel 指标 (6.2.6) 处理。 触发器在 6.1.3.2 中讨论。
操作#
在 6.1 的基本示例中,操作脚本是添加到监控系统中以终止所有 yes 进程的脚本。 当满足 CPUUser 超过 50 节拍的条件时,脚本将运行。 操作是独立脚本或内置命令,当满足条件时执行,并且在成功时具有退出代码 0。 满足的条件可以是
来自健康检查的 FAIL、PASS、UNKNOWN 或无数据。
触发器条件。 这可以是条件表达式的 FAIL 或 PASS。
状态抖动 (6.2.7)
可以从监控模式的操作子模式中列出可以运行的操作。
1[headnode->monitoring->action]% list
2Type Name (key) Run on Action
3----------- ---------------- ------- ---------------------------------------------------
4Drain Drain Active Drain node from all WLM
5Email Send e-mail Active Send e-mail
6Event Event Active Send an event to users with connected client
7ImageUpdate ImageUpdate Active Update the image on the node
8PowerOff PowerOff Active Power off a device
9PowerOn PowerOn Active Power on a device
10PowerReset PowerReset Active Power reset a device
11Reboot Reboot Node Reboot a node
12Script killallyesaction Node /cm/local/apps/cmd/scripts/actions/killallyes
13Script killprocess Node /cm/local/apps/cmd/scripts/actions/killprocess.pl
14Script remount Node /cm/local/apps/cmd/scripts/actions/remount
15Script testaction Node /cm/local/apps/cmd/scripts/actions/testaction
16Shutdown Shutdown Node Shutdown a node
17Undrain Undrain Active Undrain node from all WLM
Base View 等效项可以使用点击路径 监控>操作 访问。 监控操作的配置在 6.1.3.1 中进一步讨论。
严重性#
严重性是管理员为触发器分配的正整数值。 它采用六个建议值之一(表 12)。
表 12. 严重性值

严重性级别在 AlertLevel 指标 (6.2.6) 中使用。 管理员也可以在健康检查脚本的返回值中设置它们 (6.2.2)。 默认情况下,健康检查 FAIL 响应的严重性值为 15,健康检查 UNKNOWN 响应的严重性值为 10,健康检查 PASS 响应的严重性值为 0 (6.2.2)。
AlertLevel#
AlertLevel 是一种特殊的 metric。 当发生具有关联严重性 (6.2.5) 的事件时,将对其进行采样和重新计算。 AlertLevel 指标有三种类型
AlertLevel(计数):处于注意级别及以上的事件数。 此指标向管理员警报问题的数量。
AlertLevel(最大值):所有事件的最新值的最大严重性。 此指标向管理员警报最重要问题的严重性。
AlertLevel(总和):所有事件的最新严重性值的总和。 此指标向管理员警报问题的总体严重性。
抖动#
抖动或状态抖动是指可测量触发器 (6.2.3) 检测到变化时,变化过于频繁。 也就是说,可测量项在多个样本中多次进出区域。 在 6.1 的基本示例中,如果 CPUUser 指标在五分钟内跨越阈值区域五次(抖动检测的默认值),则默认情况下会将其检测为抖动。 然后,抖动警报将记录在事件查看器中,并且如果配置为这样做,也可以启动抖动操作。
数据生产者#
数据生产者生成可测量项。 有时它可以是一组可测量项,如正在使用的数据生产者提供的可测量项中所示
1[headnode->monitoring->measurable]% list -f name:25,producer:15 | grep ProcStat
2BlockedProcesses ProcStat
3CPUGuest ProcStat
4CPUIdle ProcStat
5CPUIrq ProcStat
6CPUNice ProcStat
7CPUSoftIrq ProcStat
8CPUSteal ProcStat
9CPUSystem ProcStat
10CPUUser ProcStat
11CPUWait ProcStat
12CtxtSwitches ProcStat
13Forks ProcStat
14Interrupts ProcStat
15RunningProcesses ProcStat
有时它可能只有一个可测量项,如使用的数据生产者提供
1[headnode->monitoring->measurable]% list -f name:25,producer:15 | grep ssh2node ssh2node ssh2node
它甚至可能没有可测量项,而只是一个尚未使用的可测量项的空容器。
在 cmsh 中,可以按如下方式列出所有数据生产者(已使用和未使用)
1[headnode->monitoring->setup]% list
Base View 中的等效项是使用点击路径 监控>数据生产者。
可以使用 monitoringproducers 命令列出为实体(例如头节点 headnode)配置的数据生产者
1[headnode->device[headnode]]% monitoringproducers
2Type Name Arguments Measurables Node execution filters
3------------------ ----------------- ------------ ------------ --------------------
4AlertLevel AlertLevel 3 / 231 <0 in submode>
5CMDaemonState CMDaemonState 1 / 231 <0 in submode>
6ClusterTotal ClusterTotal 18 / 231 <1 in submode>
7Collection NFS 32 / 231 <0 in submode>
8Collection sdt 0 / 231 <0 in submode>
9DeviceState DeviceState 1 / 231 <1 in submode>
10HealthCheckScript chrootprocess 1 / 231 <1 in submode>
11HealthCheckScript cmsh 1 / 231 <1 in submode>
12HealthCheckScript default gateway 1 / 231 <0 in submode>
13HealthCheckScript diskspace 1 / 231 <0 in submode>
14HealthCheckScript dmesg 1 / 231 <0 in submode>
15HealthCheckScript exports 1 / 231 <0 in submode>
16HealthCheckScript failedprejob 1 / 231 <1 in submode>
17HealthCheckScript hardware-profile 0 / 231 <1 in submode>
18HealthCheckScript ib 1 / 231 <0 in submode>
19HealthCheckScript interfaces 1 / 231 <0 in submode>
20HealthCheckScript ldap 1 / 231 <0 in submode>
21HealthCheckScript lustre 1 / 231 <0 in submode>
22HealthCheckScript mounts 1 / 231 <0 in submode>
23HealthCheckScript mysql 1 / 231 <1 in submode>
24HealthCheckScript ntp 1 / 231 <0 in submode>
25HealthCheckScript oomkiller 1 / 231 <0 in submode>
26HealthCheckScript opalinkhealth 1 / 231 <0 in submode>
27HealthCheckScript rogueprocess 1 / 231 <1 in submode>
28HealthCheckScript schedulers 1 / 231 <0 in submode>
29HealthCheckScript smart 1 / 231 <0 in submode>
30HealthCheckScript ssh2node 1 / 231 <1 in submode>
31Job JobSampler 0 / 231 <1 in submode>
32JobQueue JobQueueSampler 7 / 231 <1 in submode>
33MonitoringSystem MonitoringSystem 36 / 231 <1 in submode>
34ProcMemInfo ProcMemInfo 10 / 231 <0 in submode>
35ProcMount ProcMounts 2 / 231 <0 in submode>
36ProcNetDev ProcNetDev 18 / 231 <0 in submode>
37ProcNetSnmp ProcNetSnmp 21 / 231 <0 in submode>
38ProcPidStat ProcPidStat 5 / 231 <0 in submode>
39ProcStat ProcStat 14 / 231 <0 in submode>
40ProcVMStat ProcVMStat 6 / 231 <0 in submode>
41Smart SmartDisk 0 / 231 <0 in submode>
42SysBlockStat SysBlockStat 20 / 231 <0 in submode>
43SysInfo SysInfo 5 / 231 <0 in submode>
44UserCount UserCount 3 / 231 <1 in submode>
显示的数据生产者是为实体配置的生产者,即使实体未使用任何可测量项。 Base View 中的数据生产者配置在 Bright Cluster Manager 管理员手册的第 12.4.1 节中进一步讨论。
Base View 的主要监控界面#
Base View 除了具有默认设置模式外,还有一些其他显示模式和日志记录查看模式,可以使用 Base View 标准显示 (图 11) 右上角的 11 个图标进行选择。
图 11. Base View 右上角图标
接下来从左到右描述这 11 个图标
切换深色主题选项允许 Base View 的显示使用较深的主题。
搜索框允许搜索资源,并提供预测文本建议。
- 设置模式在 Base View 首次启动时处于活动状态。
设置模式在其左侧有一个导航面板,显示集群的资源作为可展开的项目。 其中一个资源是监控。 此资源不应与 Bright View 监控模式混淆,后者由下一个图标启动。 监控资源是关于配置如何监控项目以及如何收集其数据值。
监控模式允许可视化根据 Bright View 监控资源的规范收集的数据值。 可视化允许配置图形。
记帐模式通常允许可视化用户使用的作业资源,尽管它可用于可视化其他聚合实体使用的作业资源。 这有助于跟踪用户消耗的资源。
计费模式允许监控选定组运行的作业在一段时间内请求的资源。
事件图标允许查看事件日志。
操作结果图标允许查看操作结果的日志。
后台任务图标允许查看后台任务。
未保存的实体图标允许查看未保存的实体。
帐户处理图标允许管理 Base View 用户的帐户设置。
使用 Base View 进行监控可视化#
Base View 菜单栏中的监控图标(图 11)启动了一个直观的可视化工具,它是了解系统在一段时间内的行为的主要 GUI 工具。 使用此工具,可以将系统的测量值和状态视为可调整大小和可叠加的图形。 可以放大和缩小特定时间的图形,可以将图形彼此叠加,也可以将图形排列成巨大的网格。 还可以调整、存储和调用图形比例设置,以便下次启动会话时使用。
Base View 可视化工具的替代方案是 CLI cmsh。 它具有相同的功能,因为可以使用它根据可配置参数选择和研究数据值。 借助 unix 管道和绘图实用程序,甚至可以使用 cmsh 绘制数据值并在图形上显示数据值。 但是,使用 cmsh 进行监控的优势在于其他方面:cmsh 更适用于编写脚本或检查预先确定的指标和健康检查,而不是对系统进行快速的视觉检查。 这是因为 cmsh 需要更熟悉选项,并且专为文本输出而不是交互式图形而设计。
有关使用 cmsh 进行监控的更多信息,请参阅 Base Command Manager 管理员手册的 第 12.5 节 和 第 12.6 节。
现在描述使用 Base View 可视化监控图形。
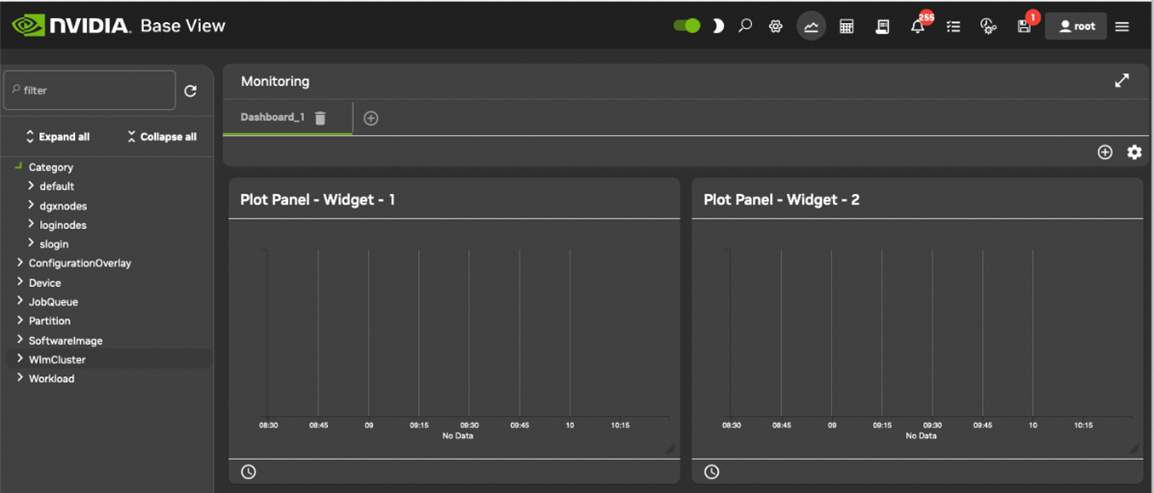
监控窗口#
从 Base View 的菜单栏中选择监控图标(图 11)会启动一个用于可视化数据的监控窗口。 默认情况下,这会显示空白绘图面板——图形轴,x 轴上有一个时间刻度,回溯到过去某个时间,并且没有绘制 y 轴可测量数据值。 Base View 的监控窗口如 图 12 所示。
图 12. Base View 监控窗口
查找和选择要绘制的可测量项#
要绘制可测量项,应从左侧的导航菜单中选择它所属的实体。 选择后,可以选择该可测量项的类,然后可以选择可测量项本身。 例如,要绘制头节点 headnode 的可测量项 CPUUser,可以从导航点击路径 设备>headnode>CPU>CPUUser 中选择它。
有时,使用过滤器搜索框更容易找到可测量项。 在此处输入 CPUUser 会显示包含该文本的所有可测量项(图 13)。 搜索不区分大小写。
图 13. Base View 监控过滤器搜索框
过滤器搜索框也可以处理一些简单的正则表达式,其中 .* 和 | 具有通常的含义。
dgx001.*cpuuserdgx001cpuuser
(dgx001|dgx002).*cpuuserdgx002dgx001
/(正斜杠)允许根据数据路径进行过滤。它对应于树状层次结构中的导航深度。
1dgx001/cpu/cpu user
搜索数据路径与 dgx001/cpu/cpu user 匹配的可测量指标。
绘制可测量指标#
一旦选择了可测量指标,就可以将其拖放到绘图面板中。这将导致数据值被绘制出来。
当可测量指标被绘制到面板中时,将显示两个图形图。较小的底部图表示轮询值,以柱状图显示。较大的上部图表示插值折线图。
可以设置不同类型的插值。要快速了解不同类型插值效果,https://bl.ocks.org/mbostock/4342190 是一个交互式概述,展示了它们在一小部分值上的工作方式。
可以使用鼠标滚轮在绘图面板的绘图区域中展开或收缩时间轴。调整大小以鼠标指针的位置为中心。