部署 Slurm#
本文档是NVIDIA DGX BasePOD:部署指南,以 NVIDIA DGX A100 系统为特色的一部分。
工作负载管理系统有助于在节点集群上调度作业。以下步骤描述了如何设置 Slurm,以便必须显式请求 GPU。 这样,就可以更轻松地在多人之间共享 GPU 和 CPU 计算资源,而不会让用户互相干扰。
注意
在完成本文档中的步骤之前,请完成部署 Kubernetes。
警告
# 提示符表示您在头节点上以 root 用户身份执行的命令。% 提示符表示您在 cmsh 中执行的命令。
安装并验证 Slurm#
启动交互式设置工具。
1# cm-wlm-setup --disable --wlm-cluster-name=slurm --yes-i-really-mean-it 2# cm-wlm-setup
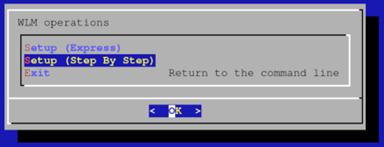
选择“Setup (Step By Step)”(逐步设置),然后选择“OK”(确定)。
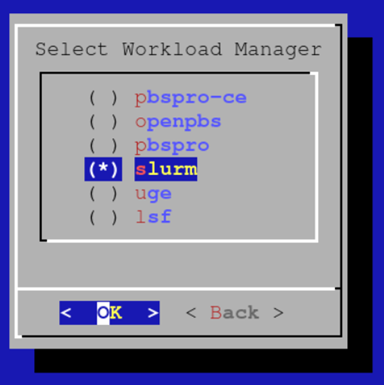
选择 slurm 作为工作负载管理系统,然后选择“OK”(确定)。
输入 Slurm 集群的名称,然后选择“OK”(确定)。

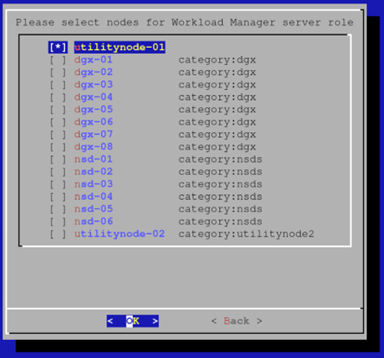
选择头节点作为 Slurm 服务器。
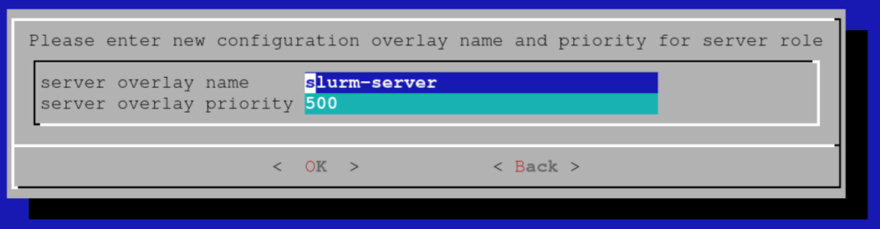
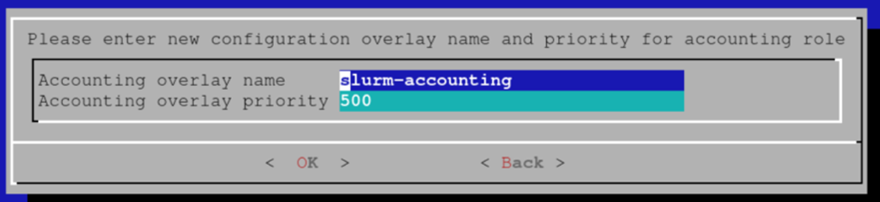
设置配置覆盖的覆盖名称和优先级,然后选择“OK”(确定)。此示例使用默认值。
选择“yes”(是)以配置 GPU 资源,然后选择“OK”(确定)。
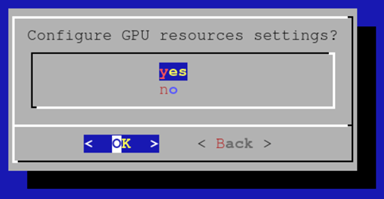
最初,cm-wlm-setup 将设置没有 GPU 的 Slurm 客户端。 假设没有要设置的无 GPU 节点,取消选择所有类别并按“OK”(确定)。
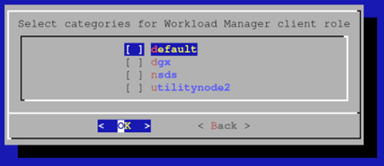
假设没有无 GPU 的计算节点,请在以下屏幕上取消选择所有选项,然后按“OK”(确定)。
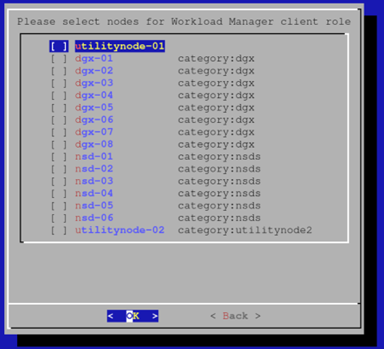
输入没有 GPU 的 Slurm 客户端的覆盖名称和优先级,然后选择“OK”(确定)。 该示例使用默认值。
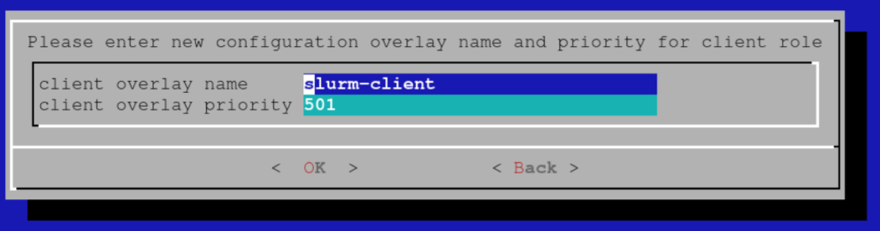
为带有 GPU 的 Slurm 客户端的配置覆盖选择合适的名称。 该示例使用默认值。
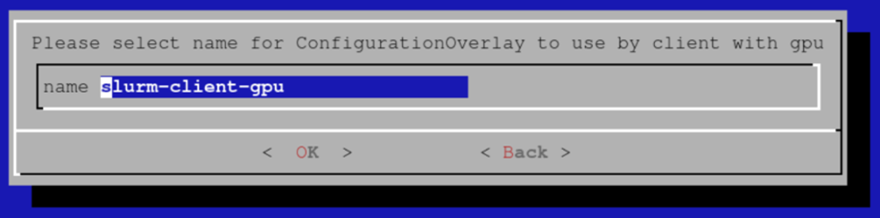
选择您要包含在上一步中创建的配置覆盖中的带有 GPU 的计算节点类别。
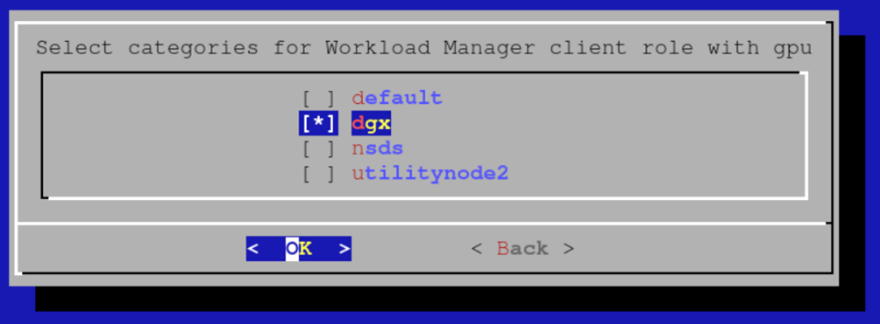
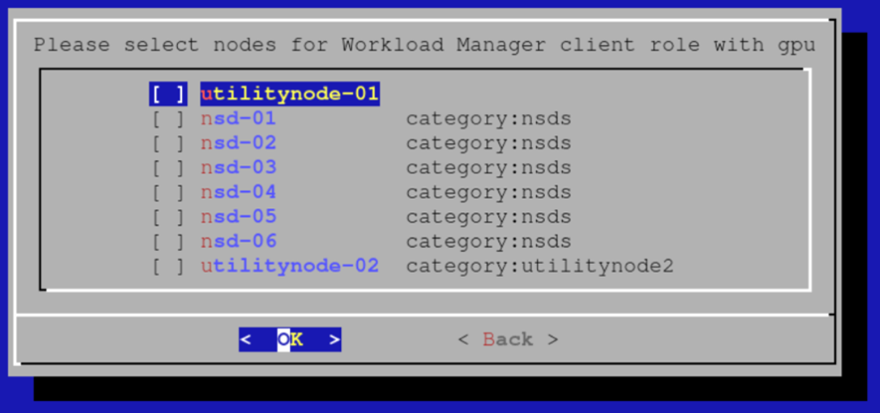
选择应添加到配置覆盖的任何其他带有 GPU 的节点。
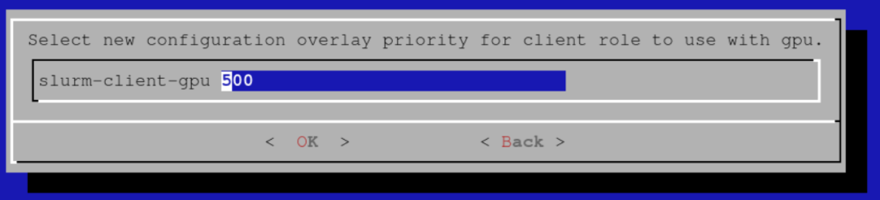
为配置覆盖选择优先级。 该示例使用默认值。
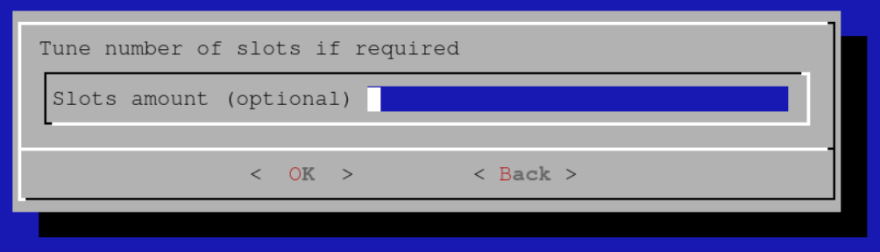
保持插槽数未配置。
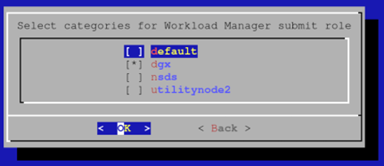
选择 GPU 计算节点类别作为将从中提交作业的节点。 如果您有登录节点类别,您也会希望添加它。 我们将在下一个屏幕中添加头节点
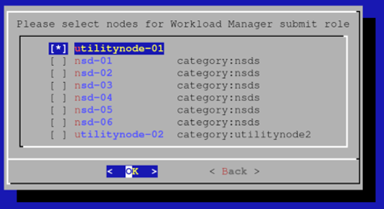
选择您将从中提交作业的其他节点(例如,集群的头节点)。
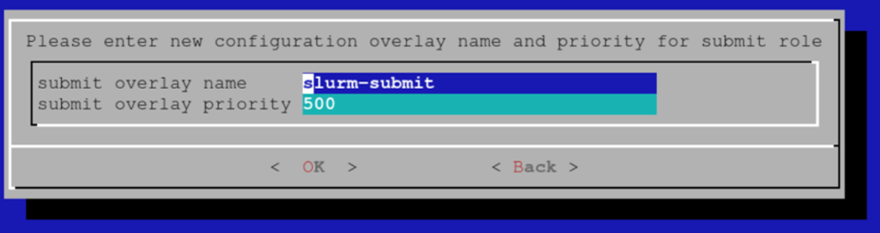
为提交主机的配置覆盖选择名称(默认值即可)
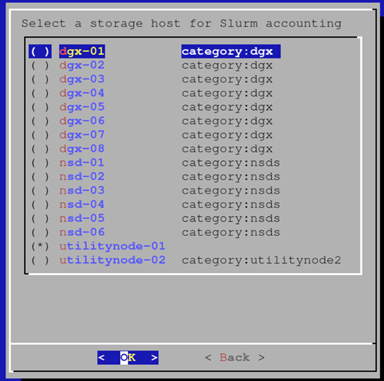
为记帐节点的配置覆盖选择名称。
选择头节点作为记帐节点。
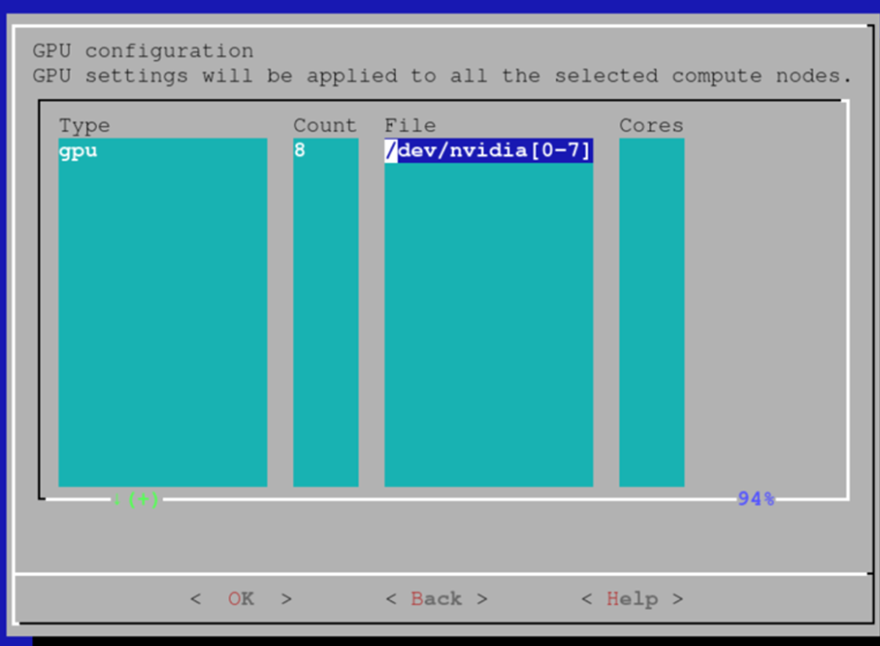
在每个节点中添加 8 个 GPU 作为可以请求的 GPU 资源。 也可以依赖 Slurm GPU 自动检测功能。 有关详细信息,请参阅 Base Command Manager (BCM) 文档。
除非将使用 CUDA 多进程管理 (MPS),否则将 MPS 设置留空。 如果要配置 MPS,则需要一些额外的设置步骤才能通过 prolog/epilog 启动/停止 MPS 守护程序。

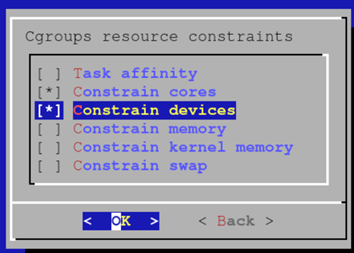
启用以下 cgroup 资源约束,以确保作业无法使用它们未请求的 CPU 核心或 GPU
创建一个默认队列。 稍后始终可以定义更多队列
选择“Save config & deploy”(保存配置并部署),然后选择“OK”(确定)。
存储配置以供稍后使用。
设置完成后,您将需要使用 cmsh 重新启动所有计算节点。
1device power reset -c dgx
节点恢复运行后,您可以通过检查来验证 Slurm 是否正常工作
1[root@utilitynode-01 ~]# sinfo 2PARTITION AVAIL TIMELIMIT NODES STATE NODELIST 3defq* up infinite 8 idle dgx-[01-08]
默认情况下,Slurm 配置为不允许在同一节点上运行多个作业。 要更改此行为并允许(例如)在单个节点上最多同时运行 8 个作业。
1[root@utilitynode-01 ~]# cmsh 2[utilitynode-01]% wlm use slurm 3[utilitynode-01->wlm[slurm]]% jobqueue 4[utilitynode-01->wlm[slurm]->jobqueue]% use defq 5[utilitynode-01->wlm[slurm]->jobqueue[defq]]% get oversubscribe 6NO 7[utilitynode-01->wlm[slurm]->jobqueue[defq]]% set oversubscribe YES:8 8[utilitynode-01->wlm[slurm]->jobqueue*[defq*]]% commit 9[utilitynode-01->wlm[slurm]->jobqueue[defq]]%
要验证 GPU 预留是否正常工作,请首先尝试不分配 GPU。
1[root@utilitynode-01 ~]# srun nvidia-smi 2No devices were found 3srun: error: dgx-06: task 0: Exited with exit code 6 4[root@utilitynode-01 ~]#
然后尝试分配,例如,两个 GPU。
1[root@utilitynode-01 ~]# srun --gres=gpu:2 nvidia-smi 2Thu Mar 4 08:50:44 2021 3+-----------------------------------------------------------------------------+ 4| NVIDIA-SMI 450.102.04 Driver Version: 450.102.04 CUDA Version: 11.0 | 5|-------------------------------+----------------------+----------------------+ 6| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | 7| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | 8| | | MIG M. | 9|===============================+======================+======================| 10| 0 A100-SXM4-40GB On | 00000000:07:00.0 Off | 0 | 11| N/A 30C P0 54W / 400W | 0MiB / 40537MiB | 0% Default | 12| | | Disabled | 13+-------------------------------+----------------------+----------------------+ 14| 1 A100-SXM4-40GB On | 00000000:0F:00.0 Off | 0 | 15| N/A 30C P0 53W / 400W | 0MiB / 40537MiB | 0% Default | 16| | | Disabled | 17+-------------------------------+----------------------+----------------------+ 18 19+-----------------------------------------------------------------------------+ 20| Processes: | 21| GPU GI CI PID Type Process name GPU Memory | 22| ID ID Usage | 23|=============================================================================| 24| No running processes found | 25+-----------------------------------------------------------------------------+
下一步#
完成此页面上的步骤后,您可以(可选)部署 Jupyter 或配置高可用性。