Run:ai 简介#
本文档介绍了如何通过使用 NVIDIA Base Command™ Manager (BCM) 软件的简化部署,在 NVIDIA DGX BasePOD™ 配置上部署 Run:ai Atlas 平台。
Run:ai Atlas 平台使 IT 组织能够在任何基础设施上构建具有类似云的资源可访问性和管理功能的 AI 环境。它还使研究人员能够使用他们选择的任何机器学习 (ML) 和数据科学工具。该平台建立在高性能计算 (HPC) 的强大分布式计算和调度概念之上,并作为 Kubernetes (K8s) 插件实现。它可以加速数据科学工作流程,并为 IT 团队创建可见性,使他们现在可以更有效地管理有价值的资源,并最终减少 GPU 闲置时间。
该平台由 Run:ai 集群(图 1,右)和 Run:ai 控制平面或后端(图 1,左)组成。对于在 BCM 上的安装,该平台托管控制平面组件,客户将集群组件部署到 BCM 创建的 K8s 集群或多个集群上。
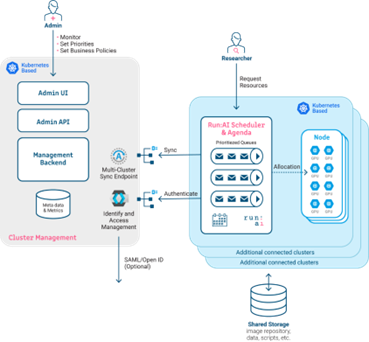
Run:ai 调度器扩展了默认 K8s 调度器的功能,但不会替换它。Run:ai 调度器使用基于项目配额的业务规则来调度研究人员和数据科学家发送的工作负载。Fractional GPU 是 Run:ai 的一项技术,使研究人员能够分配 GPU 的子集而不是整个 GPU,从而提高底层资源利用率。此外,Run:ai 代理和其他监控工具负责将监控数据发送到 Run:ai 控制平面。
通过 Run:ai,研究人员和数据科学家有多种方法可以提交工作负载并与之交互。他们可以使用 Run:ai CLI 提交 ML 工作负载,也可以通过将 YAML 文件直接发送到 K8s、通过 K8s 或 Run:ai API,或者通过 Run:ai 研究人员用户界面 (UI) 提交。研究人员 UI 支持基于模板简单地提交工作负载,这些模板预先填充了工作负载提交的必要字段。这使管理员能够为新用户加入平台提供简化的流程。通过 Run:ai Web UI 交付的模板实现了部署 Jupyter Notebook 的简化方法,同时 UI 还使研究人员和数据科学家能够在 Notebook 运行后直接连接到他们的 Notebook。
Run:ai Atlas 平台为 IT 部门提供了他们所需的对其 AI 和 ML 环境的控制和可见性,同时还抽象化了所有复杂的底层基础设施,使研究人员和数据科学家能够利用他们选择的工具来推动企业内的创新。
以下部分详细介绍了在 DGX BasePOD 配置上安装 Run:ai 的首选方法。