部署 Kubernetes#
在所有必需的公有云实例部署和配置为通用用途后,环境已准备好进行 K8s 部署。在混合环境中,用于部署本地 K8s 的相同工具也用于在公有云中部署 K8s。
以 root 用户身份在 Head 节点上运行
cm-kubernetes-setupCLI 向导。cm-kubernetes-setup
选择 部署 以开始部署,然后选择 确定。
选择 Kubernetes v1.21,然后选择 确定。
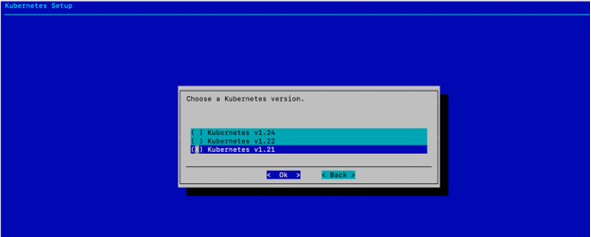
选择 K8s 版本 1.21 是为了与本地 DGX BasePOD 部署中部署的版本相匹配。
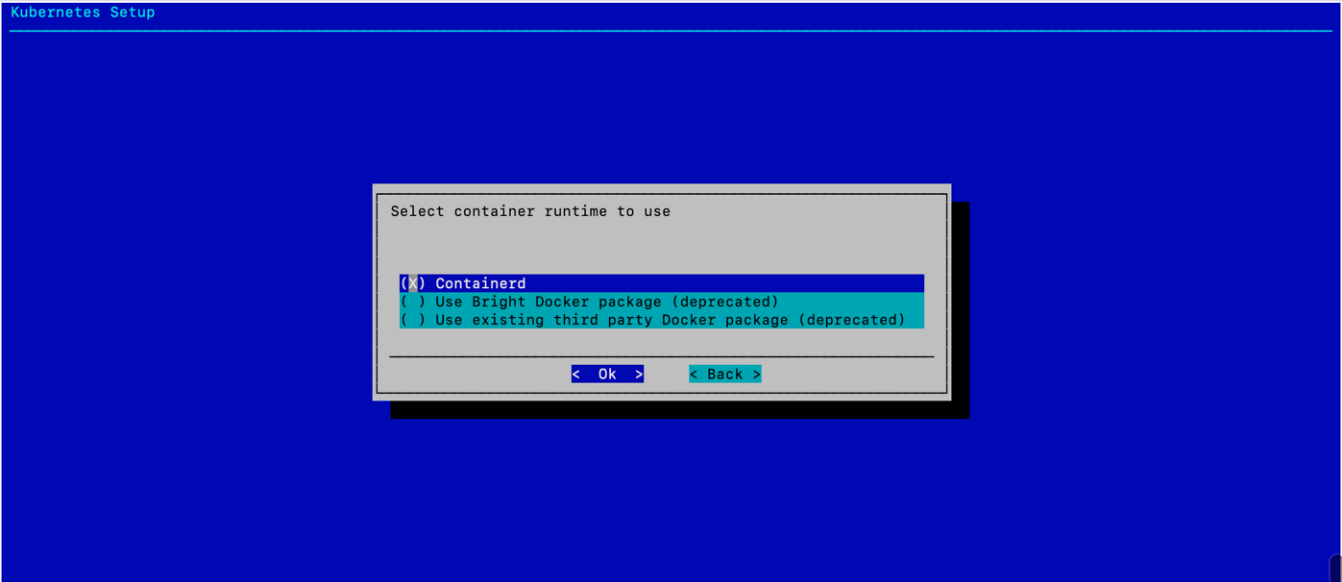
选择 Containerd(默认应已选中),然后选择 确定。
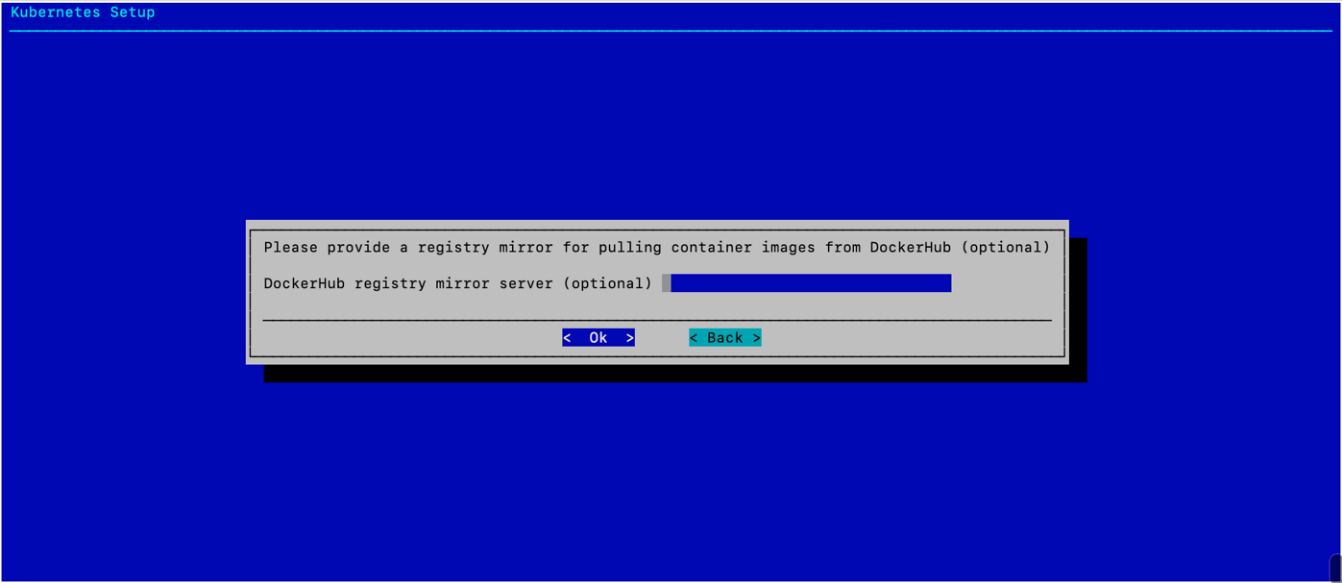
(可选)提供注册表镜像,然后选择 确定。
此示例部署不需要镜像。
配置 K8s 集群的基本值,然后选择 确定。
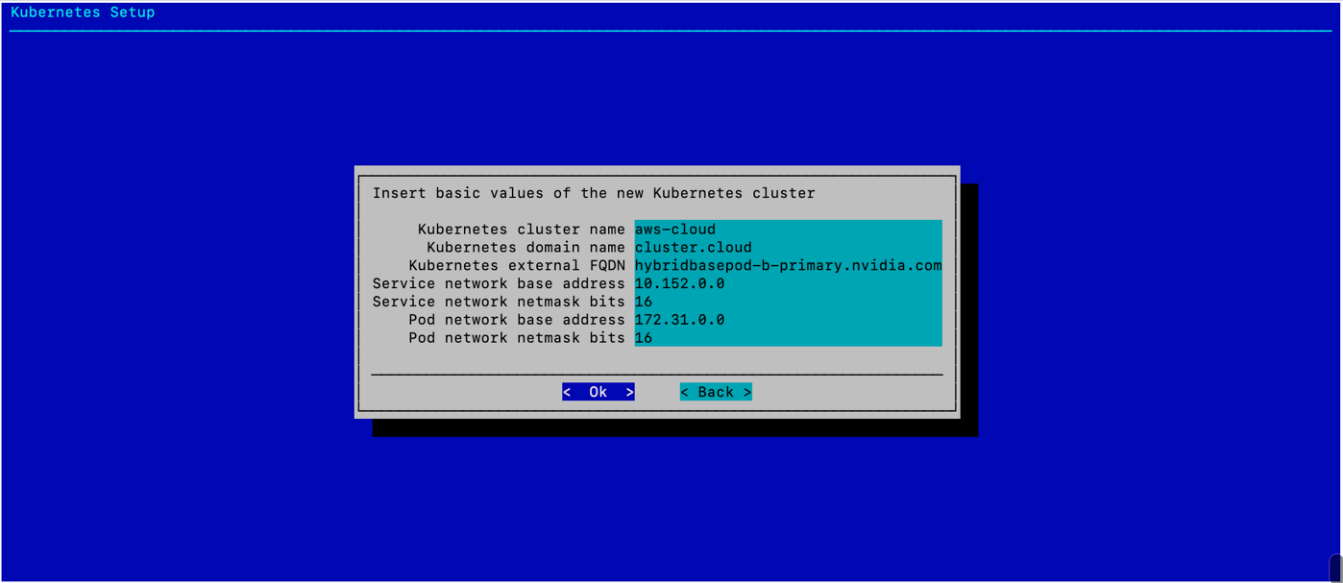
选择易于理解 K8s 部署正在使用公有云资源的名称。此外,确保服务和 Pod 网络子网不与集群中现有的子网重叠。
选择“是”以将 K8s API 服务器暴露给外部网络,然后选择 确定。
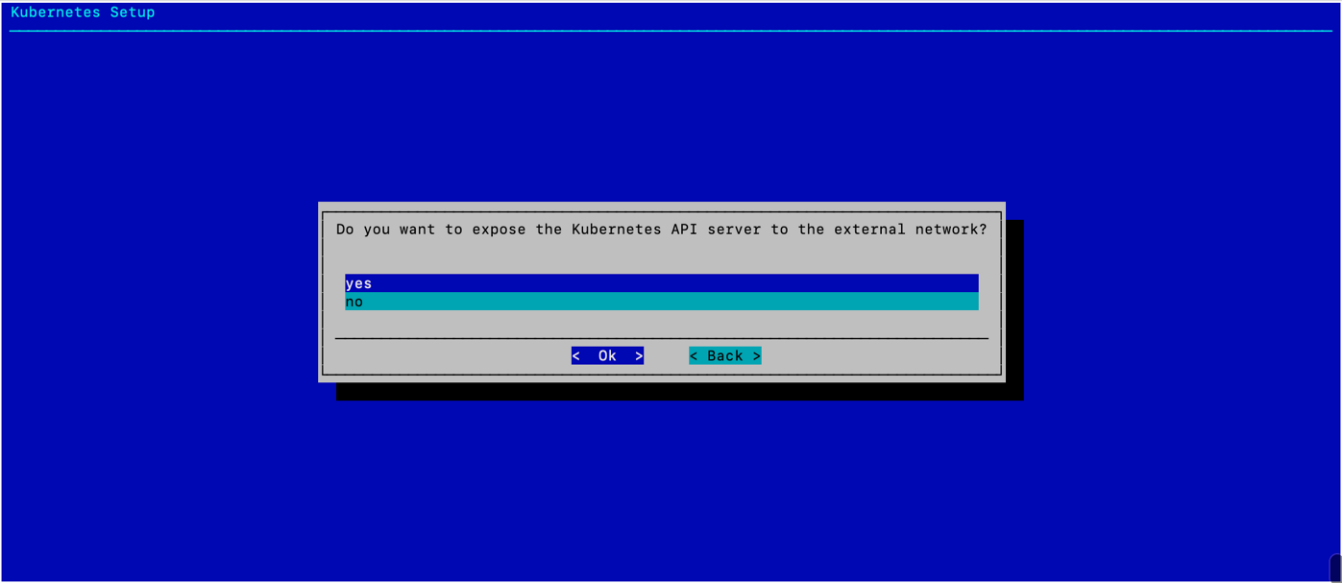
这允许用户从 Head 节点使用 K8s 集群。
为基于公有云的 K8s 环境选择 vpc-us-west-2-private,然后选择 确定。
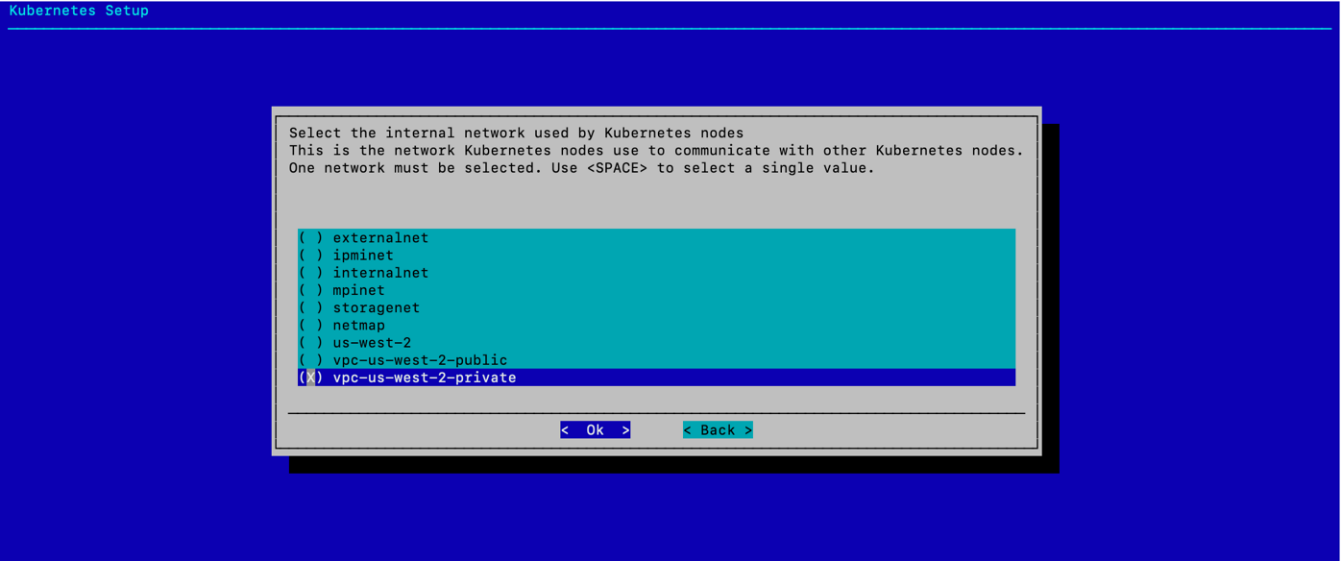
这使内部 K8s 流量完全保留在公有云中。
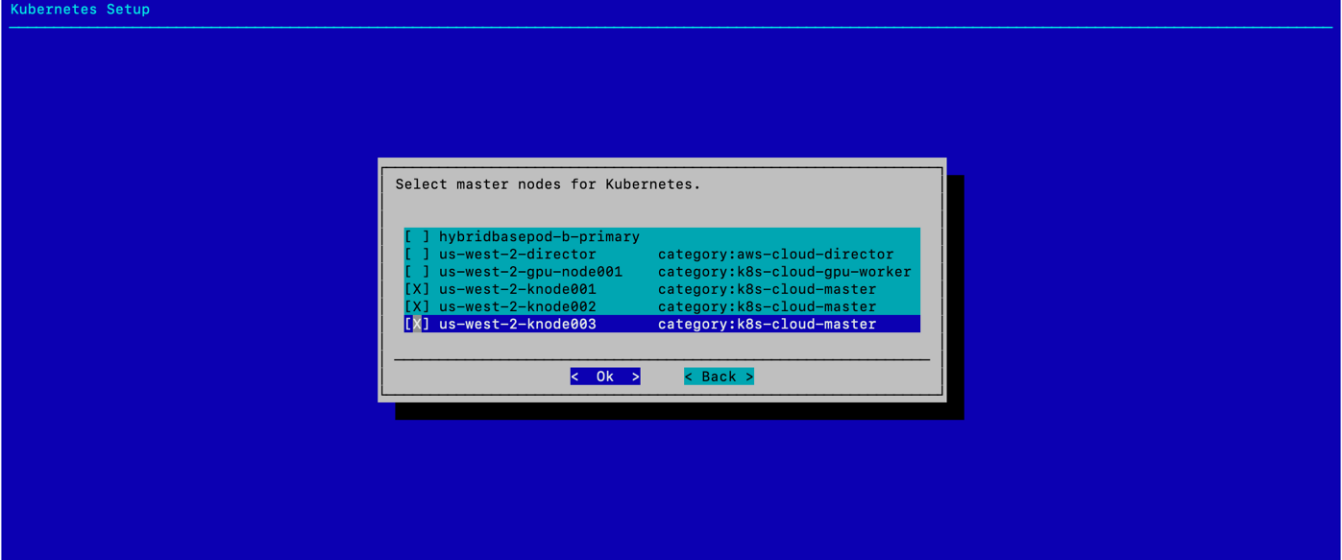
选择三个 k8s-cloud-master 节点,然后选择 确定。
为 Worker 节点类别选择 k8s-cloud-gpu-worker,然后选择 确定。
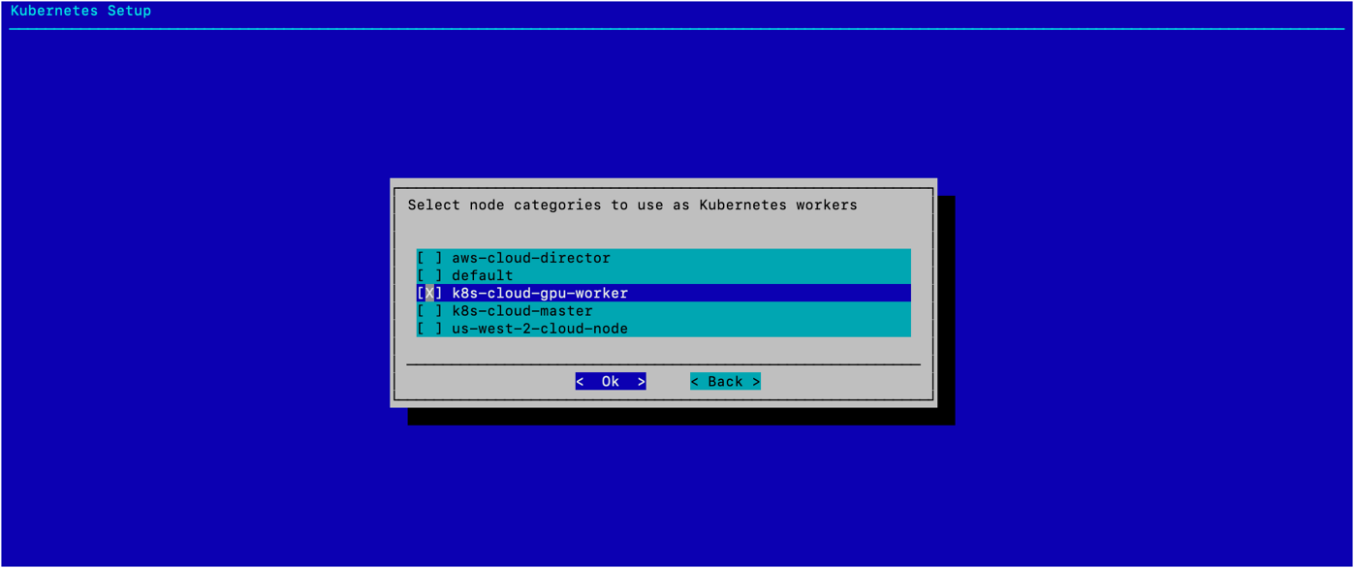
选择 确定,无需配置任何单独的 K8s 节点。
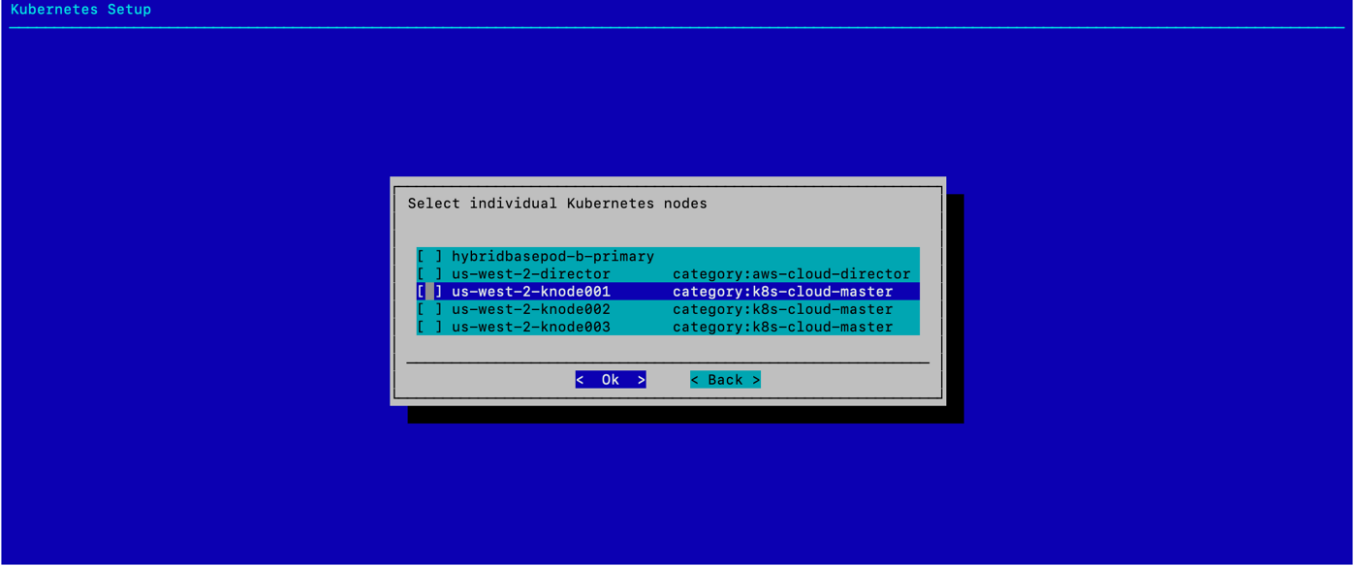
为 Etcd 节点选择三个 knode 系统,然后选择 确定。
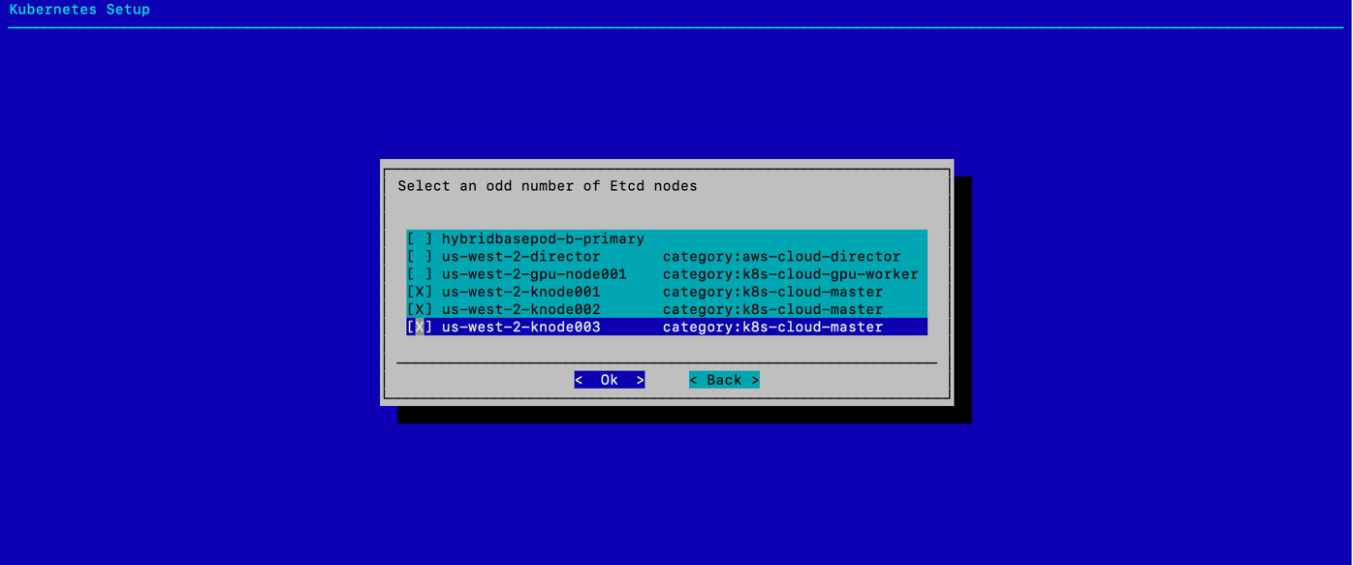
配置 K8s 主要组件,然后选择 确定。
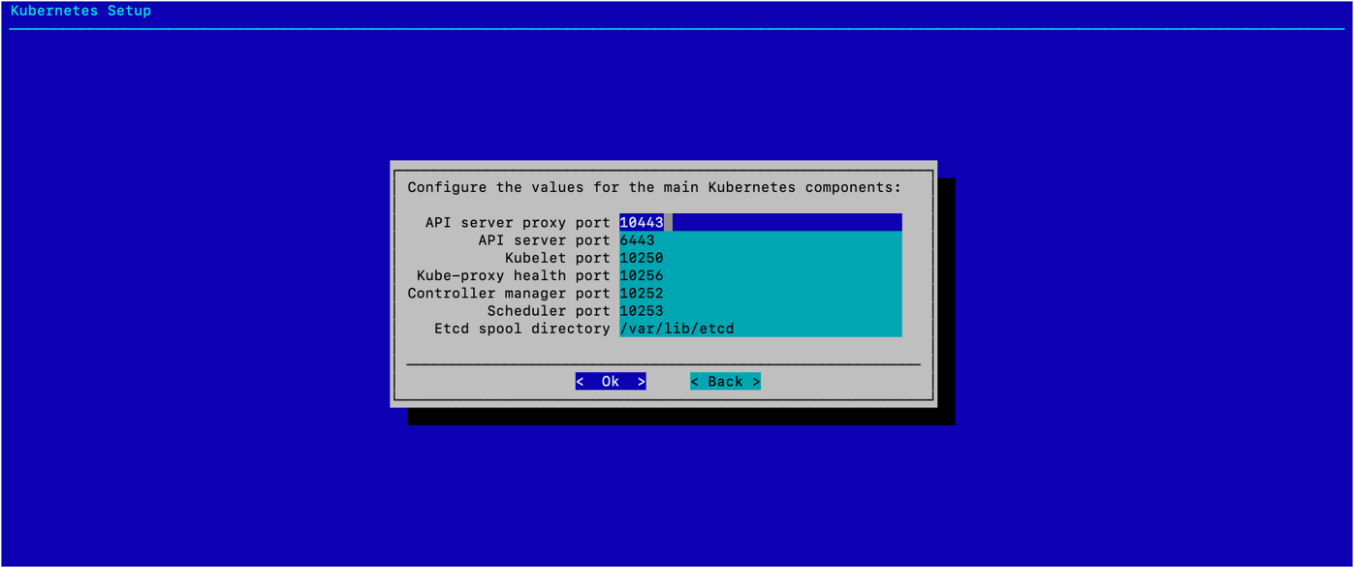
除非环境需要不同的值,否则在此处使用默认端口和路径。此部署中使用了默认值。
选择 Calico 网络插件,然后选择 确定。
选择“是”以安装 Kyverno 策略引擎,然后选择 确定。
选择“否”以拒绝为 Kyverno 配置 HA,然后选择 确定。
此部署不满足 Kyverno HA 的最低节点要求。
选择是否安装 Kyverno 策略,然后选择 确定。
除非配置需要,否则选择 否。
选择要安装的 Operator 包,然后选择 确定。
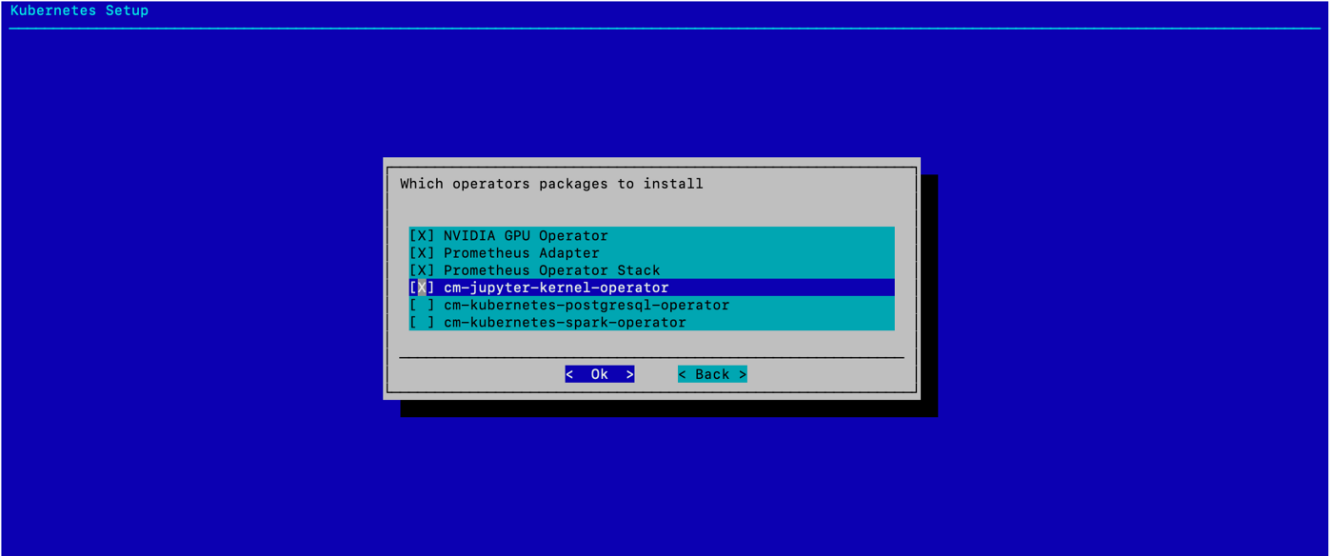
如屏幕截图所示,选择 NVIDIA GPU Operator、Prometheus Adapter、Prometheus Adapter Stack 和 cm-jupyter-kernel-operator。
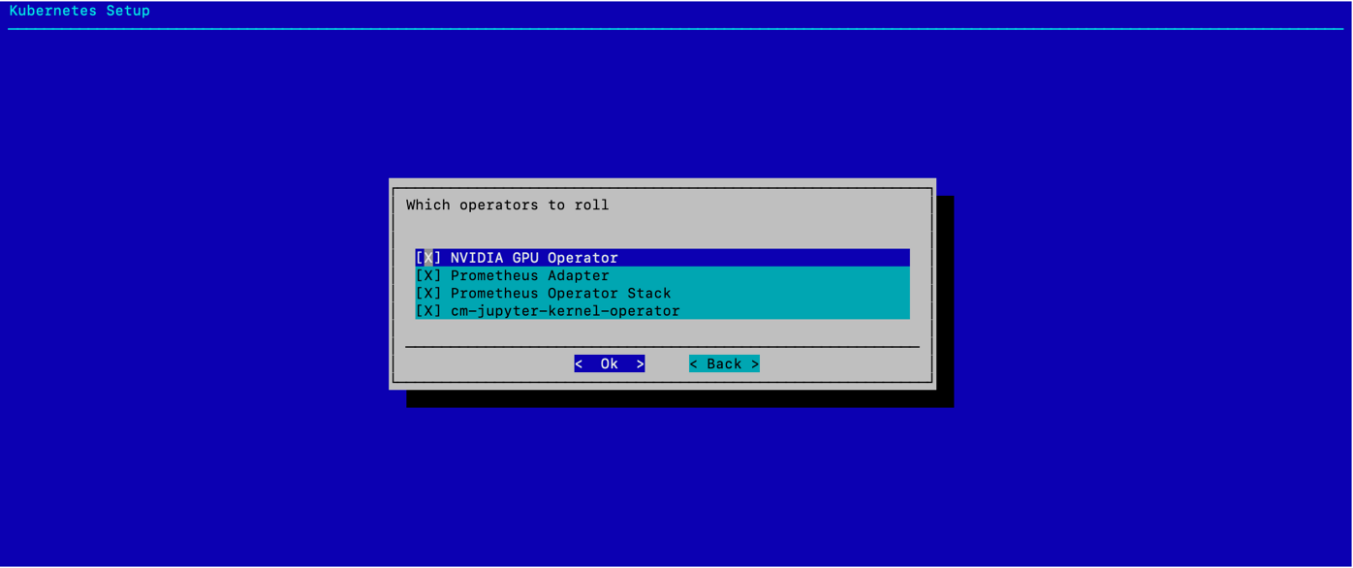
选择相同的四个 Operator 以使用默认值进行汇总,然后选择 确定。
选择要部署的插件,然后选择 确定。
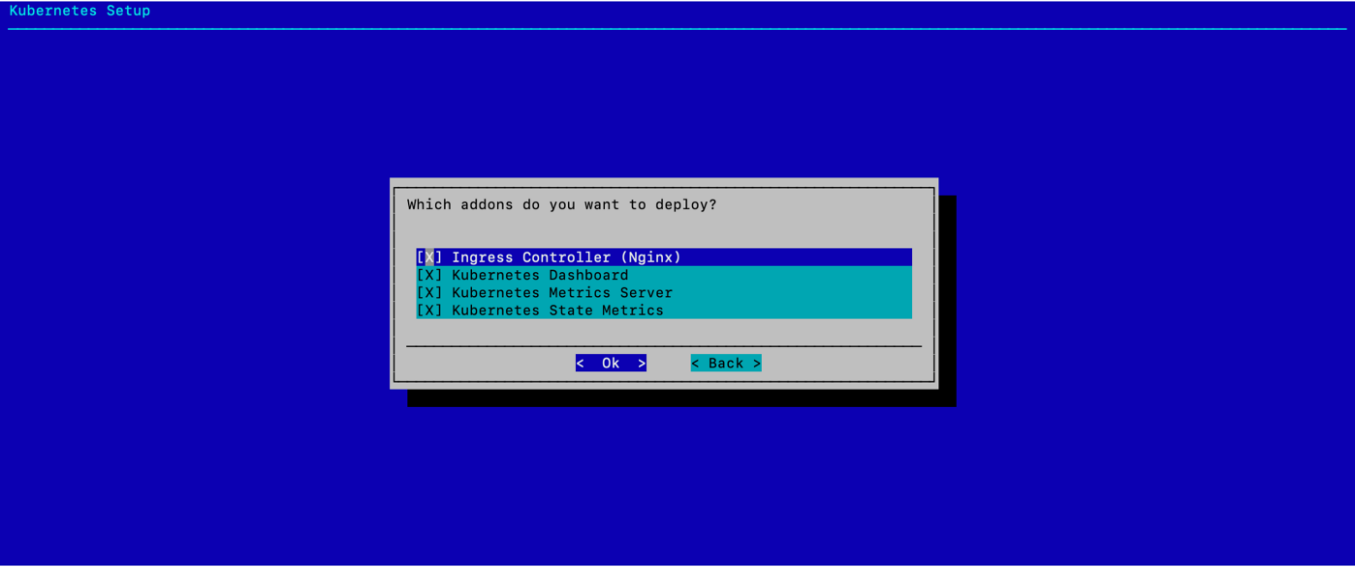
如屏幕截图所示,选择 Ingress Controller (Nginx)、Kubernetes Dashboard、Kubernetes Metrics Server 和 Kubernetes State Metrics。
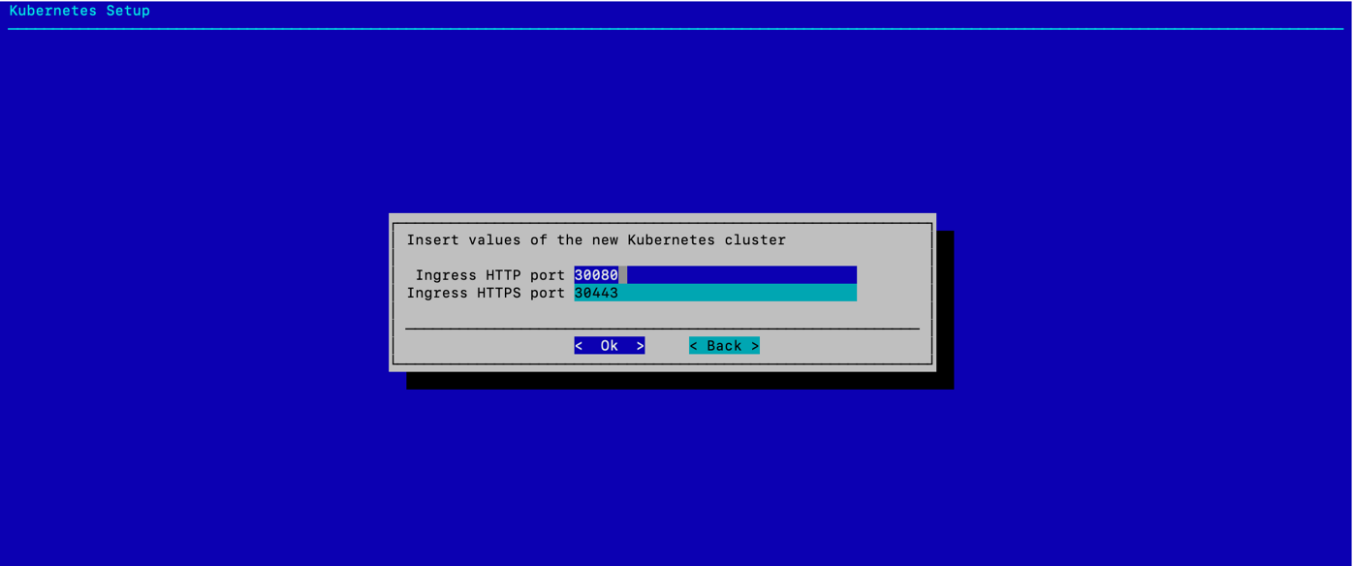
选择集群的 Ingress 端口,然后选择 确定。
除非需要特定的 Ingress 端口,否则使用默认值。
当被询问是否安装 Bright NVIDIA 包时,选择 否,然后选择 确定。
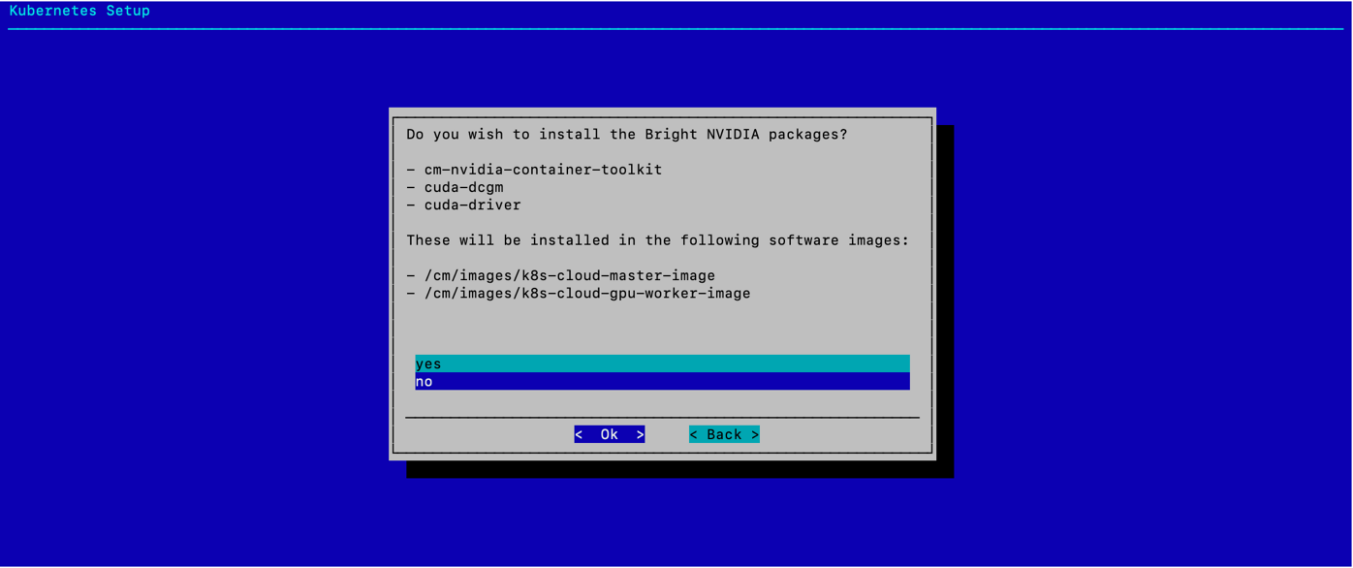
由于 K8s 控制平面节点没有 GPU,因此 GPU Operator 管理 NVIDIA OS 组件。
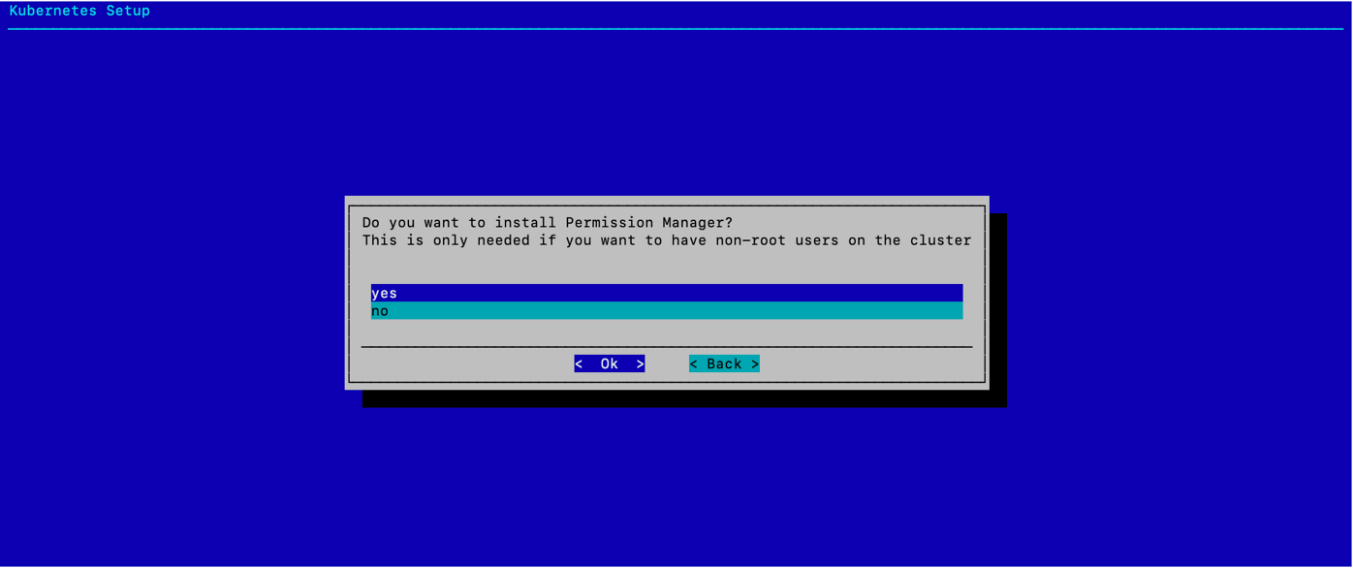
选择“是”以部署 Permission Manager,然后选择 确定。
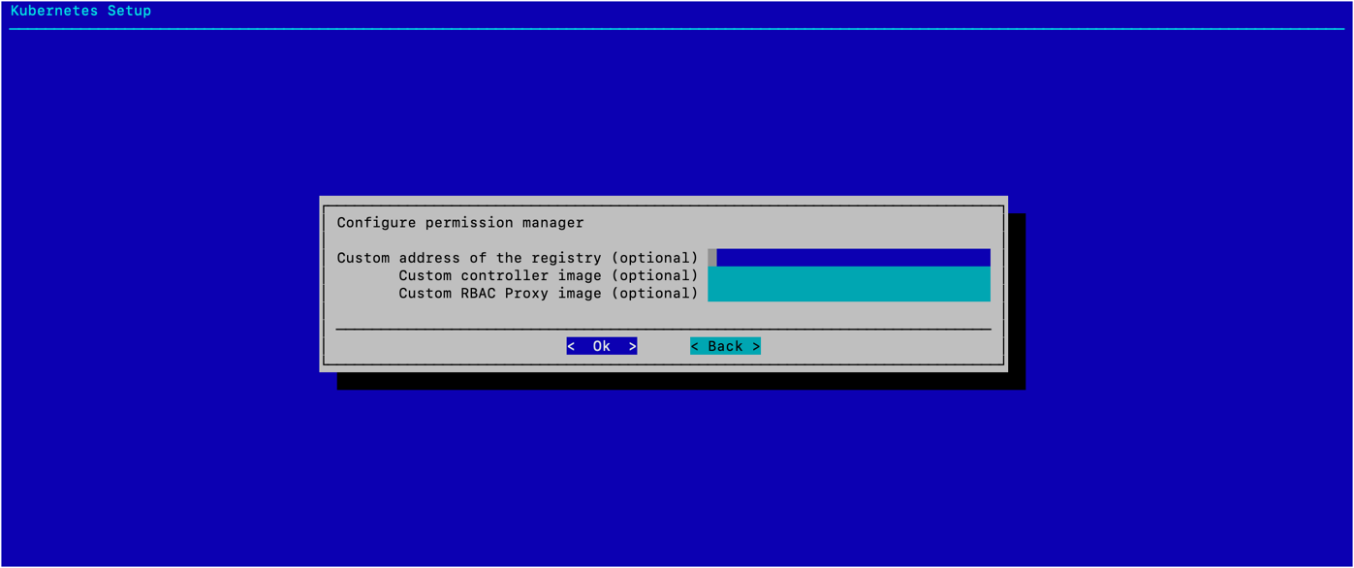
选择 确定,无需配置任何可选值。
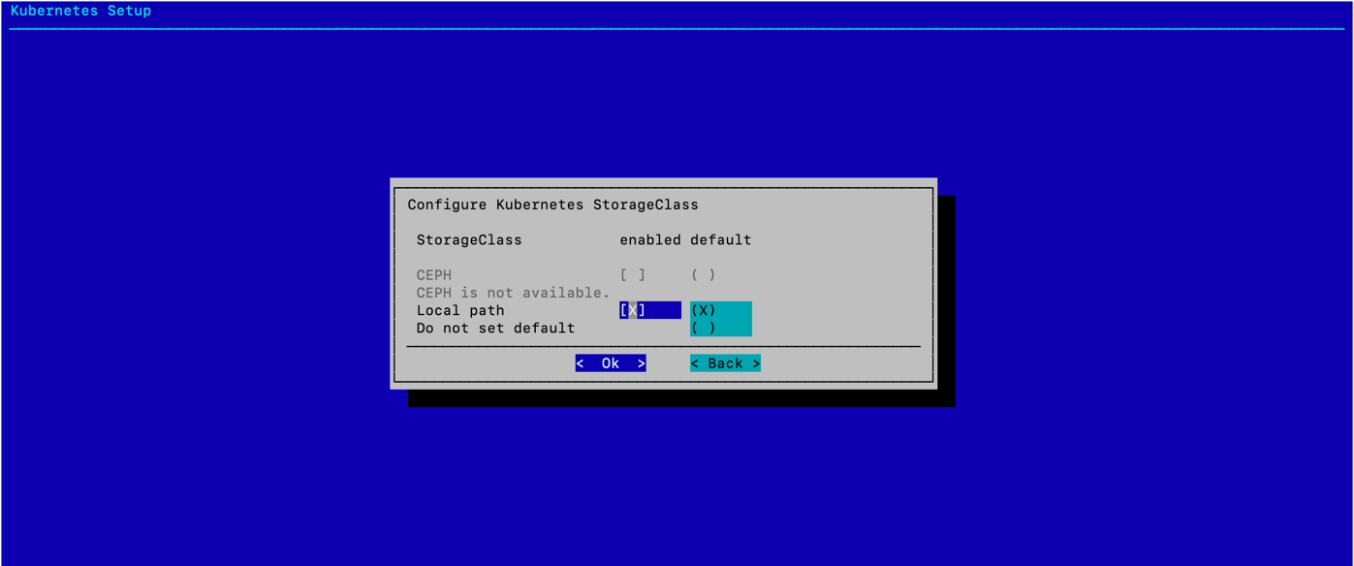
为本地路径存储类同时选择 enabled 和 default,然后选择 确定。
选择 确定,无需更改任何默认值。
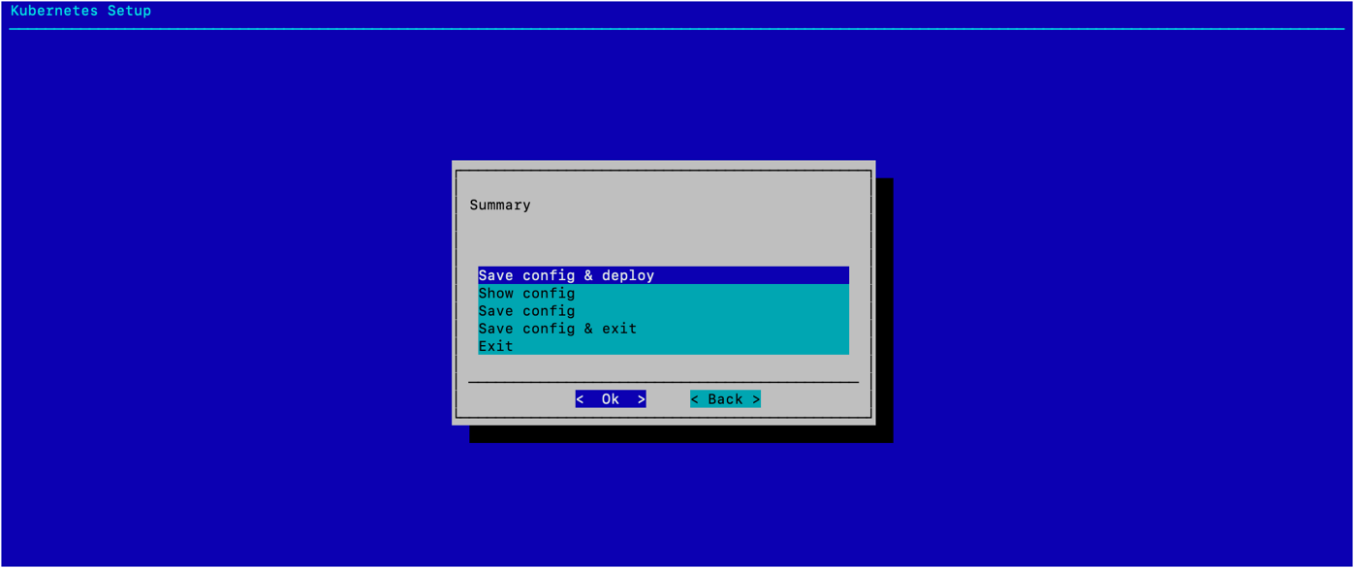
选择 保存配置 & 部署,然后选择 确定。
将文件路径更改为 /root/cm-kubernetes-setup-cloud.conf,然后选择 确定。
更改文件路径是为了避免与初始本地部署中现有的 K8s 配置文件发生名称冲突。等待安装完成。
验证 K8s 集群是否正确安装。
如果已加载本地部署的 K8s 模块,则可能需要卸载该模块,或者使用 switch 命令作为快捷方式来卸载本地模块并加载公有云模块。
1module load kubernetes/aws-cloud/ 2kubectl cluster-info 3Kubernetes control plane is running at https://:10443 4CoreDNS is running at https://:10443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy 5 6To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
1kubectl get nodes 2NAME STATUS ROLES AGE VERSION 3us-west-2-gpu-node001 Ready worker 6m48s v1.21.4 4us-west-2-knode001 Ready control-plane,master 6m48s v1.21.4 5us-west-2-knode002 Ready control-plane,master 6m48s v1.21.4 6us-west-2-knode003 Ready control-plane,master 6m48s v1.21.4
验证 GPU 作业是否可以在 K8s 集群上运行。
将以下文本保存到名为 gpu.yaml 的文件中。
1apiVersion: v1 2kind: Pod 3metadata: 4 name: gpu-pod-pytorch 5spec: 6 restartPolicy: Never 7 containers: 8 - name: pytorch-container 9 image: nvcr.io/nvidia/pytorch:22.08-py3 10 command: 11 - nvidia-smi 12 resources: 13 limits: 14 nvidia.com/gpu: 1
使用
kubectlapply 执行代码。kubectl apply -f gpu.yaml
使用
kubectl logs检查结果。输出应如下所示。
1kubectl logs gpu-pod-pytorch 2Tue Feb 14 22:25:53 2023 3+-----------------------------------------------------------------------------+ 4| NVIDIA-SMI 525.85.12 Driver Version: 525.85.12 CUDA Version: 12.0 | 5|-------------------------------+----------------------+----------------------+ 6| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | 7| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | 8| | | MIG M. | 9|===============================+======================+======================| 10| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 | 11| N/A 28C P8 14W / 70W | 2MiB / 15360MiB | 0% Default | 12| | | N/A | 13+-------------------------------+----------------------+----------------------+ 14 15+-----------------------------------------------------------------------------+ 16| Processes: | 17| GPU GI CI PID Type Process name GPU Memory | 18| ID ID Usage | 19|=============================================================================| 20| No running processes found | 21+-----------------------------------------------------------------------------+