初始集群设置#
DGX BasePOD 的部署阶段包括使用 BCM 来配置和管理集群。
配置 NFS 服务器。
用户主目录 (home/) 和共享数据目录 (cm_shared/) 必须在主节点之间共享(例如 DGX OS 镜像),并且必须存储在 NFS 文件系统上以实现 HA 可用性。由于 DGX BasePOD 不强制规定 NFS 存储的性质,因此配置不在本文档的范围之内。此 DGX BasePOD 部署使用 站点调查 /var/nfs/general 中提供的 NFS 导出路径。建议 NFS 服务器导出文件 /etc/exports 使用以下参数。
/var/nfs/general *(rw,sync,no_root_squash,no_subtree_check)
将 DGX 系统配置为默认 PXE 启动。
使用 KVM 或崩溃车,连接到 DGX 系统,进入 BIOS 菜单,并将 启动选项 #1 配置为 [NETWORK]。
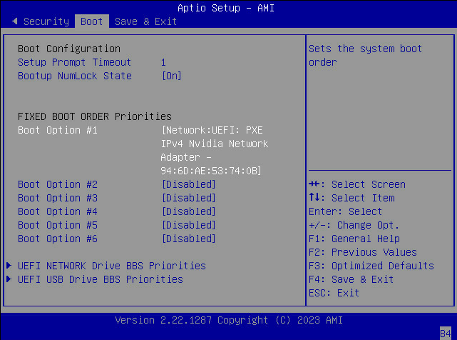
确保其他启动选项为 [Disabled] 并转到下一个屏幕。
将 启动选项 #1 和 启动选项 #2 设置为对 Storage 4-2 和 Storage 5 2 使用 IPv4。
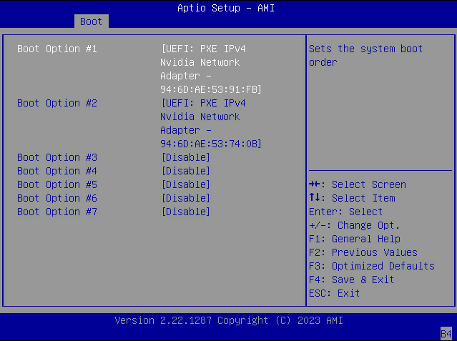
确保其他启动选项为 [Disabled]。
选择 保存并退出。
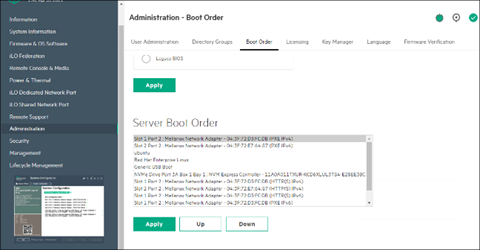
在故障转移主节点和 CPU 节点上,确保网络启动配置为首选选项。确保主节点和 CPU 节点上连接到网络的 Mellanox 端口也设置为以太网模式。
这是一个系统将从网络启动的示例,使用 插槽 1 端口 2 和 插槽 2 端口 2。
下载 BCM 安装程序 ISO。
将 ISO 刻录到 DVD 或可启动 USB 设备。
它也可以作为虚拟介质挂载,并使用 BMC 进行安装。后者的具体机制因供应商而异。
确保目标主节点的 BIOS 配置为 UEFI 模式,并且其启动顺序配置为启动包含 BCM 安装程序镜像的介质。
启动安装介质。
在 grub 菜单中,选择 启动 Base Command Manager 图形安装程序。
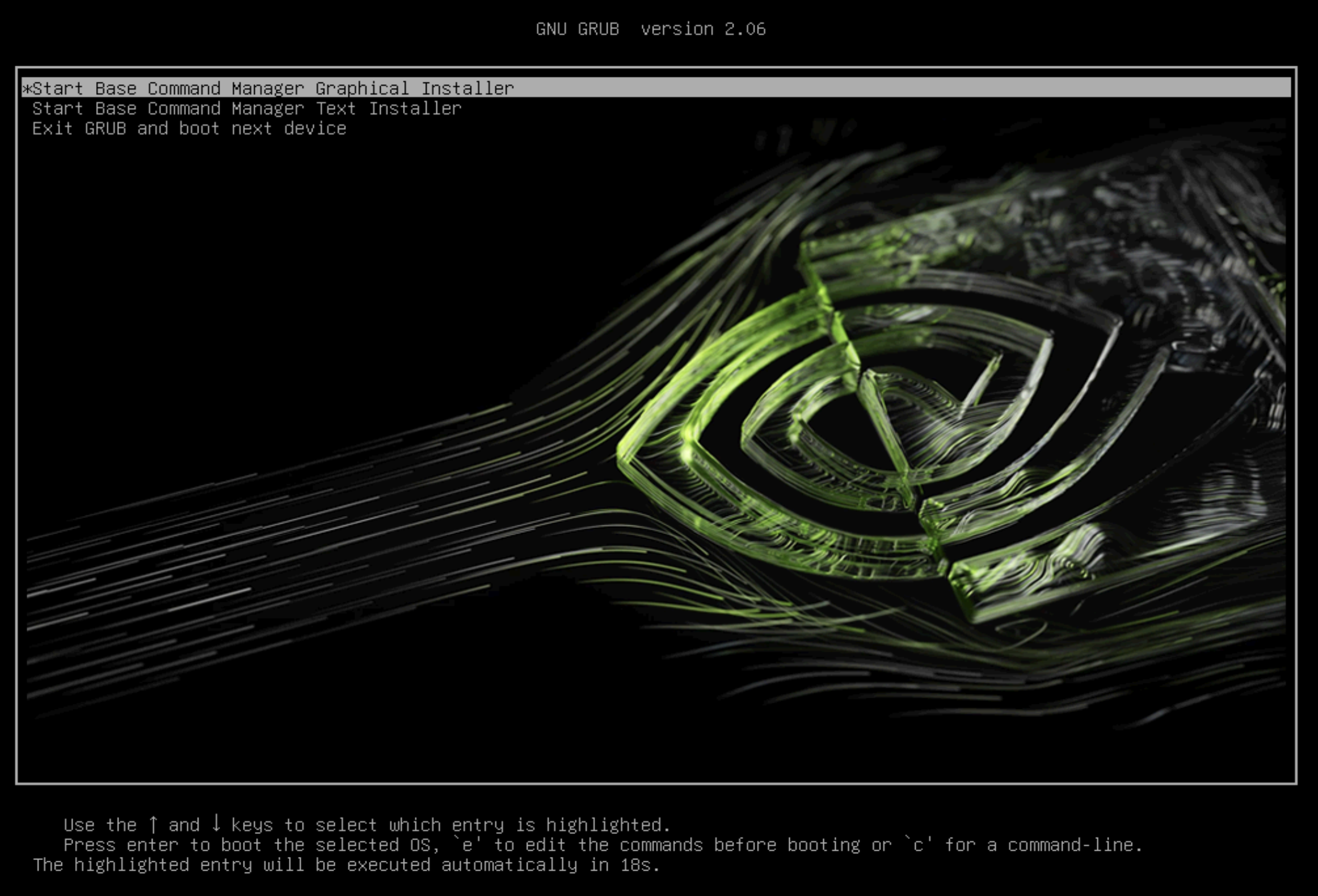
在启动画面上选择 开始安装。
通过选中 我同意 接受 NVIDIA EULA 的条款,然后选择 下一步。
通过选中 我同意 接受 Ubuntu Server UELA 的条款,然后选择 下一步。
除非另有指示,否则选择 下一步,无需修改启动时要加载的内核模块。
验证 硬件信息 是否正确,然后选择 下一步。
例如,目标存储设备和有线主机网络接口都存在(在本例中,三个 NVMe 驱动器是目标存储设备,而 ens1np0 和 ens2np01 是有线主机网络接口)。
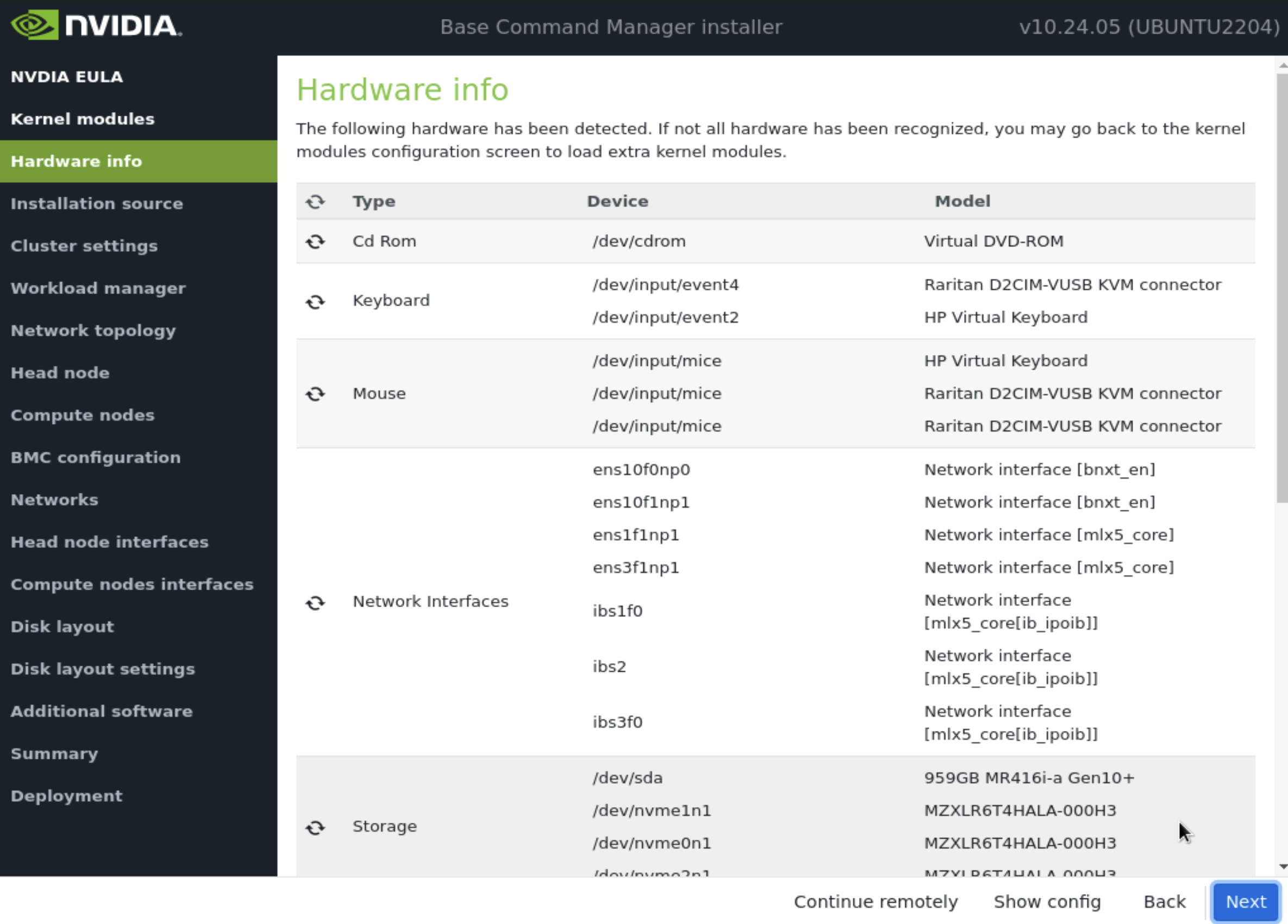
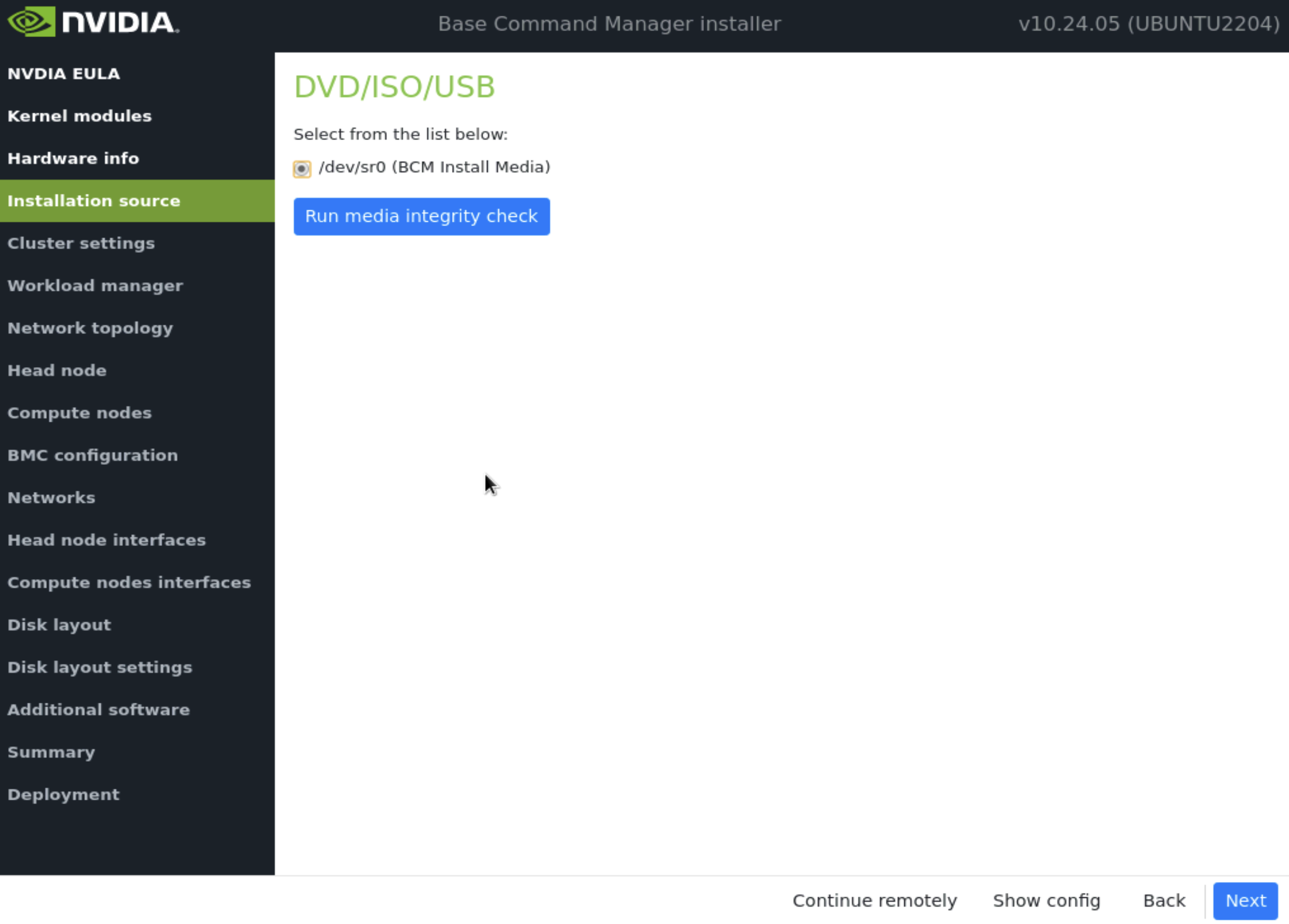
在 安装源 屏幕上,选择合适的源,然后选择 下一步。
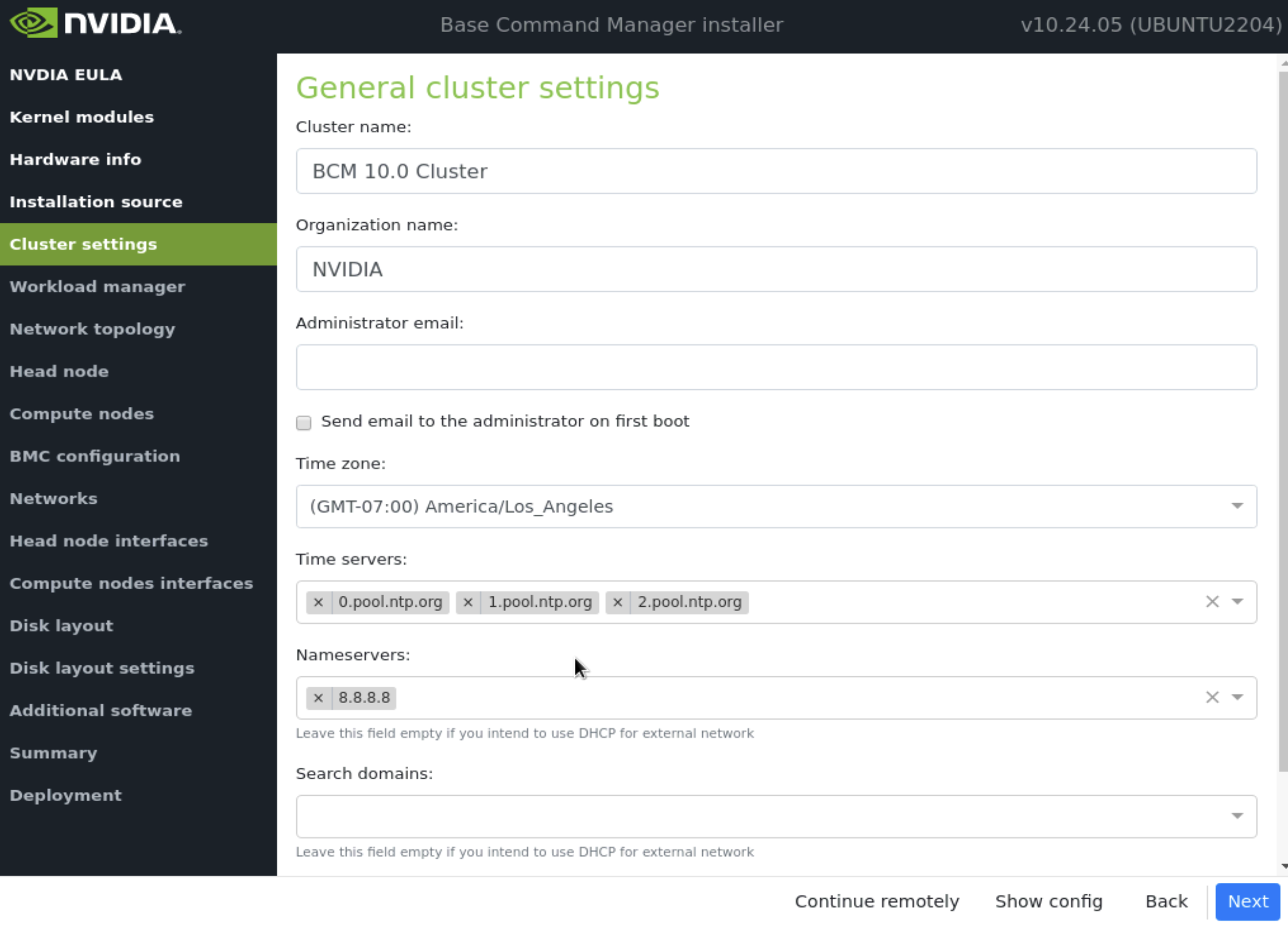
在 集群设置 屏幕上,根据站点调查输入所需信息,然后选择 下一步。
注意
确保 DNS 和 NTP 服务器可以从主节点访问。
在 工作负载管理器 屏幕上,选择 None,然后选择 下一步。

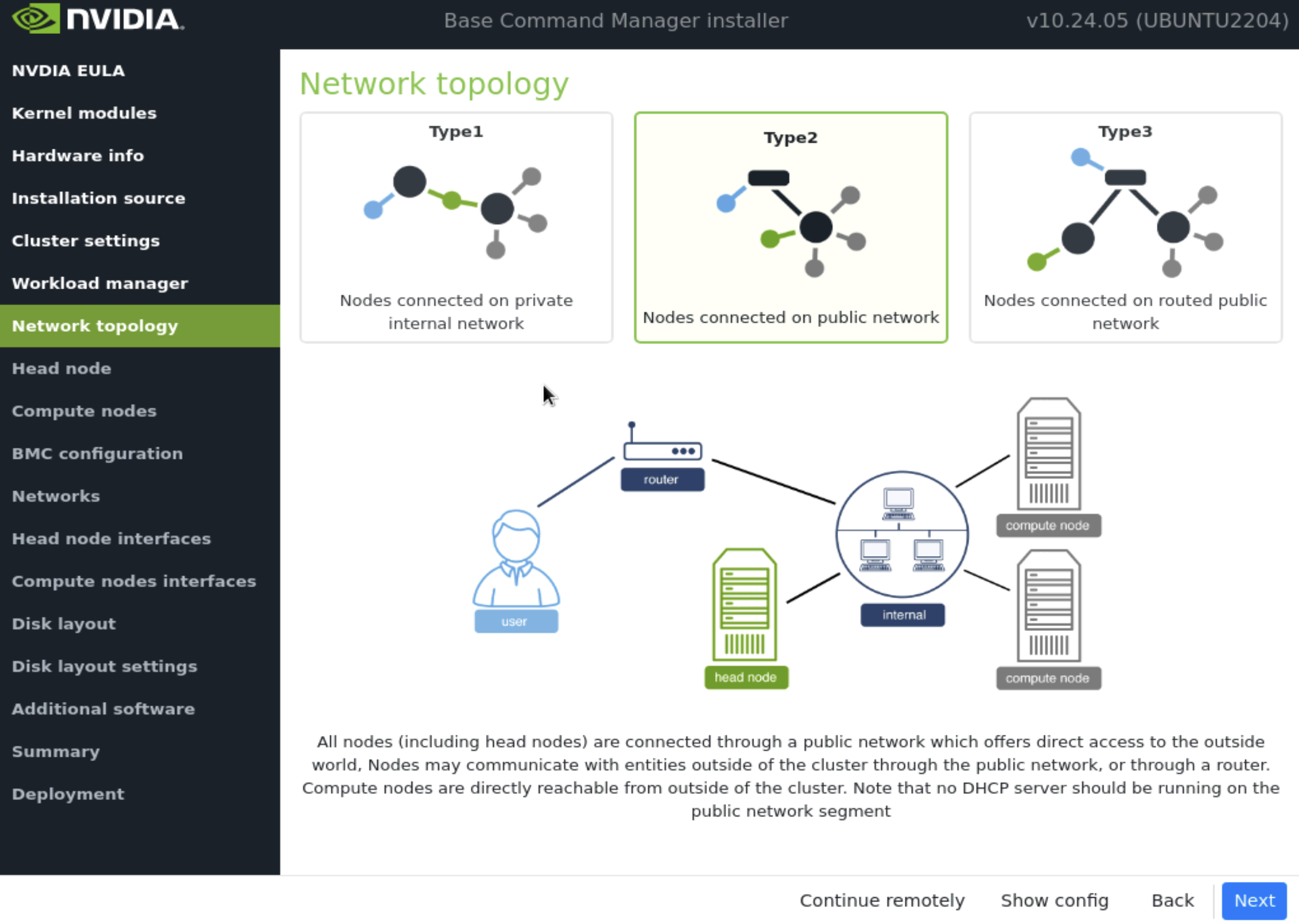
在 网络拓扑 屏幕上,选择数据中心环境的网络类型,然后选择 下一步。
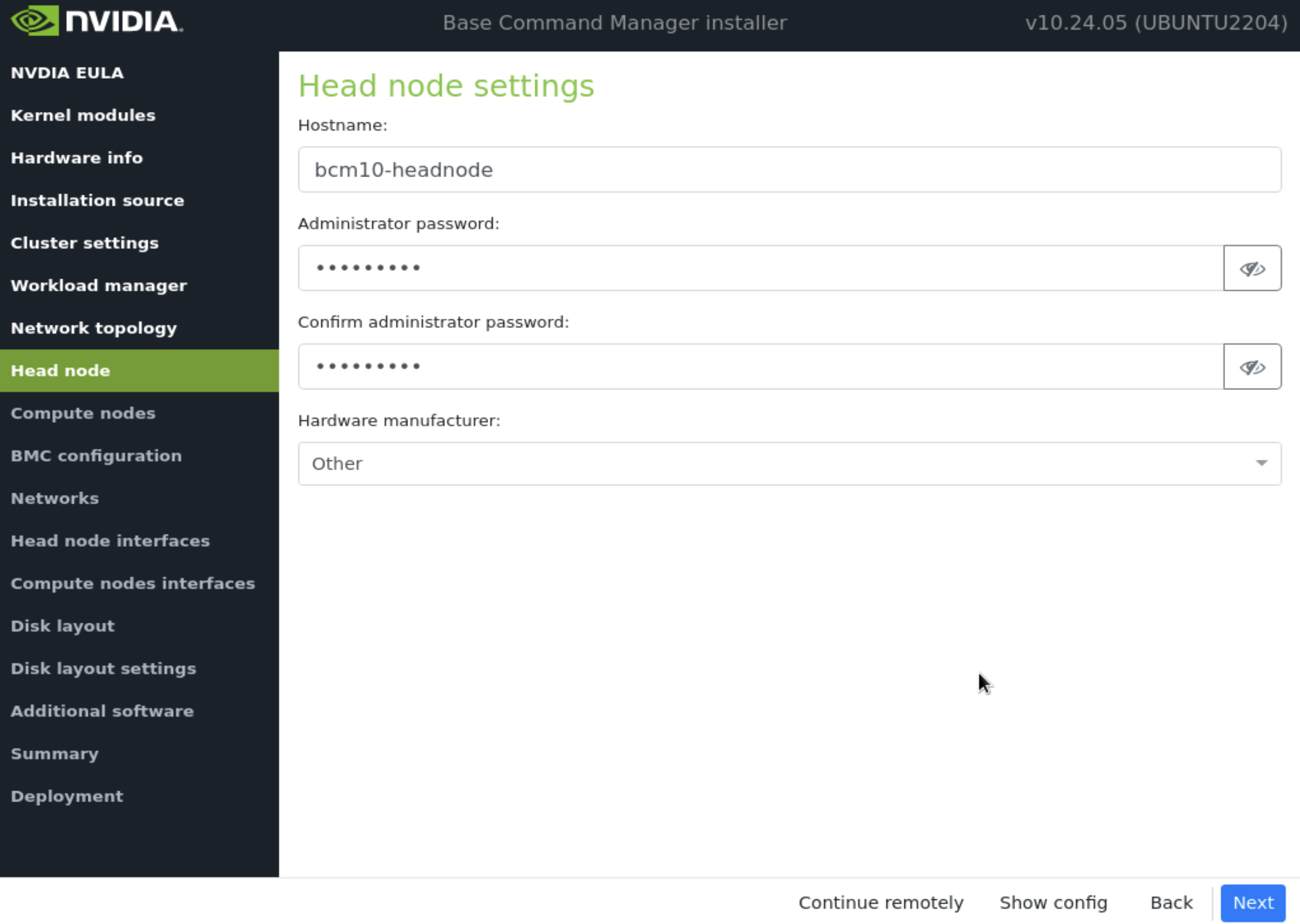
在 主节点 屏幕上,输入主机名和管理员密码,硬件制造商选择 Other,然后选择 下一步。
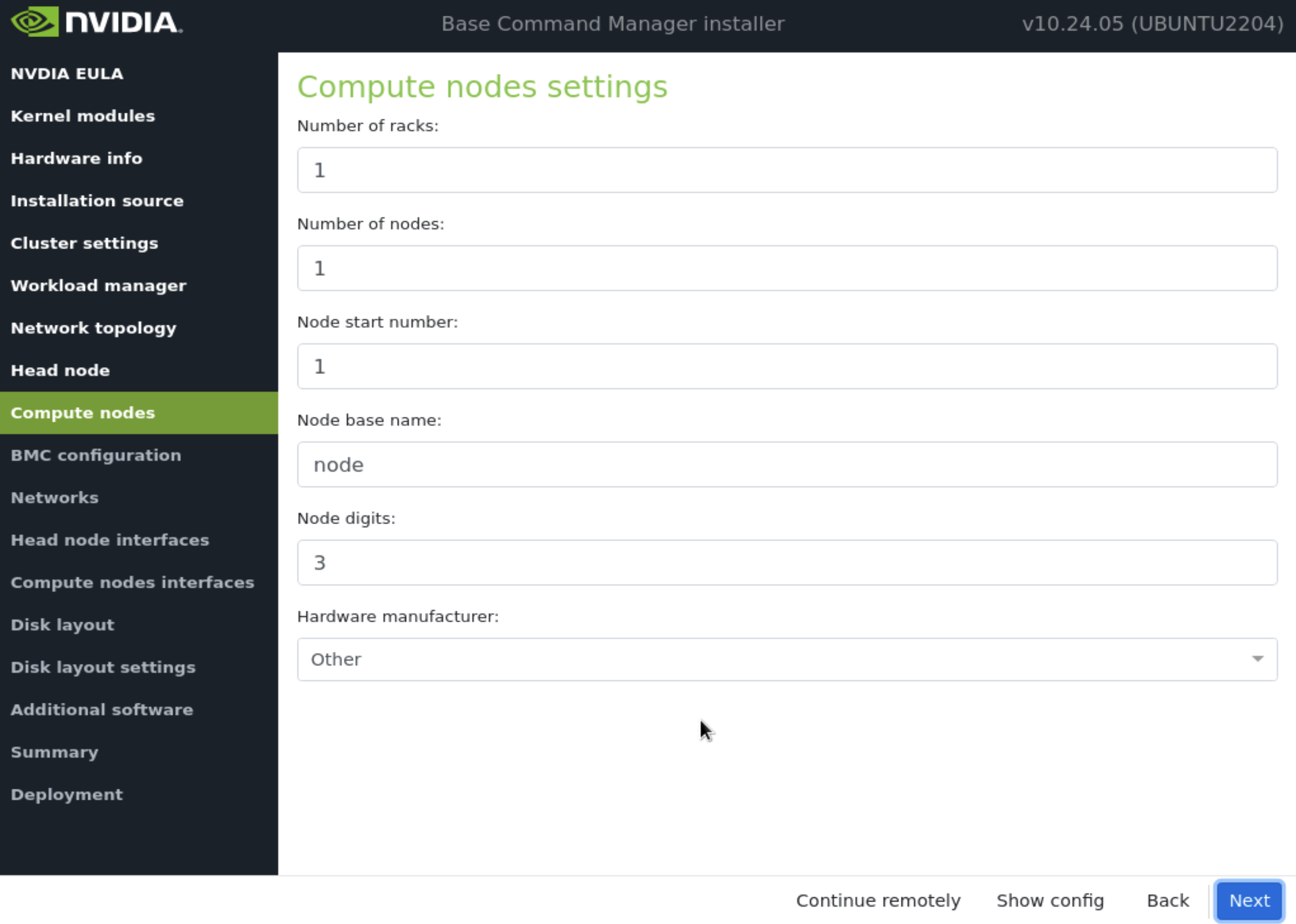
在计算节点中接受默认值,然后选择 下一步。这些值将在安装后期更新。
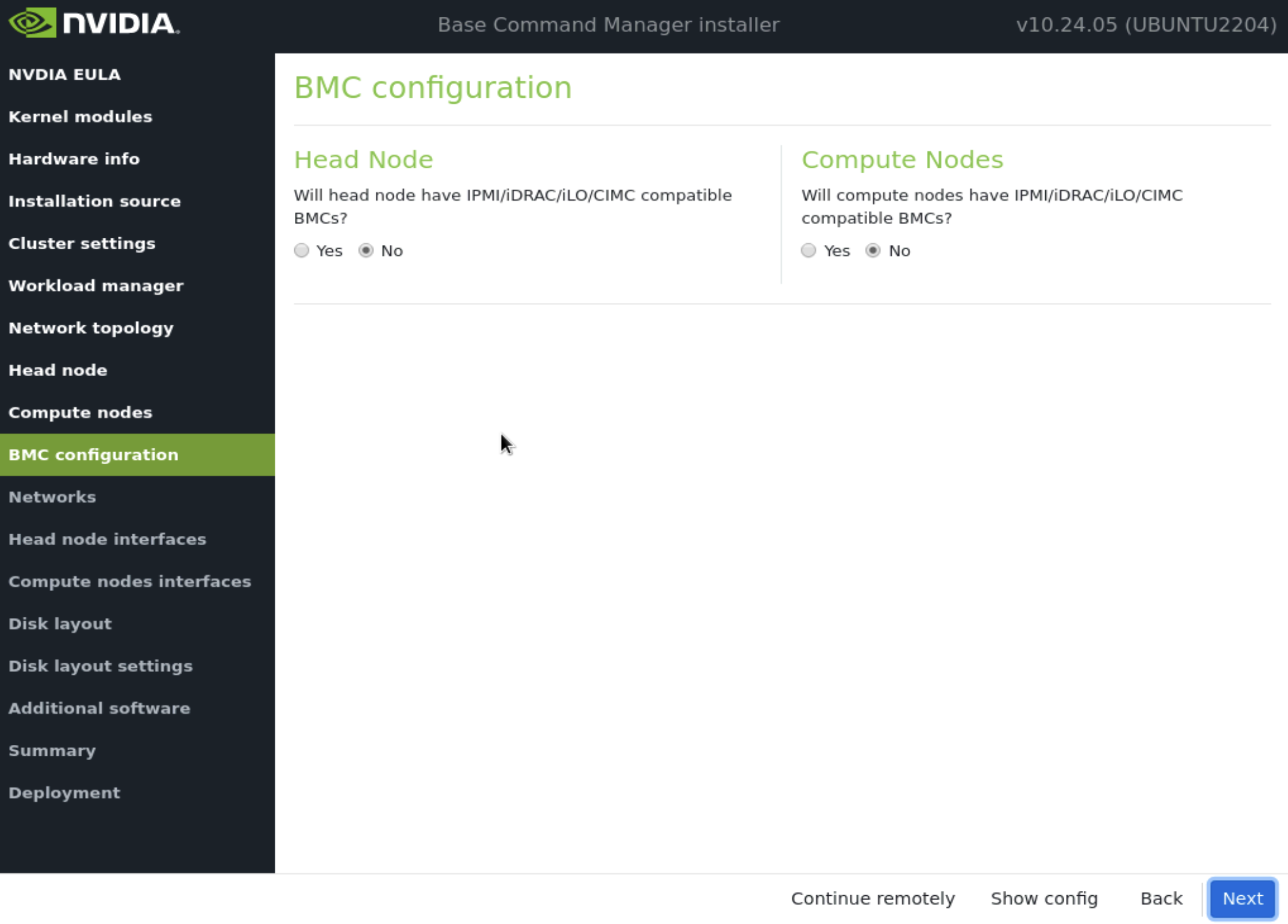
在 BMC 配置 屏幕上,主节点 和 计算节点 都选择 No,然后选择 下一步。
这些将在安装后阶段稍后更新。
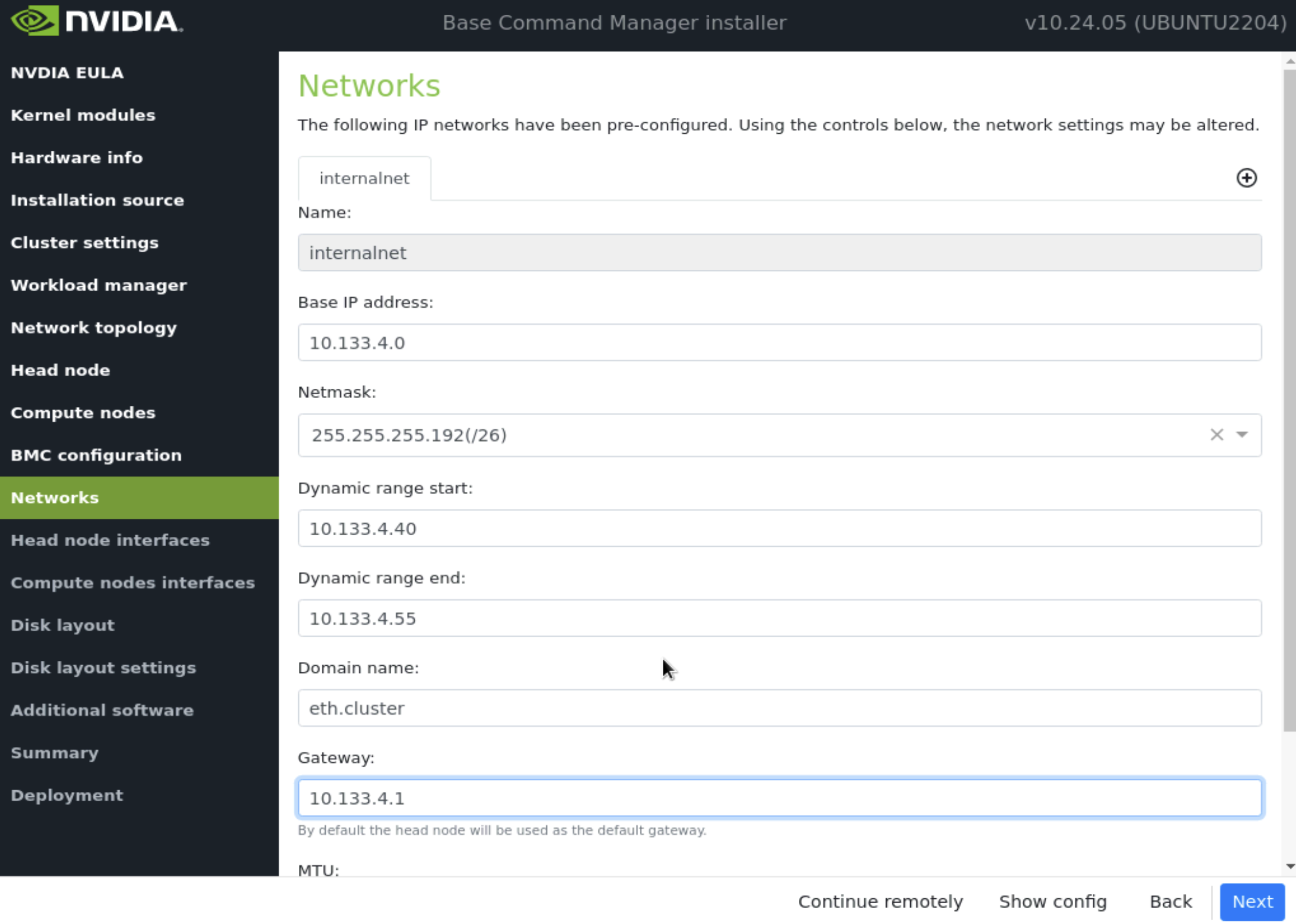
在 Networks 屏幕上,输入 internalnet 的所需信息,然后选择 下一步。
由于指定了 Type 2 网络,因此没有其他网络选项卡(例如,internalnet 或 ipminet)。
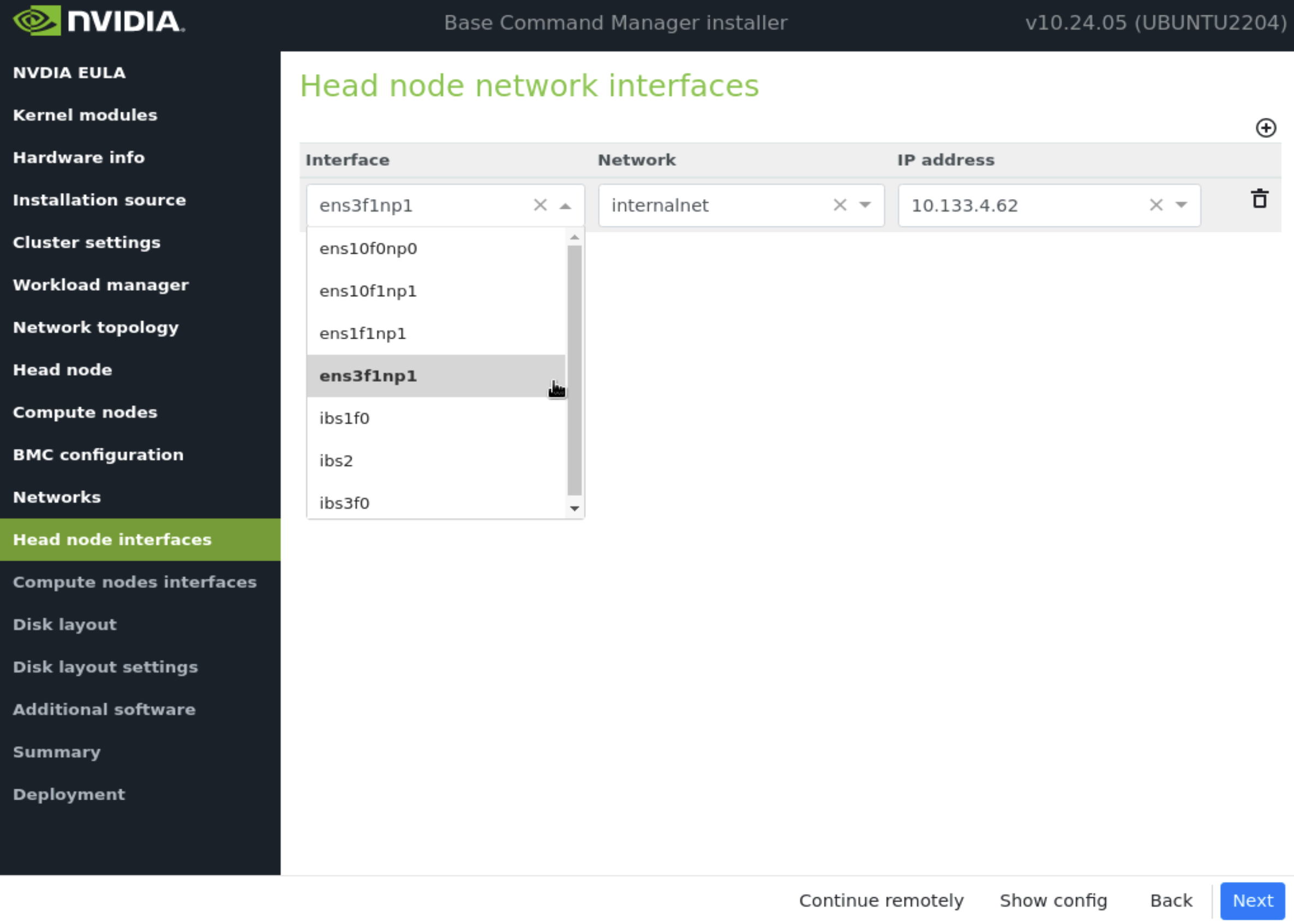
在主节点接口屏幕上,确保一个接口配置了主节点的目标 internalnet IP,然后选择 下一步。
其他接口将由安装后脚本配置。确保正在配置正确的接口。
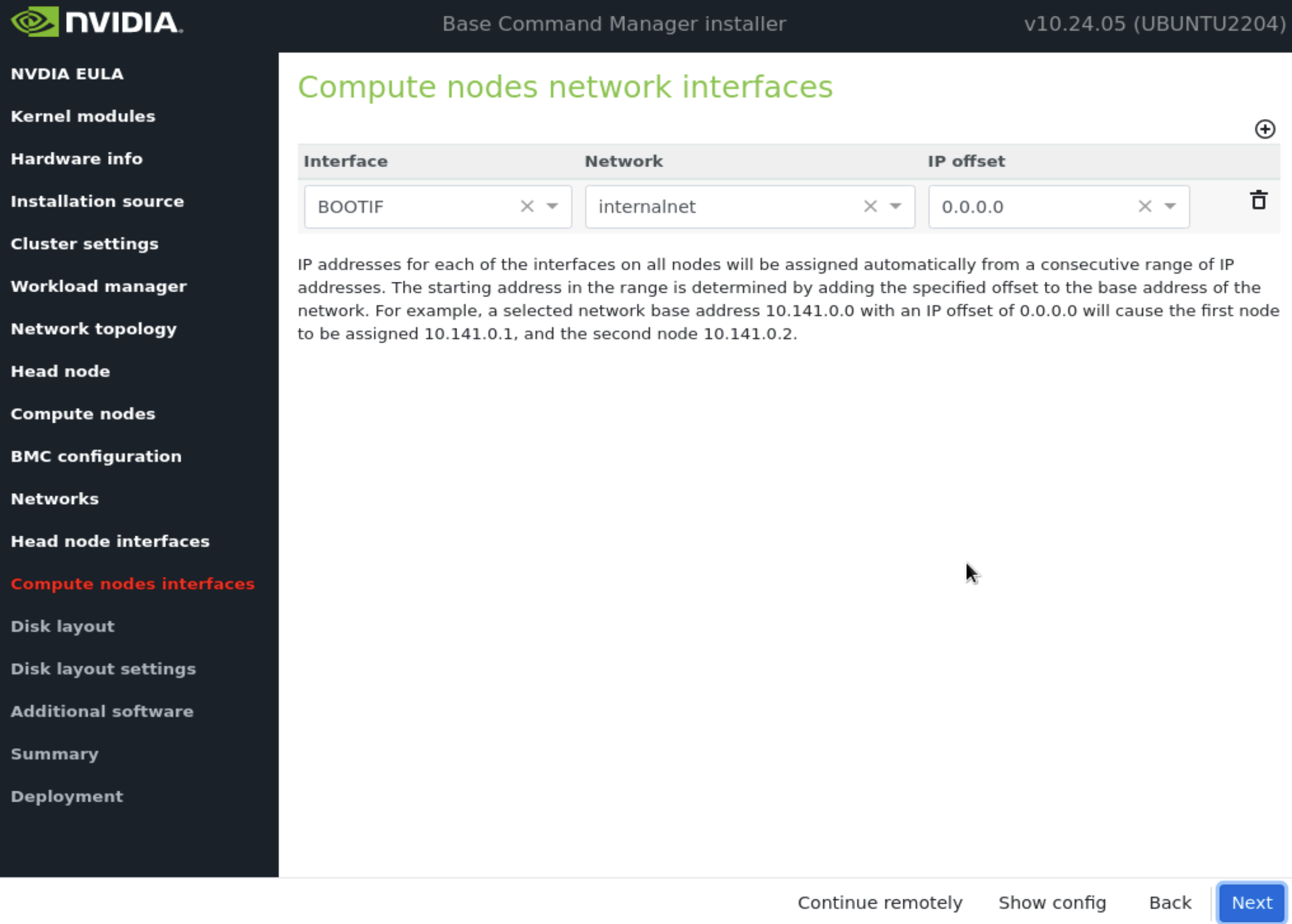
在 计算节点接口 屏幕上,保留默认条目,然后选择 下一步。
这些将在安装后更新。
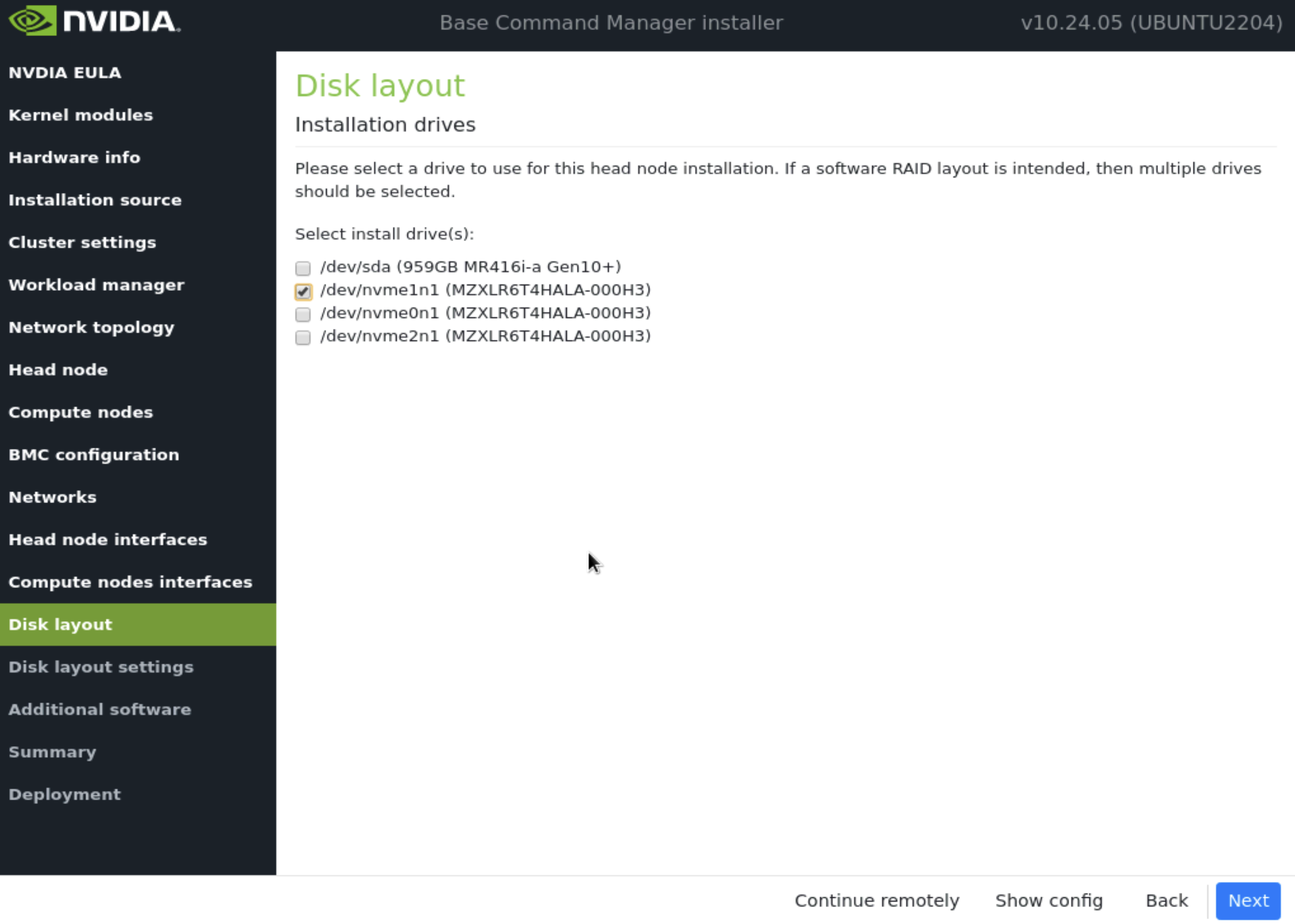
在 磁盘布局 屏幕上,选择目标安装位置(在本例中为 nvme0n1),然后选择 下一步。
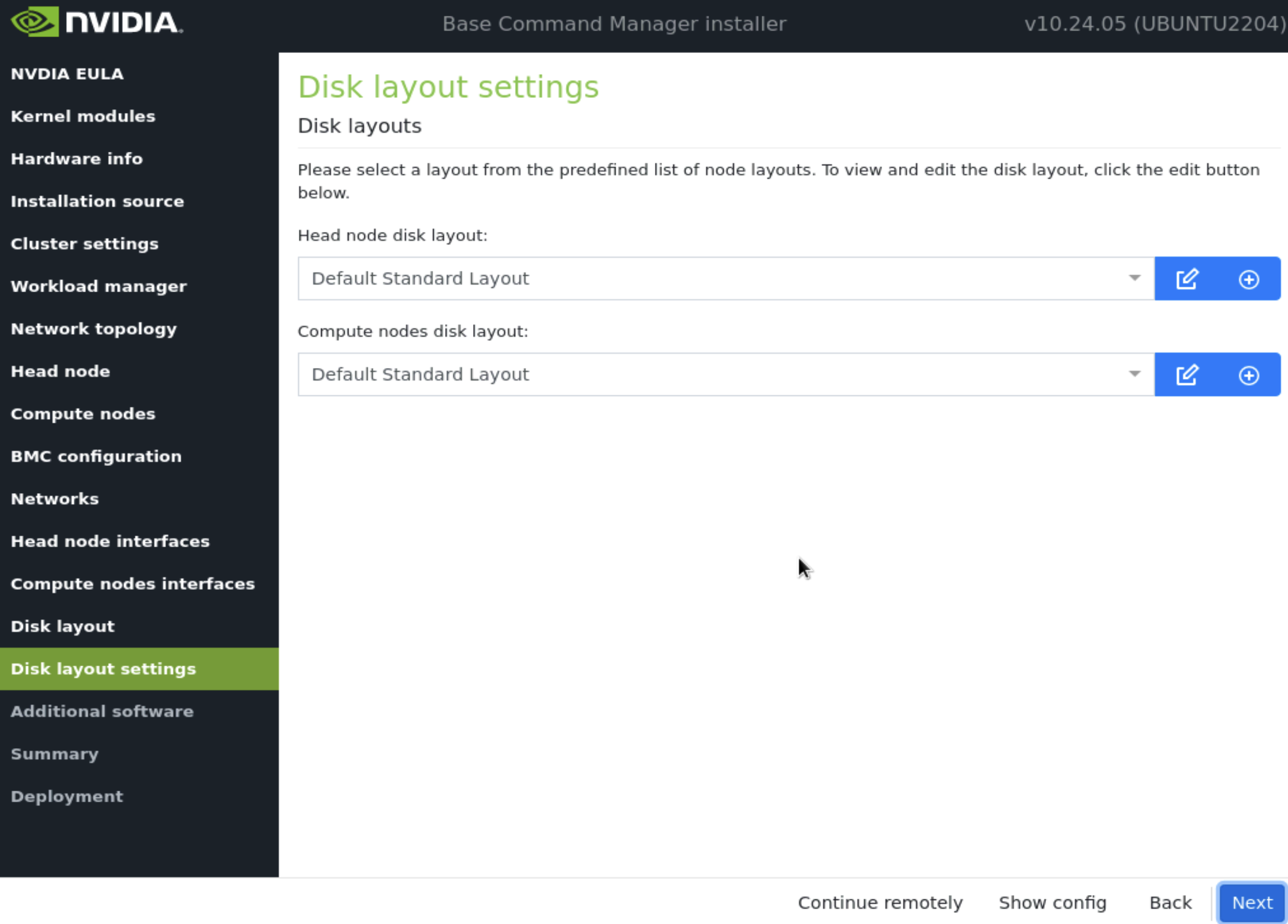
在 磁盘布局 设置屏幕上,接受默认值,然后选择 下一步。
这些设置将在安装后步骤中稍后更新。
在 附加软件 屏幕中,选择与 DGX H100 兼容的最新版本 OFED,然后选择 下一步。
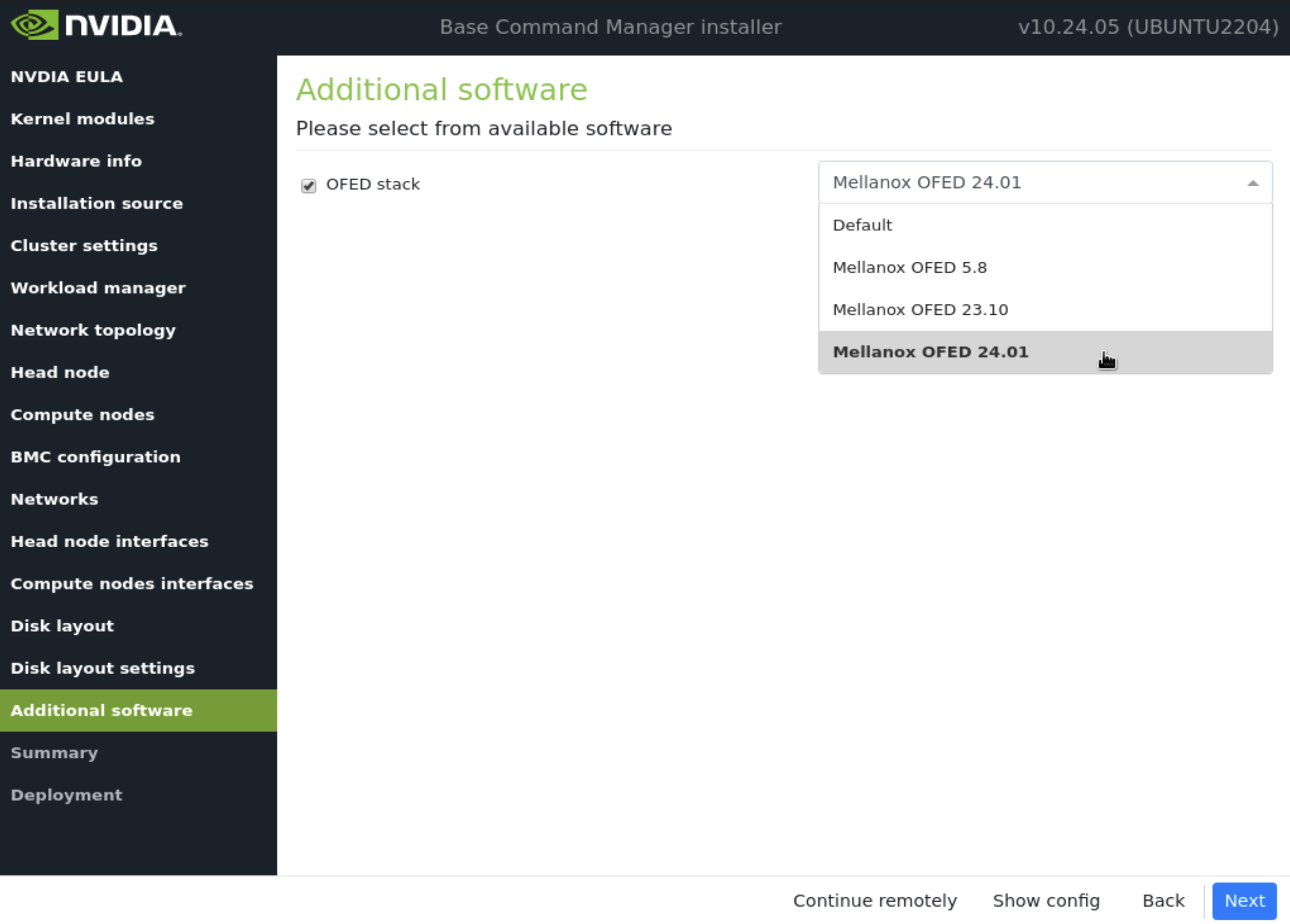
确认 摘要屏幕 上的信息,然后选择 下一步。
摘要屏幕提供了一个机会,在部署开始之前确认主节点和基本集群配置。此配置将在部署完成后为 DGX SuperPOD 更新/修改。如果值与预期不符,请使用“返回”按钮导航到相应的屏幕以纠正任何错误。
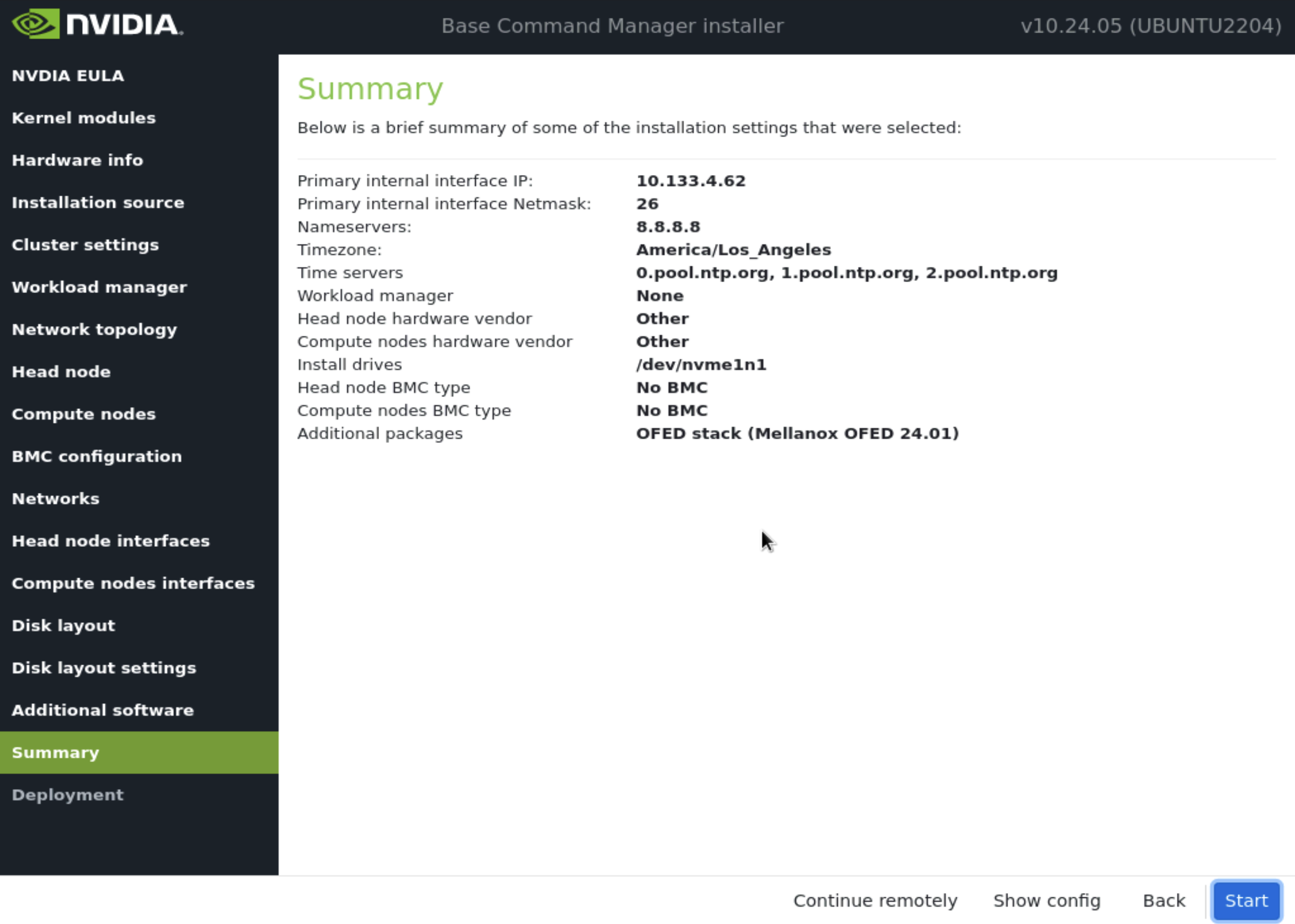
部署完成后,选择 重启。
一旦主节点完成重启,使用 root 凭据 ssh 登录。
通过运行 request-license 命令并提供产品密钥和其他信息来许可集群。
request-license
Product Key (XXXXXX-XXXXXX-XXXXXX-XXXXXX-XXXXXX): Country Name (2 letter code): US State or Province Name (full name): California Locality Name (e.g. city): Santa Clara Organization Name (e.g. company): NVIDIA Organizational Unit Name (e.g. department): Demo Cluster Name: Demo Cluster Private key data saved to /cm/local/apps/cmd/etc/cluster.key.new Warning: Permanently added 'bcm10-headnode' (ED25519) to the list of known hosts. MAC Address of primary head node (bcm10-headnode) for ens3f1np1 [08:C0:EB:F5:72:0F]:
如果为 HA 设置第二个主节点,请输入其主要带内接口的 mac 地址。
Will this cluster use a high-availability setup with 2 head nodes? [y/N] y MAC Address of secondary head node for eth0 [XX:XX:XX:XX:XX:XX]: 5c:6f:69:24:dd:54 Certificate request data saved to /cm/local/apps/cmd/etc/cluster.csr.new Submit certificate request to http://licensing.brightcomputing.com/licensing/index.cgi ? [Y/n] Y Contacting http://licensing.brightcomputing.com/licensing/index.cgi... License granted. License data was saved to /cm/local/apps/cmd/etc/cluster.pem.new Install license? [Y/n] Y ========= Certificate Information ======== Version: 10 Edition: Advanced OEM: NVIDIA Common name: Demo Cluster Organization: NVIDIA Organizational unit: Demo Locality: Santa Clara State: California Country: US Serial: 2369865 Starting date: 04/Oct/2023 Expiration date: 01/Sep/2024 MAC address / Cloud ID: 08:C0:EB:F5:72:0F|5C:6F:69:24:DD:54 Licensed tokens: 8192 Pay-per-use nodes: Yes Accounting & Reporting: Yes Allow edge sites: Yes License type: Free ========================================== Is the license information correct ? [Y/n] Y Backup directory of old license: /var/spool/cmd/backup/certificates/2024-05-31_08.25.05 Installed new license Revoke all existing cmd certificates Waiting for CMDaemon to stop: OK Installing admin certificates Waiting for CMDaemon to start: OK mysql: [Warning] Using a password on the command line interface can be insecure. Copy cluster certificate to 3 images / node-installers Copy cluster certificate to /cm/images/default-image//cm/local/apps/cmd/etc/cluster.pem Copy cluster certificate to /cm/node-installer//cm/local/apps/cmd/etc/cluster.pem Copy cluster certificate to /cm/images/dgx-os-6.1-h100-image//cm/local/apps/cmd/etc/cluster.pem Copy cluster certificate to /cm/images/dgx-os-6.1-a100-image//cm/local/apps/cmd/etc/cluster.pem mysql: [Warning] Using a password on the command line interface can be insecure. Regenerating certificates for users New license was installed. In order to allow compute nodes to obtain a new node certificate, all compute nodes must be rebooted. Please issue the following command to reboot all compute nodes: pdsh -g computenode reboot