简介
NVIDIA® 系统管理 (NVSM) 是 NVIDIA 软件堆栈,用于管理和监控 NVIDIA 设计的服务器,例如 NVIDIA DGX™、CGX 和 RTX 服务器。
NVSM 是一个“常时开启”的健康监控引擎,它可以主动捕捉问题,而不是像其他工具那样需要在事后运行。凭借对底层平台的深入了解,NVSM 拥有进行最佳健康检查的列表以及每次检查需要发生的频率。
NVSM CLI 和 API 减轻了用户对以下方面的需求:
深入了解 ipmitool、dmidecode、lspci、storcli、mdadm 和 lsblk 等工具。
深入了解平台细节,例如预期的 PCIe 层次结构、存储层次结构或错误阈值。
手动关联来自多个工具的信息;在许多情况下,需要手动解析一个工具的输出,以了解如何使用下一个工具。例如,SEL 记录中的 BDF 与 lspci 中的 BDF 只是为了确定哪个设备有故障。
NVSM 捕捉到一些客户可能永远不会注意到的问题。例如,某些 PCIe 链路可能以较低的链路宽度/速度运行,导致作业运行缓慢。如果没有 NVSM,客户可能会怀疑他们的作业有问题,或者更糟糕的是,认为 DGX 就是这么慢。
NVSM 提供:
按需健康检查套件,运行一系列测试并报告与预期结果的偏差。
创建 NVIDIA 支持报告问题时所需的所有相关系统日志包的功能。
安全的 REST API 接口,无需用户/脚本登录系统。因此,使用这些 API 可以轻松开发远程管理软件应用程序。
可以启用 Prometheus 指标导出器,以便外部 Prometheus 服务器可以从目标 DGX 节点拉取关键系统指标。
如果启用 NVSM 的呼叫中心功能,即使在客户注意到平台问题之前,也会自动代表客户创建支持票证。
此外,NVSM 还提供其他通知机制,如电子邮件和 PagerDuty。
目前,NVSM 支持以下 DGX 系统:
DGX 服务器:本文档中描述的完整 NVSM 功能。
DGX Station:功能仅限于使用 CLI 检查系统健康状况并获取诊断信息。
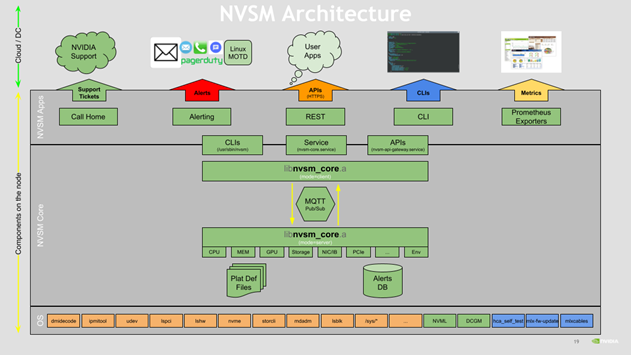
以下是 NVSM 架构的高级图表:
注意:
DGX Station 不支持“常时开启”功能。
可配置的“常时开启”功能
NVSM 包含以下可以使用 NVSM CLI 配置的功能:
健康监控器警报
健康监控器策略
健康监控器警报
警报是需要注意的重要事件。当健康监控器检测到其监控的子系统中发生此类事件时,它会生成警报以通知用户。默认行为是将警报记录在持久存储中,并向注册用户发送电子邮件通知。有关配置用户以接收警报电子邮件通知的详细信息,请参阅使用 NVSM CLI部分。
每个警报都有一个“状态”。活动警报可以处于“严重”或“警告”状态。在此,“严重”表示需要立即采取行动的事件,“警告”表示需要用户注意的事件。当警报条件消除时,警报状态变为“已清除”。有关如何查看数据库中记录的已生成警报的详细信息,请参阅使用 NVSM CLI部分。
健康监控器警报列表
下表描述了每个警报 ID:
消息和详细信息 |
警报 ID |
组件 ID |
严重性 |
建议措施 |
|---|---|---|---|---|
不支持的驱动器配置。受影响的组件 URI:{{ index .Params "Uri" }} |
NV-DRIVE-01 |
驱动器插槽 <> |
警告 |
请参阅下面的建议措施 A。 |
系统进入降级模式,{{ index .Params "DriveSlot" }} 中的驱动器不受支持。 |
NV-DRIVE-07 |
驱动器插槽 <> |
警告 |
请参阅下面的建议措施 A。 |
不支持的 SED 驱动器配置。 |
NV-DRIVE-09 |
卷标 |
警告 |
请参阅下面的建议措施 A。 |
不支持的卷加密配置。 |
NV-DRIVE-10 |
卷标 |
严重 |
请参阅下面的建议措施 A。 |
M.2 驱动器固件版本不匹配。 |
NV-DRIVE-11 |
驱动器插槽 <> |
警告 |
请参阅下面的建议措施 A。 |
系统进入降级模式,卷 {{ index .Params "ComponentName" }} 正在重建中。 |
NV-VOL-01 |
卷名 |
警告 |
请参阅下面的建议措施 A。 |
系统进入降级模式,卷 {{ index .Params "ComponentName" }} 重建失败。 |
NV-VOL-02 |
卷名 |
严重 |
请参阅下面的建议措施 A。 |
系统进入降级模式,卷 {{ index .Params "ComponentName" }} 处于降级状态。 |
NV-VOL-03 |
卷名 |
严重 |
请参阅下面的建议措施 A。 |
系统进入降级模式,卷 {{ index .Params "ComponentName" }} 处于非活动或失败状态。 |
NV-VOL-04 |
卷名 |
严重 |
请参阅下面的建议措施 A。 |
Raid-0 卷 {{ index .Params "ComponentName" }} 配置错误。 |
NV-VOL-05 |
卷名 |
警告 |
请参阅下面的建议措施 A。 |
用于缓存的 Raid-0 数据卷不存在。 |
NV-VOL-06 |
信息 |
请参阅下面的建议措施 A。 |
|
引导卷上缺少 EFI 分区。运行 ‘blkid’ 以检查分区类型。 |
NV-VOL-09 |
卷名 |
严重 |
请参阅下面的建议措施 A。 |
存储卷 {{ index .Params "ComponentName" }} 利用率接近 {{ index .Params "Capacity" }} 字节的 90%。 |
NV-VOL-10 |
卷名 |
严重 |
请参阅下面的建议措施 A。 |
系统进入降级模式,{} 报告错误。 (电源模块发生故障。) |
NV-PSU-01 |
<PSU#>,其中 # 是 PSU 编号。 |
严重 |
请参阅下面的建议措施 A。 |
系统进入降级模式,{} 报告错误。 (工作温度超过组件的热规格。) |
NV-PSU-02 |
<PSU#>,其中 # 是 PSU 编号。 |
警告 |
请参阅下面的建议措施 A。 |
系统进入降级模式,{} 报告错误。 (PSU 的输入丢失) |
NV-PSU-03 |
<PSU#>,其中 # 是 PSU 编号。 |
严重 |
请参阅下面的建议措施 A。 |
系统进入降级模式,{} 报告错误。(电源模块的输入电压超出范围) (电源模块的输入电压超出范围) |
NV-PSU-04 |
<PSU#>,其中 # 是 PSU 编号。 |
严重 |
请参阅下面的建议措施 A。 |
系统进入降级模式,{} 报告错误。 (PSU 丢失) |
NV-PSU-05 |
<PSU#>,其中 # 是 PSU 编号。 |
警告 |
请参阅下面的建议措施 A。 |
检测到电源模块故障。 (系统以降级的性能模式运行。) |
NV-PSU-06 |
警告 |
纠正 PSU 上观察到的问题。然后参阅下面的建议措施 A。 |
|
检测到电源模块故障。 (系统处于电源故障状态) |
NV-PSU-07 |
严重 |
纠正 PSU 上观察到的问题。然后参阅下面的建议措施 A。 |
|
系统进入降级模式,{} 报告错误。 (工作温度超过组件的热规格。) |
NV-PDB-01 |
<PDB#>,其中 # 是 PDB 编号 |
严重 |
请参阅下面的建议措施 A。 |
系统进入降级模式,{} 报告错误。 (风扇速度读数已降至预期速度设置以下。) |
NV-FAN-01 |
<FAN#_F> 或 <FAN#_R> 其中 # 是风扇模块编号。 F 表示前风扇。 R 表示后风扇。 |
严重 |
请参阅下面的建议措施 A。 |
系统进入降级模式,{} 报告错误。 (风扇读数无法访问。) |
NV-FAN-02 |
<FAN#_F> 或 <FAN#_R> 其中 # 是风扇模块编号。 F 表示前风扇。 R 表示后风扇。 |
严重 |
请参阅下面的建议措施 A。 |
系统进入降级模式,{} 报告错误。 (发生不可恢复的 CPU 内部错误。) |
NV-CPU-01 |
<CPU#> 其中 # 是 CPU 插槽编号(CPU0 或 CPU1) |
严重 |
请参阅下面的建议措施 A。 |
系统进入降级模式,{} 报告错误。 (CPU Thermtrip 已发生,处理器插槽温度超过组件的热规格。) |
NV-CPU-02 |
<CPU#> 其中 # 是 CPU 插槽编号(CPU0 或 CPU1) |
严重 |
请参阅下面的建议措施 A。 |
系统进入降级模式,{} 报告错误。 (处理器插槽温度超过组件的热规格。) |
NV-CPU-03 |
严重 |
请参阅下面的建议措施 A。 |
|
系统进入降级模式,{} 报告错误。 (处理器插槽温度超过组件的热规格。) |
NV-CPU-04 |
严重 |
请参阅下面的建议措施 A。 |
|
系统进入降级模式,{} 报告错误。 (报告了不可纠正的错误。) |
NV-DIMM-01 |
<CPU#_DIMM_@$> 其中 # = (1, 2) @ = (A, B, C, D, E, F) $ = (1, 2) |
严重 |
请参阅下面的建议措施 A。 |
系统进入降级模式,{} 报告错误。 (报告的可纠正错误超过配置的阈值。) |
NV-DIMM-02 |
<CPU#_DIMM_@$> 其中 # = (1, 2) @ = (A, B, C, D, E, F) $ = (1, 2) |
警告 |
请参阅下面的建议措施 A。 |
系统进入降级模式,{} 报告错误。 (在 DIMM 上观察到不可恢复的错误,无法获得错误的具体详细信息。) |
NV-DIMM-03 |
<CPU#_DIMM_@$> 其中 # = (1, 2) @ = (A, B, C, D, E, F) $ = (1, 2) |
严重 |
请参阅下面的建议措施 A。 |
系统进入降级模式,{} 报告错误。 (此插槽中不应存在 DIMM,请验证 DIMM 详细信息。) |
NV-DIMM-04 |
请参阅下面的建议措施 A。 |
||
系统进入降级模式,GPU 报告错误 (GPU 报告了严重错误。) |
NV-GPU-01 |
严重 |
请参阅下面的建议措施 A。 |
|
GPU{} 功率限制配置不正确 (预期限制(功率:200000W,时钟:1597MHz),实际限制(功率:200000W,时钟:1163MHz)。) |
NV-GPU-02 |
严重 |
请参阅下面的建议措施 A。 |
|
系统进入降级模式,{ID} 报告错误。 ({ BDF1, BDF2} 之间观察到链路速度降低,预期链路速度为 {},实际链路速度为 {}) |
NV-PCI-01 |
警告 |
请参阅下面的建议措施 A。 |
|
系统进入降级模式,{ID} 报告错误。 ({BDF1, BDF2} 之间观察到链路宽度降低,预期链路宽度为 {},实际链路宽度为 {}) |
NV-PCI-02 |
警告 |
请参阅下面的建议措施 A。 |
|
系统进入降级模式,{ID} 报告错误。 (在 {BDF} 上报告了可纠正错误。) |
NV-PCI-03 |
警告 |
请参阅下面的建议措施 A。 |
|
系统进入降级模式,{ID} 报告错误。 (在 {BDF} 上报告了不可纠正错误) |
NV-PCI-04 |
严重 |
请参阅下面的建议措施 A。 |
|
系统进入降级模式,{ID} 报告错误。 ({BDF} 上缺少设备) |
NV-PCI-05 |
严重 |
请参阅下面的建议措施 A。 |
|
系统进入降级模式,{ID} 报告错误。 ({BDF} 上为 {} 禁用了设备错误报告) |
NV-PCI-06 |
严重 |
请参阅下面的建议措施 A。 |
|
系统进入降级模式,{ID} 报告错误。 ({BDF} 上的设备已禁用) |
NV-PCI-07 |
严重 |
请参阅下面的建议措施 A。 |
|
系统进入降级模式,控制器 {{ index .Params "ComponentName" }} 报告错误。 |
NV-CONTROLLER-01 |
控制器名称 |
警告 |
请参阅下面的建议措施 A。 |
系统进入降级模式,存储控制器 {{ index .Params "ComponentName" }} 报告 PHY 错误。 |
NV-CONTROLLER-02 |
控制器名称 |
警告 |
请参阅下面的建议措施 A。 |
系统进入降级模式,控制器 {{ index .Params "ComponentName" }} 设置为低于预期速度的速度。 |
NV-CONTROLLER-03 |
控制器名称 |
警告 |
请参阅下面的建议措施 A。 |
系统进入降级模式,控制器 {{ index .Params "ComponentName" }} 报告错误。 |
NV-CONTROLLER-04 |
控制器名称 |
警告 |
请参阅下面的建议措施 A。 |
系统进入降级模式,控制器 {{ index .Params "ComponentName" }} 报告错误。 |
NV-CONTROLLER-05 |
控制器名称 |
严重 |
请参阅下面的建议措施 A。 |
系统进入降级模式,控制器 {{ index .Params "ComponentName" }} 报告错误。 |
NV-CONTROLLER-06 |
控制器名称 |
严重 |
请参阅下面的建议措施 A。 |
需要清除控制器 {{ index .Params "ComponentName" }} 的 LEDStatus。 |
NV-CONTROLLER-07 |
控制器名称 |
严重 |
请参阅下面的建议措施 A。 |
{} 上出现链路错误。 (网络链路已断开) |
NV-NET-01 |
警告 |
请参阅下面的建议措施 B。 |
|
在 {} 上观察到网络流量错误。 (在 {} 网络端口上,{} 的 Rx 冲突率已超过阈值 {}。) |
NV-NET-02 |
警告 |
请参阅下面的建议措施 B。 |
|
在 {} 上观察到网络流量错误。 (在 {} 网络端口上,{} 的 Tx 冲突率已超过阈值 {}。) |
NV-NET-03 |
警告 |
请参阅下面的建议措施 B。 |
|
在 {} 上观察到网络流量错误。 (在 {} 网络端口上,{} 的 CRC 错误率已超过阈值 {}。) |
NV-NET-04 |
严重 |
请参阅下面的建议措施 B。 |
|
{} 报告错误。 ({} 网络端口已禁用。) |
NV-NET-05 |
严重 |
请参阅下面的建议措施 B。 |
|
端口 {} 上出现以太网接口错误。 ({} 以太网健康检查失败,在线 NVRAM 测试失败。) |
NV-ETH-01 |
严重 |
请参阅下面的建议措施 B。 |
|
{} 上出现以太网接口配置错误。 ({} 的以太网接口上缺少 MAC 地址。) |
NV-ETH-02 |
严重 |
请参阅下面的建议措施 B。 |
|
IB 驱动程序错误。 (HCA 自检报告 IB 驱动程序初始化失败。) |
NV-IB-01 |
严重 |
请参阅下面的建议措施 C。 |
|
IB 端口 {} 上的计数器错误 (IB 端口上的 {} HCA 自检报告计数器错误。) |
NV-IB-02 |
严重 |
请参阅下面的建议措施 B。 |
|
IB 端口 {} 上的配置错误。 ({} HCA 上缺少 GUID。) |
NV-IB-03 |
严重 |
请参阅下面的建议措施 D。 |
|
系统进入降级模式,{} 报告致命错误 (NVSwitch Id {} 报告了严重错误,SXID 错误为 {}) |
NV-NVSWITCH-01 |
严重 |
请参阅下面的建议措施 A。 |
|
系统进入降级模式,{} 报告非致命错误 (NVSwitch Id {} 报告了严重错误,SXID 错误为 {}) |
NV-NVSWITCH-02 |
警告 |
请参阅下面的建议措施 A。 |
建议措施
(A)
运行 ‘sudo nvsm dump health’
在此地址向 NVIDIA 企业支持部门开具案例:https://nvid.nvidia.com/dashboard/
附加此通知和来自 /tmp/nvsm-health- <hostname>-<timestamp>.tar.xz 的 nvsysinfo 日志文件
(B)
检查物理链路连接
在此地址向 NVIDIA 企业支持部门开具案例:https://nvid.nvidia.com/dashboard/
(C)
检查 OFED 安装故障排除
在此地址向 NVIDIA 企业支持部门开具案例:https://nvid.nvidia.com/dashboard/
(D)
检查子网管理器的状态
在此地址向 NVIDIA 企业支持部门开具案例:https://nvid.nvidia.com/dashboard/
健康监控器策略
用户可以使用健康监控器策略调整健康监控器行为的某些方面。这包括警报通知的电子邮件相关配置、有选择地禁用要监控的设备等详细信息。有关支持的策略以及如何使用 CLI 配置它们的详细信息,请参阅使用 NVSM CLI部分。
验证安装
在使用 NVSM 之前,您可以验证安装以确保所有服务都存在。
使用 systemctl 验证 NVSM 服务
NVSM 是 DGX OS 映像的一部分,并在 DGX 启动时由 systemd 启动。以下是在 NVSM 下运行的服务:
nvsm-api-gateway.servicenvsm-core.servicenvsm-mqtt.servicenvsm-notifier.servicenvsm.service
您可以使用 systemctl 命令验证每个 NVSM 服务是否已启动并正在运行。例如,以下命令验证核心服务:
$ sudo systemctl status nvsm-core
您可以使用以下命令查看所有 NVSM 服务及其状态:
$ sudo systemctl status -all nvsm*
使用 nvsm status 验证 NVSM 服务
nvsm status 命令显示 NVSM 服务及其状态,示例输出:
$ sudo nvsm status
SERVICE ENABLED ACTIVE SUB DESCRIPTION
================================================================================
nvsm-mqtt.service enabled active running MQTT broker for NVSM API for signaling within NVSM API components
nvsm-core.service enabled active running NVSM Core Service for System Management
nvsm-api-gateway.service enabled active running NVSM API Server to provide DGX System Management APIs
nvsm-notifier.service enabled active running NVSM Notifier service.
Overall
================================================================================
Overall Health: Healthy
Overall Status: Active
如果您在 NVSM 启动时运行 nvsm status,则输出类似于以下示例:
$ sudo nvsm status
SERVICE ENABLED ACTIVE SUB DESCRIPTION
================================================================================
nvsm-mqtt.service enabled active running MQTT broker for NVSM API for signaling within NVSM API components
nvsm-core.service enabled activating start-post NVSM Core Service for System Management
nvsm-api-gateway.service enabled inactive dead NVSM API Server to provide DGX System Management APIs
nvsm-notifier.service enabled inactive dead NVSM Notifier service.
Overall
================================================================================
Overall Health: Transient
Overall Status: Starting
Recommendations:
================================================================================
0. NVSM is starting, this state should be transient, please try again later
1. nvsm-core.service is activating. If it stay in this state, please run "journalctl -fu nvsm-core.service" for more details
注意:
仅当所有 NVSM 服务都已启动并正在运行时,nvsm CLI 命令才有效。
如果任何子服务失败或卡在启动中,请运行以下命令以获取更多信息:
sudo systemctl status <service-name>
例如:
sudo systemctl status nvsm-core.service