GPU 驱动程序升级#
关于升级 GPU 驱动程序#
NVIDIA 驱动程序守护程序集在升级时需要特别考虑,因为驱动程序内核模块必须在每次驱动程序容器重启时卸载并重新加载。 因此,在驱动程序升级过程中必须执行以下步骤
禁用所有 GPU 驱动程序的客户端。
卸载当前的 GPU 驱动程序内核模块。
启动更新后的 GPU 驱动程序 Pod。
安装更新后的 GPU 驱动程序并加载更新后的内核模块。
启用 GPU 驱动程序的客户端。
GPU Operator 支持多种方法来管理和自动化此驱动程序升级过程。
注意
GPU Operator 仅管理容器化驱动程序的生命周期。 预安装在主机上的驱动程序不受 GPU Operator 管理。
使用升级控制器进行升级#
NVIDIA 建议使用升级控制器进行升级,并且该控制器在 GPU Operator 中默认启用。 该控制器自动化升级过程并生成指标和事件,以便您可以监控升级过程。
步骤
通过更改集群策略中的
driver.version值来升级驱动程序$ kubectl patch clusterpolicies.nvidia.com/cluster-policy \ --type='json' \ -p='[{"op": "replace", "path": "/spec/driver/version", "value":"510.85.02"}]'
(可选)对于每个节点,监控升级状态
$ kubectl get node -l nvidia.com/gpu.present \ -ojsonpath='{range .items[*]}{.metadata.name}{"\t"}{.metadata.labels.nvidia\.com/gpu-driver-upgrade-state}{"\n"}{end}'
示例输出
k8s-node-1 upgrade-required k8s-node-2 upgrade-required k8s-node-3 upgrade-required
您可以通过运行上述命令定期轮询升级状态。 当输出显示
upgrade-done时,GPU 驱动程序升级完成k8s-node-1 upgrade-done k8s-node-2 upgrade-done k8s-node-3 upgrade-done
配置选项#
您可以在集群策略中设置以下字段来配置升级控制器
driver:
upgradePolicy:
# autoUpgrade (default=true): Switch which enables / disables the driver upgrade controller.
# If set to false all other options are ignored.
autoUpgrade: true
# maxParallelUpgrades (default=1): Number of nodes that can be upgraded in parallel. 0 means infinite.
maxParallelUpgrades: 1
# maximum number of nodes with the driver installed, that can be unavailable during
# the upgrade. Value can be an absolute number (ex: 5) or
# a percentage of total nodes at the start of upgrade (ex:
# 10%). Absolute number is calculated from percentage by rounding
# up. By default, a fixed value of 25% is used.'
maxUnavailable: 25%
# waitForCompletion: Options for the 'wait-for-completion' state, which will wait for a user-defined group of pods
# to complete before upgrading the driver on a node.
waitForCompletion:
# timeoutSeconds (default=0): The length of time to wait before giving up. 0 means infinite.
timeoutSeconds: 0
# podSelector (default=""): The label selector defining the group of pods to wait for completion of. "" means to wait on none.
podSelector: ""
# gpuPodDeletion: Options for the 'pod-deletion' state, which will evict all pods on the node allocated a GPU.
gpuPodDeletion:
# force (default=false): Delete pods even if they are not managed by a controller (e.g. ReplicationController, ReplicaSet,
# Job, DaemonSet or StatefulSet).
force: false
# timeoutSeconds (default=300): The length of time to wait before giving up. 0 means infinite. When the timeout is met,
# the GPU pod(s) will be forcefully deleted.
timeoutSeconds: 300
# deleteEmptyDir (default=false): Delete pods even if they are using emptyDir volumes (local data will be deleted).
deleteEmptyDir: false
# drain: Options for the 'drain' state, which will drain the node (i.e. 'kubectl drain'). This is only performed if
# enabled and the 'pod-deletion' state cannot successfully remove all pods using GPU.
drain:
# enable (default=false): Switch for allowing node drain during the upgrade process
enable: false
# force (default=false): Delete pods even if they are not managed by a controller (e.g. ReplicationController, ReplicaSet,
# Job, DaemonSet or StatefulSet).
force: false
# podSelector (default=""): The label selector to filter pods on the node. "" will drain all pods.
podSelector: ""
# timeoutSeconds (default=300): The length of time to wait before giving up. 0 means infinite. When the timeout is met,
# the GPU pod(s) will be forcefully deleted.
timeoutSeconds: 300
# deleteEmptyDir (default=false): Delete pods even if they are using emptyDir volumes (local data will be deleted).
deleteEmptyDir: false
如果您为 maxUnavailable 指定一个值,并且也指定了 maxParallelUpgrades,则 maxUnavailable 值会对 maxParallelUpgrades 的值应用额外的约束,以确保并行升级的数量不会导致超过预期数量的节点在升级期间变得不可用。 例如,如果您指定 maxUnavailable=100% 和 maxParallelUpgrades=1,则一次升级一个节点。
maxUnavailable 值也适用于集群中当前不可用的节点。 如果您隔离了集群中的节点,并且 maxUnavailable 值已由隔离节点的数量满足,则升级不会进行。
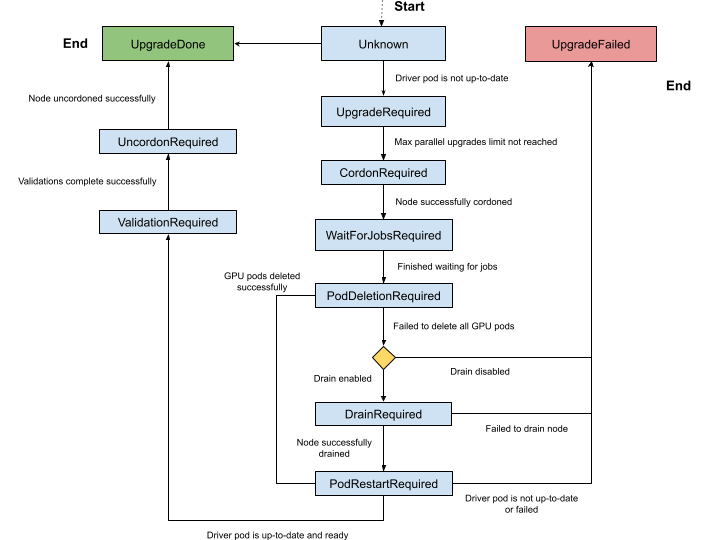
升级状态机#
升级控制器通过明确定义的状态机管理驱动程序升级。 节点标签 nvidia.com/gpu-driver-upgrade-state 指示节点当前所处的状态。 可能的状态集是
未知(空):升级控制器已禁用或节点尚未处理。
upgrade-required:NVIDIA 驱动程序 Pod 不是最新的,需要升级。 此阶段不执行任何操作。cordon-required:节点将被标记为不可调度,以准备驱动程序升级。wait-for-jobs-required:节点将等待一组 Pod/作业完成,然后再继续。pod-deletion-required:分配了 GPU 的 Pod 将从节点中删除。 如果 Pod 删除失败,并且在 ClusterPolicy 中启用了 drain,则节点状态将设置为drain-required。drain-required:节点将被排空。 如果所有 GPU Pod 都已从节点中成功删除,则跳过此状态。pod-restart-required:节点上运行的 NVIDIA 驱动程序 Pod 将被重启并升级到新版本。validation-required:在继续之前,需要验证部署在节点上的新驱动程序。 GPU Operator 在名为operator-validator的 Pod 中执行验证。uncordon-required:节点将被标记为可调度,以完成升级过程。upgrade-done:NVIDIA 驱动程序 Pod 是最新的,并且在节点上运行。upgrade-failed:驱动程序升级期间发生故障。
完整的状态机如下图所示。
暂停驱动程序升级#
要暂停集群中的自动驱动程序升级过程,请切换集群策略中的 driver.upgradePolicy.autoUpgrade 标志。 整个状态机暂停,并有效地禁用任何待处理节点的升级。 您可以再次将标志切换为 true 以重新启用升级控制器并恢复任何待处理的升级。
跳过驱动程序升级#
要跳过特定节点上的驱动程序升级,请使用 nvidia.com/gpu-driver-upgrade.skip=true 标记节点。
指标和事件#
GPU Operator 在升级过程中生成以下指标,这些指标可以被 Prometheus 抓取。
gpu_operator_auto_upgrade_enabled:如果启用驱动程序自动升级,则为 1;否则为 0。gpu_operator_nodes_upgrades_in_progress:正在升级驱动程序 Pod 的节点总数。gpu_operator_nodes_upgrades_done:驱动程序 Pod 已成功升级的节点总数。gpu_operator_nodes_upgrades_failed:驱动程序 Pod 升级失败的节点总数。gpu_operator_nodes_upgrades_available:可以开始驱动程序 Pod 升级的节点总数。gpu_operator_nodes_upgrades_pending:驱动程序 Pod 升级待处理的节点总数。
GPU Operator 在升级过程中生成事件。 最常见的事件是状态转换或特定状态下的故障。 以下是为一个节点升级生成的一组事件示例。
$ kubectl get events -n default --sort-by='.lastTimestamp' | grep GPUDriverUpgrade
示例输出
10m Normal GPUDriverUpgrade node/localhost.localdomain Successfully updated node state label to [upgrade-required]
10m Normal GPUDriverUpgrade node/localhost.localdomain Successfully updated node state label to [cordon-required]
10m Normal GPUDriverUpgrade node/localhost.localdomain Successfully updated node state label to [wait-for-jobs-required]
10m Normal GPUDriverUpgrade node/localhost.localdomain Successfully updated node state label to [pod-deletion-required]
10m Normal GPUDriverUpgrade node/localhost.localdomain Successfully updated node state label to [pod-restart-required]
7m Normal GPUDriverUpgrade node/localhost.localdomain Successfully updated node state label to [validation-required]
6m Normal GPUDriverUpgrade node/localhost.localdomain Successfully updated node state label to [uncordon-required]
6m Normal GPUDriverUpgrade node/localhost.localdomain Successfully updated node state label to [upgrade-done]
故障排除#
如果特定节点的升级失败,则该节点被标记为 upgrade-failed 状态。
查看升级状态标签
$ kubectl get node -l nvidia.com/gpu.present \ -ojsonpath='{range .items[*]}{.metadata.name}{"\t"}{.metadata.labels.nvidia\.com/gpu-driver-upgrade-state}{"\n"}{end}'
示例输出
k8s-node-1 upgrade-done k8s-node-2 upgrade-done k8s-node-3 upgrade-failed
检查事件以确定升级失败的阶段
$ kubectl get events -n default --sort-by='.lastTimestamp' | grep GPUDriverUpgrade
(可选)检查 gpu-operator 容器中升级控制器的日志
$ kubectl logs -n gpu-operator gpu-operator-xxxxx | grep controllers.Upgrade
在解决特定节点的升级故障后,您可以通过将其置于
upgrade-required状态来重新启动节点上的升级过程$ kubectl label node <node-name> nvidia.com/gpu-driver-upgrade-state=upgrade-required --overwrite
不使用升级控制器进行升级#
如果升级控制器被禁用或您的 GPU Operator 版本不支持升级控制器,则名为 k8s-driver-manager 的组件负责执行驱动程序升级过程。 k8s-driver-manager 是驱动程序 Daemonset 中的一个 initContainer,它确保在卸载当前驱动程序模块并继续进行新驱动程序安装之前,禁用所有现有的 GPU 驱动程序客户端。 此方法仍然自动化了核心驱动程序升级过程,但缺乏升级控制器提供的可观察性以及其他控制,例如暂停/跳过升级。 此外,为了支持升级控制器,未来将不会向 k8s-driver-manager 添加任何新功能。
步骤
通过更改 ClusterPolicy 中的
driver.version值来升级驱动程序$ kubectl patch clusterpolicies.nvidia.com/cluster-policy --type='json' -p='[{"op": "replace", "path": "/spec/driver/version", "value":"510.85.02"}]'
(可选)要监控升级状态,请观察新的驱动程序 Pod 在 GPU 工作节点上的部署
$ kubectl get pods -n gpu-operator -lapp=nvidia-driver-daemonset -w
配置选项#
以下配置选项可用于 k8s-driver-manager。 这些选项允许用户控制 GPU Pod 驱逐和节点排空行为。
driver:
manager:
env:
- name: ENABLE_GPU_POD_EVICTION
value: "true"
- name: ENABLE_AUTO_DRAIN
value: "true"
- name: DRAIN_USE_FORCE
value: "false"
- name: DRAIN_POD_SELECTOR_LABEL
value: ""
- name: DRAIN_TIMEOUT_SECONDS
value: "0s"
- name: DRAIN_DELETE_EMPTYDIR_DATA
value: "false"
ENABLE_GPU_POD_EVICTION环境变量使k8s-driver-manager能够尝试仅从节点驱逐 GPU Pod,然后再尝试节点排空。 只有当此操作失败且启用了ENABLE_AUTO_DRAIN时,节点才会被排空。必须启用
DRAIN_USE_FORCE环境变量,才能驱逐不受任何复制控制器(如 Deployment、Daemon Set、Stateful Set 和 Replica Set)管理的 GPU Pod。必须启用
DRAIN_DELETE_EMPTYDIR_DATA环境变量,才能删除使用emptyDir类型卷的 GPU Pod。
注意
由于每当 NVIDIA 驱动程序守护程序集规范更新时,GPU Pod 都会被驱逐,因此可能并不总是希望允许这种情况自动发生。 为了防止这种情况,可以将 ClusterPolicy 中的 daemonsets.updateStrategy 参数设置为 OnDelete 。 使用 OnDelete 更新策略,只有在手动删除旧的驱动程序 Pod 后,才会在节点上部署具有更新规范的新驱动程序 Pod。 因此,管理员可以控制何时在任何给定节点上推出驱动程序 Pod 的规范更新。 有关 DaemonSet 更新策略的更多信息,请参阅 Kubernetes 文档。