EFLOW 用户指南
描述了如何在启用 EFLOW 的 Windows 设备上部署 CUDA 和 NVIDIA GPU 加速的云原生应用程序。
1. EFLOW 用户指南
1.1. 简介
Windows 上的 Azure IoT Edge for Linux(也称为 EFLOW)是 Microsoft 的一项技术,用于在 Windows Edge 设备上部署 Linux AI 容器。本文档详细介绍了如何在启用 EFLOW 的 Windows 设备上部署 NVIDIA® CUDA® 和 NVIDIA GPU 加速的云原生应用程序。
EFLOW 包含以下组件
启用虚拟化的 Windows 主机操作系统
Linux 虚拟机
IoT Edge 运行时
IoT Edge 模块,或任何其他 docker 兼容的容器化应用程序(在 moby/containerd 上运行)
GeForce RTX GPU 的 GPU 加速 IoT Edge 模块支持基于 GPU 半虚拟化,这是 Linux 上 Windows 子系统上 CUDA 的基础。因此,EFLOW 的 CUDA 和计算支持得益于 WSL 2 上现有的 CUDA 支持。
WSL 2 上的 CUDA 通过使 CUDA 开发人员能够在 Windows 桌面计算机上构建、开发和容器化 GPU 加速的 NVIDIA AI/ML Linux 应用程序,然后在云端的 Linux 实例上进行部署,从而提高了 CUDA 开发人员的生产力。但 EFLOW 的目标是在边缘部署 AI。容器化的 NVIDIA GPU 加速 Linux 应用程序,无论托管在 Azure IoT Hub 还是 NGC 注册表中,都可以无缝部署在边缘,例如零售服务中心或医院。这些边缘部署通常是由 IT 管理的设备,这些设备根深蒂固于 Windows 设备以实现可管理性,但该领域中 AI/ML 用例的出现寻求 Linux 和 Windows 应用程序的融合,不仅要共存,还要在同一设备上无缝通信。
由于 EFLOW 上的 CUDA 支持主要基于 WSL 2,因此请参阅 CUDA on WSL 2 文档中的“软件支持”、“限制”和“已知问题”部分,以了解 EFLOW 上可用的 NVIDIA 软件支持范围。本文档中也涵盖了 EFLOW 的任何其他先决条件。
以下部分详细介绍了 EFLOW 的安装、开箱即用的 CUDA 支持的先决条件,以及在 EFLOW 上运行现有 GPU 加速容器的示例说明。
1.2. 设置与安装
请访问 Microsoft EFLOW 文档页面,了解适合您需求的各种安装选项
有关最新的安装说明,请访问 http://aka.ms/AzEFLOW-install。
有关 EFLOW PowerShell API 的详细信息,请访问 http://aka.ms/AzEFLOW-PowerShell。
为了快速设置,我们在以下部分中包含了通过 Powershell 进行安装的步骤。
1.2.1. 驱动程序安装
在目标 Windows 设备上,首先安装与您设备上的 NVIDIA GPU 兼容的 NVIDIA GeForce 或 NVIDIA RTX GPU Windows 驱动程序。EFLOW VM 支持部署容器化的 CUDA 应用程序,因此只需在主机系统上安装驱动程序。CUDA 工具包无法直接在 EFLOW 中安装。
可以直接部署来自 NGC 注册表的 NVIDIA 提供的 CUDA 容器。如果您正在准备 CUDA docker 容器,请确保已安装必要的工具链。
由于 EFLOW 基于 WSL,因此混合 Linux on Windows 环境的软件堆栈限制适用,并非所有 NVIDIA 软件堆栈都受支持。请参阅您感兴趣的 SDK 的用户指南以确定支持情况。
1.2.2. EFLOW 安装
在提升的 powershell 提示符下执行以下操作
-
启用 HyperV。 Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Hyper-V -All
Path : Online : True RestartNeeded : False
-
设置执行策略并验证。
Set-ExecutionPolicy -ExecutionPolicy AllSigned -Force Get-ExecutionPolicy AllSigned
-
下载并安装 EFLOW。
$msiPath = $([io.Path]::Combine($env:TEMP, 'AzureIoTEdge.msi')) $ProgressPreference = 'SilentlyContinue' Invoke-WebRequest "https://aka.ms/AzEFLOWMSI_1_4_LTS_X64" -OutFile $msiPath Start-Process -Wait msiexec -ArgumentList "/i","$([io.Path]::Combine($env:TEMP, 'AzureIoTEdge.msi'))","/qn"
-
确定主机操作系统配置。
>Get-EflowHostConfiguration | format-list FreePhysicalMemoryInMB : 35502 NumberOfLogicalProcessors : {64, 64} DiskInfo : @{Drive=C:; FreeSizeInGB=798} GpuInfo : @{Count=1; SupportedPassthroughTypes=System.Object[]; Name=NVIDIA RTX A2000} -
部署 EFLOW。
部署 EFLOW 将设置 EFLOW 运行时和虚拟机。
默认情况下,EFLOW 仅为工作负载保留 1024MB 的系统内存,这不足以支持 GPU 加速配置。为了进行 GPU 加速,您必须在 EFLOW 部署时显式保留系统内存;否则,将没有足够的系统内存来运行您的容器化应用程序。为了防止内存不足错误,请根据需要显式保留内存;请参见以下示例。(有关在官方文档中部署 EFLOW 的可用命令行参数选项的更多详细信息,请参阅官方文档)。
1.2.3. CUDA 支持的先决条件
仅支持 x86 64 位。
GeForce RTX GPU 产品。
Windows 10/11(专业版、企业版、IoT 企业版)- Windows 10 用户必须使用 2021 年 11 月更新版本 19044.1620 或更高版本。
Deploy-Eflow 默认仅分配 1024 MB 内存,将其设置为更大的值以防止 OOM 问题,有关更多详细信息,请查看 MS 文档,网址为 https://learn.microsoft.com/en-us/azure/iot-edge/reference-iot-edge-for-linux-on-windows-functions#deploy-eflow。
也适用特定于平台的其他先决条件。请参阅 https://learn.microsoft.com/en-us/azure/iot-edge/gpu-acceleration?view=iotedge-1.4。
1.3. 连接到 EFLOW 虚拟机
Get-EflowVmAddr
[10/13/2022 11:41:16] Querying IP and MAC addresses from virtual machine (IPP1-1490-EFLOW)
- Virtual machine MAC: 00:15:5d:b2:40:c7
- Virtual machine IP : 172.24.14.242 retrieved directly from virtual machine
00:15:5d:b2:40:c7
172.24.14.242
Connect-EflowVm
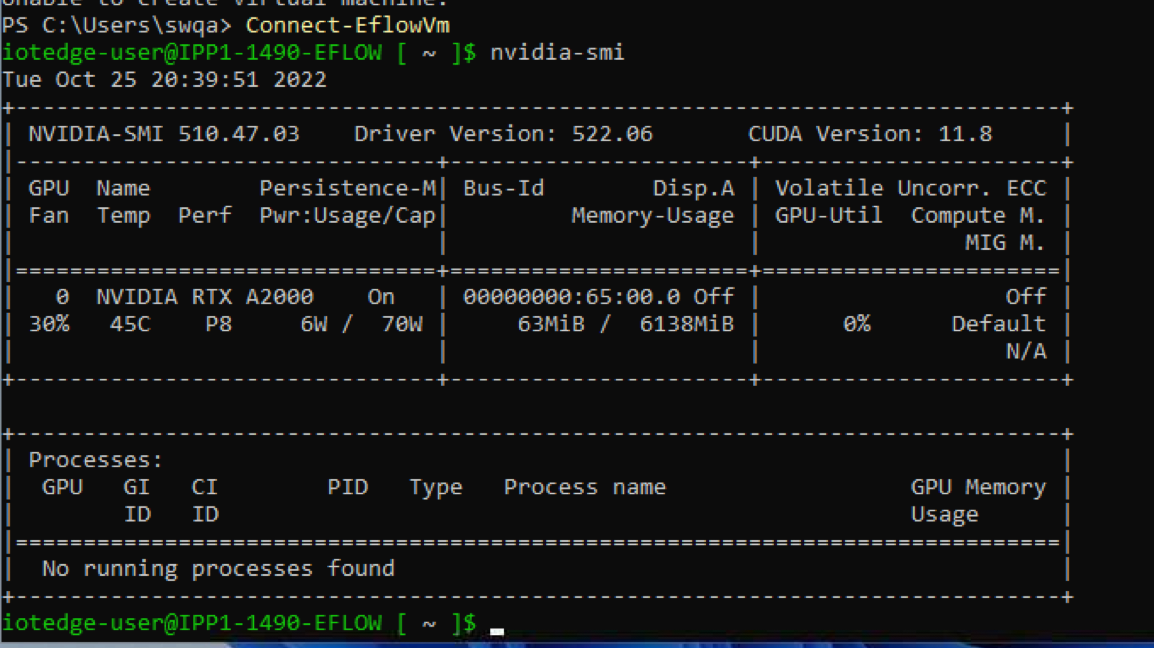
1.4. 运行 nvidia-smi
1.5. 运行 GPU 加速的容器
让我们从 NGC 运行一个 N 体模拟容器化的 CUDA 示例,但这次在 EFLOW 内部。
iotedge-user@IPP1-1490-EFLOW [ ~ ]$ sudo docker run --gpus all --env NVIDIA_DISABLE_REQUIRE=1 nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark
Unable to find image 'nvcr.io/nvidia/k8s/cuda-sample:nbody' locally
nbody: Pulling from nvidia/k8s/cuda-sample
22c5ef60a68e: Pull complete
1939e4248814: Pull complete
548afb82c856: Pull complete
a424d45fd86f: Pull complete
207b64ab7ce6: Pull complete
f65423f1b49b: Pull complete
2b60900a3ea5: Pull complete
e9bff09d04df: Pull complete
edc14edf1b04: Pull complete
1f37f461c076: Pull complete
9026fb14bf88: Pull complete
Digest: sha256:59261e419d6d48a772aad5bb213f9f1588fcdb042b115ceb7166c89a51f03363
Status: Downloaded newer image for nvcr.io/nvidia/k8s/cuda-sample:nbody
Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance.
-fullscreen (run n-body simulation in fullscreen mode)
-fp64 (use double precision floating point values for simulation)
-hostmem (stores simulation data in host memory)
-benchmark (run benchmark to measure performance)
-numbodies=<N> (number of bodies (>= 1) to run in simulation)
-device=<d> (where d=0,1,2.... for the CUDA device to use)
-numdevices=<i> (where i=(number of CUDA devices > 0) to use for simulation)
-compare (compares simulation results running once on the default GPU and once on the CPU)
-cpu (run n-body simulation on the CPU)
-tipsy=<file.bin> (load a tipsy model file for simulation)
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
> Windowed mode
> Simulation data stored in video memory
> Single precision floating point simulation
> 1 Devices used for simulation
GPU Device 0: "Ampere" with compute capability 8.6
> Compute 8.6 CUDA device: [NVIDIA RTX A2000]
26624 bodies, total time for 10 iterations: 31.984 ms
= 221.625 billion interactions per second
= 4432.503 single-precision GFLOP/s at 20 flops per interaction
iotedge-user@IPP1-1490-EFLOW [ ~ ]$
1.6. 故障排除
nvidia-container-cli:需求错误:不满足条件:cuda>=11.7”,需要添加“–env NVIDIA_DISABLE_REQUIRE=1”
从主机上的驱动程序启动容器时,无法正确确定 CUDA 版本。
内存不足
如果发生内存不足错误,请增加 EFLOW 保留的系统内存。请参阅 https://learn.microsoft.com/en-us/azure/iot-edge/reference-iot-edge-for-linux-on-windows-functions#deploy-eflow。
2. 通知
2.1. 通知
本文档仅供参考,不应被视为对产品的特定功能、条件或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含的信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对因使用此类信息而产生的后果或使用不承担任何责任,也不对因使用此类信息而可能导致的任何专利侵权或第三方其他权利承担任何责任。本文档不承诺开发、发布或交付任何材料(如下定义)、代码或功能。
NVIDIA 保留随时对此文档进行更正、修改、增强、改进和任何其他更改的权利,恕不另行通知。
客户在下订单前应获取最新的相关信息,并应验证此类信息是否为最新且完整。
NVIDIA 产品根据订单确认时提供的 NVIDIA 标准销售条款和条件出售,除非 NVIDIA 和客户的授权代表签署的单独销售协议(“销售条款”)另有约定。NVIDIA 特此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档未直接或间接形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、飞机、航天或生命支持设备,也不适用于 NVIDIA 产品的故障或失灵可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在此类设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,包含和/或使用此类产品由客户自行承担风险。
NVIDIA 不保证基于本文档的产品将适用于任何特定用途。NVIDIA 不一定对每个产品的所有参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合并适用于客户计划的应用,并为应用执行必要的测试,以避免应用或产品的默认设置。客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同条件和/或要求。NVIDIA 对因以下原因可能引起或归因于以下原因的任何默认、损坏、成本或问题不承担任何责任:(i)以与本文档相悖的任何方式使用 NVIDIA 产品,或(ii)客户产品设计。
本文档未授予 NVIDIA 的任何专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。NVIDIA 发布的有关第三方产品或服务的信息并不构成 NVIDIA 授予的使用此类产品或服务的许可,也不构成对此类产品或服务的保证或认可。使用此类信息可能需要从第三方获得专利或第三方其他知识产权下的许可,或从 NVIDIA 获得 NVIDIA 专利或其他知识产权下的许可。
只有在事先获得 NVIDIA 书面批准的情况下,才能复制本文档中的信息,并且复制的信息必须未经修改,完全符合所有适用的出口法律和法规,并附带所有相关的条件、限制和通知。
本文档以及所有 NVIDIA 设计规范、参考板、文件、图纸、诊断、列表和其他文档(统称为“材料”,单独或一起)均按“原样”提供。NVIDIA 对材料不作任何明示、暗示、法定或其他方面的保证,并明确否认所有关于非侵权、适销性和特定用途适用性的暗示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对任何损害(包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害)承担责任,无论因何种原因造成,也无论责任理论如何,只要是因使用本文档而引起的,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因遭受任何损害,但 NVIDIA 对此处描述的产品对客户的累计总责任应根据产品的销售条款进行限制。
2.2. OpenCL
OpenCL 是 Apple Inc. 的商标,已获得 Khronos Group Inc. 的许可使用。
2.3. 商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其关联的各自公司的商标。