入门指南#
在本节中,我们将展示如何使用 cuSPARSELt 实现稀疏矩阵-矩阵乘法。我们首先概述工作流程,展示设置计算的主要步骤。然后,我们描述如何安装库以及如何编译它。最后,我们提供一个逐步的代码示例,并附带额外的注释。
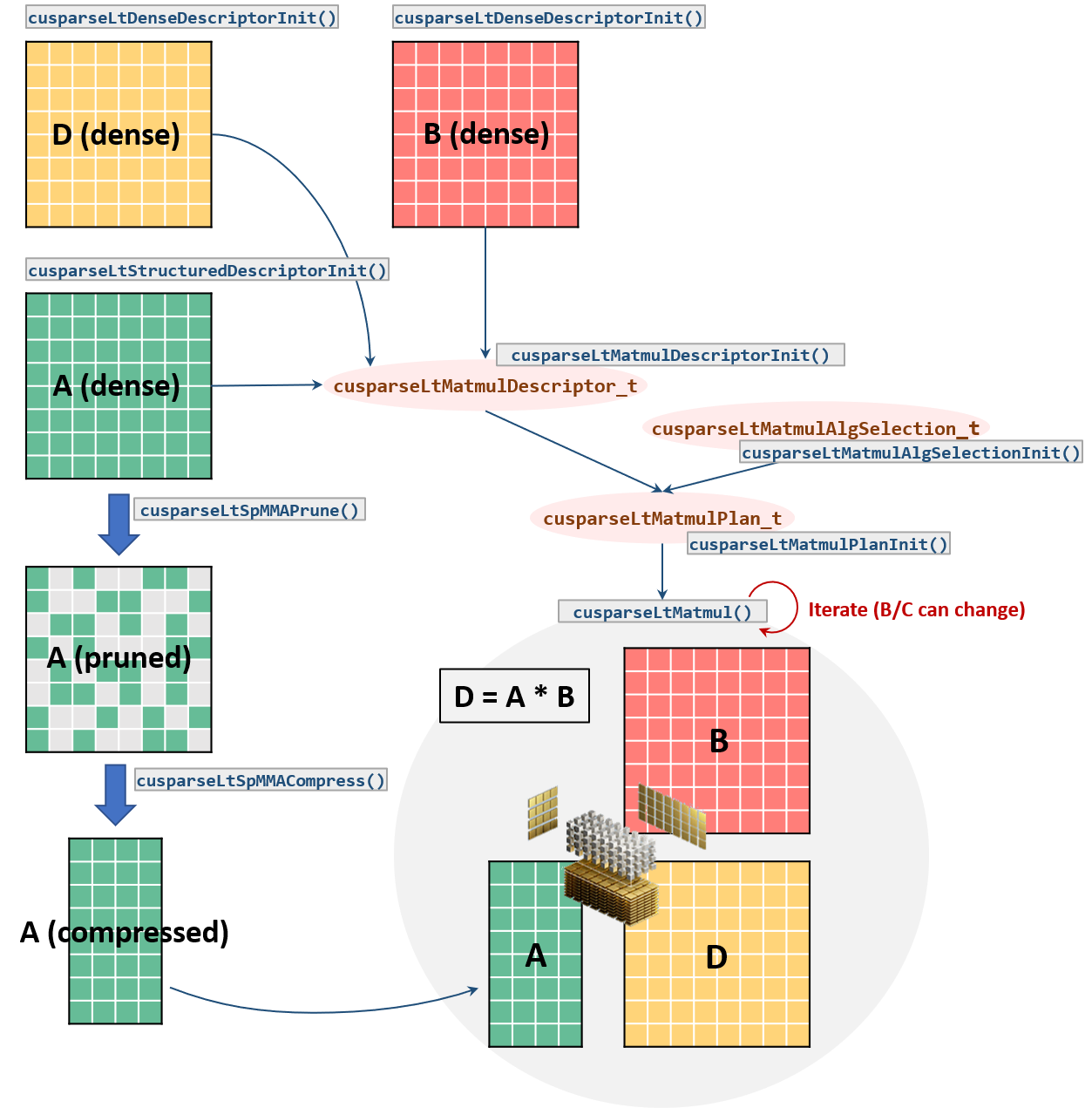
cuSPARSELt 工作流程#
特别是,该模型依赖于以下高级阶段
A. 问题定义:指定矩阵形状、数据类型、运算等。B. 用户偏好/约束:用户算法选择或限制可行实现(候选)的搜索空间C. 计划:收集执行的描述符,并在需要时“查找”最佳实现D. 执行:执行实际计算
更详细地说,常见的流程包括以下步骤
1. 初始化库句柄:cusparseLtInit()。2. 指定输入/输出矩阵特征:cusparseLtDenseDescriptorInit()、cusparseLtStructuredDescriptorInit()。3. 初始化矩阵乘法描述符及其属性(例如,运算、计算类型等):cusparseLtMatmulDescriptorInit()。4. 初始化算法选择描述符:cusparseLtMatmulAlgSelectionInit()。5. 初始化矩阵乘法计划:cusparseLtMatmulPlanInit()。6. 剪枝A矩阵:cusparseLtSpMMAPrune()。如果用户提供自定义矩阵剪枝,则不需要此步骤。7. 压缩剪枝后的矩阵:cusparseLtSpMMACompress()。8. 计算所需的工作区大小:cusparseLtMatmulGetWorkspace。分配此大小的设备缓冲区。9. 执行矩阵乘法:cusparseLtMatmul()。此步骤可以针对不同的输入值重复多次。10. 销毁矩阵描述符、矩阵乘法计划和库句柄:cusparseLtMatDescriptorDestroy()、cusparseLtMatmulPlanDestroy()cusparseLtDestroy()。
安装和编译#
从 developer.nvidia.com/cusparselt/downloads 下载 cuSPARSELt 软件包
先决条件#
硬件要求#
GPU,最低支持计算能力 8.0
在此处查看 NVIDIA GPU 的计算能力列表:https://developer.nvidia.com/cuda-gpus
有关基于 GPU 计算能力的功能支持的详细列表,请参阅主要特性。
软件要求#
CUDA 12.8 工具包或更高版本以及 CUDA 兼容驱动程序(请参阅 CUDA 驱动程序发行说明)。
Linux#
假设 cuSPARSELt 已在 CUSPARSELT_DIR 中解压,我们相应地更新库路径
export LD_LIBRARY_PATH=${CUSPARSELT_DIR}/lib64:${LD_LIBRARY_PATH}
要编译我们将在下面讨论的示例代码 (matmul_example.cpp),
nvcc matmul_example.cpp -I {CUSPARSELT_PATH}/include/ -l cusparse -l cusparseLt -L ${CUSPARSELT_PATH}/lib/
请注意,之前的命令将 cusparseLt 链接为共享库。使用库的静态版本链接代码需要额外的标志
nvcc matmul_example.cpp -I${CUSPARSELT_DIR}/include \
-Xlinker=${CUSPARSELT_DIR}/lib64/libcusparseLt_static.a \
-o matmul_static -ldl -lcuda
Windows#
假设 cuSPARSELt 已在 CUSPARSELT_DIR 中解压,我们相应地更新库路径
setx PATH "%CUSPARSELT_DIR%\lib:%PATH%"
要编译我们将在下面讨论的示例代码 (matmul_example.cpp),
nvcc.exe matmul_example.cpp -I "%CUSPARSELT_DIR%\include" -lcusparseLt -lcuda -o matmul.exe
请注意,之前的命令将 cusparseLt 链接为共享库。使用库的静态版本链接代码需要额外的标志
nvcc.exe matmul_example.cpp -I %CUSPARSELT_DIR%\include \
-Xlinker=/WHOLEARCHIVE:"%CUSPARSELT_DIR%\lib\cusparseLt_static.lib" \
-Xlinker=/FORCE -lcuda -o matmul.exe
代码示例#
以下代码示例展示了使用 cuSPARSELt 的常用步骤,并执行矩阵乘法。
完整代码可以在 cuSPARSELt 示例 1 中找到。
一个更高级的示例,演示了批量稀疏 GEMM、激活函数和偏置的用法,可以在 cuSPARSELt 示例 2 中找到。
#include <cusparseLt.h> // cusparseLt header
// Device pointers and coefficient definitions
float alpha = 1.0f;
float beta = 0.0f;
__half* dA = ...
__half* dB = ...
__half* dC = ...
//--------------------------------------------------------------------------
// cusparseLt data structures and handle initialization
cusparseLtHandle_t handle;
cusparseLtMatDescriptor_t matA, matB, matC;
cusparseLtMatmulDescriptor_t matmul;
cusparseLtMatmulAlgSelection_t alg_sel;
cusparseLtMatmulPlan_t plan;
cudaStream_t stream = nullptr;
cusparseLtInit(&handle);
//--------------------------------------------------------------------------
// matrix descriptor initialization
cusparseLtStructuredDescriptorInit(&handle, &matA, num_A_rows, num_A_cols,
lda, alignment, type, order,
CUSPARSELT_SPARSITY_50_PERCENT);
cusparseLtDenseDescriptorInit(&handle, &matB, num_B_rows, num_B_cols, ldb,
alignment, type, order);
cusparseLtDenseDescriptorInit(&handle, &matC, num_C_rows, num_C_cols, ldc,
alignment, type, order);
//--------------------------------------------------------------------------
// matmul, algorithm selection, and plan initialization
cusparseLtMatmulDescriptorInit(&handle, &matmul, opA, opB, &matA, &matB,
&matC, &matC, compute_type);
cusparseLtMatmulAlgSelectionInit(&handle, &alg_sel, &matmul,
CUSPARSELT_MATMUL_ALG_DEFAULT);
cusparseLtMatmulPlanInit(&handle, &plan, &matmul, &alg_sel);
//--------------------------------------------------------------------------
// Prune the A matrix (in-place) and check the correctness
cusparseLtSpMMAPrune(&handle, &matmul, dA, dA, CUSPARSELT_PRUNE_SPMMA_TILE,
stream);
int *d_valid;
cudaMalloc((void**) &d_valid, sizeof(d_valid));
cusparseLtSpMMAPruneCheck(&handle, &matmul, dA, &d_valid, stream);
int is_valid;
cudaMemcpyAsync(&is_valid, d_valid, sizeof(d_valid), cudaMemcpyDeviceToHost,
stream);
cudaStreamSynchronize(stream);
if (is_valid != 0) {
std::printf("!!!! The matrix has been pruned in a wrong way. "
"cusparseLtMatmul will not provided correct results\n");
return EXIT_FAILURE;
}
//--------------------------------------------------------------------------
// Matrix A compression
size_t compressed_size;
cusparseLtSpMMACompressedSize(&handle, &plan, &compressed_size);
cudaMalloc((void**) &dA_compressed, compressed_size);
cusparseLtSpMMACompress(&handle, &plan, dA, dA_compressed, stream);
//--------------------------------------------------------------------------
// Allocate workspace
size_t workspace_size;
void* d_workspace = nullptr;
cusparseLtMatmulGetWorkspace(&handle, &plan, &workspace_size);
cudaMalloc((void**) &d_workspace, workspace_size);
//--------------------------------------------------------------------------
// Perform the matrix multiplication
int num_streams = 0;
cudaStream_t* streams = nullptr;
cusparseLtMatmul(&handle, &plan, &alpha, dA_compressed, dB, &beta, dC, dD,
d_workspace, streams, num_streams);
//--------------------------------------------------------------------------
// Destroy descriptors, plan and handle
cusparseLtMatDescriptorDestroy(&matA);
cusparseLtMatDescriptorDestroy(&matB);
cusparseLtMatDescriptorDestroy(&matC);
cusparseLtMatmulPlanDestroy(&plan);
cusparseLtDestroy(&handle);