cuSOLVER API 参考
cuSOLVER 的 API 参考指南,cuSOLVER 是一个 GPU 加速库,用于稠密和稀疏矩阵的分解和线性系统求解。
1. 简介
cuSolver 库是一个基于 cuBLAS 和 cuSPARSE 库的高级软件包。它由两个模块组成,分别对应于两组 API
单 GPU 上的 cuSolver API
单节点多 GPU 上的 cuSolverMG API
它们中的每一个都可以独立使用,也可以与其他工具包库协同使用。为简化表示,cuSolver 表示单 GPU API,cuSolverMg 表示多 GPU API。
cuSolver 的目的是提供有用的类 LAPACK 功能,例如常用的矩阵分解和三角求解例程(用于稠密矩阵)、稀疏最小二乘求解器和特征值求解器。此外,cuSolver 还提供了一个新的重构库,该库对于求解具有共享稀疏模式的矩阵序列非常有用。
cuSolver 在一个保护伞下结合了三个独立的组件。cuSolver 的第一部分称为 cuSolverDN,处理稠密矩阵分解和求解例程,例如 LU、QR、SVD 和 LDLT,以及有用的实用程序,例如矩阵和向量置换。
接下来,cuSolverSP 提供了一组基于稀疏 QR 分解的新稀疏例程。并非所有矩阵都具有良好的稀疏模式,以便在分解中实现并行性,因此 cuSolverSP 库还提供了一条 CPU 路径来处理那些类似顺序的矩阵。对于那些具有丰富并行性的矩阵,GPU 路径将提供更高的性能。该库旨在从 C 和 C++ 中调用。
最后一部分是 cuSolverRF,这是一个稀疏重构包,当求解一系列仅系数发生变化但稀疏模式保持不变的矩阵时,它可以提供非常好的性能。
cuSolver 库的 GPU 路径假定数据已在设备内存中。开发人员有责任分配内存,并使用标准 CUDA 运行时 API 例程(例如 cudaMalloc()、cudaFree()、cudaMemcpy() 和 cudaMemcpyAsync())在 GPU 内存和 CPU 内存之间复制数据。
cuSolverMg 是 GPU 加速的 ScaLAPACK。目前,cuSolverMg 支持一维列块循环布局,并提供对称特征值求解器。
注意
cuSolver 库需要计算能力 (CC) 为 5.0 或更高的 CUDA 计算硬件。有关与所有 NVIDIA GPU 对应的计算能力列表,请参阅《CUDA C++ 编程指南》。
1.1. cuSolverDN:稠密 LAPACK
cuSolverDN 库旨在求解以下形式的稠密线性系统
其中系数矩阵 \(A\in R^{nxn}\) 、右侧向量 \(b\in R^{n}\) 和解向量 \(x\in R^{n}\)
cuSolverDN 库提供 QR 分解和带部分主元的 LU 分解来处理一般矩阵 A,该矩阵可能是不对称的。还为对称/Hermitian 矩阵提供了 Cholesky 分解。对于对称不定矩阵,我们提供 Bunch-Kaufman (LDL) 分解。
cuSolverDN 库还提供了有用的双对角化例程和奇异值分解 (SVD)。
cuSolverDN 库的目标是 LAPACK 中计算密集型且流行的例程,并提供与 LAPACK 兼容的 API。用户可以使用 cuSolverDN 加速这些耗时的例程,并将其他例程保留在 LAPACK 中,而无需对现有代码进行重大更改。
1.2. cuSolverSP:稀疏 LAPACK
cuSolverSP 库主要旨在求解稀疏线性系统
和最小二乘问题
其中稀疏矩阵 \(A\in R^{mxn}\) 、右侧向量 \(b\in R^{m}\) 和解向量 \(x\in R^{n}\) 。对于线性系统,我们要求 m=n。
核心算法基于稀疏 QR 分解。矩阵 A 以 CSR 格式接受。如果矩阵 A 是对称/Hermitian 的,则用户必须提供完整矩阵,即填充缺失的下部或上部。
如果矩阵 A 是对称正定的,并且用户只需要求解 \(Ax = b\) ,则 Cholesky 分解可以工作,并且用户只需要提供 A 的下三角部分。
在线性和最小二乘求解器的基础上,cuSolverSP 库提供了一个基于移位逆幂法的简单特征值求解器,以及一个用于计算复平面中某个框中包含的特征值数量的函数。
注意
cuSolverSp 已弃用,将在未来的主要版本中删除。建议迁移到新的稀疏直接求解器软件包 cuDSS,您可以在 CUDALibrarySamples/cuSOLVERSp2cuDSS 中找到过渡示例以供参考。
1.3. cuSolverRF:重构
cuSolverRF 库旨在通过快速重构来加速线性系统集的求解,当给定相同稀疏模式中的新系数时
其中给出了系数矩阵序列 \(A_{i}\in R^{nxn}\) 、右侧 \(f_{i}\in R^{n}\) 和解 \(x_{i}\in R^{n}\) ,其中 i=1,...,k。
当系数矩阵 \(A_{i}\) 的稀疏模式以及用于最小化填充的重新排序和 LU 分解期间使用的主元在这些线性系统中保持相同时,cuSolverRF 库适用。在这种情况下,第一个线性系统 (i=1) 需要完整的 LU 分解,而后续线性系统 (i=2,...,k) 仅需要 LU 重构。后者可以使用 cuSolverRF 库执行。
请注意,由于系数矩阵的稀疏模式、重新排序和主元保持不变,因此生成的三角因子 \(L_{i}\) 和 \(U_{i}\) 的稀疏模式也保持不变。因此,完整 LU 分解和 LU 重构之间的真正区别在于,所需内存是提前知道的。
注意
cuSolverRf 已弃用,将在未来的主要版本中删除。建议迁移到新的稀疏直接求解器软件包 cuDSS,您可以在 CUDALibrarySamples/cuSOLVERSp2cuDSS 中找到过渡示例以供参考。
1.4. 命名约定
cuSolverDN 库提供两种不同的 API;legacy 和 generic。
旧版 API 中的函数可用于数据类型 float、double、cuComplex 和 cuDoubleComplex。旧版 API 的命名约定如下
|
其中 <t> 可以是 S、D、C、Z 或 X,分别对应于数据类型 float、double、cuComplex、cuDoubleComplex 和通用类型。<operation> 可以是 Cholesky 分解 (potrf)、带部分主元的 LU 分解 (getrf)、QR 分解 (geqrf) 和 Bunch-Kaufman 分解 (sytrf)。
通用 API 中的函数为每个例程提供单个入口点,并支持 64 位整数来定义矩阵和向量维度。通用 API 的命名约定与数据无关,如下所示
|
其中 <operation> 可以是 Cholesky 分解 (potrf)、带部分主元的 LU 分解 (getrf) 和 QR 分解 (geqrf)。
cuSolverSP 库函数可用于数据类型 float、double、cuComplex 和 cuDoubleComplex。命名约定如下
|
其中 cuSolverSp 是 GPU 路径,cusolverSpHost 是相应的 CPU 路径。<t> 可以是 S、D、C、Z 或 X,分别对应于数据类型 float、double、cuComplex、cuDoubleComplex 和通用类型。
<matrix data format> 是 csr,压缩稀疏行格式。
<operation> 可以是 ls、lsq、eig、eigs,分别对应于线性求解器、最小二乘求解器、特征值求解器和框中特征值的数量。
<output matrix data format> 可以是 v 或 m,分别对应于向量或矩阵。
<based on> 描述了使用的算法。例如,qr(稀疏 QR 分解)用于线性求解器和最小二乘求解器中。
所有函数都具有返回类型 cusolverStatus_t,并在后续章节中进行更详细的解释。
例程 |
数据格式 |
操作 |
输出格式 |
基于 |
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
cuSolverRF 库例程可用于数据类型 double。大多数例程都遵循命名约定
|
其中尾部的可选 Host 限定符指示数据是在主机上访问还是在设备上访问,设备是默认值。<operation> 可以是 Setup、Analyze、Refactor、Solve、ResetValues、AccessBundledFactors 和 ExtractSplitFactors。
最后,cuSolverRF 库例程的返回类型为 cusolverStatus_t。
1.5. 异步执行
cuSolver 库函数更倾向于尽可能保持异步执行。开发人员始终可以使用 cudaDeviceSynchronize() 函数来确保特定 cuSolver 库例程的执行已完成。
开发人员还可以使用 cudaMemcpy() 例程,分别使用 cudaMemcpyDeviceToHost 和 cudaMemcpyHostToDevice 参数将数据从设备复制到主机,反之亦然。在这种情况下,无需调用 cudaDeviceSynchronize(),因为使用上述参数调用 cudaMemcpy() 是阻塞的,并且仅在主机上的结果准备就绪时才完成。
1.6. 库属性
libraryPropertyType 数据类型是库属性类型的枚举(即,CUDA 版本 X.Y.Z 将产生 MAJOR_VERSION=X、MINOR_VERSION=Y、PATCH_LEVEL=Z)。
typedef enum libraryPropertyType_t
{
MAJOR_VERSION,
MINOR_VERSION,
PATCH_LEVEL
} libraryPropertyType;
以下代码可以显示 cusolver 库的版本。
int major=-1,minor=-1,patch=-1;
cusolverGetProperty(MAJOR_VERSION, &major);
cusolverGetProperty(MINOR_VERSION, &minor);
cusolverGetProperty(PATCH_LEVEL, &patch);
printf("CUSOLVER Version (Major,Minor,PatchLevel): %d.%d.%d\n", major,minor,patch);
1.7. 高精度包
cusolver 库在必要时使用高精度进行迭代细化。
2. 使用 CUSOLVER API
2.1. 一般描述
本章介绍如何使用 cuSolver 库 API。它不是 cuSolver API 数据类型和函数的参考;该参考在后续章节中提供。
2.1.1. 线程安全
该库是线程安全的,其函数可以从多个主机线程调用。
2.1.2. 标量参数
在 cuSolver API 中,标量参数可以通过主机上的引用传递。
2.1.3. 使用流的并行性
如果应用程序执行多个小的独立计算,或者如果它在计算的同时进行数据传输,则可以使用 CUDA 流来重叠这些任务。
应用程序可以在概念上将流与每个任务关联起来。为了实现任务之间计算的重叠,开发人员应
使用函数
cudaStreamCreate()创建 CUDA 流,并且通过调用例如 cusolverDnSetStream(),在调用实际的 cuSolverDN 例程之前,设置要由每个单独的 cuSolver 库例程使用的流。
然后,在可能的情况下,在 GPU 上自动重叠在单独流中执行的计算。当单个任务执行的计算相对较小,并且不足以使 GPU 充满工作负载,或者当存在可以与计算并行执行的数据传输时,此方法特别有用。
2.1.4. 如何链接 cusolver 库
cusolver 库提供动态库 libcusolver.so 和静态库 libcusolver_static.a。如果用户将应用程序与 libcusolver.so 链接,则还需要 libcublas.so、libcublasLt.so 和 libcusparse.so。如果用户将应用程序与 libcusolver_static.a 链接,则还需要以下库:libcudart_static.a、libculibos.a、libcusolver_lapack_static.a、libcusolver_metis_static.a、libcublas_static.a 和 libcusparse_static.a。
2.1.5. 链接第三方 LAPACK 库
从 CUDA 10.1 update 2 开始,NVIDIA LAPACK 库 libcusolver_lapack_static.a 是 LAPACK 的一个子集,仅包含 GPU 加速的 stedc 和 bdsqr。用户必须将 libcusolver_static.a 与 libcusolver_lapack_static.a 链接,才能成功构建应用程序。在 CUDA 10.1 update 2 之前,用户可以使用第三方 LAPACK 库(例如 MKL)替换 libcusolver_lapack_static.a。在 CUDA 10.1 update 2 中,第三方 LAPACK 库不再影响 cusolver 库的行为,无论是功能还是性能。此外,用户不能将 libcusolver_lapack_static.a 用作独立的 LAPACK 库,因为它只是 LAPACK 的一个子集。
如果您使用
libcusolver_static.a,则必须显式链接libcusolver_lapack_static.a,否则链接器将报告缺少符号。libcusolver_lapack_static.a和其他第三方 LAPACK 库之间没有符号冲突,这允许将同一个应用程序链接到libcusolver_lapack_static.a和另一个第三方 LAPACK 库。libcusolver_lapack_static.a构建在libcusolver.so内部。因此,如果您使用libcusolver.so,则无需指定 LAPACK 库。即使您将应用程序与第三方 LAPACK 库链接,libcusolver.so也不会从第三方 LAPACK 库中获取任何例程。
2.1.6. info 的约定
每个 LAPACK 例程都会返回一个 info,指示无效参数的位置。如果 info = -i,则表示第 i 个参数无效。为了与 LAPACK 中的从 1 开始的索引保持一致,cusolver 不会将无效的 handle 报告到 info 中。相反,cusolver 会为无效的 handle 返回 CUSOLVER_STATUS_NOT_INITIALIZED。
2.1.7. _bufferSize 的用法
cuSolver 库内部没有 cudaMalloc,用户必须显式分配设备工作区。例程 xyz_bufferSize 用于查询例程 xyz 的工作区大小,例如 xyz = potrf。为了简化 API,xyz_bufferSize 遵循与 xyz 几乎相同的签名,即使它仅依赖于某些参数,例如,设备指针不用于决定工作区的大小。在大多数情况下,xyz_bufferSize 在准备实际设备数据(由设备指针指向)之前或在分配设备指针之前被调用。在这种情况下,用户可以将空指针传递给 xyz_bufferSize 而不会破坏功能。
2.1.8. cuSOLVERDn 日志记录
可以通过在启动目标应用程序之前设置以下环境变量来启用 cuSOLVERDn 日志记录机制
CUSOLVERDN_LOG_LEVEL=<level>- 其中<level>是以下级别之一0- 关闭 - 日志记录已禁用(默认)1- 错误 - 仅记录错误2- 跟踪 - 启动 CUDA 内核的 API 调用将记录其参数和重要信息3- 提示 - 可能提高应用程序性能的提示4- 信息 - 提供有关库执行的常规信息,可能包含有关启发式状态的详细信息5- API 跟踪 - API 调用将记录其参数和重要信息
CUSOLVERDN_LOG_MASK=<mask>- 其中 mask 是以下掩码的组合0- 关闭1- 错误2- 跟踪4- 提示8- 信息16- API 跟踪
CUSOLVERDN_LOG_FILE=<file_name>- 其中文件名是日志文件的路径。文件名可能包含%i,这将替换为进程 ID,例如<file_name>_%i.log。如果未定义CUSOLVERDN_LOG_FILE,则日志消息将打印到 stdout。
另一种选择是使用实验性的 cusolverDn 日志记录 API。请参阅:cusolverDnLoggerSetCallback(), cusolverDnLoggerSetFile(), cusolverDnLoggerOpenFile(), cusolverDnLoggerSetLevel(), cusolverDnLoggerSetMask(), cusolverDnLoggerForceDisable()。
2.1.9. 确定性结果
在本文档中,如果一个函数对于每次使用相同输入参数、硬件和软件环境执行都计算出完全相同的按位结果,则该函数被声明为确定性的。相反,一个非确定性函数可能会由于浮点运算顺序的变化而计算出按位不同的结果,例如,四个值 a、b、c、d 的和 s 可以以不同的顺序计算
s = (a + b) + (c + d)s = (a + (b + c)) + ds = a + (b + (c + d))…
由于浮点运算的非结合性,所有结果都可能是按位不同的。
默认情况下,cuSolverDN 计算确定性结果。为了提高某些函数的性能,可以使用 cusolverDnSetDeterministicMode() 允许非确定性结果。
2.2. cuSolver 类型参考
2.2.1. cuSolverDN 类型
支持 float、double、cuComplex 和 cuDoubleComplex 数据类型。前两个是标准 C 数据类型,而后两个是从 cuComplex.h 导出的。此外,cuSolverDN 使用了 cuBLAS 中的一些常用类型。
2.2.1.1. cusolverDnHandle_t
这是一种指向不透明 cuSolverDN 上下文的指针类型,用户必须在调用任何其他库函数之前通过调用 cusolverDnCreate() 来初始化它。未初始化的 Handle 对象将导致意外行为,包括 cuSolverDN 崩溃。通过 cusolverDnCreate() 创建和返回的句柄必须传递给每个 cuSolverDN 函数。
2.2.1.2. cublasFillMode_t
此类型指示填充了密集矩阵的哪个部分(下部或上部),并因此应由函数使用。
值 |
含义 |
|---|---|
|
填充了矩阵的下部。 |
|
填充了矩阵的上部。 |
|
填充了完整矩阵。 |
请注意,BLAS 实现通常使用 Fortran 字符 ‘L’ 或 ‘l’ (lower) 和 ‘U’ 或 ‘u’ (upper) 来描述填充了矩阵的哪个部分。
2.2.1.3. cublasOperation_t
cublasOperation_t 类型指示需要对密集矩阵执行哪个操作。
值 |
含义 |
|---|---|
|
选择非转置操作。 |
|
选择转置操作。 |
|
选择共轭转置操作。 |
请注意,BLAS 实现通常使用 Fortran 字符 ‘N’ 或 ‘n’ (非转置)、‘T’ 或 ‘t’ (转置)和 ‘C’ 或 ‘c’ (共轭转置)来描述需要对密集矩阵执行哪些操作。
2.2.1.4. cusolverEigType_t
cusolverEigType_t 类型指示求解器是哪种类型的特征值求解器。
值 |
含义 |
|---|---|
|
A*x = lambda*B*x |
|
A*B*x = lambda*x |
|
B*A*x = lambda*x |
请注意,LAPACK 实现通常使用 Fortran 整数 1 (A*x = lambda*B*x)、2 (A*B*x = lambda*x)、3 (B*A*x = lambda*x) 来指示求解器是哪种类型的特征值求解器。
2.2.1.5. cusolverEigMode_t
cusolverEigMode_t 类型指示是否计算特征向量。
值 |
含义 |
|---|---|
|
仅计算特征值。 |
|
同时计算特征值和特征向量。 |
请注意,LAPACK 实现通常使用 Fortran 字符 'N' (仅计算特征值)、'V' (同时计算特征值和特征向量)来指示是否计算特征向量。
2.2.1.6. cusolverIRSRefinement_t
cusolverIRSRefinement_t 类型指示特定 cusolver 函数将使用哪种求解器类型。我们的大多数实验表明,CUSOLVER_IRS_REFINE_GMRES 是最佳选择。
有关细化过程的更多详细信息,请参阅 Azzam Haidar、Stanimire Tomov、Jack Dongarra 和 Nicholas J. Higham。2018 年。《利用 GPU tensor cores for fast FP16 arithmetic to speed up mixed-precision iterative refinement solvers》。《国际高性能计算、网络、存储和分析会议论文集》(SC ‘18)。IEEE Press,Piscataway,NJ,USA,第 47 条,共 11 页。
CUSOLVER_IRS_REFINE_NOT_SET求解器未设置;此值是在创建
params结构时设置的值。IRS 求解器将返回错误。CUSOLVER_IRS_REFINE_NONE无细化求解器,IRS 求解器执行因式分解,然后执行求解,而无需任何细化。例如,如果 IRS 求解器是
cusolverDnIRSXgesv(),则这等效于没有细化的 Xgesv 例程,其中因式分解以最低精度执行。例如,如果主精度为 CUSOLVER_R_64F,而最低精度也为 CUSOLVER_R_64F,则这等效于调用cusolverDnDgesv()。CUSOLVER_IRS_REFINE_CLASSICAL经典迭代细化求解器。类似于 LAPACK 例程中使用的求解器。
CUSOLVER_IRS_REFINE_GMRES基于 GMRES(广义最小残差)的迭代细化求解器。在最近的研究中,GMRES 方法因其能够用作优于经典迭代细化方法的细化求解器而受到科学界的关注。根据我们的实验,我们推荐此设置。
CUSOLVER_IRS_REFINE_CLASSICAL_GMRES经典迭代细化求解器,它在内部使用 GMRES(广义最小残差)来求解每次迭代的校正方程。我们将经典细化迭代称为外迭代,而 GMRES 称为内迭代。请注意,如果内部 GMRES 的容差设置得非常低,例如设置为机器精度,则外部经典细化迭代将仅执行一次迭代,因此此选项的行为将类似于
CUSOLVER_IRS_REFINE_GMRES。CUSOLVER_IRS_REFINE_GMRES_GMRES类似于
CUSOLVER_IRS_REFINE_CLASSICAL_GMRES,它由经典细化过程组成,该过程使用 GMRES 来求解内部校正系统;这里是一个基于 GMRES(广义最小残差)的迭代细化求解器,它在内部使用另一个 GMRES 来求解预处理系统。
2.2.1.7. cusolverDnIRSParams_t
这是一种指向不透明 cusolverDnIRSParams_t 结构的指针类型,该结构保存迭代细化线性求解器的参数,例如 cusolverDnXgesv()。使用下面描述的相应辅助函数来创建/销毁此结构或设置/获取求解器参数。
2.2.1.8. cusolverDnIRSInfos_t
这是一种指向不透明 cusolverDnIRSInfos_t 结构的指针类型,该结构保存有关迭代细化线性求解器(例如 cusolverDnXgesv())的已执行调用的信息。使用下面描述的相应辅助函数来创建/销毁此结构或检索求解信息。
2.2.1.9. cusolverDnFunction_t
cusolverDnFunction_t 类型指示 cusolverDnSetAdvOptions() 需要配置哪个例程。值 CUSOLVERDN_GETRF 对应于例程 Getrf。
值 |
含义 |
|---|---|
|
对应于 |
2.2.1.10. cusolverAlgMode_t
cusolverAlgMode_t 类型指示 cusolverDnSetAdvOptions() 选择的算法。每个例程支持的算法集在例程的文档中详细描述。
默认算法为 CUSOLVER_ALG_0。用户也可以提供 NULL 以使用默认算法。
2.2.1.11. cusolverStatus_t
这与稀疏 LAPACK 部分中的 cusolverStatus_t 相同。
2.2.1.12. cusolverDnLoggerCallback_t
cusolverDnLoggerCallback_t 是一种回调函数指针类型。
参数
参数 |
内存 |
输入/输出 |
描述 |
|---|---|---|---|
|
输出 |
请参阅 cuSOLVERDn 日志记录 |
|
|
输出 |
记录此消息的 API 的名称。 |
|
|
输出 |
日志消息。 |
使用以下函数设置回调函数:cusolverDnLoggerSetCallback()。
2.2.1.13. cusolverDeterministicMode_t
cusolverDeterministicMode_t 类型指示具有相同输入的多个 cuSolver 函数执行是否具有相同的按位相等结果(确定性)或可能具有按位不同的结果(非确定性)。与仅包含原子函数用法的 cublasAtomicsMode_t 相比,cusolverDeterministicMode_t 包括所有非确定性编程模式。可以使用 cusolverDnSetDeterministicMode() 和 cusolverDnGetDeterministicMode() 例程分别设置和查询确定性模式。
值 |
含义 |
|---|---|
|
计算确定性结果。 |
|
允许非确定性结果。 |
2.2.1.14. cusolverStorevMode_t
指定定义基本反射器的向量的存储方式。
值 |
含义 |
|---|---|
|
按列。 |
|
按行。 |
2.2.1.15. cusolverDirectMode_t
指定将基本反射器相乘以形成块反射器的顺序。
值 |
含义 |
|---|---|
|
向前。 |
|
向后。 |
2.2.2. cuSolverSP 类型
支持 float、double、cuComplex 和 cuDoubleComplex 数据类型。前两个是标准 C 数据类型,而后两个是从 cuComplex.h 导出的。
2.2.2.1. cusolverSpHandle_t
这是一种指向不透明 cuSolverSP 上下文的指针类型,用户必须在调用任何其他库函数之前通过调用 cusolverSpCreate() 来初始化它。未初始化的 Handle 对象将导致意外行为,包括 cuSolverSP 崩溃。通过 cusolverSpCreate() 创建和返回的句柄必须传递给每个 cuSolverSP 函数。
2.2.2.2. cusparseMatDescr_t
我们已选择与 cuSPARSE 中存在的结构保持相同的结构来描述矩阵的形状和属性。这使得可以使用相同的矩阵描述来调用 cuSPARSE 或 cuSOLVER。
typedef struct {
cusparseMatrixType_t MatrixType;
cusparseFillMode_t FillMode;
cusparseDiagType_t DiagType;
cusparseIndexBase_t IndexBase;
} cusparseMatDescr_t;
请阅读 cuSPARSE 库的文档以了解 cusparseMatDescr_t 的每个字段。
2.2.2.3. cusolverStatus_t
这是库函数返回的状态类型,它可以具有以下值。
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZEDcuSolver 库未初始化。这通常是由于缺少先前的调用、cuSolver 例程调用的 CUDA Runtime API 中的错误或硬件设置中的错误造成的。
更正方法: 在函数调用之前调用
cusolverDnCreate();并检查硬件、驱动程序的适当版本和 cuSolver 库是否已正确安装。CUSOLVER_STATUS_ALLOC_FAILEDcuSolver 库内部的资源分配失败。这通常是由
cudaMalloc()失败引起的。更正方法: 在函数调用之前,尽可能多地释放先前分配的内存。
CUSOLVER_STATUS_INVALID_VALUE向函数传递了不支持的值或参数(例如,负向量大小)。
更正方法: 确保传递的所有参数都具有有效值。
CUSOLVER_STATUS_ARCH_MISMATCH该函数需要设备架构中缺少的功能;通常是由于缺少对原子操作或双精度运算的支持而引起的。
更正方法: 在计算能力为 5.0 或更高的设备上编译并运行应用程序。
CUSOLVER_STATUS_EXECUTION_FAILEDGPU 程序执行失败。这通常是由 GPU 上内核启动失败引起的,这可能是由多种原因引起的。
更正方法: 检查硬件、驱动程序的适当版本和 cuSolver 库是否已正确安装。
CUSOLVER_STATUS_INTERNAL_ERROR内部 cuSolver 操作失败。此错误通常是由
cudaMemcpyAsync()失败引起的。更正方法: 检查硬件、驱动程序的适当版本和 cuSolver 库是否已正确安装。此外,检查作为参数传递给例程的内存是否在例程完成之前被释放。
CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED此函数不支持矩阵类型。这通常是由于向函数传递了无效的矩阵描述符而引起的。
更正方法: 检查
descrA中的字段是否已正确设置。CUSOLVER_STATUS_NOT_SUPPORTED不支持参数组合,例如不支持批量版本或不支持
M < N。更正方法: 查阅文档,并使用受支持的配置。
2.2.3. cuSolverRF 类型
cuSolverRF 仅支持 double。
2.2.3.1. cusolverRfHandle_t
cusolverRfHandle_t 是指向包含 cuSolverRF 库句柄的不透明数据结构的指针。用户必须在任何其他 cuSolverRF 库调用之前通过调用 cusolverRfCreate() 来初始化句柄。句柄将传递给所有其他 cuSolverRF 库调用。
2.2.3.2. cusolverRfMatrixFormat_t
cusolverRfMatrixFormat_t 是一个枚举,指示 cusolverRfSetupDevice()、cusolverRfSetupHost()、cusolverRfResetValues()、cusolveRfExtractBundledFactorsHost() 和 cusolverRfExtractSplitFactorsHost() 例程假定的输入/输出矩阵格式。
值 |
含义 |
|---|---|
|
假定矩阵格式为 CSR。(默认) |
|
假定矩阵格式为 CSC。 |
2.2.3.3. cusolverRfNumericBoostReport_t
cusolverRfNumericBoostReport_t 是一个枚举,指示在 cusolverRfRefactor() 和 cusolverRfSolve() 例程期间是否使用了数值提升(pivot)。默认情况下,数值提升处于禁用状态。
值 |
含义 |
|---|---|
|
未使用数值提升。(默认) |
|
使用了数值提升。 |
2.2.3.4. cusolverRfResetValuesFastMode_t
cusolverRfResetValuesFastMode_t 是一个枚举,指示用于 cusolverRfResetValues() 例程的模式。快速模式需要额外的内存,建议仅在需要非常快速地调用 cusolverRfResetValues() 时使用。
值 |
含义 |
|---|---|
|
快速模式已禁用。(默认) |
|
快速模式已启用。 |
2.2.3.5. cusolverRfFactorization_t
cusolverRfFactorization_t 是一个枚举,指示 cusolverRfRefactor() 例程中的重构使用了哪种(内部)算法。
值 |
含义 |
|---|---|
|
算法 0。(默认) |
|
算法 1。 |
|
算法 2。基于多米诺骨牌的方案。 |
2.2.3.6. cusolverRfTriangularSolve_t
cusolverRfTriangularSolve_t 是一个枚举,指示 cusolverRfSolve() 例程中的三角求解使用了哪种(内部)算法。
值 |
含义 |
|---|---|
|
算法 1。(默认) |
|
算法 2。基于多米诺骨牌的方案。 |
|
算法 3。基于多米诺骨牌的方案。 |
2.2.3.7. cusolverRfUnitDiagonal_t
cusolverRfUnitDiagonal_t 是一个枚举,指示在 cusolverRfSetupDevice()、cusolverRfSetupHost() 和 cusolverRfExtractSplitFactorsHost() 例程中,单位对角线是否以及存储在输入/输出三角因子中的位置。
值 |
含义 |
|---|---|
|
单位对角线存储在下三角因子中(默认)。 |
|
单位对角线存储在上三角因子中。 |
|
假定单位对角线在下三角因子中。 |
|
假定单位对角线在上三角因子中。 |
2.2.3.8. cusolverStatus_t
cusolverStatus_t 是一个枚举,指示 cuSolverRF 库调用的成功或失败。它由所有 cuSolver 库例程返回,并且它使用与稀疏和密集 Lapack 例程相同的枚举值。
2.3. cuSolver 格式参考
2.3.1. 索引基格式
cuSolver 中同时支持从 1 开始和从 0 开始的索引。
2.3.2. 向量(密集)格式
假定向量在线性内存中存储。例如,向量
表示为
2.3.3. 矩阵(密集)格式
假定密集矩阵以列优先顺序存储在内存中。可以使用原始矩阵的前导维度访问子矩阵。例如,m*n (子)矩阵
表示为
其元素在线性内存中排列如下:
其中 lda \(\geq\) m 是 A 的主导维度。
2.3.4. 矩阵 (CSR) 格式
在 CSR 格式中,矩阵由以下参数表示
参数 |
类型 |
大小 |
含义 |
|---|---|---|---|
|
|
矩阵中的行数(和列数)。 |
|
|
|
矩阵中非零元素的数量。 |
|
|
|
|
偏移数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵中的非零元素。假定此数组按行和每行内的列进行排序。 |
|
|
|
值数组,对应于矩阵中的非零元素。假定此数组按行和每行内的列进行排序。 |
请注意,在我们的 CSR 格式中,稀疏矩阵假定以行优先顺序存储,换句话说,索引数组首先按行索引排序,然后在每行内按列索引排序。此外,还假定每对行和列索引仅出现一次。
例如,4x4 矩阵
表示为
2.3.5. 矩阵 (CSC) 格式
在 CSC 格式中,矩阵由以下参数表示
参数 |
类型 |
大小 |
含义 |
|---|---|---|---|
|
|
矩阵中的行数(和列数)。 |
|
|
|
矩阵中非零元素的数量。 |
|
|
|
|
偏移数组,对应于数组 |
|
|
|
行索引数组,对应于矩阵中的非零元素。假定此数组按列和每列内的行进行排序。 |
|
|
|
值数组,对应于矩阵中的非零元素。假定此数组按列和每列内的行进行排序。 |
请注意,在我们的 CSC 格式中,稀疏矩阵假定以列优先顺序存储,换句话说,索引数组首先按列索引排序,然后在每列内按行索引排序。此外,还假定每对行和列索引仅出现一次。
例如,4x4 矩阵
表示为
2.4. cuSolverDN:稠密 LAPACK 函数参考
本节介绍 cuSolverDN 的 API,它提供稠密 LAPACK 函数的子集。
2.4.1. cuSolverDN 辅助函数参考
本节介绍 cuSolverDN 辅助函数。
2.4.1.1. cusolverDnCreate()
cusolverStatus_t
cusolverDnCreate(cusolverDnHandle_t *handle);
此函数初始化 cuSolverDN 库,并在 cuSolverDN 上下文中创建句柄。必须在调用任何其他 cuSolverDN API 函数之前调用它。它分配访问 GPU 所需的硬件资源。此函数分配 4 MiB 或 32 MiB 内存(对于计算能力为 9.0 及更高版本的 GPU),这将用作首次调用 cusolverDnSetStream() 的用户定义流的 cuBLAS 工作区。对于默认流和所有其他情况,cuBLAS 将管理其自己的工作区。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向 cuSolverDN 上下文句柄的指针。 |
返回状态
CUSOLVER_STATUS_SUCCESS初始化成功。
CUSOLVER_STATUS_NOT_INITIALIZEDCUDA 运行时初始化失败。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
2.4.1.2. cusolverDnDestroy()
cusolverStatus_t
cusolverDnDestroy(cusolverDnHandle_t handle);
此函数释放 cuSolverDN 库使用的 CPU 端资源。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
返回状态
CUSOLVER_STATUS_SUCCESS关闭成功。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
2.4.1.3. cusolverDnSetStream()
cusolverStatus_t
cusolverDnSetStream(cusolverDnHandle_t handle, cudaStream_t streamId)
此函数设置 cuSolverDN 库用于执行其例程的流。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
库要使用的流。 |
返回状态
CUSOLVER_STATUS_SUCCESS流已成功设置。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
2.4.1.4. cusolverDnGetStream()
cusolverStatus_t
cusolverDnGetStream(cusolverDnHandle_t handle, cudaStream_t *streamId)
此函数查询 cuSolverDN 库用于执行其例程的流。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
返回状态
CUSOLVER_STATUS_SUCCESS流已成功设置。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
2.4.1.5. cusolverDnLoggerSetCallback()
cusolverStatus_t cusolverDnLoggerSetCallback(cusolverDnLoggerCallback_t callback);
此函数设置日志记录回调函数。
参数
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
指向回调函数的指针。请参阅 cusolverDnLoggerCallback_t。 |
返回状态
CUSOLVER_STATUS_SUCCESS如果回调函数已成功设置。
有关有效返回代码的完整列表,请参阅 cusolverStatus_t。
2.4.1.6. cusolverDnLoggerSetFile()
cusolverStatus_t cusolverDnLoggerSetFile(FILE* file);
此函数设置日志记录输出文件。注意:一旦使用此函数调用注册,提供的文件句柄就不得关闭,除非再次调用该函数以切换到不同的文件句柄。
参数
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
指向打开文件的指针。文件应具有写入权限。 |
返回状态
CUSOLVER_STATUS_SUCCESS如果日志记录文件已成功设置。
有关有效返回代码的完整列表,请参阅 cusolverStatus_t。
2.4.1.7. cusolverDnLoggerOpenFile()
cusolverStatus_t cusolverDnLoggerOpenFile(const char* logFile);
此函数在给定路径中打开日志记录输出文件。
参数
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
日志记录输出文件的路径。 |
返回状态
CUSOLVER_STATUS_SUCCESS如果日志记录文件已成功打开。
有关有效返回代码的完整列表,请参阅 cusolverStatus_t。
2.4.1.8. cusolverDnLoggerSetLevel()
cusolverStatus_t cusolverDnLoggerSetLevel(int level);
此函数设置日志记录级别的数值。
参数
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
日志记录级别的数值。请参阅 cuSOLVERDn 日志记录。 |
返回状态
CUSOLVER_STATUS_INVALID_VALUE如果该值不是有效的日志记录级别。请参阅 cuSOLVERDn 日志记录。
CUSOLVER_STATUS_SUCCESS如果日志记录级别已成功设置。
有关有效返回代码的完整列表,请参阅 cusolverStatus_t。
2.4.1.9. cusolverDnLoggerSetMask()
cusolverStatus_t cusolverDnLoggerSetMask(int mask);
此函数设置日志记录掩码的数值。
参数
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
日志记录掩码的数值。请参阅 cuSOLVERDn 日志记录。 |
返回状态
CUSOLVER_STATUS_SUCCESS如果日志记录掩码已成功设置。
有关有效返回代码的完整列表,请参阅 cusolverStatus_t。
2.4.1.10. cusolverDnLoggerForceDisable()
cusolverStatus_t cusolverDnLoggerForceDisable();
此函数禁用整个运行的日志记录。
返回状态
CUSOLVER_STATUS_SUCCESS如果日志记录已成功禁用。
有关有效返回代码的完整列表,请参阅 cusolverStatus_t。
2.4.1.11. cusolverDnSetDeterministicMode()
cusolverStatus_t
cusolverDnSetDeterministicMode(cusolverDnHandle_t handle, cusolverDeterministicMode_t mode)
此函数为 handle 设置所有 cuSolverDN 函数的确定性模式。为了提高性能,可以允许非确定性结果。受影响的函数包括 cusolverDn<t>geqrf()、cusolverDn<t>syevd()、cusolverDn<t>syevdx()、cusolverDn<t>gesvd()(如果 m > n)、cusolverDn<t>gesvdj()、cusolverDnXgeqrf()、cusolverDnXsyevd()、cusolverDnXsyevdx()、cusolverDnXgesvd()(如果 m > n)、cusolverDnXgesvdr() 和 cusolverDnXgesvdp()。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
要与 |
返回状态
CUSOLVER_STATUS_SUCCESS模式已成功设置。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INTERNAL_ERROR发生内部错误。
2.4.1.12. cusolverDnGetDeterministicMode()
cusolverStatus_t
cusolverDnGetDeterministicMode(cusolverDnHandle_t handle, cusolverDeterministicMode_t* mode)
此函数查询为 handle 设置的确定性模式。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS模式已成功设置。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUEmode是一个NULL指针。
2.4.1.13. cusolverDnCreateSyevjInfo()
cusolverStatus_t
cusolverDnCreateSyevjInfo(
syevjInfo_t *info);
此函数创建 syevj、syevjBatched 和 sygvj 的结构并将其初始化为默认值。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向 |
返回状态
CUSOLVER_STATUS_SUCCESS结构已成功初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
2.4.1.14. cusolverDnDestroySyevjInfo()
cusolverStatus_t
cusolverDnDestroySyevjInfo(
syevjInfo_t info);
此函数销毁并释放结构所需的任何内存。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS资源已成功释放。
2.4.1.15. cusolverDnXsyevjSetTolerance()
cusolverStatus_t
cusolverDnXsyevjSetTolerance(
syevjInfo_t info,
double tolerance)
此函数配置 syevj 的容差。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向 |
|
|
|
数值特征值的精度。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
2.4.1.16. cusolverDnXsyevjSetMaxSweeps()
cusolverStatus_t
cusolverDnXsyevjSetMaxSweeps(
syevjInfo_t info,
int max_sweeps)
此函数配置 syevj 中最大扫描次数。默认值为 100。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向 |
|
|
|
最大扫描次数。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
2.4.1.17. cusolverDnXsyevjSetSortEig()
cusolverStatus_t
cusolverDnXsyevjSetSortEig(
syevjInfo_t info,
int sort_eig)
如果 sort_eig 为零,则不对特征值进行排序。此函数仅适用于 syevjBatched。syevj 和 sygvj 始终按升序对特征值进行排序。默认情况下,特征值始终按升序排序。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向 syevj 结构的指针。 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
2.4.1.18. cusolverDnXsyevjGetResidual()
cusolverStatus_t
cusolverDnXsyevjGetResidual(
cusolverDnHandle_t handle,
syevjInfo_t info,
double *residual)
此函数报告 syevj 或 sygvj 的残差。它不支持 syevjBatched。如果用户在 syevjBatched 之后调用此函数,则会返回错误 CUSOLVER_STATUS_NOT_SUPPORTED。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指向 |
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_SUPPORTED不支持批量版本。
2.4.1.19. cusolverDnXsyevjGetSweeps()
cusolverStatus_t
cusolverDnXsyevjGetSweeps(
cusolverDnHandle_t handle,
syevjInfo_t info,
int *executed_sweeps)
此函数报告 syevj 或 sygvj 的已执行扫描次数。它不支持 syevjBatched。如果用户在 syevjBatched 之后调用此函数,则会返回错误 CUSOLVER_STATUS_NOT_SUPPORTED。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指向 |
|
|
|
已执行扫描次数。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_SUPPORTED不支持批量版本。
2.4.1.20. cusolverDnCreateGesvdjInfo()
cusolverStatus_t
cusolverDnCreateGesvdjInfo(
gesvdjInfo_t *info);
此函数创建 gesvdj 和 gesvdjBatched 的结构并将其初始化为默认值。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向 |
返回状态
CUSOLVER_STATUS_SUCCESS结构已成功初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
2.4.1.21. cusolverDnDestroyGesvdjInfo()
cusolverStatus_t
cusolverDnDestroyGesvdjInfo(
gesvdjInfo_t info);
此函数销毁并释放结构所需的任何内存。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS资源已成功释放。
2.4.1.22. cusolverDnXgesvdjSetTolerance()
cusolverStatus_t
cusolverDnXgesvdjSetTolerance(
gesvdjInfo_t info,
double tolerance)
此函数配置 gesvdj 的容差。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向 |
|
|
|
数值奇异值的精度。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
2.4.1.23. cusolverDnXgesvdjSetMaxSweeps()
cusolverStatus_t
cusolverDnXgesvdjSetMaxSweeps(
gesvdjInfo_t info,
int max_sweeps)
此函数配置 gesvdj 中最大扫描次数。默认值为 100。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向 |
|
|
|
最大扫描次数。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
2.4.1.24. cusolverDnXgesvdjSetSortEig()
cusolverStatus_t
cusolverDnXgesvdjSetSortEig(
gesvdjInfo_t info,
int sort_svd)
如果 sort_svd 为零,则不对奇异值进行排序。此函数仅适用于 gesvdjBatched。gesvdj 始终按降序对奇异值进行排序。默认情况下,奇异值始终按降序排序。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
2.4.1.25. cusolverDnXgesvdjGetResidual()
cusolverStatus_t
cusolverDnXgesvdjGetResidual(
cusolverDnHandle_t handle,
gesvdjInfo_t info,
double *residual)
此函数报告 gesvdj 返回的内部残差的 Frobenius 范数。请注意,这不是根据以下公式计算的精确残差的 Frobenious 范数:
此函数不支持 gesvdjBatched。如果用户在 gesvdjBatched 之后调用此函数,则会返回错误 CUSOLVER_STATUS_NOT_SUPPORTED。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指向 |
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_SUPPORTED不支持批量版本
2.4.1.26. cusolverDnXgesvdjGetSweeps()
cusolverStatus_t
cusolverDnXgesvdjGetSweeps(
cusolverDnHandle_t handle,
gesvdjInfo_t info,
int *executed_sweeps)
此函数报告 gesvdj 的已执行扫描次数。它不支持 gesvdjBatched。如果用户在 gesvdjBatched 之后调用此函数,则会返回错误 CUSOLVER_STATUS_NOT_SUPPORTED。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指向 |
|
|
|
已执行扫描次数。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_SUPPORTED不支持批量版本
2.4.1.27. cusolverDnIRSParamsCreate()
cusolverStatus_t
cusolverDnIRSParamsCreate(cusolverDnIRSParams_t *params);
此函数创建 IRS 求解器(例如 cusolverDnIRSXgesv() 或 cusolverDnIRSXgels() 函数)的参数结构,并将其初始化为默认值。由此函数创建的 params 结构可以被相同或不同 IRS 求解器的一个或多个调用使用。请注意,在 CUDA 10.2 中,行为有所不同,并且每次调用 IRS 求解器都需要创建一个新的 params 结构。另请注意,用户还可以更改 params 的配置,然后调用新的 IRS 实例,但请注意,之前的调用已完成,因为在之前的调用完成之前对配置进行的任何更改都可能影响它。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向 |
返回状态
CUSOLVER_STATUS_SUCCESS结构已成功创建和初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
2.4.1.28. cusolverDnIRSParamsDestroy()
cusolverStatus_t
cusolverDnIRSParamsDestroy(cusolverDnIRSParams_t params);
此函数销毁并释放 Params 结构所需的任何内存。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS资源已成功释放。
CUSOLVER_STATUS_IRS_PARAMS_NOT_INITIALIZED未创建
Params结构。CUSOLVER_STATUS_IRS_INFOS_NOT_DESTROYED并非所有与此
Params结构关联的Infos结构都已销毁。
2.4.1.29. cusolverDnIRSParamsSetSolverPrecisions()
cusolverStatus_t
cusolverDnIRSParamsSetSolverPrecisions(
cusolverDnIRSParams_t params,
cusolverPrecType_t solver_main_precision,
cusolverPrecType_t solver_lowest_precision );
此函数为迭代精化求解器 (IRS) 设置主精度和最低精度。主精度是指输入和输出数据类型的精度。最低精度是指在 LU 分解过程中,求解器可以使用的最低计算精度。请注意,用户必须在首次调用 IRS 求解器之前设置主精度和最低精度,因为它们在创建 params 结构时不是默认设置的,因为它取决于输入输出数据类型和用户请求。它是 cusolverDnIRSParamsSetSolverMainPrecision() 和 cusolverDnIRSParamsSetSolverLowestPrecision() 的包装器。下表描述了主精度/最低精度的所有可能组合。通常,最低精度定义了可以实现的速度提升。最低精度相对于主精度(例如,输入/输出数据类型)的性能比率定义了可以获得的速度提升的上限。更准确地说,它取决于许多因素,但对于大型矩阵尺寸,它是矩阵-矩阵秩-k 乘积(例如,GEMM,其中 K 为 256,M=N=矩阵大小)的比率,它定义了可能的速度提升。例如,如果输入输出精度是实双精度 CUSOLVER_R_64F,最低精度是 CUSOLVER_R_32F,那么对于大型问题规模,我们可以期望最多 2 倍的速度提升。如果最低精度是 CUSOLVER_R_16F,那么我们可以期望 3-4 倍。合理的策略应考虑右侧的数量、矩阵的大小以及收敛速度。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
允许的输入/输出数据类型(例如,实双精度数据为 CUSOLVER_R_FP64)。有关支持的精度,请参见下表。 |
|
|
|
允许的最低计算类型(例如,半精度计算为 CUSOLVER_R_16F)。有关支持的精度,请参见下表。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_PARAMS_NOT_INITIALIZED未创建
Params结构。
输入/输出数据类型(例如,主精度) |
最低精度的支持值 |
|---|---|
|
|
|
|
|
|
|
|
2.4.1.30. cusolverDnIRSParamsSetSolverMainPrecision()
cusolverStatus_t
cusolverDnIRSParamsSetSolverMainPrecision(
cusolverDnIRSParams_t params,
cusolverPrecType_t solver_main_precision);
此函数为迭代精化求解器 (IRS) 设置主精度。主精度是指输入和输出数据的类型。请注意,用户必须在首次调用 IRS 求解器之前设置主精度和最低精度,因为它们在创建 params 结构时不是默认设置的,因为它取决于输入输出数据类型和用户请求。用户可以通过调用此函数或调用 cusolverDnIRSParamsSetSolverPrecisions() 来设置它,后者同时设置主精度和最低精度。有关主精度/最低精度的所有可能组合,请参见上面 cusolverDnIRSParamsSetSolverPrecisions() 部分中的表格。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
允许的输入/输出数据类型(例如,实双精度数据为 CUSOLVER_R_FP64)。有关支持的精度,请参见上面 cusolverDnIRSParamsSetSolverPrecisions() 部分中的表格。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_PARAMS_NOT_INITIALIZED未创建
Params结构。
2.4.1.31. cusolverDnIRSParamsSetSolverLowestPrecision()
cusolverStatus_t
cusolverDnIRSParamsSetSolverLowestPrecision(
cusolverDnIRSParams_t params,
cusolverPrecType_t lowest_precision_type);
此函数设置迭代精化求解器将使用的最低精度。最低精度是指在 LU 分解过程中,求解器可以使用的最低计算精度。请注意,用户必须在首次调用 IRS 求解器之前设置主精度和最低精度,因为它们在创建 params 结构时不是默认设置的,因为它取决于输入输出数据类型和用户请求。通常,最低精度定义了可以实现的速度提升。最低精度相对于主精度(例如,输入/输出数据类型)的性能比率在某种程度上定义了可以获得的速度提升的上限。更准确地说,它取决于许多因素,但对于大型矩阵尺寸,它是矩阵-矩阵秩-k 乘积(例如,GEMM,其中 K 为 256,M=N=矩阵大小)的比率,它定义了可能的速度提升。例如,如果输入输出精度是实双精度 CUSOLVER_R_64F,最低精度是 CUSOLVER_R_32F,那么对于大型问题规模,我们可以期望最多 2 倍的速度提升。如果最低精度是 CUSOLVER_R_16F,那么我们可以期望 3-4 倍。合理的策略应考虑右侧的数量、矩阵的大小以及收敛速度。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
允许的最低计算类型(例如,半精度计算为 CUSOLVER_R_16F)。有关支持的精度,请参见上面 cusolverDnIRSParamsSetSolverPrecisions() 部分中的表格。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_PARAMS_NOT_INITIALIZED未创建 Params 结构。
2.4.1.32. cusolverDnIRSParamsSetRefinementSolver()
cusolverStatus_t
cusolverDnIRSParamsSetRefinementSolver(
cusolverDnIRSParams_t params,
cusolverIRSRefinement_t solver);
此函数设置要在迭代精化求解器函数(例如 cusolverDnIRSXgesv() 或 cusolverDnIRSXgels() 函数)中使用的精化求解器。请注意,用户必须在首次调用 IRS 求解器之前设置精化算法,因为它在创建 params 时不是默认设置的。下表描述了可以设置的值及其含义的详细信息。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
IRS 求解器(例如 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_PARAMS_NOT_INITIALIZED未创建
Params结构。CUSOLVER_IRS_REFINE_NOT_SET未设置求解器,此值是在创建 params 结构时设置的值。IRS 求解器将返回错误。
CUSOLVER_IRS_REFINE_NONE无精化求解器;IRS 求解器执行因式分解,然后执行求解,无需任何精化。例如,如果 IRS 求解器是
cusolverDnIRSXgesv(),则这等效于没有精化的 Xgesv 例程,并且因式分解以最低精度执行。例如,如果主精度是 CUSOLVER_R_64F,最低精度也是 CUSOLVER_R_64F,那么这等效于调用cusolverDnDgesv()。CUSOLVER_IRS_REFINE_CLASSICAL经典迭代细化求解器。类似于 LAPACK 例程中使用的求解器。
CUSOLVER_IRS_REFINE_GMRES基于 GMRES(广义最小残差)的迭代细化求解器。在最近的研究中,GMRES 方法因其能够用作优于经典迭代细化方法的细化求解器而受到科学界的关注。根据我们的实验,我们推荐此设置。
CUSOLVER_IRS_REFINE_CLASSICAL_GMRES经典迭代精化求解器,它在内部使用 GMRES(广义最小残差法)来求解每次迭代的校正方程。我们将经典精化迭代称为外部迭代,而 GMRES 称为内部迭代。请注意,如果内部 GMRES 的容差设置得非常低(例如,设置为机器精度),则外部经典精化迭代将仅执行一次迭代,因此此选项的行为将类似于
CUSOLVER_IRS_REFINE_GMRES。CUSOLVER_IRS_REFINE_GMRES_GMRES类似于
CUSOLVER_IRS_REFINE_CLASSICAL_GMRES,它由经典精化过程组成,该过程使用 GMRES 来求解内部校正系统,这里是一个基于 GMRES(广义最小残差)的迭代精化求解器,它在内部使用另一个 GMRES 来求解预处理系统。
2.4.1.33. cusolverDnIRSParamsSetTol()
cusolverStatus_t
cusolverDnIRSParamsSetTol(
cusolverDnIRSParams_t params,
double val );
此函数设置精化求解器的容差。默认情况下,它的设置使得所有 RHS 都满足
RNRM < SQRT(N)*XNRM*ANRM*EPS*BWDMAX 其中
RNRM 是残差的无穷范数
XNRM 是解的无穷范数
ANRM 是矩阵 A 的无穷算子范数
EPS 是输入/输出数据类型的机器epsilon,它与 LAPACK <X>LAMCH(‘Epsilon’) 相匹配
BWDMAX,BWDMAX 的值固定为 1.0
用户可以使用此函数将容差更改为更低或更高的值。我们的目标是让用户拥有更多控制权,使其能够调查和控制 IRS 求解器的每个细节。请注意,无论输入/输出数据类型是什么,容差值始终为实双精度。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
双精度实数值,精化容差将设置为该值。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_PARAMS_NOT_INITIALIZED未创建
Params结构。
2.4.1.34. cusolverDnIRSParamsSetTolInner()
cusolverStatus_t
cusolverDnIRSParamsSetTolInner(
cusolverDnIRSParams_t params,
double val );
当精化求解器由两级求解器组成时(例如,CUSOLVER_IRS_REFINE_CLASSICAL_GMRES 或 CUSOLVER_IRS_REFINE_GMRES_GMRES 情况),此函数设置内部精化求解器的容差。 在单级精化求解器(例如 CUSOLVER_IRS_REFINE_CLASSICAL 或 CUSOLVER_IRS_REFINE_GMRES)的情况下,它不被引用。 默认情况下,它设置为 1e-4。 此函数设置内部求解器(例如,内部 GMRES)的容差。 例如,如果精化求解器设置为 CUSOLVER_IRS_REFINE_CLASSICAL_GMRES,则设置此容差意味着内部 GMRES 求解器将在经典精化求解器的每次外部迭代中收敛到该容差。 我们的目标是让用户拥有更多控制权,使其能够调查和控制 IRS 求解器的每个细节。 请注意,无论输入/输出数据类型是什么,容差值始终为实双精度。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
双精度实数值,内部精化求解器的容差将设置为该值。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_PARAMS_NOT_INITIALIZED未创建
Params结构。
2.4.1.35. cusolverDnIRSParamsSetMaxIters()
cusolverStatus_t
cusolverDnIRSParamsSetMaxIters(
cusolverDnIRSParams_t params,
int max_iters);
此函数设置允许的最大精化迭代总次数,超过此次数后求解器将停止。 Total 表示任何迭代,这意味着外部迭代和内部迭代的总和(当设置两级精化求解器时,内部迭代才有意义)。 默认值设置为 50。 我们的目标是让用户拥有更多控制权,使其能够调查和控制 IRS 求解器的每个细节。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
精化求解器允许的最大迭代总次数。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_PARAMS_NOT_INITIALIZED未创建
Params结构。
2.4.1.36. cusolverDnIRSParamsSetMaxItersInner()
cusolverStatus_t
cusolverDnIRSParamsSetMaxItersInner(
cusolverDnIRSParams_t params,
cusolver_int_t maxiters_inner );
此函数设置内部精化求解器允许的最大迭代次数。 在单级精化求解器(例如 CUSOLVER_IRS_REFINE_CLASSICAL 或 CUSOLVER_IRS_REFINE_GMRES)的情况下,它不被引用。 内部精化求解器将在达到内部容差或 MaxItersInner 值后停止。 默认情况下,它设置为 50。 请注意,此值不能大于 MaxIters,因为 MaxIters 是允许的迭代总次数。 请注意,如果用户在此函数调用后调用 cusolverDnIRSParamsSetMaxIters,则 SetMaxIters 具有优先级,并将 MaxItersInner 覆盖为 (MaxIters, MaxItersInner) 的最小值。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
内部精化求解器允许的最大内部迭代次数。 当精化求解器是两级求解器(例如 CUSOLVER_IRS_REFINE_CLASSICAL_GMRES 或 CUSOLVER_IRS_REFINE_GMRES_GMRES)时,此参数有意义。 该值应小于或等于 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_PARAMS_NOT_INITIALIZED未创建
Params结构。CUSOLVER_STATUS_IRS_PARAMS_INVALID如果该值大于
MaxIters。
2.4.1.37. cusolverDnIRSParamsEnableFallback()
cusolverStatus_t
cusolverDnIRSParamsEnableFallback(
cusolverDnIRSParams_t params );
此函数启用回退到主精度,以防迭代精化求解器 (IRS) 未能收敛。 换句话说,如果 IRS 求解器未能收敛,则求解器将返回一个未收敛代码(例如,niter < 0),但可以返回未收敛的解(例如,禁用回退),或者可以回退(例如,启用回退)到主精度(即输入/输出数据的精度),并从头开始解决问题,返回良好的解。 这是默认行为,它将保证 IRS 求解器始终提供良好的解。 提供此函数是因为我们提供了 cusolverDnIRSParamsDisableFallback,它允许用户禁用回退,因此此函数允许用户重新启用它。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_PARAMS_NOT_INITIALIZED未创建
Params结构。
2.4.1.38. cusolverDnIRSParamsDisableFallback()
cusolverStatus_t
cusolverDnIRSParamsDisableFallback(
cusolverDnIRSParams_t params );
此函数禁用回退到主精度,以防迭代精化求解器 (IRS) 未能收敛。 换句话说,如果 IRS 求解器未能收敛,则求解器将返回一个未收敛代码(例如,niter < 0),但可以返回未收敛的解(例如,禁用回退),或者可以回退(例如,启用回退)到主精度(即输入/输出数据的精度),并从头开始解决问题,返回良好的解。 此函数禁用回退,返回的解是精化求解器在返回之前能够达到的任何解。 禁用回退不能保证解是好的解。 但是,如果用户希望在 IRS 在一定次数的迭代后未收敛的情况下继续获得较低精度的解,则他们需要禁用回退。 用户可以通过调用 cusolverDnIRSParamsEnableFallback 重新启用它。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_PARAMS_NOT_INITIALIZED未创建
Params结构。
2.4.1.39. cusolverDnIRSParamsGetMaxIters()
cusolverStatus_t
cusolverDnIRSParamsGetMaxIters(
cusolverDnIRSParams_t params,
cusolver_int_t *maxiters );
此函数返回 params 结构中当前设置的允许的最大迭代次数(例如,默认的 MaxIters,或者用户在使用 cusolverDnIRSParamsSetMaxIters 设置的值)。 请注意,此函数返回 params 配置中的当前设置,不要与 cusolverDnIRSInfosGetMaxIters 混淆,后者返回特定 IRS 求解器调用允许的最大迭代次数。 为了更清楚,params 结构可以用于多次调用 IRS 求解器。 用户可以在调用之间更改允许的 MaxIters,而 cusolverDnIRSInfosGetMaxIters 中的 Infos 结构包含有关特定调用的信息,不能用于不同的调用,因此,cusolverDnIRSInfosGetMaxIters 返回该调用允许的 MaxIters。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
当前设置的最大迭代次数。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_PARAMS_NOT_INITIALIZED未创建
Params结构。
2.4.1.40. cusolverDnIRSInfosCreate()
cusolverStatus_t
cusolverDnIRSInfosCreate(
cusolverDnIRSInfos_t* infos )
此函数创建并初始化 Infos 结构,该结构将保存迭代精化求解器 (IRS) 调用的精化信息。 此类信息包括收敛所需的总迭代次数 (Niters)、外部迭代次数(当使用两级预处理器(例如 CUSOLVER_IRS_REFINE_CLASSICAL_GMRES)时有意义)、该调用允许的最大迭代次数以及指向收敛历史残差范数矩阵的指针。 Infos 结构需要在调用 IRS 求解器之前创建。 Infos 结构仅对 IRS 求解器的一次调用有效,因为它保存了有关该求解的信息,因此每次求解都需要自己的 Infos 结构。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向 |
返回状态
CUSOLVER_STATUS_SUCCESS结构已成功初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
2.4.1.41. cusolverDnIRSInfosDestroy()
cusolverStatus_t
cusolverDnIRSInfosDestroy(
cusolverDnIRSInfos_t infos );
此函数销毁并释放 Infos 结构所需的任何内存。 此函数销毁有关求解器调用的所有信息(例如,执行的 Niters、执行的 OuterNiters、残差历史等); 因此,只有在用户完成信息处理后才应调用此函数。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS资源已成功释放。
CUSOLVER_STATUS_IRS_INFOS_NOT_INITIALIZEDInfos结构未创建。
2.4.1.42. cusolverDnIRSInfosGetMaxIters()
cusolverStatus_t
cusolverDnIRSInfosGetMaxIters(
cusolverDnIRSInfos_t infos,
cusolver_int_t *maxiters );
此函数返回为 IRS 求解器的相应调用设置的最大允许迭代次数。 请注意,此函数返回该调用发生时设置的设置,不要与 cusolverDnIRSParamsGetMaxIters 混淆,后者返回 params 配置结构中的当前设置。 为了更清楚,params 结构可以用于多次调用 IRS 求解器。 用户可以在调用之间更改允许的 MaxIters,而 cusolverDnIRSInfosGetMaxIters 中的 Infos 结构包含有关特定调用的信息,不能用于不同的调用,因此 cusolverDnIRSInfosGetMaxIters 返回该调用允许的 MaxIters。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
当前设置的最大迭代次数。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_INFOS_NOT_INITIALIZEDInfos结构未创建。
2.4.1.43. cusolverDnIRSInfosGetNiters()
cusolverStatus_t cusolverDnIRSInfosGetNiters(
cusolverDnIRSInfos_t infos,
cusolver_int_t *niters );
此函数返回 IRS 求解器执行的总迭代次数。 如果为负数,则表示 IRS 求解器未收敛,如果用户未禁用回退到全精度,则发生了回退到全精度解,并且解是良好的。 请参阅相应的 IRS 线性求解器函数(例如 cusolverDnXgesv() 或 cusolverDnXgels())中负 niters 值的描述。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
IRS 求解器执行的总迭代次数。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_INFOS_NOT_INITIALIZEDInfos结构未创建。
2.4.1.44. cusolverDnIRSInfosGetOuterNiters()
cusolverStatus_t
cusolverDnIRSInfosGetOuterNiters(
cusolverDnIRSInfos_t infos,
cusolver_int_t *outer_niters );
此函数返回 IRS 求解器的外部精化循环执行的迭代次数。 当精化求解器由单级求解器(例如 CUSOLVER_IRS_REFINE_CLASSICAL 或 CUSOLVER_IRS_REFINE_GMRES)组成时,它与 Niters 相同。 当精化求解器由两级求解器(例如 CUSOLVER_IRS_REFINE_CLASSICAL_GMRES 或 CUSOLVER_IRS_REFINE_GMRES_GMRES)组成时,它是外部循环的迭代次数。 有关更多详细信息,请参阅 cusolverIRSRefinement_t 的描述。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
IRS 求解器的外部精化循环的迭代次数。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_INFOS_NOT_INITIALIZEDInfos结构未创建。
2.4.1.45. cusolverDnIRSInfosRequestResidual()
cusolverStatus_t cusolverDnIRSInfosRequestResidual(
cusolverDnIRSInfos_t infos );
此函数指示 IRS 求解器将精化阶段的收敛历史(残差范数)存储在矩阵中,该矩阵可以通过 cusolverDnIRSInfosGetResidualHistory() 函数返回的指针访问。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_INFOS_NOT_INITIALIZEDInfos结构未创建。
2.4.1.46. cusolverDnIRSInfosGetResidualHistory()
cusolverStatus_t
cusolverDnIRSInfosGetResidualHistory(
cusolverDnIRSInfos_t infos,
void **residual_history );
如果用户在调用 IRS 函数之前调用了 cusolverDnIRSInfosRequestResidual(),则 IRS 求解器会将精化阶段的收敛历史(残差范数)存储在矩阵中,该矩阵可以通过此函数返回的指针访问。 残差范数的数据类型取决于输入和输出数据类型。 如果输入/输出数据类型是双精度实数或复数(CUSOLVER_R_FP64 或 CUSOLVER_C_FP64),则此残差将是实双精度 (FP64) double 类型,否则,如果输入/输出数据类型是单精度实数或复数(CUSOLVER_R_FP32 或 CUSOLVER_C_FP32),则此残差将是实单精度 FP32 float 类型。
残差历史矩阵由两列组成(即使对于多右侧情况 NRHS),行数为 MaxIters+1,因此矩阵大小为 (MaxIters+1,2)。 只有前 OuterNiters+1 行包含残差范数,其他行(例如,OuterNiters+2:Maxiters+1)是垃圾数据。 在第一列中,每行“i”指定到此外部迭代“i”为止发生的总迭代次数,在第二列中,指定与此外部迭代“i”对应的残差范数。 因此,第一行(例如,外部迭代“0”)由初始残差(例如,精化循环开始之前的残差)组成,然后连续行是在精化循环的每次外部迭代中获得的残差。 请注意,它仅包含外部循环的历史记录。
如果精化求解器是 CUSOLVER_IRS_REFINE_CLASSICAL 或 CUSOLVER_IRS_REFINE_GMRES,则 OuterNiters=Niters(Niters 是执行的总迭代次数),并且有 Niters+1 行范数,这些范数对应于 Niters 外部迭代。
如果精化求解器是 CUSOLVER_IRS_REFINE_CLASSICAL_GMRES 或 CUSOLVER_IRS_REFINE_GMRES_GMRES,则 OuterNiters <= Niters 对应于外部精化循环执行的外部迭代。 因此,有 OuterNiters+1 个残差范数,其中行“i”对应于外部迭代“i”,第一列指定到此步骤为止执行的总迭代次数(外部和内部),第二列对应于此步骤的残差范数。
例如,假设用户指定 CUSOLVER_IRS_REFINE_CLASSICAL_GMRES 作为精化求解器,并假设它需要 3 次外部迭代才能收敛,并且在每次外部迭代中分别需要 4,3,3 次内部迭代。 这总共包含 10 次迭代。 第 0 行对应于精化开始之前的第一个残差,因此其第一列中为 0。 在对应于外部迭代 1 的第 1 行中,它将为 4(4 是到目前为止执行的总迭代次数),在第 2 行中,它将为 7,在第 3 行中,它将为 10。
总之,让我们定义 ldh=Maxiters+1,残差矩阵的前导维度。 然后 residual_history[i] 显示在外部迭代“i”处执行的总迭代次数,residual_history[i+ldh] 对应于此外部迭代的残差范数。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
返回指向收敛历史残差范数矩阵的 void 指针。 有关残差范数数据类型与输入数据类型之间关系的说明,请参见上文。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_IRS_INFOS_NOT_INITIALIZEDInfos结构未创建CUSOLVER_STATUS_INVALID_VALUE调用此函数时,未预先调用
cusolverDnIRSInfosRequestResidual()。
2.4.1.47. cusolverDnCreateParams()
cusolverStatus_t
cusolverDnCreateParams(
cusolverDnParams_t *params);
此函数创建 64 位 API 的结构并将其初始化为默认值。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向 |
返回状态
CUSOLVER_STATUS_SUCCESS结构已成功初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
2.4.1.48. cusolverDnDestroyParams()
cusolverStatus_t
cusolverDnDestroyParams(
cusolverDnParams_t params);
此函数销毁并释放结构所需的任何内存。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS资源已成功释放。
2.4.1.49. cusolverDnSetAdvOptions()
cusolverStatus_t
cusolverDnSetAdvOptions (
cusolverDnParams_t params,
cusolverDnFunction_t function,
cusolverAlgMode_t algo );
此函数配置 64 位 API 例程 function 的算法 algo。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向 |
|
|
|
要配置的例程。 |
|
|
|
要配置的算法。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_INVALID_VALUEfunction和algo的错误组合。
2.4.2. 稠密线性求解器参考(旧版)
本节介绍 cuSolverDN 的线性求解器 API,包括 Cholesky 分解、带部分主元的 LU 分解、QR 分解和 Bunch-Kaufman (LDLT) 分解。
2.4.2.1. cusolverDn<t>potrf()
这些辅助函数计算工作缓冲区所需的必要大小。
cusolverStatus_t
cusolverDnSpotrf_bufferSize(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
float *A,
int lda,
int *Lwork );
cusolverStatus_t
cusolverDnDpotrf_bufferSize(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
double *A,
int lda,
int *Lwork );
cusolverStatus_t
cusolverDnCpotrf_bufferSize(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuComplex *A,
int lda,
int *Lwork );
cusolverStatus_t
cusolverDnZpotrf_bufferSize(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuDoubleComplex *A,
int lda,
int *Lwork);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSpotrf(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
float *A,
int lda,
float *Workspace,
int Lwork,
int *devInfo );
cusolverStatus_t
cusolverDnDpotrf(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
double *A,
int lda,
double *Workspace,
int Lwork,
int *devInfo );
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCpotrf(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuComplex *A,
int lda,
cuComplex *Workspace,
int Lwork,
int *devInfo );
cusolverStatus_t
cusolverDnZpotrf(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuDoubleComplex *A,
int lda,
cuDoubleComplex *Workspace,
int Lwork,
int *devInfo );
此函数计算 Hermitian 正定矩阵的 Cholesky 分解。
A 是一个 \(n \times n\) Hermitian 矩阵,只有下半部分或上半部分有意义。 输入参数 uplo 指示使用矩阵的哪一部分。 该函数将保持其他部分不变。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_LOWER,则仅处理 A 的下三角部分,并将其替换为下三角 Cholesky 因子 L。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_UPPER,则仅处理 A 的上三角部分,并将其替换为上三角 Cholesky 因子 U。
用户必须提供工作空间,该工作空间由输入参数 Workspace 指向。 输入参数 Lwork 是工作空间的大小,它由 potrf_bufferSize() 返回。
如果 Cholesky 分解失败,即 A 的某些前导子式不是正定的,或者等效地,L 或 U 的某些对角线元素不是实数。 输出参数 devInfo 将指示 A 的最小前导子式,该子式不是正定的。
如果输出参数 devInfo = -i(小于零),则第 i 个参数错误(不包括句柄)。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指示是否存储矩阵 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
工作空间,大小为 |
|
|
|
|
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n<0或lda<max(1,n))。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.2.2. cusolverDnPotrf() [已弃用]
[[已弃用]] 请改用 cusolverDnXpotrf()。 该例程将在下一个主要版本中删除。
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnPotrf_bufferSize(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cublasFillMode_t uplo,
int64_t n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType computeType,
size_t *workspaceInBytes )
以下例程
cusolverStatus_t
cusolverDnPotrf(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cublasFillMode_t uplo,
int64_t n,
cudaDataType dataTypeA,
void *A,
int64_t lda,
cudaDataType computeType,
void *pBuffer,
size_t workspaceInBytes,
int *info )
使用通用 API 接口计算 Hermitian 正定矩阵的 Cholesky 分解。
A 是一个 \(n \times n\) Hermitian 矩阵,只有下半部分或上半部分有意义。 输入参数 uplo 指示使用矩阵的哪一部分。 该函数将保持另一部分不变。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_LOWER,则仅处理 A 的下三角部分,并将其替换为下三角 Cholesky 因子 L。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_UPPER,则仅处理 A 的上三角部分,并将其替换为上三角 Cholesky 因子 U。
用户必须提供工作空间,该工作空间由输入参数 pBuffer 指向。 输入参数 workspaceInBytes 是工作空间的大小(以字节为单位),它由 cusolverDnPotrf_bufferSize() 返回。
如果 Cholesky 分解失败,即 A 的某些前导子式不是正定的,或者等效地,L 或 U 的某些对角线元素不是实数。 输出参数 info 将指示 A 的最小前导子式,该子式不是正定的。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
目前,cusolverDnPotrf 仅支持默认算法。
|
默认算法。 |
cusolverDnPotrf_bufferSize 和 cusolverDnPotrf 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
指示是否存储矩阵 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
计算的数据类型。 |
|
|
|
工作空间。 类型为 |
|
|
|
|
|
|
|
如果 |
通用 API 有两种不同的类型,dataTypeA 是矩阵 A 的数据类型,computeType 是运算的计算类型。 cusolverDnPotrf 仅支持以下四种组合。
数据类型和计算类型的有效组合
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n<0或lda<max(1,n))。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.2.3. cusolverDn<t>potrs()
cusolverStatus_t
cusolverDnSpotrs(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
int nrhs,
const float *A,
int lda,
float *B,
int ldb,
int *devInfo);
cusolverStatus_t
cusolverDnDpotrs(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
int nrhs,
const double *A,
int lda,
double *B,
int ldb,
int *devInfo);
cusolverStatus_t
cusolverDnCpotrs(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
int nrhs,
const cuComplex *A,
int lda,
cuComplex *B,
int ldb,
int *devInfo);
cusolverStatus_t
cusolverDnZpotrs(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
int nrhs,
const cuDoubleComplex *A,
int lda,
cuDoubleComplex *B,
int ldb,
int *devInfo);
此函数求解线性方程组
其中 A 是一个 \(n \times n\) Hermitian 矩阵,只有下半部分或上半部分有意义。 输入参数 uplo 指示使用矩阵的哪一部分。 该函数将保持另一个部分不变。
用户必须首先调用 potrf 以分解矩阵 A。 如果输入参数 uplo 是 CUBLAS_FILL_MODE_LOWER,则 A 是对应于 \(A = L*L^H\) 的下三角 Cholesky 因子 L。 如果输入参数 uplo 是 CUBLAS_FILL_MODE_UPPER,则 A 是对应于 \(A = U^{H}*U\) 的上三角 Cholesky 因子 U。
该操作是就地操作,即矩阵 X 使用相同的前导维度 ldb 覆盖矩阵 B。
如果输出参数 devInfo = -i(小于零),则第 i 个参数错误(不包括句柄)。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指示是否存储矩阵 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n<0、nrhs<0、lda<max(1,n)或ldb<max(1,n))。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.2.4. cusolverDnPotrs() [已弃用]
[[已弃用]] 请使用 cusolverDnXpotrs() 代替。此例程将在下一个主要版本中移除。
cusolverStatus_t
cusolverDnPotrs(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cublasFillMode_t uplo,
int64_t n,
int64_t nrhs,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType dataTypeB,
void *B,
int64_t ldb,
int *info)
此函数求解线性方程组
其中 A 是一个 \(n \times n\) 埃尔米特矩阵,使用通用 API 接口时,只有下半部分或上半部分是有意义的。输入参数 uplo 指示使用矩阵的哪一部分。该函数将保持另一部分不变。
用户必须首先调用 cusolverDnPotrf 来分解矩阵 A。如果输入参数 uplo 是 CUBLAS_FILL_MODE_LOWER,则 A 是对应于 \(A = L*L^H\) 的下三角 Cholesky 因子 L。如果输入参数 uplo 是 CUBLAS_FILL_MODE_UPPER,则 A 是对应于 \(A = U^{H}*U\) 的上三角 Cholesky 因子 U。
该操作是就地操作,即矩阵 X 使用相同的前导维度 ldb 覆盖矩阵 B。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
目前,cusolverDnPotrs 仅支持默认算法。
|
默认算法。 |
用于 cusolverDnPotrs 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
指示是否存储矩阵 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
如果 |
通用 API 有两种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeB 是矩阵 B 的数据类型。cusolverDnPotrs 仅支持以下四种组合。
数据类型和计算类型的有效组合
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n<0、nrhs<0、lda<max(1,n)或ldb<max(1,n))。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.2.5. cusolverDn<t>potri()
这些辅助函数计算工作缓冲区所需的必要大小。
cusolverStatus_t
cusolverDnSpotri_bufferSize(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
float *A,
int lda,
int *Lwork );
cusolverStatus_t
cusolverDnDpotri_bufferSize(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
double *A,
int lda,
int *Lwork );
cusolverStatus_t
cusolverDnCpotri_bufferSize(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuComplex *A,
int lda,
int *Lwork );
cusolverStatus_t
cusolverDnZpotri_bufferSize(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuDoubleComplex *A,
int lda,
int *Lwork);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSpotri(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
float *A,
int lda,
float *Workspace,
int Lwork,
int *devInfo );
cusolverStatus_t
cusolverDnDpotri(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
double *A,
int lda,
double *Workspace,
int Lwork,
int *devInfo );
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCpotri(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuComplex *A,
int lda,
cuComplex *Workspace,
int Lwork,
int *devInfo );
cusolverStatus_t
cusolverDnZpotri(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuDoubleComplex *A,
int lda,
cuDoubleComplex *Workspace,
int Lwork,
int *devInfo );
此函数使用 Cholesky 分解计算正定矩阵 A 的逆矩阵
由 potrf() 计算得出。
A 是一个 \(n \times n\) 矩阵,包含由 Cholesky 分解计算出的三角因子 L 或 U。只有下半部分或上半部分是有意义的,输入参数 uplo 指示使用矩阵的哪一部分。该函数将保持另一部分不变。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_LOWER,则仅处理 A 的下三角部分,并将其替换为 A 的逆矩阵的下三角部分。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_UPPER,则仅处理 A 的上三角部分,并将其替换为 A 的逆矩阵的上三角部分。
用户必须提供工作空间,该工作空间由输入参数 Workspace 指向。输入参数 Lwork 是工作空间的大小,由 potri_bufferSize() 返回。
如果逆矩阵的计算失败,即 L 或 U 的某些前导主子式为空,则输出参数 devInfo 将指示 L 或 U 的最小前导主子式,该主子式不是正定的。
如果输出参数 devInfo = -i (小于零),则第 i-th 个参数错误(不包括句柄)。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指示是否存储矩阵 |
|
|
|
矩阵 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
工作空间,大小为 |
|
|
|
|
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n<0或lda<max(1,n))。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.2.6. cusolverDn<t>getrf()
这些辅助函数计算所需工作缓冲区的大小。
请访问 cuSOLVER 库示例 - getrf 获取代码示例。
cusolverStatus_t
cusolverDnSgetrf_bufferSize(cusolverDnHandle_t handle,
int m,
int n,
float *A,
int lda,
int *Lwork );
cusolverStatus_t
cusolverDnDgetrf_bufferSize(cusolverDnHandle_t handle,
int m,
int n,
double *A,
int lda,
int *Lwork );
cusolverStatus_t
cusolverDnCgetrf_bufferSize(cusolverDnHandle_t handle,
int m,
int n,
cuComplex *A,
int lda,
int *Lwork );
cusolverStatus_t
cusolverDnZgetrf_bufferSize(cusolverDnHandle_t handle,
int m,
int n,
cuDoubleComplex *A,
int lda,
int *Lwork );
S 和 D 数据类型分别是单精度实数和双精度实数。
cusolverStatus_t
cusolverDnSgetrf(cusolverDnHandle_t handle,
int m,
int n,
float *A,
int lda,
float *Workspace,
int *devIpiv,
int *devInfo );
cusolverStatus_t
cusolverDnDgetrf(cusolverDnHandle_t handle,
int m,
int n,
double *A,
int lda,
double *Workspace,
int *devIpiv,
int *devInfo );
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCgetrf(cusolverDnHandle_t handle,
int m,
int n,
cuComplex *A,
int lda,
cuComplex *Workspace,
int *devIpiv,
int *devInfo );
cusolverStatus_t
cusolverDnZgetrf(cusolverDnHandle_t handle,
int m,
int n,
cuDoubleComplex *A,
int lda,
cuDoubleComplex *Workspace,
int *devIpiv,
int *devInfo );
此函数计算 \(m \times n\) 矩阵的 LU 分解
其中 A 是一个 \(m \times n\) 矩阵,P 是置换矩阵,L 是对角线为单位元素的下三角矩阵,U 是上三角矩阵。
用户必须提供工作空间,该工作空间由输入参数 Workspace 指向。输入参数 Lwork 是工作空间的大小,它由 getrf_bufferSize() 返回。
如果 LU 分解失败,即矩阵 A (U) 是奇异的,则输出参数 devInfo=i 指示 U(i,i) = 0。
如果输出参数 devInfo = -i(小于零),则第 i 个参数错误(不包括句柄)。
如果 devIpiv 为空,则不执行主元选择。分解为 A=L*U,这在数值上是不稳定的。
无论 LU 分解是否失败,输出参数 devIpiv 都包含主元选择序列,第 i 行与第 devIpiv(i) 行互换。
用户可以结合使用 getrf 和 getrs 来完成线性求解器。
备注:getrf 使用最快的实现方式,需要大小为 m*n 的大型工作空间。用户可以通过 Getrf 和 cusolverDnSetAdvOptions(params, CUSOLVERDN_GETRF, CUSOLVER_ALG_1) 选择具有最小工作空间的传统实现方式。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
工作空间,大小为 |
|
|
|
大小至少为 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
m,n<0或lda<max(1,m))。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.2.7. cusolverDnGetrf() [已弃用]
[[已弃用]] 请使用 cusolverDnXgetrf() 代替。此例程将在下一个主要版本中移除。
下面的辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnGetrf_bufferSize(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
int64_t m,
int64_t n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType computeType,
size_t *workspaceInBytes )
以下函数
cusolverStatus_t
cusolverDnGetrf(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
int64_t m,
int64_t n,
cudaDataType dataTypeA,
void *A,
int64_t lda,
int64_t *ipiv,
cudaDataType computeType,
void *pBuffer,
size_t workspaceInBytes,
int *info )
计算 \(m \times n\) 矩阵的 LU 分解
其中 A 是一个 \(m \times n\) 矩阵,P 是置换矩阵,L 是对角线为单位元素的下三角矩阵,U 是使用通用 API 接口的上三角矩阵。
如果 LU 分解失败,即矩阵 A (U) 是奇异的,则输出参数 info=i 指示 U(i,i) = 0。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
如果 ipiv 为空,则不执行主元选择。分解为 A=L*U,这在数值上是不稳定的。
无论 LU 分解是否失败,输出参数 ipiv 都包含主元选择序列,第 i 行与第 ipiv(i) 行互换。
用户必须提供工作空间,该工作空间由输入参数 pBuffer 指向。输入参数 workspaceInBytes 是工作空间的大小(以字节为单位),它由 cusolverDnGetrf_bufferSize() 返回。
用户可以结合使用 cusolverDnGetrf 和 cusolverDnGetrs 来完成线性求解器。
目前,cusolverDnGetrf 支持两种算法。要选择传统实现方式,用户必须调用 cusolverDnSetAdvOptions。
|
默认算法。最快,需要一个大小为 |
|
传统实现方式 |
用于 cusolverDnGetrf_bufferSize 和 cusolverDnGetrf 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
大小至少为 |
|
|
|
计算的数据类型。 |
|
|
|
工作空间。 类型为 |
|
|
|
|
|
|
|
如果 |
通用 API 有两种不同的类型,dataTypeA 是矩阵 A 的数据类型,computeType 是运算的计算类型。cusolverDnGetrf 仅支持以下四种组合。
数据类型和计算类型的有效组合
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
m,n<0或lda<max(1,m))。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.2.8. cusolverDn<t>getrs()
请访问 cuSOLVER 库示例 - getrf 获取代码示例。
cusolverStatus_t
cusolverDnSgetrs(cusolverDnHandle_t handle,
cublasOperation_t trans,
int n,
int nrhs,
const float *A,
int lda,
const int *devIpiv,
float *B,
int ldb,
int *devInfo );
cusolverStatus_t
cusolverDnDgetrs(cusolverDnHandle_t handle,
cublasOperation_t trans,
int n,
int nrhs,
const double *A,
int lda,
const int *devIpiv,
double *B,
int ldb,
int *devInfo );
cusolverStatus_t
cusolverDnCgetrs(cusolverDnHandle_t handle,
cublasOperation_t trans,
int n,
int nrhs,
const cuComplex *A,
int lda,
const int *devIpiv,
cuComplex *B,
int ldb,
int *devInfo );
cusolverStatus_t
cusolverDnZgetrs(cusolverDnHandle_t handle,
cublasOperation_t trans,
int n,
int nrhs,
const cuDoubleComplex *A,
int lda,
const int *devIpiv,
cuDoubleComplex *B,
int ldb,
int *devInfo );
此函数求解具有多个右手边的线性系统
其中 A 是一个 \(n \times n\) 矩阵,并且已由 getrf 进行 LU 分解,即 A 的下三角部分是 L,A 的上三角部分(包括对角元素)是 U。B 是一个 \(n\times {nrhs}\) 右手边矩阵。
输入参数 trans 由下式定义
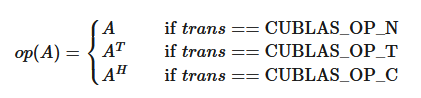
输入参数 devIpiv 是 getrf 的输出。它包含主元索引,用于置换右手边。
如果输出参数 devInfo = -i(小于零),则第 i 个参数错误(不包括句柄)。
用户可以结合使用 getrf 和 getrs 来完成线性求解器。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
运算 |
|
|
|
矩阵 |
|
|
|
右手边的数量。 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
大小至少为 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n<0或lda<max(1,n)或ldb<max(1,n))。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.2.9. cusolverDnGetrs() [已弃用]
[[已弃用]] 请使用 cusolverDnXgetrs() 代替。此例程将在下一个主要版本中移除。
cusolverStatus_t
cusolverDnGetrs(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cublasOperation_t trans,
int64_t n,
int64_t nrhs,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
const int64_t *ipiv,
cudaDataType dataTypeB,
void *B,
int64_t ldb,
int *info )
此函数求解具有多个右手边的线性系统
其中 A 是一个 \(n \times n\) 矩阵,并且已由 cusolverDnGetrf 进行 LU 分解,即 A 的下三角部分是 L,A 的上三角部分(包括对角元素)是 U。B 是一个 n×nrhs :math:` times nrhs` 右手边矩阵,使用通用 API 接口。
输入参数 trans 由下式定义
输入参数 ipiv 是 cusolverDnGetrf 的输出。它包含主元索引,用于置换右手边。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
用户可以结合使用 cusolverDnGetrf 和 cusolverDnGetrs 来完成线性求解器。
目前,cusolverDnGetrs 仅支持默认算法。
cusolverDnGetrs 支持的算法
|
默认算法。 |
用于 cusolverDnGetrs 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
运算 |
|
|
|
矩阵 |
|
|
|
右手边的数量。 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
大小至少为 |
|
|
|
数组 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
如果 |
通用 API 有两种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeB 是矩阵 B 的数据类型。cusolverDnGetrs 仅支持以下四种组合。
数据类型和计算类型的有效组合
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n<0或lda<max(1,n)或ldb<max(1,n))。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.2.10. cusolverDn<t1><t2>gesv()
这些函数仿照 LAPACK 中的函数 DSGESV 和 ZCGESV 而建。它们使用基于 LU 分解 Xgesv 的混合精度迭代细化技术来计算具有一个或多个右手边的线性方程组的解。这些函数在功能上类似于全精度 LU 求解器(Xgesv,其中 X 表示 Z、C、D、S),但它在内部使用较低的精度,以便提供更快的求解时间,混合精度由此得名。混合精度迭代细化技术意味着求解器以较低精度计算 LU 分解,然后迭代地细化解,以达到输入/输出数据类型精度的精度。
其中 A 是 n-by-n 矩阵,X 和 B 是 n-by-nrhs 矩阵。
函数 API 设计尽可能接近 LAPACK API,以便被视为快速简便的直接替换。参数和行为与 LAPACK 对应项基本相同。下面给出了这些函数的描述以及与 LAPACK 的差异。<t1><t2>gesv() 函数由两个浮点精度指定。cusolver<t1><t2>gesv() 首先尝试以较低精度分解矩阵,并在迭代细化过程中使用此分解来获得具有与主精度
如果满足以下条件,迭代细化过程将停止
ITER > ITERMAX
或者对于所有 RHS,我们有
RNRM < SQRT(N)*XNRM*ANRM*EPS*BWDMAX
其中
ITER 是迭代细化过程中当前迭代的次数
RNRM 是残差的无穷范数
XNRM 是解的无穷范数
ANRM 是矩阵 A 的无穷算子范数
EPS 是与 LAPACK
LAMCH(‘Epsilon’) 匹配的机器 epsilon
ITERMAX 和 BWDMAX 的值分别固定为 50 和 1.0。
该函数返回值描述求解过程的结果。CUSOLVER_STATUS_SUCCESS 表示该函数成功完成,否则,它指示 API 参数之一是否不正确,或者该函数是否未成功完成。有关错误的更多详细信息将在 niters 和 dinfo API 参数中。请参阅下面的描述以获取更多详细信息。用户应提供设备内存上分配的所需工作空间。可以通过调用相应的函数 <t1><t2>gesv_bufferSize() 查询所需的字节数。
请注意,除了 LAPACK 中提供的两个混合精度函数(例如,dsgesv 和 zcgesv)之外,我们还提供了一组大型的混合精度函数,其中包括 half、bfloat 和 tensorfloat 作为较低精度,以及相同精度函数(,主精度和最低精度相等
Tensor Float (TF32) 是 NVIDIA Ampere 架构 GPU 引入的,是迭代细化求解器最强大的 tensor core 加速计算模式。它能够解决来自不同 HPC 应用的最广泛的问题,并为实数和复数系统分别提供高达 4 倍和 5 倍的加速。在 Volta 和 Turing 架构 GPU 上,建议使用 half precision tensor core 加速。如果迭代细化求解器未能收敛到所需的精度(主精度,INOUT 数据精度),建议使用主精度作为内部最低精度(即,FP64 情况下的 cusolverDn[DD,ZZ]gesv)。
接口函数 |
主精度 (矩阵、右手边和解的数据类型) |
允许的最低精度 在内部使用 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
* 具有 LAPACK 对应项
cusolverDn<t1><t2>gesv_bufferSize() 函数将返回相应的 cusolverDn<t1><t2>gesv() 函数所需的工作空间缓冲区大小(以字节为单位)。
cusolverStatus_t
cusolverDnZZgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
int * dipiv,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnZCgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
int * dipiv,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnZKgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
int * dipiv,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnZEgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
int * dipiv,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnZYgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
int * dipiv,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnCCgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
cuComplex * dA,
int ldda,
int * dipiv,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnCKgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
cuComplex * dA,
int ldda,
int * dipiv,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnCEgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
cuComplex * dA,
int ldda,
int * dipiv,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnCYgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
cuComplex * dA,
int ldda,
int * dipiv,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnDDgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
double * dA,
int ldda,
int * dipiv,
double * dB,
int lddb,
double * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnDSgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
double * dA,
int ldda,
int * dipiv,
double * dB,
int lddb,
double * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnDHgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
double * dA,
int ldda,
int * dipiv,
double * dB,
int lddb,
double * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnDBgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
double * dA,
int ldda,
int * dipiv,
double * dB,
int lddb,
double * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnDXgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
double * dA,
int ldda,
int * dipiv,
double * dB,
int lddb,
double * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnSSgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
float * dA,
int ldda,
int * dipiv,
float * dB,
int lddb,
float * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnSHgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
float * dA,
int ldda,
int * dipiv,
float * dB,
int lddb,
float * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnSBgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
float * dA,
int ldda,
int * dipiv,
float * dB,
int lddb,
float * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnSXgesv_bufferSize(
cusolverHandle_t handle,
int n,
int nrhs,
float * dA,
int ldda,
int * dipiv,
float * dB,
int lddb,
float * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cusolverDN 库上下文的句柄。 |
|
|
|
方阵 |
|
|
|
要解的右手边数量。应为非负数。 |
|
|
|
大小为 |
|
|
|
用于存储矩阵 |
|
|
|
主元选择序列。未使用,可以为 |
|
|
|
大小为 |
|
|
|
用于存储右侧矩阵 |
|
|
|
大小为 |
|
|
|
用于存储解向量矩阵 |
|
|
|
指向设备工作空间的指针。未使用,可以为 |
|
|
|
指向变量的指针,该变量将存储临时工作空间所需的字节大小。不能为 NULL。 |
cusolverStatus_t cusolverDnZZgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
int * dipiv,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnZCgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
int * dipiv,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnZKgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
int * dipiv,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnZEgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
int * dipiv,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnZYgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
int * dipiv,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnCCgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
cuComplex * dA,
int ldda,
int * dipiv,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnCKgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
cuComplex * dA,
int ldda,
int * dipiv,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnCEgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
cuComplex * dA,
int ldda,
int * dipiv,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnCYgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
cuComplex * dA,
int ldda,
int * dipiv,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnDDgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
double * dA,
int ldda,
int * dipiv,
double * dB,
int lddb,
double * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnDSgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
double * dA,
int ldda,
int * dipiv,
double * dB,
int lddb,
double * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnDHgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
double * dA,
int ldda,
int * dipiv,
double * dB,
int lddb,
double * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnDBgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
double * dA,
int ldda,
int * dipiv,
double * dB,
int lddb,
double * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnDXgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
double * dA,
int ldda,
int * dipiv,
double * dB,
int lddb,
double * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnSSgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
float * dA,
int ldda,
int * dipiv,
float * dB,
int lddb,
float * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnSHgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
float * dA,
int ldda,
int * dipiv,
float * dB,
int lddb,
float * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnSBgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
float * dA,
int ldda,
int * dipiv,
float * dB,
int lddb,
float * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnSXgesv(
cusolverDnHandle_t handle,
int n,
int nrhs,
float * dA,
int ldda,
int * dipiv,
float * dB,
int lddb,
float * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cusolverDN 库上下文的句柄。 |
|
|
|
方阵 |
|
|
|
要解的右手边数量。应为非负数。 |
|
|
|
大小为 |
|
|
|
用于存储矩阵 |
|
|
|
定义因式分解置换的向量 - 行 |
|
|
|
大小为 |
|
|
|
用于存储右侧矩阵 |
|
|
|
大小为 |
|
|
|
用于存储解向量矩阵 |
|
|
|
指向设备内存中已分配大小为 |
|
|
|
已分配设备工作空间的大小。应至少为 |
|
|
|
如果
|
|
|
|
返回时 IRS 求解器的状态。如果为 0 - 求解成功。如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数,例如
n<0lda<max(1,n)ldb<max(1,n)ldx<max(1,n)
CUSOLVER_STATUS_ARCH_MISMATCHIRS 求解器支持计算能力 7.0 及以上版本。最低精度选项 CUSOLVER_[CR]_16BF 和 CUSOLVER_[CR]_TF32 仅在计算能力 8.0 及以上版本上可用。
CUSOLVER_STATUS_INVALID_WORKSPACElwork_bytes小于所需的工作空间。CUSOLVER_STATUS_IRS_OUT_OF_RANGE与 niters <0 相关的数值错误,有关更多详细信息,请参阅
niters描述。CUSOLVER_STATUS_INTERNAL_ERROR发生内部错误,请检查
dinfo和niters参数以获取更多详细信息。
2.4.2.11. cusolverDnIRSXgesv()
此函数旨在执行与 cusolverDn<T1><T2>gesv() 函数相同的功能,但封装在更通用和专业的接口中,使用户可以更好地控制函数参数,并提供更多关于输出的信息。cusolverDnIRSXgesv() 允许对求解器参数进行额外的控制,例如设置
求解器的主精度(输入/输出精度)
求解器内部使用的最低精度
细化求解器类型
细化阶段中允许的最大迭代次数
细化求解器的容差
回退到主精度
以及更多
通过配置参数结构 gesv_irs_params 及其辅助函数。有关可以设置哪些配置及其含义的更多详细信息,请参阅 cuSolverDN 辅助函数部分中所有以 cusolverDnIRSParamsxxxx() 开头的函数。此外,cusolverDnIRSXgesv() 还提供了关于输出的额外信息,例如每次迭代的收敛历史记录(例如,残差范数)和收敛所需的迭代次数。有关可以检索哪些信息及其含义的更多详细信息,请参阅 cuSolverDN 辅助函数部分中所有以 cusolverDnIRSInfosxxxx() 开头的函数。
该函数返回值描述求解过程的结果。CUSOLVER_STATUS_SUCCESS 表示函数成功完成;否则,它表示 API 参数之一不正确,或者 params/infos 结构的配置不正确,或者函数未成功完成。有关错误的更多详细信息,可以通过检查 niters 和 dinfo API 参数找到。有关更多详细信息,请参阅下面的描述。用户应为 cusolverDnIRSXgesv() 函数提供设备上分配的所需工作空间。函数所需的字节数可以通过调用相应的函数 cusolverDnIRSXgesv_bufferSize() 查询。请注意,如果用户希望通过 params 结构设置特定配置,则应在调用 cusolverDnIRSXgesv_bufferSize() 之前设置它,以获取所需工作空间的大小。
Tensor Float (TF32) 是 NVIDIA Ampere 架构 GPU 引入的,是迭代细化求解器最强大的张量核心加速计算模式。它能够解决 HPC 中由不同应用引起的范围最广的问题,并分别为实数和复数系统提供高达 4 倍和 5 倍的加速。在 Volta 和 Turing 架构 GPU 上,建议使用半精度张量核心加速。在迭代细化求解器无法收敛到所需精度(主精度、INOUT 数据精度)的情况下,建议使用主精度作为内部最低精度。
下表提供了与输入/输出数据类型对应的最低精度的所有可能组合值。请注意,如果最低精度与输入/输出数据类型匹配,则将使用主精度因式分解。
输入/输出数据类型(例如,主精度) |
最低精度的支持值 |
|---|---|
|
|
|
|
|
|
|
|
cusolverDnIRSXgesv_bufferSize() 函数返回给定 gesv_irs_params 配置的相应 cusolverDnXgesv() 调用所需的 workspace 缓冲区大小(以字节为单位)。
cusolverStatus_t
cusolverDnIRSXgesv_bufferSize(
cusolverDnHandle_t handle,
cusolverDnIRSParams_t gesv_irs_params,
cusolver_int_t n,
cusolver_int_t nrhs,
size_t * lwork_bytes);
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cusolverDn 库上下文的句柄。 |
|
|
|
|
|
|
|
方阵 |
|
|
|
要解的右手侧的数量。应为非负数。请注意,如果选择的 IRS 细化求解器为 CUSOLVER_IRS_REFINE_GMRES、CUSOLVER_IRS_REFINE_GMRES_GMRES、CUSOLVER_IRS_REFINE_CLASSICAL_GMRES,则 |
|
|
|
指向变量的指针,在调用 |
cusolverStatus_t cusolverDnIRSXgesv(
cusolverDnHandle_t handle,
cusolverDnIRSParams_t gesv_irs_params,
cusolverDnIRSInfos_t gesv_irs_infos,
int n,
int nrhs,
void * dA,
int ldda,
void * dB,
int lddb,
void * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * dinfo);
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cusolverDn 库上下文的句柄。 |
|
|
|
配置参数结构,可以为任何 IRS 求解器的一次或多次调用服务 |
|
|
|
Info 结构,其中将存储有关特定求解的信息。 |
|
|
|
方阵 |
|
|
|
要解的右手侧的数量。应为非负数。请注意,如果选择的 IRS 细化求解器为 CUSOLVER_IRS_REFINE_GMRES、CUSOLVER_IRS_REFINE_GMRES_GMRES、CUSOLVER_IRS_REFINE_CLASSICAL_GMRES,则 |
|
|
|
大小为 |
|
|
|
用于存储矩阵 |
|
|
|
大小为 |
|
|
|
用于存储右侧矩阵 |
|
|
|
大小为 |
|
|
|
用于存储解向量矩阵 |
|
|
|
指向设备内存中已分配大小为 lwork_bytes 的工作空间的指针。 |
|
|
|
已分配设备工作空间的大小。应至少为 |
|
|
|
如果 iter 为
|
|
|
|
返回时 IRS 求解器的状态。如果为 0 - 求解成功。如果 dinfo = - |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数,例如
n<0lda<max(1,n)ldb<max(1,n)ldx<max(1,n)
CUSOLVER_STATUS_ARCH_MISMATCHIRS 求解器支持计算能力 7.0 及以上版本。最低精度选项 CUSOLVER_[CR]_16BF 和 CUSOLVER_[CR]_TF32 仅在计算能力 8.0 及以上版本上可用。
CUSOLVER_STATUS_INVALID_WORKSPACElwork_bytes小于所需的工作空间。如果用户调用了cusolverDnIRSXgesv_bufferSize()函数,然后更改了一些配置设置(例如最低精度),则可能会发生这种情况。CUSOLVER_STATUS_IRS_OUT_OF_RANGE与 niters <0 相关的数值错误,有关更多详细信息,请参阅 niters 描述。
CUSOLVER_STATUS_INTERNAL_ERROR发生内部错误,请检查
dinfo和niters参数以获取更多详细信息。CUSOLVER_STATUS_IRS_PARAMS_NOT_INITIALIZED未创建配置参数
gesv_irs_params结构。CUSOLVER_STATUS_IRS_PARAMS_INVALIDgesv_irs_params结构中的一个配置参数无效。CUSOLVER_STATUS_IRS_PARAMS_INVALID_PRECgesv_irs_params结构中的主精度和/或最低精度配置参数无效,请检查上表以获取支持的组合。CUSOLVER_STATUS_IRS_PARAMS_INVALID_MAXITERgesv_irs_params结构中的 maxiter 配置参数无效。CUSOLVER_STATUS_IRS_PARAMS_INVALID_REFINEgesv_irs_params结构中的细化求解器配置参数无效。CUSOLVER_STATUS_IRS_NOT_SUPPORTEDgesv_irs_params结构中的一个配置参数不受支持。例如,如果 nrhs >1,并且细化求解器设置为CUSOLVER_IRS_REFINE_GMRES。CUSOLVER_STATUS_IRS_INFOS_NOT_INITIALIZED未创建信息结构
gesv_irs_infos。CUSOLVER_STATUS_ALLOC_FAILEDCPU 内存分配失败,很可能是在分配存储残差范数的残差数组期间。
2.4.2.12. cusolverDn<t>geqrf()
这些辅助函数计算所需工作缓冲区的大小。
cusolverStatus_t
cusolverDnSgeqrf_bufferSize(cusolverDnHandle_t handle,
int m,
int n,
float *A,
int lda,
int *Lwork );
cusolverStatus_t
cusolverDnDgeqrf_bufferSize(cusolverDnHandle_t handle,
int m,
int n,
double *A,
int lda,
int *Lwork );
cusolverStatus_t
cusolverDnCgeqrf_bufferSize(cusolverDnHandle_t handle,
int m,
int n,
cuComplex *A,
int lda,
int *Lwork );
cusolverStatus_t
cusolverDnZgeqrf_bufferSize(cusolverDnHandle_t handle,
int m,
int n,
cuDoubleComplex *A,
int lda,
int *Lwork );
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSgeqrf(cusolverDnHandle_t handle,
int m,
int n,
float *A,
int lda,
float *TAU,
float *Workspace,
int Lwork,
int *devInfo );
cusolverStatus_t
cusolverDnDgeqrf(cusolverDnHandle_t handle,
int m,
int n,
double *A,
int lda,
double *TAU,
double *Workspace,
int Lwork,
int *devInfo );
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCgeqrf(cusolverDnHandle_t handle,
int m,
int n,
cuComplex *A,
int lda,
cuComplex *TAU,
cuComplex *Workspace,
int Lwork,
int *devInfo );
cusolverStatus_t
cusolverDnZgeqrf(cusolverDnHandle_t handle,
int m,
int n,
cuDoubleComplex *A,
int lda,
cuDoubleComplex *TAU,
cuDoubleComplex *Workspace,
int Lwork,
int *devInfo );
此函数计算 \(m \times n\) 矩阵的 QR 分解
其中 A 是 \(m \times n\) 矩阵,Q 是 \(m \times n\) 矩阵,R 是 \(n \times n\) 上三角矩阵。
用户必须提供工作空间,该工作空间由输入参数 Workspace 指向。输入参数 Lwork 是工作空间的大小,它由 geqrf_bufferSize() 返回。
矩阵 R 在 A 的上三角部分(包括对角线元素)中被覆盖。
矩阵 Q 不是显式形成的,而是将一系列 Householder 向量存储在 A 的下三角部分中。Householder 向量的引导非零元素被假定为 1,这样输出参数 TAU 包含比例因子 τ。如果 v 是原始 Householder 向量,q 是对应于 τ 的新 Householder 向量,满足以下关系
如果输出参数 devInfo = -i(小于零),则第 i 个参数错误(不包括句柄)。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
<type> 维度至少为 |
|
|
|
工作空间,大小为 |
|
|
|
工作数组 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
m,n<0或lda<max(1,m))。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.2.13. cusolverDnGeqrf() [已弃用]
[[已弃用]] 请改用 cusolverDnXgeqrf()。该例程将在下一个主要版本中删除。
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnGeqrf_bufferSize(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
int64_t m,
int64_t n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType dataTypeTau,
const void *tau,
cudaDataType computeType,
size_t *workspaceInBytes )
以下例程
cusolverStatus_t
cusolverDnGeqrf(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
int64_t m,
int64_t n,
cudaDataType dataTypeA,
void *A,
int64_t lda,
cudaDataType dataTypeTau,
void *tau,
cudaDataType computeType,
void *pBuffer,
size_t workspaceInBytes,
int *info )
计算 \(m \times n\) 矩阵的 QR 分解
其中 A 是 \(m \times n\) 矩阵,Q 是 \(m \times n\) 矩阵,R 是 \(n \times n\) 上三角矩阵,使用通用 API 接口。
用户必须提供工作空间,该工作空间由输入参数 pBuffer 指向。输入参数 workspaceInBytes 是工作空间的大小(以字节为单位),它由 cusolverDnGeqrf_bufferSize() 返回。
矩阵 R 在 A 的上三角部分(包括对角线元素)中被覆盖。
矩阵 Q 不是显式形成的,而是将一系列 Householder 向量存储在 A 的下三角部分中。Householder 向量的引导非零元素被假定为 1,这样输出参数 TAU 包含比例因子 τ。如果 v 是原始 Householder 向量,q 是对应于 τ 的新 Householder 向量,满足以下关系
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
目前,cusolverDnGeqrf 仅支持默认算法。
cusolverDnGeqrf 支持的算法
|
默认算法。 |
cusolverDnGeqrf_bufferSize 和 cusolverDnGeqrf 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度至少为 |
|
|
|
计算的数据类型。 |
|
|
|
工作空间。 类型为 |
|
|
|
工作数组 |
|
|
|
如果 |
通用 API 有两种不同的类型,dataTypeA 是矩阵 A 和数组 tau 的数据类型,computeType 是运算的计算类型。cusolverDnGeqrf 仅支持以下四种组合。
数据类型和计算类型的有效组合
DataTypeA |
ComputeType |
含义 |
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
m,n<0或lda<max(1,m))。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.2.14. cusolverDn<t1><t2>gels()
这些函数使用基于 QR 分解 Xgels 的混合精度迭代细化技术计算具有一个或多个右手侧的线性方程组的解。这些函数在功能上类似于全精度 LAPACK QR(最小二乘)求解器(Xgels,其中 X 表示 Z、C、D、S),但它在内部使用较低精度,以便提供更快的求解时间,混合精度名称由此而来。混合精度迭代细化技术意味着求解器以较低精度计算 QR 分解,然后迭代地细化解,以达到输入/输出数据类型精度的精度。<t1> 对应于输入/输出数据类型精度,而 <t2> 表示将在其上执行因式分解的内部较低精度。
其中 A 是 m-by-n 矩阵,X 是 n-by-nrhs,B 是 m-by-nrhs 矩阵。
函数 API 的设计尽可能接近 LAPACK API,以便被视为快速简便的直接替代品。这些函数的描述如下。<t1><t2>gels() 函数由两个浮点精度指定。 <t1> 对应于主精度(例如,输入/输出数据类型精度),<t2> 表示将在其上执行因式分解的内部较低精度。cusolver<t1><t2>gels() 首先尝试以较低精度分解矩阵,并在迭代细化过程中使用此因式分解,以获得与主精度 <t1> 相同的范数向后误差的解。如果该方法未能收敛,则该方法回退到主精度因式分解和求解 (Xgels),从而始终在这些函数的输出端获得良好的解。如果 <t2> 等于 <t1>,则它不是混合精度过程,而是在同一主精度内的完整单精度因式分解、求解和细化。
如果满足以下条件,迭代细化过程将停止
ITER > ITERMAX
或者对于所有 RHS,我们有
RNRM < SQRT(N)*XNRM*ANRM*EPS*BWDMAX
其中
ITER 是迭代细化过程中当前迭代的次数
RNRM 是残差的无穷范数
XNRM 是解的无穷范数
ANRM 是矩阵 A 的无穷算子范数
EPS 是与
LAPACK<t1>LAMCH('Epsilon')匹配的机器 epsilon
值 ITERMAX 和 BWDMAX 分别固定为 50 和 1.0。
该函数返回值描述求解过程的结果。CUSOLVER_STATUS_SUCCESS 表示函数成功完成;否则,它表示 API 参数之一不正确,或者函数未成功完成。有关错误的更多详细信息将在 niters 和 dinfo API 参数中。有关更多详细信息,请参阅下面的描述。用户应提供设备内存上分配的所需工作空间。所需字节数可以通过调用相应的函数 <t1><t2>gels_bufferSize() 查询。
我们提供了一大组混合精度函数,其中包括 half、bfloat 和 tensorfloat 作为较低精度以及相同精度函数(例如,主精度和最低精度相等,<t2> 等于 <t1>)。下表指定了哪些精度将用于哪些接口函数
Tensor Float (TF32) 是 NVIDIA Ampere 架构 GPU 引入的,是迭代细化求解器最强大的张量核心加速计算模式。它能够解决 HPC 中由不同应用引起的范围最广的问题,并分别为实数和复数系统提供高达 4 倍和 5 倍的加速。在 Volta 和 Turing 架构 GPU 上,建议使用半精度张量核心加速。在迭代细化求解器无法收敛到所需精度(主精度、INOUT 数据精度)的情况下,建议使用主精度作为内部最低精度(即 FP64 情况下的 cusolverDn[DD,ZZ]gels)。
接口函数 |
主精度(矩阵、右手侧和解数据类型) |
允许在内部使用的最低精度 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
cusolverDn<t1><t2>gels_bufferSize() 函数将返回相应的 cusolverDn<t1><t2>gels() 函数所需的工作空间缓冲区大小(以字节为单位)。
cusolverStatus_t
cusolverDnZZgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnZCgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnZKgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnZEgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnZYgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnCCgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
cuComplex * dA,
int ldda,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnCKgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
cuComplex * dA,
int ldda,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnCEgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
cuComplex * dA,
int ldda,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnCYgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
cuComplex * dA,
int ldda,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnDDgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
double * dA,
int ldda,
double * dB,
int lddb,
double * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnDSgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
double * dA,
int ldda,
double * dB,
int lddb,
double * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnDHgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
double * dA,
int ldda,
double * dB,
int lddb,
double * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnDBgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
double * dA,
int ldda,
double * dB,
int lddb,
double * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnDXgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
double * dA,
int ldda,
double * dB,
int lddb,
double * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnSSgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
float * dA,
int ldda,
float * dB,
int lddb,
float * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnSHgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
float * dA,
int ldda,
float * dB,
int lddb,
float * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnSBgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
float * dA,
int ldda,
float * dB,
int lddb,
float * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
cusolverStatus_t
cusolverDnSXgels_bufferSize(
cusolverHandle_t handle,
int m,
int n,
int nrhs,
float * dA,
int ldda,
float * dB,
int lddb,
float * dX,
int lddx,
void * dwork,
size_t * lwork_bytes);
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cusolverDN 库上下文的句柄。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
要解的右手边数量。应为非负数。 |
|
|
|
大小为 |
|
|
|
用于存储矩阵 |
|
|
|
大小为 |
|
|
|
用于存储右侧矩阵 |
|
|
|
大小为 |
|
|
|
用于存储解向量矩阵 |
|
|
|
指向设备工作空间的指针。未使用,可以为 |
|
|
|
指向变量的指针,该变量将存储临时工作空间所需的字节大小。不能为 NULL。 |
cusolverStatus_t cusolverDnZZgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnZCgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnZKgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnZEgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnZYgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
cuDoubleComplex * dA,
int ldda,
cuDoubleComplex * dB,
int lddb,
cuDoubleComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnCCgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
cuComplex * dA,
int ldda,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnCKgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
cuComplex * dA,
int ldda,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnCEgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
cuComplex * dA,
int ldda,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnCYgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
cuComplex * dA,
int ldda,
cuComplex * dB,
int lddb,
cuComplex * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnDDgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
double * dA,
int ldda,
double * dB,
int lddb,
double * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnDSgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
double * dA,
int ldda,
double * dB,
int lddb,
double * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnDHgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
double * dA,
int ldda,
double * dB,
int lddb,
double * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnDBgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
double * dA,
int ldda,
double * dB,
int lddb,
double * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnDXgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
double * dA,
int ldda,
double * dB,
int lddb,
double * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnSSgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
float * dA,
int ldda,
float * dB,
int lddb,
float * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnSHgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
float * dA,
int ldda,
float * dB,
int lddb,
float * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnSBgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
float * dA,
int ldda,
float * dB,
int lddb,
float * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
cusolverStatus_t cusolverDnSXgels(
cusolverDnHandle_t handle,
int m,
int n,
int nrhs,
float * dA,
int ldda,
float * dB,
int lddb,
float * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * niter,
int * dinfo);
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cusolverDN 库上下文的句柄。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
要解的右手边数量。应为非负数。 |
|
|
|
大小为 |
|
|
|
用于存储矩阵 |
|
|
|
大小为 |
|
|
|
用于存储右侧矩阵 |
|
|
|
大小为 |
|
|
|
用于存储解向量矩阵 |
|
|
|
指向设备内存中已分配大小为 lwork_bytes 的工作空间的指针。 |
|
|
|
已分配设备工作空间的大小。应至少为 |
|
|
|
如果 iter 为
|
|
|
|
返回时 IRS 求解器的状态。如果为 0 - 求解成功。如果 dinfo = - |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数,例如
n<0ldda<max(1,m)lddb<max(1,m)lddx<max(1,n)
CUSOLVER_STATUS_ARCH_MISMATCHIRS 求解器支持计算能力 7.0 及以上版本。最低精度选项 CUSOLVER_[CR]_16BF 和 CUSOLVER_[CR]_TF32 仅在计算能力 8.0 及以上版本上可用。
CUSOLVER_STATUS_INVALID_WORKSPACElwork_bytes小于所需的工作空间。CUSOLVER_STATUS_IRS_OUT_OF_RANGE与 niters <0 相关的数值错误,有关更多详细信息,请参阅 niters 描述。
CUSOLVER_STATUS_INTERNAL_ERROR发生内部错误;请检查
dinfo和niters参数以获取更多详细信息。
2.4.2.15. cusolverDnIRSXgels()
此函数旨在执行与 cusolverDn<T1><T2>gels() 函数相同的功能,但封装在更通用和专业的接口中,使用户可以更好地控制函数参数,并提供更多关于输出的信息。cusolverDnIRSXgels() 允许对求解器参数进行额外的控制,例如设置
求解器的主精度(输入/输出精度),
求解器内部使用的最低精度,
细化求解器类型
细化阶段中允许的最大迭代次数
细化求解器的容差
回退到主精度
以及其他
通过配置参数结构 gels_irs_params 及其辅助函数。有关可以设置的配置及其含义的更多详细信息,请参阅 cuSolverDN 辅助函数部分中所有以 cusolverDnIRSParamsxxxx() 开头的函数。此外,cusolverDnIRSXgels() 提供了有关输出的附加信息,例如每次迭代的收敛历史记录(例如,残差范数)以及收敛所需的迭代次数。有关可以检索的信息及其含义的更多详细信息,请参阅 cuSolverDN 辅助函数部分中所有以 cusolverDnIRSInfosxxxx() 开头的函数。
函数返回值描述了解算过程的结果。CUSOLVER_STATUS_SUCCESS 表示函数成功完成;否则,表示 API 参数之一不正确,或者 params/infos 结构的配置不正确,或者函数未成功完成。有关错误的更多详细信息,可以通过检查 niters 和 dinfo API 参数找到。有关更多详细信息,请参阅下面的描述。用户应为 cusolverDnIRSXgels() 函数提供设备上分配的所需工作空间。可以通过调用相应的函数 cusolverDnIRSXgels_bufferSize() 查询该函数所需的字节数。请注意,如果用户希望通过 params 结构设置特定配置,则应在调用 cusolverDnIRSXgels_bufferSize() 之前设置,以获取所需工作空间的大小。
下表提供了与输入/输出数据类型对应的最低精度的所有可能组合值。请注意,如果最低精度与输入/输出数据类型匹配,则将使用主精度分解
Tensor Float (TF32) 是 NVIDIA Ampere 架构 GPU 引入的,是迭代细化求解器最强大的张量核心加速计算模式。它能够解决 HPC 中来自不同应用的最广泛的问题,并为实数和复数系统分别提供高达 4 倍和 5 倍的加速。在 Volta 和 Turing 架构 GPU 上,建议使用半精度张量核心加速。如果迭代细化求解器无法收敛到所需的精度(主精度、INOUT 数据精度),建议使用主精度作为内部最低精度。
输入/输出数据类型(例如,主精度) |
最低精度的支持值 |
|---|---|
|
|
|
|
|
|
|
|
cusolverDnIRSXgels_bufferSize() 函数返回相应的 cusolverDnXgels() 调用在给定 gels_irs_params 配置下所需的 workspace 缓冲区大小(以字节为单位)。
cusolverStatus_t
cusolverDnIRSXgels_bufferSize(
cusolverDnHandle_t handle,
cusolverDnIRSParams_t gels_irs_params,
cusolver_int_t m,
cusolver_int_t n,
cusolver_int_t nrhs,
size_t * lwork_bytes);
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cusolverDn 库上下文的句柄。 |
|
|
|
Xgels 配置参数 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
要解的右手边的数量。应为非负数。请注意,如果选择的 IRS 细化求解器是 |
|
|
|
指向变量的指针,其中在调用 |
cusolverStatus_t cusolverDnIRSXgels(
cusolverDnHandle_t handle,
cusolverDnIRSParams_t gels_irs_params,
cusolverDnIRSInfos_t gels_irs_infos,
int m,
int n,
int nrhs,
void * dA,
int ldda,
void * dB,
int lddb,
void * dX,
int lddx,
void * dWorkspace,
size_t lwork_bytes,
int * dinfo);
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cusolverDn 库上下文的句柄。 |
|
|
|
配置参数结构,可以为任何 IRS 求解器的一次或多次调用服务 |
|
|
|
Info 结构,其中将存储有关特定解的信息。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
要解的右手侧的数量。应为非负数。请注意,如果选择的 IRS 细化求解器为 CUSOLVER_IRS_REFINE_GMRES、CUSOLVER_IRS_REFINE_GMRES_GMRES、CUSOLVER_IRS_REFINE_CLASSICAL_GMRES,则 |
|
|
|
大小为 |
|
|
|
用于存储矩阵 |
|
|
|
大小为 |
|
|
|
用于存储右侧矩阵 |
|
|
|
大小为 |
|
|
|
用于存储解向量矩阵 |
|
|
|
指向设备内存中已分配大小为 lwork_bytes 的工作空间的指针。 |
|
|
|
已分配的设备工作空间的大小。应至少为 |
|
|
|
如果
|
|
|
|
返回时 IRS 求解器的状态。如果为 0 - 求解成功。如果 dinfo = - |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数,例如
n<0ldda<max(1,m)lddb<max(1,m)lddx<max(1,n)
CUSOLVER_STATUS_ARCH_MISMATCHIRS 求解器支持计算能力 7.0 及以上版本。最低精度选项 CUSOLVER_[CR]_16BF 和 CUSOLVER_[CR]_TF32 仅在计算能力 8.0 及以上版本上可用。
CUSOLVER_STATUS_INVALID_WORKSPACElwork_bytes小于所需的工作空间。如果用户调用了cusolverDnIRSXgels_bufferSize()函数,然后更改了一些配置设置(例如最低精度),则可能会发生这种情况。CUSOLVER_STATUS_IRS_OUT_OF_RANGE与
niters<0 相关的数值错误;有关更多详细信息,请参阅niters描述。CUSOLVER_STATUS_INTERNAL_ERROR发生内部错误,请检查
dinfo和niters参数以获取更多详细信息。CUSOLVER_STATUS_IRS_PARAMS_NOT_INITIALIZED未创建配置参数
gels_irs_params结构。CUSOLVER_STATUS_IRS_PARAMS_INVALIDgels_irs_params结构中的配置参数之一无效。CUSOLVER_STATUS_IRS_PARAMS_INVALID_PRECgels_irs_params结构中的主精度和/或最低精度配置参数无效,请检查上表以获取支持的组合。CUSOLVER_STATUS_IRS_PARAMS_INVALID_MAXITERgels_irs_params结构中的 maxiter 配置参数无效。CUSOLVER_STATUS_IRS_PARAMS_INVALID_REFINEgels_irs_params结构中的细化求解器配置参数无效。CUSOLVER_STATUS_IRS_NOT_SUPPORTEDgels_irs_params结构中的配置参数之一不受支持。例如,如果 nrhs >1,并且细化求解器设置为CUSOLVER_IRS_REFINE_GMRES。CUSOLVER_STATUS_IRS_INFOS_NOT_INITIALIZED未创建信息结构
gels_irs_infos。CUSOLVER_STATUS_ALLOC_FAILEDCPU 内存分配失败,很可能是在分配存储残差范数的残差数组期间。
2.4.2.16. cusolverDn<t>ormqr()
这些辅助函数计算所需工作缓冲区的大小。请访问 cuSOLVER 库示例 - ormqr 以获取代码示例。
cusolverStatus_t
cusolverDnSormqr_bufferSize(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasOperation_t trans,
int m,
int n,
int k,
const float *A,
int lda,
const float *tau,
const float *C,
int ldc,
int *lwork);
cusolverStatus_t
cusolverDnDormqr_bufferSize(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasOperation_t trans,
int m,
int n,
int k,
const double *A,
int lda,
const double *tau,
const double *C,
int ldc,
int *lwork);
cusolverStatus_t
cusolverDnCunmqr_bufferSize(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasOperation_t trans,
int m,
int n,
int k,
const cuComplex *A,
int lda,
const cuComplex *tau,
const cuComplex *C,
int ldc,
int *lwork);
cusolverStatus_t
cusolverDnZunmqr_bufferSize(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasOperation_t trans,
int m,
int n,
int k,
const cuDoubleComplex *A,
int lda,
const cuDoubleComplex *tau,
const cuDoubleComplex *C,
int ldc,
int *lwork);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSormqr(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasOperation_t trans,
int m,
int n,
int k,
const float *A,
int lda,
const float *tau,
float *C,
int ldc,
float *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnDormqr(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasOperation_t trans,
int m,
int n,
int k,
const double *A,
int lda,
const double *tau,
double *C,
int ldc,
double *work,
int lwork,
int *devInfo);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCunmqr(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasOperation_t trans,
int m,
int n,
int k,
const cuComplex *A,
int lda,
const cuComplex *tau,
cuComplex *C,
int ldc,
cuComplex *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnZunmqr(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasOperation_t trans,
int m,
int n,
int k,
const cuDoubleComplex *A,
int lda,
const cuDoubleComplex *tau,
cuDoubleComplex *C,
int ldc,
cuDoubleComplex *work,
int lwork,
int *devInfo);
此函数用以下公式覆盖 \(m \times n\) 矩阵 C:
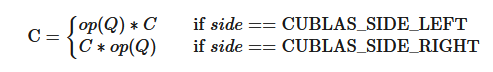
Q 的运算由下式定义:
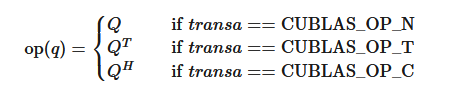
Q 是一个酉矩阵,由 A 的 QR 分解 (geqrf) 中的一系列基本反射向量构成。
Q=H(1)H(2) … H(k)
如果 side = CUBLAS_SIDE_LEFT,则 Q 的阶数为 m;如果 side = CUBLAS_SIDE_RIGHT,则 Q 的阶数为 n。
用户必须提供由输入参数 work 指向的工作空间。输入参数 lwork 是工作空间的大小,它由 geqrf_bufferSize() 或 ormqr_bufferSize() 返回。请注意,工作空间的大小(以字节为单位)等于 sizeof(<type>) * lwork。
如果输出参数 devInfo = -i(小于零),则第 i 个参数错误(不包括句柄)。
用户可以组合 geqrf、ormqr 和 trsm 来完成线性求解器或最小二乘求解器。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDn 库上下文的句柄。 |
|
|
|
指示矩阵 |
|
|
|
运算 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
定义矩阵 Q 的基本反射的数量。 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
<type> 维度至少为 |
|
|
|
<type> 大小为 |
|
|
|
矩阵 |
|
|
|
工作空间,大小为 |
|
|
|
工作数组 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
m,n<0或错误的lda或ldc)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.2.17. cusolverDn<t>orgqr()
这些辅助函数计算所需工作缓冲区的大小。请访问 cuSOLVER 库示例 - orgqr 以获取代码示例。
cusolverStatus_t
cusolverDnSorgqr_bufferSize(
cusolverDnHandle_t handle,
int m,
int n,
int k,
const float *A,
int lda,
const float *tau,
int *lwork);
cusolverStatus_t
cusolverDnDorgqr_bufferSize(
cusolverDnHandle_t handle,
int m,
int n,
int k,
const double *A,
int lda,
const double *tau,
int *lwork);
cusolverStatus_t
cusolverDnCungqr_bufferSize(
cusolverDnHandle_t handle,
int m,
int n,
int k,
const cuComplex *A,
int lda,
const cuComplex *tau,
int *lwork);
cusolverStatus_t
cusolverDnZungqr_bufferSize(
cusolverDnHandle_t handle,
int m,
int n,
int k,
const cuDoubleComplex *A,
int lda,
const cuDoubleComplex *tau,
int *lwork);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSorgqr(
cusolverDnHandle_t handle,
int m,
int n,
int k,
float *A,
int lda,
const float *tau,
float *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnDorgqr(
cusolverDnHandle_t handle,
int m,
int n,
int k,
double *A,
int lda,
const double *tau,
double *work,
int lwork,
int *devInfo);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCungqr(
cusolverDnHandle_t handle,
int m,
int n,
int k,
cuComplex *A,
int lda,
const cuComplex *tau,
cuComplex *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnZungqr(
cusolverDnHandle_t handle,
int m,
int n,
int k,
cuDoubleComplex *A,
int lda,
const cuDoubleComplex *tau,
cuDoubleComplex *work,
int lwork,
int *devInfo);
此函数用以下公式覆盖 \(m \times n\) 矩阵 A:
其中 Q 是一个酉矩阵,由存储在 A 中的一系列基本反射向量构成。
用户必须提供由输入参数 work 指向的工作空间。输入参数 lwork 是工作空间的大小,它由 orgqr_bufferSize() 返回。请注意,工作空间的大小(以字节为单位)等于 sizeof(<type>) * lwork。
如果输出参数 devInfo = -i(小于零),则第 i 个参数错误(不包括句柄)。
用户可以组合 geqrf 和 orgqr 来完成正交化。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
定义矩阵 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
<type> 维度为 |
|
|
|
工作空间,大小为 |
|
|
|
工作数组 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
m,n,k<0、n>m、k>n或lda<m)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.2.18. cusolverDn<t>sytrf()
这些辅助函数计算所需缓冲区的大小。
cusolverStatus_t
cusolverDnSsytrf_bufferSize(cusolverDnHandle_t handle,
int n,
float *A,
int lda,
int *lwork );
cusolverStatus_t
cusolverDnDsytrf_bufferSize(cusolverDnHandle_t handle,
int n,
double *A,
int lda,
int *lwork );
cusolverStatus_t
cusolverDnCsytrf_bufferSize(cusolverDnHandle_t handle,
int n,
cuComplex *A,
int lda,
int *lwork );
cusolverStatus_t
cusolverDnZsytrf_bufferSize(cusolverDnHandle_t handle,
int n,
cuDoubleComplex *A,
int lda,
int *lwork );
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSsytrf(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
float *A,
int lda,
int *devIpiv,
float *work,
int lwork,
int *devInfo );
cusolverStatus_t
cusolverDnDsytrf(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
double *A,
int lda,
int *devIpiv,
double *work,
int lwork,
int *devInfo );
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCsytrf(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuComplex *A,
int lda,
int *devIpiv,
cuComplex *work,
int lwork,
int *devInfo );
cusolverStatus_t
cusolverDnZsytrf(cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuDoubleComplex *A,
int lda,
int *devIpiv,
cuDoubleComplex *work,
int lwork,
int *devInfo );
此函数使用 Bunch-Kaufman 对角线枢轴计算对称不定矩阵的分解。
A 是一个 \(n \times n\) 对称矩阵,只有下部或上部有意义。输入参数 uplo 指示使用矩阵的哪一部分。如果 devIpiv 为 null,则不执行枢轴运算,这在数值上不稳定。
如果输入参数 uplo 为 CUBLAS_FILL_MODE_LOWER,则仅处理 A 的下三角部分,并替换为下三角因子 L 和分块对角矩阵 D。D 的每个块都是 1x1 或 2x2 块,具体取决于枢轴运算。
如果输入参数 uplo 为 CUBLAS_FILL_MODE_UPPER,则仅处理 A 的上三角部分,并替换为上三角因子 U 和分块对角矩阵 D。
用户必须提供由输入参数 work 指向的工作空间。输入参数 lwork 是工作空间的大小,它由 sytrf_bufferSize() 返回。请注意,工作空间的大小(以字节为单位)等于 sizeof(<type>) * lwork。当不执行枢轴运算时,输入矩阵 A 的另一个三角部分用作工作空间。
如果 Bunch-Kaufman 分解失败,即 A 是奇异的。输出参数 devInfo = i 将指示 D(i,i)=0。
如果输出参数 devInfo = -i(小于零),则第 i 个参数错误(不包括句柄)。
输出参数 devIpiv 包含枢轴序列。如果 devIpiv(i) = k > 0,则 D(i,i) 是 1x1 块,并且 A 的第 i-th 行/列与 A 的第 k-th 行/列互换。如果 uplo 为 CUBLAS_FILL_MODE_UPPER 且 devIpiv(i-1) = devIpiv(i) = -m < 0,则 D(i-1:i,i-1:i) 是 2x2 块,并且第 (i-1)-th 行/列与第 m-th 行/列互换。如果 uplo 为 CUBLAS_FILL_MODE_LOWER 且 devIpiv(i+1) = devIpiv(i) = -m < 0,则 D(i:i+1,i:i+1) 是 2x2 块,并且第 (i+1)-th 行/列与第 m-th 行/列互换。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指示是否存储矩阵 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
大小至少为 |
|
|
|
工作空间,大小为 |
|
|
|
工作空间 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n<0或lda<max(1,n))。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.2.19. cusolverDn<t>potrfBatched()
S 和 D 数据类型分别是实值单精度和双精度。请访问 cuSOLVER 库示例 - potrfBatched 以获取代码示例。
cusolverStatus_t
cusolverDnSpotrfBatched(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
float *Aarray[],
int lda,
int *infoArray,
int batchSize);
cusolverStatus_t
cusolverDnDpotrfBatched(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
double *Aarray[],
int lda,
int *infoArray,
int batchSize);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCpotrfBatched(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuComplex *Aarray[],
int lda,
int *infoArray,
int batchSize);
cusolverStatus_t
cusolverDnZpotrfBatched(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuDoubleComplex *Aarray[],
int lda,
int *infoArray,
int batchSize);
此函数计算一系列 Hermitian 正定矩阵的 Cholesky 分解。
每个 Aarray[i] for i=0,1,..., batchSize-1 都是一个 \(n \times n\) Hermitian 矩阵,只有下部或上部有意义。输入参数 uplo 指示使用矩阵的哪一部分。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_LOWER,则仅处理 A 的下三角部分,并将其替换为下三角 Cholesky 因子 L。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_UPPER,则仅处理 A 的上三角部分,并将其替换为上三角 Cholesky 因子 U。
如果 Cholesky 分解失败,即 A 的某些前导子式不是正定的,或者等效地,L 或 U 的某些对角元素不是实数。输出参数 infoArray 将指示 A 的最小前导子式,该子式不是正定的。
infoArray 是大小为 batchsize 的整数数组。如果 potrfBatched 返回 CUSOLVER_STATUS_INVALID_VALUE,则 infoArray[0] = -i(小于零),表示第 i-th 个参数错误(不包括句柄)。如果 potrfBatched 返回 CUSOLVER_STATUS_SUCCESS,但 infoArray[i] = k 为正数,则表示第 i-th 个矩阵不是正定的,并且 Cholesky 分解在第 k 行失败。
备注:A 的另一部分用作工作空间。例如,如果 uplo 为 CUBLAS_FILL_MODE_UPPER,则 A 的上三角包含 Cholesky 因子 U,并且在 potrfBatched 之后,A 的下三角被破坏。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指示存储下部还是上部;另一部分用作工作空间。 |
|
|
|
矩阵 |
|
|
|
指向 <type> 数组的指针数组,该数组的维度为 |
|
|
|
用于存储每个矩阵 |
|
|
|
大小为 |
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
n<0或lda<max(1,n)或batchSize<1)。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.2.20. cusolverDn<t>potrsBatched()
cusolverStatus_t
cusolverDnSpotrsBatched(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
int nrhs,
float *Aarray[],
int lda,
float *Barray[],
int ldb,
int *info,
int batchSize);
cusolverStatus_t
cusolverDnDpotrsBatched(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
int nrhs,
double *Aarray[],
int lda,
double *Barray[],
int ldb,
int *info,
int batchSize);
cusolverStatus_t
cusolverDnCpotrsBatched(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
int nrhs,
cuComplex *Aarray[],
int lda,
cuComplex *Barray[],
int ldb,
int *info,
int batchSize);
cusolverStatus_t
cusolverDnZpotrsBatched(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
int nrhs,
cuDoubleComplex *Aarray[],
int lda,
cuDoubleComplex *Barray[],
int ldb,
int *info,
int batchSize);
此函数求解一系列线性系统
其中每个 Aarray[i] for i=0,1,..., batchSize-1 都是一个 \(n \times n\) Hermitian 矩阵,只有下部或上部有意义。输入参数 uplo 指示使用矩阵的哪一部分。
用户必须首先调用 potrfBatched 来分解矩阵 Aarray[i]。如果输入参数 uplo 为 CUBLAS_FILL_MODE_LOWER,则 A 是对应于 \(A = L*L^{H}\) 的下三角 Cholesky 因子 L。如果输入参数 uplo 为 CUBLAS_FILL_MODE_UPPER,则 A 是对应于 \(A = U^{H}*U\) 的上三角 Cholesky 因子 U。
该操作是就地操作,即矩阵 X 使用相同的前导维度 ldb 覆盖矩阵 B。
输出参数 info 是一个标量。如果 info = -i(小于零),则第 i-th 个参数错误(不包括句柄)。
备注 1:仅支持 nrhs=1。
备注 2:来自 potrfBatched 的 infoArray 指示矩阵是否为正定矩阵。来自 potrsBatched 的 info 仅显示哪个输入参数错误(不包括句柄)。
备注 3:A 的另一部分用作工作空间。例如,如果 uplo 为 CUBLAS_FILL_MODE_UPPER,则 A 的上三角包含 Cholesky 因子 U,并且在 potrsBatched 之后,A 的下三角被破坏。
请访问 cuSOLVER 库示例 - potrfBatched 以获取代码示例。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指示矩阵 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
指向 <type> 数组的指针数组,该数组的维度为 |
|
|
|
用于存储每个矩阵 |
|
|
|
指向维度为 |
|
|
|
用于存储每个矩阵 |
|
|
|
如果 |
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
n<0,nrhs<0,lda<max(1,n),ldb<max(1,n)或batchSize<0)。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3. 稠密特征值求解器参考(旧版)
本章节介绍 cuSolverDN 的特征值求解器 API,包括双对角化和 SVD。
2.4.3.1. cusolverDn<t>gebrd()
这些辅助函数计算所需工作缓冲区的大小。
cusolverStatus_t
cusolverDnSgebrd_bufferSize(
cusolverDnHandle_t handle,
int m,
int n,
int *Lwork );
cusolverStatus_t
cusolverDnDgebrd_bufferSize(
cusolverDnHandle_t handle,
int m,
int n,
int *Lwork );
cusolverStatus_t
cusolverDnCgebrd_bufferSize(
cusolverDnHandle_t handle,
int m,
int n,
int *Lwork );
cusolverStatus_t
cusolverDnZgebrd_bufferSize(
cusolverDnHandle_t handle,
int m,
int n,
int *Lwork );
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSgebrd(cusolverDnHandle_t handle,
int m,
int n,
float *A,
int lda,
float *D,
float *E,
float *TAUQ,
float *TAUP,
float *Work,
int Lwork,
int *devInfo );
cusolverStatus_t
cusolverDnDgebrd(cusolverDnHandle_t handle,
int m,
int n,
double *A,
int lda,
double *D,
double *E,
double *TAUQ,
double *TAUP,
double *Work,
int Lwork,
int *devInfo );
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCgebrd(cusolverDnHandle_t handle,
int m,
int n,
cuComplex *A,
int lda,
float *D,
float *E,
cuComplex *TAUQ,
cuComplex *TAUP,
cuComplex *Work,
int Lwork,
int *devInfo );
cusolverStatus_t
cusolverDnZgebrd(cusolverDnHandle_t handle,
int m,
int n,
cuDoubleComplex *A,
int lda,
double *D,
double *E,
cuDoubleComplex *TAUQ,
cuDoubleComplex *TAUP,
cuDoubleComplex *Work,
int Lwork,
int *devInfo );
此函数通过正交变换将一般 \(m \times n\) 矩阵 A 约简为实上或下双对角形式 B:\(Q^{H}*A*P = B\)
如果 m>=n,B 是上双对角矩阵;如果 m<n,B 是下双对角矩阵。
矩阵 Q 和 P 以以下方式覆盖到矩阵 A 中
如果
m>=n,对角线和第一条超对角线被上双对角矩阵B覆盖;对角线以下的元素,与数组TAUQ一起,表示正交矩阵Q,作为初等反射器的乘积;第一条超对角线以上的元素,与数组TAUP一起,表示正交矩阵P,作为初等反射器的乘积。如果
m<n,对角线和第一条次对角线被下双对角矩阵B覆盖;第一条次对角线以下的元素,与数组TAUQ一起,表示正交矩阵Q,作为初等反射器的乘积;对角线以上的元素,与数组TAUP一起,表示正交矩阵P,作为初等反射器的乘积。
用户必须提供由输入参数 Work 指向的工作空间。输入参数 Lwork 是工作空间的大小,它由 gebrd_bufferSize() 返回。
如果输出参数 devInfo = -i(小于零),则第 i 个参数错误(不包括句柄)。
备注:gebrd 仅支持 m>=n。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
维度为 |
|
|
|
维度为 |
|
|
|
维度为 |
|
|
|
工作空间,大小为 |
|
|
|
|
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
m,n<0,或lda<max(1,m))。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.2. cusolverDn<t>orgbr()
这些辅助函数计算所需工作缓冲区的大小。
cusolverStatus_t
cusolverDnSorgbr_bufferSize(
cusolverDnHandle_t handle,
cublasSideMode_t side,
int m,
int n,
int k,
const float *A,
int lda,
const float *tau,
int *lwork);
cusolverStatus_t
cusolverDnDorgbr_bufferSize(
cusolverDnHandle_t handle,
cublasSideMode_t side,
int m,
int n,
int k,
const double *A,
int lda,
const double *tau,
int *lwork);
cusolverStatus_t
cusolverDnCungbr_bufferSize(
cusolverDnHandle_t handle,
cublasSideMode_t side,
int m,
int n,
int k,
const cuComplex *A,
int lda,
const cuComplex *tau,
int *lwork);
cusolverStatus_t
cusolverDnZungbr_bufferSize(
cusolverDnHandle_t handle,
cublasSideMode_t side,
int m,
int n,
int k,
const cuDoubleComplex *A,
int lda,
const cuDoubleComplex *tau,
int *lwork);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSorgbr(
cusolverDnHandle_t handle,
cublasSideMode_t side,
int m,
int n,
int k,
float *A,
int lda,
const float *tau,
float *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnDorgbr(
cusolverDnHandle_t handle,
cublasSideMode_t side,
int m,
int n,
int k,
double *A,
int lda,
const double *tau,
double *work,
int lwork,
int *devInfo);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCungbr(
cusolverDnHandle_t handle,
cublasSideMode_t side,
int m,
int n,
int k,
cuComplex *A,
int lda,
const cuComplex *tau,
cuComplex *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnZungbr(
cusolverDnHandle_t handle,
cublasSideMode_t side,
int m,
int n,
int k,
cuDoubleComplex *A,
int lda,
const cuDoubleComplex *tau,
cuDoubleComplex *work,
int lwork,
int *devInfo);
此函数生成由 gebrd 在将矩阵 A 约简为双对角形式时确定的酉矩阵 Q 或 P**H 之一:\(Q^{H}*A*P = B\)
Q 和 P**H 分别定义为初等反射器 H(i) 或 G(i) 的乘积。
用户必须提供由输入参数 work 指向的工作空间。输入参数 lwork 是工作空间的大小,它由 orgbr_bufferSize() 返回。请注意,工作空间的大小(以字节为单位)等于 sizeof(<type>) * lwork。
如果输出参数 devInfo = -i(小于零),则第 i 个参数错误(不包括句柄)。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
如果 |
|
|
|
矩阵 |
|
|
|
如果 |
|
|
|
如果 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
工作空间,大小为 |
|
|
|
工作数组 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
m,n<0或错误的lda)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.3. cusolverDn<t>sytrd()
这些辅助函数计算所需工作缓冲区的大小。
cusolverStatus_t
cusolverDnSsytrd_bufferSize(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
const float *A,
int lda,
const float *d,
const float *e,
const float *tau,
int *lwork);
cusolverStatus_t
cusolverDnDsytrd_bufferSize(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
const double *A,
int lda,
const double *d,
const double *e,
const double *tau,
int *lwork);
cusolverStatus_t
cusolverDnChetrd_bufferSize(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
const cuComplex *A,
int lda,
const float *d,
const float *e,
const cuComplex *tau,
int *lwork);
cusolverStatus_t
cusolverDnZhetrd_bufferSize(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
const cuDoubleComplex *A,
int lda,
const double *d,
const double *e,
const cuDoubleComplex *tau,
int *lwork);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSsytrd(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
float *A,
int lda,
float *d,
float *e,
float *tau,
float *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnDsytrd(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
double *A,
int lda,
double *d,
double *e,
double *tau,
double *work,
int lwork,
int *devInfo);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnChetrd(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuComplex *A,
int lda,
float *d,
float *e,
cuComplex *tau,
cuComplex *work,
int lwork,
int *devInfo);
cusolverStatus_t CUDENSEAPI cusolverDnZhetrd(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuDoubleComplex *A,
int lda,
double *d,
double *e,
cuDoubleComplex *tau,
cuDoubleComplex *work,
int lwork,
int *devInfo);
此函数通过正交变换将一般对称(Hermitian)\(n \times n\) 矩阵 A 约简为实对称三对角形式 T:\(Q^{H}*A*Q = T\)
作为输出,A 包含 T 和 Householder 反射向量。如果 uplo = CUBLAS_FILL_MODE_UPPER,则 A 的对角线和第一条超对角线被三对角矩阵 T 的相应元素覆盖,并且第一条超对角线以上的元素与数组 tau 一起表示正交矩阵 Q,作为初等反射器的乘积;如果 uplo = CUBLAS_FILL_MODE_LOWER,则 A 的对角线和第一条次对角线被三对角矩阵 T 的相应元素覆盖,并且第一条次对角线以下的元素与数组 tau 一起表示正交矩阵 Q,作为初等反射器的乘积。
用户必须提供由输入参数 work 指向的工作空间。输入参数 lwork 是工作空间的大小,它由 sytrd_bufferSize() 返回。请注意,工作空间的大小(以字节为单位)等于 sizeof(<type>) * lwork。
如果输出参数 devInfo = -i(小于零),则第 i 个参数错误(不包括句柄)。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指定存储 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
维度为 |
|
|
|
维度为 |
|
|
|
工作空间,大小为 |
|
|
|
|
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
n<0,或lda<max(1,n),或uplo不是CUBLAS_FILL_MODE_LOWER或CUBLAS_FILL_MODE_UPPER)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.4. cusolverDn<t>ormtr()
这些辅助函数计算所需工作缓冲区的大小。
cusolverStatus_t
cusolverDnSormtr_bufferSize(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasFillMode_t uplo,
cublasOperation_t trans,
int m,
int n,
const float *A,
int lda,
const float *tau,
const float *C,
int ldc,
int *lwork);
cusolverStatus_t
cusolverDnDormtr_bufferSize(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasFillMode_t uplo,
cublasOperation_t trans,
int m,
int n,
const double *A,
int lda,
const double *tau,
const double *C,
int ldc,
int *lwork);
cusolverStatus_t
cusolverDnCunmtr_bufferSize(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasFillMode_t uplo,
cublasOperation_t trans,
int m,
int n,
const cuComplex *A,
int lda,
const cuComplex *tau,
const cuComplex *C,
int ldc,
int *lwork);
cusolverStatus_t
cusolverDnZunmtr_bufferSize(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasFillMode_t uplo,
cublasOperation_t trans,
int m,
int n,
const cuDoubleComplex *A,
int lda,
const cuDoubleComplex *tau,
const cuDoubleComplex *C,
int ldc,
int *lwork);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSormtr(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasFillMode_t uplo,
cublasOperation_t trans,
int m,
int n,
float *A,
int lda,
float *tau,
float *C,
int ldc,
float *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnDormtr(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasFillMode_t uplo,
cublasOperation_t trans,
int m,
int n,
double *A,
int lda,
double *tau,
double *C,
int ldc,
double *work,
int lwork,
int *devInfo);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCunmtr(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasFillMode_t uplo,
cublasOperation_t trans,
int m,
int n,
cuComplex *A,
int lda,
cuComplex *tau,
cuComplex *C,
int ldc,
cuComplex *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnZunmtr(
cusolverDnHandle_t handle,
cublasSideMode_t side,
cublasFillMode_t uplo,
cublasOperation_t trans,
int m,
int n,
cuDoubleComplex *A,
int lda,
cuDoubleComplex *tau,
cuDoubleComplex *C,
int ldc,
cuDoubleComplex *work,
int lwork,
int *devInfo);
此函数用以下公式覆盖 \(m \times n\) 矩阵 C:
其中 Q 是由来自 sytrd 的一系列初等反射向量构成的酉矩阵。
对 Q 的操作定义为
用户必须提供由输入参数 work 指向的工作空间。输入参数 lwork 是工作空间的大小,它由 ormtr_bufferSize() 返回。请注意,工作空间的大小(以字节为单位)等于 sizeof(<type>) * lwork。
如果输出参数 devInfo = -i(小于零),则第 i 个参数错误(不包括句柄)。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
|
|
|
|
|
|
|
|
运算 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
大小为 |
|
|
|
矩阵 |
|
|
|
工作空间,大小为 |
|
|
|
工作数组 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
m,n<0或错误的lda或ldc)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.5. cusolverDn<t>orgtr()
这些辅助函数计算所需工作缓冲区的大小。
cusolverStatus_t
cusolverDnSorgtr_bufferSize(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
const float *A,
int lda,
const float *tau,
int *lwork);
cusolverStatus_t
cusolverDnDorgtr_bufferSize(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
const double *A,
int lda,
const double *tau,
int *lwork);
cusolverStatus_t
cusolverDnCungtr_bufferSize(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
const cuComplex *A,
int lda,
const cuComplex *tau,
int *lwork);
cusolverStatus_t
cusolverDnZungtr_bufferSize(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
const cuDoubleComplex *A,
int lda,
const cuDoubleComplex *tau,
int *lwork);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSorgtr(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
float *A,
int lda,
const float *tau,
float *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnDorgtr(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
double *A,
int lda,
const double *tau,
double *work,
int lwork,
int *devInfo);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCungtr(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuComplex *A,
int lda,
const cuComplex *tau,
cuComplex *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnZungtr(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int n,
cuDoubleComplex *A,
int lda,
const cuDoubleComplex *tau,
cuDoubleComplex *work,
int lwork,
int *devInfo);
此函数生成酉矩阵 Q,该矩阵定义为由 sytrd 返回的 n 阶 n-1 个初等反射器的乘积。
用户必须提供由输入参数 work 指向的工作空间。输入参数 lwork 是工作空间的大小,它由 orgtr_bufferSize() 返回。请注意,工作空间的大小(以字节为单位)等于 sizeof(<type>) * lwork。
如果输出参数 devInfo = -i(小于零),则第 i 个参数错误(不包括句柄)。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
|
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
工作空间,大小为 |
|
|
|
工作数组 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
n<0或错误的lda)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.6. cusolverDn<t>gesvd()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnSgesvd_bufferSize(
cusolverDnHandle_t handle,
int m,
int n,
int *lwork );
cusolverStatus_t
cusolverDnDgesvd_bufferSize(
cusolverDnHandle_t handle,
int m,
int n,
int *lwork );
cusolverStatus_t
cusolverDnCgesvd_bufferSize(
cusolverDnHandle_t handle,
int m,
int n,
int *lwork );
cusolverStatus_t
cusolverDnZgesvd_bufferSize(
cusolverDnHandle_t handle,
int m,
int n,
int *lwork );
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSgesvd (
cusolverDnHandle_t handle,
signed char jobu,
signed char jobvt,
int m,
int n,
float *A,
int lda,
float *S,
float *U,
int ldu,
float *VT,
int ldvt,
float *work,
int lwork,
float *rwork,
int *devInfo);
cusolverStatus_t
cusolverDnDgesvd (
cusolverDnHandle_t handle,
signed char jobu,
signed char jobvt,
int m,
int n,
double *A,
int lda,
double *S,
double *U,
int ldu,
double *VT,
int ldvt,
double *work,
int lwork,
double *rwork,
int *devInfo);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCgesvd (
cusolverDnHandle_t handle,
signed char jobu,
signed char jobvt,
int m,
int n,
cuComplex *A,
int lda,
float *S,
cuComplex *U,
int ldu,
cuComplex *VT,
int ldvt,
cuComplex *work,
int lwork,
float *rwork,
int *devInfo);
cusolverStatus_t
cusolverDnZgesvd (
cusolverDnHandle_t handle,
signed char jobu,
signed char jobvt,
int m,
int n,
cuDoubleComplex *A,
int lda,
double *S,
cuDoubleComplex *U,
int ldu,
cuDoubleComplex *VT,
int ldvt,
cuDoubleComplex *work,
int lwork,
double *rwork,
int *devInfo);
此函数计算 \(m \times n\) 矩阵 A 的奇异值分解 (SVD) 以及相应的左奇异向量和/或右奇异向量。SVD 写为
其中 Σ 是一个 \(m \times n\) 矩阵,除了其 min(m,n) 个对角元素外,其余均为零,U 是一个 \(m \times m\) 酉矩阵,V 是一个 \(n \times n\) 酉矩阵。Σ 的对角元素是 A 的奇异值;它们是实数且非负,并以降序返回。U 和 V 的前 min(m,n) 列分别是 A 的左奇异向量和右奇异向量。
用户必须提供由输入参数 work 指向的工作空间。输入参数 lwork 是工作空间的大小,它由 gesvd_bufferSize() 返回。请注意,工作空间的大小(以字节为单位)等于 sizeof(<type>) * lwork。
如果输出参数 devInfo = -i(小于零),则第 i-th 个参数错误(不包括 handle)。如果 bdsqr 未收敛,则 devInfo 指定中间双对角形式有多少条超对角线未收敛到零。
rwork 是维度为 (min(m,n)-1) 的实数数组。如果 devInfo>0 且 rwork 不为 NULL,则 rwork 包含上双对角矩阵的未收敛超对角元素。这与 LAPACK 略有不同,LAPACK 在类型为 real 时将未收敛的超对角元素放在 work 中;在类型为 complex 时放在 rwork 中。如果用户不需要来自超对角线的信息,rwork 可以是 NULL 指针。
请访问 cuSOLVER 库示例 - gesvd 以获取代码示例。
备注 1:gesvd 仅支持 m>=n。
备注 2:该例程返回 \(V^{H}\),而不是 V。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指定用于计算矩阵 |
|
|
|
指定用于计算矩阵 V**T 的全部或部分的选项:= ‘A’:V**T 的所有 N 行都将在数组 VT 中返回;= ‘S’:V**T 的前 min(m,n) 行(右奇异向量)将在数组 VT 中返回;= ‘O’:V**T 的前 min(m,n) 行(右奇异向量)将在数组 A 上被覆盖;= ‘N’:不计算 V**T 的任何行(不计算右奇异向量)。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
工作空间,大小为 |
|
|
|
|
|
|
|
维度为 min(m,n)-1 的实数数组。如果 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
m,n<0或lda<max(1,m)或ldu<max(1,m)或ldvt<max(1,n))。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.7. cusolverDnGesvd() [已弃用]
[[已弃用]] 请改用 cusolverDnXgesvd()。该例程将在下一个主要版本中删除。
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t cusolverDnGesvd_bufferSize(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
signed char jobu,
signed char jobvt,
int64_t m,
int64_t n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType dataTypeS,
const void *S,
cudaDataType dataTypeU,
const void *U,
int64_t ldu,
cudaDataType dataTypeVT,
const void *VT,
int64_t ldvt,
cudaDataType computeType,
size_t *workspaceInBytes);
以下例程
cusolverStatus_t cusolverDnGesvd(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
signed char jobu,
signed char jobvt,
int64_t m,
int64_t n,
cudaDataType dataTypeA,
void *A,
int64_t lda,
cudaDataType dataTypeS,
void *S,
cudaDataType dataTypeU,
void *U,
int64_t ldu,
cudaDataType dataTypeVT,
void *VT,
int64_t ldvt,
cudaDataType computeType,
void *pBuffer,
size_t workspaceInBytes,
int *info);
此函数计算 \(m \times n\) 矩阵 A 的奇异值分解 (SVD) 以及相应的左奇异向量和/或右奇异向量。SVD 写为
其中 Σ 是一个 \(m \times n\) 矩阵,除了其 min(m,n) 个对角元素外,其余均为零,U 是一个 \(m \times m\) 酉矩阵,V 是一个 \(n \times n\) 酉矩阵。Σ 的对角元素是 A 的奇异值;它们是实数且非负,并以降序返回。U 和 V 的前 min(m,n) 列分别是 A 的左奇异向量和右奇异向量。
用户必须提供由输入参数 pBuffer 指向的工作空间。输入参数 workspaceInBytes 是工作空间的大小(以字节为单位),它由 cusolverDnGesvd_bufferSize() 返回。
如果输出参数 info = -i(小于零),则第 i-th 个参数错误(不包括 handle)。如果 bdsqr 未收敛,则 info 指定中间双对角形式有多少条超对角线未收敛到零。
目前,cusolverDnGesvd 仅支持默认算法。
cusolverDnGesvd 支持的算法
|
默认算法。 |
备注 1:gesvd 仅支持 m>=n。
备注 2:该例程返回 \(V^{H}\),而不是 V。
cusolverDnGesvd_bufferSize 和 cusolverDnGesvd 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
指定用于计算矩阵 |
|
|
|
指定用于计算矩阵 V**T 的全部或部分的选项:= ‘A’:V**T 的所有 N 行都将在数组 VT 中返回;= ‘S’:V**T 的前 min(m,n) 行(右奇异向量)将在数组 VT 中返回;= ‘O’:V**T 的前 min(m,n) 行(右奇异向量)将在数组 A 上被覆盖;= ‘N’:不计算 V**T 的任何行(不计算右奇异向量)。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
计算的数据类型。 |
|
|
|
工作空间。 类型为 |
|
|
|
由 |
|
|
|
如果 |
通用 API 有三种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeS 是向量 S 的数据类型,dataTypeU 是矩阵 U 的数据类型,dataTypeVT 是矩阵 VT 的数据类型,computeType 是操作的计算类型。cusolverDnGesvd 仅支持以下四种组合。
数据类型和计算类型的有效组合
DataTypeA |
DataTypeS |
DataTypeU |
DataTypeVT |
ComputeType |
含义 |
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
m,n<0或lda<max(1,m)或ldu<max(1,m)或ldvt<max(1,n))。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.8. cusolverDn<t>gesvdj()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnSgesvdj_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int econ,
int m,
int n,
const float *A,
int lda,
const float *S,
const float *U,
int ldu,
const float *V,
int ldv,
int *lwork,
gesvdjInfo_t params);
cusolverStatus_t
cusolverDnDgesvdj_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int econ,
int m,
int n,
const double *A,
int lda,
const double *S,
const double *U,
int ldu,
const double *V,
int ldv,
int *lwork,
gesvdjInfo_t params);
cusolverStatus_t
cusolverDnCgesvdj_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int econ,
int m,
int n,
const cuComplex *A,
int lda,
const float *S,
const cuComplex *U,
int ldu,
const cuComplex *V,
int ldv,
int *lwork,
gesvdjInfo_t params);
cusolverStatus_t
cusolverDnZgesvdj_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int econ,
int m,
int n,
const cuDoubleComplex *A,
int lda,
const double *S,
const cuDoubleComplex *U,
int ldu,
const cuDoubleComplex *V,
int ldv,
int *lwork,
gesvdjInfo_t params);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSgesvdj(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int econ,
int m,
int n,
float *A,
int lda,
float *S,
float *U,
int ldu,
float *V,
int ldv,
float *work,
int lwork,
int *info,
gesvdjInfo_t params);
cusolverStatus_t
cusolverDnDgesvdj(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int econ,
int m,
int n,
double *A,
int lda,
double *S,
double *U,
int ldu,
double *V,
int ldv,
double *work,
int lwork,
int *info,
gesvdjInfo_t params);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCgesvdj(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int econ,
int m,
int n,
cuComplex *A,
int lda,
float *S,
cuComplex *U,
int ldu,
cuComplex *V,
int ldv,
cuComplex *work,
int lwork,
int *info,
gesvdjInfo_t params);
cusolverStatus_t
cusolverDnZgesvdj(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int econ,
int m,
int n,
cuDoubleComplex *A,
int lda,
double *S,
cuDoubleComplex *U,
int ldu,
cuDoubleComplex *V,
int ldv,
cuDoubleComplex *work,
int lwork,
int *info,
gesvdjInfo_t params);
此函数计算 \(m \times n\) 矩阵 A 的奇异值分解 (SVD) 以及相应的左奇异向量和/或右奇异向量。SVD 写为
其中 Σ 是一个 \(m \times n\) 矩阵,除了其 min(m,n) 个对角元素外,其余均为零,U 是一个 \(m \times m\) 酉矩阵,V 是一个 \(n \times n\) 酉矩阵。Σ 的对角元素是 A 的奇异值;它们是实数且非负,并以降序返回。U 和 V 的前 min(m,n) 列分别是 A 的左奇异向量和右奇异向量。
gesvdj 具有与 gesvd 相同的功能。不同之处在于 gesvd 使用 QR 算法,而 gesvdj 使用 Jacobi 方法。Jacobi 方法的并行性使 GPU 在中小型矩阵上具有更好的性能。此外,用户可以配置 gesvdj 以执行达到一定精度的近似。
gesvdj 迭代地生成一系列酉矩阵,以将矩阵 A 变换为以下形式
其中 S 是对角矩阵,而 E 的对角线为零。
在迭代过程中,E 的 Frobenius 范数单调递减。当 E 趋于零时,S 是奇异值的集合。在实践中,如果满足以下条件,Jacobi 方法将停止:
其中 eps 是给定的容差。请注意,如果计算实际残差范数
被计算出来,它与 \({\|{E}\|}_{F}\) 的差异将在舍入误差的量级 \(N = max(m, n)\) 之内,以仍然具有标准的 SVD 精度期望
\(O(N)\) 通常是 \(N\),但常数取决于扫描次数,这给出了 \(sweeps * N\) 的上限舍入误差界限。
gesvdj 有两个参数来控制精度。第一个参数是容差 (eps)。默认值是机器精度,但用户可以使用函数 cusolverDnXgesvdjSetTolerance 来设置先验容差。第二个参数是最大扫描次数,它控制 Jacobi 方法的迭代次数。默认值为 100,但用户可以使用函数 cusolverDnXgesvdjSetMaxSweeps 来设置适当的界限。实验表明,15 次扫描足以收敛到机器精度。gesvdj 在满足容差或达到最大扫描次数时停止。
Jacobi 方法具有二次收敛性,因此精度与扫描次数不成比例。为了保证一定的精度,用户应仅配置容差。
用户必须提供工作空间,该空间由输入参数 work 指向。输入参数 lwork 是工作空间的大小,它由 gesvdj_bufferSize() 返回。请注意,工作空间的字节大小等于 sizeof(<type>) * lwork。
如果输出参数 info = -i (小于零),则表示第 i-th 个参数错误(不包括 handle)。如果 info = min(m,n)+1,则 gesvdj 在给定的容差和最大扫描次数下未收敛。
如果用户设置了不合适的容差,gesvdj 可能不会收敛。例如,容差不应小于机器精度。
请访问 cuSOLVER Library Samples - gesvdj 以获取代码示例。
注 1:gesvdj 支持 m 和 n 的任何组合。
注 2:该例程返回 V,而不是 \(V^{H}\) 。这与 gesvd 不同。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指定选项以仅计算奇异值或同时计算奇异向量: |
|
|
|
|
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
<type> 大小为 |
|
|
|
|
|
|
|
如果 |
|
|
|
填充了 Jacobi 算法参数和 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
m,n<0或lda<max(1,m)或ldu<max(1,m)或ldv<max(1,n)或jobz不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTOR)。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.9. cusolverDn<t>gesvdjBatched()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnSgesvdjBatched_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int m,
int n,
const float *A,
int lda,
const float *S,
const float *U,
int ldu,
const float *V,
int ldv,
int *lwork,
gesvdjInfo_t params,
int batchSize);
cusolverStatus_t
cusolverDnDgesvdjBatched_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int m,
int n,
const double *A,
int lda,
const double *S,
const double *U,
int ldu,
const double *V,
int ldv,
int *lwork,
gesvdjInfo_t params,
int batchSize);
cusolverStatus_t
cusolverDnCgesvdjBatched_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int m,
int n,
const cuComplex *A,
int lda,
const float *S,
const cuComplex *U,
int ldu,
const cuComplex *V,
int ldv,
int *lwork,
gesvdjInfo_t params,
int batchSize);
cusolverStatus_t
cusolverDnZgesvdjBatched_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int m,
int n,
const cuDoubleComplex *A,
int lda,
const double *S,
const cuDoubleComplex *U,
int ldu,
const cuDoubleComplex *V,
int ldv,
int *lwork,
gesvdjInfo_t params,
int batchSize);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSgesvdjBatched(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int m,
int n,
float *A,
int lda,
float *S,
float *U,
int ldu,
float *V,
int ldv,
float *work,
int lwork,
int *info,
gesvdjInfo_t params,
int batchSize);
cusolverStatus_t
cusolverDnDgesvdjBatched(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int m,
int n,
double *A,
int lda,
double *S,
double *U,
int ldu,
double *V,
int ldv,
double *work,
int lwork,
int *info,
gesvdjInfo_t params,
int batchSize);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCgesvdjBatched(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int m,
int n,
cuComplex *A,
int lda,
float *S,
cuComplex *U,
int ldu,
cuComplex *V,
int ldv,
cuComplex *work,
int lwork,
int *info,
gesvdjInfo_t params,
int batchSize);
cusolverStatus_t
cusolverDnZgesvdjBatched(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int m,
int n,
cuDoubleComplex *A,
int lda,
double *S,
cuDoubleComplex *U,
int ldu,
cuDoubleComplex *V,
int ldv,
cuDoubleComplex *work,
int lwork,
int *info,
gesvdjInfo_t params,
int batchSize);
此函数计算一系列通用 \(m \times n\) 矩阵的奇异值和奇异向量
其中 \(\Sigma_{j}\) 是一个实数 \(m \times n\) 对角矩阵,除了其 min(m,n) 对角线元素外,其余均为零。\(U_{j}\) (左奇异向量) 是一个 \(m \times m\) 酉矩阵,\(V_{j}\) (右奇异向量) 是一个 \(n \times n\) 酉矩阵。\(\Sigma_{j}\) 的对角线元素是 \(A_{j}\) 的奇异值,按降序或非排序顺序排列。
gesvdjBatched 对每个矩阵执行 gesvdj。它要求所有矩阵的大小 m,n 都不大于 32,并且以连续方式打包,
每个矩阵都是列优先的,leading dimension 为 lda,因此随机访问的公式为 \(A_{k}\operatorname{(i,j)} = {A\lbrack\ i\ +\ lda*j\ +\ lda*n*k\rbrack}\) 。
参数 S 也以连续方式包含每个矩阵的奇异值,
S 的随机访问公式为 \(S_{k}\operatorname{(j)} = {S\lbrack\ j\ +\ min(m,n)*k\rbrack}\) 。
除了容差和最大扫描次数外,gesvdjBatched 还可以通过函数 cusolverDnXgesvdjSetSortEig 按降序(默认)或按原样(不排序)选择奇异值。如果用户将几个小矩阵打包到一个矩阵的对角块中,则非排序选项可以分隔这些小矩阵的奇异值。
gesvdjBatched 无法通过函数 cusolverDnXgesvdjGetResidual 和 cusolverDnXgesvdjGetSweeps 报告残差和执行的扫描次数。调用上述两个函数都将返回 CUSOLVER_STATUS_NOT_SUPPORTED。用户需要显式计算残差。
用户必须提供工作空间,该空间由输入参数 work 指向。输入参数 lwork 是工作空间的大小,它由 gesvdjBatched_bufferSize() 返回。请注意,工作空间的字节大小等于 sizeof(<type>) * lwork。
输出参数 info 是大小为 batchSize 的整数数组。如果函数返回 CUSOLVER_STATUS_INVALID_VALUE,则第一个元素 info[0] = -i (小于零) 表示第 i-th 个参数错误(不包括 handle)。否则,如果 info[i] = min(m,n)+1,则 gesvdjBatched 在给定的容差和最大扫描次数下未收敛到第 i-th 个矩阵。
请访问 cuSOLVER Library Samples - gesvdjBatched 以获取代码示例。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指定选项以仅计算奇异值或同时计算奇异向量: |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
<type> 大小为 |
|
|
|
|
|
|
|
维度为 |
|
|
|
填充了 Jacobi 算法参数的结构体。主机线程退出例程后,可以销毁 |
|
|
|
矩阵的数量。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
m,n<0或lda<max(1,m)或ldu<max(1,m)或ldv<max(1,n)或jobz不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTOR,或者batchSize<0)。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.10. cusolverDn<t>gesvdaStridedBatched()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnSgesvdaStridedBatched_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int rank,
int m,
int n,
const float *A,
int lda,
long long int strideA,
const float *S,
long long int strideS,
const float *U,
int ldu,
long long int strideU,
const float *V,
int ldv,
long long int strideV,
int *lwork,
int batchSize);
cusolverStatus_t
cusolverDnDgesvdaStridedBatched_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int rank,
int m,
int n,
const double *A,
int lda,
long long int strideA,
const double *S,
long long int strideS,
const double *U,
int ldu,
long long int strideU,
const double *V,
int ldv,
long long int strideV,
int *lwork,
int batchSize);
cusolverStatus_t
cusolverDnCgesvdaStridedBatched_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int rank,
int m,
int n,
const cuComplex *A,
int lda,
long long int strideA,
const float *S,
long long int strideS,
const cuComplex *U,
int ldu,
long long int strideU,
const cuComplex *V,
int ldv,
long long int strideV,
int *lwork,
int batchSize);
cusolverStatus_t
cusolverDnZgesvdaStridedBatched_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int rank,
int m,
int n,
const cuDoubleComplex *A,
int lda,
long long int strideA,
const double *S,
long long int strideS,
const cuDoubleComplex *U,
int ldu,
long long int strideU,
const cuDoubleComplex *V,
int ldv,
long long int strideV,
int *lwork,
int batchSize);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSgesvdaStridedBatched(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int rank,
int m,
int n,
const float *A,
int lda,
long long int strideA,
float *S,
long long int strideS,
float *U,
int ldu,
long long int strideU,
float *V,
int ldv,
long long int strideV,
float *work,
int lwork,
int *info,
double *h_R_nrmF,
int batchSize);
cusolverStatus_t
cusolverDnDgesvdaStridedBatched(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int rank,
int m,
int n,
const double *A,
int lda,
long long int strideA,
double *S,
long long int strideS,
double *U,
int ldu,
long long int strideU,
double *V,
int ldv,
long long int strideV,
double *work,
int lwork,
int *info,
double *h_R_nrmF,
int batchSize);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCgesvdaStridedBatched(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int rank,
int m,
int n,
const cuComplex *A,
int lda,
long long int strideA,
float *S,
long long int strideS,
cuComplex *U,
int ldu,
long long int strideU,
cuComplex *V,
int ldv,
long long int strideV,
cuComplex *work,
int lwork,
int *info,
double *h_R_nrmF,
int batchSize);
cusolverStatus_t
cusolverDnZgesvdaStridedBatched(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
int rank,
int m,
int n,
const cuDoubleComplex *A,
int lda,
long long int strideA,
double *S,
long long int strideS,
cuDoubleComplex *U,
int ldu,
long long int strideU,
cuDoubleComplex *V,
int ldv,
long long int strideV,
cuDoubleComplex *work,
int lwork,
int *info,
double *h_R_nrmF,
int batchSize);
此函数 gesvda (a 代表近似) 近似计算高瘦 \(m \times n\) 矩阵 A 的奇异值分解以及相应的左右奇异向量。SVD 的 economy form 形式可以写成
其中 Σ 是一个 \(n \times n\) 矩阵。U 是一个 \(m \times n\) 酉矩阵,V 是一个 \(n \times n\) 酉矩阵。Σ 的对角线元素是 A 的奇异值;它们是实数且非负,并按降序返回。U 和 V 是 A 的左右奇异向量。
gesvda 计算 A**T*A 或 A**H*A (如果 A 是复数) 的特征值,以近似计算奇异值和奇异向量。它生成矩阵 U 和 V 并将矩阵 A 转换为以下形式
其中 S 是对角矩阵,E 取决于舍入误差。在某些条件下,U、V 和 S 近似于单精度机器零的奇异值和奇异向量。一般来说,V 是酉矩阵,S 比 U 更准确。如果奇异值远离零,则左奇异向量 U 是准确的。换句话说,奇异值和左奇异向量的精度取决于奇异值与零之间的距离。由于 A**T*A 或 A**H*A 的计算会极大地放大误差,因此建议仅在条件良好的数据上使用 gesvda。
输入参数 rank 决定了在参数 S、U 和 V 中计算的奇异值和奇异向量的数量。
输出参数 h_RnrmF 计算残差的 Frobenius 范数。要计算 h_RnrmF,需要 info != NULL。
如果参数 rank 等于 n。否则,h_RnrmF 报告
在 Frobenius 范数意义上,即 U 离酉矩阵有多远。
gesvdaStridedBatched 对每个矩阵执行 gesvda。它要求所有矩阵的大小 m,n 相同,并且以连续方式打包,
每个矩阵都是列优先的,leading dimension 为 lda,因此随机访问的公式为 \(A_{k}\operatorname{(i,j)} = {A\lbrack\ i\ +\ lda*j\ +\ strideA*k\rbrack}\) 。类似地,S 的随机访问公式为 \(S_{k}\operatorname{(j)} = {S\lbrack\ j\ +\ StrideS*k\rbrack}\) ,U 的随机访问公式为 \(U_{k}\operatorname{(i,j)} = {U\lbrack\ i\ +\ ldu*j\ +\ strideU*k\rbrack}\) ,V 的随机访问公式为 \(V_{k}\operatorname{(i,j)} = {V\lbrack\ i\ +\ ldv*j\ +\ strideV*k\rbrack}\) 。
用户必须提供工作空间,该空间由输入参数 work 指向。输入参数 lwork 是工作空间的大小,它由 gesvdaStridedBatched_bufferSize() 返回。请注意,工作空间的字节大小等于 sizeof(<type>) * lwork。
输出参数 info 是大小为 batchSize 的整数数组。如果函数返回 CUSOLVER_STATUS_INVALID_VALUE,则第一个元素 info[0] = -i (小于零) 表示第 i-th 个参数错误(不包括 handle)。否则,如果 info[i] = min(m,n)+1,则 gesvdaStridedBatched 未能收敛到第 i-th 个矩阵。如果 0 < info[i] < min(m,n)+1,则 gesvdaStridedBatched 无法完全计算第 i-th 个矩阵的 SVD;前导奇异值 Si[k],0 <= k <= info[i]-1,以及相应的奇异向量可能仍然有用。在这种情况下,如果请求 h_RnrmF,则 h_RnrmF 报告残差,就好像 rank 设置为 info[i]-1 一样。
请访问 cuSOLVER Library Samples - gesvdaStridedBatched 以获取代码示例。
注 1:该例程返回 V,而不是 \(V^{H}\) 。这与 gesvd 不同。
注 2:该例程仅支持 m >=n。
注 3:建议使用 FP64 数据类型,即 DgesvdaStridedBatched 或 ZgesvdaStridedBatched。
注 4:如果用户对奇异值和奇异向量的精度有信心,例如,某些条件成立(所需的奇异值远离零),则可以通过将空指针传递给 h_RnrmF 来提高性能,即不计算残差范数。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指定选项以仅计算奇异值或同时计算奇异向量: |
|
|
|
奇异值的数量(从最大到最小)。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
类型为 long long int 的值,用于给出 |
|
|
|
维度为 |
|
|
|
类型为 long long int 的值,用于给出 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
类型为 long long int 的值,用于给出 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
类型为 long long int 的值,用于给出 |
|
|
|
<type> 大小为 |
|
|
|
|
|
|
|
维度为 |
|
|
|
大小为 |
|
|
|
矩阵的数量。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效的参数(
m,n<0或lda<max(1,m)或ldu<max(1,m)或ldv<max(1,n)或strideA<lda*n或strideS<rank或strideU<ldu*rank或strideV<ldv*rank或batchSize<1或jobz不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTOR)。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.11. cusolverDn<t>syevd()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnSsyevd_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const float *A,
int lda,
const float *W,
int *lwork);
cusolverStatus_t
cusolverDnDsyevd_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const double *A,
int lda,
const double *W,
int *lwork);
cusolverStatus_t
cusolverDnCheevd_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const cuComplex *A,
int lda,
const float *W,
int *lwork);
cusolverStatus_t
cusolverDnZheevd_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const cuDoubleComplex *A,
int lda,
const double *W,
int *lwork);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSsyevd(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
float *A,
int lda,
float *W,
float *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnDsyevd(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
double *A,
int lda,
double *W,
double *work,
int lwork,
int *devInfo);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCheevd(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
cuComplex *A,
int lda,
float *W,
cuComplex *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnZheevd(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
cuDoubleComplex *A,
int lda,
double *W,
cuDoubleComplex *work,
int lwork,
int *devInfo);
此函数计算对称(埃尔米特)\(n \times n\) 矩阵 A 的特征值和特征向量。标准的对称特征值问题是
其中 Λ 是实数 \(n \times n\) 对角矩阵。V 是 \(n \times n\) 酉矩阵。Λ 的对角元素是 A 的特征值,按升序排列。
用户必须提供工作空间,该空间由输入参数 work 指向。输入参数 lwork 是工作空间的大小,它由 syevd_bufferSize() 返回。请注意,工作空间的大小(以字节为单位)等于 sizeof(<type>) * lwork。
如果输出参数 devInfo = -i (小于零),则第 i-th 个参数错误(不包括 handle)。如果 devInfo = i (大于零),则中间三对角形式的 i 个非对角元素未收敛到零。
如果 jobz = CUSOLVER_EIG_MODE_VECTOR,则 A 包含矩阵 A 的标准正交特征向量。特征向量通过分治算法计算。
请访问 cuSOLVER Library Samples - syevd 以获取代码示例。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指定选项以仅计算特征值或计算特征对: |
|
|
|
指定存储 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
工作空间,大小为 |
|
|
|
|
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效的参数(
n<0,或lda<max(1,n),或jobz不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTOR,或uplo不是CUBLAS_FILL_MODE_LOWER或CUBLAS_FILL_MODE_UPPER)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.12. cusolverDnSyevd() [已弃用]
[[已弃用]] 请改用 cusolverDnXsyevd()。此例程将在下一个主要版本中移除。
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnSyevd_bufferSize(
cusolverDnHandle_t handle,
cusolverParams_t params,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType dataTypeW,
const void *W,
cudaDataType computeType,
size_t *workspaceInBytes);
以下例程
cusolverStatus_t
cusolverDnSyevd(
cusolverDnHandle_t handle,
cusolverParams_t params,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType dataTypeW,
const void *W,
cudaDataType computeType,
void *pBuffer,
size_t workspaceInBytes,
int *info);
使用通用 API 接口计算对称(埃尔米特)\(n \times n\) 矩阵 A 的特征值和特征向量。标准的对称特征值问题是
其中 Λ 是实数 \(n \times n\) 对角矩阵。V 是 \(n \times n\) 酉矩阵。Λ 的对角元素是 A 的特征值,按升序排列。
用户必须提供工作空间,该空间由输入参数 pBuffer 指向。输入参数 workspaceInBytes 是工作空间的大小(以字节为单位),它由 cusolverDnSyevd_bufferSize() 返回。
如果输出参数 info = -i (小于零),则第 i-th 个参数错误(不包括 handle)。如果 info = i (大于零),则中间三对角形式的 i 个非对角元素未收敛到零。
如果 jobz = CUSOLVER_EIG_MODE_VECTOR,则 A 包含矩阵 A 的标准正交特征向量。特征向量通过分治算法计算。
目前,cusolverDnSyevd 仅支持默认算法。
cusolverDnSyevd 支持的算法
|
默认算法。 |
cusolverDnSyevd_bufferSize 和 cusolverDnSyevd 的输入参数列表
|
|
|
|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
指定选项以仅计算特征值或计算特征对: |
|
|
|
指定存储 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
计算的数据类型。 |
|
|
|
工作空间。 类型为 |
|
|
|
|
|
|
|
如果 |
通用 API 具有三种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeW 是矩阵 W 的数据类型,computeType 是操作的计算类型。cusolverDnSyevd 仅支持以下四种组合。
数据类型和计算类型的有效组合
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效的参数(
n<0,或lda<max(1,n),或jobz不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTOR,或uplo不是CUBLAS_FILL_MODE_LOWER或CUBLAS_FILL_MODE_UPPER)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.13. cusolverDn<t>syevdx()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnSsyevdx_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
const float *A,
int lda,
float vl,
float vu,
int il,
int iu,
int *h_meig,
const float *W,
int *lwork);
cusolverStatus_t
cusolverDnDsyevdx_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
const double *A,
int lda,
double vl,
double vu,
int il,
int iu,
int *h_meig,
const double *W,
int *lwork);
cusolverStatus_t
cusolverDnCheevdx_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
const cuComplex *A,
int lda,
float vl,
float vu,
int il,
int iu,
int *h_meig,
const float *W,
int *lwork);
cusolverStatus_t
cusolverDnZheevdx_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
const cuDoubleComplex *A,
int lda,
double vl,
double vu,
int il,
int iu,
int *h_meig,
const double *W,
int *lwork);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSsyevdx(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
float *A,
int lda,
float vl,
float vu,
int il,
int iu,
int *h_meig,
float *W,
float *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnDsyevdx(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
double *A,
int lda,
double vl,
double vu,
int il,
int iu,
int *h_meig,
double *W,
double *work,
int lwork,
int *devInfo);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCheevdx(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
cuComplex *A,
int lda,
float vl,
float vu,
int il,
int iu,
int *h_meig,
float *W,
cuComplex *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnZheevdx(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
cuDoubleComplex *A,
int lda,
double vl,
double vu,
int il,
int iu,
int *h_meig,
double *W,
cuDoubleComplex *work,
int lwork,
int *devInfo);
此函数计算对称(埃尔米特)\(n \times n\) 矩阵 A 的所有或部分选定的特征值,以及可选的特征向量。标准的对称特征值问题是
其中 Λ 是实数 n×h_meig 对角矩阵。V 是 n×h_meig 酉矩阵。h_meig 是例程计算的特征值/特征向量的总数,当请求整个频谱(例如,range = CUSOLVER_EIG_RANGE_ALL)时,h_meig 等于 n。Λ 的对角元素是 A 的特征值,按升序排列。
用户必须提供工作空间,该空间由输入参数 work 指向。输入参数 lwork 是工作空间的大小,它由 syevdx_bufferSize() 返回。请注意,工作空间的大小(以字节为单位)等于 sizeof(<type>) * lwork。
如果输出参数 devInfo = -i (小于零),则第 i-th 个参数错误(不包括 handle)。如果 devInfo = i (大于零),则中间三对角形式的 i 个非对角元素未收敛到零。
如果 jobz = CUSOLVER_EIG_MODE_VECTOR,则 A 包含矩阵 A 的标准正交特征向量。特征向量通过分治算法计算。
请访问 cuSOLVER Library Samples - syevdx 以获取代码示例。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指定选项以仅计算特征值或计算特征对: |
|
|
|
指定需要计算哪些特征值和可选特征向量的选择选项: |
|
|
|
指定存储 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
实数值,对于 (C, S) 或 (Z, D) 精度分别为 float 或 double。如果 |
|
|
|
整数。如果 |
|
|
|
整数。找到的特征值总数。0 <= |
|
|
|
维度为 |
|
|
|
工作空间,大小为 |
|
|
|
|
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效的参数(
n<0,或lda<max(1,n),或jobz不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTOR,或range不是CUSOLVER_EIG_RANGE_ALL或CUSOLVER_EIG_RANGE_V或CUSOLVER_EIG_RANGE_I,或uplo不是CUBLAS_FILL_MODE_LOWER或CUBLAS_FILL_MODE_UPPER)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.14. cusolverDnSyevdx() [已弃用]
[[已弃用]] 请改用 cusolverDnXsyevdx()。此例程将在下一个主要版本中移除。
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnSyevdx_bufferSize(
cusolverDnHandle_t handle,
cusolverParams_t params,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
void *vl,
void *vu,
int64_t il,
int64_t iu,
int64_t *h_meig,
cudaDataType dataTypeW,
const void *W,
cudaDataType computeType,
size_t *workspaceInBytes);
以下例程
cusolverStatus_t
cusolverDnSyevdx (
cusolverDnHandle_t handle,
cusolverParams_t params,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
void *vl,
void *vu,
int64_t il,
int64_t iu,
int64_t *h_meig,
cudaDataType dataTypeW,
const void *W,
cudaDataType computeType,
void *pBuffer,
size_t workspaceInBytes,
int *info);
使用通用 API 接口计算对称(埃尔米特)\(n \times n\) 矩阵 A 的所有或部分选定的特征值,以及可选的特征向量。标准的对称特征值问题是
其中 Λ 是实数 n×h_meig 对角矩阵。V 是 n×h_meig 酉矩阵。h_meig 是例程计算的特征值/特征向量的总数,当请求整个频谱(例如,range = CUSOLVER_EIG_RANGE_ALL)时,h_meig 等于 n。Λ 的对角元素是 A 的特征值,按升序排列。
用户必须提供工作空间,该空间由输入参数 pBuffer 指向。输入参数 workspaceInBytes 是工作空间的大小(以字节为单位),它由 cusolverDnSyevdx_bufferSize() 返回。
如果输出参数 info = -i (小于零),则第 i-th 个参数错误(不包括 handle)。如果 info = i (大于零),则中间三对角形式的 i 个非对角元素未收敛到零。
如果 jobz = CUSOLVER_EIG_MODE_VECTOR,则 A 包含矩阵 A 的标准正交特征向量。特征向量通过分治算法计算。
目前,cusolverDnSyevdx 仅支持默认算法。
cusolverDnSyevdx 支持的算法
|
默认算法。 |
cusolverDnSyevdx_bufferSize 和 cusolverDnSyevdx 的输入参数列表
|
|
|
|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
指定选项以仅计算特征值或计算特征对: |
|
|
|
指定需要计算哪些特征值和可选特征向量的选择选项: |
|
|
|
指定存储 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
如果 |
|
|
|
整数。如果 |
|
|
|
整数。找到的特征值总数。0 <= h_meig <= n。如果 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
计算的数据类型。 |
|
|
|
工作空间。 类型为 |
|
|
|
|
|
|
|
如果 |
通用 API 具有三种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeW 是矩阵 W 的数据类型,computeType 是操作的计算类型。cusolverDnSyevdx 仅支持以下四种组合。
数据类型和计算类型的有效组合
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。 |
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。 |
CUSOLVER_STATUS_INVALID_VALUE传递了无效的参数(
n<0,或lda<max(1,n),或jobz不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTOR,或range不是CUSOLVER_EIG_RANGE_ALL或CUSOLVER_EIG_RANGE_V或CUSOLVER_EIG_RANGE_I,或uplo不是CUBLAS_FILL_MODE_LOWER或CUBLAS_FILL_MODE_UPPER)。 |CUSOLVER_STATUS_ARCH_MISMATCH该设备仅支持计算能力 5.0 及以上。 |
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。 |
2.4.3.15. cusolverDn<t>sygvd()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnSsygvd_bufferSize(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const float *A,
int lda,
const float *B,
int ldb,
const float *W,
int *lwork);
cusolverStatus_t
cusolverDnDsygvd_bufferSize(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const double *A,
int lda,
const double *B,
int ldb,
const double *W,
int *lwork);
cusolverStatus_t
cusolverDnChegvd_bufferSize(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const cuComplex *A,
int lda,
const cuComplex *B,
int ldb,
const float *W,
int *lwork);
cusolverStatus_t
cusolverDnZhegvd_bufferSize(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const cuDoubleComplex *A,
int lda,
const cuDoubleComplex *B,
int ldb,
const double *W,
int *lwork);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSsygvd(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
float *A,
int lda,
float *B,
int ldb,
float *W,
float *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnDsygvd(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
double *A,
int lda,
double *B,
int ldb,
double *W,
double *work,
int lwork,
int *devInfo);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnChegvd(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
cuComplex *A,
int lda,
cuComplex *B,
int ldb,
float *W,
cuComplex *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnZhegvd(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
cuDoubleComplex *A,
int lda,
cuDoubleComplex *B,
int ldb,
double *W,
cuDoubleComplex *work,
int lwork,
int *devInfo);
此函数计算对称(埃尔米特)\(n \times n\) 矩阵对 (A,B) 的特征值和特征向量。广义对称正定特征值问题是

矩阵 B 是正定矩阵。Λ 是一个实数 \(n \times n\) 对角矩阵。Λ 的对角元素是 (A, B) 的特征值,并按升序排列。V 是一个 \(n \times n\) 正交矩阵。特征向量按如下方式归一化
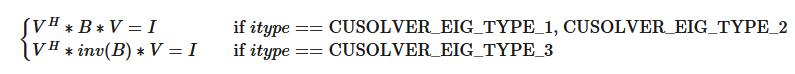
用户必须提供工作空间,该空间由输入参数 work 指向。输入参数 lwork 是工作空间的大小,它由 sygvd_bufferSize() 返回。请注意,工作空间的大小(以字节为单位)等于 sizeof(<type>) * lwork。
如果输出参数 devInfo = -i (小于零),则第 i-th 个参数错误(不包括句柄)。如果 devInfo = i (i > 0 且 i<=n) 且 jobz = CUSOLVER_EIG_MODE_NOVECTOR,则中间三对角形式的 i 个非对角元素未收敛到零。如果 devInfo = N + i (i > 0),则 B 的 i 阶顺序主子式不是正定的。B 的分解无法完成,并且未计算特征值或特征向量。
如果 jobz = CUSOLVER_EIG_MODE_VECTOR,则 A 包含矩阵 A 的正交特征向量。特征向量通过分治算法计算。
请访问 cuSOLVER 库示例 - sygvd 查看代码示例。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指定要解决的问题类型
|
|
|
|
指定选项以仅计算特征值或计算特征对: |
|
|
|
指定存储 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
工作空间,大小为 |
|
|
|
|
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
n<0,或lda<max(1,n),或ldb<max(1,n),或itype不是 1、2 或 3,或jobz不是 'N' 或 'V',或uplo不是CUBLAS_FILL_MODE_LOWER或CUBLAS_FILL_MODE_UPPER)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.16. cusolverDn<t>sygvdx()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnSsygvdx_bufferSize(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
const float *A,
int lda,
const float *B,
int ldb,
float vl,
float vu,
int il,
int iu,
int *h_meig,
const float *W,
int *lwork);
cusolverStatus_t
cusolverDnDsygvdx_bufferSize(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
const double *A,
int lda,
const double *B,
int ldb,
double vl,
double vu,
int il,
int iu,
int *h_meig,
const double *W,
int *lwork);
cusolverStatus_t
cusolverDnChegvdx_bufferSize(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
const cuComplex *A,
int lda,
const cuComplex *B,
int ldb,
float vl,
float vu,
int il,
int iu,
int *h_meig,
const float *W,
int *lwork);
cusolverStatus_t
cusolverDnZhegvdx_bufferSize(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
const cuDoubleComplex *A,
int lda,
const cuDoubleComplex *B,
int ldb,
double vl,
double vu,
int il,
int iu,
int *h_meig,
const double *W,
int *lwork);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSsygvdx(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
float *A,
int lda,
float *B,
int ldb,
float vl,
float vu,
int il,
int iu,
int *h_meig,
float *W,
float *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnDsygvdx(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
double *A,
int lda,
double *B,
int ldb,
double vl,
double vu,
int il,
int iu,
int *h_meig,
double *W,
double *work,
int lwork,
int *devInfo);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnChegvdx(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
cuComplex *A,
int lda,
cuComplex *B,
int ldb,
float vl,
float vu,
int il,
int iu,
int *h_meig,
float *W,
cuComplex *work,
int lwork,
int *devInfo);
cusolverStatus_t
cusolverDnZhegvdx(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int n,
cuDoubleComplex *A,
int lda,
cuDoubleComplex *B,
int ldb,
double vl,
double vu,
int il,
int iu,
int *h_meig,
double *W,
cuDoubleComplex *work,
int lwork,
int *devInfo);
此函数计算对称(Hermitian)\(n \times n\) 矩阵对 (A,B) 的所有或部分特征值,以及可选的特征向量。广义对称正定特征值问题是
其中矩阵 B 是正定的。Λ 是一个实数 \(n \times {h\_meig}\) 对角矩阵。Λ 的对角元素是 (A, B) 的特征值,并按升序排列。V 是一个 \(n \times {h\_meig}\) 正交矩阵。h_meig 是例程计算的特征值/特征向量的数量,当请求整个频谱(例如,range = CUSOLVER_EIG_RANGE_ALL)时,h_meig 等于 n。特征向量按如下方式归一化
用户必须提供工作空间,该空间由输入参数 work 指向。输入参数 lwork 是工作空间的大小,它由 sygvdx_bufferSize() 返回。请注意,工作空间的大小(以字节为单位)等于 sizeof(<type>) * lwork。
如果输出参数 devInfo = -i (小于零),则第 i-th 个参数错误(不包括句柄)。如果 devInfo = i (i > 0 且 i<=n) 且 jobz = CUSOLVER_EIG_MODE_NOVECTOR,则中间三对角形式的 i 个非对角元素未收敛到零。如果 devInfo = n + i (i > 0),则 B 的 i 阶顺序主子式不是正定的。B 的分解无法完成,并且未计算特征值或特征向量。
如果 jobz = CUSOLVER_EIG_MODE_VECTOR,则 A 包含矩阵 A 的正交特征向量。特征向量通过分治算法计算。
请访问 cuSOLVER 库示例 - sygvdx 查看代码示例。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指定要解决的问题类型
|
|
|
|
指定选项以仅计算特征值或计算特征对: |
|
|
|
指定需要计算特征值和可选特征向量的选择选项: |
|
|
|
指定存储 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
实数值浮点型或双精度型,分别用于 (C, S) 或 (Z, D) 精度。如果 |
|
|
|
整数。如果 |
|
|
|
整数。找到的特征值总数。0 <= h_meig <= n。如果 |
|
|
|
维度为 |
|
|
|
工作空间,大小为 |
|
|
|
|
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
n<0,或lda<max(1,n),或ldb<max(1,n),或itype不是CUSOLVER_EIG_TYPE_1或CUSOLVER_EIG_TYPE_2或CUSOLVER_EIG_TYPE_3,或jobz不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTORL,或range不是CUSOLVER_EIG_RANGE_ALL或CUSOLVER_EIG_RANGE_V或CUSOLVER_EIG_RANGE_I,或uplo不是CUBLAS_FILL_MODE_LOWER或CUBLAS_FILL_MODE_UPPER)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.17. cusolverDn<t>syevj()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnSsyevj_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const float *A,
int lda,
const float *W,
int *lwork,
syevjInfo_t params);
cusolverStatus_t
cusolverDnDsyevj_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const double *A,
int lda,
const double *W,
int *lwork,
syevjInfo_t params);
cusolverStatus_t
cusolverDnCheevj_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const cuComplex *A,
int lda,
const float *W,
int *lwork,
syevjInfo_t params);
cusolverStatus_t
cusolverDnZheevj_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const cuDoubleComplex *A,
int lda,
const double *W,
int *lwork,
syevjInfo_t params);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSsyevj(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
float *A,
int lda,
float *W,
float *work,
int lwork,
int *info,
syevjInfo_t params);
cusolverStatus_t
cusolverDnDsyevj(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
double *A,
int lda,
double *W,
double *work,
int lwork,
int *info,
syevjInfo_t params);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCheevj(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
cuComplex *A,
int lda,
float *W,
cuComplex *work,
int lwork,
int *info,
syevjInfo_t params);
cusolverStatus_t
cusolverDnZheevj(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
cuDoubleComplex *A,
int lda,
double *W,
cuDoubleComplex *work,
int lwork,
int *info,
syevjInfo_t params);
此函数计算对称(埃尔米特)\(n \times n\) 矩阵 A 的特征值和特征向量。标准的对称特征值问题是
其中 Λ 是一个实数 \(n \times n\) 对角矩阵。Q 是一个 \(n \times n\) 酉矩阵。Λ 的对角元素是 A 的特征值,并按升序排列。
syevj 具有与 syevd 相同的功能。不同之处在于 syevd 使用 QR 算法,而 syevj 使用 Jacobi 方法。Jacobi 方法的并行性使 GPU 在中小型矩阵上具有更好的性能。此外,用户可以配置 syevj 以执行达到一定精度的近似。
它是如何工作的?
syevj 迭代地生成酉矩阵序列以将矩阵 A 变换为以下形式
其中 W 是对角矩阵,E 是没有对角线的对称矩阵。
在迭代过程中,E 的 Frobenius 范数单调递减。当 E 降至零时,W 是特征值集。实际上,如果满足以下条件,Jacobi 方法将停止
其中 eps 是给定的容差。
syevj 有两个参数来控制精度。第一个参数是容差 (eps)。默认值为机器精度,但用户可以使用函数 cusolverDnXsyevjSetTolerance 设置先验容差。第二个参数是最大扫描次数,它控制 Jacobi 方法的迭代次数。默认值为 100,但用户可以使用函数 cusolverDnXsyevjSetMaxSweeps 设置合适的界限。实验表明,15 次扫描足以收敛到机器精度。syevj 在满足容差或达到最大扫描次数时停止。
Jacobi 方法具有二次收敛性,因此精度与扫描次数不成正比。为了保证一定的精度,用户应仅配置容差。
在 syevj 之后,用户可以通过函数 cusolverDnXsyevjGetResidual 查询残差,并通过函数 cusolverDnXsyevjGetSweeps 查询执行的扫描次数。但是,用户需要注意的是,残差是 E 的 Frobenius 范数,而不是单个特征值的精度,即
与 syevd 相同,用户必须提供由输入参数 work 指向的工作空间。输入参数 lwork 是工作空间的大小,它由 syevj_bufferSize() 返回。请注意,工作空间的大小(以字节为单位)等于 sizeof(<type>) * lwork。
如果输出参数 info = -i (小于零),则第 i-th 个参数错误(不包括句柄)。如果 info = n+1,则 syevj 在给定的容差和最大扫描次数下不收敛。
如果用户设置了不合适的容差,则 syevj 可能不收敛。例如,容差不应小于机器精度。
如果 jobz = CUSOLVER_EIG_MODE_VECTOR,则 A 包含标准正交特征向量 V。
请访问 cuSOLVER 库示例 - syevj 查看代码示例。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指定选项以仅计算特征值或计算特征对: |
|
|
|
指定存储 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
工作空间,大小为 |
|
|
|
|
|
|
|
如果 |
|
|
|
填充了 Jacobi 算法的参数和 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效的参数(
n<0,或lda<max(1,n),或jobz不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTOR,或uplo不是CUBLAS_FILL_MODE_LOWER或CUBLAS_FILL_MODE_UPPER)。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.18. cusolverDn<t>sygvj()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnSsygvj_bufferSize(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const float *A,
int lda,
const float *B,
int ldb,
const float *W,
int *lwork,
syevjInfo_t params);
cusolverStatus_t
cusolverDnDsygvj_bufferSize(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const double *A,
int lda,
const double *B,
int ldb,
const double *W,
int *lwork,
syevjInfo_t params);
cusolverStatus_t
cusolverDnChegvj_bufferSize(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const cuComplex *A,
int lda,
const cuComplex *B,
int ldb,
const float *W,
int *lwork,
syevjInfo_t params);
cusolverStatus_t
cusolverDnZhegvj_bufferSize(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const cuDoubleComplex *A,
int lda,
const cuDoubleComplex *B,
int ldb,
const double *W,
int *lwork,
syevjInfo_t params);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSsygvj(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
float *A,
int lda,
float *B,
int ldb,
float *W,
float *work,
int lwork,
int *info,
syevjInfo_t params);
cusolverStatus_t
cusolverDnDsygvj(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
double *A,
int lda,
double *B,
int ldb,
double *W,
double *work,
int lwork,
int *info,
syevjInfo_t params);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnChegvj(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
cuComplex *A,
int lda,
cuComplex *B,
int ldb,
float *W,
cuComplex *work,
int lwork,
int *info,
syevjInfo_t params);
cusolverStatus_t
cusolverDnZhegvj(
cusolverDnHandle_t handle,
cusolverEigType_t itype,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
cuDoubleComplex *A,
int lda,
cuDoubleComplex *B,
int ldb,
double *W,
cuDoubleComplex *work,
int lwork,
int *info,
syevjInfo_t params);
此函数计算对称(埃尔米特)\(n \times n\) 矩阵对 (A,B) 的特征值和特征向量。广义对称正定特征值问题是
矩阵 B 是正定矩阵。Λ 是一个实数 \(n \times n\) 对角矩阵。Λ 的对角元素是 (A, B) 的特征值,并按升序排列。V 是一个 \(n \times n\) 正交矩阵。特征向量按如下方式归一化
此函数具有与 sygvd 相同的功能,不同之处在于 sygvd 中的 syevd 被 sygvj 中的 syevj 替换。因此,sygvj 继承了 syevj 的属性,用户可以使用 cusolverDnXsyevjSetTolerance 和 cusolverDnXsyevjSetMaxSweeps 来配置容差和最大扫描次数。
但是,残差的含义与 syevj 不同。sygvj 首先计算矩阵 B 的 Cholesky 分解,
将问题转换为标准特征值问题,然后调用 syevj。
例如,类型 I 的标准特征值问题是
其中矩阵 M 是对称矩阵
残差是 syevj 在矩阵 M 上的结果,而不是 A 上的结果。
用户必须提供工作空间,该空间由输入参数 work 指向。输入参数 lwork 是工作空间的大小,它由 sygvj_bufferSize() 返回。请注意,工作空间的大小(以字节为单位)等于 sizeof(<type>) * lwork。
如果输出参数 info = -i (小于零),则第 i-th 个参数错误(不包括句柄)。如果 info = i (i > 0 且 i<=n),则 B 不是正定的,B 的分解无法完成,并且未计算特征值或特征向量。如果 info = n+1,则 syevj 在给定的容差和最大扫描次数下不收敛。在这种情况下,特征值和特征向量仍然被计算,因为不收敛来自不合适的容差或最大扫描次数。
如果 jobz = CUSOLVER_EIG_MODE_VECTOR,则 A 包含正交特征向量 V。
请访问 cuSOLVER 库示例 - sygvj 查看代码示例。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指定要解决的问题类型: |
|
|
|
指定选项以仅计算特征值或计算特征对: |
|
|
|
指定存储 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
工作空间,大小为 |
|
|
|
|
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n<0,或lda<max(1,n),或ldb<max(1,n),或itype不是 1、2 或 3,或jobz不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTOR,或uplo不是CUBLAS_FILL_MODE_LOWER或CUBLAS_FILL_MODE_UPPER)。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.3.19. cusolverDn<t>syevjBatched()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnSsyevjBatched_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const float *A,
int lda,
const float *W,
int *lwork,
syevjInfo_t params,
int batchSize
);
cusolverStatus_t
cusolverDnDsyevjBatched_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const double *A,
int lda,
const double *W,
int *lwork,
syevjInfo_t params,
int batchSize
);
cusolverStatus_t
cusolverDnCheevjBatched_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const cuComplex *A,
int lda,
const float *W,
int *lwork,
syevjInfo_t params,
int batchSize
);
cusolverStatus_t
cusolverDnZheevjBatched_bufferSize(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
const cuDoubleComplex *A,
int lda,
const double *W,
int *lwork,
syevjInfo_t params,
int batchSize
);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverDnSsyevjBatched(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
float *A,
int lda,
float *W,
float *work,
int lwork,
int *info,
syevjInfo_t params,
int batchSize
);
cusolverStatus_t
cusolverDnDsyevjBatched(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
double *A,
int lda,
double *W,
double *work,
int lwork,
int *info,
syevjInfo_t params,
int batchSize
);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverDnCheevjBatched(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
cuComplex *A,
int lda,
float *W,
cuComplex *work,
int lwork,
int *info,
syevjInfo_t params,
int batchSize
);
cusolverStatus_t
cusolverDnZheevjBatched(
cusolverDnHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int n,
cuDoubleComplex *A,
int lda,
double *W,
cuDoubleComplex *work,
int lwork,
int *info,
syevjInfo_t params,
int batchSize
);
此函数计算一系列对称(埃尔米特)\(n \times n\) 矩阵的特征值和特征向量
其中 \(\Lambda_{j}\) 是一个实数 \(n \times n\) 对角矩阵。\(Q_j\) 是一个 \(n \times n\) 酉矩阵。\(\Lambda_j\) 的对角元素是 \(A_j\) 的特征值,可以是升序排列或非排序顺序。
syevjBatched 对每个矩阵执行 syevj。它要求所有矩阵的大小相同 n 并且以连续的方式打包,
每个矩阵都是列优先的,leading dimension 为 lda,因此随机访问的公式为 \(A_{k}\operatorname{(i,j)} = {A\lbrack\ i\ +\ lda*j\ +\ lda*n*k\rbrack}\) 。
参数 W 也以连续的方式包含每个矩阵的特征值,
W 的随机访问公式是 \(W_{k}\operatorname{(j)} = {W\lbrack\ j\ +\ n*k\rbrack}\) 。
除了容差和最大扫描次数外,syevjBatched 可以通过函数 cusolverDnXsyevjSetSortEig 对特征值进行升序排序(默认)或选择原样(不排序)。如果用户将几个微小矩阵打包到一个矩阵的对角块中,则非排序选项可以分离这些微小矩阵的频谱。
syevjBatched 无法通过函数 cusolverDnXsyevjGetResidual 和 cusolverDnXsyevjGetSweeps 报告残差和执行的扫描次数。调用上述两个函数中的任何一个都将返回 CUSOLVER_STATUS_NOT_SUPPORTED。用户需要显式计算残差。
用户必须提供由输入参数 work 指向的工作空间。输入参数 lwork 是工作空间的大小,它由 syevjBatched_bufferSize() 返回。请注意,工作空间的大小(以字节为单位)等于 sizeof(<type>) * lwork。
输出参数 info 是大小为 batchSize 的整数数组。如果函数返回 CUSOLVER_STATUS_INVALID_VALUE,则第一个元素 info[0] = -i (小于零)表示第 i-th 个参数错误(不包括句柄)。否则,如果 info[i] = n+1,则 syevjBatched 在给定的容差和最大扫描次数下,在第 i-th 个矩阵上不收敛。
如果 jobz = CUSOLVER_EIG_MODE_VECTOR,则 \(A_j\) 包含正交特征向量 \(V_j\)。
请访问 cuSOLVER 库示例 - syevjBatched 以获取代码示例。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指定选项以仅计算特征值或计算特征对: |
|
|
|
指定存储 |
|
|
|
每个矩阵 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
维度为 |
|
|
|
大小为 |
|
|
|
|
|
|
|
维度为 |
|
|
|
填充了 Jacobi 算法参数的结构。 |
|
|
|
矩阵的数量。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n<0,或lda<max(1,n),或jobz不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTOR,或uplo不是CUBLAS_FILL_MODE_LOWER或CUBLAS_FILL_MODE_UPPER),或batchSize<0。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.4. 密集线性求解器参考(64 位 API)
本节介绍 cuSolverDN 的线性求解器 64 位 API,包括 Cholesky 分解、带部分主元的 LU 分解和 QR 分解。
2.4.4.1. cusolverDnXpotrf()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnXpotrf_bufferSize(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cublasFillMode_t uplo,
int64_t n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType computeType,
size_t *workspaceInBytesOnDevice,
size_t *workspaceInBytesOnHost)
以下例程
cusolverStatus_t
cusolverDnXpotrf(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cublasFillMode_t uplo,
int64_t n,
cudaDataType dataTypeA,
void *A,
int64_t lda,
cudaDataType computeType,
void *bufferOnDevice,
size_t workspaceInBytesOnDevice,
void *bufferOnHost,
size_t workspaceInBytesOnHost,
int *info )
使用通用 API 接口计算 Hermitian 正定矩阵的 Cholesky 分解。
A 是一个 \(n \times n\) Hermitian 矩阵,只有下三角或上三角部分有意义。输入参数 uplo 指示使用矩阵的哪个部分。该函数将保留其他部分不变。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_LOWER,则仅处理 A 的下三角部分,并将其替换为下三角 Cholesky 因子 L。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_UPPER,则仅处理 A 的上三角部分,并将其替换为上三角 Cholesky 因子 U。
用户必须提供设备和主机工作空间,它们由输入参数 bufferOnDevice 和 bufferOnHost 指向。输入参数 workspaceInBytesOnDevice (和 workspaceInBytesOnHost)是以字节为单位的设备(和主机)工作空间大小,它由 cusolverDnXpotrf_bufferSize() 返回。
如果 Cholesky 分解失败,即 A 的某些前导子式不是正定的,或者等效地,L 或 U 的某些对角线元素不是实数。 输出参数 info 将指示 A 的最小前导子式,该子式不是正定的。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
目前,cusolverDnXpotrf 仅支持默认算法。
请访问 cuSOLVER 库示例 - Xpotrf 以获取代码示例。
cusolverDnXpotrf 支持的算法
|
默认算法。 |
用于 cusolverDnXpotrf_bufferSize 和 cusolverDnXpotrf 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
指示是否存储矩阵 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
计算的数据类型。 |
|
|
|
设备工作空间。类型为 |
|
|
|
|
|
|
|
主机工作空间。类型为 |
|
|
|
|
|
|
|
如果 |
通用 API 有两种不同的类型,dataTypeA 是矩阵 A 的数据类型,computeType 是运算的计算类型。cusolverDnXpotrf 仅支持以下四种组合。
数据类型和计算类型的有效组合
DataTypeA |
ComputeType |
含义 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n<0或lda<max(1,n))。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.4.2. cusolverDnXpotrs()
cusolverStatus_t
cusolverDnXpotrs(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cublasFillMode_t uplo,
int64_t n,
int64_t nrhs,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType dataTypeB,
void *B,
int64_t ldb,
int *info)
此函数求解线性方程组
其中 A 是一个 \(n \times n\) 埃尔米特矩阵,使用通用 API 接口时,只有下半部分或上半部分是有意义的。输入参数 uplo 指示使用矩阵的哪一部分。该函数将保持另一部分不变。
用户必须首先调用 cusolverDnXpotrf 来分解矩阵 A。如果输入参数 uplo 是 CUBLAS_FILL_MODE_LOWER,则 A 是对应于 \(A = L*L^{H}\) 的下三角 Cholesky 因子 L。如果输入参数 uplo 是 CUBLAS_FILL_MODE_UPPER,则 A 是对应于 \(A = U^{H}*U\) 的上三角 Cholesky 因子 U。
该操作是就地操作,即矩阵 X 使用相同的前导维度 ldb 覆盖矩阵 B。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
目前,cusolverDnXpotrs 仅支持默认算法。
请访问 cuSOLVER 库示例 - Xpotrf 以获取代码示例。
cusolverDnXpotrs 支持的算法
|
默认算法。 |
用于 cusolverDnXpotrs 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
指示是否存储矩阵 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
如果 |
通用 API 有两种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeB 是矩阵 B 的数据类型。cusolverDnXpotrs 仅支持以下四种组合。
数据类型和计算类型的有效组合
dataTypeA |
dataTypeB |
含义 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n<0、nrhs<0、lda<max(1,n)或ldb<max(1,n))。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.4.3. cusolverDnXgetrf()
下面的辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t cusolverDnXgetrf_bufferSize(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
int64_t m,
int64_t n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType computeType,
size_t *workspaceInBytesOnDevice,
size_t *workspaceInBytesOnHost)
以下函数
cusolverStatus_t
cusolverDnXgetrf(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
int64_t m,
int64_t n,
cudaDataType dataTypeA,
void *A,
int64_t lda,
int64_t *ipiv,
cudaDataType computeType,
void *bufferOnDevice,
size_t workspaceInBytesOnDevice,
void *bufferOnHost,
size_t workspaceInBytesOnHost,
int *info )
计算 \(m \times n\) 矩阵的 LU 分解
其中 A 是一个 \(m \times n\) 矩阵,P 是一个置换矩阵,L 是一个单位对角线下三角矩阵,而 U 是一个使用通用 API 接口的上三角矩阵。
如果 LU 分解失败,即矩阵 A (U) 是奇异的,则输出参数 info=i 指示 U(i,i) = 0。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
如果 ipiv 为空,则不执行主元选择。分解为 A=L*U,这在数值上是不稳定的。
无论 LU 分解是否失败,输出参数 ipiv 都包含主元选择序列,第 i 行与第 ipiv(i) 行互换。
用户必须提供设备和主机工作空间,它们由输入参数 bufferOnDevice 和 bufferOnHost 指向。输入参数 workspaceInBytesOnDevice (和 workspaceInBytesOnHost)是以字节为单位的设备(和主机)工作空间大小,它由 cusolverDnXgetrf_bufferSize() 返回。
用户可以将 cusolverDnXgetrf 和 cusolverDnGetrs 组合起来完成线性求解器。
目前,cusolverDnXgetrf 支持两种算法。要选择旧版实现,用户必须调用 cusolverDnSetAdvOptions。
请访问 cuSOLVER 库示例 - Xgetrf 以获取代码示例。
cusolverDnXgetrf 支持的算法
|
默认算法。最快,需要一个大小为 |
|
传统实现方式 |
用于 cusolverDnXgetrf_bufferSize 和 cusolverDnXgetrf 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
大小至少为 |
|
|
|
计算的数据类型。 |
|
|
|
设备工作空间。类型为 |
|
|
|
|
|
|
|
主机工作空间。类型为 |
|
|
|
|
|
|
|
如果 |
通用 API 有两种不同的类型,dataTypeA 是矩阵 A 的数据类型,computeType 是运算的计算类型。cusolverDnXgetrf 仅支持以下四种组合。
数据类型和计算类型的有效组合
DataTypeA |
ComputeType |
含义 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
m,n<0或lda<max(1,m))。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.4.4. cusolverDnXgetrs()
cusolverStatus_t
cusolverDnXgetrs(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cublasOperation_t trans,
int64_t n,
int64_t nrhs,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
const int64_t *ipiv,
cudaDataType dataTypeB,
void *B,
int64_t ldb,
int *info )
此函数求解具有多个右手边的线性系统
其中 A 是一个 \(n \times n\) 矩阵,并且已通过 cusolverDnXgetrf 进行 LU 分解,即 A 的下三角部分是 L,A 的上三角部分(包括对角元素)是 U。B 是一个 \(n \times {nrhs}\) 右侧矩阵,使用通用 API 接口。
输入参数 trans 由下式定义
输入参数 ipiv 是 cusolverDnXgetrf 的输出。它包含主元索引,用于置换右侧。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
用户可以将 cusolverDnXgetrf 和 cusolverDnXgetrs 组合起来完成线性求解器。
目前,cusolverDnXgetrs 仅支持默认算法。
请访问 cuSOLVER 库示例 - Xgetrf 以获取代码示例。
cusolverDnXgetrs 支持的算法
|
默认算法。 |
用于 cusolverDnXgetrs 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
运算 |
|
|
|
矩阵 |
|
|
|
右手边的数量。 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
大小至少为 |
|
|
|
数组 |
|
|
|
<type> 维度为 |
|
|
|
用于存储矩阵 |
|
|
|
如果 |
通用 API 有两种不同的类型:dataTypeA 是矩阵 A 的数据类型,dataTypeB 是矩阵 B 的数据类型。cusolverDnXgetrs 仅支持以下四种组合
数据类型和计算类型的有效组合
DataTypeA |
dataTypeB |
含义 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n<0或lda<max(1,n)或ldb<max(1,n))。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.4.5. cusolverDnXgeqrf()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnXgeqrf_bufferSize(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
int64_t m,
int64_t n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType dataTypeTau,
const void *tau,
cudaDataType computeType,
size_t *workspaceInBytesOnDevice,
size_t *workspaceInBytesOnHost)
以下例程
cusolverStatus_t cusolverDnXgeqrf(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
int64_t m,
int64_t n,
cudaDataType dataTypeA,
void *A,
int64_t lda,
cudaDataType dataTypeTau,
void *tau,
cudaDataType computeType,
void *bufferOnDevice,
size_t workspaceInBytesOnDevice,
void *bufferOnHost,
size_t workspaceInBytesOnHost,
int *info )
计算 \(m \times n\) 矩阵的 QR 分解
其中 A 是一个 \(m \times n\) 矩阵,Q 是一个 \(m \times n\) 矩阵,而 R 是一个使用通用 API 接口的 \(n \times n\) 上三角矩阵。
用户必须提供设备和主机工作空间,它们由输入参数 bufferOnDevice 和 bufferOnHost 指向。输入参数 workspaceInBytesOnDevice (和 workspaceInBytesOnHost)是以字节为单位的设备(和主机)工作空间大小,它由 cusolverDnXgeqrf_bufferSize() 返回。
矩阵 R 在 A 的上三角部分(包括对角线元素)中被覆盖。
矩阵 Q 不是显式形成的,而是将一系列 Householder 向量存储在 A 的下三角部分中。Householder 向量的引导非零元素被假定为 1,这样输出参数 TAU 包含比例因子 τ。如果 v 是原始 Householder 向量,q 是对应于 τ 的新 Householder 向量,满足以下关系
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
目前,cusolverDnXgeqrf 仅支持默认算法。
请访问 cuSOLVER 库示例 - Xgeqrf 以获取代码示例。
cusolverDnXgeqrf 支持的算法
|
默认算法。 |
用于 cusolverDnXgeqrf_bufferSize 和 cusolverDnXgeqrf 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
维度至少为 |
|
|
|
计算的数据类型。 |
|
|
|
设备工作空间。类型为 |
|
|
|
|
|
|
|
主机工作空间。类型为 |
|
|
|
|
|
|
|
如果 |
通用 API 有两种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeTau 是数组 tau 的数据类型,computeType 是运算的计算类型。cusolverDnXgeqrf 仅支持以下四种组合。
数据类型和计算类型的有效组合
DataTypeA |
ComputeType |
含义 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
m,n<0或lda<max(1,m))。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.4.6. cusolverDnXsytrs()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnXsytrs_bufferSize(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int64_t n,
int64_t nrhs,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
const int64_t *devIpiv,
cudaDataType dataTypeB,
void *B,
int64_t ldb,
size_t *workspaceInBytesOnDevice,
size_t *workspaceInBytesOnHost);
以下例程
cusolverStatus_t cusolverDnXsytrs(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
int64_t n,
int64_t nrhs,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
const int64_t *devIpiv,
cudaDataType dataTypeB,
void *B,
int64_t ldb,
void *bufferOnDevice,
size_t workspaceInBytesOnDevice,
void *bufferOnHost,
size_t workspaceInBytesOnHost,
int *devInfo);
使用通用 API 接口求解线性方程组。
A 包含来自 cusolverDnXsytrf() 的分解,只有下三角或上三角部分有意义,另一部分不会被触及。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_LOWER,则分解的详细信息存储为
如果输入参数 uplo 是 CUBLAS_FILL_MODE_UPPER,则分解的详细信息存储为
用户必须提供可以通过 cusolverDnXsytrf() 获得的主元索引,以及由输入参数 bufferOnDevice 和 bufferOnHost 指向的设备和主机工作空间。输入参数 workspaceInBytesOnDevice 和 workspaceInBytesOnHost 是设备和主机工作空间的大小(以字节为单位),它们由 cusolverDnXsytrs_bufferSize() 返回。要在没有主元的情况下分解和求解对称系统,用户应在调用 cusolverDnXsytrf 和 cusolverDnXsytrs 时设置 devIpiv = NULL。
如果输出参数 devInfo = -i(小于零),则第 i 个参数错误(不包括句柄)。
用于 cusolverDnXsytrs_bufferSize 和 cusolverDnXsytrs 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指示是否存储矩阵 |
|
|
|
矩阵 |
|
|
|
右手边的数量。 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
大小至少为 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
设备工作空间。类型为 |
|
|
|
|
|
|
|
主机工作空间。类型为 |
|
|
|
|
|
|
|
如果 |
通用 API 有两种不同的类型:dataTypeA 是矩阵 A 的数据类型,dataTypeB 是矩阵 A 的数据类型。cusolverDnXsytrs 仅支持以下四种组合
数据类型和计算类型的有效组合
DataTypeA |
DataTypeB |
含义 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n<0或lda<max(1,n))。CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED不支持的数据类型。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.4.7. cusolverDnXtrtri()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnXtrtri_bufferSize(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
cublasDiagType_t diag,
int64_t n,
cudaDataType dataTypeA,
void *A,
int64_t lda,
size_t *workspaceInBytesOnDevice,
size_t *workspaceInBytesOnHost);
以下例程
cusolverStatus_t
cusolverDnXtrtri(
cusolverDnHandle_t handle,
cublasFillMode_t uplo,
cublasDiagType_t diag,
int64_t n,
cudaDataType dataTypeA,
void *A,
int64_t lda,
void *bufferOnDevice,
size_t workspaceInBytesOnDevice,
void *bufferOnHost,
size_t workspaceInBytesOnHost,
int *info);
使用通用 API 接口计算三角矩阵的逆矩阵。
A 是一个 \(n \times n\) 三角矩阵,只有下三角或上三角部分有意义。输入参数 uplo 指示使用矩阵的哪个部分。该函数将保留其他部分不变。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_LOWER,则仅处理 A 的下三角部分,并替换为下三角逆矩阵。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_UPPER,则仅处理 A 的上三角部分,并替换为上三角逆矩阵。
用户必须提供设备和主机工作空间,它们由输入参数 bufferOnDevice 和 bufferOnHost 指向。输入参数 workspaceInBytesOnDevice 和 workspaceInBytesOnHost 是设备和主机工作空间的大小(以字节为单位),它们由 cusolverDnXtrtri_bufferSize() 返回。
如果矩阵求逆失败,则输出参数 info = i 显示 A(i,i) = 0。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
请访问 cuSOLVER 库示例 - Xtrtri 以获取代码示例。
用于 cusolverDnXtrtri_bufferSize 和 cusolverDnXtrtri 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
指示是否存储矩阵 |
|
|
|
枚举的单位对角线类型。 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
设备工作空间。类型为 |
|
|
|
|
|
|
|
主机工作空间。类型为 |
|
|
|
|
|
|
|
如果 |
有效数据类型
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_NOT_SUPPORTED不支持的数据类型。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n<0或lda<max(1,n))。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.4.8. cusolverDnXlarft()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t cusolverDnXlarft_bufferSize(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cusolverDirectMode_t direct,
cusolverStorevMode_t storev,
int64_t n,
int64_t k,
cudaDataType dataTypeV,
const void *V,
int64_t ldv,
cudaDataType dataTypeTau,
const void *tau,
cudaDataType dataTypeT,
void *T,
int64_t ldt,
cudaDataType computeType,
size_t *workspaceInBytesOnDevice,
size_t *workspaceInBytesOnHost)
以下例程
cusolverStatus_t cusolverDnXlarft(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cusolverDirectMode_t direct,
cusolverStorevMode_t storev,
int64_t n,
int64_t k,
cudaDataType dataTypeV,
const void *V,
int64_t ldv,
cudaDataType dataTypeTau,
const void *tau,
cudaDataType dataTypeT,
void *T,
int64_t ldt,
cudaDataType computeType,
void *bufferOnDevice,
size_t workspaceInBytesOnDevice,
void *bufferOnHost,
size_t workspaceInBytesOnHost)
形成实数块反射器 H 的三角因子 T,该反射器的阶数为 n,定义为 k 个初等反射器的乘积。如果
direct == CUBLAS_DIRECT_FORWARD:\(H = H(1) H(2) ... H(k)\) 且T为上三角矩阵;
direct == CUBLAS_DIRECT_BACKWARD:\(H = H(k) ... H(2) H(1)\) 且T为下三角矩阵。
仅支持 storev == CUBLAS_STOREV_COLUMNWISE,这表示定义初等反射器 H(i) 的向量存储在数组 V 的第 i 列中,并且 \(H = I - V * T * V^{T}\) (对于复数类型,\(H = I - V * T * V^{H}\))。
用户必须提供设备和主机工作空间,这些工作空间由输入参数 bufferOnDevice 和 bufferOnHost 指向。输入参数 workspaceInBytesOnDevice (和 workspaceInBytesOnHost)是设备(和主机)工作空间的大小(以字节为单位),它由 cusolverDnXlarft_bufferSize() 返回。
目前,仅支持 n >= k 的情况。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
指定将基本反射器相乘以形成块反射器的顺序。 |
|
|
|
指定定义基本反射器的向量的存储方式。 |
|
|
|
块反射器 |
|
|
|
三角因子 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
数组 |
|
|
|
数组 |
|
|
|
维度 |
|
|
|
数组 |
|
|
|
维度 |
|
|
|
数组 |
|
|
|
计算的数据类型。 |
|
|
|
设备工作空间。类型为 |
|
|
|
|
|
|
|
主机工作空间。类型为 |
|
|
|
|
通用 API 有四种不同的类型
dataTypeV是数组V的数据类型
dataTypeTau是数组tau的数据类型
dataTypeT是数组T的数据类型
computeType是运算的计算类型
cusolverDnXlarft 仅支持以下四种组合。
数据类型和计算类型的有效组合
DataTypeV |
DataTypeTau |
DataTypeT |
ComputeType |
含义 |
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n == 0、k > n或storev == CUBLAS_STOREV_ROWWISE)。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.5. 密集特征值求解器参考(64 位 API)
本节介绍 cuSolverDN 的特征值求解器 API,包括双对角化和 SVD。
2.4.5.1. cusolverDnXgesvd()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnXgesvd_bufferSize(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
signed char jobu,
signed char jobvt,
int64_t m,
int64_t n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType dataTypeS,
const void *S,
cudaDataType dataTypeU,
const void *U,
int64_t ldu,
cudaDataType dataTypeVT,
const void *VT,
int64_t ldvt,
cudaDataType computeType,
size_t *workspaceInBytesOnDevice,
size_t *workspaceInBytesOnHost)
以下例程
cusolverStatus_t
cusolverDnXgesvd(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
signed char jobu,
signed char jobvt,
int64_t m,
int64_t n,
cudaDataType dataTypeA,
void *A,
int64_t lda,
cudaDataType dataTypeS,
void *S,
cudaDataType dataTypeU,
void *U,
int64_t ldu,
cudaDataType dataTypeVT,
void *VT,
int64_t ldvt,
cudaDataType computeType,
void *bufferOnDevice,
size_t workspaceInBytesOnDevice,
void *bufferOnHost,
size_t workspaceInBytesOnHost,
int *info)
此函数计算 \(m \times n\) 矩阵 A 的奇异值分解 (SVD) 以及相应的左奇异向量和/或右奇异向量。SVD 写为
其中 Σ 是一个 \(m \times n\) 矩阵,除了其 min(m,n) 个对角元素外,其余均为零,U 是一个 \(m \times m\) 酉矩阵,V 是一个 \(n \times n\) 酉矩阵。Σ 的对角元素是 A 的奇异值;它们是实数且非负,并以降序返回。U 和 V 的前 min(m,n) 列分别是 A 的左奇异向量和右奇异向量。
用户必须提供设备和主机工作空间,这些工作空间由输入参数 bufferOnDevice 和 bufferOnHost 指向。输入参数 workspaceInBytesOnDevice (和 workspaceInBytesOnHost)是设备(和主机)工作空间的大小(以字节为单位),它由 cusolverDnXgesvd_bufferSize() 返回。
如果输出参数 info = -i(小于零),则第 i-th 个参数错误(不包括 handle)。如果 bdsqr 未收敛,则 info 指定中间双对角形式有多少条超对角线未收敛到零。
目前,cusolverDnXgesvd 仅支持默认算法。
cusolverDnXgesvd 支持的算法
|
默认算法。 |
请访问 cuSOLVER 库示例 - Xgesvd 以获取代码示例。
备注 1:gesvd 仅支持 m>=n。
备注 2:该例程返回 \(V^H\) ,而不是 V。
cusolverDnXgesvd_bufferSize 和 cusolverDnXgesvd 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
指定用于计算矩阵 |
|
|
|
指定用于计算矩阵 V**T 的全部或部分的选项:= ‘A’:V**T 的所有 N 行都将在数组 VT 中返回;= ‘S’:V**T 的前 min(m,n) 行(右奇异向量)将在数组 VT 中返回;= ‘O’:V**T 的前 min(m,n) 行(右奇异向量)将在数组 A 上被覆盖;= ‘N’:不计算 V**T 的任何行(不计算右奇异向量)。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
计算的数据类型。 |
|
|
|
设备工作空间。类型为 |
|
|
|
|
|
|
|
主机工作空间。类型为 |
|
|
|
|
|
|
|
如果 |
通用 API 有三种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeS 是向量 S 的数据类型,dataTypeU 是矩阵 U 的数据类型,dataTypeVT 是矩阵 VT 的数据类型,computeType 是运算的计算类型。cusolverDnXgesvd 仅支持以下四种组合。
数据类型和计算类型的有效组合
DataTypeA |
DataTypeS |
DataTypeU |
DataTypeVT |
ComputeType |
含义 |
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
m,n<0或lda<max(1,m)或ldu<max(1,m)或ldvt<max(1,n))。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.5.2. cusolverDnXgesvdp()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnXgesvdp_bufferSize(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cusolverEigMode_t jobz,
int econ,
int64_t m,
int64_t n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType dataTypeS,
const void *S,
cudaDataType dataTypeU,
const void *U,
int64_t ldu,
cudaDataType dataTypeV,
const void *V,
int64_t ldv,
cudaDataType computeType,
size_t *workspaceInBytesOnDevice,
size_t *workspaceInBytesOnHost)
以下例程
cusolverStatus_t
cusolverDnXgesvdp(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cusolverEigMode_t jobz,
int econ,
int64_t m,
int64_t n,
cudaDataType dataTypeA,
void *A,
int64_t lda,
cudaDataType dataTypeS,
void *S,
cudaDataType dataTypeU,
void *U,
int64_t ldu,
cudaDataType dataTypeV,
void *V,
int64_t ldv,
cudaDataType computeType,
void *bufferOnDevice,
size_t workspaceInBytesOnDevice,
void *bufferOnHost,
size_t workspaceInBytesOnHost,
int *d_info,
double *h_err_sigma)
此函数计算 \(m \times n\) 矩阵 A 的奇异值分解 (SVD) 以及相应的左奇异向量和/或右奇异向量。SVD 写为
其中 Σ 是一个 \(m \times n\) 矩阵,除了其 min(m,n) 个对角元素外,其余均为零,U 是一个 \(m \times m\) 酉矩阵,V 是一个 \(n \times n\) 酉矩阵。Σ 的对角元素是 A 的奇异值;它们是实数且非负,并以降序返回。U 和 V 的前 min(m,n) 列分别是 A 的左奇异向量和右奇异向量。
cusolverDnXgesvdp 结合了 [14] 中的极分解和 cusolverDnXsyevd 来计算 SVD。它比基于 QR 算法的 cusolverDnXgesvd 快得多。但是,当矩阵 A 的奇异值接近于零时,[14] 中的极分解可能无法提供完整的酉矩阵。为了解决奇异值接近于零时的问题,我们添加了一个小的扰动,以便极分解可以提供正确的结果。其结果是不精确的奇异值被此扰动偏移。输出参数 h_err_sigma 是此扰动的大小。换句话说,h_err_sigma 显示了 SVD 的精度。
用户必须提供设备和主机工作空间,这些工作空间由输入参数 bufferOnDevice 和 bufferOnHost 指向。输入参数 workspaceInBytesOnDevice (和 workspaceInBytesOnHost)是设备(和主机)工作空间的大小(以字节为单位),它由 cusolverDnXgesvdp_bufferSize() 返回。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
目前,cusolverDnXgesvdp 仅支持默认算法。
cusolverDnXgesvdp 支持的算法
|
默认算法。 |
请访问 cuSOLVER 库示例 - Xgesvdp 以获取代码示例。
备注 1:gesvdp 也支持 n>=m。
备注 2:该例程返回 V,而不是 \(V^{H}\)
cusolverDnXgesvdp_bufferSize 和 cusolverDnXgesvdp 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
指定选项,以仅计算奇异值或同时计算奇异向量
|
|
|
|
|
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
计算的数据类型。 |
|
|
|
设备工作空间。类型为 |
|
|
|
|
|
|
|
主机工作空间。类型为 |
|
|
|
|
|
|
|
如果 |
|
|
|
扰动的大小,显示 SVD 的精度。 |
通用 API 有三种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeS 是向量 S 的数据类型,dataTypeU 是矩阵 U 的数据类型,dataTypeV 是矩阵 V 的数据类型,computeType 是运算的计算类型。cusolverDnXgesvdp 仅支持以下四种组合
数据类型和计算类型的有效组合
DataTypeA |
DataTypeS |
DataTypeU |
DataTypeV |
ComputeType |
含义 |
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
m,n<0或lda<max(1,m)或ldu<max(1,m)或ldv<max(1,n))。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.5.3. cusolverDnXgesvdr()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnXgesvdr_bufferSize (
cusolverDnHandle_t handle,
cusolverDnParams_t params,
signed char jobu,
signed char jobv,
int64_t m,
int64_t n,
int64_t k,
int64_t p,
int64_t niters,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType dataTypeSrand,
const void *Srand,
cudaDataType dataTypeUrand,
const void *Urand,
int64_t ldUrand,
cudaDataType dataTypeVrand,
const void *Vrand,
int64_t ldVrand,
cudaDataType computeType,
size_t *workspaceInBytesOnDevice,
size_t *workspaceInBytesOnHost )
以下例程
cusolverStatus_t
cusolverDnXgesvdr(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
signed char jobu,
signed char jobv,
int64_t m,
int64_t n,
int64_t k,
int64_t p,
int64_t niters,
cudaDataType dataTypeA,
void *A,
int64_t lda,
cudaDataType dataTypeSrand,
void *Srand,
cudaDataType dataTypeUrand,
void *Urand,
int64_t ldUrand,
cudaDataType dataTypeVrand,
void *Vrand,
int64_t ldVrand,
cudaDataType computeType,
void *bufferOnDevice,
size_t workspaceInBytesOnDevice,
void *bufferOnHost,
size_t workspaceInBytesOnHost,
int *d_info)
此函数计算 \(m \times n\) 矩阵 A 的近似秩-k 奇异值分解 (k-SVD) 以及相应的左奇异向量和/或右奇异向量。k-SVD 可以写成
其中 Σ 是一个 \(k \times k\) 矩阵,除了对角线元素外,其余元素均为零,U 是一个 \(m \times k\) 正交矩阵,V 是一个 \(k \times n\) 正交矩阵。Σ 的对角线元素是 A 的近似奇异值;它们是实数且非负,并以降序返回。U 和 V 的列是 A 的前 k 个左奇异向量和右奇异向量。
cusolverDnXgesvdr 实现了 [15] 中描述的随机方法,以计算 k-SVD,如果在 [15] 中描述的条件成立,则该 k-SVD 具有很高的概率是准确的。cusolverDnXgesvdr 旨在计算频谱中非常小的一部分(意味着 k 与 min(m,n) 相比非常小)的 A,速度快且质量好,尤其是在矩阵的维度很大时。
该方法的精度取决于 A 的频谱、幂迭代次数 niters、过采样参数 p 以及 p 与矩阵 A 维度之间的比率。更大的过采样值 p 或更多的迭代次数 niters 可能会产生更准确的近似值,但也会增加 cusolverDnXgesvdr 的运行时间。
我们的建议是使用两次迭代并将过采样设置为至少 2k。一旦求解器提供足够的精度,请调整 k 和 niters 的值以获得更好的性能。
用户必须提供设备和主机工作空间,这些工作空间由输入参数 bufferOnDevice 和 bufferOnHost 指向。输入参数 workspaceInBytesOnDevice (和 workspaceInBytesOnHost)是设备(和主机)工作空间的大小(以字节为单位),它由 cusolverDnXgesvdr_bufferSize() 返回。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
目前,cusolverDnXgesvdr 仅支持默认算法。
cusolverDnXgesvdr 支持的算法
|
默认算法。 |
请访问 cuSOLVER 库示例 - Xgesvdr 以获取代码示例。
备注 1:gesvdr 也支持 n>=m。
备注 2:该例程返回 V,而不是 \(V^{H}\)
cusolverDnXgesvdr_bufferSize 和 cusolverDnXgesvdr 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
指定用于计算矩阵 |
|
|
|
指定用于计算矩阵 V 的全部或部分的选项:= ‘S’:V 数组中返回 V 的前 k 行(右奇异向量);= ‘N’:不计算 V 的行(不计算右奇异向量)。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
过采样。子空间的大小将为 |
|
|
|
幂方法的迭代次数。 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
计算的数据类型。 |
|
|
|
设备工作空间。类型为 |
|
|
|
|
|
|
|
主机工作空间。类型为 |
|
|
|
|
|
|
|
如果 |
通用 API 有五种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeS 是向量 S 的数据类型,dataTypeU 是矩阵 U 的数据类型,dataTypeV 是矩阵 V 的数据类型,computeType 是运算的计算类型。cusolverDnXgesvdr 仅支持以下四种组合。
数据类型和计算类型的有效组合
DataTypeA |
DataTypeS |
DataTypeU |
DataTypeV |
ComputeType |
含义 |
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
m,n<0或lda<max(1,m)或ldu<max(1,m)或ldv<max(1,n))。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.5.4. cusolverDnXsyevd()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnXsyevd_bufferSize(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int64_t n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType dataTypeW,
const void *W,
cudaDataType computeType,
size_t *workspaceInBytesOnDevice,
size_t *workspaceInBytesOnHost)
以下例程
cusolverStatus_t
cusolverDnXsyevd(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int64_t n,
cudaDataType dataTypeA,
void *A,
int64_t lda,
cudaDataType dataTypeW,
void *W,
cudaDataType computeType,
void *bufferOnDevice,
size_t workspaceInBytesOnDevice,
void *bufferOnHost,
size_t workspaceInBytesOnHost,
int *info)
使用通用 API 接口计算对称(埃尔米特)\(n \times n\) 矩阵 A 的特征值和特征向量。标准的对称特征值问题是
其中 Λ 是实数 \(n \times n\) 对角矩阵。V 是 \(n \times n\) 酉矩阵。Λ 的对角元素是 A 的特征值,按升序排列。
用户必须提供设备和主机工作空间,这些工作空间由输入参数 bufferOnDevice 和 bufferOnHost 指向。输入参数 workspaceInBytesOnDevice (和 workspaceInBytesOnHost)是设备(和主机)工作空间的大小(以字节为单位),它由 cusolverDnXsyevd_bufferSize() 返回。
如果输出参数 info = -i (小于零),则第 i-th 个参数错误(不包括 handle)。如果 info = i (大于零),则中间三对角形式的 i 个非对角元素未收敛到零。
如果 jobz = CUSOLVER_EIG_MODE_VECTOR,则 A 包含矩阵 A 的标准正交特征向量。特征向量通过分治算法计算。
请访问 cuSOLVER 库示例 - Xsyevd 以获取代码示例。
目前,cusolverDnXsyevd 仅支持默认算法。
cusolverDnXsyevd 支持的算法
|
默认算法。 |
cusolverDnXsyevd_bufferSize 和 cusolverDnXsyevd 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
指定选项以仅计算特征值或计算特征对: |
|
|
|
指定存储 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
计算的数据类型。 |
|
|
|
设备工作空间。类型为 |
|
|
|
|
|
|
|
主机工作空间。类型为 |
|
|
|
|
|
|
|
如果 |
通用 API 有三种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeW 是矩阵 W 的数据类型,computeType 是运算的计算类型。cusolverDnXsyevd 仅支持以下四种组合。
数据类型和计算类型的有效组合
DataTypeA |
DataTypeW |
ComputeType |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效的参数(
n<0,或lda<max(1,n),或jobz不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTOR,或uplo不是CUBLAS_FILL_MODE_LOWER或CUBLAS_FILL_MODE_UPPER)。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.5.5. cusolverDnXsyevdx()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnXsyevdx_bufferSize(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int64_t n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
void *vl,
void *vu,
int64_t il,
int64_t iu,
int64_t *h_meig,
cudaDataType dataTypeW,
const void *W,
cudaDataType computeType,
size_t *workspaceInBytesOnDevice,
size_t *workspaceInBytesOnHost)
以下例程
cusolverStatus_t cusolverDnXsyevdx(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cusolverEigMode_t jobz,
cusolverEigRange_t range,
cublasFillMode_t uplo,
int64_t n,
cudaDataType dataTypeA,
void *A,
int64_t lda,
void * vl,
void * vu,
int64_t il,
int64_t iu,
int64_t *meig64,
cudaDataType dataTypeW,
void *W,
cudaDataType computeType,
void *bufferOnDevice,
size_t workspaceInBytesOnDevice,
void *bufferOnHost,
size_t workspaceInBytesOnHost,
int *info)
使用通用 API 接口计算对称(埃尔米特)\(n \times n\) 矩阵 A 的所有或部分选定的特征值,以及可选的特征向量。标准的对称特征值问题是
其中 Λ 是实数 n×h_meig 对角矩阵。V 是 n×h_meig 酉矩阵。h_meig 是例程计算的特征值/特征向量的总数,当请求整个频谱(例如,range = CUSOLVER_EIG_RANGE_ALL)时,h_meig 等于 n。Λ 的对角元素是 A 的特征值,按升序排列。
用户必须提供设备和主机工作空间,这些工作空间由输入参数 bufferOnDevice 和 bufferOnHost 指向。输入参数 workspaceInBytesOnDevice (和 workspaceInBytesOnHost)是设备(和主机)工作空间的大小(以字节为单位),它由 cusolverDnXsyevdx_bufferSize() 返回。
如果输出参数 info = -i (小于零),则第 i-th 个参数错误(不包括 handle)。如果 info = i (大于零),则中间三对角形式的 i 个非对角元素未收敛到零。
如果 jobz = CUSOLVER_EIG_MODE_VECTOR,则 A 包含矩阵 A 的标准正交特征向量。特征向量通过分治算法计算。
目前,cusolverDnXsyevdx 仅支持默认算法。
请访问 cuSOLVER 库示例 - Xsyevdx 以获取代码示例。
cusolverDnXsyevdx 支持的算法
|
默认算法。 |
cusolverDnXsyevdx_bufferSize 和 cusolverDnXsyevdx 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
指定选项以仅计算特征值或计算特征对: |
|
|
|
指定需要计算哪些特征值和可选特征向量的选择选项: |
|
|
|
指定存储 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
如果 |
|
|
|
整数。如果 |
|
|
|
整数。找到的特征值总数。0 <= h_meig <= n。如果 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
计算的数据类型。 |
|
|
|
设备工作空间。类型为 |
|
|
|
|
|
|
|
主机工作空间。类型为 |
|
|
|
|
|
|
|
如果 |
通用 API 有三种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeW 是矩阵 W 的数据类型,computeType 是运算的计算类型。cusolverDnXsyevdx 仅支持以下四种组合
数据类型和计算类型的有效组合
DataTypeA |
DataTypeW |
ComputeType |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效的参数(
n<0,或lda<max(1,n),或jobz不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTOR,或range不是CUSOLVER_EIG_RANGE_ALL或CUSOLVER_EIG_RANGE_V或CUSOLVER_EIG_RANGE_I,或uplo不是CUBLAS_FILL_MODE_LOWER或CUBLAS_FILL_MODE_UPPER)。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.5.6. cusolverDnXsyevBatched()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnXsyevBatched_bufferSize(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int64_t n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType dataTypeW,
const void *W,
cudaDataType computeType,
size_t *workspaceInBytesOnDevice,
size_t *workspaceInBytesOnHost,
int64_t batchSize)
以下例程
cusolverStatus_t
cusolverDnXsyevBatched(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int64_t n,
cudaDataType dataTypeA,
void *A,
int64_t lda,
cudaDataType dataTypeW,
void *W,
cudaDataType computeType,
void *bufferOnDevice,
size_t workspaceInBytesOnDevice,
void *bufferOnHost,
size_t workspaceInBytesOnHost,
int *info,
int64_t batchSize)
计算一系列对称(厄米特)\(n \times n\) 矩阵的特征值和特征向量
其中 \(\Lambda_j\) 是一个实数 \(n \times n\) 对角矩阵。\(V_j\) 是一个 \(n \times n\) 酉矩阵。\(\Lambda_j\) 的对角线元素是 \(A_j\) 的特征值,按升序排列。
syevBatched 对每个矩阵执行特征分解。它要求所有矩阵的大小都相同 n 并且以连续方式打包,
每个矩阵都是列优先的,leading dimension 为 lda,因此随机访问的公式为 \(A_{k}\operatorname{(i,j)} = {A\lbrack\ i\ +\ lda*j\ +\ lda*n*k\rbrack}\) 。
参数 W 也以连续方式包含每个矩阵的特征值,
W 的随机访问公式是 \(W_{k}\operatorname{(j)} = {W\lbrack\ j\ +\ n*k\rbrack}\) 。
用户必须提供设备和主机工作空间,这些工作空间由输入参数 bufferOnDevice 和 bufferOnHost 指向。输入参数 workspaceInBytesOnDevice 和 workspaceInBytesOnHost 表示设备和主机工作空间的大小(以字节为单位),并由 cusolverDnXsyevBatched_bufferSize() 返回。
输出参数 info 是大小为 batchSize 的整数数组。如果函数返回 CUSOLVER_STATUS_INVALID_VALUE,则第一个元素 info[0] = -i (小于零) 表示第 i-th 个参数错误 (不包括 handle)。否则,如果 info[i] > 0,则 syevBatched 在第 i-th 个矩阵上不收敛。
如果 jobz = CUSOLVER_EIG_MODE_VECTOR,则 \(A_{j}\) 包含矩阵 \(A_{j}\) 的标准正交特征向量。
目前,cusolverDnXsyevBatched 仅支持默认算法。
cusolverDnXsyevBatched 支持的算法
|
默认算法。 |
cusolverDnXsyevBatched_bufferSize 和 cusolverDnXsyevBatched 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
指定选项以仅计算特征值或计算特征对: |
|
|
|
指定存储 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
计算的数据类型。 |
|
|
|
设备工作空间。类型为 |
|
|
|
|
|
|
|
主机工作空间。类型为 |
|
|
|
|
|
|
|
维度为 |
|
|
|
矩阵的数量。 |
通用 API 有三种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeW 是数组 W 的数据类型,computeType 是操作的计算类型。cusolverDnXsyevBatched 仅支持以下四种组合
数据类型和计算类型的有效组合
DataTypeA |
DataTypeW |
ComputeType |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
n<0,或lda<max(1,n),或jobz不是CUSOLVER_EIG_MODE_NOVECTOR,或uplo不是CUBLAS_FILL_MODE_LOWER,或CUBLAS_FILL_MODE_UPPER,或batchSize<0)。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.4.5.7. cusolverDnXgeev()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverDnXgeev_bufferSize(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cusolverEigMode_t jobvl,
cusolverEigMode_t jobvr,
int64_t n,
cudaDataType dataTypeA,
const void *A,
int64_t lda,
cudaDataType dataTypeW,
const void *W,
cudaDataType dataTypeVL,
const void *VL,
int64_t ldvl,
cudaDataType dataTypeVR,
const void *VR,
int64_t ldvr,
cudaDataType computeType,
size_t *workspaceInBytesOnDevice,
size_t *workspaceInBytesOnHost)
以下例程
cusolverStatus_t
cusolverDnXgeev(
cusolverDnHandle_t handle,
cusolverDnParams_t params,
cusolverEigMode_t jobvl,
cusolverEigMode_t jobvr,
int64_t n,
cudaDataType dataTypeA,
void *A,
int64_t lda,
cudaDataType dataTypeW,
void *W,
cudaDataType dataTypeVL,
void *VL,
int64_t ldvl,
cudaDataType dataTypeVR,
void *VR,
int64_t ldvr,
cudaDataType computeType,
void *bufferOnDevice,
size_t workspaceInBytesOnDevice,
void *bufferOnHost,
size_t workspaceInBytesOnHost,
int *info)
计算 n 乘 n 实数非对称或复数非 Hermitian 矩阵 A 的特征值,以及可选的左和/或右特征向量。A 的右特征向量 v(j) 满足
其中 w(j) 是其特征值。A 的左特征向量 u(j) 满足
其中 \(u(j)^{H}\) 表示 u(j) 的共轭转置。
计算出的特征向量被归一化为欧几里得范数等于 1,且最大分量为实数。
如果 A 是实数值的,则有两种选项可以在 W 中返回特征值。第一个选项将所有数据类型设置为实数值类型。然后 W 包含 2*n 个条目。前 n 个条目保存实部,后 n 个条目保存虚部。通过设置指针 WR = W,WI = W+n,可以恢复具有实部 WR 和虚部 WI 的单独数组的 LAPACK 接口。第二个选项对 W 使用复数数据类型。然后 W 的长度为 n 个条目;每个实特征值都存储为复数,并且对于每对复共轭对,都会返回两个特征值。计算仍然完全在实数算术中执行。
用户必须提供设备和主机工作空间,这些工作空间由输入参数 bufferOnDevice 和 bufferOnHost 指向。输入参数 workspaceInBytesOnDevice 和 workspaceInBytesOnHost 表示设备和主机工作空间的大小(以字节为单位),并由 cusolverDnXgeev_bufferSize() 返回。
如果输出参数 info = -i (小于零),则第 i-th 个参数错误 (不包括 handle)。如果 info = 0,则 QR 算法收敛,并且 W 包含 A 的计算出的特征值,并且如果请求,则已计算出相应的左和/或右特征向量。如果 info = i (大于零),则 QR 算法未能计算出所有特征值,并且未计算出任何特征向量。W 的元素 i+1:n 包含已收敛的特征值。
备注 1: geev 仅支持右特征向量的计算。因此,必须设置 jobvl = CUSOLVER_EIG_MODE_NOVECTOR。
备注 2: geev 使用平衡来改善特征值和特征向量的条件。
备注 3: geev 是一种混合 CPU-GPU 算法。使用 pinned host memory 可以获得最佳性能。
备注 4: geev 不支持任何 n*ld >= 2^31 的输入或输出矩阵。
目前,cusolverDnXgeev 仅支持默认算法。
请访问 cuSOLVER 库示例 - Xgeev 以获取代码示例。
cusolverDnXgeev 支持的算法表
|
默认算法。 |
cusolverDnXgeev_bufferSize 和 cusolverDnXgeev 的输入参数列表
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverDN 库上下文的句柄。 |
|
|
|
由 |
|
|
|
指定是否计算左特征向量。 |
|
|
|
指定是否计算右特征向量。 |
|
|
|
矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
保存 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
数组 |
|
|
|
维度为 |
|
|
|
用于存储矩阵 |
|
|
|
计算的数据类型。 |
|
|
|
设备工作空间。类型为 |
|
|
|
|
|
|
|
主机工作空间。类型为 |
|
|
|
|
|
|
|
如果 |
通用 API 有五种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeW 是数组 W 的数据类型,dataTypeVL 是矩阵 VL 的数据类型,dataTypeVR 是矩阵 VR 的数据类型,computeType 是操作的计算类型。cusolverDnXgeev 仅支持以下四种组合
数据类型和计算类型的有效组合
DataTypeA |
DataTypeW |
DataTypeVL |
DataTypeVR |
ComputeType |
含义 |
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
32F 混合实数-复数 |
|
|
|
|
|
|
|
|
|
|
|
64F 混合实数-复数 |
|
|
|
|
|
|
|
|
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
jobvl不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTOR,或jobvr不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTOR,n<0,或lda < max(1,n),或如果jobvl为CUSOLVER_EIG_MODE_VECTOR,则ldvl < n,或如果jobvr为CUSOLVER_EIG_MODE_VECTOR,则ldvr < n)。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.5. cuSolverSP:稀疏 LAPACK 函数参考
本节介绍 cuSolverSP 的 API,它为 CSR 或 CSC 格式的稀疏矩阵提供 LAPACK 函数的子集。
2.5.1. 辅助函数参考
2.5.1.1. cusolverSpCreate()
cusolverStatus_t
cusolverSpCreate(cusolverSpHandle_t *handle)
此函数初始化 cuSolverSP 库并在 cuSolver 上下文中创建句柄。必须在调用任何其他 cuSolverSP API 函数之前调用它。它分配访问 GPU 所需的硬件资源。
输出
|
指向 cuSolverSP 上下文句柄的指针。 |
返回状态
CUSOLVER_STATUS_SUCCESS初始化成功。
CUSOLVER_STATUS_NOT_INITIALIZEDCUDA 运行时初始化失败。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
2.5.1.2. cusolverSpDestroy()
cusolverStatus_t
cusolverSpDestroy(cusolverSpHandle_t handle)
此函数释放 cuSolverSP 库使用的 CPU 端资源。
输入
|
cuSolverSP 上下文的句柄。 |
返回状态
CUSOLVER_STATUS_SUCCESS关闭成功。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
2.5.1.3. cusolverSpSetStream()
cusolverStatus_t
cusolverSpSetStream(cusolverSpHandle_t handle, cudaStream_t streamId)
此函数设置 cuSolverSP 库用于执行其例程的流。
输入
|
cuSolverSP 上下文的句柄。 |
|
库要使用的流。 |
返回状态
CUSOLVER_STATUS_SUCCESS流已成功设置。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
2.5.1.4. cusolverSpXcsrissym()
cusolverStatus_t
cusolverSpXcsrissymHost(cusolverSpHandle_t handle,
int m,
int nnzA,
const cusparseMatDescr_t descrA,
const int *csrRowPtrA,
const int *csrEndPtrA,
const int *csrColIndA,
int *issym);
此函数检查 A 是否具有对称模式。输出参数 issym 报告 1 (如果 A 是对称的);否则,它报告 0。
矩阵 A 是一个 \(m \times m\) 稀疏矩阵,它由四个数组 csrValA、csrRowPtrA、csrEndPtrA 和 csrColIndA 以 CSR 存储格式定义。
支持的矩阵类型为 CUSPARSE_MATRIX_TYPE_GENERAL。
csrlsvlu 和 csrlsvqr 不接受非通用矩阵。用户必须将矩阵扩展到其缺失的上/下部分,否则结果将不符合预期。用户可以使用 csrissym 检查矩阵是否具有对称模式。
备注 1:仅提供 CPU 路径。
备注 2:用户必须检查返回的状态以获取有效信息。该函数将 A 转换为 CSC 格式并比较 CSR 和 CSC 格式。如果 CSC 由于资源不足而失败,则 issym 未定义,并且此状态只能通过返回状态代码来检测。
输入
参数 |
MemorySpace |
描述 |
|---|---|---|
|
|
cuSolverSP 库上下文的句柄。 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
包含每行开头的 |
|
|
包含最后一行末尾加一的 |
|
|
矩阵 |
输出
参数 |
MemorySpace |
描述 |
|---|---|---|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
m,nnzA<=0),基索引不是 0 或 1。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED不支持的矩阵类型。
2.5.2. 高级函数参考
本节介绍 cuSolverSP 的高级 API,包括线性求解器、最小二乘求解器和特征值求解器。高级 API 旨在易于使用,因此它在后台自动分配任何所需的内存。如果主机或 GPU 系统内存不足,则会返回错误。
2.5.2.1. cusolverSp<t>csrlsvlu() [已弃用]
[[已弃用]] 此函数已弃用,将在未来的主要版本中删除。请改用 cuDSS 库,以获得更好的性能和支持。对于过渡,请访问 cuDSS 库示例 以获取代码示例。
cusolverStatus_t
cusolverSpScsrlsvlu[Host](cusolverSpHandle_t handle,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const float *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const float *b,
float tol,
int reorder,
float *x,
int *singularity);
cusolverStatus_t
cusolverSpDcsrlsvlu[Host](cusolverSpHandle_t handle,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const double *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const double *b,
double tol,
int reorder,
double *x,
int *singularity);
cusolverStatus_t
cusolverSpCcsrlsvlu[Host](cusolverSpHandle_t handle,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const cuComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const cuComplex *b,
float tol,
int reorder,
cuComplex *x,
int *singularity);
cusolverStatus_t
cusolverSpZcsrlsvlu[Host](cusolverSpHandle_t handle,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const cuDoubleComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const cuDoubleComplex *b,
double tol,
int reorder,
cuDoubleComplex *x,
int *singularity);
此函数求解线性方程组
其中 A 是一个 \(n \times n\) 稀疏矩阵,它由三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。b 是大小为 n 的右侧向量,x 是大小为 n 的解向量。
支持的矩阵类型为 CUSPARSE_MATRIX_TYPE_GENERAL。如果矩阵 A 是对称/Hermitian 矩阵,并且仅使用或有意义的是下/上部分,则用户必须将矩阵扩展到其缺失的上/下部分,否则结果将是错误的。
线性系统通过稀疏 LU 分解和部分主元法求解
cusolver 库提供三种重排序方案:symrcm、symamd 和 csrmetisnd,以减少零填充,这会极大地影响 LU 分解的性能。如果 reorder 为 1(2 或 3),则输入参数 reorder 可以启用 symrcm (symamd 或 csrmetisnd);否则,不执行任何重排序。
如果 reorder 非零,则 csrlsvlu 执行
其中 \(Q = {symrcm}(A + A^{T})\) 。
如果 A 在给定的容差 (max(tol,0)) 下是奇异的,则 U 的某些对角线元素为零,即
输出参数 singularity 是使得 U(j,j)≈0 的最小索引 j。如果 A 是非奇异的,则 singularity 为 -1。该索引是基于 0 的,与 A 的基索引无关。例如,如果 A 的第二列与第一列相同,则 A 是奇异的,并且 singularity = 1,这意味着 U(1,1)≈0。
备注 1:csrlsvlu 执行传统的带部分选主元的 LU 分解,第 k 列的主元是根据中间矩阵的第 k 列动态确定的。csrlsvlu 遵循 Gilbert 和 Peierls 的算法 [4],该算法使用深度优先搜索和拓扑排序来求解三角系统(Davis 在他的著作 [1] 中也详细描述了该算法)。自 CUDA 10.1 起,csrlsvlu 将增量重新分配内存以存储 L 和 U。此功能可以避免过度估计 QR 分解的大小。在某些情况下,QR 的零填充量可能比 LU 高一个数量级。
备注 2:仅提供 CPU (Host) 路径。
输入
参数 |
cusolverSp 内存空间 |
*主机内存空间 |
描述 |
|---|---|---|---|
|
|
|
cuSolverSP 库上下文的句柄。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
|
|
|
|
整数数组,大小为 |
|
|
|
整数数组,大小为 |
|
|
|
大小为 |
|
|
|
用于判断是否奇异的容差。 |
|
|
|
如果 |
输出
参数 |
cusolverSp 内存空间 |
*主机内存空间 |
描述 |
|---|---|---|---|
|
|
|
大小为 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n,nnzA<=0,基索引不是 0 或 1,reorder不是 0,1,2,3)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED不支持的矩阵类型。
2.5.2.2. cusolverSpcsrlsvqr()
cusolverStatus_t
cusolverSpScsrlsvqr[Host](cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const float *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const float *b,
float tol,
int reorder,
float *x,
int *singularity);
cusolverStatus_t
cusolverSpDcsrlsvqr[Host](cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const double *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const double *b,
double tol,
int reorder,
double *x,
int *singularity);
cusolverStatus_t
cusolverSpCcsrlsvqr[Host](cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const cuComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const cuComplex *b,
float tol,
int reorder,
cuComplex *x,
int *singularity);
cusolverStatus_t
cusolverSpZcsrlsvqr[Host](cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const cuDoubleComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const cuDoubleComplex *b,
double tol,
int reorder,
cuDoubleComplex *x,
int *singularity);
此函数求解线性方程组
A 是一个 \(m \times m\) 稀疏矩阵,通过三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。b 是大小为 m 的右手边向量,x 是大小为 m 的解向量。
支持的矩阵类型为 CUSPARSE_MATRIX_TYPE_GENERAL。如果矩阵 A 是对称/Hermitian 矩阵,并且仅使用或有意义的是下/上部分,则用户必须将矩阵扩展到其缺失的上/下部分,否则结果将是错误的。
线性系统通过稀疏 QR 分解求解,
如果 A 在给定的容差 (max(tol,0)) 下是奇异的,则 R 的一些对角元素为零,即
输出参数 singularity 是使得 R(j,j)≈0 的最小索引 j。如果 A 是非奇异的,则 singularity 为 -1。singularity 是基于 0 的,与 A 的基索引无关。例如,如果 A 的第二列与第一列相同,则 A 是奇异的,并且 singularity = 1,这意味着 R(1,1)≈0。
cusolver 库提供了三种重排序方案:symrcm、symamd 和 csrmetisnd,以减少零填充,这会极大地影响 QR 分解的性能。如果 reorder 为 1(2 或 3),则输入参数 reorder 可以启用 symrcm (symamd 或 csrmetisnd),否则不执行重排序。
输入
参数 |
cusolverSp 内存空间 |
*主机内存空间 |
描述 |
|---|---|---|---|
|
|
|
cuSolverSP 库上下文的句柄。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
|
|
|
|
整数数组,大小为 |
|
|
|
整数数组,大小为 |
|
|
|
大小为 |
|
|
|
用于判断是否奇异的容差。 |
|
|
|
如果 |
输出
参数 |
cusolverSp 内存空间 |
*主机内存空间 |
描述 |
|---|---|---|---|
|
|
|
大小为 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
m,nnz<=0,基索引不是 0 或 1,reorder不是 0,1,2,3)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED不支持的矩阵类型。
2.5.2.3. cusolverSpcsrlsvchol() [[已弃用]]
[[已弃用]] 此函数已弃用,将在未来的主要版本中删除。请改用 cuDSS 库,以获得更好的性能和支持。对于过渡,请访问 cuDSS 库示例 以获取代码示例。
cusolverStatus_t
cusolverSpScsrlsvchol[Host](cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const float *csrVal,
const int *csrRowPtr,
const int *csrColInd,
const float *b,
float tol,
int reorder,
float *x,
int *singularity);
cusolverStatus_t
cusolverSpDcsrlsvchol[Host](cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const double *csrVal,
const int *csrRowPtr,
const int *csrColInd,
const double *b,
double tol,
int reorder,
double *x,
int *singularity);
cusolverStatus_t
cusolverSpCcsrlsvchol[Host](cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const cuComplex *csrVal,
const int *csrRowPtr,
const int *csrColInd,
const cuComplex *b,
float tol,
int reorder,
cuComplex *x,
int *singularity);
cusolverStatus_t
cusolverSpZcsrlsvchol[Host](cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const cuDoubleComplex *csrVal,
const int *csrRowPtr,
const int *csrColInd,
const cuDoubleComplex *b,
double tol,
int reorder,
cuDoubleComplex *x,
int *singularity);
此函数求解线性方程组
A 是一个 \(m \times m\) 对称正定稀疏矩阵,通过三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。b 是大小为 m 的右手边向量,x 是大小为 m 的解向量。
支持的矩阵类型为 CUSPARSE_MATRIX_TYPE_GENERAL,并且忽略 A 的上三角部分(如果参数 reorder 为零)。换句话说,假设输入矩阵 A 分解为 \(A = L + D + U\),其中 L 是下三角矩阵,D 是对角矩阵,U 是上三角矩阵。该函数将忽略 U,并将 A 视为具有公式 \(A = L + D + L^{H}\) 的对称矩阵。如果参数 reorder 非零,则用户必须将 A 扩展为完整矩阵,否则解将是错误的。
线性系统通过稀疏 Cholesky 分解求解,
其中 G 是 Cholesky 因子,一个下三角矩阵。
输出参数 singularity 有两个含义
如果
A不是正定的,则存在某个整数k,使得A(0:k, 0:k)不是正定的。singularity是此类k的最小值。如果
A是正定的,但在容差 (max(tol,0)) 下接近奇异,即存在某个整数k,使得 \(G\begin{pmatrix} {k,k} \\ \end{pmatrix}<={tol}\)。singularity是此类k的最小值。
singularity 是基于 0 的。如果 A 是正定的且在容差下不接近奇异,则 singularity 为 -1。如果用户想知道 A 是否是正定的,则 tol=0 就足够了。
cusolver 库提供了三种重排序方案:symrcm、symamd 和 csrmetisnd,以减少零填充,这会极大地影响 Cholesky 分解的性能。如果 reorder 为 1(2 或 3),则输入参数 reorder 可以启用 symrcm (symamd 或 csrmetisnd),否则不执行重排序。
备注 1:该函数适用于就地(x 和 b 指向同一内存块)和异地操作。
备注 2:该函数仅适用于 32 位索引。如果矩阵 G 具有较大的零填充,导致非零元素的数量大于 \(2^{31}\),则返回 CUSOLVER_STATUS_ALLOC_FAILED。
输入
参数 |
cusolverSp 内存空间 |
*主机内存空间 |
描述 |
|---|---|---|---|
|
|
|
cuSolverSP 库上下文的句柄。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
|
|
|
|
整数数组,大小为 |
|
|
|
整数数组,大小为 |
|
|
|
大小为 |
|
|
|
用于判断奇异性的容差。 |
|
|
|
如果 |
输出
参数 |
cusolverSp 内存空间 |
*主机内存空间 |
描述 |
|---|---|---|---|
|
|
|
大小为 |
|
|
|
如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
m,nnz<=0,基索引不是 0 或 1,reorder不是 0,1,2,3)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED不支持的矩阵类型。
2.5.2.4. cusolverSpcsrlsqvqr()
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverSpScsrlsqvqr[Host](cusolverSpHandle_t handle,
int m,
int n,
int nnz,
const cusparseMatDescr_t descrA,
const float *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const float *b,
float tol,
int *rankA,
float *x,
int *p,
float *min_norm);
cusolverStatus_t
cusolverSpDcsrlsqvqr[Host](cusolverSpHandle_t handle,
int m,
int n,
int nnz,
const cusparseMatDescr_t descrA,
const double *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const double *b,
double tol,
int *rankA,
double *x,
int *p,
double *min_norm);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverSpCcsrlsqvqr[Host](cusolverSpHandle_t handle,
int m,
int n,
int nnz,
const cusparseMatDescr_t descrA,
const cuComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const cuComplex *b,
float tol,
int *rankA,
cuComplex *x,
int *p,
float *min_norm);
cusolverStatus_t
cusolverSpZcsrlsqvqr[Host](cusolverSpHandle_t handle,
int m,
int n,
int nnz,
const cusparseMatDescr_t descrA,
const cuDoubleComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const cuDoubleComplex *b,
double tol,
int *rankA,
cuDoubleComplex *x,
int *p,
double *min_norm);
此函数求解以下最小二乘问题
A 是一个 \(m \times n\) 稀疏矩阵,通过三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。b 是大小为 m 的右手边向量,x 是大小为 n 的最小二乘解向量。
支持的矩阵类型为 CUSPARSE_MATRIX_TYPE_GENERAL。如果 A 是方阵、对称/Hermitian 矩阵,并且仅使用下/上三角部分或有意义,则用户必须将矩阵扩展到其缺失的上/下三角部分,否则结果将是错误的。
此函数仅在 m 大于或等于 n 时有效,换句话说,A 是一个高矩阵。
最小二乘问题通过带列主元的稀疏 QR 分解求解,
如果 A 是满秩的(即 A 的所有列都是线性独立的),则矩阵 P 是单位矩阵。假设 A 的秩为 k,小于 n,则置换矩阵 P 按以下方式对 A 的列进行重排序
其中 \(R_{11}\) 和 A 具有相同的秩,但 \(R_{22}\) 几乎为零,即 \(A_{2}\) 的每一列都是 \(A_{1}\) 的线性组合。
输入参数 tol 决定数值秩。\(R_{22}\) 中每个条目的绝对值小于或等于 tolerance=max(tol,0)。
输出参数 rankA 表示 A 的数值秩。
假设 \(y = P*x\) 和 \(c = Q^{H}*b\),最小二乘问题可以转化为
或以矩阵形式
输出参数 min_norm 是 \(\left. \|c_{2} \right.\|\),即最小二乘问题的最小值。
如果 A 不是满秩的,则上述方程没有唯一解。最小二乘问题等价于
或等价于另一个最小二乘问题
输出参数 x 是 \(P^{T}*y\),即最小二乘问题的解。
输出参数 p 是一个大小为 n 的向量。它对应于置换矩阵 P。p(i)=j 表示 (P*x)(i) = x(j)。如果 A 是满秩的,则 p=0:n-1。
备注 1:p 始终是基于 0 的,与 A 的基索引无关。
备注 2:仅提供 CPU (Host) 路径。
输入
参数 |
cusolverSp 内存空间 |
*主机内存空间 |
描述 |
|---|---|---|---|
|
|
|
cuSolver 库上下文的句柄。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
|
|
|
|
整数数组,大小为 |
|
|
|
整数数组,大小为 |
|
|
|
大小为 |
|
|
|
用于判断 |
输出
参数 |
cusolverSp 内存空间 |
*主机内存空间 |
描述 |
|---|---|---|---|
|
|
|
|
|
|
|
大小为 |
|
|
|
大小为 |
|
|
|
|
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
m,n,nnz<=0),基索引不是 0 或 1。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED不支持的矩阵类型。
2.5.2.5. cusolverSpcsreigvsi()
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverSpScsreigvsi[Host](cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const float *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
float mu0,
const float *x0,
int maxite,
float tol,
float *mu,
float *x);
cusolverStatus_t
cusolverSpDcsreigvsi[Host](cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const double *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
double mu0,
const double *x0,
int maxite,
double tol,
double *mu,
double *x);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverSpCcsreigvsi[Host](cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const cuComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
cuComplex mu0,
const cuComplex *x0,
int maxite,
float tol,
cuComplex *mu,
cuComplex *x);
cusolverStatus_t
cusolverSpZcsreigvsi(cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const cuDoubleComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
cuDoubleComplex mu0,
const cuDoubleComplex *x0,
int maxite,
double tol,
cuDoubleComplex *mu,
cuDoubleComplex *x);
此函数通过逆迭代法求解简单特征值问题 \(A*x = \lambda*x\)。
A 是一个 \(m \times m\) 稀疏矩阵,通过三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。输出参数 x 是大小为 m 的近似特征向量,
以下逆迭代法逐步修正特征对,直到收敛。
它接受以下几个参数
mu0 是特征值的初始猜测值。如果 mu 是单根,则逆迭代法将收敛到最接近 mu0 的特征值 mu。否则,逆迭代法可能不会收敛。
x0 是初始特征向量。如果用户没有偏好,只需随机选择 x0 即可。x0 必须是非零的。它可以不是单位长度。
tol 是用于判断收敛的容差。如果 tol 小于零,则将其视为零。
maxite 是最大迭代次数。当逆迭代法由于容差太小或所需的特征值不是单根而无法收敛时,它很有用。
逆迭代法
给定特征值 μ0 的初始猜测值和初始向量 x0
支持的矩阵类型为 CUSPARSE_MATRIX_TYPE_GENERAL。如果 A 是对称/Hermitian 矩阵,并且仅使用下/上三角部分或有意义,则用户必须将矩阵扩展到其缺失的上/下三角部分,否则结果将是错误的。
备注 1:[cu|h]solver[S|D]csreigvsi 仅允许 mu0 为实数。如果 A 是对称的,则此方法有效。否则,非实特征值在复平面上有一个共轭对应值,即使特征值是单根,逆迭代法也不会收敛到该特征值。用户必须将 A 扩展为复数,并使用不在实轴上的 mu0 调用 [cu|h]solver[C|Z]csreigvsi。
备注 2:容差 tol 不应小于 |mu0|*eps,其中 eps 是机器零。否则,逆迭代可能由于容差过小而无法收敛。
输入
参数 |
cusolverSp 内存空间 |
*主机内存空间 |
描述 |
|---|---|---|---|
|
|
|
cuSolver 库上下文的句柄。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
|
|
|
|
整数数组,大小为 |
|
|
|
整数数组,大小为 |
|
|
|
特征值的初始猜测值。 |
|
|
|
特征向量的初始猜测值,大小为 |
|
|
|
逆迭代法中的最大迭代次数。 |
|
|
|
用于收敛的容差。 |
输出
参数 |
cusolverSp 内存空间 |
*主机内存空间 |
描述 |
|---|---|---|---|
|
|
|
在容差下最接近 |
|
|
|
大小为 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
m,nnz<=0),基索引不是 0 或 1。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED不支持的矩阵类型。
2.5.2.6. cusolverSpcsreigs()
cusolverStatus_t
solverspScsreigs[Host](cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const float *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
cuComplex left_bottom_corner,
cuComplex right_upper_corner,
int *num_eigs);
cusolverStatus_t
cusolverSpDcsreigs[Host](cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const double *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
cuDoubleComplex left_bottom_corner,
cuDoubleComplex right_upper_corner,
int *num_eigs);
cusolverStatus_t
cusolverSpCcsreigs[Host](cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const cuComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
cuComplex left_bottom_corner,
cuComplex right_upper_corner,
int *num_eigs);
cusolverStatus_t
cusolverSpZcsreigs[Host](cusolverSpHandle_t handle,
int m,
int nnz,
const cusparseMatDescr_t descrA,
const cuDoubleComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
cuDoubleComplex left_bottom_corner,
cuDoubleComplex right_upper_corner,
int *num_eigs);
此函数通过轮廓积分计算给定框 B 中代数特征值的数量
其中闭合线 C 是框 B 的边界,框 B 是由两个点指定的矩形,一个是左下角(输入参数 left_bottom_corner),另一个是右上角(输入参数 right_upper_corner)。P(z)=det(A - z*I) 是 A 的特征多项式。
A 是一个 \(m \times m\) 稀疏矩阵,通过三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。
输出参数 num_eigs 是框 B 中代数特征值的数量。由于以下几个原因,此数字可能不准确
轮廓
C接近某些特征值,甚至穿过某些特征值。由于粗糙的网格尺寸,数值积分不准确。默认分辨率是沿轮廓
C均匀分布的 1200 个网格。
即使 csreigs 可能不准确,它仍然可以为用户提供一些关于磁盘定理分辨率较差的区域中特征值数量的概念。例如,拉普拉斯算子的有限差分标准 3 点模板是一个三对角矩阵,磁盘定理将显示“所有特征值都在区间 [0, 4*N^2] 中”,其中 N 是网格数。在这种情况下,csreigs 对于 [0, 4*N^2] 内的任何区间都很有用。
备注 1:如果 A 在实数域中是对称的,或在复数域中是 Hermitian 的,则所有特征值都是实数。用户仍然需要指定一个框,而不是一个区间。框的高度可以远小于宽度。
备注 2:仅提供 CPU (Host) 路径。
输入
参数 |
cusolverSp 内存空间 |
*主机内存空间 |
描述 |
|---|---|---|---|
|
|
|
cuSolverSP 库上下文的句柄。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
|
|
|
|
整数数组,大小为 |
|
|
|
整数数组,大小为 |
|
|
|
框的左下角。 |
|
|
|
框的右上角。 |
输出
参数 |
cusolverSp 内存空间 |
*主机内存空间 |
描述 |
|---|---|---|---|
|
|
|
框中代数特征值的数量。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
m,nnz<=0),基索引不是 0 或 1。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED不支持的矩阵类型。
2.5.3. 底层函数参考
本节介绍 cuSolverSP 的底层 API,包括 symrcm 和批量 QR。
2.5.3.1. cusolverSpXcsrsymrcm()
cusolverStatus_t
cusolverSpXcsrsymrcmHost(cusolverSpHandle_t handle,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const int *csrRowPtrA,
const int *csrColIndA,
int *p);
此函数实现对称反向 Cuthill-McKee 置换。它返回一个置换向量 p,使得 A(p,p) 将非零元素集中到对角线附近。这等效于 MATLAB 中的 symrcm,但由于伪外围查找器中的启发式方法不同,结果可能不相同。cuSolverSP 库基于以下两篇论文实现了 symrcm
E. Cuthill 和 J. McKee, Reducing the bandwidth of sparse symmetric matrices, ACM ‘69 Proceedings of the 1969 24th national conference, Pages 157-172
Alan George, Joseph W. H. Liu, An Implementation of a Pseudoperipheral Node Finder, ACM Transactions on Mathematical Software (TOMS) Volume 5 Issue 3, Sept. 1979, Pages 284-295
输出参数 p 是一个大小为 n 的整数数组。它表示一个置换数组,并使用基于 0 的约定进行索引。置换数组 p 对应于置换矩阵 P,并满足以下关系
A 是一个 \(n \times n\) 稀疏矩阵,通过三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。
支持的矩阵类型为 CUSPARSE_MATRIX_TYPE_GENERAL。在内部,rcm 在 \(A + A^{T}\) 上工作,如果矩阵不是对称的,则用户不需要扩展矩阵。
备注 1:仅提供 CPU (Host) 路径。
输入
参数 |
*主机内存空间 |
描述 |
|---|---|---|
|
|
cuSolverSP 库上下文的句柄。 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
整数数组,大小为 |
|
|
矩阵 |
输出
参数 |
hsolver |
描述 |
|---|---|---|
|
|
大小为 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n,nnzA<=0),基索引不是 0 或 1。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED不支持的矩阵类型。
2.5.3.2. cusolverSpXcsrsymmdq()
cusolverStatus_t
cusolverSpXcsrsymmdqHost(cusolverSpHandle_t handle,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const int *csrRowPtrA,
const int *csrColIndA,
int *p);
此函数实现基于商图的对称最小度算法。它返回一个置换向量 p,使得 A(p,p) 在 Cholesky 分解期间具有较少的零填充。cuSolverSP 库基于以下两篇论文实现了 symmdq
Patrick R. Amestoy, Timothy A. Davis, Iain S. Duff, An Approximate Minimum Degree Ordering Algorithm, SIAM J. Matrix Analysis Applic. Vol 17, no 4, pp. 886-905, Dec. 1996.
Alan George, Joseph W. Liu, A Fast Implementation of the Minimum Degree Algorithm Using Quotient Graphs, ACM Transactions on Mathematical Software, Vol 6, No. 3, September 1980, page 337-358.
输出参数 p 是一个包含 n 个元素的整数数组。它表示一个基于 0 索引的置换数组。置换数组 p 对应于一个置换矩阵 P,并满足以下关系
A 是一个 \(n \times n\) 稀疏矩阵,通过三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。
支持的矩阵类型为 CUSPARSE_MATRIX_TYPE_GENERAL。在内部,mdq 在 \(A + A^{T}\) 上工作,如果矩阵不是对称的,用户无需扩展矩阵。
备注 1:仅提供 CPU (Host) 路径。
输入
参数 |
*主机内存空间 |
描述 |
|---|---|---|
|
|
cuSolverSP 库上下文的句柄。 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
整数数组,大小为 |
|
|
矩阵 |
输出
参数 |
hsolver |
描述 |
|---|---|---|
|
|
大小为 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n,nnzA<=0),基索引不是 0 或 1。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED不支持的矩阵类型。
2.5.3.3. cusolverSpXcsrsymamd()
cusolverStatus_t
cusolverSpXcsrsymamdHost(cusolverSpHandle_t handle,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const int *csrRowPtrA,
const int *csrColIndA,
int *p);
此函数实现了基于商图的对称近似最小度算法。它返回一个置换向量 p,使得 A(p,p) 在 Cholesky 分解期间具有更少的零填充。 cuSolverSP 库实现了基于以下论文的 symamd
Patrick R. Amestoy, Timothy A. Davis, Iain S. Duff, An Approximate Minimum Degree Ordering Algorithm, SIAM J. Matrix Analysis Applic. Vol 17, no 4, pp. 886-905, Dec. 1996.
输出参数 p 是一个包含 n 个元素的整数数组。它表示一个基于 0 索引的置换数组。置换数组 p 对应于一个置换矩阵 P,并满足以下关系
A 是一个 \(n \times n\) 稀疏矩阵,通过三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。
支持的矩阵类型为 CUSPARSE_MATRIX_TYPE_GENERAL。在内部,amd 在 \(A + A^{T}\) 上工作,如果矩阵不是对称的,用户无需扩展矩阵。
备注 1:仅提供 CPU (Host) 路径。
输入
参数 |
*主机内存空间 |
描述 |
|---|---|---|
|
|
cuSolverSP 库上下文的句柄。 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
整数数组,大小为 |
|
|
矩阵 |
输出
参数 |
hsolver |
描述 |
|---|---|---|
|
|
大小为 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n,nnzA<=0),基索引不是 0 或 1。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED不支持的矩阵类型。
2.5.3.4. cusolverSpXcsrmetisnd()
cusolverStatus_t
cusolverSpXcsrmetisndHost(
cusolverSpHandle_t handle,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const int *csrRowPtrA,
const int *csrColIndA,
const int64_t *options,
int *p);
此函数是 METIS_NodeND 的一个包装器。它返回一个置换向量 p,使得 A(p,p) 在嵌套剖分期间具有更少的零填充。 cuSolverSP 库链接了 libcusolver_metis_static.a,它是 64 位的 metis-5.1.0 。
参数 options 是 metis 的配置。对于那些没有 metis 经验的用户,请将 options = NULL 设置为默认值。
输出参数 p 是一个包含 n 个元素的整数数组。它表示一个基于 0 索引的置换数组。置换数组 p 对应于一个置换矩阵 P,并满足以下关系
A 是一个 \(n \times n\) 稀疏矩阵,通过三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。
支持的矩阵类型为 CUSPARSE_MATRIX_TYPE_GENERAL。在内部,csrmetisnd 在 \(A + A^{T}\) 上工作,如果矩阵不是对称的,用户无需扩展矩阵。
备注 1:仅提供 CPU (Host) 路径。
输入
参数 |
*主机内存空间 |
描述 |
|---|---|---|
|
|
cuSolverSP 库上下文的句柄。 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
整数数组,大小为 |
|
|
矩阵 |
|
|
配置 |
输出
参数 |
*主机内存空间 |
描述 |
|---|---|---|
|
|
大小为 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n,nnzA<=0),基索引不是 0 或 1。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED不支持的矩阵类型。
2.5.3.5. cusolverSpXcsrzfd()
cusolverStatus_t
cusolverSpScsrzfdHost(
cusolverSpHandle_t handle,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const float *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
int *P,
int *numnz)
cusolverStatus_t
cusolverSpDcsrzfdHost(
cusolverSpHandle_t handle,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const double *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
int *P,
int *numnz)
cusolverStatus_t
cusolverSpCcsrzfdHost(
cusolverSpHandle_t handle,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const cuComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
int *P,
int *numnz)
cusolverStatus_t
cusolverSpZcsrzfdHost(
cusolverSpHandle_t handle,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const cuDoubleComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
int *P,
int *numnz)
此函数实现了 MC21,无零对角线算法。它返回一个置换向量 p,使得 A(p,:) 没有零对角线。
A 是一个 \(n \times n\) 稀疏矩阵,它由三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。支持的矩阵类型为 CUSPARSE_MATRIX_TYPE_GENERAL。
输出参数 p 是一个包含 n 个元素的整数数组。它表示一个基于 0 索引的置换数组。置换数组 p 对应于一个置换矩阵 P,并满足以下关系
输出参数 numnz 描述了置换矩阵 A(p,:) 中非零对角线的数量。如果 numnz 小于 n,则矩阵 A 具有结构奇异性。
备注 1:仅提供 CPU (Host) 路径。
备注 2:此例程不会最大化置换矩阵的对角线值。用户不能期望此例程可以使“无枢轴 LU 分解”稳定。
输入
参数 |
*主机内存空间 |
描述 |
|---|---|---|
|
|
cuSolverSP 库上下文的句柄。 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
<type> 数组,包含 |
|
|
整数数组,大小为 |
|
|
矩阵 |
输出
参数 |
*主机内存空间 |
描述 |
|---|---|---|
|
|
大小为 |
|
|
置换矩阵对角线上的非零元素数量。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
n,nnzA<=0),基索引不是 0 或 1。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED不支持的矩阵类型。
2.5.3.6. cusolverSpXcsrperm()
cusolverStatus_t
cusolverSpXcsrperm_bufferSizeHost(cusolverSpHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
int *csrRowPtrA,
int *csrColIndA,
const int *p,
const int *q,
size_t *bufferSizeInBytes);
cusolverStatus_t
cusolverSpXcsrpermHost(cusolverSpHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
int *csrRowPtrA,
int *csrColIndA,
const int *p,
const int *q,
int *map,
void *pBuffer);
给定一个左置换向量 p(对应于置换矩阵 P)和一个右置换向量 q(对应于置换矩阵 Q),此函数计算矩阵 A 的置换,通过
A 是一个 \(m \times n\) 稀疏矩阵,它由三个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。
此操作是就地进行的,即矩阵 A 将被 B 覆盖。
置换向量 p 和 q 是基于 0 的索引。p 执行行置换,而 q 执行列置换。也可以使用 MATLAB 命令 \(B = {A(p,q)}\) 来置换矩阵 A。
此函数仅计算 B 的稀疏模式。用户可以使用参数 map 来获取 csrValB。参数 map 是一个输入/输出参数。如果用户在调用 csrperm 之前设置 map=0:1:(nnzA-1),则 csrValB=csrValA(map)。
支持的矩阵类型为 CUSPARSE_MATRIX_TYPE_GENERAL。如果 A 是对称的并且只提供了下/上三角部分,则用户必须将 \(A + A^{T}\) 传递给此函数。
此函数需要 csrperm_bufferSize() 返回的缓冲区大小。 pBuffer 的地址必须是 128 字节的倍数。如果不是,则返回 CUSOLVER_STATUS_INVALID_VALUE。
例如,如果矩阵 A 是
并且左置换向量 p=(0,2,1),右置换向量 q=(2,1,0),那么 \(P*A*Q^{T}\) 是
备注 1:仅提供 CPU (Host) 路径。
备注 2:用户可以结合使用 csrsymrcm 和 csrperm 来获得 \(P*A*P^{T}\),它在 QR 分解期间具有更少的零填充。
输入
参数 |
cusolverSp 内存空间 |
描述 |
|---|---|---|
|
|
cuSolver 库上下文的句柄。 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
矩阵 |
|
|
包含矩阵 |
|
|
矩阵 |
|
|
大小为 |
|
|
大小为 |
|
|
包含 |
|
|
用户分配的缓冲区,其大小由 |
输出
参数 |
hsolver |
描述 |
|---|---|---|
|
|
包含矩阵 |
|
|
包含矩阵 |
|
|
包含将矩阵 |
|
|
缓冲区的字节数。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
m,n,nnzA<=0),基索引不是 0 或 1。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED不支持的矩阵类型。
2.5.3.7. cusolverSpXcsrqrBatched()
创建和销毁方法启动和结束 csrqrInfo 对象的生命周期。
cusolverStatus_t
cusolverSpCreateCsrqrInfo(csrqrInfo_t *info);
cusolverStatus_t
cusolverSpDestroyCsrqrInfo(csrqrInfo_t info);
分析对于所有数据类型都是相同的,但每种数据类型都有唯一的缓冲区大小。
cusolverStatus_t
cusolverSpXcsrqrAnalysisBatched(cusolverSpHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const int *csrRowPtrA,
const int *csrColIndA,
csrqrInfo_t info);
cusolverStatus_t
cusolverSpScsrqrBufferInfoBatched(cusolverSpHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const float *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
int batchSize,
csrqrInfo_t info,
size_t *internalDataInBytes,
size_t *workspaceInBytes);
cusolverStatus_t
cusolverSpDcsrqrBufferInfoBatched(cusolverSpHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const double *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
int batchSize,
csrqrInfo_t info,
size_t *internalDataInBytes,
size_t *workspaceInBytes);
计算复数值数据类型的缓冲区大小。
cusolverStatus_t
cusolverSpCcsrqrBufferInfoBatched(cusolverSpHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const cuComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
int batchSize,
csrqrInfo_t info,
size_t *internalDataInBytes,
size_t *workspaceInBytes);
cusolverStatus_t
cusolverSpZcsrqrBufferInfoBatched(cusolverSpHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const cuDoubleComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
int batchSize,
csrqrInfo_t info,
size_t *internalDataInBytes,
size_t *workspaceInBytes);
S 和 D 数据类型分别是实值单精度和双精度。
cusolverStatus_t
cusolverSpScsrqrsvBatched(cusolverSpHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const float *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const float *b,
float *x,
int batchSize,
csrqrInfo_t info,
void *pBuffer);
cusolverStatus_t
cusolverSpDcsrqrsvBatched(cusolverSpHandle_t handle,
int m,
int n,
int nnz,
const cusparseMatDescr_t descrA,
const double *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const double *b,
double *x,
int batchSize,
csrqrInfo_t info,
void *pBuffer);
C 和 Z 数据类型分别是复值单精度和双精度。
cusolverStatus_t
cusolverSpCcsrqrsvBatched(cusolverSpHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const cuComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const cuComplex *b,
cuComplex *x,
int batchSize,
csrqrInfo_t info,
void *pBuffer);
cusolverStatus_t
cusolverSpZcsrqrsvBatched(cusolverSpHandle_t handle,
int m,
int n,
int nnzA,
const cusparseMatDescr_t descrA,
const cuDoubleComplex *csrValA,
const int *csrRowPtrA,
const int *csrColIndA,
const cuDoubleComplex *b,
cuDoubleComplex *x,
int batchSize,
csrqrInfo_t info,
void *pBuffer);
批量稀疏 QR 分解用于解决一组最小二乘问题
或一组线性系统
其中每个 \(A_{j}\) 都是一个 \(m \times n\) 稀疏矩阵,它由四个数组 csrValA、csrRowPtrA 和 csrColIndA 以 CSR 存储格式定义。
支持的矩阵类型为 CUSPARSE_MATRIX_TYPE_GENERAL。如果 A 是对称的并且只提供了下/上三角部分,则用户必须将 \(A + A^{H}\) 传递给此函数。
使用批量稀疏 QR 的先决条件有两个方面。首先,所有矩阵 \(A_{j}\) 必须具有相同的稀疏模式。其次,最小二乘问题中不使用列主元,因此仅当 \(A_{j}\) 对于所有 j = 1,2,..., batchSize 都满秩时,解才有效。所有矩阵都具有相同的稀疏模式,因此仅使用一个 csrRowPtrA 和 csrColIndA 副本。但是数组 csrValA 依次存储 \(A_{j}\) 的系数。换句话说, csrValA[k*nnzA : (k+1)*nnzA] 是 \(A_{k}\) 的值。
批量 QR 使用不透明数据结构 csrqrInfo 来保存中间数据,例如,QR 分解的矩阵 Q 和矩阵 R。用户需要在批量 QR 操作中的任何函数之前,先通过 cusolverSpCreateCsrqrInfo 创建 csrqrInfo。在调用 cusolverSpDestroyCsrqrInfo 之前,csrqrInfo 不会释放内部数据。
批量稀疏 QR 中有三个例程,cusolverSpXcsrqrAnalysisBatched、cusolverSp[S|D|C|Z]csrqrBufferInfoBatched 和 cusolverSp[S|D|C|Z]csrqrsvBatched。
首先,cusolverSpXcsrqrAnalysisBatched 是分析阶段,用于分析 QR 分解的矩阵 Q 和矩阵 R 的稀疏模式。并行性也在分析阶段提取。一旦分析阶段完成,就知道了执行 QR 所需的工作空间大小。但是,cusolverSpXcsrqrAnalysisBatched 使用 CPU 来分析矩阵 A 的结构,这可能会消耗大量内存。如果主机内存不足以完成分析,则返回 CUSOLVER_STATUS_ALLOC_FAILED。分析所需的内存与 QR 分解中的零填充成正比。用户可能需要执行某种重排序以最小化零填充,例如 MATLAB 中的 colamd 或 symrcm。cuSolverSP 库提供了 symrcm (cusolverSpXcsrsymrcm)。
其次,用户需要选择合适的 batchSize 并为稀疏 QR 准备工作空间。批量稀疏 QR 中使用了两个内存块。一个是用于存储矩阵 Q 和矩阵 R 的内部内存块。另一个是用于执行数值分解的工作空间。前者的尺寸与 batchSize 成正比,尺寸由 cusolverSp[S|D|C|Z]csrqrBufferInfoBatched 的返回参数 internalDataInBytes 指定。而后者的尺寸几乎与 batchSize 无关,尺寸由 cusolverSp[S|D|C|Z]csrqrBufferInfoBatched 的返回参数 workspaceInBytes 指定。内部内存块在首次调用 cusolverSp[S|D|C|Z]csrqrsvBatched 期间隐式分配。用户只需要为 cusolverSp[S|D|C|Z]csrqrsvBatched 分配工作空间。
用户可以通过查询 cusolverSp[S|D|C|Z]csrqrBufferInfoBatched 来找到最大 batchSize,而不是尝试所有批量矩阵。例如,用户可以增加 batchSize,直到 internalDataInBytes 和 workspaceInBytes 的总和大于可用设备内存的大小。
假设用户需要执行 253 个线性求解器,并且可用设备内存为 2GB。如果 cusolverSp[S|D|C|Z]csrqrsvBatched 只能负担 batchSize 为 100,则用户必须调用三次 cusolverSp[S|D|C|Z]csrqrsvBatched 才能完成所有求解。用户使用 batchSize 100 调用 cusolverSp[S|D|C|Z]csrqrBufferInfoBatched。不透明的 info 将记住此 batchSize,并且任何后续对 cusolverSp[S|D|C|Z]csrqrsvBatched 的调用都不能超过此值。在本例中,前两次调用 cusolverSp[S|D|C|Z]csrqrsvBatched 将使用 batchSize 100,最后一次调用 cusolverSp[S|D|C|Z]csrqrsvBatched 将使用 batchSize 53。
示例:假设 A0、A1、..、A9 具有相同的稀疏模式,以下代码通过批量稀疏 QR 求解 10 个线性系统 \(A_{j}x_{j} = b_{j}{,\ j\ =\ 0,2,...,\ 9}\)。
// Suppose that A0, A1, .., A9 are m x m sparse matrix represented by CSR format,
// Each matrix Aj has nonzero nnzA, and shares the same csrRowPtrA and csrColIndA.
// csrValA is aggregation of A0, A1, ..., A9.
int m ; // number of rows and columns of each Aj
int nnzA ; // number of nonzeros of each Aj
int *csrRowPtrA ; // each Aj has the same csrRowPtrA
int *csrColIndA ; // each Aj has the same csrColIndA
double *csrValA ; // aggregation of A0,A1,...,A9
const int batchSize = 10; // 10 linear systems
cusolverSpHandle_t handle; // handle to cusolver library
csrqrInfo_t info = NULL;
cusparseMatDescr_t descrA = NULL;
void *pBuffer = NULL; // working space for numerical factorization
// step 1: create a descriptor
cusparseCreateMatDescr(&descrA);
cusparseSetMatIndexBase(descrA, CUSPARSE_INDEX_BASE_ONE); // A is base-1
cusparseSetMatType(descrA, CUSPARSE_MATRIX_TYPE_GENERAL); // A is a general matrix
// step 2: create empty info structure
cusolverSpCreateCsrqrInfo(&info);
// step 3: symbolic analysis
cusolverSpXcsrqrAnalysisBatched(
handle, m, m, nnzA,
descrA, csrRowPtrA, csrColIndA, info);
// step 4: allocate working space for Aj*xj=bj
cusolverSpDcsrqrBufferInfoBatched(
handle, m, m, nnzA,
descrA,
csrValA, csrRowPtrA, csrColIndA,
batchSize,
info,
&internalDataInBytes,
&workspaceInBytes);
cudaMalloc(&pBuffer, workspaceInBytes);
// step 5: solve Aj*xj = bj
cusolverSpDcsrqrsvBatched(
handle, m, m, nnzA,
descrA, csrValA, csrRowPtrA, csrColIndA,
b,
x,
batchSize,
info,
pBuffer);
// step 7: destroy info
cusolverSpDestroyCsrqrInfo(info);
有关代码示例,请参考 cuSOLVER Library Samples - csrqr。
备注 1:仅提供 GPU(设备)路径。
输入
参数 |
cusolverSp 内存空间 |
描述 |
|---|---|---|
|
|
cuSolverSP 库上下文的句柄。 |
|
|
每个矩阵 |
|
|
每个矩阵 |
|
|
每个矩阵 |
|
|
每个矩阵 |
|
|
<type> 数组,包含矩阵 |
|
|
包含每一行的起始位置和最后一行的末尾位置加一的 |
|
|
包含每个矩阵 |
|
|
<type> 数组,包含右手边向量 |
|
|
要解决的系统数量。 |
|
|
用于 QR 分解的不透明结构。 |
|
|
用户分配的缓冲区,其大小由 |
输出
参数 |
cusolverSp 内存空间 |
描述 |
|---|---|---|
|
|
<type> 数组,包含解向量 |
|
|
内部数据的字节数。 |
|
|
数值分解中缓冲区的字节数。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
m,n,nnzA<=0),基索引不是 0 或 1。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
CUSOLVER_STATUS_MATRIX_TYPE_NOT_SUPPORTED不支持的矩阵类型。
2.6. cuSolverRF:重构参考
本节介绍 cuSolverRF 的 API,这是一个用于快速重构的库。
2.6.1. cusolverRfAccessBundledFactorsDevice() [[已弃用]]
[[已弃用]] 此函数已弃用,将在未来的主要版本中删除。请改用 cuDSS 库,以获得更好的性能和支持。对于过渡,请访问 cuDSS 库示例 以获取代码示例。
cusolverStatus_t
cusolverRfAccessBundledFactorsDevice(/* Input */
cusolverRfHandle_t handle,
/* Output (in the host memory) */
int* nnzM,
/* Output (in the device memory) */
int** Mp,
int** Mi,
double** Mx);
此例程允许直接访问存储在 cuSolverRF 库句柄中的下三角 L 和上三角 U 因子。这些因子被压缩成一个矩阵 M=(L-I)+U,其中不存储 L 的单位对角线。 假设之前已调用 cusolverRfRefactor() 以生成这些三角因子。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
|
|
|
矩阵 |
|
|
|
偏移量数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵 |
|
|
|
值数组,对应于矩阵 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_EXECUTION_FAILEDGPU 上启动内核失败。
2.6.2. cusolverRfAnalyze() [[已弃用]]
[[已弃用]] 此函数已弃用,将在未来的主要版本中删除。请改用 cuDSS 库,以获得更好的性能和支持。对于过渡,请访问 cuDSS 库示例 以获取代码示例。
cusolverStatus_t
cusolverRfAnalyze(cusolverRfHandle_t handle);
此例程根据用户选择的算法,执行 LU 重构中可用并行性的适当分析。
假设之前已调用 cusolverRfSetup[Host|Device]() 以创建分析所需的内部数据结构。
对于单个线性系统,此例程只需要调用一次
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_EXECUTION_FAILEDGPU 上启动内核失败。
CUSOLVER_STATUS_ALLOC_FAILED内存分配失败。
cusolverRfSetupDevice() [[已弃用]]
[[已弃用]] 此函数已弃用,将在未来的主要版本中删除。请改用 cuDSS 库,以获得更好的性能和支持。对于过渡,请访问 cuDSS 库示例 以获取代码示例。
cusolverStatus_t
cusolverRfSetupDevice(/* Input (in the device memory) */
int n,
int nnzA,
int* csrRowPtrA,
int* csrColIndA,
double* csrValA,
int nnzL,
int* csrRowPtrL,
int* csrColIndL,
double* csrValL,
int nnzU,
int* csrRowPtrU,
int* csrColIndU,
double* csrValU,
int* P,
int* Q,
/* Output */
cusolverRfHandle_t handle);
此例程组装 cuSolverRF 库的内部数据结构。它通常是在调用 cusolverRfCreate() 例程之后调用的第一个例程。
此例程接受(在设备上)原始矩阵 A、下三角 (L) 和上三角 (U) 因子,以及从第一个 (i=1) 线性系统的完整 LU 分解得到的左 (P) 和右 (Q) 置换作为输入
置换 P 和 Q 分别表示应用于原始矩阵 A 的所有左和右重排序的最终组合。但是,这些置换通常与部分主元和重排序以最小化填充相关联。
对于单个线性系统,此例程只需要调用一次
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
偏移量数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵中的非零元素。 假设此数组按行和列在每行中排序。数组大小为 |
|
|
|
值数组,对应于矩阵中的非零元素。 假设此数组按行和列在每行中排序。数组大小为 |
|
|
|
矩阵 |
|
|
|
偏移量数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵 |
|
|
|
值数组,对应于矩阵 |
|
|
|
矩阵 |
|
|
|
偏移量数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵 |
|
|
|
值数组,对应于矩阵 |
|
|
|
左置换(通常与主元相关)。数组大小为 |
|
|
|
右置换(通常与重排序相关)。数组大小为 |
|
|
|
cuSolverRF 库的句柄。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了不支持的值或参数。
CUSOLVER_STATUS_ALLOC_FAILED内存分配失败。
CUSOLVER_STATUS_EXECUTION_FAILEDGPU 上启动内核失败。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.6.3. cusolverRfSetupHost()
cusolverStatus_t
cusolverRfSetupHost(/* Input (in the host memory) */
int n,
int nnzA,
int* h_csrRowPtrA,
int* h_csrColIndA,
double* h_csrValA,
int nnzL,
int* h_csrRowPtrL,
int* h_csrColIndL,
double* h_csrValL,
int nnzU,
int* h_csrRowPtrU,
int* h_csrColIndU,
double* h_csrValU,
int* h_P,
int* h_Q,
/* Output */
cusolverRfHandle_t handle);
此例程组装 cuSolverRF 库的内部数据结构。它通常是在调用 cusolverRfCreate() 例程之后调用的第一个例程。
此例程接受(在主机上)原始矩阵 A、下三角 (L) 和上三角 (U) 因子,以及从第一个 (i=1) 线性系统的完整 LU 分解得到的左 (P) 和右 (Q) 置换作为输入
置换 P 和 Q 分别表示应用于原始矩阵 A 的所有左和右重排序的最终组合。但是,这些置换通常与部分主元和重排序以最小化填充相关联。
对于单个线性系统,此例程只需要调用一次
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
偏移量数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵中的非零元素。 假设此数组按行和列在每行中排序。数组大小为 |
|
|
|
值数组,对应于矩阵中的非零元素。 假设此数组按行和列在每行中排序。数组大小为 |
|
|
|
矩阵 |
|
|
|
偏移量数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵 |
|
|
|
值数组,对应于矩阵 |
|
|
|
矩阵 |
|
|
|
偏移数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵 |
|
|
|
值数组,对应于矩阵 |
|
|
|
左置换(通常与主元相关)。数组大小为 |
|
|
|
右置换(通常与重排序相关)。数组大小为 |
|
|
|
cuSolverRF 库的句柄。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了不支持的值或参数。
CUSOLVER_STATUS_ALLOC_FAILED内存分配失败。
CUSOLVER_STATUS_EXECUTION_FAILEDGPU 上启动内核失败。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.6.4. cusolverRfCreate()
cusolverStatus_t cusolverRfCreate(cusolverRfHandle_t *handle);
此例程初始化 cuSolverRF 库。它分配所需的资源,并且必须在任何其他 cuSolverRF 库例程之前调用。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向 cuSolverRF 库句柄的指针。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED内存分配失败。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.6.5. cusolverRfExtractBundledFactorsHost() [[已弃用]]
[[已弃用]] 此函数已弃用,将在未来的主要版本中删除。请改用 cuDSS 库,以获得更好的性能和支持。对于过渡,请访问 cuDSS 库示例 以获取代码示例。
cusolverStatus_t
cusolverRfExtractBundledFactorsHost(/* Input */
cusolverRfHandle_t handle,
/* Output (in the host memory) */
int* h_nnzM,
int** h_Mp,
int** h_Mi,
double** h_Mx);
此例程从 cuSolverRF 库句柄中提取下三角 (L) 和上三角 (U) 因子到主机内存中。这些因子被压缩成一个单一矩阵 M=(L-I)+U,其中 (L) 的单位对角线未被存储。假定之前已调用 cusolverRfRefactor() 以生成这些三角因子。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
|
|
|
矩阵 |
|
|
|
偏移数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵中的非零元素。假定此数组按行和每行内的列排序。数组大小为 |
|
|
|
值数组,对应于矩阵中的非零元素。假定此数组按行和每行内的列排序。数组大小为 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED内存分配失败。
CUSOLVER_STATUS_EXECUTION_FAILEDGPU 上启动内核失败。
2.6.6. cusolverRfExtractSplitFactorsHost() [[已弃用]]
[[已弃用]] 此函数已弃用,将在未来的主要版本中删除。请改用 cuDSS 库,以获得更好的性能和支持。对于过渡,请访问 cuDSS 库示例 以获取代码示例。
cusolverStatus_t
cusolverRfExtractSplitFactorsHost(/* Input */
cusolverRfHandle_t handle,
/* Output (in the host memory) */
int* h_nnzL,
int** h_Lp,
int** h_Li,
double** h_Lx,
int* h_nnzU,
int** h_Up,
int** h_Ui,
double** h_Ux);
此例程从 cuSolverRF 库句柄中提取下三角 (L) 和上三角 (U) 因子到主机内存中。假定之前已调用 cusolverRfRefactor() 以生成这些三角因子。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
|
|
|
矩阵 |
|
|
|
偏移数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵 |
|
|
|
值数组,对应于矩阵 |
|
|
|
矩阵 |
|
|
|
偏移数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵 |
|
|
|
值数组,对应于矩阵 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ALLOC_FAILED内存分配失败。
CUSOLVER_STATUS_EXECUTION_FAILEDGPU 上启动内核失败。
2.6.7. cusolverRfDestroy()
cusolverStatus_t cusolverRfDestroy(cusolverRfHandle_t handle);
此例程关闭 cuSolverRF 库。它释放已获取的资源,并且必须在所有 cuSolverRF 库例程之后调用。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库句柄。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
2.6.8. cusolverRfGetMatrixFormat()
cusolverStatus_t
cusolverRfGetMatrixFormat(cusolverRfHandle_t handle,
cusolverRfMatrixFormat_t *format,
cusolverRfUnitDiagonal_t *diag);
此例程获取在 cusolverRfSetupDevice()、cusolverRfSetupHost()、cusolverRfResetValues()、cusolverRfExtractBundledFactorsHost() 和 cusolverRfExtractSplitFactorsHost() 例程中使用的矩阵格式。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
|
|
|
枚举的矩阵格式类型。 |
|
|
|
枚举的单位对角线类型。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
2.6.9. cusolverRfGetNumericProperties()
cusolverStatus_t
cusolverRfGetNumericProperties(cusolverRfHandle_t handle,
double *zero,
double *boost);
此例程获取用于检查 “零” 主元并在 cusolverRfRefactor() 和 cusolverRfSolve() 例程中提升它的数值。只有当 boost > 0.0 时,才会使用数值提升。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
|
|
|
标志零主元的阈值。 |
|
|
|
用于替换零主元的值(如果后者被标志)。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
2.6.10. cusolverRfGetNumericBoostReport()
cusolverStatus_t
cusolverRfGetNumericBoostReport(cusolverRfHandle_t handle,
cusolverRfNumericBoostReport_t *report);
此例程获取数值提升是否在 cusolverRfRefactor() 和 cusolverRfSolve() 例程中使用的报告。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
|
|
|
枚举的提升报告类型。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
2.6.11. cusolverRfGetResetValuesFastMode()
cusolverStatus_t
cusolverRfGetResetValuesFastMode(cusolverRfHandle_t handle,
cusolverRfResetValuesFastMode_t *fastMode);
此例程获取在 cusolverRfResetValues 例程中使用的模式。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
|
|
|
枚举的模式类型。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
2.6.12. cusolverRfGetAlgs()
cusolverStatus_t
cusolverRfGetAlgs(cusolverRfHandle_t handle,
cusolverRfFactorization_t* fact_alg,
cusolverRfTriangularSolve_t* solve_alg);
此例程获取用于 cusolverRfRefactor() 中的重构和 cusolverRfSolve() 中的三角求解的算法。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
|
|
|
枚举的算法类型。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
2.6.13. cusolverRfRefactor() [[已弃用]]
[[已弃用]] 此函数已弃用,将在未来的主要版本中删除。请改用 cuDSS 库,以获得更好的性能和支持。对于过渡,请访问 cuDSS 库示例 以获取代码示例。
cusolverStatus_t cusolverRfRefactor(cusolverRfHandle_t handle);
此例程执行 LU 重构
探索 GPU 上的可用并行性。假定之前已调用 cusolverRfAnalyze() 以查找可用的并行性。
此例程可以多次调用,每个线性系统一次
对于用于重构和求解例程 cusolverRfRefactor() 和 cusolverRfSolve() 的算法组合存在一些约束。错误的组合会生成错误代码 CUSOLVER_STATUS_INVALID_VALUE。下表总结了支持的算法组合
用于求解和重构例程的兼容算法。
分解 |
求解 |
|---|---|
|
|
|
|
|
|
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_EXECUTION_FAILEDGPU 上启动内核失败。
CUSOLVER_STATUS_ZERO_PIVOT在计算过程中遇到零主元。
2.6.14. cusolverRfResetValues() [[已弃用]]
[[已弃用]] 此函数已弃用,将在未来的主要版本中删除。请改用 cuDSS 库,以获得更好的性能和支持。对于过渡,请访问 cuDSS 库示例 以获取代码示例。
cusolverStatus_t
cusolverRfResetValues(/* Input (in the device memory) */
int n,
int nnzA,
int* csrRowPtrA,
int* csrColIndA,
double* csrValA,
int* P,
int* Q,
/* Output */
cusolverRfHandle_t handle);
此例程使用新系数矩阵的值更新内部数据结构。假定自上次调用 cusolverRfSetup[Host|Device] 例程以来,数组 csrRowPtrA、csrColIndA、P 和 Q 没有更改。此假设反映了系数矩阵的稀疏模式以及为最小化填充和主元选择而进行的重排序在以下线性系统集中保持不变
此例程可以多次调用,每个线性系统一次
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
偏移量数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵中的非零元素。 假设此数组按行和列在每行中排序。数组大小为 |
|
|
|
值数组,对应于矩阵中的非零元素。 假设此数组按行和列在每行中排序。数组大小为 |
|
|
|
左置换(通常与主元相关)。数组大小为 |
|
|
|
右置换(通常与重排序相关)。数组大小为 |
|
|
|
cuSolverRF 库的句柄。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了不支持的值或参数。
CUSOLVER_STATUS_EXECUTION_FAILEDGPU 上启动内核失败。
2.6.15. cusolverRfSetMatrixFormat()
cusolverStatus_t
cusolverRfSetMatrixFormat(cusolverRfHandle_t handle,
cusolverRfMatrixFormat_t format,
cusolverRfUnitDiagonal_t diag);
此例程设置在 cusolverRfSetupDevice()、cusolverRfSetupHost()、cusolverRfResetValues()、cusolverRfExtractBundledFactorsHost() 和 cusolverRfExtractSplitFactorsHost() 例程中使用的矩阵格式。它可以在 cusolverRfSetupDevice() 和 cusolverRfSetupHost() 例程之前调用一次。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
|
|
|
枚举的矩阵格式类型。 |
|
|
|
枚举的单位对角线类型。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE枚举的模式参数错误。
2.6.16. cusolverRfSetNumericProperties()
cusolverStatus_t
cusolverRfSetNumericProperties(cusolverRfHandle_t handle,
double zero,
double boost);
此例程设置用于检查 “零” 主元并在 cusolverRfRefactor() 和 cusolverRfSolve() 例程中提升它的数值。它可以在 cusolverRfRefactor() 和 cusolverRfSolve() 例程之前多次调用。只有当 boost > 0.0 时,才会使用数值提升。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
|
|
|
标志零主元的阈值。 |
|
|
|
用于替换零主元的值(如果后者被标志)。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
2.6.17. cusolverRfSetResetValuesFastMode()
cusolverStatus_t
cusolverRfSetResetValuesFastMode(cusolverRfHandle_t handle,
cusolverRfResetValuesFastMode_t fastMode);
此例程设置在 cusolverRfResetValues 例程中使用的模式。快速模式需要额外的内存,并且仅在需要非常快速地调用 cusolverRfResetValues() 时才推荐使用。它可以在 cusolverRfAnalyze() 例程之前调用一次。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
|
|
|
枚举的模式类型。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE枚举的模式参数错误。
2.6.18. cusolverRfSetAlgs()
cusolverStatus_t
cusolverRfSetAlgs(cusolverRfHandle_t handle,
cusolverRfFactorization_t fact_alg,
cusolverRfTriangularSolve_t alg);
此例程设置用于 cusolverRfRefactor() 中的重构和 cusolverRfSolve() 中的三角求解的算法。它可以在 cusolverRfAnalyze() 例程之前调用一次。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
|
|
|
枚举的算法类型。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
2.6.19. cusolverRfSolve() [[已弃用]]
[[已弃用]] 此函数已弃用,将在未来的主要版本中删除。请改用 cuDSS 库,以获得更好的性能和支持。对于过渡,请访问 cuDSS 库示例 以获取代码示例。
cusolverStatus_t
cusolverRfSolve(/* Input (in the device memory) */
cusolverRfHandle_t handle,
int *P,
int *Q,
int nrhs,
double *Temp,
int ldt,
/* Input/Output (in the device memory) */
double *XF,
/* Input */
int ldxf);
此例程使用 LU 重构产生的下三角 \(L\in R^{nxn}\) 和上三角 \(U\in R^{nxn}\) 因子执行前向和后向求解
假定该重构已通过先前调用 cusolverRfRefactor() 例程计算得出。
该例程可以求解具有多个右侧项 (RHS) 的线性系统
即使目前仅支持单个 RHS。
此例程可以多次调用,每个线性系统一次
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
|
|
|
左置换(通常与主元相关)。数组大小为 |
|
|
|
右置换(通常与重排序相关)。数组大小为 |
|
|
|
要解的右侧项的数量。 |
|
|
|
包含临时工作空间的稠密矩阵(大小为 |
|
|
|
稠密矩阵 Temp 的前导维度 ( |
|
|
|
包含右侧项 |
|
|
|
稠密矩阵 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了不支持的值或参数。
CUSOLVER_STATUS_EXECUTION_FAILEDGPU 上启动内核失败。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.6.20. cusolverRfBatchSetupHost()
cusolverStatus_t
cusolverRfBatchSetupHost(/* Input (in the host memory) */
int batchSize,
int n,
int nnzA,
int* h_csrRowPtrA,
int* h_csrColIndA,
double *h_csrValA_array[],
int nnzL,
int* h_csrRowPtrL,
int* h_csrColIndL,
double *h_csrValL,
int nnzU,
int* h_csrRowPtrU,
int* h_csrColIndU,
double *h_csrValU,
int* h_P,
int* h_Q,
/* Output */
cusolverRfHandle_t handle);
此例程为批量操作组装 cuSolverRF 库的内部数据结构。它在调用 cusolverRfCreate() 例程之后,以及任何其他批量例程之前调用。
批量操作假定用户具有以下线性系统
其中集合中的每个矩阵:\(\{ A_{j}\}\) 具有相同的稀疏模式,并且非常相似,以至于可以使用相同的置换 P 和 Q 进行分解。换句话说,\(A_{j}{,\ j>1}\) 是 \(A_{1}\) 的小扰动。
此例程接受(在主机上)原始矩阵 A(稀疏模式和批量值)、下三角 (L) 和上三角 (U) 因子,以及来自第一个 (i=1) 线性系统的完整 LU 分解的左置换 (P) 和右置换 (Q) 作为输入
置换 P 和 Q 分别表示应用于原始矩阵 A 的所有左和右重排序的最终组合。但是,这些置换通常与部分主元和重排序以最小化填充相关联。
备注 1:矩阵 A、L 和 U 必须是 CSR 格式且基于 0 的。
备注 2:为了获得最佳性能,batchSize 应为 32 的倍数且大于或等于 32。该算法是内存受限的,一旦达到带宽限制,就无法通过更大的 batchSize 来提高性能。实际上,batchSize 为 32 - 128 通常足以获得良好的性能,但在某些情况下,更大的 batchSize 可能是有益的。
以下例程对于单个线性系统只需要调用一次
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
批量模式下的矩阵数量。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
偏移量数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵中的非零元素。 假设此数组按行和列在每行中排序。数组大小为 |
|
|
|
大小为 |
|
|
|
矩阵 |
|
|
|
偏移量数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵 |
|
|
|
值数组,对应于矩阵 |
|
|
|
矩阵 |
|
|
|
偏移数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵 |
|
|
|
值数组,对应于矩阵 |
|
|
|
左置换(通常与主元相关)。数组大小为 |
|
|
|
右置换(通常与重排序相关)。数组大小为 |
|
|
|
cuSolverRF 库的句柄。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了不支持的值或参数。
CUSOLVER_STATUS_ALLOC_FAILED内存分配失败。
CUSOLVER_STATUS_EXECUTION_FAILEDGPU 上启动内核失败。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.6.21. cusolverRfBatchAnalyze()
cusolverStatus_t cusolverRfBatchAnalyze(cusolverRfHandle_t handle);
此例程执行批量 LU 重构中可用并行性的适当分析。
假定之前已调用 cusolverRfBatchSetup[Host]() 以创建分析所需的内部数据结构。
以下例程对于单个线性系统只需要调用一次
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_EXECUTION_FAILEDGPU 上启动内核失败。
CUSOLVER_STATUS_ALLOC_FAILED内存分配失败。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.6.22. cusolverRfBatchResetValues()
cusolverStatus_t
cusolverRfBatchResetValues(/* Input (in the device memory) */
int batchSize,
int n,
int nnzA,
int* csrRowPtrA,
int* csrColIndA,
double* csrValA_array[],
int *P,
int *Q,
/* Output */
cusolverRfHandle_t handle);
此例程使用新系数矩阵的值更新内部数据结构。假定自上次调用 cusolverRfbatch_setup_host 例程以来,数组 csrRowPtrA、csrColIndA、P 和 Q 没有更改。
此假设反映了系数矩阵的稀疏模式以及为最小化填充和主元选择而进行的重排序在以下线性系统集中保持不变
输入参数 csrValA_array 是设备内存上的指针数组。csrValA_array(j) 指向矩阵:\(A_{j}\),该矩阵也在设备内存上。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
批量模式下的矩阵数量。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
偏移量数组,对应于数组 |
|
|
|
列索引数组,对应于矩阵中的非零元素。 假设此数组按行和列在每行中排序。数组大小为 |
|
|
|
大小为 |
|
|
|
左置换(通常与主元相关)。数组大小为 |
|
|
|
右置换(通常与重排序相关)。数组大小为 |
|
|
|
cuSolverRF 库的句柄。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了不支持的值或参数。
CUSOLVER_STATUS_EXECUTION_FAILEDGPU 上启动内核失败。
2.6.23. cusolverRfBatchRefactor()
cusolverStatus_t cusolverRfBatchRefactor(cusolverRfHandle_t handle);
此例程执行 LU 重构
探索 GPU 上的可用并行性。假定之前已调用 cusolverRfBatchAnalyze() 以查找可用的并行性。
备注:cusolverRfBatchRefactor() 不会报告任何 LU 重构失败。用户必须调用 cusolverRfBatchZeroPivot() 以了解哪个矩阵的 LU 重构失败。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_EXECUTION_FAILEDGPU 上启动内核失败。
2.6.24. cusolverRfBatchSolve()
cusolverStatus_t
cusolverRfBatchSolve(/* Input (in the device memory) */
cusolverRfHandle_t handle,
int *P,
int *Q,
int nrhs,
double *Temp,
int ldt,
/* Input/Output (in the device memory) */
double *XF_array[],
/* Input */
int ldxf);
为了求解 \(A_{j}*x_{j} = b_{j}\),首先我们通过 \(M_{j}*Q*x_{j} = P*b_{j}\) 重新形成方程,其中 \(M_{j} = P*A_{j}*Q^{T}\)。然后通过 cusolverRfBatch_Refactor() 执行重构 \(M_{j} = L_{j}*U_{j}\)。此外,cusolverRfBatch_Solve() 接管其余步骤,包括
\(z_{j} = P*b_{j}\)
\(M_{j}*y_{j} = z_{j}\)
\(x_{j} = Q^{T}*y_{j}\)
输入参数 XF_array 是设备内存上的指针数组。XF_array(j) 指向矩阵 \(x_{j}\),该矩阵也在设备内存上。
备注 1:仅支持单个 rhs。
备注 2:后向求解期间不报告奇点。如果某个矩阵 \(A_{j}\) 重构失败,并且 \(U_{j}\) 具有一些零对角线,则后向求解将计算出 NAN。用户必须调用 cusolverRfBatch_Zero_Pivot 以检查重构是否成功。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
|
|
|
左置换(通常与主元相关)。数组大小为 |
|
|
|
右置换(通常与重排序相关)。数组大小为 |
|
|
|
要解的右侧项的数量。 |
|
|
|
包含临时工作空间的稠密矩阵(大小为 |
|
|
|
稠密矩阵 Temp 的前导维度 ( |
|
|
|
大小为 |
|
|
|
稠密矩阵 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了不支持的值或参数。
CUSOLVER_STATUS_EXECUTION_FAILEDGPU 上启动内核失败。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
2.6.25. cusolverRfBatchZeroPivot()
cusolverStatus_t
cusolverRfBatchZeroPivot(/* Input */
cusolverRfHandle_t handle
/* Output (in the host memory) */
int *position);
虽然 \(A_{j}\) 彼此接近,但这并不意味着每个 j 都存在 \(M_{j} = P*A_{j}*Q^{T} = L_{j}*U_{j}\)。用户可以通过检查 position 数组中的相应值来查询哪个矩阵的 LU 重构失败。输入参数 position 是大小为 batchSize 的整数数组。
第 j-th 个分量表示矩阵 \(A_{j}\) 的重构结果。如果 position(j) 为 -1,则矩阵 \(A_{j}\) 的 LU 重构成功。如果 position(j) 为 k >= 0,则矩阵 \(A_{j}\) 不可 LU 分解,并且其矩阵 \(U_{j}{(j,j)}\) 为零。
如果存在一个 \(A_{j}\) 的 LU 重构失败,则 cusolverRfBatch_Zero_Pivot 的返回值是 CUSOLVER_STATUS_ZERO_PIVOT。如果返回错误代码 CUSOLVER_STATUS_ZERO_PIVOT,用户可以重做 LU 分解以获得新的置换 P 和 Q。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverRF 库的句柄。 |
|
|
|
大小为 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_ZERO_PIVOT在计算过程中遇到零主元。
3. 使用 CUSOLVERMG API
3.1. 通用描述
本节介绍如何使用 cuSolverMG 库 API。它不是 cuSolverMG API 数据类型和函数的参考;这些内容在后续章节中提供。
3.1.1. 线程安全
仅当每个线程有一个 cuSolverMG 上下文时,该库才是线程安全的。
3.1.2. 确定性
当前,当满足以下条件时,给定工具包版本的所有 cuSolverMG API 例程都会生成相同的按位结果
参与计算的所有 GPU 具有相同的计算能力和相同数量的 SM。
切片大小在运行之间保持不变。
逻辑 GPU 的数量保持不变。GPU 的顺序并不重要,因为它们都具有相同的计算能力。
3.1.3. 切片策略
cuSolverMG 的切片策略与 ScaLAPACK 兼容。当前版本仅支持 1-D 列块循环、列主序 PACKED 格式。
图 1.a 显示了维度为 M_A x N_A 的矩阵 A 的分区。每个列切片有 T_A 列。有七列切片,标记为 0,1,2,3,4,5,6,以 循环 方式分布到三个 GPU 中,即每个 GPU 依次获取一个列切片。例如,GPU 0 具有列切片 0、3、6(黄色切片),而 GPU 1 获取 GPU 0 旁边的列切片(蓝色切片)。并非所有 GPU 都具有相同数量的切片;在此示例中,GPU 0 有三个切片,其他 GPU 只有两个切片。
图 1.b 显示了在每个 GPU 中本地存储这些列切片的两种可能格式。左侧称为 PACKED 格式,右侧是 UNPACKED 格式。PACKED 格式在一个连续的内存块中聚合三个列切片,而 UNPACKED 格式将这三个列切片分布到不同的内存块中。它们之间唯一的区别是 PACKED 格式可以进行一次大的 GEMM 调用,而不是 UNPACKED 格式中的三次 GEMM 调用。因此,理论上讲,PACKED 格式可以比 UNPACKED 格式提供更好的性能。cuSolverMG 在 API 中仅支持 PACKED 格式。为了获得最佳性能,用户只需选择合适的切片大小 T_A 来对矩阵进行分区,不要太小,例如 256 或以上就足够了。
还有另一个参数,称为 LLD_A,用于控制每个 GPU 中本地矩阵的前导维度。LLD_A 必须大于或等于 M_A。LLD_A 的目的是为了提高 GEMM 的性能。对于小问题,如果 LLD_A 是 2 的幂,则 GEMM 会更快。但是对于大问题,LLD_A 没有显示出明显的改进。cuSolverMG 仅支持 LLD_A=M_A。
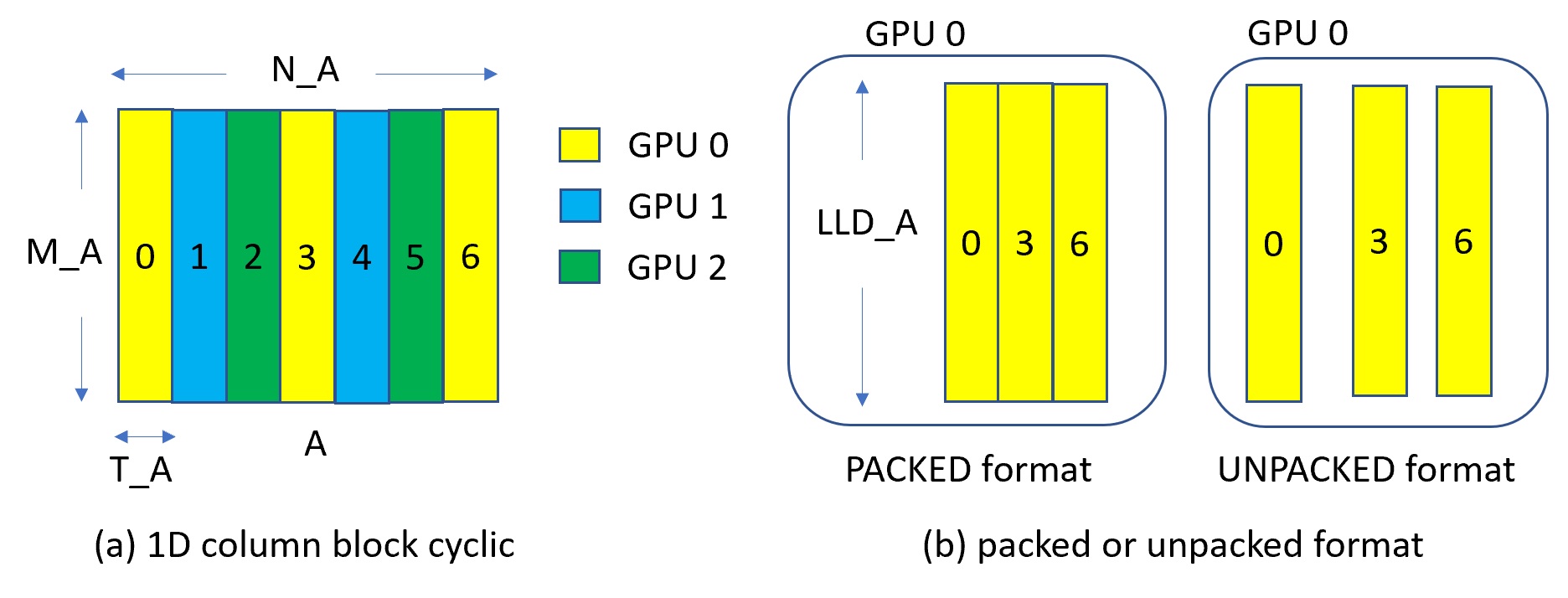
cuSolverMG 用于 3 个 GPU 的切片示例
cuSolverMG 中的处理网格是 GPU ID 列表,类似于 ScaLAPACK 中的进程 ID。cuSolverMG 仅支持 1D 列块循环,因此也仅支持 1D 网格。假设 deviceId 是 GPU ID 列表,则 deviceId=1,1,1 和 deviceId=2,1,0 都是有效的。前者描述了选择运行 cuSolverMG 例程的三个逻辑设备,并且都具有相同的物理 ID 0。后者仍然使用三个逻辑设备,但是每个设备都具有不同的物理 ID。当前设计仅接受 32 个逻辑设备,也就是说,deviceId 的长度小于或等于 32。图 1 使用 deviceId=0,1,2。
实际上,矩阵 A 分布在 deviceId 中列出的 GPU 中。如果用户选择 deviceId=1,1,1,则所有列切片都位于 GPU 1 中,这将限制问题的大小,因为一个 GPU 的内存容量有限。此外,多 GPU 例程增加了通过片外总线进行数据通信的额外开销,如果不支持或未使用 NVLINK,则会对性能产生很大的影响。在单个 GPU 上运行可能比使用具有相同 GPU ID 的设备运行多 GPU 版本更快。
3.1.4. 全局矩阵与局部矩阵
在稠密线性代数中,操作矩阵 A 的子矩阵很简单,只需将指针移动到相对于 A 的子矩阵的起始点即可。例如,gesvd(10,10, A) 是 A(0:9,0:9) 的 SVD。gesvd(10,10, A + 5 + 2*lda ) 是以 A(5,2) 开头的 10x10 子矩阵的 SVD。
但是,操作分布式矩阵的子矩阵并不简单,因为子矩阵的不同起始点会更改该子矩阵的布局分布。ScaLAPACK 引入了两个参数 IA 和 JA 来定位子矩阵。图 2 显示了维度为 M_A x N_A 的(全局)矩阵 A。sub(A) 是 A 的 M x N 子矩阵,起始于 IA 和 JA。请注意,IA 和 JA 是基于 1 的。
给定一个分布式矩阵 A,用户可以通过调用 syevd(A, IA, JA) 或将 sub(A) 收集到另一个分布式矩阵 B 并调用 syevd(B, IB=1, JB=1) 来计算子矩阵 sub(A) 的特征值。
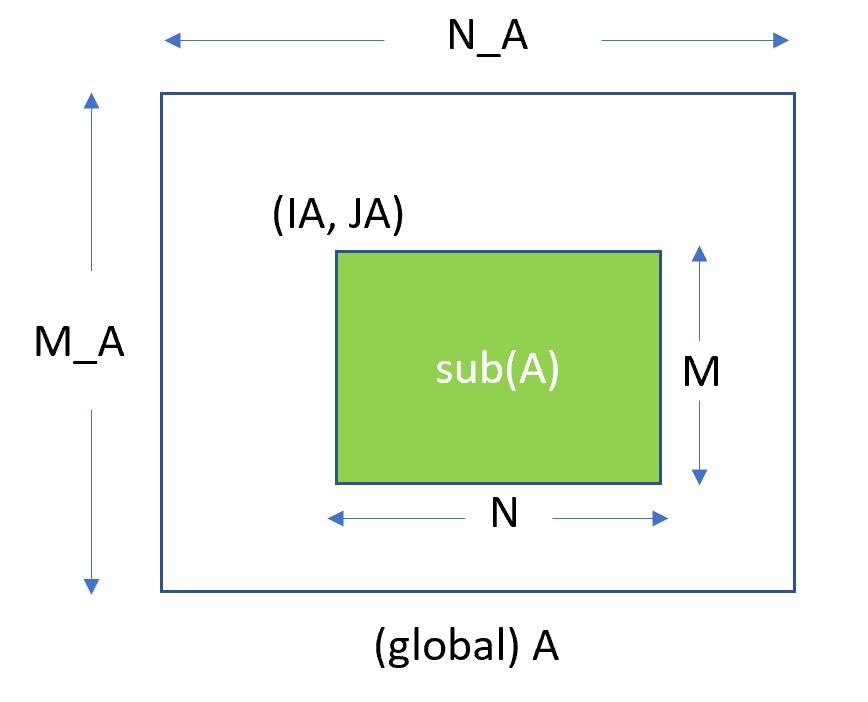
全局矩阵和局部矩阵
3.1.5. _bufferSize 的用法
在 cuSolverMG 库中没有 cudaMalloc,因此用户必须显式地分配设备工作空间。例程 xyz_bufferSize 用于查询例程 xyz 的工作空间大小,例如 xyz = syevd。为了简化 API,xyz_bufferSize 遵循与 xyz 几乎相同的签名,即使它仅依赖于某些参数,例如,设备指针不用于确定工作空间的大小。在大多数情况下,xyz_bufferSize 在准备实际设备数据(由设备指针指向)之前或在分配设备指针之前被调用。在这种情况下,用户可以传递空指针给 xyz_bufferSize 而不会破坏功能。
xyz_bufferSize 返回每个设备所需的 bufferSize。该大小是元素的数量,而不是字节数。
3.1.6. 同步
所有例程都是同步(阻塞调用)方式。数据在例程结束后准备就绪。但是,用户必须在调用例程之前准备好分布式数据。例如,如果用户有多个流来设置矩阵,则需要流同步或设备同步来保证分布式矩阵已准备就绪。
3.1.7. 上下文切换
用户无需在每次 cuSolverMG 调用后通过 cudaSetDevice() 恢复设备。所有例程都会将设备设置回调用者所设置的状态。
3.1.8. NVLINK
通过 NVLINK 的点对点通信可以显著减少 GPU 之间数据交换的开销。cuSolverMG 不会隐式启用 NVLINK,而是将此选项交还给用户,以避免干扰其他库。示例代码 H.1 展示了如何启用点对点通信。
3.2. cuSolverMG 类型参考
3.2.1. cuSolverMG 类型
支持 float、double、cuComplex 和 cuDoubleComplex 数据类型。前两个是标准 C 数据类型,而后两个是从 cuComplex.h 导出的。此外,cuSolverMG 使用了 cuBLAS 中的一些常用类型。
3.2.2. cusolverMgHandle_t
这是一种指向不透明 cuSolverMG 上下文的指针类型,用户必须在调用任何其他库函数之前通过调用 cusolverMgCreate() 来初始化它。未初始化的句柄对象将导致意外行为,包括 cuSolverMG 崩溃。cusolverMgCreate() 创建并返回的句柄必须传递给每个 cuSolverMG 函数。
3.2.3. cusolverMgGridMapping_t
此类型指示网格的布局。
值 |
含义 |
|---|---|
|
行主序。 |
|
列主序。 |
3.2.4. cudaLibMgGrid_t
分布式网格的不透明结构。
3.2.5. cudaLibMgMatrixDesc_t
分布式矩阵描述符的不透明结构。
3.3. 辅助函数参考
3.3.1. cusolverMgCreate()
cusolverStatus_t
cusolverMgCreate(cusolverMgHandle_t *handle)
此函数初始化 cuSolverMG 库并在 cuSolverMG 上下文上创建句柄。它必须在调用任何其他 cuSolverMG API 函数之前调用。它分配访问 GPU 所需的硬件资源。
输出
|
指向 cuSolverMG 上下文句柄的指针。 |
返回状态
CUSOLVER_STATUS_SUCCESS初始化成功。
CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
3.3.2. cusolverMgDestroy()
cusolverStatus_t
cusolverMgDestroy( cusolverMgHandle_t handle)
此函数释放 cuSolverMG 库使用的 CPU 端资源。
输入
|
cuSolverMG 上下文的句柄。 |
返回状态
CUSOLVER_STATUS_SUCCESS关闭成功。
3.3.3. cusolverMgDeviceSelect()
cusolverStatus_t
cusolverMgDeviceSelect(
cusolverMgHandle_t handle,
int nbDevices,
int deviceId[] )
此函数向 cuSolverMG 句柄注册设备(GPU)的子集。此设备子集在后续 API 调用中使用。数组 deviceId 包含逻辑设备 ID 的列表。“逻辑”一词表示允许重复的设备 ID。例如,假设用户系统中只有一个 GPU,例如设备 0。如果用户设置 deviceId=0,0,0,则 cuSolverMG 将它们视为三个独立的 GPU,每个 GPU 一个流,因此并发内核启动仍然有效。当前设计仅支持最多 32 个逻辑设备。
输入
|
指向 cuSolverMG 上下文句柄的指针。 |
|
逻辑设备的数量。 |
|
大小为 |
返回状态
CUSOLVER_STATUS_SUCCESS初始化成功。
CUSOLVER_STATUS_INVALID_VALUEnbDevices必须大于零,且小于或等于 32。CUSOLVER_STATUS_ALLOC_FAILED资源无法分配。
CUSOLVER_STATUS_INTERNAL_ERROR设置内部流和事件时发生内部错误。
3.3.4. cusolverMgCreateDeviceGrid()
cusolverStatus_t
cusolverMgCreateDeviceGrid(
cusolverMgGrid_t* grid,
int32_t numRowDevices,
int32_t numColDevices,
const int32_t deviceId[],
cusolverMgGridMapping_t mapping)
此函数设置设备网格。
仅支持 1-D 列块循环,因此 numRowDevices 必须等于 1。
警告
cusolverMgCreateDeviceGrid() 必须与 cusolverMgDeviceSelect() 一致,即 numColDevices 必须等于 cusolverMgDeviceSelect() 中的 nbDevices。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向不透明结构的指针。 |
|
|
|
行中的设备数量。 |
|
|
|
列中的设备数量。 |
|
|
|
大小为 |
|
|
|
行主序或列主序。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_INVALID_VALUEnumColDevices不大于 0。numRowDevices不为 1。
3.3.5. cusolverMgDestroyGrid()
cusolverStatus_t
cusolverMgDestroyGrid(
cusolverMgGrid_t grid)
此函数释放网格的资源。
参数 |
MemSpace |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
指向不透明结构的指针。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
3.3.6. cusolverMgCreateMatrixDesc()
cusolverStatus_t
cusolverMgCreateMatrixDesc(
cusolverMgMatrixDesc_t * desc,
int64_t numRows,
int64_t numCols,
int64_t rowBlockSize,
int64_t colBlockSize,
cudaDataType_t dataType,
const cusolverMgGrid_t grid)
此函数设置矩阵描述符 desc。
仅支持 1-D 列块循环,因此 numRows 必须等于 rowBlockSize。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
矩阵描述符。 |
|
|
|
全局 A 的行数。 |
|
|
|
全局 A 的列数。 |
|
|
|
每个 tile 的行数。 |
|
|
|
每个 tile 的列数。 |
|
|
|
矩阵的数据类型。 |
|
|
|
指向网格结构的指针。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_INVALID_VALUEnumRows、numCols或rowBlockSize或colBlockSize小于 0。numRows不等于rowBlockSize。
3.3.7. cusolverMgDestroyMatrixDesc()
cusolverStatus_t
cusolverMgDestroyMatrixDesc(
cusolverMgMatrixDesc_t desc)
此函数释放矩阵描述符 desc。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
矩阵描述符。 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
3.4. 稠密线性求解器参考
本节介绍 cuSolverMG 的线性求解器 API。
3.4.1. cusolverMgPotrf()
以下辅助函数可以计算 cusolverMgPotrf 预分配缓冲区所需的大小
cusolverStatus_t
cusolverMgPotrf_bufferSize(
cusolverMgHandle_t handle,
cublasFillMode_t uplo,
int N,
void *array_d_A[],
int IA,
int JA,
cudaLibMgMatrixDesc_t descrA,
cudaDataType computeType,
int64_t *lwork)
以下例程
cusolverStatus_t
cusolverMgPotrf(
cusolverMgHandle_t handle,
cublasFillMode_t uplo,
int N,
void *array_d_A[],
int IA,
int JA,
cudaLibMgMatrixDesc_t descrA,
cudaDataType computeType,
void *array_d_work[],
int64_t lwork,
int *info)
使用通用 API 接口计算 Hermitian 正定矩阵的 Cholesky 分解。
A 是一个 \(n \times n\) Hermitian 矩阵;只有下部或上部是有意义的。输入参数 uplo 指示使用矩阵的哪个部分。该函数将保持其他部分不变。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_LOWER,则仅处理 A 的下三角部分,并替换为下三角 Cholesky 因子 L
如果输入参数 uplo 是 CUBLAS_FILL_MODE_UPPER,则仅处理 A 的上三角部分,并替换为上三角 Cholesky 因子 U
用户必须在 array_d_work 中提供设备工作空间。array_d_work 是维度为 G 的主机指针数组,其中 G 是设备数量。array_d_work[j] 是指向第 j 个设备中设备内存的设备指针。array_d_work[j] 的数据类型为 computeType。array_d_work[j] 的大小为 lwork,它是每个设备的元素数量,由 cusolverMgPotrf_bufferSize() 返回。
如果 Cholesky 分解失败,即 A 的某些前导子式不是正定的,或者等效地,L 或 U 的某些对角线元素不是实数。 输出参数 info 将指示 A 的最小前导子式,该子式不是正定的。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
通用 API 有两种不同的类型,dataTypeA 是矩阵 A 的数据类型,computeType 是操作的计算类型和工作空间的数据类型 (array_d_work)。descrA 包含 dataTypeA,因此没有 dataTypeA 的显式参数。cusolverMgPotrf 仅支持以下四种组合。
请访问 cuSOLVER 库示例 - MgPotrf 以获取代码示例。
数据类型和计算类型的有效组合
DataTypeA |
ComputeType |
含义 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverMg 库上下文的句柄。 |
|
|
|
指示是否存储矩阵 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
全局数组 A 中的行索引,指示 |
|
|
|
全局数组 A 中的列索引,指示 |
|
|
|
分布式矩阵 A 的矩阵描述符。 |
|
|
|
用于计算的数据类型。 |
|
|
|
维度为 |
|
|
|
|
|
|
|
如果 如果 如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
M,N<0)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
3.4.2. cusolverMgPotrs()
以下辅助函数可以计算 cusolverMgPotrs 预分配缓冲区所需的大小。
cusolverStatus_t
cusolverMgPotrs_bufferSize(
cusolverMgHandle_t handle,
cublasFillMode_t uplo,
int n,
int nrhs,
void *array_d_A[],
int IA,
int JA,
cudaLibMgMatrixDesc_t descrA,
void *array_d_B[],
int IB,
int JB,
cudaLibMgMatrixDesc_t descrB,
cudaDataType computeType,
int64_t *lwork )
以下例程
cusolverStatus_t
cusolverMgPotrs(
cusolverMgHandle_t handle,
cublasFillMode_t uplo,
int n,
int nrhs,
void *array_d_A[],
int IA,
int JA,
cudaLibMgMatrixDesc_t descrA,
void *array_d_B[],
int IB,
int JB,
cudaLibMgMatrixDesc_t descrB,
cudaDataType computeType,
void *array_d_work[],
int64_t lwork,
int *info)
此函数求解线性方程组
其中 A 是一个 \(n \times n\) Hermitian 矩阵,使用通用 API 接口时,只有下部或上部是有意义的。输入参数 uplo 指示使用矩阵的哪个部分。该函数将保持其他部分不变。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_LOWER,则矩阵 A 应包含先前由 cusolverMgPotrf 例程计算的 Cholesky 分解的下三角因子。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_UPPER,则矩阵 A 应包含先前由 cusolverMgPotrf 例程计算的 Cholesky 分解的上三角因子。
该操作是就地进行的,即矩阵 B 在退出时包含线性系统的解。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
用户必须在 array_d_work 中提供设备工作空间。array_d_work 是维度为 G 的主机指针数组,其中 G 是设备数量。array_d_work[j] 是指向第 j 个设备中设备内存的设备指针。array_d_work[j] 的数据类型为 computeType。array_d_work[j] 的大小为 lwork,它是每个设备的元素数量,由 cusolverMgPotrs_bufferSize() 返回。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
通用 API 有四种不同的类型:dataTypeA 是矩阵 A 的数据类型,dataTypeB 是矩阵 B 的数据类型,computeType 是操作的计算类型和工作空间的数据类型 (array_d_work)。descrA 包含 dataTypeA,descrB 包含 dataTypeB,因此没有 dataTypeA 和 dataTypeB 的显式参数。cusolverMgPotrs 仅支持以下四种组合。
请访问 cuSOLVER 库示例 - MgPotrf 以获取代码示例。
数据类型和计算类型的有效组合
DataTypeA |
DataTypeB |
ComputeType |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverMg 库上下文的句柄。 |
|
|
|
指示是否存储矩阵 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
全局数组 A 中的行索引,指示 |
|
|
|
全局数组 A 中的列索引,指示 |
|
|
|
分布式矩阵 A 的矩阵描述符。 |
|
|
|
维度为 |
|
|
|
全局数组 B 中的行索引,指示 |
|
|
|
全局数组 B 中的列索引,指示 |
|
|
|
分布式矩阵 B 的矩阵描述符。 |
|
|
|
用于计算的数据类型。 |
|
|
|
维度为 |
|
|
|
|
|
|
|
如果 如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
M,N<0)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
3.4.3. cusolverMgPotri()
以下辅助函数可以计算 cusolverMgPotri 预分配缓冲区所需的大小。
cusolverStatus_t
cusolverMgPotri_bufferSize(
cusolverMgHandle_t handle,
cublasFillMode_t uplo,
int N,
void *array_d_A[],
int IA,
int JA,
cudaLibMgMatrixDesc_t descrA,
cudaDataType computeType,
int64_t *lwork)
以下例程
cusolverStatus_t
cusolverMgPotri(
cusolverMgHandle_t handle,
cublasFillMode_t uplo,
int N,
void *array_d_A[],
int IA,
int JA,
cudaLibMgMatrixDesc_t descrA,
cudaDataType computeType,
void *array_d_work[],
int64_t lwork,
int *info)
此函数使用 Cholesky 分解计算 Hermitian 正定矩阵 A 的逆矩阵
由 cusolverMgPotrf() 计算。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_LOWER,则在输入时,矩阵 A 包含由 cusolverMgPotrf 计算的 A 的下三角因子。仅处理 A 的下三角部分,并替换为 A 的逆矩阵的下三角部分。
如果输入参数 uplo 是 CUBLAS_FILL_MODE_UPPER,则在输入时,矩阵 A 包含由 cusolverMgPotrf 计算的 A 的上三角因子。仅处理 A 的上三角部分,并替换为 A 的逆矩阵的上三角部分。
用户必须在 array_d_work 中提供设备工作空间。array_d_work 是维度为 G 的主机指针数组,其中 G 是设备数量。array_d_work[j] 是指向第 j 个设备中设备内存的设备指针。array_d_work[j] 的数据类型为 computeType。array_d_work[j] 的大小为 lwork,它是每个设备的元素数量,由 cusolverMgPotri_bufferSize() 返回。
如果逆矩阵的计算失败,即 L 或 U 的某些前导主子式为空,则输出参数 info 将指示 L 或 U 的最小前导主子式,该子式不是正定的。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
通用 API 有两种不同的类型,dataTypeA 是矩阵 A 的数据类型,computeType 是操作的计算类型和工作空间的数据类型 (array_d_work)。descrA 包含 dataTypeA,因此没有 dataTypeA 的显式参数。cusolverMgPotri 仅支持以下四种组合。
请访问 cuSOLVER 库示例 - MgPotrf 以获取代码示例。
数据类型和计算类型的有效组合
DataTypeA |
ComputeType |
含义 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverMg 库上下文的句柄。 |
|
|
|
指示是否存储矩阵 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
全局数组 A 中的行索引,指示 |
|
|
|
全局数组 A 中的列索引,指示 |
|
|
|
分布式矩阵 A 的矩阵描述符。 |
|
|
|
用于计算的数据类型。 |
|
|
|
维度为 |
|
|
|
|
|
|
|
如果 如果 如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_NOT_INITIALIZED库未初始化。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
M,N<0)。CUSOLVER_STATUS_ARCH_MISMATCH设备仅支持计算能力 5.0 及以上。
CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
3.4.4. cusolverMgGetrf()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverMgGetrf_bufferSize(
cusolverMgHandle_t handle,
int M,
int N,
void *array_d_A[],
int IA,
int JA,
cudaLibMgMatrixDesc_t descrA,
int *array_d_IPIV[],
cudaDataType_t computeType,
int64_t *lwork);
cusolverStatus_t
cusolverMgGetrf(
cusolverMgHandle_t handle,
int M,
int N,
void *array_d_A[],
int IA,
int JA,
cudaLibMgMatrixDesc_t descrA,
int *array_d_IPIV[],
cudaDataType_t computeType,
void *array_d_work[],
int64_t lwork,
int *info );
此函数计算 \(M \times N\) 矩阵的 LU 分解
其中 A 是一个 \(M \times N\) 矩阵,P 是置换矩阵,L 是具有单位对角线的下三角矩阵,U 是上三角矩阵。
用户必须在 array_d_work 中提供设备工作空间。array_d_work 是维度为 G 的主机指针数组,其中 G 是设备数量。array_d_work[j] 是指向第 j 个设备中设备内存的设备指针。array_d_work[j] 的数据类型为 computeType。array_d_work[j] 的大小为 lwork,它是每个设备的元素数量,由 cusolverMgGetrf_bufferSize() 返回。
如果 LU 分解失败,即矩阵 A (U) 是奇异的,则输出参数 info=i 指示 U(i,i) = 0。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
如果 array_d_IPIV 为空,则不执行 pivoting。分解为 A=L*U,这在数值上不稳定。
array_d_IPIV 必须与 array_d_A 一致,即 JA 是 sub(A) 的第一列,也是 sub(IPIV) 的第一列。
无论 LU 分解是否失败,输出参数 array_d_IPIV 都包含 pivoting 序列,行 i 与行 array_d_IPIV(i) 互换。
通用 API 有三种不同的类型,dataTypeA 是矩阵 A 的数据类型,computeType 是操作的计算类型和工作空间的数据类型 (array_d_work)。descrA 包含 dataTypeA,因此没有 dataTypeA 的显式参数。cusolverMgGetrf 仅支持以下四种组合。
请访问 cuSOLVER 库示例 - MgGetrf 以获取代码示例。
数据类型和计算类型的有效组合
DataTypeA |
ComputeType |
含义 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
备注 1:tile 大小 TA 必须小于或等于 512。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverMg 库上下文的句柄。 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
全局数组 A 中的行索引,指示 |
|
|
|
全局数组 A 中的列索引,指示 |
|
|
|
分布式矩阵 A 的矩阵描述符。 |
|
|
|
维度为 |
|
|
|
用于计算的数据类型。 |
|
|
|
维度为 |
|
|
|
|
|
|
|
如果 如果 如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数 (
M,N<0)。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
3.4.5. cusolverMgGetrs()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverMgGetrs_bufferSize(
cusolverMgHandle_t handle,
cublasOperation_t TRANS,
int N,
int NRHS,
void *array_d_A[],
int IA,
int JA,
cudaLibMgMatrixDesc_t descrA,
int *array_d_IPIV[],
void *array_d_B[],
int IB,
int JB,
cudaLibMgMatrixDesc_t descrB,
cudaDataType_t computeType,
int64_t *lwork);
cusolverStatus_t
cusolverMgGetrs(
cusolverMgHandle_t handle,
cublasOperation_t TRANS,
int N,
int NRHS,
void *array_d_A[],
int IA,
int JA,
cudaLibMgMatrixDesc_t descrA,
int *array_d_IPIV[],
void *array_d_B[],
int IB,
int JB,
cudaLibMgMatrixDesc_t descrB,
cudaDataType_t computeType,
void *array_d_work[],
int64_t lwork,
int *info );
此函数求解具有多个右手边的线性系统
其中 A 是一个 \(N \times N\) 矩阵,并且已由 getrf 进行 LU 分解,即 A 的下三角部分为 L,A 的上三角部分(包括对角线元素)为 U。B 是一个 \(N \times {NRHS}\) 右侧矩阵。解矩阵 X 覆盖右侧矩阵 B。
输入参数 TRANS 由以下定义
用户必须在 array_d_work 中提供设备工作空间。array_d_work 是维度为 G 的主机指针数组,其中 G 是设备数量。array_d_work[j] 是指向第 j 个设备中设备内存的设备指针。array_d_work[j] 的数据类型为 computeType。array_d_work[j] 的大小为 lwork,它是每个设备的元素数量,由 cusolverMgGetrs_bufferSize() 返回。
如果 array_d_IPIV 为空,则不执行 pivoting。否则,array_d_IPIV 是 getrf 的输出。它包含 pivot 索引,用于置换右侧。
如果输出参数 info = -i(小于零),则第 i 个参数错误(不包括句柄)。
通用的 API 有三种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeB 是矩阵 B 的数据类型,而 computeType 是运算的计算类型和工作空间(array_d_work)的数据类型。descrA 包含 dataTypeA,因此没有 dataTypeA 的显式参数。descrB 包含 dataTypeB,因此没有 dataTypeB 的显式参数。cusolverMgGetrs 仅支持以下四种组合。
数据类型和计算类型的有效组合
DataTypeA |
DataTypeB |
ComputeType |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
备注 1:tile 大小 TA 必须小于或等于 512。
备注 2:仅支持 TRANS=CUBLAS_OP_N。
请访问 cuSOLVER 库示例 - MgGetrf 以获取代码示例。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverMG 库上下文的句柄。 |
|
|
|
运算 |
|
|
|
矩阵 |
|
|
|
矩阵 |
|
|
|
维度为 |
|
|
|
全局数组 A 中的行索引,指示 |
|
|
|
全局数组 A 中的列索引,指示 |
|
|
|
分布式矩阵 A 的矩阵描述符。 |
|
|
|
维度为 |
|
|
|
维度为 |
|
|
|
全局数组 B 中的行索引,指示 |
|
|
|
全局数组 B 中的列索引,指示 |
|
|
|
分布式矩阵 B 的矩阵描述符。 |
|
|
|
用于计算的数据类型。 |
|
|
|
维度为 |
|
|
|
|
|
|
|
如果 如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
N<0或NRHS<0)。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
3.5. 稠密特征值求解器参考
本节介绍 cuSolverMG 的特征值求解器 API。
3.5.1. cusolverMgSyevd()
以下辅助函数可以计算预分配缓冲区所需的大小。
cusolverStatus_t
cusolverMgSyevd_bufferSize(
cusolverMgHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int N,
void *array_d_A[],
int IA,
int JA,
cudaLibMgMatrixDesc_t descrA,
void *W,
cudaDataType_t dataTypeW,
cudaDataType_t computeType,
int64_t *lwork
);
cusolverStatus_t
cusolverMgSyevd(
cusolverMgHandle_t handle,
cusolverEigMode_t jobz,
cublasFillMode_t uplo,
int N,
void *array_d_A[],
int IA,
int JA,
cudaLibMgMatrixDesc_t descrA,
void *W,
cudaDataType_t dataTypeW,
cudaDataType_t computeType,
void *array_d_work[],
int64_t lwork,
int *info );
此函数计算对称(Hermitian)\(N \times N\) 矩阵 A 的特征值和特征向量。标准的对称特征值问题是
其中 Λ 是一个实数 \(N \times N\) 对角矩阵。V 是一个 \(N \times N\) 酉矩阵。Λ 的对角元素是 A 的特征值,按升序排列。
cusolverMgSyevd 在 W 中返回特征值,并在 A 中覆盖特征向量。W 是一个主机 \(1 \times N\) 向量。
通用的 API 有三种不同的类型,dataTypeA 是矩阵 A 的数据类型,dataTypeW 是向量 W 的数据类型,而 computeType 是运算的计算类型和工作空间(array_d_work)的数据类型。descrA 包含 dataTypeA,因此没有 dataTypeA 的显式参数。cusolverMgSyevd 仅支持以下四种组合。
数据类型和计算类型的有效组合
DataTypeA |
DataTypeW |
ComputeType |
含义 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
用户必须在 array_d_work 中提供设备工作空间。array_d_work 是维度为 G 的主机指针数组,其中 G 是设备数量。array_d_work[j] 是指向第 j 个设备中设备内存的设备指针。array_d_work[j] 的数据类型是 computeType。array_d_work[j] 的大小是 lwork,它是每个设备的元素数量,由 cusolverMgSyevd_bufferSize() 返回。
array_d_A 也是维度为 G 的主机指针数组。array_d_A[j] 是指向第 j 个设备中设备内存的设备指针。array_d_A[j] 的数据类型是 dataTypeA。array_d_A[j] 的大小约为 N*TA*(每个设备的块)。用户必须手动准备 array_d_A(有关代码示例,请参见cuSOLVER 库示例 - MgSyevd)。
如果输出参数 info = -i (小于零),则第 i-th 个参数错误(不包括句柄)。如果 info = i (大于零),则算法未能收敛所有特征值。
如果 jobz = CUSOLVER_EIG_MODE_VECTOR,则 A 包含矩阵 A 的标准正交特征向量。特征向量通过分治算法计算。
备注 1:仅支持 CUBLAS_FILL_MODE_LOWER,因此用户必须准备 A 的下三角部分。
备注 2:仅支持 IA=1 和 JA=1。
备注 3:tile size TA 必须小于或等于 1024。为了获得最佳性能,TA 应为 256 或 512。
请访问 cuSOLVER 库示例 - MgSyevd 以获取代码示例。
参数 |
内存 |
输入/输出 |
含义 |
|---|---|---|---|
|
|
|
cuSolverMG 库上下文的句柄。 |
|
|
|
指定是仅计算特征值还是计算特征对的选项
|
|
|
|
指定存储
仅支持 |
|
|
|
矩阵 |
|
|
|
维度为 如果 如果 如果 |
|
|
|
全局数组 A 中的行索引,指示 |
|
|
|
全局数组 A 中的列索引,指示 |
|
|
|
分布式矩阵 A 的矩阵描述符。 |
|
|
|
维度为 |
|
|
|
向量 W 的数据类型。 |
|
|
|
用于计算的数据类型。 |
|
|
|
维度为 |
|
|
|
|
|
|
|
如果 如果 如果 |
返回状态
CUSOLVER_STATUS_SUCCESS操作已成功完成。
CUSOLVER_STATUS_INVALID_VALUE传递了无效参数(
N<0,或lda<max(1,N),或jobz不是CUSOLVER_EIG_MODE_NOVECTOR或CUSOLVER_EIG_MODE_VECTOR,或uplo不是CUBLAS_FILL_MODE_LOWER,或IA和JA不是 1,或N大于全局A的维度,或dataType和computeType的组合无效)。CUSOLVER_STATUS_INTERNAL_ERROR内部操作失败。
4. 致谢
NVIDIA 感谢以下个人和机构的贡献
来自 netlib 的 CPU LAPACK 例程,CLAPACK-3.2.1 (http://www.netlib.org/clapack/)
以下是 CLAPACK-3.2.1 的许可证。
版权所有 (c) 1992-2008 The University of Tennessee。保留所有权利。
在满足以下条件的前提下,允许以源代码和二进制形式重新分发和使用,无论是否经过修改:
源代码的重新分发必须保留上述版权声明、此条件列表和以下免责声明。
二进制形式的重新分发必须在随发行版提供的文档和/或其他材料中复制上述版权声明、此条件列表和以下免责声明。
未经事先书面许可,不得使用版权持有者或其贡献者的名称来背书或推广源自本软件的产品。
本软件由版权持有者和贡献者“按原样”提供,并且不提供任何明示或暗示的保证,包括但不限于对适销性和特定用途适用性的暗示保证。在任何情况下,版权所有者或贡献者均不对任何直接、间接、附带、特殊、惩戒性或后果性损害(包括但不限于采购替代商品或服务;使用、数据或利润损失;或业务中断)承担责任,无论其是如何造成的,也无论其基于何种责任理论,无论是在合同、严格责任还是侵权行为(包括疏忽或其他)中,即使已被告知此类损害的可能性。
METIS-5.1.0 (http://glaros.dtc.umn.edu/gkhome/metis/metis/overview)
以下是 METIS 的许可证(Apache 2.0 许可证)。
版权所有 1995-2013, Regents of the University of Minnesota
根据 Apache License, Version 2.0(“许可证”)获得许可;除非遵守许可证,否则您不得使用此文件。您可以在以下网址获取许可证副本
https://apache.ac.cn/licenses/LICENSE-2.0
除非适用法律要求或书面同意,否则根据许可证分发的软件按“原样”分发,不附带任何明示或暗示的保证或条件。请参阅许可证,了解有关权限和限制的具体语言。
QD (A C++/fortran-90 double-double and quad-double package) (http://crd-legacy.lbl.gov/~dhbailey/mpdist/)
以下是 QD 的许可证(修改后的 BSD 许可证)。
版权所有 (c) 2003-2009, The Regents of the University of California, through Lawrence Berkeley National Laboratory (subject to receipt of any required approvals from U.S. Dept. of Energy) 保留所有权利。
在满足以下条件的前提下,允许以源代码和二进制形式重新分发和使用,无论是否经过修改:
源代码的重新分发必须保留版权声明、此条件列表和以下免责声明。
二进制形式的重新分发必须在随发行版提供的文档和/或其他材料中复制版权声明、此条件列表和以下免责声明。
未经事先书面许可,不得使用加州大学、劳伦斯伯克利国家实验室、美国能源部的名称或其贡献者的名称来背书或推广源自本软件的产品。
本软件由版权持有者和贡献者“按原样”提供,并且不提供任何明示或暗示的保证,包括但不限于对适销性和特定用途适用性的暗示保证。在任何情况下,版权所有者或贡献者均不对任何直接、间接、附带、特殊、惩戒性或后果性损害(包括但不限于采购替代商品或服务;使用、数据或利润损失;或业务中断)承担责任,无论其是如何造成的,也无论其基于何种责任理论,无论是在合同、严格责任还是侵权行为(包括疏忽或其他)中,即使已被告知此类损害的可能性。
您没有义务向任何人提供对源代码(“增强”)的功能、功能或性能的任何错误修复、补丁或升级;但是,如果您选择公开或直接向劳伦斯伯克利国家实验室提供您的增强,而没有对此类增强施加单独的书面许可协议,则您在此授予以下许可:非独占、免版税的永久许可,以安装、使用、修改、准备衍生作品、合并到其他计算机软件中、分发和再许可此类增强或其衍生作品,以二进制和源代码形式。
5. 参考书目
[1] Timothy A. Davis, 稀疏线性系统的直接方法, siam 2006。
[2] E. Chuthill 和 J. McKee, 减少稀疏对称矩阵的带宽, ACM ‘69 1969 年第 24 届全国会议论文集, 第 157-172 页。
[3] Alan George, Joseph W. H. Liu, 伪外围节点查找器的实现, ACM Transactions on Mathematical Software (TOMS) 第 5 卷第 3 期, 1979 年 9 月 第 284-295 页。
[4] J. R. Gilbert 和 T. Peierls, 与算术运算成比例的时间内的稀疏部分主元, SIAM J. Sci. Statist. Comput., 9 (1988), pp. 862-874。
[5] Alan George 和 Esmond Ng, 用于稀疏系统的部分主元高斯消元法的实现, SIAM J. Sci. and Stat. Comput., 6(2), 390-409。
[6] Alan George 和 Esmond Ng, 用于稀疏部分主元高斯消元法的符号分解, SIAM J. Sci. and Stat. Comput., 8(6), 877-898。
[7] John R. Gilbert, Xiaoye S. Li, Esmond G. Ng, Barry W. Peyton, 计算稀疏 QR 和 LU 分解的行和列计数, BIT 2001, Vol. 41, No. 4, pp. 693-711。
[8] Patrick R. Amestoy, Timothy A. Davis, Iain S. Duff, 近似最小度排序算法, SIAM J. Matrix Analysis Applic. Vol 17, no 4, pp. 886-905, 1996 年 12 月。
[9] Alan George, Joseph W. Liu, 使用商图的最小度算法的快速实现, ACM Transactions on Mathematical Software, Vol 6, No. 3, 1980 年 9 月, 第 337-358 页。
[10] Alan George, Joseph W. Liu, 大型稀疏正定系统的计算机解法, Englewood Cliffs, New Jersey: Prentice-Hall, 1981。
[11] Iain S. Duff, ALGORITHM 575 用于无零对角线的置换, ACM Transactions on Mathematical Software, Vol 7, No 3, 1981 年 9 月, 第 387-390 页
[12] Iain S. Duff 和 Jacko Koster, 关于将大型条目置换到稀疏矩阵对角线的算法, SIAM Journal on Matrix Analysis and Applications, 2001, Vol. 22, No. 4 : pp. 973-996
[13] “用于划分不规则图的快速和高质量多级方案”。George Karypis 和 Vipin Kumar。SIAM Journal on Scientific Computing, Vol. 20, No. 1, pp. 359-392, 1999。
[14] YUJI NAKATSUKASA, ZHAOJUN BAI, AND FRANC¸OIS GYGI, 用于计算矩阵极分解的优化 Halley 迭代, SIAM J. Matrix Anal. Appl., 31 (5): 2700-2720,2010
[15] Halko, Nathan, Per-Gunnar Martinsson 和 Joel A. Tropp。“通过随机性寻找结构:用于构建近似矩阵分解的概率算法。” SIAM review 53.2 (2011): 217-288。
6. 声明
6.1. 声明
本文档仅供参考,不应被视为对产品的特定功能、条件或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含的信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对因使用此类信息或因其使用而可能导致的专利或第三方其他权利的任何侵权行为的后果或使用不承担任何责任。本文档不构成对开发、发布或交付任何材料(定义如下)、代码或功能的承诺。
NVIDIA 保留在任何时候对本文档进行更正、修改、增强、改进和任何其他更改的权利,恕不另行通知。
客户在下订单前应获取最新的相关信息,并应核实此类信息是否为最新且完整。
NVIDIA 产品的销售受 NVIDIA 在订单确认时提供的标准销售条款和条件的约束,除非 NVIDIA 和客户的授权代表签署的个别销售协议另有约定(“销售条款”)。NVIDIA 在此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档不直接或间接形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命支持设备,也不适用于 NVIDIA 产品的故障或失灵可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在上述设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不作任何陈述或保证,保证基于本文档的产品将适用于任何特定用途。NVIDIA 不一定对每种产品的全部参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适用于并适合客户计划的应用,并为该应用执行必要的测试,以避免应用或产品的默认设置。客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同的条件和/或要求。NVIDIA 对可能基于或归因于以下原因的任何默认设置、损坏、成本或问题不承担任何责任:(i) 以任何违反本文档的方式使用 NVIDIA 产品或 (ii) 客户产品设计。
本文档未授予 NVIDIA 专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予的使用此类产品或服务的许可,也不构成对其的保证或认可。使用此类信息可能需要获得第三方在其专利或其他知识产权下的许可,或获得 NVIDIA 在 NVIDIA 专利或其他知识产权下的许可。
仅在事先获得 NVIDIA 书面批准的情况下,才允许复制本文档中的信息,复制时不得进行更改,并且必须完全遵守所有适用的出口法律和法规,并附带所有相关的条件、限制和声明。
本文档和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均“按原样”提供。NVIDIA 对材料不作任何明示、暗示、法定或其他方面的保证,并且明确声明不承担所有关于不侵权、适销性和特定用途适用性的暗示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对任何损害(包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害)承担责任,无论其是如何造成的,也无论其责任理论如何,即使 NVIDIA 已被告知此类损害的可能性。尽管客户可能因任何原因遭受任何损害,但 NVIDIA 对本文所述产品的客户承担的累计总责任应根据产品的销售条款进行限制。
6.2. OpenCL
OpenCL 是 Apple Inc. 的商标,经 Khronos Group Inc. 许可使用。
6.3. 商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其相关联的各自公司的商标。