在分布式机器学习中使用张量并行性的 cuBLASMp#
cuBLASMp 非常适合在分布式机器学习中执行一些最常用的 GEMM。cuBLASMp 0.3.0 版本添加了两种流行的变体:AllGather+GEMM (AG+GEMM) 和 GEMM+ReduceScatter (GEMM+RS),两者都使用 NVSHMEM 后端实现,并实现了通信-计算重叠。
cublasMpMatmul 是执行这些操作的推荐 API。
传统 PBLAS 术语中的 AllGather+GEMM 和 GEMM+ReduceScatter#
AllGather+GEMM 和 GEMM+ReduceScatter 算法都是传统 PBLAS GEMM 操作的特殊情况,cuBLASMp 和 ScaLAPACK (P?GEMM) 中都使用了该操作。
具体来说,数据布局是 2D 块循环数据布局的特例,即没有循环分布的 1D 布局
对于 AG+GEMM,
A和B以列优先顺序存储,并在进程之间按列(行优先)分布,C和D以列优先顺序存储,并在进程之间按行(列优先)分布。这转化为A和B的进程网格为1 x nprocs(1行进程和nproc列),以及C和D的输出进程网格为nprocs x 1。A和B的行数为row block size,列数为column block size * nprocs。C和D的行数为row block size * nprocs。这使得两种布局都是 1D 和非循环的。对于 GEMM+RS,
A和B按行(列优先)分布,C和D按列(行优先)分布。A和B的进程网格为nprocs x 1,C和D的输出进程网格为1 x nprocs。
关于 Python 和 cuBLASMp 数据排序#
一般注意事项#
由于张量并行性的主要用户将从 Python 使用 cuBLASMp,因此了解 Python 和 cuBLASMp 使用的数据排序约定非常重要。Python 使用 C 顺序矩阵,而 cuBLASMp 使用 Fortran 顺序矩阵
C 顺序矩阵按行连续存储元素。Python 使用此约定。
Fortran 顺序矩阵按列连续存储元素。cuBLASMp 和 cuBLAS 使用此约定。
C 顺序(行优先)矩阵的转置实际上是 Fortran 顺序(列优先)矩阵。
在分布式环境中,按行分布的矩阵
A等效于按列分布的矩阵A.T。
output.T (cuBLASMp) 等于 output (Python)#
我们迎合了 torch.nn 存储转置权重 (weights_t) 的约定。
如果目标是计算 input * weights = output,我们按如下方式使用 cuBLASMp
注意
如果 input * weights = output,则 weights_t * input.T = output.T。Fortran 顺序的 output.T,当在 Python 中被视为 C 顺序数组时,等效于 output。
Python 调用 C 函数的包装器(TransformerEngine 示例),调用
cublasMpMatmul请求weights_t * input的 TN GEMM。(A = weights_t转置,B = input未转置)。这等效于weights_t.T * input。将给定数组视为 Fortran 顺序(参见 c.),cuBLASMp 有效地将操作视为
weights_t.T * input.T的 TN GEMM (==weights_t.T.T * input.T==weights_t * input.T==output.T)。output.T,当在 Python 中被视为 C 顺序数组时,等效于output。
注意
此处使用的方法并非 cuBLASMp 特有,并且之前已记录在案;例如,请参阅:PyTorch(行优先)如何与 cuBLAS(列优先)交互?
AllGather+GEMM#
问题定义#
对于具有通信-计算重叠的 AllGather+GEMM,cuBLASMp 当前要求其参数 A 和 B 在进程之间按列(行优先)分布(进程网格为 1 行和 nproc 列)。C 和 D 矩阵必须按行(列优先,进程网格为 nproc 行和 1 列)分布。仅支持 D = alpha * A.T * B + beta * C 操作。B 将使用 AllGather 收集。
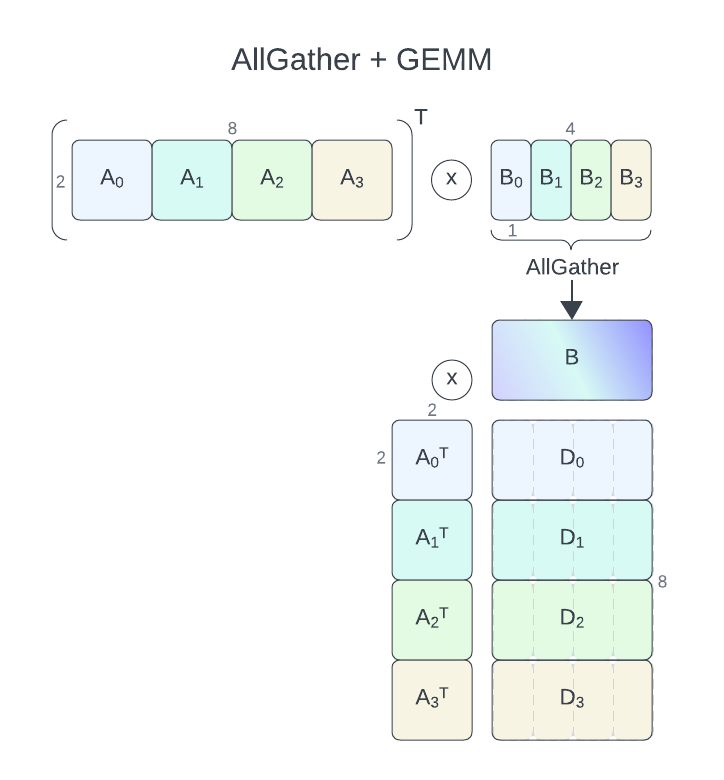
注意
这等效于 A.T (weights_t) 和 B.T (input) 在进程之间按行分布,而 D.T (output) 在进程之间按列分布,在 Python 中以 C 顺序查看。
示例#
在此,我们将假设用户遵循 CUDA 库示例 存储库中描述的通用设置,并专注于 GEMM 特定部分。对于此示例,我们将使用 4 个进程,全局 A 和 B 矩阵的大小分别为 2 x 8(每个进程 2 x 2)和 2 x 4(每个进程 2 x 1)。输出矩阵 D 的大小将为 8 x 4(每个进程 2 x 4)。我们将假设原地矩阵乘法 (C == D)。
一旦创建了 CAL 通信器并初始化了 cuBLASMp 句柄,我们就需要使用适当的描述符来描述网格和矩阵。以下代码片段演示了描述进程网格布局的网格描述符的初始化。
cublasMpGrid_t grid_col_major = nullptr;
cublasMpGrid_t grid_row_major = nullptr;
cublasMpGridCreate(nranks, 1, CUBLASMP_GRID_LAYOUT_COL_MAJOR, cal_comm, &grid_col_major);
cublasMpGridCreate(1, nranks, CUBLASMP_GRID_LAYOUT_ROW_MAJOR, cal_comm, &grid_row_major);
grid_row_major 及其 1 行和 nranks 列将用于 A 和 B,而 grid_col_major(nranks 行和 1 列)将用于 D。
注意
如果 NVSHMEM 未由用户初始化,则 cuBLASMp 将在创建第一个网格时对其进行初始化。如果 NVSHMEM 已经初始化,则不会重新初始化。如果 cuBLASMp 是初始化 NVSHMEM 的一方,则它只会调用 nvshmem_finalize。
接下来,我们需要使用适当的描述符来描述矩阵中存储的数据。以下代码片段演示了这一点
cublasMpMatrixDescriptor_t descA = nullptr;
cublasMpMatrixDescriptor_t descB = nullptr;
cublasMpMatrixDescriptor_t descD = nullptr;
// Global sizes
const int64_t k = 2; // Number of rows in A and B
const int64_t m = 8; // Number of columns in A
const int64_t n = 4; // Number of columns in B
// Local sizes on each process
const int64_t mbA = 2; // Row block size of A (each process has 1 block, all the rows = k)
const int64_t nbA = 2; // Col block size of A (each process has 1 block, m / nproc columns)
const int64_t mbB = 2; // Row block size of B (each process has 1 block, all the rows = k)
const int64_t nbB = 1; // Col block size of B (each process has 1 block, each process has n / nproc columns)
const int64_t mbD = nbA; // Row block size of D (has to match the layout of A, each process has 1 block = 4 rows)
const int64_t nbD = nbB; // Col block size of D (has to match the layout of B, each process has 4 blocks = 4x2 columns)
cublasMpMatrixDescriptorCreate(k, m, mbA, nbA, 0, 0, mbA, cuda_input_type, grid_row_major, &descA);
cublasMpMatrixDescriptorCreate(k, n, mbB, nbB, 0, 0, mbB, cuda_input_type, grid_row_major, &descB);
cublasMpMatrixDescriptorCreate(m, n, mbD, nbD, 0, 0, mbD, cuda_output_type, grid_col_major, &descD);
此处应注意,D 的块大小必须与 A 和 B 的块大小匹配。这就是为什么每个进程在逻辑上将其 D 的 4 列拆分为 4 个块,每个块 1 列宽。这仅用于允许 cuBLASMp 正确执行平铺 GEMM,并且不会更改原始输入或输出数据在内存中的布局方式。
在下一步中,我们初始化 cublasMpMatmulDescriptor_t 以描述我们要执行的 GEMM 操作
cublasMpMatmulDescriptor_t matmulDesc = nullptr;
const cublasComputeType_t cublas_compute_type = CUBLAS_COMPUTE_32F;
const cublasOperation_t transA = CUBLAS_OP_T;
const cublasOperation_t transB = CUBLAS_OP_N;
const cublasMpMatmulAlgoType_t algoType = CUBLASMP_MATMUL_ALGO_TYPE_SPLIT_P2P;
cublasMpMatmulDescriptorCreate(&matmulDesc, cublas_compute_type);
cublasMpMatmulDescriptorAttributeSet(matmulDesc, CUBLASMP_MATMUL_DESCRIPTOR_ATTRIBUTE_TRANSA, &transA, sizeof(transA));
cublasMpMatmulDescriptorAttributeSet(matmulDesc, CUBLASMP_MATMUL_DESCRIPTOR_ATTRIBUTE_TRANSB, &transB, sizeof(transB));
cublasMpMatmulDescriptorAttributeSet(matmulDesc, CUBLASMP_MATMUL_DESCRIPTOR_ATTRIBUTE_ALGO_TYPE, &algoType, sizeof(algoType));
有了这个,我们可以通过调用 cublasMpMatmul_bufferSize 来查询所需的工作区大小
compute_t alpha = 1.0;
compute_t beta = 0.0;
size_t workspaceInBytesOnDevice = 0;
size_t workspaceInBytesOnHost = 0;
cublasMpMatmul_bufferSize(
handle,
matmulDesc,
m,
n,
k,
&alpha,
A,
1, // row index of the first element of A
1, // col index of the first element of A
descA,
B,
1, // row index of the first element of B
1, // col index of the first element of B
descB,
&beta,
D,
1, // row index of the first element of C
1, // col index of the first element of C
descD,
D,
1, // row index of the first element of D
1, // col index of the first element of D
descD,
&workspaceInBytesOnDevice,
&workspaceInBytesOnHost);
有了这个,我们就可以分配所需的工作区了
void* d_work = nvshmem_malloc(workspaceInBytesOnDevice);
std::vector<int8_t> h_work(workspaceInBytesOnHost);
注意
工作区 d_work 必须使用 nvshmem_malloc 分配,以确保所有进程都可以访问它。使用 nvshmem_malloc 分配 B 将进一步提高性能,因为它允许避免额外复制部分 B。
如果可能,以上所有步骤都应作为初始化阶段的一部分执行。实际的 GEMM 操作通过 cublasMpMatmul 调用执行。最好,它应该是性能关键路径上唯一的函数调用。其参数几乎完全镜像 cublasMpMatmul_bufferSize 的参数
cublasMpMatmul(
handle,
matmulDesc,
m,
n,
k,
&alpha,
A,
1,
1,
descA,
B,
1,
1,
descB,
&beta,
D,
1,
1,
descD,
D,
1,
1,
descD,
d_work,
workspaceInBytesOnDevice,
h_work.data(),
workspaceInBytesOnHost);
GEMM+ReduceScatter#
问题定义#
对于具有通信-计算重叠的 GEMM+ReduceScatter,cuBLASMp 当前要求其参数 A 和 B 在进程之间按行(列优先)分布(进程网格为 nproc 行和 1 列)。C 和 D 矩阵必须按列(行优先,进程网格为 1 行和 nproc 列)分布。仅支持 D = alpha * A.T * B + beta * C 操作。每个进程将计算输出的一部分 \({\alpha}A_i^T * B_i + {\beta}C_i = D_i'\),然后使用 ReduceScatter 操作将其缩减并在进程之间拆分,从而得到 \(D_i\)。D 在进程之间按列(行优先)分布。
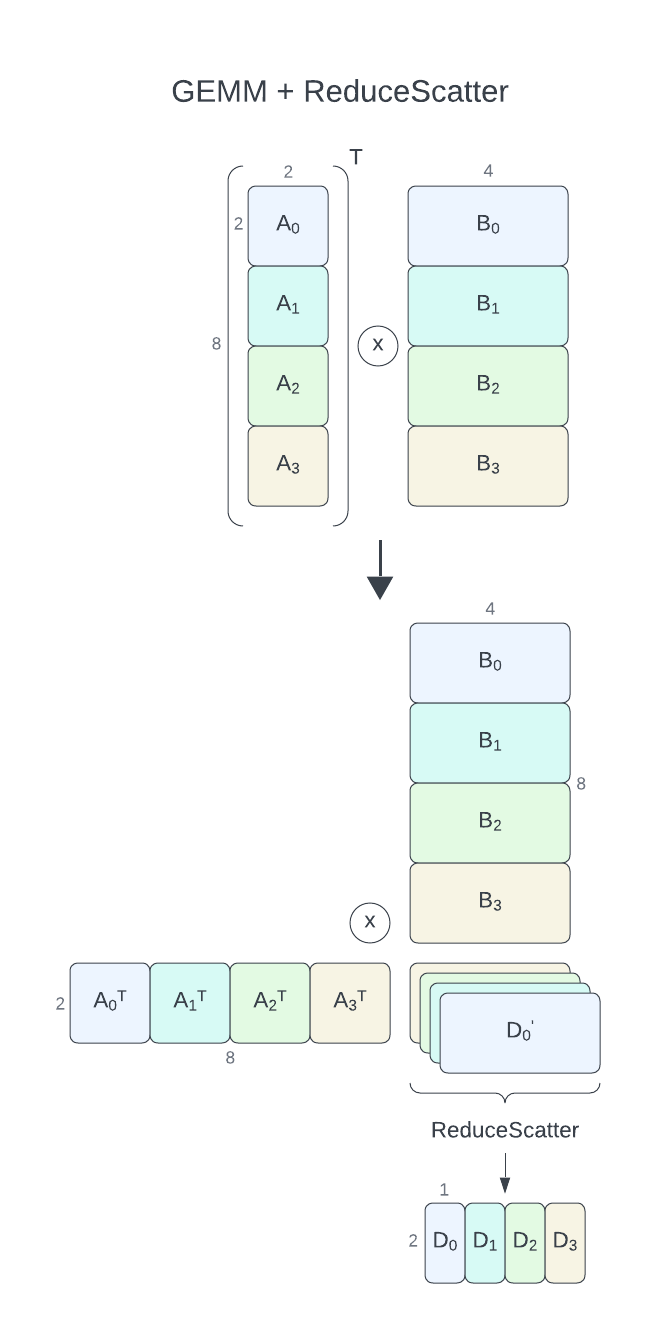
注意
这等效于 A.T (weights_t) 和 B.T (input) 在进程之间按列分布,而 D.T (output) 在进程之间按行分布,在 Python 中以 C 顺序查看。
示例#
与 AllGather+GEMM 示例一样,我们假设用户遵循 CUDA 库示例 存储库中描述的通用设置,并专注于 GEMM 特定部分。对于此示例,我们将使用 4 个进程和以下矩阵
A大小为8 x 2(每个进程2 x 2)B大小为8 x 4(每个进程2 x 4)D大小为2 x 4(每个进程2 x 1)
我们假设原地矩阵乘法 (C == D)。
我们像上一个示例中一样描述网格
cublasMpGrid_t grid_col_major = nullptr;
cublasMpGrid_t grid_row_major = nullptr;
cublasMpGridCreate(nranks, 1, CUBLASMP_GRID_LAYOUT_COL_MAJOR, cal_comm, &grid_col_major);
cublasMpGridCreate(1, nranks, CUBLASMP_GRID_LAYOUT_ROW_MAJOR, cal_comm, &grid_row_major);
在此,grid_col_major(nranks 行和 1 列)将用于 A 和 B,而 grid_row_major(1 行和 nranks 列)将用于 D。
接下来,我们创建矩阵描述符
cublasMpMatrixDescriptor_t descA = nullptr;
cublasMpMatrixDescriptor_t descB = nullptr;
cublasMpMatrixDescriptor_t descD = nullptr;
// Global sizes
const int64_t k = 8; // Number of rows in A and B
const int64_t m = 2; // Number of columns in A
const int64_t n = 4; // Number of columns in B
// Local sizes on each process
const int64_t mbA = 2; // Row block size of A (each process has 1 block, k / nproc rows)
const int64_t nbA = 2; // Col block size of A (each process has 1 block, all the columns = m)
const int64_t mbB = 2; // Row block size of B (each process has 1 block, k / nproc rows)
const int64_t nbB = 1; // Col block size of B (each process has 4 blocks, n / nproc columns = 4x1 = 4 columns)
const int64_t mbD = nbA; // Row block size of D (has to match the layout of A, each process has 1 block = 4 rows)
const int64_t nbD = 1; // Col block size of D (each process has 1 block, 1 column)
cublasMpMatrixDescriptorCreate(k, m, mbA, nbA, 0, 0, mbA, cuda_input_type, grid_col_major, &descA);
cublasMpMatrixDescriptorCreate(k, n, mbB, nbB, 0, 0, mbB, cuda_input_type, grid_col_major, &descB);
cublasMpMatrixDescriptorCreate(m, n, mbD, nbD, 0, 0, mbD, cuda_output_type, grid_row_major, &descD);
与之前一样,D 的块大小必须与 A 和 B 的块大小匹配。这次,D 的列块大小更具约束性,并强制 B 在逻辑上拆分为 4 个块,每个块 1 列宽。同样,它不会更改数据布局,仅用于对齐 GEMM 瓦片。
接下来,我们初始化 cublasMpMatmulDescriptor_t 以描述我们要执行的 GEMM 操作
cublasMpMatmulDescriptor_t matmulDesc = nullptr;
const cublasComputeType_t cublas_compute_type = CUBLAS_COMPUTE_32F;
const cublasOperation_t transA = CUBLAS_OP_T;
const cublasOperation_t transB = CUBLAS_OP_N;
const cublasMpMatmulAlgoType_t algoType = CUBLASMP_MATMUL_ALGO_TYPE_SPLIT_P2P;
cublasMpMatmulDescriptorCreate(&matmulDesc, cublas_compute_type);
cublasMpMatmulDescriptorAttributeSet(matmulDesc, CUBLASMP_MATMUL_DESCRIPTOR_ATTRIBUTE_TRANSA, &transA, sizeof(transA));
cublasMpMatmulDescriptorAttributeSet(matmulDesc, CUBLASMP_MATMUL_DESCRIPTOR_ATTRIBUTE_TRANSB, &transB, sizeof(transB));
cublasMpMatmulDescriptorAttributeSet(matmulDesc, CUBLASMP_MATMUL_DESCRIPTOR_ATTRIBUTE_ALGO_TYPE, &algoType, sizeof(algoType));
查询所需的工作区大小
compute_t alpha = 1.0;
compute_t beta = 0.0;
size_t workspaceInBytesOnDevice = 0;
size_t workspaceInBytesOnHost = 0;
cublasMpMatmul_bufferSize(
handle,
matmulDesc,
m,
n,
k,
&alpha,
A,
1, // row index of the first element of A
1, // col index of the first element of A
descA,
B,
1, // row index of the first element of B
1, // col index of the first element of B
descB,
&beta,
D,
1, // row index of the first element of C
1, // col index of the first element of C
descD,
D,
1, // row index of the first element of D
1, // col index of the first element of D
descD,
&workspaceInBytesOnDevice,
&workspaceInBytesOnHost);
有了这个,我们就可以分配所需的工作区了
void* d_work = nvshmem_malloc(workspaceInBytesOnDevice);
std::vector<int8_t> h_work(workspaceInBytesOnHost);
并执行 GEMM
cublasMpMatmul(
handle,
matmulDesc,
m,
n,
k,
&alpha,
A,
1,
1,
descA,
B,
1,
1,
descB,
&beta,
D,
1,
1,
descD,
D,
1,
1,
descD,
d_work,
workspaceInBytesOnDevice,
h_work.data(),
workspaceInBytesOnHost);
一般假设和限制#
GPU 必须是 P2P 可访问的或通过 InfiniBand NIC 连接。
基于多播的算法
CUBLASMP_MATMUL_ALGO_TYPE_SPLIT_MULTICAST和CUBLASMP_MATMUL_ALGO_TYPE_ATOMIC_MULTICAST需要通过 NVSwitch 连接的SM 9.0GPU。CUBLASMP_MATMUL_ALGO_TYPE_SPLIT_MULTICAST和CUBLASMP_MATMUL_ALGO_TYPE_ATOMIC_MULTICAST的输出必须是 16 位半精度、bfloat16 或 32 位单精度。FP8 支持需要
SM 9.0。