性能#
评估过程#
本节介绍 Riva 文本到语音 (TTS) 服务在不同 GPU 上的延迟和吞吐量数据。TTS 服务的性能是在不同数量的并行流下测量的。每个并行流在 LJSpeech 数据集的 10 个输入字符串上执行了 20 次迭代。每个流向 Riva 服务器发送请求,并等待接收到所有音频块后才发送另一个请求。测量了到第一个音频块的延迟、连续音频块之间的延迟以及吞吐量。下图显示了如何测量延迟。
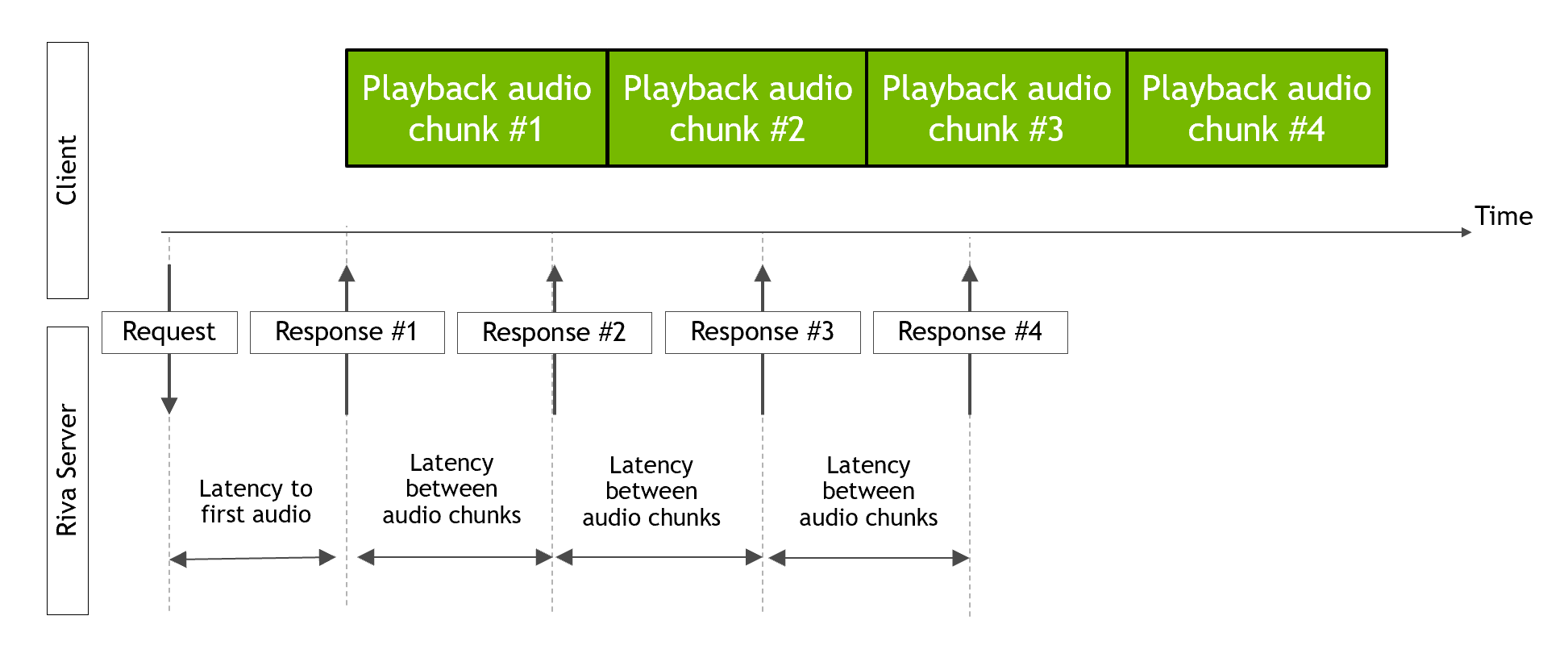
Riva 镜像中提供的 Riva TTS 性能客户端 riva_tts_perf_client 用于测量性能。客户端的源代码可以在 Riva C++ Clients 中获取。
以下命令用于生成以下表格
riva_tts_perf_client \
--num_parallel_requests=<num_streams> \
--num_iterations=<20*num_streams> \
--online=true \
--text_file=$test_file \
--write_output_audio=false
其中 test_file 是指向 ljs_audio_text_test_filelist_small.txt 文件的路径。
结果#
到第一个音频块的延迟、音频块之间的延迟和吞吐量在以下表格中报告。吞吐量(生成的音频时长 / 计算时间)以 RTFX 为单位测量。
注意
表格中的值是三次试验的平均值。表格中的值根据三次试验计算的标准偏差四舍五入到最后一位有效数字。如果标准偏差小于平均值的 0.001,则将相应的值四舍五入,如同标准偏差等于该值的 0.001。
有关收集这些测量的硬件信息,请参阅 硬件规格 部分。
流数量 |
首个音频延迟 (ms) |
音频块之间延迟 (ms) |
吞吐量 (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
平均值 |
p90 |
p95 |
p99 |
平均值 |
p90 |
p95 |
p99 |
||
1 |
22 |
24.2 |
25 |
25.3 |
2.84 |
3.1 |
3.15 |
4.02 |
150.8 |
4 |
40 |
50 |
60 |
70 |
5 |
8 |
9 |
12 |
340 |
8 |
63 |
84 |
90 |
100 |
8 |
12 |
14 |
18 |
420 |
16 |
120 |
143 |
154 |
200 |
14.3 |
17.8 |
19.4 |
23 |
460 |
32 |
323 |
340 |
355 |
390 |
14.5 |
17.9 |
19.9 |
23.9 |
440 |
流数量 |
首个音频延迟 (ms) |
音频块之间延迟 (ms) |
吞吐量 (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
平均值 |
p90 |
p95 |
p99 |
平均值 |
p90 |
p95 |
p99 |
||
1 |
17 |
19 |
19.3 |
20 |
2.5 |
3.035 |
3.08 |
3.16 |
185 |
4 |
30 |
42 |
50 |
60 |
4 |
6 |
7 |
9 |
430 |
8 |
60 |
80 |
80 |
90 |
6 |
10 |
11 |
14 |
500 |
16 |
100 |
120 |
130 |
2000 |
7.7 |
13 |
14.6 |
18.2 |
500 |
32 |
200 |
230 |
242 |
500 |
9.5 |
13 |
14.6 |
18.63 |
700 |
流数量 |
首个音频延迟 (ms) |
音频块之间延迟 (ms) |
吞吐量 (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
平均值 |
p90 |
p95 |
p99 |
平均值 |
p90 |
p95 |
p99 |
||
1 |
21.5 |
24.3 |
24.7 |
25.5 |
2.4 |
3.3 |
3.5 |
4 |
162 |
4 |
40 |
55 |
60 |
70 |
5 |
7 |
8 |
10 |
300 |
8 |
60 |
80 |
86 |
100 |
6.8 |
10 |
11 |
13 |
440 |
16 |
100 |
122 |
133 |
170 |
9.7 |
14.4 |
16.4 |
21 |
600 |
32 |
300 |
310 |
320 |
2000 |
12 |
17 |
19.4 |
24 |
500 |
本地部署硬件规格#
GPU |
|
|---|---|
NVIDIA DGX A100 40GB |
|
CPU |
|
型号 |
AMD EPYC 7742 64 核处理器 |
每核线程数 |
2 |
插槽数 |
2 |
每插槽核心数 |
64 |
NUMA 节点数 |
8 |
频率加速 |
已启用 |
CPU 最大 MHz |
2250 |
CPU 最小 MHz |
1500 |
内存 |
|
型号 |
Micron DDR4 36ASF8G72PZ-3G2B2 3200MHz |
配置的内存速度 |
2933 MT/s |
内存大小 |
32x64GB (总共 2048GB) |
GPU |
|
|---|---|
NVIDIA H100 80GB HBM3 |
|
CPU |
|
型号 |
Intel(R) Xeon(R) Platinum 8480CL |
每核线程数 |
2 |
插槽数 |
2 |
每插槽核心数 |
56 |
NUMA 节点数 |
2 |
CPU 最大 MHz |
3800 |
CPU 最小 MHz |
800 |
内存 |
|
型号 |
Micron DDR5 MTC40F2046S1RC48BA1 4800MHz |
配置的内存速度 |
4400 MT/s |
内存大小 |
32x64GB (总共 2048GB) |
GPU |
|
|---|---|
NVIDIA L40 |
|
CPU |
|
型号 |
AMD EPYC 7763 64 核处理器 |
每核线程数 |
1 |
插槽数 |
2 |
每插槽核心数 |
64 |
NUMA 节点数 |
8 |
频率加速 |
已启用 |
CPU 最大 MHz |
3529 |
CPU 最小 MHz |
1500 |
内存 |
|
型号 |
Samsung DDR4 M393A4K40DB3-CWE 3200MHz |
配置的内存速度 |
3200 MT/s |
内存大小 |
16x32GB (总共 512GB) |
性能考量#
当服务器在高负载下运行时,请求可能会超时,因为服务器在完全生成前一个请求之前不会开始新请求的推理,以便可以释放推理槽。这样做是为了最大化 TTS 服务的吞吐量并允许实时交互。