文本嵌入 NIM 概述#
NeMo 文本检索器 NIM (Text Retriever NIM) API 提供对最先进模型的轻松访问,这些模型是企业语义搜索应用程序的基础构建块,能够快速、大规模地提供准确的答案。开发人员可以使用这些 API 从头到尾创建强大的副驾驶、聊天机器人和 AI 助手。Text Retriever NIM 模型构建于 NVIDIA 软件平台之上,整合了 CUDA、TensorRT 和 Triton,可提供开箱即用的 GPU 加速。
NeMo Retriever 文本嵌入 NIM - 提升文本问答检索性能,为许多下游 NLP 任务提供高质量的嵌入。
NeMo Retriever 文本重排序 NIM - 通过微调的重排序器进一步增强检索性能,找到最相关的段落,以便在查询 LLM 时作为上下文提供。有关更多信息,请参阅文本重排序 NIM 文档。
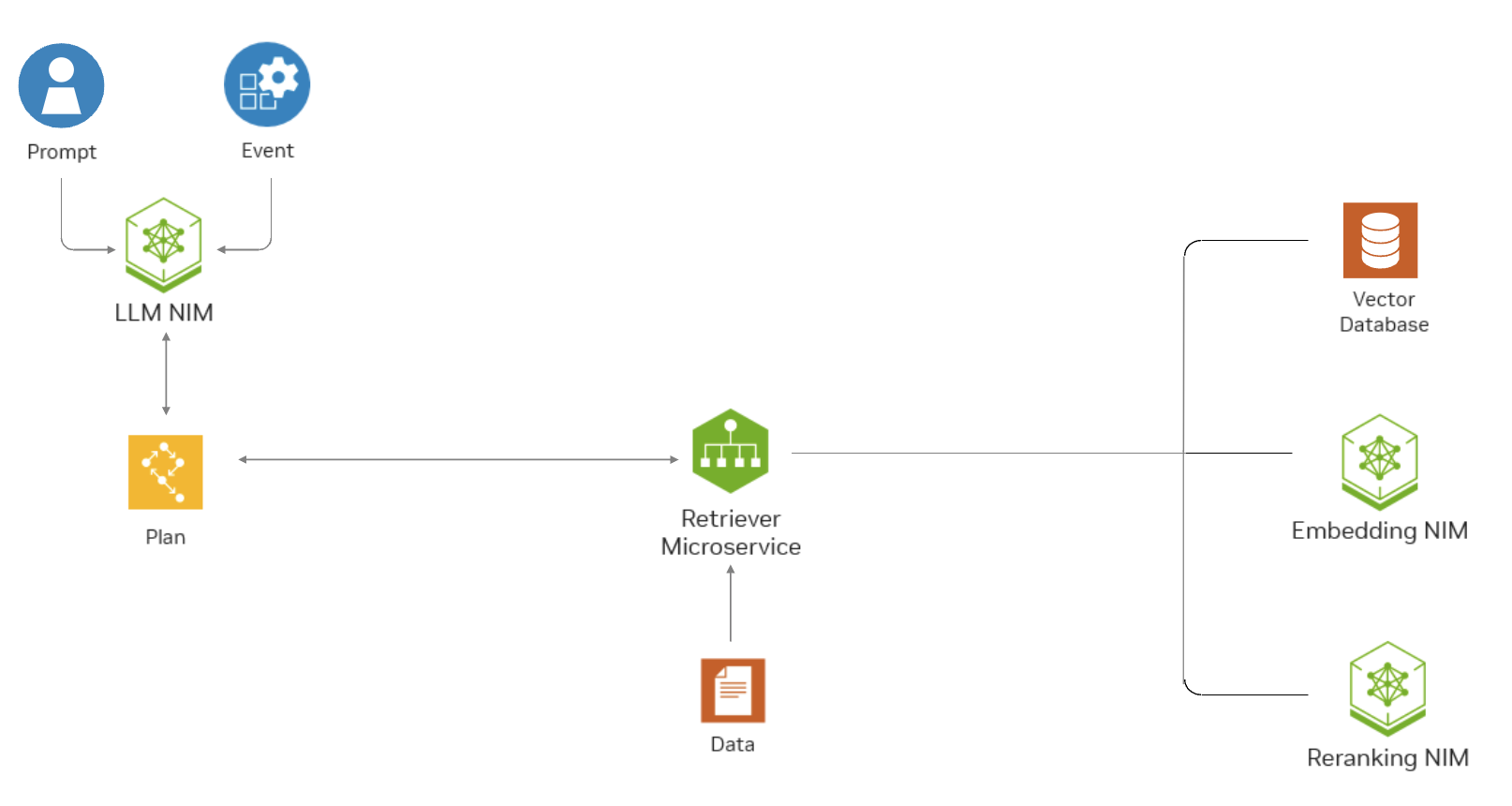
此图表显示了文本检索器 NIM API 如何帮助问答 RAG 应用程序在企业环境中找到最相关的数据。
文本嵌入 NIM#
NeMo Retriever 文本嵌入 NIM(文本嵌入 NIM)将最先进的文本嵌入模型的强大功能带入您的应用程序,提供无与伦比的自然语言处理和理解能力。您可以将文本嵌入 NIM 用于语义搜索、检索增强生成 (RAG),或任何使用文本嵌入的应用程序。文本嵌入 NIM 构建于 NVIDIA 软件平台之上,整合了 CUDA、TensorRT 和 Triton,可提供开箱即用的 GPU 加速。
架构#
每个文本嵌入 NIM 都将一个嵌入模型(例如 NV-EmbedQA-Mistral7B-v2)打包到一个 Docker 容器镜像中。所有文本嵌入 NIM Docker 容器都通过 NVIDIA TritonTM 推理服务器 加速,并公开与 OpenAI 的 API 标准兼容的 API。
有关支持模型的完整列表,请参阅支持模型。
企业级功能#
文本嵌入 NIM 具有企业级功能,例如高性能推理服务器、灵活的集成和企业级安全性。
高性能:文本嵌入 NIM 针对高性能深度学习推理进行了优化,采用 NVIDIA TensorRTTM 和 NVIDIA TritonTM 推理服务器。
可扩展部署:文本嵌入 NIM 可以从少量用户无缝扩展到数百万用户。
灵活集成:文本嵌入 NIM 可以轻松集成到现有数据管道和应用程序中。除了自定义 NVIDIA 扩展之外,还为开发人员提供了与 OpenAI 兼容的 API。
企业级安全性:文本嵌入 NIM 具有安全功能,例如使用 safetensors、持续修补 CVE 以及通过我们的内部渗透测试进行持续监控。
应用场景#
检索增强生成#
在检索增强生成 (RAG) 应用程序中,我们使用嵌入模型将知识库(离线)和用户问题(在线)编码为上下文嵌入,以便 LLM 可以检索最相关的上下文,并为用户提供正确的答案。我们需要高质量的嵌入模型来确保检索到的上下文具有高相关性。
1. 编码知识库(离线):给定一个包含文本、PDF、HTML 或其他格式文档的知识库,我们首先将知识库拆分为块,然后使用嵌入模型将每个块编码为密集向量表示,也称为嵌入。生成的嵌入以及其对应的文档和其他元数据保存在向量数据库中。下图说明了知识库编码过程。

2. 部署(在线):部署后,RAG 应用程序可以访问向量数据库并实时回答问题。为了回答用户问题,RAG 应用程序首先从向量数据库中查找相关块,然后使用检索到的块作为上下文来生成响应。
阶段 1:根据用户查询从向量数据库检索
首先使用嵌入模型将用户查询嵌入为密集向量。然后,查询嵌入用于在向量数据库中搜索与用户查询最相关的文档块。下图说明了检索过程。

阶段 2:使用 LLM 生成利用检索到的上下文的响应
最相关的块被连接起来,形成用户查询的上下文。LLM 将上下文和用户查询结合起来生成响应。下图说明了响应生成过程。

文本分类和聚类#
文本嵌入可用于文本分类任务,例如情感分析和主题分类。它们还可以用于聚类任务,例如主题发现和推荐系统。高质量的嵌入模型通过捕获密集向量表示中的上下文信息来提高这些任务的性能。
自定义应用#
文本嵌入 NIM API 设计为通用型。开发人员可以根据其特定的用例利用文本嵌入进行各种应用,实验并将 API 无缝集成到他们的项目中。