在 Google Kubernetes Engine (GKE) 上部署 NVIDIA NIM#
NVIDIA NIM 是一组易于使用的微服务,旨在加速在云、数据中心和工作站中部署生成式 AI 模型。NIM 使您可以轻松地在自己管理的环境中自托管大型语言模型 (LLM),同时仍然为您提供行业标准 API,以构建强大的副驾驶、聊天机器人和 AI 助手,从而改变您的业务。
Google Kubernetes Engine (GKE) 是一项托管式 Kubernetes 服务,提供可扩展且安全的平台,用于部署、管理和扩展容器化应用程序。GKE 提供自动化升级和修复、自动扩缩、集群管理、网络安全等功能。
在 GKE 上部署 NIM 有两种选择
您可以使用集成的 GKE Kubernetes 应用程序上的 NIM — 当您想快速查看部署在 GKE 上的 NIM 的运行示例时,请使用此选项。
您可以通过 Terraform 和 Helm 创建您自己的集群 — 当您希望完全控制您的集群和 NIM 部署时,请使用此选项。
集成的 GKE Kubernetes 应用程序上的 NIM#
NIM 与 GKE 集成,作为一个随时可部署的 Kubernetes 应用程序,您可以在自己的集群中部署和使用。使用本节中的文档执行以下操作
验证先决条件#
在使用集成的 GKE Kubernetes 应用程序上的 NIM 之前,您需要以下条件
一个 Google Cloud Platform (GCP) 帐户。
为您的帐户配置的结算方式。
您拥有所有权的项目(或已具有足够权限的服务帐户的项目)。所需的服务帐户角色如下
Artifact Registry Reader
Cloud Infrastructure Manager Admin
Cloud Infrastructure Manager Agent
Compute Network Admin
Kubernetes Engine Admin
Kubernetes Engine Node Service Account
Service Account Admin
Service Account User
Service Usage Admin
Storage Admin
部署 NIM#
使用以下步骤通过集成的 Kubernetes 应用程序在 GKE 上部署 NIM。
登录到 Google Cloud 控制台。
打开 GCP Marketplace 上的 NVIDIA NIM 页面。
单击启动。将出现新的 NVIDIA NIM 部署页面。
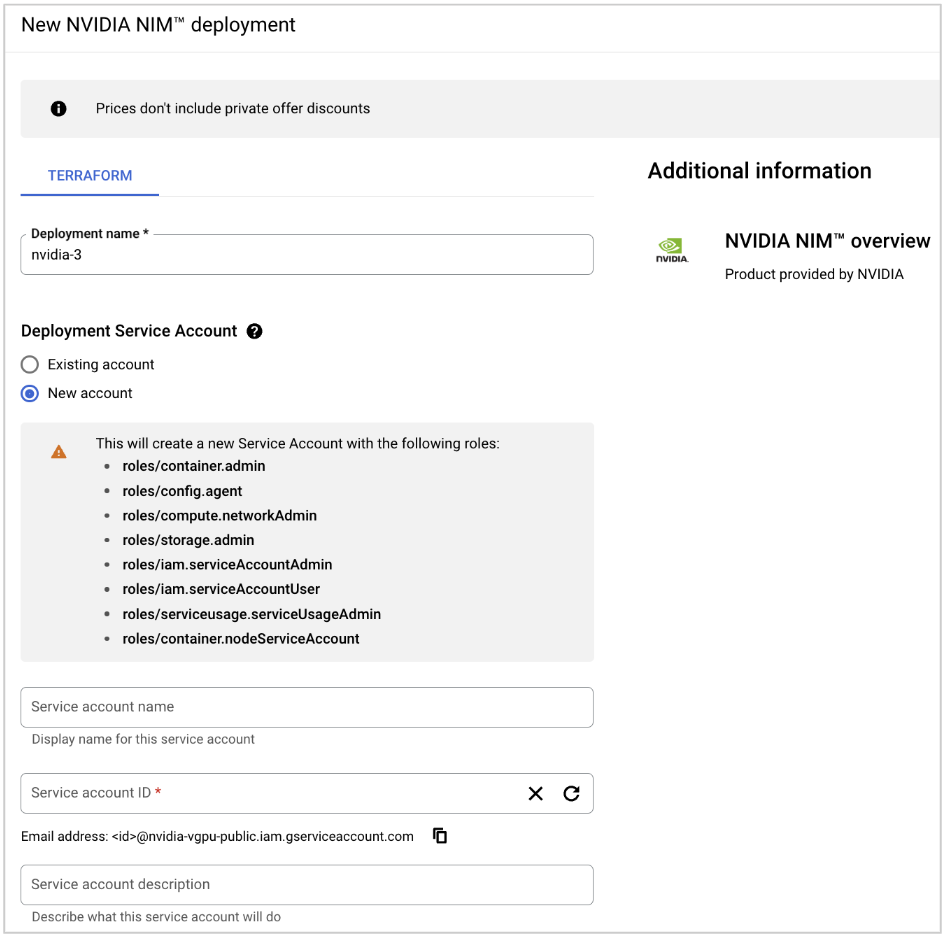
输入部署名称。
对于部署服务帐户,选择现有帐户或创建新帐户,并提供所有帐户详细信息。
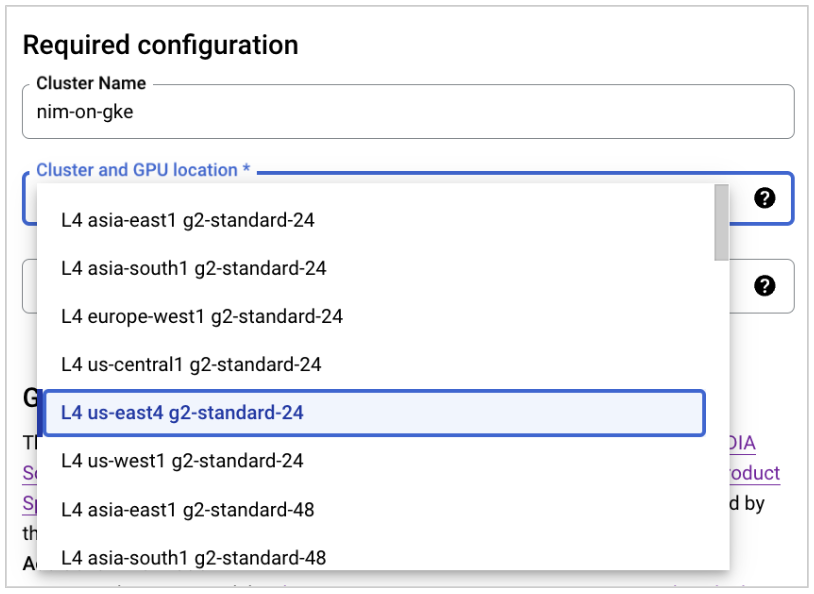
对于集群和 GPU 位置,选择适当的区域和 GPU。
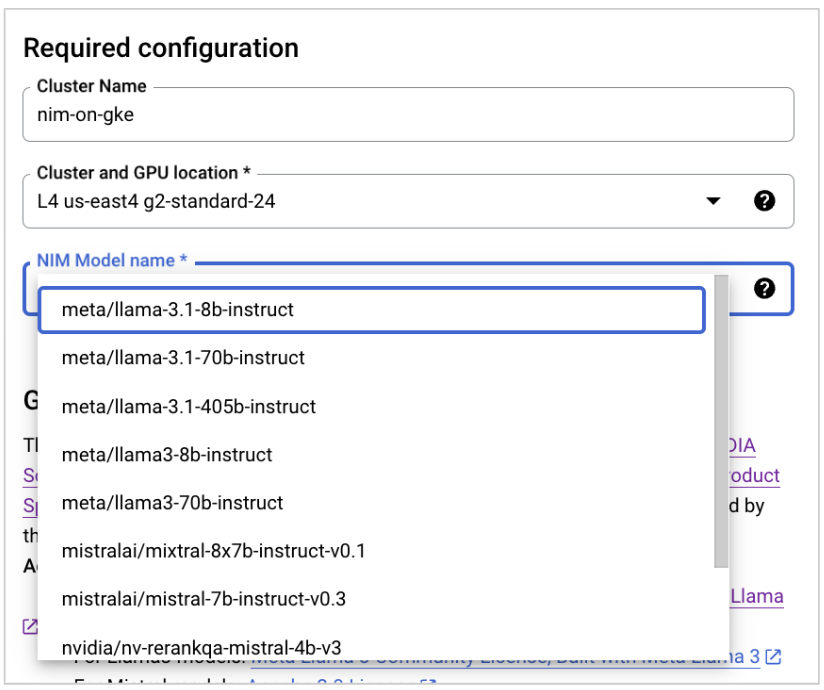
对于 NIM 模型名称,选择您要使用的模型。
阅读并同意条款和条件。
单击部署。部署大约需要 15-20 分钟,具体取决于 NIM 模型和集群参数。
测试您的 NIM#
通过从选项菜单中选择连接来连接到新集群。
通过运行以下代码获取 GKE 集群的凭据。
1gcloud container clusters get-credentials $CLUSTER --region $REGION --project $PROJECT
通过运行以下代码设置到 NIM 容器的端口转发。
1kubectl -n nim port-forward service/my-nim-nim-llm 8000:8000 &
针对 NIM 端点运行推理请求,如以下代码所示。有关更多信息,请参阅 GitHub 上的 nim-deploy/cloud-service-providers/google-cloud/gke/README.md。
注意
确保代码中的 URL 和模型名称正确。
1curl -X GET 'https://:8000/v1/health/ready' 2 3curl -X GET 'https://:8000/v1/models' 4 5curl -X 'POST' \ 6 'https://:8000/v1/chat/completions' \ 7 -H 'accept: application/json' \ 8 -H 'Content-Type: application/json' \ 9 -d '{ 10"messages": [ 11 { 12 "content": "You are a polite and respectful chatbot helping people plan a vacation.", 13 "role": "system" 14 }, 15 { 16 "content": "What should I do for a 4 day vacation in Spain?", 17 "role": "user" 18 } 19], 20"model": "meta/llama-3.1-8b-instruct", 21"max_tokens": 4096, 22"top_p": 1, 23"n": 1, 24"stream": false, 25"stop": "\n", 26"frequency_penalty": 0.0 27}'
注意
对于重新排序模型,请使用以下调用
1# rerank-qa 2curl -X 'POST' \ 3'https://:8000/v1/ranking' \ 4-H 'accept: application/json' \ 5-H 'Content-Type: application/json' \ 6-d '{ 7"query": {"text": "which way should i go?"}, 8"model": "nvidia/nv-rerankqa-mistral-4b-v3", 9"passages": [ 10{ 11"text": "two roads diverged in a yellow wood, and sorry i could not travel both and be one traveler, long i stood and looked down one as far as i could to where it bent in the undergrowth;" 12}, 13{ 14"text": "then took the other, as just as fair, and having perhaps the better claim because it was grassy and wanted wear, though as for that the passing there had worn them really about the same," 15}, 16{ 17"text": "and both that morning equally lay in leaves no step had trodden black. oh, i marked the first for another day! yet knowing how way leads on to way i doubted if i should ever come back." 18} 19] 20}'
注意
对于嵌入模型,请使用以下调用
1# embed 2curl -X "POST" \ 3"https://:8000/v1/embeddings" \ 4-H 'accept: application/json' \ 5-H 'Content-Type: application/json' \ 6-d '{ 7"input": ["Hello world"], 8"model": "nvidia/nv-embedqa-e5-v5", 9"input_type": "query" 10}'
(可选)您还可以使用 NVIDIA Gen-AI 性能工具加载测试并获取性能指标,例如已部署模型的吞吐量和延迟。有关更多信息,请参阅 NIM for LLM Benchmarking Guide。
释放资源#
完成 NIM 后,请使用以下步骤释放资源。
导航到解决方案部署页面。
单击您的部署旁边的三个点,然后单击删除。
通过 Terraform 和 Helm 创建您自己的集群#
如果您希望完全控制您的集群和 NIM 部署,则可以利用 Terraform 脚本和 Helm chart。请按照 GitHub 项目 nim-deploy/cloud-service-providers/google-cloud/gke 中的说明进行操作。