1. NVIDIA GPUDirect Storage O_DIRECT Requirements Guide#
NVIDIA® GPUDirect Storage® O_DIRECT 需求指南旨在帮助您了解 GDS 在利用 O_DIRECT fcntl.h 文件模式在 GPU 内存和存储之间建立直接数据路径时如何提供显著优势。
2. 简介#
本节介绍了 GDS 的 cuFile 部分的 O_DIRECT 需求。
注意
O_DIRECT 是 CUDA 工具包 12.2(GDS 版本 1.7)之前唯一支持的模式。CUDA 12.2(GDS 版本 1.7)引入了对非 O_DIRECT 文件描述符的支持。本指南的其余部分仍然适用于依赖于 GDS 优势的应用,这些应用表达了使用 O_DIRECT 文件模式的意图。
NVIDIA® GPUDirect® Storage (GDS) 是 GPUDirect 系列的最新成员。GDS 实现了 GPU 内存和存储之间直接内存访问 (DMA) 传输的直接数据路径,避免了通过 CPU 的反弹缓冲区。使用此直接路径可以缓解有效的系统带宽瓶颈,并降低 CPU 的延迟和利用率负载。
当 GDS 可以利用 O_DIRECT (fcntl.h) 文件模式在 GPU 内存和存储之间建立直接数据路径时,它可以提供显著的优势。要实现 O_DIRECT 模式的性能优势,必须满足许多条件,并且并非所有文件系统都始终满足这些条件。这些条件可能取决于传输大小、是读取还是写入、写入是写入新数据(超出文件末尾或写入文件中的空洞),以及许多其他条件,例如是否需要校验和。本文档描述了可以使用 O_DIRECT(GDS 依赖于 O_DIRECT)的条件。
本指南的目标受众包括
最终用户和管理员,他们:
了解文件系统,以便他们能够仔细考虑他们启用的功能的影响。
比较不同文件系统的支持,以确定合适的模型以及如何使用它们。
评估有效使用或未能有效使用 O_DIRECT 的案例的加权比例。
中间件开发人员,他们:
考虑设计权衡,这些权衡可以提高供应商层有效使用 O_DIRECT 的可能性。
文件系统供应商和实施者,他们:
加速他们对使用 O_DIRECT 处理各种案例的评估,因为他们在新的或定制的文件系统中启用 GDS。
3. GPUDirect Storage 需求#
本节提供了一些关于 GDS 在何处可以最有效使用的基本背景知识。
这些信息使技术水平不同的读者能够大致了解 GDS 可以在多大程度上使做出不同设计选择的文件系统受益。
3.1. 基本需求概述#
GDS 架构具有以下关键需求:
内核存储驱动程序可以使用从 GDS 内核模块
nvidia-fs.ko的回调获得的地址,对用户数据执行到 GPU 内存或从 GPU 内存执行的 DMA。存储设备附近的设备具有 DMA 引擎,可以通过 PCIe 连接到 GPU 内存缓冲区。
对于本地存储,NVMe 设备执行 DMA。
对于远程存储,NIC 设备执行 RDMA。
在用户级别或内核级别或两者级别运行的文件系统堆栈,永远不需要访问 CPU 系统内存中的数据。
相反,数据直接在存储和 GPU 内存之间传输,这是通过专门使用 O_DIRECT 模式用于给定文件的文件系统实现的。
图 1 说明了可视化 O_DIRECT 条件的一种方式。它涵盖了数据路径到存储中是否存在运算符 ( ) 的情况,以及该运算符是在 CPU 还是 GPU 中。如果运算符在 CPU 中,则无法使用 O_DIRECT。
) 的情况,以及该运算符是在 CPU 还是 GPU 中。如果运算符在 CPU 中,则无法使用 O_DIRECT。
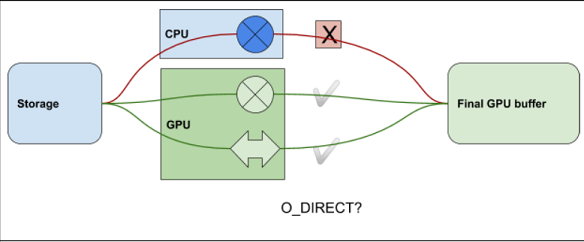
图 1 基本需求概述#
如果来自(或去往)存储的数据必须在 CPU 中处理(由交叉运算符象征),则不能使用 O_DIRECT。如果数据仅通过 GPU,则可以使用 O_DIRECT,无论那里是否存在转换运算符(由 GPU 上的校验和之类的交叉运算符象征),或者根本没有操作(由干净的箭头象征)。
网络文件系统或网络块设备中缺少对 RDMA 的支持意味着需要将数据复制到系统内存中的套接字缓冲区。这种需求与上面列出的基本需求不兼容。
如果使用 GDS 的条件不成立,例如,因为文件的挂载未启用 GDS,或者 nvidia-fs.ko 驱动程序不可用,则可以使用兼容模式,这是一种 cuFile 功能,可以回退到通过 CPU 反弹缓冲区进行复制。您可以在 cufile.json 文件中启用兼容模式。用户可以通过创建自己的副本并将相应的环境变量指向该用户的副本来覆盖系统的 cufile.json 文件版本。在兼容模式之外,如果 O_DIRECT 不可能,API 将会失败。
注意
从 CUDA 工具包 12.2(GDS 版本 1.7)开始,即使与 cuFile API 一起使用的文件描述符以非 O_DIRECT 模式打开,API 也可以在兼容模式下工作。即使在这种情况下,API 也会在存储和 gpu 缓冲区之间存在直接路径时利用 GDS 路径。对于所有其他情况,API 会通过页面缓存来处理以非 O_DIRECT 模式打开的 fd。这可以看作是兼容模式利用页面缓存,页面缓存通常可以用于具有高时间局部性的小型文件 I/O,例如应用程序标头或元数据的情况。
3.2. 客户端和服务器#
在本地文件或块系统中,软件堆栈执行所有 IO。在分布式文件或块系统中,至少涉及两个代理。客户端发出读取或写入请求,服务器为其提供服务。文件系统有两种类型:
基于块的
网络连接的
基于块的系统可以在本地或远程提供服务,而网络连接的文件系统始终是远程的。
考虑客户端和服务器之间的以下交互:
NIC 和 GPU 内存之间的直接数据路径发生在客户端上。
要启用此直接路径,必须首先在客户端驱动程序上启用 GDS。
RDMA 是一种通过网络访问远程数据的协议,它使用 NIC 直接 DMA 到客户端内存中。
如果没有 RDMA,则没有直接路径,分布式文件和块系统的 GDS 依赖于 GPUDirect RDMA,以实现 NIC 和 GPU 内存之间的直接路径。
使用 RDMA 也依赖于服务器端支持。
服务器端不支持 RDMA 的文件系统实现将不支持 GDS。例如,NFS 仅适用于服务器端 NFS 而不是 RDMA 支持,但这已成为大多数 NFS 供应商自 GDS 诞生以来就提供的功能。
3.3. O_DIRECT 不适用的情况#
在 POSIX 中,文件打开的模式由一组标志控制。其中一个标志 O_DIRECT 表示用户不希望在 CPU 系统内存中缓冲传输,而是希望使传输更直接。例如,O_DIRECT 通常禁用页面缓存的使用。尽管此标志表示用户意图,但实现仍然可以做出自己的权衡。
例如,实现可能会决定区别对待小型传输和采用更直接路径的较大型传输。在另一个示例中,文件系统可能会为用户提供一个选项,以启用页面缓存的预读。但是,此选项可能与用户对文件使用 O_DIRECT 的请求冲突。在这种情况下,实现如何处理相互冲突的请求取决于实现策略。因此,O_DIRECT 可以被视为一种提示。
下面列出了几种情况,在这些情况下,文件系统当前不支持用户使用 O_DIRECT 的请求,在特定情况下未使用 O_DIRECT,或者从根本上来说不可行。这些情况根据做出选择或权衡并影响该选项的代理进行划分。
以下是一些附加信息:
可能与用户相关:
用户缓冲的 IO:传输可能在传输到内核之前在用户空间中缓冲。
当许多小型事务具有良好的空间和时间局部性时,可以使用这种情况。
可能与中间件相关:
元数据管理:数据有效负载可能存在元数据。
元数据可能采用多种形式,包括数据有效负载的校验和、在延长文件时必须更新的文件大小以及填充空洞时文件布局的映射。
分层存储模型:某些实现使用分层方案,其中一些数据驻留在 CPU 系统内存中,并且可以实现更短的延迟和更高的带宽。
存在逐渐变慢但容量更高的外部存储层。这种分层方案的一个示例是闪存和旋转磁盘。
预读:有时使用的一种优化,尤其适用于缓冲 IO 和许多小的连续传输,是预测接下来将要使用的内容并将其缓冲到 CPU 系统内存中。
检查或转换数据:当 CPU 在 IO 事务之前(或之后)检查或转换数据时,此过程会干扰存储和 GPU 内存之间的直接传输。
仅文件系统:
内核缓冲的 IO:如果时间和空间局部性良好,并且从内核内存复制的带宽和延迟明显优于从存储复制,则可以使用诸如 fscache 之类的机制来维护系统内存中的副本。
内联数据:小型文件的存储和管理方式与大型文件不同。
块分配:有多种策略可用于分配文件中的空间,并且可能对客户端和服务器端活动产生影响。
在某些情况下,中间件执行与文件系统相同的一些功能。与对文件系统的低级调用相比,中间件可能具有更多可用的上下文信息,并且它可能会采取措施来提高文件系统可以使用 O_DIRECT 的可能性。考虑计算校验和的情况。用户可能能够控制是否甚至使用校验和。如果启用了校验和,则中间件可能会通过以下方式进行干预:
它可以调用 GPU 内核来计算校验和,并将校验和数据与有效负载并排放置,以便可以使用一个 cuFileWrite 将数据写回存储。
它可以再次调用 GPU 内核来计算到不同缓冲区的校验和,并使用两个 cuFileWrite 来写入校验和和有效负载。
在这些情况下,对文件系统的请求可以使用 O_DIRECT。
3.3.1. 缓冲 IO#
当未指定 O_DIRECT 时,Linux 虚拟文件系统 (VFS) 使用缓冲 IO,并且可能存在多层缓存。缓存示例可能包括以下内容:
页面缓存,由 fscache 支持。
文件系统特定的页面池,例如 ZFS 自适应重放缓存 (ARC) 和 Spectrum Storage (GPFS) 页面池。
3.3.2. 内联文件#
基于 Linux 的文件系统通过使用通用的 VFS 接口来打开、关闭、读取和写入文件来实现。用户数据以文件形式组织,文件以下列方式表示:
Inode,其主要目的是存储元数据。
固定块,通常称为保存用户内容的页面。
典型的块大小为 4096 字节。
内联文件的数据小于页面大小,并且足够小以适合 inode。通常,文件系统提供标志来检测 inode 是否为内联。Inode 通常被读入系统内存,因此内联用户数据与元数据一起复制到系统内存中。
在基于 RDMA 的网络连接文件系统中,小于指定大小阈值的文件以内联方式在远程过程调用 (RPC) 中发送。此过程涉及在系统内存中缓冲,这需要额外复制用户数据,而不是直接数据传输。对于某些文件系统(例如 ext4 和 Lustre),可以在文件系统级别或按 inode 禁用内联文件模式。
3.3.3. 写入的块分配#
在将数据写入文件之前,必须分配数据块。有关更多信息,请参阅内联文件。为了使文件系统支持 O_DIRECT 模式来写入文件,存储中的可用数据块必须可用并准备好供文件系统使用。否则,在以下情况下,用户数据可以缓冲到系统页面缓存中,这使得直接数据传输成为不可能。以下是一些文件系统因块分配而需要回退到缓冲模式的情况列表:
注意
如果这些功能在存储服务器上实现,并且客户端不执行缓冲,则这些限制不适用于分布式文件系统。
扩展写入:正在发生的写入会增加文件大小。
分配写入:写入尚未分配的块。
写入预分配块:该块已在存储中分配,但在写入数据之前需要更新元数据。
空洞填充:写入文件中间的空洞,这是一个稀疏块。
写入时复制 (COW) 文件系统:当写入数据缓冲区涉及在 CPU 系统内存中缓存时触发的复制操作。
延迟分配或刷新时分配:分配是被动的(非主动的),以减少慢速随机写入或用于旋转磁盘的大型顺序写入时的磁盘碎片。
对于网络连接存储或分布式文件系统,文件系统架构决定了分配决策是在本地、每个客户端还是在远程服务器上做出。如果块分配处理在服务器端完成,则不会有 CPU 缓冲妨碍直接传输。如果块分配在客户端处理,则可能会有一些障碍。
3.3.4. 检查或转换用户数据#
以下是一些需要将用户数据复制到系统内存中的情况列表,以便文件系统可以在读取或写入传输过程中检查或转换用户数据:
数据日志用于跟踪尚未提交到持久性存储的更改。
数据日志通常禁用 O_DIRECT。一般来说,除非存在高速日志媒体,否则 O_DIRECT 用例不需要数据日志。元数据日志不需要访问用户数据。
可以在写入期间计算校验和,并在读取时进行检查。
对于具有校验和支持的网络文件系统,校验和通常在客户端上执行,以检测网络损坏,此外还在服务器上计算校验和。
可以在网络客户端上提供客户端压缩和重复数据删除,以实现带宽改进,此外还可以在服务器端进行压缩以进行数据存储。
内联重复数据删除需要查看用户内容,以使用 MD5 或 SHA1 算法确定指纹。同样,客户端加密可以提供从客户端到服务器的更安全通信。
纠删码可以由文件系统或块设备执行。
在这种情况下,数据在执行到磁盘池或网络服务器的 DMA 之前被复制到 CPU 系统内存中。对于分布式块设备,纠删码决策在客户端执行。
同步复制涉及在 DMA 操作到远程块设备或服务器之前将数据复制到系统内存中,具体取决于恢复时间目标。
3.3.5. 总结#
在许多情况下,完全不使用 CPU 系统内存的 O_DIRECT 模式是不适用的。这些情况的相关性取决于本地或分布式文件系统实现,在某些情况下,还取决于用户选择的功能集。供应商可以提供他们自己对这些问题相关性的评估。
4. 声明#
本文档仅供参考之用,不应视为对产品的特定功能、条件或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含的信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对因使用此类信息或因其使用而可能导致的侵犯专利或第三方的其他权利的后果或使用不承担任何责任。本文档不承诺开发、发布或交付任何材料(如下定义)、代码或功能。
NVIDIA 保留在任何时候对本文档进行更正、修改、增强、改进和任何其他更改的权利,恕不另行通知。
客户应在下订单前获取最新的相关信息,并应验证此类信息是否为最新且完整。
NVIDIA 产品的销售受 NVIDIA 在订单确认时提供的标准销售条款和条件的约束,除非 NVIDIA 和客户的授权代表签署的单独销售协议(“销售条款”)另有约定。NVIDIA 在此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档不直接或间接地形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命维持设备,也不适用于 NVIDIA 产品的故障或故障可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在上述设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不作任何陈述或保证,保证基于本文档的产品将适用于任何特定用途。NVIDIA 不一定会对每种产品的所有参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合客户计划的应用和用途,并为该应用执行必要的测试,以避免应用或产品的默认设置。客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同条件和/或要求。NVIDIA 对可能基于或归因于以下原因的任何默认设置、损坏、成本或问题不承担任何责任:(i) 以任何与本文档相悖的方式使用 NVIDIA 产品,或 (ii) 客户产品设计。
本文档未授予 NVIDIA 专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成对其的保证或认可。使用此类信息可能需要获得第三方在其专利或其他知识产权下的许可,或者获得 NVIDIA 在其专利或其他 NVIDIA 知识产权下的许可。
只有在事先获得 NVIDIA 书面批准的情况下,才允许复制本文档中的信息,复制时不得进行更改,并且必须完全遵守所有适用的出口法律和法规,并附带所有相关的条件、限制和声明。
本文档和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均按“原样”提供。NVIDIA 对材料不作任何明示、暗示、法定或其他形式的保证,并且明确否认所有关于非侵权、适销性和特定用途适用性的暗示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对因使用本文档而引起的任何损害(包括但不限于任何直接、间接、特殊、偶然、惩罚性或后果性损害,无论如何造成,也无论责任理论如何)负责,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因而遭受任何损害,但 NVIDIA 对本文所述产品的客户的累计总责任应根据产品的销售条款进行限制。
5. OpenCL#
OpenCL 是 Apple Inc. 的商标,已获得 Khronos Group Inc. 的许可使用。
6. 商标#
NVIDIA、NVIDIA 徽标、CUDA、DGX、DGX-1、DGX-2、DGX-A100、Tesla 和 Quadro 是 NVIDIA Corporation 在美国和其他国家/地区的商标和/或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。