集体操作¶
集体操作必须为每个 rank(因此也是 CUDA 设备)调用,使用相同的计数和相同的数据类型,以形成完整的集体操作。 否则将导致未定义的行为,包括挂起、崩溃或数据损坏。
AllReduce¶
AllReduce 操作对跨设备的数据执行归约(例如,求和、最小值、最大值),并将结果存储在每个 rank 的接收缓冲区中。
在 k 个 rank 之间的求和 allreduce 操作中,每个 rank 将提供一个 N 个值的输入数组,并在 N 个值的输出数组中接收相同的结果,其中 out[i] = in0[i]+in1[i]+…+in(k-1)[i]。
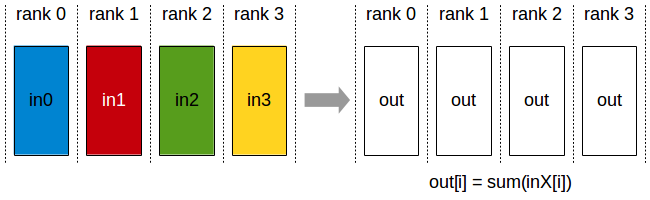
All-Reduce 操作:每个 rank 接收跨 rank 的输入值的归约结果。
相关链接: ncclAllReduce()。
Broadcast¶
Broadcast 操作将 N 元素缓冲区从根 rank 复制到所有 rank。
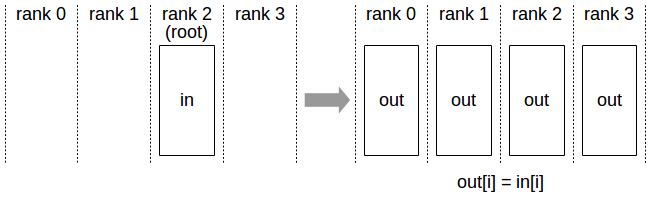
Broadcast 操作:所有 rank 从“根” rank 接收数据。
重要提示:root 参数是 rank 之一,而不是设备号,因此会受到不同 rank 到设备映射的影响。
相关链接: ncclBroadcast()。
Reduce¶
Reduce 操作执行与 AllReduce 相同的操作,但仅将结果存储在指定根 rank 的接收缓冲区中。
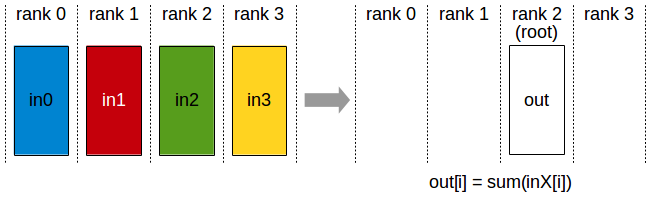
Reduce 操作:一个 rank 接收跨 rank 的输入值的归约结果。
重要提示:root 参数是 rank 之一(不是设备号),因此会受到不同 rank 到设备映射的影响。
注意:Reduce 操作后跟 Broadcast 操作,等效于 AllReduce 操作。
相关链接: ncclReduce()。
AllGather¶
AllGather 操作从 k 个 rank 收集 N 个值到一个大小为 k*N 的输出缓冲区中,并将该结果分发给所有 rank。
输出按 rank 索引排序。 因此,AllGather 操作会受到不同 rank 到设备映射的影响。
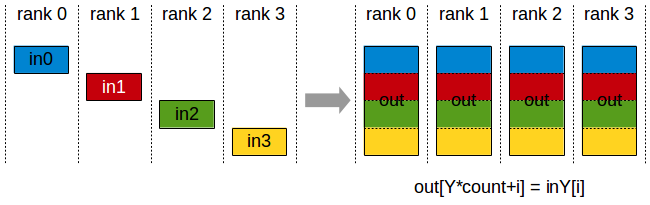
AllGather 操作:每个 rank 接收来自所有 rank 的数据聚合,并按 rank 的顺序排列。
注意:执行 ReduceScatter,然后执行 AllGather,等效于 AllReduce 操作。
相关链接: ncclAllGather()。
ReduceScatter¶
ReduceScatter 操作执行与 Reduce 相同的操作,不同之处在于结果在 rank 之间以相等大小的块分散,每个 rank 根据其 rank 索引获得一块数据。
ReduceScatter 操作受不同 rank 到设备映射的影响,因为 rank 决定了数据布局。
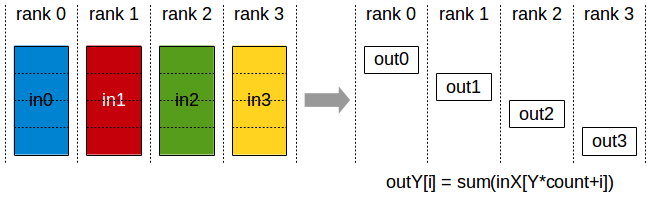
Reduce-Scatter 操作:输入值在 rank 之间进行归约,每个 rank 接收结果的子部分。
相关链接: ncclReduceScatter()