高级 GPU 配置(可选)#
GPU 分区#
计算工作负载可以受益于使用独立的 GPU 分区。GPU 分区的灵活性允许单个 GPU 被小型、中型和大型工作负载共享和使用。GPU 分区可以是执行深度学习工作负载的有效选项。一个例子是深度学习训练和推理工作流程,这些工作流程利用较小的数据集,但高度依赖于数据/模型的大小,用户可能需要减少批量大小。
下图说明了一个 GPU 分区用例,其中多租户、多个用户共享单个 A100 (40GB)。在这种用例中,单个 A100 可用于多个工作负载,例如深度学习训练、微调、推理、Jupyter Notebook、调试等。
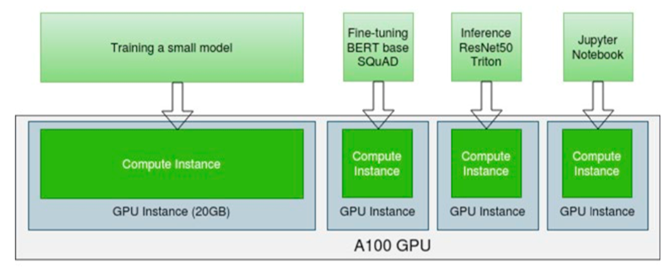
使用两种不同的 NVIDIA GPU 技术,GPU 使用 NVIDIA AI 企业版软件时间分区或多实例 GPU (MIG) 空间分区进行分区。请参阅GPU 分区技术简报以了解差异。
NVIDIA AI 企业版软件分区#
使用 NVIDIA AI 企业版软件分区,配置文件为虚拟机分配自定义数量的专用 GPU 内存。NVIDIA AI 企业版主机软件设置正确的内存量,以满足所述虚拟机工作流程中的特定需求。每个虚拟机都有专用的 GPU 内存,必须相应地分配,以确保其具有处理预期计算负载所需的资源。
NVIDIA AI 企业版主机软件允许最多八个虚拟机共享每个物理 GPU,方法是将可用 GPU 的图形资源分配给虚拟机,并采用平衡方法。根据每张线路卡中 GPU 的数量,可以分配多种虚拟机类型。
NVIDIA AI 企业版配置文件#
这些配置文件代表了虚拟 GPU 非常灵活的部署选项,GPU 内存大小各不相同。GPU 内存的划分定义了每个 GPU 可能的 vGPU 数量。
C 系列 vGPU 类型针对计算密集型工作负载进行了优化。因此,它们仅支持单个显示头,最大分辨率为 4096×2160,并且不提供 NVIDIA RTX 图形加速。
务必考虑部署中将使用哪种 vGPU 配置文件,因为这将最终决定可以部署多少 vGPU 支持的虚拟机。
在 3.0 版本中添加。
VMware vSphere 8.0 引入了附加最多 8 个 vGPU 和 32 个直通设备的功能。此外,可以将多个异构的完整或分数配置文件附加到单个虚拟机。来自虚拟机内部的示例。
nvidia@nvidia-demo:~$ nvidia-smi
Wed Nov 23 15:38:07 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.60 Driver Version: 525.60 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GRID T4-4C On | 00000000:02:01.0 Off | 0 |
| N/A N/A P8 N/A / N/A | 0MiB / 4096MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 1 GRID T4-8C On | 00000000:02:02.0 Off | 0 |
| N/A N/A P8 N/A / N/A | 0MiB / 8192MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 2 GRID T4-16C On | 00000000:02:05.0 Off | 0 |
| N/A N/A P8 N/A / N/A | 0MiB / 16384MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 3 GRID T4-4C On | 00000000:02:06.0 Off | 0 |
| N/A N/A P8 N/A / N/A | 0MiB / 4096MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 4 GRID T4-8C On | 00000000:02:07.0 Off | 0 |
| N/A N/A P8 N/A / N/A | 0MiB / 8192MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 5 GRID T4-16C On | 00000000:02:08.0 Off | 0 |
| N/A N/A P8 N/A / N/A | 0MiB / 16384MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
注意
8.0 之前的 VMware vSphere 版本仅允许以下配置。不允许使用多个异构 vGPU 配置文件,并且单个虚拟机最多只能附加 4 个 vGPU。
警告
在 NVIDIA AI 企业版 2.x 及更早版本中,使用 vSphere 7.0U3c 或更早版本时,所有共享的 GPU 资源都必须分配相同的分数 vGPU 配置文件。这意味着您不能在使用 NVIDIA AI 企业版软件的单个 GPU 上混合 vGPU 配置文件。
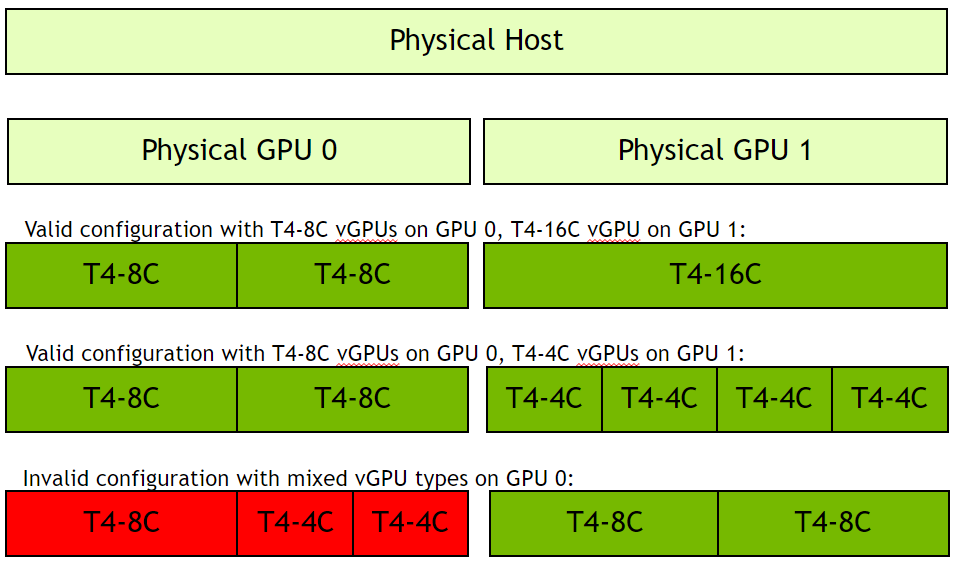
在下图中,右侧以绿色显示了有效配置,其中虚拟机共享 T4 GPU 上的单个 GPU 资源(GPU 1),并且所有虚拟机都分配了同构配置文件,例如 8GB、4GB 或 16GB C 配置文件。由于服务器中安装了两个 GPU,因此另一个 T4(GPU 0)可以与 GPU 1 不同的方式进行分区/分数化。红色显示了无效配置,其中单个 GPU 使用 8C 和 4C 配置文件共享。vGPU 不支持异构配置文件,虚拟机将无法成功启动。
调度策略#
NVIDIA AI 企业版提供三种 GPU 调度选项,以适应客户的各种 QoS 要求。但是,由于 AI 企业版工作负载通常是长时间运行的操作,因此建议实施固定份额或平均份额调度器以获得最佳性能。
固定份额调度始终保证相同的专用服务质量。固定份额调度策略保证在共享同一物理 GPU 的所有 vGPU 之间实现相等的 GPU 性能。
平均份额调度为每个正在运行的虚拟机提供相等的 GPU 资源。随着 vGPU 的添加或删除,分配的 GPU 处理周期份额会相应变化,从而导致在利用率低时性能提高,而在利用率高时性能降低。
尽力而为调度以更高的规模提供一致的性能,因此降低了每个用户的 TCO。尽力而为调度器利用轮询调度算法,该算法根据实际需求共享 GPU 资源,从而实现最佳的资源利用率。这带来了具有优化的用户密度和良好 QoS 的一致性能。尽力而为调度策略在空闲和未充分利用的时间内最佳地利用 GPU,从而实现优化的密度和良好的 QoS。
有关 GPU 调度的更多信息,请参见此处。
RmPVMRL 注册表项#
RmPVMRL 注册表项设置 NVIDIA vGPU 的调度策略。
注意
您只能在基于 Pascal、Volta、Turing 和 Ampere 架构的 GPU 上更改 vGPU 调度策略。
类型
Dword
内容
值 |
含义 |
|---|---|
0x00(默认) |
尽力而为调度器 |
0x01 |
具有默认时间片长度的平均份额调度器 |
0x00TT0001 |
具有用户定义的时间片长度 TT 的平均份额调度器 |
0x11 |
具有默认时间片长度的固定份额调度器 |
0x00TT0011 |
具有用户定义的时间片长度 TT 的固定份额调度器 |
示例
默认时间片长度取决于 vGPU 类型允许的每个物理 GPU 的最大 vGPU 数量。
最大 vGPU 数量 |
默认时间片长度 |
|---|---|
小于或等于 8 |
2 毫秒 |
大于 8 |
1 毫秒 |
TT
范围为 01 到 1E 的两位十六进制数字以毫秒 (ms) 为单位设置平均份额和固定份额调度器的时间片长度。最小长度为 1 毫秒,最大长度为 30 毫秒。
如果 TT 为 00,则长度设置为 vGPU 类型的默认长度。
如果 TT 大于 1E,则长度设置为 30 毫秒。
示例
此示例将 vGPU 调度器设置为具有默认时间片长度的平均份额调度器。
RmPVMRL=0x01
此示例将 vGPU 调度器设置为时间片长度为 3 毫秒的平均份额调度器。
RmPVMRL=0x00030001
此示例将 vGPU 调度器设置为具有默认时间片长度的固定份额调度器。
RmPVMRL=0x11
此示例将 vGPU 调度器设置为时间片长度为 24 (0x18) 毫秒的固定份额调度器。
RmPVMRL=0x00180011
更改所有 GPU 的 vGPU 调度策略#
在您的虚拟机监控程序命令 shell 中执行此任务。
以虚拟机监控程序主机上的 root 用户身份打开命令 shell。在所有受支持的虚拟机监控程序上,您都可以使用安全外壳 (SSH) 来完成此操作。将 RmPVMRL 注册表项设置为设置所需 GPU 调度策略的值。
在 VMware vSphere SSH CLI 中,使用
esxcli set命令。# esxcli system module parameters set -m nvidia -p "NVreg_RegistryDwords=RmPVMRL=value"注意
其中 <value> 是设置您想要的 vGPU 调度策略的值,例如
0x01 - 具有默认时间片长度的平均份额调度器
0x00030001 - 时间片为 3 毫秒的平均份额调度器
0x011 - 具有默认时间片长度的固定份额调度器
0x00180011 - 时间片为 24 毫秒 (0x18) 的固定份额调度器
默认时间片长度取决于 vGPU 类型允许的每个物理 GPU 的最大 vGPU 数量。
最大 vGPU 数量
默认时间片长度
小于或等于 8
2 毫秒
大于 8
1 毫秒
重新启动您的虚拟机监控程序主机。
更改所选 GPU 的 vGPU 调度策略#
在您的虚拟机监控程序命令 shell 中执行此任务
以虚拟机监控程序主机上的 root 用户身份打开命令 shell。在所有受支持的虚拟机监控程序上,您都可以使用安全外壳 (SSH) 来完成此操作。
使用
lspci命令获取您要更改调度行为的每个 GPU 的 PCI 域和总线/设备/功能 (BDF)。将
lspci的输出管道传输到 grep 命令,以仅显示 NVIDIA GPU 的信息。# lspci | grep NVIDIA此示例中列出的 NVIDIA GPU 的 PCI 域为 0000,BDF 为 85:00.0 和 86:00.0。
10000:85:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [M60] (rev a1) 20000:86:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [M60] (rev a1)
使用模块参数
NVreg_RegistryDwordsPerDevice为每个 GPU 设置 pci 和 RmPVMRL 注册表项。使用
esxcli set命令# esxcli system module parameters set -m nvidia -p "NVreg_RegistryDwordsPerDevice=pci=pci-domain:pci-bdf;RmPVMRL=value [;pci=pci-domain:pci-bdf;RmPVMRL=value...]"对于每个 GPU,提供以下信息
pci-domain
GPU 的 PCI 域。
pci-bdf
GPU 的 PCI 设备 BDF。
value
0x00 - 将 vGPU 调度策略设置为具有默认时间片长度的平均份额调度器。
0x00030001 - 将 vGPU 调度策略设置为时间片为 3 毫秒的平均份额调度器。
0x011 - 将 vGPU 调度策略设置为具有默认时间片长度的固定份额调度器。
0x00180011 - 将 vGPU 调度策略设置为时间片为 24 毫秒 (0x18) 的固定份额调度器。
对于所有支持的值,请参见RmPVMRL 注册表项。
重新启动您的虚拟机监控程序主机。
恢复默认 vGPU 调度器设置#
在您的虚拟机监控程序命令 shell 中执行此任务。
以虚拟机监控程序主机上的 root 用户身份打开命令 shell。在所有受支持的虚拟机监控程序上,您都可以使用安全外壳 (SSH) 来完成此操作。
通过将模块参数设置为空字符串来取消设置
RmPVMRL注册表项。# esxcli system module parameters set -m nvidia -p "module-parameter="module-parameter
要设置的模块参数,这取决于是否为所有 GPU 或选定的 GPU 更改了调度行为
对于所有 GPU,设置
NVreg_RegistryDwords模块参数。对于选定的 GPU,设置
NVreg_RegistryDwordsPerDevice模块参数。
例如,要在为所有 GPU 更改默认 vGPU 调度器设置后恢复它们,请输入此命令
# esxcli system module parameters set -m nvidia -p "NVreg_RegistryDwords="重新启动您的虚拟机监控程序主机。
vSphere 的 NVIDIA 多实例 GPU 配置#
NVIDIA A100 Tensor Core GPU 基于 NVIDIA Ampere 架构,可加速数据中心中的 AI、数据分析和 HPC 等计算工作负载。vGPU 上的 MIG 支持始于 NVIDIA AI 企业版软件 12 版本,使用户可以灵活地在 MIG 模式或非 MIG 模式下使用 NVIDIA A100。当 NVIDIA A100 处于非 MIG 模式时,NVIDIA vGPU 软件使用时间分区和 GPU 时间片调度。MIG 模式在空间上对 GPU 硬件进行分区,以便每个 MIG 都可以完全隔离,并具有其流式多处理器 (SM)、高带宽和内存。MIG 还可以对可用的 GPU 计算资源进行分区。
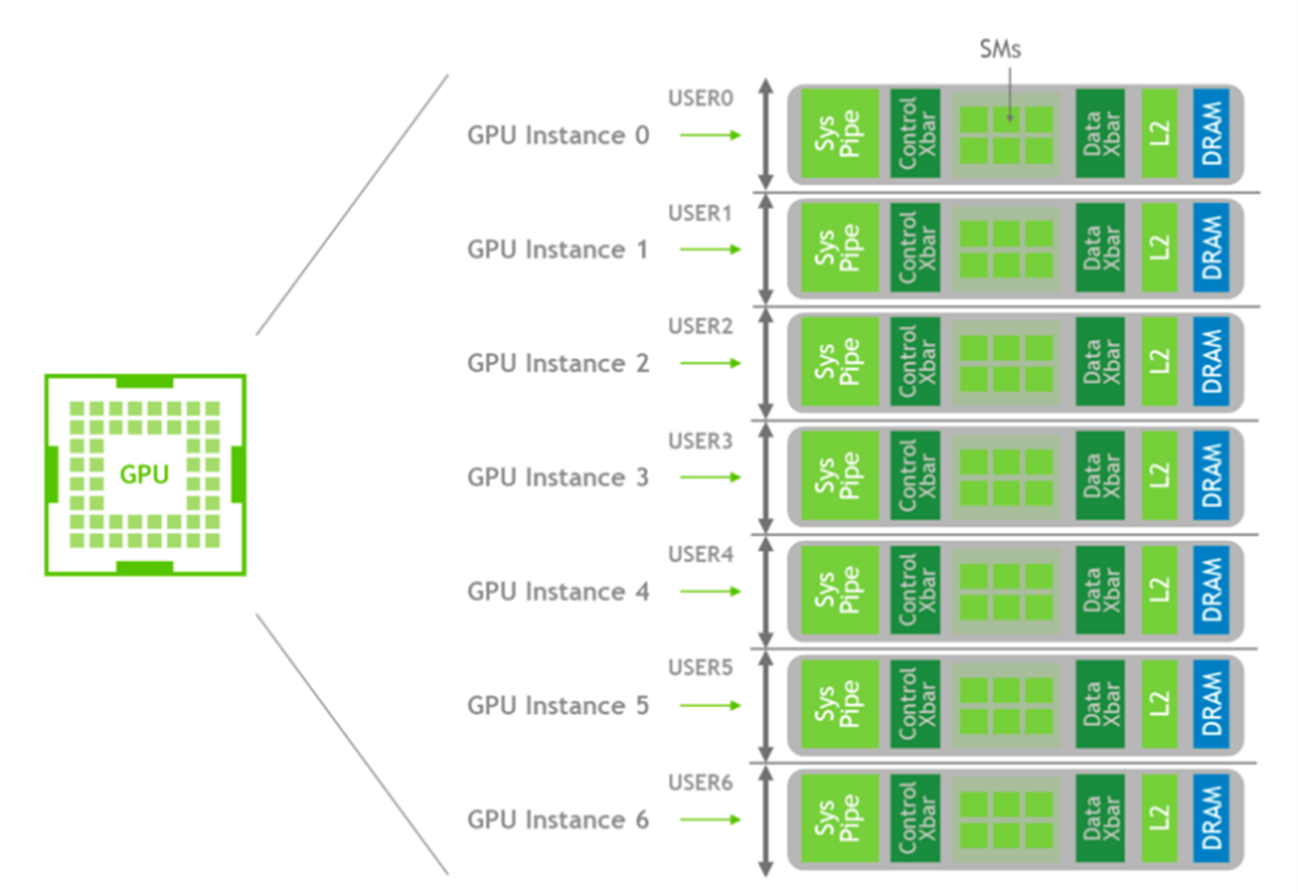
每个实例的处理器都具有通过整个内存系统的单独且隔离的路径。片上交叉开关端口、L2 缓存库、内存控制器和 DRAM 地址总线都唯一地分配给单个实例。这确保了即使其他任务破坏其缓存或使 DRAM 接口饱和,特定用户的工作负载也可以以可预测的吞吐量和延迟运行,并使用相同的 L2 缓存分配和 DRAM 带宽。
单个 NVIDIA A100-40GB 具有八个可用的 GPU 内存切片,每个切片具有 5 GB 内存,但只有七个可用的 SM 切片。有七个 SM 切片,而不是八个,因为启用 MIG 模式时,某些 SM 覆盖了操作开销。MIG 模式使用 nvidia-smi 配置(或重新配置),并且具有您可以选择的配置文件,以满足 HPC、深度学习或加速计算工作负载的需求。
总之,MIG 在空间上将 NVIDIA GPU 分区为独立的 GPU 实例,但对于计算工作负载,与 vGPU 时间分区相比,它提供了更低的延迟优势。下表总结了 A100 MIG 功能与 NVIDIA AI 企业版软件之间的相似之处和不同之处,同时还突出了组合使用时的额外灵活性。
NVIDIA A100 启用 MIG(40GB)虚拟 GPU 类型 |
NVIDIA A100 禁用 MIG(40GB)虚拟 GPU 类型 |
|
|---|---|---|
GPU 分区 |
空间(硬件) |
时间(软件) |
分区数 |
7 |
10 |
计算资源 |
专用 |
共享 |
计算实例分区 |
是 |
否 |
地址空间隔离 |
是 |
是 |
容错 |
是(最高质量) |
是 |
低延迟响应 |
是(最高质量) |
是 |
NVLink 支持 |
否 |
是 |
多租户 |
是 |
是 |
GPUDirect RDMA |
是(GPU 实例) |
是 |
异构配置文件 |
是 |
否 |
管理 - 需要超级用户 |
是 |
否 |
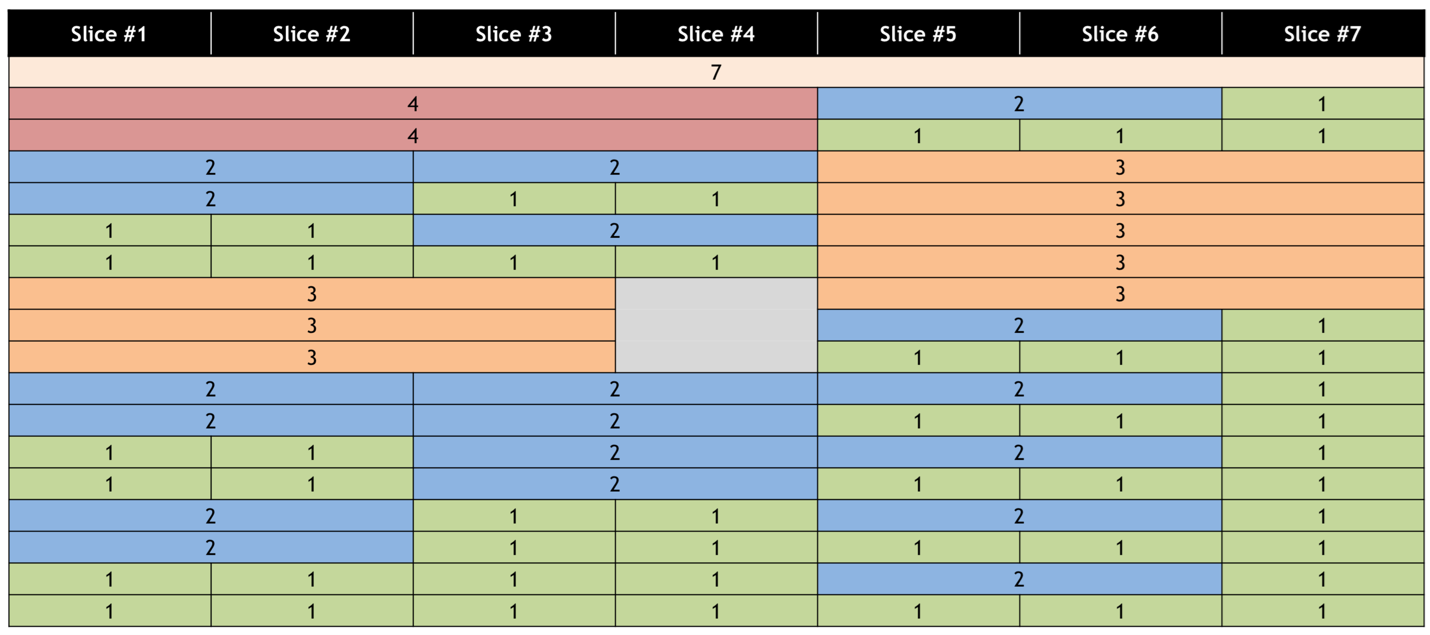
当虚拟机使用 MIG 支持的虚拟 GPU 时,引入 vGPU 的功能之一是能够拥有不同大小(异构)的分区 GPU 实例。下表说明了当 NVIDIA A100 启用 MIG 模式时,18 种可能的尺寸组合。
注意
当使用 vCS 并且启用 MIG 模式时,NVIDIA AI 企业版软件将 MIG 支持的 vGPU 资源识别为 1:1 或完整 GPU 配置文件。
NVIDIA AI 企业版软件仅支持带有 Linux 客户操作系统的 MIG。为了支持带有 NVIDIA vGPU 的 GPU 实例,必须配置 GPU 并启用 MIG 模式。有关更多信息,请参见虚拟 GPU 软件文档中配置用于 MIG 支持的 vGPU 的 GPU。有关 MIG 功能的一般信息,请参见NVIDIA 多实例 GPU 用户指南。
术语#
GPU 上下文#
GPU 上下文类似于 CPU 进程。它封装了在 GPU 上执行操作所需的所有资源,包括不同的地址空间、内存分配等。此外,GPU 上下文还具有以下属性
故障隔离
单独调度
不同的地址空间
GPU 引擎#
GPU 引擎在 GPU 上执行工作。最常用的引擎是计算/图形引擎,它执行计算指令。其他引擎包括复制引擎 (CE)(负责执行 DMA)、NVDEC(用于视频解码)等。每个引擎都可以独立调度,并且可以为不同的 GPU 上下文执行工作。
GPU 内存切片#
GPU 内存切片是 A100 GPU 内存的最小部分,包括相应的内存控制器和缓存。GPU 内存切片大约是 GPU 总内存资源(包括容量和带宽)的八分之一。
GPU SM 切片#
GPU SM 切片是 A100 GPU 上 SM 的最小部分。当配置为 MIG 模式时,GPU SM 切片大约是 GPU 中可用 SM 总数的七分之一。
GPU 切片#
GPU 切片是 A100 GPU 的最小部分,它结合了单个 GPU 内存切片和单个 GPU SM 切片。
GPU 实例#
GPU 实例 (GI) 是 GPU 切片和 GPU 引擎(DMA、NVDEC 等)的组合。GPU 实例中的任何内容始终共享所有 GPU 内存切片和其他 GPU 引擎,但其 SM 切片可以进一步细分为计算实例 (CI)。GPU 实例提供内存 QoS。每个 GPU 切片都包含专用的 GPU 内存资源,这些资源限制了可用容量和带宽,并提供内存 QoS。因此,每个 GPU 内存切片获得 GPU 总内存资源的八分之一,每个 GPU SM 切片获得 SM 总数的七分之一。
计算实例#
GPU 实例可以细分为多个计算实例。计算实例 (CI) 包含父 GPU 实例的 SM 切片子集和其他 GPU 引擎(DMA、NVDEC 等)。CI 共享内存和引擎。
可以使用 GI(GPU 实例)创建的切片数量不是任意的。NVIDIA 驱动程序 API 提供了多个“GPU 实例配置文件”,用户可以通过指定其中一个配置文件来创建 GI。
只要有足够的切片来满足请求,就可以在给定的 GPU 上通过混合和匹配这些配置文件来创建多个 GI。
配置文件名称 |
内存比例 |
SM 比例 |
硬件单元 |
可用实例数量 |
|---|---|---|---|---|
MIG 1g.5gb |
1/8 |
1/7 |
0 个 NVDEC |
7 |
MIG 2g.10gb |
2/8 |
2/7 |
1 个 NVDEC |
3 |
MIG 3g.20gb |
4/8 |
3/7 |
2 个 NVDEC |
2 |
MIG 4g.20gb |
4/8 |
4/7 |
2 个 NVDEC |
1 |
MIG 7g.40gb |
完整 |
7/7 |
5 个 NVDEC |
1 |
MIG 前提条件#
以下前提条件适用于在 MIG 模式下使用 A100 时。
仅在 NVIDIA A100 产品和使用 A100 的相关系统上受支持(请参见NVIDIA 认证系统。)
需要 CUDA 11 和 NVIDIA AI 企业版驱动程序 450.73 或更高版本
需要 CUDA 11 支持的 Linux 操作系统发行版
VMware vSphere 7 Update 2
SR-IOV 在 BIOS 设置中启用
可以使用 NVIDIA 管理库 (NVML) API 或其命令行界面 nvidia-smi 以编程方式管理 MIG。请注意,以下示例中的某些 nvidia-smi 输出可能会被裁剪,以突出显示与简洁性相关的部分。有关 MIG 命令的更多信息,请参见nvidia-smi 主页或输入命令。
nvidia-smi mig --help
启用 MIG 模式#
为了支持带有 NVIDIA vGPU 的 GPU 实例,必须配置 GPU 并启用 MIG 模式。此外,必须在物理 GPU 上创建和配置 GPU 实例,然后再进行 MIG 启用和虚拟机配置。或者,您可以在 GPU 实例中创建计算实例。如果您未在 GPU 实例中创建计算实例,则可以稍后从客户虚拟机为单个 vGPU 添加计算实例。
确保满足以下前提条件
NVIDIA AI 企业版主机软件已安装在虚拟机监控程序主机上。
满足常规前提条件和 MIG 前提条件。
您在虚拟机监控程序主机上具有 root 用户权限。
GPU 未在 vCenter 中配置为直通。
GPU 未被任何其他进程使用,例如 CUDA 应用程序、监控应用程序或
nvidia-smi命令。
以虚拟机监控程序主机上的 root 用户身份打开命令 shell。您可以使用安全外壳 (SSH) 来完成此操作。
使用
nvidia-smi命令确定是否启用了 MIG 模式。默认情况下,MIG 模式已禁用。此示例显示 GPU 0 上禁用了 MIG 模式。1nvidia-smi -i 0 2+-----------------------------------------------------------------------------+ 3| NVIDIA-SMI 470.63 Driver Version: 470.63 CUDA Version: N/A | 4|-------------------------------+----------------------+----------------------+ 5| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | 6| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | 7| | | MIG M. | 8|===============================+======================+======================| 9| 0 A100-SXM4-40GB Off | 00000000:36:00.0 Off | 0 | 10| N/A 29C P0 62W / 400W | 0MiB / 40537MiB | 6% Default | 11| | | Disabled | 12+-------------------------------+----------------------+----------------------+
如果禁用了 MIG 模式,请启用它。
nvidia-smi -i [gpu-ids] -mig 1
gpu-ids
逗号分隔的 GPU 索引、PCI 总线 ID 或 UUID 列表指定了您要启用 MIG 模式的 GPU。如果省略 gpu-ids,则会在系统中的所有 GPU 上启用 MIG 模式。
此示例在 GPU 0 上启用 MIG 模式。
1nvidia-smi -i 0 -mig 1 2Enabled MIG Mode for GPU 00000000:36:00.0 3All done.
注意
如果另一个进程正在使用 GPU,则
nvidia-smi将失败并显示警告消息,指示 GPU 的 MIG 模式处于待启用状态。在这种情况下,请停止所有正在使用 GPU 的进程,然后重试该命令。接下来,重置 GPU。
nvidia-smi -i 0 –gpu-reset
查询您在其上启用了 MIG 模式的 GPU,以确认已启用 MIG 模式。
此示例以逗号分隔值 (CSV) 格式查询 GPU 0 的 PCI 总线 ID 和 MIG 模式。
1nvidia-smi -i 0 --query-gpu=pci.bus_id,mig.mode.current --format=csv 2pci.bus_id, mig.mode.current 300000000:36:00.0, Enabled
注意
当分配虚拟机时,VMware vSphere 会自动创建 GPU 实例。
使用 GPU 实例进行虚拟机配置#
要启用 vGPU 支持并为您的虚拟机附加 GPU 实例,您必须编辑虚拟机设置。
确认虚拟机已关闭电源。
在清单窗口中单击虚拟机。右键单击虚拟机,然后选择编辑设置
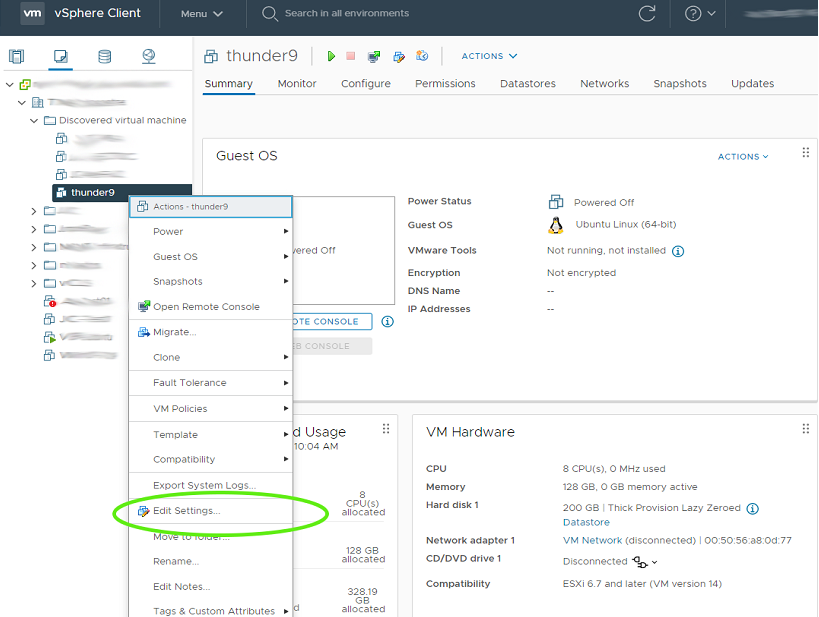
单击添加新设备*按钮。导航显示设备类型下拉菜单。选择PCI 设备
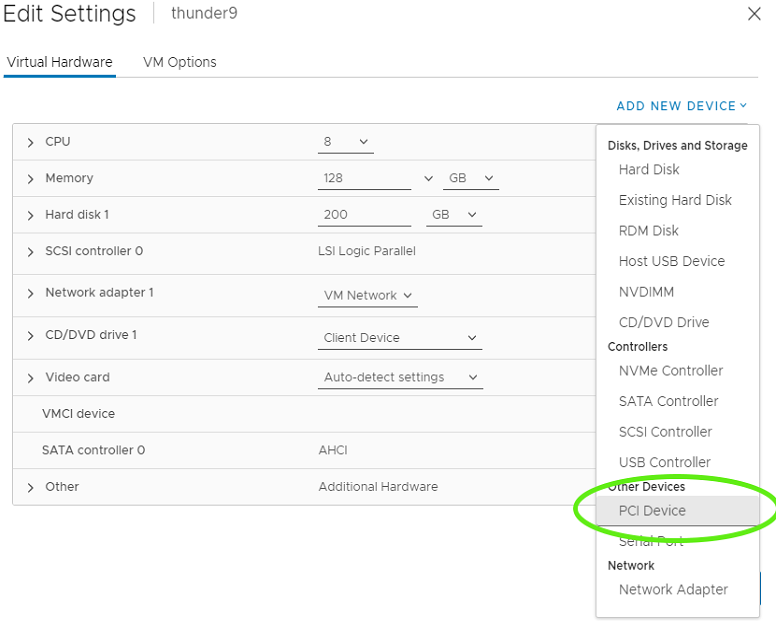
选择PCI 设备以继续。新的 PCI 设备显示已添加 NVIDIA vGPU 设备。
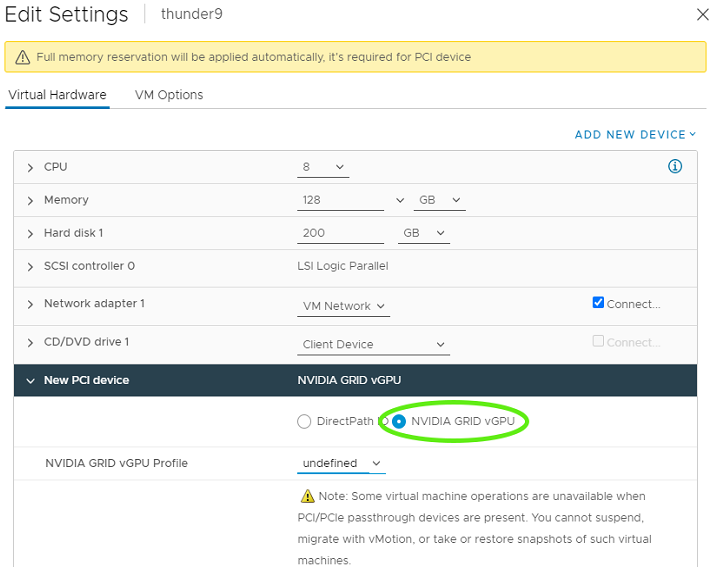
展开新 PCI 设备,单击 GPU 配置文件下拉菜单,然后选择适当的配置。
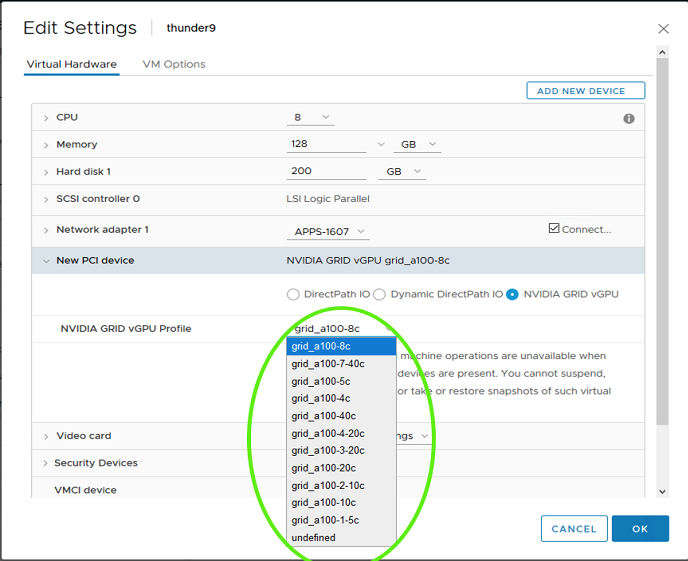
注意
标准计算配置文件由三个组件组成:grid_a100-40c。MIG 特定的 vGPU 配置文件具有一个额外的数字,该数字映射到
nvidia-smi mig -lgip: **grid_a100-4-20c**的输出中显示的分数部分。单击确定以完成配置。
使用 MIG GPU 实例启动虚拟机。
重要提示
nvidia-smi不支持显示 MIG 实例的 GPU 利用率。但是,vGPU 分区支持此功能。
使用 GPU 实例进行虚拟机配置#
您可以从客户虚拟机内部为单个 vGPU 添加计算实例。如果要替换在为 MIG 支持的 vGPU 配置 GPU 时创建的计算实例,则可以在从客户虚拟机内部添加计算实例之前将其删除。确保满足以下前提条件
您在客户虚拟机上具有 root 用户权限。
GPU 实例未被任何其他进程使用,例如 CUDA 应用程序、监控应用程序或
nvidia-smi命令。
列出可以在客户虚拟机命令 shell 中创建的计算实例
nvidia-smi mig -lcip
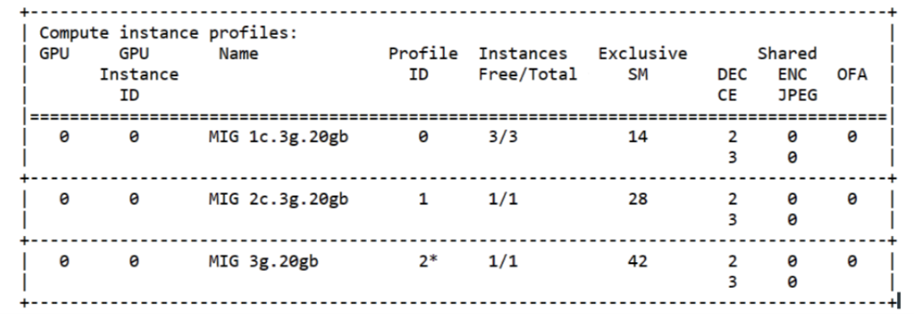
在每个 GPU 实例中创建您需要的计算实例。
nvidia-smi mig -cci -gi <gpu-instance-ids>
其中
<gpu-instance-ids>是逗号分隔的 GPU 实例 ID 列表,用于指定要在其中创建计算实例的 GPU 实例。例如,要创建配置文件 #2 (3g.20gb) 的计算实例。nvidia-smi mig -cci 2 -gi 0
如果要创建多个计算实例并并行运行应用程序,请参见用户指南,了解更复杂的场景。
重要提示
为避免客户虚拟机和虚拟机监控程序主机之间状态不一致,请勿在 GPU 实例上从虚拟机监控程序创建计算实例,而是在其上运行活动的客户虚拟机。相反,请从客户虚拟机内部创建计算实例,如 NVIDIA vGPU 软件:修改 MIG 支持的 vGPU 配置中所述。
可选:更新 MIG 启用的 vGPU 的容器#
要在 MIG 启用的 vGPU 上运行容器,您需要更新 nvidia-docker2 软件包。按照此处的说明进行操作。
1curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
2 && distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
3 && curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list \
4 && sudo apt-get update
1sudo apt-get install -y nvidia-docker2 \
2 && sudo systemctl restart docker
要测试 VM 上 NVIDIA 容器工具包的安装,请执行以下命令
sudo docker run –runtime=nvidia -e NVIDIA_VISIBLE_DEVICES=MIG-GPU-786035d5-1e85-11b2-9fec-ac9c9a792daf/0/0 nvidia/cuda nvidia-smi
注意
NVIDIA_VISIBLE_DEVICES 支持两种格式来指定 MIG 设备
MIG-<GPU-UUID>/<GPU 实例 ID>/<计算 实例 ID>GPUDeviceIndex>:<MIGDeviceIndex>
销毁 GPU 实例#
当虚拟机未分配给 GPU 实例时,该实例应自动销毁;但是,可能需要使用 nvidia-smi 手动销毁 GPU 实例。
以下示例显示了如何在之前的示例中创建的 CI 和 GI 可以被销毁。
1sudo nvidia-smi mig -dci -ci 0,1,2 -gi 1
2Successfully destroyed compute instance ID 0 from GPU 0 GPU instance ID 1
3Successfully destroyed compute instance ID 1 from GPU 0 GPU instance ID 1
4Successfully destroyed compute instance ID 2 from GPU 0 GPU instance ID 1
可以验证 MIG 设备现在已被拆除。
1nvidia-smi
2+-----------------------------------------------------------------------------+
3| MIG devices: |
4+------------------+----------------------+-----------+-----------------------+
5| GPU GI CI MIG | Memory-Usage | Vol| Shared |
6| ID ID Dev | | SM Unc| CE ENC DEC OFA JPG|
7| | | ECC| |
8|==================+======================+===========+=======================|
9| No MIG devices found |
10+-----------------------------------------------------------------------------+
11
12+-----------------------------------------------------------------------------+
13| Processes: |
14| GPU GI CI PID Type Process name GPU Memory |
15| ID ID Usage |
16|=============================================================================|
17| No running processes found |
18+-----------------------------------------------------------------------------+
NVIDIA AI 企业版的 GPU 聚合#
NVIDIA AI 企业版支持 GPU 聚合,其中虚拟机可以访问多个 GPU,这对于特定的计算密集型工作负载是必需的。NVIDIA AI 企业版支持对等计算。以下部分描述了这两种技术以及如何在 VMWare ESXi 中部署 GPU 聚合。
对等 NVIDIA NVLINK#
NVIDIA AI 企业版支持对等计算,其中多个 GPU 通过 NVIDIA NVLink 连接。与传统的基于 PCIe 的解决方案相比,这实现了一种高速、直接的 GPU 到 GPU 互连,可为多 GPU 系统配置提供更高的带宽。下图说明了对等 NVLINK
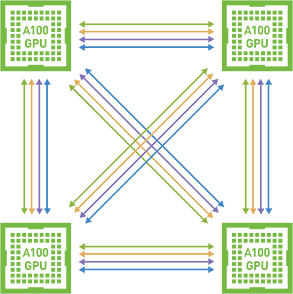
这种对等通信允许从 CUDA 内核内部访问 GPU 之间的设备内存,并消除了系统内存分配和复制开销。它还提供了更方便的多 GPU 编程。
仅 Linux 支持基于 NVLink 的对等 CUDA 传输。当前,vGPU 不支持 NVSwitch。因此,仅支持直接连接。对等通信仅限于单个虚拟机内部,并且不在多个虚拟机之间进行通信。没有 SLI 支持;因此,此支持中不包括图形,仅包括 CUDA。仅在 vGPU、虚拟机监控程序版本和客户操作系统版本的子集上支持基于 NVLink 的对等 CUDA 传输。不支持基于 PCIe 的对等传输。非 MIG 和 C 系列全帧缓冲 (1:1) vGPU 配置文件受 NVLink 支持。有关支持的 GPU 列表,请参阅NVIDIA AI 企业版最新发行说明。
重要提示
对于具有四个以上 GPU 的服务器,多 vGPU 配置将仅支持在推荐的 NUMA 节点上手动配置的 GPU 直通配置。
通过 SSH 连接到 ESXi 主机,例如,使用 Putty。
在命令窗口中键入
nvidia-smi。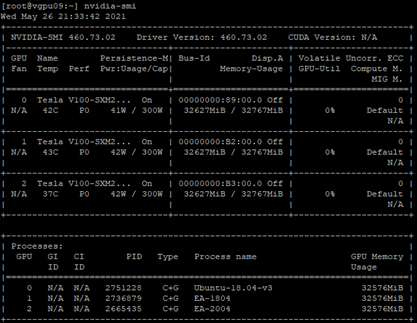
注意
此示例中 V100 显卡的外形尺寸为 SXM2。
通过键入以下命令来检测 GPU 之间的拓扑
nvidia-smi topo -m

注意
GPU0 和 GPU1 通过 NVLINK 连接,GPU1 和 GPU2 以及 GPU0 和 GPU2 也是如此。例如,GPU0 和 GPU1 应分配给单个虚拟机。
使用以下方法从
nvidia-smi获取hexid1[root@vgpu09:~] nvidia-smi 2Wed August 18 19:20:22 2021 3+-----------------------------------------------------------------------------+ 4| NVIDIA-SMI 470.63 Driver Version: 470.63 CUDA Version: N/A | 5|-------------------------------+----------------------+----------------------+ 6| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | 7| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | 8| | | MIG M. | 9|===============================+======================+======================| 10| 0 Tesla V100-SXM2... On | 00000000:89:00.0 Off | 0 | 11| N/A 41C P0 41W / 300W | 32627MiB / 32767MiB | 0% Default | 12| | | N/A | 13+-------------------------------+----------------------+----------------------+ 14| 1 Tesla V100-SXM2... On | 00000000:b2:00.0 Off | 0 | 15| N/A 43C P0 41W / 300W | 32627MiB / 32767MiB | 0% Default | 16| | | N/A | 17+-------------------------------+----------------------+----------------------+ 18| 2 Tesla V100-SXM2... On | 00000000:B3:00.0 Off | 0 | 19| N/A 36C P0 42W / 300W | 32627MiB / 32767MiB | 0% Default | 20| | | N/A | 21+-------------------------------+----------------------+----------------------+ 22+-----------------------------------------------------------------------------+
注意
GPU 0 的 ID 为
00000000:89:00.0GPU 1 的 ID 为
00000000:b2:00.0GPU 2 的 ID 为
00000000:B3:00.0
在虚拟机高级配置中,为 3 个 GPU 添加密钥
1pciPassthru0.cfg.gpu-pci-id = "ssss:bb:dd.f" 2pciPassthru0.cfg.gpu-pci-id = "ssss:bb:dd.f" 3pciPassthru0.cfg.gpu-pci-id = "ssss:bb:dd.f"
注意
NVLINK 仅在非 MIG 模式下受支持。
设备组#
在 3.0 版本中添加。
设备组使 vSphere 8 中使用互补硬件设备的虚拟机更简单。vSphere 8 GA 中支持 NIC 和 GPU 设备。
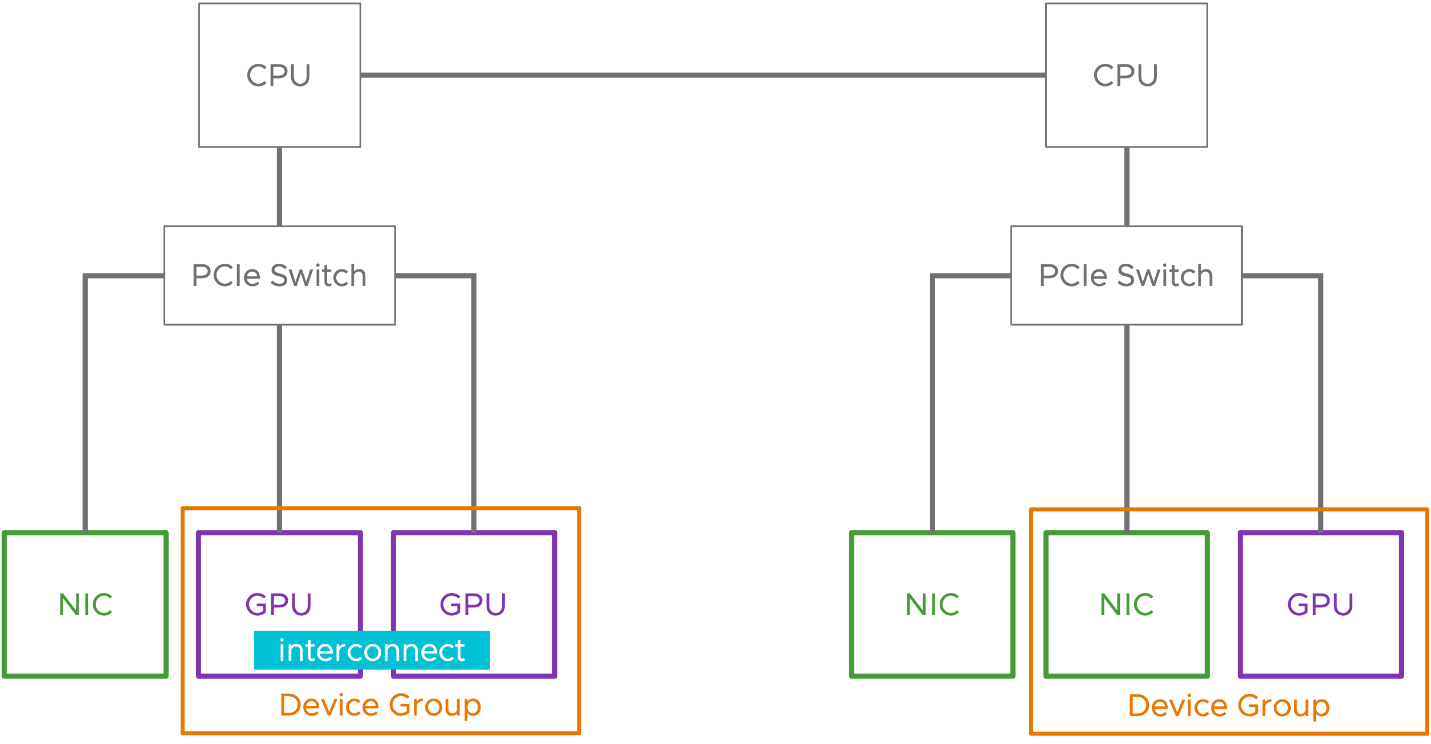
设备组可以由共享公共 PCIe 交换机的两个或多个硬件设备或彼此之间共享直接互连的设备组成。设备组在硬件层发现,并作为表示该组的单个单元呈现给 vSphere。
使用设备组简化硬件消耗#
设备组使用现有的添加新 PCI 设备工作流程添加到虚拟机。vSphere DRS 和 vSphere HA 知道设备组,并将适当地放置虚拟机以满足设备组。
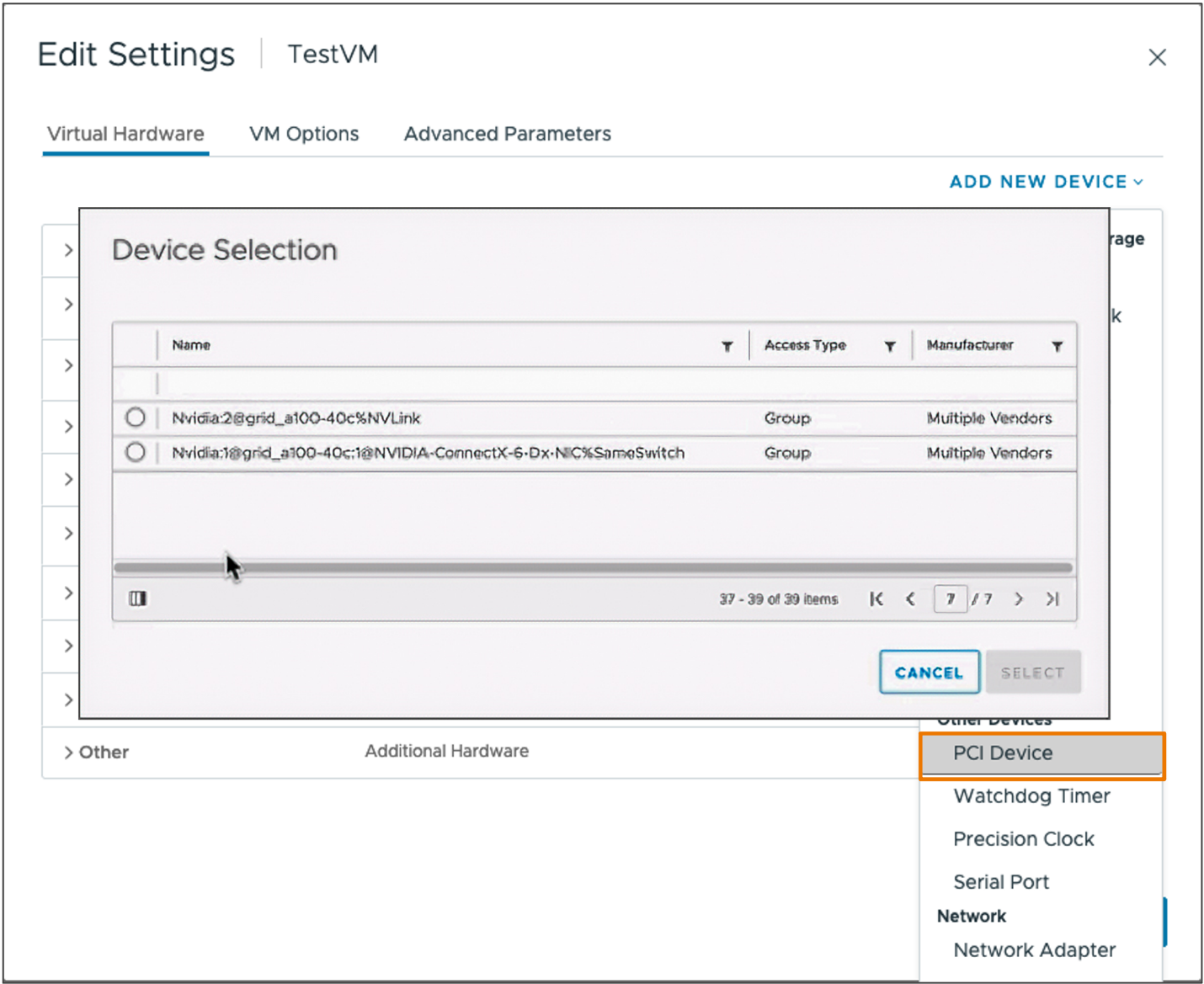
有关设备组的更多信息,请参见vSphere 8 新增功能指南的 AI 和 ML 部分以及vSphere 8 扩展机器学习支持:NVIDIA GPU 和 NIC 的设备组技术杂志博客。
页面退役和 ECC#
NVIDIA AI 企业版支持 ECC 和动态页面退役。此功能将通过退役单元所属的页面来“退役”不良的帧缓冲存储单元。动态页面退役是针对质量下降的单元自动完成的。此功能可以提高原本良好的板卡的使用寿命,因此是在受支持产品上的重要弹性功能,尤其是在 HPC 和企业环境中。页面退役可能仅在启用 ECC 时发生。但是,一旦页面被退役,即使以后禁用 ECC,它也将永久列入黑名单。有关更多信息,请参阅 NVIDIA 开发者专区页面退役文档。
在 NVIDIA AI 企业版上支持的所有 GPU 上都提供了这些页面退役和 ECC 功能。
禁用和启用 ECC 内存#
支持 NVIDIA AI 企业版软件的特定 GPU 支持纠错码 (ECC) 内存。ECC 内存通过检测和处理双位错误来提高数据完整性。但是,并非所有 GPU、vGPU 类型和虚拟机监控程序软件版本都支持带有 NVIDIA vGPU 的 ECC 内存。
在支持带有 NVIDIA vGPU 的 ECC 内存的 GPU 上,C 系列 vGPU 支持 ECC 内存,但 A 系列和 B 系列 vGPU 不支持。在没有 HBM2 内存的物理 GPU 上,vGPU 可用的帧缓冲量会减少。所有类型的 vGPU 都会受到影响,而不仅仅是支持 ECC 内存的 vGPU。
在物理 GPU 上启用 ECC 内存的效果如下
ECC 内存在物理 GPU 上的所有受支持 vGPU 上都作为一项功能公开。
在支持 ECC 内存的虚拟机中,ECC 内存已启用,并可以选择在虚拟机中禁用 ECC。
ECC 内存可以为单个虚拟机启用或禁用。在虚拟机中启用或禁用 ECC 内存不会影响 vGPU 可用的帧缓冲区数量。
此任务取决于您是要更改物理 GPU 还是 vGPU 的 ECC 内存设置。
对于物理 GPU,请从 hypervisor 主机执行此任务。
对于 vGPU,请从分配了 vGPU 的虚拟机执行此任务。
注意
必须在 vGPU 所在的物理 GPU 上启用 ECC 内存。
禁用 ECC 内存#
在开始之前,请确保您的 hypervisor 上安装了 NVIDIA AI Enterprise Host Software。如果您要更改 vGPU 的 ECC 内存设置,请确保已在分配了 vGPU 的虚拟机中安装 NVIDIA AI Enterprise 软件图形驱动程序。如果您还没有可用的虚拟机,请参阅创建您的第一个 NVIDIA AI Enterprise 虚拟机。
使用
nvidia-smi列出所有物理 GPU 或 vGPU 的状态,并检查是否已启用 ECC。1# nvidia-smi -q 2 3==============NVSMI LOG============== 4 5Timestamp : Mon Jul 13 18:36:45 2020 6Driver Version : 450.55 7 8Attached GPUs : 1 9GPU 0000:02:00.0 10 11[...] 12 13 Ecc Mode 14 Current : Enabled 15 Pending : Enabled 16 17[...]
将每个已启用 ECC 的 GPU 的 ECC 状态更改为关闭。
如果您想将主机或虚拟机上分配给虚拟机的所有 GPU 的 ECC 状态更改为关闭,请运行以下命令
# nvidia-smi -e 0如果您想将特定 GPU 或 vGPU 的 ECC 状态更改为关闭,请运行以下命令
# nvidia-smi -i id -e 0
id是nvidia-smi报告的 GPU 或 vGPU 的索引。此示例禁用索引为0000:02:00.0的 GPU 的 ECC。# nvidia-smi -i 0000:02:00.0 -e 0重启主机或重启虚拟机。
确认 GPU 或 vGPU 的 ECC 现在已禁用。
1# nvidia—smi —q 2 3==============NVSMI LOG============== 4 5Timestamp : Mon Jul 13 18:37:53 2020 6Driver Version : 450.55 7 8Attached GPUs : 1 9GPU 0000:02:00.0 10[...] 11 12 Ecc Mode 13 Current : Disabled 14 Pending : Disabled 15 16[...]
启用 ECC 内存#
如果 ECC 内存适合您的工作负载,并且您的 hypervisor 软件和 GPU 支持 ECC 内存,但您的 GPU 或 vGPU 上禁用了 ECC 内存,请启用它。此任务取决于您是要更改物理 GPU 还是 vGPU 的 ECC 内存设置。
对于物理 GPU,请从 hypervisor 主机执行此任务。
对于 vGPU,请从分配了 vGPU 的虚拟机执行此任务。
注意
必须在 vGPU 所在的物理 GPU 上启用 ECC 内存。
在开始之前,请确保您的 hypervisor 上安装了 NVIDIA AI Enterprise Host Software。如果您要更改 vGPU 的 ECC 内存设置,请确保已在分配了 vGPU 的虚拟机中安装 NVIDIA vGPU 软件图形驱动程序。
使用
nvidia-smi列出所有物理 GPU 或 vGPU 的状态,并检查是否已禁用 ECC。1# nvidia-smi -q 2 3==============NVSMI LOG============== 4 5Timestamp : Mon Jul 13 18:36:45 2020 6Driver Version : 450.55 7 8Attached GPUs : 1 9GPU 0000:02:00.0 10 11[...] 12 13 Ecc Mode 14 Current : Disabled 15 Pending : Disabled 16 17[...]
将每个已启用 ECC 的 GPU 或 vGPU 的 ECC 状态更改为开启。
如果您想将主机或虚拟机上分配给虚拟机的所有 GPU 的 ECC 状态更改为开启,请运行以下命令
# nvidia-smi -e 1如果您想将特定 GPU 或 vGPU 的 ECC 状态更改为开启,请运行以下命令
# nvidia-smi -i id -e 1id是nvidia-smi报告的 GPU 或 vGPU 的索引。此示例启用索引为
0000:02:00.0的 GPU 的 ECC。# nvidia-smi -i 0000:02:00.0 -e 1
重启主机或重启虚拟机。
确认 GPU 或 vGPU 的 ECC 现在已启用。
1# nvidia—smi —q 2 3==============NVSMI LOG============== 4 5Timestamp : Mon Jul 13 18:37:53 2020 6Driver Version : 450.55 7 8Attached GPUs : 1 9GPU 0000:02:00.0 10[...] 11 12 Ecc Mode 13 Current : Enabled 14 Pending : Enabled 15 16[...]