设置 NVIDIA vGPU 设备#
为了增强 RHEL 主机上虚拟机 (VM) 的 AI 功能,您可以从物理 GPU 创建多个 vGPU 配置文件,并将这些设备分配给多个访客虚拟机。在特定的 NVIDIA GPU 上,通过 RHEL KVM 虚拟化支持此功能,并且只能将一个中介设备分配给单个访客虚拟机。
注意
NVIDIA AI Enterprise 在 Red Hat Enterprise Linux 与 KVM 上,每个 VM 最多支持 16 个 vGPU
注意
Red Hat Enterprise Linux 访客操作系统支持仅限于使用 Docker 运行容器,而不支持 Kubernetes。依赖于 Kubernetes 的 NVIDIA AI Enterprise 功能(例如,GPU Operator 的使用)在Red Hat Enterprise Linux 上不受支持。
管理 NVIDIA vGPU 设备#
NVIDIA vGPU 技术可以将物理 NVIDIA GPU 设备划分为多个虚拟设备。这些中介设备随后可以作为虚拟 GPU 分配给多个 VM。因此,这些 VM 可以共享单个物理 GPU 的性能。
重要提示
将物理 GPU 分配给 VM(无论是否使用 vGPU 设备),都会使主机无法使用该 GPU。
设置 NVIDIA vGPU 设备#
要设置 NVIDIA vGPU 功能,请为您的 GPU 设备下载 NVIDIA vGPU 驱动程序,创建中介设备,并将它们分配给预期的虚拟机。有关详细说明,请参见下文。
注意
请参考此处以获取使用 RHEL KVM 利用 NVIDIA vGPU 的受支持 GPU 的列表。
如果您不知道您的主机正在使用哪个 GPU,请安装 lshw 软件包并使用 lshw -C display 命令。以下示例显示系统正在使用与 vGPU 兼容的 NVIDIA A100 GPU。
# lshw -C display
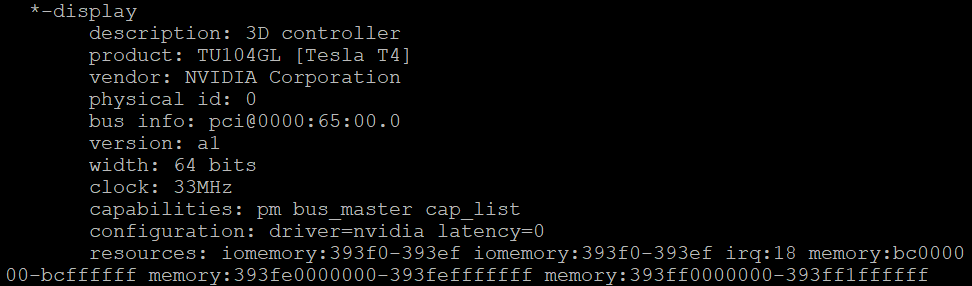
现在我们已经验证了主机上存在 NVIDIA GPU,我们将在 VM 中安装 NVIDIA AI Enterprise Guest 驱动程序,以完全启用 GPU 操作。
NVIDIA 驱动程序#
NVIDIA 驱动程序是安装在操作系统上的软件驱动程序,负责与 NVIDIA GPU 通信。
NVIDIA AI Enterprise 驱动程序可以通过从 NVIDIA Enterprise Licensing Portal、NVIDIA Download Drivers 网页下载,或从 NGC Catalog 拉取来获得。请查看NVIDIA AI Enterprise 快速入门指南,了解有关许可授权证书的更多详细信息。
使用 CLS 安装 NVIDIA 驱动程序#
本节将介绍为 CLS 用户正确安装、配置和许可 NVIDIA 驱动程序所需的步骤。
现在您已经安装了 Linux,NVIDIA AI Enterprise Driver 将完全启用 GPU 操作。在继续 NVIDIA 驱动程序安装之前,请确认 Nouveau 已禁用。禁用 Nouveau 的说明位于RHEL 部分。
使用 NGC 下载 NVIDIA AI Enterprise 软件驱动程序#
重要提示
在开始之前,您需要生成或使用现有的API 密钥。
从浏览器中,转到 https://ngc.nvidia.com/signin/email,然后输入您的电子邮件和密码。
在右上角,单击您的用户帐户图标,然后选择设置。
单击获取 API 密钥以打开设置 > API 密钥页面。
注意
API 密钥是用于验证您对 NGC 容器注册表的访问权限的机制。
单击生成 API 密钥以生成您的 API 密钥。
注意
将出现警告消息,告知您如果创建新密钥,旧的 API 密钥将失效。
单击确认以生成密钥。
您的 API 密钥将出现。
重要提示
您只需要生成一次 API 密钥。NGC 不会保存您的密钥,因此请将其存储在安全的地方。(您可以通过单击 API 密钥右侧的复制图标将 API 密钥复制到剪贴板。)如果您丢失了 API 密钥,您可以从 NGC 网站生成新的密钥。当您生成新的 API 密钥时,旧的密钥将失效。
运行以下命令以安装 AMD64 的 NGC CLI
AMD64 Linux 安装:Linux 的 NGC CLI 二进制文件在 Ubuntu 16.04 及更高版本发行版上受支持。
下载、解压缩并从命令行安装,方法是移动到您具有执行权限的目录,然后运行以下命令
wget --content-disposition https://ngc.nvidia.com/downloads/ngccli_linux.zip && unzip ngccli_linux.zip && chmod u+x ngc-cli/ngc
注意
Windows NGC CLI、Arm64 MacOs 或 Intel MacOs 的 NGC CLI 安装程序可以在此处找到
检查二进制文件的 MD5 哈希值,以确保文件在下载过程中未损坏。
$ md5sum -c ngc.md5
将当前目录添加到路径。
$ echo "export PATH=\"\$PATH:$(pwd)\"" >> ~/.bash_profile && source ~/.bash_profile
您必须配置 NGC CLI 以供您使用,以便您可以运行命令。输入以下命令,并在提示时输入您的 API 密钥。
1$ ngc config set 2 3Enter API key [no-apikey]. Choices: [<VALID_APIKEY>, 'no-apikey']: 4 5Enter CLI output format type [ascii]. Choices: [ascii, csv, json]: ascii 6 7Enter org [no-org]. Choices: ['no-org']: 8 9Enter team [no-team]. Choices: ['no-team']: 10 11Enter ace [no-ace]. Choices: ['no-ace']: 12 13Successfully saved NGC configuration to /home/$username/.ngc/config
下载 NVIDIA AI Enterprise 软件驱动程序。
使用 .run 文件和 RHEL 安装 NVIDIA 驱动程序#
重要提示
在开始驱动程序安装之前,需要禁用安全启动,如安装 Red Hat Enterprise Linux 8.4 部分所示。
使用以下命令,通过 subscription-manager 将机器注册到 RHEL。
subscription-manager register满足 EPEL 对 DKMS 的外部依赖性。
dnf install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm dnf install dkms
注意
有关更多信息,请参阅EPEL 入门文档。
对于 RHEL 8,请确保系统具有来自 Red Hat 存储库的正确 Linux 内核源代码。
dnf install -y kernel-devel-$(uname -r) kernel-headers-$(uname -r)
注意
NVIDIA 驱动程序要求在驱动程序安装时以及每次重建驱动程序时,都必须安装正在运行的内核版本的内核头文件和开发包。例如,如果您的系统正在运行内核版本 4.4.0,则还必须安装 4.4.0 内核头文件和开发包。
安装 NVIDIA 驱动程序的其他依赖项。
1dnf install elfutils-libelf-devel.x86_64 2dnf install -y tar bzip2 make automake gcc gcc-c++ pciutils libglvnd-devel
更新正在运行的内核
dnf install -y kernel kernel-core kernel-modules
更新后,确认系统具有来自 Red Hat 存储库的正确 Linux 内核源代码。
dnf install -y kernel-devel-$(uname -r) kernel-headers-$(uname -r)
下载 NVIDIA AI Enterprise 软件驱动程序。
ngc registry resource download-version "nvidia/vgpu/vgpu-guest-driver-x_x:xxx.xx.xx"
注意
其中
x_x:xxx.xx.xx是来自 NGC Catalog 的当前驱动程序版本。导航到包含 NVIDIA Driver .run 文件的目录。然后,使用 chmod 命令将可执行权限添加到 NVIDIA Driver 文件。
1sudo chmod +x NVIDIA-Linux-x86_64-xxx.xx.xx-grid.run
注意
其中
xxx.xx.xx是来自 NGC Catalog 的当前驱动程序版本。从控制台 shell 中,运行驱动程序安装程序并接受默认值。
sudo sh ./NVIDIA-Linux-x86_64-xxx.xx.xx-grid.run
注意
其中
xxx.xx.xx是来自 NGC Catalog 的当前驱动程序版本。注意
接受任何警告并忽略 CC 版本检查
重启系统。
sudo reboot系统重启后,确认您可以从 nvidia-smi 的输出中看到您的 NVIDIA vGPU 设备。
nvidia-smi
安装 NVIDIA vGPU 计算驱动程序后,您可以许可您正在使用的任何 NVIDIA AI Enterprise Software 许可产品。
创建 NVIDIA vGPU 设备#
完成后,检查内核是否已加载 nvidia_vgpu_vfio 模块,以及 nvidia-vgpu-mgr.service 服务是否正在运行。
# lsmod | grep nvidia_vgpu_vfio
1nvidia_vgpu_vfio 45011 0
2nvidia 14333621 10 nvidia_vgpu_vfio
3mdev 20414 2 vfio_mdev,nvidia_vgpu_vfio
4vfio 32695 3 vfio_mdev,nvidia_vgpu_vfio,vfio_iommu_type1
# systemctl status nvidia-vgpu-mgr.service
1nvidia-vgpu-mgr.service - NVIDIA vGPU Manager Daemon
2Loaded: loaded (/usr/lib/systemd/system/nvidia-vgpu-mgr.service; enabled; vendor preset: disabled)
3Active: active (running) since Fri 2018-03-16 10:17:36 CET; 5h 8min ago
4Main PID: 1553 (nvidia-vgpu-mgr)
5[...]
如果基于 NVIDIA Ampere GPU 设备创建 vGPU,请确保为物理 GPU 启用虚拟功能。有关说明,请参阅在 Linux 上使用 KVM Hypervisor 创建支持 SR-IOV 的 NVIDIA vGPU。
生成设备 UUID。
# uuidgen
示例结果。
30820a6f-b1a5-4503-91ca-0c10ba58692a
准备一个 XML 文件,其中包含中介设备的配置,该配置基于检测到的 GPU 硬件。例如,以下配置在 NVIDIA T4 卡上配置 nvidia-321 vGPU 类型的介导设备,该卡在 0000:65:00.0 PCI 总线上运行,并使用上一步中生成的 UUID。
1<device>
2 <parent>pci_0000_65_00_0</parent>
3 <capability type="mdev">
4 <type id="nvidia-321"/>
5 <uuid>d7462e1e-eda8-4f59-b760-6cecd9ec3671</uuid>
6 </capability>
7</device>
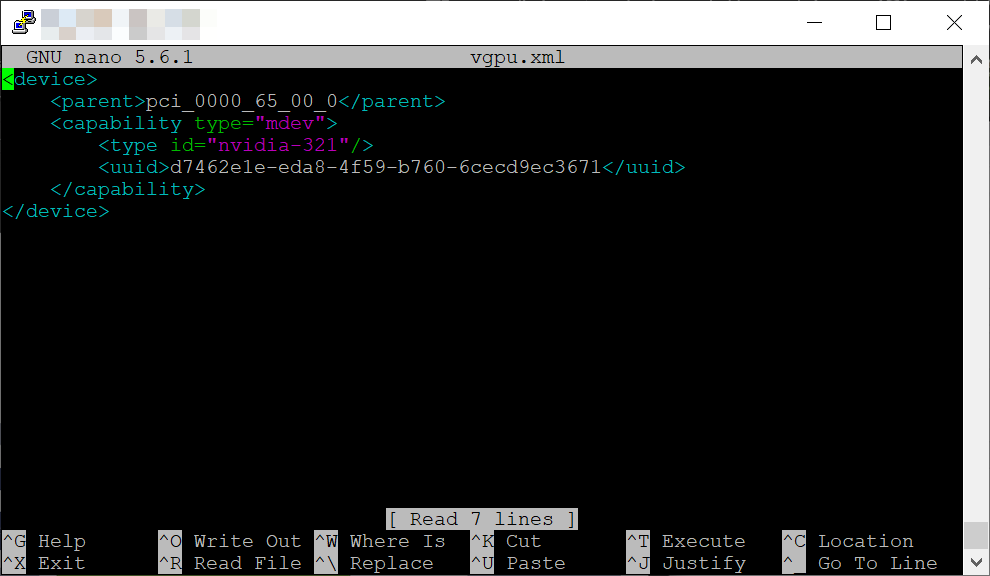
要查找您的 vGPU 配置文件名称和描述,请导航到 mdev_supported_types 并列出描述和名称。下面显示了一个使用 NVIDIA T4 的示例,配置文件名称为 nvidia-321,它对应于 T4-16C NVIDIA vGPU 配置文件。
cd /sys/bus/pci/devices/0000:65:00.0/mdev_supported_types/nvidia-321

注意
有关如何查找各种 NVIDIA vGPU 配置文件的正确配置文件名称的更多信息,请参考此处。
根据您准备的 XML 文件定义 vGPU 中介设备。例如
# virsh nodedev-define vgpu.xml
提示
验证中介设备是否列为非活动状态。
# virsh nodedev-list --cap mdev --inactive
mdev_30820a6f_b1a5_4503_91ca_0c10ba58692a_0000_01_00_0
启动您创建的 vGPU 中介设备。
# virsh nodedev-start mdev_30820a6f_b1a5_4503_91ca_0c10ba58692a_0000_01_00_0
Device mdev_30820a6f_b1a5_4503_91ca_0c10ba58692a_0000_01_00_0 started
提示
确保中介设备列为活动状态。
# virsh nodedev-list --cap mdev
mdev_30820a6f_b1a5_4503_91ca_0c10ba58692a_0000_01_00_0
设置 vGPU 设备在主机重启后自动启动。
# virsh nodedev-autostart mdev_30820a6f_b1a5_4503_91ca_0c10ba58692a_0000_01_00_0
Device mdev_d196754e_d8ed_4f43_bf22_684ed698b08b_0000_9b_00_0 marked as autostarted
将中介设备附加到您想要共享 vGPU 资源的 VM。为此,请将以下行以及先前生成的 UUID 添加到 VM 的 XML 配置中的 <devices/> 部分。
首先导航到 VM 的 XML 配置所在的位置,路径为
cd /etc/libvirt/qemu/
然后使用 nano 编辑 XML 配置,并查找 <devices/> 部分,将以下内容添加到 VM 的 XML 配置中。
1<hostdev mode='subsystem' type='mdev' managed='no' model='vfio-pci' display='off'>
2 <source>
3 <address uuid='d7462e1e-eda8-4f59-b760-6cecd9ec3671'/>
4 </source>
5</hostdev>
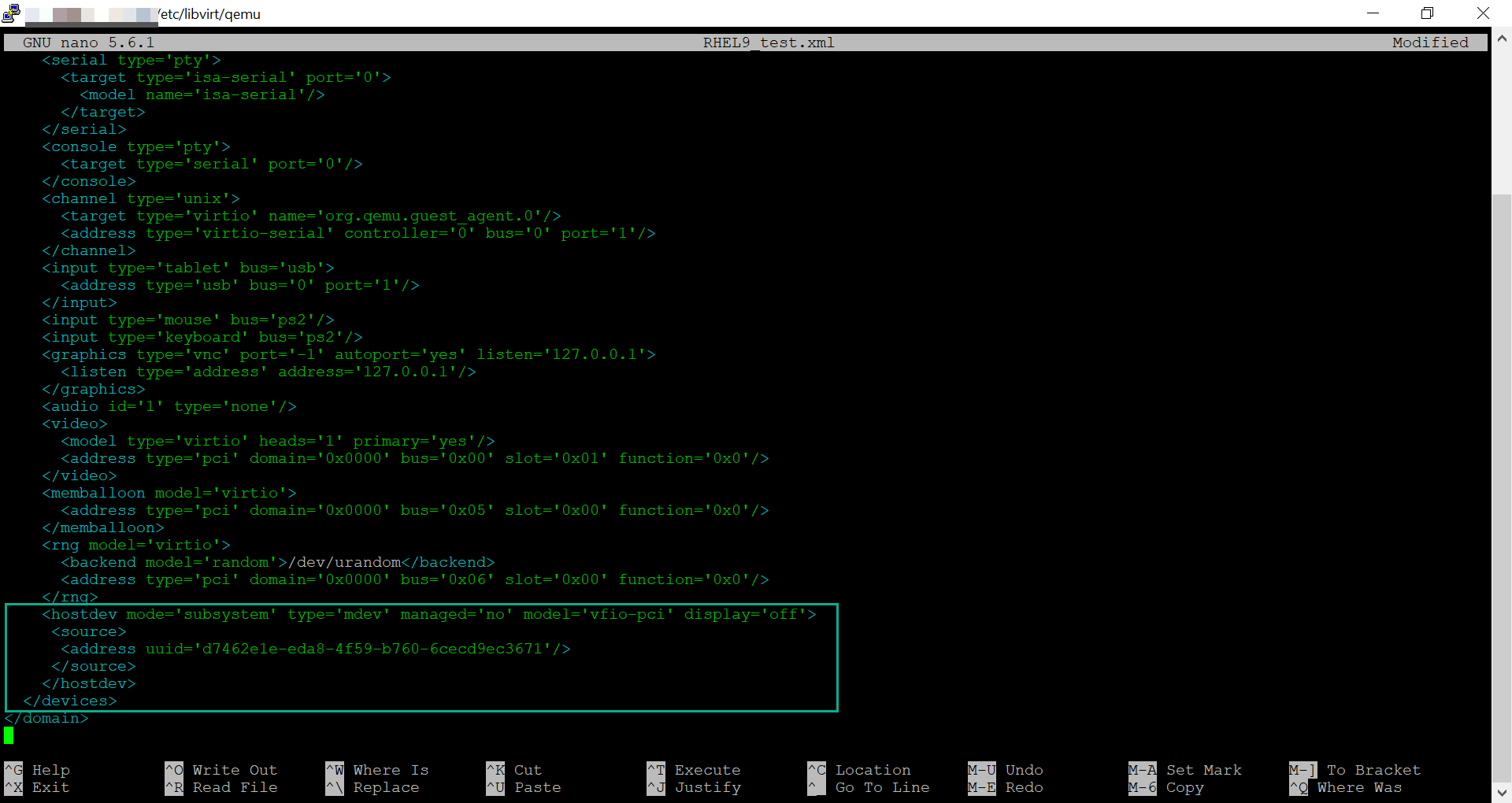
重要提示
每个 UUID 一次只能分配给一个 VM。此外,如果 VM 没有 QEMU 视频设备(例如 virtio-vga),则还在 <hostdev> 行上添加 ramfb='on' 参数。
现在我们将验证创建的 vGPU 的功能,并确保它被列为活动状态和持久状态。
# virsh nodedev-info mdev_30820a6f_b1a5_4503_91ca_0c10ba58692a_0000_01_00_0
1Name: virsh nodedev-autostart mdev_30820a6f_b1a5_4503_91ca_0c10ba58692a_0000_01_00_0
2Parent: pci_0000_01_00_0
3Active: yes
4Persistent: yes
5Autostart: yes
启动 VM 并验证访客操作系统是否检测到中介设备为 NVIDIA GPU。例如
# lspci -d 10de: -k

安装 NVIDIA vGPU 计算驱动程序后,您可以许可您正在使用的任何 NVIDIA AI Enterprise Software 许可产品。
注意
有关如何在 KVM 虚拟机管理程序中管理 NVIDIA vGPU 的更多信息,请参阅NVIDIA vGPU 软件文档,以及 man virsh 命令,了解使用 virsh 管理访客虚拟机。
提示
有关如何更改时间分片 vGPU 的 vGPU 调度策略的说明,请参阅NVIDIA vGPU 发行说明。
许可 VM#
要使用 NVIDIA vGPU 软件许可的产品,分配了物理或虚拟 GPU 的每个客户端系统都必须能够从 NVIDIA 许可系统获取许可证。客户端系统可以是配置了 NVIDIA vGPU 的 VM、配置为 GPU 直通的 VM,或是在裸机部署中分配了物理 GPU 的物理主机。