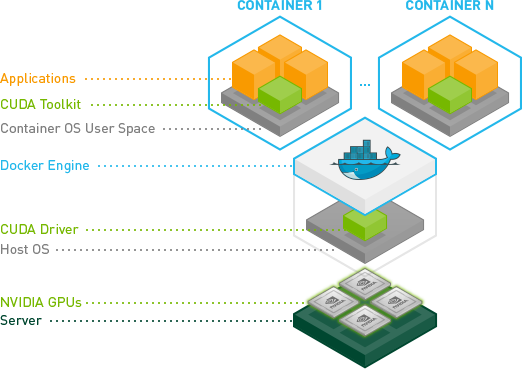
计算工作流#
多 GPU 深度学习工作流#
在虚拟化环境中,部署虚拟 GPU (vGPU) 进行深度学习训练可以使用四种不同的方法进行架构设计
单个虚拟机分配完整或部分分区的 vGPU
单个虚拟机使用多个 NVIDIA NVLink vGPU 设备
多节点 (虚拟机)
许多数据科学家都在寻求扩展计算资源,以减少完成神经网络训练和实时产生结果所需的时间。采用多 GPU 方法使科学家们更接近于取得突破,因为他们可以更快速地试验不同的神经网络和算法。随着科学家们训练越来越多的模型,模型的大小和数据消耗可能会显著增长。
模型可能足够小,可以在服务器内的一个或多个 GPU 上运行,但随着数据集的增长,训练时间也会增长。这就是多节点分布式训练非常适合许多组织的地方。目标是使用大型数据集构建模型,该模型理解数据背后的模式和关系,而不仅仅是数据本身。这需要在整个训练过程中在多节点之间交换数据,而带有 ATS 的 GPUDirect RDMA 提供节点之间的高性能网络连接。为了说明本指南编写的多节点方法,至少需要两个或更多虚拟机。此架构用于演示目的,每个虚拟机都分配了一个完整的 GPU。建议每个组织评估自身需求,并选择正确的架构方法来执行深度学习工作流。以下章节将更详细地描述四种不同的方法,以帮助进行架构选择
单虚拟机 – 完整或部分分区 vGPU#
GPU 分区特别适用于那些不能完全饱和 GPU 的计算或内存容量的工作负载。一些 AI GPU 工作负载不需要完整的 GPU。例如,如果您正在进行演示、构建 POC 代码或测试较小的模型,则不需要 NVIDIA A100 Tensor Core GPU 提供的 40 GB GPU 内存。如果没有 GPU 分区,执行此类工作的用户将分配到整个 GPU,无论他们是否正在使用它。这种用例提高了 GPU 利用率,适用于那些未充分利用 GPU 的中小型工作负载。例如,深度学习训练和推理工作流,它们使用较小的数据集。GPU 分区提供了一种尝试不同超参数的有效方法,但高度依赖于数据/模型的大小,用户可能需要减小批次大小。使用两种不同的 NVIDIA GPU 技术,GPU 使用 NVIDIA vGPU 软件时间分区或多实例 GPU (MIG) 空间分区进行分区。请参阅 GPU 分区技术简报 以了解差异。有关如何部署 MIG 分区的更多信息,请参阅 NVIDIA AI Enterprise 部署指南。
注意
确保虚拟机已配置为使用正确的 NUMA 亲缘性。
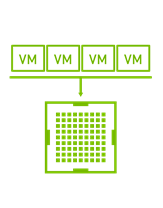
单虚拟机使用多个 NVIDIA NVLink vGPU 设备#
NVIDIA AI Enterprise 支持对等计算,其中多个 GPU 通过 NVIDIA NVLink 连接。这实现了一种高速、直接的 GPU 到 GPU 互连,与传统的基于 PCIe 的解决方案相比,为多 GPU 系统配置提供更高的带宽。下图说明了对等 NVLink。
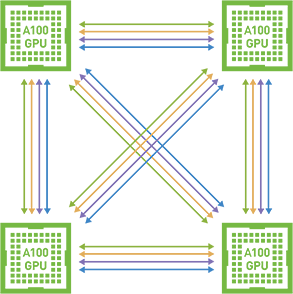
仅 Linux 支持通过 NVLink 的对等 CUDA 传输。对等通信仅限于单个虚拟机内,不进行虚拟机之间的通信。不支持 SLI;因此,此支持不包括图形,仅支持 CUDA。通过 NVLink 的对等 CUDA 传输仅在部分 vGPU、Hypervisor 版本和 Guest OS 版本上受支持。不支持通过 PCIe 的对等通信。NVLink 支持非 MIG 和 C 系列全帧缓冲区 (1:1) vGPU 配置文件。有关支持的 GPU 列表,请参阅 vGPU 最新版本说明。
重要提示
对于具有四个以上 GPU 的服务器,多 vGPU 配置将仅支持在推荐的 NUMA 节点上手动配置的 GPU 直通配置。
多节点 (虚拟机)#
跨多个 GPU 扩展可以缩短训练时间;但是,训练库需要支持 GPU 间通信,而这些通信可能会产生开销。通常,用户需要修改训练代码以促进 GPU 间通信。Horovod 是一个开源库,支持开箱即用的多节点训练,并包含在 TensorFlow 的 NVIDIA AI Enterprise 容器镜像中。Horovod 使用高级算法,可以利用高性能网络的特性,例如带有 ATS 的 RDMA。
通过本指南,您将熟悉配置带有 ATS 的 RDMA 以及使用 2 个虚拟机执行高性能多节点训练。通过使用本指南中概述的步骤,企业可以使用 Horovod 等工具扩展到所需的任意数量的虚拟机。
注意
Horovod 既支持多 GPU 也支持多节点;因此,可以使用相同的代码进行扩展,只需对批次大小进行微调。
下图说明了使用的多节点架构。服务器安装了 VMware vSphere 7.0 Update 2,并托管了 2 个虚拟机。服务器有两个 A100 GPU。因此,每个虚拟机都分配了一个完整的 A100-40C vGPU 配置文件。
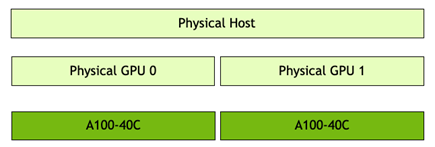
注意
在版本 2.0 中添加。
对于具有 4 个以上 GPU 的服务器,多 vGPU 配置将仅支持手动配置的 GPU 直通配置(即不使用 AH 的动态直接路径 的配置);只要用户在推荐的 NUMA 节点上配置 GPU
远程直接内存访问 (RDMA) 与地址转换服务 (ATS)#
RDMA 允许从一台计算机的内存直接访问另一台计算机的内存,而无需操作系统或 CPU 的参与。NVIDIA ConnectX 网络适配器已通过 VMware over RDMA 认证,这可以将 CPU 通信任务卸载,从而提高应用程序性能并提高基础设施投资回报率。诸如 InfiniBand 和基于融合以太网的 RDMA (RoCE) 等网络协议支持 RDMA。在本指南中,我们将为 RoCE 配置 NVIDIA ConnectX-6 Dx。带有 ATS 的 RDMA 使 GPU 能够完全访问 CPU 内存。在本指南中,我们将在 NVIDIA ConnectX-6 Dx NIC、VMware ESXi 和虚拟机上启用 ATS。
NVIDIA Container Toolkit#
NVIDIA Container Toolkit 允许用户构建和运行 GPU 加速的 Docker 容器。该工具包包括一个容器运行时库和实用程序,用于配置容器以自动利用 NVIDIA GPU。完整的文档和常见问题解答可在存储库 wiki 上找到。