部署 Cloud Native Service Add-On Pack#
NVIDIA Cloud Native Stack
本指南将逐步介绍在上游 Kubernetes 部署(例如 NVIDIA Cloud Native Stack)上部署和设置 NVIDIA Cloud Native Service Add-On Pack 的步骤。这是最简单的部署配置,其中提供的所有组件都直接安装在集群上,无需与外部服务集成。
注意
使用上游 Kubernetes 的 NVIDIA Cloud Native Stack 部署仅应用于评估和开发目的。它并非设计用于生产环境。
以下步骤假定已满足要求部分的要求,并且已按照上一节中的步骤设置了 NVIDIA Cloud Native Stack K8S 集群。
确保 kubeconfig 可用,并通过 KUBECONFIG 环境变量或您的用户默认位置 (.kube/config) 进行设置。
确保 FQDN 和通配符 DNS 条目可用,并且对于创建的 K8S 集群是可解析的。
从 Enterprise Catalog 将 NVIDIA Cloud Native Service Add-on Pack 下载到您从此处提供的实例上。
ngc registry resource download-version "nvaie/nvidia_cnpack:0.2.1"
注意
如果您仍然需要安装和设置带有 API 密钥的 NGC CLI,请通过自动加载资源来执行此操作。说明可以在此处找到。
使用以下命令导航到安装程序的目录
cd nvidia_cnpack_v0.2.1
使用以下模板创建安装的配置文件作为最小配置文件。有关所有可用配置选项的完整详细信息,请参考附录的高级用法部分。
注意
请务必更改
wildcardDomain字段,以匹配在要求部分中描述的 DNS FQDN 和通配符记录。1apiVersion: v1alpha1 2kind: NvidiaPlatform 3spec: 4 platform: 5 wildcardDomain: "*.my-cluster.my-domain.com" 6 externalPort: 443 7 ingress: 8 enabled: true 9 postgres: 10 enabled: true 11 certManager: 12 enabled: true 13 trustManager: 14 enabled: true 15 keycloak: 16 databaseStorage: 17 accessModes: 18 - ReadWriteOnce 19 resources: 20 requests: 21 storage: 1G 22 storageClassName: local-path 23 volumeMode: Filesystem 24 prometheus: 25 storage: 26 accessModes: 27 - ReadWriteOnce 28 resources: 29 requests: 30 storage: 1G 31 storageClassName: local-path 32 volumeMode: Filesystem 33 grafana: 34 enabled: true 35 elastic: 36 enabled: true
注意
如果您安装了 local-path-provisioner,则 storageClassName 可以保留显示的值:local-path
通过以下命令使安装程序可执行
chmod +x ./nvidia-cnpack-linux-x86_64
在实例上运行以下命令以设置 NVIDIA Cloud Native Service Add-on Pack
./nvidia-cnpack-linux-x86_64 create -f config.yaml
安装完成后,通过以下命令检查所有 Pod 是否运行状况良好
kubectl get pods -A
输出应类似于以下屏幕截图
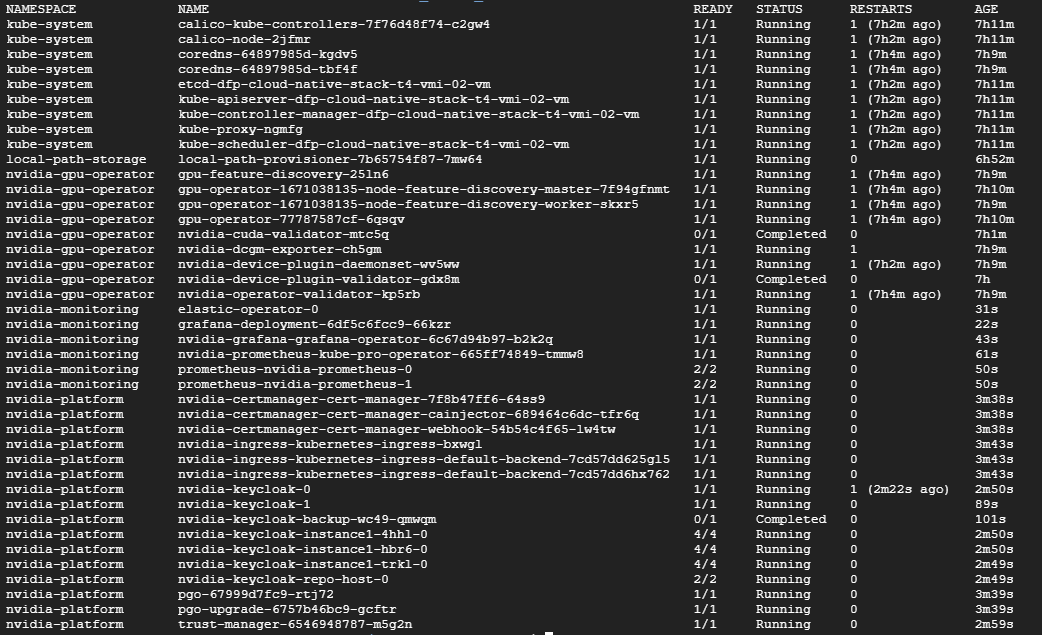
作为安装的一部分,安装程序将创建 nvidia-platform 和 nvidia-monitoring 命名空间,其中包含与已部署服务交互所需的大多数组件和信息。
默认 Keycloak 实例 URL 为:https://auth.my-cluster.my-domain.com
默认管理员凭据可以在 nvidia-platform 命名空间中找到,位于名为 keycloak-initial-admin 的 secret 中,通过以下命令
1kubectl get secret keycloak-initial-admin -n nvidia-platform -o jsonpath='{.data.username}' | base64 -d 2kubectl get secret keycloak-initial-admin -n nvidia-platform -o jsonpath='{.data.password}' | base64 -d
默认 Grafana 实例 URL 为:https://dashboards.my-cluster.my-domain.com
默认 Grafana 凭据可以在 nvidia-monitoring 命名空间中找到,位于名为 grafana-admin-credentials 的 secret 中,通过以下命令
1kubectl get secret grafana-admin-credentials -n nvidia-monitoring -o jsonpath='{.data.GF_SECURITY_ADMIN_USER}' | base64 -d 2kubectl get secret grafana-admin-credentials -n nvidia-monitoring -o jsonpath='{.data.GF_SECURITY_ADMIN_PASSWORD}' | base64 -d
您可以根据您的用例配置集群上安装的组件和服务。具体示例可以在 NVIDIA AI 工作流指南中找到。